
Power Length-Biased New XLindley Distribution: Properties and Modeling of Real Data


Abstract
1. Introduction
- Introduce the power length-biased new XLindley distribution as a novel probability model for lifetime data.
- Explore and validate the statistical properties of the proposed distribution and demonstrate its suitability for modeling datasets with increasing, decreasing, and inverted bathtub-shaped hazard rates.
- Estimate the parameters of the proposed distribution using the maximum likelihood estimation (MLE) method and assess the efficiency of the MLE estimators through simulated observations.
- Illustrate the applicability of the proposed distribution by fitting it to real datasets in comparison with existing competing models and demonstrate its superior fit.
2. PLNXL Distribution and Its Properties
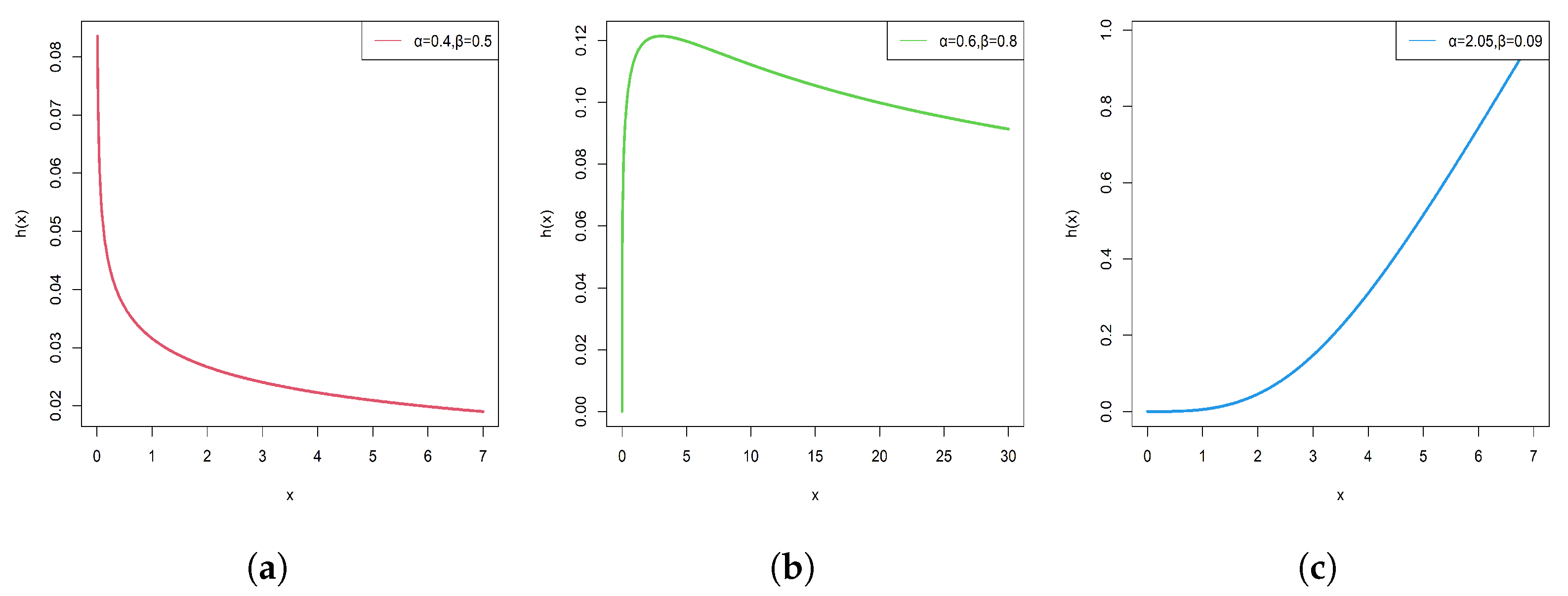
2.1. The PLNXL and Its Shape
- (i)
- decreasing if ;
- (ii)
- unimodal if .
2.2. Reliability Analysis
- (i)
- increasing if ;
- (ii)
- decreasing if ;
- (iii)
- IBT-shaped if .
- (i)
- increasing if ;
- (ii)
- decreasing if ;
- (iii)
- bathtub-shaped if .
2.3. The Raw Moments
2.4. Entropy
3. Model Parameter Estimation
3.1. ML Estimation
3.2. Asymptotic Confidence Interval
4. Generation of Random Observations and Simulation Study
4.1. Algorithm to Generate Random Observations
- Step 1: Generate n observations and from the following GG distributions: and , respectively.
- Step 2: Generate n observations from the uniform over .
- Step 3: If , set ; else, set .Simulation studies can be carried out to evaluate the effectiveness of estimating techniques, among other things, using these generated data.
4.2. A Simulation Study
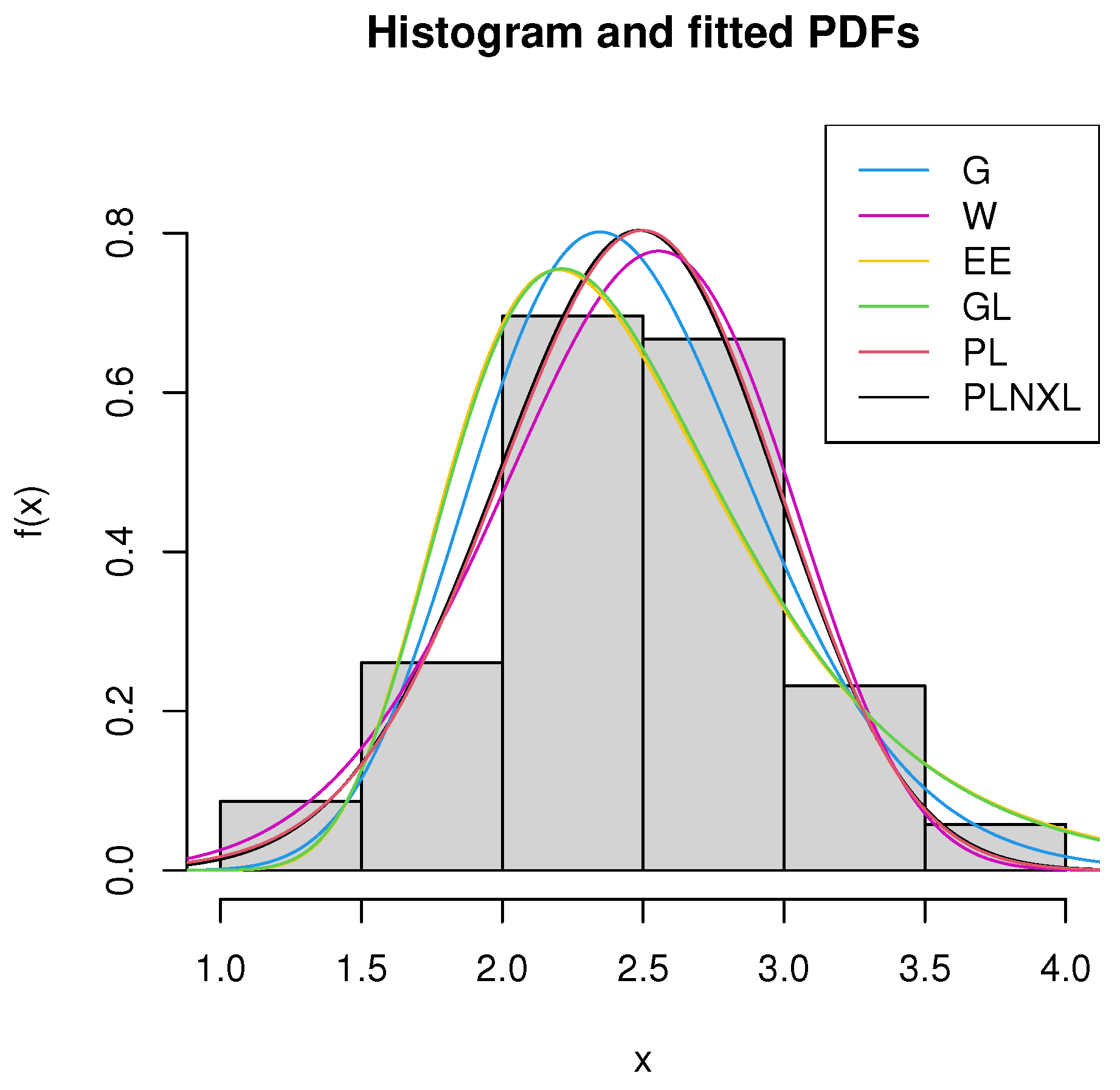
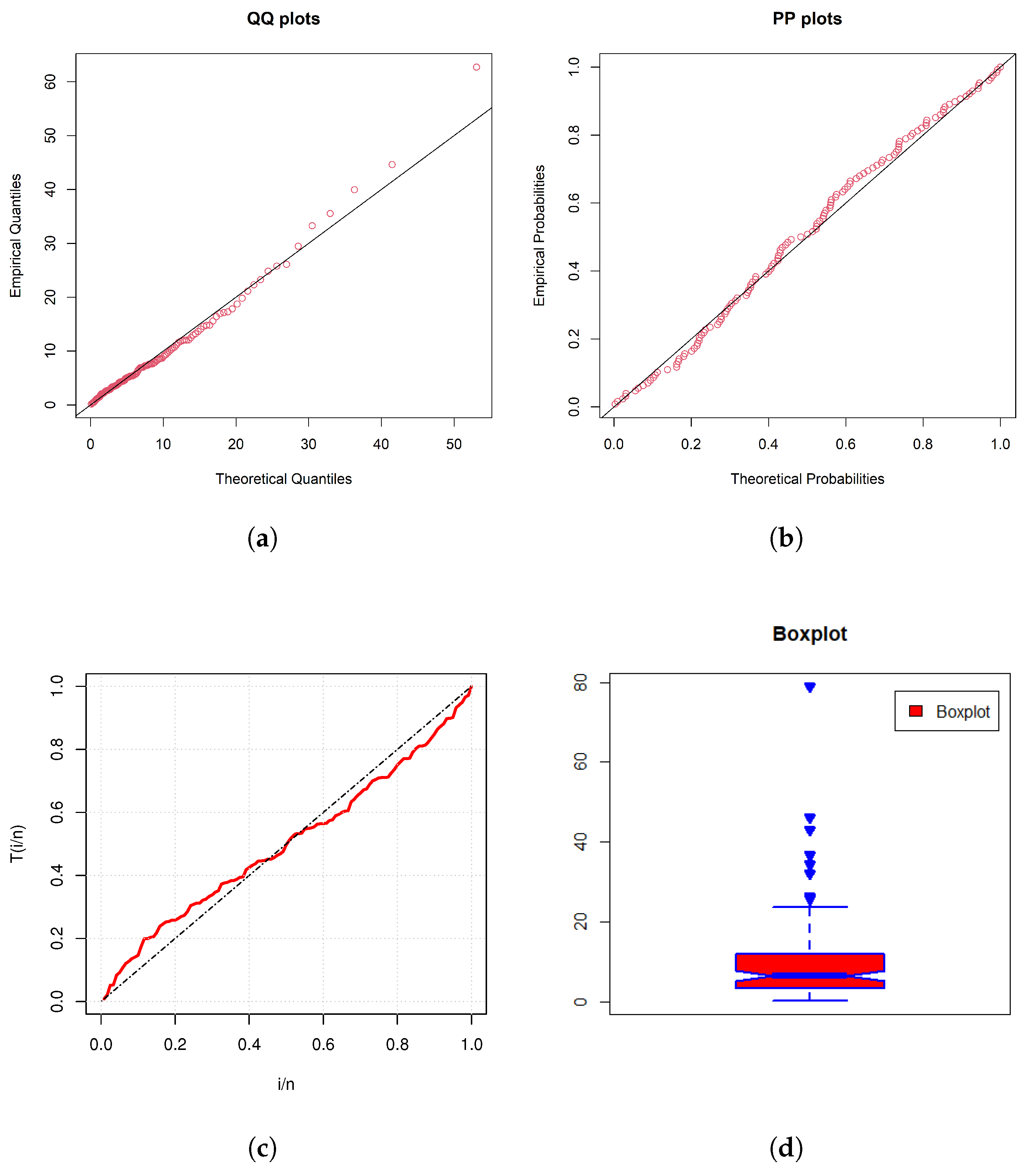
5. Applications to Real-Life Data Sets
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- (i)
- If , the coefficients a, b, and c are negative. If , a is negative, b and c are zero. Hence, is negative in this case. Thus, is decreasing.
- (ii)
- The roots of are
- (i)
- It can be observed that A, B, C, and D are all positive if , ; thus, . It can also be observed that if , , , hence, . Therefore, if , , is increasing.
- (ii)
- Furthermore, if , , A, B, C, and D are negative, hence, . This implies that is decreasing if , . If , , C, and D are zero, A and B are negative, which implies (3) is decreasing.
- (iii)
- If , , the sign of A is negative and signs of C and D are positive. The sign of B is positive if , and it is negative if . If , B is zero.Hence, if , , the number of times the change occurs in signs of A, B, C, and D is one. Using the Descartes’ rule of signs, the equation has only one positive root if the number of sign changes in A, B, C, and D is one.Moreover, since ,will be initially positive and then change the sign to negative one time. Hence, is IBT-shaped.
References
- Bennett, S. Log-logistic regression models for survival data. Appl. Stat. 1983, 32, 165–171. [Google Scholar] [CrossRef]
- Efron, B. Logistic regression, survival analysis, and the Kaplan-Meier curve. J. Am. Stat. Assoc. 1988, 83, 414–425. [Google Scholar] [CrossRef]
- Langlands, A.; Pocock, S.; Kerr, G.; Gore, S. Long-term survival of patients with breast cancer: A study of the curability of the disease. Br. Med. J. 1979, 2, 1247–1251. [Google Scholar] [CrossRef]
- Aalen, O.O.; Gjessing, H.K. Understanding the shape of the hazard rate: A process point of view. Stat. Sci. 2001, 16, 1–22. [Google Scholar] [CrossRef]
- Bae, S.J.; Kuo, W.; Kvam, P.H. Degradation models and implied lifetime distributions. Reliab. Eng. Syst. Saf. 2007, 92, 601–608. [Google Scholar] [CrossRef]
- Crowder, M.J.; Kimber, A.C.; Smith, R.L.; Sweeting, T.J. Statistical Analysis of Reliability Data; Chapman and Hall/CRC: Boca Raton, FL, USA, 1991. [Google Scholar]
- Lai, C.; Xie, M. Stochastic Aging and Dependence for Reliability; Springer: New York, NY, USA, 2006. [Google Scholar]
- Lindley, D. Fiducial distributions and Bayes’ theorem. J. R. Stat. Soc. Ser. B 1958, 20, 102–107. [Google Scholar] [CrossRef]
- Benchiha, S.A.; Al-Omari, A.I. Generalized quasi Lindley distribution: Theoretical properties, estimation methods and applications. Electron. J. Appl. Stat. Anal. 2021, 14, 167. [Google Scholar]
- Irshad, M.; Maya, R.; Al-Omari, A.I.; Arun, S.; Alomani, G. The extended Farlie-Gumbel-Morgenstern bivariate Lindley distribution: Concomitants of order statistics and estimation. Electron. J. Appl. Stat. Anal. 2021, 14, 373–388. [Google Scholar]
- Benchiha, S.; Al-Omari, A.I.; Alotaibi, N.; Shrahili, M. Weighted generalized quasi Lindley distribution: Different methods of estimation, applications for COVID-19 and engineering data. AIMS Math. 2021, 6, 11850–11878. [Google Scholar] [CrossRef]
- Chouia, S.; Zeghdoudi, H. The XLindley distribution: Properties and application. J. Stat. Theory Appl. 2021, 20, 318–327. [Google Scholar] [CrossRef]
- Khodja, N.; Gemeay, A.M.; Zeghdoudi, H.; Karakaya, K.; Alshangiti, A.M.; Bakr, M.E.; Balogun, O.S.; Muse, A.H.; Hussam, E. Modeling voltage real data set by a new version of Lindley distribution. IEEE Access 2023, 11, 67220–67229. [Google Scholar] [CrossRef]
- Metiri, F.; Zeghdoudi, H.; Ezzebsa, A. On the characterisation of XLindley distribution by truncated moments. properties and application. Oper. Res. Decis. 2022, 32, 97–109. [Google Scholar]
- Zinhom, E.; Nassar, M.; Radwan, S.; Elmasry, A. The wrapped XLindley distribution. Environ. Ecol. Stat. 2003, 30, 669–686. [Google Scholar] [CrossRef]
- Etaga, H.O.; Nwankwo, M.P.; Oramulu, D.O.; Anabike, I.C.; Obulezi, O.J. The double XLindley distribution: Properties and applications. Sch. J. Phys. Math. Stat. 2023, 10, 192–202. [Google Scholar] [CrossRef]
- Beghriche, A.; Tashkandy, Y.A.; Bakr, M.E.; Zeghdoudi, H.; Gemeay, A.M.; Hossain, M.M.; Muse, A.H. The inverse XLindley distribution: Properties and application. IEEE Access 2023, 11, 47272–47281. [Google Scholar] [CrossRef]
- MirMostafaee, S. The exponentiated new XLindley distribution: Properties, and Applications. J. Data Sci. Model. 2023, 2, 185–208. [Google Scholar]
- Gemeay, A.M.; Ezzebsa, A.; Zeghdoudi, H.; Tanış, C.; Tashkandy, Y.A.; Bakr, M.; Kumar, A. The power new XLindley distribution: Statistical inference, fuzzy reliability, and applications. Heliyon 2024, 10, e36594. [Google Scholar] [CrossRef]
- Alghamdi, F.M.; Ahsan-ul Haq, M.; Hussain, M.N.S.; Hussam, E.; Almetwally, E.M.; Aljohani, H.M.; Mustafa, M.S.; Alshawarbeh, E.; Yusuf, M. Discrete poisson quasi-XLindley distribution with mathematical properties, regression model, and data analysis. J. Radiat. Res. Appl. Sci. 2024, 17, 100874. [Google Scholar] [CrossRef]
- Alomair, A.M.; Ahmed, M.; Tariq, S.; Ahsan-ul Haq, M.; Talib, J. An exponentiated XLindley distribution with properties, inference and applications. Heliyon 2024, 10, e25472. [Google Scholar] [CrossRef]
- Musekwa, R.R.; Makubate, B. A flexible generalized XLindley distribution with application to engineering. Sci. Afr. 2024, 24, e02192. [Google Scholar] [CrossRef]
- Alsadat, N. A new extension of XLindley distribution with mathematical properties, estimation, and application on the rainfall data. Heliyon 2024, 10, e38143. [Google Scholar] [CrossRef] [PubMed]
- Kouadria, M.; Zeghdoudi, H. The truncated new-XLindley distribution with applications. J. Comput. Anal. Appl. 2025, 34, 53–64. [Google Scholar]
- Rao, C.R. On discrete distributions arising out of methods of ascertainment. Sankhya A 1965, 27, 311–324. [Google Scholar]
- ul Haq, M.A.; Usman, R.M.; Hashmi, S.; Al-Omeri, A.I. The Marshall-Olkin length-biased exponential distribution and its applications. J. King Saud Univ.-Sci. 2019, 31, 246–251. [Google Scholar] [CrossRef]
- Rajagopalan, V.; Ganaie, R.A.; Rather, A.A. A new length biased distribution with applications. Sci. Technol. Dev. 2019, 8, 161–174. [Google Scholar]
- Hassan, A.S.; Almetwally, E.M.; Khaleel, M.A.; Nagy, H.F. Weighted power Lomax distribution and its length biased version: Properties and estimation based on censored samples. Pak. J. Stat. Oper. Res. 2021, 17, 343–356. [Google Scholar] [CrossRef]
- Chaito, T.; Khamkong, M. The length–biased Weibull–Rayleigh distribution for application to hydrological data. Lobachevskii J. Math. 2021, 42, 3253–3265. [Google Scholar] [CrossRef]
- Alzoubi, L. Length-biased Loai distribution: Statistical properties and application. Electron. J. Appl. Stat. Anal. 2024, 17, 278. [Google Scholar]
- Bryson, M.; Siddique, M. Some criteria for aging. J. Am. Stat. Assoc. 1969, 64, 1472–1483. [Google Scholar] [CrossRef]
- Gupta, R.; Akman, O. Mean residual life function for certain types of non-monotonic ageing. Commun. Stat.-Stoch. Model. 1995, 11, 219–225. [Google Scholar]
- Rényi, A. On measures of information and entropy. In Proceedings of the Fourth Berkeley Symposium on Mathematics, Statistics and Probability 1960; University of California Press: Berkeley, CA, USA, 1961; pp. 547–561. [Google Scholar]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Kızılaslan, F. Classical and bayesian estimation of reliability in a multicomponent stress–strength model based on the proportional reversed hazard rate mode. Math. Comput. Simul. 2017, 136, 36–62. [Google Scholar] [CrossRef]
- Agiwal, V. Bayesian estimation of stress strength reliability from inverse Chen distribution with application on failure time data. Ann. Data Sci. 2023, 10, 317–347. [Google Scholar] [CrossRef]
- Xu, A.; Fang, G.; Zhuang, L.; Gu, C. A multivariate student-t process model for dependent tail-weighted degradation data. IISE Trans. 2024. [Google Scholar] [CrossRef]
- Zhuang, L.; Xu, A.; Wang, Y.; Tang, Y. Remaining useful life prediction for two-phase degradation model based on reparameterized inverse Gaussian process. Eur. J. Oper. Res. 2024, 319, 877–890. [Google Scholar] [CrossRef]
- Gradshteyn, I.; Ryzhik, I. Tables of Integrals, Series, and Products; Academic Press: New York, NY, USA, 2007. [Google Scholar]
- Lehmann, L.; Casella, G. Theory of Point Estimation; Springer: New York, NY, USA, 1998. [Google Scholar]
- Bader, M.G.; Priest, A.M. Statistical aspects of fibre and bundle strength in hybrid composites. In Progress in Science and Engineering Composites. Vol. 4th International Conference on Composite Materials (ICCM-IV); Hayashi, T., Kawata, K., Umekawa, S., Eds.; Japan Society Society for Composite Materials: Tokyo, Japan, 1982; pp. 1129–1136. [Google Scholar]
- Ghitany, M.; Al-Mutairi, D.; Balakrishnan, N.; Al-Enezi, L. Power Lindley distribution and associated inference. Comput. Stat. Data Anal. 2013, 64, 20–33. [Google Scholar] [CrossRef]
- Aarset, M. How to identify a bathtub hazard rate. IEEE Trans. Reliab. 1987, 36, 106–108. [Google Scholar] [CrossRef]
- Gupta, R.; Kundu, D. Exponentiated exponential family: An alternative to gamma and Weibull distributions. Biom. J. 2001, 43, 117–130. [Google Scholar] [CrossRef]
- Nadarajah, S.; Bakouch, H.; Tahmasbi, R. A generalized Lindley distribution. Sankhya B 2011, 73, 331–359. [Google Scholar] [CrossRef]
- Lee, E.; Wang, J. Statistical Methods for Survival Data Analysis; John Wiley and Sons: New York, NY, USA, 2003. [Google Scholar]
- Abouammoh, A.; Alshingiti, A. Reliability estimation of generalized inverted exponential distribution. J. Stat. Comput. Simul. 2009, 79, 1301–1315. [Google Scholar] [CrossRef]
- Barco, K.; Mazucheli, J.; Janeiro, V. The inverse power Lindley distribution. Commun. Stat.-Simul. Comput. 2017, 46, 6308–6323. [Google Scholar] [CrossRef]
- Bhati, D.; Malik, M.; Vaman, H. Lindley–exponential distribution: Properties and applications. Metron 2015, 73, 335–357. [Google Scholar] [CrossRef]
- Xu, A.; Wang, R.; Weng, X.; Wu, Q.; Zhuang, L. Strategic integration of adaptive sampling and ensemble techniques in federated learning for aircraft engine remaining useful life prediction. Appl. Soft Comput. 2005, 175, 113067. [Google Scholar] [CrossRef]
- Al-Omari, A.I. The efficiency of l ranked set sampling in estimating the distribution function. Afr. Mat. 2015, 26, 1457–1466. [Google Scholar] [CrossRef]
- Al-Omari, A.I.; Bouza, C.N. Review of ranked set sampling: Modifications and applications. Rev. Investig. Oper. 2014, 3, 215–240. [Google Scholar]
- Al-Omari, A.I. Estimation of the population median of symmetric and asymmetric distributions using double robust extreme ranked set sampling. Investig. Oper. 2010, 31, 199–207. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Parameters | n | AE | Bias | MSE | AW (CP) |
|---|---|---|---|---|---|---|
| I | 20 | 0.6449 | 0.0449 | 0.0167 | 0.4288 (0.9418) | |
| 20 | 0.5749 | −0.0250 | 0.0396 | 0.7295 (0.8936) | ||
| 50 | 0.6162 | 0.0162 | 0.0048 | 0.2591 (0.95) | ||
| 50 | 0.5898 | −0.0101 | 0.0153 | 0.4752 (0.9266) | ||
| 100 | 0.6087 | 0.0087 | 0.0022 | 0.1810 (0.9514) | ||
| 100 | 0.5928 | −0.0071 | 0.0075 | 0.3386 (0.9394) | ||
| 150 | 0.6055 | 0.0055 | 0.0014 | 0.1470 (0.9470) | ||
| 150 | 0.5956 | −0.0043 | 0.0050 | 0.2775 (0.9432) | ||
| II | 20 | 3.5332 | 0.2332 | 0.4780 | 2.3489 (0.9474) | |
| 20 | 0.0982 | −0.0017 | 0.0037 | 0.2259 (0.8480) | ||
| 50 | 3.3969 | 0.0969 | 0.1519 | 1.4283 (0.9468) | ||
| 50 | 0.0983 | −0.0016 | 0.0014 | 0.1472 (0.9018) | ||
| 100 | 3.3487 | 0.0487 | 0.0701 | 0.9957 (0.9480) | ||
| 100 | 0.0990 | −0.0009 | 0.0007 | 0.1056 (0.9226) | ||
| 150 | 3.3298 | 0.0298 | 0.0424 | 0.8083 (0.9536) | ||
| 150 | 0.0994 | −0.0005 | 0.0004 | 0.0868 (0.9364) | ||
| III | 20 | 2.1542 | 0.1542 | 0.1894 | 1.4322 (0.9432) | |
| 20 | 1.4691 | −0.0308 | 0.0952 | 1.1467 (0.9242) | ||
| 50 | 2.0556 | 0.0556 | 0.0557 | 0.8643 (0.946) | ||
| 50 | 1.4874 | −0.0125 | 0.0367 | 0.7314 (0.9396) | ||
| 100 | 2.0279 | 0.0279 | 0.0248 | 0.6029 (0.9514) | ||
| 100 | 1.4965 | −0.0034 | 0.0179 | 0.5189 (0.9462) | ||
| 150 | 2.0152 | 0.0152 | 0.0162 | 0.4892 (0.9520) | ||
| 150 | 1.4997 | −0.0002 | 0.0117 | 0.4242 (0.9512) |
| MODEL | MLEs | K-S | AD | CvM | AIC | BIC |
|---|---|---|---|---|---|---|
| G | (3.9530) | |||||
| (1.6299) | ||||||
| W | (0.3294) | |||||
| (0.0019) | ||||||
| EE | (32.9253) | |||||
| (0.1798) | ||||||
| GL | (23.8138) | |||||
| (0.1850) | ||||||
| PL | (0.3138) | |||||
| (0.0160) | ||||||
| PLNXL | (0.3050) | |||||
| (0.0356) |
| MODEL | MLEs | K-S | AD | CvM | AIC | BIC |
|---|---|---|---|---|---|---|
| GIE | (0.0883) | 0.20669 (0.0001) | 9.3928 (0.0001) | 1.8347 (0.0001) | 918.4048 | 924.1088 |
| (0.2704) | ||||||
| IG | (0.0514) | 0.1909 (0.0002) | 8.3938 (0.0001) | 1.5675 (0.0001) | 913.8611 | 919.5652 |
| (0.2196) | ||||||
| IW | (0.2192) | 0.1408 (0.0124) | 6.1183 (0.0009) | 0.9787 (0.0027) | 892.0015 | 897.7056 |
| (0.0424) | ||||||
| IPL | (0.0412) | 0.1481 (0.0073) | 6.3977 (0.0006) | 1.0213 (0.0021) | 895.6256 | 901.3297 |
| (0.2272) | ||||||
| LN | (0.0948) | 0.0617 (0.714) | 0.8030 (0.4786) | 0.1186 (0.5019) | 834.1887 | 839.8928 |
| (0.0670) | ||||||
| LE | (0.0137) | 0.0621 (0.7067) | 0.5244 (0.7217) | 0.0897 (0.6384) | 828.0985 | 833.8026 |
| (0.1637) | ||||||
| PLNXL | (0.0426) | 0.0532 (0.8604) | 0.4334 (0.8148) | 0.0696 (0.7548) | 826.6529 | 832.3570 |
| (0.0808) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kharvi, S.; Irshad, M.R.; Al-Omari, A.I.; Alsultan, R. Power Length-Biased New XLindley Distribution: Properties and Modeling of Real Data. Mathematics 2025, 13, 1394. https://doi.org/10.3390/math13091394
Kharvi S, Irshad MR, Al-Omari AI, Alsultan R. Power Length-Biased New XLindley Distribution: Properties and Modeling of Real Data. Mathematics. 2025; 13(9):1394. https://doi.org/10.3390/math13091394
Chicago/Turabian StyleKharvi, Suresha, Muhammed Rasheed Irshad, Amer Ibrahim Al-Omari, and Rehab Alsultan. 2025. "Power Length-Biased New XLindley Distribution: Properties and Modeling of Real Data" Mathematics 13, no. 9: 1394. https://doi.org/10.3390/math13091394
APA StyleKharvi, S., Irshad, M. R., Al-Omari, A. I., & Alsultan, R. (2025). Power Length-Biased New XLindley Distribution: Properties and Modeling of Real Data. Mathematics, 13(9), 1394. https://doi.org/10.3390/math13091394