1. Introduction
As the core control center of rail transit systems, the train control system (TCS) plays a crucial role in ensuring safe and efficient train operations. The train positioning system, serving as a critical component of TCS, provides real-time precise position information that forms the foundation for key functions such as train protection curve calculation and movement authority generation. Current positioning solutions predominantly employ a hybrid architecture combining onboard equipment (e.g., odometers and Doppler radars) with wayside facilities (e.g., balises and track circuits) [
1], with satellite positioning technology additionally integrated in specific lines such as the Qinghai–Tibet Railway [
2]. However, existing train positioning technologies based on vehicle-ground collaboration present a significant technical–economic contradiction: the pursuit of high-precision positioning necessitates high-density deployment of ground-based infrastructure, resulting in exponentially increasing system operation and maintenance costs. Notably, as rail transit systems evolve toward automated operation and intelligent maintenance paradigms [
3], conventional positioning methodologies relying on dedicated ground equipment are becoming increasingly inadequate to meet the dual requirements of economic viability and operational reliability demanded by advanced train control systems. Consequently, achieving a technological breakthrough in ground equipment-independent autonomous train positioning has emerged as a critical pathway for advancing intelligent rail transportation development. Therefore, research on autonomous train positioning methodologies holds substantial theoretical significance and engineering application value, particularly in addressing the evolving needs of next-generation rail transit systems.
To address these technical challenges, researchers have conducted extensive explorations from multiple dimensions, leading to several representative solutions: machine vision-based roadside feature recognition [
4], LiDAR point cloud matching [
5], mobile communication-based base station positioning [
6], and laser ranging-based dynamic correction [
7]. Experimental data indicate that machine vision methods perform well for positioning under adequate illumination conditions but experience performance degradation in low-light environments, with complete functional failure occurring under adverse meteorological conditions (e.g., fog, rain, or snow). Although LiDAR point cloud matching technology overcomes illumination limitations inherent in optical imaging, its point cloud resolution remains visibility-dependent, failing to completely eliminate performance degradation or failure in severe weather scenarios. While mobile communication-based positioning solutions can leverage existing infrastructure, they exhibit significantly increased positioning errors in environments with pronounced multipath effects, such as tunnels. The laser ranging system demonstrates relatively low architectural complexity but is prone to position divergence in feature-sparse environments. Comprehensive analysis reveals that existing single-sensor modalities exhibit significant performance boundaries in complex operational environments, highlighting the technical bottleneck of current solutions in meeting the full-scenario positioning requirements of rail transit under diverse working conditions. In this context, multi-source information fusion positioning technology has emerged as a research focus [
8], demonstrating enhanced environmental adaptability and higher reliability through coordinated integration of heterogeneous sensor data.
Notably, while improving positioning performance, multi-source fusion technology introduces significant computational demands: the exponential growth of data volume from multi-sensor acquisition, coupled with the requirement for sophisticated modeling to achieve heterogeneous data fusion. This poses substantial challenges to the processing capacity of onboard security computers, often necessitating auxiliary computing units in conventional architectures. Although cloud computing offers advantages in elastic computing resources, the data transmission between cloud platforms and onboard terminals suffers from unpredictable communication latency and bandwidth consumption. In contrast, edge computing demonstrates unique strengths in reducing latency sensitivity and communication overhead through its proximal deployment characteristics, thereby providing a viable technical pathway for engineering implementation of multi-source fusion positioning systems [
9].
Edge computing demonstrates excellent performance in fast sensing and the computing of massive sensor data to optimize decision-making [
10]. H. Song et al. [
11] break the data segregation under an autonomous train control system (ATCS) by applying data prediction and edge computing-based information fusion to process real dynamic data and estimate train speed and position. L. Zhu et al. [
12] proposed a collaborative train and edge computing framework to provide real-time communication and computation services. L. Li et al. [
13] proposed a Mobile Edge Computing (MEC) framework for millimeter-wave train–ground communication systems and a resource allocation and computation offloading (RACO) algorithm. M. Saki et al. [
14] proposed a new framework for a future data-driven Railway Condition Monitoring (RCM) system and designed an edge processing unit. E. Pencheva et al. [
15] designed a new mobile edge service to provide core functionality for many railroad use cases, supporting data sessions for application launch and operation. Although existing methods have made significant advancements in edge computing and multi-sensor fusion for train positioning, they face limitations in ensuring reliable performance under dynamic conditions [
16].
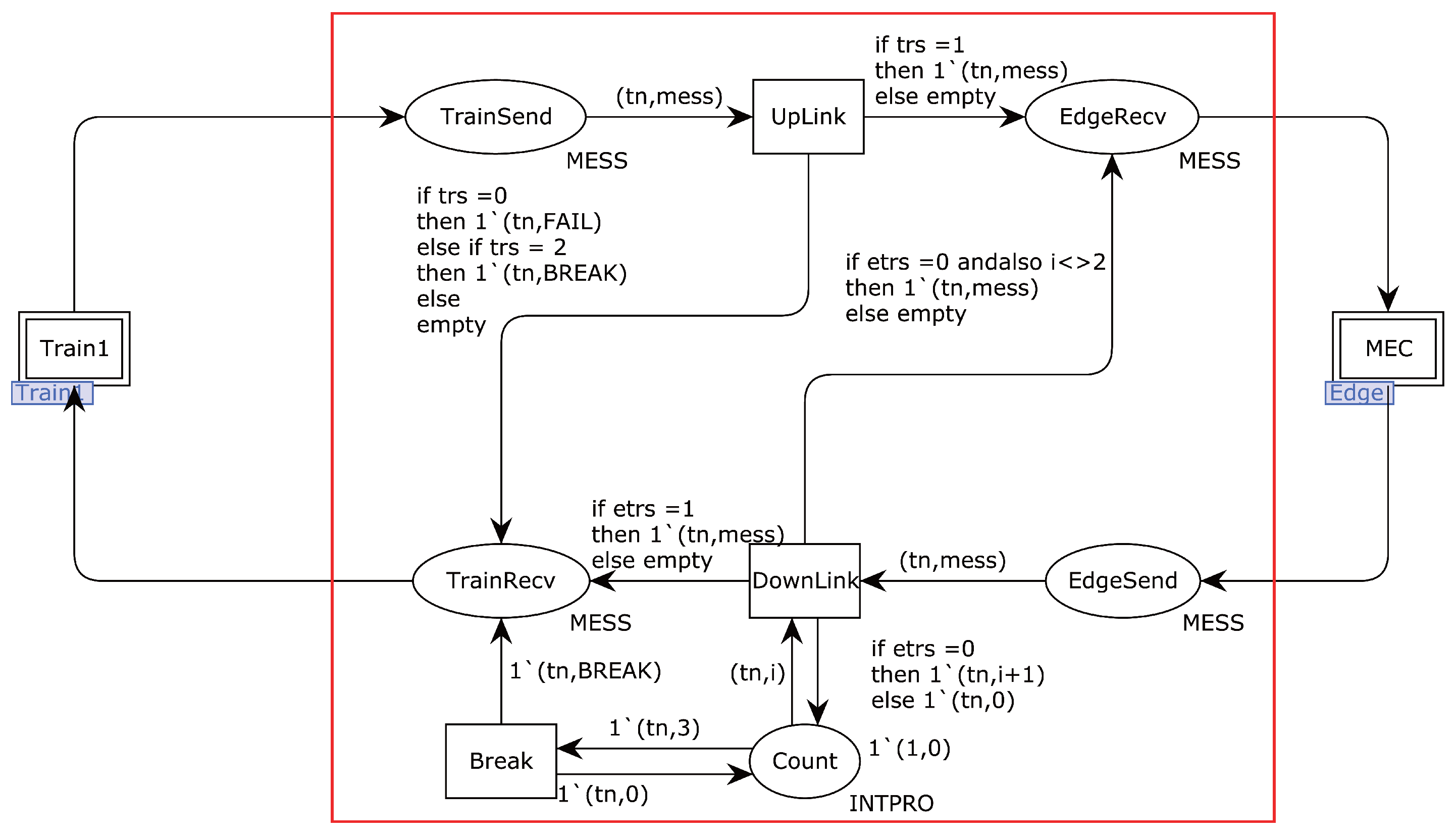
Additionally, the complex operating environment of trains under edge computing may lead to data transmission failures, and the dynamic changes in the computing resources capacity of edge servers may cause delays in processing the train’s positioning data [
17]. Therefore, designing the data processing flow for fusion positioning methods of trains under edge computing and validating their reliability holds significant theoretical and practical value. Before a system is implemented in practical applications, verifying its reliability is crucial. To achieve this, an essential procedure that translates the system’s behaviors and performances into a computerized model is necessary. Formal methods play a pivotal role in this context by providing a clear and unambiguous description of a system’s properties using rigorous mathematical symbols and rules. This approach not only facilitates the identification of logical and functional deficiencies, but also significantly enhances design reliability [
18].
The main contributions of this paper are as follows:
A novel train fusion positioning method is introduced, leveraging edge computing to reduce onboard computational load and enhance real-time positioning accuracy.
A CPN model is proposed to ensure the system’s reliability and functional safety, providing a formal verification framework.
State-space analysis is conducted to validate the system’s safety under various fault conditions, demonstrating resilience during communication failures and limited computing resources.
Numerical experiments analyze factors influencing data processing delays, and a reference boundary for train tracking under edge computing is calculated to ensure safe operations.
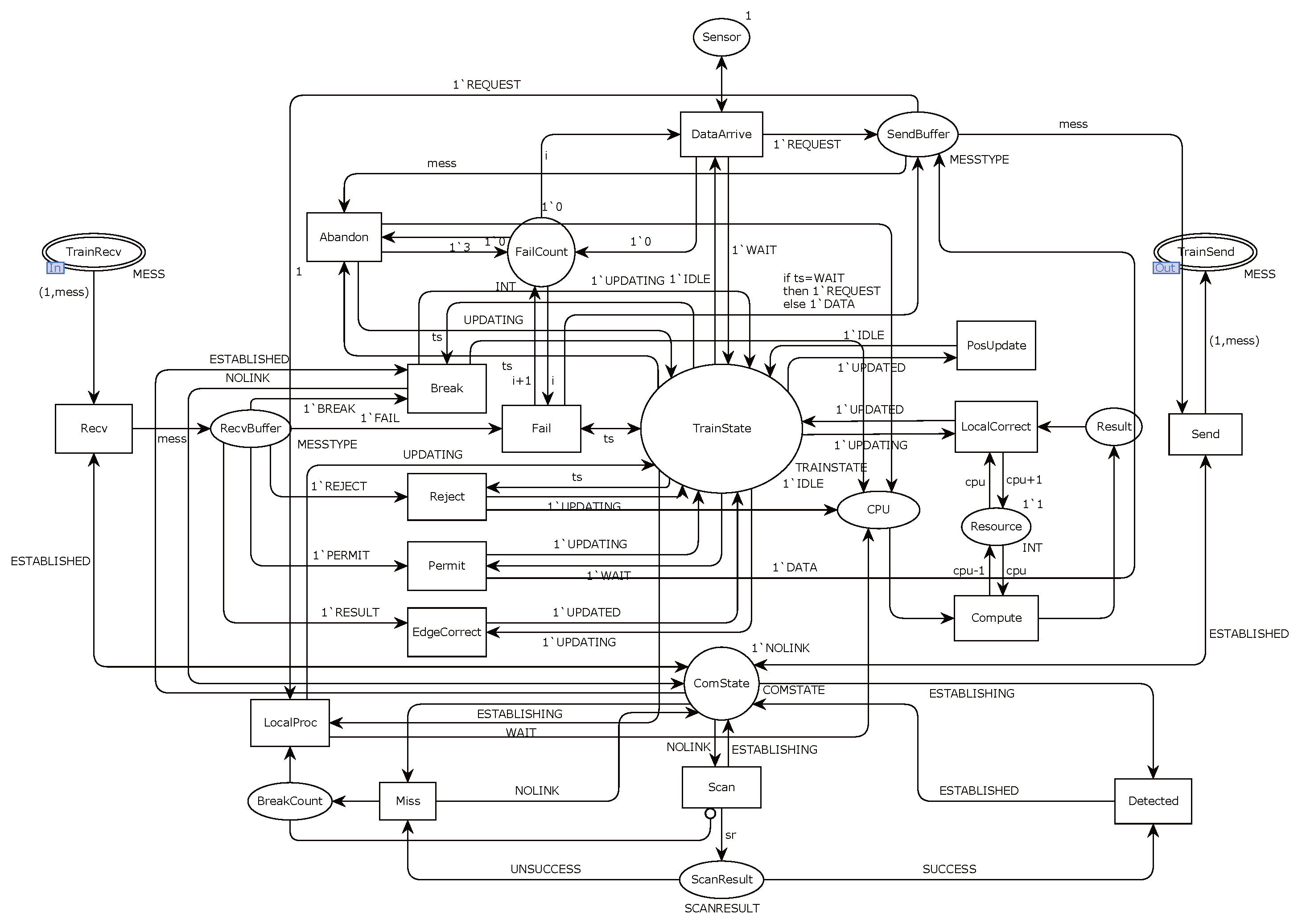
3. System Structure of Train Fusion Positioning Method Based on Edge Computing
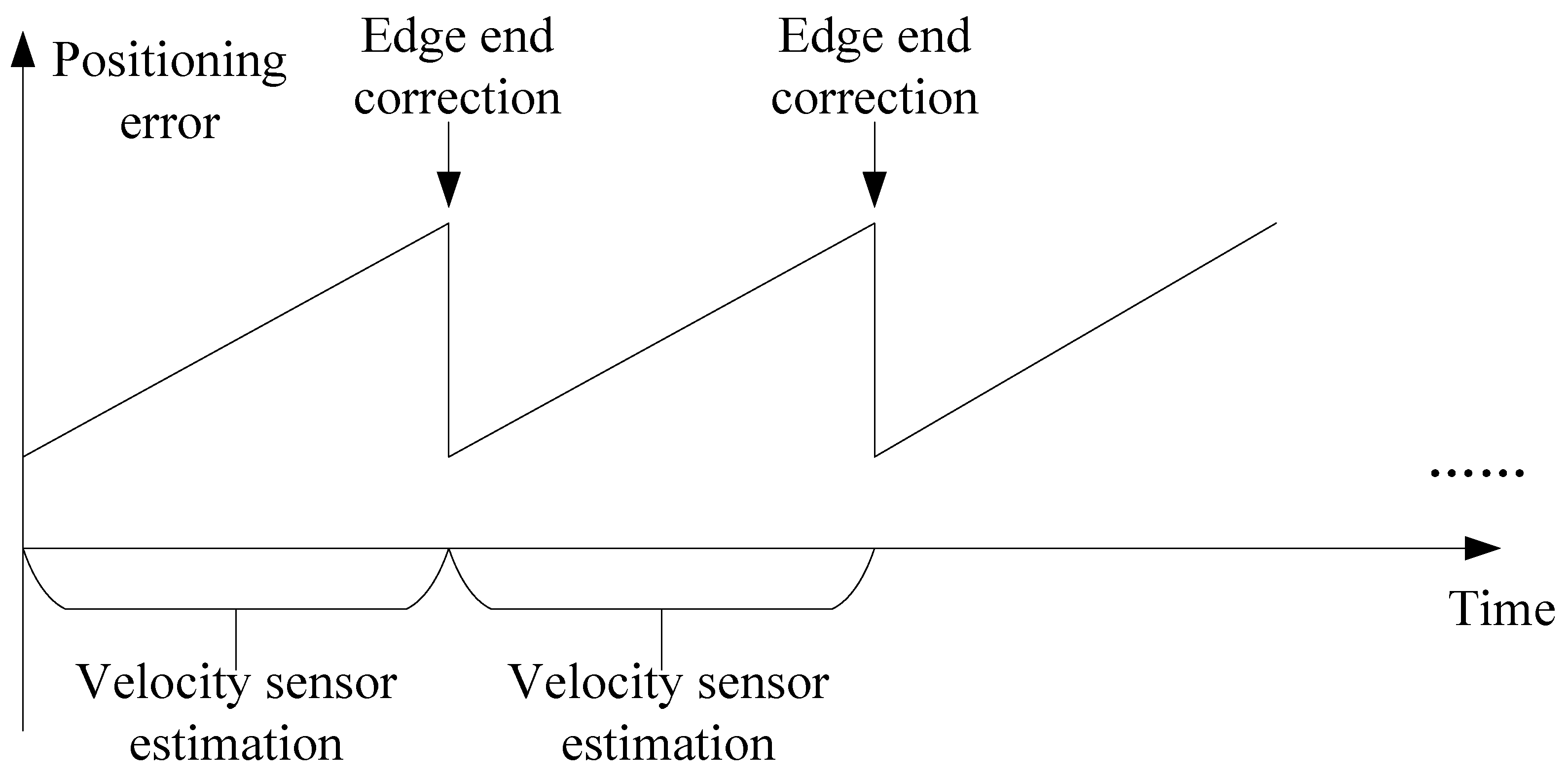
Coasting and slipping during train operation can cause gradual positioning errors if only the speed sensor is used [
30]. To reduce these errors and improve accuracy, the train calculates the traveled distance with the speed sensor and regularly transmits data from other onboard sensors, such as GNSS and INS, to the edge server via the train–ground communication link. The edge server processes these data and sends back the corrected position, ensuring more precise and reliable positioning, as shown in
Figure 1.
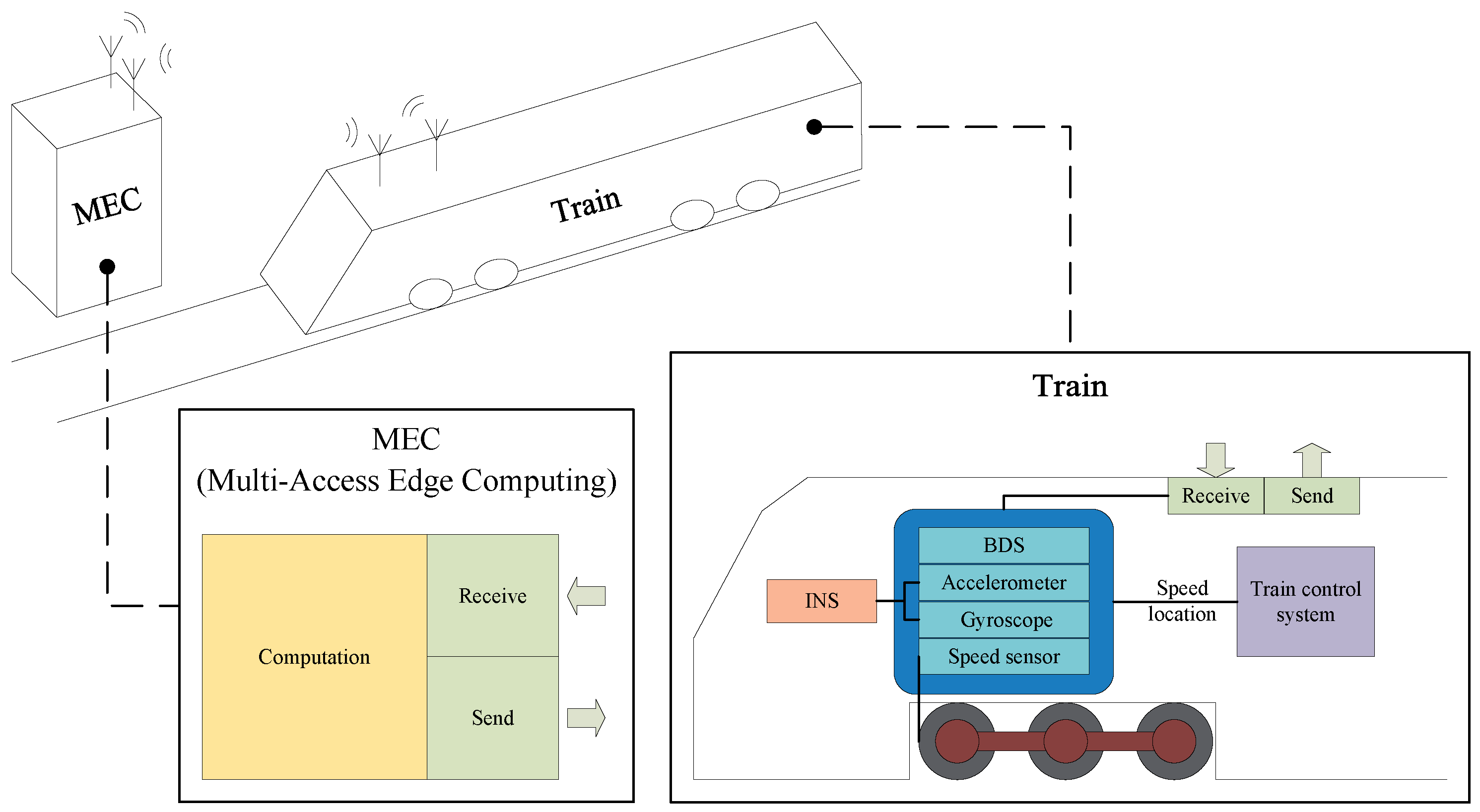
In the edge computing-based train fusion positioning framework, a variety of sensors are installed on the train to monitor its operational status, including speed sensors, GNSS, and Inertial Navigation System (INS) devices. These sensors generate real-time data that are essential for determining the train’s position. The onboard system utilizes speed data to calculate the traveled distance, which serves as the basis for initial positioning. The edge device, located on the ground, consists of computing units and wireless transceivers that receive, process, and transmit the sensor data back to the train, as illustrated in
Figure 2.
The train module uses an extended Kalman filter (EKF) for real-time sensor data fusion, incorporating inputs from GNSS, inertial sensors, and speed sensors. In the edge module, we utilize a dynamic task allocation algorithm to prioritize computational resources based on the real-time processing needs of multiple trains. The multi-sensor fusion technique leverages a weighted fusion strategy to balance sensor reliability and minimize positioning errors. For details on the offloading algorithm used in the specific example, readers can refer to our previously published papers [
31].
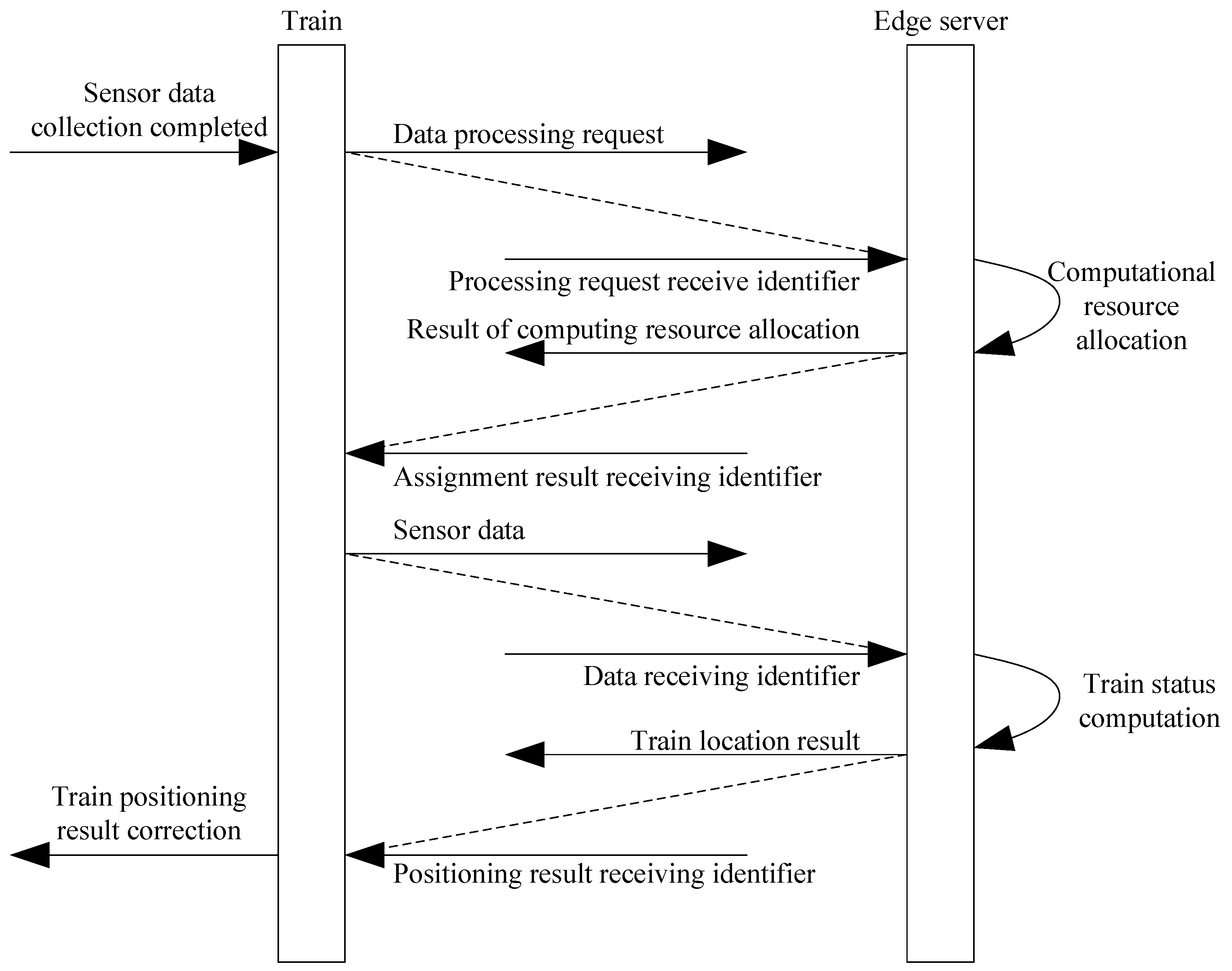
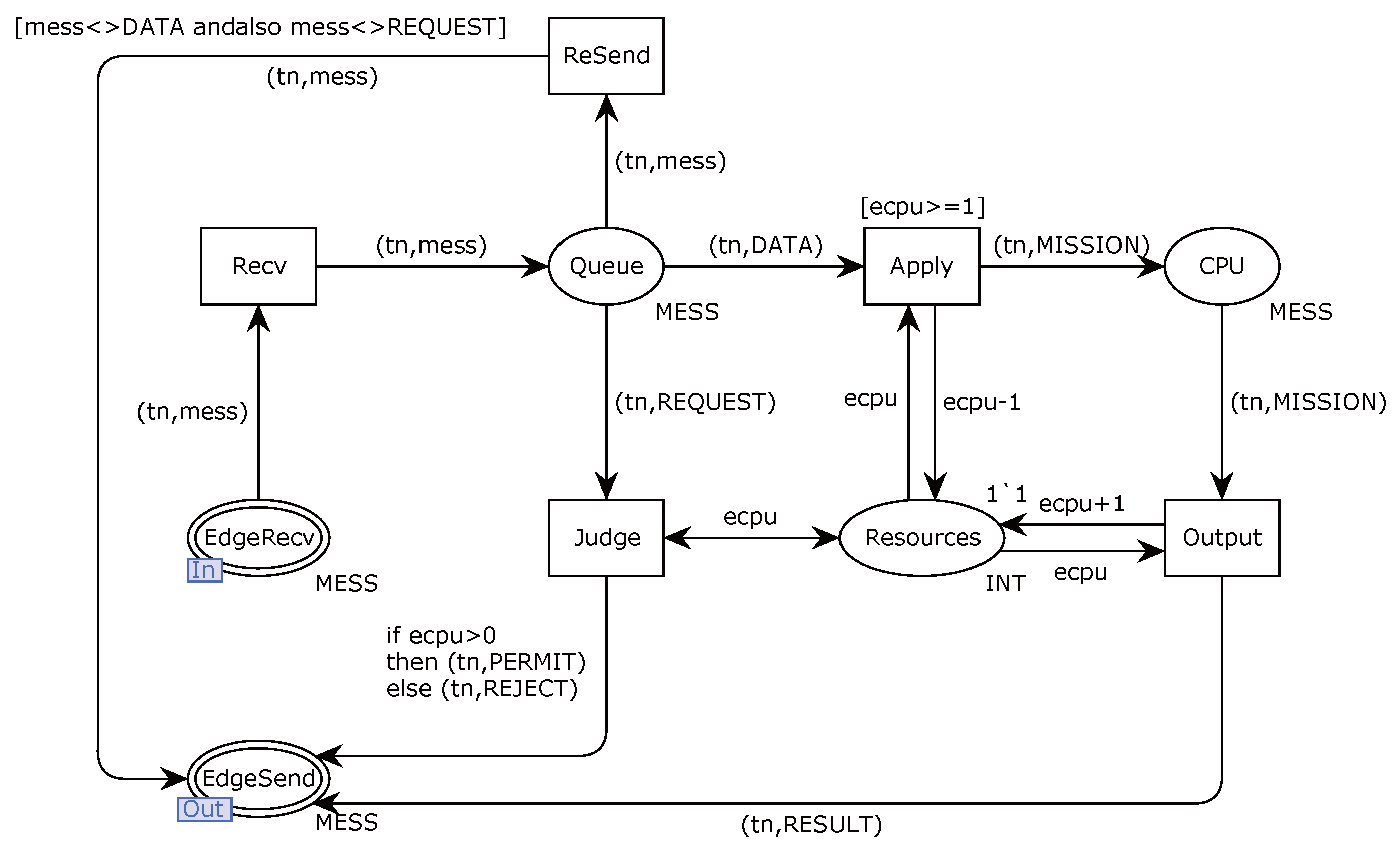
The communication sequence between the onboard system and the edge server follows a structured process, as illustrated in
Figure 3. First, the train collects sensor data
, where
t represents the current time:
After completing the data collection, the train sends a data processing request
and identification
to the edge server:
where
represents the algorithm complexity, the edge server allocates computational resources
based on its current load
and transmits the result back to the train:
Once the train receives the resource allocation, it sends the collected sensor data
to the edge server for processing:
The edge server processes the sensor data and performs the necessary calculations to generate the positioning result
:
Finally, the edge server transmits the positioning result back to the train, and the train updates its position accordingly:
This sequence ensures the efficient processing and correction of the train’s position by leveraging edge computing, reducing onboard computational load while maintaining real-time positioning accuracy.
6. Numerical Performance Analysis
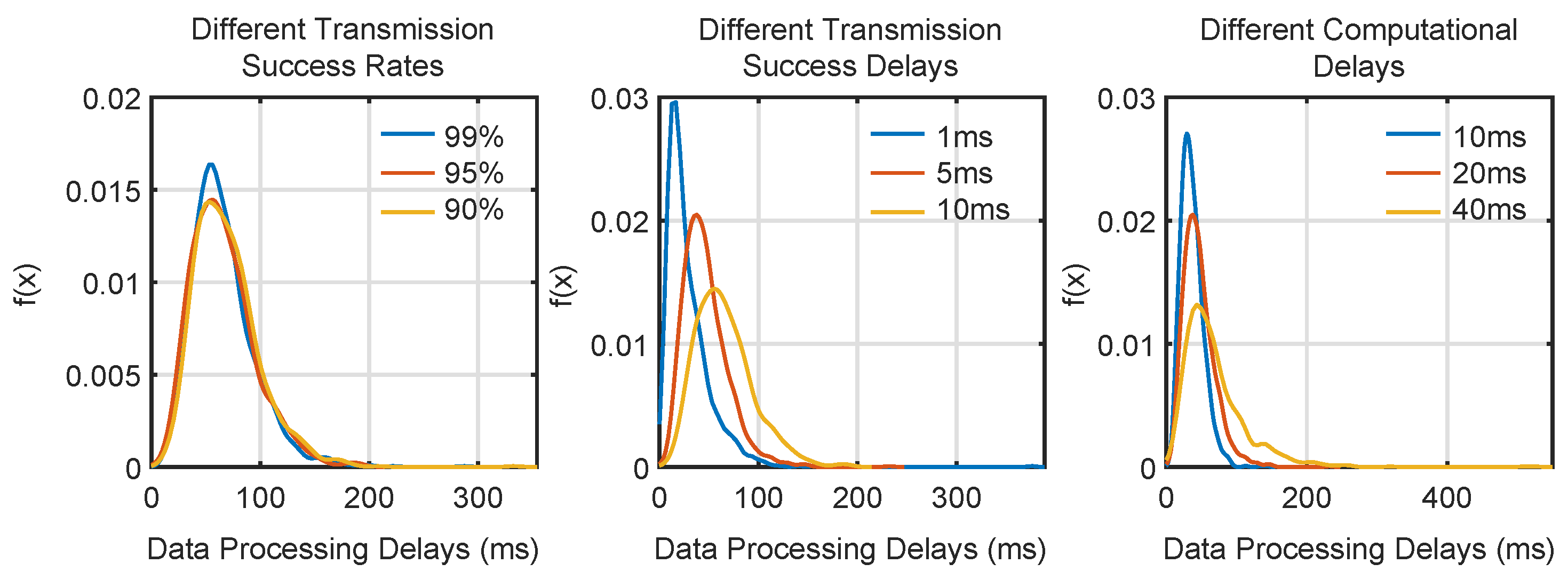
On the basis of verifying the functional safety of the method, the performance of the method under different conditions was analyzed. In the train fusion positioning method under edge computing, the data transmission success rate, transmission delay, and edge server computing delay will all affect the data processing timeliness of the method. Adding conditional triggering rules to directed arcs in the model and injecting random delay parameters into specific transitions can simulate the impact of the above disadvantages on the method. The method process is simulated based on the established CPN model, and the data monitor of CPN Tools is used to record the data processing delay of each position correction process. Based on the collected simulation data, the probability density distribution of data processing delays under different levels of influencing factors is obtained, as shown in
Figure 7.
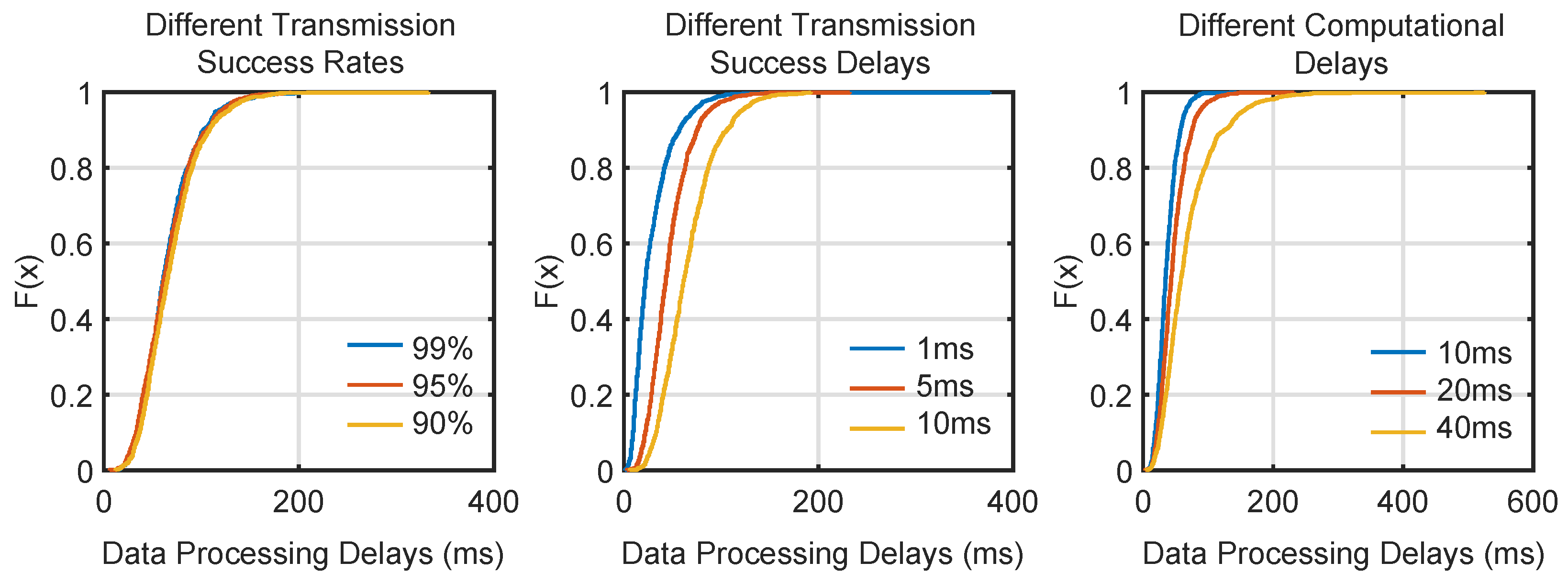
The corresponding cumulative distribution is shown in
Figure 8. It can be seen that changes in different data transmission delays have the greatest impact on method data processing latency, followed by edge server computing latency, and data transmission failure rate has the least impact. Hence, transmission delay plays the most significant role in influencing data processing time, likely due to the inherent limitations of train–ground communication systems. In high-speed environments, even minor transmission disruptions can lead to significant delays in data relay between the train and edge server. These delays are exacerbated by environmental factors such as signal interference or train velocity.
In order to further verify the above conclusion, the orthogonal experimental method was used to conduct a qualitative analysis of each influencing factor based on the simulation results. The specific selected influencing factor levels are shown in
Table 6.
According to the influencing factor level table, a three-factor and three-level orthogonal experiment was designed to obtain the model simulation results and conduct range analysis and variance analysis, as shown in
Table 7,
Table 8 and
Table 9. It can be seen from the range analysis results that compared with the other two factors, the transmission delay factor has the largest range value, indicating that changes in transmission delay have the greatest impact on data processing delays. In addition, in order to avoid errors in the results of one-sided range analysis, variance analysis was performed on the experimental results. From the variance analysis output results, it can be seen that the transmission delay factor corresponds to the largest
F value, which also shows that the transmission delay is the largest influencing factor of data processing delay, which is consistent with the range analysis results.
It can be seen from the analysis that the positioning method designed in this article requires multiple information interactions between the train and the edge server, and the data transmission delay will significantly affect the data processing efficiency. Under edge computing, data are mainly processed through edge servers, and the computing delay of the server will also have a significant impact on data processing efficiency. Under normal circumstances, the failure probability of method data transmission under edge computing is low, and the retransmission mechanism designed by the method can effectively reduce the impact of data transmission failure. The data transmission failure rate has a limited impact on the data processing delay of the method. To sum up, in the actual system development process, we should focus on reducing the data transmission delay in the train-to-ground communication process.
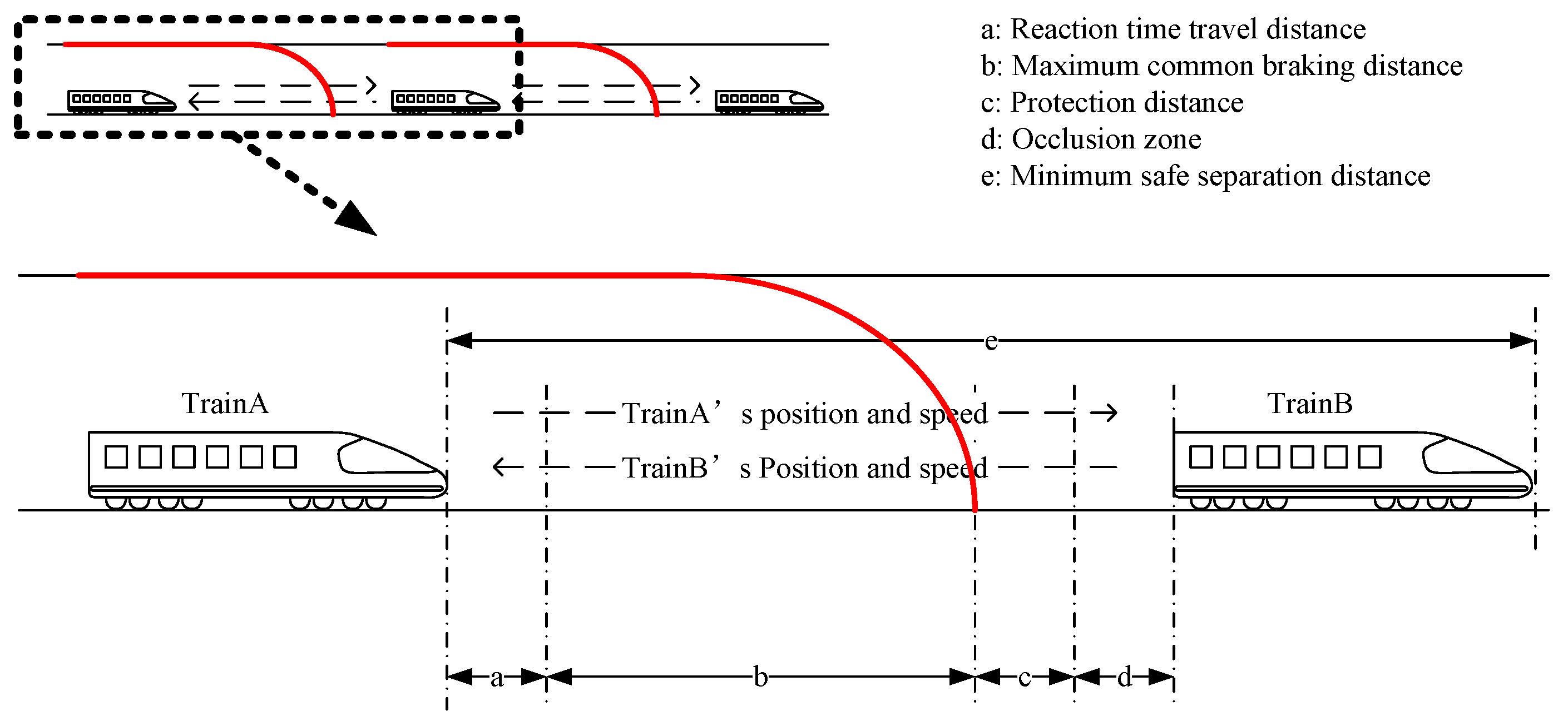
Based on the qualitative analysis results, in order to further ensure the reliability of the method, the train tracking interval under edge computing is calculated based on the mapping relationship between data processing delay and train safety tracking interval. The tracking interval represents the time interval between adjacent trains passing a certain same point, reflecting the line’s capacity. It is mainly determined by the train length
, braking reaction time travel distance
, braking distance
, safety margin distance
, and the distance from the front train to the entrance of the blockage zone where it is located
. The details are as follows:
If the train runs in a uniform deceleration state during the deceleration process and the common braking deceleration is
a, the tracking interval is as follows, where
v is the train speed:
The corresponding train speed protection curve is obtained according to the tracking separation distance, as shown in
Figure 9.
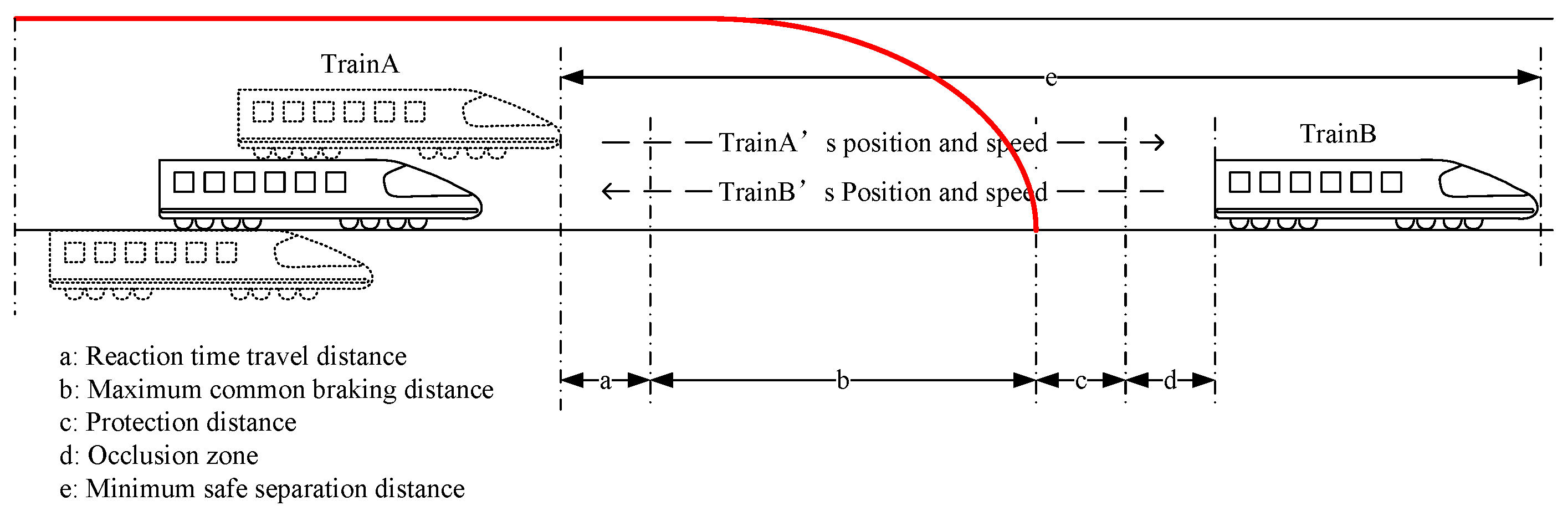
When the train has positioning errors, it will affect the tracking interval. At this time, the tracking interval of the train needs to consider the size of the train positioning error, as shown in
Figure 10.
The increase in data processing delay will lead to an increase in train positioning error, thus affecting the train tracking interval. The tracking interval considering the impact of the data processing delay is as follows, where
is the additional data processing delay.
Based on the simulation results, the distribution of data processing delays of the method under the worst case scenario (equal probability of communication link interruption, packet loss and bit error, and successful transmission during the communication process) is analyzed.
The simulation parameters are derived from the relevant literature, and their values are presented in
Table 10. The function
in the table represents the exponential distribution, where
. The delay follows an exponential distribution, expressed as follows:
where the mean of the distribution is
and the variance is
. This distribution is used for modeling data transmission delays, edge computing delays, onboard computing delays, and communication chain building delays.
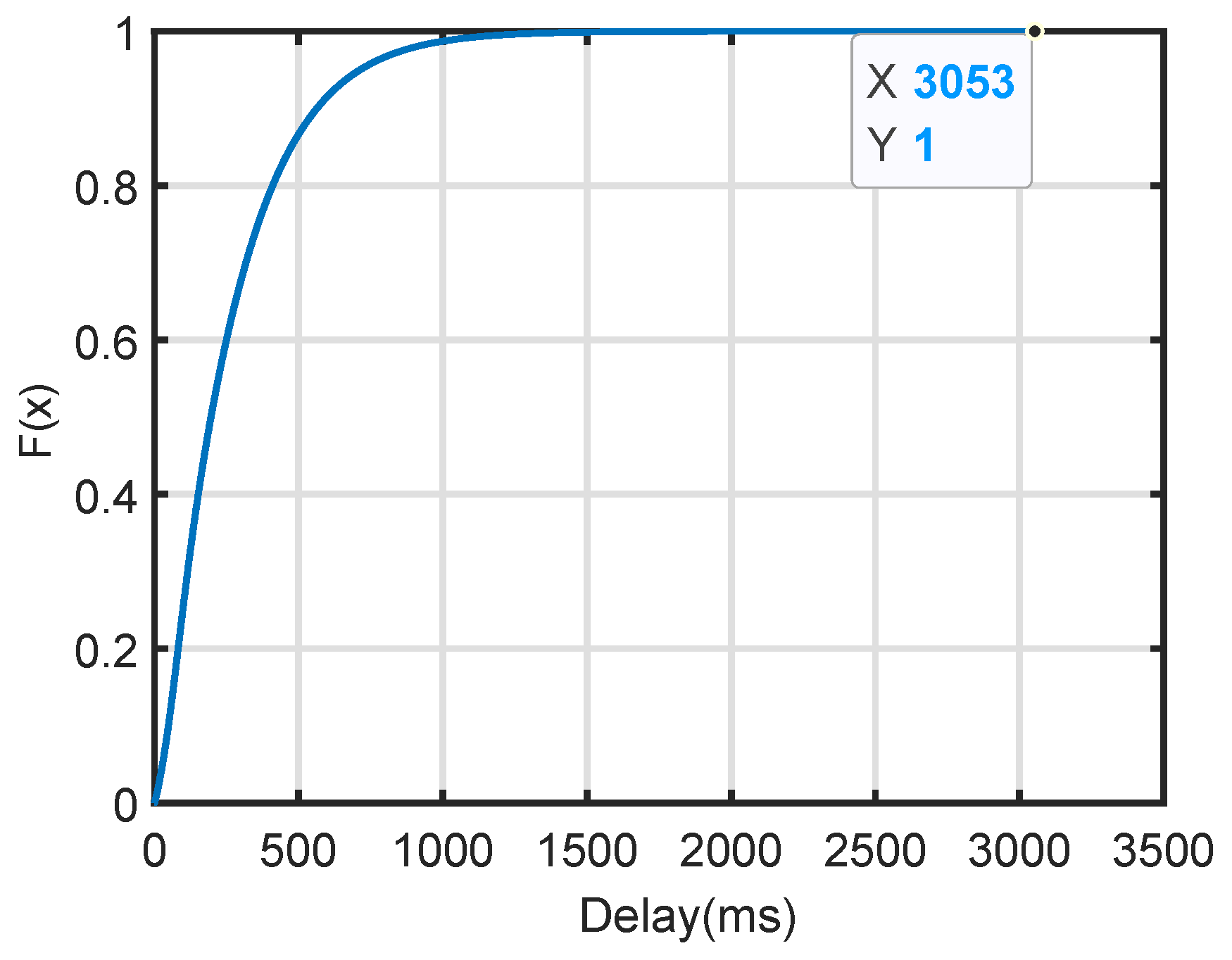
As shown in
Figure 11, the maximum processing time for train positioning data during the simulation is 3053 milliseconds. To prevent unnecessary braking within
data processing cycles, the minimum tracking interval, calculated using Equation (
11), must be more than 159 s. This ensures that the two trains maintain a safe operational distance under the edge computing-based train fusion positioning method.
The current operational status of rail transit systems in China indicates that train tracking intervals predominantly exceed 180 s. The novel train positioning system proposed in this study not only establishes a robust autonomous positioning solution, but also provides technical support for achieving shorter operational intervals through enhanced positioning accuracy. This system demonstrates significant potential for improving transportation efficiency in existing rail networks, while holding substantial engineering application value for advancing high-density train scheduling.
7. Conclusions
This study presents a comprehensive model of a train fusion positioning method utilizing edge computing, constructed and validated through the use of CPNs. Initially, the data processing flow of the method is rigorously defined within a hierarchical CPN model. Following the confirmation of the model’s validity, the method’s functional safety is assessed using state-space analysis. The findings indicate that the proposed positioning method maintains the integrity of train positioning functions across various fault scenarios. Further analysis identifies the three primary factors influencing the data processing delay of the method, highlighting that the delay in data transmission significantly impacts the positioning accuracy. Thus, enhancing the data transmission rate is pivotal in the design of actual systems. Moreover, by examining the relationship between positioning data processing delays and the minimal tracking interval, the study calculates the shortest tracking interval that ensures safe train operations under specified conditions, effectively mitigating potential train conflicts due to processing delays.
Despite these contributions, the study acknowledges several limitations that pave the way for future research. Firstly, the employed CPN model, while effective in abstractly simulating the method’s workflow, requires further refinement to mirror the intricacies of real-world systems more closely and achieve higher fidelity in the simulation of information exchange processes. Secondly, the optimization method for computational resources on edge servers is based on the assumption of simultaneous data arrival from all trains, an idealization that overlooks the stochastic nature of data arrival in practical implementations. Addressing this gap by considering the randomness in data arrival could enhance the method’s applicability. Lastly, the GNSS/INS fusion method’s reliance on historical data for training introduces variability in model performance due to differences in driving patterns influenced by human or external factors, suggesting a need to improve model generalizability and reduce prediction errors. Addressing these limitations will significantly advance the development of real-time, accurate train control systems.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}