

Incorporating Prior Information in Latent Structures Identification for Panel Data Models

Abstract
1. Introduction
1.1. Literature Review
1.2. Contributions and Organization
2. Model and Proposed Estimation Method
2.1. Panel Heterogeneity with Prior Constraint Information
2.2. A Regularized Approach
2.3. ADMM Implementation
| Algorithm 1: ADMM algorithm for panel data models with prior constraints |
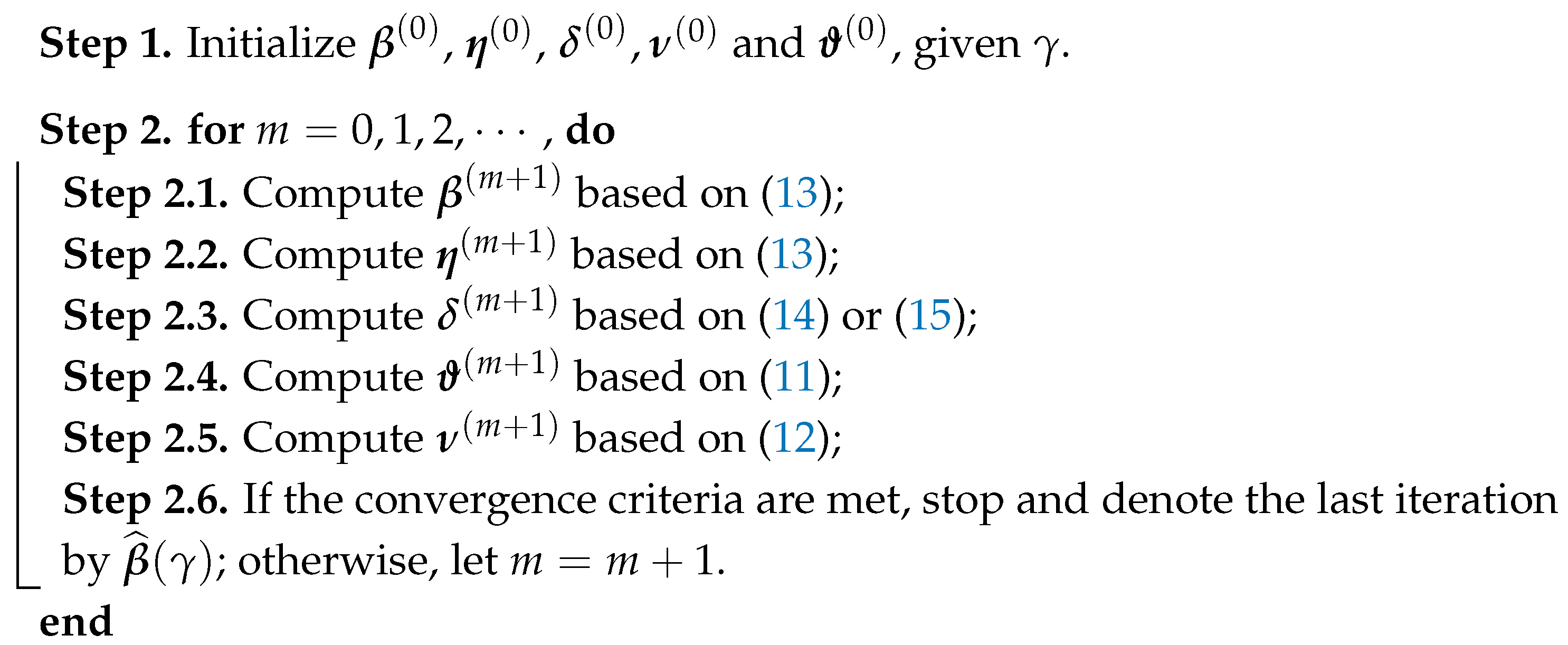 |
2.4. Initial Values and Tuning Parameter
3. Theoretical Analysis
3.1. Convergence of the Algorithm
3.2. Asymptotic Property
4. Simulation Studies
4.1. Basic Setup
- (i)
- (equality constraint:) For , the sum of coefficients for each individual is the same. For , the sum of all elements equals zero, and for , the coefficients for the first regressor remain constant across all individuals.
- (ii)
- (inequality constraint:) For , all elements in the coefficient matrix are required to be greater than zero.
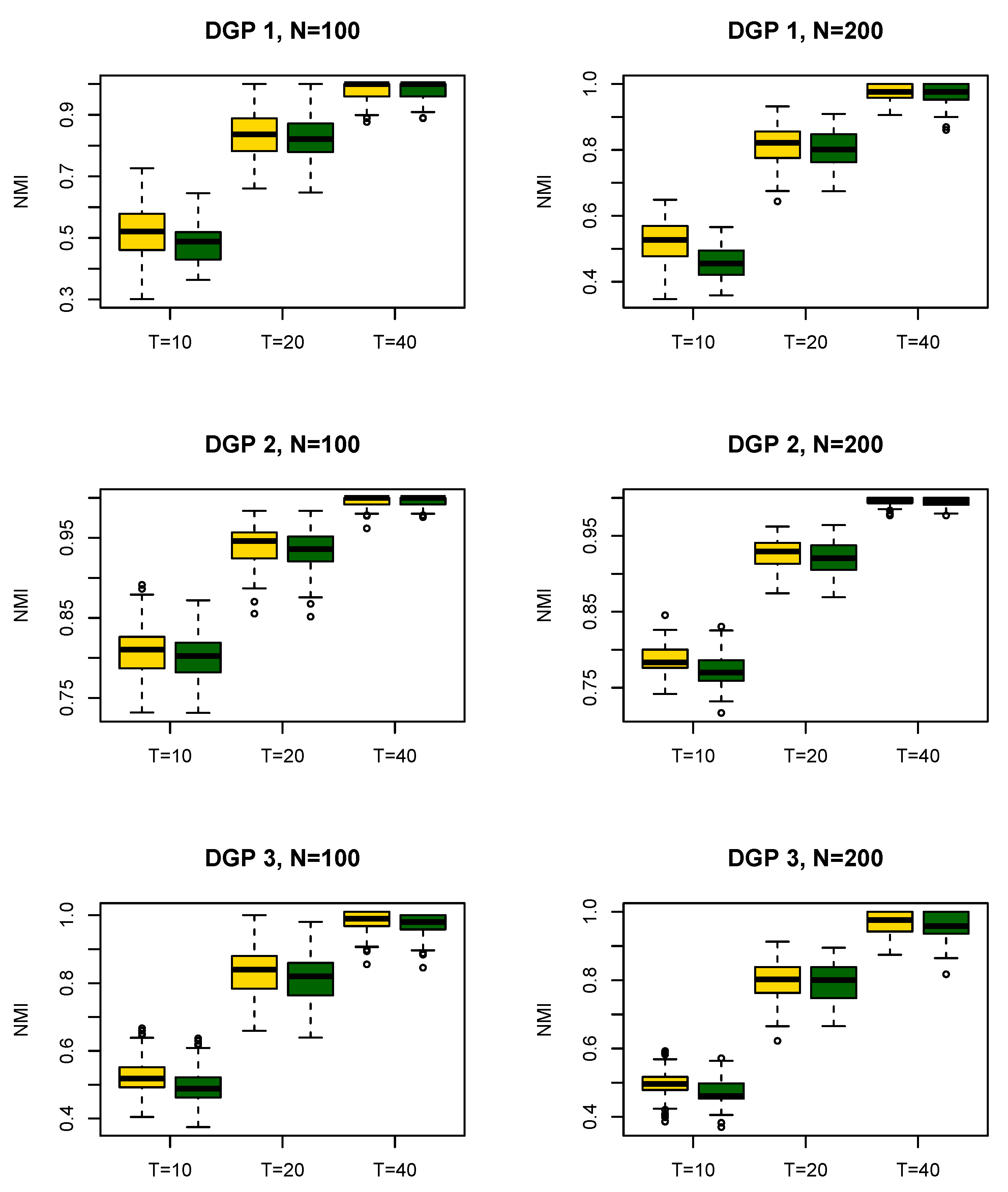
4.2. Simulation Results
5. Empirical Analysis
6. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1
Appendix B. Proofs
Appendix B.1
Appendix B.2
- (1).
- In the event , for any and ;
- (2).
- There exists an event such that . Over the event , there exists a neighborhood of , denoted by such that for any and the inequality strictly holds when .
Appendix B.3
Appendix C. Testing for Heterogeneity
| Algorithm A1: Residual bootstrap procedure |
|
References
- Hsiao, C. Analysis of Panel Data; Number 54; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Bonhomme, S.; Manresa, E. Grouped patterns of heterogeneity in panel data. Econometrica 2015, 83, 1147–1184. [Google Scholar] [CrossRef]
- Su, L.; Chen, Q. Testing homogeneity in panel data models with interactive fixed effects. Econom. Theory 2013, 29, 1079–1135. [Google Scholar] [CrossRef]
- Phillips, P.C.; Sul, D. Transition modeling and econometric convergence tests. Econometrica 2007, 75, 1771–1855. [Google Scholar] [CrossRef]
- Su, L.; Shi, Z.; Phillips, P.C. Identifying latent structures in panel data. Econometrica 2016, 84, 2215–2264. [Google Scholar] [CrossRef]
- Ke, Z.T.; Fan, J.; Wu, Y. Homogeneity pursuit. J. Am. Stat. Assoc. 2015, 110, 175–194. [Google Scholar] [CrossRef]
- Xiao, D.; Ke, Y.; Li, R. Homogeneity structure learning in large-scale panel data with heavy-tailed errors. J. Mach. Learn. Res. 2021, 22, 1–42. [Google Scholar]
- Zhang, Y.; Wang, H.J.; Zhu, Z. Quantile-regression-based clustering for panel data. J. Econom. 2019, 213, 54–67. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. Stat. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Huang, W.; Jin, S.; Su, L. Identifying latent grouped patterns in cointegrated panels. Econom. Theory 2020, 36, 410–456. [Google Scholar] [CrossRef]
- Huang, W.; Su, L.; Zhuang, Y. Detecting unobserved heterogeneity in efficient prices via classifier-lasso. J. Bus. Econ. Stat. 2023, 41, 509–522. [Google Scholar] [CrossRef]
- Su, L.; Ju, G. Identifying latent grouped patterns in panel data models with interactive fixed effects. J. Econom. 2018, 206, 554–573. [Google Scholar] [CrossRef]
- Su, L.; Wang, X.; Jin, S. Sieve estimation of time-varying panel data models with latent structures. J. Bus. Econ. Stat. 2019, 37, 334–349. [Google Scholar] [CrossRef]
- Mehrabani, A. Estimation and identification of latent group structures in panel data. J. Econom. 2023, 235, 1464–1482. [Google Scholar] [CrossRef]
- Ando, T.; Bai, J. Panel data models with grouped factor structure under unknown group membership. J. Appl. Econom. 2016, 31, 163–191. [Google Scholar] [CrossRef]
- Liu, R.; Shang, Z.; Zhang, Y.; Zhou, Q. Identification and estimation in panel models with overspecified number of groups. J. Econom. 2020, 215, 574–590. [Google Scholar] [CrossRef]
- Bai, J. Estimating multiple breaks one at a time. Econom. Theory 1997, 13, 315–352. [Google Scholar] [CrossRef]
- Wang, W.; Su, L. Identifying latent group structures in nonlinear panels. J. Econom. 2021, 220, 272–295. [Google Scholar] [CrossRef]
- Su, L.; Wang, W.; Xu, X. Identifying latent group structures in spatial dynamic panels. J. Econom. 2023, 235, 1955–1980. [Google Scholar] [CrossRef]
- Wang, Y.; Phillips, P.C.; Su, L. Panel data models with time-varying latent group structures. J. Econom. 2024, 240, 105685. [Google Scholar] [CrossRef]
- Beer, J.C.; Aizenstein, H.J.; Anderson, S.J.; Krafty, R.T. Incorporating prior information with fused sparse group lasso: Application to prediction of clinical measures from neuroimages. Biometrics 2019, 75, 1299–1309. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Jin, B. Pairwise fusion approach incorporating prior constraint information. Commun. Math. Stat. 2020, 8, 47–62. [Google Scholar] [CrossRef]
- Li, F.; Sang, H. Spatial homogeneity pursuit of regression coefficients for large datasets. J. Am. Stat. Assoc. 2019, 114, 1050–1062. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, J.; Zhu, Z. Learning coefficient heterogeneity over networks: A distributed spanning-tree-based fused-lasso regression. J. Am. Stat. Assoc. 2024, 119, 485–497. [Google Scholar] [CrossRef]
- Wang, W.; Phillips, P.C.; Su, L. Homogeneity pursuit in panel data models: Theory and application. J. Appl. Econom. 2018, 33, 797–815. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers; Now Publishers Inc.: Delft, The Netherlands, 2011. [Google Scholar]
- Ke, Y.; Li, J.; Zhang, W. Structure identification in panel data analysis. Ann. Stat. 2016, 44, 1193–1233. [Google Scholar] [CrossRef]
- Ma, S.; Huang, J. A concave pairwise fusion approach to subgroup analysis. J. Am. Stat. Assoc. 2017, 112, 410–423. [Google Scholar] [CrossRef]
- Jeon, J.-J.; Kwon, S.; Choi, H. Homogeneity detection for the high-dimensional generalized linear model. Comput. Stat. Data Anal. 2017, 114, 61–74. [Google Scholar] [CrossRef]
- Zhang, C.-H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef]
- Belloni, A.; Chernozhukov, V. Least squares after model selection in high-dimensional sparse models. Bernoulli 2013, 19, 521–547. [Google Scholar] [CrossRef]
- Shiu, A.; Lam, P.-L. Electricity consumption and economic growth in china. Energy Policy 2004, 32, 47–54. [Google Scholar] [CrossRef]
- Xu, S.-C.; He, Z.-X.; Long, R.-Y. Factors that influence carbon emissions due to energy consumption in china: Decomposition analysis using lmdi. Appl. Energy 2014, 127, 182–193. [Google Scholar] [CrossRef]
- Akkemik, K.A.; Göksal, K.; Li, J. Energy consumption and income in chinese provinces: Heterogeneous panel causality analysis. Appl. Energy 2012, 99, 445–454. [Google Scholar] [CrossRef]
- Wang, N.; Fu, X.; Wang, S. Economic growth, electricity consumption, and urbanization in china: A tri-variate investigation using panel data modeling from a regional disparity perspective. J. Clean. Prod. 2021, 318, 128529. [Google Scholar] [CrossRef]
- Pesaran, M.H. Estimation and inference in large heterogeneous panels with a multifactor error structure. Econometrica 2006, 74, 967–1012. [Google Scholar] [CrossRef]
- Miao, K.; Li, K.; Su, L. Panel threshold models with interactive fixed effects. J. Econom. 2020, 219, 137–170. [Google Scholar] [CrossRef]
- Tseng, P. Convergence of a block coordinate descent method for nondifferentiable minimization. J. Optim. Theory Appl. 2001, 109, 475–494. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Notation | Illustration | |
|---|---|---|
| Observed quantities | the univariate response variable | |
| the explanatory variables | ||
| the prior constraint information set | ||
| N | the number of all individuals | |
| T | the number of observations for each individual | |
| Unknown parameters | the fixed effect of the ith individual | |
| the slope of the ith individual | ||
| the latent group structures | ||
| the membership of the kth group | ||
| the common slope of the kth group | ||
| K | the number of latent groups |
| Methods | Penalty Forms | Prior Information |
|---|---|---|
| C-Lasso [5] | No prior information | |
| Panel-CARDS [26] | An ordered segmentation | |
| PAGFL [15] | Adaptive weights ’s | |
| Our work | A convex set |
| DGP | No-Prior [5] | Prior | Oracle | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Bias | −0.025 | −0.008 | −0.002 | −0.007 | −0.004 | −0.003 | 0.010 | −0.001 | −0.002 |
| SD | 0.088 | 0.042 | 0.029 | 0.084 | 0.041 | 0.029 | 0.054 | 0.037 | 0.029 | |
| ESE | 0.060 | 0.041 | 0.029 | 0.062 | 0.042 | 0.029 | 0.058 | 0.041 | 0.029 | |
| ECP | 0.830 | 0.920 | 0.970 | 0.850 | 0.950 | 0.960 | 0.980 | 0.960 | 0.970 | |
| 2 | Bias | −0.011 | −0.015 | −0.001 | 0.008 | −0.004 | −0.001 | −0.004 | −0.007 | 0.000 |
| SD | 0.086 | 0.040 | 0.027 | 0.089 | 0.042 | 0.027 | 0.062 | 0.040 | 0.027 | |
| ESE | 0.060 | 0.042 | 0.029 | 0.061 | 0.042 | 0.029 | 0.058 | 0.041 | 0.029 | |
| ECP | 0.780 | 0.980 | 0.960 | 0.830 | 0.950 | 0.960 | 0.940 | 0.980 | 0.970 | |
| 3 | Bias | 0.005 | 0.003 | 0.003 | 0.018 | 0.005 | 0.004 | 0.005 | 0.004 | 0.003 |
| SD | 0.078 | 0.042 | 0.031 | 0.077 | 0.043 | 0.032 | 0.060 | 0.042 | 0.031 | |
| ESE | 0.066 | 0.043 | 0.029 | 0.065 | 0.043 | 0.029 | 0.058 | 0.041 | 0.029 | |
| ECP | 0.910 | 0.970 | 0.930 | 0.920 | 0.960 | 0.920 | 0.940 | 0.950 | 0.930 | |
| With Prior Information | Without Prior Information | |||||
|---|---|---|---|---|---|---|
| Group 1 | Group 2 | Group 1 | Group 2 | Group 3 | Group 4 | Group 5 |
| 0.9837 | 1.0879 | 3.4351 | ||||
| Anhui | Beijing | Guangdong | Shandong | Zhejiang | Anhui | Beijing |
| Fujian | Gansu | Jiangsu | Fujian | Gansu | ||
| Guangdong | Guizhou | Guangxi | Guizhou | |||
| Guangxi | Heilongjiang | Hainan | Heilongjiang | |||
| Hainan | Jilin | Hebei | Jilin | |||
| Hebei | Jiangxi | Henan | Jiangxi | |||
| Henan | Ningxia | Hubei | Ningxia | |||
| Hubei | Qinghai | Hunan | Qinghai | |||
| Hunan | Shannxi | Liaoning | Shannxi | |||
| Jiangsu | Tianjin | Inner Mongolia | Tianjin | |||
| Liaoning | Chongqing | Shanxi | Chongqing | |||
| Inner Mongolia | Shanghai | |||||
| Shandong | Sichuan | |||||
| Shanxi | Xinjiang | |||||
| Shanghai | Yunan | |||||
| Sichuan | ||||||
| Xinjiang | ||||||
| Yunnan | ||||||
| Zhejiang | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Luo, X.; Liao, M. Incorporating Prior Information in Latent Structures Identification for Panel Data Models. Mathematics 2025, 13, 1505. https://doi.org/10.3390/math13091505
Li Y, Luo X, Liao M. Incorporating Prior Information in Latent Structures Identification for Panel Data Models. Mathematics. 2025; 13(9):1505. https://doi.org/10.3390/math13091505
Chicago/Turabian StyleLi, Yi, Xingxing Luo, and Mengqi Liao. 2025. "Incorporating Prior Information in Latent Structures Identification for Panel Data Models" Mathematics 13, no. 9: 1505. https://doi.org/10.3390/math13091505
APA StyleLi, Y., Luo, X., & Liao, M. (2025). Incorporating Prior Information in Latent Structures Identification for Panel Data Models. Mathematics, 13(9), 1505. https://doi.org/10.3390/math13091505