1. Introduction and Background
The Information Theory provides various concepts of broad use in Probability and Statistics which are finalized to measure the information content of stochastic models. Apart from the classical differential entropy, which constitutes a useful tool for the analysis of absolutely continuous random variables, some information measures based on cumulative notions have been attracting an increasing amount of attention in the recent literature. Among such measures, in this paper we focus on the cumulative (past) inaccuracy of bivariate random lifetimes, which is a suitable extension of the cumulative entropy. We also deal with the mutual information, which is strictly related to the Shannon entropy, and is one of the most commonly adopted notions for bivariate random variables. Indeed, the mutual information is a measure of the mutual dependence of two random variables, and can be evaluated by means of the joint (and marginal) distributions.
We recall some recent papers dealing with stochastic models and information measures of interest in the reliability theory. Navarro et al. [
1] presented some stochastic ordering and properties of aging classes of dynamic cumulative residual entropy, where Psarrakos and Navarro [
2] generalized the concept of cumulative residual entropy by relating this concept to the mean time between record values, and also considered the dynamic version of this new measure. Moreover, Tahmasebi and Eskandarzadeh [
3] proposed a new extension of the cumulative entropy based on
k-th lower record values. Sordo and Psarrakos [
4] provided comparison results for the cumulative residual entropy of systems and their dynamic versions.
Motivated by some of the articles mentioned above, in this paper we aim to investigate some applications of the previously mentioned information measures to the k-lower record values. Record values are widely studied in the literature as a suitable tool to convey essential information in stochastic models. More recently, they have also been attracting attention in applied contexts related to high-dimensional data, where it is computationally more convenient to determine the rank rather than the specific values of the observations under investigation.
More specifically, within the scope of this paper, we propose to study the cumulative measure of inaccuracy in k-lower record values and the parent random variable of a random sample. The context of dynamic observations will be also considered by analyzing the dynamic cumulative inaccuracy and related characterization results. We present some properties of the proposed measures, as well as the empirical cumulative measure of inaccuracy in k-lower record values. Moreover, the investigation focuses also on the mutual information measure, finalized to measure the degree of dependency between lower record values.
In the remaining part of this section, we recall the relevant notions that will be used in the following, and provide the plan of the paper. Specifically, we discuss the basic definitions and properties of the information measures mentioned above, i.e., the cumulative inaccuracy and the mutual information. Then, we mention the essential results on the lower record values and recall certain useful stochastic orders. We shall look into nonnegative random variables, with the case of truncated support being treatable in a similar way.
Throughout the paper, “log” means natural logarithm, prime denotes derivative, and the terms “increasing” and “decreasing” are used in a non-strict sense. Finally, as is customary, we assume that is vanishing.
1.1. Notions of Information Theory
Consider an absolutely continuous random vector having nonnegative components. We denote by the joint probability density function (PDF) by and , the marginal PDFs, and by and , the cumulative distribution functions (CDFs) of X and Y, respectively.
Bearing in mind the applications in the reliability theory, we assume that
X and
Y denote random lifetimes of suitable systems having support
. Let
be the (Shannon) differential entropy of
X.
is defined similarly, and the bivariate entropy of
is given by
. Moreover, the conditional entropy of
Y given by
X is expressed by:
whereas the mutual information of
is defined as:
We recall that
is a measure of dependence between
X and
Y, with
if, and only if
X and
Y are independent. Furthermore,
is largely adopted to assess the information content in a variety of applied fields, such as signal processing and pattern recognition. Due to (
3), the mutual information can be expressed in terms of suitable entropies as follows (see, for example, Ebrahimi et al. [
5]):
See also Ebrahimi et al. [
6] and Ahmadi et al. [
7] for various results of interest in the reliability theory involving dynamic measures for multivariate distributions based on the mutual information.
Among the notions involving cumulative versions of information measures, we now recall the cumulative (past) inaccuracy of
, given by:
As specified in
Section 1 of Kundu et al. [
8], the measure given in (
5) can be viewed as the cumulative analogue of the Kerridge inaccuracy measure of
X and
Y, which is expressed as
(cf. Kerridge [
9]). The relevant difference is that Equation (
5) involves the CDFs instead of the PDFs. In many real situations, it is more convenient to deal with distribution functions which carry information about the fact that an event occurs prior or after the current time. Moreover, the measure given in (
5) provides information content when using
, the CDF asserted by the experimenter due to missing or incorrect information in experiments, instead of the true distribution
. Clearly, if
F and
G are identical, then
identifies with the cumulative entropy studied by Di Crescenzo and Longobardi [
10] and by Navarro et al. [
1]. See
Section 5 of Kumar and Taneja [
11] for various results involving (
5) and the related dynamic version, i.e., the dynamic cumulative past inaccuracy measure. We finally recall that the cumulative inaccuracy (
5) and the cumulative entropy are also involved in the definition of other information measures of interest (see, for instance, Park et al. [
12], and Di Crescenzo and Longobardi [
13] for the cumulative Kullback-Leibler information).
1.2. Lower Record Values
Record values are often studied in various fields due to their relevance in specific applications. If statistical observations are difficult to obtain, or when experimental observations are destroyed and access to them is not available, then the researchers are forced to make inference about the distribution of the observations of used record amounts. Suppose, for example, that it is required to estimate the water level of a river solely based on the available records of previous flooding. Similarly, consider variables such as record rainfall, record temperature, wind speed record, and other quantities of interest in meteorology. In such cases, the analysis of statistical observations, if performed by resorting to lower or upper record values.
Let us now recall some basic notions about lower record values that will be used in this paper. Let
X be an absolutely continuous nonnegative random variable with CDF
and PDF
, and let
be a sequence of independent random variables, distributed identically as
X. An observation
,
, will be called a lower record value if its value is less than the values of all previous observations. Thus,
is a lower record value if
for every
. For a fixed positive integer
k, similarly to Dziubdziela and Kopociński [
14], we define the sequence
of
k-th lower record times for the sequence
as follows:
where
denotes the
j-th order statistic in a sample of size
m (see also Malinowska and Szynal [
15]). Then,
is called a sequence of
k-th lower record values of
. Since the ordinary record values are contained in the
k-records, the results for usual records can be obtained as a special case by setting
. The PDF of
, for
and
, is given by:
and the joint PDF of
, for
,
, is:
where
are the cumulative reversed hazard rate and the reversed hazard rate of
X, respectively. Hence, the conditional PDF of
given
,
, is given by:
By using the well-known relation
we see that the CDF corresponding to Equation (
7) can be obtained as:
We note that the sequence of
k-th
upper record times is denoted as
. It is defined similarly to
by reverting the last inequality in (
6) (see, for instance, Dziubdziela and Kopociński [
14] or Tahmasebi et al. [
16]). Record values apply in problems such as industrial stress testing, meteorological analysis, hydrology, sport, and economics. In reliability theory, record values are used to study things such as technical systems which are subject to shocks, e.g., peaks of voltages. For more details about records and their applications, one may refer to Arnold et al. [
17]. Several authors investigated measures of inaccuracy for ordered random variables. Thapliyal and Taneja [
18] proposed the measure of inaccuracy between the
i-th order statistic and the parent random variable. Moreover, Thapliyal and Taneja [
19] developed measures of dynamic cumulative residual and past inaccuracy. They studied characterization results of these dynamic measures under a proportional hazard model and proportional reversed hazard model. The same authors introduced the measure of residual inaccuracy of order statistics and proved a related characterization result (cf. Thapliyal and Taneja [
20]). Equality of Rényi entropies of upper and lower
k-records is also known to provide a characteristic property of symmetric distributions (see Fashandi and Ahmadi [
21]). Furthermore, it is worth mentioning that the analysis of lower record values is related to the generalized cumulative entropy. For instance, its role in the study of a new measure of association based on the log-odds rate has recently been pinpointed by Asadi [
22]. Finally, recent contributions on a measure of past entropy for
nth upper
k-record values can be found in Goel et al. [
23].
1.3. Stochastic Orders and Related Notions
Aiming to use stochastic orders to perform suitable comparisons, here we recall some relevant definitions. Let X and Y be random variables, where X is said to be smaller than Y, according to the
- -
usual stochastic ordering (denoted by ) if for all ; it is known that for all increasing functions ;
- -
likelihood ratio ordering (denoted by ) if is increasing in x;
- -
decreasing convex order, denoted by , if for all decreasing convex functions , such that the expectations exist.
Moreover, we say that
X has a
decreasing reversed hazard rate (DRHR) if
is decreasing in
x. For specific details on these notions, see, for instance, Shaked and Shanthikumar [
24], and for applications of the decreasing convex order, see Ma [
25].
1.4. Plan of the Paper
In this investigation, we propose the cumulative measure of inaccuracy and study characterization results of a dynamic cumulative inaccuracy measure. Also, we study the degree of dependency among the sequence of k-th lower record values through the mutual information of record values.
The paper is organized as follows: In
Section 2, we consider a measure of inaccuracy associated with
and
X. We provide some results and properties of such a measure, including an application to the proportional reversed hazards model. In
Section 3, we propose the dynamic version of inaccuracy associated with
and
X, and provide a characterization result. In
Section 4, we study the problem of estimating the cumulative measure of inaccuracy by means of the empirical cumulative inaccuracy in
k-lower record values. The rest of the section is devoted to a simple application to real data, with the discussion of some special cases, and a central limit theorem for the empirical cumulative measure of inaccuracy in the case of exponentially distributed random samples. Finally, in
Section 5 we investigate the mutual information between sequences of lower record values, aiming to measure their degree of dependency. Specifically, we show that this measure is distribution-free and can be computed by using the distribution of the
k-th lower record values of the sequence from the uniform distribution.
2. Cumulative Measure of Inaccuracy
Let us now consider the cumulative measure of inaccuracy between
and the parent non-negative random variable, say
X. Recalling (
5) and (
11), we have:
with
given in (
9). According to the comments given in
Section 1.1,
can be used to gain information concerning an experiment for which the distribution of the
k-lower record values is compared with the parent distribution. Noting that, due to (
7),
being a random variable with density function
and recalling that
is the reversed hazard rate of
X (see (
9)), from (
12) we obtain:
Remark 1. Making use of the generalized cumulative entropy introduced in Definition 1.1 of Tahmasebi and Eskandarzadeh [3], given by:from (13) one has that the cumulative measure of inaccuracy between and X can be expressed: as a size-biased combination of generalized cumulative entropies through the following weighted sum with linearly increasing weights: Furthermore, from (11) and (12) we obtain an alternative expression, that is: In the following proposition we provide another form of .
Proposition 1. Let X be a nonnegative random variable with cdf F; for the cumulative measure of inaccuracy between and X, we have: Proof. By (
12) and the relation
, we have:
By using Fubini’s theorem, we get:
and the result thus follows. □
Hereafter, we present some examples and properties of .
Example 1. - (i)
If X is uniformly distributed in , then: - (ii)
If X is exponentially distributed with mean , then: - (iii)
If X has an inverse Weibull distribution with cdf , , with and , then:
For suitable choices of n and k, such inaccuracy measures are plotted in Figure 1, where the parameters are chosen so that the considered distributions have a unity mean, i.e., (i) , (ii) , and (iii) , recalling that the mean of an inverse Weibull distribution is (see de Gusmão et al. [26]). In all cases, is decreasing in k and increasing in n. Let us now discuss the effect of identical linear transformations on .
Proposition 2. Let and ; for , it holds that: Proof. Recalling (
14), it is not hard to see that:
, so that the proof immediately follows. □
Remark 2. Let X be a symmetric random variable with respect to the finite mean , i.e., for all . Then the following relation holds:where, similarly to (12), the latter term defines the cumulative residual measure of inaccuracy between the k-th upper record value and X. Here, as usual, denotes the survival function of X, and denotes the survival function of the k-th upper record value . Hereafter, we obtain an upper bound for .
Proposition 3. Let X be an absolutely continuous non-negative random variable with a cumulative reversed hazard rate , such that the following function is finite: Proof. By (
12), from
and Fubini’s theorem, we obtain:
thus completing the proof. □
Now we can prove a property of the considered inaccuracy measure by means of stochastic orderings. For that, we use the notions recalled in
Section 1.3.
Theorem 1. Suppose that the non-negative random variable X is DRHR. Then, for , one has: Proof. Recalling that
is the PDF of
, provided in Equation (
7), then the ratio
is increasing in
x. Therefore,
, and this implies that
, i.e.,
for all increasing functions
such that these expectations exist. (For more details, see Shaked and Shanthikumar [
24]). Thus, since
X is DRHR and
is its reversed hazard rate, then
is increasing in
x. As a consequence, from (
13) we have:
where
is expressed in (
13). The proof is thus completed. □
Theorem 2. Let X and Y be two non-negative random variables, such that ; then we have: Here, similarly to (6), denotes the k-th lower record times for the sequence with distribution function , and is the distribution function of Y. Proof. Due to (
18),
is a decreasing convex function in
x. The proof then immediately follows from Proposition 3. □
Let us now investigate the cumulative measure of inaccuracy within the proportional reversed hazards model (PRHM). We recall that two random variables
X and
satisfy the PRHM if their distribution functions are related by the following identity, for
:
For some properties of such a model associated with aging notions and the reversed relevation transform, see Gupta and Gupta [
27] and Di Crescenzo and Toomaj [
28], respectively.
In this case, we assume that
X and
are non-negative, absolutely continuous random variables. Due to Equation (
20) and making use of (
5) and (
11), and noting that
, we obtain the cumulative measure of inaccuracy between
and
as follows, for
:
with
expressed in (
9). Moreover, if
is a positive integer, then the last expression can be rewritten in terms of the generalized cumulative entropy (
14) as follows:
We recall that in this case, i.e., when , the PRHM expresses that is distributed as the first-order statistics of a random sample having size and taken from the distribution of X.
Let us now obtain suitable bounds under the PRHM.
Proposition 4. Let X and be non-negative, absolutely continuous random variables satisfying the PRHM as specified in (20), with . If , then for any we have: Proof. Clearly, for
it is
for all
, and then the thesis immediately follows from (
14) and (
21). □
We conclude this section with a remark on the cumulative measure of inaccuracy for bivariate first lower record values.
Remark 3. Consider two identically distributed sequences of random variables and , and denote by and the corresponding first lower record times. Then, for and making use of (11) it is not hard to see that the cumulative measure of inaccuracy between and is given by:where is the reversed hazard rate of the underlying distribution. 3. Dynamic Cumulative Measure of Inaccuracy
In this section, we study the dynamic version of the inaccuracy measure
. Let
X be the random lifetime of a brand new system that begins to work at time 0 and is observed only at deterministic inspection times. Clearly, if the system is found failed at time
t, then the conditional distribution function of
, known as the past lifetime, is given by
,
. In a sequence of i.i.d. failure times having the same distribution as
X, if the information about the
k-th lower failure times is available, then
is the conditional probability that the
k-th lower failure time is smaller that
x, given that it is smaller than
t, for
, where
is the CDF given in (
11). Hence, the dynamic cumulative measure of inaccuracy between
and
X is expressed by the inaccuracy measure between the corresponding past lifetimes, i.e.,:
where
is the mean inactivity time of the random variable
. Clearly, recalling (
12) and assuming that
X is a
bona fide random variable, from (
22) we have
. Moreover, if
for all
, since
, we immediately have:
We can now obtain a characterization result for .
Theorem 3. Let X be a non-negative, absolutely continuous random variable with distribution function . If the dynamic cumulative inaccuracy (22) is finite for all , then characterizes the distribution function of X. Proof. Differentiating both sides of (
22) with respect to
t, we obtain:
where
and
are the reversed hazard rates, and where we have set
Taking again the derivative with respect to
t, we get:
Suppose that there are two CDFs,
F and
, such that for all
t,
and having reversed hazard rates
and
, respectively. Then, from (
23) we get, for all
t:
where
for
and
. By using Theorem 2.1 and Lemma 2.2 of Gupta and Kirmani [
29], we obtain
, for all
t. Since the reversed hazard rate function characterizes the distribution function uniquely, the proof is completed. □
4. Empirical Cumulative Measure of Inaccuracy
In this section, we address the problem of estimating the cumulative measure of inaccuracy by means of the empirical cumulative inaccuracy in lower record values. Let
be a random sample of size
m from an absolutely continuous CDF
. Then, according to (
12), the
empirical cumulative measure of inaccuracy is defined as:
where
is the empirical distribution of the sample,
being the indicator function. Let
denote the order statistics of the sample. Then, (
24) can be written as:
Finally, recalling that:
from Equation (
25) we see that the empirical cumulative measure of inaccuracy can be expressed as:
where
are the sample spacings.
The following example provides an application of the empirical cumulative measure of inaccuracy to real data.
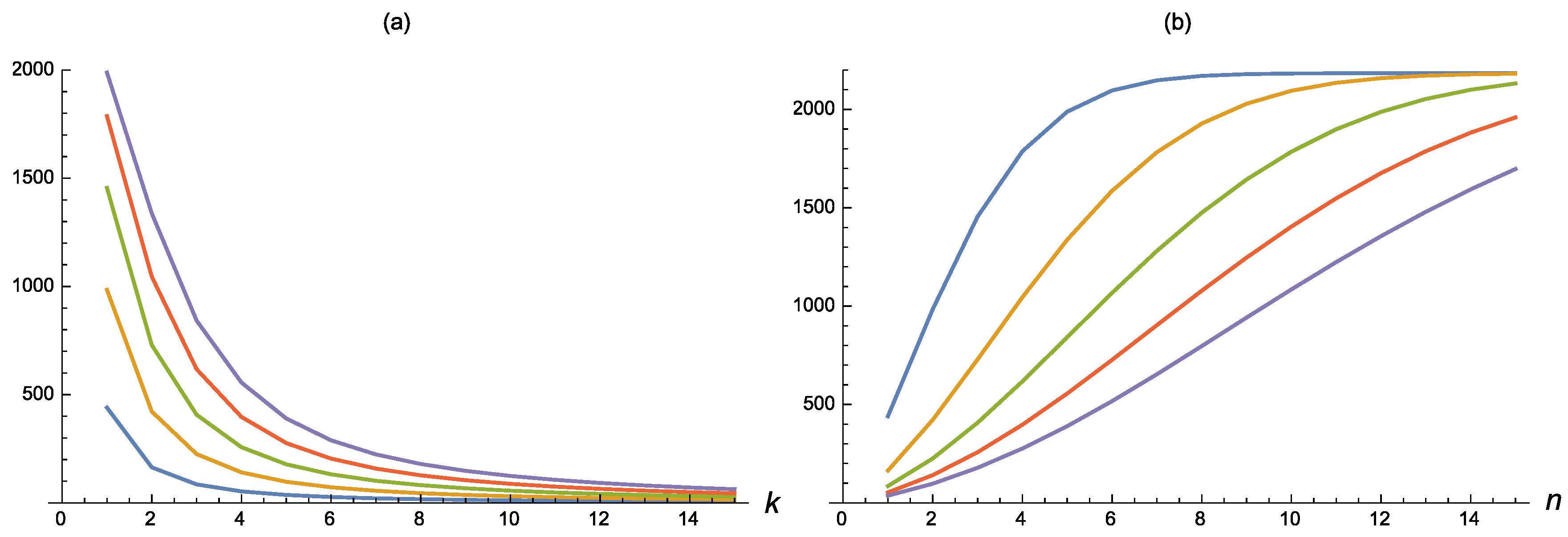
Example 2. Consider the sample data by Abouammoh and Abdulghani [30] concerning the lifetimes (in days) of patients suffering from blood cancer. The evaluation of the corresponding empirical cumulative measure of inaccuracy, obtained by means of Equation (26), shows that the values of are decreasing in k and increasing in n (see Figure 2). Let us now discuss two special cases concerning populations from the uniform distribution and the exponential distribution.
Example 3. Consider the random sample from a population uniformly distributed in . In this case, the sample spacings (27) are independent and follow the beta distribution with parameters 1 and m (for more details, see Pyke [31]). Hence, making use of (26), the mean and the variance of the empirical cumulative measure of inaccuracy are, respectively:and Table 1 shows the values of the mean (28) and the variance (29) for , and for sample sizes , with . We note that is increasing in m and n. Example 4. Let be a random sample drawn from the exponential distribution with parameter λ. Then, from (26) we see that the empirical cumulative measure of inaccuracy can be expressed as the following sum of independent and exponentially distributed random variables: Indeed, in this case, the sample spacings defined in (27) are independent and exponentially distributed with mean (for more details, see Pyke [31]), so that the mean and the variance of are given by:whereand In Table 2, for , we show the values of the mean and the variance (31) for sample sizes , with and . One can easily see that is increasing in m, whereas is decreasing in m. Hereafter, we show a central limit theorem for the empirical cumulative measure of inaccuracy in the same case as Example 4.
Theorem 4. If is a random sample drawn from the exponential distribution with parameter λ, then: Proof. With reference to the notation adopted in Example 4, by setting
,
, for large
m, we have:
and recalling that
for the exponential distribution:
where
Hence, for a suitable function
, for large
m, it holds that:
The Lyapunov’s condition of the central limit theorem is thus fulfilled, this giving the proof. □
5. Mutual Information of Lower Record Values
In this section, we study the degree of dependency between the sequences of lower record values by means of the mutual information. Recall the basic relations given in Equations (
3) and (
4).
First, with reference to (
1), in the following theorem we obtain the entropy of
k-th lower record values.
Theorem 5. Let be a sequence of IID random variables having finite entropy. The entropy of for all is given by:where is the digamma function, and: Proof. As customary, we denote by
and
the PDF and CDF of
. By (
7), we have:
By taking
, we get:
Hence, making use of Equation (A.8) of Zahedi and Shakil [
32], after some calculations we finally get: Equation (
32). □
It is worth noting the analogies between Equation (
33) and the function
considered by Baratpour et al. [
33] for the analysis of the upper record values.
In the following lemma we express the mutual information between and in terms of the digamma function.
Lemma 1. Let be the k-th lower record values from the uniform distribution over interval . Then, the mutual information between and , for , is given by: Proof. In this case, recalling (
9), we have
,
. Hence, making use of Equations (
2), (
4), (
8) and (
10), for
we get:
where
Hence, by straightforward calculations we obtain:
where
. Similarly, by (
32) we have
Recalling (
4), the thesis thus follows from (
35) and (
36). □
Let us now come to the main result of this section. Recall that the mutual information of
is defined in (
3).
Theorem 6. Under the assumptions of Theorem 5, the following result holds:
- (i)
The mutual information between the m-th and the n-th k-lower records is distribution-free, and is given by: - (ii)
The mutual information is increasing in m.
Proof. - (i)
Let and , where denotes the pseudo-inverse function of F, i.e., the quantile function of X. Then, and are the m-th and n-th k-lower records of the uniform distribution over the interval . By the invariance property of mutual information, we have: , thus the result follows from Lemma 1.
- (ii)
By taking
in (
37), we get:
so that
It is not hard to see that the right-hand-side is positive, and the proof thus follows. □
It is useful to assess the mutual information between the k-th lower record values, such as when such values correspond to successive failures of a repairable system. Hence, the information provided in Theorem 6 is useful for constructing suitable replacement criteria of components, in order to avoid failures and to improve system availability.
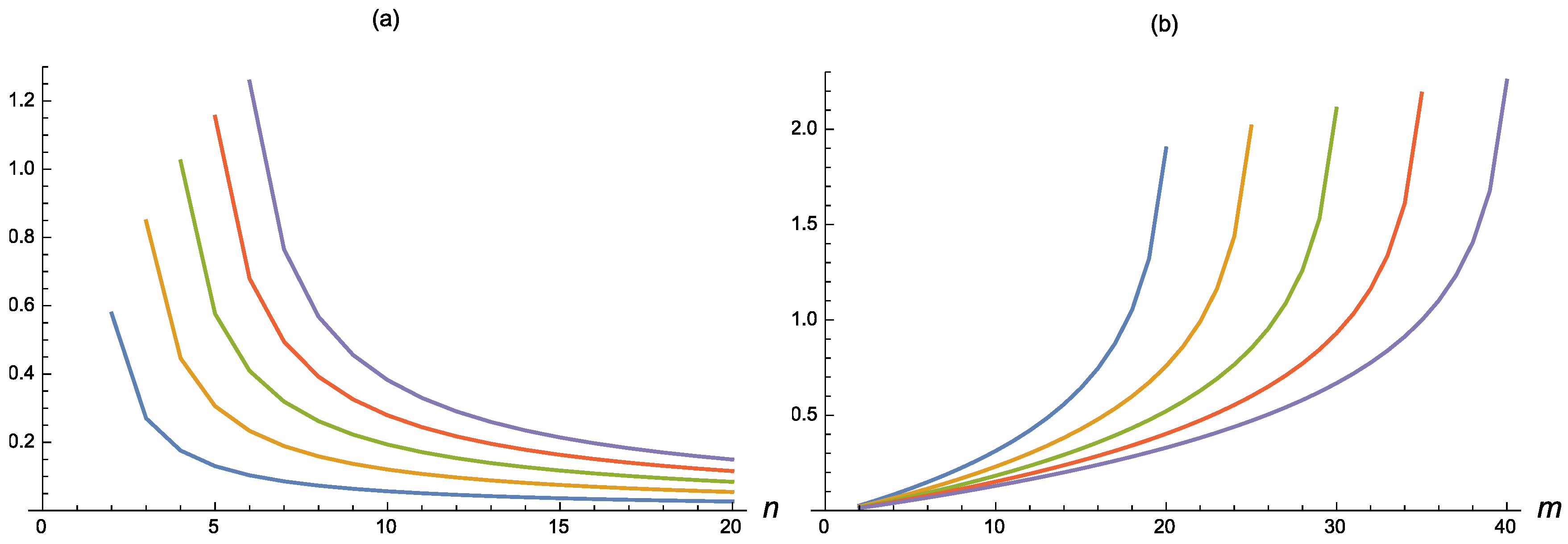
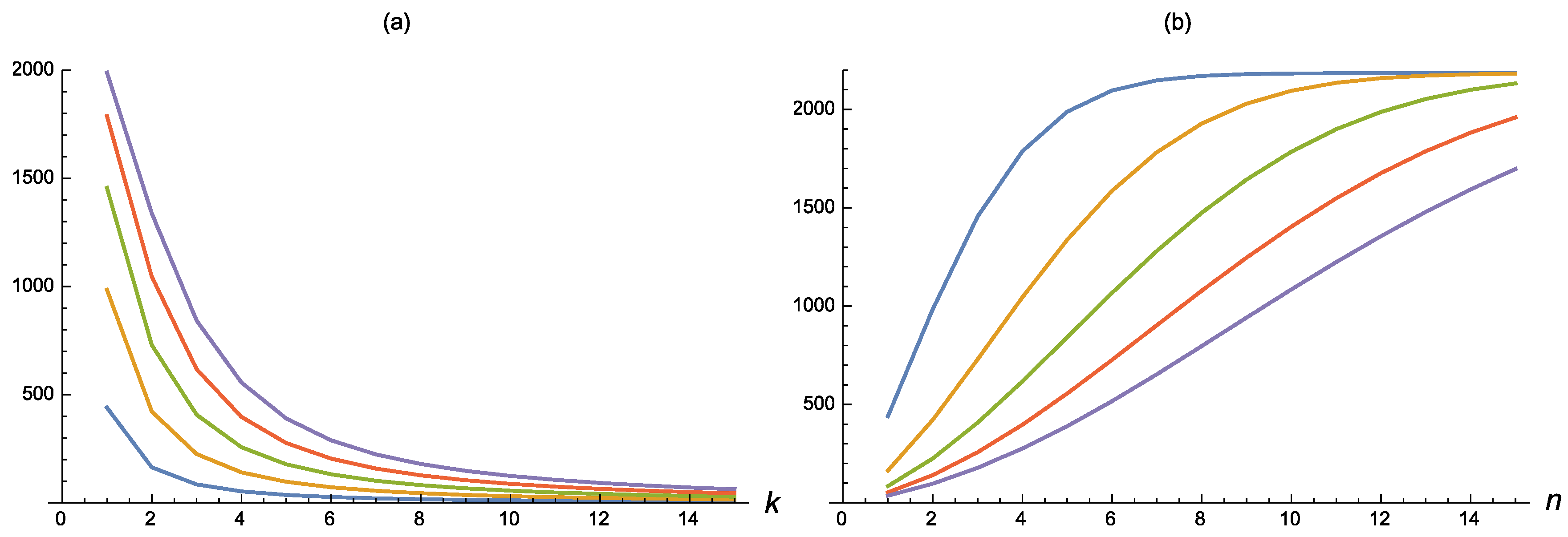
The mutual information between the
m-th and the
n-th
k-lower records, determined in Equation (
37), is shown in
Figure 3 for different choices of
m and
n. For fixed values of
m, such an information measure is decreasing in
n, whereas for fixed
n, it is increasing in
m.
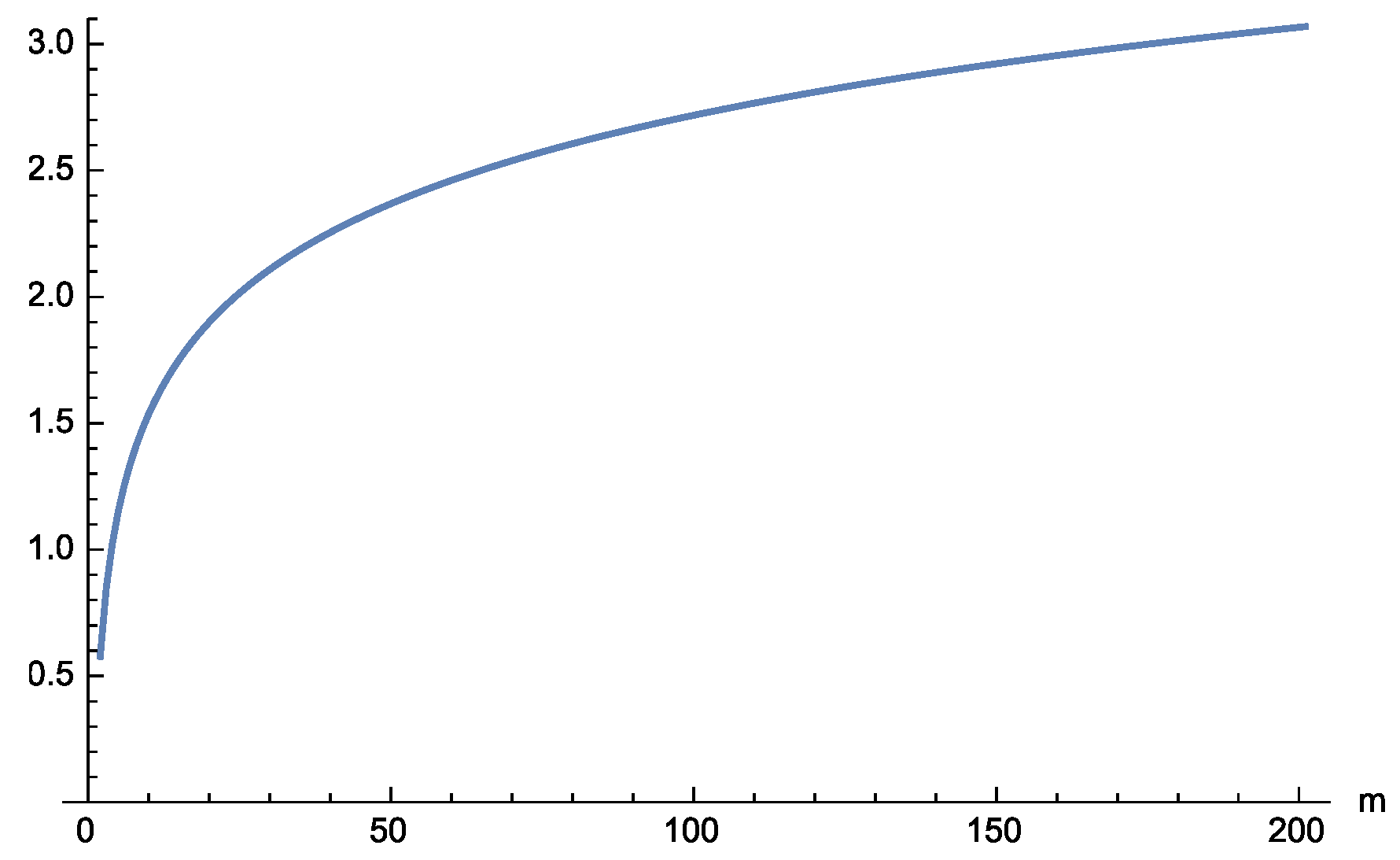
Finally,
Figure 4 shows that
is increasing in
m, in agreement with the point
(ii) of Theorem 6.
6. Conclusions
In this paper, we discussed the concept of inaccuracy between and X in a random sample generated by X. We proposed a dynamic version of cumulative inaccuracy and studied a related characterization result. We also proved that can uniquely determine the parent distribution F. Moreover, we constructed bounds for characterization results of . Also, we estimated the cumulative measure of inaccuracy by means of the empirical cumulative inaccuracy in lower record values. These concepts can be applied in measuring the inaccuracy contained in the associated past lifetime. Finally, we studied the degree of dependency among the sequence of k-th lower record values in terms of mutual information. We showed that is distribution-free and can be computed by using the distribution of the k-th lower record values of the sequence from the uniform distribution.



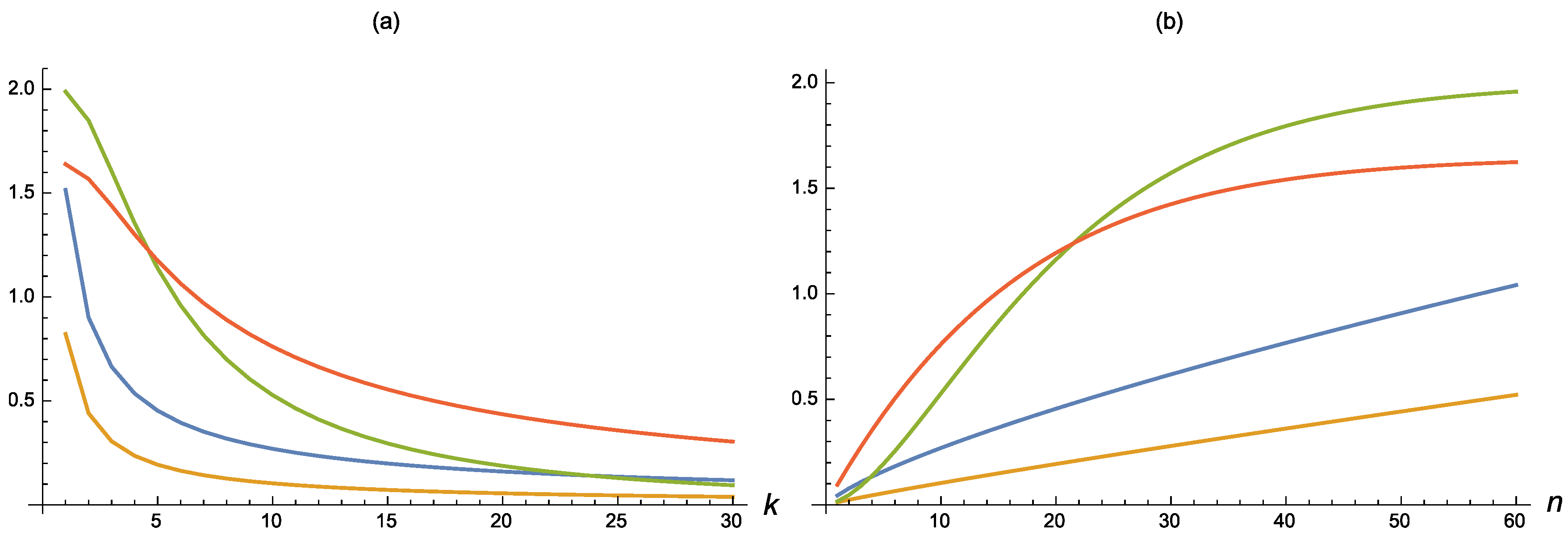

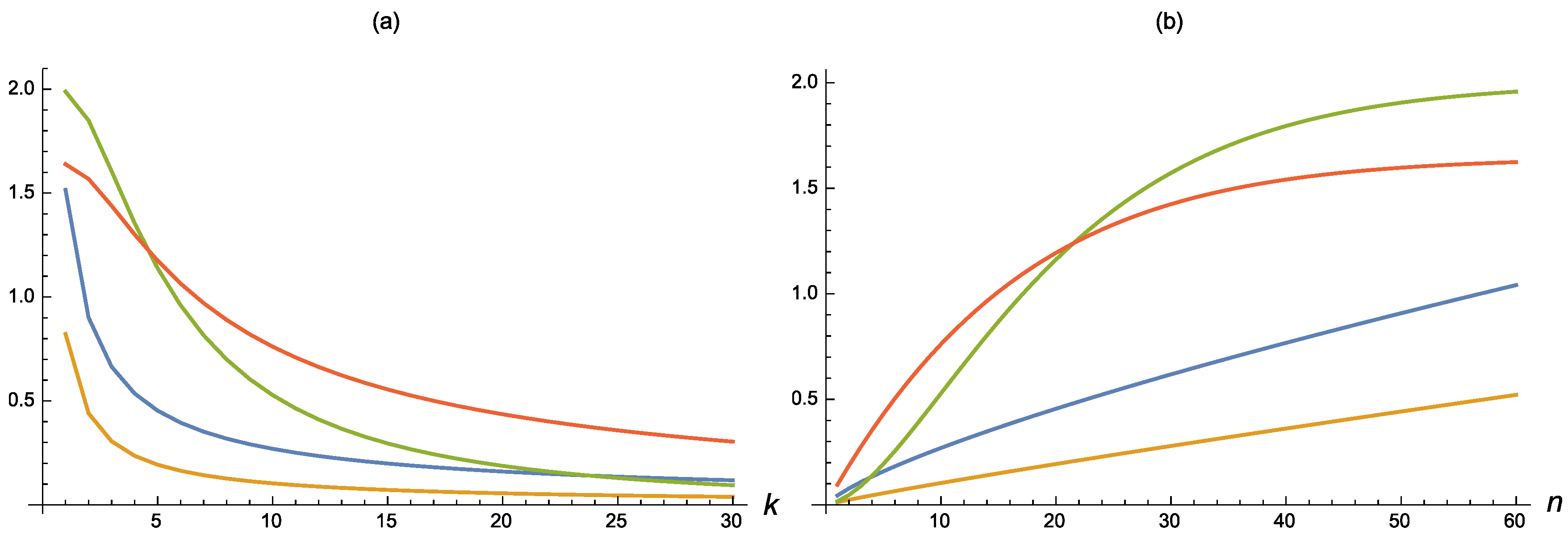{kind=link}
{kind=link}
{kind=link}
{kind=link}