Abstract
We address the problem of approximating a set-valued function F, where given its samples , with . We revisit an existing method that approximates set-valued functions by interpolating signed-distance functions. This method provides a high-order approximation for general topologies but loses accuracy near points where F undergoes topological changes. To address this, we introduce new techniques that enhance efficiency and maintain high-order accuracy across . Building on the foundation of previous publication, we introduce new techniques to improve the method’s efficiency and extend its high-order approximation accuracy throughout the entire interval . Particular focus is placed on identifying and analyzing the behavior of F near topological transition points. To address this, two algorithms are introduced. The first algorithm employs signed-distance quasi-interpolation, incorporating specialized adjustments to effectively handle singularities at points of topological change. The second algorithm leverages an implicit function representation of , offering an alternative and robust approach to its approximation. These enhancements improve accuracy and stability in handling set-valued functions with changing topologies.
Keywords:
set-valued functions; approximation algorithms; general topologies; implicit representation MSC:
65D17; 65D40; 65W25
1. Introduction
We address the problem of approximating set-valued functions from a finite set of samples. Specifically, we focus on the class of set-valued functions F that map to —the collection of all compact subsets of . The images of F can possess an arbitrary topological genus and may include the empty set. To facilitate a high-order approximation, we assume that the graph of F has a -smooth boundary.
In [1], a general method for interpolating set-valued functions of any dimension and topology was introduced. Numerical algorithms derived from this work have been applied in various domains, including computer graphics animation (e.g., [2]). This method leverages the interpolation of signed-distance functions and is reviewed in detail in the Preliminaries Section below. The error analysis in [1] is confined to closed sub-intervals in where the topology of F remains unchanged. This paper aims to extend the approximation results from [1] to the entire interval .
Recently, in [3], the author, in collaboration with Q. Muzaffar and N. Dyn, developed efficient algorithms for interpolating a set-valued function that maps a closed interval to compact sets in . These algorithms utilize samples of F at equidistant points in , specifically the 1D sets , where . Each algorithm computes a set-valued function that matches F at the given sample points. A thorough analysis of the approximation error for the computed interpolants is also provided. The algorithms are inspired by the concept of ‘metric polynomial interpolation’, based on the theory presented in [4]. According to this theory, a ‘metric polynomial interpolant’ consists of a collection of polynomial interpolants applied to all the ‘metric chains’ derived from the given samples of F. The algorithm proposed in [3] identifies and computes a small, finite subset of ‘significant metric chains’, which is sufficient for accurately approximating F.
In the setting of 1D set-valued functions explored in [3], the authors provide a detailed discussion on the global approximation error over . The key contribution of [3] is its method and analysis for achieving a high-order approximation rate, even near points of topology change.
In this paper, for the general case of d-dimensional set-valued functions, we build upon one of the approximation techniques introduced in [3] to attain high-order approximation of set-valued functions near points of topology change. Additionally, we utilize the implicit function representation of sets, as proposed in [1].
In analyzing real-valued function approximation, achieving high-order accuracy typically requires the function to be sufficiently smooth. Similarly, for the approximation of a set-valued function F, we assume in this work that the graph of F, defined as , has smooth boundaries.
We consider, without loss of generality, the approximation of a set-valued function for , based on its samples , where . Our goal is to construct an approximation of the set for any .
One approach to represent the set is through its boundaries. Here, we define the boundary of a compact set in as the set itself minus its interior. Approximating in this representation involves approximating its boundaries.
A second way to represent is through an inclusion algorithm that determines whether a point in belongs to the set . In this paper, we utilize both approaches: representing the approximation to either by computing its boundary or by applying an inclusion algorithm.
Another target of approximation is the graph of F, denoted as . This approximation can similarly be achieved either through an explicit representation of the boundaries of or via an implicit inclusion-based approach.
For dimensions , established methods are available for addressing this problem:
- For , the boundaries of are curves in . In [3], an approximation order , as , is achieved for . The order depends on the degree of the polynomials and splines used in the algorithms presented in [3], assuming the boundaries of are sufficiently smooth.
- For , the boundaries of are surfaces in . We remark that the case has many practical applications as it amounts to reproducing a 3D object (the graph of F) from its parallel 2D cross-sections (the samples of F). A variety of methods devised for this case are in [1,5,6,7]. None of these methods claim an approximation error higher than .
- For , the boundaries of the graph of F are 3D manifolds in , which are complicated to imagine. On the other hand, the evolution of F as a function of t is a familiar entity, which is the animation of the changing 3D sets in between the given sets. At each animation frame, we display the 2D boundary of the approximated 3D object . Based upon the method in [1], an efficient algorithm for solving this problem is presented in [2].
A recent study [8] builds on the 1D results from [3] to develop high-order approximation methods for the more general case of d-dimensional set-valued functions, .
This paper introduces a distinct approximation approach, building on several approximation results developed in recent years by the author and collaborators [1,3,9,10,11,12,13,14,15].
2. Preliminaries
2.1. Review of Multidimensional Reconstruction by Set-Valued Approximations
In [1], the approximation of a set-valued function for is studied, based on its samples , where . The independent variable of F is denoted by t, while the variables in are represented by . It is assumed that the graph of F, denoted as , has a smooth boundary. We denote by for brevity and its boundary by . It is assumed that consists of a finite number of -continuous hypersurfaces that are mutually disconnected. The given samples are denoted as , with their respective boundaries , for . Each is a compact set in , while is a compact set in .
The sampled sets can have different topological structures and representations, such as boundaries or inclusion formulas. It is assumed that the distance from any point in to the set’s boundary can always be measured.
The first step in [1] involves defining a distance field representation for each of the given samples. For each sample , the corresponding distance field function is defined on as follows:
where represents the Euclidean distance in .
Next, we use univariate interpolation with respect to the parameter t to interpolate the distance values for points sharing the same d-coordinates across the cross-sections. The resulting interpolant, denoted by , evaluated at a point t, approximates the Euclidean distance (in ) between the point x and the boundary of the set . Once this approximated distance field is available, the set is approximated by the set
This approach, known as the Distance Field Interpolation method (DFI), is introduced in [1] with a theoretical approximation result specifically formulated for the case . However, this result can be easily extended to higher dimensions as follows:
Theorem 1.
Let Ω be a closed -dimensional domain whose boundary consists of a finite number of mutually disconnected, -continuous hypersurfaces. Let , , represent the planes that are locally tangent to and let δ be any positive constant. Suppose a finite-support interpolation method of approximation order is used to interpolate the values . For each , consider any point satisfying that represents a discrepancy between and the reconstructed domain, i.e.,
Then, the distance of this point to the boundary satisfies
The above approximation result applies only to points not close to the tangency planes . In most cases, these special values correspond to points of topology change, meaning that for a small , the genus of the set differs from that of . The primary goal of this paper is to address this limitation in the DFI method and to introduce a new approach that achieves high-order global approximation of both F and .
Remark 1.
As with the approximation order result in (3), the theoretical findings in this paper are asymptotic in nature. In practice, the proposed methods yield accurate results as long as h is sufficiently small relative to the minimal radius of curvature of , the boundary hypersurfaces of .
2.2. Approximating Piecewise-Smooth Functions
An efficient method for approximating piecewise-smooth functions is introduced in [13].
The paper primarily focuses on approximating functions with jump discontinuities in their derivatives but also extends the discussion to other types of singularities. For example, it considers singularities of the form for , where
In this case, the derivative limit from the right at s is not finite.
The algorithm proposed in [13] follows a three-step procedure. First, it identifies the singularity interval by analyzing the errors in a spline quasi-interpolation approximation. Next, a nonlinear optimization method is applied to obtain a high-order approximation of the singularity, determining key parameters such as the location s and the exponent . Finally, the initial approximation is refined using the extracted singularity details. The method achieves high-order approximation rates, formally established and proven in [13].
2.3. Spline Quasi-Interpolation Operators
In this paper, we employ spline quasi-interpolation operators for two key approximation tasks. First, we use univariate quasi-interpolation to approximate piecewise-smooth functions. Second, we construct an implicit function representation of boundary surfaces by applying spline-based quasi-interpolation operators to gridded data. The multivariate quasi-interpolation operators are derived through tensor products of the univariate quasi-interpolation operators introduced below.
Suppose and is a constant. Consider , the -degree B-spline supported on the interval , with equidistant knots . Define the vector where and denotes the floor function. The following explicit local quasi-interpolation operator accurately reproduces polynomials of degree up to , and it approximates f with an error of order as ; see [16]:
where is a linear functional given by
A general formula for the coefficients , where , is provided in [16].
3. Improving the DFI Method
3.1. The Signed-Distance Function
The Distance Field Interpolation (DFI) method introduced in [1] assumes that the boundary of the graph of the approximated function is smooth. However, the corresponding distance field function is generally only piecewise smooth and may contain points where its derivative is singular. We denote the distance field function as
where represents the boundary of . In Theorem 1, we introduced the set of values where the planes are tangent to . We now denote by the corresponding points in such that lies on the tangent to . The first step in our improved method involves obtaining a high-order approximation of the values . These values serve as potential locations for singularities in the signed-distance function when viewed as a function of t.
For a given , the DFI method employs spline interpolation to approximate the signed-distance functions using its sampled values . The roots of this interpolant are then used to approximate the intersection of the line with . The accuracy of these approximations varies depending on the location of . In some cases, the method provides good results, while in others, the approximation may be significantly inaccurate. The most problematic cases arise when is close to one of the critical points , which correspond to the tangency locations of .
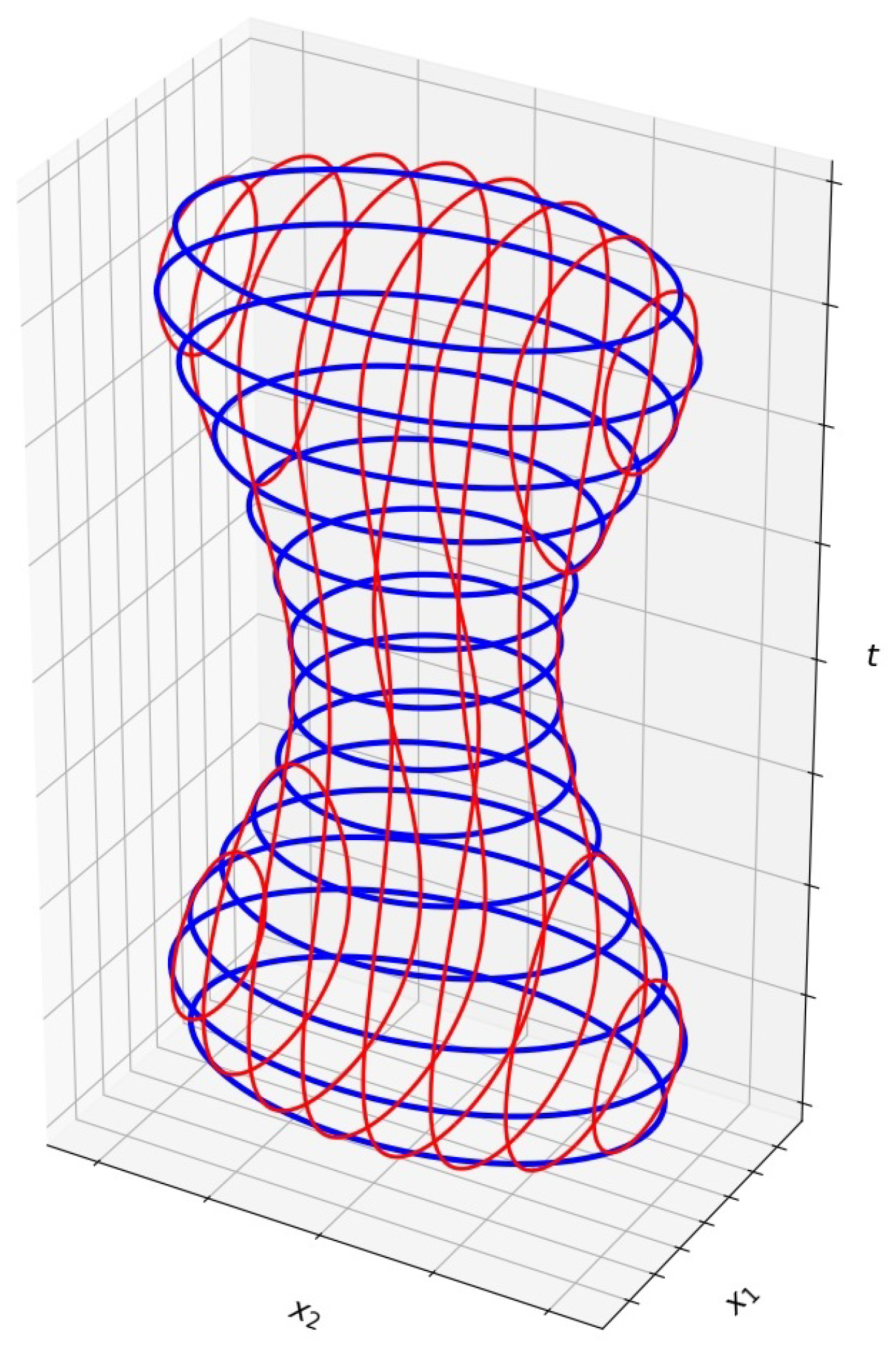
Figure 1 illustrates the challenges near tangency points. The figure depicts the graph of a continuous function , with smooth boundaries. The blue curves represent the boundaries of the given samples of F. The lowermost and uppermost points of the graph correspond to tangency points. As evident from the figure, the given samples do not provide sufficient information over a large neighborhood of these points. Typically, if the spacing between the given samples is h, the size of these neighborhoods is .
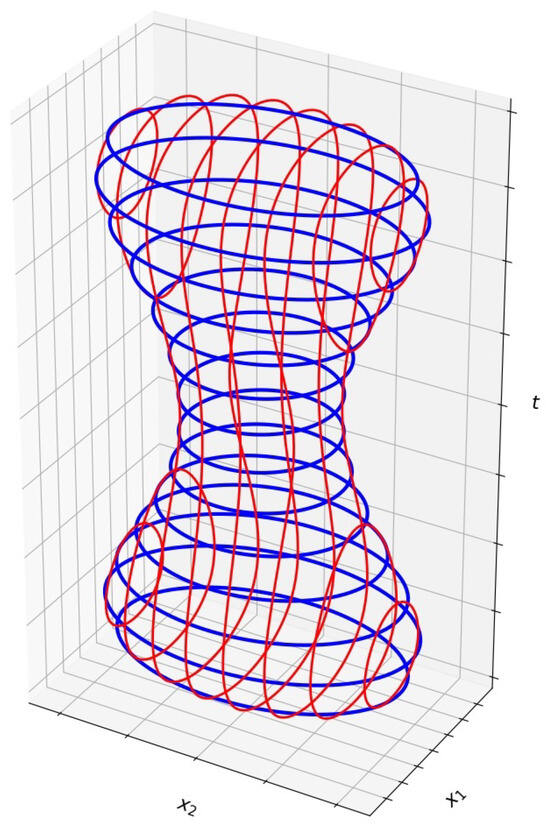
Figure 1.
An example () of and the given samples (in blue).
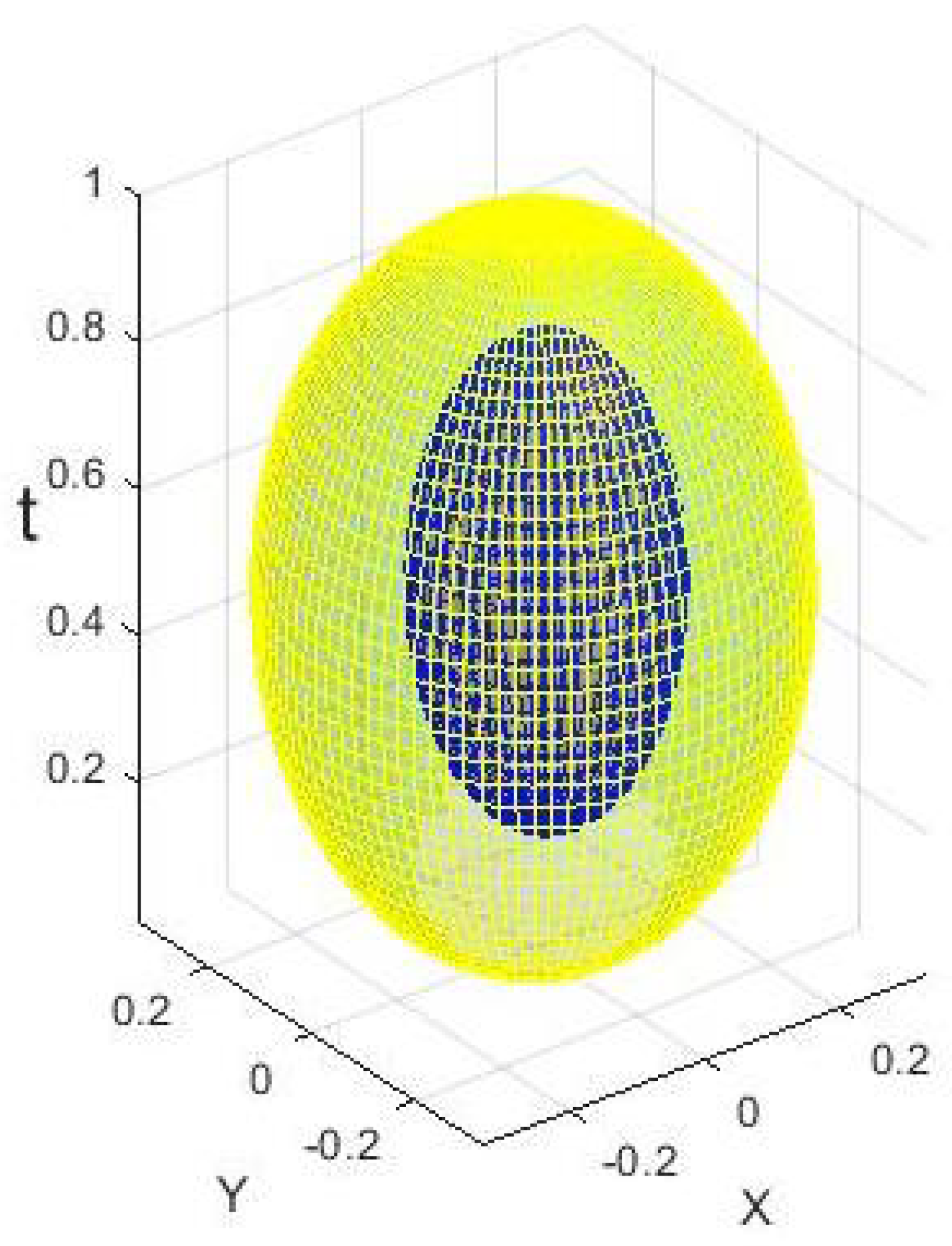
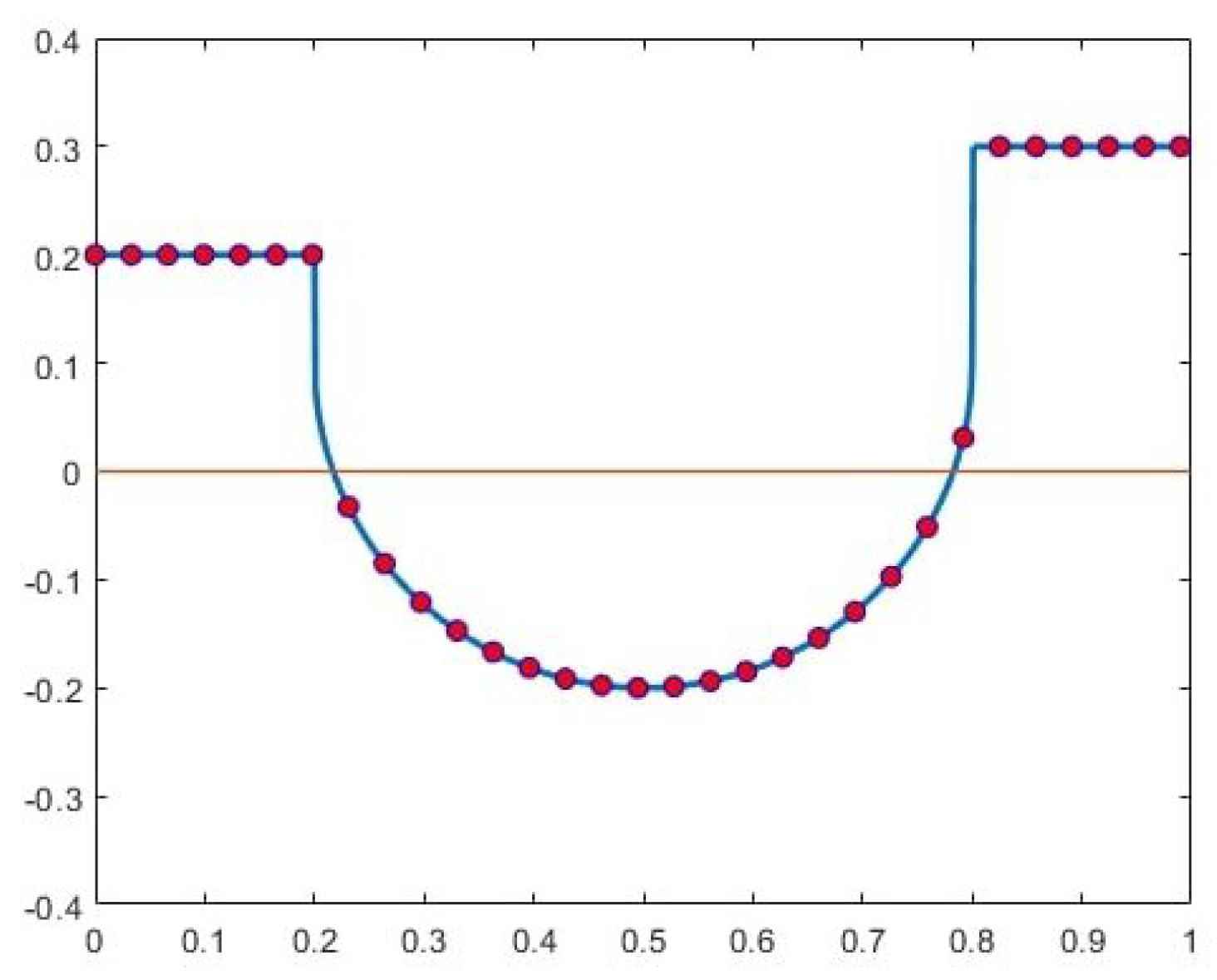
Another way to approach the problem is by examining the behavior of the signed-distance function near tangency points, offering deeper insight into a potential solution. Figure 2 illustrates this concept with the graph of a 2D set-valued function F, depicting a yellow ellipsoid containing a blue ellipsoidal hole. The planes and are tangent to the lower and upper boundaries of the hole, respectively. These parameter values also mark points where the topology of changes: for and , is a disc, whereas for , forms an annulus. Relevant to this specific case, Figure 3 presents the graph of the signed-distance function, as a function of t, for an near the hole. The function exhibits singularities at and , characterized by the forms
Such singularities typically occur in the signed-distance function near smooth holes in . The circles in the graph represent the given data points, and the objective is to approximate the intersection of the graph with the line without prior knowledge of the location or nature of the singularities. Additionally, the figure reveals that the density of data points along the graph decreases as we approach the singular points. This specific example serves as a reference while presenting our proposed solution to the problem.
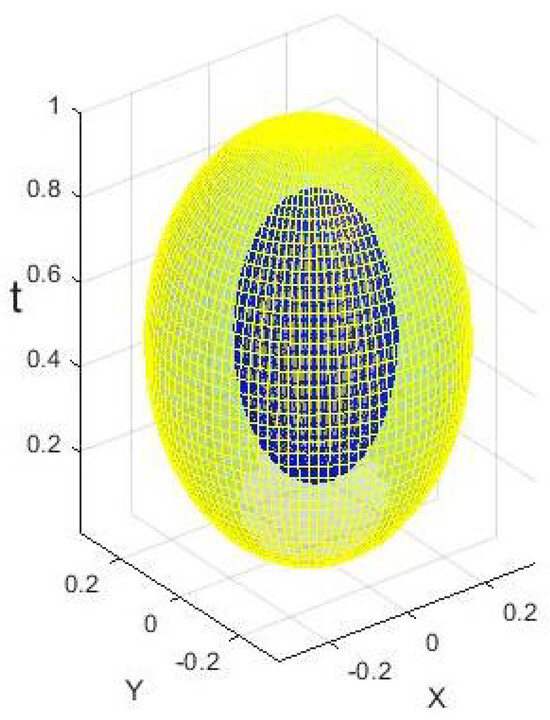
Figure 2.
An example () of - Ellipsoid with an ellipsoidal hole.
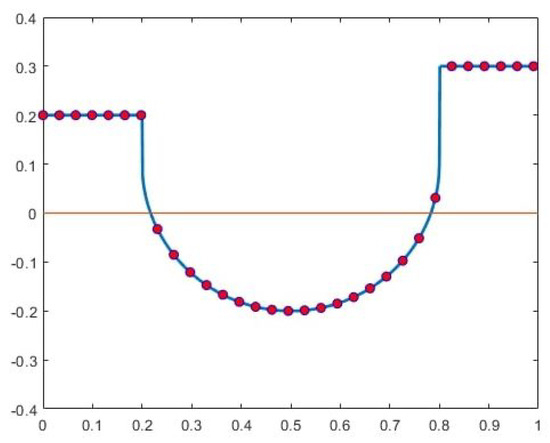
Figure 3.
A typical signed-distance function with singularities.
3.2. High-Order Approximation of Singular Signed-Distance Functions
We now describe the algorithm for approximating the function , as shown in Figure 3. Our approach is based on the method presented in [13], adapted to suit our specific needs.
- 1.
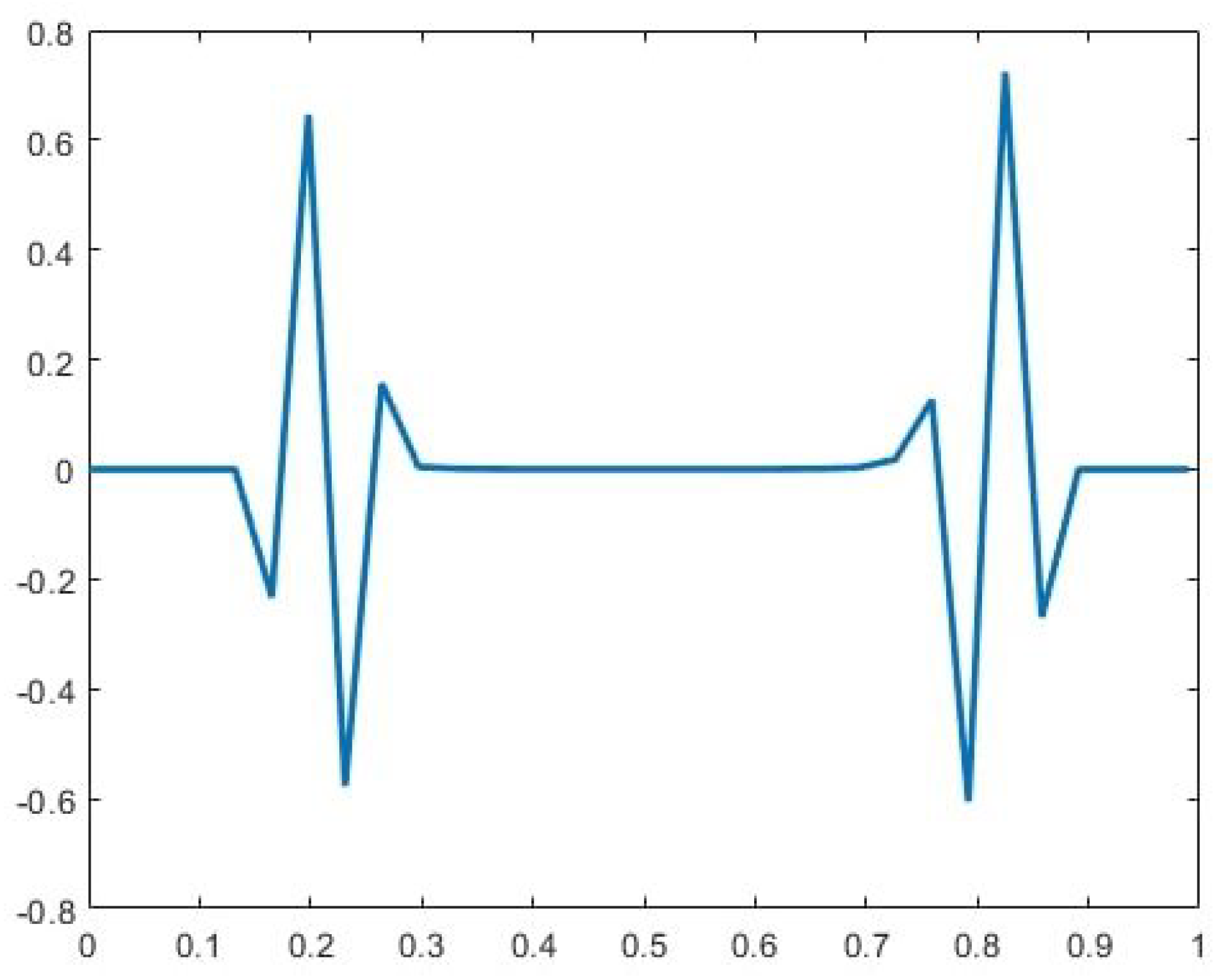
- Deriving the signature of the singularitiesWe begin by applying a p-degree quasi-interpolation operator (see Section 2.3) to the given data (represented by the circles in Figure 3). To facilitate this process, we extend the values to the left and right by padding with zero values.Next, we compute the errors in the quasi-interpolation approximation at the given data points:We recall that the quasi-interpolation operator is a local operator, utilizing only a finite number of data points for each t. It provides an approximation order to functions. Consequently, the errors remain small at points where the signed-distance function is smooth but become significantly larger near the singular points and . Additionally, large errors appear near the boundary points and . For our application, we focus on the neighborhood of the singular points and disregard the large errors near the boundaries. We refer to the values as ‘the signature of ’. For instance, the signature of the function in Figure 3 (with ) is illustrated in Figure 4.
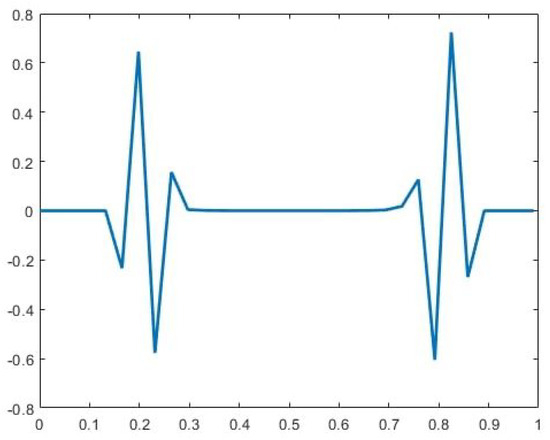 Figure 4. An example of the signature of with singularities.
Figure 4. An example of the signature of with singularities. - 2.
- Using the signature to identify singularity parametersThe next step, following [13], is to identify a singular function whose signature closely matches that of . As observed in Figure 4, for sufficiently small h, the effects of different singularities are well separated and can be analyzed independently.In our case, while the exact locations of the singularities are unknown, their type is known. To address the left singularity in the given example, we fit a singular function of the formThe unknown singularity location s along with the unknown coefficients are determined by performing minimization of the difference between the signature of and , i.e.,where the indices and specify the interval of high signature corresponding to the left singularity. The operator computes the error of the quasi-interpolation approximation at . The parameter q is chosen as to achieve the highest possible approximation order. We denote the resulting optimal parameters as , .As proved in [13], the resulting singularity parameters approximate the exact singularity parameters with a high order of accuracy. In particular, the singularity location satisfies as .
- 3.
- The ‘corrected approximation’ framework.We can now construct the desired approximation of with the above singularity information. This process is performed locally, relying upon the locality property of the quasi-interpolation operator .First, we apply to the smoothed data , whereThis yields the smooth-part approximation . Following [13], the final approximation is obtained by correcting the smooth-part approximation by reintroducing the singular component:Using the error estimates from [13], we obtain
- 4.
- Computational aspectsThe optimization problem in (10) is linear in the unknown coefficients but non-linear in the singularity location s. However, since is an approximation of one of the values where a tangent plane is tangent to , and given that there are only a finite number of such values, much of the computational effort involved in solving the nonlinear problem can be reduced. Specifically, once is well approximated for a particular point , the same approximation can be used for all points in a neighborhood of , significantly reducing the need for repeated nonlinear optimization.In general, the singularity exponent is also unknown. However, the assumption that is smooth implies that, in non-degenerate cases, the singularity exponent is expected to be . Nevertheless, other possible exponents, such as and , should also be considered.Remark 2(Approximating the tangency point ). The parameters obtained in the approximation can also be utilized to derive an estimate of the tangency point . Specifically, the value serves as an approximation of the distance between and . Additionally, recall that computing each distance involves determining the direction to the nearest point on the boundary. Let be the direction associated with , where is the closest point to s satisfying . Then, the approximation of is given byWhile the approximation achieves approximation order , the approximation of is of order .
3.3. The Improved DFI Approximation
In Section 2.1, the function is approximated by interpolating the data , resulting in the approximation . However, the new approach deviates from interpolation. Similarly to the original DFI method, instead of using Equation (2), we define the improved approximation of the set by the set
With this improvement, the approximation results established in Theorem 1 are now enhanced as follows.
Theorem 2.
Let Ω be a closed -dimensional domain whose boundary consists of a finite number of mutually disconnected hypersurfaces that are -continuous. Suppose we use the quasi-interpolation method using the operator to obtain the approximation . For each , consider any point where the reconstructed set disagrees with the true set , i.e.,
Then, the distance from to the boundary satisfies
Proof.
If the plane is not close to a plane that is locally tangent to , the result follows from [1], as stated in Theorem 1 above. Assume now that the plane is tangent to at the point . Without loss of generality, suppose the singularity in the signed-distance function near the tangency point has the form given in (9). Using the algorithms in Section 3.2, we obtain an approximation . If lies between s and , the result follows from the earlier observation that as , along with the assumption that is -smooth.
The challenging situation is when and is near . For a point of disagreement as defined in (15), it follows that and have opposite signs. Applying the error estimate (13), we conclude that as . The proof follows by noting that
□
4. Building Implicit Approximation of
4.1. Implicit Approximation of Smooth Curves and Hypersurfaces
When approximating a set with smooth boundaries, a natural and constructive approach is to approximate its boundaries directly. An effective method, applicable in any dimension, is to use an implicit representation. Specifically, the approximation of a -dimensional hypersurface in is defined as the zero-level set of a function . A key insight in this context is the following curve approximation result, as presented in [10].
Proposition 1.
Assume Γ is a -smooth curve in with a minimal curvature radius greater than R. Furthermore, suppose its R-neighborhood is neither self-intersecting nor intersecting the boundaries of . Let P be a square mesh of points in with mesh size . The curve Γ subdivides into two domains, and , thereby partitioning the mesh points P into two corresponding subsets, and . We assign signed-distance values to the mesh points P as follows:
Let be the quasi-interpolation operator that maps vectors of values on P to the space of bi-cubic splines on . Define as the bi-cubic spline obtained by applying to a perturbed signed-distance dataset
Let be the zero-level curve of . Then, the Hausdorff distance between Γ and satisfies
The above result can be naturally extended to higher dimensions and higher-order approximations as follows.
Proposition 2.
Assume Γ is a -smooth hypersurface in with a minimal curvature radius greater than R. Furthermore, suppose that the R-neighborhood of Γ is not self-intersecting and is not intersecting the boundaries of . Let P be a square mesh of points in , with mesh size . The hypersurface Γ subdivides into two domains and , thereby partitioning the mesh points P into two corresponding subsets, and . We assign signed-distance values to the mesh points P as follows:
Consider to be the quasi-interpolation operator mapping vectors of values on P to the space of -order tensor product splines on . Let be the -order tensor product spline defined by applying to a perturbed signed-distance data
and let be the zero-level hypersurface of . Then,
4.2. Estimating the Distance of a Point from a Hypersurface
To compute distances from a hypersurface , we propose using the projection procedure introduced in [12] and later extended to manifolds in [14].
Given a set of points X on an unknown hypersurface and a query point p near , the procedure identifies a local reference plane and projects p onto a point near the hypersurface. This projection is computed through a local least-squares fit using a polynomial patch . The distance , or the Euclidean distance , serves as a second-order approximation of . A higher approximation order of can be obtained by evaluating . The approximation order depends on the smoothness of , the fill-distance of the set X, and the degree of the local polynomial approximation. A precise formulation of this relationship is provided below.
Definition 1
(Fill-distance). The fill-distance of a set of points X with respect to a hypersurface (or manifold) Γ is defined as the diameter of the largest open ball centered at a point on Γ that does not contain any point of X.
Proposition 3.
Let Γ be a d-dimensional hypersurface, and let X be a set of points on Γ with fill-distance . Consider a point p near Γ. Let be the local polynomial patch defined by the projection procedure in [14], with total degree . Then, the distance from p to Γ satisfies
The proof follows from the approximation properties of local moving least-squares, as outlined in [11].
4.3. Distributing Points near
To generate the implicit function representation, we adopt the approach outlined in [9]. In the first step, we distribute a set of points, denoted as , around the boundaries of the body, ensuring that they remain at a small, controlled distance from the boundary. These points must be densely distributed near the boundaries of the object to guarantee a high-quality approximation of the signed-distance function.
The primary source of points comes from the boundary of the given samples. These points are distributed along the boundaries of the given sets , with a fill-distance of approximately h relative to the boundaries. We denote this collection of points as . It is important to note that this collection is not unique; the method of selecting the points depends on the representation of the given samples.
On its own, is not sufficient for providing an efficient approximation of the boundary of F. Specifically, these points do not adequately cover regions of the boundary of , particularly near points where the boundary is tangent to the plane . This limitation is clearly illustrated in the upper and lower sections of the boundary in Figure 1.
To ensure complete coverage of the boundary of , we propose two approaches outlined below.
4.4. Completion of near Tangency Points
We propose two methods for adding the missing information near the tangency points. Both methods utilize the local singularity expansion defined in Section 3.2, with parameters specified by (10). We assume that a good approximation of the tangency points is already available, as described in Remark 2, for .
First, we estimate the size of the neighborhood around where additional points need to be inserted. The size of this neighborhood is determined using the parameter in . A simple analysis shows that this neighborhood corresponds to a ball with radius . To define the missing points, we consider the set of points
where and is the closed ball of radius R centered at x.
For each , we apply the procedure outlined in Section 3 and find the zero of , . The point serves as an approximation of the intersection of the line in with . This process is repeated for all neighborhoods around the tangency points. The collection of all points forms the set of points , which, when combined with the points , constitutes the required set of points for constructing the implicit function.
An alternative, computationally simpler approach to complete the points is inspired by a similar technique used in [3] for the case , and proceeds as follows.
We construct a local polynomial approximation of the boundary of near each tangency point. This polynomial is obtained by performing a local least-squares fitting to the points in that are the closest to . By using a polynomial of total degree , we achieve a local approximation of order to the boundary . The points near are then computed as follows:
We apply this construction to all neighborhoods of the tangency points, gathering the resulting points into the set
We then redefine the complete set as
In both approaches, the points in provide a well-approximated representation of while maintaining a fill-distance of order with respect to .
Remark 3
(Approximation orders of ). Each of the algorithms described above generates points near with a specific approximation order as .
- In the first approach, according to Theorem 2, the approximation order is , where k is the smoothness index of the boundary.
- For the second approach, where is the degree of the polynomial used for the local approximation.
4.5. Building and Analyzing the Implicit Function Approximation
Our goal is to construct a tensor product cubic spline , whose zero-level set provides the approximation to . Following the approach in [10], we look for S, which is an approximation to the signed-distance function from . To construct S, we first overlay a uniform (d+1)-dimensional grid of points P on the domain .
Recalling that , each point lies on one of the given cross-sections . This allows us to determine whether p is inside or outside . To each point p, we assign the value of its approximate distance from , with a plus sign if it is inside and a negative sign if it is outside.
For each point , we aim to approximate its distance from using the procedure outlined in Section 4.2. Instead of exact data on the boundary of , we utilize the points , which are located at a distance from (see Remark 3). By applying the projection approach from Proposition 3, and choosing a sufficiently high degree for the local polynomial approximation, we achieve distance estimations with an error of as .
Using the quasi-interpolation operators introduced in Section 2.3, we construct a bivariate spline S of degree m on a uniform grid with knot spacing , using the signed-distance values collected at the points P.
We define the zero-level of the resulting spline S as , which serves as the desired approximation of . The following approximation result follows directly from Proposition 2.
Corollary 1.
Let the boundary satisfy the smoothness assumptions stated in Proposition 2. Suppose the approximated signed-distance values at the grid points P are defined as described above. Let S be the tensor product spline of degree m, constructed using quasi-interpolation applied to these approximated signed-distance values. Denoting the zero-level of S by , we obtain the following error bound:
where ν is defined in Remark 3.
5. Summary
In this work, we introduce ideas and algorithms for the high-order approximation of d-dimensional set-valued functions. In particular, we improve the approximation results of [1], demonstrating that a high approximation rate can be achieved even near points of topological change.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Levin, D. Multidimensional reconstruction by set-valued approximations. IMA J. Numer. Anal. 1986, 6, 173–184. [Google Scholar] [CrossRef]
- Cohen-Or, D.; Solomovic, A.; Levin, D. Three-dimensional distance field metamorphosis. ACM Trans. Graph. (TOG) 1998, 17, 116–141. [Google Scholar] [CrossRef]
- Dyn, N.; Levin, D.; Muzaffar, Q. Interpolation of set-valued functions. IMA J. Numer. Anal. 2024, drae031. [Google Scholar] [CrossRef]
- Dyn, N.; Farkhi, E.; Mokhov, A. Approximation of Set-Valued Functions: Adaptation of Classical Approximation Operators; Imperial College Press: London, UK, 2014. [Google Scholar]
- Barequet, G.; Shapiro, D.; Tal, A. Multilevel sensitive reconstruction of polyhedral surfaces from parallel slices. Vis. Comput. 2000, 16, 116–133. [Google Scholar] [CrossRef]
- Kels, S.; Dyn, N. Reconstruction of 3D objects from 2D cross-sections with the 4-point subdivision scheme adapted to sets. Comput. Graph. 2011, 35, 741–746. [Google Scholar] [CrossRef]
- Schumaker, L.L. Reconstruction of 3-D objects using splines. In Proceedings of the Curves and Surfaces in Computer Vision and Graphics, Santa Clara, CA, USA, 13–15 February 1990; Volume 1251. [Google Scholar]
- Dyn, N.; Levin, D. Approximation of Set-Valued Functions with images sets in Rd. arXiv 2025, arXiv:2501.14591. [Google Scholar]
- Amat, S.; Levin, D.; Ruiz-Alvárez, J.; Yáñez, D.F. Global and explicit approximation of piecewise-smooth two-dimensional functions from cell-average data. IMA J. Numer. Anal. 2023, 43, 2299–2319. [Google Scholar] [CrossRef]
- Amat, S.; Levin, D.; Ruiz-Álvarez, J. A two-stage approximation strategy for piecewise smooth functions in two and three dimensions. IMA J. Numer. Anal. 2022, 42, 3330–3359. [Google Scholar] [CrossRef]
- Levin, D. The approximation power of moving least-squares. Math. Comput. 1998, 67, 1517–1531. [Google Scholar] [CrossRef]
- Levin, D. Mesh-independent surface interpolation. In Geometric Modeling for Scientific Visualization; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Lipman, Y.; Levin, D. Approximating piecewise-smooth functions. IMA J. Numer. Anal. 2010, 30, 1159–1183. [Google Scholar]
- Sober, B.; Levin, D. Manifold approximation by moving least-squares projection (MMLS). Constr. Approx. 2020, 52, 433–478. [Google Scholar]
- Dyn, N.; Farkhi, E.; Mokhov, A. Approximations of set-valued functions by metric linear operators. Constr. Approx. 2007, 25, 193–209. [Google Scholar] [CrossRef]
- Speleers, H. Hierarchical spline spaces: Quasi-interpolants and local approximation estimates. Adv. Comput. Math. 2017, 43, 235–255. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).