


I-NeRV: A Single-Network Implicit Neural Representation for Efficient Video Inpainting
Abstract
1. Introduction
- We develop a video neural representation network (I-NeRV) that performs efficient and automated video inpainting, surpassing SOTA methods and improving PSNR by on benchmark tasks.
- We propose a suitably large embedding scale and adapt decoder features accordingly, enabling richer feature information to be passed to the decoder and significantly enhancing inpainting effectiveness.
- We integrate a random mask mechanism into the encoder, wherein video frames are partially occluded before encoding. This design further improves feature extraction and makes the network robust to complex corruption patterns.
2. Related Work
2.1. Implicit Neural Representation of Video
2.2. Video Inpainting
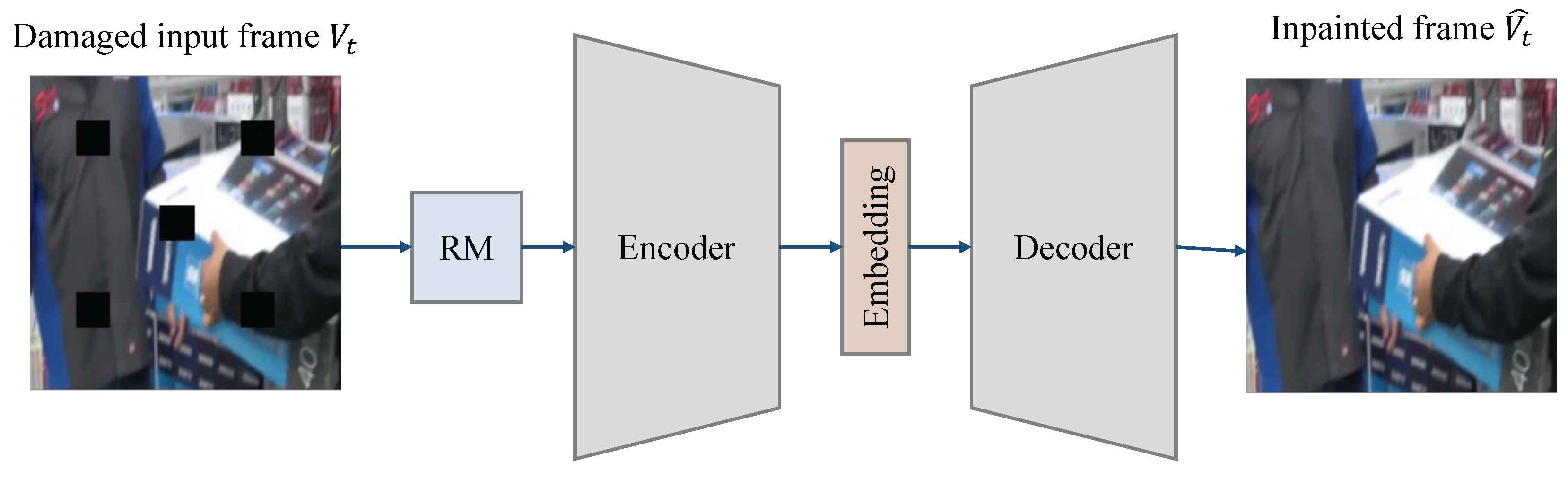
3. Our Proposed Design
3.1. The Overall Architecture
3.2. Random Mask Module
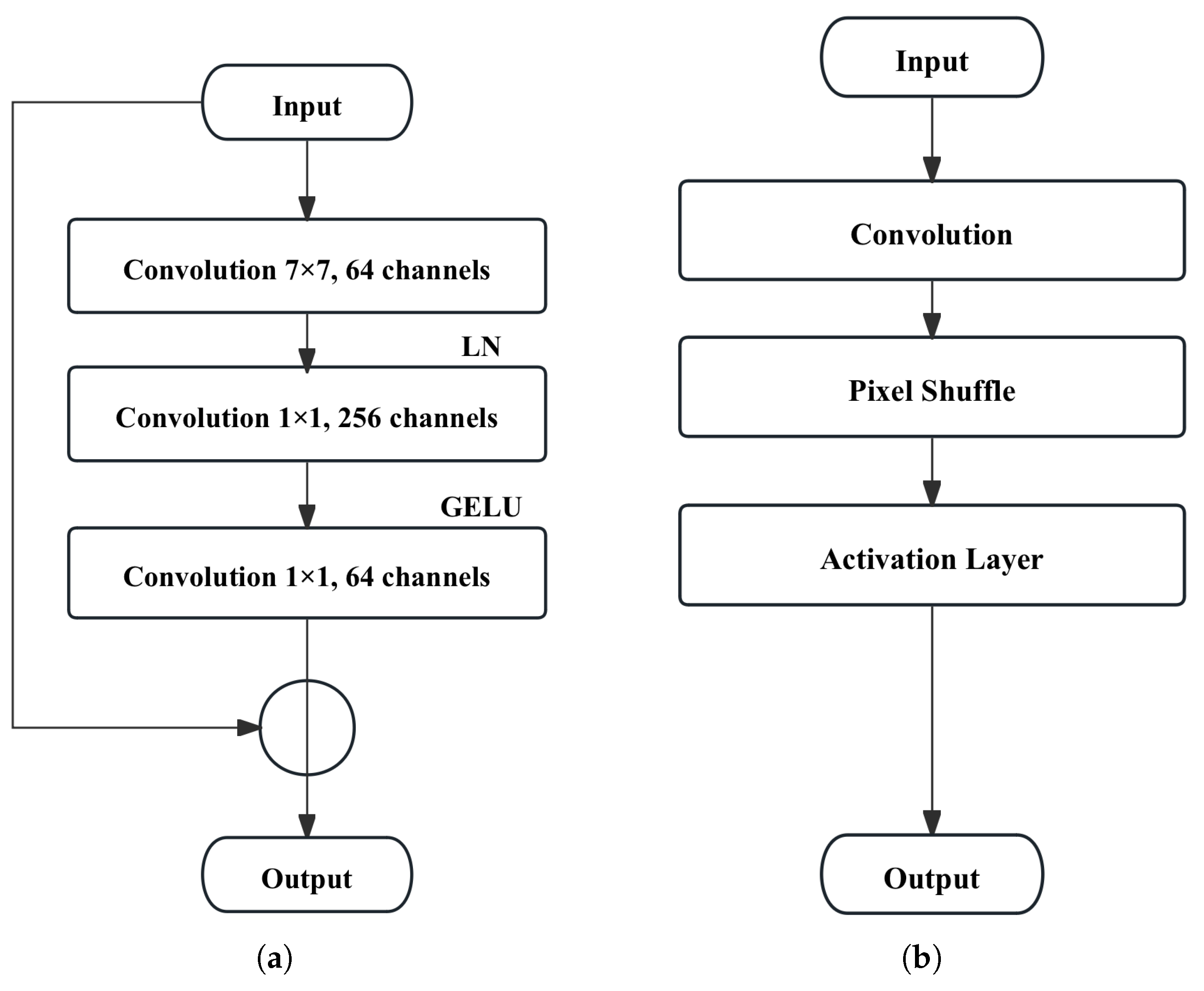
3.3. Encoder Sub-Network
3.3.1. Encoder
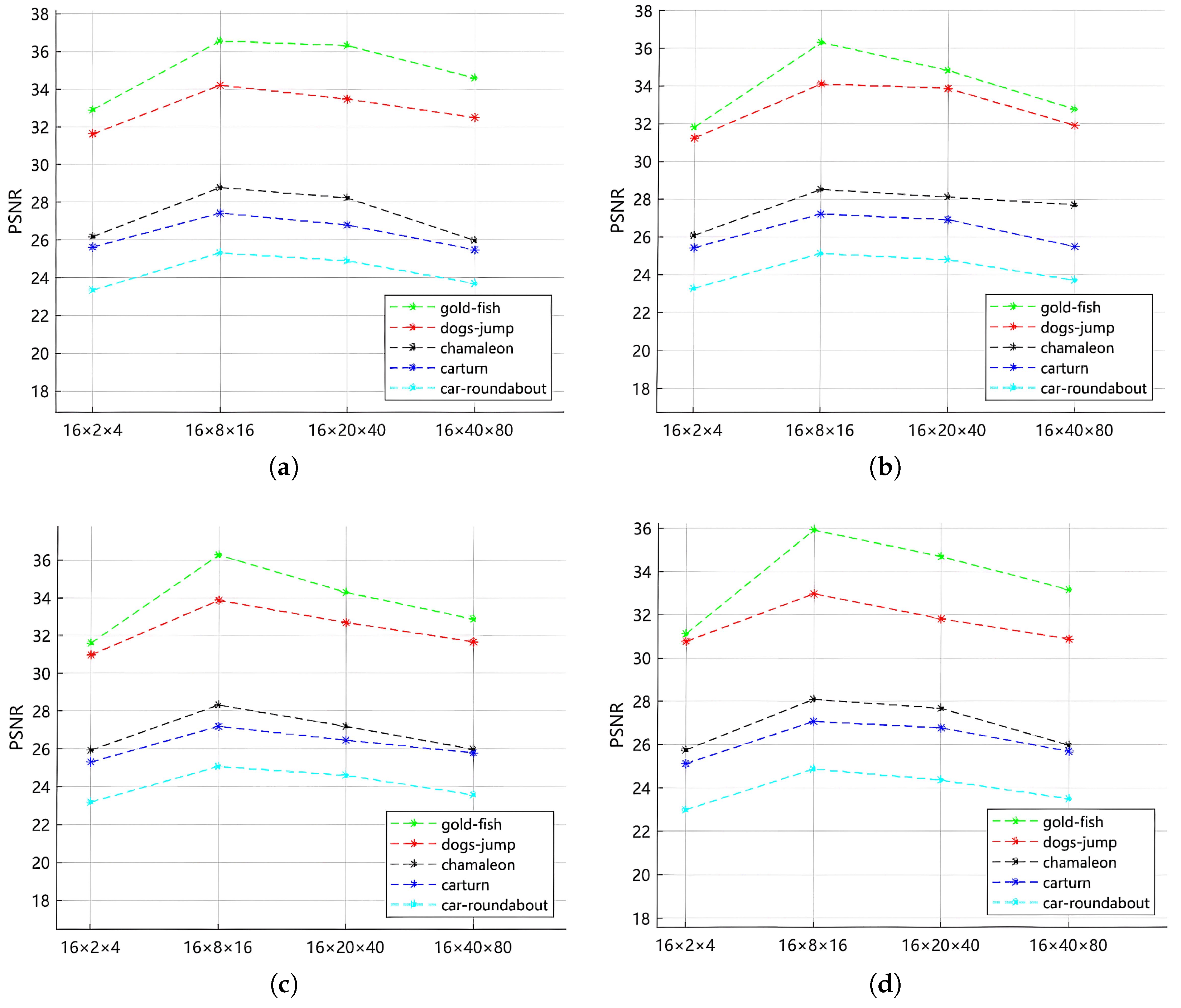
3.3.2. Embedding Size Design
3.3.3. Decoder
3.4. Loss Function
3.5. I-NeRV Video Inpainting Process
| Algorithm 1: I-NeRV video inpainting Process |
 |
4. Experiment
4.1. Experiment Data
4.2. Experiment Configuration
4.3. Evaluation Indicator
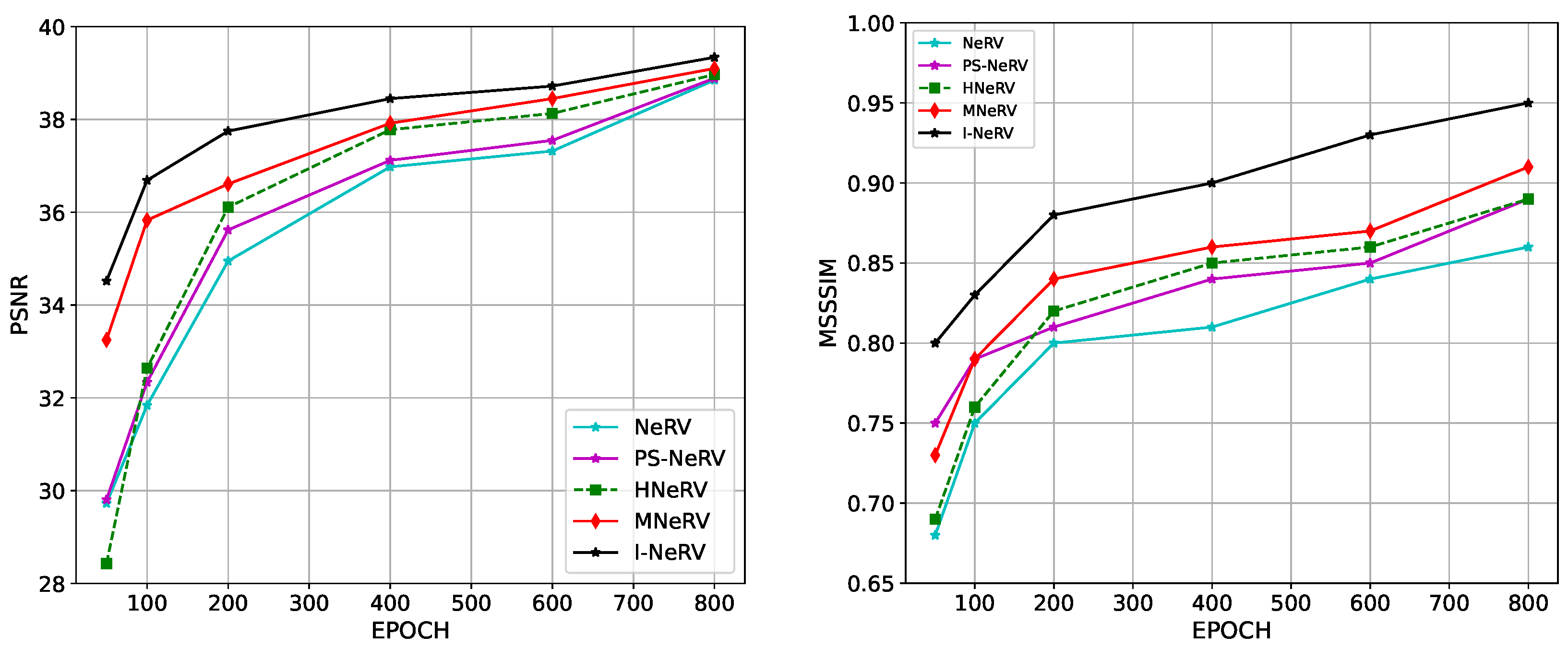
4.4. Experimental Result and Analysis
4.5. Ablation Experiment
Random Mask Module and Embedding Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guo, Y.; Xi, Y.; Wang, H.; Wang, M.; Wang, C.; Jia, X. FedEDB: Building a Federated and Encrypted Data Store Via Consortium Blockchains. IEEE Trans. Knowl. Data Eng. 2024, 36, 6210–6224. [Google Scholar]
- Wang, H.; Jiang, T.; Guo, Y.; Guo, F.; Bie, R.; Jia, X. Label Noise Correction for Federated Learning: A Secure, Efficient and Reliable Realization. In Proceedings of the 40th IEEE International Conference on Data Engineering (ICDE’24), Utrecht, The Netherlands, 13–16 May 2024. [Google Scholar]
- Bai, Z.; Wang, M.; Guo, F.; Guo, Y.; Cai, C.; Bie, R.; Jia, X. SecMdp: Towards Privacy-Preserving Multimodal Deep Learning in End-Edge-Cloud. In Proceedings of the 2024 IEEE 40th International Conference on Data Engineering (ICDE), Utrecht, The Netherlands, 13–16 May 2024; pp. 1659–1670. [Google Scholar]
- Guo, Y.; Zhao, Y.; Hou, S.; Wang, C.; Jia, X. Verifying in the Dark: Verifiable Machine Unlearning by Using Invisible Backdoor Triggers. IEEE Trans. Inf. Forensics Secur. 2024, 19, 708–721. [Google Scholar] [CrossRef]
- Zhang, Y.; Van Rozendaal, T.; Brehmer, J.; Nagel, M.; Cohen, T. Implicit neural video compression. arXiv 2021, arXiv:2112.11312. [Google Scholar]
- Dupont, E.; Loya, H.; Alizadeh, M.; Goliński, A.; Teh, Y.W.; Doucet, A. Coin++: Neural compression across modalities. arXiv 2022, arXiv:2201.12904. [Google Scholar]
- Dupont, E.; Goliński, A.; Alizadeh, M.; Teh, Y.W.; Doucet, A. Coin: Compression with implicit neural representations. arXiv 2021, arXiv:2103.03123. [Google Scholar]
- Xian, W.; Huang, J.B.; Kopf, J.; Kim, C. Space-time neural irradiance fields for free-viewpoint video. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 9421–9431. [Google Scholar]
- Wang, P.; Liu, L.; Liu, Y.; Theobalt, C.; Komura, T.; Wang, W. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. arXiv 2021, arXiv:2106.10689. [Google Scholar]
- Niemeyer, M.; Mescheder, L.; Oechsle, M.; Geiger, A. Differentiable volumetric rendering: Learning implicit 3D representations without 3D supervision. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3504–3515. [Google Scholar]
- Littwin, G.; Wolf, L. Deep meta functionals for shape representation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1824–1833. [Google Scholar]
- Li, Z.; Niklaus, S.; Snavely, N.; Wang, O. Neural scene flow fields for space-time view synthesis of dynamic scenes. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 6498–6508. [Google Scholar]
- Yu, A.; Ye, V.; Tancik, M.; Kanazawa, A. pixelNeRF: Neural radiance fields from one or few images. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4578–4587. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar]
- Tancik, M.; Casser, V.; Yan, X.; Pradhan, S.; Mildenhall, B.; Srinivasan, P.P.; Barron, J.T.; Kretzschmar, H. Block-NeRF: Scalable large scene neural view synthesis. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 8248–8258. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-NeRF: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5855–5864. [Google Scholar]
- Chen, H.; He, B.; Wang, H.; Ren, Y.; Lim, S.N.; Shrivastava, A. NeRV: Neural representations for videos. Adv. Neural Inf. Process. Syst. 2021, 34, 21557–21568. [Google Scholar]
- Bai, Y.; Dong, C.; Wang, C.; Yuan, C. Ps-NeRV: Patch-wise stylized neural representations for videos. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 41–45. [Google Scholar]
- Chen, H.; Gwilliam, M.; Lim, S.N.; Shrivastava, A. HNeRV: A hybrid neural representation for videos. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10270–10279. [Google Scholar]
- Kim, S.; Yu, S.; Lee, J.; Shin, J. Scalable neural video representations with learnable positional features. Adv. Neural Inf. Process. Syst. 2022, 35, 12718–12731. [Google Scholar]
- Bauer, M.; Dupont, E.; Brock, A.; Rosenbaum, D.; Schwarz, J.R.; Kim, H. Spatial functa: Scaling functa to imagenet classification and generation. arXiv 2023, arXiv:2302.03130. [Google Scholar]
- Chen, H.; Gwilliam, M.; He, B.; Lim, S.N.; Shrivastava, A. CNeRV: Content-adaptive neural representation for visual data. arXiv 2022, arXiv:2211.10421. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Kwan, H.M.; Gao, G.; Zhang, F.; Gower, A.; Bull, D. HiNeRV: Video Compression with Hierarchical Encoding-based Neural Representation. Adv. Neural Inf. Process. Syst. 2024, 36, 72692–72704. [Google Scholar]
- Zhou, S.; Li, C.; Chan, K.C.; Loy, C.C. ProPainter: Improving propagation and transformer for video inpainting. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 10477–10486. [Google Scholar]
- Zhang, Z.; Wu, B.; Wang, X.; Luo, Y.; Zhang, L.; Zhao, Y.; Vajda, P.; Metaxas, D.; Yu, L. AVID: Any-Length Video Inpainting with Diffusion Model. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 7162–7172. [Google Scholar]
- Wang, H.; Gan, W.; Hu, S.; Lin, J.Y.; Jin, L.; Song, L.; Wang, P.; Katsavounidis, I.; Aaron, A.; Kuo, C.C.J. MCL-JCV: A JND-based H.264/AVC video quality assessment dataset. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1509–1513. [Google Scholar]
- Mercat, A.; Viitanen, M.; Vanne, J. UVG dataset: 50/120fps 4K sequences for video codec analysis and development. In Proceedings of the MMSys ’20: 11th ACM Multimedia Systems Conference, Istanbul, Turkey, 8–11 June 2020; pp. 297–302. [Google Scholar]
- Chang, Q.; Yu, H.; Fu, S.; Zeng, Z.; Chen, C. MNeRV: A Multilayer Neural Representation for Videos. arXiv 2024, arXiv:2407.07347. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Convolution Kernel Size | Embedding Size | PSNR |
|---|---|---|
| 27.404 | ||
| 30.144 | ||
| 29.046 | ||
| 27.962 | ||
| 27.94 | ||
| 30.458 | ||
| 29.942 | ||
| 28.452 | ||
| 27.566 | ||
| 30.25 | ||
| 29.7 | ||
| 28.292 | ||
| 27.15 | ||
| 29.784 | ||
| 29.06 | ||
| 27.84 |
| Data Set | NeRV | PS-NeRV | HNeRV | MNeRV | I-NeRV |
|---|---|---|---|---|---|
| gold-fish | 31.89 | 32.65 | 32.91 | 35.69 | 36.55 |
| dogs-jump | 30.76 | 31.37 | 31.63 | 33.13 | 34.21 |
| chameleon | 25.23 | 25.98 | 26.18 | 27.29 | 28.78 |
| car-turn | 24.57 | 25.41 | 25.63 | 26.67 | 27.43 |
| car-roundabout | 22.48 | 23.12 | 23.35 | 24.47 | 25.32 |
| avg |
| Data Set | RM Module | Embedding | HNeRV |
|---|---|---|---|
| gold-fish | × | × | |
| √ | × | ||
| √ | √ | 36.55/0.9485 | |
| dogs-jump | × | × | 31.63/0.9299 |
| √ | × | ||
| √ | √ | 34.21/0.9609 | |
| chameleon | × | × | 26.18/0.9197 |
| √ | × | 26.84/0.9266 | |
| √ | √ | 28.78/0.9305 | |
| car-turn | × | × | |
| √ | × | 25.97/0.8697 | |
| √ | √ | 27.43/0.8804 | |
| car-roundabout | × | × | |
| √ | × | ||
| √ | √ | 25.32/0.8873 |
| Loss Function | PSNR | MSSSIM |
|---|---|---|
| 35.12 | 0.9622 | |
| 34.08 | 0.9617 | |
| 34.08 | 0.9617 | |
| 35.66 | 0.9528 | |
| 35.49 | 0.9625 | |
| 36.64 | 0.9649 | |
| 36.17 | 0.9634 | |
| 36.33 | 0.9628 | |
| 34.75 | 0.9619 | |
| 36.18 | 0.9637 | |
| 36.26 | 0.9639 | |
| 36.07 | 0.9648 | |
| 36.67 | 0.9651 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, J.; Fu, S.; Man, J. I-NeRV: A Single-Network Implicit Neural Representation for Efficient Video Inpainting. Mathematics 2025, 13, 1188. https://doi.org/10.3390/math13071188
Ji J, Fu S, Man J. I-NeRV: A Single-Network Implicit Neural Representation for Efficient Video Inpainting. Mathematics. 2025; 13(7):1188. https://doi.org/10.3390/math13071188
Chicago/Turabian StyleJi, Jie, Shuxuan Fu, and Jiaju Man. 2025. "I-NeRV: A Single-Network Implicit Neural Representation for Efficient Video Inpainting" Mathematics 13, no. 7: 1188. https://doi.org/10.3390/math13071188
APA StyleJi, J., Fu, S., & Man, J. (2025). I-NeRV: A Single-Network Implicit Neural Representation for Efficient Video Inpainting. Mathematics, 13(7), 1188. https://doi.org/10.3390/math13071188