


Adaptive Transformer-Based Deep Learning Framework for Continuous Sign Language Recognition and Translation

 ,
,  ,
,  , and
, and
Abstract
1. Introduction
- To increase translation performance and relieve the poorly guided difficulty of end-to-end SLT, we suggest an adaptive video representation enhanced Transformer (AVRET), which is both simple and effective. The Transformer-based network may accommodate three more AVRET modules at no additional cost;
- We built the first CSL video dataset based on a news corpus, CSL-FocusOn, and describe and offer a method for collecting CSL videos. It is easy to extend and has a vast corpus of contents.
2. Related Works
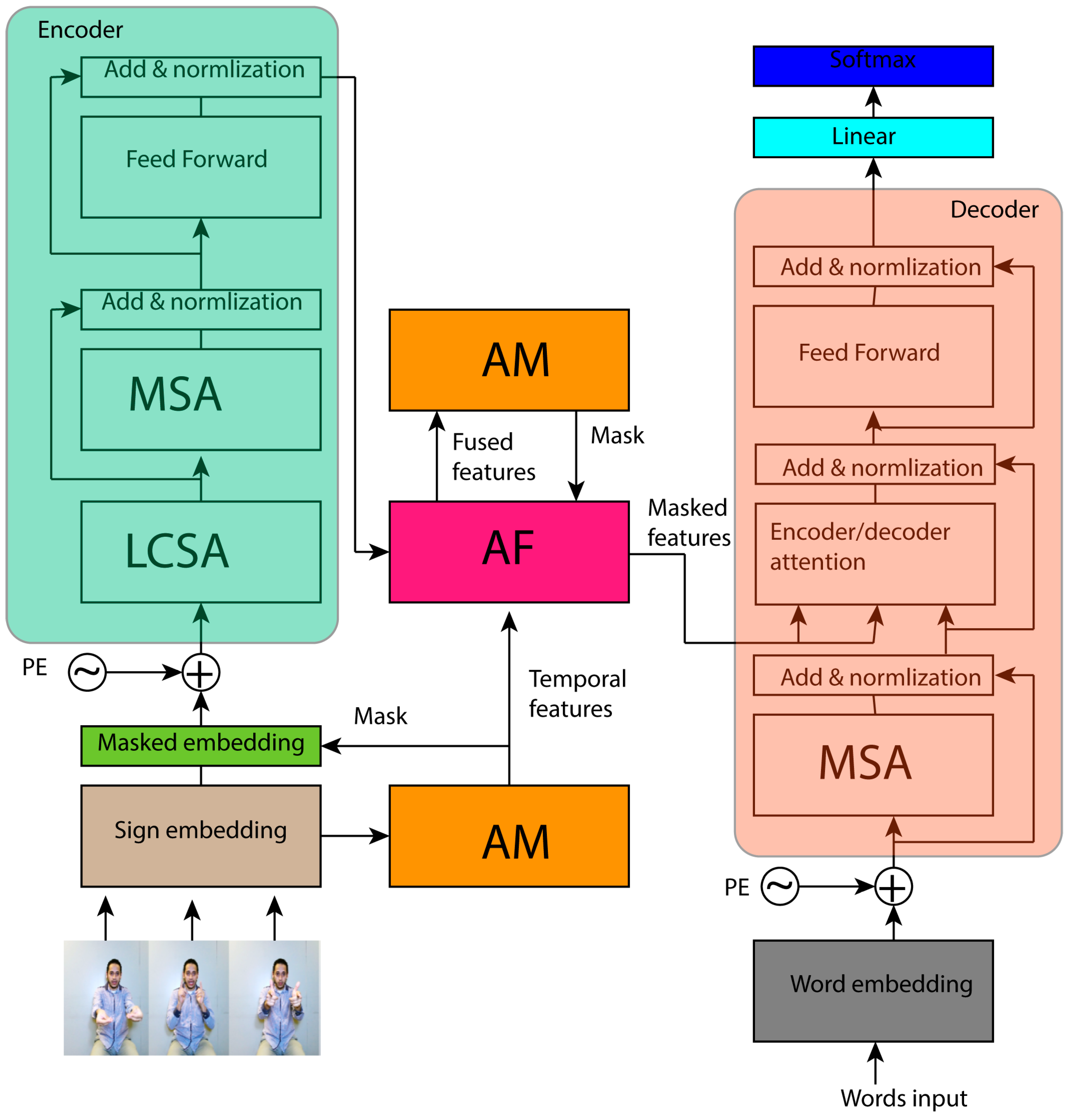
3. Proposed Approach
3.1. Overview
3.2. Adaptive Masking
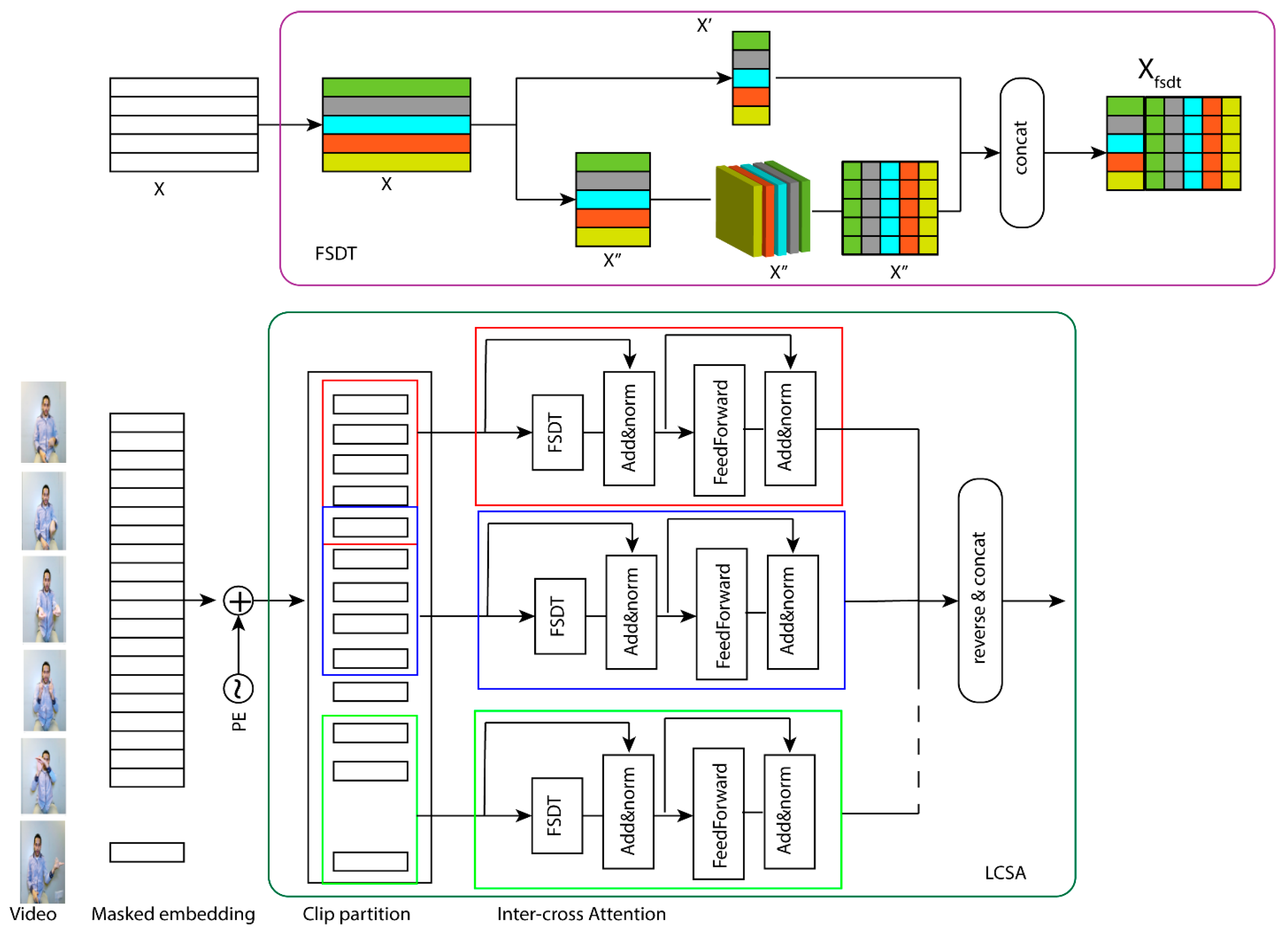
3.3. Local Clip Self-Attention
3.4. Adaptive Fusion
3.5. Loss Function with Joint Design
4. Experiments and Results
4.1. Dataset
4.2. Implementation Details
4.3. Results and Comparison Study
4.4. Discussion
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Camgoz, N.C.; Hadfield, S.; Koller, O.; Ney, H.; Bowden, R. Neural sign language translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7784–7793. [Google Scholar]
- Orbay, A.; Akarun, L. Neural sign language translation by learning tokenization. In Proceedings of the 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 222–228. [Google Scholar]
- Li, D.; Xu, C.; Yu, X.; Zhang, K.; Swift, B.; Suominen, H.; Li, H. TSPNet: Hierarchical feature learning via temporal semantic pyramid for sign language translation. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; pp. 12034–12045. [Google Scholar]
- Yin, A.; Zhong, T.; Tang, L.; Jin, W.; Jin, T.; Zhao, Z. Gloss attention for gloss-free sign language translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 2551–2562. [Google Scholar]
- Zhou, B.; Chen, Z.; Clapés, A.; Wan, J.; Liang, Y.; Escalera, S.; Lei, Z.; Zhang, D. Gloss-free sign language translation: Improving from visual-language pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 20871–20881. [Google Scholar]
- Wei, C.; Zhao, J.; Zhou, W.; Li, H. Semantic boundary detection with reinforcement learning for continuous sign language recognition. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1138–1149. [Google Scholar] [CrossRef]
- Yin, W.; Hou, Y.; Guo, Z.; Liu, K. Spatial–temporal enhanced network for continuous sign language recognition. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 1684–1695. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, J.; Shen, Z.; Chen, X.; Wu, Q.; Gui, Z.; Senhadji, L.; Shu, H. Improving End-to-end Sign Language Translation with Adaptive Video Representation Enhanced Transformer. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 8327–8342. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Sign language transformers: Joint end-to-end sign language recognition and translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10023–10033. [Google Scholar]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.; Fan, H.; Xie, S.; Wu, C.-Y.; Yuille, A.; Feichtenhofer, C. Masked feature prediction for self-supervised visual pre-training. arXiv 2021, arXiv:2112.09133. [Google Scholar]
- Pan, T.; Song, Y.; Yang, T.; Jiang, W.; Liu, W. VideoMoCo: Contrastive video representation learning with temporally adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11205–11214. [Google Scholar]
- Yan, L.; Ma, S.; Wang, Q.; Chen, Y.; Zhang, X.; Savakis, A.; Liu, D. Video captioning using global–local representation. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6642–6656. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Fan, C.; Yi, J.; Tao, J.; Tian, Z.; Liu, B.; Wen, Z. Gated recurrent fusion with joint training framework for robust end-to-end speech recognition. IEEE ACM Trans. Audio Speech Lang. Process. 2021, 29, 198–209. [Google Scholar] [CrossRef]
- Jiang, W.; Zhou, W.; Hu, H. Double-stream position learning transformer network for image captioning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7706–7718. [Google Scholar] [CrossRef]
- Yin, K.; Read, J. Better sign language translation with STMC transformer. In Proceedings of the 28th International Conference on Computational Linguistics, Online, 8–13 December 2020; pp. 5975–5989. [Google Scholar]
- Zhou, H.; Zhou, W.; Zhou, Y.; Li, H. Spatial–temporal multi-cue network for sign language recognition and translation. IEEE Trans. Multimed. 2022, 24, 768–779. [Google Scholar] [CrossRef]
- Liu, T.; Zhang, C.; Lam, K.-M.; Kong, J. Decouple and resolve: Transformer-based models for online anomaly detection from weakly labeled videos. IEEE Trans. Inf. Forensics Secur. 2023, 18, 15–28. [Google Scholar] [CrossRef]
- Zhang, C.; Su, J.; Ju, Y.; Lam, K.-M.; Wang, Q. Efficient inductive vision transformer for oriented object detection in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5616320. [Google Scholar] [CrossRef]
- Xie, P.; Zhao, M.; Hu, X. PiSLTRc: Position-informed sign language transformer with content-aware convolution. IEEE Trans. Multimed. 2022, 24, 3908–3919. [Google Scholar] [CrossRef]
- Yin, A.; Zhao, Z.; Liu, J.; Jin, W.; Zhang, M.; Zeng, X.; He, X. SimulSLT: End-to-end simultaneous sign language translation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 4118–4127. [Google Scholar]
- Chen, Y.; Wei, F.; Sun, X.; Wu, Z.; Lin, S. A simple multi-modality transfer learning baseline for sign language translation. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 5110–5120. [Google Scholar]
- Kan, J.; Hu, K.; Hagenbuchner, M.; Tsoi, A.C.; Bennamoun, M.; Wang, Z. Sign language translation with hierarchical spatio-temporal graph neural network. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2022; pp. 2131–2140. [Google Scholar]
- Fu, B.; Ye, P.; Zhang, L.; Yu, P.; Hu, C.; Shi, X.; Chen, Y. A token-level contrastive framework for sign language translation. arXiv 2022, arXiv:2204.04916. [Google Scholar]
- Zhou, H.; Zhou, W.; Qi, W.; Pu, J.; Li, H. Improving sign language translation with monolingual data by sign back-translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1316–1325. [Google Scholar]
- Huang, J.; Huang, Y.; Wang, Q.; Yang, W.; Meng, H. Self-supervised representation learning for videos by segmenting via sampling rate order prediction. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 3475–3489. [Google Scholar] [CrossRef]
- Jenni, S.; Meishvili, G.; Favaro, P. Video representation learning by recognizing temporal transformations. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 425–442. [Google Scholar]
- Tao, L.; Wang, X.; Yamasaki, T. An improved inter-intra contrastive learning framework on self-supervised video representation. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5266–5280. [Google Scholar] [CrossRef]
- Gan, C.; Gong, B.; Liu, K.; Su, H.; Guibas, L.J. Geometry guided convolutional neural networks for self-supervised video representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5589–5597. [Google Scholar]
- Korbar, B.; Tran, D.; Torresani, L. Cooperative learning of audio and video models from self-supervised synchronization. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 2–8 December 2018; pp. 7763–7774. [Google Scholar]
- Sun, C.; Myers, A.; Vondrick, C.; Murphy, K.; Schmid, C. VideoBERT: A joint model for video and language representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7464–7473. [Google Scholar]
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Multi-channel transformers for multi-articulatory sign language translation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 301–319. [Google Scholar]
- Ye, J.; Jiao, W.; Wang, X.; Tu, Z.; Xiong, H. Cross-modality data augmentation for end-to-end sign language translation. arXiv 2023, arXiv:2305.11096. [Google Scholar]
- Luqman, H. ArabSign: A multi-modality dataset and benchmark for continuous Arabic Sign Language recognition. In Proceedings of the 2023 IEEE 17th International Conference on Automatic Face and Gesture Recognition (FG), Waikoloa Beach, HI, USA, 5–8 January 2023; pp. 1–8. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RGB resolution | 1920 × 1080 |
| Number of signers | 6 |
| Depth resolution | 512 × 424 |
| Vocabulary size | 95 |
| Minimum video duration | 1.3 s |
| Maximum video duration | 10.4 s |
| FPS | 30 |
| Average words/sample | 3.1 |
| Repetitions/sentence | ≥30 |
| Body joints | 21 |
| Total hours | 10.13 |
| Total Samples | 9335 |
| Model | Gloss Free | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dev | Test | |||||||||
| ROUGE | BLEU1 | BLEU2 | BLEU3 | BLEU4 | ROUGE | BLEU1 | BLEU2 | BLEU3 | BLEU4 | |
| Multi-channel [36] | 44.59 | 19.51 | 43.57 | 18.5 | ||||||
| STMC-T [19] | 39.76 | 40.73 | 29.42 | 22.61 | 18.21 | 39.82 | 39.07 | 26.74 | 21.86 | 15.74 |
| SimulSLT [23] | 36.38 | 36.21 | 23.88 | 17.41 | 13.57 | 35.88 | 37.01 | 24.70 | 17.98 | 14.10 |
| RNN bahdanau [1] | 31.80 | 31.87 | 19.11 | 13.16 | 9.94 | 31.80 | 32.24 | 19.03 | 12.83 | 9.58 |
| RNN luong [1] | 32.60 | 31.58 | 18.98 | 13.22 | 10 | 30.70 | 29.86 | 17.52 | 11.96 | 9 |
| Multitask-T [2] | 36.28 | 37.22 | 23.88 | 17.08 | 13.25 | |||||
| TSPNet-Joint [3] | 34.96 | 36.10 | 23.12 | 16.88 | 13.41 | |||||
| GASLT [4] | 39.86 | 39.07 | 26.74 | 21.86 | 15.74 | |||||
| ADTR-VLP (ours) | 47.92 | 47.01 | 35.03 | 27.84 | 22.91 | 46.91 | 46.89 | 34.84 | 27.48 | 22.73 |
| With gloss | ||||||||||
| SLTT-S2T [10] | 45.54 | 32.60 | 25.30 | 20.69 | 45.34 | 32.31 | 24.83 | 20.17 | ||
| SignBT [27] | 50.29 | 51.11 | 37.90 | 29.80 | 24.45 | 49.54 | 50.80 | 37.75 | 29.72 | 24.32 |
| PiSLTRcS2T [22] | 47.89 | 46.51 | 33.78 | 26.78 | 21.48 | 48.13 | 46.22 | 33.56 | 26.04 | 21.29 |
| HSTGNN [25] | 46.10 | 33.40 | 27.50 | 22.60 | 45.20 | 34.70 | 27.50 | 22.79 | ||
| ConSLT [26] | 48.73 | 36.53 | 29.03 | 24 | ||||||
| XmDA [35] | 48.05 | 22.90 | 47.33 | 46.84 | 34.69 | 27.50 | 22.79 | |||
| MMTLB [34] | 45.84 | 47.31 | 33.64 | 25.83 | 20.76 | 45.93 | 47.40 | 34.30 | 26.47 | 21.44 |
| ADTR (ours) | 50.28 | 50.37 | 37.91 | 29.84 | 24.53 | 50.89 | 51.49 | 38.72 | 30.44 | 24.93 |
| {k1, k2} | Dev | Test |
| {0, 0} | 22.74 | 22.98 |
| {0, 2} | 23.62 | 23.22 |
| {0, 4} | 23.77 | 23.51 |
| {0, 6} | 22.26 | 22.79 |
| {0, 10} | 20.54 | 20.93 |
| {2, 0} | 23.18 | 23.73 |
| {2, 2} | 23.89 | 24.31 |
| {2, 4} | 24.53 | 24.91 |
| {2, 6} | 22.78 | 23.01 |
| {4, 0} | 23.31 | 23.76 |
| {4, 2} | 23.56 | 23.28 |
| {4, 4} | 21.28 | 21.66 |
| {r1, r2} | Dev | Test |
| {0, 4} | 22.45 | 22.67 |
| {2, 0} | 22.12 | 21.85 |
| {2, 4} | 22.61 | 22.96 |
| {4, 2} | 23.42 | 22.78 |
| Encoder Attention | Dev | Test |
|---|---|---|
| MSA | 22.45 | 22.89 |
| MSA/ICA | 21.68 | 22.28 |
| CCP/MSA | 22.83 | 23.35 |
| CP/MSA | 23.34 | 23.76 |
| CP/LCSA | 23.66 | 24.27 |
| CP/MSA/MSA | 23.78 | 24.46 |
| CP/LCSA/MSA | 24.52 | 24.92 |
| Fusion | Dev | Test |
|---|---|---|
| GRF [16] | 23.94 | 24.58 |
| 21.78 | 22.47 | |
| 22.95 | 23.58 | |
| 23.73 | 24.04 | |
| 24.64 | 24.98 | |
| ) | 23.32 | 22.97 |
| ) | 23.84 | 24.43 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Said, Y.; Boubaker, S.; Altowaijri, S.M.; Alsheikhy, A.A.; Atri, M. Adaptive Transformer-Based Deep Learning Framework for Continuous Sign Language Recognition and Translation. Mathematics 2025, 13, 909. https://doi.org/10.3390/math13060909
Said Y, Boubaker S, Altowaijri SM, Alsheikhy AA, Atri M. Adaptive Transformer-Based Deep Learning Framework for Continuous Sign Language Recognition and Translation. Mathematics. 2025; 13(6):909. https://doi.org/10.3390/math13060909
Chicago/Turabian StyleSaid, Yahia, Sahbi Boubaker, Saleh M. Altowaijri, Ahmed A. Alsheikhy, and Mohamed Atri. 2025. "Adaptive Transformer-Based Deep Learning Framework for Continuous Sign Language Recognition and Translation" Mathematics 13, no. 6: 909. https://doi.org/10.3390/math13060909
APA StyleSaid, Y., Boubaker, S., Altowaijri, S. M., Alsheikhy, A. A., & Atri, M. (2025). Adaptive Transformer-Based Deep Learning Framework for Continuous Sign Language Recognition and Translation. Mathematics, 13(6), 909. https://doi.org/10.3390/math13060909