1. Introduction
In fluid mechanics, geophysics, biology, and many other fields, the partial differential equation (PDE) model serves as a crucial tool for characterizing various phenomena. Related problems encompass physical model building, the solution of partial differential equations, and parameter inversion. The process of solving a partial differential equation involves obtaining a spatially accurate solution or a numerical solution under the known partial differential equation and other constraints [
1,
2,
3,
4].
Traditional numerical solution methods for partial differential equations rely on a discrete scheme based finite difference systems, commonly referred to as the computational fluid dynamics (CFD) method. Examples include the Runge–Kutta method, the prediction correction method, the finite element method [
5], the finite difference method [
6], and the finite volume method [
7], among others. In contrast to traditional solving methods, neural networks exhibit distinct advantages in solving differential equations. Neural networks possess a powerful data fitting capacity, and even a small-scale neural network can handle simple partial differential equations [
8]. Employing the neural network approach to solve differential equations effectively addresses issues such as poor adaptability and conditional limitations of grid sections. Compared with traditional numerical methods, the neural network method requires fewer sampling points to achieve higher accuracy. Moreover, once a neural network model is trained, it can be directly utilized to calculate the numerical results at any point within the obtained domain. Starting in the 1990s, scholars initiated research on the mathematical foundations and methods of using neural networks to solve differential equations. In 1990, Hornik et al. [
9] demonstrated that under certain conditions, a multilayer neural network can approximate any function and its derivative, even when the function only has a generalized derivative. This finding laid the groundwork for neural network-based solutions to partial differential equations. In 1998, Lagaris and Likas [
10] put forward a method for solving the first boundary value problem using an artificial neural network (ANN). In 2011, Kumar and Yadav [
11] investigated multilayer neural network (MLP) and radial basis function neural network (RBF) models for solving differential equations and compared and summarized the applications of MLP and RBF in this regard. In 2018, Winovich et al. [
12] proposed a quantitative uncertainty convolutional neural network (ConvPDE-UQ) for the problem of heterogeneous elliptic partial differential equations on different domains. Also in 2018, Long and Dong et al. [
13,
14] introduced a novel feed-forward neural network (PDE-Net). Its core concept is to approximate the differential operator with a convolution kernel, construct a network to approximate the nonlinear partial differential equation system, and achieve long-term prediction of its solution. A convolutional network is essentially an input-to-output mapping capable of learning numerous mapping relationships between input and output without the need for any precise mathematical expressions between them. However, due to the increase in dimensions, the solution accuracy of the convolutional neural network model [
15] is slightly diminished. Most of the above-mentioned neural network-based methods for solving partial differential equations are focused on the initial boundary value problem. The network takes space coordinates or time variables as inputs and outputs the solution values in space. When constructing solutions by integrating partial differential equations with neural networks, the optimization objectives typically consist of two parts: the errors at the initial solution and boundary value sampling points and the errors at the sampling points within the domain subject to the differential equation constraints.
In addition, when we need to rapidly obtain accurate solutions for a set of partial differential equations, one approach we can adopt is the neuronal operator method. This method can be learned based on the mapping from the source-term function to the solution function of the partial differential equation set [
16].
Fourier transform holds a significant position in deep learning models. It aids in the proof of the universal approximation theorem [
17] and can also accelerate the training of convolutional neural networks [
18]. Keivan Alizadeh Vahid et al. [
19] proposed the extension of the butterfly operation in traditional fast Fourier transform and its application to the design of convolutional neural network architectures. They demonstrated that the computational complexity of the alternative network layer through butterfly transformation was reduced from
N to
. Experiments also confirmed that the proposed scheme effectively enhanced the model’s accuracy. Integrating Fourier transform into the neural network model can effectively decrease the model’s computational complexity. Moreover, the physical trends in the data can be effectively captured through Fourier transform, which offers great advantages for solving partial differential equations. Li [
20] proposed the neural operator method, which can be evaluated at any point in time and in any space. Additionally, a general approximation theorem for neural operators was summarized and proven. Li [
21] put forward the Fourier neural operator, where the integral operator operates directly in Fourier space through parameterization. Evidently, the neural operator approach is a fully data-driven method, necessitating a large number of high-quality datasets. However, in the analysis of complex physical, biological, or engineering systems, the cost of data acquisition is often prohibitively high. As a result, we inevitably encounter the challenge of drawing long-term conclusions with partial information, making these methods inefficient. Kushnure et al. [
22] proposed an architecture named MS U-Net for multi-scale feature representation and recalibration. This architecture uses the Res2Net module to retain the contextual information of segmented objects, and it squeezes and motivates the network to recalibrate multi-scale feature channels, thereby enhancing the network’s ability to describe high-level features. In the literature [
23], for the same data preprocessing process, the feature representations of each modality learned by the network are fused at later stages. In the last layer of convolution, a larger-scale feature map is connected to achieve the communication of contextual information between feature maps of different sizes.
This integration of multi-scale feature representation and recalibration mechanisms allows the network to better capture both local and global information, which is crucial for solving complex partial differential equations. By leveraging these advanced techniques, the model can achieve higher accuracy and efficiency in solving PDEs, even in scenarios where data are limited or incomplete.
In many applications in the fields of science and engineering, solving partial differential equations (PDEs) is a crucial task. The method of combining Fourier transform and neural operator recalibration provides a powerful framework for this task.
As one of the key technologies, Fourier transform can extract the information features in the frequency domain and accurately capture the key information of the equations. Meanwhile, convolutional neural networks can be used to extract the high-level internal features of the system. By adopting a connection-based mechanism to reduce the number of network layers, the relevant models can effectively solve PDEs from the global and internal characteristics of the system.
Take U-Net as an example. It extracts image features in the form of convolution, and its essence is to capture the changes in the image by calculating the derivatives of image pixels. In contrast, the Fourier neural operator calculates derivatives in the form of filter operators and achieves fast calculation with the help of convolution functions. By transforming the problem into the frequency domain, the Fourier operator can effectively capture the global features of the signal; reduce the impact of high-frequency noise; and, thus, improve the stability and accuracy of the solution [
24].
Compared with many existing hybrid modeling methods, such as the combination of deep learning and traditional numerical methods proposed by M, F and J [
25], they mainly rely on local modeling in the spatial domain and often ignore the globality of the frequency-domain features. Although this local modeling method is effective in some cases, when dealing with PDEs with complex boundary conditions and multi-scale features, it often encounters the dilemmas of low computational efficiency and insufficient accuracy.
The innovation of this study lies in combination of the powerful feature extraction ability of U-Net with the frequency-domain analysis ability of Fourier transform to construct a unified framework. Specifically, first, U-Net is used for local feature modeling in the spatial domain, which enhances the generalization ability of the network in dealing with nonlinear and high-dimensional problems. Subsequently, Fourier transform is used to convert the PDE into a frequency-domain representation to capture its global features and periodic information. This fusion strategy not only improves the solution efficiency but also significantly enhances the adaptability of the model in the face of complex physical phenomena.
Based on the above concepts, this study further proposes a U-Net neural network model based on the Fourier neural operator. This model uses multiple low-order constrained convolutional kernels to approximate high-order differential operators, thereby more accurately describing the properties of differential equations. In the model design, the feed-forward neural operator, as the core component, contains adjustable parameters that can be continuously optimized through training. This design not only improves the solution accuracy of the model but also provides support for long-term effective and stable numerical solutions.
3. Algorithm
3.1. Setting of Input Signal and Function Space
The input signal () serves as the key factor for a model to gather characteristic information, and its quality sets the upper limit of the model’s achievable accuracy. In this paper, we primarily consider two function spaces:
The Orthogonal (Chebyshev) Polynomial Component of the Gaussian Random Field (GRF) and the Gaussian Random Field (GRF).
Typically, we employ a zero-mean Gaussian random field, expressed as follows:
where the covariance function is the Gaussian kernel given by
The length scale (l) is of great significance, as it determines the smoothness of the sampling function. When the value of l is large, the resulting u function is smoother, which is of great importance in studying phenomena at different scales.
After selecting the function space, sampling needs to be carried out from this space. The specific approach is to scatter points within the specified region to obtain sample points. Subsequently, is integrated, and the resulting value is used as the input data of the model. By constructing the model in this way, an approximate solution (y) is obtained. To comprehensively evaluate the performance of the model, multiple different test sets (u) are generated by randomly selecting data so as to examine the performance of the model under different data distributions.
Gaussian random field with the radial-basis function kernel:
Suppose there is a stochastic process () that follows a specific Gaussian random-field distribution, that is, .
Then,
can be represented by the following integral form:
In the above expression,
W and
B are independent standard Brownian motions that introduce randomness to
. To further simplify the expression, variable substitution is carried out, applying the change of variable corresponding to
. After the transformation,
can be rewritten as follows:
The, linear interpolation (
) is applied on the interval of
where we recall the error estimate of the linear interpolation on
(according to Taylor’s expansion) as
where
lies in between
a and
b. Then, according to the Borel–Cantelli lemma, we have
where
C is an absolute value of a Gaussian random variable with a finite variance. Therefore, taking a piecewise linear interpolation of
with
m points leads to convergence of order
3.2. Structure Based on a U-Net Neural Network and Fourier Neural Operator
Theorem 1 (Universal approximation)
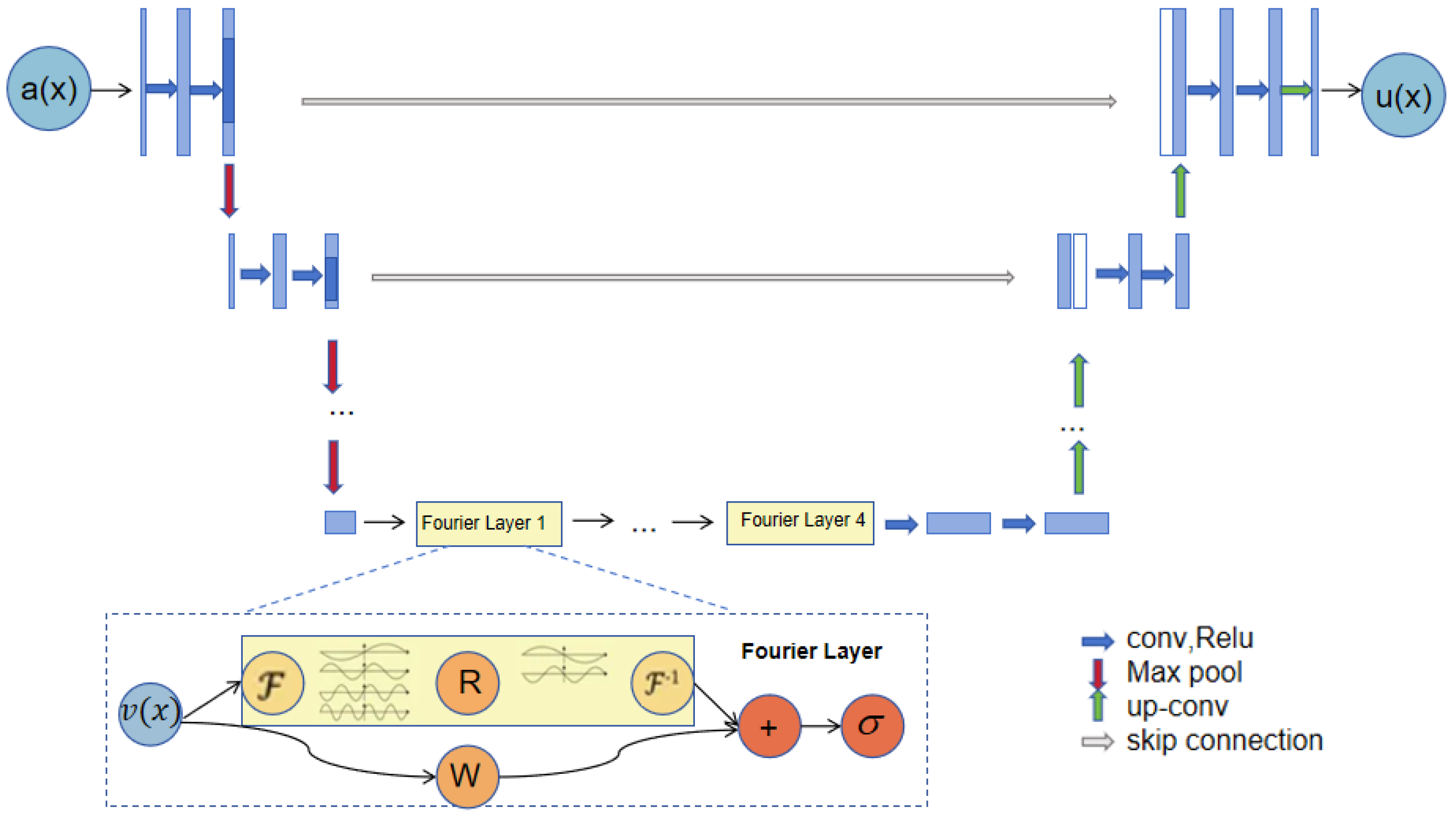
. Let . Consider as a continuous operator. Let be a compact subset. For any , there exists a UNO , continuous as an operator (), satisfying The U-Net neural network, as a classic deep learning architecture, has a unique structure. The first half is mainly responsible for feature extraction, while the second half focuses on the up-sampling operation. This structure is called the encoder–decoder structure. In this study, a Fourier neural operator with adjustable parameters is introduced As shown in the
Figure 1. By skillfully integrating the feature information extracted by the U-Net neural network into the Fourier operator, the operational efficiency and solution accuracy of the algorithm can be significantly improved.
Step 1: When constructing the algorithm framework,
P and
Q are defined to represent the left-contracting path and the right-expanding path of the U-Net neural network, respectively:
Among them, represents the number of channels used in the neural network. Usually, the value of is greater than or . In the actual operation, the left-contracting path (P) of U-Net is used to lift the input data to a high-dimensional channel space; then, the right-expanding path (Q) is used to project the data in the channel space to the final output space.
The left encoder network (P) has a structure similar to that of a convolutional neural network. The operation process of a given input function (a: ) includes two repeated convolution operations, a rectified linear unit (ReLU activation function), and a max-pooling layer. When performing the down-sampling operation, the algorithm’s step size is set to 2.
The convolutional layer is expressed as follows:
where
is a convolution operation,
W is the convolution kernel, and
b is bias.
ReLU activation functions:
Pooling layer: The maximum pooling layer is usually used to reduce the spatial dimension and help to obtain the features of the image:
The result is input a into the encoder (left-contracting path (P)) of the U-net neural network. Through convolution, ReLU activation function, and max-pooling layer operations, the input is lifted to the high-dimensional channel space ().
Step 2: Then, we introduce the nonlinear integral Fourier operator (
):
Four-layer integral operators and activation functions are applied to the obtained feature (
), which is updated specifically according to the following formula:
where
is an activation function and
is a linear transformation that can handle lower Fourier patterns and filter out higher patterns (
and
) into the nucleus (
to
), corresponding to something to learn from the data.
Step 3: The result (
) is, again, input into the U-Net neural network decoder (
Q), as well as deconvolution, jump connection, and other operations, helping to retain high-resolution details.
Similar to the encoder, the decoder also applies the convolution and activation functions to handle the feature graph.
The updated result is input into the decoder (right-expanding path (Q)) of the U-net neural network. It is processed through operations such as deconvolution and skip connection and finally output as .
Step 4: The final output results and the original sample are used to calculate the loss according to the loss function; finally, the loss function is used to optimize the U-Net network and the Fourier operator to obtain the optimal parameter value.
where
where
represents the initial and boundary training datasets. The loss term (
) corresponds to constraints imposed by the initial data and boundary data.
were the set expressed as
represents the collocation points for
, with the loss function (
) enforcing the structural constraints imposed by equations.
The parameters of the U-Net network and the Fourier operator are optimized by the loss function to obtain the best parameter values and minimize the loss.
- (a)
The complete structure of the neural operator: The entire operation process of the neural operator starts from input a. First, the input data are upgraded to a high-dimensional channel space through the U-Net encoder. Then, four layers of integral operators and activation functions are applied to deeply process the data. After that, the processed data are sent to the target dimension through the U-Net decoder; finally, u is output.
- (b)
Fourier layer: The operation of the Fourier layer starts from input . First, Fourier transform () is applied to transform the data into the frequency domain. Then, a linear transformation (R) is performed on the low-frequency signals to filter out the high-frequency signals. After that, inverse Fourier transform () is applied to transform the data back into the time domain. At the bottom, a local linear transformation (W) is also applied to further process the data.
Definition 1 (Fourier integraloperator (κ)L)
. Updates are made by defining the representation of as follows: The above formula can be seen as a combination of linear connections and nonlinear transformations and by the activation function. Nonlinear transformation () is implemented by a kernel integral operator: The selected kernel form is , formally similar to the convolution operation. Thus, it can be expressed by Fourier transform as follows: A parameter matrix () is introduced, which can transform the Fourier modes and filter out the higher modes. The Fourier neural operator is finally expressed as follows:where , , and are all in a function space. 4. Experiment
This section mainly uses the UNO model to solve the 1DBurgers equation, the 2DDarcy flow equation, and the 2D Navier–Stokes equation. First, we introduce the experimental configuration and the experimental parameter settings. Then, we explain the experimental effect. Finally, we solve the partial differential equation according to the model framework introduced and proposed in this chapter, comparing the merits of this model in solving partial differential equations. We obtain the solution speed, the solution result, and the error with the real solution of the model in the three equations.
4.1. Burgers Equation
In this paper, we choose the 1DBurgers equation, which is a nonlinear partial differential equation. The equations considered in this paper are formally expressed as follows:
where
is the unknown function, which depends on the time variable (
t) and the spatial variable (
x);
is the viscosity coefficient; the initial condition is
; and the boundary condition is the periodic boundary condition.
is randomly sampled, , modes = 16, width = 64, and batch size = 20. The forced term = 0, the viscosity coefficient is , the grid is , and other grids are directly subsampled. The network input is , the output is , we have 8192 in 2048 grid samples with average sampling, neural network input dimensions of (20, 128, 2), and input neural operator dimensions of (20, 128, 64). The accuracy of the equation label determines the model accuracy; if the label accuracy is poor, the model has no sense.
The approximate solution is
u, and the true solution is uacc, with an error of
,
. The solver is a GPU, the error is
, and a training label of G is an approximate solution.
It is expected that any f = net (x, y) has G (f, x, y) satisfying the solution constraint regularization of the corresponding PDE.
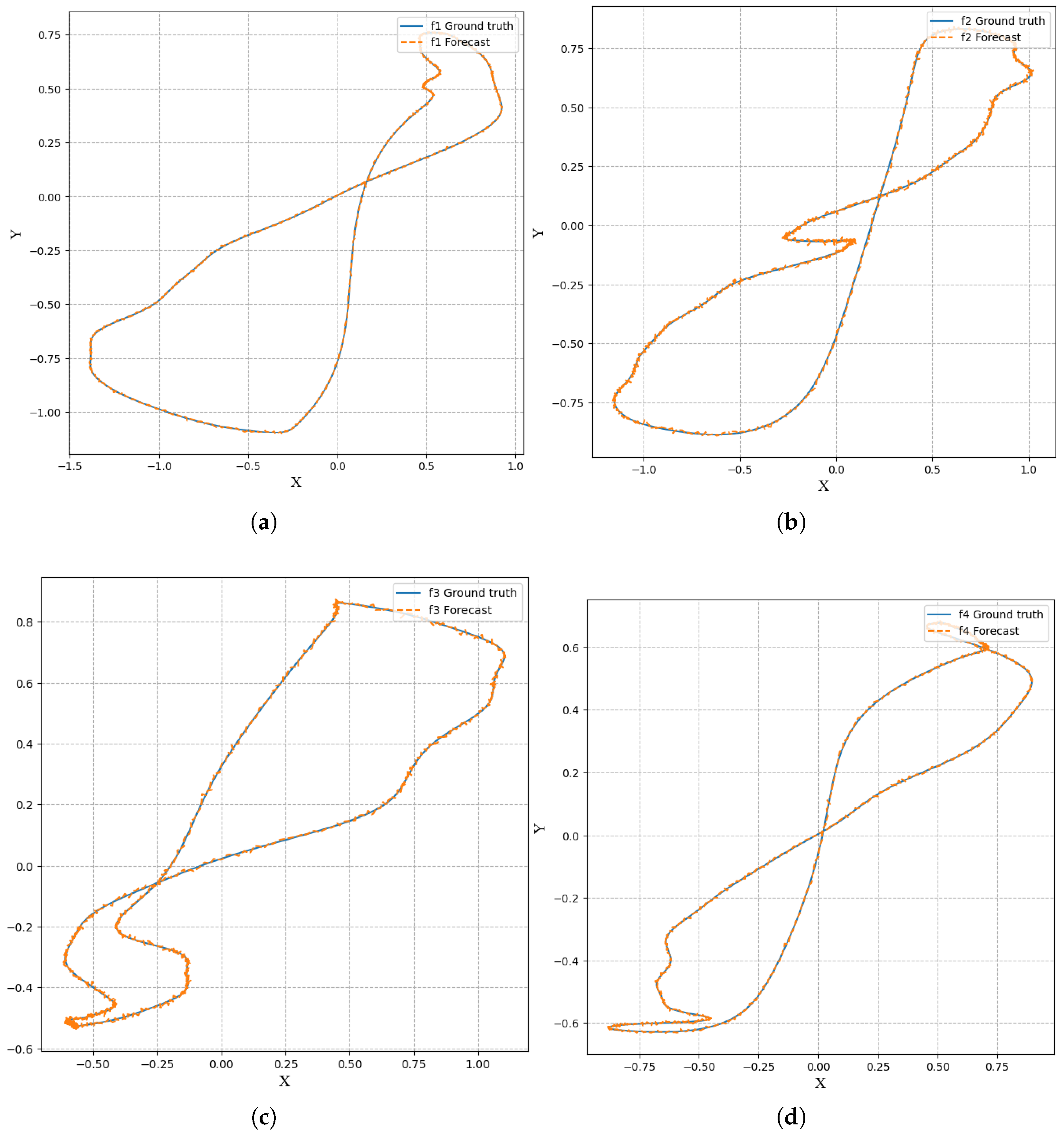
Figure 2 randomly intercepts several algorithm results from different periods, showing the error between the prediction and the true value of the algorithm, without much change to the naked eye and a good visualization effect.
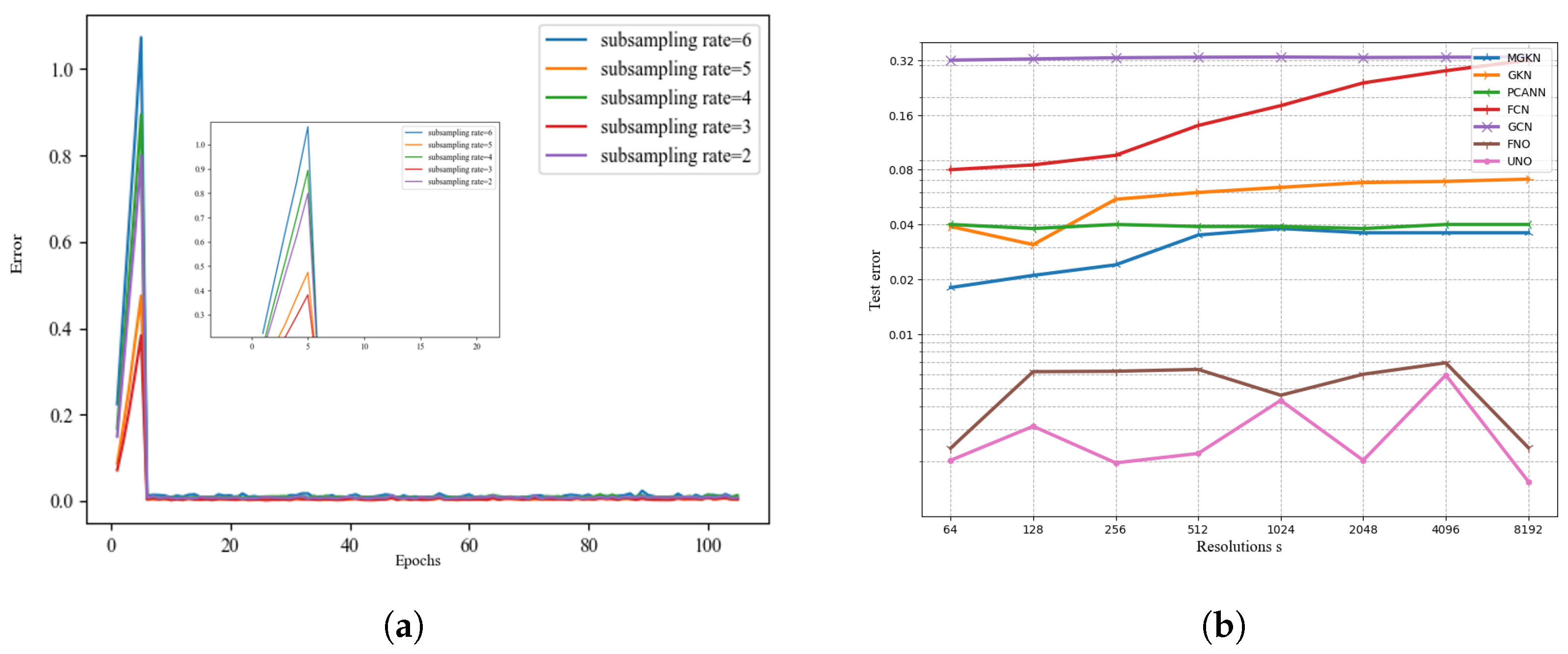
Figure 3 compares the errors as the number of iterations increases when the subsampling rate varies. We can see that when the subsampling rate is 3 and 5, the error is minimized and the algorithm is better than in other cases. It can be seen from the algorithm comparison diagram on the right of
Figure 3 and
Table 1 that the different algorithms exhibit the ability to solve the partial differential equations in the one-dimensional Burgers equation experiment. The UNO model uses convolution to extract physical feature information. The jump connection reduces the information loss of the model. The results are more accurate than those achieved by other algorithms.
4.2. Darcy Flow
In this paper, we choose the steady-state 2DDarcy flow equation as a second-order linear elliptic partial differential equation:
where the boundary condition is the Dirichlet boundary condition,
a is the diffusion coefficient,
,
is the solution, and the external force is
.
We processed the dataset as follows: first, is a probability measure with zero Neumann boundary conditions on LaPraaca, where and . The external force is fixed to be . The coefficient () was sampled from , and the solution (u) was obtained using the traditional finite element method on the and grids in Matlab. Datasets with different resolutions can be generated by downsampling. We parameterized a two-dimensional Fourier neural operator consisting of four Fourier layers with 20 frequencies per channel and width = 64.
The loss function can be written in the following form:
In the experimental section, the FNO model, ResNet model, TFNET model, and UNO model were used to solve the 2DDarcy flow equation.
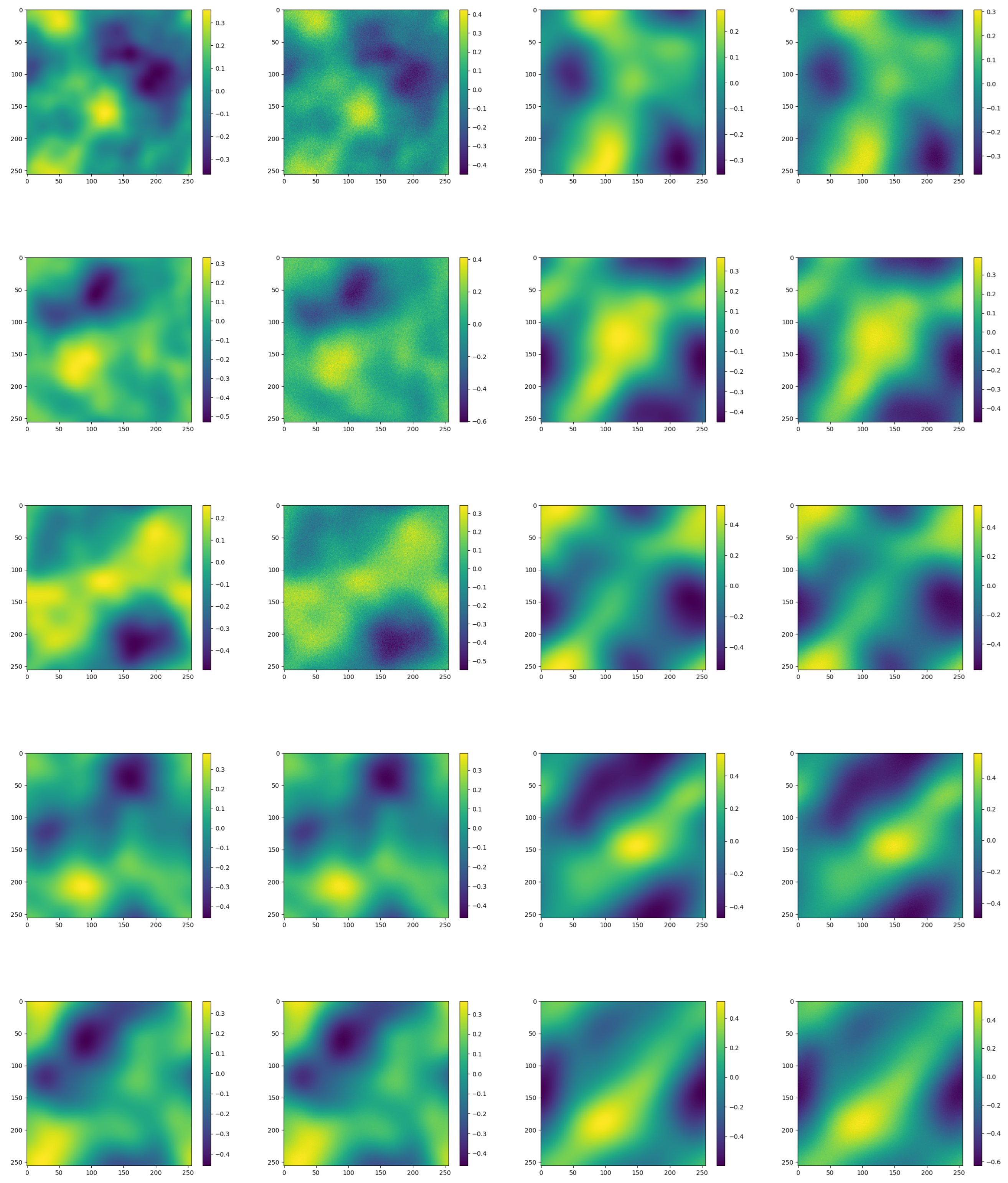
The true and model solutions of the equations and their errors are shown in
Figure 4.
Figure 4 shows the contrast between the true and predicted values from 1 s to 5 s and the error situation per second.
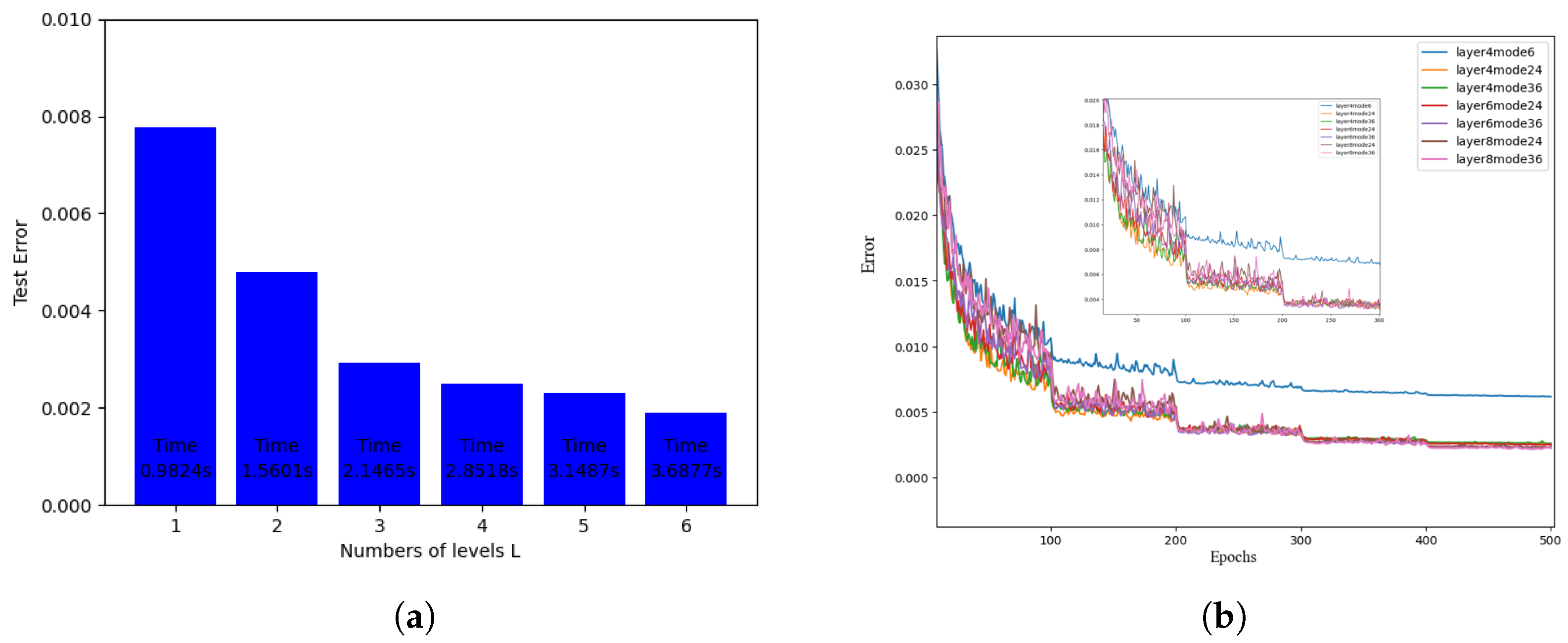
Figure 5 (left) shows that the number of Fourier neural operator layers varies. When the number of Fourier neural operator layers is 1, it takes the least time and the test error is the largest. When the number of levels increases, the duration increases, but the test error is reduced. Three, four, or five layers are most reasonable, depending on the situation. Here, we consider a four-layer Fourier operator. The right image introduces the effect of different numbers of Fourier neural operator layers and the filtered models on the algorithm error as the number of iterations increases. As the number of iterations increases, the error becomes smaller. For the four-layer Fourier neural operator with 24 filtered-out models, the effect is better, and the performance is better. Then, the algorithm model selects the four-layer Fourier neural operator.
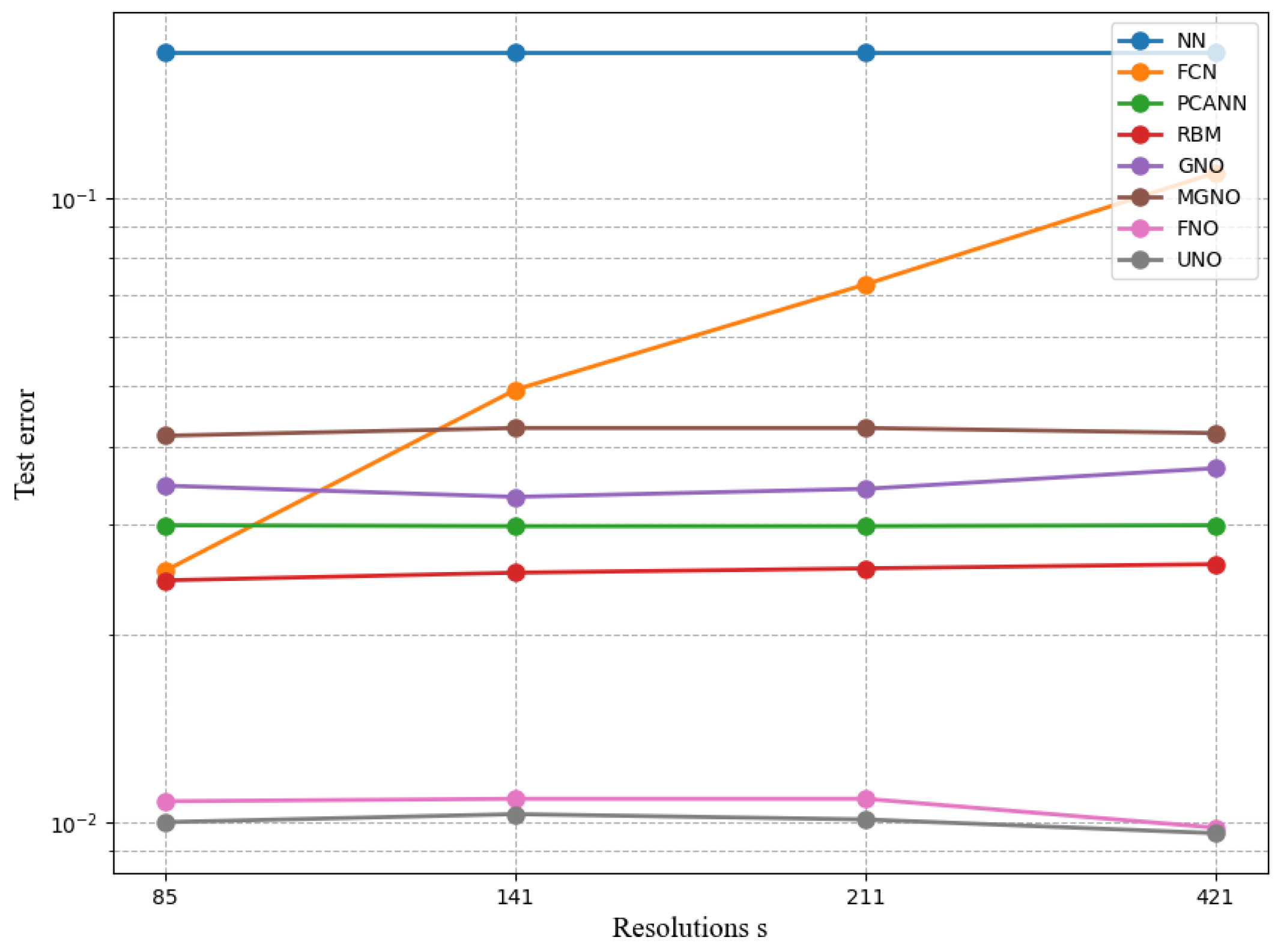
It can be seen from
Figure 6 and
Table 2 that when different algorithms contrast error maps at resolutions of
,
,
, and
, UNO has lower and more stable error loss values compared to the most similar FNO algorithm.
4.3. Navier–Stokes Equation
In this paper, the incompressible fluid equation of motion, namely the two-dimensional Navier–Stokes equation is chosen for experiments. The equation used in this paper is expressed as follows:
where
is the fluid velocity; ∇ represents the gradient operator;
represents the initial condition, namely the initial vorticity;
represents the viscosity coefficient; and
for the external force acting on the fluid. This article sets the external force to
.
The experimental scenario is the vorticity form of the sticky, non-compresable NS equation in two dimensions. The vorticity field is simplified by directing on x and y to obtain the velocity field (u) and v using the NS equation. Using the vorticity equation as the loss function, the output layer of the neural network needs a neuron to represent w, and the automatic differentiation only needs to guide this one variable, which is often less difficult to optimize. This scenario inputs the vorticity field variable at time t at [0, 10) to the FNO model, with resolutions of and , that is, to generate the dataset, the initial vorticity condition () is sampled randomly from the distribution of , with periodic boundary conditions. The input variable dimensions are [64, 64, 10] and [256, 256, 10]. It is hoped that the FNO model can output the value of the vorticity field at time , that is, learn the evolution relationship of the vorticity time series and realize a model similar to the time-series prediction.
The loss functions are defined as follows:
Figure 7 shows images of true and predicted values from 1 s to 10 s, from top to bottom. As can be seen from the image comparison per second, the visualization results are relatively consistent, with minimal error.
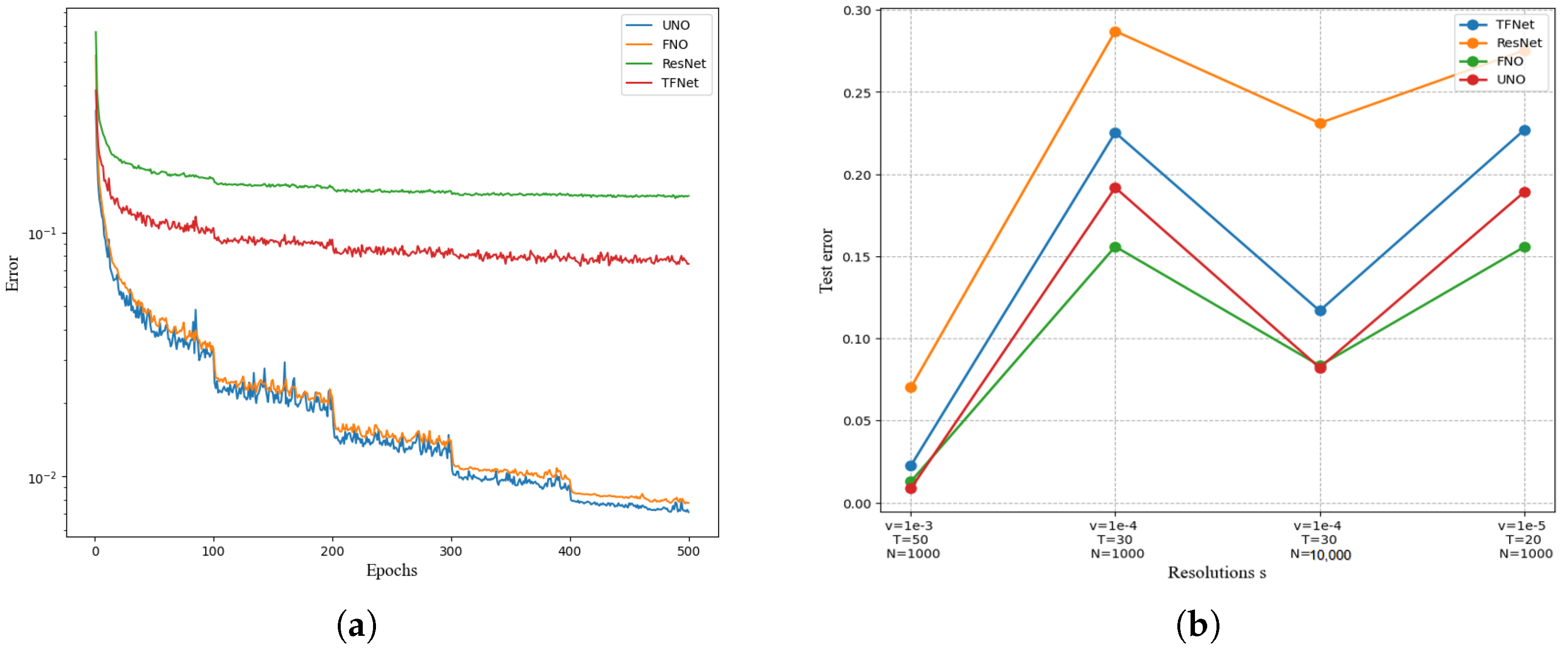
As shown in
Figure 8, FNO and UNO achieve the best results. By comparing time and data points, suitable algorithms are selected. The errors of the UNO and FNO algorithms continue to decrease steadily with the number of iterations, with great advantages compared with other models. The error of the UNO algorithm drops faster, with an obvious decreasing process at 100, 200, 300, and 400, showing a continuous jitter decreasing trend, with obvious advantages in solving the equation. The RENET and TFNET models are less effective, and compared with UNO and FNO, the curves are relatively smooth and the errors are larger during iteration.
Figure 8 and
Table 3 also compares the experimental errors of UNO and FNO, RENET, and TFNET on the dataset. The figure shows N = 10,000 data points and T = 50. When the viscosity coefficient is
, the UNO error is the smallest, and UNO has higher accuracy. When the number of data points is N = 1000, UNO is worse than FNO, but when the number of data points increases to N = 10,000, the UNO error is the lowest among the compared algorithms, and 400.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}