


Multiscale Interaction Purification-Based Global Context Network for Industrial Process Fault Diagnosis


Abstract
1. Introduction
- MIPGC-Net is presented as a new fault diagnosis method for industrial processes. The method innovatively implements the collaborative modeling of local multiscale features and global temporal features, which effectively makes up for the lack of multiscale information in the traditional temporal modeling process. Specifically, local features are extracted by convolutional operations and multiple sets of convolutional kernels are cascaded and combined to obtain multiscale features. Meanwhile, wide temporal dependencies are introduced to capture the global context information, thus forming a more complete feature representation;
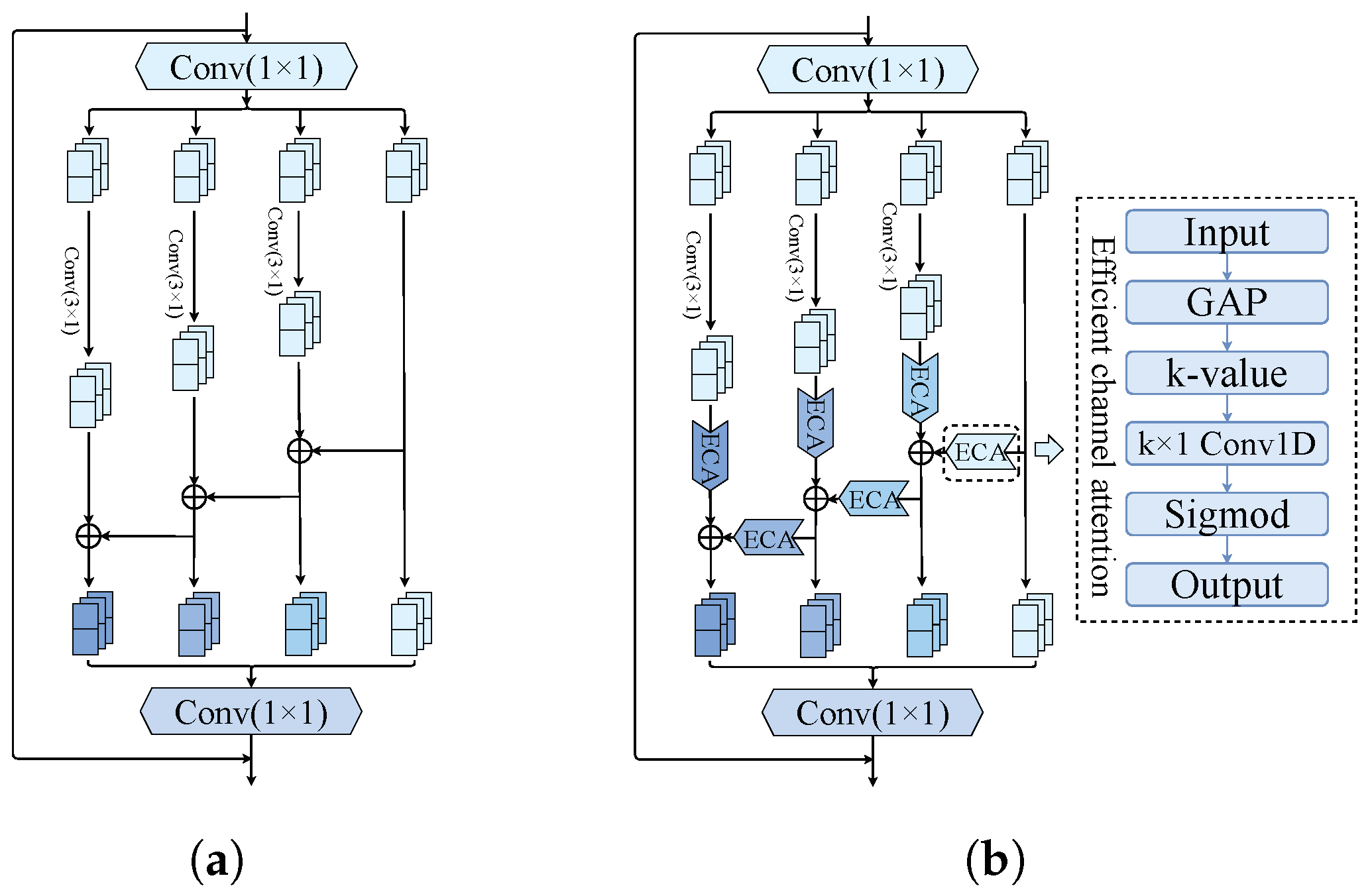
- An MFIR module is designed. This module uses multiple small convolution kernels to construct a multiscale residual module through a hierarchical structure. This design enables us to generate feature combinations with varying numbers, sizes, and scales of receptive fields. The equivalent receptive fields are larger, and richer features can be acquired than using the same number of convolution kernels. This module not only realizes the feature interaction between different scales, but also purifies the feature expression through the ECA mechanism;
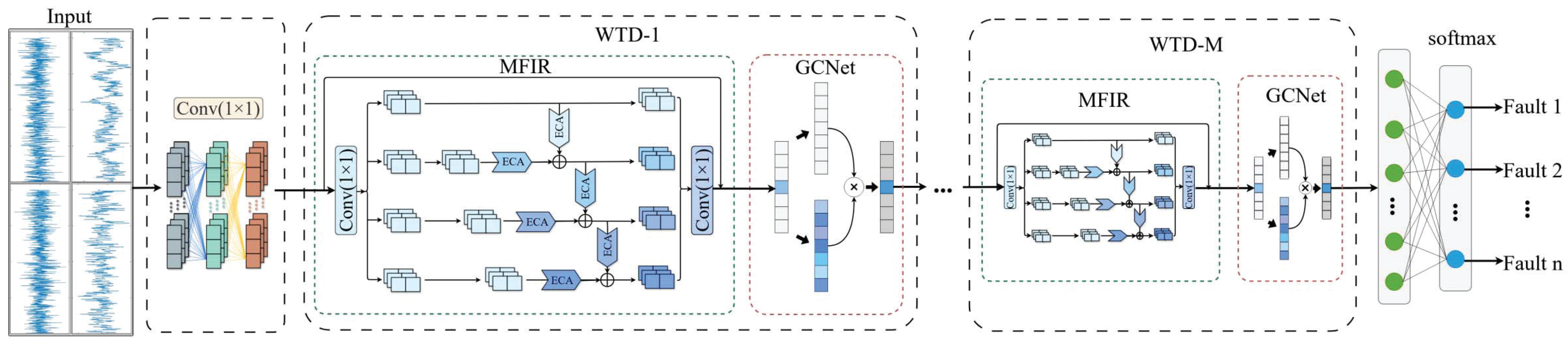
- A WTD sub-network is proposed. By integrating the MFIR module with the GCNet, a unified model is established to capture local and global characteristics. The output features of this sub-network contain both the multiscale information and the wide temporal dependencies. Compared with traditional multiscale methods and temporal modeling methods, the WTD sub-network can provide richer and more discriminative feature representations for industrial process fault diagnosis.
2. Related Works
2.1. Multiscale Feature Extraction
2.2. Capture of Wide Temporal Dependency
3. Proposed Method
3.1. MFIR Module
3.2. WTD Sub-Network

3.3. MIPGC-Net Method for Fault Diagnosis
| Algorithm 1 MIPGC-Net training process for industrial process fault diagnosis. |
|
4. Experiments and Discussion
4.1. Evaluation Metrics
4.2. Experiment Setting
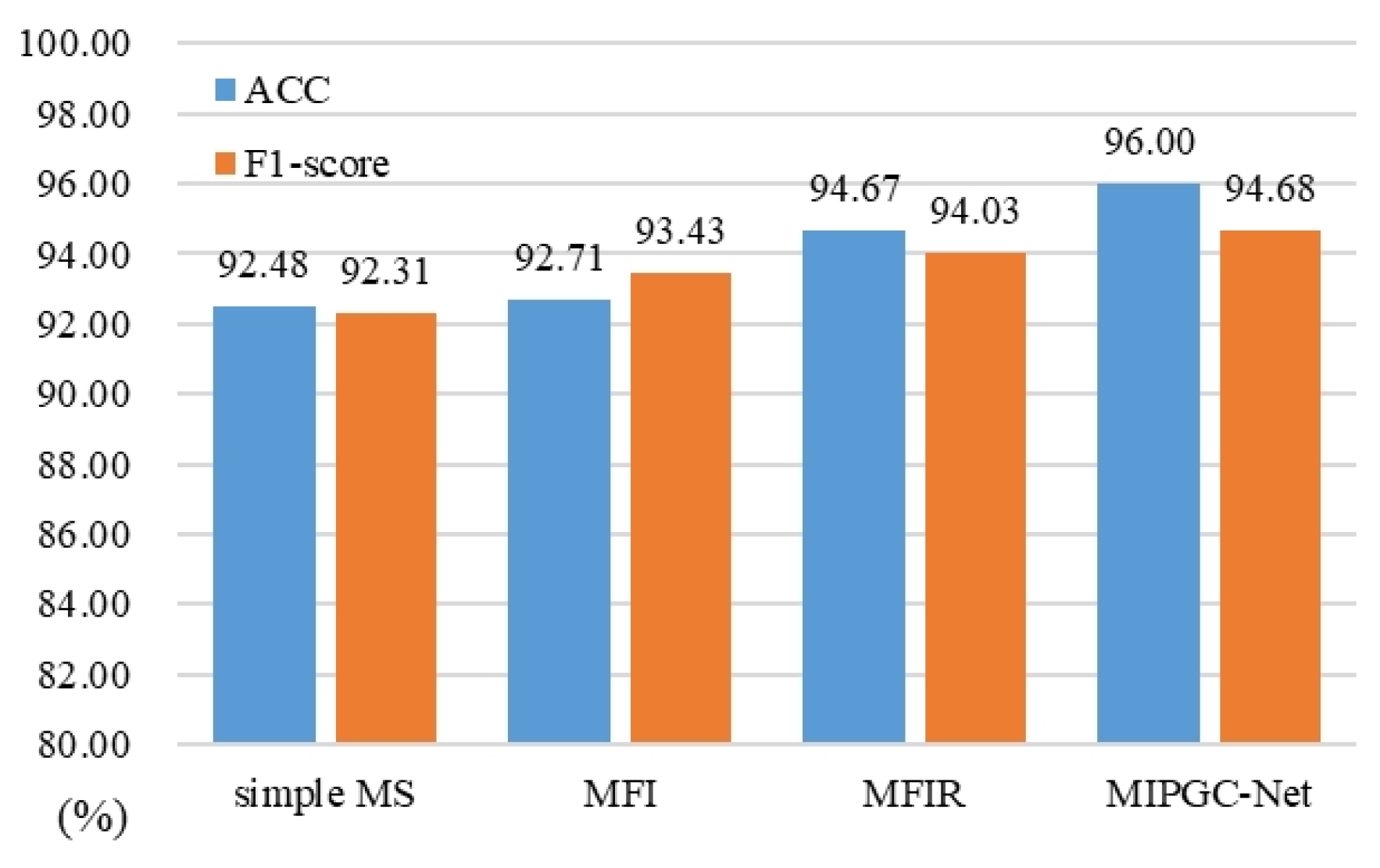
4.3. Ablation Study
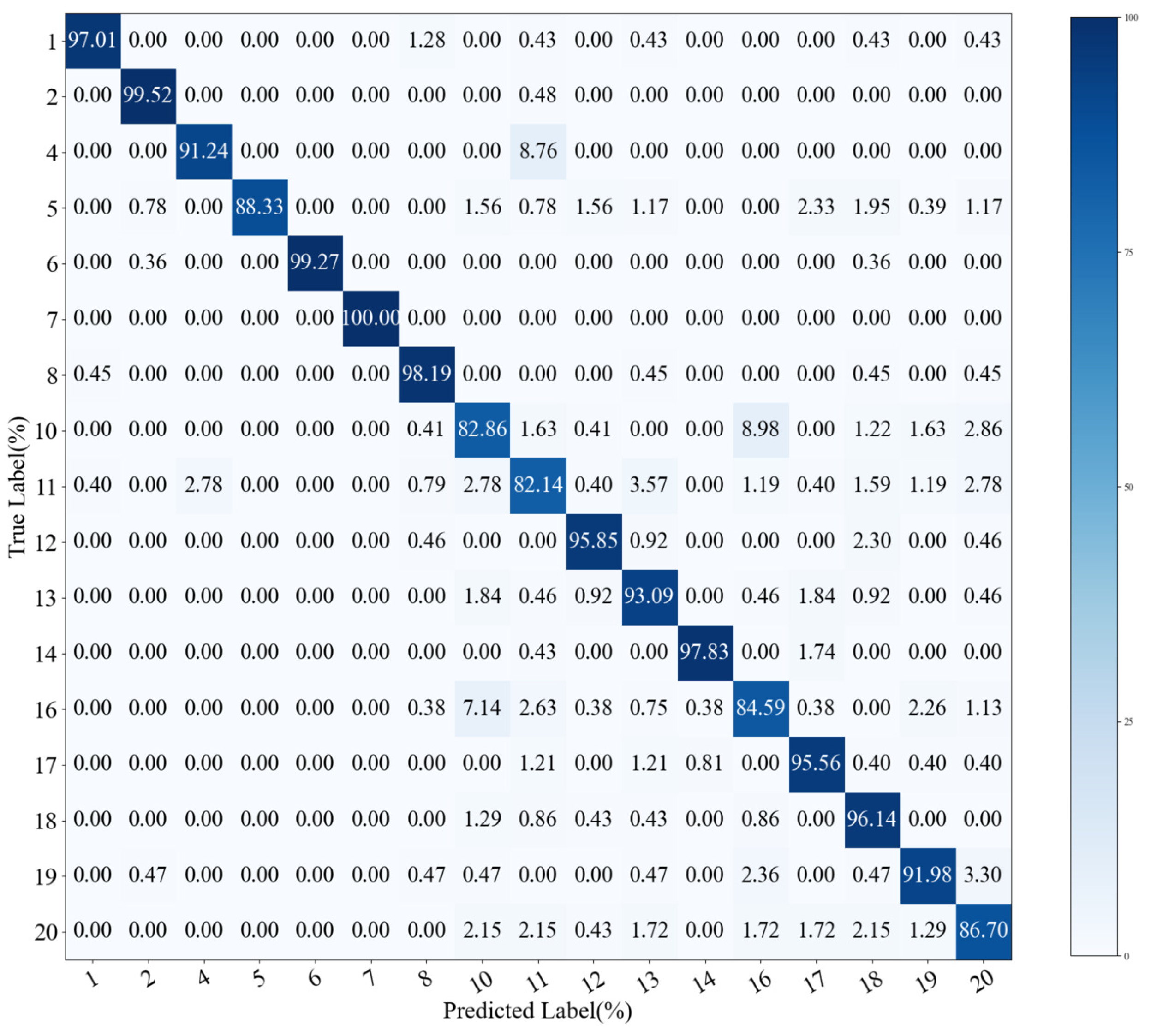
4.4. Comparison Study in the TE Process
4.5. Comparison Study in the CSTR Process
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, Y.; Shi, H.; Tan, S.; Song, B.; Tao, Y. Semi-Supervised Relevance Variable Selection and Hierarchical Feature Regularization Variational Autoencoder for Nonlinear Quality-Related Process Monitoring. IEEE Trans. Instrum. Meas. 2023, 72, 3536711. [Google Scholar] [CrossRef]
- Yu, E.; Luo, L.; Peng, X.; Tong, C. A multigroup fault detection and diagnosis framework for large-scale industrial systems using nonlinear multivariate analysis. Expert Syst. Appl. 2022, 206, 117859. [Google Scholar] [CrossRef]
- He, Y.; Li, K.; Zhang, N.; Xu, Y.; Zhu, Q. Fault diagnosis using improved discrimination locality preserving projections integrated with sparse autoencoder. IEEE Trans. Instrum. Meas. 2021, 70, 3527108. [Google Scholar] [CrossRef]
- Yu, F.; Liu, J.; Liu, D. Multimode Process Monitoring Based on Modified Density Peak Clustering and Parallel Variational Autoencoder. Mathematics 2022, 10, 2526. [Google Scholar] [CrossRef]
- Li, Z.; Tian, L.; Jiang, Q.; Yan, X. Fault diagnostic method based on deep learning and multimodel feature fusion for complex industrial processes. Ind. Eng. Chem. Res. 2020, 59, 18061–18069. [Google Scholar] [CrossRef]
- Zhou, K.; Wang, R.; Tong, Y.; Wei, X.; Song, K.; Chen, X. Domain generalization of chemical process fault diagnosis by maximizing domain feature distribution alignment. Process Saf. Environ. Prot. 2024, 185, 817–830. [Google Scholar] [CrossRef]
- Yu, W.; Zhao, C. Broad convolutional neural network based industrial process fault diagnosis with incremental learning capability. IEEE Trans. Ind. Electron. 2020, 67, 5081–5091. [Google Scholar] [CrossRef]
- Chen, Z.; Ke, H.; Xu, J.; Peng, T.; Yang, C. Multichannel Domain Adaptation Graph Convolutional Networks-Based Fault Diagnosis Method and With Its Application. IEEE Trans. Ind. Inform. 2023, 19, 7790–7800. [Google Scholar] [CrossRef]
- Yang, F.; Tian, X.; Ma, L.; Shi, X. An optimized variational mode decomposition and symmetrized dot pattern image characteristic information fusion-Based enhanced CNN ball screw vibration intelligent fault diagnosis approach. Measurement 2024, 229, 114382. [Google Scholar] [CrossRef]
- Yu, F.; Liu, J.; Liu, D.; Wang, H. Supervised convolutional autoencoder-based fault-relevant feature learning for fault diagnosis in industrial processes. J. Taiwan Inst. Chem. Eng. 2022, 132, 104200. [Google Scholar] [CrossRef]
- Guo, X.; Guo, Q.; Li, Y. Dual-noise autoencoder combining pseudo-labels and consistency regularization for process fault classification. Can. J. Chem. Eng. 2024, 103, 1853–1867. [Google Scholar] [CrossRef]
- Tian, W.; Liu, Z.; Li, L.; Zhang, S.; Li, C. Identification of abnormal conditions in high-dimensional chemical process based on feature selection and deep learning. Chin. J. Chem. Eng. 2020, 28, 1875–1883. [Google Scholar] [CrossRef]
- Wang, Y.; Pan, Z.; Yuan, X.; Yang, C.; Gui, W. A novel deep learning based fault diagnosis approach for chemical process with extended deep belief network. ISA Trans. 2020, 96, 457–467. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Bi, K.; Qiu, T. Bidirectional Recurrent Neural Network-Based Chemical Process Fault Diagnosis. Ind. Eng. Chem. Res. 2020, 59, 824–834. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, T.; Huang, X.; Cao, L.; Zhou, Q. Fault diagnosis of rotating machinery based on recurrent neural networks. Measurement 2021, 171, 108774. [Google Scholar] [CrossRef]
- Zhang, S.; Qiu, T. Semi-supervised LSTM ladder autoencoder for chemical process fault diagnosis and localization. Chem. Eng. Sci. 2022, 251, 117467. [Google Scholar] [CrossRef]
- Qin, R.; Lv, F.; Ye, H.; Zhao, J. Unsupervised transfer learning for fault diagnosis across similar chemical processes. Process Saf. Environ. Prot. 2024, 190, 1011–1027. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, Y.; Zhao, Z.; Chen, X.; Hu, J. Dynamic model-assisted transferable network for liquid rocket engine fault diagnosis using limited fault samples. Reliab. Eng. Syst. Saf. 2024, 243, 109837. [Google Scholar] [CrossRef]
- Jia, L.; Chow, T.W.S.; Wang, Y.; Yuan, Y. Multiscale Residual Attention Convolutional Neural Network for Bearing Fault Diagnosis. IEEE Trans. Instrum. Meas. 2022, 71, 3519413. [Google Scholar] [CrossRef]
- Li, T.; Zhao, Z.; Sun, C.; Cheng, L.; Chen, X.; Yan, R.; Gao, R.X. WaveletKernelNet: An Interpretable Deep Neural Network for Industrial Intelligent Diagnosis. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 2302–2312. [Google Scholar] [CrossRef]
- Shao, S.; Yan, R.; Lu, Y.; Wang, P.; Gao, R.X. DCNN-Based Multi-Signal Induction Motor Fault Diagnosis. IEEE Trans. Instrum. Meas. 2020, 69, 2658–2669. [Google Scholar] [CrossRef]
- Tang, S.; Zhu, Y.; Yuan, S. Intelligent fault identification of hydraulic pump using deep adaptive normalized CNN and synchrosqueezed wavelet transform. Reliab. Eng. Syst. Saf. 2022, 224, 108560. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Xu, P.; Liu, J.; Zhang, W.; Wang, H.; Huang, Y. Multiscale Kernel Entropy Component Analysis with Application to Complex Industrial Process Monitoring. IEEE Trans. Autom. Sci. Eng. 2024, 21, 3757–3772. [Google Scholar] [CrossRef]
- Huang, W.; Cheng, J.; Yang, Y.; Guo, G. An improved deep convolutional neural network with multi-scale information for bearing fault diagnosis. Neurocomputing 2019, 359, 77–92. [Google Scholar] [CrossRef]
- Song, Q.; Jiang, P. A multi-scale convolutional neural network based fault diagnosis model for complex chemical processes. Process Saf. Environ. Prot. 2022, 159, 575–584. [Google Scholar] [CrossRef]
- Yin, J.; Yan, X. A multi-scale low rank convolutional autoencoder for process monitoring of nonlinear uncertain systems. Process Saf. Environ. Prot. 2024, 188, 53–63. [Google Scholar] [CrossRef]
- Zhao, S.; Duan, Y.; Roy, N.; Zhang, B. A deep learning methodology based on adaptive multiscale CNN and enhanced highway LSTM for industrial process fault diagnosis. Reliab. Eng. Syst. Saf. 2024, 249, 110208. [Google Scholar] [CrossRef]
- Liu, R.; Wang, F.; Yang, B.; Qin, S.J. Multiscale Kernel Based Residual Convolutional Neural Network for Motor Fault Diagnosis Under Nonstationary Conditions. IEEE Trans. Ind. Inform. 2020, 16, 3797–3806. [Google Scholar] [CrossRef]
- Chadha, G.S.; Panambilly, A.; Schwung, A.; Ding, S.X. Bidirectional deep recurrent neural networks for process fault classification. ISA Trans. 2020, 106, 330–342. [Google Scholar] [CrossRef]
- Zhang, C.; Hu, D.; Yang, T. Anomaly detection and diagnosis for wind turbines using long short-term memory-based stacked denoising autoencoders and XGBoost. Reliab. Eng. Syst. Saf. 2022, 222, 108445. [Google Scholar] [CrossRef]
- Wu, H.; Triebe, M.J.; Sutherland, J.W. A transformer-based approach for novel fault detection and fault classification/diagnosis in manufacturing: A rotary system application. J. Manuf. Syst. 2023, 67, 439–452. [Google Scholar] [CrossRef]
- Zhao, S.; Duan, Y.; Roy, N.; Zhang, B. A novel fault diagnosis framework empowered by LSTM and attention: A case study on the Tennessee Eastman process. Can. J. Chem. Eng. 2025, 103, 1763–1785. [Google Scholar] [CrossRef]
- Deng, A.; Hooi, B. Graph neural network-based anomaly detection in multivariate time series. Proc. Aaai Conf. Artif. Intell. 2021, 35, 4027–4035. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- Lyu, P.; Zhang, K.; Yu, W.; Wang, B.; Liu, C. A novel RSG-based intelligent bearing fault diagnosis method for motors in high-noise industrial environment. Adv. Eng. Inform. 2022, 52, 101564. [Google Scholar] [CrossRef]
- Tong, J.; Tang, S.; Zheng, J.; Zhao, H.; Wu, Y. A novel residual global context shrinkage network based fault diagnosis method for rotating machinery under noisy conditions. Meas. Sci. Technol. 2024, 35, 075108. [Google Scholar] [CrossRef]
- Xia, P.; Huang, Y.; Qin, C.; Xiao, D.; Gong, L.; Liu, C.; Du, W. Adaptive Feature Utilization with Separate Gating Mechanism and Global Temporal Convolutional Network for Remaining Useful Life Prediction. IEEE Sens. J. 2023, 23, 21408–21420. [Google Scholar] [CrossRef]
- Lomov, I.; Lyubimov, M.; Makarov, I.; Zhukov, L.E. Fault detection in Tennessee Eastman process with temporal deep learning models. J. Ind. Inf. Integr. 2021, 23, 100216. [Google Scholar] [CrossRef]
- Morales-Forero, A.; Bassetto, S. Case Study: A Semi-Supervised Methodology for Anomaly Detection and Diagnosis. In Proceedings of the 2019 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Macao, China, 15–18 December 2019; pp. 1031–1037. [Google Scholar]
- Wang, W.; Yu, Z.; Ding, W.; Jiang, Q. Deep discriminative feature learning based on classification-enhanced neural networks for visual process monitoring. J. Taiwan Inst. Chem. Eng. 2024, 156, 105384. [Google Scholar] [CrossRef]
- Nawaz, M.; Maulud, A.S.; Zabiri, H.; Suleman, H.; Tufa, L.D. Multiscale framework for real-time process monitoring of nonlinear chemical process systems. Ind. Eng. Chem. Res. 2020, 59, 18595–18606. [Google Scholar] [CrossRef]
- Liu, L.; Liu, J.; Wang, H.; Tan, S.; Guo, Q.; Sun, X. A KLMS Dual Control Chart Based on Dynamic Nearest Neighbor Kernel Space. IEEE Trans. Ind. Inform. 2023, 19, 6950–6962. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale | Width | ACC | F1-Score | Time(s) | Scale | Width | ACC | F1-Score | Time(s) |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2 | 0.8774 | 0.8679 | 190 | 8 | 2 | 0.9463 | 0.9337 | 355 |
| 4 | 0.9407 | 0.9284 | 361 | 4 | 0.9528 | 0.9398 | 548 | ||
| 6 | 0.9537 | 0.9412 | 750 | 6 | 0.9527 | 0.9401 | 977 | ||
| 8 | 0.9491 | 0.9367 | 1233 | 8 | 0.9558 | 0.9428 | 1528 | ||
| 10 | 0.9552 | 0.9424 | 1859 | 10 | 0.9502 | 0.9373 | 2271 | ||
| 12 | 0.9531 | 0.9412 | 2730 | 12 | 0.9558 | 0.9436 | 3222 | ||
| Avg | 0.9382 | 0.9263 | 1788 | Avg | 0.9523 | 0.9396 | 1484 | ||
| 4 | 2 | 0.9367 | 0.9266 | 248 | 10 | 2 | 0.9503 | 0.9377 | 400 |
| 4 | 0.9488 | 0.9363 | 437 | 4 | 0.9535 | 0.9408 | 651 | ||
| 6 | 0.9466 | 0.9340 | 885 | 6 | 0.9527 | 0.9399 | 1109 | ||
| 8 | 0.9537 | 0.9419 | 1385 | 8 | 0.9501 | 0.9374 | 1699 | ||
| 10 | 0.9576 | 0.9449 | 1972 | 10 | 0.9549 | 0.9424 | 2440 | ||
| 12 | 0.9499 | 1.9370 | 2852 | 12 | 0.9539 | 0.9412 | 3466 | ||
| Avg | 0.9489 | 0.9368 | 1297 | Avg | 0.9526 | 0.9399 | 1628 | ||
| 6 | 2 | 0.9473 | 0.9346 | 281 | 12 | 2 | 0.9473 | 0.9349 | 419 |
| 4 | 0.9476 | 0.9348 | 478 | 4 | 0.9539 | 0.9408 | 693 | ||
| 6 | 0.9600 | 0.9468 | 934 | 6 | 0.9546 | 0.9420 | 1209 | ||
| 8 | 0.9535 | 0.9409 | 1415 | 8 | 0.9568 | 0.9435 | 1799 | ||
| 10 | 0.9523 | 0.9401 | 2107 | 10 | 0.9539 | 0.9412 | 2623 | ||
| 12 | 0.9524 | 0.9397 | 3075 | 12 | 0.9523 | 0.9391 | 3715 | ||
| Avg | 0.9522 | 0.9395 | 1382 | Avg | 0.9531 | 0.9403 | 1743 |
| Faults | CNN | ResNet | Auto-LSTM | LSTM-LAE | ACEL | Transformer | Att-LSTM | MIPGC-Net | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | |
| 1 | 98.80 | 99.34 | 99.15 | 99.57 | 99.00 | 99.38 | 99.33 | 99.27 | 99.27 | 99.52 | 100.00 | 97.50 | 99.31 | 98.28 | 99.29 | 99.26 |
| 2 | 99.06 | 99.53 | 99.02 | 99.51 | 98.88 | 99.29 | 99.34 | 99.63 | 99.21 | 99.58 | 98.73 | 98.94 | 97.85 | 98.54 | 98.60 | 98.77 |
| 4 | 98.52 | 93.91 | 90.94 | 93.98 | 98.52 | 95.37 | 97.31 | 95.60 | 97.51 | 96.59 | 98.76 | 96.18 | 99.02 | 95.86 | 97.38 | 96.19 |
| 5 | 97.97 | 97.87 | 94.50 | 97.15 | 98.75 | 98.82 | 98.41 | 98.95 | 98.82 | 99.37 | 100.00 | 97.74 | 99.20 | 98.76 | 99.45 | 98.89 |
| 6 | 98.70 | 99.35 | 99.46 | 99.73 | 99.83 | 99.92 | 98.96 | 99.48 | 99.25 | 99.62 | 100.00 | 99.82 | 100.00 | 100.00 | 100.00 | 100.00 |
| 7 | 99.76 | 99.70 | 99.80 | 99.90 | 99.25 | 99.62 | 99.70 | 99.81 | 99.62 | 99.79 | 100.00 | 99.76 | 100.00 | 100.00 | 100.00 | 100.00 |
| 8 | 91.94 | 92.31 | 98.25 | 96.05 | 94.66 | 95.56 | 91.59 | 93.77 | 96.27 | 96.73 | 96.20 | 97.31 | 88.63 | 91.38 | 98.66 | 96.29 |
| 10 | 62.87 | 72.45 | 89.35 | 91.44 | 82.38 | 83.97 | 86.02 | 84.08 | 86.05 | 82.27 | 86.23 | 86.59 | 85.63 | 86.06 | 89.17 | 89.09 |
| 11 | 71.25 | 78.57 | 90.69 | 87.86 | 80.57 | 85.97 | 81.64 | 85.69 | 85.31 | 88.11 | 86.08 | 88.89 | 85.09 | 82.86 | 89.94 | 88.29 |
| 12 | 81.60 | 88.29 | 97.28 | 96.96 | 93.79 | 94.26 | 93.56 | 91.65 | 97.30 | 96.29 | 93.46 | 96.05 | 89.50 | 91.49 | 97.61 | 95.85 |
| 13 | 92.04 | 88.00 | 95.82 | 96.33 | 92.41 | 94.22 | 88.49 | 91.62 | 93.96 | 96.42 | 90.54 | 93.27 | 84.86 | 89.17 | 98.97 | 94.53 |
| 14 | 95.61 | 97.38 | 99.42 | 99.04 | 97.52 | 98.13 | 97.20 | 98.23 | 98.75 | 99.07 | 98.77 | 97.97 | 97.94 | 97.74 | 99.38 | 98.61 |
| 16 | 70.68 | 59.08 | 91.61 | 89.30 | 81.33 | 80.27 | 85.03 | 85.46 | 66.23 | 67.73 | 88.66 | 93.59 | 84.27 | 89.09 | 88.79 | 90.45 |
| 17 | 93.59 | 93.67 | 94.44 | 96.38 | 94.94 | 95.07 | 94.72 | 93.60 | 95.75 | 96.29 | 92.23 | 92.82 | 90.30 | 93.42 | 97.87 | 94.25 |
| 18 | 90.61 | 93.40 | 94.62 | 96.26 | 91.87 | 94.98 | 90.34 | 94.37 | 93.50 | 95.74 | 91.52 | 88.36 | 86.12 | 89.84 | 94.36 | 92.49 |
| 19 | 74.06 | 69.71 | 91.80 | 86.01 | 86.95 | 78.56 | 88.46 | 86.25 | 84.91 | 80.49 | 96.98 | 95.95 | 92.92 | 89.21 | 92.67 | 91.64 |
| 20 | 77.14 | 76.70 | 86.62 | 87.99 | 92.06 | 90.62 | 90.35 | 83.74 | 89.12 | 87.95 | 94.50 | 89.57 | 87.94 | 78.95 | 89.87 | 84.90 |
| Avg | 87.89 | 88.19 | 94.87 | 94.91 | 93.10 | 93.18 | 92.97 | 93.01 | 92.99 | 93.03 | 94.86 | 94.72 | 92.27 | 92.39 | 96.00 | 94.68 |
| Index | CNN | ResNet | Auto-LSTM | LSTM-LAE | ACEL | Transformer | Att-LSTM | MIPGC-Net |
|---|---|---|---|---|---|---|---|---|
| Training time (s) | 4.78 | 4.25 | 3.30 | 10.50 | 11.60 | 19.38 | 23.13 | 3.43 |
| Inference time (μs) | 2.56 | 4.25 | 3.20 | 1.80 | 1.71 | 13.50 | 12.31 | 4.89 |
| Params (M) | 1.04 | 3.85 | 3.30 | 2.14 | 2.60 | 1.66 | 4.04 | 3.07 |
| Flops (M) | 4.08 | 9.81 | 6.30 | 4.18 | 5.20 | 130.00 | 15.70 | 4.28 |
| KL-divergence | 1.09 | 1.11 | 0.50 | 0.61 | 0.94 | 0.63 | 1.72 | 0.50 |
| Silhouette scores | 0.29 | 0.48 | 0.49 | 0.43 | 0.37 | 0.52 | 0.27 | 0.52 |
| Davies–Bouldin | 1.87 | 0.93 | 0.96 | 1.35 | 1.16 | 0.89 | 1.49 | 0.77 |
| Faults | Descriptions | Magnitude |
|---|---|---|
| 1 | step change | kmol/m3 |
| 2 | ramp change | kmol/(m3· min) |
| 3 | random disturbance | |
| 4 | slow drift | |
| 5 | Heat exchanger fouling | J/(min−2· K) |
| 6 | random measured noise |
| Faults | CNN | ResNet | Auto-LSTM | LSTM-LAE | ACEL | Transformer | Att-LSTM | MIPGC-Net | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | |
| 1 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 99.72 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 2 | 100.00 | 95.24 | 99.71 | 95.88 | 100.00 | 91.86 | 98.00 | 95.28 | 100.00 | 92.59 | 100.00 | 94.98 | 99.14 | 91.32 | 100.00 | 97.36 |
| 3 | 87.71 | 93.31 | 87.71 | 93.31 | 80.57 | 89.24 | 88.00 | 92.63 | 81.43 | 89.76 | 85.14 | 91.98 | 35.43 | 51.67 | 92.00 | 95.69 |
| 4 | 98.57 | 98.43 | 99.14 | 97.61 | 95.71 | 97.67 | 96.00 | 97.96 | 99.43 | 98.72 | 96.57 | 97.97 | 87.14 | 74.94 | 98.57 | 98.43 |
| 5 | 99.43 | 99.71 | 99.71 | 99.86 | 99.71 | 99.86 | 99.71 | 99.86 | 99.14 | 99.57 | 99.71 | 99.57 | 99.43 | 99.71 | 99.71 | 99.86 |
| 6 | 100.00 | 98.87 | 99.43 | 98.86 | 99.71 | 96.81 | 100.00 | 95.89 | 100.00 | 99.29 | 99.43 | 96.13 | 100.00 | 93.58 | 100.00 | 98.87 |
| Avg | 97.62 | 97.59 | 97.62 | 97.59 | 95.95 | 95.91 | 96.95 | 96.94 | 96.67 | 96.61 | 96.81 | 96.77 | 86.86 | 85.20 | 98.38 | 98.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Liu, J.; Xu, P.; Jiang, L.; Sun, X.; Tang, H. Multiscale Interaction Purification-Based Global Context Network for Industrial Process Fault Diagnosis. Mathematics 2025, 13, 1371. https://doi.org/10.3390/math13091371
Huang Y, Liu J, Xu P, Jiang L, Sun X, Tang H. Multiscale Interaction Purification-Based Global Context Network for Industrial Process Fault Diagnosis. Mathematics. 2025; 13(9):1371. https://doi.org/10.3390/math13091371
Chicago/Turabian StyleHuang, Yukun, Jianchang Liu, Peng Xu, Lin Jiang, Xiaoyu Sun, and Haotian Tang. 2025. "Multiscale Interaction Purification-Based Global Context Network for Industrial Process Fault Diagnosis" Mathematics 13, no. 9: 1371. https://doi.org/10.3390/math13091371
APA StyleHuang, Y., Liu, J., Xu, P., Jiang, L., Sun, X., & Tang, H. (2025). Multiscale Interaction Purification-Based Global Context Network for Industrial Process Fault Diagnosis. Mathematics, 13(9), 1371. https://doi.org/10.3390/math13091371