

Evolutionary Reinforcement Learning: A Systematic Review and Future Directions

 , , ,
, , ,
Abstract
1. Introduction
- How have previous studies explored the integration of EAs to address the limitations of traditional reinforcement learning?
- What strategies have been proposed in the literature to improve EvoRL’s efficiency and scalability?
- How do existing approaches aim to enhance EvoRL’s robustness in complex environments?
1.1. Contributions
- Multidimensional classification. We have taken a comprehensive look at the EvoRL field, categorizing different approaches and strategies in detail. This detailed classification covers not only EvoRL’s multiple techniques and strategies, such as genetic algorithms and policy gradients, but also their application to complex problem-solving.
- Challenges in EvoRL. We provide an in-depth analysis of the challenges and limitations of current research, including issues encountered by reinforcement learning and EvoRL, and provide their corresponding solutions.
- Constructive open issues. This review presents a summary of emerging topics, including the scalability to high-dimensional spaces, adaptability to dynamic environments, adversarial robustness, ethics, and fairness in EvoRL.
- Promising future directions. We identify key research gaps and propose future directions for EvoRL, highlighting the need for meta-evolutionary strategies, self-adaptation and self-improvement mechanisms, model scalability, interpretability, and explainability, as well as the incorporation of EvoRL within Large Language Models (LLMs).
1.2. Article Organization
2. Literature Review Methodology
- Collection Phase: We established a comprehensive collection strategy that encompassed multiple databases and integrated various keyword combinations.
- Screening Phase: We applied predefined inclusion and exclusion criteria to systematically screen the collected literature. This process involved an initial review of titles and abstracts, followed by a detailed full-text assessment to ensure the selected studies were highly relevant to the research question.
- Analysis Phase: After identifying the eligible studies, we conducted systematic data extraction and quality assessment. Subsequently, we performed qualitative or quantitative analysis on the extracted data to synthesize the findings from existing studies and explore their implications and limitations.
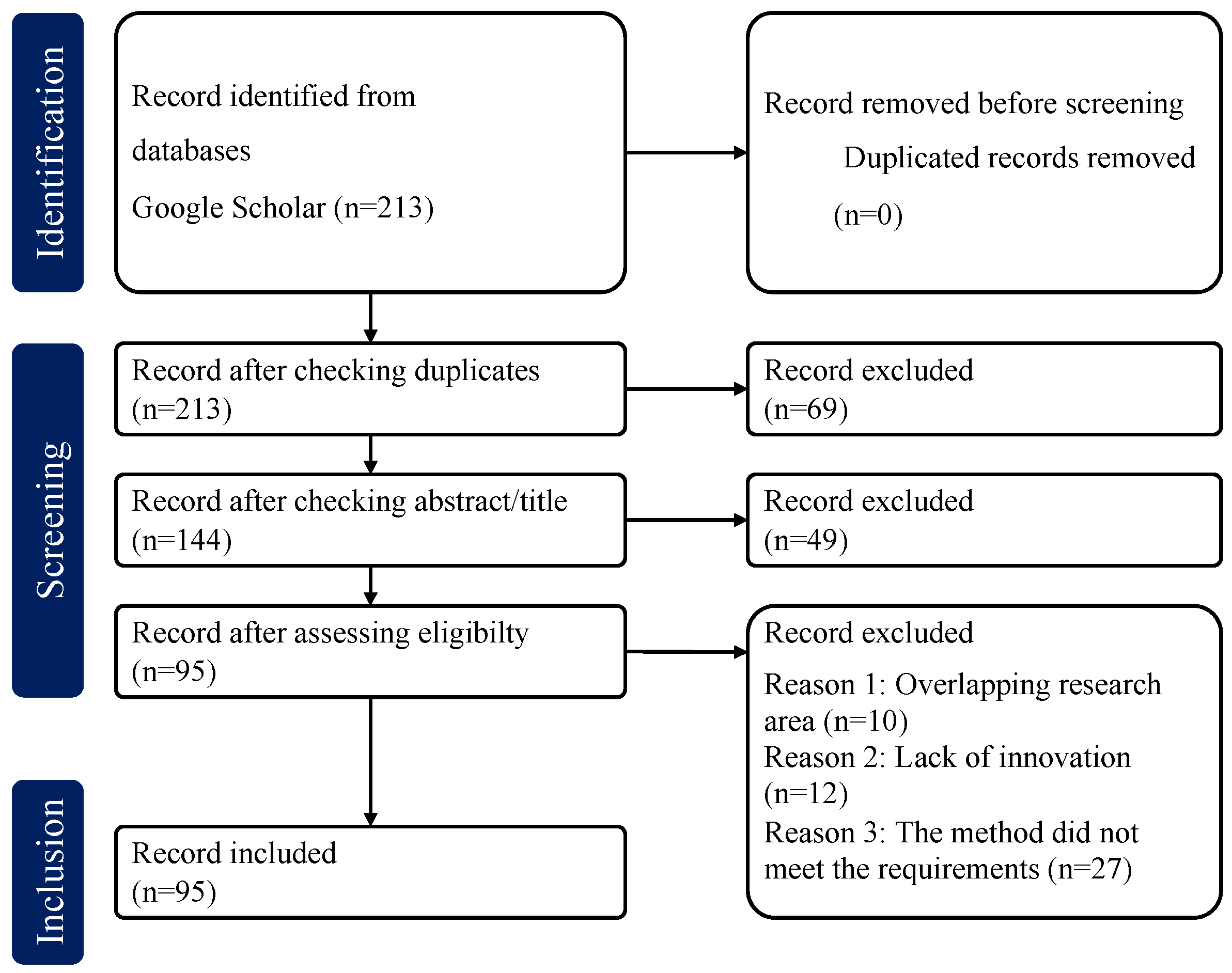
2.1. Collection Phase
- The considered literature spanned from 2000 to 2024, with the search primarily conducted on the Google Scholar database.
- Keywords and their synonyms related to “Evolutionary Reinforcement Learning” were used to ensure the coverage of the core literature in the field (e.g., Evolutionary Strategy, Genetic Algorithm).
- The included literature must have explicitly applied EAs or reinforcement learning methods and demonstrated theoretical or applied innovation.
- Through the removal of duplicate articles and the application of inclusion and exclusion criteria, 213 relevant articles were ultimately obtained.
2.2. Screening Phase
2.3. Analysis Phase
- Categorization of Methodologies: We classified existing methodologies into three reinforcement learning paradigms and five EA implementation mechanisms, revealing the dominant technical integration patterns.
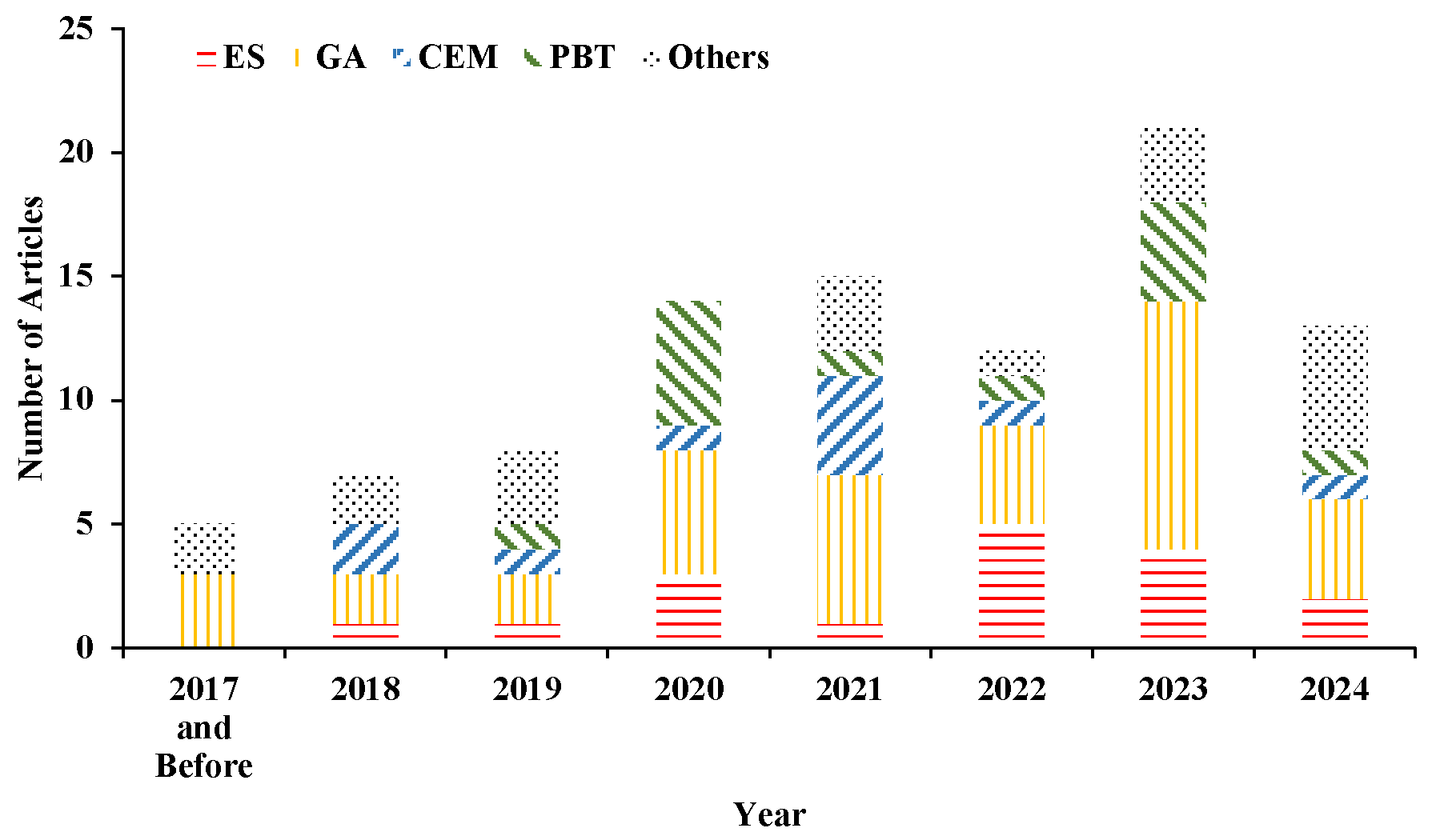
- Chronological Analysis: We constructed the annual publication distribution (Figure 2) to quantitatively visualize the phased evolution of research activity in EvoRL.
- Benchmark Task Clustering: We identified three core testing scenarios (continuous control, multi-task, and multi-objective optimization) through the attribute clustering of benchmark tasks, establishing clear mapping relationships between task characteristics and algorithmic preferences.
- Mainstream Benchmarking Practices: We extracted prevalent comparison algorithms (primarily A2C, SAC, and DDPG) to identify mainstream benchmarking practices in reinforcement learning research.
- Performance Metric Categorization: We systematically categorized performance metrics, emphasizing the cumulative reward, convergence speed, and computational cost, to reflect differentiated assessment requirements across heterogeneous testing environments.
- Comparison with Existing Reviews: We compared our collected literature with prior review studies [19,21,22], confirming that all articles covered in these works were included in our analysis. Additionally, we incorporated more recent publications to ensure the timeliness and comprehensiveness of our study.
3. Background
3.1. Reinforcement Learning
3.2. Evolutionary Algorithms
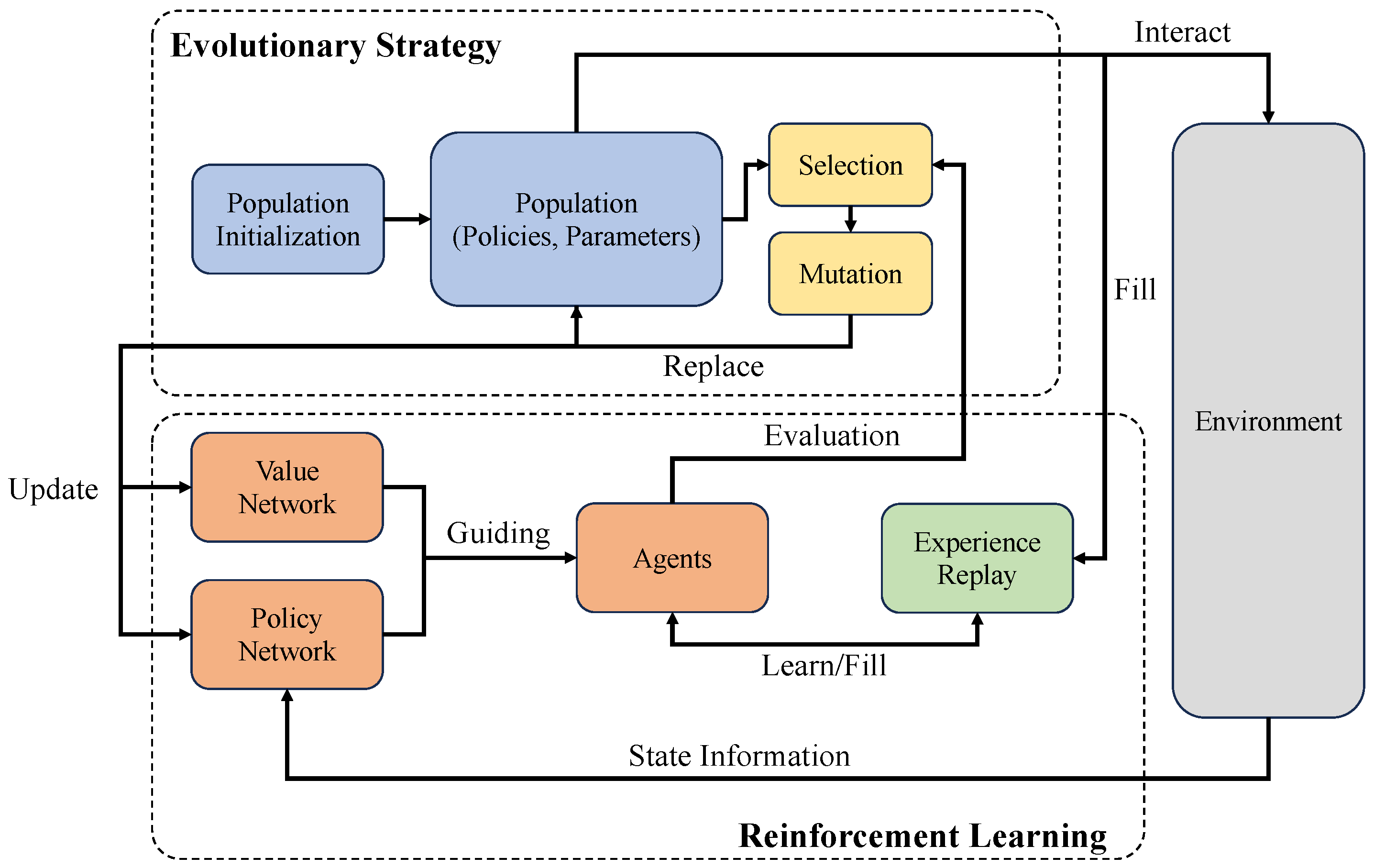
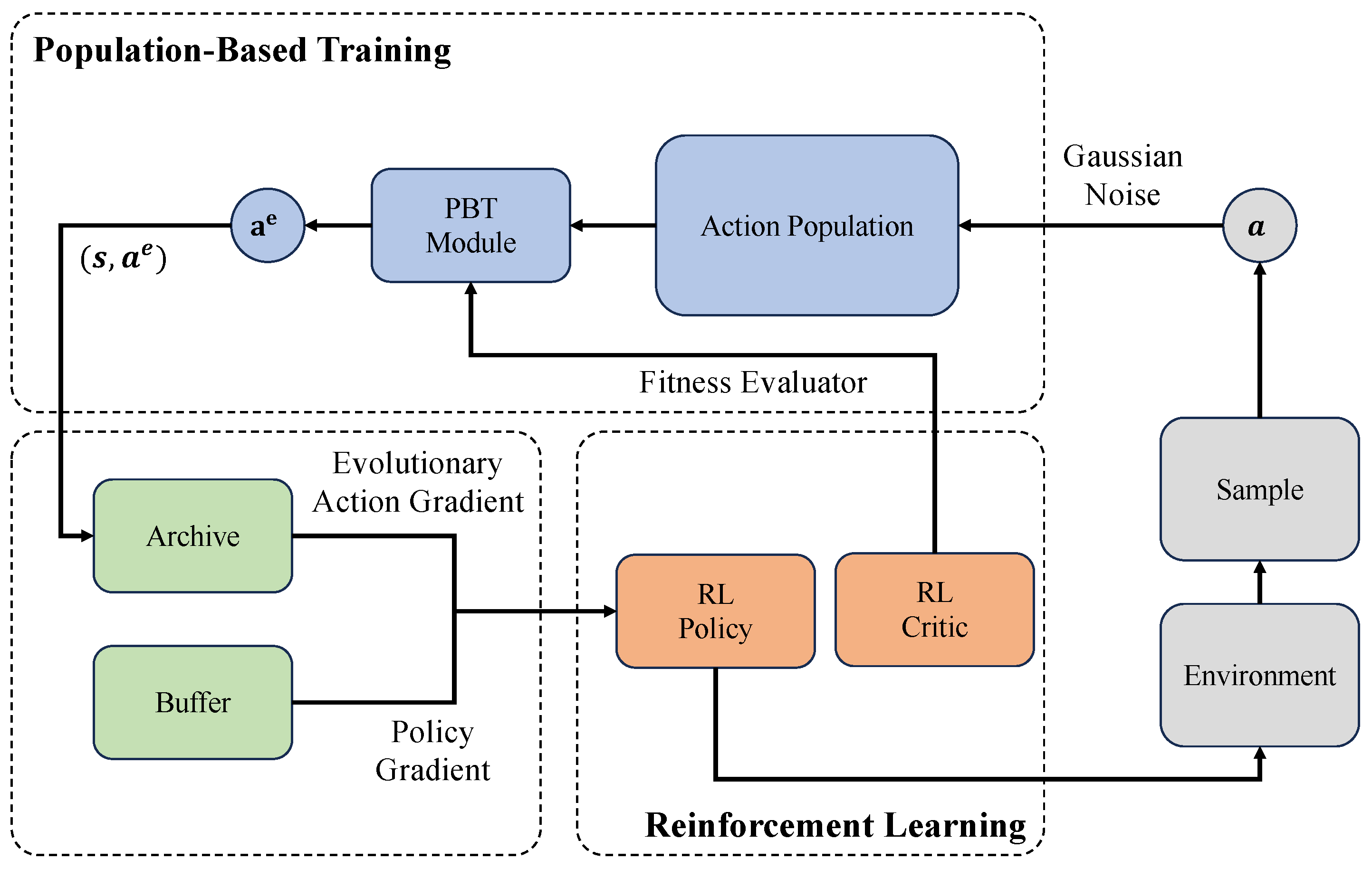
4. Methods of Evolutionary Reinforcement Learning
4.1. Evolutionary Strategy
4.2. Genetic Algorithm
4.3. Cross-Entropy Method
4.4. Population-Based Training
4.5. Other EAs
5. Challenges in Evolutionary Reinforcement Learning
5.1. Issues Encountered by Reinforcement Learning
5.1.1. Parameter Sensitivity
5.1.2. Sparse Rewards
5.1.3. Local Optima
5.1.4. Multi-Task Challenges
5.1.5. Policy Search
5.1.6. Computational Efficiency
5.2. Issues Encountered by Evolutionary Reinforcement Learning
5.2.1. Sample Efficiency
5.2.2. Algorithm Complexity
5.2.3. Performance
6. Open Issues and Future Directions
6.1. Open Issues
6.1.1. Scalability to High-Dimensional Spaces
6.1.2. Adaptability to Dynamic Environments
6.1.3. Adversarial Robustness in EvoRL
6.1.4. Ethics and Fairness
6.2. Future Directions
6.2.1. Meta-Evolutionary Strategies
6.2.2. Self-Adaptation and Self-Improvement Mechanisms
6.2.3. Model Scalability
6.2.4. Heterogeneous Networks and Multi-Agent Systems
6.2.5. Interpretability and Explainability
6.2.6. Incorporation in Large Language Models
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| EA | Evolutionary Algorithm |
| RL | Reinforcement Learning |
| EvoRL | Evolutionary Reinforcement Learning |
| ES | Evolutionary Strategy |
| GA | Genetic Algorithm |
| CEM | Cross-Entropy Method |
| PBT | Population-Based Training |
| DRL | Deep Reinforcement Learning |
| EGPG | Evolution-Guided Policy Gradient |
| CERL | Collaborative Evolutionary Reinforcement Learning |
References
- Lin, Y.; Liu, Y.; Lin, F.; Zou, L.; Wu, P.; Zeng, W.; Chen, H.; Miao, C. A survey on reinforcement learning for recommender systems. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 13164–13184. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Lin, Y.; Liu, Y.; You, H.; Wu, P.; Lin, F.; Zhou, X. Self-Supervised Reinforcement Learning with dual-reward for knowledge-aware recommendation. Appl. Soft Comput. 2022, 131, 109745. [Google Scholar] [CrossRef]
- Zhao, X.; Xia, L.; Zhang, L.; Ding, Z.; Yin, D.; Tang, J. Deep reinforcement learning for page-wise recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 95–103. [Google Scholar]
- de Lacerda, M.G.P.; de Lima Neto, F.B.; Ludermir, T.B.; Kuchen, H. Out-of-the-box parameter control for evolutionary and swarm-based algorithms with distributed reinforcement learning. Swarm Intell. 2023, 17, 173–217. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, Y.; Liu, X. Pns: Population-guided novelty search for reinforcement learning in hard exploration environments. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 5627–5634. [Google Scholar]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Coello, C.A.C. Evolutionary Algorithms for Solving Multi-Objective Problems; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Nilsson, O.; Cully, A. Policy gradient assisted map-elites. In Proceedings of the Genetic and Evolutionary Computation Conference, Lisbon, Portugal, 15–19 July 2021; pp. 866–875. [Google Scholar]
- Khadka, S.; Tumer, K. Evolution-guided policy gradient in reinforcement learning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2018; Volume 31. [Google Scholar]
- Shi, L.; Li, S.; Zheng, Q.; Yao, M.; Pan, G. Efficient novelty search through deep reinforcement learning. IEEE Access 2020, 8, 128809–128818. [Google Scholar] [CrossRef]
- Khadka, S.; Majumdar, S.; Nassar, T.; Dwiel, Z.; Tumer, E.; Miret, S.; Liu, Y.; Tumer, K. Collaborative evolutionary reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 3341–3350. [Google Scholar]
- Lü, S.; Han, S.; Zhou, W.; Zhang, J. Recruitment-imitation mechanism for evolutionary reinforcement learning. Inf. Sci. 2021, 553, 172–188. [Google Scholar] [CrossRef]
- Franke, J.K.; Köhler, G.; Biedenkapp, A.; Hutter, F. Sample-efficient automated deep reinforcement learning. arXiv 2020, arXiv:2009.01555. [Google Scholar]
- Gupta, A.; Savarese, S.; Ganguli, S.; Fei-Fei, L. Embodied intelligence via learning and evolution. Nat. Commun. 2021, 12, 5721. [Google Scholar] [CrossRef]
- Pierrot, T.; Macé, V.; Cideron, G.; Perrin, N.; Beguir, K.; Sigaud, O. Sample Efficient Quality Diversity for Neural Continuous Control. 2020. Available online: https://openreview.net/forum?id=8FRw857AYba (accessed on 10 February 2025).
- Marchesini, E.; Corsi, D.; Farinelli, A. Genetic soft updates for policy evolution in deep reinforcement learning. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Eriksson, A.; Capi, G.; Doya, K. Evolution of meta-parameters in reinforcement learning algorithm. In Proceedings of the Proceedings 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003) (Cat. No. 03CH37453), Las Vegas, NV, USA, 27 October–1 November 2003; Volume 1, pp. 412–417. [Google Scholar]
- Tjanaka, B.; Fontaine, M.C.; Togelius, J.; Nikolaidis, S. Approximating gradients for differentiable quality diversity in reinforcement learning. In Proceedings of the Genetic and Evolutionary Computation Conference, Boston, MA, USA, 9–13 July 2022; pp. 1102–1111. [Google Scholar]
- Majid, A.Y.; Saaybi, S.; Francois-Lavet, V.; Prasad, R.V.; Verhoeven, C. Deep reinforcement learning versus evolution strategies: A comparative survey. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 11939–11957. [Google Scholar] [CrossRef]
- Wang, Y.; Xue, K.; Qian, C. Evolutionary diversity optimization with clustering-based selection for reinforcement learning. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Li, N.; Ma, L.; Yu, G.; Xue, B.; Zhang, M.; Jin, Y. Survey on evolutionary deep learning: Principles, algorithms, applications, and open issues. ACM Comput. Surv. 2023, 56, 1–34. [Google Scholar] [CrossRef]
- Zhu, Q.; Wu, X.; Lin, Q.; Ma, L.; Li, J.; Ming, Z.; Chen, J. A survey on Evolutionary Reinforcement Learning algorithms. Neurocomputing 2023, 556, 126628. [Google Scholar] [CrossRef]
- Sigaud, O. Combining evolution and deep reinforcement learning for policy search: A survey. ACM Trans. Evol. Learn. 2023, 3, 1–20. [Google Scholar] [CrossRef]
- Bai, H.; Cheng, R.; Jin, Y. Evolutionary Reinforcement Learning: A Survey. Intell. Comput. 2023, 2, 0025. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; Prisma Group. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. Int. J. Surg. 2010, 8, 336–341. [Google Scholar] [CrossRef]
- Yang, P.; Zhang, L.; Liu, H.; Li, G. Reducing idleness in financial cloud services via multi-objective evolutionary reinforcement learning based load balancer. Sci. China Inf. Sci. 2024, 67, 120102. [Google Scholar] [CrossRef]
- Lin, Q.; Chen, Y.; Ma, L.; Chen, W.N.; Li, J. ERL-TD: Evolutionary Reinforcement Learning Enhanced with Truncated Variance and Distillation Mutation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 13826–13836. [Google Scholar]
- Liang, P.; Chen, Y.; Sun, Y.; Huang, Y.; Li, W. An information entropy-driven evolutionary algorithm based on reinforcement learning for many-objective optimization. Expert Syst. Appl. 2024, 238, 122164. [Google Scholar] [CrossRef]
- Lin, Y.; Chen, H.; Xia, W.; Lin, F.; Wu, P.; Wang, Z.; Li, Y. A Comprehensive Survey on Deep Learning Techniques in Educational Data Mining. arXiv 2023, arXiv:2309.04761. [Google Scholar]
- Chen, X.; Yao, L.; McAuley, J.; Zhou, G.; Wang, X. A survey of deep reinforcement learning in recommender systems: A systematic review and future directions. arXiv 2021, arXiv:2109.03540. [Google Scholar]
- Vikhar, P.A. Evolutionary algorithms: A critical review and its future prospects. In Proceedings of the 2016 IEEE International Conference on Global Trends in Signal Processing, Information Computing and Communication (ICGTSPICC), Jalgaon, India, 22–24 December 2016; pp. 261–265. [Google Scholar]
- Hoffmeister, F.; Bäck, T. Genetic algorithms and evolution strategies: Similarities and differences. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Dortmund, Germany, 1–3 October 1990; Springer: Berlin/Heidelberg, Germany, 1990; pp. 455–469. [Google Scholar]
- Vent, W. Rechenberg, Ingo, Evolutionsstrategie—Optimierung Technischer Systeme nach Prinzipien der Biologischen Evolution. 170 S. mit 36 Abb. Frommann-Holzboog-Verlag. Stuttgart 1973. Broschiert; Wiley Online Library: Hoboken, NJ, USA, 1975. [Google Scholar]
- Slowik, A.; Kwasnicka, H. Evolutionary algorithms and their applications to engineering problems. Neural Comput. Appl. 2020, 32, 12363–12379. [Google Scholar] [CrossRef]
- Ho, S.L.; Yang, S. The cross-entropy method and its application to inverse problems. IEEE Trans. Magn. 2010, 46, 3401–3404. [Google Scholar] [CrossRef]
- Botev, Z.I.; Kroese, D.P.; Rubinstein, R.Y.; L’Ecuyer, P. The cross-entropy method for optimization. In Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2013; Volume 31, pp. 35–59. [Google Scholar]
- Huang, K.; Lale, S.; Rosolia, U.; Shi, Y.; Anandkumar, A. CEM-GD: Cross-Entropy Method with Gradient Descent Planner for Model-Based Reinforcement Learning. arXiv 2021, arXiv:2112.07746. [Google Scholar]
- Das, S.; Suganthan, P.N. Differential evolution: A survey of the state-of-the-art. IEEE Trans. Evol. Comput. 2010, 15, 4–31. [Google Scholar] [CrossRef]
- Jaderberg, M.; Dalibard, V.; Osindero, S.; Czarnecki, W.M.; Donahue, J.; Razavi, A.; Vinyals, O.; Green, T.; Dunning, I.; Simonyan, K.; et al. Population based training of neural networks. arXiv 2017, arXiv:1711.09846. [Google Scholar]
- Hein, D.; Udluft, S.; Runkler, T.A. Interpretable policies for reinforcement learning by genetic programming. Eng. Appl. Artif. Intell. 2018, 76, 158–169. [Google Scholar] [CrossRef]
- Tang, J.; Liu, G.; Pan, Q. A review on representative swarm intelligence algorithms for solving optimization problems: Applications and trends. IEEE/CAA J. Autom. Sin. 2021, 8, 1627–1643. [Google Scholar] [CrossRef]
- Sachdeva, E.; Khadka, S.; Majumdar, S.; Tumer, K. Maedys: Multiagent evolution via dynamic skill selection. In Proceedings of the Genetic and Evolutionary Computation Conference, Lisbon, Portugal, 15–19 July 2021; pp. 163–171. [Google Scholar]
- Shi, L.; Li, S.; Cao, L.; Yang, L.; Zheng, G.; Pan, G. FiDi-RL: Incorporating Deep Reinforcement Learning with Finite-Difference Policy Search for Efficient Learning of Continuous Control. arXiv 2019, arXiv:1907.00526. [Google Scholar]
- Ajani, O.S.; Mallipeddi, R. Adaptive evolution strategy with ensemble of mutations for reinforcement learning. Knowl.-Based Syst. 2022, 245, 108624. [Google Scholar] [CrossRef]
- Tang, Y.; Choromanski, K. Online hyper-parameter tuning in off-policy learning via evolutionary strategies. arXiv 2020, arXiv:2006.07554. [Google Scholar]
- Chen, Z.; Zhou, Y.; He, X.; Jiang, S. A Restart-based Rank-1 Evolution Strategy for Reinforcement Learning. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 2130–2136. [Google Scholar]
- Yang, P.; Zhang, H.; Yu, Y.; Li, M.; Tang, K. Evolutionary reinforcement learning via cooperative coevolutionary negatively correlated search. Swarm Evol. Comput. 2022, 68, 100974. [Google Scholar] [CrossRef]
- Ajani, O.S.; Kumar, A.; Mallipeddi, R. Covariance matrix adaptation evolution strategy based on correlated evolution paths with application to reinforcement learning. Expert Syst. Appl. 2024, 246, 123289. [Google Scholar] [CrossRef]
- Liu, H.; Li, Z.; Huang, K.; Wang, R.; Cheng, G.; Li, T. Evolutionary reinforcement learning algorithm for large-scale multi-agent cooperation and confrontation applications. J. Supercomput. 2024, 80, 2319–2346. [Google Scholar] [CrossRef]
- Sun, H.; Xu, Z.; Song, Y.; Fang, M.; Xiong, J.; Dai, B.; Zhou, B. Zeroth-order supervised policy improvement. arXiv 2020, arXiv:2006.06600. [Google Scholar]
- Houthooft, R.; Chen, Y.; Isola, P.; Stadie, B.; Wolski, F.; Jonathan Ho, O.; Abbeel, P. Evolved policy gradients. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2018; Volume 31. [Google Scholar]
- Callaghan, A.; Mason, K.; Mannion, P. Evolutionary Strategy Guided Reinforcement Learning via MultiBuffer Communication. arXiv 2023, arXiv:2306.11535. [Google Scholar]
- Martinez, A.D.; Del Ser, J.; Osaba, E.; Herrera, F. Adaptive multifactorial evolutionary optimization for multitask reinforcement learning. IEEE Trans. Evol. Comput. 2021, 26, 233–247. [Google Scholar] [CrossRef]
- Li, W.; He, S.; Mao, X.; Li, B.; Qiu, C.; Yu, J.; Peng, F.; Tan, X. Multi-agent evolution reinforcement learning method for machining parameters optimization based on bootstrap aggregating graph attention network simulated environment. J. Manuf. Syst. 2023, 67, 424–438. [Google Scholar] [CrossRef]
- Zheng, B.; Cheng, R. Rethinking Population-assisted Off-policy Reinforcement Learning. arXiv 2023, arXiv:2305.02949. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K.; Christensen, H.I. Co-evolution of shaping rewards and meta-parameters in reinforcement learning. Adapt. Behav. 2008, 16, 400–412. [Google Scholar] [CrossRef]
- Zhang, H.; An, T.; Yan, P.; Hu, K.; An, J.; Shi, L.; Zhao, J.; Wang, J. Exploring cooperative evolution with tunable payoff’s loners using reinforcement learning. Chaos Solitons Fractals 2024, 178, 114358. [Google Scholar] [CrossRef]
- Song, Y.; Ou, J.; Pedrycz, W.; Suganthan, P.N.; Wang, X.; Xing, L.; Zhang, Y. Generalized model and deep reinforcement learning-based evolutionary method for multitype satellite observation scheduling. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 2576–2589. [Google Scholar] [CrossRef]
- Garau-Luis, J.J.; Miao, Y.; Co-Reyes, J.D.; Parisi, A.; Tan, J.; Real, E.; Faust, A. Multi-objective evolution for generalizable policy gradient algorithms. In Proceedings of the ICLR 2022 Workshop on Generalizable Policy Learning in Physical World, Virtual, 29 April 2022. [Google Scholar]
- Hu, C.; Pei, J.; Liu, J.; Yao, X. Evolving Constrained Reinforcement Learning Policy. arXiv 2023, arXiv:2304.09869. [Google Scholar]
- Bodnar, C.; Day, B.; Lió, P. Proximal distilled evolutionary reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–8 February 2020; Volume 34, pp. 3283–3290. [Google Scholar]
- Wang, Y.; Zhang, T.; Chang, Y.; Wang, X.; Liang, B.; Yuan, B. A surrogate-assisted controller for expensive evolutionary reinforcement learning. Inf. Sci. 2022, 616, 539–557. [Google Scholar] [CrossRef]
- Pierrot, T.; Macé, V.; Chalumeau, F.; Flajolet, A.; Cideron, G.; Beguir, K.; Cully, A.; Sigaud, O.; Perrin-Gilbert, N. Diversity policy gradient for sample efficient quality-diversity optimization. In Proceedings of the Genetic and Evolutionary Computation Conference, Boston, MA, USA, 9–13 July 2022; pp. 1075–1083. [Google Scholar]
- Hao, J.; Li, P.; Tang, H.; Zheng, Y.; Fu, X.; Meng, Z. ERL-RE2: Efficient Evolutionary Reinforcement Learning with Shared State Representation and Individual Policy Representation. arXiv 2022, arXiv:2210.17375. [Google Scholar]
- Kalashnikov, D.; Irpan, A.; Pastor, P.; Ibarz, J.; Herzog, A.; Jang, E.; Quillen, D.; Holly, E.; Kalakrishnan, M.; Vanhoucke, V.; et al. Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation. arXiv 2018, arXiv:1806.10293. [Google Scholar]
- Shao, L.; You, Y.; Yan, M.; Yuan, S.; Sun, Q.; Bohg, J. Grac: Self-guided and self-regularized actor-critic. In Proceedings of the Conference on Robot Learning, PMLR, Auckland, New Zealand, 14–18 December 2022; pp. 267–276. [Google Scholar]
- Pourchot, A.; Sigaud, O. CEM-RL: Combining evolutionary and gradient-based methods for policy search. arXiv 2018, arXiv:1810.01222. [Google Scholar]
- Kim, N.; Baek, H.; Shin, H. PGPS: Coupling Policy Gradient with Population-Based Search. 2020. Available online: https://openreview.net/forum?id=PeT5p3ocagr (accessed on 10 February 2025).
- Zheng, H.; Wei, P.; Jiang, J.; Long, G.; Lu, Q.; Zhang, C. Cooperative heterogeneous deep reinforcement learning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2020; Volume 33, pp. 17455–17465. [Google Scholar]
- Shi, Z.; Singh, S.P. Soft actor-critic with cross-entropy policy optimization. arXiv 2021, arXiv:2112.11115. [Google Scholar]
- Liu, J.; Feng, L. Diversity evolutionary policy deep reinforcement learning. Comput. Intell. Neurosci. 2021, 2021, 5300189. [Google Scholar] [CrossRef]
- Yu, X.; Hu, Z.; Luo, W.; Xue, Y. Reinforcement learning-based multi-objective differential evolution algorithm for feature selection. Inf. Sci. 2024, 661, 120185. [Google Scholar] [CrossRef]
- Wang, Z.Z.; Zhang, K.; Chen, G.D.; Zhang, J.D.; Wang, W.D.; Wang, H.C.; Zhang, L.M.; Yan, X.; Yao, J. Evolutionary-assisted reinforcement learning for reservoir real-time production optimization under uncertainty. Pet. Sci. 2023, 20, 261–276. [Google Scholar] [CrossRef]
- Ma, Y.; Liu, T.; Wei, B.; Liu, Y.; Xu, K.; Li, W. Evolutionary Action Selection for Gradient-Based Policy Learning. In Proceedings of the International Conference on Neural Information Processing, New Orleans, LA, USA, 28 November–9 December 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 579–590. [Google Scholar]
- Jung, W.; Park, G.; Sung, Y. Population-guided parallel policy search for reinforcement learning. arXiv 2020, arXiv:2001.02907. [Google Scholar]
- Doan, T.; Mazoure, B.; Abdar, M.; Durand, A.; Pineau, J.; Hjelm, R.D. Attraction-repulsion actor-critic for continuous control reinforcement learning. arXiv 2019, arXiv:1909.07543. [Google Scholar]
- Marchesini, E.; Corsi, D.; Farinelli, A. Exploring safer behaviors for deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Pomona, CA, USA, 24–28 October 2022; Volume 36, pp. 7701–7709. [Google Scholar]
- Majumdar, S.; Khadka, S.; Miret, S.; McAleer, S.; Tumer, K. Evolutionary reinforcement learning for sample-efficient multiagent coordination. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 6651–6660. [Google Scholar]
- Long, Q.; Zhou, Z.; Gupta, A.; Fang, F.; Wu, Y.; Wang, X. Evolutionary population curriculum for scaling multi-agent reinforcement learning. arXiv 2020, arXiv:2003.10423. [Google Scholar]
- Shen, R.; Zheng, Y.; Hao, J.; Meng, Z.; Chen, Y.; Fan, C.; Liu, Y. Generating Behavior-Diverse Game AIs with Evolutionary Multi-Objective Deep Reinforcement Learning. In Proceedings of the IJCAI, Yokohama, Japan, 11–17 July 2020; pp. 3371–3377. [Google Scholar]
- Fernandez, F.C.; Caarls, W. Parameters tuning and optimization for reinforcement learning algorithms using evolutionary computing. In Proceedings of the 2018 IEEE International Conference on Information Systems and Computer Science (INCISCOS), Quito, Ecuador, 13–15 November 2018; pp. 301–305. [Google Scholar]
- Kamio, S.; Iba, H. Adaptation technique for integrating genetic programming and reinforcement learning for real robots. IEEE Trans. Evol. Comput. 2005, 9, 318–333. [Google Scholar] [CrossRef]
- Co-Reyes, J.D.; Miao, Y.; Peng, D.; Real, E.; Levine, S.; Le, Q.V.; Lee, H.; Faust, A. Evolving reinforcement learning algorithms. arXiv 2021, arXiv:2101.03958. [Google Scholar]
- AbuZekry, A.; Sobh, I.; Hadhoud, M.; Fayek, M. Comparative study of NeuroEvolution algorithms in reinforcement learning for self-driving cars. Eur. J. Eng. Sci. Technol. 2019, 2, 60–71. [Google Scholar] [CrossRef]
- Kelly, S.; Voegerl, T.; Banzhaf, W.; Gondro, C. Evolving hierarchical memory-prediction machines in multi-task reinforcement learning. Genet. Program. Evolvable Mach. 2021, 22, 573–605. [Google Scholar] [CrossRef]
- Girgin, S.; Preux, P. Feature discovery in reinforcement learning using genetic programming. In Proceedings of the European Conference on Genetic Programming, Naples, Italy, 26–28 March 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 218–229. [Google Scholar]
- Zhu, Q.; Wu, X.; Lin, Q.; Chen, W.N. Two-Stage Evolutionary Reinforcement Learning for Enhancing Exploration and Exploitation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 20892–20900. [Google Scholar]
- Wu, X.; Zhu, Q.; Chen, W.N.; Lin, Q.; Li, J.; Coello, C.A.C. Evolutionary Reinforcement Learning with Action Sequence Search for Imperfect Information Games. Inf. Sci. 2024, 676, 120804. [Google Scholar] [CrossRef]
- Zuo, M.; Gong, D.; Wang, Y.; Ye, X.; Zeng, B.; Meng, F. Process knowledge-guided autonomous evolutionary optimization for constrained multiobjective problems. IEEE Trans. Evol. Comput. 2023, 28, 193–207. [Google Scholar] [CrossRef]
- Peng, L.; Yuan, Z.; Dai, G.; Wang, M.; Tang, Z. Reinforcement learning-based hybrid differential evolution for global optimization of interplanetary trajectory design. Swarm Evol. Comput. 2023, 81, 101351. [Google Scholar] [CrossRef]
- Li, Y. Reinforcement learning in practice: Opportunities and challenges. arXiv 2022, arXiv:2202.11296. [Google Scholar]
- Sehgal, A.; La, H.; Louis, S.; Nguyen, H. Deep reinforcement learning using genetic algorithm for parameter optimization. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 596–601. [Google Scholar]
- Aydeniz, A.A.; Loftin, R.; Tumer, K. Novelty seeking multiagent evolutionary reinforcement learning. In Proceedings of the Genetic and Evolutionary Computation Conference, Lisbon, Portugal, 15–19 July 2023; pp. 402–410. [Google Scholar]
- Zhu, S.; Belardinelli, F.; León, B.G. Evolutionary reinforcement learning for sparse rewards. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Lille, France, 10–14 July 2021; pp. 1508–1512. [Google Scholar]
- Li, P.; Hao, J.; Tang, H.; Zheng, Y.; Fu, X. Race: Improve multi-agent reinforcement learning with representation asymmetry and collaborative evolution. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 19490–19503. [Google Scholar]
- Chang, S.; Yang, J.; Choi, J.; Kwak, N. Genetic-gated networks for deep reinforcement learning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2018; Volume 31. [Google Scholar]
- Tang, Y. Guiding Evolutionary Strategies with Off-Policy Actor-Critic. In Proceedings of the AAMAS, Online, 3–7 May 2021; pp. 1317–1325. [Google Scholar]
- Simmons-Edler, R.; Eisner, B.; Mitchell, E.; Seung, S.; Lee, D. Q-learning for continuous actions with cross-entropy guided policies. arXiv 2019, arXiv:1903.10605. [Google Scholar]
- Zhang, N.; Gupta, A.; Chen, Z.; Ong, Y.S. Multitask neuroevolution for reinforcement learning with long and short episodes. IEEE Trans. Cogn. Dev. Syst. 2022, 15, 1474–1486. [Google Scholar] [CrossRef]
- Rasouli, A.; Tsotsos, J.K. Autonomous vehicles that interact with pedestrians: A survey of theory and practice. IEEE Trans. Intell. Transp. Syst. 2019, 21, 900–918. [Google Scholar] [CrossRef]
- Bai, Y.; Zhao, H.; Zhang, X.; Chang, Z.; Jäntti, R.; Yang, K. Towards Autonomous Multi-UAV Wireless Network: A Survey of Reinforcement Learning-Based Approaches. IEEE Commun. Surv. Tutor. 2023, 25, 3038–3067. [Google Scholar] [CrossRef]
- Li, J.Y.; Zhan, Z.H.; Tan, K.C.; Zhang, J. A meta-knowledge transfer-based differential evolution for multitask optimization. IEEE Trans. Evol. Comput. 2021, 26, 719–734. [Google Scholar] [CrossRef]
- Aleti, A.; Moser, I. A systematic literature review of adaptive parameter control methods for evolutionary algorithms. ACM Comput. Surv. CSUR 2016, 49, 1–35. [Google Scholar] [CrossRef]
- Zhan, Z.H.; Wang, Z.J.; Jin, H.; Zhang, J. Adaptive distributed differential evolution. IEEE Trans. Cybern. 2019, 50, 4633–4647. [Google Scholar] [CrossRef]
- Van Houdt, G.; Mosquera, C.; Nápoles, G. A review on the long short-term memory model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Ajao, L.A.; Apeh, S.T. Secure edge computing vulnerabilities in smart cities sustainability using petri net and genetic algorithm-based reinforcement learning. Intell. Syst. Appl. 2023, 18, 200216. [Google Scholar] [CrossRef]
- Hong, J.; Zhu, Z.; Yu, S.; Wang, Z.; Dodge, H.H.; Zhou, J. Federated adversarial debiasing for fair and transferable representations. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 617–627. [Google Scholar]
- Petrović, A.; Nikolić, M.; Radovanović, S.; Delibašić, B.; Jovanović, M. FAIR: Fair adversarial instance re-weighting. Neurocomputing 2022, 476, 14–37. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- De Lange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A continual learning survey: Defying forgetting in classification tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3366–3385. [Google Scholar]
- Liu, J.; Zhang, H.; Yu, T.; Ren, L.; Ni, D.; Yang, Q.; Lu, B.; Zhang, L.; Axmacher, N.; Xue, G. Transformative neural representations support long-term episodic memory. Sci. Adv. 2021, 7, eabg9715. [Google Scholar] [CrossRef]
- Elsayed, S.M.; Sarker, R.A.; Essam, D.L. An improved self-adaptive differential evolution algorithm for optimization problems. IEEE Trans. Ind. Inform. 2012, 9, 89–99. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, X.; Su, H.; Zhu, J. A comprehensive survey of continual learning: Theory, method and application. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5362–5383. [Google Scholar] [CrossRef]
- Maschler, B.; Vietz, H.; Jazdi, N.; Weyrich, M. Continual learning of fault prediction for turbofan engines using deep learning with elastic weight consolidation. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020; Volume 1, pp. 959–966. [Google Scholar]
- Parmas, P.; Seno, T. Proppo: A message passing framework for customizable and composable learning algorithms. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2022; Volume 35, pp. 29152–29165. [Google Scholar]
- Shi, Q.; Wu, N.; Wang, H.; Ma, X.; Hanzo, L. Factor graph based message passing algorithms for joint phase-noise estimation and decoding in OFDM-IM. IEEE Trans. Commun. 2020, 68, 2906–2921. [Google Scholar] [CrossRef]
- Nazib, R.A.; Moh, S. Reinforcement learning-based routing protocols for vehicular ad hoc networks: A comparative survey. IEEE Access 2021, 9, 27552–27587. [Google Scholar] [CrossRef]
- Zhang, T.; Yu, L.; Yue, D.; Dou, C.; Xie, X.; Chen, L. Coordinated voltage regulation of high renewable-penetrated distribution networks: An evolutionary curriculum-based deep reinforcement learning approach. Int. J. Electr. Power Energy Syst. 2023, 149, 108995. [Google Scholar] [CrossRef]
- Yang, X.; Chen, N.; Zhang, S.; Zhou, X.; Zhang, L.; Qiu, T. An Evolutionary Reinforcement Learning Scheme for IoT Robustness. In Proceedings of the 2023 IEEE 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Rio de Janeiro, Brazil, 24–26 May 2023; pp. 756–761. [Google Scholar]
- Ikeda, T.; Shibuya, T. Centralized training with decentralized execution reinforcement learning for cooperative multi-agent systems with communication delay. In Proceedings of the 2022 IEEE 61st Annual Conference of the Society of Instrument and Control Engineers (SICE), Kumamoto, Japan, 6–9 September 2022; pp. 135–140. [Google Scholar]
- Porebski, S. Evaluation of fuzzy membership functions for linguistic rule-based classifier focused on explainability, interpretability and reliability. Expert Syst. Appl. 2022, 199, 117116. [Google Scholar] [CrossRef]
- Belkina, A.C.; Ciccolella, C.O.; Anno, R.; Halpert, R.; Spidlen, J.; Snyder-Cappione, J.E. Automated optimized parameters for T-distributed stochastic neighbor embedding improve visualization and analysis of large datasets. Nat. Commun. 2019, 10, 5415. [Google Scholar] [CrossRef]
- Kherif, F.; Latypova, A. Principal component analysis. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 209–225. [Google Scholar]
- Min, B.; Ross, H.; Sulem, E.; Veyseh, A.P.B.; Nguyen, T.H.; Sainz, O.; Agirre, E.; Heintz, I.; Roth, D. Recent advances in natural language processing via large pre-trained language models: A survey. ACM Comput. Surv. 2021, 56, 1–40. [Google Scholar] [CrossRef]
- Chang, E.Y. Examining GPT-4: Capabilities, Implications and Future Directions. In Proceedings of the 10th International Conference on Computational Science and Computational Intelligence, Las Vegas, NV, USA, 13–15 December 2023. [Google Scholar]
- Zhong, S.; Huang, Z.; Wen, W.; Qin, J.; Lin, L. Sur-adapter: Enhancing text-to-image pre-trained diffusion models with large language models. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 567–578. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evolutionary Algorithm | RL Algorithm | Method | Evaluation Metric | Compared Algorithm | Benchmark Task |
|---|---|---|---|---|---|
| Evolutionary Strategy | Value function | AEES [44] | Cumulative return | A2C, SAC, DDPG, TRPO | Continuous control |
| OHT-ES [45] | Asymptotic performance | TD3 | Continuous control | ||
| Policy gradient | R-R1-ES [46] | Reward | OpenAI-ES, NS-ES | Continuous/Discrete Control | |
| CCNCS [47] | Time budget | PPO, A3C | Discrete Control | ||
| cCMA-ES [48] | Error | CMA-ES | Continuous control | ||
| MARL-ES [49] | Convergence | MADDPG | Continuous control | ||
| Actor–critic | ZOSPI [50] | Reward | SAC, TD3 | Continuous control | |
| EPG [51] | Return, KL | PPO | Continuous control | ||
| ES-TD3 [52] | Mean, std error, median | TD3, CEM-RL | Continuous control | ||
| Genetic Algorithm | Value function | A-MFEA-RL [53] | Time budget | SAC, PPO | Multi-task |
| MAERL [54] | MAE, RMSE, MME | TD3 | Parameter Optimization | ||
| ERLGA [55] | Return | NA | Continuous control | ||
| COE-RL [56] | Time budget, episode | NA | Continuous control | ||
| PGGRL [57] | Time budget | NA | Discrete Control | ||
| DRL-GA [58] | Time budget | IGA, KBGA, DPABC, NS | Multi-task | ||
| Policy gradient | MERL [26] | Convergence | PPO, IPG | Multi-objective | |
| MetaPG [59] | Entropy, return | SAC | Continuous control | ||
| ERL-TD [27] | Time budget | SAC, TD3, DDPG | Continuous control | ||
| Actor–critic | ECRL [60] | Constraint, reward | IPO | Continuous control | |
| PDERL [61] | Reward | TD3, PPO | Continuous control | ||
| SERL [62] | Step | DDPG | Continuous control | ||
| QD-PG-PF [63] | Training curve | DPG | Continuous control | ||
| ERL-Re [64] | Return | TD3 | Continuous control | ||
| Cross-Entropy Method | Value function | QT-OPT [65] | Success rate | NA | Continuous control |
| RL-RVEA [28] | HV values | MaOEAIGD, RVEA | Multi-objective | ||
| Policy gradient | GRAC [66] | Return | TD3, SAC, DDPG, TRPO, CEM | Continuous control | |
| Actor–critic | CEM-RL [67] | Training curve | TD3 | Continuous control | |
| PGPS [68] | Return | CEM, PPO, DDPG, CERL, SAC | Continuous control | ||
| CSPC [69] | Return | SAC, PPO, CEM | Continuous control | ||
| SAC-CEPO [70] | Return | SAC | Continuous control | ||
| DEPRL [71] | Return | CEM, TD3 | Continuous control | ||
| Population-Based Training | Value function | RLMODE [72] | Mean, STD | NSGAII | Multi-objective |
| Policy gradient | SBARL [4] | NA | TD3 | Parameter optimization | |
| EARL [73] | NPV | SAC | Parameter optimization | ||
| Actor–critic | EAS-TD3 [74] | Return | TD3 | Continuous control | |
| PS3-TD3 [75] | Reward | TD3 | Continuous control | ||
| ARAC [76] | Return | CERL, TD3 | Continuous control | ||
| SOS-PPO [77] | Reward | PPO | Multi-objective | ||
| MERL [78] | Success rate | MADDPG, MATD3 | Multi-agent | ||
| EPC-MARL [79] | Reward | MADDPG | Multi-agent | ||
| EMOGI [80] | Win rate, duration | A3C | Multi-objective | ||
| Other EAs | Value function | ECRL [81] | Reward | NA | Parameter optimization |
| AGPRL [82] | Q-value | NA | Continuous control | ||
| TDDQN [83] | Q-value | DQN | Multi-task | ||
| DDQN-RS [84] | MLHP | DDQN | Continuous control | ||
| Policy gradient | EGPRL [85] | Reward | NA | Multi-task | |
| GPRL [40] | Error | NA | Continuous control | ||
| GPFDM [86] | Reward | NA | Continuous control | ||
| Actor–critic | FiDi-RL [43] | NA | NA | Continuous control | |
| TERL [87] | Convergence | ESAC, CEM-RL, ERL | Multi-objective | ||
| ERL-A2S [88] | Task result | PDERL, ERL, TD3, PPO | Multi-objective |
| Issue | Solution | Method | RL Algorithm | Evo Algorithm |
|---|---|---|---|---|
| Parameter Sensitivity | EA dynamically adjusts parameters | SBARL [4] | Policy gradient | Population-based training |
| MAEDyS [42] | Policy gradient | Evolutionary computing | ||
| EA enhances parameter space diversity | GA-DRL [92] | Actor–critic | Genetic algorithms | |
| NS-MERL [93] | Actor–critic | Evolutionary strategy | ||
| Sparse Rewards | EA accelerates search process | PS3-TD3 [75] | Actor–critic | Population-based training |
| PNS-RL [5] | Actor–critic | Evolutionary strategy | ||
| EA enhances policy space diversity | GEATL [94] | Actor–critic | Genetic algorithm | |
| RACE [95] | Actor–critic | Genetic algorithm | ||
| Local Optima | EA enhances policy space diversity | EARL [73] | Policy gradient | Population-based training |
| G2AC [96] | Actor–critic | Genetic algorithm | ||
| DEPRL [71] | Actor–critic | Cross-entropy method | ||
| Multi-Task Difficulties | EA enhances policy combination and synergy | EGPRL [85] | Policy gradient | Genetic programming |
| Policy Search | EA-integrated process for policy generation | AGPRL [82] | Value function | Genetic programming |
| GPRL [40] | Policy gradient | Genetic programming | ||
| GPFDM [86] | Policy gradient | Genetic programming | ||
| Computational Efficiency | EA-integrated process for policy generation | FiDi-RL [43] | Actor–critic | Random search |
| CERM-ACER [97] | Actor–critic | Cross-entropy method | ||
| CGP [98] | Actor–critic | Cross-entropy method |
| Issue | Solution | Method | RL Algorithm | Evo Algorithm |
|---|---|---|---|---|
| Sample Efficiency | Projection techniques are applied | NuEMT [99] | Actor–critic | Evolutionary strategy |
| Optimize action selection | EAS-TD3 [74] | Actor–critic | Evolutionary strategy | |
| Algorithm Complexity | Different mutation policies for each subset | AEES [44] | Value function | Evolutionary strategy |
| Parallel exploration | CCNCS [47] | Policy gradient | Evolutionary strategy | |
| Performance | Unify search space | A-MFEA-RL [53] | Value function | Genetic algorithm |
| Lagrange relaxation coefficient | ECRL [60] | Actor–critic | Genetic algorithm | |
| Incorporate surrogate models into EvoRL framework | SERL [62] | Actor–critic | Genetic algorithm | |
| Enhance mutation strength adaptation | R-R1-ES [46] | Policy gradient | Evolutionary strategy | |
| Combine with a novelty-based fitness function | NS-MERL [93] | Actor–critic | Evolutionary strategy | |
| Novel mutation operator | PDERL [61] | Actor–critic | Genetic algorithm |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.; Lin, F.; Cai, G.; Chen, H.; Zou, L.; Liu, Y.; Wu, P. Evolutionary Reinforcement Learning: A Systematic Review and Future Directions. Mathematics 2025, 13, 833. https://doi.org/10.3390/math13050833
Lin Y, Lin F, Cai G, Chen H, Zou L, Liu Y, Wu P. Evolutionary Reinforcement Learning: A Systematic Review and Future Directions. Mathematics. 2025; 13(5):833. https://doi.org/10.3390/math13050833
Chicago/Turabian StyleLin, Yuanguo, Fan Lin, Guorong Cai, Hong Chen, Linxin Zou, Yunxuan Liu, and Pengcheng Wu. 2025. "Evolutionary Reinforcement Learning: A Systematic Review and Future Directions" Mathematics 13, no. 5: 833. https://doi.org/10.3390/math13050833
APA StyleLin, Y., Lin, F., Cai, G., Chen, H., Zou, L., Liu, Y., & Wu, P. (2025). Evolutionary Reinforcement Learning: A Systematic Review and Future Directions. Mathematics, 13(5), 833. https://doi.org/10.3390/math13050833