1. Introduction
With the advent of the Industry 4.0 era, industries such as manufacturing, energy, and finance are undergoing unprecedented digital transformation. This transformation advances automation and signifies a shift toward data-driven intelligent production and decision-making. Accurate time series forecasting is vital to address challenges such as production efficiency, inventory management, energy consumption planning, and financial market prediction. Errors in demand forecasting can lead to serious consequences, including inventory shortages, excess stock, increased costs, or missed business opportunities. Recent developments in machine learning and deep learning models, such as Recurrent Neural Networks (RNNs) [
1], Long Short-Term Memory (LSTM) [
2], Gated Recurrent Unit (GRU) [
3], and Transformer models [
4], have significantly improved forecasting accuracy. These models capture nonlinear patterns and long-term dependencies in time series data. However, they often function as black-box models, limiting their interpretability and reducing business decision-makers’ confidence in their results. Understanding the contribution of different features is essential for enhancing trust and optimizing the model.
Interpretability has become a crucial research topic in machine learning. Methods such as Shapley Additive Explanations (SHAPs) [
5], Local Interpretable Model-agnostic Explanations (LIMEs) [
6], and TimeSHAP [
7] provide insights into feature importance for individual predictions. However, these methods are primarily designed for static datasets or classification tasks, and their effectiveness is limited when applied to time series regression models. Furthermore, traditional feature selection methods, such as Recursive Feature Elimination (RFE) [
8], are commonly used in static machine learning tasks but are not specifically tailored for time series forecasting, which involves temporal dependencies and dynamic patterns.
To address these challenges, this research proposes a linear time series forecasting model architecture based on seasonal decomposition. Using an additive model, the approach decomposes the time series into trend, seasonality, and residual components. This choice is based on initial data analysis, which revealed that seasonal variations were relatively stable across datasets. Thus, an additive decomposition was deemed appropriate for our data. A multiplicative decomposition would have been more suitable if the seasonal fluctuations had grown or shrunk in proportion to the series level. We further introduce an augmented feature generator to enrich the feature set with differences, rolling statistics, and moving averages to improve predictive performance. Finally, we develop a gradient-based feature importance method and a gradient feature elimination algorithm to provide interpretability and optimize feature selection for time-series-forecasting models.
The proposed method is validated using three datasets: an order demand dataset from a manufacturing company, an energy load dataset, and a solar radiation dataset. Results demonstrate that the proposed approach improves prediction accuracy while enhancing model interpretability, showing its applicability across various domains.
The remainder of this paper is organized as follows—
Section 2 reviews related work.
Section 3 introduces our approach.
Section 4 describes experiments and results.
Section 5 concludes the paper.
3. Approach
In our research, we propose a linear time series model architecture based on seasonal decomposition, combined with an augmented feature generator to produce augmented features, further improving the model’s accuracy in predicting order demand for the coming weeks and addressing inventory issues. Additionally, we introduce a gradient-based feature importance method to provide interpretability to complex time series models. Using this method, we also implement a gradient feature elimination algorithm to reduce noise and overfitting, further optimizing model accuracy.
Finally, to comprehensively evaluate the effectiveness of our proposed method, we tested it using private datasets and two different open-source datasets: a machine energy consumption dataset and a solar radiation energy dataset. The selection of these datasets demonstrates the generalizability and performance of our method across different types of time-series-forecasting problems.
3.1. Architecture
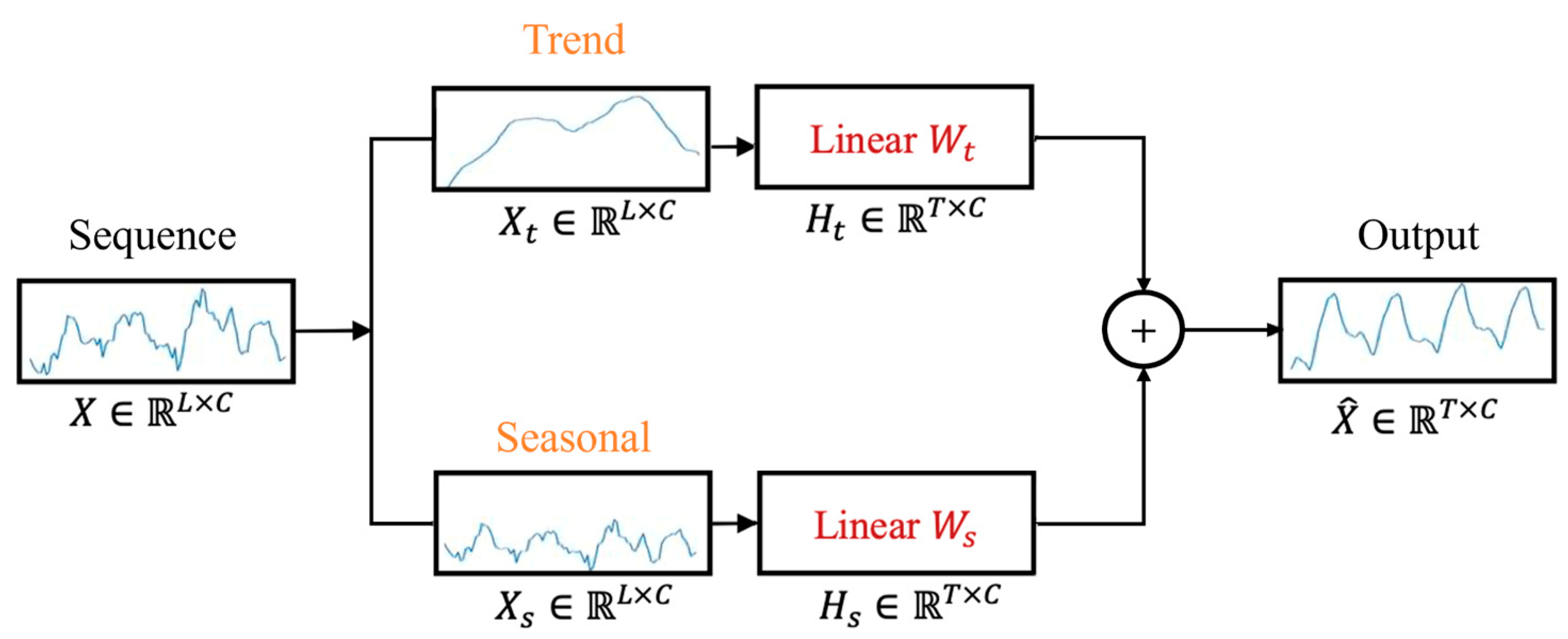
This study proposes a time-series-forecasting framework based on a seasonal decomposition linear model for time series prediction tasks. This framework combines an augmented features generator and a gradient feature importance method to optimize model performance and interpretability. First, we decompose the target data using the seasonal decompose function mentioned in
Section 3.4, dividing the time series into trend, seasonality, and residual components. This allows the model to make predictions based on the decomposed trend and seasonal time series data, thereby improving prediction accuracy.
Next, we use the Augmented Features Generator proposed in
Section 3.5 for the target data to generate augmented features. These features include differences, rolling statistics, exponential moving averages, rates of change, and Fourier transforms to comprehensively capture the time series characteristics.
To fully utilize the decomposed time series, augmented features, and support data, we preprocess all data using the data-preprocessing methods mentioned in
Section 3.3, converting it into a format suitable for training time series models. Then, we use the DLinear model discussed in
Section 2. We train two DLinear models, one focusing on the trend and the other on seasonality, allowing the models to specialize in individually predicting trend and seasonal components.
After training the models, we use the gradient feature importance method proposed in
Section 3.6 to generate the current gradient feature importance results, providing interpretability for the complex time series model. We employ the gradient feature elimination algorithm described in
Section 3.7 to improve model prediction accuracy further. This algorithm iteratively removes features with the lowest gradient importance, reducing model complexity and preventing overfitting, thereby enhancing prediction accuracy.
Finally, we combine the trend, seasonality, and residual component predictions to obtain the final prediction results. The overall architecture is shown in
Figure 2.
3.2. Time Series Data Definition
Time series data refers to data collected, recorded, or measured at consecutive time points and is characterized by data points that vary over time. This paper uses multidimensional data, including target sequences and support sequential data, to infer predictions for single or multiple time points. Here is our data definition:
Target data: This is the primary series for which we wish to make predictions, using past time points to forecast future values. The target data is a vector comprising values representing the target variable over a series of time points, denoted by , where is the number of time points in the data, and mathematically represented as , with indicating the transpose of the vector.
Support data: These are support data sequences related to the forecasting target sequence. These sequences are typically used as additional information to aid in predictions. The -th support data is represented as a vector containing values representing the -th variable over a series of time points, denoted by , where is the number of time points in the data, and mathematically represented as , with indicating the transpose of the vector.
Multidimensional data X: This integrates the target data
and support data
, where each row represents a time point, consisting of the values of the target variable in the first column, and the values of support variables from
in subsequent columns.
can be represented as a matrix:
This multidimensional data framework facilitates in-depth analysis of time series, enhancing the accuracy and reliability of forecasting models by comprehensively considering both the target data and its related support data.
3.3. Data Processing
- (1)
Normalization
During the training of machine learning models, significant discrepancies in the numerical range of raw data can adversely affect the learning efficacy of the models, especially when using gradient descent-based algorithms where the objective function may not operate properly. To facilitate better learning by the model, we employ min–max scaling to preprocess the data, adjusting all feature values in the raw data to a range of the following
:
where
represents the normalized data,
represents the original data, and
and
are the minimum and maximum values of the original data, respectively.
- (2)
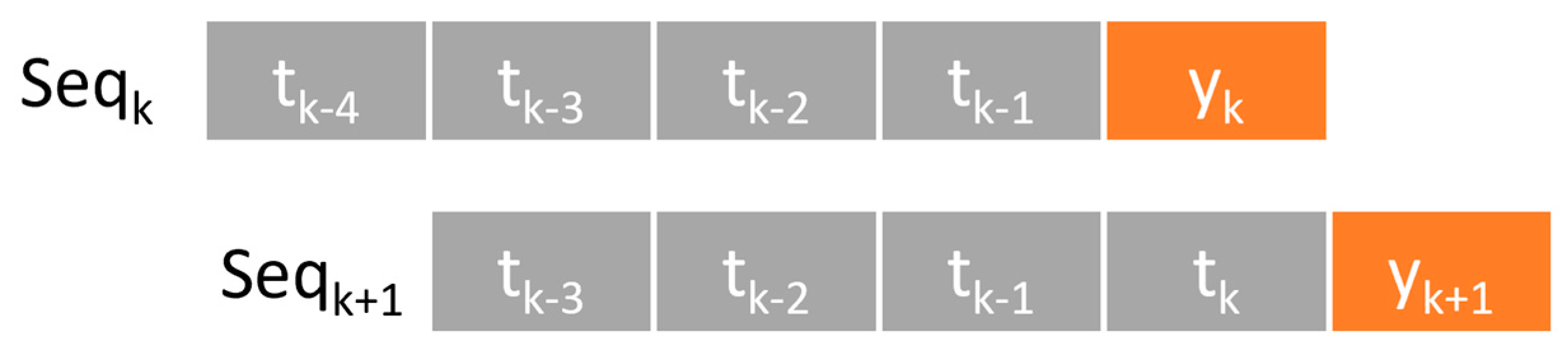
Serialize Data
In the training process of time series models, it is essential to transform the data into a suitable format. The window-sliding method accomplishes this transformation. The principle of window sliding involves moving a fixed-size window over the time series data, organizing the data within each window into a sequence, and using the value of the next time step at the end of each window as the prediction target, as shown in
Figure 3. For cases with only the target sequence, we represent the sequence as a vector of time series
, where
represents the values from previous time points within the window,
represents the number of time points, indicating the number of prime time points included in each sequence, and
is the target value to predict. For multidimensional scenarios, the sequence is represented as
, where
indicates the values from the target sequence at the
-th time point within the window,
are values from support sequences
, with
representing the value of the
-th support sequences at the
-th time point within the window,
being the number of support sequences in the multidimensional time series,
representing the number of time points, and
being the target value to predict.
For each sequence set, including target and multidimensional sequences, we can represent it as follows:
where
indicates data points in the time series,
is the target prediction value,
is the current time point index, and
is the window size.
where
represents the value of the
-th support sequence at time point
, and
is the total number of support sequences.
- (3)
De-Normalization
After the model completes its predictions, we must transform the predicted results back to the original data’s numerical range to compare the expected sequence and measure the model’s performance. This process is called de-normalization, and its formula is as follows:
where
is the normalized prediction result,
is the de-normalized prediction result, and
and
are the minimum and maximum values of the original data
, respectively.
3.4. Seasonal Decomposition
In time series analysis, seasonal decomposition is a common technique to identify and decompose a sequence into trend, seasonality, and residual components. In this study, we employ the seasonal decompose function from Python’s stats models library to implement seasonal decomposition. This function uses moving average techniques to extract the trend from the time series and calculate the seasonality and residuals accordingly, enhancing subsequent model predictions’ accuracy.
Seasonal decomposition breaks the time series into three subseries:
Trend: Represents the long-term changes in the time series. It shows whether the overall trend of the data over time is upward, downward, or stable. The trend is obtained using moving averages as a filter.
Seasonality: Captures the seasonal patterns within the series, i.e., repetitive behaviors occurring at fixed time intervals. The seasonality is the average of the detrended series for each period.
Residual: Comprises parts of the data that cannot be explained by the trend and seasonality, also known as random fluctuations or noise. Residuals contain other influencing factors not captured by the model, such as sporadic events or random fluctuations. Residuals are calculated by removing the trend and seasonality from the original series.
We expect the model to exhibit improved predictive accuracy when dealing with decomposed trend and seasonal time series data through this decomposition technique.
The seasonal decompose function supports two decomposition models: additive and multiplicative.
- (1)
Additive Model
The additive model assumes that the time series is a linear combination of trend, seasonality, and residuals. It can be represented as follows:
where
is the original time series value at time
,
is the trend component,
is the seasonal component, and
is the residual.
- (2)
Multiplicative Model
The multiplicative model assumes that the time series is a product of the trend, seasonality, and residuals. It is typically used when significant seasonal variations are related to the trend. It can be expressed as follows:
where each term has the same meaning as the additive model.
Additive vs. Multiplicative Seasonality—When to Use Which: The key distinction between these models lies in whether seasonal fluctuations remain constant or vary with the overall level of the series. In an additive decomposition, seasonal effects are roughly constant in amplitude regardless of the trend level, making it suitable when seasonal patterns do not scale with the series. In contrast, a multiplicative decomposition is appropriate when seasonal effects scale proportionally with the trend (for example, when higher sales volumes come with proportionally more significant seasonal increases). This difference is also reflected in how seasonal indices are calculated. For an additive model, seasonal index (e.g., monthly or weekly seasonal effects) are typically computed by taking the arithmetic mean of the detrended values for each season, and they are often normalized to sum to zero over a complete cycle (ensuring no net seasonal bias is added). For a multiplicative model, seasonal indices are derived as ratios of the original values to the trend (or deseasonalized values), and these factors are usually normalized so that their geometric mean equals one over a cycle (ensuring no overall scale change is introduced). In practice, if the seasonal pattern’s amplitude increases or decreases with the series level, a multiplicative approach (sometimes after transforming the data logarithmically) would capture the dynamics better; otherwise, the additive approach is preferred. In our case, initial exploration of the datasets indicated that an additive seasonal effect was adequate, as seasonal fluctuations were relatively stable and did not exhibit strong dependence on the trend component.
The framework isolates the trend and seasonal components by decomposing each time series using the appropriate model (additive in this study). We expect the model to exhibit improved predictive accuracy when dealing with these separated components since it can independently focus on learning the trend and seasonality patterns rather than the conflated raw series. Any unexplained variation remains in the residual component, which contains factors not captured by the model (such as sporadic events or random noise). These residuals are calculated by removing the estimated trend and seasonal components from the original series.
3.5. Augmented Features Generator
In this section, we introduce an augmented features generator to create additional features from the original target sequence, aiming to improve the predictive accuracy of our time series model. These features include first- and second-order differences, rolling statistics, exponential moving averages, rates of change, and Fourier transform features, among others, to capture the time series characteristics comprehensively.
- (1)
First and Second-Order Difference Features
Calculating a time series’ first- and second-order differences is a common technique to stabilize a non-stationary series, making patterns more straightforward to model. The first-order difference (the difference between adjacent time points) often removes a constant trend component and highlights short-term changes. The second-order difference (the difference in the first-order differences) helps capture the acceleration or deceleration in the rate of change in the data, making it particularly useful for detecting more complex or nonlinear trends in the data. By applying these differencing operations, we mitigate underlying trend effects or seasonality to some extent and stabilize the series, leading to more reliable predictions by the model on the transformed data.
- (2)
Rolling Statistical Features
Rolling statistical features, calculated using a moving window, capture local properties of the sequence and extract time-related information. These features compute statistics (such as maximum, minimum, mean, standard deviation, median, and percentiles) over a fixed-size window that slides through time. At each time step, the window yields a statistic summarizing the recent history, thereby providing the model with contextual information about recent values. Rolling features can highlight local trends and variability that single-point observations cannot.
- (3)
Exponential Moving Average (EMA)
The exponential moving average is a smoothing technique that reduces short-term noise in the data. It assigns exponentially decaying weights to past observations, giving more weight to recent data points. This helps capture recent trends or shifts faster than a simple moving average while smoothing out irregular fluctuations.
- (4)
Rate of Change
The rate of change measures the relative change between consecutive data points, often expressed as a percentage. This feature indicates the series’ momentum—whether values increase or decrease and how rapidly. By including the rate of change, the model can capture sudden jumps or drops and steady growth/decline patterns in the time series.
- (5)
Fourier Transform Features
The Fourier transform decomposes a time series into a spectrum of frequencies. We can identify dominant cyclic patterns by converting the time-domain data into the frequency domain. In our feature set, we include characteristics derived from the Fourier transform (such as the prominent frequency components’ amplitudes and phases or summary statistics like the mean of real/imaginary parts) to help the model recognize seasonality or periodic behavior that might not be immediately obvious in the time domain.
- (6)
Lag Features
We also include lag features, simply past values of the target time series used as additional inputs for forecasting. By feeding the model recent historical values (e.g., the value one-time step ago, two-time steps ago, etc.), we enable it to capture temporal dependencies directly. Lag features are a straightforward yet powerful way to incorporate autoregressive information into the model.
3.6. Gradient Feature Importance
In our research, we propose a gradient-based feature importance method as an innovative explainability framework to address the challenge of interpretability in time-series-forecasting models. Traditional model interpretation methods, such as SHAP [
5], LIME [
6], and Anchors [
19], while influential in many domains, encounter limitations when interpreting time series models. These methods typically ignore the sequential nature of data or are designed for classification contexts. TimeSHAP [
7] provides some interpretability for RNN predictions by perturbing sequences, but it has not been adapted for regression tasks in time series.
Instead, our gradient feature importance approach leverages the model’s gradients concerning input features to quantify each feature’s contribution to the prediction. This method directly applies to our linear model and augmented features framework, offering insight into how each feature (including those generated by the augmented features generator) influences the forecast.
Using gradients for importance has the advantage of being model-specific and sequence-aware: it considers how slight changes in a feature at a given time step would affect the prediction, thereby capturing the temporal context. We compute the gradient of the model’s output concerning each input feature dimension; a larger magnitude indicates that changes in that feature would significantly impact the prediction, hence higher importance. By averaging or otherwise aggregating these gradient-based importance scores over the evaluation period, we obtain an importance ranking of features for the model’s forecasting task. This gradient feature importance forms the basis for the subsequent feature elimination strategy.
The gradient feature importance results are illustrated in
Figure 4. As shown, ‘Quantity_in_stock’ emerges as the most significant feature, followed by ‘change_rate’, ‘rolling_max’, and others. The least important feature is ‘Inbound’. The pseudocode for the algorithm is presented in Algorithm 1.
| Algorithm 1 Gradient Feature Importance Algorithm |
- Input:
Trained model M, Training dataset , Feature set , Number of features N. - Output:
Importance score for each feature .
- 1:
▷ Initialize importance scores - 2:
for each in D do - 3:
- 4:
▷ Compute loss - 5:
for each feafure fj in F do - 6:
▷ Accumulate absolute gradient - 7:
end for - 8:
end for - 9:
for each feafure fj in F do - 10:
▷ Calculate the average gradient - 11:
end for - 12:
return ▷ Return importance scores for all features
|
3.7. Gradient Feature Elimination
Building on the importance ranking, we implement a gradient feature elimination algorithm to iteratively remove less essential features and observe the impact on model performance. Starting with the complete feature set (including all augmented features), we gradually eliminate the feature with the lowest importance score and retrain or re-evaluate the model. If the model’s accuracy remains acceptable (or improves due to noise reduction), we continue eliminating the next least important feature. This process continues until removing any additional feature causes a significant drop in performance, indicating that all remaining features are crucial. The result is a simplified model with a smaller set of features, often leading to reduced overfitting risk, improved generalization, and more straightforward interpretability since fewer features are involved. We provide the results of this procedure in the Experimental Section to demonstrate how feature elimination based on gradient importance can maintain or even enhance forecasting accuracy while using a more parsimonious input feature set.
The algorithm pseudocode is shown in Algorithm 2.
| Algorithm 2 Gradient Feature Elimination Algorithm |
- Input:
Trained model M, Training dataset , Number of Features N, P is patience. - Output:
Reduced feature set
|
| 1: | ▷ Initialize feature set |
| 2: | ▷ Initialize best validation loss |
| 3: | ▷ Initialize patience counter |
| 4: while do |
| 5: |
| 6: | ▷ Find feature with lowest importance |
| 7: | ▷ Remove least important feature |
| 8: Retrain model M using feature set F |
| 9: Evaluate validation loss | ▷ Evaluate model performance |
| 10: if then |
| 11: | ▷ Update best validation loss |
| 12: | ▷Reset patience counter |
| 13: else |
| 14: | ▷Increment patience counter |
| 15: end if |
| 16: if then |
| 17: return F | ▷Return reduced feature set |
| 18: end if |
| 19: end while |
| 20: return F | ▷Return reduced feature set |
3.8. Calculate Inventory Improvement from the Order Dataset
With the advent of Industry 4.0, the manufacturing sector actively pursues intelligent management models, where inventory management is critical. To effectively reduce inventory levels, we rely not only on the internal customer order quantities introduced by ERP systems but also utilize our proposed linear time series model architecture based on seasonal decomposition and augmented features with an augmented features generator to improve forecast accuracy. Further, we integrate the gradient feature importance method and gradient feature elimination algorithm to ensure the interpretability of the forecast results and optimize the model.
Finally, we calculate the improvement in inventory based on the forecast results to verify whether our proposed method can effectively reduce inventory levels and address issues of inventory shortages. Through such methods, we aim to achieve more competent inventory management in manufacturing, thereby reducing costs and better meeting customer demands.
First, we update the weekly inventory levels based on the quantities of incoming and outgoing goods using the following calculation:
where
is the inventory level for week
+ 1,
is the inventory level for week
,
is the quantity of goods received during week
, and
is the quantity of goods dispatched during week
.
To calculate the post-forecast inventory levels, we subtract the actual order quantity from the forecasted order quantity each week and then add this difference to the initial inventory level. In other words, the new inventory level is the initial inventory level plus the cumulative difference between forecasted and actual order quantities:
where
is the post-forecast inventory level,
is the initial inventory level,
is the forecasted order quantity for week
,
is the actual order quantity for week
, and
is the total number of weeks.
Finally, we compare the post-forecast inventory level with the original inventory level to assess the improvement in inventory management. If the post-forecast inventory level is higher than the original, it indicates an improvement in inventory management; otherwise, it may indicate a deterioration. To evaluate the effectiveness of inventory management improvements, we calculate the percentage difference between the post-forecast and original inventory levels:
where
represents the post-forecast inventory level, and
represents the original inventory level for a week
.
Through the methods described above, we can calculate the improvement in inventory from the order forecast dataset, thereby guiding manufacturers to adjust their inventory management strategies and reduce inventory costs.
4. Implementation and Experiments
4.1. Datasets and Environment
- (1)
Datasets
Datasets: We utilized three datasets to validate our model. The first dataset consists of weekly order data from a collaborating manufacturer’s ERP (Enterprise Resource Planning) system. In addition to customer product orders, we calculated weekly inventory inputs, outputs, transaction quantities, and stock levels as part of this dataset, yielding several features related to inventory movement. The prediction target for this dataset is the customer order quantity. By forecasting this target, we aim to convert the predictions into order recommendations that help reduce the number of weeks with insufficient inventory and optimize overall inventory levels.
The second dataset is a public electric load dataset containing energy load readings for a specific machine collected over time. This dataset spans from November 2016 to November 2019. Features provided include the machine’s energy load and environmental or temporal context features, such as low temperature, high temperature, and time attributes (year, month, day, and hour). In this case, the prediction target is the machine’s energy consumption (Load). These additional features allow the model to account for daily and seasonal temperature effects or time-of-day usage patterns that might influence the energy load.
The third dataset is a public solar radiation dataset consisting of meteorological data from the HI-SEAS weather station, covering four months from September 2016 to December 2016. This dataset includes six features: solar radiation (the target variable to forecast), temperature, humidity, and barometric pressure. The goal is to predict solar radiation energy based on the recent history of these variables, which is relevant for applications like solar panel output forecasting or climate analysis.
Table 1 below summarizes the key details of these three datasets, including the data collection period (Time Range), the number of features, and the train/validation/test split sizes.
- (2)
Time-Series Visualization Analysis
Exploratory data analysis of the above datasets provides insight into their trend and seasonal characteristics. In
Figure 5, we visualize the time series of each dataset to assess the presence of trends and seasonality and determine the nature of any seasonal effects (additive or multiplicative).
Order dataset: The weekly order time series (2020/03–2023/08) exhibits a notable upward trend over the three years, indicating increasing order quantities over time. We also observe a repeating pattern that corresponds roughly to annual seasonality—for instance, peaks and troughs occurring at similar times each year—suggesting a seasonal effect. The amplitude of these seasonal fluctuations remains relatively consistent from year to year despite the rising trend (i.e., the seasonal peaks increase roughly in line with the overall growth but not disproportionately so). This indicates an additive seasonal effect: the seasonal component adds a similar absolute amount each year. In other words, the seasonal pattern is stable (the difference between peak and trough orders is about the same each year), and it does not scale with the level of the series. This visual observation supports our additive decomposition model for the order dataset’s seasonality. In
Figure 5 are time series plots of the order datasets in
Table 1. Each subplot shows the entire dataset time, illustrating trends and seasonal patterns.
Electric load dataset: The machine energy load series (2016/11–2019/11) shows a strong periodic pattern corresponding to daily and weekly cycles. The visualization shows a regular cyclical fluctuation every 24 h (high loads during certain hours and lower during others) and a repeating weekly pattern (differences between weekdays and weekends, for example). There is no clear long-term upward or downward trend over the three years; the baseline load level appears relatively steady aside from routine fluctuations. The seasonality in this context is the daily cycle (and possibly weekly pattern), and its magnitude does not change significantly over time—peak usage each day remains in a similar range throughout the dataset. This suggests an additive seasonal effect for the electric load data as well. The seasonal component (daily usage pattern) adds and subtracts roughly the same load regardless of the month or year. We do not see the seasonal amplitude growing or shrinking systematically over the years, meaning a multiplicative model is unnecessary here. The consistent daily cycle confirms that additive decomposition is suitable for isolating the recurring patterns in this dataset. In
Figure 6 are time series plots of the Electric Load dataset in
Table 1. Each subplot shows the entire dataset time, illustrating trends and seasonal patterns.
Solar radiation dataset: The solar radiation series (2016/09–2016/12) is dominated by a pronounced daily cycle due to the day–night alternation. Each day shows a sharp increase in radiation in the morning, a peak around midday, and a decline to zero at night. Over the four months, there is a slight trend: the peak daily radiation tends to decline as the months progress from September into December, reflecting shorter days and lower solar angles in late autumn. Despite this downward trend in the overall level of radiation, the seasonal pattern (daily cycle) is pretty regular in shape. The daytime peak’s amplitude decreases moderately from September to December, but this can largely be attributed to the trend of changing seasons (moving toward winter) rather than a change like daily fluctuations. Because the baseline at night is zero, a purely multiplicative seasonal model is impractical (multiplicative decomposition would imply zero seasonal factors at night). Instead, we treat the daily cycle as an additive seasonal effect superimposed on a slowly declining trend. The seasonal component contributes roughly the same form each day (with its peak height gradually decreasing in tandem with the trend). An additive model can adequately capture this behavior: the diminishing peak is interpreted as the trend component reducing over time, while the seasonal component remains similar. Thus, we apply an additive decomposition for the solar radiation dataset—the daily seasonality is added to a downward trend over the four months.
Figure 7 shows time series plots of the solar radiation datasets in
Table 1. Each subplot shows the entire dataset time, illustrating trends and seasonal patterns.
Our visual analysis of all three datasets reveals that each time series contains identifiable trend and seasonal components. Crucially, the seasonal effects appear additive for all cases: seasonal patterns maintain a relatively constant magnitude and do not scale multiplicatively with the overall level of the series. As implemented in our proposed model, these observations justify additive seasonal decomposition across the datasets. If any dataset had shown clear evidence of seasonality with amplitude proportional to its trend (which would indicate a multiplicative effect), we would have adjusted our approach accordingly; however, no such behavior was observed in these three cases.
- (3)
Environment
All model training and experiments were conducted on a machine with an NVIDIA RTX A6000 GPU (NVIDIA, Santa Clara, CA, USA).
Table 2 details the software and hardware environment used. The models were implemented in PyTorch 2.2.0 and trained under Ubuntu Linux.
4.2. Training Procedure and Evaluation Metrics
- (1)
Seasonal Decomposition and Data Restoration
In our research framework, seasonal decomposition on the target variable is necessary. Seasonal decomposition divides the time series data into trend, seasonal, and residual components. As mentioned in
Section 3.4, the sum of these three sub-series equals the original series. We use the trend and seasonal components, combined with support data, to train the models separately. Finally, we need to restore the decomposed data to evaluate prediction accuracy. Therefore, we sum the model-predicted trend, seasonal components, and the residual values obtained through seasonal decomposition to derive the complete prediction results.
- (2)
Experimental Setup
Before training the models, we split the datasets into training, validation, and testing sets in an 8:1:1 ratio. The common hyperparameters set for all models are as follows: The number of training epochs is 200, and the batch size is 400, or the highest possible size if the data are insufficient. The time series length is 60, and the mean squared error (MSE) is the loss function. The optimizer is adaptive moment estimation (Adam) with an initial learning rate of 0.001. The learning rate is reduced by 10% if there is no improvement in validation accuracy for nineteen epochs.
- (3)
Evaluation Metrics
In this study, we employ multiple metrics to assess our time series prediction models. We chose Mean Square Error (MSE) as the loss function, which calculates the average of the squares of the differences between predicted and actual values:
where
is the predicted value at time
,
is the actual value at time
, and
is the total number of predictions.
To comprehensively assess model performance, we selected the following three evaluation metrics: Mean Absolute Error (MAE), Root Mean Square Error (RMSE), and the Coefficient of Determination denoted as :
- (a)
Mean Absolute Error (MAE):
Measuring the average absolute difference between the predicted and actual values, representing the average distance from the valid values, it uses absolute values instead of squares, making it less sensitive to outliers.
where
is the predicted value at time
,
is the actual value at time
, and
is the total number of predictions.
- (b)
Root Mean Square Error (RMSE):
This measures the average square root of the squared differences between predicted and actual values, more sensitive to large error outliers:
where
is the predicted value at time
,
is the actual value at time
, and
is the total number of predictions.
- (c)
Coefficient of Determination ():
This measures how well the prediction model explains the variance of the real data, focusing on the variability of the mean error. The closer its value is to 1, the stronger the model’s predictive power:
where
is the predicted value at time
,
is the actual value at time
,
is the average of all actual values
, and
is the total number of predictions.
4.3. Experimental Results
To evaluate and demonstrate the feasibility of our proposed method, we present the experimental results of various analyses step by step. First, in
Section 4.3.1, we introduce the impact of the augmented features generator by comparing model accuracy before and after using the augmented features. Next, in
Section 4.3.2, we conduct experiments for the gradient-based feature importance method, verifying its effectiveness by analyzing evaluation metrics for each iteration of feature elimination and showcasing the importance rankings of different features. Then,
Section 4.3.3 integrates our linear time series model architecture based on seasonal decomposition to perform single-point and multi-point forecasting; these results are compared with other models to assess the accuracy of our method in practical applications. Finally,
Section 4.3.4 presents an inventory improvement analysis, illustrating the practical benefits in inventory management when our forecasting method is applied to the order demand data. The following subsections detail these results.
4.3.1. Impact of Augmented Features Generator
In this part of the experiment, we explore how including augmented features (as described in
Section 3) affects model accuracy. We compare two scenarios: the baseline linear decomposition model using only the original features and the same model augmented with additional features (differences, rolling statistics, etc.).
Table 3 reports the prediction performance (using MAE, RMSE, and R2) on the order dataset with and without the augmented features. We observe that the model with augmented features outperforms the one without across all metrics. For instance, the MAE and RMSE are lower when augmented features are included, indicating more precise predictions. The R2 is higher, indicating that the model explains more variance in the order quantities. This improvement demonstrates that the new features generated by our augmented-features generator indeed provide valuable information that boosts forecasting accuracy. We find similar trends in the other two datasets (electric load and solar radiation), as shown later in
Table 4 and
Table 5, confirming that the augmented-features generator consistently enhances the predictive performance of the linear model in different contexts.
Similarly,
Table 4 and
Table 5 present the performance of the electric load and solar radiation datasets, respectively, comparing models with and without augmented features. The results mirror those of the order dataset: augmented features lead to uniformly better forecasting accuracy. These consistent improvements across all three datasets highlight the generalizability of our augmented-feature approach. By capturing trend dynamics, seasonality changes, and other patterns more effectively, these features help the linear model adapt to different types of time series data. From
Table 3,
Table 4 and
Table 5, we conclude that the augmented-features generator yields superior performance across all MAE, RMSE, and R2 datasets. This demonstrates that our augmented feature set can significantly enhance the prediction accuracy of the time series model, validating the effectiveness of our feature-engineering approach.
4.3.2. Gradient Feature Importance and Feature Elimination
This section evaluates the proposed gradient-based feature importance method and the iterative feature elimination procedure. We experimented on each dataset, progressively removing the least essential feature (as determined by the gradient importance score) and recording the model’s performance at each step.
Figure 4 illustrates the feature importance results for the order dataset. As shown, “Quantity_in_stock” emerges as the most significant feature, followed by “change_rate”, “rolling_max”, and others; the least important feature, in this case, is “Inbound”. We then eliminate features in ascending order of importance and track the performance. For clarity, the pseudocode of the feature elimination algorithm is provided in Algorithm 1. Throughout this elimination process on the order dataset, we find that the model’s MAE and RMSE remain relatively stable until the most critical features begin to be removed, at which point performance degrades. This indicates that a subset of top-ranked features (approximately the top 5–6 features out of the complete set in this dataset) is sufficient to achieve near-optimal accuracy. By removing the rest, we simplify the model with minimal loss in accuracy. We observed a similar pattern with the electric load and solar radiation datasets, confirming that our gradient-based importance reliably identifies which features can be pruned.
Figure 4. Gradient Feature Importance for the order dataset (left) and the effect of iterative feature elimination on MAE (right). The bar chart (left) ranks features by their importance score (absolute gradient magnitude). The line plot (right) shows how the model’s MAE changes as features are removed individually in order of increasing importance (removing the least significant first). We see that MAE stays low and nearly flat until only the top few features remain; at this point, it rises, indicating those features were crucial. Following feature elimination, we have a reduced feature set that simplifies the model. Importantly, this reduction also tends to reduce noise and overfitting. By focusing only on the most relevant features, the model generalizes better to new data, as evidenced by slightly improved validation R2 in some cases after eliminating unimportant features. The interpretability is also enhanced, as decision-makers can concentrate on a handful of key factors (inventory levels and recent changes in the order data scenario) that drive the forecasts. This experiment verifies that our gradient feature importance method effectively explains model behavior and that the gradient-based feature elimination strategy can streamline the model without sacrificing accuracy.
Table 6,
Table 7 and
Table 8 show that the gradient feature elimination algorithm allows the model to achieve better accuracy in specific iterations compared to the initial iteration. This demonstrates that the gradients of each feature can effectively measure feature importance. It also indicates that this method effectively identifies the features that contribute most to the model’s predictions. This helps users understand the importance of each feature, making the time series model interpretable, and it also assists in further optimizing the model through the gradient feature elimination algorithm.
4.3.3. Forecasting Performance of Decomposition-Based Linear Model
After validating the components of our approach (augmented features and feature selection), we integrate everything into our linear time series model architecture based on seasonal decomposition and evaluate its forecasting performance. We test our model on forecasting horizons (predicting 1 step, 3 steps ahead, and 6 steps ahead) and compare the results with benchmark models, including standard linear models and recent deep learning approaches. These comparisons are carried out on each of the three datasets.
For the order dataset (one-week ahead forecasting),
Table 9 summarizes the forecasting accuracy using different models: our proposed model, a baseline linear model without decomposition, a decomposition-only model without augmented features, and advanced models like LSTM or Transformer-based forecasters. Our proposed model achieves the lowest error (and highest R2) among the linear models and is competitive with the deep learning models, especially considering the interpretability and efficiency gains of our approach.
For the electric load dataset (1-h ahead forecasting),
Table 10 shows the results. The electric load data have a strong daily periodicity, which all models attempt to capture. Our decomposition-based model again shows robust performance, significantly outperforming the baseline linear model and coming close to the accuracy of more complex models.
For the solar radiation dataset (1-h ahead forecasting),
Table 11 presents the results. This dataset’s strong daily cycle and short duration make forecasting challenging once we move beyond a few hours. Still, our method provides reasonable forecasts and surpasses the standard linear baseline. In the 1-h ahead scenario, our model’s MAE and RMSE are only slightly higher than those of a specialized neural network model, demonstrating that a cleverly engineered linear model can perform admirably even for highly nonlinear data like solar radiation.
4.3.4. Inventory Improvement Analysis
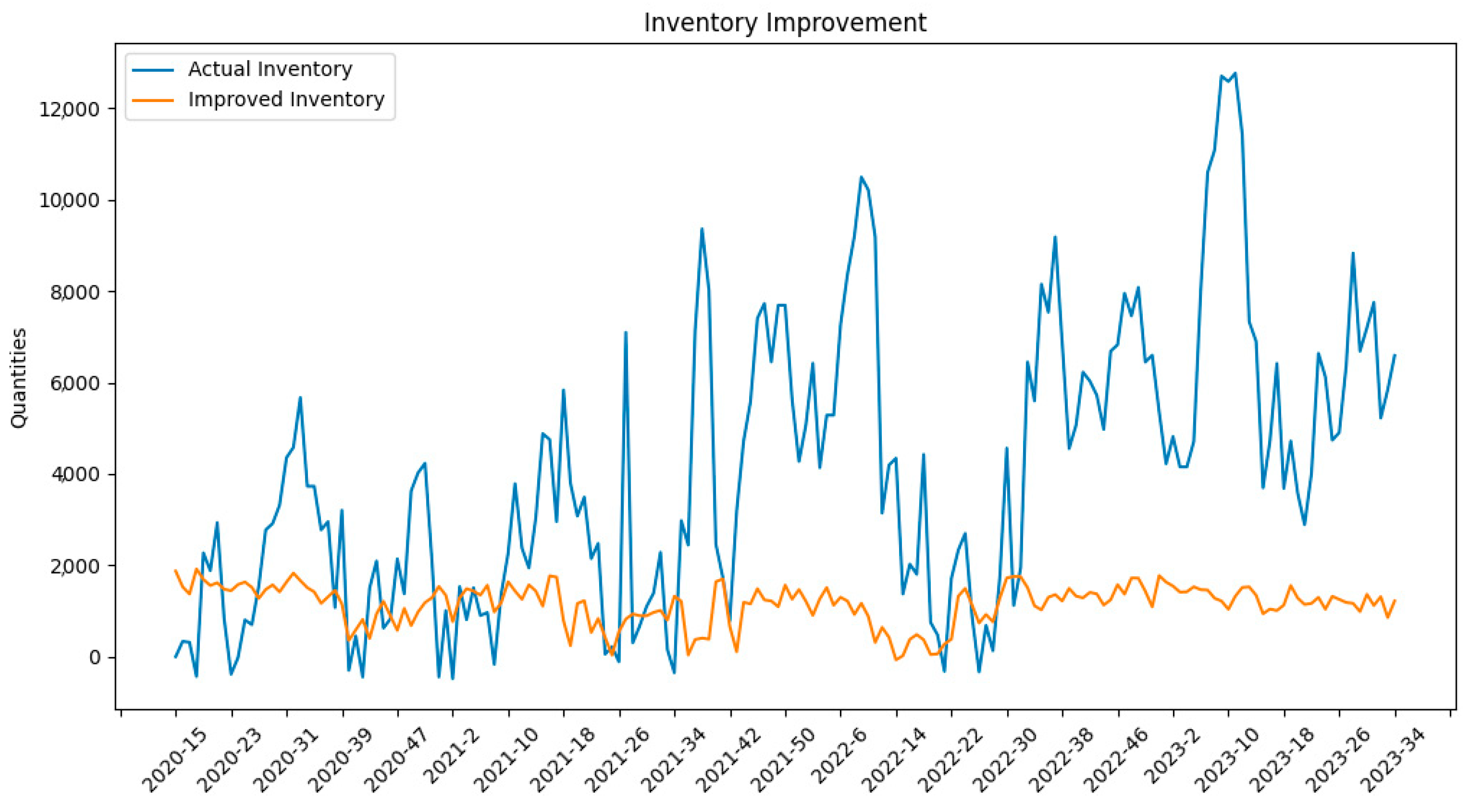
An important practical aspect of our work is evaluating how improved forecasting translates into better decision-making outcomes. To assess this, we carried out an inventory management simulation for the order dataset. We took the forecasting results of our model. We used them to drive an ordering policy for the manufacturer’s inventory and then compared inventory levels and stockout occurrences to the original scenario. As shown in
Figure 8, our method effectively reduces overall inventory levels by about 80.62% compared to the original data without increasing stockouts. The stockout issue in the original data (where certain weeks had insufficient inventory to meet demand) is resolved within 12 weeks of applying our forecasting-based policy. The figure illustrates how inventory on hand evolves under the original vs. the new approach. Initially, both strategies start at the same inventory level; as our model’s order recommendations kick in, the inventory held begins to drop to a much lower trajectory while still covering the demand. By the end of the simulation period, the original system was carrying a large stock surplus, whereas our system maintained a leaner inventory that met all orders. This result is significant for the manufacturer—it implies that adopting our forecasting model to plan inventory could free up working capital tied in excess stock and reduce holding costs while avoiding the lost sales or disruption caused by stockouts.
For the order dataset (three-week ahead forecasting),
Table 12 reports the performance. With the longer horizon, the error increases for all models (as expected), but our model’s performance degrades more gracefully compared to others. We attribute this to the decomposition effectively isolating trend and seasonality, and to the augmented features providing the model with richer information to handle multi-step dependencies.
For the electric load dataset (3-h ahead forecasting),
Table 13 provides the results. As the horizon extends to 3 h, the errors increase relative to the 1-h case, but our decomposition-based model still maintains strong performance. It continues to outperform the baseline linear model and remains competitive with the more complex models at this intermediate horizon.
For the solar radiation dataset (3-h ahead forecasting),
Table 14 shows the results. We observe the forecast error growing compared to the 1-h horizon, yet our method continues to exceed the baseline linear model’s accuracy. The performance remains strong given the nonlinear, short-cycle nature of the data, indicating the effectiveness of our decomposition and feature-engineering approach at this intermediate horizon.
For the order dataset (six-week ahead forecasting),
Table 15 shows the performance comparison. As expected, the prediction error further increases for all models at this longer horizon. Nonetheless, our model’s accuracy degrades more gracefully than the others, maintaining a relatively better R2 and lower error than the competing approaches at six weeks ahead.
For the electric load dataset (6-h ahead forecasting),
Table 16 reports the results. At this longer horizon, all models experience higher errors; however, our model maintains a relatively low RMSE compared to the deep learning models. This highlights our model’s ability to capture the essential structure of the series, likely due to the explicit modeling of daily seasonality and trend components in the decomposition.
For the solar radiation dataset (6-h ahead forecasting),
Table 17 shows the performance comparison. In this scenario, the gap between our linear model and the neural network models widens, suggesting that incorporating additional nonlinear components or exogenous variables might further improve performance for longer horizons on this dataset. Nonetheless, our method still outperforms the standard linear baseline and provides reasonable forecasts even at this challenging horizon, confirming that our approach is broadly effective across different types of time series.
Figure 8 shows an inventory level comparison before and after applying our forecasting method on the order dataset. The blue curve shows the original inventory levels over time (which are high and include some periods of stockouts), and the orange curve shows the improved inventory levels using our forecast-driven order recommendations. Our method keeps inventory much lower and more stable and, crucially, eliminates stockout events (weeks where inventory would drop to zero).
By quantitatively demonstrating improvements in an operational metric (inventory level), our forecasting approach’s benefits extend beyond error metrics—they can translate into tangible gains for business operations.
5. Conclusions and Future Work
In this work, we presented a linear model for time series forecasting that balances accuracy, interpretability, and efficiency. The model is built on a seasonal decomposition framework (using an additive model due to the stable seasonal patterns observed in the data) combined with an augmented-features generator and a gradient-based feature importance mechanism. Our results on three diverse datasets (product orders, machine energy load, and solar radiation) showed that this approach can achieve high forecasting accuracy on par with more complex models. The decomposition of time series into trend and seasonality allowed the linear model to focus on simplified sub-problems, while the augmented features captured additional structure (like acceleration/deceleration and frequency components) that further boosted performance. The gradient feature importance and elimination steps added interpretability and feature optimization, enabling the model to remain parsimonious without sacrificing predictive power.
We also demonstrated the practical impact of our method in a real-world scenario by showing significant improvements in inventory management when our forecasts are used for decision-making. This underscores the value of interpretable and reliable forecasting models in operational settings: not only can they produce accurate predictions, but they can do so in a way that stakeholders trust and act upon, leading to concrete benefits.
Despite these successes, there are several avenues for future work. First, while we adopted an additive decomposition model across all datasets (given that seasonal effects did not appear to scale with the series level in our cases), future research could explore adaptive or hybrid decomposition approaches that dynamically select between additive and multiplicative models based on data characteristics. For instance, a model could perform a preliminary check on seasonal variability and choose the decomposition type accordingly or even switch models if a time series exhibits regime changes in its seasonal behavior. Second, the current augmented feature set could be expanded with domain-specific features or nonlinear transformations. Although our linear model benefited from features capturing nonlinearity indirectly, another strategy is incorporating mild nonlinear modeling elements (like piecewise linear components or interactions between features) to handle patterns that pure linearity might miss. Third, our gradient-based importance method is well-suited to our linear model; applying similar ideas to more complex models (like neural networks) is not straightforward due to their nonlinear nature, so developing analogous interpretability techniques for deep time series models would be valuable. Finally, in our implementation, we trained the trend and seasonal forecasting models sequentially (one after the other). A possible improvement is to train or optimize them jointly or in parallel, which could reduce computation time and improve how the two components complement each other.
In conclusion, our study highlights that with thoughtful decomposition and feature engineering, simple linear models can offer a compelling blend of accuracy and interpretability for time series forecasting. By making model predictions more transparent and tying them to actionable insights (such as optimized inventory levels), we pave the way for broader acceptance and integration of advanced forecasting methods in industry practice. Future works will further bridge the gap between model complexity and interpretability, ensuring that improvements in predictive performance translate into real-world value.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}