Estimating the Expected Discounted Penalty Function in a Compound Poisson Insurance Risk Model with Mixed Premium Income


Abstract
1. Introduction
2. Preliminaries on Expected Discounted Penalty Function
2.1. Fourier-Cosine Series Expansion
2.2. The Fourier Transform of Expected Discounted Penalty Function
3. Estimation Procedure
- (1)
- Dataset of surplus levels:where is the observed surplus level at time .
- (2)
- Dataset of claim numbers and claim sizes:where is the total claim number up to time .
- (3)
- Dataset of premium numbers and claim sizes:where is the total premium number up to time .
4. Consistency Properties
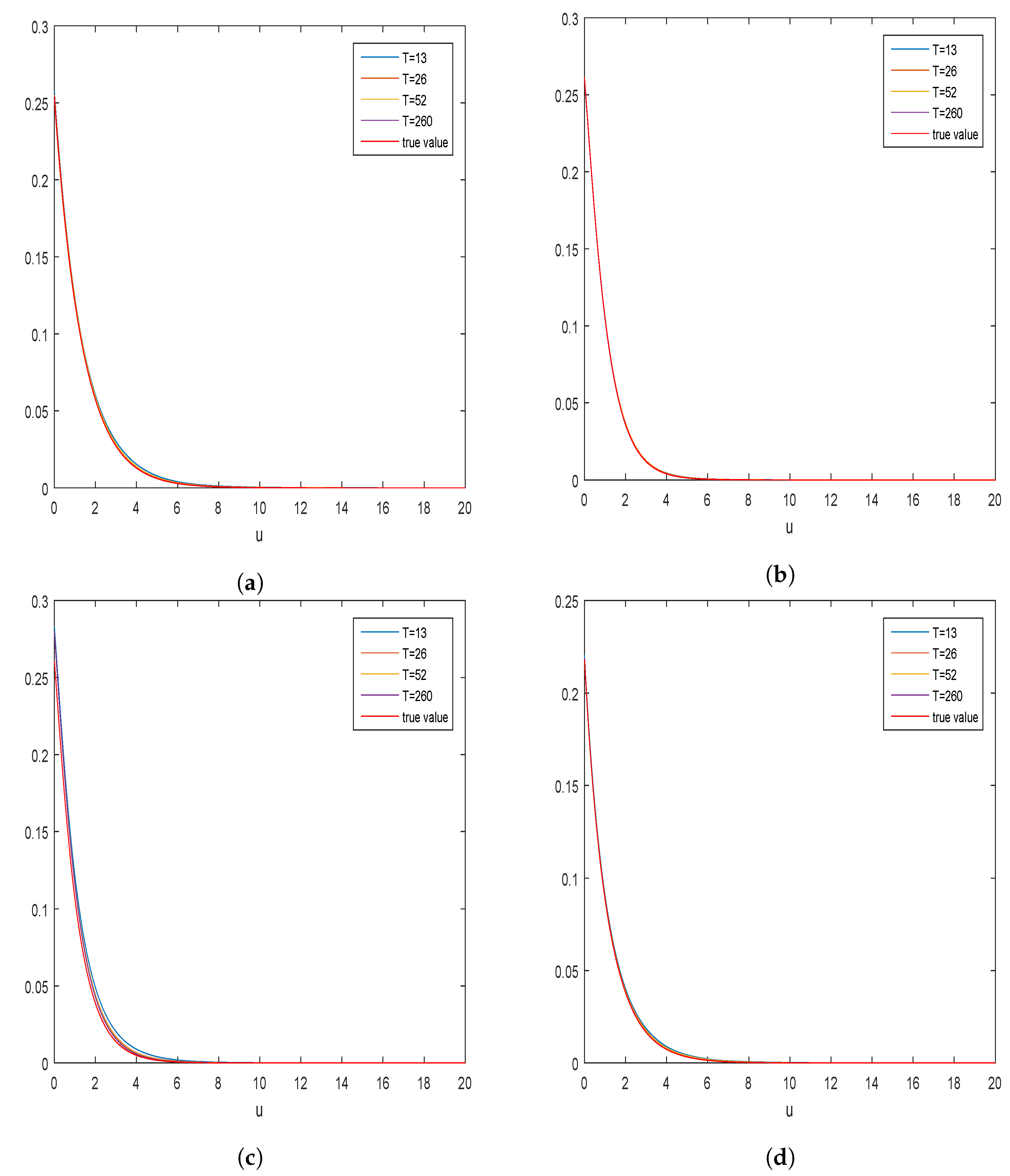
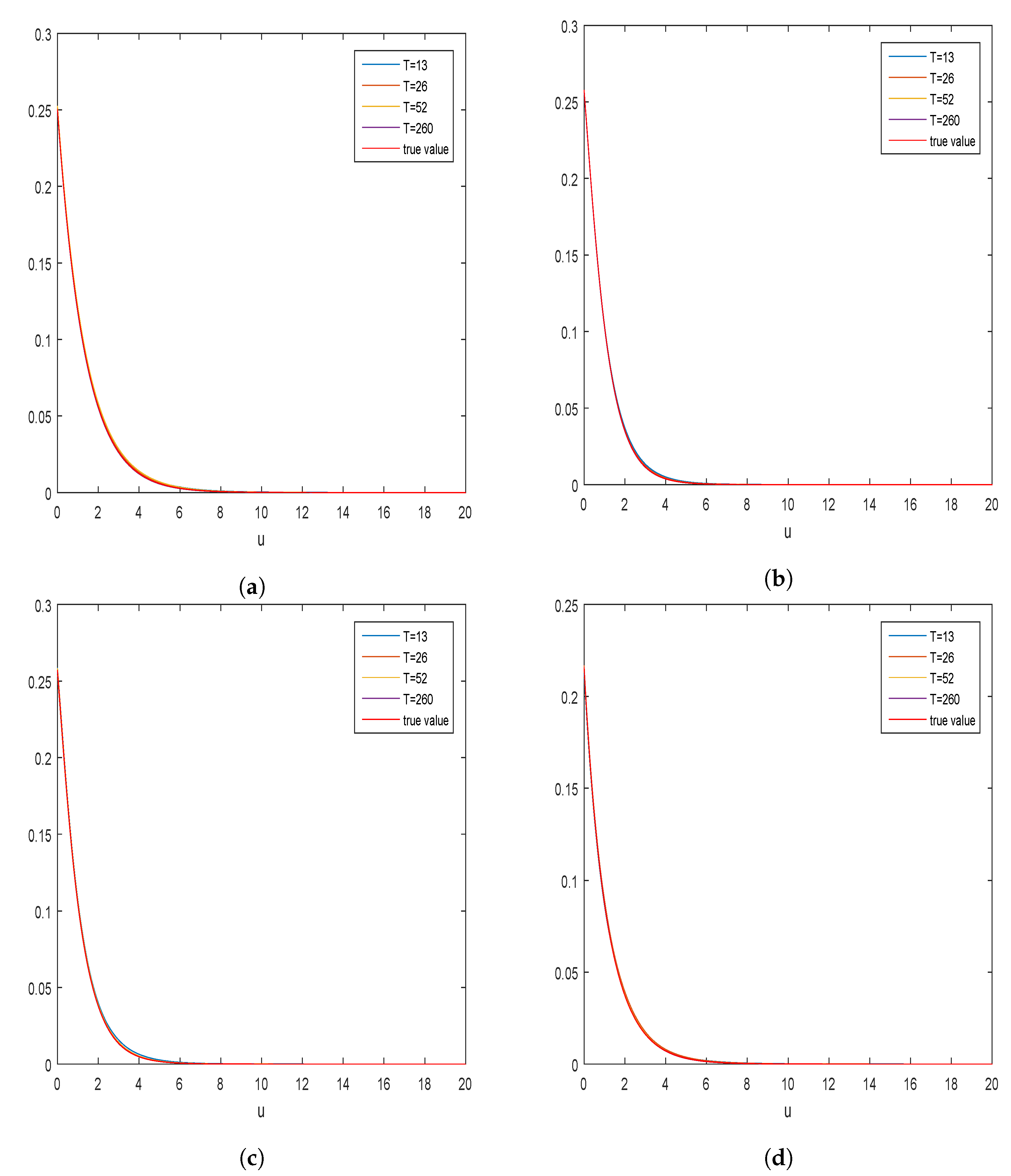
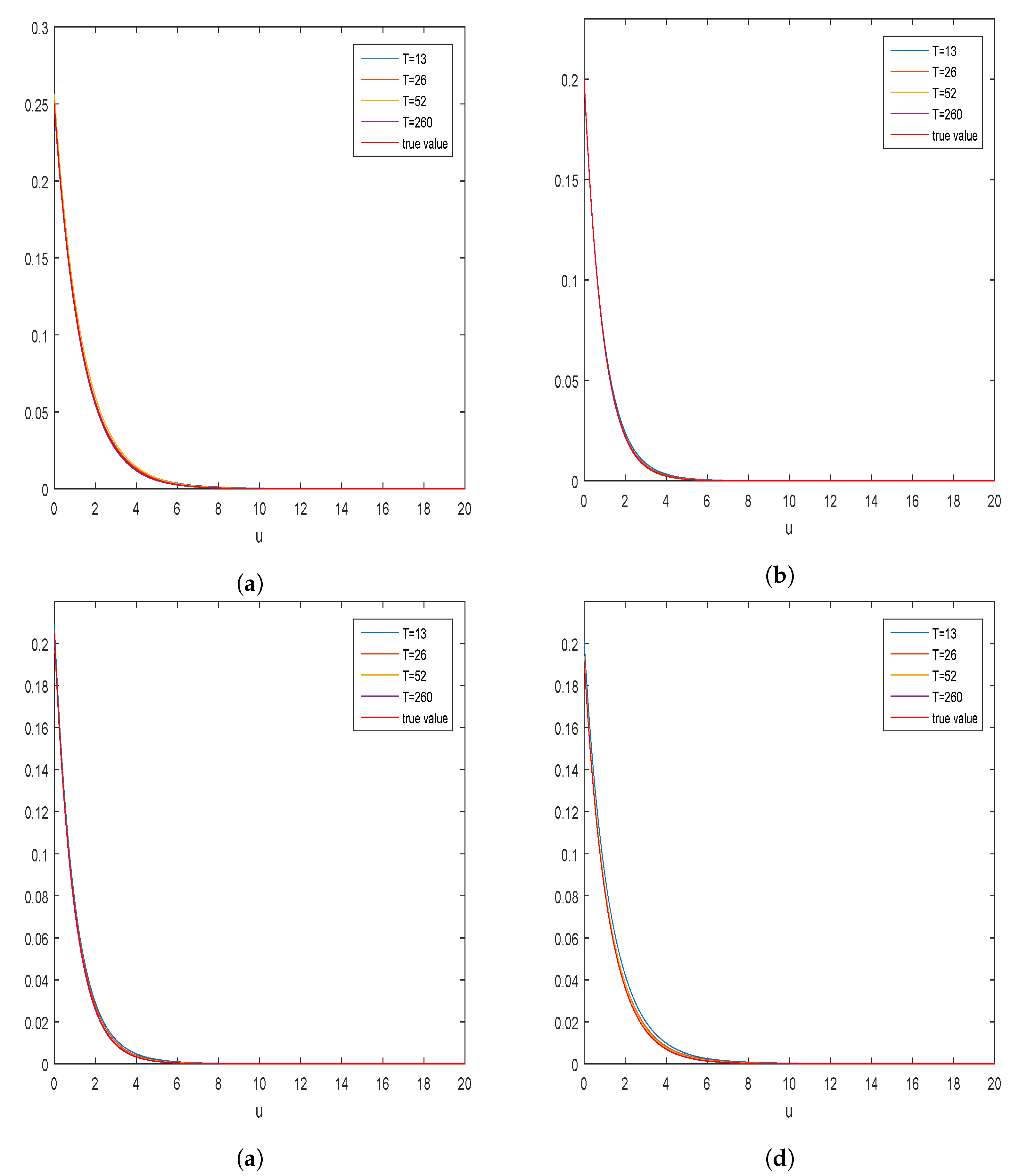
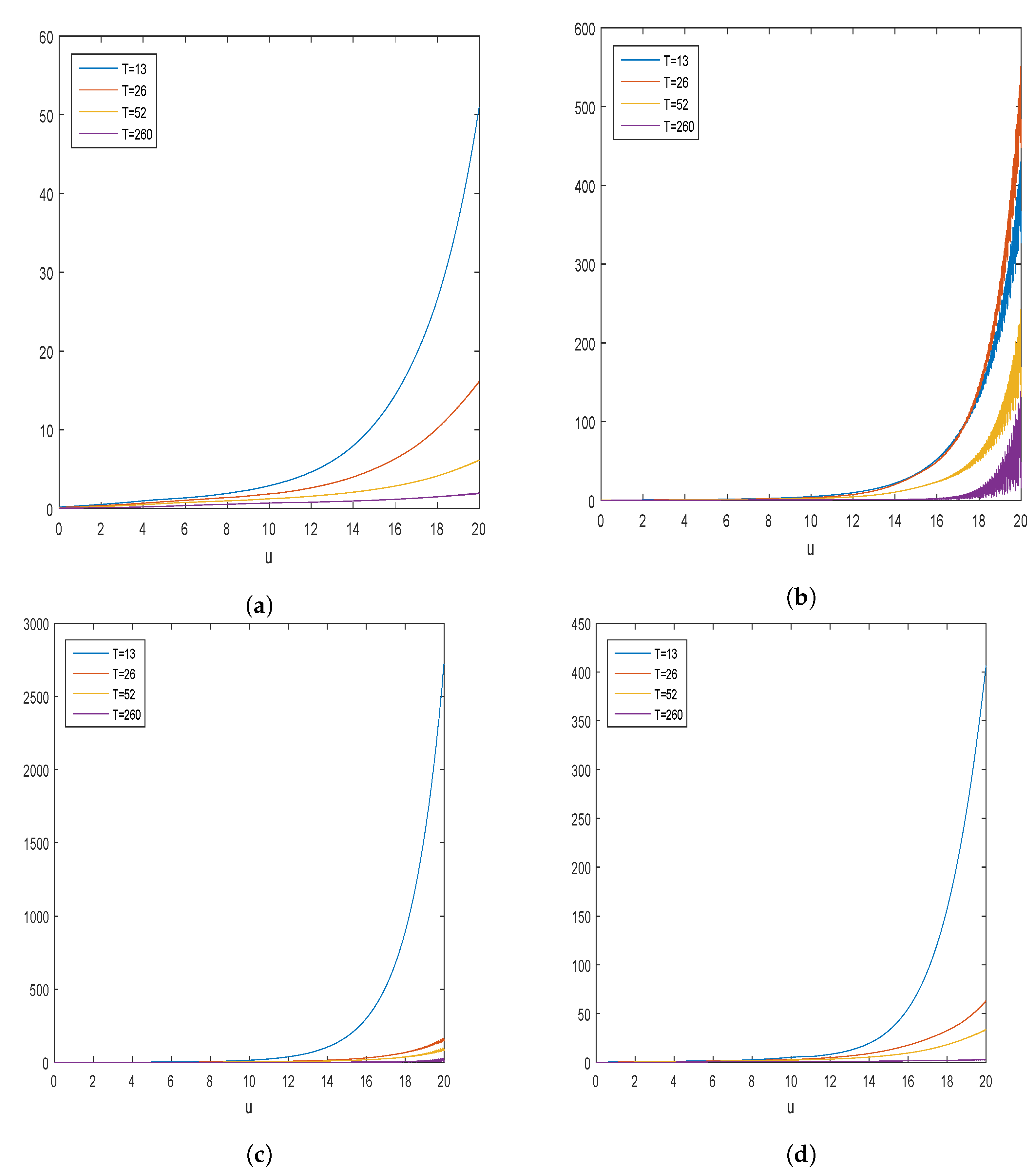
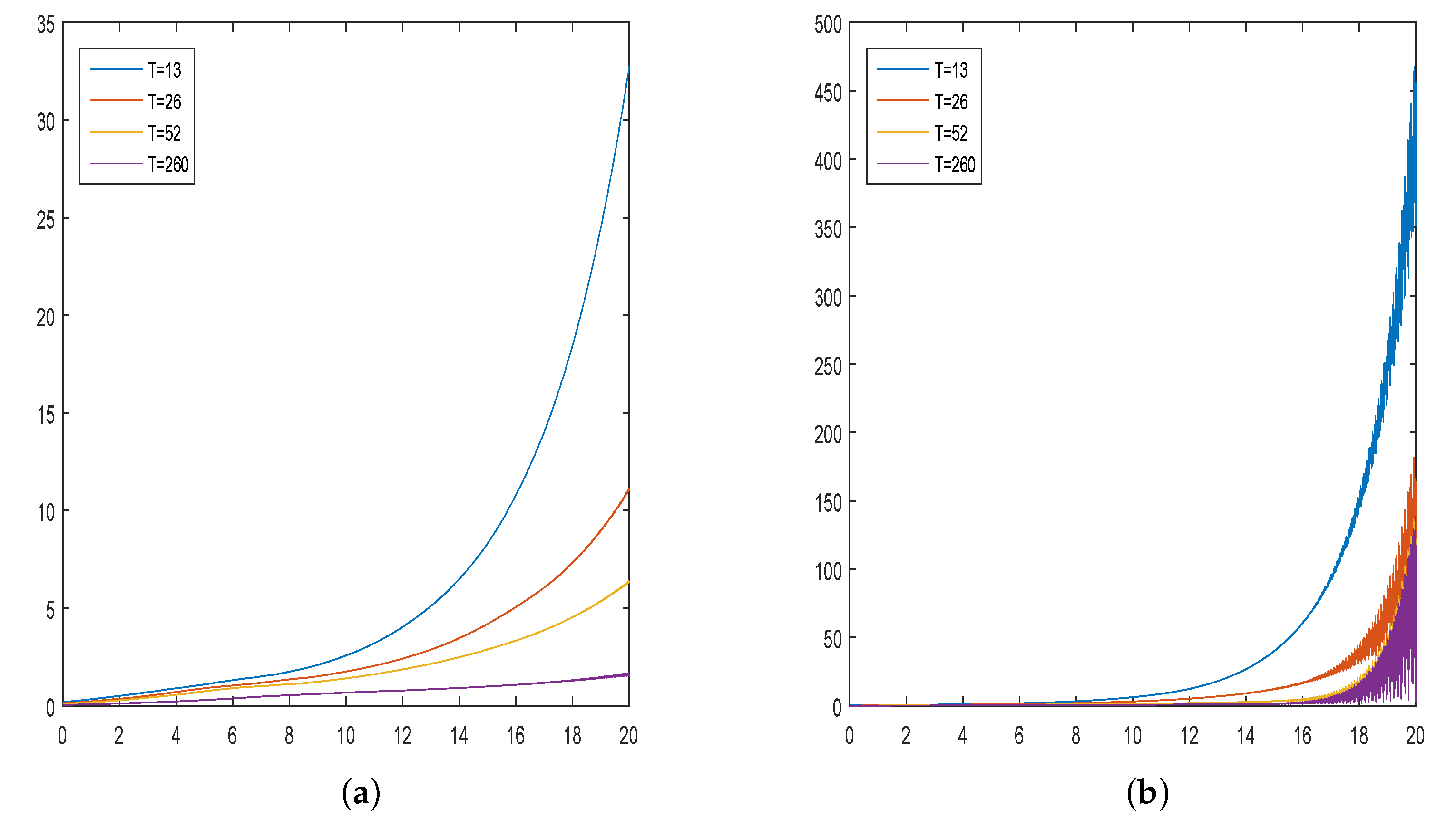
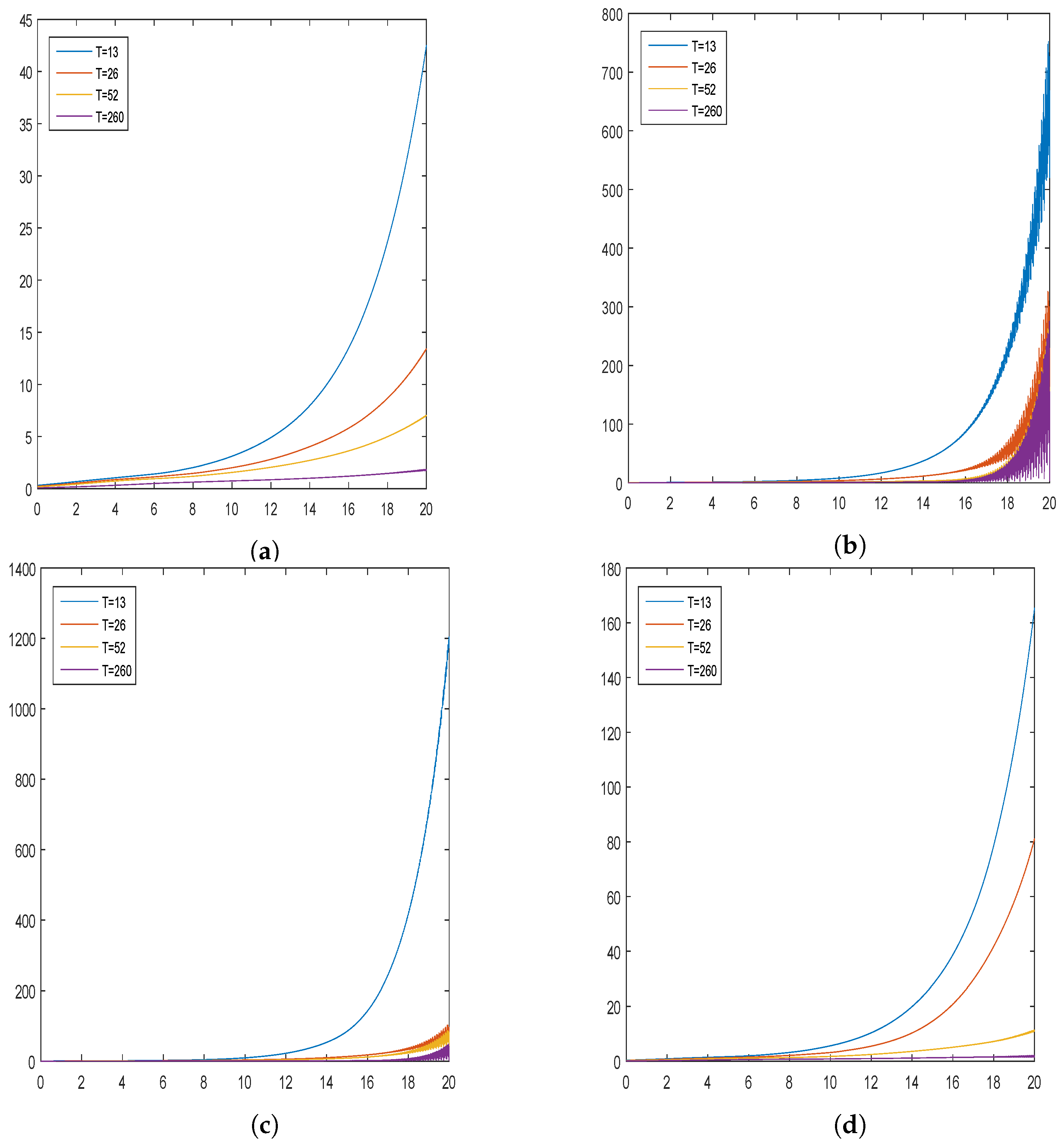
5. Simulation Studies
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gerber, H.U.; Shiu, E.S.W. On the time value of ruin. N. Am. Actuar. J. 1998, 2, 48–78. [Google Scholar] [CrossRef]
- Lin, X.S.; Willmot, G.E.; Drekic, S. The classical risk model with a constant dividend barrier: Analysis of the Gerber-Shiu discounted penalty function. Insur. Math. Econ. 2003, 33, 391–408. [Google Scholar]
- Yuen, K.C.; Wang, G.J.; Li, W.K. The Gerber-Shiu expected discounted penalty function for risk processes with interest and a constant dividend barrier. Insur. Math. Econ. 2007, 40, 104–112. [Google Scholar] [CrossRef]
- Yuen, K.C.; Zhou, M.; Guo, J.Y. On a risk model with debit interest and dividend payments. Stat. Probab. Lett. 2008, 78, 2426–2432. [Google Scholar] [CrossRef]
- Zhao, X.H.; Yin, C.C. The Gerber-Shiu expected discounted penalty function for Lévy insurance risk processes. Acta Math. Sin. 2010, 26, 575–586. [Google Scholar] [CrossRef]
- Chi, Y.C. Analysis of expected discounted penalty function for a general jump diffusion risk model and applications in finance. Insur. Math. Econ. 2010, 46, 385–396. [Google Scholar] [CrossRef]
- Yin, C.C.; Wang, C.W. The perturbed compound Poisson risk process with investment and debit Interest. Methodol. Comput. Appl. 2010, 12, 391–413. [Google Scholar] [CrossRef]
- Chi, Y.C.; Lin, X.S. On the threshold dividend strategy for a generalized jump-diffusion risk model. Insur. Math. Econ. 2011, 48, 326–337. [Google Scholar] [CrossRef]
- Shen, Y.; Yin, C.C.; Yuen, K.C. Alternative approach to the optimality of the threshold strategy for spectrally negative Lévy processes. Acta Math. Appl. Sin. Engl. 2013, 29, 705–716. [Google Scholar] [CrossRef]
- Yin, C.C.; Yuen, K.C. Exact joint laws associated with spectrally negative Lévy processes and applications to insurance risk theory. Front. Math. China 2014, 9, 1453–1471. [Google Scholar] [CrossRef]
- Zhao, Y.X.; Yao, D.J. Optimal dividend and capital injection problem with a random time horizon and a ruin penalty in the dual model. Appl. Math. Ser. B 2015, 30, 325–339. [Google Scholar] [CrossRef]
- Li, S.M.; Lu, Y.; Sendova, K.P. The expected discounted penalty function: From infinite time to finite time. Scand. Actuar. J. 2019. [Google Scholar] [CrossRef]
- Li, Y.Q.; Yin, C.C.; Zhou, X.W. On the last exit times for spectrally negative Lévy processes. J. Appl. Probab. 2017, 54, 474–489. [Google Scholar] [CrossRef]
- Dong, H.; Yin, C.C.; Dai, H.S. Spectrally negative Lévy risk model under Erlangized barrier strategy. J. Comput. Appl. Math. 2019, 351, 101–116. [Google Scholar] [CrossRef]
- Wang, W.Y.; Zhang, Z.M. Computing the Gerber-Shiu function by frame duality projection. Scand. Actuar. J. 2019. [Google Scholar] [CrossRef]
- Willmot, G.E.; Dickson, D.C.M. The Gerber-Shiu discounted penalty function in the stationary renewal risk model. Insur. Math. Econ. 2003, 32, 403–411. [Google Scholar] [CrossRef]
- Wang, C.W.; Yin, C.C.; Li, E.Q. On the classical risk model with credit and debit interests under absolute ruin. Stat. Probab. Lett. 2010, 80, 427–436. [Google Scholar] [CrossRef]
- Yin, C.C.; Yuen, K.C. Optimality of the threshold dividend strategy for the compound Poisson model. Stat. Probab. Lett. 2011, 81, 1841–1846. [Google Scholar] [CrossRef]
- Dong, H.; Yin, C.C. Complete monotonicity of the probability of ruin and DE Finetti’s dividend problem. J. Syst. Sci. Complex. 2012, 25, 178–185. [Google Scholar] [CrossRef]
- Yu, W.G. Some results on absolute ruin in the perturbed insurance risk model with investment and debit interests. Econ. Model. 2013, 31, 625–634. [Google Scholar] [CrossRef]
- Yin, C.C.; Shen, Y.; Wen, Y.Z. Exit problems for jump processes with applications to dividend problems. J. Comput. Appl. Math. 2013, 245, 30–52. [Google Scholar] [CrossRef]
- Zeng, Y.; Li, D.P.; Gu, A.L. Robust equilibrium reinsurance-investment strategy for a mean-variance insurer in a model with jumps. Insur. Math. Econ. 2016, 66, 138–152. [Google Scholar] [CrossRef]
- Zhao, Y.X.; Wang, R.M.; Yao, D.J. Optimal dividend and equity issuance in the perturbed dual model under a penalty for ruin. Commun. Stat. Theory Methods 2016, 45, 365–384. [Google Scholar] [CrossRef]
- Yu, W.G.; Huang, Y.J.; Cui, C.R. The absolute ruin insurance risk model with a threshold dividend strategy. Symmetry 2018, 10, 377. [Google Scholar] [CrossRef]
- Boucherie, R.J.; Boxma, O.J.; Sigman, K. A note on negative customers, GI/G/1 workload, and risk process. Probab. Eng. Inf. Sci. 1997, 11, 305–311. [Google Scholar] [CrossRef]
- Boikov, A.V. The Cramér-Lundberg model with stochastic premium process. Theory Probab. Appl. 2003, 47, 489–493. [Google Scholar] [CrossRef]
- Temnov, G. Risk process with random income. J. Math. Sci. 2004, 123, 3780–3794. [Google Scholar] [CrossRef]
- Bao, Z.H. The expected discounted penalty at ruin in the risk process with random income. Appl. Math. Comput. 2006, 179, 559–566. [Google Scholar] [CrossRef]
- Bao, Z.H.; Ye, Z.X. The Gerber-Shiu discounted penalty function in the delayed renewal risk process with random income. Appl. Math. Comput. 2007, 184, 857–863. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, Z.M. On a class of renewal risk model with random income. Appl. Stoch. Model. Bus. 2009, 25, 678–695. [Google Scholar] [CrossRef]
- Labbé, C.; Sendova, K.P. The expected discounted penalty function under a risk model with sochastic income. Appl. Math. Comput. 2009, 215, 1852–1867. [Google Scholar]
- Zhang, Z.M.; Yang, H. On a risk model with stochastic premiums income and dependence between income and loss. J. Comput. Appl. Math. 2010, 234, 44–57. [Google Scholar] [CrossRef]
- Zhao, Y.X.; Yin, C.C. The expected discounted penalty function under a renewal risk model with stochastic income. Appl. Math. Comput. 2012, 218, 6144–6154. [Google Scholar] [CrossRef]
- Xu, L.; Wang, R.M.; Yao, D.J. On maximizing the expected terminal utility by investment and reinsurance. J. Ind. Manag. Optim. 2008, 4, 801–815. [Google Scholar]
- Yu, W.G. On the expected discounted penalty function for a Markov regime switching risk model with stochastic premium income. Discret. Dyn. Nat. Soc. 2013, 2013, 1–9. [Google Scholar] [CrossRef]
- Yu, W.G. Randomized dividends in a discrete insurance risk model with stochastic premium income. Math. Probl. Eng. 2013, 2013, 1–9. [Google Scholar] [CrossRef]
- Zhou, J.M.; Mo, X.Y.; Ou, H.; Yang, X.Q. Expected present value of total dividends in the compound binomial model with delayed claims and random income. Acta Math. Sci. 2013, 33, 1639–1651. [Google Scholar] [CrossRef]
- Gao, J.W.; Wu, L.Y. On the Gerber-Shiu discounted penalty function in a risk model with two types of delayed-claims and random income. J. Comput. Appl. Math. 2014, 269, 42–52. [Google Scholar] [CrossRef]
- Zhou, M.; Yuen, K.C.; Yin, C.C. Optimal investment and premium control in a nonlinear diffusion model. Acta Math. Appl. Sin. Engl. 2017, 33, 945–958. [Google Scholar] [CrossRef]
- Deng, Y.C.; Liu, J.; Huang, Y.; Li, M.; Zhou, J.M. On a discrete interaction risk model with delayed claims and stochastic incomes under random discount rates. Commun. Stat. Theory Methods 2018, 47, 5867–5883. [Google Scholar] [CrossRef]
- Zeng, Y.; Li, D.P.; Chen, Z.; Yang, Z. Ambiguity aversion and optimal derivative-based pension investment with stochastic income and volatility. J. Econ. Dyn. Control 2018, 88, 70–103. [Google Scholar] [CrossRef]
- Politis, K. Semiparametric estimation for non-ruin probabilities. Scand. Actuar. J. 2003, 2003, 75–96. [Google Scholar] [CrossRef]
- Wang, Y.F.; Yin, C.C. Approximation for the ruin probabilities in a discrete time risk model with dependent risks. Stat. Probab. Lett. 2010, 80, 1335–1342. [Google Scholar] [CrossRef]
- Yuen, K.C.; Yin, C.C. Asymptotic results for tail probabilities of sums of dependent and heavy-tailed random variables. Chin. Ann. Math. B 2012, 33, 557–568. [Google Scholar] [CrossRef]
- Zhang, Z.M.; Yang, H.L.; Yang, H. On a nonparametric estimator for ruin probability in the classical risk model. Scand. Actuar. J. 2014, 2014, 309–338. [Google Scholar] [CrossRef]
- Wang, Y.F.; Yin, C.C.; Zhang, X.S. Uniform estimate for the tail probabilities of randomly weighted sums. Acta Math. Appl. Sin. Engl. 2014, 30, 1063–1072. [Google Scholar] [CrossRef]
- Zhang, Z.M. Nonparametric estimation of the finite time ruin probability in the classical risk model. Scand. Actuar. J. 2017, 2017, 452–469. [Google Scholar] [CrossRef]
- Zhang, Z.M.; Yang, H.L. Nonparametric estimate of the ruin probability in a pure-jump Lévy risk model. Insur. Math. Econ. 2013, 53, 24–35. [Google Scholar] [CrossRef]
- Zhang, Z.M.; Yang, H.L. Nonparametric estimation for the ruin probability in a Lévy risk model under low-frequency observation. Insur. Math. Econ. 2014, 59, 168–177. [Google Scholar] [CrossRef]
- Shimizu, Y.; Zhang, Z.M. Estimating Gerber-Shiu functions from discretely observed Lévy driven surplus. Insur. Math. Econ. 2017, 74, 84–98. [Google Scholar] [CrossRef]
- Peng, J.Y.; Wang, D.C. Asymptotics for ruin probabilities of a non-standard renewal risk model with dependence structures and exponential lévy process investment returns. J. Ind. Manag. Optim. 2017, 13, 155–185. [Google Scholar] [CrossRef]
- Peng, J.Y.; Wang, D.C. Uniform asymptotics for ruin probabilities in a dependent renewal risk model with stochastic return on investments. Stochastics 2018, 90, 432–471. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, K.Y.; Liu, J.J.; Zhang, Z.M. Asymptotics for a bidimensional risk model with two geometric Lévy price processes. J. Ind. Manag. Optim. 2019, 15, 481–505. [Google Scholar] [CrossRef]
- Yang, Y.; Yuen, K.C.; Liu, J.F. Asymptotics for ruin probabilities in Lévy-driven risk models with heavy-tailed claims. J. Ind. Manag. Optim. 2018, 14, 231–247. [Google Scholar] [CrossRef]
- Shimizu, Y. Estimation of the expected discounted penalty function for Lévy insurance risks. Math. Methods Stat. 2011, 20, 125–149. [Google Scholar] [CrossRef]
- Zhang, Z.M. Estimating the Gerber-Shiu function by Fourier-Sinc series expansion. Scand. Actuar. J. 2017, 2017, 898–919. [Google Scholar] [CrossRef]
- Zhang, Z.M.; Su, W. A new efficient method for estimating the Gerber-Shiu function in the classical risk model. Scand. Actuar. J. 2018, 2018, 426–449. [Google Scholar] [CrossRef]
- Zhang, Z.M.; Su, W. Estimating the Gerber-Shiu function in a Lévy risk model by Laguerre series expansion. J. Comput. Appl. Math. 2019, 346, 133–149. [Google Scholar] [CrossRef]
- Su, W.; Yong, Y.D.; Zhang, Z.M. Estimating the Gerber-Shiu function in the perturbed compound Poisson model by Laguerre series expansion. J. Math. Anal. Appl. 2019, 469, 705–729. [Google Scholar] [CrossRef]
- Fang, F.; Oosterlee, C.W. A novel option pricing method based on Fourier cosine series expansions. SIAM J. Sci. Comput. 2008, 31, 826–848. [Google Scholar] [CrossRef]
- Fang, F.; Oosterlee, C.W. Pricing early-exercise and discrete barrier options by Fourier-cosine series expansions. Numer. Math. 2009, 114, 27–62. [Google Scholar] [CrossRef]
- Zhang, B.; Oosterlee, C.W. Pricing of early-exercise Asian options under Lévy processes based on Fourier cosine expansions. Appl. Numer. Math. 2014, 78, 14–30. [Google Scholar] [CrossRef]
- Chau, K.W.; Yam, S.C.P.; Yang, H.L. Fourier-cosine method for Gerber-Shiu functions. Insur. Math. Econ. 2015, 61, 170–180. [Google Scholar] [CrossRef]
- Chau, K.W.; Yam, S.C.P.; Yang, H.L. Fourier-cosine method for ruin probabilities. J. Comput. Appl. Math. 2015, 281, 94–106. [Google Scholar] [CrossRef]
- Zhang, Z.M. Approximating the density of the time to ruin via Fourier-cosine series expansion. Astin Bull. 2017, 47, 169–198. [Google Scholar] [CrossRef]
- Yang, Y.; Su, W.; Zhang, Z.M. Estimating the discounted density of the deficit at ruin by Fourier cosine series expansion. Stat. Probab. Lett. 2019, 146, 147–155. [Google Scholar] [CrossRef]
- Dickson, D.C.M.; Hipp, C. On the time to ruin for Erlang(2) risk processes. Insur. Math. Econ. 2001, 29, 333–344. [Google Scholar] [CrossRef]
- Li, S.M.; Garrido, J. On ruin for the Erlang(n) risk process. Insur. Math. Econ. 2004, 34, 391–408. [Google Scholar] [CrossRef]
- Van Der Vaart, A.W. Asymptotic Statistics; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
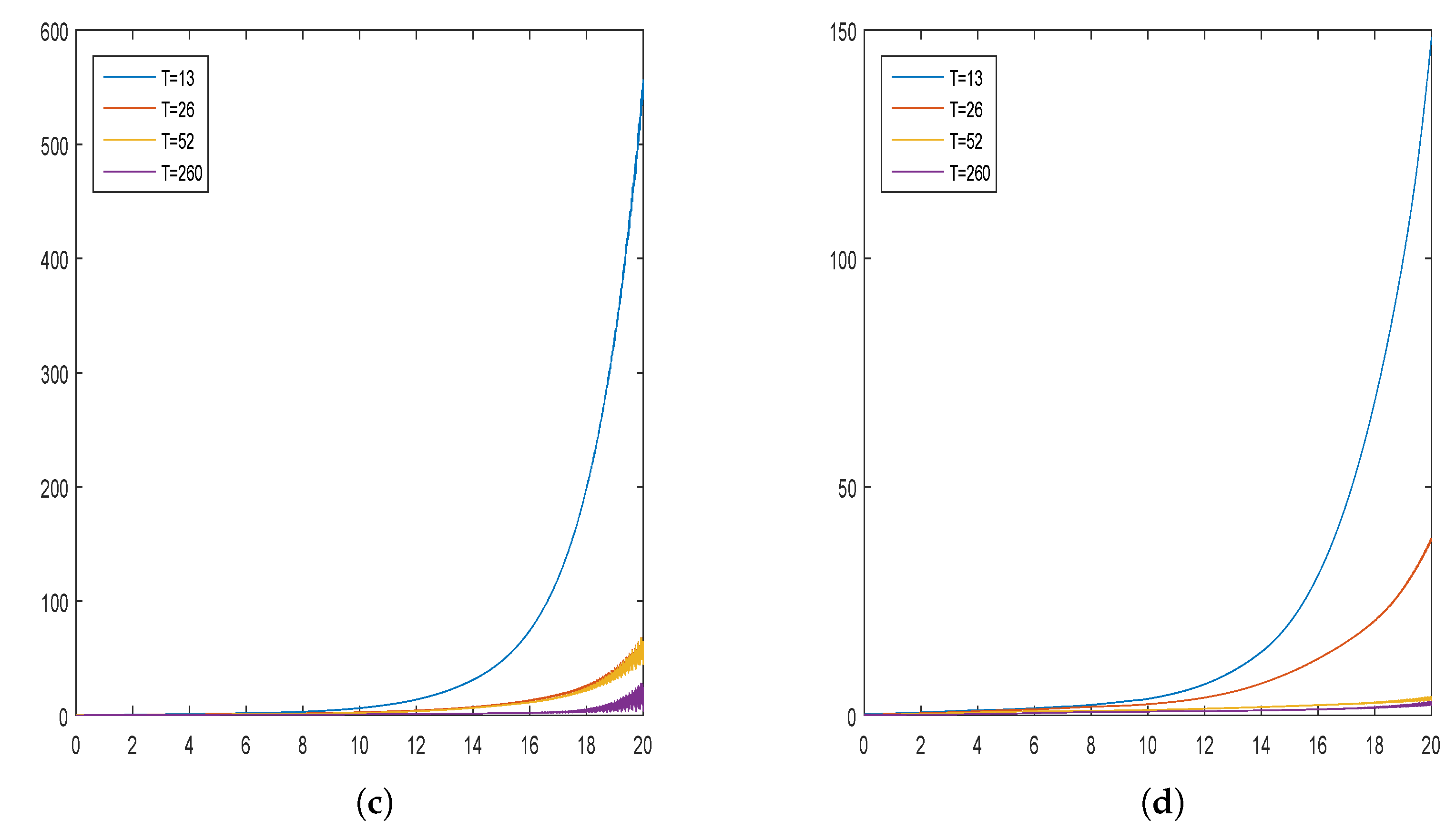{kind=link}
{kind=link}
| T | Exp | Erlang(2) | ||||
|---|---|---|---|---|---|---|
| RP | LT | EDD | RP | LT | EDD | |
| 13 | 0.00717 | 0.00644 | 0.01586 | 0.00351 | 0.00414 | 0.00412 |
| 26 | 0.00352 | 0.00316 | 0.00846 | 0.00186 | 0.00200 | 0.00214 |
| 52 | 0.00177 | 0.00199 | 0.00537 | 0.00108 | 0.00099 | 0.00095 |
| 260 | 0.00032 | 0.00034 | 0.00092 | 0.00018 | 0.00020 | 0.00019 |
| T | Com-Exp | Mix-Exp | ||||
|---|---|---|---|---|---|---|
| RP | LT | EDD | RP | LT | EDD | |
| 13 | 0.00719 | 0.00431 | 0.00527 | 0.00474 | 0.00511 | 0.01176 |
| 26 | 0.00271 | 0.00195 | 0.00277 | 0.00267 | 0.00233 | 0.00602 |
| 52 | 0.00160 | 0.00114 | 0.00124 | 0.00117 | 0.00107 | 0.00257 |
| 260 | 0.00046 | 0.00021 | 0.00024 | 0.00025 | 0.00018 | 0.00053 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Yu, W.; Huang, Y.; Yu, X.; Fan, H. Estimating the Expected Discounted Penalty Function in a Compound Poisson Insurance Risk Model with Mixed Premium Income. Mathematics 2019, 7, 305. https://doi.org/10.3390/math7030305
Wang Y, Yu W, Huang Y, Yu X, Fan H. Estimating the Expected Discounted Penalty Function in a Compound Poisson Insurance Risk Model with Mixed Premium Income. Mathematics. 2019; 7(3):305. https://doi.org/10.3390/math7030305
Chicago/Turabian StyleWang, Yunyun, Wenguang Yu, Yujuan Huang, Xinliang Yu, and Hongli Fan. 2019. "Estimating the Expected Discounted Penalty Function in a Compound Poisson Insurance Risk Model with Mixed Premium Income" Mathematics 7, no. 3: 305. https://doi.org/10.3390/math7030305
APA StyleWang, Y., Yu, W., Huang, Y., Yu, X., & Fan, H. (2019). Estimating the Expected Discounted Penalty Function in a Compound Poisson Insurance Risk Model with Mixed Premium Income. Mathematics, 7(3), 305. https://doi.org/10.3390/math7030305