A New Record of Graph Enumeration Enabled by Parallel Processing



Abstract
1. Introduction
- (1)
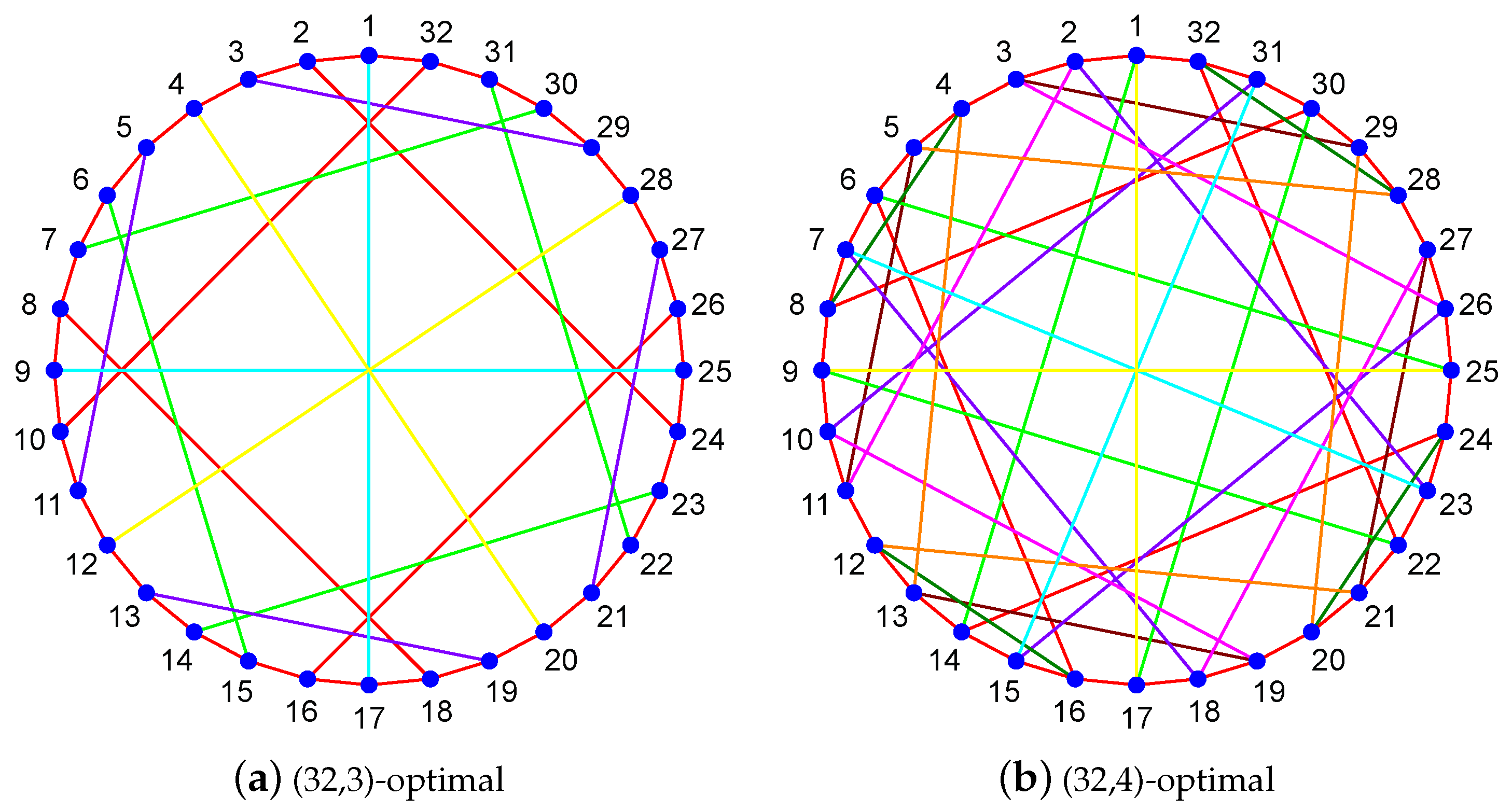
- filtered all 3-regular graphs up to order 32 with minimum average shortest path lengths (ASPL);
- (2)
- discovered thousands of 4-regular graphs of order 32 with minimum ASPL;
- (3)
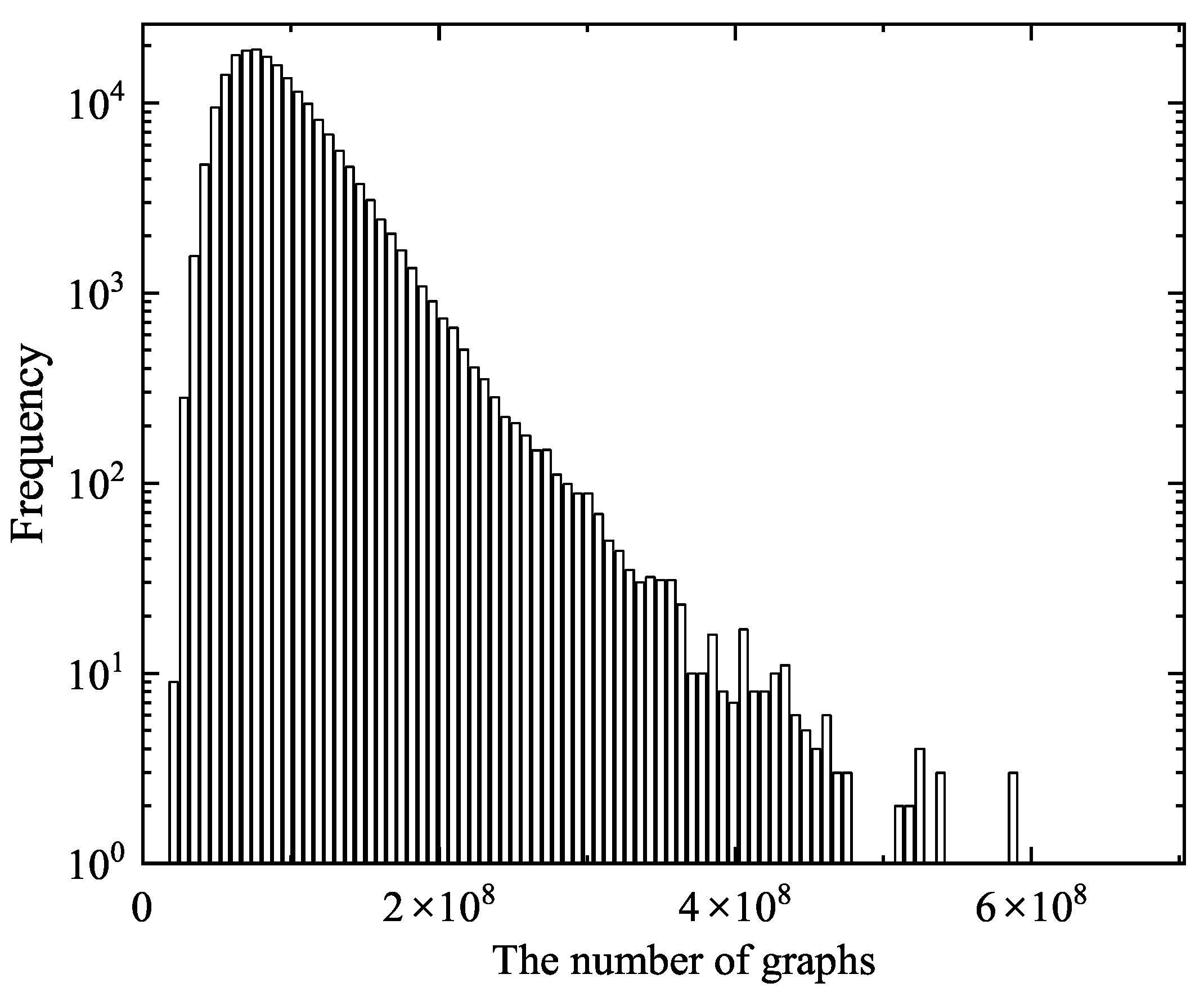
- generated the exact counts of 4-regular graphs of order 23 by using the three supercomputer clusters located in the U.S., China, and Ecuador.
2. The Enumeration Framework and Results
2.1. The Enumeration Function
2.2. Search for a Regular Graph with Minimal ASPL
2.3. Graph Counting for (23,4)-Regular Graphs
3. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Godsil, C.; Royle, G. Algebraic Graph Theory; Springer: New York, NY, USA, 2001. [Google Scholar] [CrossRef]
- Jäntschi, L. The Eigenproblem Translated for Alignment of Molecules. Symmetry 2019, 11, 1027. [Google Scholar] [CrossRef]
- Joiţa, D.M.; Jäntschi, L. Extending the Characteristic Polynomial for Characterization of C20 Fullerene Congeners. Mathematics 2017, 5, 84. [Google Scholar] [CrossRef]
- Conway, J. Five $1,000 Problems (Update 2017). In On-Line Encyclopedia of Integer Sequences; Available online: https://oeis.org/A248380/a248380.pdf (accessed on 6 August 2019).
- Hoffman, A.J.; Singleton, R.R. On Moore Graphs with Diameters 2 and 3. IBM J. Res. Dev. 1960, 4, 497–504. [Google Scholar] [CrossRef]
- Das, S.; Banerjee, A. Hyper Petersen network: yet another hypercube-like topology. In Proceedings of the 1992 Fourth Symposium on the Frontiers of Massively Parallel Computation, McLean, VA, USA, 19–21 October 1992; IEEE Computer Society Press: Washington, DC, USA, 1992. [Google Scholar] [CrossRef]
- Ohring, S.; Das, S. Folded Petersen cube networks: New competitors for the hypercubes. In Proceedings of the 1993 5th IEEE Symposium on Parallel and Distributed Processing, Dallas, TX, USA, 1–4 December 1993; IEEE Computer Society Press: Washington, DC, USA, 1993. [Google Scholar] [CrossRef]
- Ohring, S.; Das, S.K. The Folded Petersen Network: A New Communication-Efficient Multiprocessor Topology. In Proceedings of the 1993 International Conference on Parallel Processing—ICPP 93, Syracuse, NY, USA, 16–20 August 1993; Volume 1. [Google Scholar] [CrossRef]
- Seo, J.H. Three-dimensional Petersen-torus network: A fixed-degree network for massively parallel computers. J. Supercomput. 2011, 64, 987–1007. [Google Scholar] [CrossRef]
- Seo, J.H.; Kim, J.S.; Chang, H.J.; Lee, H.O. The hierarchical Petersen network: a new interconnection network with fixed degree. J. Supercomput. 2017, 74, 1636–1654. [Google Scholar] [CrossRef]
- Seo, J.H.; Lee, H.; suk Jang, M. Petersen-Torus Networks for Multicomputer Systems. In Proceedings of the 2008 Fourth International Conference on Networked Computing and Advanced Information Management, Gyeongju, Korea, 2–4 September 2008. [Google Scholar] [CrossRef]
- Robinson, R.W.; Wormald, N.C. Numbers of cubic graphs. J. Graph Theory 1983, 7, 463–467. [Google Scholar] [CrossRef]
- Robinson, R.W. Counting cubic graphs. J. Graph Theory 1977, 1, 285–286. [Google Scholar] [CrossRef]
- Meringer, M. Fast generation of regular graphs and construction of cages. J. Graph Theory 1999, 30, 137–146. [Google Scholar] [CrossRef]
- Brinkmann, G. Fast generation of cubic graphs. J. Graph Theory 1996, 23, 139–149. [Google Scholar] [CrossRef]
- Brinkmann, G.; Goedgebeur, J. Generation of Cubic Graphs and Snarks with Large Girth. J. Graph Theory 2017, 86, 255–272. [Google Scholar] [CrossRef]
- Brinkmann, G.; Coolsaet, K.; Goedgebeur, J.; Mélot, H. House of Graphs: A database of interesting graphs. Discret. Appl. Math. 2013, 161, 311–314. [Google Scholar] [CrossRef]
- OEIS Foundation Inc. The On-Line Encyclopaedia of Integer Sequences. Available online: http://oeis.org/ (accessed on 6 August 2019).
- OEIS Foundation Inc. A068934 in the On-Line Encyclopaedia of Integer Sequences. Available online: http://oeis.org/wiki/User:Jason_Kimberley/A068934 (accessed on 6 August 2019).
- Vadhan, S.P. The Complexity of Counting in Sparse, Regular, and Planar Graphs. SIAM J. Comput. 2001, 31, 398–427. [Google Scholar] [CrossRef]
- Meringer, M. Structure Enumeration and Sampling. In Handbook of Chemoinformatics Algorithms; Chapman and Hall/CRC: London, UK, 2010; pp. 233–267. [Google Scholar] [CrossRef]
- Meringer, M.; Cleaves, H.J. Exploring astrobiology using in silico molecular structure generation. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2017, 375, 20160344. [Google Scholar] [CrossRef]
- Gropp, W.; Lusk, E.; Skjellum, A. (Eds.) Using MPI: Portable Parallel Programming with the Message Passing Interface; MIT Press Ltd.: Cambridge, MA, USA, 2014. [Google Scholar]
- Deng, Y.; Guo, M.; Ramos, A.F.; Huang, X.; Xu, Z.; Liu, W. Optimal Low-Latency Network Topologies for Cluster Performance Enhancement. arXiv 2019, arXiv:1904.00513v1. [Google Scholar]
- Zhang, Y.; Huang, X.; Xu, Z.; Deng, Y. A Structured Table of Graphs with Symmetries and Other Special Properties. arXiv 2019, arXiv:1910.13539v3. [Google Scholar]
- OEIS Foundation Inc. A006820 in the On-Line Encyclopaedia of Integer Sequences. Available online: https://oeis.org/A006820 (accessed on 6 August 2019).
- Larrión, F.; Pizaña, M.; Villarroel-Flores, R. On Self-clique Shoal Graphs. Discrete Appl. Math. 2016, 205, 86–100. [Google Scholar] [CrossRef]
- Cerf, V.G.; Cowan, D.D.; Mullin, R.C.; Stanton, R.G. A partial census of trivalent generalized Moore networks. In Combinatorial Mathematics III; Springer: Berlin/Heidelberg, Germany, 1975; pp. 1–27. [Google Scholar] [CrossRef]
- Kitasuka, T.; Iida, M. A heuristic method of generating diameter 3 graphs for order/degree problem (invited paper). In Proceedings of the 2016 Tenth IEEE/ACM International Symposium on Networks-on-Chip (NOCS), Nara, Japan, 31 August–2 September 2016. [Google Scholar] [CrossRef]
- Mizuno, R.; Ishida, Y. Constructing large-scale low-latency network from small optimal networks. In Proceedings of the 2016 Tenth IEEE/ACM International Symposium on Networks-on-Chip (NOCS), Nara, Japan, 31 August–2 September 2016. [Google Scholar] [CrossRef]
- Shimizu, N.; Mori, R. Average shortest path length of graphs of diameter 3. In Proceedings of the 2016 Tenth IEEE/ACM International Symposium on Networks-on-Chip (NOCS), Nara, Japan, 31 August–2 September 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Koibuchi, M.; Fujiwara, I.; Fujita, S.; Nakano, K.; T. Uno, T.I.; Kawarabayashi, K. Graph Golf: The Order/degree Problem Competition. Available online: http://research.nii.ac.jp/graphgolf/ (accessed on 6 August 2019).
- Xu, Z.; Deng, Y. Optimal Routing for a Family of Scalable Interconnection Networks. In Proceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC’19), Denver, CO, USA, 17–22 November 2019. [Google Scholar]
- The Sunway Blue Light in Top 500 List (June 2018). Available online: https://www.top500.org/system/177447 (accessed on 6 August 2019).
- Gropp, W.; Lusk, E.L.; Sterling, T. (Eds.) Beowulf Cluster Computing with Linux (Scientific and Engineering Computation); The MIT Press: Cambridge, MA, USA, 2003. [Google Scholar]



{kind=link}
{kind=link}
| Order n | Quartics |
|---|---|
| 5 | 1 |
| 6 | 1 |
| 7 | 2 |
| 8 | 6 |
| 9 | 16 |
| 10 | 59 |
| 11 | 265 |
| 12 | 1544 |
| 13 | 10,778 |
| 14 | 88,168 |
| 15 | 805,491 |
| 16 | 8,037,418 |
| 17 | 86,221,634 |
| 18 | 985,870,522 |
| 19 | 11,946,487,647 |
| 20 | 152,808,063,181 |
| 21 | 2,056,692,014,474 |
| 22 | 28,566,273,166,527 |
| 23 | 429,668,180,677,439 |
| Cluster | Total Processed ( Graphs) | Computing Time (Core Years) | Core Speed ( Graphs/s) |
|---|---|---|---|
| SeaWulf | 66.12 | 178 | |
| Tianhe-1 | 19.53 | 113 | |
| IBM Quinde 1 | 13.25 | 56 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Huang, X.; Jimenez, F.; Deng, Y. A New Record of Graph Enumeration Enabled by Parallel Processing. Mathematics 2019, 7, 1214. https://doi.org/10.3390/math7121214
Xu Z, Huang X, Jimenez F, Deng Y. A New Record of Graph Enumeration Enabled by Parallel Processing. Mathematics. 2019; 7(12):1214. https://doi.org/10.3390/math7121214
Chicago/Turabian StyleXu, Zhipeng, Xiaolong Huang, Fabian Jimenez, and Yuefan Deng. 2019. "A New Record of Graph Enumeration Enabled by Parallel Processing" Mathematics 7, no. 12: 1214. https://doi.org/10.3390/math7121214
APA StyleXu, Z., Huang, X., Jimenez, F., & Deng, Y. (2019). A New Record of Graph Enumeration Enabled by Parallel Processing. Mathematics, 7(12), 1214. https://doi.org/10.3390/math7121214