
FeTT: Class-Incremental Learning with Feature Transformation Tuning


Abstract
1. Introduction
- We introduce to employ mixture uniform distribution to model PTM-based CIL methods, elucidating the trade-off between stability and plasticity within these methods.
- We propose to utilize the feature transformation to non-parametrically regulate the backbone feature embeddings without additional training or parameter overhead.
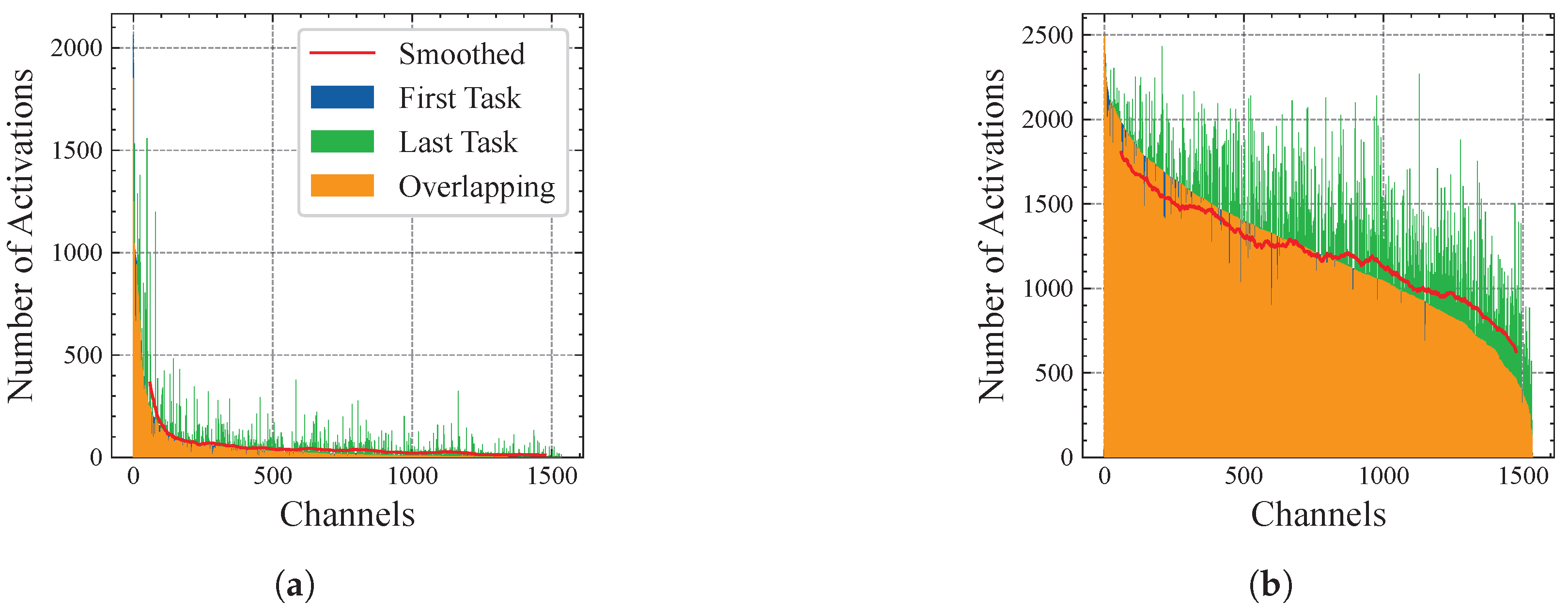
- We conduct detailed analysis on feature channel activation and examine the advantages of the FeTT model in alleviating excessive suppression.
- Extensive benchmark experiments and ablation studies validate the superior performance of the proposed model.
2. Related Work
2.1. Class-Incremental Learning
2.2. Pre-Trained Models (PTMs) and Fine-Tuning
2.3. Feature Transformation
3. Method
3.1. Preliminaries
3.1.1. Problem Formulation
3.1.2. Parameter-Efficient Fine-Tuning (PEFT)
3.2. PTM-Based CIL for Stability and Plasticity
3.2.1. Plasticity CIL Method
3.2.2. Stability CIL Method
3.3. Feature Transformation Tuning Model
| Algorithm 1 FeTT model |
|
3.4. Feature Channel Activations
4. Experimental Results
4.1. Setups
4.1.1. Datasets
4.1.2. Benchmarks
4.1.3. Evaluation Metrics
4.2. Implementation Details
4.3. Main Results
4.4. Ablation Study
4.5. Further Exploration
4.5.1. Different PTMs
4.5.2. PEFT Dataset Sizes
4.5.3. The t-SNE Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Los Alamitos, CA, USA, 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NeurIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.S.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar]
- van de Ven, G.M.; Tuytelaars, T.; Tolias, A.S. Three types of incremental learning. Nat. Mac. Intell. 2022, 4, 1185–1197. [Google Scholar]
- Chen, K.; Gal, E.; Yan, H.; Li, H. Domain Generalization with Small Data. Int. J. Comput. Vis. 2024, 132, 3172–3190. [Google Scholar]
- Li, K.; Chen, H.; Wan, J.; Yu, S. ESDB: Expand the Shrinking Decision Boundary via One-to-Many Information Matching for Continual Learning With Small Memory. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7328–7343. [Google Scholar]
- Rebuffi, S.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. iCaRL: Incremental Classifier and Representation Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 5533–5542. [Google Scholar]
- Hu, Q.; Gao, Y.; Cao, B. Curiosity-Driven Class-Incremental Learning via Adaptive Sample Selection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8660–8673. [Google Scholar]
- Luo, Y.; Ge, H.; Liu, Y.; Wu, C. Representation Robustness and Feature Expansion for Exemplar-Free Class-Incremental Learning. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 5306–5320. [Google Scholar]
- Wang, S.; Shi, W.; Dong, S.; Gao, X.; Song, X.; Gong, Y. Semantic Knowledge Guided Class-Incremental Learning. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 5921–5931. [Google Scholar]
- Belouadah, E.; Popescu, A.; Kanellos, I. A comprehensive study of class incremental learning algorithms for visual tasks. Neural Netw. 2021, 135, 38–54. [Google Scholar]
- Wang, L.; Zhang, X.; Su, H.; Zhu, J. A Comprehensive Survey of Continual Learning: Theory, Method and Application. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5362–5383. [Google Scholar]
- Cong, W.; Cong, Y.; Sun, G.; Liu, Y.; Dong, J. Self-Paced Weight Consolidation for Continual Learning. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 2209–2222. [Google Scholar]
- Mermillod, M.; Bugaiska, A.; Bonin, P. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects. Front. Psychol. 2013, 4, 504. [Google Scholar]
- Dohare, S.; Hernandez-Garcia, J.F.; Lan, Q.; Rahman, P.; Mahmood, A.R.; Sutton, R.S. Loss of plasticity in deep continual learning. Nature 2024, 632, 768–774. [Google Scholar]
- McCloskey, M.; Cohen, N.J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 1989; Volume 24, pp. 109–165. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar]
- Aljundi, R.; Babiloni, F.; Elhoseiny, M.; Rohrbach, M.; Tuytelaars, T. Memory Aware Synapses: Learning What (not) to Forget. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; Volume 11207, pp. 144–161. [Google Scholar]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Li, Z.; Hoiem, D. Learning Without Forgetting. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; Volume 9908, pp. 614–629. [Google Scholar]
- Lopez-Paz, D.; Ranzato, M. Gradient Episodic Memory for Continual Learning. In Proceedings of the Advances in Neural Information Processing Systems 30 (NeurIPS 2017), Long Beach, CA USA, 4–9 December 2017; pp. 6467–6476. [Google Scholar]
- Qiang, S.; Hou, J.; Wan, J.; Liang, Y.; Lei, Z.; Zhang, D. Mixture Uniform Distribution Modeling and Asymmetric Mix Distillation for Class Incremental Learning. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI 2023), Washington, DC, USA, 7–14 February 2023; AAAI Press: Washington, DC, USA, 2023; pp. 9498–9506. [Google Scholar]
- Yan, S.; Xie, J.; He, X. DER: Dynamically Expandable Representation for Class Incremental Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2021), Virtual, 19–25 June 2021; Computer Vision Foundation/IEEE: Washington, DC, USA, 2021; pp. 3014–3023. [Google Scholar]
- Wang, F.; Zhou, D.; Ye, H.; Zhan, D. FOSTER: Feature Boosting and Compression for Class-Incremental Learning. In Proceedings of the Uropean Conference on Computer Vision (ECCV 2022), Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; Volume 13685, pp. 398–414. [Google Scholar]
- Qiang, S.; Liang, Y.; Wan, J.; Zhang, D. Dynamic Feature Learning and Matching for Class-Incremental Learning. arXiv 2024, arXiv:2405.08533. [Google Scholar]
- Wang, Z.; Zhang, Z.; Lee, C.; Zhang, H.; Sun, R.; Ren, X.; Su, G.; Perot, V.; Dy, J.G.; Pfister, T. Learning to Prompt for Continual Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), New Orleans, LA, USA, 18–24 June 2022; IEEE: Washington, DC, USA, 2022; pp. 139–149. [Google Scholar]
- Wang, Z.; Zhang, Z.; Ebrahimi, S.; Sun, R.; Zhang, H.; Lee, C.; Ren, X.; Su, G.; Perot, V.; Dy, J.G.; et al. DualPrompt: Complementary Prompting for Rehearsal-Free Continual Learning. In Proceedings of the European Conference on Computer Vision (ECCV 2022), Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; Volume 13686, pp. 631–648. [Google Scholar]
- Smith, J.S.; Karlinsky, L.; Gutta, V.; Cascante-Bonilla, P.; Kim, D.; Arbelle, A.; Panda, R.; Feris, R.; Kira, Z. CODA-Prompt: COntinual Decomposed Attention-Based Prompting for Rehearsal-Free Continual Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023), Vancouver, BC, Canada, 17–24 June 2023; IEEE: Washington, DC, USA, 2023; pp. 11909–11919. [Google Scholar]
- Zhou, D.; Ye, H.; Zhan, D.; Liu, Z. Revisiting Class-Incremental Learning with Pre-Trained Models: Generalizability and Adaptivity are All You Need. arXiv 2023, arXiv:2303.07338. [Google Scholar]
- Zhang, W.; Huang, Y.; Zhang, W.; Zhang, T.; Lao, Q.; Yu, Y.; Zheng, W.S.; Wang, R. Continual Learning of Image Classes with Language Guidance from a Vision-Language Model. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 13152–13163. [Google Scholar]
- Lange, M.D.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.G.; Tuytelaars, T. A Continual Learning Survey: Defying Forgetting in Classification Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3366–3385. [Google Scholar]
- Zhou, D.; Sun, H.; Ning, J.; Ye, H.; Zhan, D. Continual Learning with Pre-Trained Models: A Survey. arXiv 2024, arXiv:2401.16386. [Google Scholar]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual Learning with Deep Generative Replay. In Proceedings of the Advances in Neural Information Processing Systems 30 (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 2990–2999. [Google Scholar]
- Gao, R.; Liu, W. DDGR: Continual Learning with Deep Diffusion-based Generative Replay. In Proceedings of the International Conference on Machine Learning, (ICML 2023 PMLR), Honolulu, Hawaii, USA, 23–29 July 2023; Volume 202, pp. 10744–10763. [Google Scholar]
- Douillard, A.; Cord, M.; Ollion, C.; Robert, T.; Valle, E. PODNet: Pooled Outputs Distillation for Small-Tasks Incremental Learning. In Proceedings of the European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; Volume 12365, pp. 86–102. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Virtual, 3–7 May 2021; Available online: https://openreview.net/forum?id=YicbFdNTTy (accessed on 26 March 2025).
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning (ICML 2021 PMLR), Virtual, 18–24 July 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Zheng, Z.; Ma, M.; Wang, K.; Qin, Z.; Yue, X.; You, Y. Preventing Zero-Shot Transfer Degradation in Continual Learning of Vision-Language Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2023), Paris, France, 1–6 October 2023; IEEE: Washington, DC, USA, 2023; pp. 19068–19079. [Google Scholar]
- Yu, J.; Zhuge, Y.; Zhang, L.; Hu, P.; Wang, D.; Lu, H.; He, Y. Boosting Continual Learning of Vision-Language Models via Mixture-of-Experts Adapters. arXiv 2024, arXiv:2403.11549. [Google Scholar]
- Zhang, G.; Wang, L.; Kang, G.; Chen, L.; Wei, Y. SLCA: Slow Learner with Classifier Alignment for Continual Learning on a Pre-trained Model. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2023), Paris, France, 1–6 October 2023; IEEE: Washington, DC, USA, 2023; pp. 19091–19101. [Google Scholar]
- McDonnell, M.D.; Gong, D.; Parvaneh, A.; Abbasnejad, E.; van den Hengel, A. RanPAC: Random Projections and Pre-trained Models for Continual Learning. In Proceedings of the Advances in Neural Information Processing Systems 36 (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020 PMLR), Virtual, 13–18 July 2020; Volume 119, pp. 1597–1607. [Google Scholar]
- He, K.; Girshick, R.B.; Dollár, P. Rethinking ImageNet Pre-Training. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV 2019), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Washington, DC, USA, 2019; pp. 4917–4926. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020); Virtual, 6–12 December 2020. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R.B. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation/IEEE: Washington, DC, USA, 2020; pp. 9726–9735. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.; Parekh, Z.; Pham, H.; Le, Q.V.; Sung, Y.; Li, Z.; Duerig, T. Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision. In Proceedings of the 38th International Conference on Machine Learning (ICML 2021 PMLR), Virtual, 18–24 July 2021; Volume 139, pp. 4904–4916. [Google Scholar]
- Xu, L.; Xie, H.; Qin, S.J.; Tao, X.; Wang, F.L. Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment. arXiv 2023, arXiv:2312.12148. [Google Scholar]
- Jia, M.; Tang, L.; Chen, B.; Cardie, C.; Belongie, S.J.; Hariharan, B.; Lim, S. Visual Prompt Tuning. In Proceedings of the European Conference on Computer Vision (ECCV 2022), Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; Volume 13693, pp. 709–727. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the The Tenth International Conference on Learning Representations (ICLR 2022), Virtual, 25–29 April 2022; Available online: https://openreview.net/forum?id=nZeVKeeFYf9 (accessed on 26 March 2025).
- Lian, D.; Zhou, D.; Feng, J.; Wang, X. Scaling & Shifting Your Features: A New Baseline for Efficient Model Tuning. In Proceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Chen, S.; Ge, C.; Tong, Z.; Wang, J.; Song, Y.; Wang, J.; Luo, P. AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition. In Proceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. Available online: http://proceedings.mlr.press/v37/ioffe15.html (accessed on 26 March 2025).
- Yang, S.; Liu, L.; Xu, M. Free Lunch for Few-shot Learning: Distribution Calibration. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Virtual, 3–7 May 2021; Available online: https://openreview.net/forum?id=JWOiYxMG92s (accessed on 26 March 2025).
- Luo, X.; Xu, J.; Xu, Z. Channel Importance Matters in Few-Shot Image Classification. In Proceedings of the International Conference on Machine Learning, (ICML 2022 PMLR), Baltimore, MR, USA, 17–23 July 2022; Volume 162, pp. 14542–14559. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models are Zero-Shot Reasoners. In Proceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Si, C.; Huang, Z.; Jiang, Y.; Liu, Z. FreeU: Free Lunch in Diffusion U-Net. arXiv 2023, arXiv:2309.11497. [Google Scholar]
- Vapnik, V. Principles of Risk Minimization for Learning Theory. In Proceedings of the Advances in Neural Information Processing Systems 4 (NeuIPS 1991), Denver, CO, USA, 2–5 December 1991; Morgan Kaufmann: San Francisco, CA, USA, 1991; pp. 831–838. [Google Scholar]
- Tukey, J.W. Exploratory Data Analysis; Springer: Cham, Switzerland, 1977; Volume 2. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, À.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 2921–2929. [Google Scholar]
- Bai, Y.; Zeng, Y.; Jiang, Y.; Xia, S.; Ma, X.; Wang, Y. Improving Adversarial Robustness via Channel-wise Activation Suppressing. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Virtual, 3–7 May 2021; Available online: https://openreview.net/forum?id=zQTezqCCtNx (accessed on 26 March 2025).
- Yu, L.; Twardowski, B.; Liu, X.; Herranz, L.; Wang, K.; Cheng, Y.; Jui, S.; van de Weijer, J. Semantic Drift Compensation for Class-Incremental Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation/IEEE: Washington, DC, USA, 2020; pp. 6980–6989. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-Ucsd Birds-200-2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Hendrycks, D.; Zhao, K.; Basart, S.; Steinhardt, J.; Song, D. Natural Adversarial Examples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2021), Virtual, 19–25 June 2021; Computer Vision Foundation/IEEE: Washington, DC, USA, 2021; pp. 15262–15271. [Google Scholar]
- Hendrycks, D.; Basart, S.; Mu, N.; Kadavath, S.; Wang, F.; Dorundo, E.; Desai, R.; Zhu, T.; Parajuli, S.; Guo, M.; et al. The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021), Montreal, QC, Canada, 10–17 October 2021; IEEE: Washington, DC, USA, 2021; pp. 8320–8329. [Google Scholar]
- Barbu, A.; Mayo, D.; Alverio, J.; Luo, W.; Wang, C.; Gutfreund, D.; Tenenbaum, J.; Katz, B. ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 9448–9458. [Google Scholar]
- Zhai, X.; Puigcerver, J.; Kolesnikov, A.; Ruyssen, P.; Riquelme, C.; Lucic, M.; Djolonga, J.; Pinto, A.S.; Neumann, M.; Dosovitskiy, A.; et al. A large-scale study of representation learning with the visual task adaptation benchmark. arXiv 2019, arXiv:1910.04867. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; IEEE Computer Society: Los Alamitos, CA, USA, 2009; pp. 248–255. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Ridnik, T.; Baruch, E.B.; Noy, A.; Zelnik, L. ImageNet-21K Pretraining for the Masses. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, NeurIPS Datasets and Benchmarks 2021, Virtual, December 2021. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | CIFAR B0 Inc5 | CUB B0 Inc10 | IN-R B0 Inc5 | IN-A B0 Inc10 | Obj B0 Inc10 | VTAB B0 Inc10 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P. | Fine-Tuning | ||||||||||||
| Fine-Tuning Adapter | |||||||||||||
| LwF [21] | |||||||||||||
| L2P [27] | |||||||||||||
| DualPrompt [28] | |||||||||||||
| CODA-Prompt [29] | |||||||||||||
| S. | SimpleCIL [30] | ||||||||||||
| ADAM * [30] | |||||||||||||
| Ours | SimpleCIL† | ||||||||||||
| + FeTT | |||||||||||||
| + FeTT-E | |||||||||||||
| +0.17 | +5.30 | +1.46 | |||||||||||
| ADAM (VPT) † | |||||||||||||
| + FeTT | |||||||||||||
| + FeTT-E | |||||||||||||
| +0.30 | |||||||||||||
| ADAM (SSF) † | |||||||||||||
| + FeTT | |||||||||||||
| + FeTT-E | |||||||||||||
| +0.21 | |||||||||||||
| ADAM (Adapter) † | |||||||||||||
| + FeTT | |||||||||||||
| + FeTT-E | |||||||||||||
| Baseline | Ablations | Obj | IN-A | ||||
|---|---|---|---|---|---|---|---|
| Log | Pwr | Ens. | |||||
| SimpleCIL | |||||||
| ✓ | |||||||
| ✓ | |||||||
| ✓ | |||||||
| ✓ | ✓ | ✓ | |||||
| ADAM (Adapter) | |||||||
| ✓ | |||||||
| ✓ | |||||||
| ✓ | |||||||
| ✓ | ✓ | ✓ | |||||
| Ablations | PTMs | ||||
|---|---|---|---|---|---|
| IN-1K | IN-21K | IN-1K-M | IN-21K-M | CLIP | |
| SimpleCIL | |||||
| + LogTrans | |||||
| Ablations | Obj | IN-A | ||
|---|---|---|---|---|
| IN-1K | IN-21K | IN-1K | IN-21K | |
| SimpleCIL | ||||
| + FeTT (Ours) | ||||
| + FeTT-E (Ours) | ||||
| Ablations | Number of Training Classes in First Step for PEFT | |||||
|---|---|---|---|---|---|---|
| None | 2 Classes | 5 Classes | 10 Classes | 20 Classes | 40 Classes | |
| ADAM (Adapter) | ||||||
| + FeTT (Ours) | ||||||
| + FeTT-E (Ours) | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiang, S.; Liang, Y. FeTT: Class-Incremental Learning with Feature Transformation Tuning. Mathematics 2025, 13, 1095. https://doi.org/10.3390/math13071095
Qiang S, Liang Y. FeTT: Class-Incremental Learning with Feature Transformation Tuning. Mathematics. 2025; 13(7):1095. https://doi.org/10.3390/math13071095
Chicago/Turabian StyleQiang, Sunyuan, and Yanyan Liang. 2025. "FeTT: Class-Incremental Learning with Feature Transformation Tuning" Mathematics 13, no. 7: 1095. https://doi.org/10.3390/math13071095
APA StyleQiang, S., & Liang, Y. (2025). FeTT: Class-Incremental Learning with Feature Transformation Tuning. Mathematics, 13(7), 1095. https://doi.org/10.3390/math13071095