

Improving Recommender Systems for Fake News Detection in Social Networks with Knowledge Graphs and Graph Attention Networks


Abstract
1. Introduction
- A recommender system for detecting fake news in social networks is proposed, based on the use of knowledge graphs, which maintains its performance over time compared to systems based only on text processing.
- A comprehensive open-source software package for detecting fake news in social networks was developed and implemented.
2. Overview of Existing Solutions
3. Theoretical Background
4. Proposed Solution
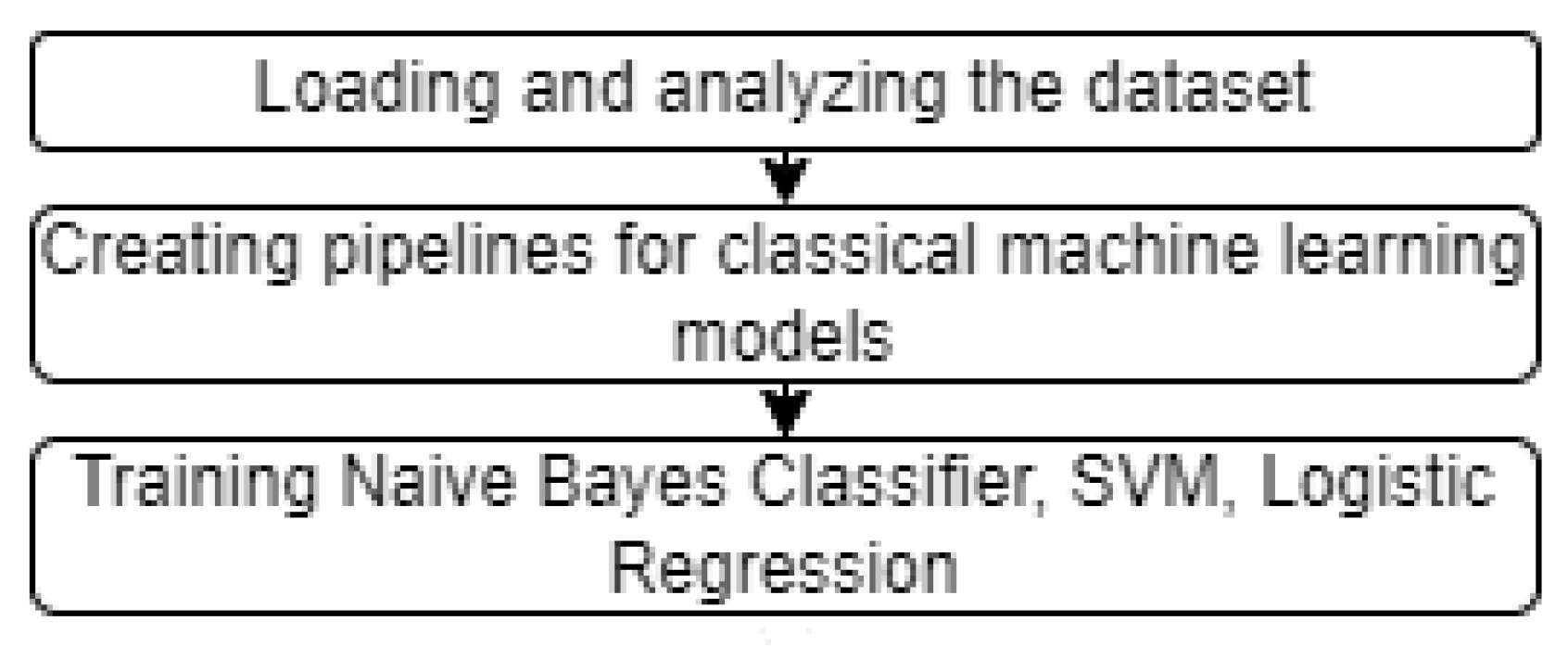
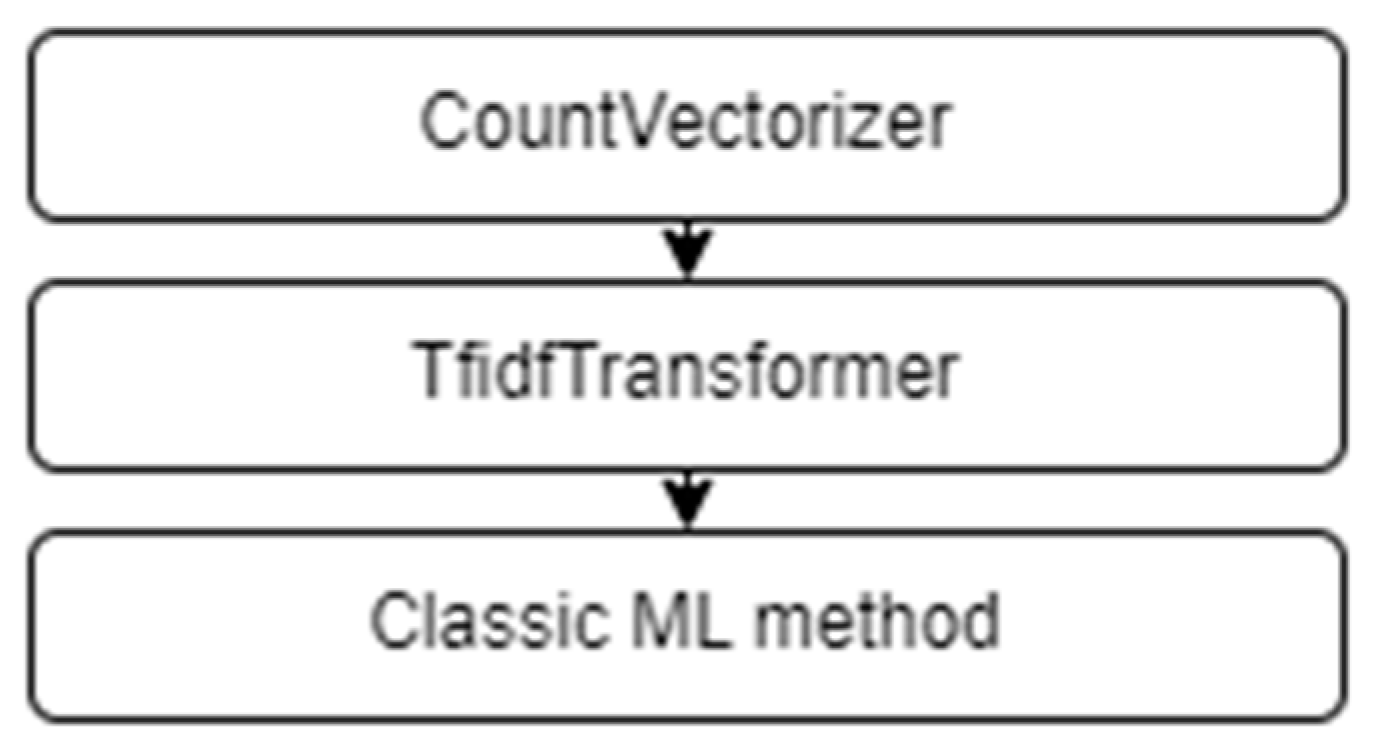
4.1. Proposed System
4.2. Software Implementation
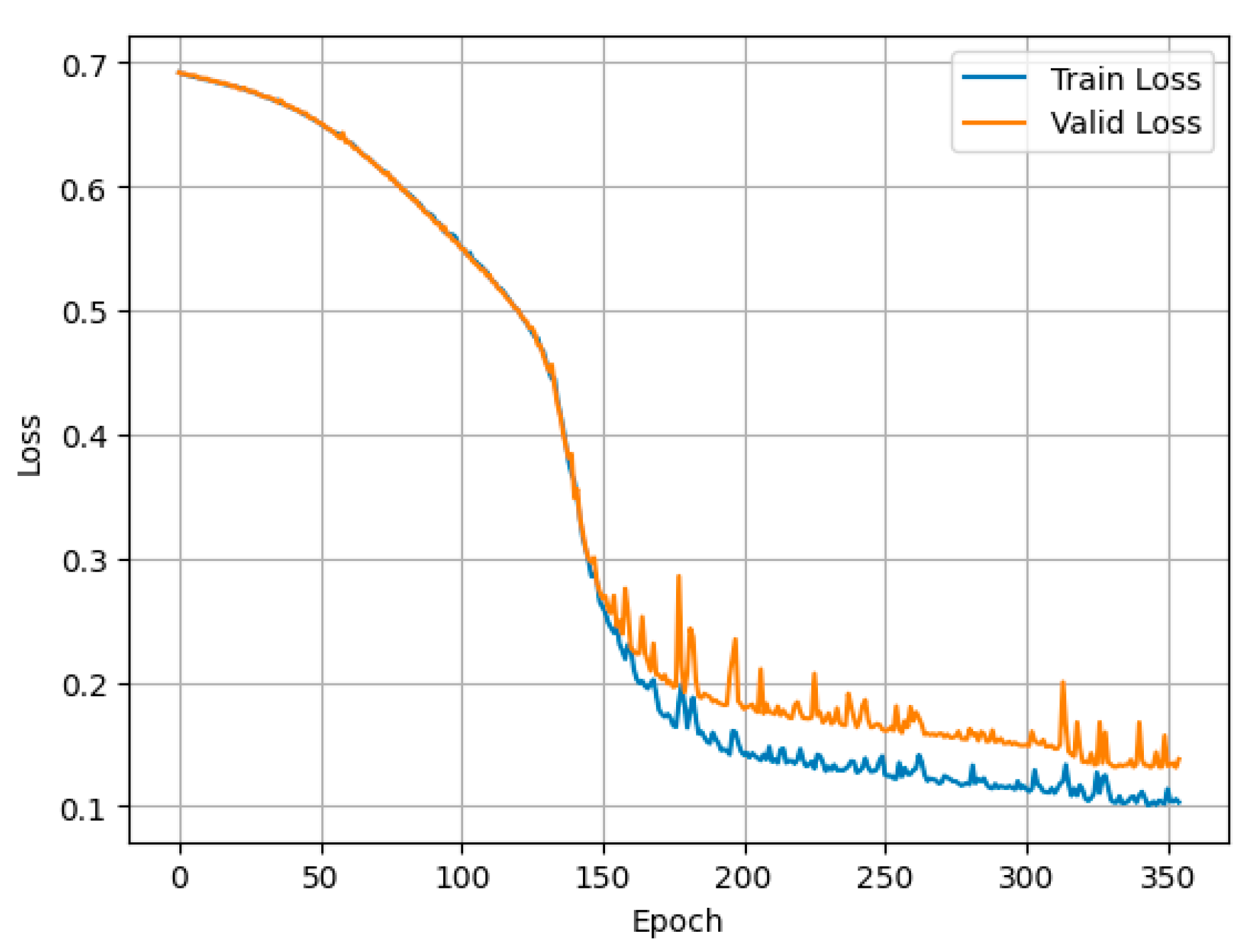
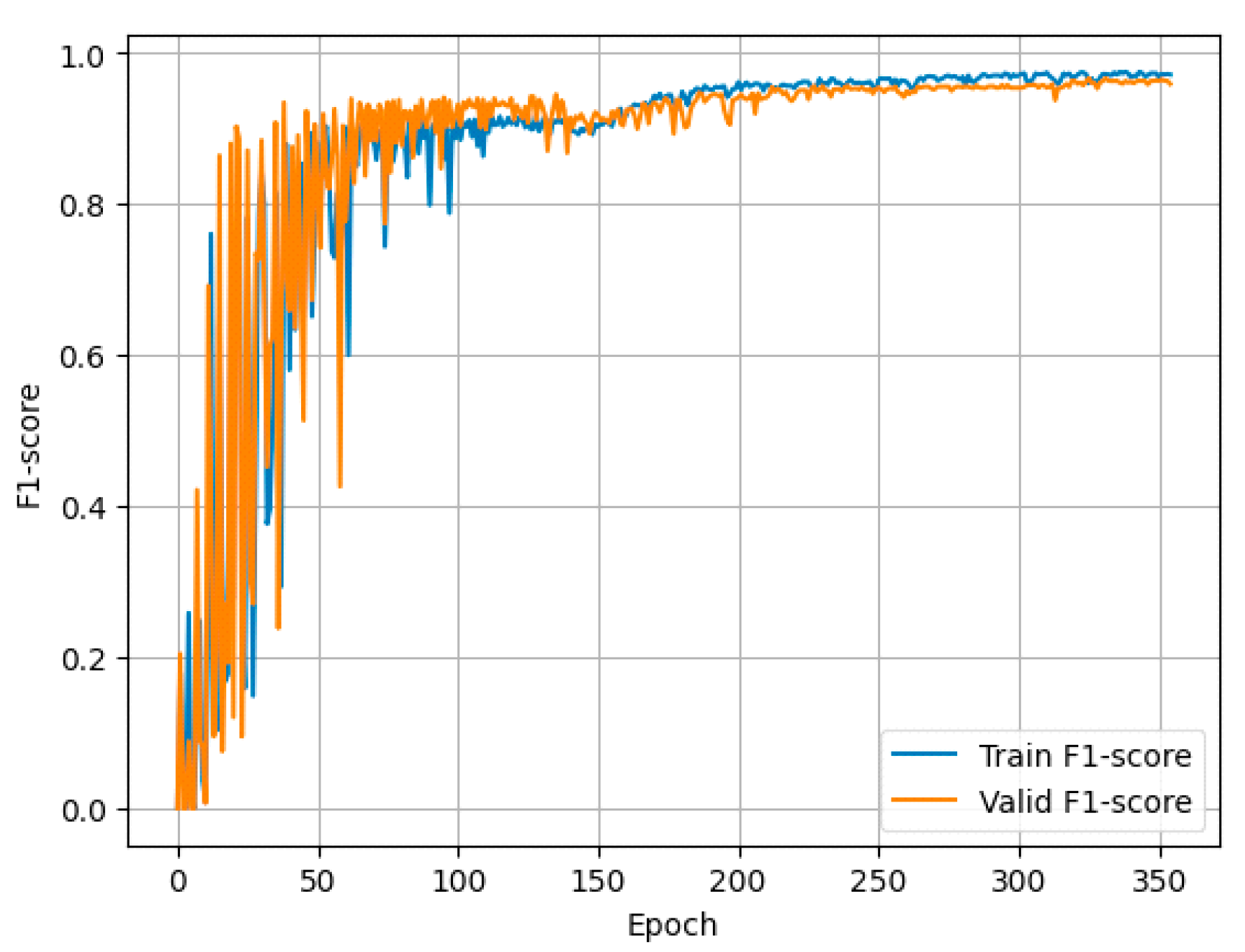
5. Evaluation
5.1. Dataset
5.2. Technique for Evaluation of the Effectiveness of the Developed Model
5.3. Comparison with Analogous Models
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shu, K.; Wang, S.; Liu, H. Exploiting Tri-Relationship for Fake News Detection. arXiv 2017, arXiv:1712.07709. [Google Scholar]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake News Detection Using Machine Learning Ensemble Methods. Complexity 2020, 2020, 8885861. [Google Scholar] [CrossRef]
- Wani, A.; Joshi, I.; Khandve, S.; Wagh, V.; Joshi, R. Evaluating Deep Learning Approaches for Covid19 Fake News Detection. Commun. Comput. Inf. Sci. 2021, 1402, 153–163. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake News Detection on Social Media. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Tian, L.; Zhang, X.; Peng, M. FakeFinder: Twitter Fake News Detection on Mobile. In Proceedings of the Companion Proceedings of the Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 79–80. [Google Scholar] [CrossRef]
- Dimou, A.; Vander Sande, M.; Colpaert, P.; Verborgh, R.; Mannens, E.; Van de Walle, R. RML: A generic language for integrated RDF mappings of heterogeneous data. Ldow 2014, 1184, 1–5. [Google Scholar]
- Farooq, M.S.; Naseem, A.; Rustam, F.; Ashraf, I. Fake news detection in Urdu language using machine learning. PeerJ Comput. Sci. 2023, 9, e1353. [Google Scholar] [CrossRef]
- Wasim, M.; Cheema, S.M.; Pires, I.M. Normalized effect size (NES): A novel feature selection model for Urdu fake news classification. PeerJ Comput. Sci. 2023, 9, e1612. [Google Scholar] [CrossRef]
- Ala’raj, M.; Majdalawieh, M.; Abbod, M.F. Improving binary classification using filtering based on k-NN proximity graphs. J. Big Data 2020, 7, 15. [Google Scholar]
- Alkhateem, Y.N.S.; Mejri, M. Auto Encoder Fixed-Target Training Features Extraction Approach for Binary Classification Problems. Asian J. Res. Comput. Sci. 2023, 15, 32–43. [Google Scholar] [CrossRef]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef]
- BERTology. Hugging Face—The AI Community Building the Future. Available online: https://huggingface.co/docs/transformers/bertology (accessed on 24 December 2024).
- Raza, S.; Ding, C. Fake news detection based on news content and social contexts: A transformer-based approach. Int. J. Data Sci. Anal. 2022, 13, 335–362. [Google Scholar] [CrossRef]
- Malik, M.S.I.; Imran, T.; Mona Mamdouh, J. How to detect propaganda from social media? Exploitation of semantic and fine-tuned language models. PeerJ Comput. Sci. 2023, 9, e1248. [Google Scholar] [CrossRef]
- Obeidat, R.; Gharaibeh, M.; Abdullah, M.; Alharahsheh, Y. Multi-label multi-class COVID-19 Arabic Twitter dataset with fine-grained misinformation and situational information annotations. PeerJ Comput. Sci. 2022, 8, e1151. [Google Scholar] [CrossRef]
- Faldu, K.; Sheth, A.; Kikani, P.; Akbari, H. KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding. arXiv 2021, arXiv:2104.08145. [Google Scholar] [CrossRef]
- Ostendorff, M.; Bourgonje, P.; Berger, M.; Moreno-Schneider, J.; Rehm, G.; Gipp, B. Enriching BERT with Knowledge Graph Embeddings for Document Classification. In Proceedings of the 15th Conference on Natural Language Processing, Erlangen, Germany, 9–11 October 2019; pp. 1–8. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for knowledge graph completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-BERT: Enabling Language Representation with Knowledge Graph. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020; pp. 2901–2908. [Google Scholar]
- Monti, F.; Frasca, F.; Eynard, D.; Mannion, D.; Bronstein, M.M. Fake news detection on social media using geometric deep learning. arXiv 2019, arXiv:1902.06673. [Google Scholar]
- Hu, L.; Yang, T.; Zhang, L.; Zhong, W.; Tang, D.; Shi, C.; Duan, N.; Zhou, M. Compare to the knowledge: Graph neural fake news detection with external knowledge. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; pp. 754–763. [Google Scholar] [CrossRef]
- Feng, W.; Li, Y.; Li, B.; Jia, Z.; Chu, Z. BiMGCL: Rumor detection via bi-directional multi-level graph contrastive learning. PeerJ Comput. Sci. 2023, 9, e1659. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, X.; Zhou, Z.; Huang, F.; Li, C. Reinforced adaptive knowledge learning for multimodal fake news detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 38. [Google Scholar] [CrossRef]
- Gao, X.; Wang, X.; Chen, Z.; Zhou, W.; Hoi, S.C.H. Knowledge enhanced vision and language model for multi-modal fake news detection. IEEE Trans. Multimed. 2024, 26, 8312–8322. [Google Scholar] [CrossRef]
- Che, H.; Pan, B.; Leung, M.-F.; Cao, Y.; Yan, Z. Tensor Factorization with Sparse and Graph Regularization for Fake News Detection on Social Networks. IEEE Trans. Comput. Soc. Syst. 2024, 11, 4888–4898. [Google Scholar] [CrossRef]
- Chatzianastasis, M.; Lutzeyer, J.F.; Dasoulas, G.; Vazirgiannis, M. Graph Ordering Attention Networks. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 7006–7014. [Google Scholar]
- Zhou, Y.; Zheng, H.; Huang, X.; Hao, S.; Li, D.; Zhao, J. Graph Neural Networks: Taxonomy, Advances, and Trends. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–54. [Google Scholar] [CrossRef]
- Knyazev, B.; Tailor, G.W.; Amer, M.R. Understanding Attention and Generalization in Graph Neural Networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–7. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762v5. [Google Scholar]
- Brody, S.; Alon, U.; Yahav, E. How Attentive are Graph Attention Networks? arXiv 2022, arXiv:2105.14491v3. [Google Scholar]
- A1gord/FakeNewsDetection. Available online: https://github.com/A1gord/FakeNewsDetection (accessed on 15 October 2024).
- NumPy v1.24 Manual. Available online: https://numpy.org/doc/stable/ (accessed on 15 October 2024).
- pandas—Python Data Analysis Library. Available online: https://pandas.pydata.org/ (accessed on 15 October 2024).
- Matplotlib 3.7.1 Documentation. Available online: https://matplotlib.org/stable/contents.html (accessed on 15 October 2024).
- PyTorch Documentation. Available online: https://pytorch.org/docs/stable/index.html (accessed on 15 October 2024).
- PyG Documentation. Available online: https://pytorch-geometric.readthedocs.io/en/latest/ (accessed on 15 October 2024).
- Shu, K. FakeNewsNet: A Data Repository with News Content, Social Context and Spatiotemporal Information for Studying Fake News on Social Media. Big Data 2020, 8, 171–188. [Google Scholar]
- Li, Q.; Zhou, W. Connecting the Dots Between Fact Verification and Fake News Detection. arXiv 2022, arXiv:2010.05202v1. [Google Scholar] [CrossRef]
- Gossip Cop. Available online: http://gossipcop.com/ (accessed on 24 September 2024).
- PolitiFact. Available online: https://www.politifact.com/ (accessed on 24 September 2024).
- D’Ulizia, A.; Caschera, M.C.; Ferri, F.; Grifoni, P. Fake news detection: A survey of evaluation datasets. PeerJ Comput. Sci. 2021, 7, e518. [Google Scholar] [CrossRef]
- Fake News. Kaggle. Available online: https://www.kaggle.com/datasets/algord/fake-news (accessed on 24 September 2024).
- Dou, Y. User Preference-aware Fake News Detection. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar] [CrossRef]
- Song, C.; Shu, K.; Wu, B. Temporally evolving graph neural network for fake news detection. Inf. Process. Manag. 2021, 58, 102712. [Google Scholar]
- Matsumoto, H.; Yoshida, S.; Muneyasu, M. Propagation-Based Fake News Detection Using Graph Neural Networks with Transformer. In Proceedings of the 2021 IEEE 10th Global Conference on Consumer Electronics, Kyoto, Japan, 12–15 October 2021; pp. 19–20. [Google Scholar]


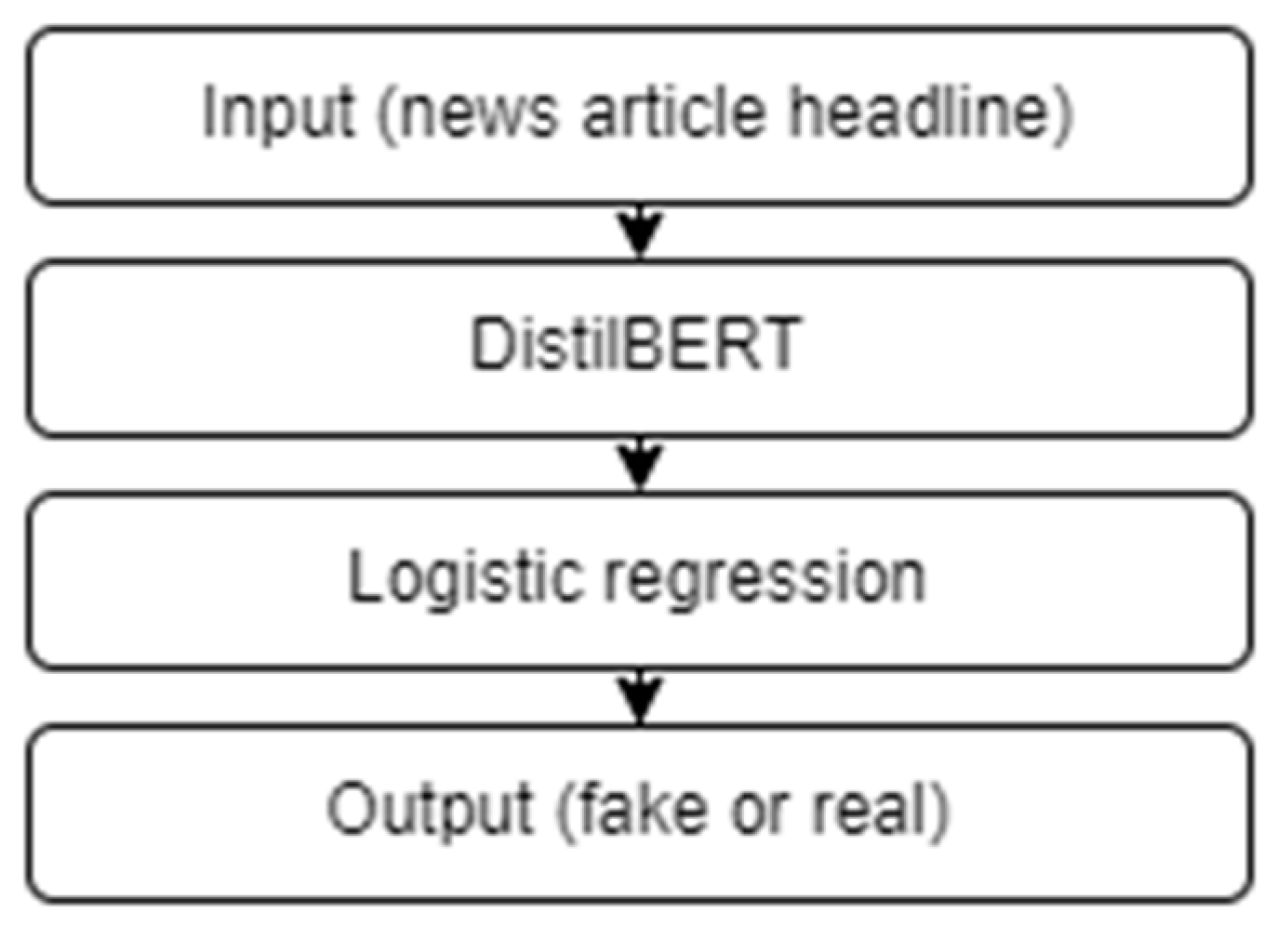

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year [Ref] | Algorithms | Features | Best Performance |
|---|---|---|---|
| 2023 [7] | Classical Machine Learning | Word, character and functional n-grams | F1 (89%) |
| 2023 [8] | Classical Machine Learning | Word, character and functional n-grams | F1 (88%) |
| 2021 [11] | FakeBERT | GloVe, TF-IDF, word2Vec | Accuracy (98%) |
| 2022 [13] | VGCN-BERT | Title and social context of news | F1 (74%) |
| 2023 [14] | BERT-320 | FastText | F1 (83%) |
| 2022 [15] | AraBERT-COV19 | TF-IDF | F1 (81%) |
| 2019 [20] | GCN | User activity | F1 (84%) |
| 2021 [21] | CompareNet | BiLSTM | F1 (72%) |
| 2023 [22] | BiMGCL | Propagation structure of news | F1 (86%) |
| 2024 [23] | AKA-Fake | Multimodal | F1 (93%) |
| 2024 [24] | Language model + KG | Multimodal | Accuracy (91%) |
| Category | Features | PolitiFact | GossipCop | |||
|---|---|---|---|---|---|---|
| Fake | Real | Fake | Real | |||
| News Content | Linguistic | News articles | 432 | 624 | 5323 | 16,817 |
| News articles with text | 420 | 528 | 4947 | 16,694 | ||
| Visual | News articles with images | 336 | 447 | 1650 | 16,767 | |
| Social Content | User | User posting tweets | 95,553 | 249,887 | 265,155 | 80,137 |
| User involved in likes | 113,473 | 401,363 | 348,852 | 145,078 | ||
| User involved in retweets | 106,195 | 346,459 | 239,483 | 118,894 | ||
| User involved in replies | 40,585 | 186,675 | 106,325 | 50,799 | ||
| Post | Tweets posting news | 164,892 | 399,237 | 519,581 | 876,967 | |
| Response | Tweets with replies | 11,975 | 41,852 | 39,717 | 11,912 | |
| Tweets with likes | 31,692 | 93,839 | 96,906 | 41,889 | ||
| Tweets with retweets | 23,489 | 67,035 | 56,552 | 24,955 | ||
| Network | Followers | 405,509,460 | 1,012,218,640 | 630,231,413 | 293,001,487 | |
| Followees | 449,463,557 | 1,071,492,603 | 619,207,586 | 308,428,225 | ||
| Average followers | 1299.98 | 982.67 | 1020.99 | 933.64 | ||
| Average followees | 1440.89 | 1040.21 | 1003.14 | 982.80 | ||
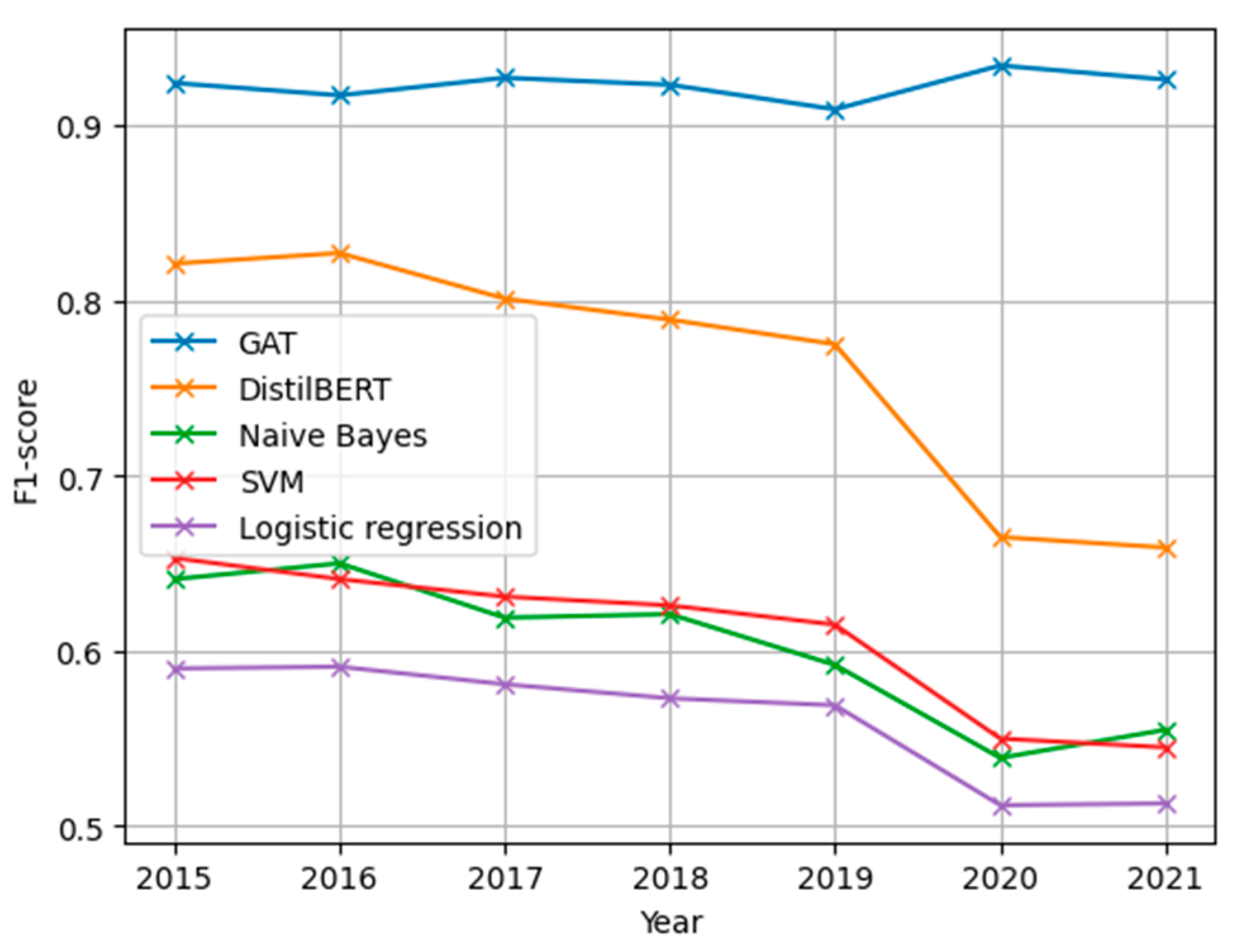
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Naive Bayes | 85% | 63% | 65% | 64% |
| SVM | 85% | 67% | 63% | 65% |
| Logistic regression | 83% | 59% | 53% | 56% |
| DistilBERT | 84% | 79% | 86% | 82% |
| GAT | 96% | 96% | 95% | 95% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Golovin, A.; Zhukova, N.; Delhibabu, R.; Subbotin, A. Improving Recommender Systems for Fake News Detection in Social Networks with Knowledge Graphs and Graph Attention Networks. Mathematics 2025, 13, 1011. https://doi.org/10.3390/math13061011
Golovin A, Zhukova N, Delhibabu R, Subbotin A. Improving Recommender Systems for Fake News Detection in Social Networks with Knowledge Graphs and Graph Attention Networks. Mathematics. 2025; 13(6):1011. https://doi.org/10.3390/math13061011
Chicago/Turabian StyleGolovin, Aleksei, Nataly Zhukova, Radhakrishnan Delhibabu, and Alexey Subbotin. 2025. "Improving Recommender Systems for Fake News Detection in Social Networks with Knowledge Graphs and Graph Attention Networks" Mathematics 13, no. 6: 1011. https://doi.org/10.3390/math13061011
APA StyleGolovin, A., Zhukova, N., Delhibabu, R., & Subbotin, A. (2025). Improving Recommender Systems for Fake News Detection in Social Networks with Knowledge Graphs and Graph Attention Networks. Mathematics, 13(6), 1011. https://doi.org/10.3390/math13061011