3.1. Scalar Multiplication
Let
be an integer and
P be a point in
. The scalar multiplication
of
P is defined by
. The computation of
is lengthy. To reduce the duration, first,
k is converted to a binary representation, as follows:
where
for
. Let
be non-negative integers such that
with
. Then, using Horner’s rule, Equation (
3) can be represented as
For example, suppose that
and
. Then,
As the idea behind the proposed method comes from the sliding window [
21], let us briefly introduce the basic concept of the sliding window by the following example. For
k in Equation (
4) with window size
,
k can be written as
In accordance with the sliding window method, the precomputations are
point additions; a point doubling number of 9; and
,
,
, and
. The number of point doubling is the number of times a window with length
w is successively shifted one place from left to right, skipping the zeros if they are not in the window. More details on the sliding window method can be found in [
21]. With the proposed method,
is written as
In Equation (
6), for
, each
is referred to as a
w-bit word, denoted as
. For the last
r terms,
in Equation (
6) is also represented as a
w-bit word
with
for
.
For Equations (
7) and (
8), it is evident that any scalar multiplication operation can be equivalently expressed as the computation of
,
for each
i. For a small value of
w, the points
can be precomputed and stored in advance, as illustrated in
Table 1. In this table, given the point
P, the scalar
k, and the word length
w, the result of Equation (
7) or (
8) can be directly retrieved from the entry
, provided that
for
and
.
We will use the following example to demonstrate how to look up values in
Table 1. Suppose that
; we precompute all eight possible combinations, as shown in the following table. For the value of
k according to Equation (
5), for the combination 110, we obtain the result from the table entry
, which is
.
| |
| 0 |
| P |
| |
| |
| |
| |
| |
| |
Therefore, given point
P, scalar
k, and word length
w,
can be computed with the following Algorithm 1,
ScalarMUL.
| Algorithm 1 ScalarMUL |
| 1. | Set
|
| 2. | Using P to create table L, as shown in Table 1 |
| 3. | Set
and
|
| 4. | For downto 0 |
| 5. | do |
| 6. | |
| 7. | |
| 8. | Enddo |
| 9. | |
| 10. | |
| 11. | return Q |
3.2. Reducing Inverse in the Repeating Point Doubling
The sliding window method [
21] shifts a window of length
and skips over runs of zeros between them while disregarding the fixed digit boundaries. However, in the
ScalarMUL algorithm, the binary representation of
k is partitioned into fixed-length bit-words of size
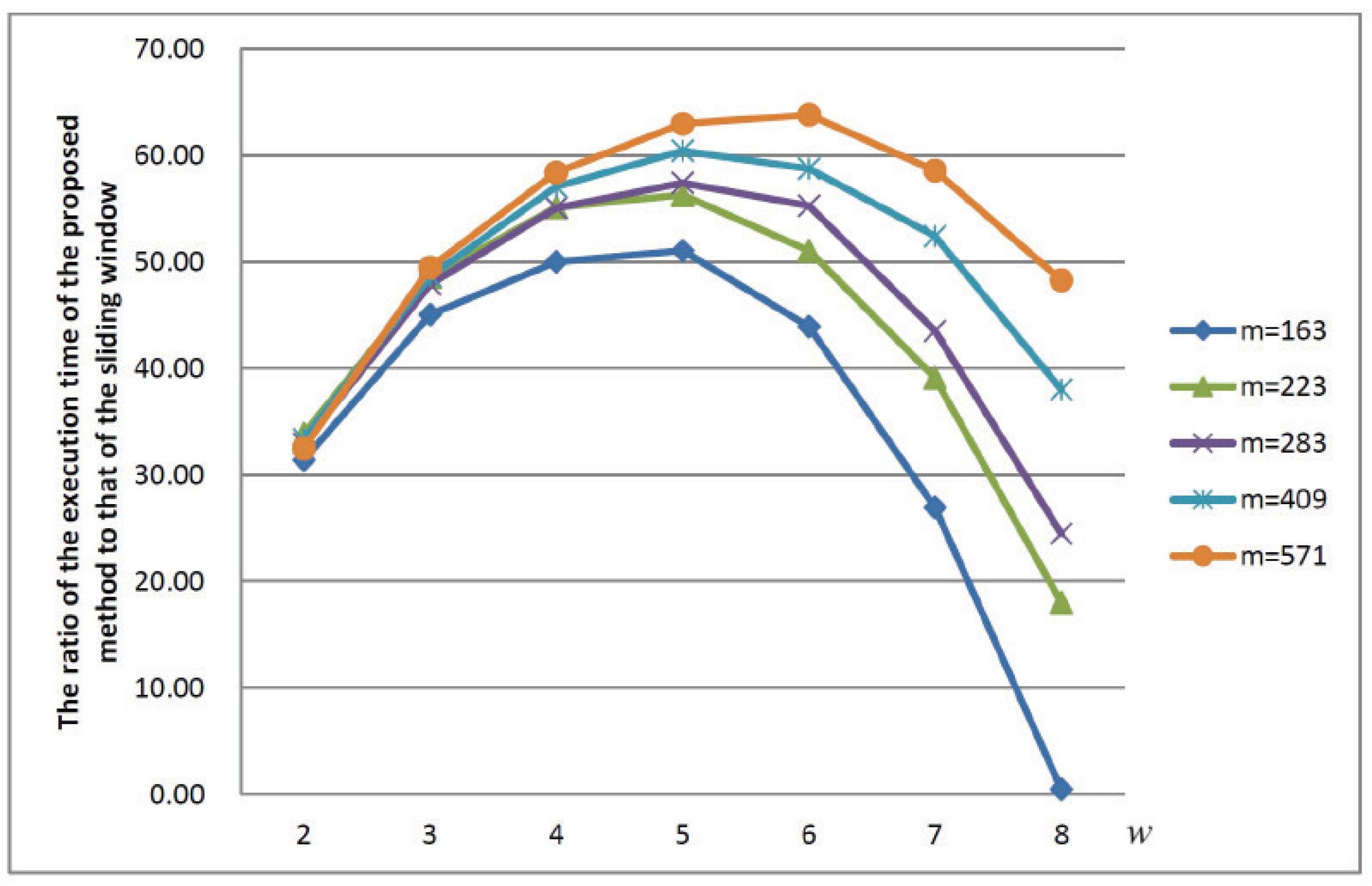
w, where each word is processed sequentially. This approach can also be extended to the sliding window method, as will be demonstrated in
Section 4 with the experimental results. Within the
ScalarMUL algorithm, it is necessary to compute
in step 7 and
in step 9.
According to the definition of scalar multiplication
of
Q and the associative property of point addition on the elliptic curve
, for any positive integer
n,
can be expressed as the point doubling of
. Specifically,
. Traditionally, as described in Equation (
2),
can be computed using the following Algorithm 2, referred to as
Tradition. In the
Tradition algorithm, line 4 employs Equation (
2) to compute
. Each iteration performs a point-doubling operation on
Q requiring five XORs (additions), two multiplications, and one inverse operation. The addition, multiplication, and square operations mentioned here are all operations defined within
.
| Algorithm 2 Tradition |
| 1. | Set
|
| 2. | For downto 0 |
| 3. | do |
| 4. | |
| 5. | Enddo |
| 6. | return
Q |
To obtain
, we have to compute
. Therefore, in the computation, there are
n inverse operations,
XORs,
multiplications, and
squares. Since the inverse operation is computationally expensive, we have developed optimized formulas to replace the point-doubling computation in the
Tradition algorithm. The derived formulas are designed to ensure that only a single inverse operation is required when computing
of a given point
Q, significantly improving computational efficiency. Let
be a point in
. For
, let
be the point doubling of
. Then,
is the scalar multiplication
of
. Let
be the slope of the tangent line passing through the point
. Then, to derive formulas for
obtained from
via the iteration of point doubling, first, consider
. We have
where
and
.
In what follows, the formula for will be omitted until and are obtained.
For
,
where
and
.
For
,
where
and
.
For
,
where
and
The formulas for
and
can be extended iteratively for arbitrarily large values of
n, allowing us to compute
for any desired
n. However, the derivation process becomes increasingly laborious and cumbersome as
n grows larger, making it impractical for manual computation. Before establishing that there is only one inverse operation involved in the computation of scalar multiplication, it will be helpful to introduce the following recurrence relations. By following Equations (
9)–(
12), let
, and
. Then,
For
, the following relationships can be easily derived:
Table 2 is an illustration of Equations (
9)–(
12) to compute
and
. In the example, the curve is defined over
. For
, the computations of
and
are shown in
Appendix A.
Lemma 1. For , and .
Proof of Lemma 1. We will proceed with induction on
n. Equations (
9)–(
12) show the basis step for
and
. For the inductive step,
This lemma holds. □
Corollary 1. For , .
Proof of Corollary 1. According to Lemma 1,
,
□
Given a point
and a positive integer
n, the
n-times point doubling
of
Q can be efficiently computed using the following Algorithm 3, referred to as
PDNTimes.
| Algorithm 3 PDNTimes |
| 1. | Set
|
| 2. | If , then |
| 3. | ; |
| 4. | ; |
| 5. | |
| 6. | |
| 7. | For upto n |
| 8. | do |
| 9. | |
| 10. | |
| 11. | |
| 12. | Enddo |
| 13. | |
| 14. | |
| 15. | |
| 16. | |
| 17. | |
| 18. | |
| 19. | EndIf |
| 20. | return
|
In the PDNTimes algorithm, the computational complexity can be broken down as follows:
Lines 5 and 6: These lines involve 3 XOR operations, 2 multiplications, and 2 square operations.
Lines 9–11: Each iteration of the loop in these lines requires 5 XOR operations, 6 multiplications, and 6 square operations.
Lines 13–17: These lines consist of 2 XOR operations, 4 multiplications, 3 square operations, and 1 inverse operation.
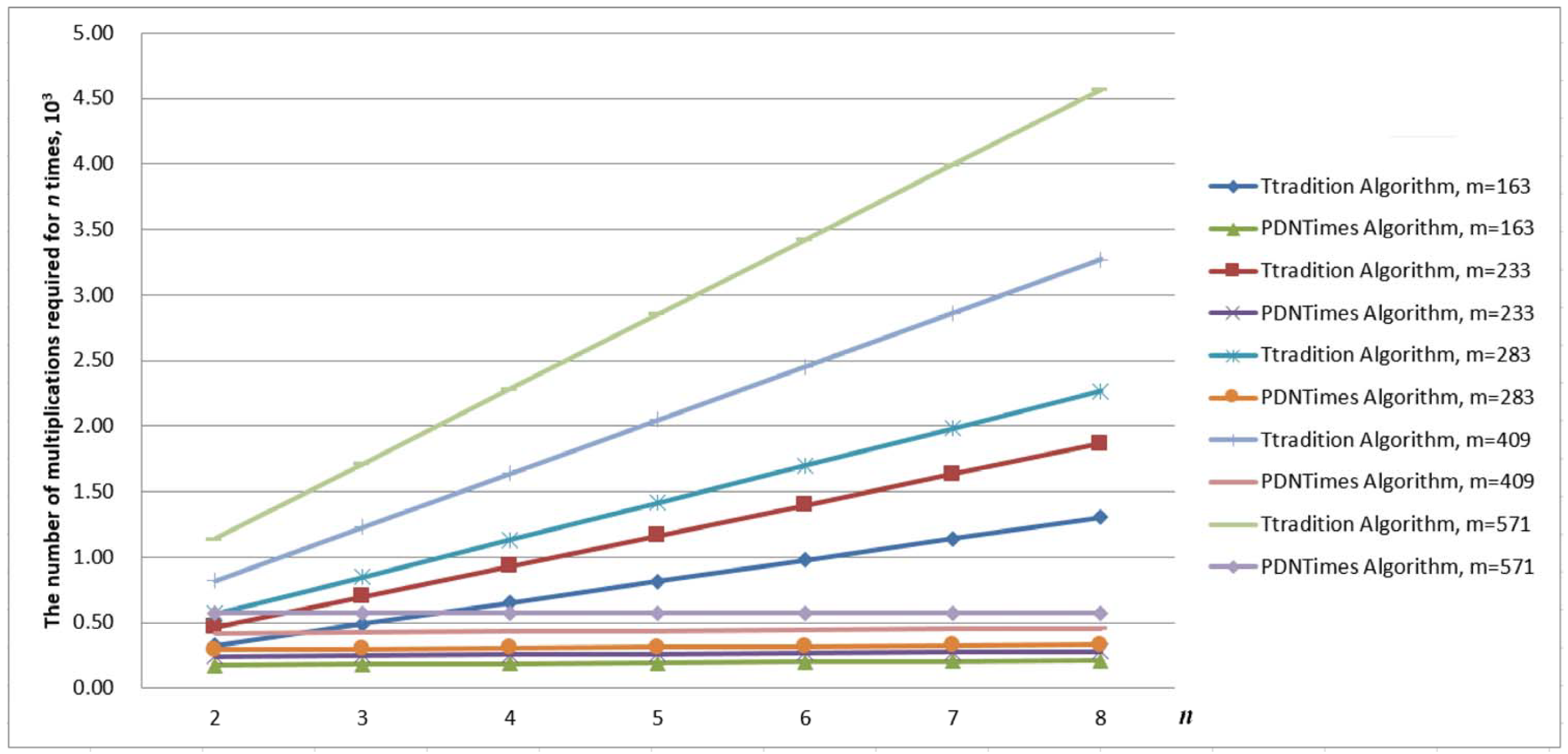
Therefore, a total of XORs, multiplications, and squares are required. However, in the case of hardware devices, the time complexity of adding any two n-bit numbers is currently , while the time complexity of their multiplication is .
Lemma 2. Over , let be an integer and Q be a point in . The computation of n times point doubling of Q requires multiplications, squares, and one inverse operation.
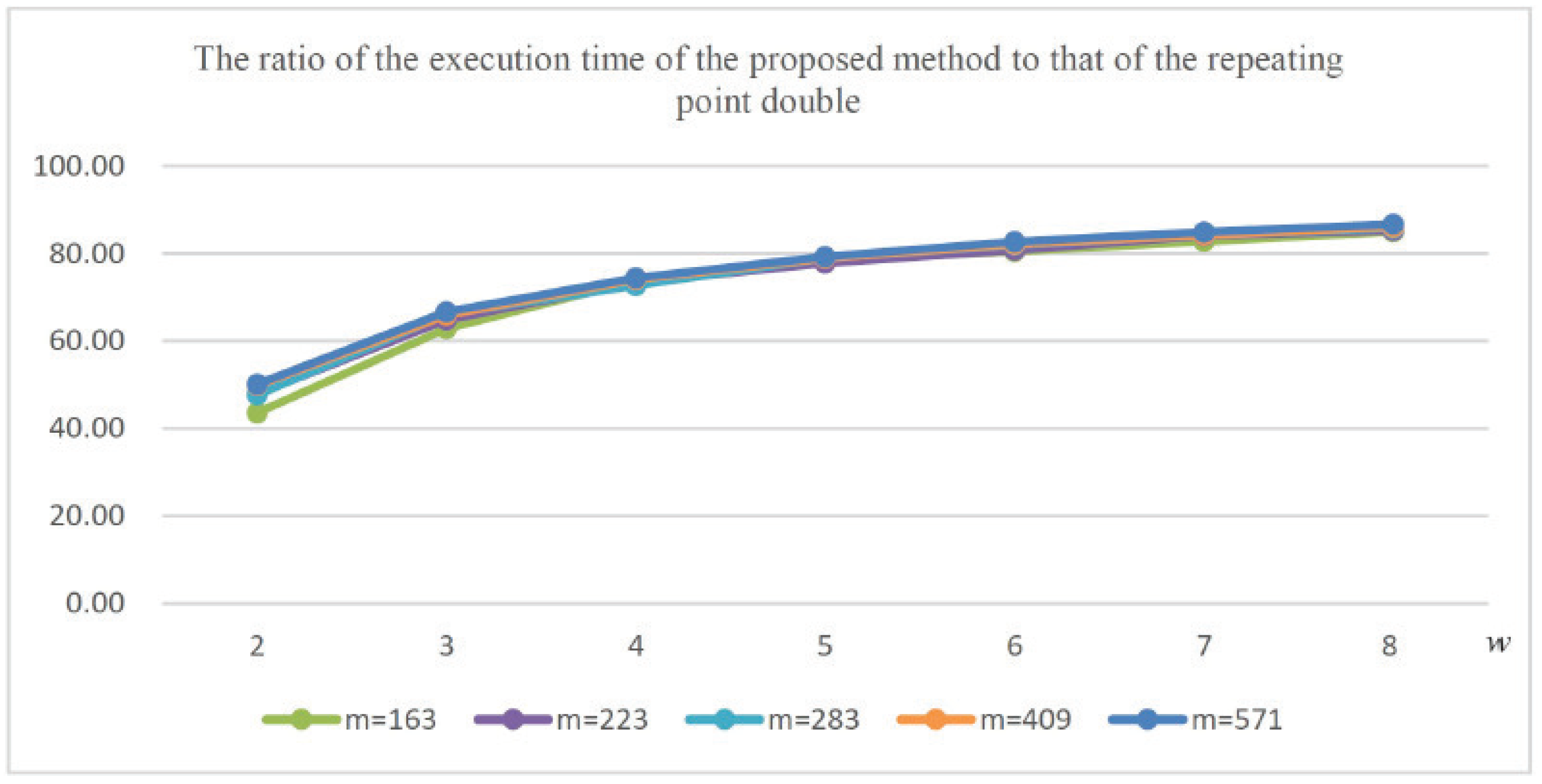
For the repeating point doubling on
,
Table 3 demonstrates the execution times of the
Tradition algorithm and the
PDNTimes algorithm involved in the
ScalarMUL algorithm. In other words, in line 7 of the
ScalarMUL algorithm, the computation of
is compared using
PDNTimes and
Tradition. Let
and
denote the execution time of the previous method and the proposed method, respectively. Then, in the table, the decreasing ratio is given by
When comparing the performance of
Tradition with that of
PDNTimes for different values of
m, it is observed that while the reduction in inverse operations has led to a decrease in computation time, the increased number of multiplication and square operations in the formula results in a slowdown of the computation time reduction as
n approaches 8. This trend is illustrated in
Figure 1. This trend is attributed to the increase in word length, which leads to longer table construction times and a corresponding rise in memory consumption. Furthermore, as depicted in the figure, this behavior remains consistent across different values of
m, indicating that the trade-off between reduced inversions and increased multiplication and square operations persists regardless of the specific parameters.
3.3. Reducing Square Operation Time
In the
PDNTimes algorithm, there are many square operations in
, and
. To further reduce the computation time for scalar multiplication or repeating point doubling, precomputations for square operations are employed again. The method we propose below will enable the square operation to utilize three main operations: XOR, bit shifting, and table lookup. Recall that
is a polynomial defined over
. Then, given an integer
, let
d and
r be integers such that
and
. Using Horner’s rule again (note that the
m we are considering is odd),
In Equation (
16), the computation of
involves sequentially evaluating the expression
for increasing values of
i. Similar to Equation (
7) (respectively, Equation (
8)), the expression
(respectively,
) represents a
w-bit word, denoted as
(respectively,
). The result of computing
, for
, and
can be found in the entry
in
Table 4 provided that
for
. In the subsequent discussion, the notation “
” will be used to denote shifting • to the left by
n positions, with all the least significant bits set to zero, where
n is a positive integer.
In Equation (
17), since the maximum degree before applying the modulo operation with respect to
is less than
m, the remainder obtained through traditional long division depends on the polynomial
. The result of this modulo operation, denoted as
, is provided in
Table 5, which represents the remainder of (
17).
Table 5 comprehensively lists all possible outcomes for
.
Therefore, the square operation
can be computed with the following Algorithm 4,
SquareMod.
| Algorithm 4 SquareMod |
| 1. | Set
|
| 2. | Make table and such as Table 4 and Table 5, respectively |
| 3. | For
to
|
| 4. | do |
| 5. | |
| 6. | |
| 7. | Enddo |
| 8. | |
| 9. | |
| 10. | |
| 11. | return C |
In the
SquareMod algorithm, for each iteration
i, the result of the equation of Equation (
17) is represented as
. In practical implementation, the term
in Equation (
17) implies that each
in
C is shifted to the left by
positions, with all lower-order bits set to zero, where
. Let
denote the maximum degree of the polynomial in Equation (
17) before applying the modulo operation with
, and let
. As
is stored in an
m-bit array in the code, there is a constraint on the shifting of
C. Specifically,
must be greater than the sum of
and the maximum degree of
. This ensures that the shifting operation does not exceed the bounds of the array and that the modulo operation can be correctly applied.
In the SquareMod algorithm, the computational time can be broken down as follows:
Lines 5 and 6: Each iteration of the loop in these lines requires 2 XOR operations, 1 shift, and 2 table lookups.
Lines 8–10: These lines consist of 3 XOR operations, 1 multiplication, and 3 table lookups.
Therefore, a total of XORs, d shifts, and table lookups are required. From the perspective of time complexity, this time is negligible compared with the time required for multiplication.
In the
ScalarMUL and
SquareMod algorithms, scalar multiplication corresponds to retrieving precomputed values stored in
Table 1,
Table 4, and
Table 5. As a result, this approach significantly enhances computational efficiency by reducing the need for repeated calculations.
Lemma 3. Given an integer w, the scalar multiplication of a point on over can be computed in iterations in the algorithms ScalarMUL and SquareMod.
In Lemma 3, the
iterations imply that a scalar multiplication of the form
of a given point
Q is performed on a given point
Q. To evaluate the execution time of the
SquareMod algorithm, a test code was implemented to execute the algorithm 100,000 times for each word length
w with
. Additionally, the memory size required for the lookup table in
SquareMod was measured for each word length. For instance, in the case of
,
Table 6 summarizes the execution time and the corresponding memory size needed for the lookup table in
SquareMod.
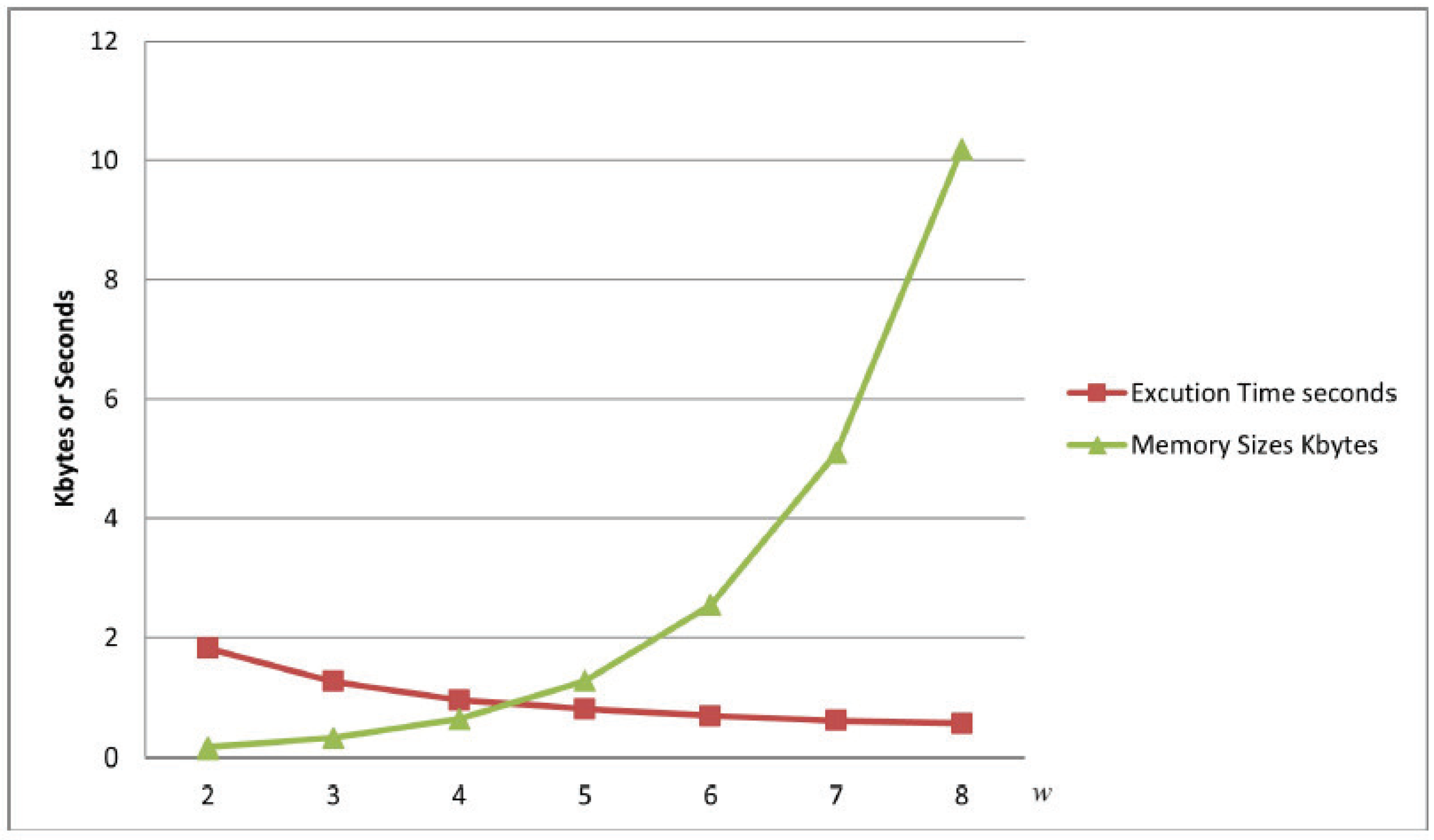
Figure 2 provides a graphical representation of the data presented in
Table 6. As evident from the table or figure, there is a trade-off between execution time and memory usage. While increasing the word length
w can enhance computational efficiency, it also results in a significant increase in the memory size required and construction times for the lookup table. This highlights the need to carefully balance performance optimization with memory constraints when implementing the
SquareMod algorithm. Finding the optimal word length will also determine the performance of scalar multiplication, meaning the efficiency of scalar multiplication is adjustable. Taking
as an example, in our program execution environment, the memory size required for each word length
w is shown in
Table 7. The execution time can be optimized by selecting an appropriate value of
w based on the hardware and software specifications of the specific execution environment.







{kind=link}
{kind=link}
{kind=link}
{kind=link}