Abstract
Encrypted traffic classification is crucial for network security and management, enabling applications like QoS control and malware detection. However, the emergence of new encryption protocols, particularly TLS 1.3, poses challenges for traditional methods. To address this, we propose CLA-BERT, which integrates packet-level and byte-level features. Unlike existing methods, CLA-BERT efficiently fuses these features using a multi-head attention mechanism, enhancing accuracy and robustness. It leverages BERT for packet-level feature extraction, while CNN and BiLSTM capture local and global dependencies in byte-level features. Experimental results show that CLA-BERT is highly robust in small-sample scenarios, achieving F1 scores of 93.51%, 94.79%, 97.10%, 97.78%, and 98.09% under varying data sizes. Moreover, CLA-BERT demonstrates outstanding performance across three encrypted traffic classification tasks, attaining F1 scores of 99.02%, 99.49%, and 97.78% for VPN service classification, VPN application classification, and TLS 1.3 application classification, respectively. Notably, in TLS 1.3 classification, it surpasses state-of-the-art methods with a 0.47% improvement in F1 score. These results confirm CLA-bert’s effectiveness and generalization capability, making it well-suited for encrypted traffic classification.
MSC:
68P25
1. Introduction
Traffic classification refers to the process of categorizing network traffic into different types or applications based on the features of network packets. This technology has been widely applied in various domains, including Quality of Service (QoS) control, pricing, resource planning for network service providers, as well as malware detection and intrusion detection [1,2]. Due to the growing demand for privacy and security from users and businesses, an increasing number of online applications are adopting encryption protocols (such as SSL/TLS) to protect data. According to the Google Internet Transparency Report of January 2025 [3], over 97% of internet traffic is currently encrypted via HTTPS. These encryption protocols offer privacy protection to users but also pose greater challenges and difficulties in traffic analysis and classification. Moreover, some malicious actors exploit encryption technologies for illegal activities, which not only disrupt the stability of cyberspace but also present significant threats to national security [4]. Therefore, to address new environments or unknown encryption strategies, capturing effective features from diverse encrypted traffic and supporting accurate and generalizable traffic classification is crucial for achieving network security and efficient management [5,6].
With the evolution of network technologies and the growing demand for application requirements, significant progress has been made in network traffic classification techniques. Researchers have proposed various solutions and frameworks to meet the diverse classification needs. The earliest solution was based on port numbers to classify traffic by identifying specific port numbers to distinguish between traffic types [2]. However, with the widespread use of port randomization and obfuscation techniques, the accuracy of this method has gradually declined, making it unsuitable for complex application scenarios. Nevertheless, port-based classification methods, due to their simplicity and low computational cost, are still used as auxiliary means in some encrypted traffic classification systems. To address the limitations of port-based classification, methods based on Deep Packet Inspection (DPI) have been proposed [7]. DPI technology performs precise traffic classification by matching patterns or keywords within data packets, effectively identifying unencrypted traffic. However, due to its heavy reliance on plaintext data, this method has gradually lost its effectiveness in the increasingly encrypted network environment.
In recent years, with the rapid development of machine learning and deep learning technologies, these methods have been widely applied to network traffic classification tasks, leading to new research directions [8]. Current mainstream encrypted traffic classification methods can be divided into two categories: machine learning methods based on statistical features and deep learning methods based on self-learned features. Machine learning methods based on statistical features design traffic statistical features manually and train classification models, making them suitable for encrypted traffic classification. However, their performance often depends on the quality of feature design and has limited generalization ability. In contrast, deep learning methods based on self-learned features, such as convolutional neural networks (CNN), can automatically extract features directly from raw traffic data, eliminating the reliance on manually designed features [9]. These methods show significant advantages in feature extraction capability, but the performance of deep learning models heavily relies on the quantity and distribution of labeled data, which can lead to biased features being learned by the model.
How to obtain unbiased and generalizable features from a large amount of unlabeled data has become a key research issue. In this context, a significant breakthrough in the field of natural language processing is the Bidirectional Encoder Representations from Transformers (BERT), proposed by the Google AI Language Team [10]. BERT learns universal features from large-scale unlabeled data through pre-training and fine-tunes with a small amount of labeled data, significantly improving the model’s generalization performance. This technology has recently been introduced into the field of encrypted traffic classification [6,11,12], achieving good results. However, most existing BERT-based encrypted traffic classification methods primarily focus on packet-level features (the overall structure of traffic) and make limited use of byte-level features (which focus on the byte sequences within each packet and the dependencies between bytes). For instance, methods like PERT [11] and ET-BERT [6] rely solely on the packet-level features extracted by BERT for classification without fully exploiting the underlying structural information of the traffic data. This approach performs poorly when facing new encrypted traffic classification tasks, especially when there is a significant distribution shift between the pre-trained data and fine-tuned data.
Therefore, how to combine packet-level features and byte-level features to fully explore the deep characteristics of data packets has become an urgent research direction in the field of encrypted traffic classification. To address this issue, in this paper, we propose the CLA-BERT model to overcome the limitations of previous pre-trained models in encrypted traffic classification. We implement the following strategies: first, the BERT model is used to extract the packet-level feature vector representation of the traffic; then, by combining convolutional neural networks (CNN) and Bidirectional Long Short-Term Memory networks (BiLSTM), we can capture both the local features and global dependencies of byte-level traffic features; finally, a multi-head attention mechanism is employed to fuse the packet-level feature vector and byte-level feature vector into the final traffic feature representation. This makes the feature representation more comprehensive and improves the classification performance, as demonstrated by experiments.
The main contributions of this paper are summarized as follows:
- A novel encrypted traffic classification model, CLA-BERT, is proposed. By combining packet-level and byte-level features, the model effectively extracts multi-layered information from encrypted traffic, significantly improving classification performance. Compared to existing methods, CLA-BERT demonstrates stronger expressiveness and accuracy when handling complex encrypted traffic.
- Small-sample experiments validate the robustness of CLA-BERT in data-scarce scenarios. Under different data volume conditions (5%, 10%, 30%, 50%, 70%), the F1 scores of CLA-BERT are 93.51%, 94.79%, 97.10%, 97.78%, and 98.09%, respectively. This result indicates that CLA-BERT can maintain highly stable classification performance with small datasets, overcoming the performance bottleneck of traditional models in small-sample scenarios.
- CLA-BERT demonstrates strong generalization ability in cross-task scenarios, achieving F1 scores of 99.02%, 99.49%, and 97.78% in VPN encryption service classification, VPN encryption application classification, and TLS 1.3 encryption application classification tasks, respectively. This indicates its strong adaptability across different encrypted traffic classification tasks. However, the performance of CLA-BERT heavily relies on the parameters of the pre-trained model. Future research could further optimize adversarial training strategies to improve the model’s robustness in environments with distribution shifts while also exploring more efficient domain adaptation methods to further enhance the model’s robustness and applicability in cross-task scenarios.
2. Related Work
2.1. Encrypted Traffic Classification Methods
With the rapid development of the internet and the widespread use of encryption technologies, the proportion of encrypted traffic in network traffic continues to rise. Traditional traffic classification methods that rely on plain text content show significant limitations when faced with encrypted traffic, making it difficult to effectively adapt to modern network environments. To address this issue, researchers have proposed various encrypted traffic classification methods, which can be broadly categorized into the following types: (1) traditional port-based classification methods, (2) Deep Packet Inspection (DPI)-based methods, (3) machine learning methods based on statistical features, and (4) deep learning-based feature self-learning methods.
2.1.1. Traditional Port-Based Classification Methods
In the early stages of internet development, network traffic classification mainly relied on parsing the port numbers of transport layer packets to identify traffic types. Since traditional applications typically used public and fixed port numbers, researchers could quickly determine traffic categories by querying the mapping between port numbers and protocols. This method, due to its simplicity and low computational cost, was widely applied and performed well in unencrypted network environments. However, with the rapid development of the internet, modern applications have gradually adopted techniques such as port randomization, port obfuscation, and network address translation (NAT), significantly weakening the applicability and accuracy of port-based classification methods. Sen et al. [13] conducted a systematic study on the applicability and limitations of port-based traffic classification methods in P2P networks. By analyzing a private dataset containing both VPN and non-VPN traffic, the study found that only about 30% of network traffic uses standard port numbers, indicating that port-based classification methods have limited coverage in modern networks. Furthermore, their classification performance is significantly constrained by the reliance on fixed port numbers, making them unsuitable for complex traffic environments.
2.1.2. Deep Packet Inspection (DPI)-Based Methods
To overcome the limitations of port-based classification, researchers have proposed Deep Packet Inspection (DPI) technology, which classifies traffic by analyzing the content of data packets (e.g., protocol fields and patterns). Wang et al. [7] introduced the Length Matching (LBM) method, incorporating the Stride-DFA matcher to accelerate regular expression matching. Experimental results show that this approach has advantages in terms of matching speed and memory consumption. Fernandes et al. [14] proposed a lightweight DPI framework (LW-DPI), which achieves efficient classification by analyzing a small number of packets, reaching 99% accuracy in P2P and email traffic classification. The FlowPrint framework, proposed by van Ede et al. [15], combines semi-supervised learning to generate application fingerprints for encrypted traffic, demonstrating strong classification ability. However, the performance of DPI significantly decreases when handling encrypted traffic, especially with the widespread use of encryption protocols like TLS. In contrast, our CLA-BERT model does not rely on plain text information, enabling effective traffic classification.
2.1.3. Machine Learning Methods Based on Statistical Features
Network traffic from different application categories typically exhibits unique statistical features, which makes traffic classification using machine learning models feasible. Statistical feature-based methods extract feature patterns of traffic behavior, avoiding the high computational cost of inspecting packet content byte-by-byte, and they do not require parsing the specific contents of the packets, making them applicable to encrypted traffic classification as well. AppScanner [16] is a typical example, which uses statistical features of packet sizes to train a random forest classifier and systematically analyzes the impact of factors such as time, device, and version on classification performance. The study shows that the passage of time and device replacement have minimal impact on fingerprint recognition, but updates to application versions significantly reduce classification accuracy due to the introduction of additional features that change traffic patterns. Alotaibi et al. [17] combined support vector machines (SVMs) with Naive Bayes and introduced a fuzzy inference system, significantly improving the decision-making ability and classification accuracy of the model. Lucia et al. [18] further extracted the lengths of the first 20 packets in encrypted malicious traffic as feature vectors and used positive and negative values to denote the packet’s transmission direction. Based on these features, they achieved high classification accuracy and low false positive rates using an SVM model. BIND [19] uses time-correlated statistical features to classify traffic by analyzing the temporal distribution and behavior patterns of traffic, further expanding the application of statistical features in traffic classification. Compared to byte-by-byte inspection methods, statistical feature-based methods have lower computational complexity, but they also exhibit significant limitations: the feature extraction and selection process heavily relies on domain experts’ experience, which is time-consuming, costly, and prone to subjective bias or human error. Moreover, these methods’ generalization ability is limited by the quality of the design when faced with diverse traffic features. In contrast, our proposed model uses a deep learning framework to automatically learn traffic features, completely eliminating the dependence on manually designed features. In encrypted traffic classification, our model demonstrates higher robustness and adaptability, effectively addressing the challenges posed by diverse and dynamically changing traffic patterns.
2.1.4. Deep Learning-Based Feature Self-Learning Methods
In recent years, the success of deep learning in fields like image recognition and natural language processing has driven its widespread application in encrypted traffic classification tasks. Unlike traditional machine learning methods, deep learning can directly learn high-level features from raw traffic data, eliminating the cumbersome process of manually designing features. Wang et al. [9] proposed an end-to-end encrypted traffic classification method based on one-dimensional convolutional neural networks (1D-CNN). This method integrates feature extraction, feature selection, and classifiers into a unified end-to-end framework, aiming to automatically learn the nonlinear relationship between raw inputs and expected outputs. Unlike traditional divide-and-conquer methods, this approach directly learns features from raw traffic data, effectively avoiding the manual feature design process. Lotfollahi et al. [20] proposed the “Deep Packet” traffic classification framework, which combines sparse autoencoders (SAEs) with convolutional neural networks (CNNs). The SAE model performs the binary classification task between normal and abnormal traffic, while the CNN model further achieves fine-grained classification of applications. Hwang et al. [21] proposed a session flow-based malicious traffic detection method. This method first truncates or pads the first N packets in the session flow to a fixed length L and converts them into a grayscale image of size N × L. It then performs traffic detection using a hybrid model composed of an autoencoder and a 1D convolutional network.
Considering the temporal characteristics of network traffic, Recurrent Neural Networks (RNNs) have been widely applied in traffic classification tasks due to their excellent sequence feature extraction capabilities. Liu et al. [22] proposed the FS-Net model, which automatically extracts sequential features from raw traffic packets. Through a multi-layer encoding–decoding structure, FS-Net mines high-dimensional sequential features from encrypted traffic and enhances the feature distinguishability and effectiveness through a reconstruction mechanism. Lin et al. [23] proposed the TSCRNN model, which combines CNNs with Bidirectional Long Short-Term Memory (BiLSTM) networks. CNNs are used to extract spatial features of the traffic, while BiLSTM focuses on extracting temporal features, achieving collaborative learning of spatial and temporal features. Liu et al. [24] proposed the Bidirectional Gated Recurrent Unit Attention (BGRUA) model, which extracts bidirectional time series features of traffic through the bidirectional modeling capability of BiGRU and applies attention mechanisms to weigh the key features. Lu et al. [25] proposed an encrypted traffic classification method based on Inception-LSTM (ICLSTM), aiming to combine the Inception module with the LSTM module to extract local spatial features and temporal sequence features of traffic. This method first converts traffic data into grayscale images, then extracts key features and achieves efficient classification through the ICLSTM neural network. Wang et al. [26] combined the powerful sequence modeling ability of Transformer models with the spatial feature extraction advantages of CNNs to propose a hybrid deep learning model for effective malicious traffic detection. Experimental results show that this hybrid model outperforms single models on multiple evaluation metrics, proving its superiority in malicious traffic detection. However, existing deep learning-based methods typically rely on large amounts of labeled data, which leads to significant performance degradation when the data are insufficient. In contrast, our method adopts a semi-supervised learning strategy, effectively reducing the dependence on labeled data.
2.2. Pre-Trained Models
Recent research has shown [10,27] that pre-trained models can effectively learn general language representations from large-scale corpora, thereby enhancing the performance of downstream tasks and avoiding the complexities of training a model from scratch. For specific tasks, optimizing and fine-tuning pre-trained models is often sufficient to achieve desirable results. In this context, some studies have started applying pre-trained models like BERT to encrypted traffic classification tasks, converting traffic data into text-like sequences, and utilizing pre-trained models to extract features.
PERT [11] was the first to apply pre-trained models to encrypted traffic classification tasks, using the ALBERT model transferred to the ISCX-VPN dataset for service identification tasks. However, the PERT model did not sufficiently design tasks for traffic representation, leading to suboptimal performance and limiting the model’s generalization ability. ET-BERT [6] designed two pre-training tasks, learning packet-level representations on a large amount of unlabeled data and fine-tuning on a small amount of labeled data, achieving good results. However, ET-BERT only focuses on packet-level features and overlooks the fine-grained byte-level features in encrypted traffic. Shi et al. [28] proposed a BERT-based Byte-Level Feature Convolutional Network (BFCN), which combines BERT and CNN to extract global traffic features through BERT and capture local byte features through CNN, thereby improving encrypted traffic classification accuracy. However, most existing methods focus on packet-level features and fail to effectively consider the fine-grained byte-level information. In contrast, the CLA-BERT method we propose demonstrates more effective advantages in combining packet-level and byte-level features.
3. Method Selection and Objectives
3.1. Basis for Method Selection
Suitability of BERT for Encrypted Traffic Classification: BERT, with its powerful sequence modeling capabilities, has achieved remarkable success in the field of Natural Language Processing (NLP). Although encrypted data lack the explicit syntax and semantic structures of natural language, their sequential nature aligns well with BERT’s modeling ability. Existing studies (e.g., PERT [11], ET-BERT [6], and BFCN [28]) have shown that BERT can effectively learn the distribution characteristics of encrypted data and capture global contextual relationships. Its self-attention mechanism can uncover implicit patterns within packet sequences, which is crucial for handling data streams from various encryption protocols and applications. Therefore, this paper selects BERT as the packet-level feature extraction module to fully model the global dependencies within packet sequences.
Complementarity of CNN and BiLSTM: Encrypted data exhibit strong randomness and lack a fixed lexical or syntactic structure. The integrity property of encryption systems [6] means that even slight changes in plaintext affect all bits of the ciphertext, resulting in byte sequences in encrypted traffic with long-range dependencies. Research has shown [12] that capturing long-distance dependencies between bytes is crucial for improving classification accuracy. CNNs can efficiently extract local byte patterns [28] (such as the fixed field structure of TLS headers), but their receptive field limitations make it difficult to capture global dependencies. On the other hand, BiLSTM can effectively capture long-range dependency features [25] (such as periodic features in encrypted payloads) by modeling bidirectionally. Therefore, this paper combines CNN and BiLSTM to cover both local and global byte-level features, enhancing the model’s expressive capability.
Necessity of Feature Interaction: Encrypted traffic classification typically relies on the synergistic effect of multi-level features. For example, identifying HTTPS traffic requires both packet-level protocol features (such as TCP window size) and byte-level payload features (such as certificate length fields). However, traditional single-level modeling methods struggle to utilize these features simultaneously, leading to feature fragmentation and information loss. To address this, this paper introduces a multi-head attention mechanism [24] to dynamically adjust the interaction weights between packet-level and byte-level features, enhancing the flexibility of feature fusion. This mechanism not only fully utilizes information from different levels but also improves the model’s generalization ability and robustness in diverse encrypted traffic scenarios.
3.2. Research Objectives
Building a Multi-Level Feature Fusion Model (Section 4): A novel encrypted traffic classification model, CLA-BERT, is proposed by combining packet-level features and byte-level features, aiming to fully exploit the multi-level information in encrypted traffic and enhance the model’s expressive capability and classification performance. The goal is to achieve a significant improvement in accuracy and robustness for CLA-BERT when handling complex encrypted traffic compared to existing methods.
Improving the Model’s Generalization Ability in Cross-Task Scenarios (Section 5.6): The adaptability of CLA-BERT across diverse encrypted traffic classification tasks will be evaluated. The objective is to ensure that the model demonstrates strong classification performance in various task scenarios, such as VPN encryption service classification, VPN encryption application classification, and TLS 1.3 encryption application classification.
Validating the Model’s Robustness in Small Sample Scenarios (Section 5.7): Through systematic small-sample experiments, the performance stability of CLA-BERT in data-scarce scenarios will be validated. The goal is to ensure that the model maintains high classification effectiveness even under limited data conditions, overcoming the performance bottlenecks typically encountered by traditional models in small sample scenarios.
4. Method
In recent years, the combination of BERT and LSTM models has achieved remarkable success in the field of Natural Language Processing (NLP), particularly in sentiment analysis and text classification tasks [29,30]. Based on this, existing studies have verified the feasibility of applying BERT to encrypted traffic classification. However, most existing methods [6,11,28] primarily focus on packet-level features and overlook the effective utilization of byte-level features within the packets. Inspired by these studies, this paper proposes the CLA-BERT model, which effectively integrates both packet-level and byte-level features of traffic.
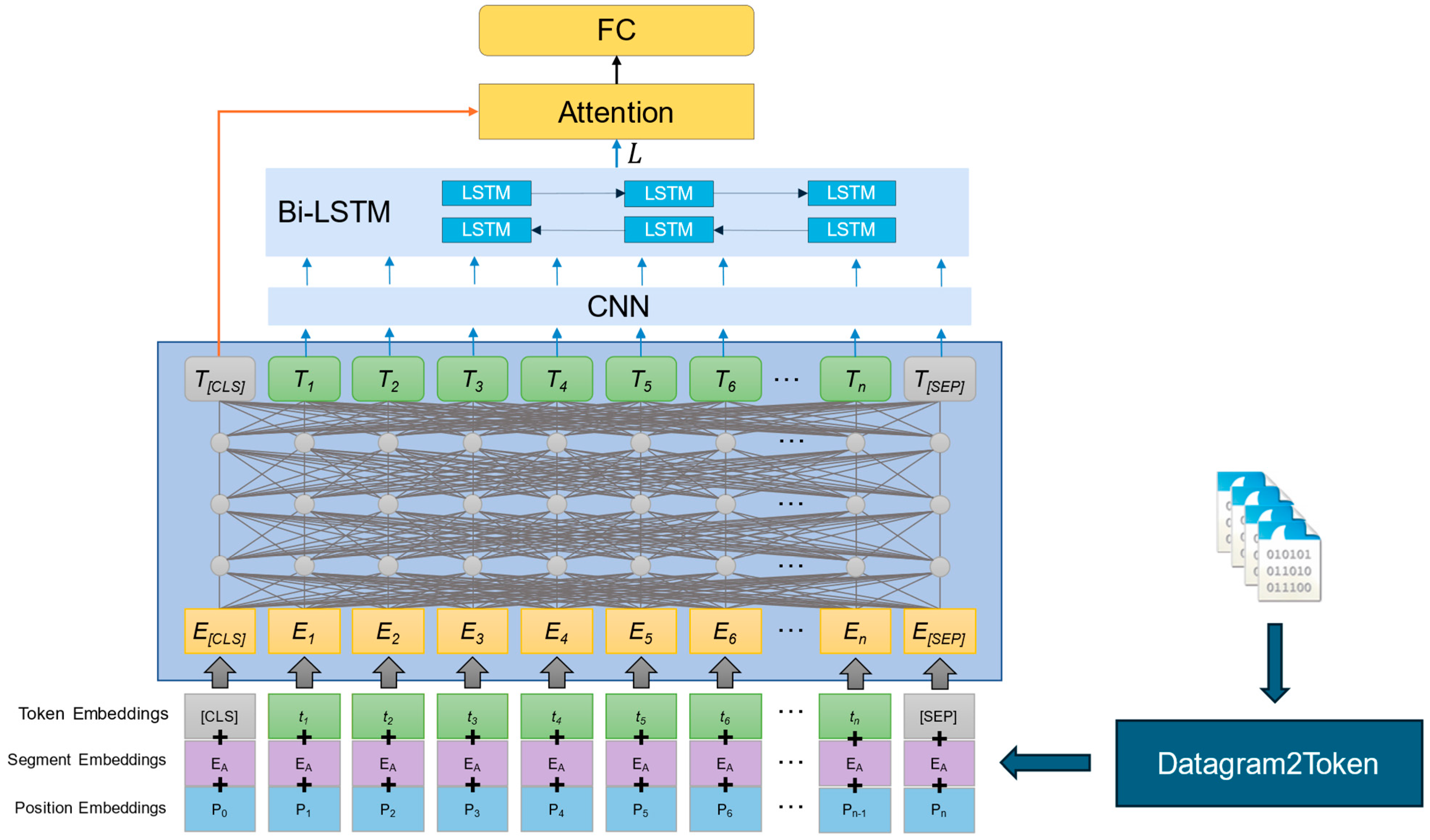
The encrypted traffic classification method proposed in this paper consists of three main steps: data preprocessing, traffic representation, and traffic classification. The model structure is shown in Figure 1. First, the raw PCAP files undergo data preprocessing, including traffic segmentation, data cleaning, length normalization, format conversion, and sequence generation operations. The entire preprocessing process is completed using the Datagram2Token tool [6]. Next, the preprocessed data undergo standardization embedding, positional embedding, and segment embedding as model input. The BERT self-attention mechanism is used to extract information containing packet-level features (T1, …, T[SEP]). Among them, compared to other tokens, T[CLS] can more comprehensively fuse the semantic information of each token in the data packets under the control of the attention mechanism and more accurately represent the entire packet’s features. Then, the byte-level feature vectors are input into convolutional neural networks (CNNs) and Bidirectional Long Short-Term Memory Networks (BiLSTMs), respectively, to capture the local features and global dependencies of byte-level traffic. Finally, the output result is . In the classification phase, T[CLS] and are input into the head attention mechanism, where information is learned in parallel across multiple feature spaces, and features are fused. Finally, the classification is performed through a fully connected layer, obtaining the final prediction result. The pseudo-code of CLA-BERT is shown in Algorithm 1.
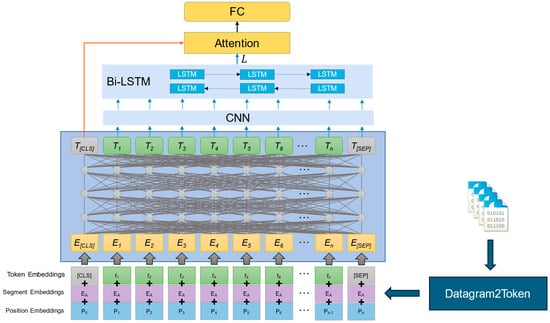
Figure 1.
Structure of the CLA-BERT model.
| Algorithm 1: CLA-BERT Pseudo-code |
Input:
|
|
4.1. Data Preprocessing
To minimize the potential impact of noise and redundant information in the original dataset on model performance and ensure consistency between the data samples and model input format, we use the Datagram2Token tool for data preprocessing. First, the raw PCAP files are segmented at the packet level. Then, invalid packets smaller than 80 bytes are removed, as they do not contain payload information. Simultaneously, traffic unrelated to the transmission content, such as ARP, ICMP, and DHCP protocol packets, is discarded. Since strong identifiers (e.g., port numbers and IP addresses) do not carry valuable discriminative information and may lead to model overfitting, we avoid focusing on these details during the model training process. To reduce bias and interference, we also remove protocol port information from the IP and TCP headers, as well as the Ethernet header. Next, the packet data are read in hexadecimal format, and the hexadecimal traffic sequences are consolidated into two-byte units, each consisting of four hexadecimal digits (i.e., two bytes). The processed data are shown in Table 1.

Table 1.
Data after preprocessing.
4.2. Traffic Representation
4.2.1. Packet-Level Feature Extraction Module Based on BERT
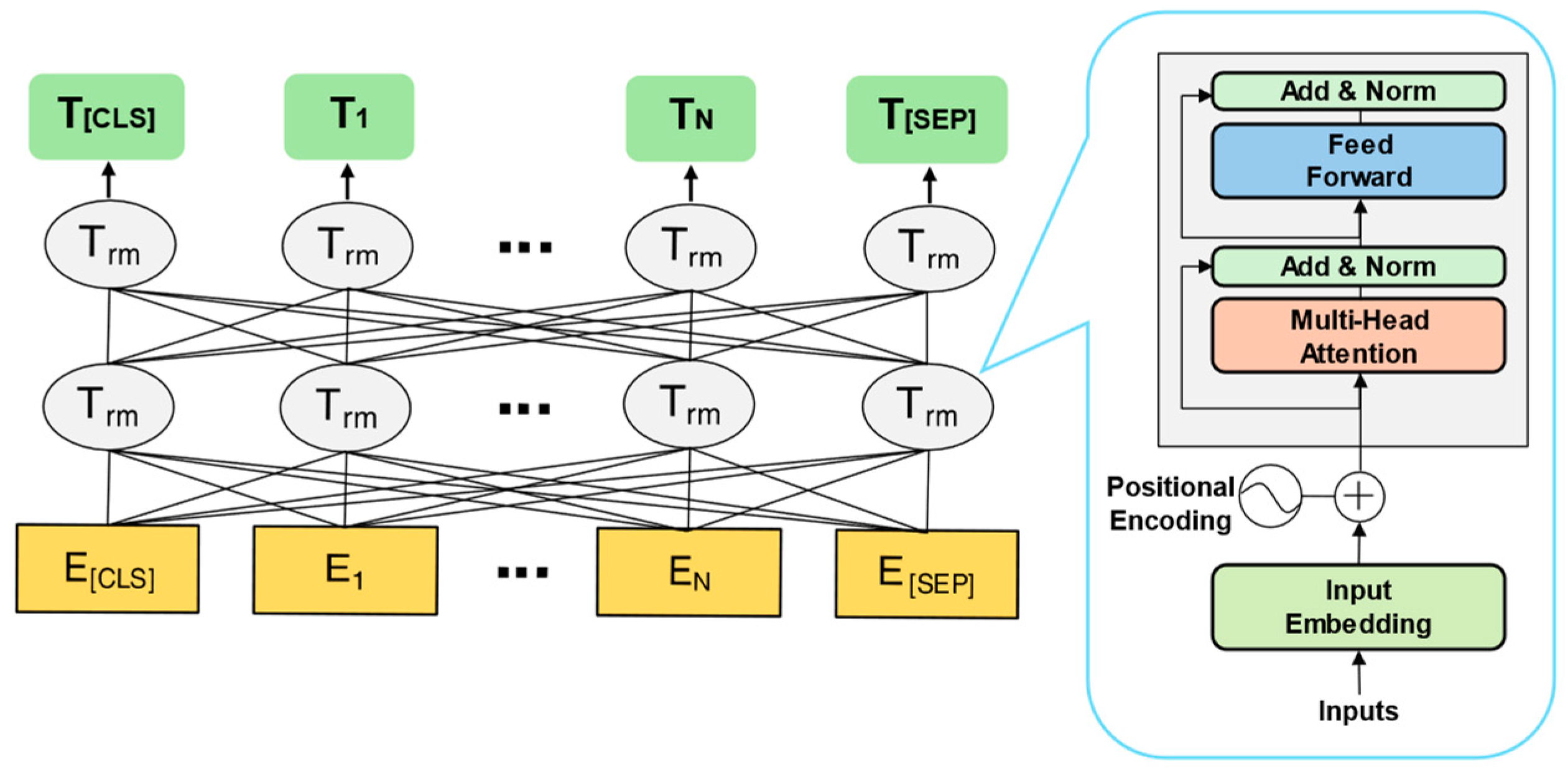
ET-BERT [6] models the context relationships at the byte level and BURST level using two self-supervised learning tasks: the network traffic-specific masked BURST task and the homogeneous BURST prediction task. This method leverages large-scale unlabeled data for pre-training, thereby optimizing the universal semantic representation of data packets. Based on this, this paper designs a packet-level feature extraction module based on ET-BERT. The module consists of 12 layers of Transformers, with the representation dimension of each input token set to 768 to enhance the expressive power of packet-level features. The workflow of the BERT model is divided into two main stages: the token embedding stage and the encoding stage.
In the token embedding stage, the model performs token embedding, positional embedding, and segment embedding:
- (1)
- Token Embedding: Token embedding converts each token in the sequence into a vector by querying a dictionary table. The value range of each token is from 0 to 65,535, and the dictionary size is 65,536. Additionally, during the token embedding process, two special tokens are added to the input sequence: [CLS] at the beginning of the sequence and [SEP] at the end of the sequence. When the input length is smaller than the model’s minimum requirement, the token [PAD] is added at the end of the sequence; if the input sequence length exceeds the model’s requirement, truncation is performed.
- (2)
- Positional Embedding: Positional embedding assigns a position number to each token in the sequence. Given the sequential nature of traffic data transmission, positional embedding ensures that the model focuses on the temporal relationships between tokens. Each input token is assigned a vector of dimension to represent its position in the sequence, with set to 768 in this paper.
- (3)
- Segment Embedding: Segment embedding distinguishes the two sentences in an input sentence pair and classifies them based on the semantic similarity between the sentences. This embedding is particularly important in the pre-training phase, although the specific pre-training process is not addressed in this paper.
In the encoding stage, the BERT model uses multiple layers of bidirectional Transformer encoders to encode the input vectors. The input vector is (E[CLS], E1, …, E[SEP]), and the corresponding output vector is (T[CLS], T1, …, T[SEP]). In this paper, the special token [CLS] from the BERT model is used to represent the packet-level features of traffic. As the starting token of the sequence input, the hidden state of [CLS] is iteratively aggregated through the multi-layer Transformer attention mechanism, effectively capturing the global semantic relationships between the data units within the traffic packet. This design has two advantages: (1) The self-attention mechanism allows the [CLS] token to establish dynamic weighted connections with all other tokens in the sequence, achieving fine-grained information fusion. (2) Through the multi-layered encoding process, [CLS] ultimately forms a vector representation that contains the full semantic information of the sequence, providing a high-differentiation packet-level feature representation for encrypted traffic classification. The BERT model architecture uses multi-layer bidirectional Transformer encoders, as shown in Figure 2.
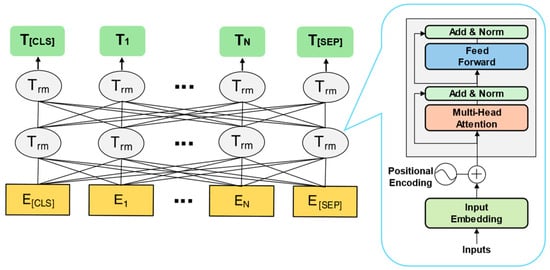
Figure 2.
Structure of BERT.
The core of the Transformer is the self-attention mechanism, which captures the relationships between any two tokens in the sequence. The main idea of the self-attention mechanism is as follows: for each input token, the model computes its relationship with other tokens in the sequence and updates each token’s representation based on these relationships. The computation process of the self-attention mechanism [24] can be expressed by Equations (1) and (2):
where is the query matrix, is the key matrix, is the value matrix, represents the input vector, denotes the dimension of the key vectors, and represents the learned weight matrix.
BERT enhances the model’s expressive capability through the use of multi-head self-attention [10]. Multi-head self-attention is an extension of the self-attention mechanism, which captures representations from different subspaces by computing multiple self-attention “heads” in parallel. Each “head” is an independent self-attention mechanism that processes the input using different query, key, and value matrices. The computation process of the multi-head self-attention mechanism [10] can be expressed by Equations (3) and (4):
where is the number of attention heads, , , is the independent weight matrix for each head, and represents the final output matrix.
Through the multi-head mechanism, BERT can simultaneously learn multiple different attention patterns, with each attention head focusing on different parts or features of the sequence. This enables BERT to have stronger modeling capabilities compared to a single self-attention mechanism, allowing it to capture richer semantic information.
4.2.2. Byte-Level Feature Extraction Module Based on CNN-BiLSTM
In recent years, methods combining CNN and LSTM have performed well in tasks such as natural language processing and time-series processing, including sentiment analysis [31]. Research has shown that using models like CNN on top of the BERT model can extract deeper features from sequences. Inspired by this, we use a combination of CNN and BiLSTM after the BERT model to extract byte-level features of the traffic. The proposed byte-level feature learning module consists of CNN and LSTM layers, aiming to extract byte-level feature representations from the raw byte data of the input packets.
In this paper, the CNN layer is first used to capture the local features of the traffic by using the output data from BERT (T1, …, T[SEP]) as input, enhancing the model’s sensitivity to local patterns. The CNN layer is composed of one-dimensional convolutional layers and ReLU activation functions, and the computation process of the CNN layer can be expressed [9] by Equations (5) and (6):
where represents the input data to the CNN, is the convolution kernel, is the bias, s denotes the size of the convolution kernel, and represents the output data.
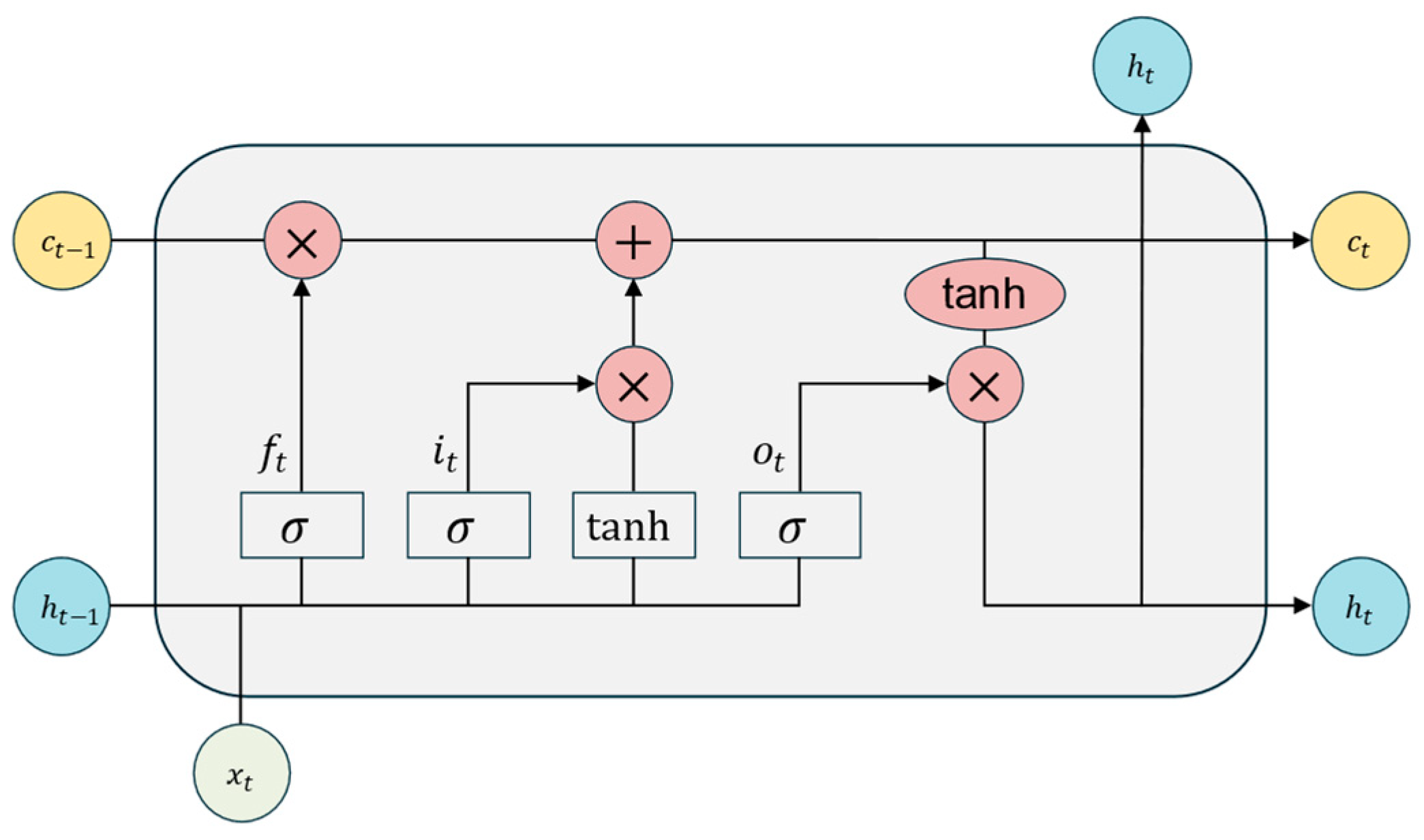
Subsequently, the output from the CNN layer is passed to the LSTM layer to capture the forward and backward dependencies of the traffic sequence. The LSTM network controls the flow of information through four main gating mechanisms, namely, the forget gate , input gate , candidate cell state , and output gate , as shown in Figure 3. The computation process [25] is as follows:
where represents the input vector at the current time step , represents the hidden state from the previous time step, denotes the cell state from the previous time step, is the weight matrix, and represents the bias.
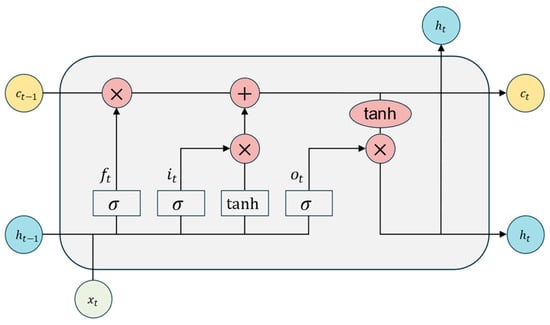
Figure 3.
Structure of LSTM.
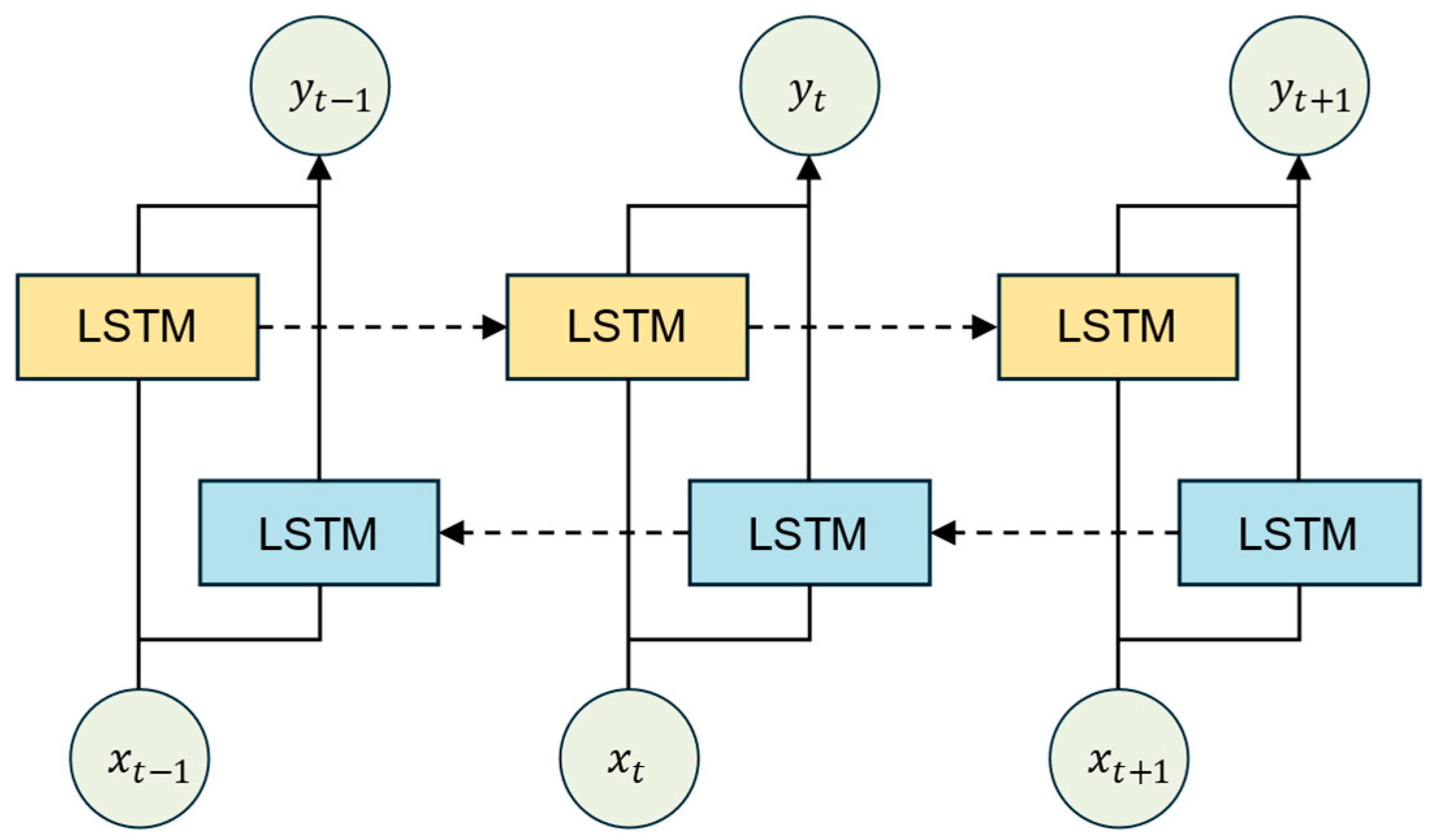
In the LSTM layer, this paper selects BiLSTM as the structure for traffic feature extraction, as shown in Figure 4. BiLSTM is a variant of LSTM, consisting of a forward LSTM and a backward LSTM, which can concatenate the forward and backward temporal information of traffic data. The computation process [25] is as follows:
where represents the input, denotes the time step, is the sequence length, represents the output of the forward LSTM, is the output of the backward LSTM, and represents the concatenated output of the bidirectional LSTM.
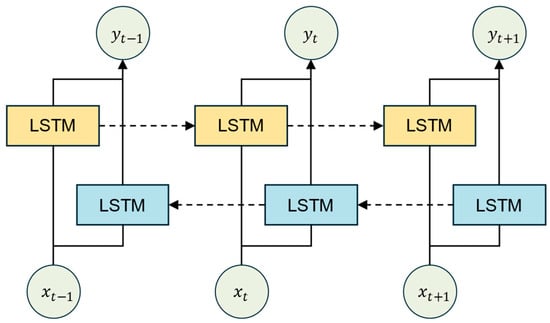
Figure 4.
Structure of BiLSTM.
The temporal information of encrypted traffic not only involves past behavior but also encompasses future trends. BiLSTM, by simultaneously considering both forward and backward temporal information, enables the model to establish connections between the past and future byte states, thereby providing a more comprehensive feature representation.
4.3. Feature Fusion and Classification Based on Attention Mechanism
This paper uses an attention mechanism-based feature fusion module to combine the outputs of the packet-level feature extraction module and the byte-level feature extraction module into a single feature vector. This approach captures the inherent dependencies between different data positions within the traffic from a global perspective and highlights key byte features. The module includes a multi-head attention layer and a feature concatenation operation, where the attention layer contains four attention heads. Specifically, the output of the BERT-based packet-level feature extraction module is used to construct the query matrix , while the output of the CNN-LSTM-based byte-level feature extraction module is used to construct the key matrix and the value matrix . The main computation formula [10] of this module is as follows:
where represents the linear mapping, denotes the concatenation operation, and represents the computation of each individual attention.
Based on the feature fusion, we perform classification through a fully connected layer. The final output represents [6] the scores of each input sample across various categories, as shown in Equation (7).
where represents the concatenated feature vector, denotes the mapping from the concatenated feature vector to the number of categories, and represents the bias of the categories.
5. Experiment
5.1. Experimental Environment and Setup
The experiments were conducted on a computer running Ubuntu 20.04 operating system and Python 3.8, equipped with an Intel(R) Xeon(R) Platinum 8481C processor and an NVIDIA GeForce RTX 4090D (24GB VRAM) GPU accelerator. In this experiment, the model is implemented and fine-tuned using the Universal Encoder Representation (UER) framework [32] and the PyTorch 1.11.0 framework. UER is an open-source framework designed for training and fine-tuning pre-trained language models, supporting a variety of pre-trained models, including BERT, GPT, and others.
The model’s parameter settings are as follows: In the BERT layer, the maximum input length is set to 128 tokens, and the token embedding dimension is 768. The batch size is set to 64, the learning rate is 2 × 10−5, the number of training epochs is set to 16, and the Adam optimizer is used.
5.2. Dataset
To comprehensively evaluate the performance of the CLA-BERT model in different encrypted traffic classification scenarios, this study selects two representative scenarios: TLS 1.3 encrypted application classification and VPN traffic detection. Experiments were conducted on two commonly used public datasets, with three encrypted traffic classification tasks, as shown in Table 2.
Table 2.
Classification task and dataset information.
In the TLS 1.3 application identification task, the experiment used the CSTNET-TLS 1.3 dataset [6] released by the Chinese Academy of Sciences. This dataset was collected from real network environments between March and July 2021, covering traffic samples from 120 applications supporting the TLS 1.3 protocol from the Alexa Top 5000 sites.
For the VPN encrypted traffic classification task, the ISCX-VPN dataset [33] was used, which was captured by the Canadian Institute for Cybersecurity. The dataset contains six types of communication applications, covering both VPN and non-VPN traffic. To further assess the model’s performance at different service and application levels, the dataset was subdivided into two datasets based on service type and application type: the ISCX-VPN-Service dataset [33], which includes 12 service categories, and the ISCX-VPN-App dataset [33], which includes 17 application categories. Through experiments on these subdivided datasets, we can more comprehensively test the adaptability of the CLA-BERT model in different traffic scenarios.
To mitigate the bias caused by data imbalance in the aforementioned dataset, we randomly selected 5000 samples from each category. For categories with fewer than 5000 samples, the sample size remained unchanged. Since the majority of categories have more than 5000 samples, and only a small number of categories have fewer than 5000 samples, undersampling or oversampling methods were not applied to handle these minority categories. Maintaining the current sample sizes helps avoid excessive artificial intervention in the minority categories, thereby ensuring the authenticity and representativeness of the dataset. Finally, the dataset was divided into training, validation, and test sets in an 8:1:1 ratio.
5.3. Evaluation Metrics
To evaluate the performance of the CLA-BERT model in different encrypted traffic classification tasks, we employed four evaluation metrics: accuracy, precision, recall, and F1 score. These metrics aim to assess the model’s classification performance on encrypted traffic from different perspectives. The specific calculation formulas are shown in Equations:
where represents the number of samples correctly classified as the target category, represents the number of samples incorrectly classified as the target category, represents the number of samples correctly classified as non-target categories, and represents the number of samples incorrectly classified as non-target categories.
5.4. Hyperparameter Experiment
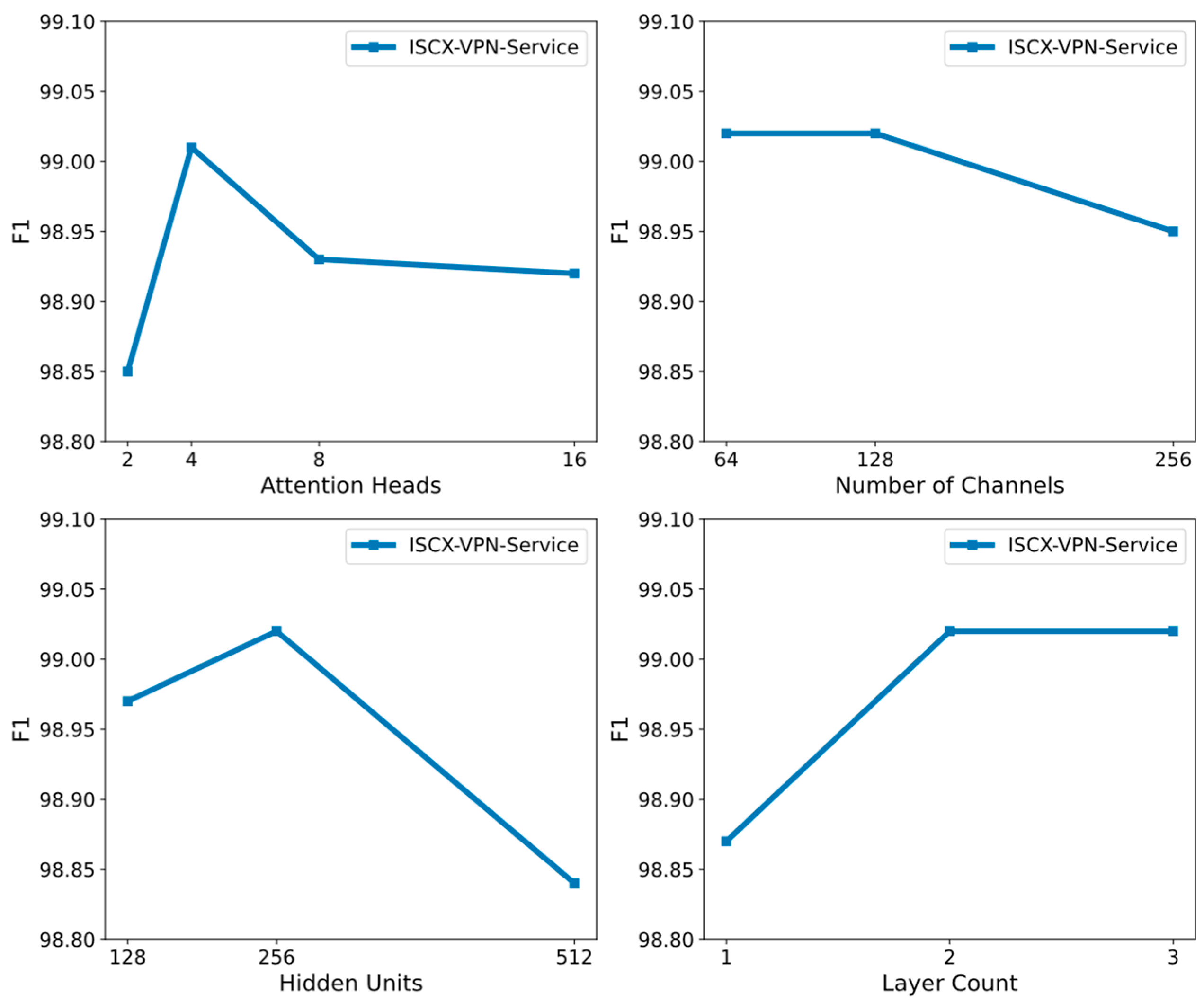
To investigate the impact of hyperparameters on model performance, we conducted multiple experiments on the ISCX-VPN-Service dataset, adjusting four key hyperparameters: the number of attention heads, the number of CNN channels, the number of BiLSTM hidden units, and the number of BiLSTM layers. The goal of these adjustments is to optimize the model’s performance in encrypted traffic classification tasks.
The experimental results (see Table 3, Figure 5) show that using four attention heads yields the best model performance, with an accuracy of 0.9902. Increasing the number of attention heads allows the model to capture more features and relationships, thereby enhancing its representational ability. However, a larger number of attention heads (such as 8 or 16) does not lead to significant performance improvement and may slightly reduce performance due to the introduction of redundant information and computational overhead. For the tuning of the number of CNN channels, both 64 and 128 channels performed well. Considering the computational cost, 64 channels are the optimal choice. Increasing the number of channels helps in extracting more features, but the computational burden also increases. Thus, 64 channels provide a good balance between performance and computational efficiency. In terms of BiLSTM hidden units, 256 units provided the best performance, balancing high accuracy and recall with reasonable computational cost. Regarding the number of BiLSTM layers, the model performance gradually improved as the number of layers increased from 1 to 3. Considering the computational cost, 2 BiLSTM layers are the most suitable choice.
Table 3.
Hyperparameter tuning results.
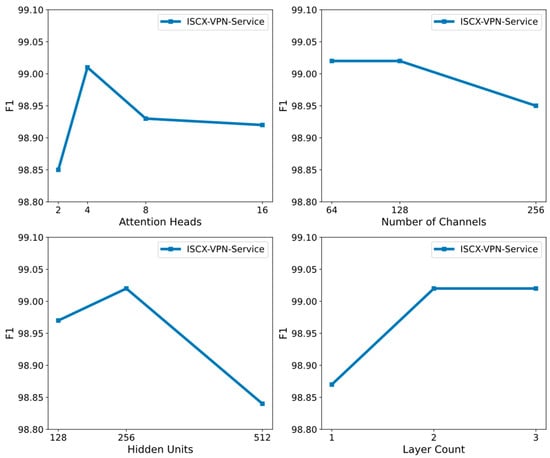
Figure 5.
Influence of hyperparameters on model performance.
In summary, we selected 64 CNN channels, 256 BiLSTM hidden units, and a 2-layer BiLSTM configuration, which ensured both computational efficiency and optimal classification performance.
5.5. Ablation Experiment
For the system evaluation of the contribution of each component to the model’s performance, this study designs an ablation experiment framework based on the ISCX-VPN-App dataset. A stratified random sampling method is employed to select 300 samples from each category to construct the training set, ensuring balanced category distribution. Four sets of control models are configured: (1) removing the CNN module (w/o CNN); (2) removing the BiLSTM architecture (w/o BiLSTM); (3) simultaneously removing both CNN and BiLSTM (w/o C&L); (4) the complete CLA-BERT model (default). The variable control method is applied to validate the collaborative effects of each module in the encrypted traffic classification task.
The experimental results are shown in Table 4. After removing the CNN component, the model’s performance slightly decreases, with an accuracy of 0.9798. After removing the BiLSTM component, the model exhibits a decrease in accuracy, precision, and recall, with the F1 score dropping to 0.9688. In the configuration where both CNN and BiLSTM components are removed (w/o C&BiL), the model’s performance further deteriorates, with the F1 score at 0.9563. This indicates that the CNN and BiLSTM components play a crucial role in improving the model’s performance.
Table 4.
Results of the ablation experiment.
Finally, when the complete CLA-BERT model is used, the model achieves the best performance, with an accuracy of 0.9824. In summary, the CNN, BiLSTM, and Multi-Head Attention (MHA) modules play an essential role in the encrypted traffic classification task. Removing any of these components significantly weakens the model’s performance, further confirming their indispensability in improving classification accuracy.
5.6. Comparative Experiment
In this section, we evaluate the performance of our proposed CLA-BERT method through comparative experiments on three different traffic classification datasets: ISCX-VPN-Service, ISCX-VPN-App, and CSTNET-TLS 1.3. We selected 14 existing traffic classification methods as baselines for comparison with CLA-BERT. These methods can be categorized into the following three groups: fingerprint-based methods (e.g., FlowPrint [15]); statistical feature-based methods (e.g., AppScanner [16], CUMUL [34], BIND [19], K-fp [35], and DF [36]); deep learning-based methods (e.g., FS-Net [22], GraphDApp [37], TSCRNN [23], Deeppacket [20], and ICLSTM [25]); and BERT-based methods (e.g., PERT [11] and ET-BERT [6]). Through these comparative experiments, we comprehensively assess the performance of CLA-BERT on different datasets.
The experimental results (see Table 5 and Table 6, Figure 6 and Figure 7) show that on the ISCX-VPN-Service, ISCX-VPN-App, and CSTNET-TLS 1.3 datasets, CLA-BERT outperforms existing methods on all evaluation metrics. Specifically, CLA-BERT achieves F1 scores of 99.02%, 99.49%, and 97.78% on these three datasets, respectively. For example, compared to traditional statistical feature-based methods (such as AppScanner and BIND), CLA-BERT performs significantly better. On the ISCX-VPN-Service dataset, CLA-BERT’s accuracy is 27.2% and 23.68% higher than that of AppScanner and BIND, respectively. On the ISCX-VPN-App dataset, CLA-BERT improves accuracy by 2.07% compared to the best-performing deep learning method, Deeppacket. This result shows that CLA-BERT performs exceptionally well in VPN-encrypted traffic classification tasks.
Table 5.
Comparison results of ISCX-VPN-Service and ISCX-VPN-App datasets.
Table 6.
Comparison results of the CSTNET-TLS 1.3 dataset.
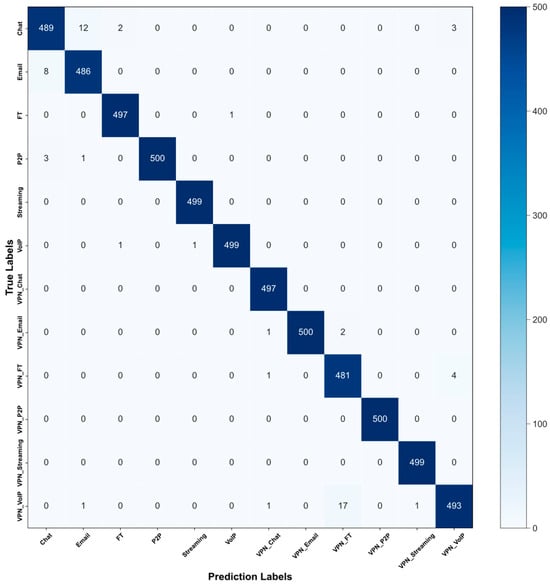
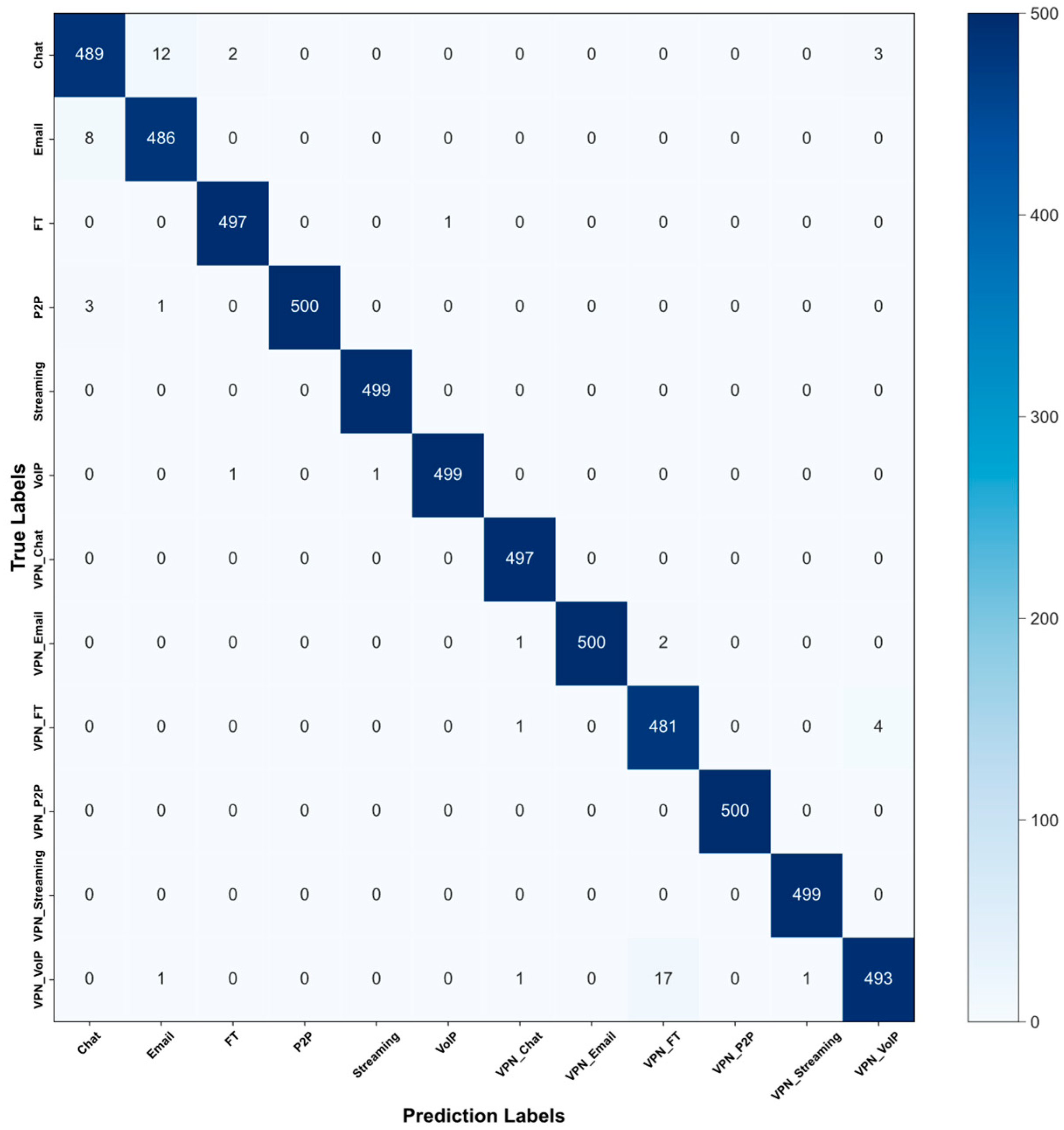
Figure 6.
Confusion matrix of the ISCX-VPN-Service dataset.
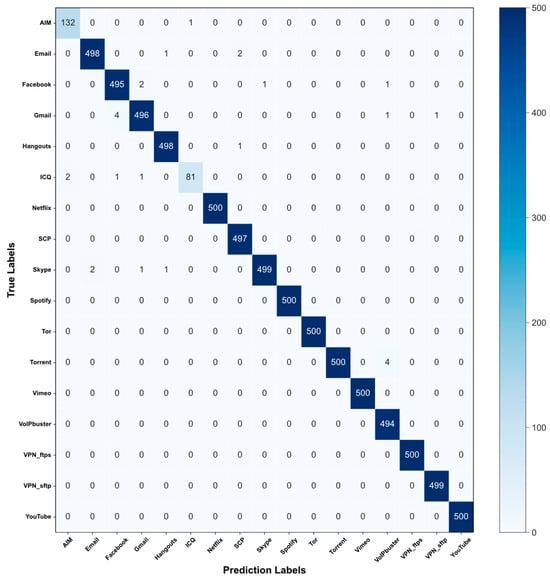
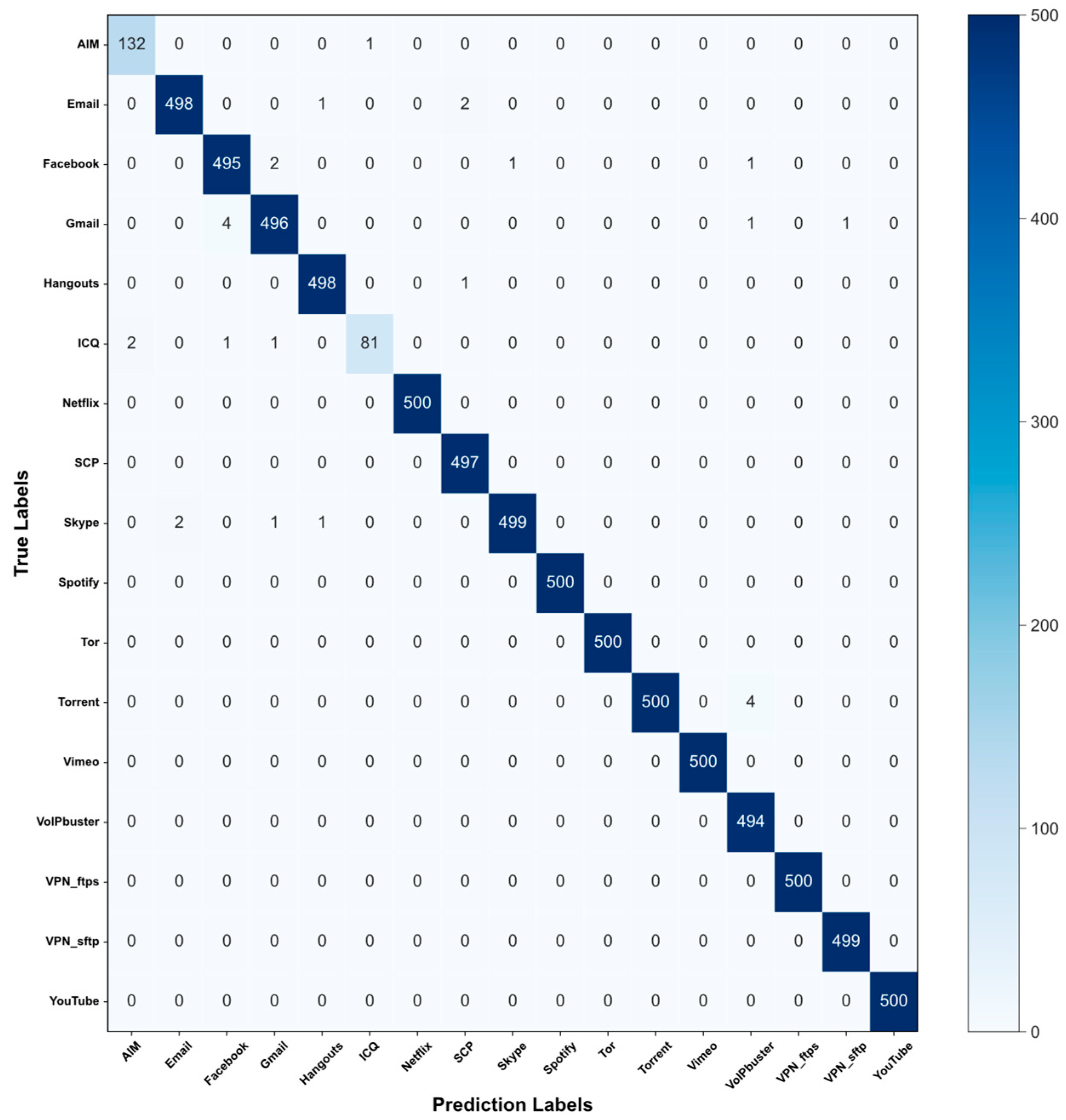
Figure 7.
Confusion matrix of the ISCX-VPN-APP dataset.
On the CSTNET-TLS 1.3 dataset, CLA-BERT was compared with BERT-based traffic classification methods (e.g., PERT and ET-BERT), and the results show that CLA-BERT improves accuracy by 8.6% and 0.38% over PERT and ET-BERT, respectively. This demonstrates that CLA-BERT, compared to using BERT alone, more effectively integrates packet-level and byte-level features, thereby enhancing the performance of encrypted traffic classification.
5.7. Small-Sample Experiment
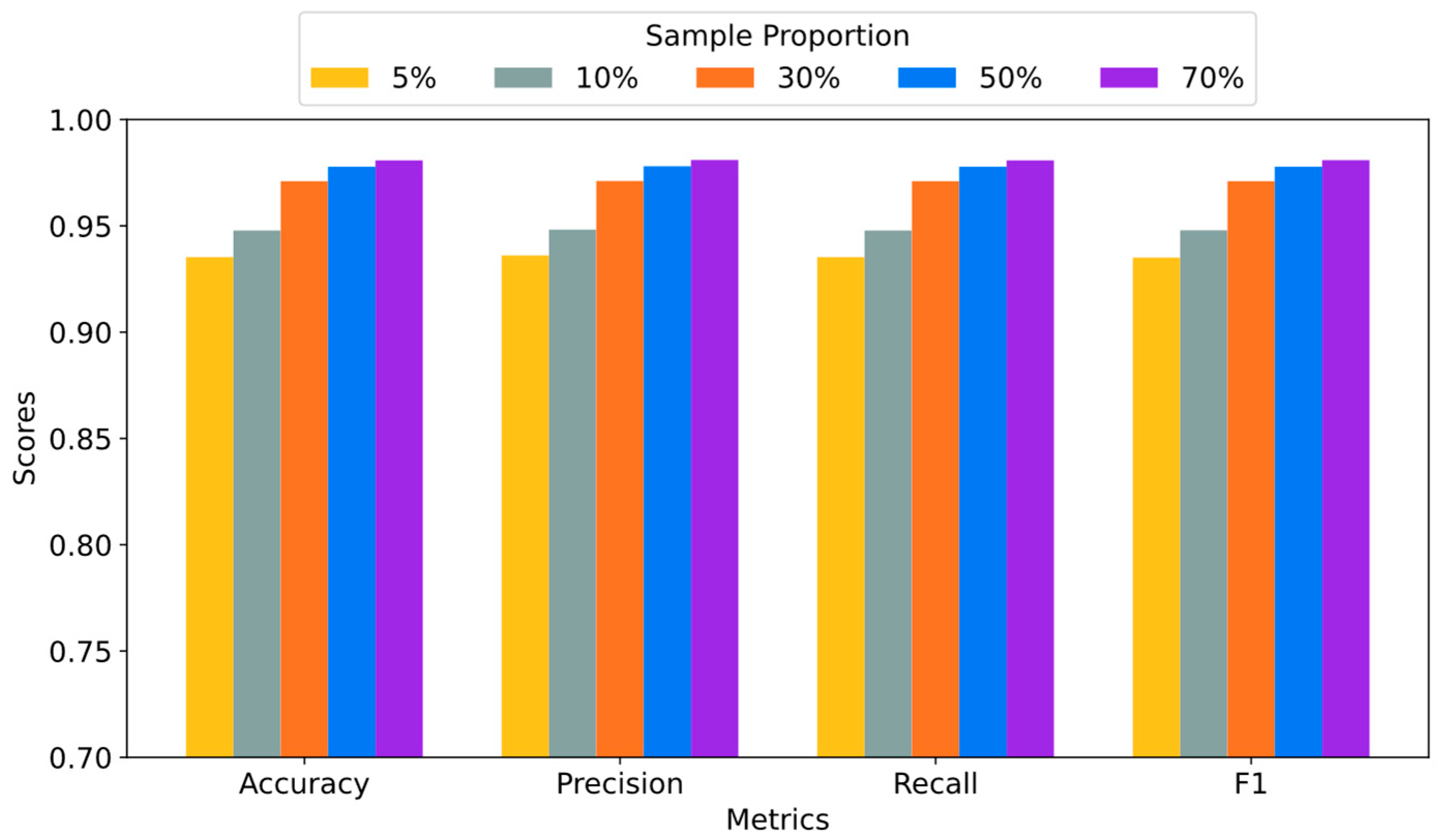
To validate the effectiveness and robustness of CLA-BERT in small-sample scenarios, we designed comparative experiments with different data proportions on the ISCX-VPN-Service dataset. The number of samples in each category was set to 1000, and random selections of 70%, 50%, 30%, 10%, and 5% of the samples were used for the small-sample experiments. This design allows us to systematically evaluate the performance changes in CLA-BERT as the data volume decreases.
The comparison results in Table 7 and Figure 8 show that the CLA-BERT method maintains relatively stable performance even as the data volume decreases. Specifically, with 5%, 10%, 30%, 50%, and 70% of the data, CLA-BERT achieves F1 scores of 93.51%, 94.79%, 97.10%, 97.78%, and 98.09%, respectively. These results indicate that, as the data volume decreases, the F1 score of CLA-BERT experiences only slight fluctuations, and its overall performance remains stable. Even with a very small dataset (5%), CLA-BERT still maintains a high F1 score, demonstrating its strong robustness in small-sample environments.
Table 7.
Results of the small-sample experiment on the ISCX-VPN-Service dataset.
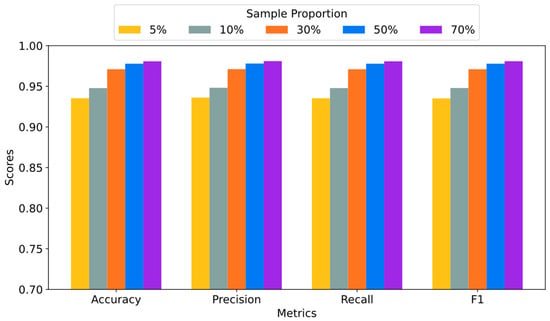
Figure 8.
Results of the small-sample experiment on the ISCX-VPN-Service dataset.
This result shows that CLA-BERT can effectively address the challenges of small-sample encrypted traffic classification and still provide stable classification performance as the data volume decreases. This offers strong support for handling sample-scarce encrypted traffic classification tasks in real-world applications.
6. Conclusions
This paper proposes a novel encrypted traffic classification method, CLA-BERT, to address the issues of single-feature dependence and insufficient exploration of deep packet-level characteristics in existing methods. The approach combines the advantages of packet-level and byte-level features, aiming to improve the performance of encrypted traffic classification.
The main conclusions of this study are summarized as follows:
- (1)
- Feature Extraction and Fusion Strategy: This study proposes a multi-level feature extraction and fusion strategy, which effectively enhances the representation capability of encrypted traffic. We extract packet-level semantic features using the BERT model, combine convolutional neural networks (CNNs) to extract byte-level local features, and introduce a Bidirectional Long Short-Term Memory network (BiLSTM) to capture sequential dependencies. This multi-granularity feature extraction framework deeply explores both packet-level and byte-level information, overcoming the limitations of traditional single-feature extraction methods. Furthermore, a multi-head attention mechanism is employed to adaptively weight and fuse packet-level and byte-level features, significantly improving the overall feature representation capability.
- (2)
- Experimental Design and Performance Evaluation: To comprehensively evaluate the performance of the CLA-BERT model, we conducted multiple experiments on two publicly available datasets, ISC-VPN and CSTNET-TLS 1.3. The experiments cover three challenging encrypted traffic classification tasks: VPN encryption service classification, VPN encryption application classification, and TLS 1.3 encryption application classification. The experimental results show that CLA-BERT performs excellently in these tasks, with accuracy rates of 99.02%, 99.65%, and 97.78%, outperforming existing mainstream methods. These results validate the proposed method’s outstanding capability in handling complex encrypted traffic classification tasks.
- (3)
- Model Analysis and Robustness Verification: To further analyze the internal mechanism of the CLA-BERT model, we conducted ablation experiments and robustness tests. The ablation experiments show that the BERT feature extraction module, CNN-BiLSTM feature extraction module, and multi-head attention fusion module all contribute to the model’s performance, demonstrating the effectiveness and rationality of the model architecture. Additionally, we designed small-sample experiments to verify the robustness of the model in data-scarce situations. The results show that even with fewer training samples, CLA-BERT can maintain stable classification performance. Specifically, with 5%, 10%, 30%, 50%, and 70% of the data, CLA-BERT’s F1 scores are 93.51%, 94.79%, 97.10%, 97.78%, and 98.09%, respectively.
In future research, we plan to further expand the application scope of CLA-BERT and extend it to a wider range of encrypted traffic classification tasks (such as different encryption protocols) to comprehensively evaluate its generalization capability and robustness. Additionally, we will introduce lightweight optimization techniques, such as model pruning and low-rank decomposition, to enhance computational efficiency and reduce resource consumption, thereby improving the model’s applicability in real-world scenarios.
Author Contributions
Conceptualization, H.H. and Y.Z.; data curation, Y.Z.; formal analysis, F.J.; funding acquisition, H.H. and F.J.; investigation, Y.Z.; methodology, H.H. and Y.Z.; project administration, H.H.; resources, F.J.; software, Y.Z.; supervision, H.H. and F.J.; validation, H.H. and Y.Z.; visualization, Y.Z.; writing—original draft, Y.Z.; writing—review and editing, H.H. and Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Key Laboratory Project of Enterprise Informatization and IoT Measurement and Control Technology for Universities in Sichuan Province (NO: 2024WYJ06), Central Guidance for Local Science and Technology Development Fund Projects (NO: 2024ZYD0266), Tibet Science and Technology Program (NO: XZ202401YD0023).
Data Availability Statement
The original contributions presented in this study are included in the article. For further inquiries, please contact the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Rezaei, S.; Liu, X. Deep learning for encrypted traffic classification: An overview. IEEE Commun. Mag. 2019, 57, 76–81. [Google Scholar] [CrossRef]
- Azab, A.; Khasawneh, M.; Alrabaee, S.; Choo, K.-K.R.; Sarsour, M. Network traffic classification: Techniques, datasets, and challenges. Digit. Commun. Netw. 2024, 10, 676–692. [Google Scholar] [CrossRef]
- Available online: https://transparencyreport.google.com/https/overview?hl=zh_CN (accessed on 2 January 2025).
- Shi, Z.; Luktarhan, N.; Song, Y.; Yin, H. Tsfn: A novel malicious traffic classification method using bert and lstm. Entropy 2023, 25, 821. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Jing, X.; Yan, Z.; Pedrycz, W. Network traffic classification for data fusion: A survey. Inf. Fusion 2021, 72, 22–47. [Google Scholar] [CrossRef]
- Lin, X.; Xiong, G.; Gou, G.; Li, Z.; Shi, J.; Yu, J. Et-bert: A contextualized datagram representation with pre-training transformers for encrypted traffic classification. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 633–642. [Google Scholar]
- Wang, X.; Jiang, J.; Tang, Y.; Liu, B.; Wang, X. StriD²FA: Scalable Regular Expression Matching for Deep Packet Inspection. In Proceedings of the 2011 IEEE International Conference on Communications (ICC), Kyoto, Japan, 5–9 June 2011; pp. 1–5. [Google Scholar]
- Xu, S.-J.; Kong, K.-C.; Jin, X.-B.; Geng, G.-G. Unveiling traffic paths: Explainable path signature feature-based encrypted traffic classification. Comput. Secur. 2025, 150, 104283. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, M.; Wang, J.; Zeng, X.; Yang, Z. End-to-end encrypted traffic classification with one-dimensional convolution neural networks. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; pp. 43–48. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- He, H.Y.; Yang, Z.G.; Chen, X.N. PERT: Payload encoding representation from transformer for encrypted traffic classification. In Proceedings of the 2020 ITU Kaleidoscope: Industry-Driven Digital Transformation (ITU K), Online, 7–11 December 2020; pp. 1–8. [Google Scholar]
- Huang, H.; Zhang, X.; Lu, Y.; Li, Z.; Zhou, S. BSTFNet: An Encrypted Malicious Traffic Classification Method Integrating Global Semantic and Spatiotemporal Features. Comput. Mater. Contin. 2024, 78, 3929. [Google Scholar] [CrossRef]
- Sen, S.; Spatscheck, O.; Wang, D. Accurate, scalable in-network identification of p2p traffic using application signatures. In Proceedings of the 13th International Conference on World Wide Web, New York, NY, USA, 17–20 May 2004; pp. 512–521. [Google Scholar]
- Fernandes, S.; Antonello, R.; Lacerda, T.; Santos, A.; Sadok, D.; Westholm, T. Slimming down deep packet inspection systems. In Proceedings of the IEEE INFOCOM Workshops 2009, Rio De Janeiro, Brazil, 19–25 April 2009; pp. 1–6. [Google Scholar]
- Van Ede, T.; Bortolameotti, R.; Continella, A.; Ren, J.; Dubois, D.J.; Lindorfer, M.; Choffnes, D.; Van Steen, M.; Peter, A. Flowprint: Semi-supervised mobile-app fingerprinting on encrypted network traffic. In Proceedings of the Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 3–26 February 2020. [Google Scholar]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. Robust smartphone app identification via encrypted network traffic analysis. IEEE Trans. Inf. Forensics Secur. 2017, 13, 63–78. [Google Scholar] [CrossRef]
- Alotaibi, F.M. Network Intrusion Detection Model Using Fused Machine Learning Technique. Comput. Mater. Contin. 2023, 75, 2479–2490. [Google Scholar]
- De Lucia, M.J.; Cotton, C. Detection of encrypted malicious network traffic using machine learning. In Proceedings of the MILCOM 2019-2019 IEEE Military Communications Conference (MILCOM), Norfolk, VA, USA, 12–14 November 2019; pp. 1–6. [Google Scholar]
- Al-Naami, K.; Chandra, S.; Mustafa, A.; Khan, L.; Lin, Z.; Hamlen, K.; Thuraisingham, B. Adaptive encrypted traffic fingerprinting with bi-directional dependence. In Proceedings of the 32nd Annual Conference on Computer Security Applications, Los Angeles, CA, USA, 5–9 December 2016; pp. 177–188. [Google Scholar]
- Lotfollahi, M.; Jafari Siavoshani, M.; Shirali Hossein Zade, R.; Saberian, M. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2020, 24, 1999–2012. [Google Scholar] [CrossRef]
- Hwang, R.-H.; Peng, M.-C.; Huang, C.-W.; Lin, P.-C.; Nguyen, V.-L. An unsupervised deep learning model for early network traffic anomaly detection. IEEE Access 2020, 8, 30387–30399. [Google Scholar] [CrossRef]
- Liu, C.; He, L.; Xiong, G.; Cao, Z.; Li, Z. Fs-net: A flow sequence network for encrypted traffic classification. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference On Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1171–1179. [Google Scholar]
- Lin, K.; Xu, X.; Gao, H. TSCRNN: A novel classification scheme of encrypted traffic based on flow spatiotemporal features for efficient management of IIoT. Comput. Netw. 2021, 190, 107974. [Google Scholar] [CrossRef]
- Liu, X.; You, J.; Wu, Y.; Li, T.; Li, L.; Zhang, Z.; Ge, J. Attention-based bidirectional GRU networks for efficient HTTPS traffic classification. Inf. Sci. 2020, 541, 297–315. [Google Scholar] [CrossRef]
- Lu, B.; Luktarhan, N.; Ding, C.; Zhang, W. ICLSTM: Encrypted traffic service identification based on inception-LSTM neural network. Symmetry 2021, 13, 1080. [Google Scholar] [CrossRef]
- Wang, K.; Gao, J.; Lei, X. MTC: A Multi-Task Model for Encrypted Network Traffic Classification Based on Transformer and 1D-CNN. Intell. Autom. Soft Comput. 2023, 37, 619–638. [Google Scholar] [CrossRef]
- Meng, X.; Lin, C.; Wang, Y.; Zhang, Y. Netgpt: Generative pretrained transformer for network traffic. arXiv 2023, arXiv:2304.09513. [Google Scholar]
- Shi, Z.; Luktarhan, N.; Song, Y.; Tian, G. BFCN: A novel classification method of encrypted traffic based on BERT and CNN. Electronics 2023, 12, 516. [Google Scholar] [CrossRef]
- Swathi, T.; Kasiviswanath, N.; Rao, A.A. An optimal deep learning-based LSTM for stock price prediction using twitter sentiment analysis. Appl. Intell. 2022, 52, 13675–13688. [Google Scholar] [CrossRef]
- Bello, A.; Ng, S.-C.; Leung, M.-F. A BERT framework to sentiment analysis of tweets. Sensors 2023, 23, 506. [Google Scholar] [CrossRef]
- Talaat, A.S. Sentiment analysis classification system using hybrid BERT models. J. Big Data 2023, 10, 110. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, H.; Zhang, J.; Zhao, X.; Liu, T.; Lu, W.; Chen, X.; Deng, H.; Ju, Q.; Du, X. Uer: An open-source toolkit for pre-training models. arXiv 2019, arXiv:1909.05658. [Google Scholar]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of encrypted and vpn traffic using time-related. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy (ICISSP), Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar]
- Panchenko, A.; Lanze, F.; Pennekamp, J.; Engel, T.; Zinnen, A.; Henze, M.; Wehrle, K. Website Fingerprinting at Internet Scale. In Proceedings of the NDSS, San Diego, CA, USA, 21–24 February 2016; p. 23477. [Google Scholar]
- Hayes, J.; Danezis, G. k-fingerprinting: A robust scalable website fingerprinting technique. In Proceedings of the 25th USENIX Security Symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; pp. 1187–1203. [Google Scholar]
- Sirinam, P.; Imani, M.; Juarez, M.; Wright, M. Deep fingerprinting: Undermining website fingerprinting defenses with deep learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 1928–1943. [Google Scholar]
- Shen, M.; Zhang, J.; Zhu, L.; Xu, K.; Du, X. Accurate decentralized application identification via encrypted traffic analysis using graph neural networks. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2367–2380. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).