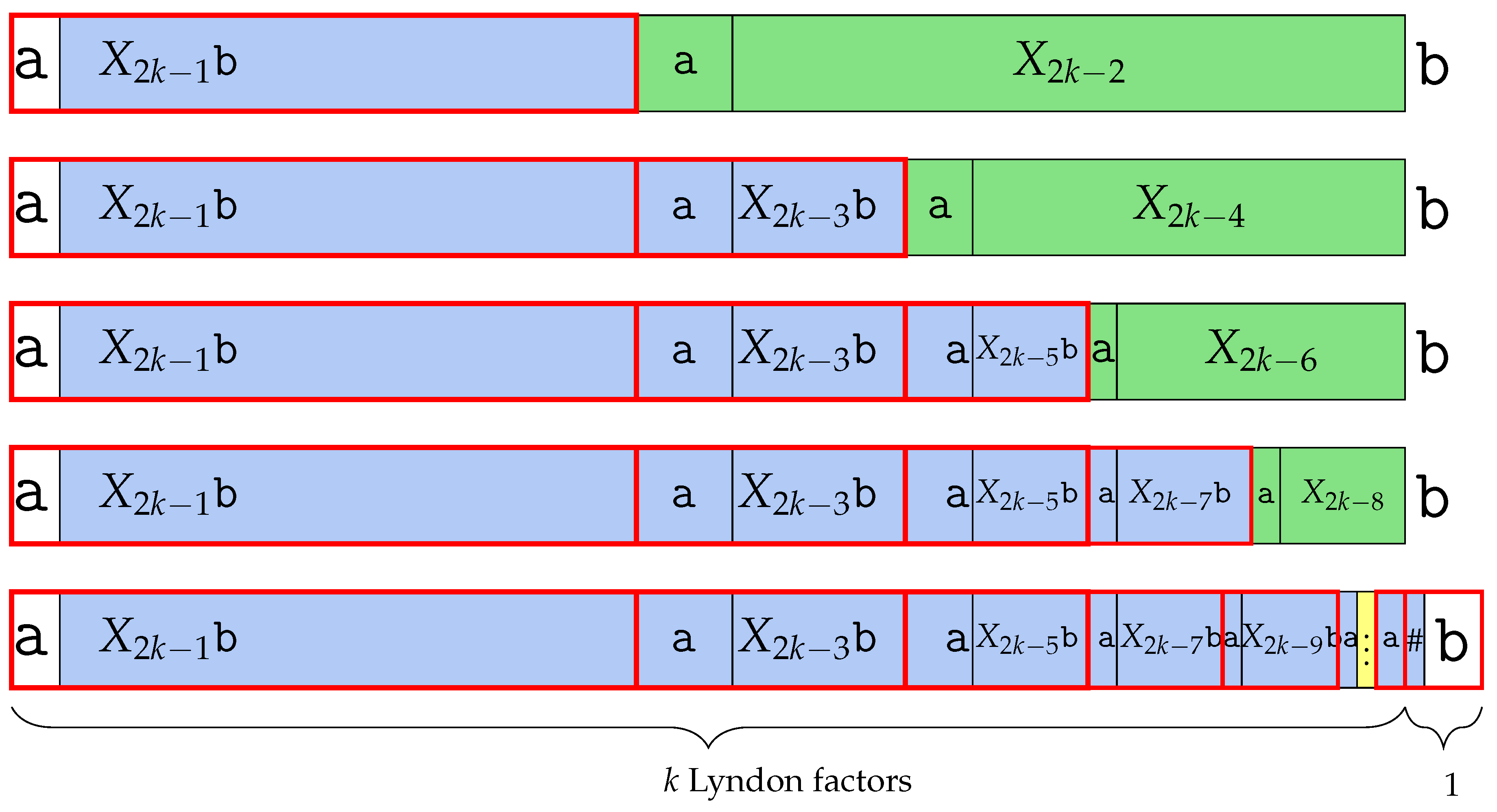
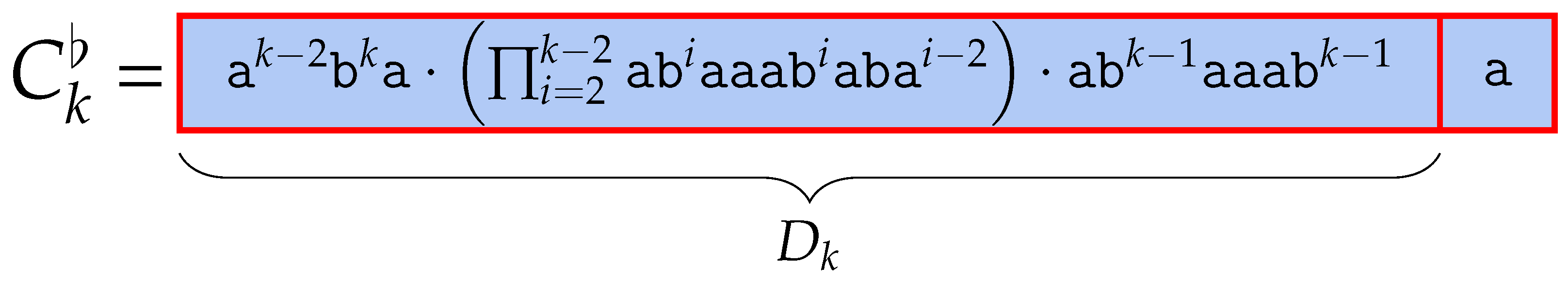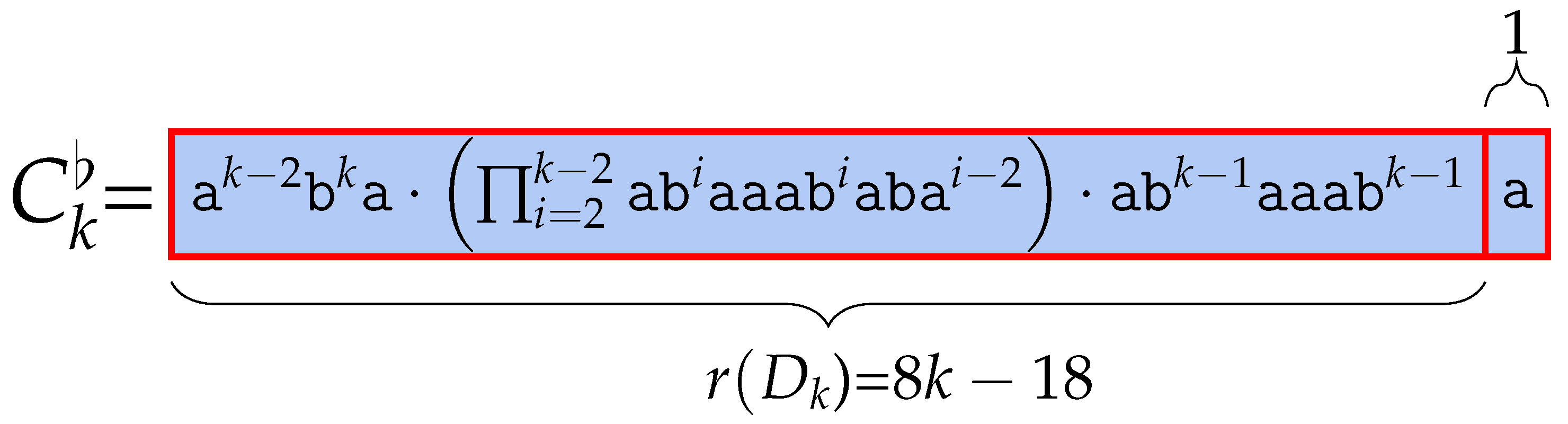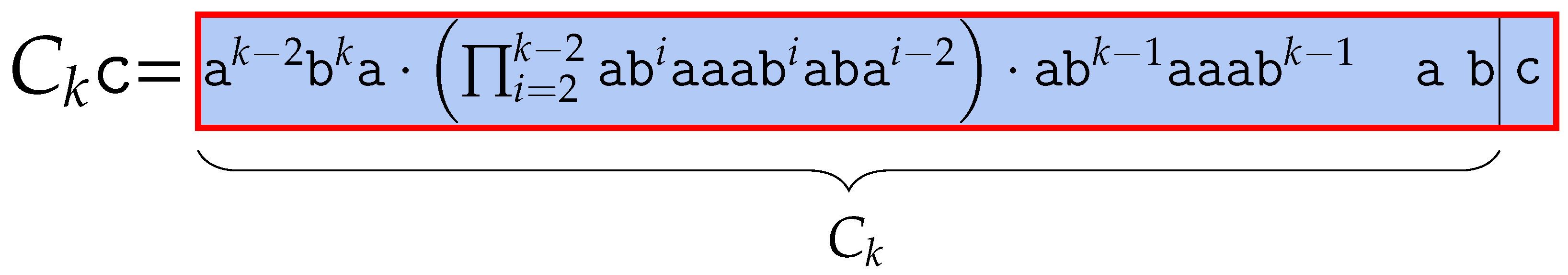5.1. BWT of After Substituting a Character
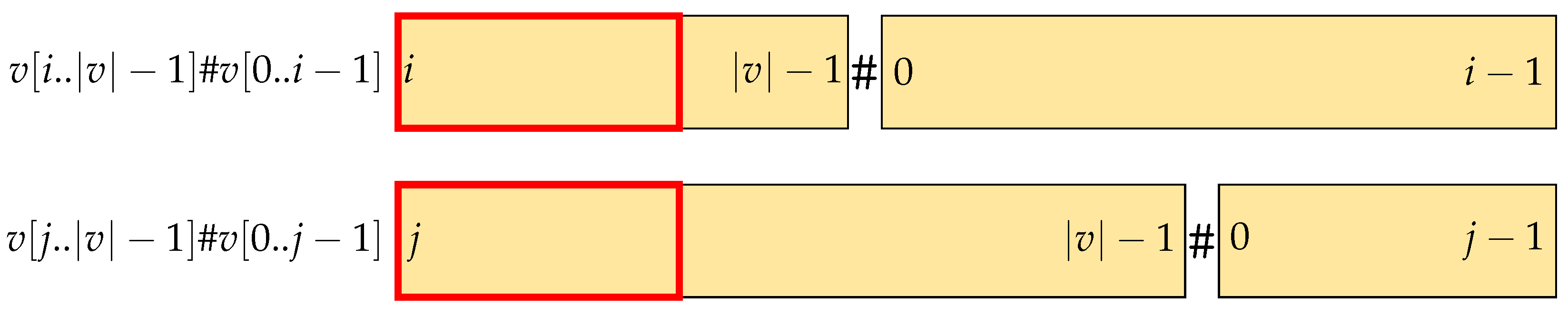
The lemmas presented below characterize the BWT of after certain modifications have been applied. Rather than deriving the entire structure of the BWT from scratch, we analyze how replacing a character affects either the relative order or the final character of the conjugates of . We let be the list of lexicographically sorted conjugates of the word .
Lemma 6. .
Proof. The first conjugate in is . Since the lexicographic order of # is smaller than all other characters, a conjugate starting with # is smaller than every conjugate starting with . # can be obtained by the last character of , which is preceded by a . □
Lemma 7. = for all .
Proof. Given integer
, the conjugates of
starting with
are
In
, a prefix
can only be obtained by concatenation of the suffix
of
, with the prefix
of
or the prefix of
of
if
. Note that all these conjugates end with an
, with the exception of the conjugate starting with
, since this is where the unique occurrence of
can be found. □
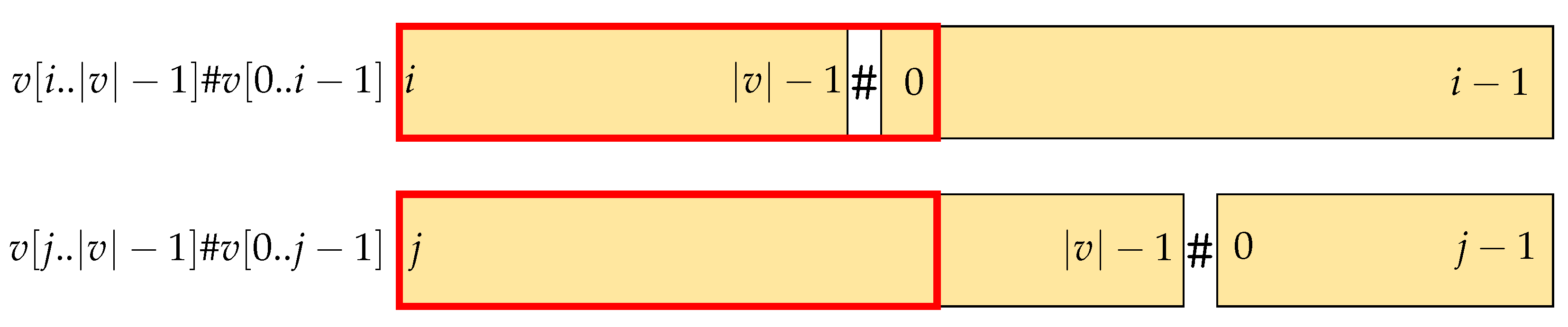
Lemma 8. .
Proof. The conjugates in
starting with
are
In , the conjugates that start with can be obtained for all from the concatenation of the suffix from with or with if . If , concatenation of the suffix of with the prefix of also makes . Also, we can sort the conjugates with following order: . All conjugates of end with a and if , of concatenated with or if also ends with . On the other hand, ends with . □
Lemma 9. .
Proof. The conjugates in
starting with
are
Each of the conjugates starting with
from Lemma 8 induces a conjugate starting with
, obtained by shifting on the left one character
. It follows that all of these conjugates end with an
. The other conjugates that start with
are those obtained by concatenating the suffix
of
with the prefix
of
which ends with
. □
Lemma 10. .
Proof. The conjugates in
starting with the prefix
are
For all two distinct integers
with
, we have
. Thus, the first conjugate in the lexicographic order starting with
is the one followed by the longest
. The smallest of these conjugates can be found from the suffix
of
, followed by the suffix
of
for all
taken in decreasing order.
By construction of , for all , these conjugates must end in a . The remaining conjugates starting with are exactly those of either or , for all , or . The conjugates can be obtained by shifting on the left one character from the conjugates starting with from Lemma 9, with the exception of one starting with since it ends with a , and the other starting with which ends with #, while the other conjugates end with an . □
Lemma 11. for all .
Proof. The conjugate in starting with for all is . This conjugate can be obtained by a suffix of , and is always preceded by a . □
Lemma 12. .
Proof. The conjugates in
starting with
are
We have as many circular occurrences of as the number of maximal character runs of in . Then, for all ,
- Case 1:
one run of in and
- Case 2:
two runs in .
For Case 1, we have one conjugate starting with for each . Since each run of within each word of is of length of at least 2, all conjugates in (1) end with . For Case 2, for all we can distinguish between two subcases, based on where starts:
- Case 2 (a):
from the first run of in , which is when or if . Since has at least 2 runs, conjugates with prefix (2.1) always end with .
- Case 2 (b):
from run for all , and . Each conjugate of Case 2 (b) is obtained by shifting two characters to the right in each conjugate in Case 2 (a). Therefore, these conjugates end with an .
Observe that only for Case 2 (b) we have conjugates starting with . Hence, the first conjugate in the lexicographic order is the one starting with , followed by those starting with .
Among the remaining conjugates, those that have the prefix start with from Case 2 (b) or from Case 2 (a). Thus, we can sort them according to lexicographic order. Then, the remaining conjugates, which start with , are obtained by only. Finally, let us focus on the conjugates from Case 2 (a), which start with . These conjugates are sorted according to the length of the runs of s following the common prefix , similarly to the sorting of conjugates from Case 2 (b). The last conjugate left is the one starting with from Case 2 (b). Since is lexicographically greater than all other cases, this is the greatest conjugate of starting with and we can conclude our claim. □
Lemma 13. for all .
Proof. The conjugates starting with
with integer
in
are
All runs of of length at least appear in either
- Case 1:
or
- Case 2:
for all .
Let us consider these two cases separately. For all , the conjugate starting within has prefix . For all , the conjugate starting within has prefix , and for , we have the conjugate with prefix . By construction, we have all the conjugates from Case 1 sorted according to the lexicographic order of the words with respect to the length of the run by obtained by .
The conjugates covered by Case 2 are sorted according to the decreasing length of the run of , following the common prefix . Only when the run of is exactly i long, its conjugate ends with . Thus, the conjugates ending with an are those starting with and , which have prefixes and . □
Lemma 14. .
Proof. The
two conjugates in
which start with
are
The conjugates with the prefix
start with
or
. These conjugates have prefixes of
and
, respectively. One can see that these conjugates taken in this order are already sorted, and both conjugates end with
. □
Lemma 15. .
Proof. The last conjugate in is . The last conjugate in lexicographic order starts with , and since the run of is maximal, it ends with , and the claim follows. □
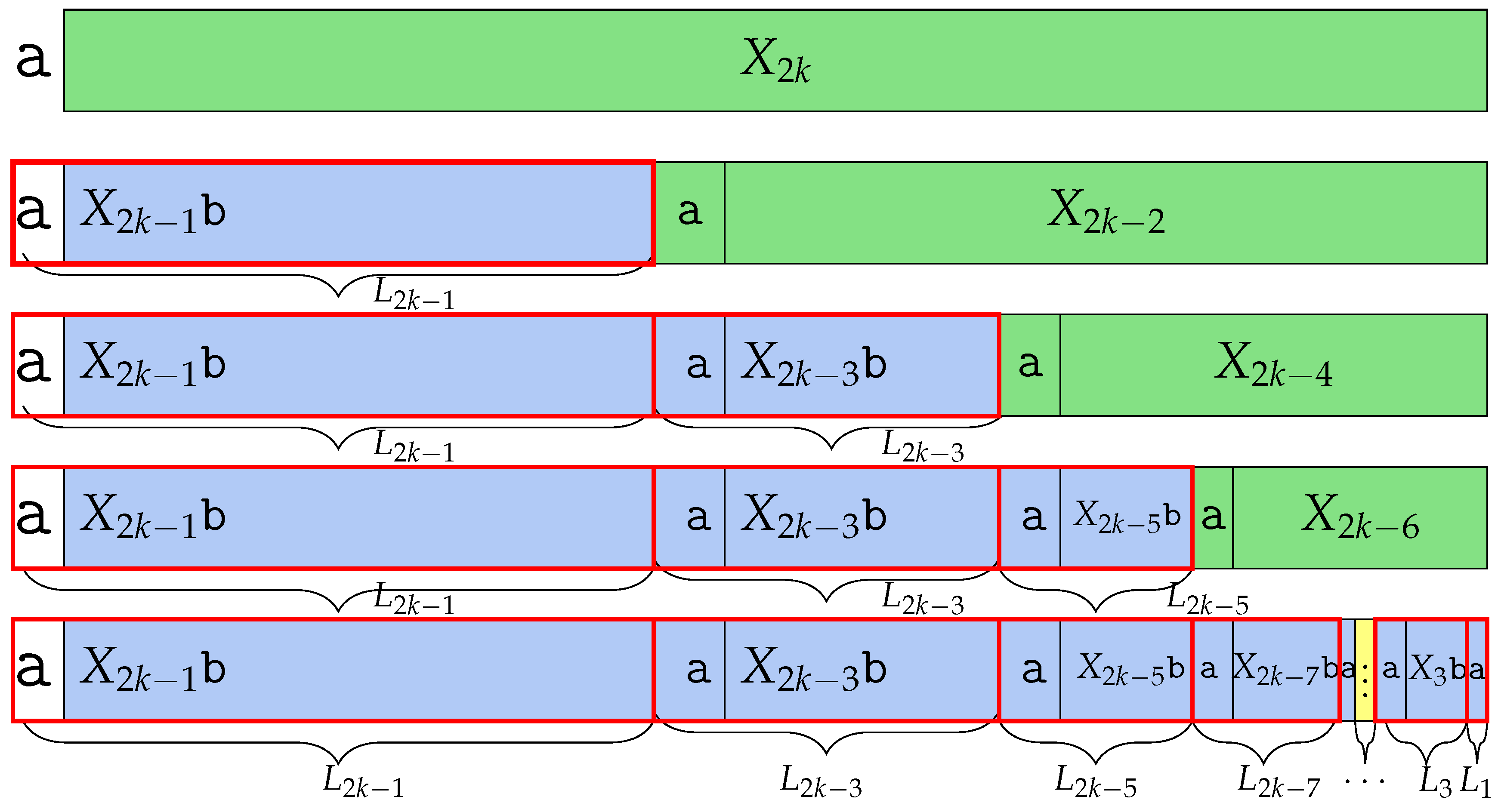
In conclusion, we define the above theorem.
Theorem 2. for every .
Proof. The BWT of the
is BWT(
) =
. We refer to
Table 2. Moreover,
which has
more runs than
, cf. Lemma 5.
The lexicographic order of # is lower than an , and a conjugate starting with # is smaller than any conjugate starting with . Moreover, every conjugate in is smaller than every one in , for every . In addition, every conjugate contributing a character to is smaller than a conjugate contributing a character to for every . And with a conjugate starting with , the number is smaller than that of . Since we considered all the disjoint ranges of conjugates of based on their common prefix, the word BWT() is . With the structure of BWT(), we can derive its number of runs. The words and have runs: we start with 1 run from = which is merged by = . And concatenating them up to adds 2 new runs each. , (), () have , 3, 5 runs, respectively. However, the boundaries between and () are merged by an ; therefore, has 2 runs. has 1 run, followed by which makes 7 runs. Then, and () repeat, making 1 and 3 runs until thus makes runs. adds 1 run. Also, adds 1 run and is the last run since does not add new runs, since it consists only of a that merges with the previous one. Altogether, we have , and the claim holds. The main difference in the runs of and occurs from the prefix beginning with that concatenates with , repeating for , while repeats only . Thus, it makes additive runs of .
Table 3,
Table 4,
Table 5,
Table 6 and ,
Table 7 . The first column partitions conjugates by common prefixes and names the common prefix shared by all conjugates in a partition. The second column shows the remaining part of the respective conjugate followed by the prefix of its partition. The remaining part of a conjugate decides its relative order inside its partition. The BWT column shows the last character of each conjugate. □
5.2. BWT of After Substituting a Character
In this subsection, we consider the word , where we swapped with in . The following series of lemmas characterize the subword of BWT() using for each range we consider.
Lemma 16. .
Proof. The first conjugate in is The first conjugate in lexicographic order must start with the longest run of s. By the definition of , the longest run of has length k, which is obtained by of , which is preceded by a . □
Lemma 17. for all .
Proof. With integer
, the conjugates starting with
in
are
For all
, the factor of
can only be obtained for all
, from
from
, or
from
, and if
,
from
. We can sort the conjugate according to the lexicographic order. Note that all these conjugates end with
, with the exception of the conjugate starting with
obtained by
and
ending with
. □
Lemma 18. .
Proof. In
, the conjugates starting with
are
We have as many circular occurrences of
as the number of maximal (circular) runs of
in
. Then, for all
, we have three cases.
- Case 1:
one run of in ,
- Case 2:
two runs in in ,
- Case 3:
one run in .
For Case 1, we have one conjugate starting with , for each . Since each run of within each word of is of length at least 2, all conjugates in Case 1 end in . For Case 2, for all , we can distinguish between two sub-cases based on where starts.
- Case 2 (a):
from the first run of in , starting with , if , or ,
- Case 2 (b):
from the second run in , starting with , if , or .
Similarly to Case 1, each conjugate for Case 2 (a), ends with . Each conjugate in Case 2 (b) is obtained by shifting two characters on the right in each conjugate in Case 2 (a). Therefore, all these conjugates end with .
For Case 3, the conjugate starting with in has as a prefix and is preceded by . Observe that only for Case 2 (b), we have one conjugate that starts with obtained by and it is the first conjugate in the lexicographic order of . Then, the conjugates start with followed by from Case 2 (a).
Among the remaining conjugates, those with the prefix start with from Case 2 (b) or from Case 3. Then, among the left conjugates, the conjugate with the prefix from Case 2 (a), for all , or from Case 2 (b) follows. The last remaining conjugates have the prefix for or , which can be obtained by Case 2 (b). Since is greater than all other conjugates, it is the greatest conjugate of starting with and we conclude this proof. □
Lemma 19. .
Proof. The conjugates in
that start with
are
For integer i, we can see that is lexicographically smaller than . Thus, the first conjugate in lexicographic order starting with is the one followed by the longest run of , and it can be found by of , followed by conjugates starting with of and of for all taken in decreasing order. By construction of , for , these conjugates must end with a . Otherwise, for , conjugates also end with , with the exception of a conjugate starting with , since it is preceded by an from . The remaining conjugates starting with are exactly those conjugates that have the prefix of the suffix if or . All of these conjugates end with , since they are preceded by . □
Lemma 20. .
Proof. The conjugates starting with
in
are
These conjugates are obtained by following four cases.
- Case 1:
concatenating suffix of with for all ,
- Case 2:
concatenating suffix of with for all ,
- Case 3:
concatenating suffix of with ,
- Case 4:
concatenating suffix of with .
The first conjugate in lexicographic order starting with is the one followed by the longest run of . The smallest of these conjugates can be found by Case 3, concatenation of the suffix of with . We can directly observe that holds for every integer . Thus, the next conjugate will have the prefix from Case 1 and from Case 2 repeating in decreasing order. Since of Case 1 and of Case 3 is preceded by a , those end with a . On the other hand, precedes for all until appears since it precedes an . Lastly, conjugates with the prefix and by Case 1 end with a . The greatest lexicographic conjugate is from Case 4 as it has the smallest runs of which is two and ends with .
We can sort all of these conjugates according to the order of the words in
□
Lemma 21. .
Proof. The conjugates in
starting with
are
Some of the conjugates starting with
can be obtained by two cases.
- Case 1:
from the concatenation of the suffix of with a prefix of of for all
or if ;
- Case 1:
from the concatenation of the suffix of with prefix of for all .
Thus, all conjugates starting with are sorted according to the lexicographic order of the words in All conjugates starting with for all or in Case 1 end with . Otherwise, conjugates starting with of Case 1 or for all of Case 2 end with . □
Lemma 22. for all .
Proof. All runs of of length of a range appear only by concatenating suffix of with prefix of for all in decreasing order. All of these conjugates end with a , with the exception of a conjugate which ends with an since suffix precedes an . Hence, the last conjugate in lexicographic order starting with is within and since the run of is maximal it ends with , and the claim follows. □
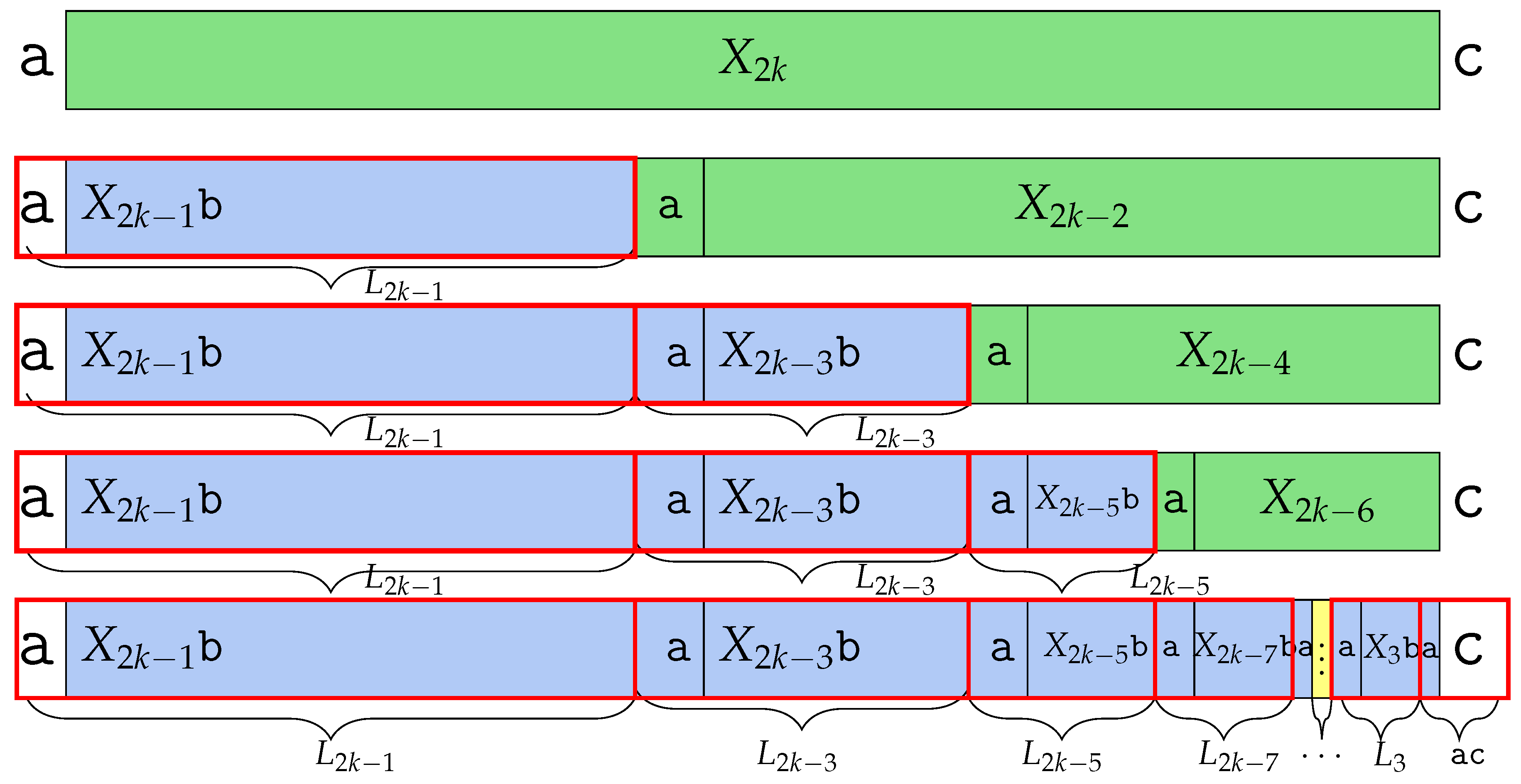
The following theorem presents the shape of the BWT of .
Theorem 3. For every .
cf.
Table 8. Proof. Let us put the result from Lemma 16 to Lemma 22 together. Every conjugate of contributing a character to is smaller than a conjugate contributing a character to , for every . Symmetrically, every conjugate in is greater than every conjugate in , when . Since we considered all the disjoint ranges of conjugates of based on their common prefix, the word is the BWT of .
With the structure of BWT(), we can derive its number of runs. The word has exactly runs: we start with 1 run from but it is merged by a from . Then, concatenating each up to adds 3 runs each. However, the boundaries between these words merge because appears continuously. Thus, each for makes 2 runs each. By counting, we observe that runs 7 times. The remaining part of the BWT, that is, has runs: the word , has 4 runs, but the first merges with a from , so we only charge 3 runs for this word. Then, and add 4 and runs, respectively. Finally, runs for 2 until . The word does not add new runs, as it consists only of an that merges with the previous one. Altogether, we have , and the claim holds. □
The following lemmas describe the BWT of after applying one specific edit operation. is a word obtained by replacing the last character of with , where is lexicographically larger than . The number of runs in the BWT of can be derived by comparing the BWT of to the BWT of , for which we explicitly counted the number of runs, so we omit these parts of the proof using , which is a list of lexicographically sorted conjugates of word . Substituting the last character with in also increases the number of runs by .
Lemma 23. .
Proof. The first conjugate in starts with . The first conjugate in lexicographic order must start with the longest run of . By the definition of , the longest run of is obtained by suffix of , preceded by a . □
Lemma 24. for all .
Proof. The conjugates in
starting with the prefix
for
are
For every integer
, the conjugates in
starting with
can only be obtained from two cases:
- Case 1:
of for all ,
- Case 2:
of for all .
We can sort these conjugates according to the lexicographic order of . Note that all these conjugates end with an , with the exception of the conjugate starting with and , since these are the only places where the occurrence of can be found. □
Lemma 25. for all .
Proof. The only conjugate in starting with for all has a prefix of . For all two distinct integers with , we have . Also, since the lexicographic order of a word in is , it is also clear that . The conjugates starting with are obtained from from and since the length of is k, all conjugates with with end with . □
Lemma 26. .
Proof. In
, the conjugates starting with
are
We have as many circular occurrences of
as the number of maximal runs of
in
. Then, for all
, we have two cases.
- Case 1:
one run in obtained by concatenating suffix of with , for each , and
- Case 3:
two runs in .
For Case 1, since each run of within each word of is of length of at least 2, all conjugates in Case 1 end with an .
For Case 2, for all , we can distinguish between two sub-cases, based on where starts, if either
- Case 2 (a):
from the first in or
- Case 2 (b):
from the second in .
For Case 2 (a), we can see that these conjugates are of the type if or . Similarly to Case 1, each conjugate for Case 2 (a) ends with . Each conjugate in Case 2 (b) is obtained by shifting two characters on the right each conjugate in Case 2 (a). Therefore, all of these conjugates end with a and have prefix of type , if or . All these conjugates end with a since is preceded by . Observe that only for Item Case 2 (b), we have conjugates starting with which is . Hence, it is the first conjugate in lexicographic order, followed by those starting with from Item Case 2 (a) and these conjugates start with .
Next, conjugates with a prefix of which is from Case 2 (b) follow, then those having prefix either start with for all from Case 1 follow in decreasing order. Then, from Case 2 (b) and , , from Case 1 follow.
The remaining conjugates are those which start with a prefix of
for
, which are obtained by
if
or
, from Case 2 (b). These conjugates are sorted according to the length of the run of
following the common prefix. Then, the result is
□
Lemma 27. .
Proof. The conjugates in
starting with the prefix
are
There are many occurrences of a conjugate starting with the prefix , and it occurs in three parts.
- Case 1:
one run of in , for all ,
- Case 1:
two runs from , for all ,
- Case 1:
one run from .
The conjugates in Case 1 start with for all . Since if only , the conjugates are sorted in decreasing order. All conjugates for end with a , except for conjugates with prefix since it is preceded by .
In Case 2, we can distinguish between two sub-cases based on where starts:
- Case 2 (a):
first run of from the prefix of ,
- Case 2 (b):
from the second run of in .
The conjugates in Case 2 (a) are the type of , if or . All of these conjugates are preceded by , thus ending with . The conjugates in Case 2 (b) start from if or and end with an .
In Case 3, only one conjugate can be found by a prefix of , which ends with .
Observe that only for Case 3 we have a conjugate with the longest run of after . Hence, the first conjugate in lexicographic order is from Case 3. It is followed by . All of these conjugates end with a .
Among the remaining conjugates, those having prefix either start with from Case 2 (a) or from Case 1. Then, the remaining conjugates with prefix are those starting with from Case 2 (a) or from Case 1. Lastly, conjugates from Case 2 (b) follow, which are for all or . All of these conjugates end with an .
We prove our claim by sorting lexicographically the conjugates in
□
Lemma 28. .
Proof. The conjugates in
starting with prefix
are
The smallest conjugate with prefix can be obtained by three cases.
- Case 1:
concatenating suffix of with ,
- Case 2:
concatenation of suffix of with if or ,
- Case 3:
concatenating suffix of with , for all .
The conjugates in Case 1 and Case 3 end with
. Also, conjugates from Case 2 end with
with an exception of a conjugate starting with
since it is preceded by an
. We conclude this proof by sorting lexicographically the conjugates in
□
Lemma 29. .
Proof. The conjugates in
starting with the prefix
are
Analogously to Lemma 28, the conjugates starting with
can be obtained from three cases.
- Case 1:
concatenating suffix of with ,
- Case 2:
concatenation of suffix of with if or ,
- Case 3:
concatenating a suffix of with , for all .
The conjugate in Case 1 is the smallest conjugate starting with
since it has a longest run of
and ends with a
. In addition, the conjugates of Case 3 end with a
since
are preceded by an
. In Case 2, all the conjugates end with
with an exception of a conjugate starting with
since it is preceded by an
. We can sort these conjugates by
□
Lemma 30. for all .
Proof. In
, the conjugates starting with prefix
for all
are
Observe that the only conjugates with the prefix for start with concatenating either to or if . One can see that these conjugates taken in this order are already sorted, and all conjugates end with a , with the exception of a conjugate starting with , since it is preceded by an , therefore ending with an . We have all conjugates ordered according to the lexicographic order of the words in. This concludes our proof. □
Lemma 31. .
Proof. The only conjugate in that starts with prefix is . Since is lexicographically larger than other characters such as , , it is the biggest conjugate in , and it ends with an . □
The following theorem puts the lemmas above together.
Theorem 4. Substituting the last character of
by
increases r by
,
cf.
Table 9. Proof. Every conjugate contributing a character to is smaller than a conjugate contributing a character to for every . By symmetry, every conjugate contributing a character to is greater than each conjugate contributing a character to for every . With the structure of the BWT of , we can easily derive its number of runs. has exactly runs: we start from 1 run from but it is merged with . and add 2 runs. Then, concatenating each and for all in a decreasing order, we add 3 and 1 runs each, which results in runs. By counting, we observe that adds 7 and 1 runs, respectively.
The word has exactly 5, 3, runs each, but since the boundaries between and merge, the first of does not count, turning into . The remaining part of BWT, that is, has runs: we start by concatenating each up to , which adds 2 runs each. The last does not add new runs, as it consists only of an that merges with the previous one. Altogether, we have , and the claim holds.
The main difference between
and
comes from
that is concatenated with
for
, which repeats
, while
repeats
only, making
more runs.
Table 10,
Table 11,
Table 12 and
Table 13 describe the scheme of the BWT of word
. We have
) =
. From Definition 1, we have
. Thus,
. □




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}