1. Introduction
The university dormitory is the place where college students spend most of their daily life. The electricity consumption is often huge without any saving actions. In the context of the nationwide call for “energy savings” in China, it is necessary to provide some effective education courses, guidance, and management approach to cultivate “energy savings” behavior (habit), and eventually to achieve the “green campus” policy. Therefore, it is desirable to establish a more accurate forecasting model to monitor electricity consumption particular from the university dormitory. However, the electricity consumption data of a university dormitory are influenced by lots of factors, such as weather conditions, holidays, population of the dormitory, social activities of university, energy policy of university, and so on [
1,
2], the electricity consumption data demonstrate the non-linearity in nature, which lead the electricity consumption forecasting work be more complicate [
3,
4].
In the past decades, many researchers proposed lots of electricity consumption forecasting models to receive more accurate forecasting results. These forecasting models are often divided into two categories [
5]: the statistical methods and the artificial intelligent (AI) models. The statistical methods only employ historical data to find out the linear relationships among time periods. There are various statistical models that contain the ARIMA models [
6,
7,
8], regression models [
9,
10,
11], exponential smoothing models [
12,
13], Kalman filtering models [
14,
15], Bayesian estimation models [
16,
17], and so on. However, the inherent shortcomings of these statistical models are that they are only defined to deal with the linear relationships among the electricity consumption and other influenced factors mentioned above, eventually, only receiving unsatisfied forecasting results [
18].
Along with advanced nonlinear computing ability, the AI models have been mature diffusely explored to improve the forecasting accuracy of electricity consumption since the 1980s, such as artificial neural networks (ANNs) [
18,
19,
20,
21,
22], expert system models [
23,
24,
25,
26], and fuzzy inference methodologies [
27,
28,
29,
30]. To further overcome the inherent drawbacks embedded in these AI models, hybrid and combined models (hybridizing or combining with other advanced AI techniques) have received lots of attention [
31,
32,
33,
34,
35,
36,
37,
38,
39], as mentioned in [
5], three kinds of these hybrid or combined models, for example, hybridizing or combining these AI models with each other [
31,
32,
33]; hybridizing or combining with the statistical models [
34,
35,
36]; and hybridizing or combining with meta-heuristic algorithms [
37,
38,
39]. It is recommended to employ any kind of hybrid or combined model to receive more satisfied forecasting results [
40]. However, these AI models (containing hybrid or combined models) also have their inherent drawbacks from the theoretical mechanisms, such as difficult to determine the network structural parameters [
41]; time-consuming to modeling [
42]; easily trapped into a local minimum [
43]; more insightful discussions of AI models in electricity consumption could be referred in [
44].
As shown in the powerful nonlinear modeling performance, the support vector regression (SVR) model [
45] has already been with abundant research results to deal with electric load forecasting [
4,
46,
47,
48,
49]. Based on the conclusions of these papers, the well determination of parameters for an SVR model by any meta-heuristic algorithm could guarantee more satisfied forecasting accuracy. Among those employed meta-heuristic algorithms in the literature, the quantum genetic algorithm (QGA) proposed in [
50] is considered to be employed in this paper, not only it is empowered by the quantum computing mechanism (QCM), but also it is a classic algorithm with mature applications to solve real problems [
51,
52]. On the other hand, it is also concluded in the literature that decomposing the time series by the empirical mode decomposition (EMD) method [
53] into several single and apparent components (namely intrinsic mode functions (IMFs)), then, separately forecasting each component, it would eventually receive higher forecasting accuracy. The EMD method had also been applied in many fields [
53,
54,
55]. Therefore, this paper would also apply the EMD method to extract the electricity consumption time series data into several IMFs, then, each IMF is forecasted by an SVR model with QGA, and the final forecasting results are summed by the forecasted value of each IMF.
However, as mentioned in [
40], the decomposed IMFs contain IMFs with different randomness and the residual IMF; then, these IMFs should be separately modeled by the proposed forecasting model to receive superior forecasting performance. Inspired by the different randomness of IMFs, these two kinds of IMFs could have many combinations to obtain more accurate forecasting results. Thus, based on the EMD method, the QGA, and the SVR model, the authors propose a new hybrid model, namely the EMD-SVR-QGA model, to compare the forecasting performance of different IMF combinations and different algorithms with the H-EMD-SVR-PSO model [
40]. The electricity consumption data of a university dormitory is decomposed by the EMD method into six IMFs. Then, these decomposed IMFs are combined into three items: item A contains the terms minus the residual term, item B contains the terms minus the top two IMFs (with high randomness), and item C only contains the terms minus the top two IMFs and the residual term contents. Items A, B, and C would be separately modeled by the SVR-QGA model proposed in [
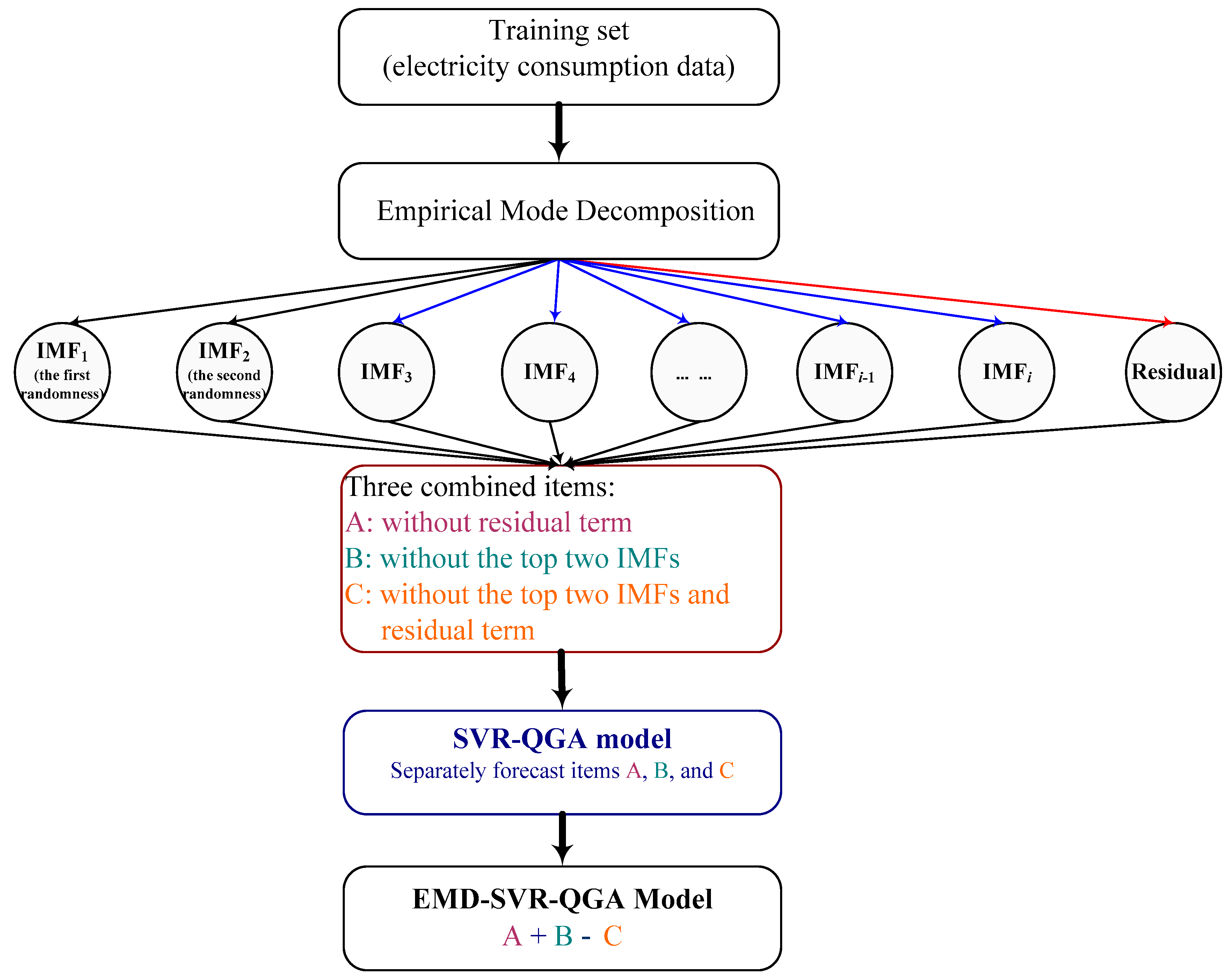
50]. For item A, there are many IMFs with different randomness, which implies that it can have neutral volatility while the SVR-QGA modeling. For item B, the residual term could be fine-tuned under the remaining IMFs (with low randomness), it is also fine while the SVR-QGA modeling. For item C, it is complete with low randomness, which is excellent during the SVR-QGA modeling. Finally, the electricity consumption forecasting results are calculated by the forecasting values of A + B − C. The forecasting details would be presented in the following sections.
To compare the forecasting performance among the proposed EMD-SVR-QGA model and other compared models, the original SVR model, the SVR-QGA model (hybridizing the QGA algorithm with an SVR model), and the H-EMD-SVR-PSO model [
40], the electricity consumption data are collected from a university dormitory, Quanshan Campus, Jiangsu Normal University, China, with daily type, from 1 September 2018 to 31 March 2019. The experimental results indicate the superiority of the proposed EMD-SVR-QGA model in terms of forecasting accuracy.
The remainder of this paper is organized as follows. The proposed EMD-SVR-QGA model is introduced in
Section 2. The numerical example against other alternative models is illustrated in
Section 3. The conclusion is shown in
Section 4.
3. Electricity Consumption Forecasting by the EMD-SVR-QGA: Case of a University Dormitory
3.1. Data Set of Experimental Examples
The electricity consumption data are collected from a real-world case, two representative university dormitories, Quanshan Campus, Jiangsu Normal University, China. The detailed background of these data is stated as follows. There are about 12 persons per dormitory room. On the campus, each week about 10 seminars and associated lectures, each seminar or lecture would attract about 200 persons. The relative weight of Dormitories’ consumption in the corresponding university campus total consumption is about 14.78%. Based on the time period of the collected data, the associated weather is in fall and winter, as the campus is located in northern China, the official heating system is available. However, if suffering from heavy snow or intense cold, the electrical heater is also used. Thus, the electricity consumption would be moderate fluctuated along with the weather conditions. Finally, due to “energy savings” activities in China, the administration department also announces some active policy to encourage “energy savings”, eventually, to achieve the “green campus”, such as record merits, award, and give honorary title, etc.
It would be further processed by the proposed EMD-SVR-QGA model to receive the forecasting electricity consumption of these two selected dormitories in the future for one month. For these two dormitories, the electricity consumption data are both collected, with daily type, from 1 September 2018 to 31 March 2019, thus, each data set contains 212 electricity consumption data. However, during the vacation period, such as the Chinese Lunar Year Festival and the winter vacation, the electricity consumption of each dormitory is almost zero, i.e., these data should be removed. Therefore, after pre-processing operation, these two data sets from two dormitories are arranged to 110 and 134 electricity consumption data, respectively.
For clear denotation of these two dormitory cases, the first dormitory with 110 electricity consumption data is denoted as dormitory I, the other one with 134 electricity consumption is denoted as dormitory II. For the division of the training and the testing sets, Dormitory I is with 88 and 22 electricity consumption data in the training and the testing sets, respectively; dormitory II is with 107 and 27 electricity consumption data in the training and the testing sets, respectively.
Besides two dormitory cases, the electric load data set, collected from New South Wales (NSW) market in Australia also used in [
40], is also employed to demonstrate the superiority of the proposed EMD-SVR-QGA model. The employed electric load data is collected from 1 to 13 August 2019, based on half-hour format, i.e., there are 48 data per day. The training set is from 1 to 10 August 2019 (in total 480 load data points), and the testing data is from 10 to 13 August 2019 (in total 144 load data points).
During the training stage of the SVR-QGA model, the rolling-based process [
58,
59], is employed to help QGA to systematic look for suitable parameter combination of an SVR model with smaller forecasting error. Specifically, the first
n electricity consumption data is fed into the SVR-QGA model to conduct the model training process, then, the (
n + 1)-th forecast value of electricity consumption and the feasible parameter combination are both obtained by the SVR-QGA model. Repeat this operation to receive the (
n + 2)-th, the (
n + 3)-th, … forecast values of electricity consumption till the required forecasting values are received. Finally, the parameter combination with the smallest testing errors are verified as the most appropriate parameter combination of an SVR model. Eventually, the testing data set will be used to compute the forecasting accuracy of the proposed SVR-QGA model.
3.2. Parameters Setting of the EMD-SVR-QGA Model
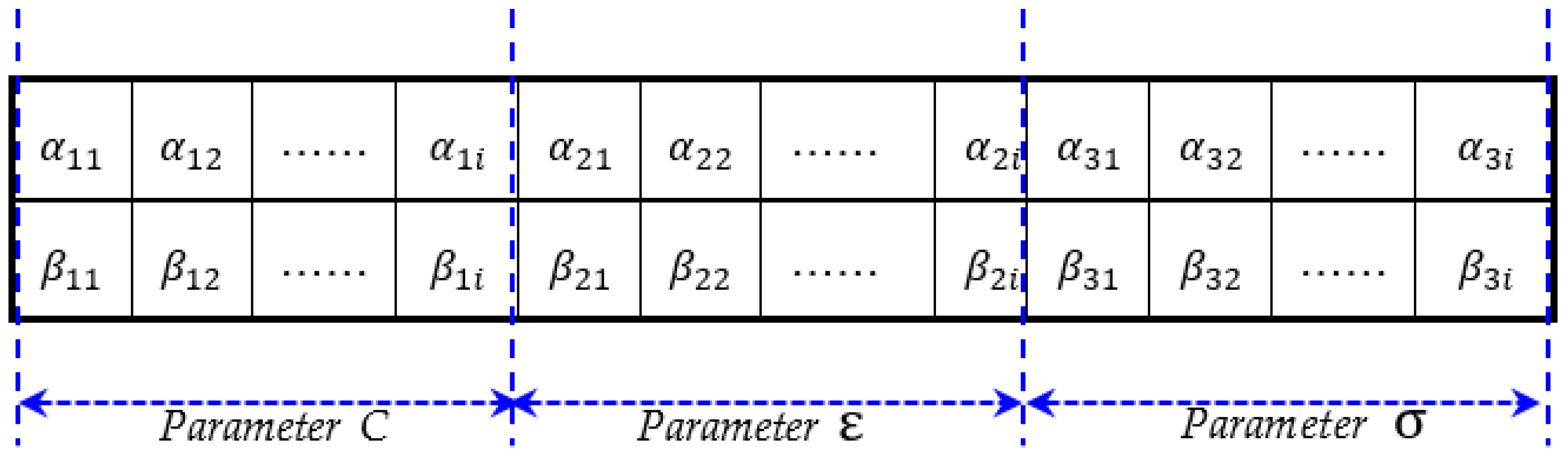
The parameters of QGA for these two dormitory cases are set practically or by referencing other experiences, the population scale (
Pscale) is set to be 200 [
50]; the generations of the population (
qmax) are no larger than 200; the qubit string length of a quantum chromosome (
m) is set as 150; the probabilities of quantum crossover (
Pcr) and quantum mutation (
Pm) are set as 0.5 and 0.1 [
50], respectively. The rotation angle,
, is between 0.1
and 0.005
[
52]. For SVR-QGA modeling, the maximal iteration for each example is all set as 10,000 in each generation; the searching range of the three parameters are set as followings,
,
, and
in both two dormitory cases;
δ is fixed as 0.001 [
50].
3.3. Forecasting Accuracy Indexes and Forecasting Performance Superiority Test
To compare the forecasting accuracy among the proposed model and other compared models, four forecasting accuracy indexes, the mean absolute percentage error (
MAPE), the root mean squared error (
RMSE), mean squared error (
RMSE), and the mean absolute error (
MAE) is employed to calculate the forecasting errors, they are defined as Equations (21)–(24).
where
N is the number of forecasts;
is the actual value for forecast point
i is the forecast of point
i.
On the other hand, it is necessary to conduct the statistical test to verify the statistical significance of the forecasting superiority of the proposed model. Based on Derrac et al. [
60] suggestions, only Wilcoxon signed-rank test is implemented in this paper. The statistic of Wilcoxon signed-rank, W, is defined as Equation (25),
where
is the total number of positive rank that the forecasting error of the proposed EMD-SVR-QGA model larger than other compared model;
is the total number of negative rank that the proposed EMD-SVR-QGA model smaller than the compared model.
If the value of W satisfies the required value of Wilcoxon distribution with an associated degree of freedom, then, the null hypothesis of equal performance of these two compared models is not accepted. It also reveals the outstanding forecasting results of the proposed EMD-SVR-QGA model outperforms significantly the compared model.
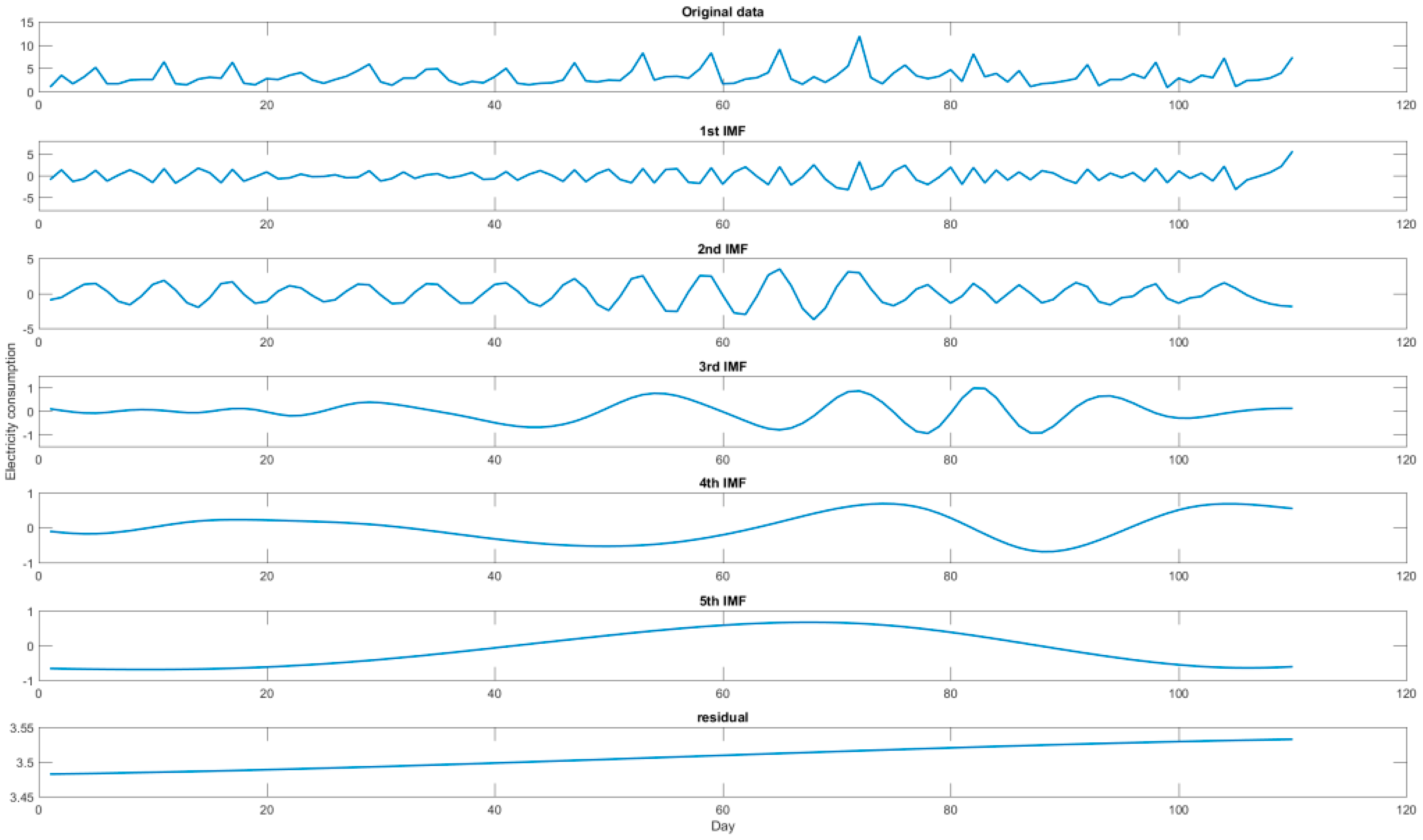
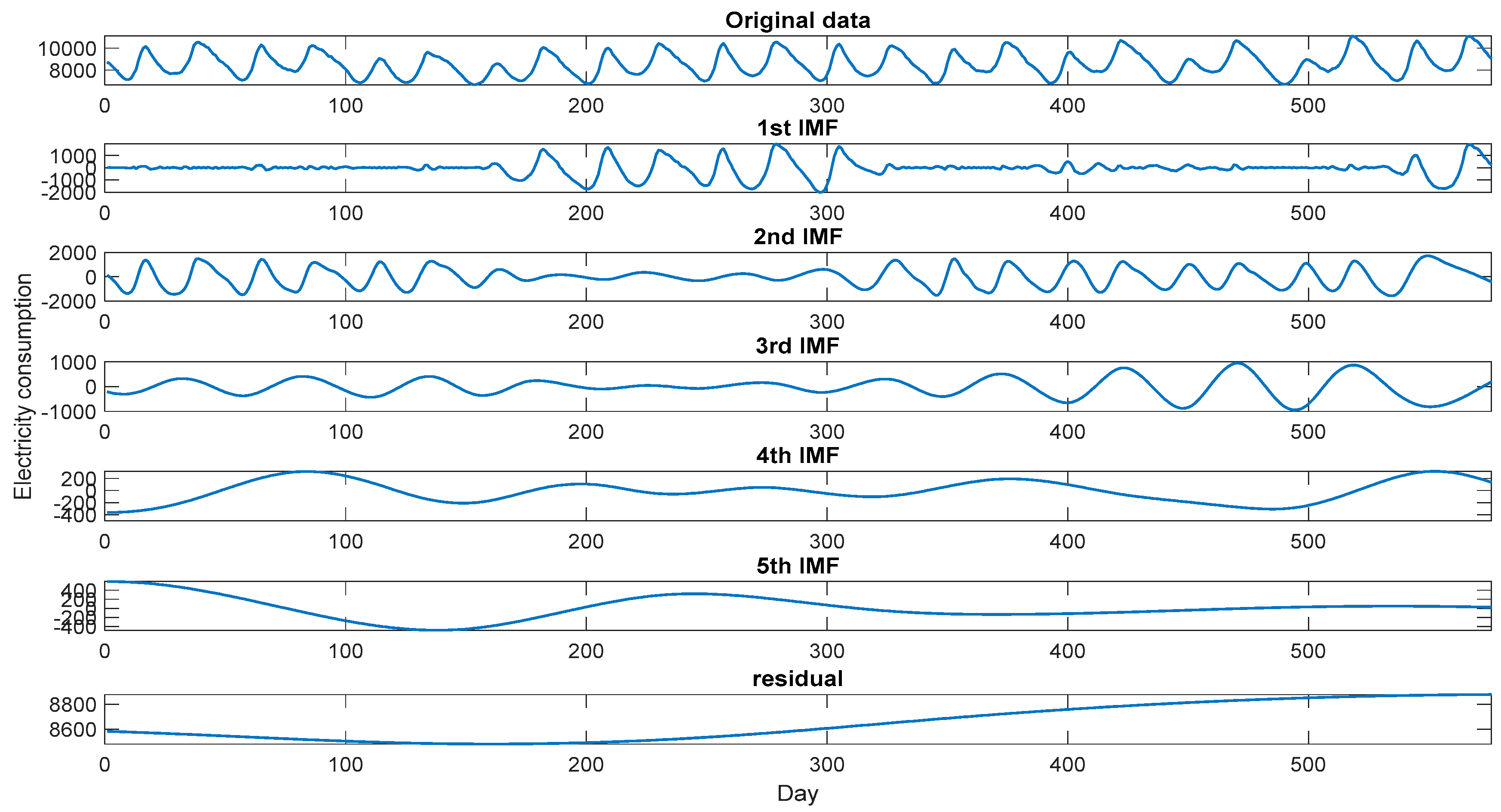
3.4. Decomposition Results and Forecasting Results for Dormitory I
For Dormitory I case, the electricity consumption data is firstly decomposed by the EMD method into six terms. These six decomposed terms are demonstrated in
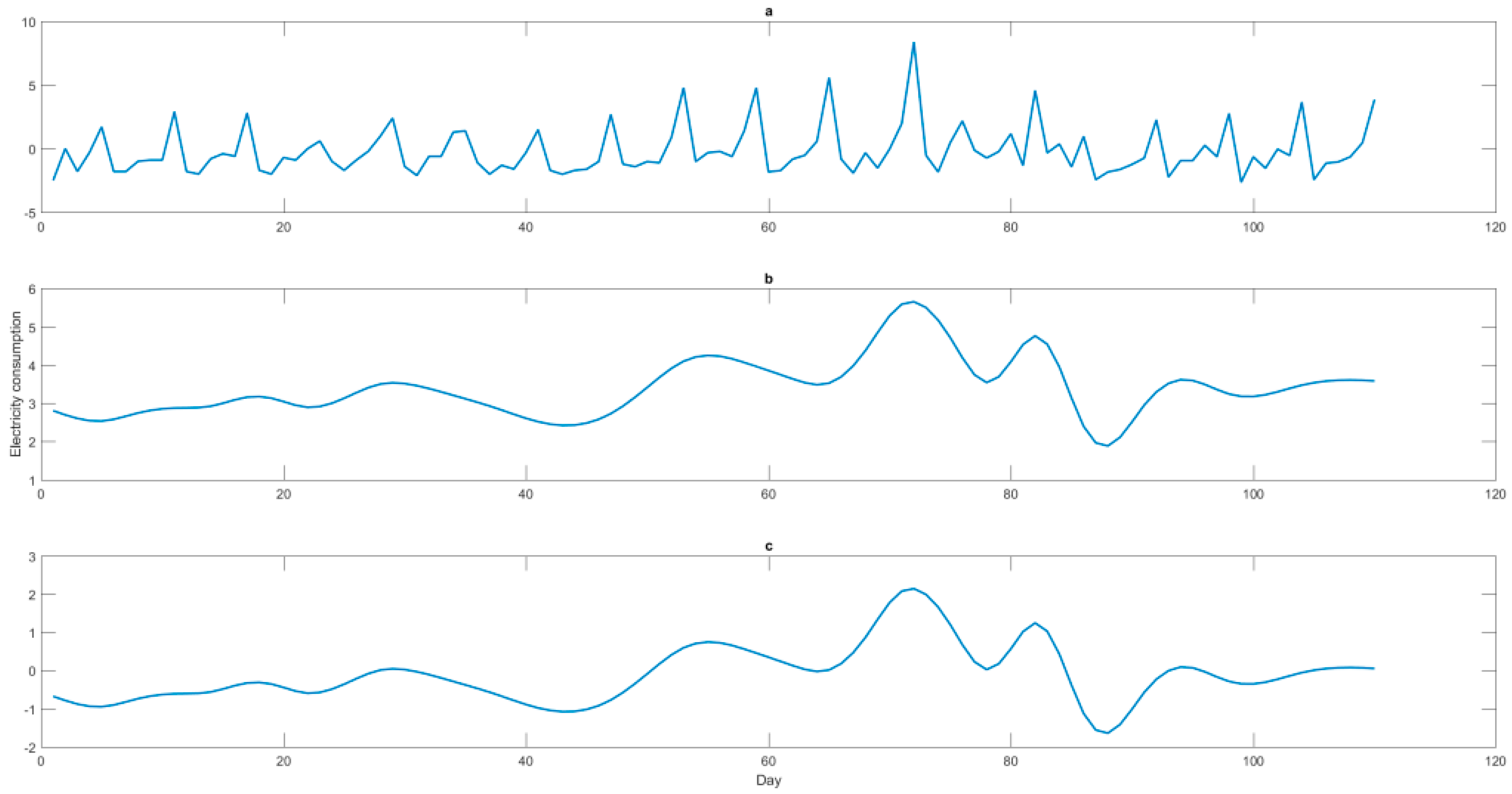
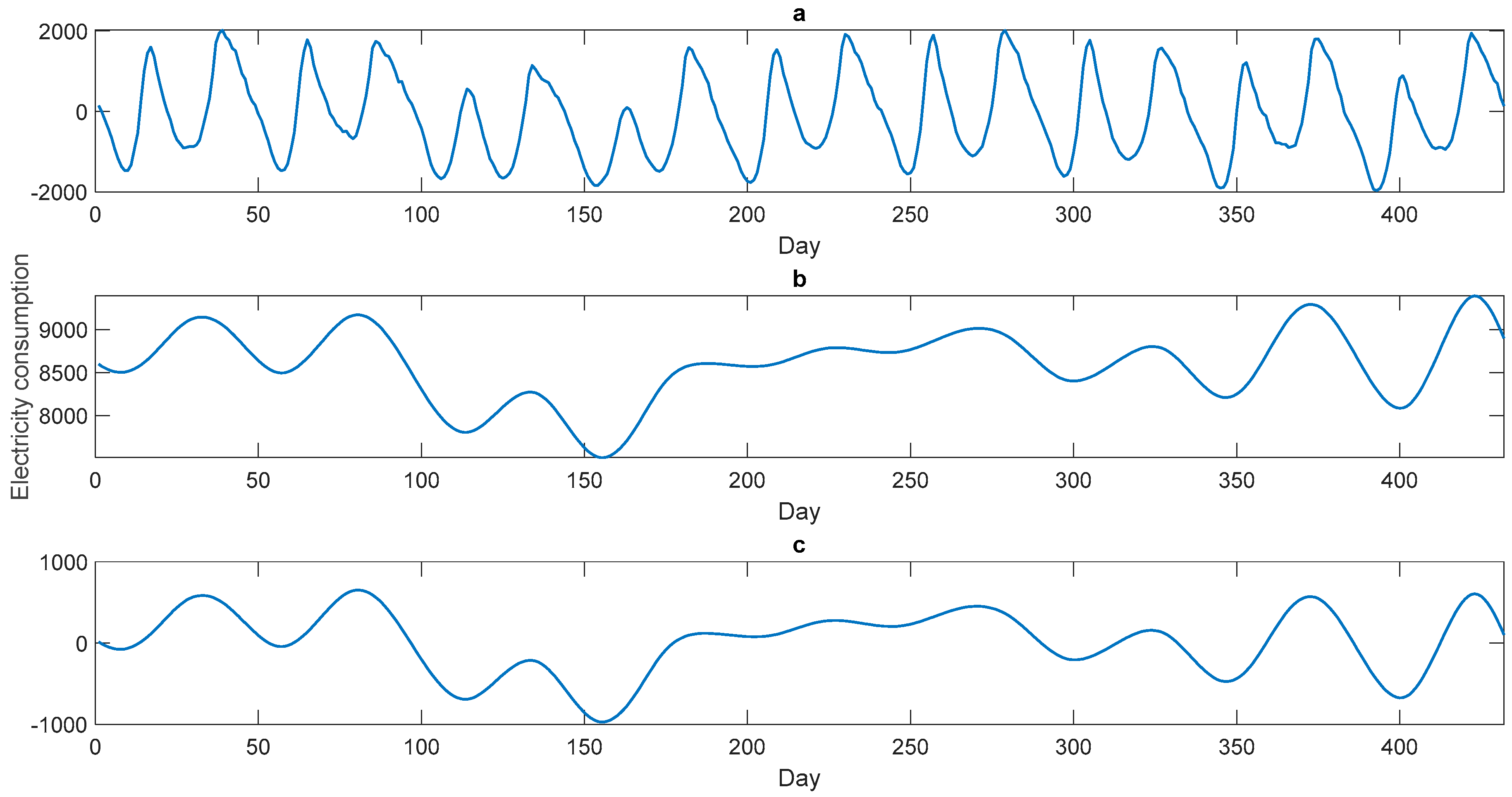
Figure 3, in which the first IMF and the second IMF are obviously the random terms, the 6th IMF is also obviously the residual term. The three items A, B, and C, defined by the six IMFs are shown in
Figure 4.
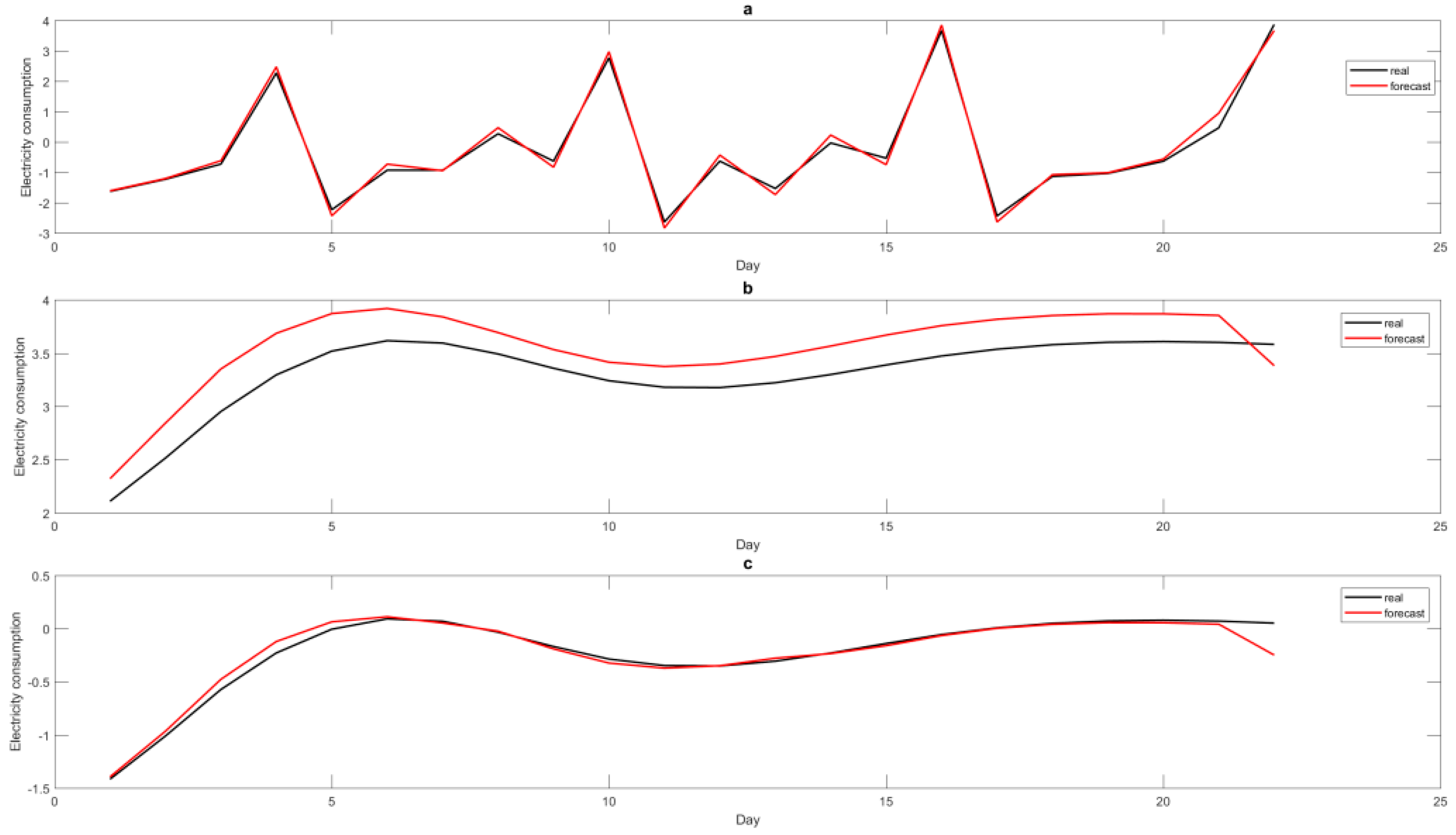
The three items A, B, and C, defined by the six IMFs are separately modeled by the SVR-QGA model, as mentioned in
Section 3.1, the rolling-based process [
58] is applied to collaborate with the QGA to determine the most appropriate parameter combination of their associated SVR-based models in the training phase. The appropriate parameter combination for each item is shown in
Table 1. In addition, the appropriate parameter combination for other compared models, including the original SVR model, the SVR-QGA model, the H-EMD-SVR-PSO model [
40], are also illustrated in
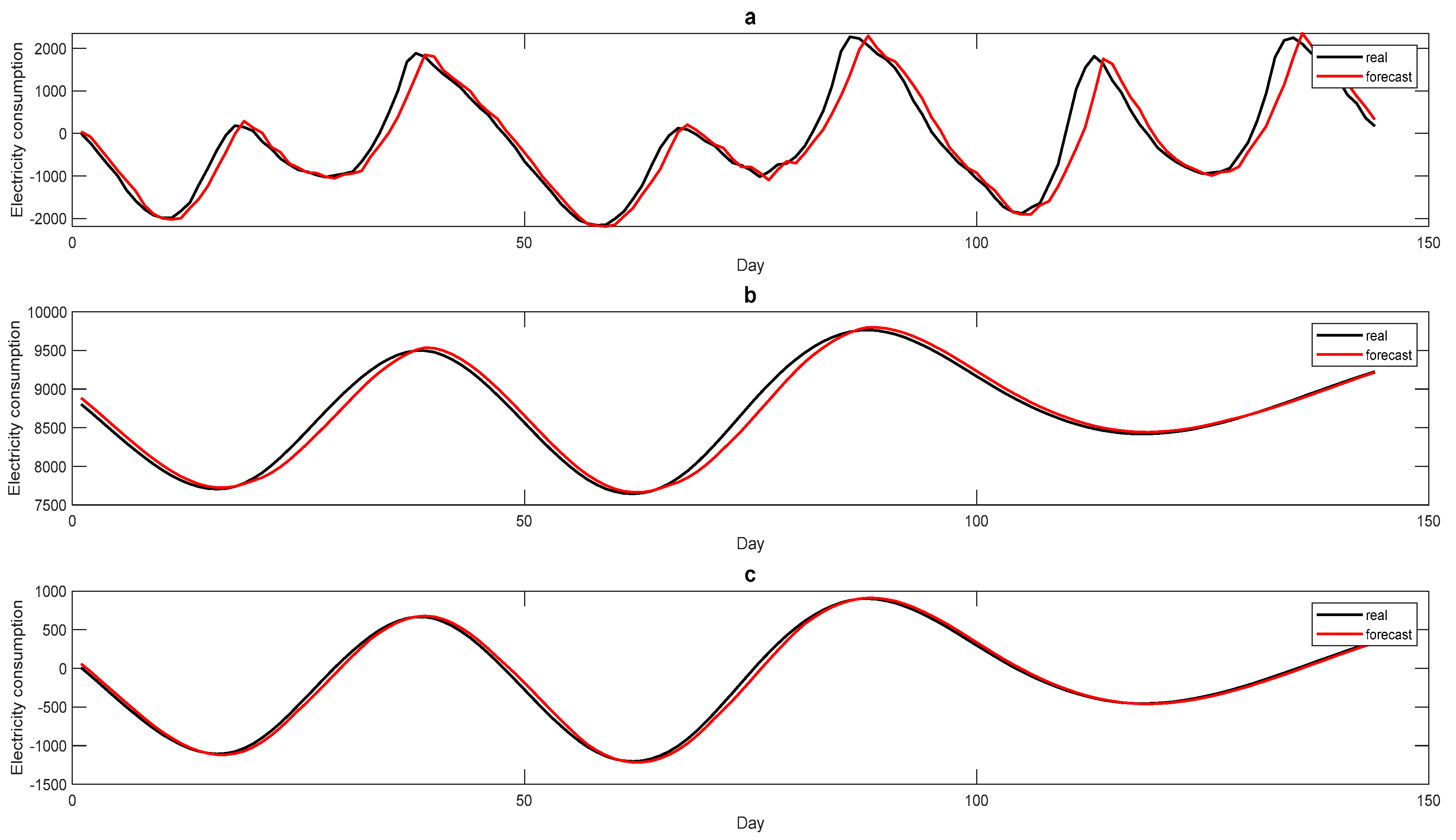
Table 1. The forecasting performances for the three items are demonstrated in
Figure 5.
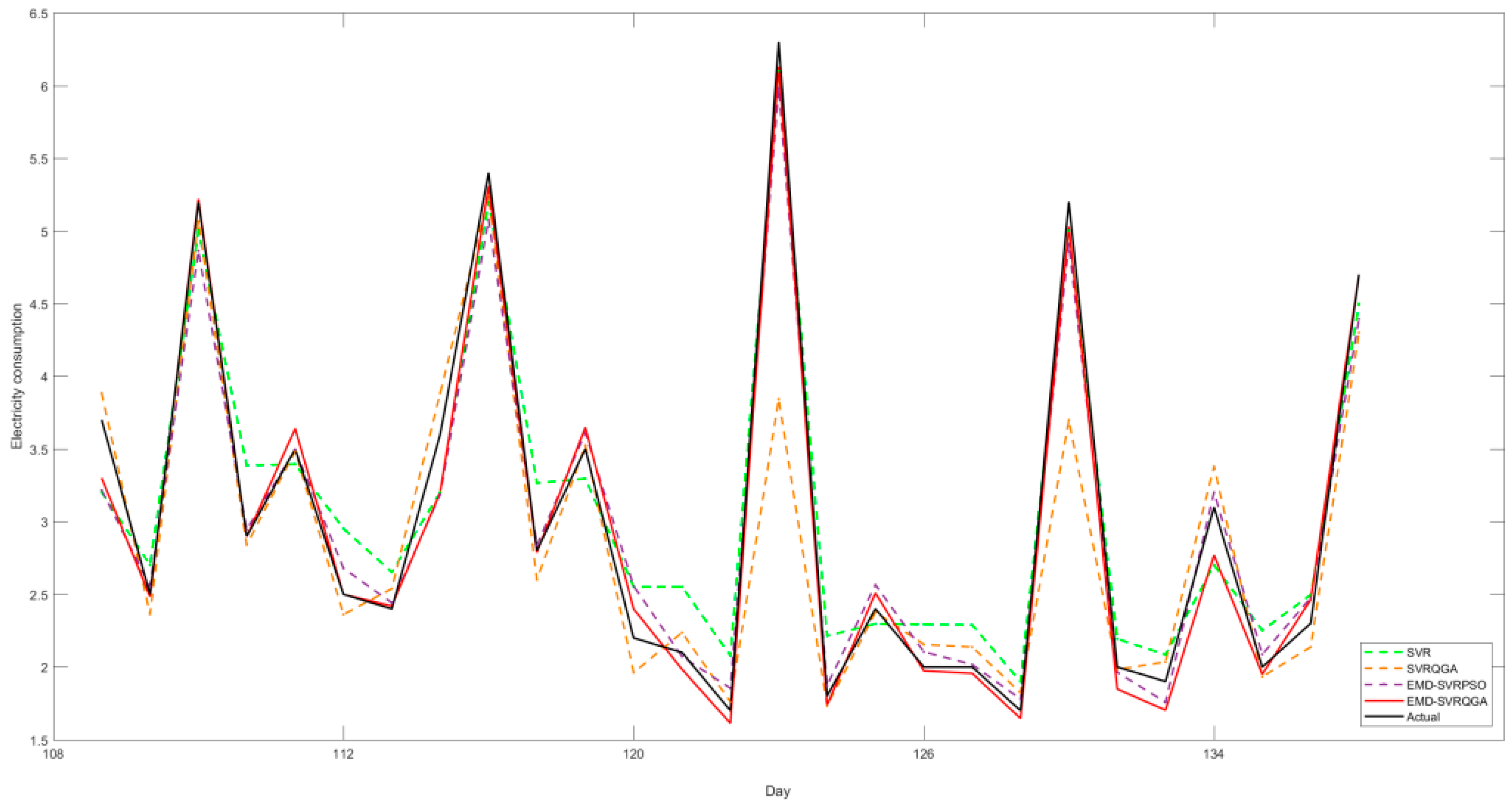
The forecasting results of the original SVR model, the SVR-QGA model [
50], the H-EMD-SVR-PSO model [
40], and the proposed EMD-SVR-QGA model are shown in
Figure 6. It illustrates the forecasting curve of the proposed EMD-SVR-QGA model has better fitting effects than other compared models. It also implies that the proposed EMD-SVR-QGA model has the potentials to capture the fluctuation variation of the electricity consumption from this dormitory. Thus, the consumption behaviors can be effectively monitored and some valuable activities regarding improving electricity consumption habits can be held to successfully save electricity consumption.
The proposed EMD-SVR-QGA model also demonstrates better generalization ability than other models. The forecasting performance of these models is listed in
Table 2. In which, it demonstrates clearly that the proposed EMD-SVR-QGA model outperforms the original SVR model, the SVR-QGA model [
50], and the H-EMD-SVR-PSO model [
40] in terms of four employed forecasting accuracy indexes. Particularly, for the H-EMD-SVR-PSO model, it also receives outstanding forecasting results, which indicates the forecasting advantages from this kind of EMD-SVR-based model. Comparing the forecasting accuracy of the EMD-SVR-QGA model and the H-EMD-SVR-PSO model, their contributions are different due to different combination types of these decomposed IMFs and the residual term. Therefore, looking for a suitable IMFs combination approach is an interesting research topic.
In addition, in
Table 2, it also can see that the forecasting accuracy of the SVR-QGA model [
50] is not superior to the EMD-SVR-based models. This is because the nonlinear effects are inherent in the electricity consumption data itself, and demonstrate the interactions among the IMFs and the residual term. After decomposition operation by the EMD method, the EMD-SVR-based models are able to well deal with this inherent non-linear data pattern by the IMFs and these defined items, A, B, and C. Therefore, the proposed EMD-SVR-QGA model can be a useful forecasting model to deal with the electricity consumption forecasting work of a university dormitory.
Finally, to verify the significant contribution of the forecasting improvement from the proposed EMD-SVR-QGA model, in this paper, the Wilcoxon signed-rank test is suggested [
59]. Wilcoxon signed-rank test is conducted on one-tail-test, under two significant levels,
α = 0.025 and
α = 0.05. The test results are shown in
Table 3, which obviously indicate that the proposed EMD-SVR-QGA model is significantly superior to other compared models.
3.5. Decomposition Results and Forecasting Results for Dormitory II
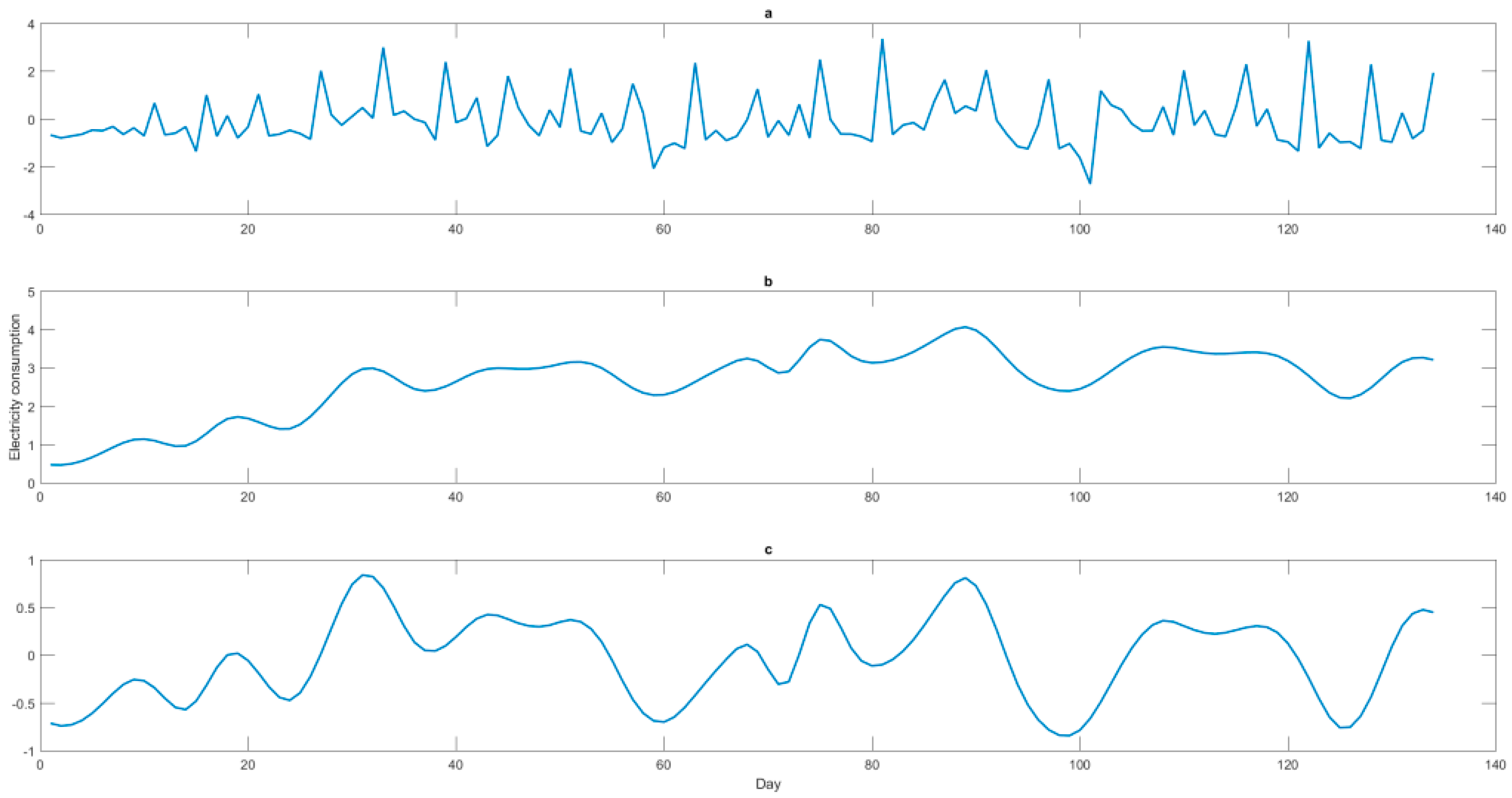
Similar to the dormitory I case, the electricity consumption data in the dormitory II case is also firstly decomposed by the EMD method into six terms. These six decomposed terms are demonstrated in
Figure 7, in which the 1st IMF and the 2nd IMF are obviously the random terms, the 6th IMF is also obviously the residual term. The three items A, B, and C, defined by the six IMFs are shown in
Figure 8.
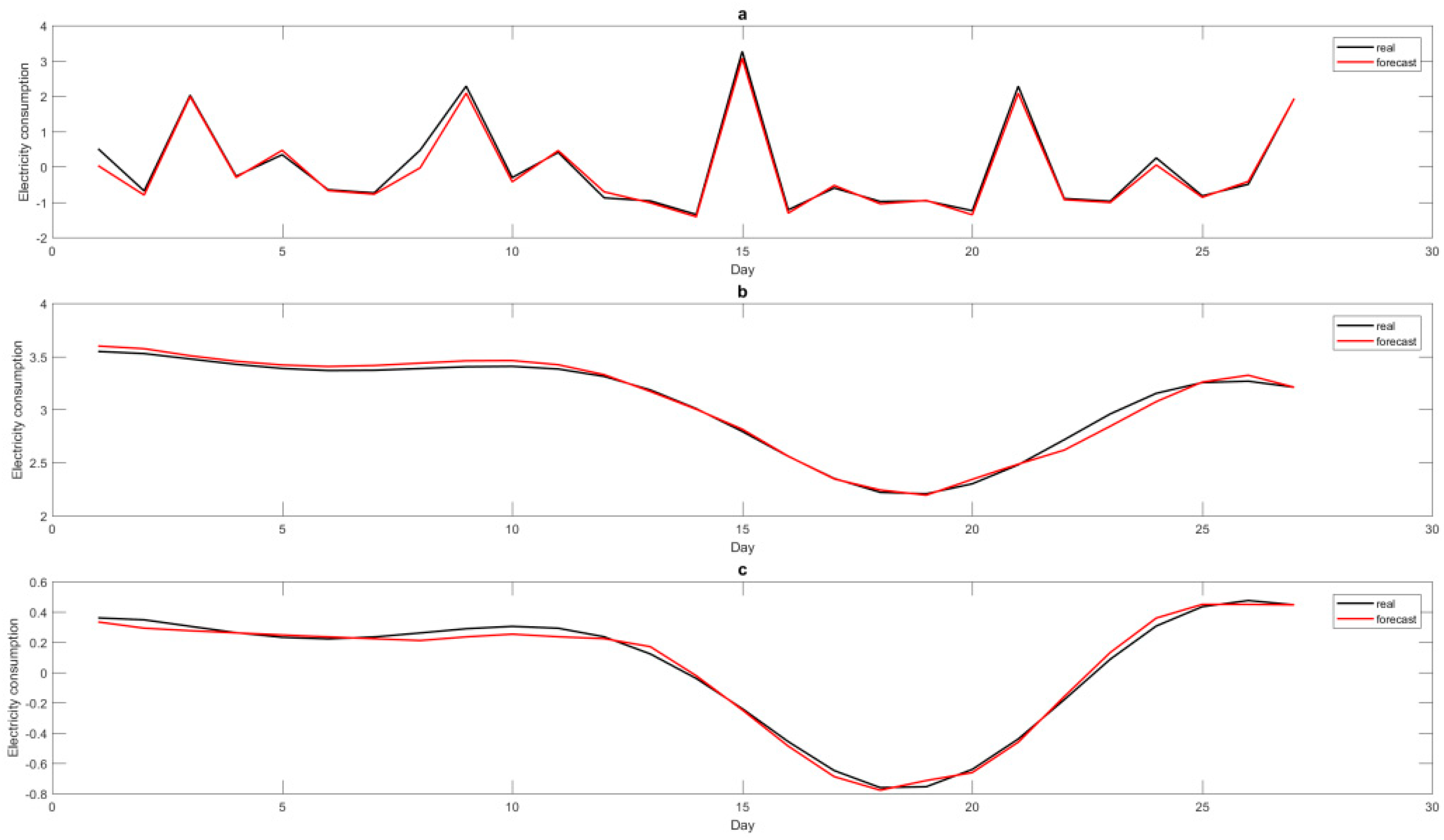
In the dormitory II case, the three items A, B, and C, defined by the six IMFs are also separately modeled by the SVR-QGA model to determine the most appropriate parameter combination of their associated SVR-based models. The appropriate parameter combination for each item for other compared models, including the original SVR model, the SVR-QGA model, the H-EMD-SVR-PSO model [
40], are illustrated in
Table 4. The forecasting performances for the three items are demonstrated in
Figure 9.
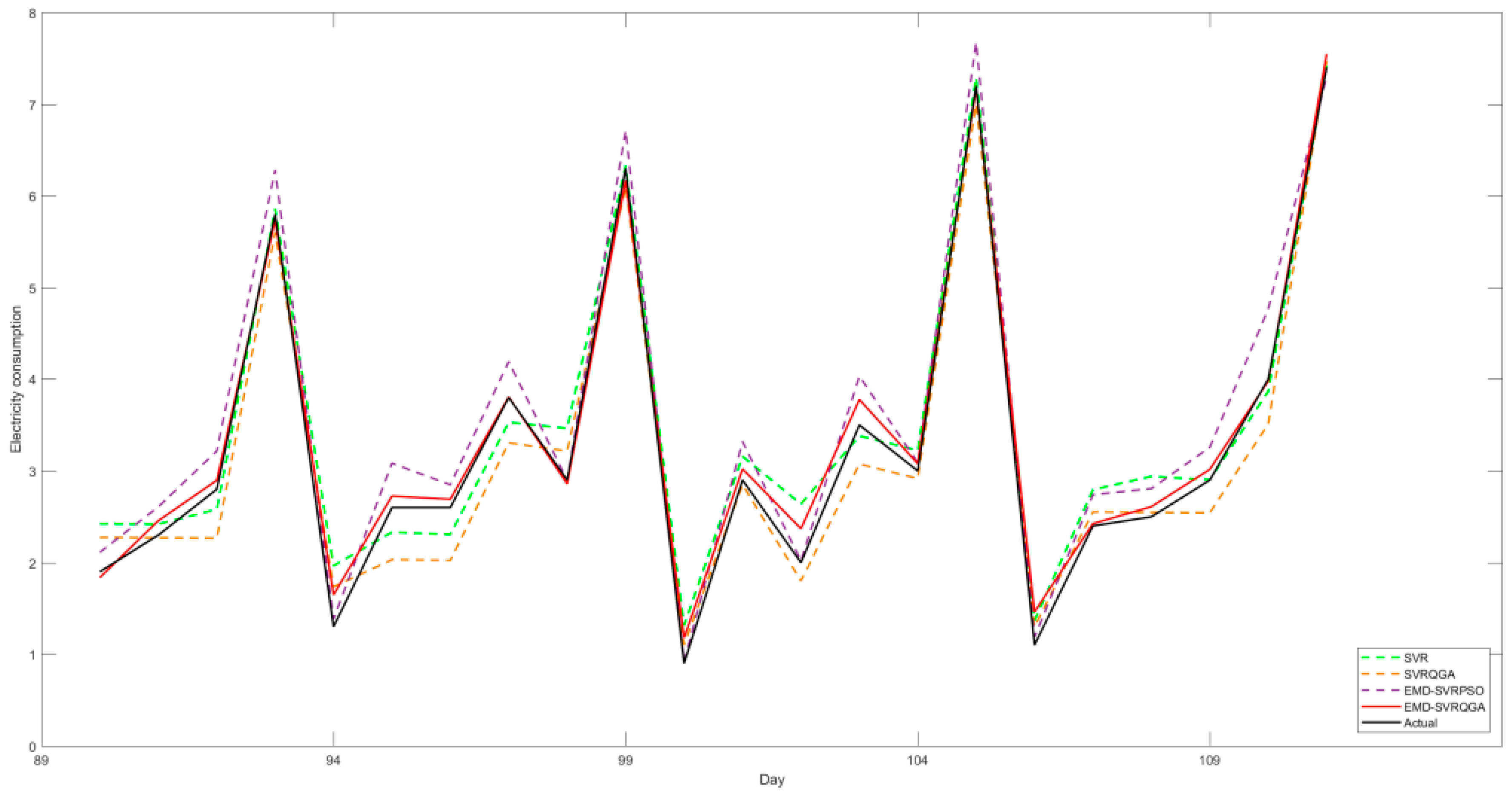
For the dormitory II case, the forecasting results of the original SVR model, the SVR-QGA model [
50], the H-EMD-SVR-PSO model [
40], and the proposed EMD-SVR-QGA model are shown in
Figure 10. It also demonstrates the forecasting curve of the proposed EMD-SVR-QGA model fits better with the actual electricity consumption than other compared models. It also implies that the proposed EMD-SVR-QGA model is qualified to well deal with the fluctuation characteristics of the electricity consumption from this dormitory. Thus, it could contribute to the campus managers providing more insight governance policy for the electricity-saving of the dormitory.
The forecasting performance of these models is listed in
Table 5. As the same results in the dormitory I case, the proposed EMD-SVR-QGA model also shows better generalization ability than other models, the original SVR model, the SVR-QGA model [
50], and the H-EMD-SVR-PSO model [
40] in terms of four employed forecasting accuracy indexes. The forecasting advantages from this kind of EMD-SVR-based model are revealed once again. Different combination types of these decomposed IMFs and the residual term could obtain different forecasting accuracy. It is deserved to look for a suitable IMFs combination approach.
Furthermore, from
Table 5, the forecasting results support the same conclusion in Dormitory I case once again: the EMD-SVR-based models able to well deal with this inherent non-linear data pattern by the IMFs and these defined items, A, B, and C. Therefore, the proposed EMD-SVR-QGA model can be a useful forecasting model to deal with the electricity consumption forecasting work of a university dormitory.
For the significance test of the forecasting performance from the proposed EMD-SVR-QGA model, the results of Wilcoxon signed-rank test, based on one-tail-test and is under two significance levels,
α = 0.025 and
α = 0.05, are shown in
Table 6. Obviously, it indicates that the proposed EMD-SVR-QGA model outperforms significantly other compared models.
3.6. Decomposition Results and Forecasting Results for New South Wales (NSW, Australia) Market
Similar to the above two dormitory cases, the electric load data in the New South Wales (NSW, Australia) market is also firstly decomposed by the EMD method into six terms. These six decomposed terms are demonstrated in
Figure 11, in which the first IMF and the second IMF are obviously the random terms, the sixth IMF is also obviously the residual term. The three items A, B, and C, defined by the six IMFs are shown in
Figure 12.
In the dormitory II case, the three items A, B, and C, defined by the six IMFs are also separately modeled by the SVR-QGA model to determine the most appropriate parameter combination of their associated SVR-based models. The appropriate parameter combination for each item for other compared models, including the original SVR model, the SVR-QGA model, the H-EMD-SVR-PSO model [
40], are illustrated in
Table 7. The forecasting performances for the three items are demonstrated in
Figure 13.
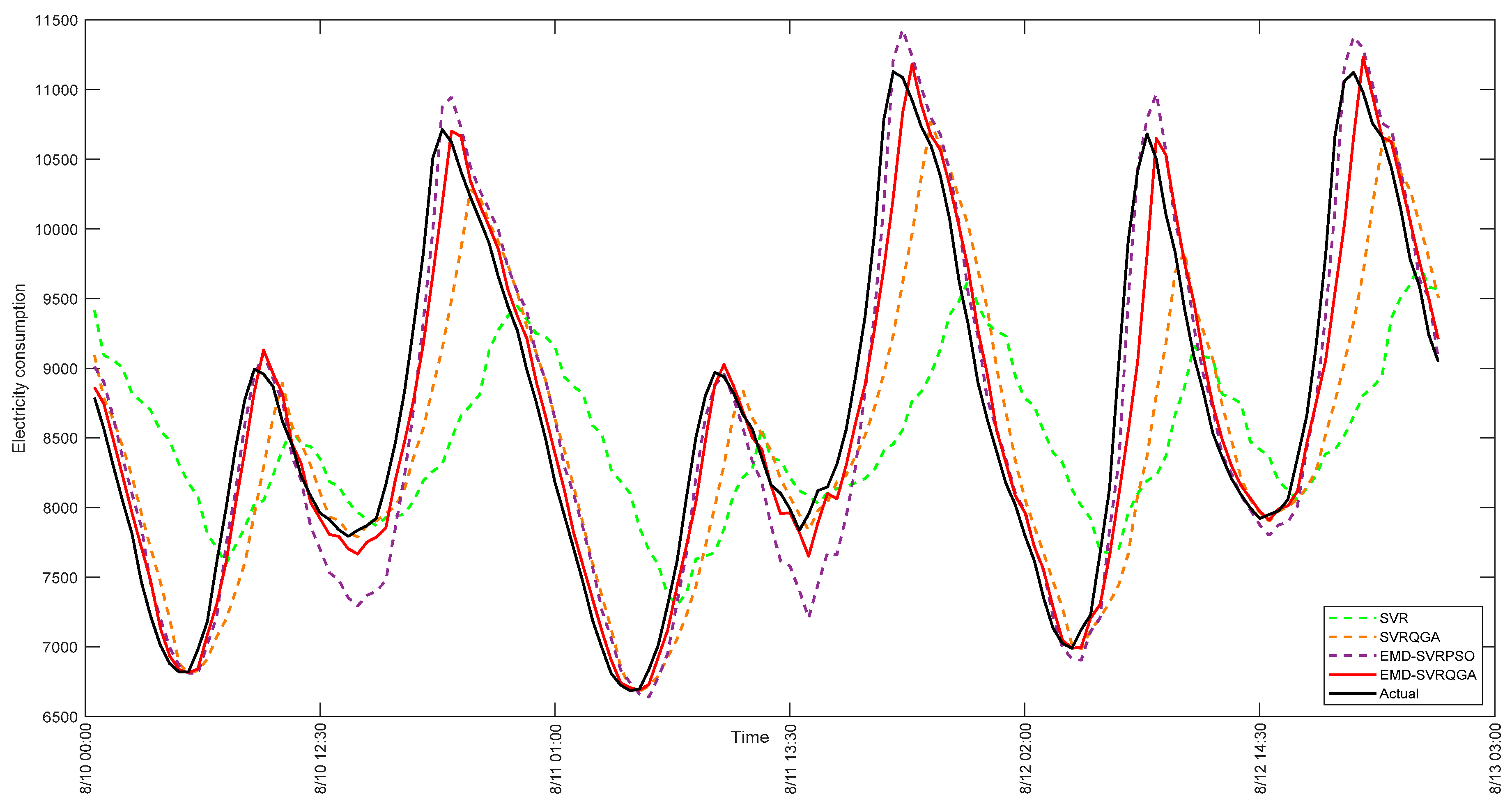
For NSW (Australia) case, the forecasting results of the original SVR model, the SVR-QGA model [
50], the H-EMD-SVR-PSO model [
40], and the proposed EMD-SVR-QGA model are shown in
Figure 14. It also demonstrates the forecasting curve of the proposed EMD-SVR-QGA model fits better with the actual electric load than other compared models. It also implies that the proposed model is qualified to well deal with the fluctuation characteristics of the electric load in real-world applications, such as the NSW market in Australia. Thus, it supports that the proposed model is useful to the campus managers to receive accurate forecasting performance.
The forecasting performance of these models is listed in
Table 5. As the same results in dormitory I case, the proposed EMD-SVR-QGA model also shows better generalization ability than other models, the original SVR model, the SVR-QGA model [
50], and the H-EMD-SVR-PSO model [
40] in terms of four employed forecasting accuracy indexes. It once again reveals the superiority of EMD-SVR-based models.
Furthermore, from
Table 8, the forecasting results also support the same conclusion in NSW (Australia) case: the EMD-SVR-based models able to well deal with this inherent non-linear data pattern by the IMFs and these defined items, A, B, and C. Therefore, the proposed EMD-SVR-QGA model is appropriate to be applied to deal with the electricity consumption forecasting work.
For the significance test of the forecasting performance from the proposed EMD-SVR-QGA model, the Wilcoxon signed-rank test is conducted as in the previous two cases, also based on one-tail-test and two significance levels,
α = 0.025 and
α = 0.05, the tested results are shown in
Table 9. Obviously, it indicates that the proposed EMD-SVR-QGA model outperforms significantly other compared models.
3.7. Discussions
As shown in [
40], they defined three items (A, B, and C) based on the excellent combination of these different decomposed IMFs, such as the random term, the middle terms, and the residual term. Therefore, a suitable combination of the decomposed IMFs, i.e., how to make good use of these IMFs, could be an interesting issue to help to improve the forecasting accuracy of the proposed model. However, due to the inherent complexity of the employed data set, the decomposition results are varied. For example, in [
40], there is only one decomposed IMF with random volatility and the best ones are not, thus, the best combination of these IMFs is demonstrated in [
40]. In addition, there may be two or more decomposed IMFs with random volatility, such as in this paper there are two terms with different randomness, therefore, we define different three items, i.e., different combinations of these decomposed IMFs (the proposed EMD-SVR-QGA model). Eventually, we receive more accurate forecasting results than the results using the combination approach (the H-EMD-SVR-PSO model) in [
40]. We would like to claim that the superiority of our proposed EMD-SVR-QGA model than the H-EMD-SVR-PSO model.
Therefore, it could be remarked that an effective combination of the decomposed IMFs could provide a clearer cue to understand the complex structure of the employed data set, then, make good use of these IMFs can help to receive more satisfying analysis results, such as forecasting accuracy improvement or classification accuracy enhancement. The exploration of the effective combination of the decomposed IMFs also inspires some interesting future research.
4. Conclusions
This paper proposes a novel EMD-SVR-QGA electricity consumption forecasting model to provide the campus managers with more accurate electricity consumption forecasting from the university dormitory. It is superior in capturing the fluctuation variation of the electricity consumption and reveals its potentials to indicate the daily patterns of the electricity consumption of the dormitory which is useful to take some valuable activities regarding improving electricity consumption habits. The proposed EMD-SVR-QGA model uses different combinations approach of the IMFs decomposed by the EMD method, to well deal with the interaction among those decomposed IMFs and the residual term and the inherent complexity in the electricity consumption data. Furthermore, this paper also applies the QGA to comprehensively search for the appropriate values of the three parameters of an SVR model, then, used the trained SVR-QGA model to forecast the defined items (A, B, and C), separately. It ensures receiving more satisfied forecasting results. Finally, two representative university dormitories’ electricity consumption data sets are used to conduct modeling, the experimental results demonstrate that the proposed model has outperformed significantly other compared models in terms of forecasting accuracy indexes, such as the original SVR model, the SVR-QGA model, and the H-EMD-SVR-PSO model.
The experimental results also indicate the very issues that the different combination of these decomposed IMFs to deal with the inherent nonlinear or other complex interactions among the data set. This issue also asks researchers to carefully study the characteristics of the IMFs, then, determine an effective combination type of these IMFs and the associated SVR-based model. For future research, we will consider hybridizing different intelligent technologies to combine the IMFs, and other useful meta-heuristic algorithm with quantum computing mechanism, to enrich the research contents to receive higher forecasting accuracy.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}