
A Hybrid Long Short-Term Memory-Graph Convolutional Network Model for Enhanced Stock Return Prediction: Integrating Temporal and Spatial Dependencies


Abstract
1. Introduction
2. Related Work
3. Method
3.1. Basis of Our Method
3.1.1. LSTM
3.1.2. GCN
3.2. Proposed Method—LSTM-GCN
3.2.1. The Idea
3.2.2. Process
- Preprocessing: PCA removes market-wide effects from return series;
- LSTM Layer: Extracts temporal patterns from 30-stock sequences;
- GCN Layer: Enriches hidden states with spatial relationships;
- Iteration: Stacked layers propagate integrated features;
- Output: Final GCN layer predicts index returns.
3.2.3. Key Algorithms
| Algorithm 1: LSTM-GCN Combined Network for Stock Return Prediction |
| Input: X: Input feature matrix of shape (num_stocks, time_steps, features) A: Adjacency matrix representing the connections between stocks W_lstm: Weight matrices for LSTM layers W_gcn: Weight matrices for GCN layers num_layers: Number of LSTM-GCN layers to stack Output: y_pred: Predicted index return 1: function LSTM_GCN_Network(X, A, W_lstm, W_gcn, num_layers): 2: Step 1: Initial input to the network 3: Initialize H as X 4: for layer in range(num_layers): 5: Step 2: LSTM Layer 6: H_lstm = LSTM_Layer(H, W_lstm[layer]) 7: 8: Step 3: GCN Layer 9: H_gcn = GCN_Layer(A, H_lstm, W_gcn[layer]) 10: 11: Step 4: Update H for the next iteration 12: H = H_gcn 13: 14: Step 5: Final LSTM Layer to obtain the prediction 15: y_pred = LSTM_Layer(H, W_lstm[num_layers]) 16: 17: return y_pred |
3.2.4. Complexity Analysis
4. Experiment
4.1. Data
4.2. Experimental Setup
- Learning Rate: 0.001;
- Batch Size: 32;
- Epochs: 200 (early stopping after 10 epochs without improvement);
- Optimizer: Adam;
- Loss: MSE;
- Initialization: Xavier.
4.3. Evaluation Metric
4.4. Results
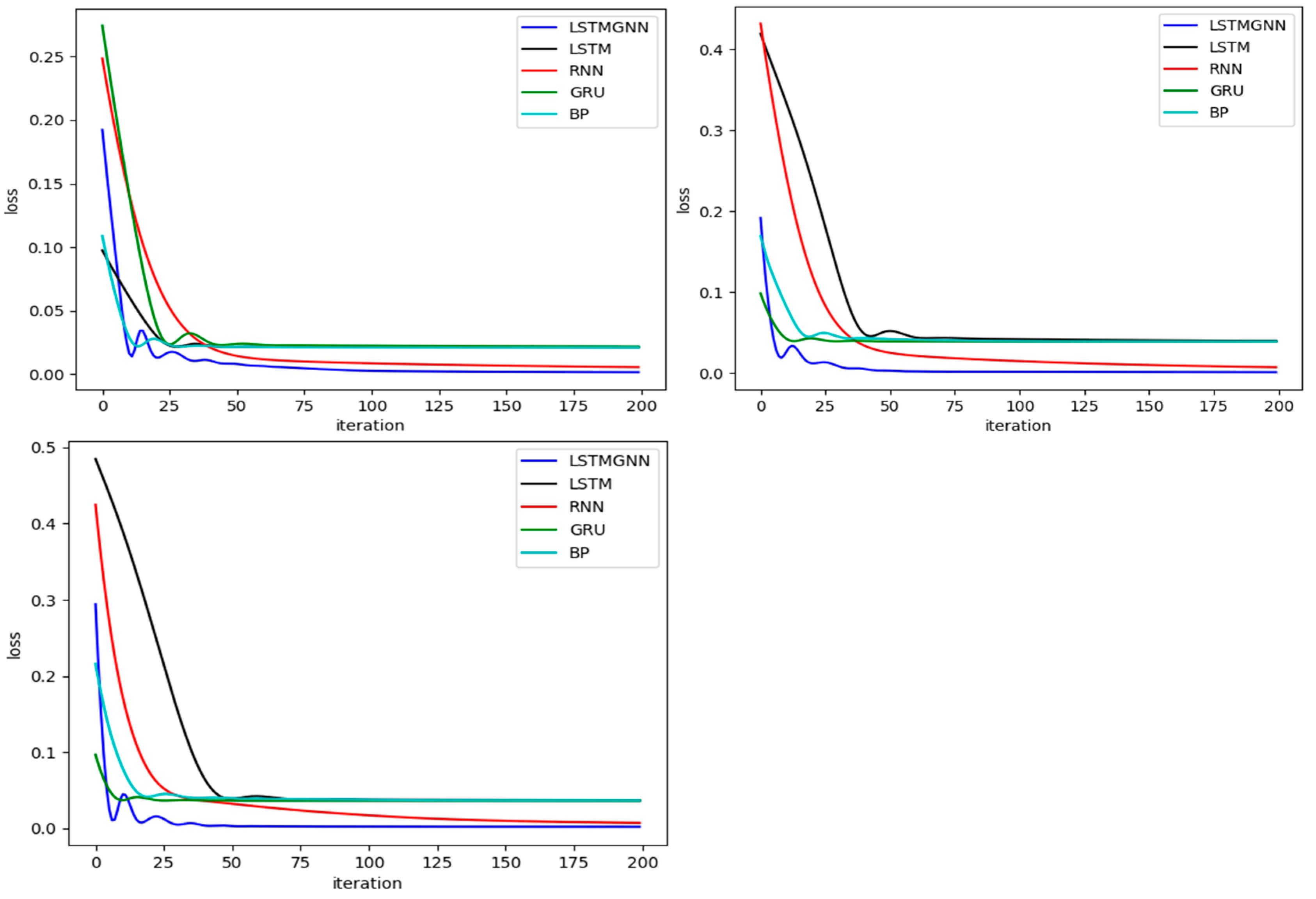
4.4.1. Iteration vs. Loss Function
4.4.2. Time vs. Price of Deep Learning
4.4.3. Time vs. Price of Machine Learning
4.4.4. Forecast Result
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:arXiv:1609.02907. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Holden-Day: San Francisco, CA, USA, 1970. [Google Scholar]
- Engle, R.F. Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized Autoregressive Conditional Heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar]
- Pramod; Mallikarjuna, P. Stock Price Prediction Using LSTM. Test Eng. Manag. 2021, 83, 5246–5251. [Google Scholar]
- Darapaneni, N.; Paduri, A.R.; Sharma, H.; Manjrekar, M.; Hindlekar, N.; Bhagat, P.; Aiyer, U.; Agarwal, Y. Stock Price Prediction Using Sentiment Analysis and Deep Learning for Indian Markets. arXiv 2022, arXiv:2204.05783. [Google Scholar]
- Qiu, J.; Wang, B.; Zhou, C. Forecasting stock prices with long-short term memory neural network based on attention mechanism. PLoS ONE 2020, 15, e0227222. [Google Scholar] [CrossRef]
- Son, J.H.; Kim, J. Asset Pricing Model Based on Graph Structure. J. Financ. Econ. 2019, 42, 27–62. [Google Scholar]
- Zhang, X.; Wei, Y. Financial Time Series Analysis Using Graph Neural Networks. J. Econ. Dyn. Control 2019, 102, 75–92. [Google Scholar]
- Shi, Y.; Meng, Q. Predicting Stock Prices Using GCN-LSTM Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4585–4597. [Google Scholar]
- Meng, Q.; Wang, J. Dynamic Graph Convolutional Networks for Modeling Evolving Relationships in Financial Markets. J. Financ. Mark. 2021, 51, 157–175. [Google Scholar]
- Liu, S.; Zhao, Y.; Wei, Y. SCINet: Time Series Analysis Using Down Sampling and Convolution Operations. Int. J. Forecast. 2020, 36, 300–315. [Google Scholar]
- Sims, C.A. Macroeconomics and Reality. Econom. J. Econom. Soc. 1980, 48, 1–48. [Google Scholar]
- Hao, P.Y.; Kung, C.F.; Chang, C.Y.; Ou, J.B. Predicting stock price trends based on financial news articles and using a novel twin support vector machine with fuzzy hyperplane. Appl. Soft Comput. 2021, 98, 106806, ISSN 1568-4946. [Google Scholar] [CrossRef]
- Adhikari, R.; Agrawal, R.K. An Introductory Study on Time Series Modeling and Forecasting. arXiv 2013, arXiv:1302.6613. [Google Scholar]
- Kabadi, M.G.; Naik, N. A Hybrid Stock Price Prediction Model Based on PRE and Deep Neural Network. Data 2022, 7, 51. [Google Scholar] [CrossRef]
- Chandar, S.K.; Sumathi, M.; Sivanandam, S.N. Integration of Genetic Algorithm with Artificial Neural Network for Stock Market Forecasting. Int. J. Syst. Assur. Eng. Manag. 2019, 10, 667–676. [Google Scholar] [CrossRef]
- Zhao, J.; Feng, S. Sequence Classification of the Limit Order Book Using Recurrent Neural Networks. J. Comput. Sci. 2017, 24, 277–286. [Google Scholar] [CrossRef]
- Kamalov, F. Stock Market Price Movement Prediction with LSTM Neural Networks. In Proceedings of the International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017; pp. 1419–1426. [Google Scholar] [CrossRef]
- Hamilton, J.D. State-space models. In Handbook of Econometrics; Engle, R.F., McFadden, D.L., Eds.; Elsevier: Amsterdam, The Netherlands, 1994; Volume 4, pp. 3039–3080. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Date | AAPL | AXP | BA | … | WMT | XOM | Index |
|---|---|---|---|---|---|---|---|
| 4 March 2021 | 118.0709 | 137.2385 | 224.710 | … | 40.5780 | 51.8341 | 30,924.14 |
| 5 March 2021 | 119.3388 | 141.7112 | 223.220 | … | 41.0839 | 53.7941 | 31,496.30 |
| 8 March 2021 | 114.3655 | 144.5390 | 224.030 | … | 40.6894 | 53.7411 | 31,802.44 |
| 9 March 2021 | 119.0144 | 139.5662 | 230.610 | … | 41.0107 | 52.9112 | 31,832.74 |
| 10 March 2021 | 117.9235 | 141.1533 | 245.340 | … | 42.0576 | 54.5357 | 32,297.02 |
| Model | Layers | Neurons/Layer | Learning Rate | Batch Size | Epochs |
|---|---|---|---|---|---|
| LSTM-GCN | 3 | 64 | 0.001 | 32 | 200 |
| LSTM | 2 | 64 | 0.001 | 32 | 200 |
| GCN | 2 | 64 | 0.002 | 32 | 200 |
| RNN | 2 | 64 | 0.001 | 32 | 200 |
| GRU | 2 | 64 | 0.001 | 32 | 200 |
| BP | 3 | 128 | 0.01 | 64 | 100 |
| Decision Tree | - | - | - | - | - |
| SVM | - | - | - | - | - |
| Model | DJIA MSE | SSE50 MSE | CSI 100 MSE | DJIA MAE | SSE50 MAE | CSI 100 MAE | DJIA R2 | SSE50 R2 | CSI 100 R2 |
|---|---|---|---|---|---|---|---|---|---|
| LSTM-GCN | 0.0055 | 0.0025 | 0.0038 | 0.052 | 0.038 | 0.044 | 0.89 | 0.92 | 0.90 |
| LSTM | 0.0212 | 0.0391 | 0.0367 | 0.103 | 0.142 | 0.135 | 0.65 | 0.58 | 0.60 |
| RNN | 0.0056 | 0.0071 | 0.0069 | 0.055 | 0.062 | 0.060 | 0.88 | 0.85 | 0.86 |
| GRU | 0.0217 | 0.0392 | 0.0361 | 0.105 | 0.143 | 0.133 | 0.64 | 0.57 | 0.61 |
| BP | 0.211 | 0.0391 | 0.0363 | 0.352 | 0.141 | 0.134 | 0.12 | 0.58 | 0.60 |
| Decision Tree | 0.0369 | 0.0065 | 0.0114 | 0.147 | 0.059 | 0.078 | 0.55 | 0.87 | 0.80 |
| SVM | 0.0643 | 0.0324 | 0.0457 | 0.198 | 0.129 | 0.156 | 0.42 | 0.63 | 0.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, S.; Li, F.; Li, W. A Hybrid Long Short-Term Memory-Graph Convolutional Network Model for Enhanced Stock Return Prediction: Integrating Temporal and Spatial Dependencies. Mathematics 2025, 13, 1142. https://doi.org/10.3390/math13071142
Shi S, Li F, Li W. A Hybrid Long Short-Term Memory-Graph Convolutional Network Model for Enhanced Stock Return Prediction: Integrating Temporal and Spatial Dependencies. Mathematics. 2025; 13(7):1142. https://doi.org/10.3390/math13071142
Chicago/Turabian StyleShi, Songze, Fan Li, and Wei Li. 2025. "A Hybrid Long Short-Term Memory-Graph Convolutional Network Model for Enhanced Stock Return Prediction: Integrating Temporal and Spatial Dependencies" Mathematics 13, no. 7: 1142. https://doi.org/10.3390/math13071142
APA StyleShi, S., Li, F., & Li, W. (2025). A Hybrid Long Short-Term Memory-Graph Convolutional Network Model for Enhanced Stock Return Prediction: Integrating Temporal and Spatial Dependencies. Mathematics, 13(7), 1142. https://doi.org/10.3390/math13071142