1. Introduction
The financial crisis of 2008 is considered by many economists as the worst financial crisis since the Great Depression of the 1930s. Consequences of the crisis were not only production curtailment but also difficulty for companies in external finance accessibility. One of the main reasons for this catastrophe was the underestimation of risk (see Jickling (2009) [
1] and Salmon et al. (2012) [
2]). Therefore, study risk measurement would be able to prevent or give a signal to avoid huge potential loss. Diverse markets lead to different risks (see Luo et al. (2015) [
3], Shahzad et al. (2018) [
4], Airouss et al. (2018) [
5], and others), and according to Zhang & Zheng (2018) [
6] and Wang et al. [
7], there is a huge difference in stock markets and banks between emerging markets and advanced countries, especially in terms of seasonality. Also, different countries have different levels of influence on the global economic performance (see Zhang (2018) [
8] and Amavilah (2017) [
9]). Furthermore, Salachas et al. (2017) [
10], Tsai (2015) [
11], and Mustafa et al. (2015) [
12] revealed the structural changes or differences among pre-crisis, crisis, and post-crisis periods via monetary policy, the connection between the oil price and the stock market, and the flight-to-quality between stock and bond markets. Therefore, measuring and comparing financial risks among BRICS (Brazil, Russia, India, China, and South Africa), G7, and G20 in different periods has important value in both practical and academic aspects. On the micro level, it is also meaningful for financial institutions, investors, and government departments to study risk measurement, thereby avoiding great loss and financial storm.
Dependence analysis of the financial market is important for effective diversification in risk management. Since the invention of copula by Sklar [
13], several researchers had made contributions to develop the copula structure from bivariate copulas, multivariate copulas to Vine copulas, hierarchical Archimedean copulas, Factor copulas, and so on. Because of the advantage in dependence measurement of copulas, copula-based methods have been commonly used to measure the dependence structure between financial assets for their characteristics. Kaishev et al. (2007) [
14] analyzed the impact of survival functions and related indexes, expectations of life, and annuity values by bivariate copulas; Li (1999) [
15] introduced multivariate copulas for analyzing default correlation. Berger and Missong (2014) [
16] adopted elliptical copulas and Value at Risk (VaR) to give advice for financial crises. So and Yeung (2014) [
17] investigated a time varying conditional dependence by vine decomposition via the Vine-GARCH model. Mejdoub and Arab (2018) [
18] tested the sensitivity of capital requirement to the dependence structure through D-Vine copulas. Pourkhanali et al. (2016) [
19] discovered that the second tier financial institutions pay a larger contribution to the systemic risk by C-Vine and D-Vine copulas. Aloui and Aïssa (2016) [
20] demonstrated the dynamic relationship among the energy, stock, and currency markets by Vine copulas. Besides, various Vine-based approaches have been adopted to solve problems like system risk, VaR, financial crisis, dynamic correlation (see Pourkhanali et al. (2016) [
19], Reboredo and Ugolini (2015) [
21], and Huang et al. (2009) [
22], So and Yeung (2014) [
17]). Moreover, Hierarchical Archimedean was introduced, and it was adopted to study portfolio credit risk (see Okhrin (2013) [
23], Mai and Scherer (2012) [
24], and Hering et al. (2010) [
25]).
According to previous literature review, copula-based methods have been widely applied to investigate the correlation structure of financial markets and risk measurement. Besides, Oh and Patton (2017) [
26] and Wu et al. (2012) [
27] pointed out that copulas can accurately measure nonlinear correlations and tail dependence, so they can measure financial risk more precisely than multivariate distributions. However, there are still some limitations. First, bivariate copulas can capture nonlinear correlations and asymmetric tail dependence, but they utilize information from only two variables (see Kaishev et al. (2007) [
14] and Craiu and Sabeti (2012) [
28]). Second, multivariate copulas, such as multivariate Gaussian, multivariate Frank, multivariate Gumbel, and multivariate Clayton copulas, may be able to measure nonlinear dependence, but they are not flexible (see Li (1999) [
15] and Kole et al. (2007) [
29]). Third, in hierarchical dependence structure for Archimedean copulas, variables are clustered more closely. So, this structure tends to be restrictive(see Joe (2014) [
30]), and it is driven by one single parameter, which limits the flexibility of the model (see Okhrin and Tetereva (2017) [
31]). Fourth, Vine copulas are more flexible than multivariate copulas (see Aas et al. (2009) [
32] and Haff et al. (2016) [
33]). However, we found that most of the papers that adopted Vine copulas have tended to use low dimensional data. As the number of dimensions grows, the dependence parameters of Vine copulas (O(d
)) increase exponentially, where d is the number of variables, and this will undoubtedly increase the calculations. Fourth, few papers have used Vine copulas to deal with data with more than 12 dimensions.Therefore, the above-mentioned copula models are not really flexible and are not easy to estimate with high dimensional data.
A recent model, named Factor copulas, may help to fix these drawbacks. To avoid the larger number of dependence parameters and huge calculation time, Krupskii and Joe (2013) proposed the Factor copula model. Factor copulas are reliable on high-dimensional data, and they have fewer dependence parameters and, therefore, a reduced calculation process [
34]. Meanwhile, Oh and Patton (2017) proposed an alternate way to construct the Factor copulas that enables the Factor copulas to link observed data to latent variables, which makes the results easier to interpret. Besides, factor copulas may be better-fitted than Vine copulas due to their simpler dependence structure, and they may be better than the classical copula models because of tail dependence [
26]. Because of the large span of data dimensions (from 5 to 19), there are different levels of development (from emerging markets to advanced countries) and complexity of various endogenous and exogenous variables, so Factor copulas may be a better choice. In this paper, Factor copulas were adopted to estimate the sensitivity of each country to latent variables, and VaR and ES were derived by Vine and Factor copulas. A comparison of VaR and Expected Shortfall (ES) between Factor and Vine copulas determined the better method for risk measurement; therefore, more reliable results could be given to cope with the potential risks.
First, we proposed the factor copula-GARCH models to measure the dependence structures of stock returns and latent economic factors. The factor copula-GARCH models are able to capture the potential skewness and kurtosis of stock returns, as well as asymmetric dependence and tail dependence between stock returns and latent economic factors. These merits were conducive to the measurement of stock market risk. Countries like France, Germany, and Italy had larger coefficients of latent variables, which implies that they are more sensitive to the latent economic factors. China and Saudi had the lowest coefficients, which means that they are less vulnerable during crisis periods. Second, G20 had the lowest risk and BRICS had the highest, implying that, with economic globalization, diversified investment could reduce risk. Third, the gap in potential risk between G7 and G20 widened from pre-crisis to post-crisis, which means that emerging markets are playing a greater role in the global economy and are mitigating the risk from G7 countries in global markets. Fourth, pre-crisis results using Factor copula models revealed strong correlations among most of the countries, and this may be an early alarm for an upcoming financial crisis.
The remainder of the paper is structured as follows:
Section 2 presents the data description.
Section 3 presents the definition of the GARCH model, Vine and Factor copulas, VaR, and ES.
Section 4 describes an empirical study of daily returns of stock indexes of BRICS, G7, and G20.
Section 5 gives a brief conclusion and a discussion of further research.
2. Methodology
Firstly, ARMA(1,1)-GJR-GARCH(1,1) models using four different distributions (normal, skew- norm, skew-t and skew-ged) in the three periods were applied to get the cumulative distribution function (CDF), and the most suitable distribution was selected by AIC and BIC. Considering the problem of modeling the joint distribution of time series data by copulas, we followed the two-step estimation [
35]. We estimated the conditional marginal distribution by the ARMA-GJR-GARCH model and obtained the parameters, including the leverage effect, at the first step. Then, we estimated C-Vine, D-Vine, and Factor copulas separately. As for VaR and ES, we conducted 10,000 simulations using the three methods for the three periods; then, we assumed that the copula structure is constant during each period and adopted the rolling window model to estimate copula estimators. Finally, we obtained the VaR and ES and compared the three methods. In this section, we briefly introduce the ARMA-GARCH model, Vine copulas, Factor copulas, tail dependence, VaR, and ES.
2.1. ARMA-GJR-GARCH
The ARMA-GJR-GARCH model that we used was presented by Harvey and Todd [
36] as the ARMA(1,1):
where y
is the conditional mean, and
is the error term. Additionally, the conditional variance model GJR-GARCH(1,1) is defined as:
where
is the leverage effect;
=
and
are i.i.d. variables of standard innovation.
We can get the parameters of GARCH model by maximizing the log likelihood and then getting its CDFs by transformation. Similarly, we used MLE to estimate the parameters of copulas with CDFs obtained from the GARCH model. Marginal distributions were selected among the skew-generalized error distribution, skewed-t distribution, skew-normal distribution, and generalized error distribution by AIC and BIC. Due to space limitations, selections of CDFs of each country during each period are not listed.
2.2. Vine Copula and Factor Copula Models
A copula is a tool to build a multivariant joint distribution from marginal distributions. Copulas are becoming more popular, since they lose the constraint of independent assumption. Briefly speaking, let
F be the CDF of
X, assume that
X = (
X,
X, ⋯,
X), and
F is the marginal distribution of
X for j = 1, ⋯,
n. According to Sklar [
13], if the margins are continuous on their domain, then a copula can build a unique joint distribution function, which is
F(x
, x
, ⋯, x
) =
C(
F, ⋯,
F). Also, copulas are suitable for modeling data with tail dependence and asymmetry. Tail dependence is used in extreme value theory, which allows us to obtain the characteristic of tail implied by a given Factor copula model. The definitions of tail dependence for two variables with marginal distribution
F,
F are:
In the following paragraph, the sequence of Vine copulas is ordered by tail dependence.
2.2.1. Vine Copulas
The basic idea of Vine copulas is to decompose a
d-dimensional copula density into a pair-copula by conditioning such that it can help to reduce the number of dimensions and get the result. It is noteworthy to mention that there are different ways to decompose the density function. In this paper, we adopted C-Vine and D-Vine copulas and selected the sequence by empirical Kendall’s tau. A graph of four-dimensional tree decomposition of C-Vine and D-Vine is shown in
Figure 1.
Firstly, we calculated the empirical Kendall’s tau of each pair. For C-Vine, we calculated each variable’s summation of its tau and then picked the variable with the greatest value as the first sequence. For example, there are four variables: W, X, Y, and Z. We calculated the summation of the empirical Kendall’s tau of W and X, W and Y, and W and Z. Similarly, this was done for , , and . Then, we set the variable with the biggest as the first sequence. Then, we calculated the of the remaining variables and set the second order. This was repeated until we got the whole sequence. For D-Vine, we picked the pair with the greatest tau, and found the second biggest pair of these two variables and set the variable with a smaller tau with the other variables as the first sequence. Then, we ordered the third sequence by the largest tau with the second variable without the ordered one. We use a four-variable selection as an example. If the tau between W and X is the greatest among all pairs, and the second biggest of W is W and Y , for X, it is Z, . If < , then we set W as the first sequence, X as the second, and then find the biggest tau among the rest of the variables and set it as the third. We repeated this step until we had obtained the complete sequence.
2.2.2. Factor Copulas
Vine copulas provide an idea to decompose multi-dimensional data into pairs, but can also cause the calculation problem. Factor copulas, as one of the latest models, have several advantages such as a simpler calculation process, and the results can be explained easily and nicely. To be specific, stock indexes are not only influenced by endogenous variables but also by exogenous variables like interest rate, political stability, and weather. While these exogenous variables cannot be neglected and measured, Factor copulas provide a way that we can treat all of these variables as latent variables such that we can get a better result.
After we have transformed the marginal distribution into a uniform distribution, that is,
F =
u∼
U (0, 1), we get the uniform random variable vector
U = (
U, ⋯,
U). Here, we adopted the Factor copula model proposed by Joe Harry from several Factor copula models (such as Hull and White [
37], Oh and Patton [
26], Vasicek [
38], etc.) due to its simplicity and traceability on parameter estimation processes. Then, the Joint CDF
C(
u, ⋯,
u) could be built by
U. Given p latent variables
V, ⋯, V and without generality, we assumed that every latent variable was i.i.d and uniformly distributed. Then, we were able to get the
Factor copula model (
5),
When
p = 1, there is only one latent variable.
C represents the joint CDF of (
U,
V), while
c pdf. Since
F =
C(u
|v
) =
∂C(u
,v
)/
∂v
, then Equation (
3) becomes:
Then the likelihood can be written as:
The Gauss–Legendre quadrature approach performs well in approximation by replacing the integral as a summation of the weighted integrands at the quadrature points. The Gauss–Legendre formula is,
where
w stands for the quadrature weights,
n is the number of quadrature points, and
x is the nodes.
After obtaining the coefficients, we generated 10,000 simulations.Then, we added weights to each country’s simulations, and got the weighted log-return predictions, that is,
where
X stands for countries contained in the studied group,
is the corresponding market capitalization, and
n = 5 for BRICS,
n = 7 for G7, and
n = 19 for G20. Similarly, we were able to get the real weighted log-returns. After that, we simply obtained the VaR and ES from the simulations.
2.3. Value at Risk
VaR is widely used in many areas to quantify the level of risk, and it was adopted by the Basel Committee for a long time. VaR can be explained intuitively and easily, and it is still a popular measurement in risk management. Mathematically, VaR is defined as:
where
∈ (0, 1) is the quantile, r
is the return, and VaR means the occurrence of the losses at the
quantile.
Every can be obtained by simulations of different quantiles based on the historical information of Vine and Factor copula GJR-GARCH models.
In order to evaluate the different forecasting method, three methods of statistical backtesting are applied to measure the absolute amount of misspecifications, which are unconditional coverage (UC), independence (IND), and conditional coverage (CC) test. The
LR, proposed by Kupiec (1995) [
39], checks whether the rate of exceedances of a VaR model is statistically different from its realized rate:
where
x is the number of outliers, and
T stands for the total number of predictions. And a likelihood ratio statistic method proposed by Christoffersen (1998) [
40], aims to test if the misspecifications are correlated in time. The likelihood ratio is defined as:
where
N is the number of observed values
i followed by
j, 1 represents a misspecification, and 0 a correct estimation.
represents the probability of observing an exceedance, where
is the conditional probability,
. The CC test is the combination of previous two tests:
The null hypothesis of the LR and LR test obeys the chi-square distribution with the degree of 1, therefore, their summation, the LR test, obeys chi-square distribution with the degree of 2. And the VaR estimates are appropriate only if the statistic is not greater than the critical value of chi-square distribution.
2.4. Expected Shortfall
According to the Basel Committee on Banking Supervision, the ES will help to ensure a more prudent capture of “tail risk” and capital adequacy during periods of significant financial market stress, and it shifted the risk measure from VaR to ES in 2016 [
41]. Additionally, in order to determine the better prediction when both Vine and Factor copulas pass the
LR,
LR, and
LR test of VaR, we introduced the ES. Similar to VaR, the ES is another risk measure applied in the field of financial risk measurement to evaluate the market risk or credit risk of a portfolio, and it is more sensitive to the shape of the fat tail situation. Here, we define ES as:
where
∈ (0, 1) is the quantile, and
VaR is the VaR. Following Rockafellar and Uryasev (2002) [
42], Equation (
14) can be written as:
where
q stands for the number of samples generated by Monte Carlo simulation,
VaR represents VaR,
the threshold value, and
r is the kth vector of simulated returns.
3. The Data
As aforementioned, the stock data in G20 countries were used for financial risk analysis. Our full sample period spans from 1 May 2003 to 31 May 2018. To avoid high volatility and the large effects of the dotcom bubble and terrorism events, like 9/11, in the early 2000s on exogenous variables in the stock market, the pre-crisis period starts in 1 May 2003. Because of the global financial crisis, 1 August 2007 is considered as a starting date of crisis periods. According to Hatzius and Stehn [
43], the crisis ended in 2013; 1 January 2013 is thus considered the beginning of the post-crisis period. In summary, the pre-crisis period is from 1 May 2003 to 31 July 2007; the crisis period is from 1 August 2007 to 31 December 2012; and the post-crisis period is from 1 January 2013 to 31 May 2018. The last 261 observations of each period were used as out-of-sample data for comparison with the predictions obtained from other observations.
The daily closing prices of stock indexes of 19 individual countries in G20 were obtained from Bloomberg, and their total market capitalization was obtained from Reuters. Market capitalization is the market value of a publicly traded company’s outstanding shares, and it is used by the investment community to rank the sizes of companies. Here, the total market capitalization of each stock market was adopted to represent the size of each market and was used to weigh portfolios containing the stock indexes because the portfolio of indexes with weighted market capitalization shows greater practical significance (see Danbolt (2018) [
44] and Dias (2013) [
45] et al.). Names of countries and stock indexes are shown in
Table 1 and descriptive statistics for market capitalization is shown in
Table 2. It is shown in
Table 2 that there are huge differences among three groups, such as the mean, median, and maximum of the G7 group is at least two times as much as BRICS. Therefore, it is more reasonable to adopt capitalization as a weight to measure the potential risk.
To calculate the VaRs and ESs, firstly, the daily closing prices of stock indexes were transformed into daily log-return, that is,
R =
Ln(
P/
P. According to our literature review, one-day ahead VaR thresholds prediction is one of the most popular ways to estimate the VaR and the size of the window is depended on sample size (see Berger and Missong (2014) [
16] and Fengler and Okhrin (2016) [
46]). In this paper, one-day ahead VaR prediction was adopted and, due to our sample size, one year of observations (261) for each period were used as out-of-sample data and the rolling window method was adopted to do the predictions of the rest of the data (the sizes of the window are 848, 1154, and 1153 for pre-crisis, during crisis and post-crisis period, respectively). To be specific, the prediction of
was based on the information set
, where
t∈ (1, 2, ⋯, 261). In this paper, we initially used the sample-in data to estimate VaR and ES. For example, the crisis period has 1414 observations in total. We first used 1154 observations to run the estimation and kept the remaining 261 to do the comparison. Then,
VaR was given by the time period from
t = 1 to
t = 1154;
VaR was given by
t = 2 to
t = 1155. In the end, in total, we obtained 261 VaRs and ESs for each period to determine the better method between Vine and Factor copulas by VaRs and ESs. Then, we showed the potential risk of BRICS, G7, and G20 by ESs. In this paper, we used R software (version 3.5.1) with the rugarch, CDvine, and CopulaModel packages to deal with the data. The related methods are discussed in the next section.
4. Empirical Results
In this section, we show the model selection for the Factor copulas; then we calculate the VaR and ES based on the estimations and simulations obtained. After this, we introduce an intuitive way to distinguish the better model among C-Vine, D-Vine, and Factor copulas. Finally, we give the graphs to discuss the potential risk in the three groups.
4.1. Estimation Results of Factor Copulas
ARMA(1,1)-GJR-GARCH(1,1) was widely adopted by filtering the time series data (see Oh and Patton (2017) [
26], Krupskii and Joe (2013) [
34], and Tachibana (2018) [
47]). And the skewed-t distribution was adopted to filter the data by information criteria. Factor copulas, such as the Gaussian copula, Frank copula, Gumbel copula, and t-copula were selected by AIC and BIC. Similarly, the best Vine copula structures were chosen in terms of AIC and BIC from 19 families, including four previous copula families.
Table 3 shows the AIC and BIC of the Factor copulas for the three groups in the three periods. According to the values of AIC and BIC, for BRICS and G20, t-copula was the best for the pre-crisis and post-crisis periods, while the Gumbel copula was the best for the crisis period; for G7, the Frank copula was the most suitable for all periods. During the pre-crisis and post-crisis periods, BRICS and G20 tended to have symmetric tail dependence, while during the crisis, they had upper tail dependence. As with the Gaussian copula, the Frank copula did not show tail dependence in the limits, but away from the extremes, the Frank copula showed less tail concentration than the Gaussian on both sides, which indicates a higher probability of getting extreme values.
The estimated results of the Factor copulas are shown in
Table 4. It is obvious to see that all of the coefficients and most of Kendall’s tau in the crisis period were much bigger than in the other two periods, which implies that all countries are more sensitive to changes in both endogenous variables (like interest rate, monetary policy, etc.) and exogenous variables (like weather, political stability, etc.). Besides, European countries, such as Germany and France, have larger rank correlations than others in all periods which indicates that they are more sensitive about the latent variables, therefore, those two big economies might have driven (and represented) the risk factor during the crisis. Additionally, in the pre-crisis period, Germany, France, and Italy, which have latent variables, had the largest Kendall’s tau values among all countries. When the European debt crisis took place, Italy was in the first batch of countries in G20 that were affected. Then, Germany and France were hugely influenced as a consequence of the crisis. Thirdly, in countries like China and Saudi, the dependence between countries, such as China and Saudi, and latent variables was tiny, which implies they are less sensitive to the latent variables, leading to relatively less damage than in other countries. The reason may be their stronger macroscopic control and government intervention or reduced market openness. It is noteworthy that China has a 0 value of dependence in pre-crisis period, which represents the little connection between Chinese stock market and latent variable. The reason might be the low level of market openness. For example, Chinese government released some monetary and financial policies, like on 30 April 2005, when the People’s Bank of China approved the Pan-Asian Bond Index Fund (Pan-Asian Fund, PAIF) to enter the inter-bank bond market, making it the first foreign institutional investor introduced in the inter-bank bond market. Therefore, there was little risk in the financial market of China during pre-crisis period. And there is no doubt that this finding is consistent with this fact. Furthermore, after the crisis, most countries tended to have a smaller Kendall’s tau value because they adopted deleverage and more strict financial regulations and supervision policies, which decreased the sensitivity and correlations with endogenous and exogenous variables.
4.2. VaR-Based Vine and Factor Copulas
We now focus on the VaR analysis using the best fitted Factor, the C-Vine and D-Vine copulas. Numbers of violations of VaR and their results for the
LR,
LR and
LR tests are also shown in
Table 5. For BRICS, all models failed to reject the null hypothesis in all periods, except with the D-Vine copula in the pre-crisis period, which implies that there is little difference between Vine and Factor copulas in this paper. As for G7, only Factor copulas completely failed to reject the null hypothesis for all periods. Additionally, for G20, Factor copulas had the best performance in predicted VaR for all periods. In the crisis period, the C-Vine and D-Vine copulas overestimated the potential risk. Besides, according to the
LR test, it shows that the exceedances of C-Vine and D-Vine copulas are highly correlated in time. Therefore, it can be concluded that Factor copulas performed better than Vine copulas in higher dimensions for this empirical work.
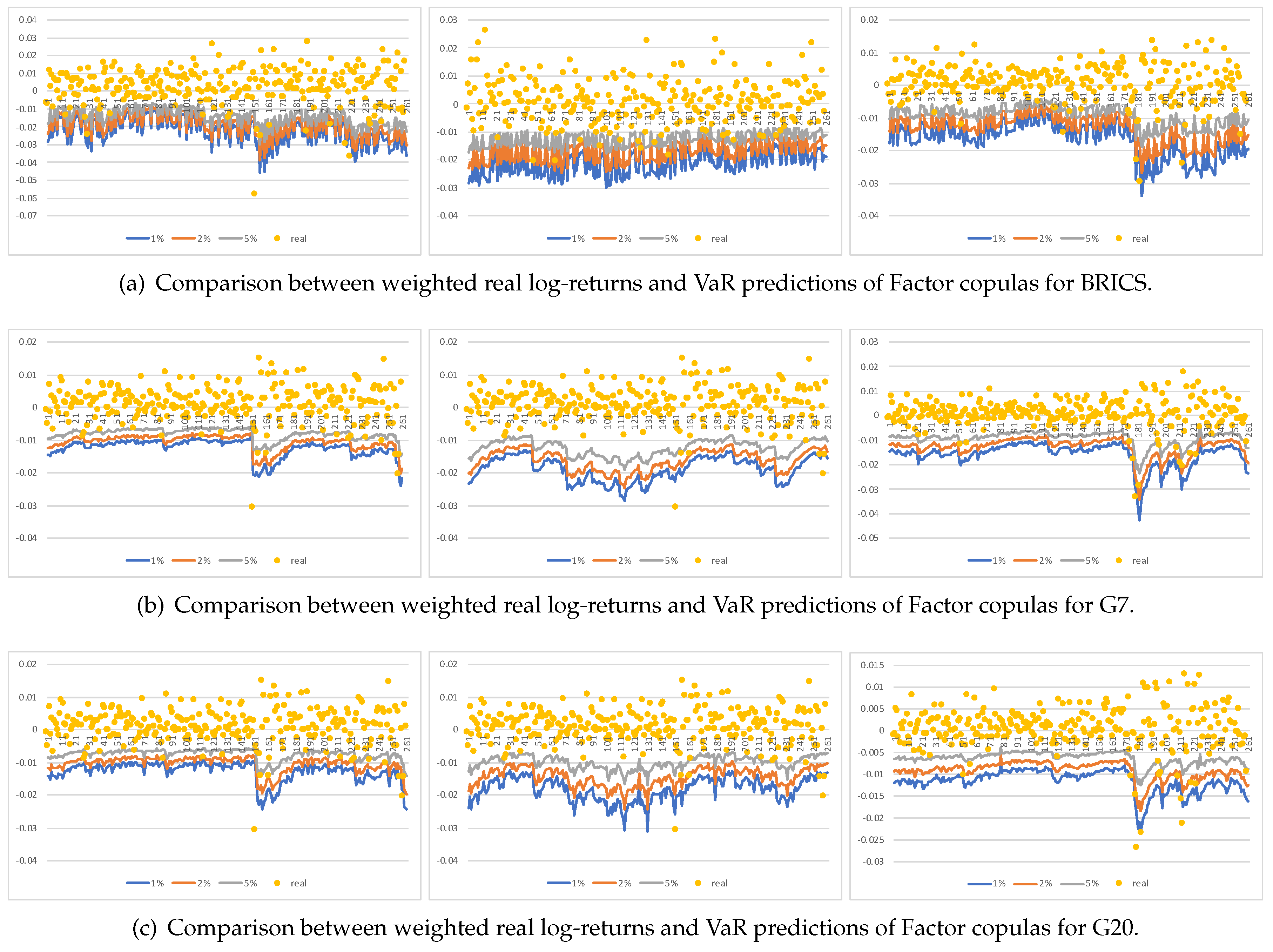
The various VaRs estimated from the Factor copulas are shown in
Figure 2 with
= 0.01, 0.02, and 0.05, respectively. We analyzed some obvious violations in the three periods. For BRICS, in the pre-crisis period, at the 152th prediction, there was an extraordinary violation on 27 February 2007. On that day, the Shanghai composite index slumped 8.84%, which was the maximum daily drawdown in the past 10 years. On the same day, many stock indexes of G7 and G20 suffered huge losses, such as SPX (America), which dropped 3.53%, S&P/TSX (Canada) which dropped 2.72%, DAX (Germany) which dropped 2.96%, and UKX (England) which dropped 2.31%, so that day was named “Black Tuesday” in many countries. The Factor copula models captured the sharp downward trend and provided a potential risk alarm for G7 and G20. For the 151th prediction in the crisis period, which refers to 31 July 2012, SPX decreased by 4.33%, and for G7 and G20, especially for G20’s VaR prediction, there were significant downward trends, which also shows the risk to investors who own portfolios that include the SPX index. In the post-crisis period, the 180th and 211th predictions were severe violations, which refer to 28 February and 23 March 2018, respectively. Partially due to a slide in the price of oil, U.S. stocks sank again on 28 February and that February was the worst month for the market in past two years. Affected by the poor performance of U.S. stock markets, 16 of the rest of the 18 countries’ stock markets suffered a drop. Additionally, after U.S. President Donald Trump slapped China with annual tariffs, on 23 March 2018, markets witnessed a steep decline. Our results show that Factor copulas successfully indicated the risk. Noteworthy as well is that, even when the causes of the decline in two cases were not the same (oil price and policy change), Factor copulas still performed well.
4.3. Estimation of ES
In order to determine the best model for prediction, an intuitive method was applied to measure the accuracy of three methods by calculating the average distance square between the real log-returns and ESs corresponding to the violations of VaR:
where
is the i-th prediction of ES, and
R is the real weighted log-return.
For BRICS, it is hard to determine which copula is the best for measuring the risk. For G7, only Factor copulas failed to reject the LR, LR and LR test, which shows the weak performance of Vine copulas in 7-dimensional data. As for G20, it was only in the pre-crisis period that the C-Vine copula performed a little bit better than the Factor copula, while in other cases, C-Vine and D-Vine copulas were overwhelmed by the Factor copula. It is clear to see that the Factor copula can provide a better prediction.
In order to compare the risk among BRICS, G7, and G20, the ES was adopted to represent the potential risk.
Figure 3 shows ES estimation of three groups in three periods by the Factor copula model and all slumps in it appear the same time as
Figure 3, which indicates that, for ES and VaR, they share the same reasons for steep fall. As for the figure for ES estimation result, there are three main findings.
Firstly, during the crisis period, potential risk was higher than in the pre-crisis and post-crisis periods, since there was a higher absolute value of ES and huge fluctuations throughout the crisis period. Additionally, because of successful remedial measures, including policy change and deleverage, the potential risk in the post-crisis period was less than in the pre-crisis period.
Secondly, in the pre-crisis period, in terms of both values and fluctuation, BRICS showed higher risk than the other two groups. In more than half of the days in the crisis and post-crisis periods, the absolute value of ES of BRICS was higher than in the other countries, and it had more fluctuation. Generally speaking, in all periods, BRICS countries contain more risk than G7 and G20, because it is more dangerous for the financial stability of banks and rate of return of investors to have frequent extreme fluctuations or sharp declines in a short time than over the long run. The reasons for the fluctuations and declines of BRICS may be immature policy, lax supervision, defective financial sectors, and so on. These drawbacks are common problems for emerging markets.
Thirdly, in the pre-crisis period, the curves of G7 and G20 are nearly overlapping, which indicates that G7 still dominates other countries in G20 group. Additionally, as time passed by, the gap between those two curves increased, and the risk for G20 was less than that of G7, since the strong economic performance of emerging markets like China and India and other developed countries which are not members of G7, like Australia and Korea, diversified the potential risk. Additionally, obviously, in the post-crisis period, the ES curve of G7 was below G20’s, which indicates the fact that G7 is more risky. It also means that other countries are playing more important roles in the global economy.
5. Conclusions
In this paper, for the purpose of risk measurement, combined with ARMA(1,1)-GJR-GARCH(1,1), two new kinds of copula were adopted to fit the data and to predict VaR and ES. In order to differentiate the risk among emerging markets, advanced economies, and the global economy, a comparison among the three groups was discussed. Several findings obtained from the Factor copula model indicate the effectiveness and practicality.
A comparison between Vine and Factor copulas is shown by both simulated data and real data, which reveals the unique advantages for the Factor copula model. Firstly, Factor copulas showed accuracy in their predictions of VaR and ES. Secondly, the stability of the predictions was proved. Thirdly, for high-dimensional data, Factor copulas tended to be better than Vine copulas, due to the overestimation of the risk of Vine copulas. Besides, for policymakers and investors, the dependence between latent variables and stock indexes obtained from Factor copulas models is consistent with common knowledge. Therefore it is recommended to adopt this method to measure the potential risk for stock markets. And the discussion of potential risk order of BRICS, G7, and G20 (BRICS was the highest and G20 was the lowest) suggests that for the purpose of diversification, the portfolio with G20 may be a good choice. Moreover, estimation results for pre-crisis period by Factor copula models implied strong correlations among most of the countries, which may be an early alarm for an upcoming financial crisis.
One-Factor copula models were adopted because of the limitation of the capacity of calculation. In this study, two or more factors were adopted at the first place, but for 19-dimensional data, the total calculation is huge. For further research, multiple-Factor copula models may be a better choice due to their modified code and higher calculation capacity computer. Besides, more detailed analysis, such as dependence between risk and oil prices or change-point analysis of the parameter of the copula, might provide more implications to policymakers.






{kind=link}
{kind=link}
{kind=link}
{kind=link}