


Open-Loop Wavefront Reconstruction with Pyramidal Sensors Using Convolutional Neural Networks

 , , , , , , and
, , , , , , and
Abstract
1. Introduction
2. Materials and Methods
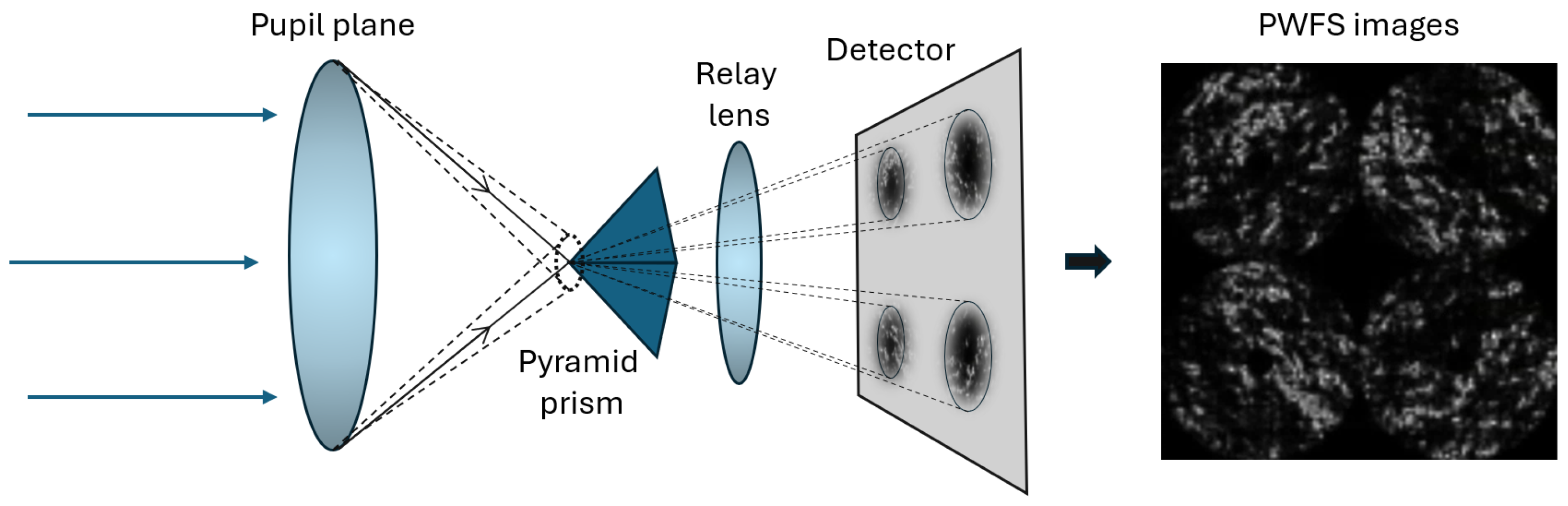
2.1. Adaptive Optics
2.2. Wavefront Error
2.3. Neural Networks
3. Experiments
3.1. Error Reduction Using Convolutional Neural Networks
3.2. Stability Experiments
- Fried parameter : It represents the characteristic size of a circular aperture within which atmospheric turbulence causes phase fluctuations of less than one radian. It can also be interpreted as the intensity or strength of the turbulence, where a lower value corresponds to stronger turbulence (leading to a more complex profile) and a higher value corresponds to weaker turbulence. During the training phase, data was used over a range of to ; consequently, for this evaluation, the chosen values were 0.04, 0.08, 0.12, and 0.16.
- Multi-layered turbulence: By overlaying multiple turbulence layers, each with specific parameters such as altitude, wind speed, the Fried parameter (), and a relative weight for each layer, an atmosphere with turbulent structures at different levels can be modeled. Each layer contributes differently to the resulting optical distortions. This approach allows for the analysis of more realistic scenarios and the evaluation of the performance of these models as atmospheric complexity increases. Although the training data only consider a single layer, previous studies such as [34,35] have demonstrated that good results can be achieved for multi-layer settings under these conditions. In this experiment, selected cases with one, two, four, and eight layers were compared.
- Wind speed: In real-world environments, where atmospheric conditions can change rapidly, this parameter is critical, as wind speed directly affects the dynamics of optical aberrations by determining how turbulent structures move across the telescope aperture. The accuracy of reconstruction, especially under high wind conditions, where temporal aliasing and reconstruction errors can increase significantly, can be considerably degraded. This approach makes sure the system remains robust against variations in wind speed. During training, a fixed wind speed of 12.6 m/s was considered, while this test experiment involves turbulent profiles with wind speeds ranging from 5 to 17.5 m/s, in steps of 2.5 m/s.
3.3. Prediction Time Evaluation
4. Results
4.1. Error Reduction Using Convolutional Neural Networks
4.2. Stability Experiments
4.3. Prediction Time Evaluation
4.4. Results Overview
5. Conclusions and Future Research Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Babcock, H.W. The possibility of compensating astronomical seeing. Publ. Astron. Soc. Pac. 1953, 65, 229. [Google Scholar] [CrossRef]
- Hardy, J.W.; Lefebvre, J.E.; Koliopoulos, C.L. Real-time atmospheric compensation. J. Opt. Soc. Am. 1977, 67, 360–369. [Google Scholar] [CrossRef]
- Kern, P.; Merkle, F.; Gaffard, J.P.; Rousset, G.; Fontanella, J.C.; Lena, P. Prototype Of An Adaptive Optical System For Astronomical Observation. In Proceedings of the Real-Time Image Processing: Concepts and Technologies, Cannes, France, 4–6 November 1988; Besson, J., Ed.; International Society for Optics and Photonics. SPIE: San Francisco, CA, USA, 1988; Volume 0860, pp. 9–15. [Google Scholar] [CrossRef]
- Beckers, J.M. Increasing the Size of the Isoplanatic Patch with Multiconjugate Adaptive Optics. In Proceedings of the Very Large Telescopes and their Instrumentation, Garching, Germany, 21–24 March 1988; European Southern Observatory Conference and Workshop Proceedings. Ulrich, M.H., Ed.; Volume 30, p. 693. [Google Scholar]
- Lamb, M.; Venn, K.; Andersen, D.; Oya, S.; Shetrone, M.; Fattahi, A.; Howes, L.; Asplund, M.; Lardière, O.; Akiyama, M.; et al. Using the multi-object adaptive optics demonstrator RAVEN to observe metal-poor stars in and towards the Galactic Centre. Mon. Not. R. Astron. Soc. 2016, 465, 3536–3557. [Google Scholar] [CrossRef]
- Hippler, S.; Feldt, M.; Bertram, T.; Brandner, W.; Cantalloube, F.; Carlomagno, B.; Absil, O.; Obereder, A.; Shatokhina, I.; Stuik, R. Single conjugate adaptive optics for the ELT instrument METIS. Exp. Astron. 2018, 47, 65–105. [Google Scholar] [CrossRef]
- Platt, B.C.; Shack, R. History and principles of Shack-Hartmann wavefront sensing. J. Refract. Surg. 2001, 17, S573–S577. [Google Scholar]
- Ragazzoni, R. Pupil plane wavefront sensing with an oscillating prism. J. Mod. Opt. 1996, 43, 289–293. [Google Scholar] [CrossRef]
- Arcidiacono, C.; Chen, X.; Yan, Z.; Zheng, L.; Agapito, G.; Wang, C.; Zhu, N.; Zhu, L.; Cai, J.; Tang, Z. Sparse aperture differential piston measurements using the pyramid wave-front sensor. In Proceedings of the Adaptive Optics Systems V, Edinburgh, UK, 26 June–1 July 2016; Marchetti, E., Close, L.M., Véran, J.P., Eds.; SPIE: San Francisco, CA, USA, 2016; Volume 9909, p. 99096K. [Google Scholar] [CrossRef]
- Agapito, G.; Pinna, E.; Esposito, S.; Heritier, C.T.; Oberti, S. Non-modulated pyramid wavefront sensor: Use in sensing and correcting atmospheric turbulence. Astron. Astrophys. 2023, 677, A168. [Google Scholar] [CrossRef]
- Archinuk, F.; Hafeez, R.; Fabbro, S.; Teimoorinia, H.; Véran, J.P. Mitigating the Non-Linearities in a Pyramid Wavefront Sensor. arXiv 2023, arXiv:2305.09805. [Google Scholar] [CrossRef]
- Hafeez, R.; Archinuk, F.; Fabbro, S.; Teimoorinia, H.; Véran, J.P. Forecasting Wavefront Corrections in an Adaptive Optics System. arXiv 2022, arXiv:2112.01437. [Google Scholar] [CrossRef]
- Landman, R.; Haffert, S.Y.; Radhakrishnan, V.M.; Keller, C.U. Self-optimizing adaptive optics control with Reinforcement Learning for high-contrast imaging. arXiv 2021, arXiv:2108.11332. [Google Scholar] [CrossRef]
- Nousiainen, J.; Rajani, C.; Kasper, M.; Helin, T.; Haffert, S.Y.; Vérinaud, C.; Males, J.R.; Van Gorkom, K.; Close, L.M.; Long, J.D.; et al. Toward on-sky adaptive optics control using reinforcement learning: Model-based policy optimization for adaptive optics. Astron. Astrophys. 2022, 664, A71. [Google Scholar] [CrossRef]
- Suárez Gómez, S.L.; García Riesgo, F.; González Gutiérrez, C.; Rodríguez Ramos, L.F.; Santos, J.D. Defocused Image Deep Learning Designed for Wavefront Reconstruction in Tomographic Pupil Image Sensors. Mathematics 2021, 9, 15. [Google Scholar] [CrossRef]
- Wong, A.P.; Norris, B.R.M.; Deo, V.; Tuthill, P.G.; Scalzo, R.; Sweeney, D.; Ahn, K.; Lozi, J.; Vievard, S.; Guyon, O. Nonlinear Wave Front Reconstruction from a Pyramid Sensor using Neural Networks. Publ. Astron. Soc. Pac. 2023, 135, 114501. [Google Scholar] [CrossRef]
- Ma, H.; Liu, H.; Qiao, Y.; Li, X.; Zhang, W. Numerical study of adaptive optics compensation based on Convolutional Neural Networks. Opt. Commun. 2019, 433, 283–289. [Google Scholar] [CrossRef]
- Swanson, R.; Lamb, M.; Correia, C.M.; Sivanandam, S.; Kutulakos, K. Closed loop predictive control of adaptive optics systems with convolutional neural networks. Mon. Not. R. Astron. Soc. 2021, 503, 2944–2954. [Google Scholar] [CrossRef]
- Freeman, R.H.; Pearson, J.E. Deformable mirrors for all seasons and reasons. Appl. Opt. 1982, 21, 580–588. [Google Scholar] [CrossRef]
- Zilberman, A.; Golbraikh, E.; Kopeika, N.; Virtser, A.; Kupershmidt, I.; Shtemler, Y. Lidar study of aerosol turbulence characteristics in the troposphere: Kolmogorov and non-Kolmogorov turbulence. Atmos. Res. 2008, 88, 66–77. [Google Scholar] [CrossRef]
- Hufnagel, R. Propagation through atmospheric turbulence. In The Infrared Handbook; USGPO: Washington, DC, USA, 1974; Chapter 6. [Google Scholar]
- Dutton, J.A. Dynamics of Atmospheric Motion: (Formerly the Ceaseless Wind); Dover: New York, NY, USA, 1995. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef]
- Hinton, G.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 15 September 2024).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Swanson, R.; Lamb, M.; Correia, C.; Sivanandam, S.; Kutulakos, K. Wavefront reconstruction and prediction with convolutional neural networks. In Proceedings of the Adaptive Optics Systems VI, Austin, TX, USA, 10–15 June 2018; Close, L.M., Schreiber, L., Schmidt, D., Eds.; International Society for Optics and Photonics. SPIE: San Francisco, CA, USA, 2018; Volume 10703, p. 107031F. [Google Scholar] [CrossRef]
- Landman, R.; Haffert, S.Y. Nonlinear wavefront reconstruction with convolutional neural networks for Fourier-based wavefront sensors. Opt. Express 2020, 28, 16644–16657. [Google Scholar] [CrossRef] [PubMed]
- Basden, A.; Bharmal, N.; Jenkins, D.; Morris, T.; Osborn, J.; Jia, P.; Staykov, L. The Durham Adaptive Optics Simulation Platform (DASP): Current status. arXiv 2018, arXiv:1802.08503. [Google Scholar] [CrossRef]
- Lozi, J.; Guyon, O.; Jovanovic, N.; Goebel, S.; Pathak, P.; Skaf, N.; Sahoo, A.; Norris, B.; Martinache, F.; M’Diaye, M.; et al. SCExAO, an instrument with a dual purpose: Perform cutting-edge science and develop new technologies. In Proceedings of the Adaptive Optics Systems VI, Austin, TX, USA, 10–15 June 2018; Schmidt, D., Schreiber, L., Close, L.M., Eds.; SPIE: San Francisco, CA, USA, 2018; p. 270. [Google Scholar] [CrossRef]
- Assémat, F.; Wilson, R.W.; Gendron, E. Method for simulating infinitely long and non stationary phase screens with optimized memory storage. Opt. Express 2006, 14, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Momeny, M.; Latif, A.M.; Agha Sarram, M.; Sheikhpour, R.; Zhang, Y.D. A noise robust convolutional neural network for image classification. Results Eng. 2021, 10, 100225. [Google Scholar] [CrossRef]
- Pérez, S.; Buendía, A.; González, C.; Rodríguez, J.; Iglesias, S.; Fernández, J.; De Cos, F.J. Enhancing Open-Loop Wavefront Prediction in Adaptive Optics through 2D-LSTM Neural Network Implementation. Photonics 2024, 11, 240. [Google Scholar] [CrossRef]
- Liu, X.; Morris, T.; Saunter, C.; de Cos Juez, F.J.; González-Gutiérrez, C.; Bardou, L. Wavefront prediction using artificial neural networks for open-loop adaptive optics. Mon. Not. R. Astron. Soc. 2020, 496, 456–464. [Google Scholar] [CrossRef]
- Sabne, A. XLA: Compiling Machine Learning for Peak Performance. 2020. Available online: https://research.google/pubs/xla-compiling-machine-learning-for-peak-performance/ (accessed on 15 September 2024).
- Ash, J.T.; Adams, R.P. On Warm-Starting Neural Network Training. arXiv 2020, arXiv:1910.08475. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Parameter | Value |
|---|---|---|
| System | Frequency | 150 Hz |
| Gain | 1 | |
| Atmosphere | No. phase screens | 1 |
| Wind speeds | 12.6 m/s | |
| Wind direction | 0–360° | |
| Screen height | Steps of 200 m up to 15,000 m | |
| 750 nm | Steps of 0.002 m, from 0.08 up to 0.16 m | |
| 20 m | ||
| Telescope | Diameter | 8.2 m |
| Central obscuration | 1.2 m | |
| PWFS | Resolution | pixels |
| Readout noise | 1 RMS | |
| Photon noise | True | |
| Wavelength | 750 nm |
| Layer | Input Shape | Output Shape | Parameters |
|---|---|---|---|
| Dense (Input) | (14,400) | (3000) | 43,203,000 |
| BatchNormalization | (3000) | (3000) | 12,000 |
| Dense | (3000) | (2000) | 6,002,000 |
| BatchNormalization | (2000) | (2000) | 8000 |
| Dense | (2000) | (1000) | 2,001,000 |
| BatchNormalization | (1000) | (1000) | 4000 |
| Dense (Output) | (1000) | (99) | 99,099 |
| Layer | Input Shape | Output Shape | Parameters |
|---|---|---|---|
| Conv2D (Input) | (120, 120, 1) | (120, 120, 32) | 544 |
| AveragePooling2D | (120, 120, 32) | (60, 60, 32) | 0 |
| Conv2D | (60, 60, 32) | (60, 60, 64) | 32,832 |
| AveragePooling2D | (60, 60, 64) | (30, 30, 64) | 0 |
| Conv2D | (30, 30, 64) | (30, 30, 128) | 131,200 |
| AveragePooling2D | (60, 60, 128) | (15, 15, 128) | 0 |
| Conv2D | (15, 15, 128) | (15, 15, 256) | 524,544 |
| AveragePooling2D | (15, 15, 256) | (5, 5, 256) | 0 |
| Conv2D | (5, 5, 256) | (5, 5, 512) | 2,097,664 |
| Flatten | (5, 5, 12) | (12,800) | 0 |
| Dense | (12,800) | (1024) | 13,108,224 |
| Dense | (1024) | (1024) | 1,049,600 |
| Dense (Output) | (1024) | (99) | 99,099 |
| Method | Std. Dev. | 95% CI Lower | 95% CI Upper |
|---|---|---|---|
| MVM | 0.0025 | 0.522 | 0.526 |
| Original NN | 0.0014 | 0.346 | 0.350 |
| CNN | 0.0005 | 0.219 | 0.221 |
| CNN (WFE Loss) | 0.0007 | 0.208 | 0.210 |
| Model | Prediction Time |
|---|---|
| Original NN | 18.77 ms |
| CNN | 14.10 ms |
| CNN (WFE Loss) | 12.74 ms |
| Layer | Input Shape | Output Shape | Parameters | |
|---|---|---|---|---|
| Graphic Card | TFLOPS | Tensor Core Generation | Tokens/s | Prediction Time |
| RTX 2080 Ti | 26.90 | 2nd | 96 | 12.74 ms |
| RTX 3080 Ti | 34.10 | 3rd | 192 | 8–11 ms |
| RTX 4090 | 82.58 | 4th | 226 | 3–6 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez-Fernández, S.; Buendía-Roca, A.; González-Gutiérrez, C.; García-Riesgo, F.; Rodríguez-Rodríguez, J.; Iglesias-Alvarez, S.; Fernández-Díaz, J.; Iglesias-Rodríguez, F.J. Open-Loop Wavefront Reconstruction with Pyramidal Sensors Using Convolutional Neural Networks. Mathematics 2025, 13, 1028. https://doi.org/10.3390/math13071028
Pérez-Fernández S, Buendía-Roca A, González-Gutiérrez C, García-Riesgo F, Rodríguez-Rodríguez J, Iglesias-Alvarez S, Fernández-Díaz J, Iglesias-Rodríguez FJ. Open-Loop Wavefront Reconstruction with Pyramidal Sensors Using Convolutional Neural Networks. Mathematics. 2025; 13(7):1028. https://doi.org/10.3390/math13071028
Chicago/Turabian StylePérez-Fernández, Saúl, Alejandro Buendía-Roca, Carlos González-Gutiérrez, Francisco García-Riesgo, Javier Rodríguez-Rodríguez, Santiago Iglesias-Alvarez, Julia Fernández-Díaz, and Francisco Javier Iglesias-Rodríguez. 2025. "Open-Loop Wavefront Reconstruction with Pyramidal Sensors Using Convolutional Neural Networks" Mathematics 13, no. 7: 1028. https://doi.org/10.3390/math13071028
APA StylePérez-Fernández, S., Buendía-Roca, A., González-Gutiérrez, C., García-Riesgo, F., Rodríguez-Rodríguez, J., Iglesias-Alvarez, S., Fernández-Díaz, J., & Iglesias-Rodríguez, F. J. (2025). Open-Loop Wavefront Reconstruction with Pyramidal Sensors Using Convolutional Neural Networks. Mathematics, 13(7), 1028. https://doi.org/10.3390/math13071028