First-Arrival Travel Times Picking through Sliding Windows and Fuzzy C-Means


Abstract
1. Introduction
2. Related Works
3. Preliminaries
3.1. Data Model
3.2. First-Arrival Picking
3.3. Fuzzy c-Means
3.4. Particle Swarm Optimization
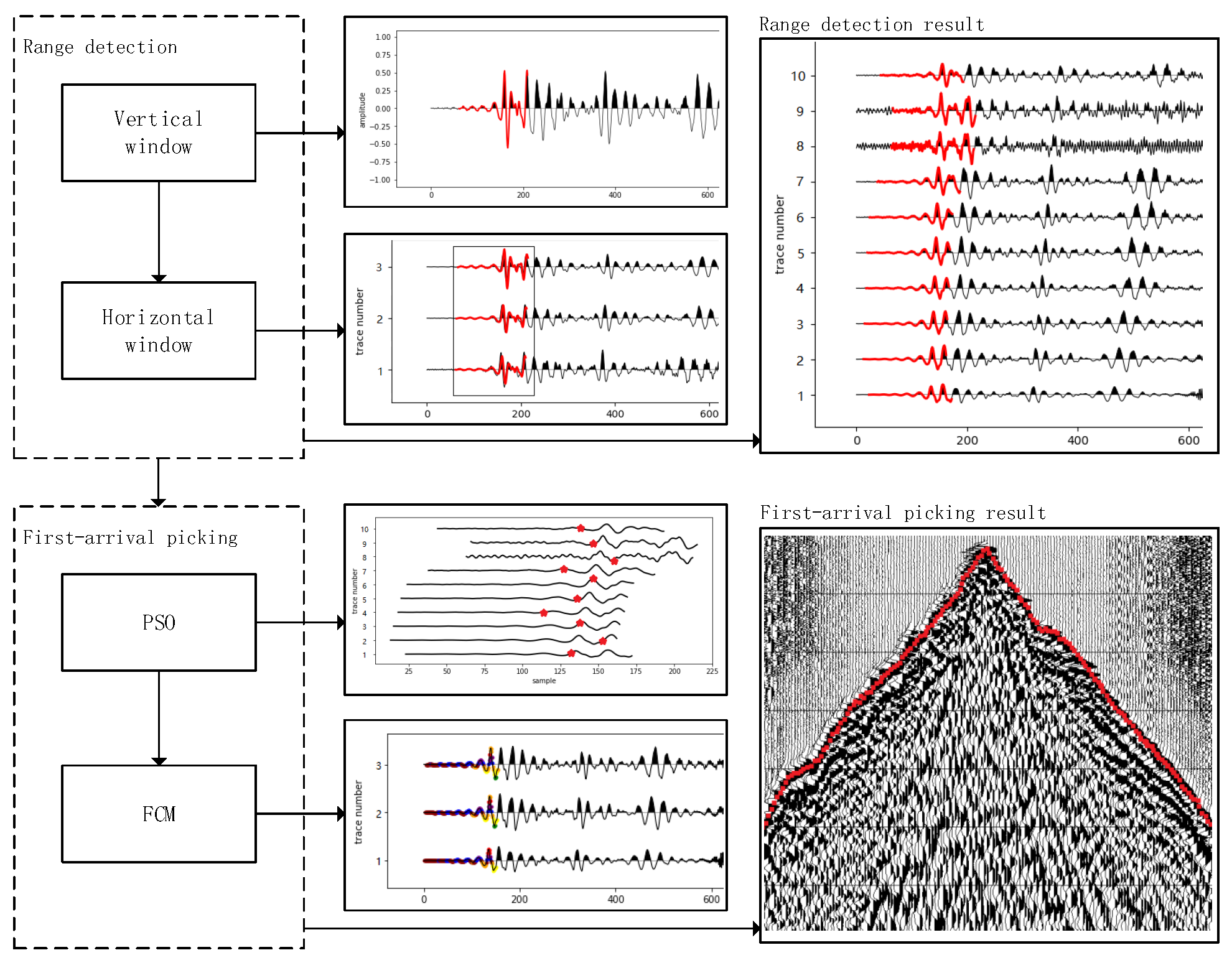
4. The Proposed Algorithm
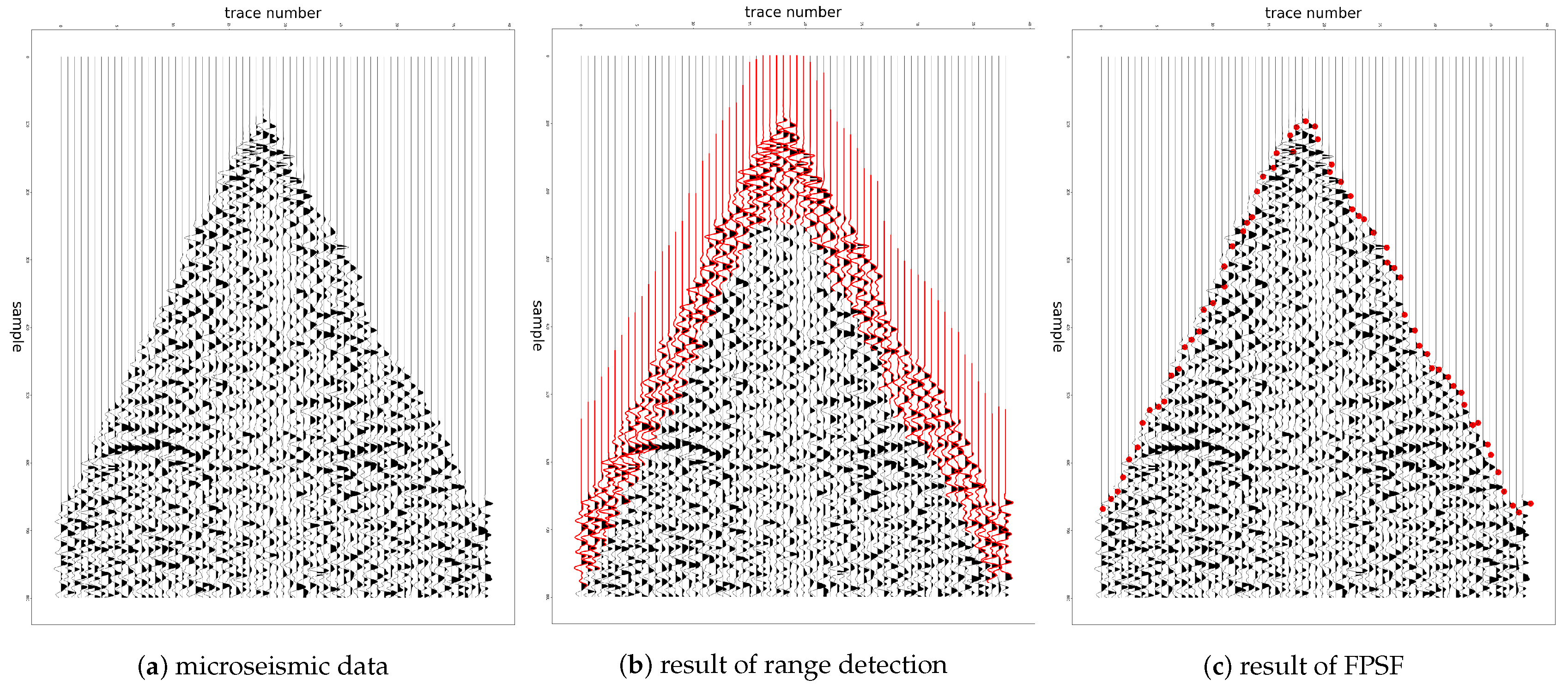
4.1. Range Detection
| Algorithm 1: Vertical Window Sliding for One Trace | |
| Input: The j-th trace , window size l, ratio weight a and search step size k. | |
| Output: The starting index of the result window . | |
| Method: verticalSliding. | |
| 1: | ; // Initialize |
| 2: | for ( step k to ) do |
| 3: | ; // The sum of the upper part |
| 4: | ; // The sum of the lower part |
| 5: | ; // Compute r |
| 6: | if () then |
| 7: | ; |
| 8: | ; // Update the starting index |
| 9: | end if |
| 10: | end for |
| 11: | return; |
| Algorithm 2: Horizontal Window Sliding | |
| Input: The starting index array of result windows , vertical window size l and horizontal window size b. | |
| Output: Range starting index array . | |
| Method: horizontalSliding. | |
| 1: | for ( to ) do |
| 2: | ; // Move the horizontal window |
| 3: | ; // Get the median of the window |
| 4: | for ( to b) do |
| 5: | if () then |
| 6: | ; // Update the value with a large difference |
| 7: | end if |
| 8: | end for |
| 9: | end for |
| 10: | return; |
4.2. First-Arrival Picking from the Range
| Algorithm 3: PSO | |
| Input: The fitness function f, the matrices of position boundary and velocity boundary , the number of particles M, the inertia weight of each particle’s velocity , the global influence weight , the inertia weight w, the maximum iteration times T and the convergent error . | |
| Output: Solution of the best particle . | |
| Method: particleSwarmOptimization. | |
| 1: | for ( to M) do |
| 2: | ; // Initialize position and velocity |
| 3: | ; |
| 4: | end for |
| 5: | ; // Initialize iteration times t |
| 6: | while ( && ) do |
| 7: | for ( to M) do |
| 8: | if () then |
| 9: | ; // Record optimal solution of each particle |
| 10: | end if |
| 11: | end for |
| 12: | ; // Find optimal particle |
| 13: | if () then |
| 14: | ; // Update global optimal particle |
| 15: | end if |
| 16: | for ( to M) do |
| 17: | ; // Update particle velocity |
| 18: | ; // Check and adjust |
| 19: | ; // Update particle position . |
| 20: | ; // Check and adjust |
| 21: | end for |
| 22: | ; |
| 23: | end while |
| 24: | return; |
| Algorithm 4: FCM | |
| Input: Original clustering center array , the first-arrival range matrix R, the number of clusters e, the fuzzy indicator and the convergent error . | |
| Output: Membership matrix U and clustering center array . | |
| Method: fuzzyClusterMethod. | |
| 1: | ; // // Initialize membership matrix U |
| 2: | ; // Compute function value J according to Equation (6) |
| 3: | while (!) do |
| 4: | ; // Update U according to Equation (7) |
| 5: | ; // Update according to Equation (8) |
| 6: | end while// Check the convergence |
| 7: | return; |
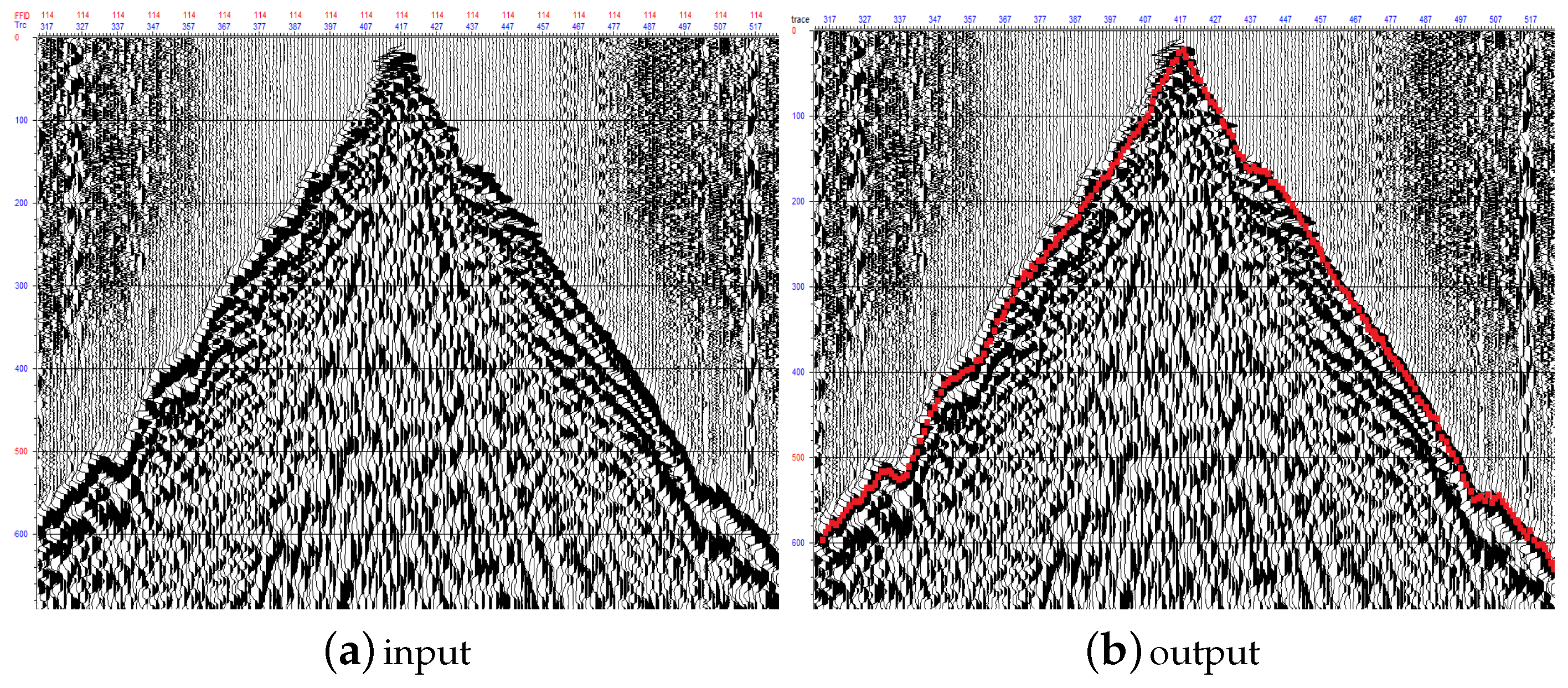
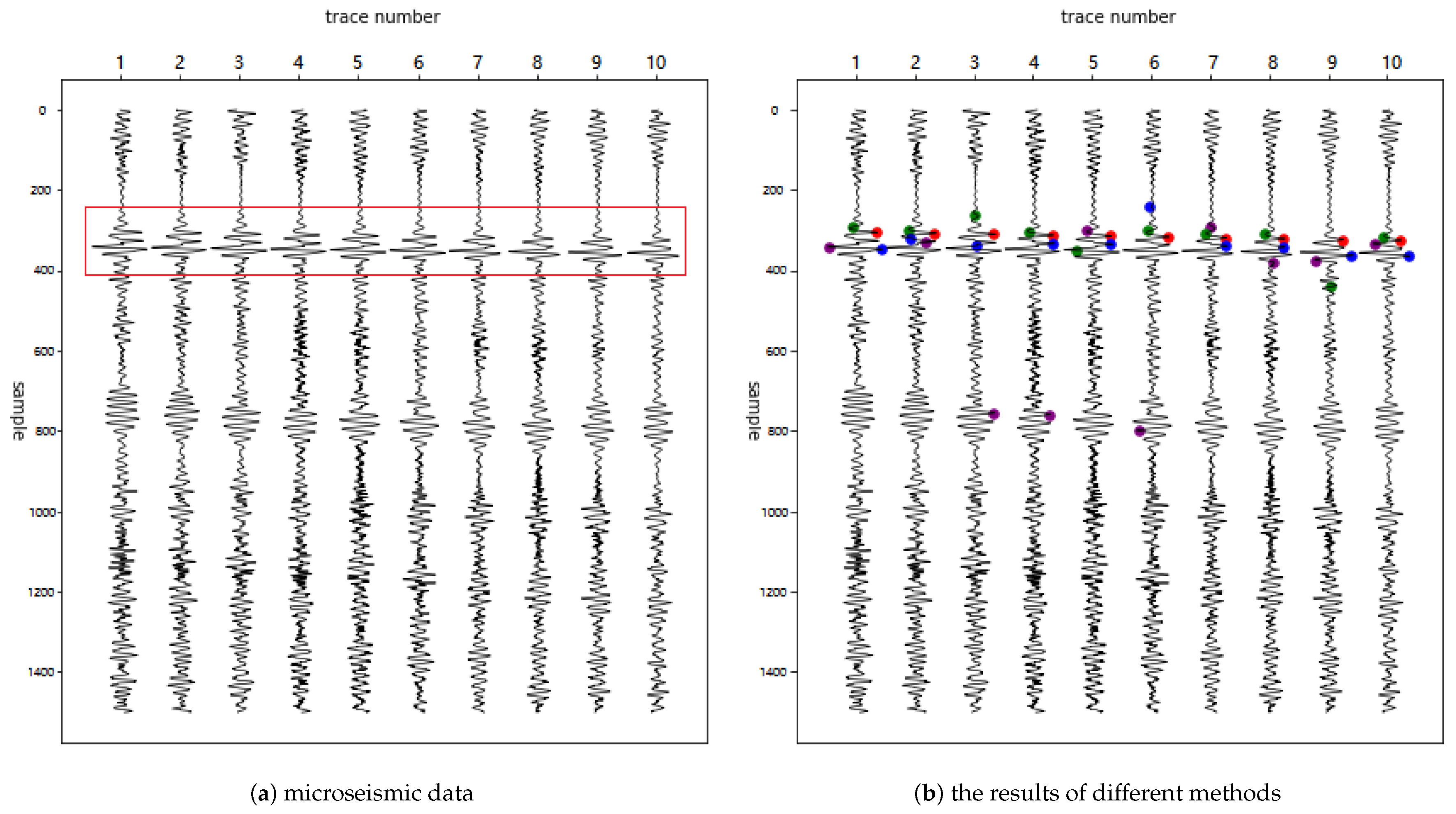
5. Experimental Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Waheed, U.B.; Flagg, G.; Yarman, C.E. First-arrival traveltime tomography for anisotropic media using the adjoint-state method. Geophysics 2016, 81, R147–R155. [Google Scholar] [CrossRef]
- Zelt, C.; Haines, S.; Powers, M.; Sheehan, J.; Rohdewald, S.; Link, C.; Hayashi, K.; Zhao, D.; Zhou, H.W.; Burton, B.; et al. Blind test of methods for obtaining 2-D near-surface seismic velocity models from first-arrival traveltimes. J. Environ. Eng. Geophys. 2013, 18, 183–194. [Google Scholar] [CrossRef]
- Sun, M.Y.; Zhang, J.; Zhang, W. Alternating first-arrival traveltime tomography and waveform inversion for near-surface imaging. Geophysics 2017, 82, R245–R257. [Google Scholar] [CrossRef]
- Zhu, X.H.; Valasek, P.; Roy, B.; Shaw, S.; Howell, J.; Whitney, S.; Whitmore, N.D.; Anno, P. Recent applications of turning-ray tomography. Geophysics 2008, 73, VE243–VE254. [Google Scholar] [CrossRef]
- Kahrizi, A.; Hashemi, H. Neuron curve as a tool for performance evaluation of MLP and RBF architecture in first break picking of seismic data. J. Appl. Geophys. 2014, 108, 159–166. [Google Scholar] [CrossRef]
- Yilmaz, Ö. Seismic Data Analysis: Processing, Inversion, and Interpretation of Seismic Data; Society of Exploration Geophysicists: Tulsa, OK, USA, 2001; Volume 1. [Google Scholar] [CrossRef]
- An, S.; Hu, T.Y.; Peng, G.X. Three-Dimensional cumulant-based coherent integration method to enhance first-break seismic signals. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2089–2096. [Google Scholar] [CrossRef]
- Akram, J.; Eaton, D.W. A review and appraisal of arrival-time picking methods for downhole microseismic data. Geophysics 2016, 81, KS71–KS91. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Lin, H.B.; Zhong, T. First arrival time picking for microseismic data based on DWSW algorithm. J. Seismol. 2018, 22, 833–840. [Google Scholar] [CrossRef]
- Hu, R.Q.; Wang, Y.C. A first arrival detection method for low SNR microseismic signal. Acta Geophys. 2018, 66, 945–957. [Google Scholar] [CrossRef]
- Lan, H.Q.; Zhang, Z.J. A high-order fast-sweeping scheme for calculating first-arrival travel times with an trregular surface. Bull. Seismol. Soc. Am. 2013, 103, 2070–2082. [Google Scholar] [CrossRef]
- Coppens, F. First arrival picking on common-offset trace collections for automatic estimation of static corrections. Geophys. Prospect. 1985, 33, 1212–1231. [Google Scholar] [CrossRef]
- Al-Ghamdi, A.S. Automatic First Arrival Picking Using Energy Ratios; ProQuest: Ann Arbor, MI, USA, 2007. [Google Scholar]
- Chen, M.; Li, Y.; Xie, J. A novel SVM-Based method for seismic first-arrival detecting. Appl. Mech. Mater. 2010, 29–32, 973–978. [Google Scholar] [CrossRef]
- Sabbione, J.I.; Velis, D. Automatic first-breaks picking: New strategies and algorithms. Geophysics 2010, 75, V67–V76. [Google Scholar] [CrossRef]
- Molyneux, J.B.; Schmitt, D.R. First-break timing: Arrival onset times by direct correlation. Geophysics 1999, 64, 1492–1501. [Google Scholar] [CrossRef]
- McCormack, M.D.; Zaucha, D.E.; Dushek, D.W. First-break refraction event picking and seismic data trace editing using neural networks. Geophysics 1993, 58, 67–78. [Google Scholar] [CrossRef]
- Zhu, D.; Li, Y.; Zhang, C. Automatic time picking for microseismic data based on a fuzzy c-means clustering algorithm. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1900–1904. [Google Scholar] [CrossRef]
- Mousa, W.A.; Al-Shuhail, A.A.; Al-Lehyani, A. A new technique for first-arrival picking of refracted seismic data based on digital image segmentation. Geophysics 2011, 76, V79–V89. [Google Scholar] [CrossRef]
- Allen, R.V. Automatic earthquake recognition and timing from single traces. Bull. Seismol. Soc. Am. 1978, 68, 1521–1532. [Google Scholar]
- Wong, J.; Han, L.J.; Bancroft, J.C.; Stewart, R.R. Automatic time-picking of first arrivals on noisy microseismic data. Can. Soc. Explor. Eeophys. Conf. Abstr. 2009, 1, 1–4. [Google Scholar]
- Takanami, T.; Kitagawa, G. Estimation of the arrival times of seismic waves by multivariate time series model. Ann. Inst. Stat. Math. 1991, 43, 407–433. [Google Scholar] [CrossRef]
- Boschetti, F.; Dentith, M.D.; List, R.D. A fractal-based algorithm for detecting first arrivals on seismic traces. Geophysics 1996, 61, 1095–1102. [Google Scholar] [CrossRef]
- Tian, N.; Fan, T.G.; Hu, G.Y.; Zhang, R.W.; Zhou, J.N.; Le, J. The roles of the spatial regularization in seismic deconvolution. Acta Geod. Geophys. 2016, 51, 43–55. [Google Scholar] [CrossRef]
- Bertrand, A.; MacBeth, C. Repeatability enhancement in deep-water permanent seismic installations: A dynamic correction for seawater velocity variations. Geophys. Prospect. 2005, 53, 229–242. [Google Scholar] [CrossRef]
- Strong, S.; Hearn, S. Statics correction methods for 3D converted-wave (PS) seismic reflection. Explor. Geophys. 2017, 48, 237–245. [Google Scholar] [CrossRef]
- Cox, M. Static Corrections for Seismic Reflection Surveys; Society of Exploration Geophysicists: Tulsa, OK, USA, 1999. [Google Scholar] [CrossRef]
- Naus-Thijssen, F.M.J.; Goupee, A.J.; Vel, S.S.; Johnson, S.E. The influence of microstructure on seismic wave speed anisotropy in the crust: Computational analysis of quartz-muscovite rocks. Geophys. J. Int. 2011, 185, 609–621. [Google Scholar] [CrossRef]
- Li, Q.H.; Jia, X.F. Generalized staining algorithm for seismic modeling and migration. Geophysics 2017, 82, T17–T26. [Google Scholar] [CrossRef]
- Hatherly, P.J. A computer method for determining seismic first arrival times. Geophysics 1982, 47, 1431–1436. [Google Scholar] [CrossRef]
- Fajaryanti, R.; Manik, H.M.; Purwanto, C. Application of multichannel seismic reflection method to measure temperature in Sulawesi Sea. IOP Conf. Ser. Earth Environ. Sci. 2018, 176, 012044. [Google Scholar] [CrossRef]
- Wang, F.Y.; Zhao, C.B.; Feng, S.Y.; Ji, J.F.; Tian, X.F.; Wei, X.Q.; Li, Y.Q.; Li, J.C.; Hua, X.S. Seismogenic structure of the 2013 Lushan M (s) 7.0 earthquake revealed by a deep seismic reflection profile. Chin. J. Geophys. Chin. Ed. 2015, 58, 3183–3192. [Google Scholar]
- Dunn, J.C. A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters. J. Cybern. 1973, 3, 32–57. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern recognition with fuzzy objective function algorithms. Adv. Appl. Pattern Recognit. 1981, 22, 203–239. [Google Scholar]
- Jia, Z.X.; Xia, Y.; Chen, Q.; Sun, Q.S.; Xia, D.S.; Feng, D.D. Fuzzy c-means clustering with weighted image patch for image segmentation. Appl. Soft Comput. 2012, 12, 1659–1667. [Google Scholar] [CrossRef]
- Shafei, B.; Steidl, G. Segmentation of images with separating layers by fuzzy c-means and convex optimization. J. Vis. Commun. Image Represent. 2012, 23, 611–621. [Google Scholar] [CrossRef]
- Szilágyi, L.; Szilágyi, S.M.; Benyó, Z. A modified FCM algorithm for fast segmentation of brain MR images. In Analysis and Design of Intelligent Systems using Soft Computing Techniques; Springer: Berlin/Heidelberg, Germany, 2007; pp. 119–127. [Google Scholar] [CrossRef]
- Ahmed, M.N.; Yamany, S.M.; Mohamed, N.; Farag, A.A.; Moriarty, T. A modified fuzzy c-means algorithm for bias field estimation and segmentation of MRI data. IEEE Trans. Med. Imaging 2002, 21, 193–199. [Google Scholar] [CrossRef] [PubMed]
- Bezdek, J.C.; Pal, S.K. Fuzzy Models for Pattern Recognition; IEEE Press: New York, NY, USA, 1992; Volume 56. [Google Scholar]
- Kennedy, J. Particle swarm optimization. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2011; pp. 760–766. [Google Scholar] [CrossRef]
- Ganguly, S.; Sahoo, N.C.; Das, D. Multi-objective particle swarm optimization based on;fuzzy-pareto-dominance for possibilistic planning of electrical;distribution systems incorporating distributed generation. Fuzzy Sets Syst. 2013, 213, 47–73. [Google Scholar] [CrossRef]
- Tsekouras, G.E.; Tsimikas, J. On training RBF neural networks using input-output fuzzy clustering and particle swarm optimization. Fuzzy Sets Syst. 2013, 221, 65–89. [Google Scholar] [CrossRef]
- Wang, G.G.; Guo, L.H.; Gandomi, A.H.; Hao, G.S.; Wang, H.Q. Chaotic krill herd algorithm. Inf. Sci. 2014, 274, 17–34. [Google Scholar] [CrossRef]
- Wang, G.G.; Tan, Y. Improving metaheuristic algorithms with information feedback models. IEEE Trans. Cybern. 2017, 49, 542–555. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Liu, Z.H.; Min, F. A PSO algorithm for multi-objective cost-sensitive attribute reduction on numeric data with error ranges. Soft Comput. 2017, 21, 7173–7189. [Google Scholar] [CrossRef]
- Ding, S.C.; Hang, J.; Wei, B.L.; Wang, Q.J. Modelling of supercapacitors based on SVM and PSO algorithms. IET Electr. Power Appl. 2018, 12, 502–507. [Google Scholar] [CrossRef]
- Keogh, E.; Chakrabarti, K.; Pazzani, M.; Mehrotra, S. Dimensionality reduction for fast similarity search in large time series databases. Knowl. Inf. Syst. 2001, 3, 263–286. [Google Scholar] [CrossRef]
- Mousas, C.; Anagnostopoulos, C.N. Learning motion features for example-based finger motion estimation for virtual characters. 3D Res. 2017, 8, 25. [Google Scholar] [CrossRef]
- Liu, H.; Xiao, G.F. Improved fuzzy clustering image segmentation algorithm based on particle swarm optimization. Comput. Eng. Appl. 2013, 49, 37–52. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning |
|---|---|
| S | The single shot gather |
| F | The first-arrival times |
| l | The vertical window size |
| b | The horizontal window size |
| The starting index of the current window | |
| a | The energy ratio weight |
| k | The search step size |
| The starting index array of result windows | |
| n | The number of traces |
| m | The number of samples for each trace |
| R | The first-arrival range matrix |
| The parameters of fitness function | |
| The parameters of fitness function | |
| B | The boundary matrix |
| The position boundary matrix | |
| The velocity range matrix | |
| g | The dimension of the input problem |
| f | The fitness function |
| M | The number of particles |
| The inertia weight of each particle’s velocity | |
| The global influence weight | |
| w | The inertia weight |
| T | The maximum iteration times |
| The convergent error | |
| The solution of the best particle | |
| U | The first-arrival range matrix |
| e | The number of clustering centers |
| The fuzzy indicator | |
| The objective function | |
| The center of the k-th cluster | |
| The distance between and |
| Data Sources (Data Length) | BNN | DC | MCM | FPSF |
|---|---|---|---|---|
| Xinjiang (300200) | ||||
| Sichuan (160064) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, L.; Jiang, Z.-y.; Min, F. First-Arrival Travel Times Picking through Sliding Windows and Fuzzy C-Means. Mathematics 2019, 7, 221. https://doi.org/10.3390/math7030221
Gao L, Jiang Z-y, Min F. First-Arrival Travel Times Picking through Sliding Windows and Fuzzy C-Means. Mathematics. 2019; 7(3):221. https://doi.org/10.3390/math7030221
Chicago/Turabian StyleGao, Lei, Zhen-yun Jiang, and Fan Min. 2019. "First-Arrival Travel Times Picking through Sliding Windows and Fuzzy C-Means" Mathematics 7, no. 3: 221. https://doi.org/10.3390/math7030221
APA StyleGao, L., Jiang, Z.-y., & Min, F. (2019). First-Arrival Travel Times Picking through Sliding Windows and Fuzzy C-Means. Mathematics, 7(3), 221. https://doi.org/10.3390/math7030221