Abstract
This study presents a novel estimator that combines the Kibria–Lukman and ridge estimators to address the challenges of multicollinearity in Conway–Maxwell–Poisson (COMP) regression models. The Conventional COMP Maximum Likelihood Estimator (CMLE) is notably susceptible to the adverse effects of multicollinearity, underscoring the necessity for alternative estimation strategies. We comprehensively compare the proposed COMP Modified Kibria–Lukman estimator (CMKLE) against existing methodologies to mitigate multicollinearity effects. Through rigorous Monte Carlo simulations and real-world applications, our results demonstrate that the CMKLE exhibits superior resilience to multicollinearity while consistently achieving lower mean squared error (MSE) values. Additionally, our findings underscore the critical role of larger sample sizes in enhancing estimator performance, particularly in the presence of high multicollinearity and over-dispersion. Importantly, the CMKLE outperforms traditional estimators, including the CMLE, in predictive accuracy, reinforcing the imperative for judicious selection of estimation techniques in statistical modeling.
Keywords:
COMP regression models; multicollinearity; over-dispersion; Kibria–Lukman estimator; ridge estimator MSC:
62J05; 62J07; 62J12
1. Introduction
Generalized linear models (GLMs) are powerful tools for modeling relationships between explanatory variables (predictors) and response variables, extending traditional linear regression to accommodate various data types, including those following distributions within the exponential family [1]. A key application of GLMs is modeling count data, which arises in social sciences, healthcare, economics, auto insurance claims, and medical research. Unlike continuous data, count data are discrete and often exhibit patterns of dispersion that complicate standard modeling approaches [2,3]. Several specialized GLMs have been developed, including Poisson and negative binomial regression models, to model count data [4,5].
Each model has strengths and limitations, depending on the specific data characteristics. The Poisson regression model, for instance, is commonly used for discrete data but assumes that the mean and variance are equal (equi-dispersion). This assumption is rarely held in practice, as count data often exhibit greater variability (over-dispersion), necessitating alternatives like the negative binomial model [2]. The negative binomial regression model addresses over-dispersion by introducing a dispersion parameter that allows for a variance greater than the mean, making it more suitable for real-world applications. However, the negative binomial model is limited to over-dispersed data and cannot accommodate under-dispersion, where the variance is less than the mean. In contrast, the COM–Poisson regression model offers greater flexibility by handling over-dispersion and under-dispersion [6,7]. This versatility allows it to be applied across a broader range of count data scenarios. The COM–Poisson distribution, introduced by Conway and Maxwell [7], generalizes the Poisson distribution and includes the geometric, Poisson, and Bernoulli distributions as special cases, making it increasingly popular for count data analysis.
In recent studies, the Conway–Maxwell–Poisson (COM–Poisson or COMP) regression model has gained considerable attention due to its ability to accommodate data with varying levels of dispersion [8,9]. This flexibility makes it a robust alternative to traditional models such as the Poisson and negative binomial regression models, which are limited to handling equi-dispersion and over-dispersion. The COMP model is useful when dealing with count data that exhibit complex dispersion patterns, as it can model over-dispersion (variance greater than the mean) and under-dispersion (variance less than the mean). This versatility has led to its growing adoption and has attracted increasing attention in recent research. The parameters of the COM–Poisson model are typically estimated using the COM–Poisson Maximum Likelihood Estimator (CMLE). However, the CMLE has a notable limitation: it becomes inefficient and produces unstable estimates in multicollinearity, a common issue where the explanatory variables are highly correlated [10,11]. Multicollinearity can inflate the variance of parameter estimates, leading to unreliable inference and predictions.
To address this issue, researchers have developed alternative estimators, which can mitigate the impact of multicollinearity by introducing a bias that stabilizes the estimates. Among these alternatives are the COM–Poisson Ridge estimator (CRE) [11], COM–Poisson Liu estimator (CLE) [12], COM–Poisson Liu-type estimator (CLTE) [9], and the COM–Poisson Kibria–Lukman estimator (CKLE) [8], among others. These shrinkage estimators combine the robustness of the COM–Poisson model with strategies to handle multicollinearity, thereby providing more stable and efficient parameter estimates. Each of these estimators has its strengths depending on the severity of multicollinearity and the specific structure of the data. For instance, the CRE introduces a penalty proportional to the size of the coefficients, effectively shrinking them towards zero to reduce variance. The CLE and CLTE, on the other hand, adjust the bias–variance trade-off more finely, making them particularly useful when the multicollinearity is moderate.
Recent advancements in alternative estimation techniques have helped mitigate the effects of multicollinearity in the COMP regression model, leading to more stable parameter estimates. As research in this field continues to evolve, the COMP model combined with shrinkage estimators shows great potential for applications involving count data, particularly in scenarios where multicollinearity exists among explanatory variables. Aladeitan et al. [13] introduced the Modified Kibria–Lukman (MKL) estimator to address multicollinearity in Poisson regression, showing that the MKL outperforms the Poisson Maximum Likelihood Estimator (PMLE), Poisson Ridge Regression Estimator (PRE), Poisson Liu Estimator (PLE), and Poisson Kibria–Lukman (PKL) estimator.
This paper aims to extend these methodologies by proposing a new COMP Modified Kibria–Lukman Estimator (COMP-MKL) as an alternative for handling multicollinearity in the COMP regression model. We will compare the performance of the proposed COMP-MKL estimator with existing estimators such as the CRE, CLE, CKLE, and CLTE using the scalar mean squared error (SMSE) criterion. Theoretical findings will be substantiated through simulation studies and real data analysis to demonstrate the superior performance of the proposed estimator over its competitors.
The paper is structured as follows: Section 2 outlines the fundamentals of the COMP regression model, reviews existing estimators, and introduces the new COMP-MKL estimator. Section 3 presents a theoretical comparison of the proposed estimator with its competitors. Section 4 reports the results of an extensive Monte Carlo simulation study, assessing the performance of the proposed and competing estimators based on the MSE criteria. Section 5 showcases a real-world data example that further validates the superiority of the proposed estimator. Section 6 provides concluding remarks, summarizing the key findings and implications for future research.
2. COMP Regression Model and Estimation
The Conway–Maxwell–Poisson (COMP) distribution, introduced by Conway and Maxwell [7], is a versatile distribution designed to handle both over-dispersed and under-dispersed count data, addressing the limitations of the traditional Poisson distribution. Its probability mass function (pmf) is given as follows:
where is the rate parameter, is the dispersion parameter, and is the normalizing constant. The flexibility of the COMP distribution stems from the dispersion parameter, allowing it to model a range of distributions, from Poisson (when ) to Bernoulli-like (as ) to geometric (when ).
The COM–Poisson regression model, introduced by Sellers and Shmueli [14], incorporates this distribution to model count data with varying levels of dispersion. The expected value of the COMP distribution can be approximated as follows:
while the variance is similarly expressed as follows:
The COMP regression model is a generalized linear model with a mean link function, typically the log link function:
where is the expected count, is a vector of covariates, and is the corresponding vector of regression coefficients. The dispersion parameter can be either fixed or modeled as a function of covariates. Given the nonlinear nature of the likelihood function in COMP regression, maximum likelihood estimation (MLE) requires iterative optimization methods. The log-likelihood function for the COMP regression model is expressed as follows:
where is the rate parameter. Since the likelihood is nonlinear in , iterative algorithms like iteratively reweighted least squares (IRLSs) or Newton–Raphson methods are employed to find the CMLE of . The CMLE is obtained by solving the following:
where the weight matrix is based on the second derivative of the log-likelihood and is the adjusted response variable. For a more comprehensive treatment of the derivation and implementation of the CMLE, refer to [8,9]. The MLE is consistent and asymptotically efficient but possesses high variance and instability when multicollinearity is present in the model. Consequently, biased estimation methods such as CRE, CLE, and CKLE are often preferred over the CMLE.
The mean squared error (SMSE) of the CMLE is given as follows:
When multicollinearity is present, the weighted cross-product matrix of the design matrix () becomes poorly conditioned, leading to instability in the coefficient estimates obtained from the conventional CMLE. To address this issue, shrinkage estimators provide a robust alternative by introducing regularization, stabilizing the regression estimates, and reducing the effects of multicollinearity. The following section will review several existing shrinkage methods specifically developed for the COMP regression model and discuss their theoretical properties and practical applications.
2.1. Shrinkage Estimators
To tackle the issue of multicollinearity in linear regression, several shrinkage estimators have been introduced, including the ridge regression estimator by Hoerl and Kennard [15], as well as the Liu and Liu-type estimators [16,17], the Kibria–Lukman estimator [18], and two-parameter estimators [19,20]. These methods have been adapted to address multicollinearity in generalized linear models, extending their application to models such as Poisson regression [4,21], negative binomial regression (NBR) [5,22], and the Conway–Maxwell–Poisson (COMP) regression model [5,6,23]. These extensions have proven effective in maintaining estimator stability in the presence of highly collinear predictors.
Sami et al. [11] developed the COMP ridge estimator (CRE) and defined it as follows:
where and k is the ridge parameter, defined in this study as . The matrix mean squared error (MMSE) is expressed as follows:
Akram et al. [12] expanded the application of the Liu estimator (LE) to the COMP regression model in the following way:
where . The Liu parameter d in this study is defined as . The MMSE is expressed as follows:
Kibria and Lukman [18] introduced a ridge-type estimator as an effective solution to the problem of multicollinearity in linear regression. Recognizing the need for similar strategies in more complex models, Abonazel et al. [8] extended this approach to the COMP regression model, resulting in what is now referred to as the COMP Kibria–Lukman estimator (CKLE). This estimator is designed to address multicollinearity by balancing bias and variance through regularization, thereby improving the stability of estimates in the COMP model. The CKLE is defined as follows:
where . The MMSE is expressed as follows:
Liu [16] introduced the Liu-type estimator to address multicollinearity in linear regression, merging the strengths of both the ridge and Liu estimators. This hybrid approach leverages the benefits of reduced variance and controlled bias. Building on this concept, Tanış and Asar [9] extended the Liu-type estimator to the Conway–Maxwell–Poisson (COMP) regression model, referred to as the COMP Liu-type estimator (CLTE). The formulation of this estimator is as follows:
where . The MMSE is expressed as follows:
Sami et al. [23] introduced a two-parameter estimator for the Conway–Maxwell–Poisson (COMP) regression model, building upon the work of Asar and Genc [21]. This estimator, known as the two-parameter estimator (CTPE), was designed to provide greater flexibility in handling multicollinearity by incorporating two tuning parameters. The CTPE estimator is defined as follows:
where . The MMSE is expressed as follows:
Additionally, Sami et al. [23] developed a two-parameter estimator for the Conway–Maxwell–Poisson (COMP) regression model, drawing from the work of Huang and Yang [22] on negative binomial regression (NBRM). This new estimator, the COMP Huang and Yang estimator (CHYE), was designed to extend the flexibility of biased estimation methods to the COMP framework. The CHYE is defined as follows:
where . The MMSE is expressed as follows:
where and .
2.2. Proposed Estimator
In this study, we introduce a new estimator that builds upon the work of Aladeitan et al. [13], who proposed the Modified Kibria–Lukman estimator specifically for the Poisson regression model. The estimator inherits the advantage of the Kibria–Lukman estimator with the ridge estimator. While many of the estimators discussed earlier can be classified as either single-parameter or two-parameter methods, the Modified Kibria–Lukman estimator, despite having a single biasing parameter, demonstrates superior performance compared to some two-parameter estimators. Recognizing the potential of this approach, we extended it to the Conway–Maxwell–Poisson (COMP) regression model, developing what we call the COMP Modified Kibria–Lukman estimator (CMKLE). The CMKLE offers improved estimator stability and accuracy in scenarios where traditional estimators may struggle due to high collinearity among predictor variables. The CMKLE is defined as follows:
where . The bias of the estimator is expressed as follows:
where The covariance matrix is defined as follows:
Hence, the MMSE is expressed as follows:
Let , , where are the ordered eigenvalues of and is matrix whose columns of the normalized eigenvectors of . Thus, we can express in terms of , then , leading to the canonical form of the CMLE. Consequently, we expressed other equations in this study in canonical form:
Furthermore, for ease of computation, we applied the same shrinkage parameters across all estimators in this study. This approach ensured an impartial and uniform comparison without favoring any estimator. Specifically, the ridge parameters k and d are defined as and respectively.
We can also evaluate the performance of the estimators using the scalar mean squared error (SMSE) instead of the MMSE. The SMSE is defined as follows:
where is the covariance matrix of and . This formulation allows us to express the matrix mean squared error in a scalar form by summing the trace of the covariance and the trace of the squared bias, making it easier to compare the performances of different estimators. Consequently, we reformulate the MMSE of all the estimators in terms of the SMSE for a more concise comparison. The SMSEs of the mentioned estimators above are obtained as follows:
3. Theoretical Comparisons
3.1. CMKLE and CMLE
The estimator is superior to the estimator in the sense of the SMSE criterion, i.e., SMSE for > 0 and if
Proof.
The difference between is obtained as follows:
The difference < 0 if for > 0 and . □
3.2. CMKLE and CRE
The estimator is superior to the estimator in the sense of the SMSE criterion, i.e., SMSE for > 0 and if
Proof.
The difference between is obtained as follows:
The difference < 0 if for > 0 and . □
3.3. CMKLE and CLE
The estimator is superior to the estimator in the sense of the SMSE criterion, i.e., SMSE for > 0 and if .
Proof.
The difference between is obtained as follows:
The difference < 0 if for > 0 and . □
3.4. The CMKLE and CKLE
The estimator is superior to the estimator in the sense of the SMSE criterion, i.e., SMSE for > 0 and , if
Proof.
The difference between is obtained as follows:
The difference < 0 if for > 0 and . □
3.5. The CMKLE and CLTE
The estimator is superior to the estimator in the sense of the SMSE criterion, i.e., SMSE for > 0 and if .
Proof.
The difference between is obtained as follows:
The difference < 0 if for > 0 and . □
3.6. CMKLE and CTPE
The estimator is superior to the estimator in the sense of the SMSE criterion, i.e., SMSE for > 0 and if
Proof.
The difference between is obtained as follows:
The difference < 0 if for > 0 and . □
3.7. CMKLE and CHYE
The estimator is superior to the estimator in the sense of the SMSE criterion, i.e., SMSE for > 0 and if
Proof.
The difference between is obtained as follows:
The difference < 0 if for > 0 and . □
4. Simulation Study
In this section, we design a Monte Carlo simulation to assess the estimators’ performance under varying conditions of multicollinearity and dispersion. The predictors are generated using the following equation:
where denotes independent standard normal random numbers, and controls the degree of correlation between predictors. Specifically, as increases, the predictors become more correlated. We investigated different levels of multicollinearity with The response variable was drawn from the Conway–Maxwell Poisson distribution:
where and represents the dispersion parameter, with indicating under-dispersion and denoting over-dispersion. The sample sizes are set to n = 30, 50, 100, and 200, and two scenarios for the number of predictors are considered: p = 4 and p = 8. The true regression coefficients β are chosen such that following the approach of similar studies in the literature [24,25].
The primary criterion for evaluating the estimators’ performances is the estimated mean squared error (MSE), which is computed as follows:
where denotes the estimate obtained in the replication of the simulation, and is the true vector of the regression parameters. Each simulation was repeated 1000 times to ensure robust and reliable results. The COMPoissonReg package in R [26] was used to generate data and estimate the parameters of the Conway–Maxwell–Poisson regression model. The model fitting was performed using the glm.cmp function from the package, which provides maximum likelihood estimates for COMP regression models [14,27]. The COMP model is fitted without standardization and an intercept. The simulation results are summarized in Table 1 and Table 2.

Table 1.
Estimated MSE values for p = 4.
Table 2.
Estimated MSE values for p = 8.
In this section, we evaluate the performance of the estimators based on their mean squared error (MSE) values across varying sample sizes, levels of multicollinearity, dispersion parameters, and the number of predictors. The results from Table 1 and Table 2 demonstrate a consistent pattern. MSE values are generally smaller for under-dispersion ( = 0.9) than over-dispersion ( = 1.25), especially as the sample size increases. The best-performing estimators exhibit lower MSEs when = 0.9, particularly with larger sample sizes and lower multicollinearity. As the dispersion parameter increases to , the MSE also increases, indicating the higher variability inherent in over-dispersed data. This trend is observed across all sample sizes, multicollinearity levels, and predictor counts.
Across both tables, the MSE decreases as the sample size increases, highlighting the advantages of larger datasets. For instance, when p = 4 and = 0.80, the MSE for n = 30 is relatively high (e.g., 0.4473 for the CMLE), whereas for n = 200, it drops significantly (e.g., 0.0239 for the CMLE). This trend is consistent across all levels of multicollinearity and dispersion, demonstrating that increasing the sample size reduces the estimator’s variance and improves overall performance. Conversely, small sample sizes (e.g., n = 30) lead to higher MSEs, particularly when combined with high multicollinearity (e.g., γ = 0.99) and over-dispersion. In these cases, the performance gap between estimators is most pronounced, with the proposed estimator showing more resilience to these conditions than its counterparts.
When multicollinearity is low (e.g., γ=0.8), all estimators tend to perform well, with the MSEs decreasing significantly as the sample size increases. For example, with = 0.9 and n = 200, the MSE values for all estimators are relatively close, indicating minimal performance differences under low correlation. However, as the correlation between predictors increases (e.g., = 0.99), the MSE rises, particularly for smaller sample sizes. For instance, with p = 4 and n = 30, the MSE for the CMLE is 3.5256, reflecting poor performance under severe multicollinearity. In contrast, the proposed estimator (CMKLE) consistently shows better robustness to multicollinearity. Although the performance difference diminishes as the sample size increases, the CMKLE still maintains superior results.
Increasing the number of predictors from p = 4 (Table 1) to p = 8 (Table 2) results in higher MSE values across all conditions. For example, with = 0.95 and n = 200, the MSE for p = 4 is 0.0412 (CMKLE), while for p = 8, it is 0.0470, reflecting the increased complexity in estimation with more predictors. The performance advantage of the CMKLE is more pronounced in smaller sample sizes, where it demonstrates greater robustness to both multicollinearity and dispersion effects. Even as the sample size increases and the performance gap narrows, the CMKLE maintains its leading position, reflecting its robustness and efficiency across a range of model complexities and data conditions.
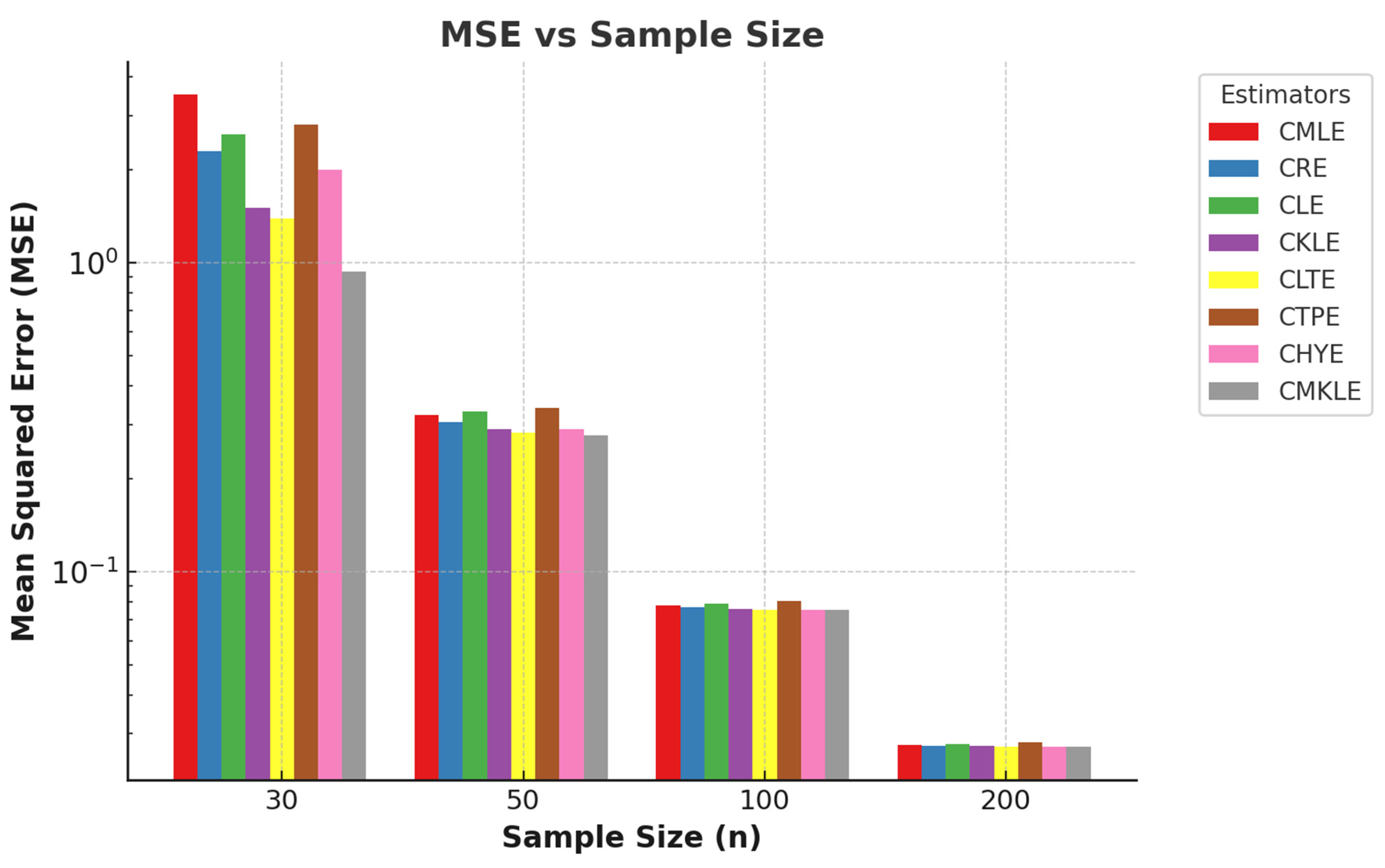
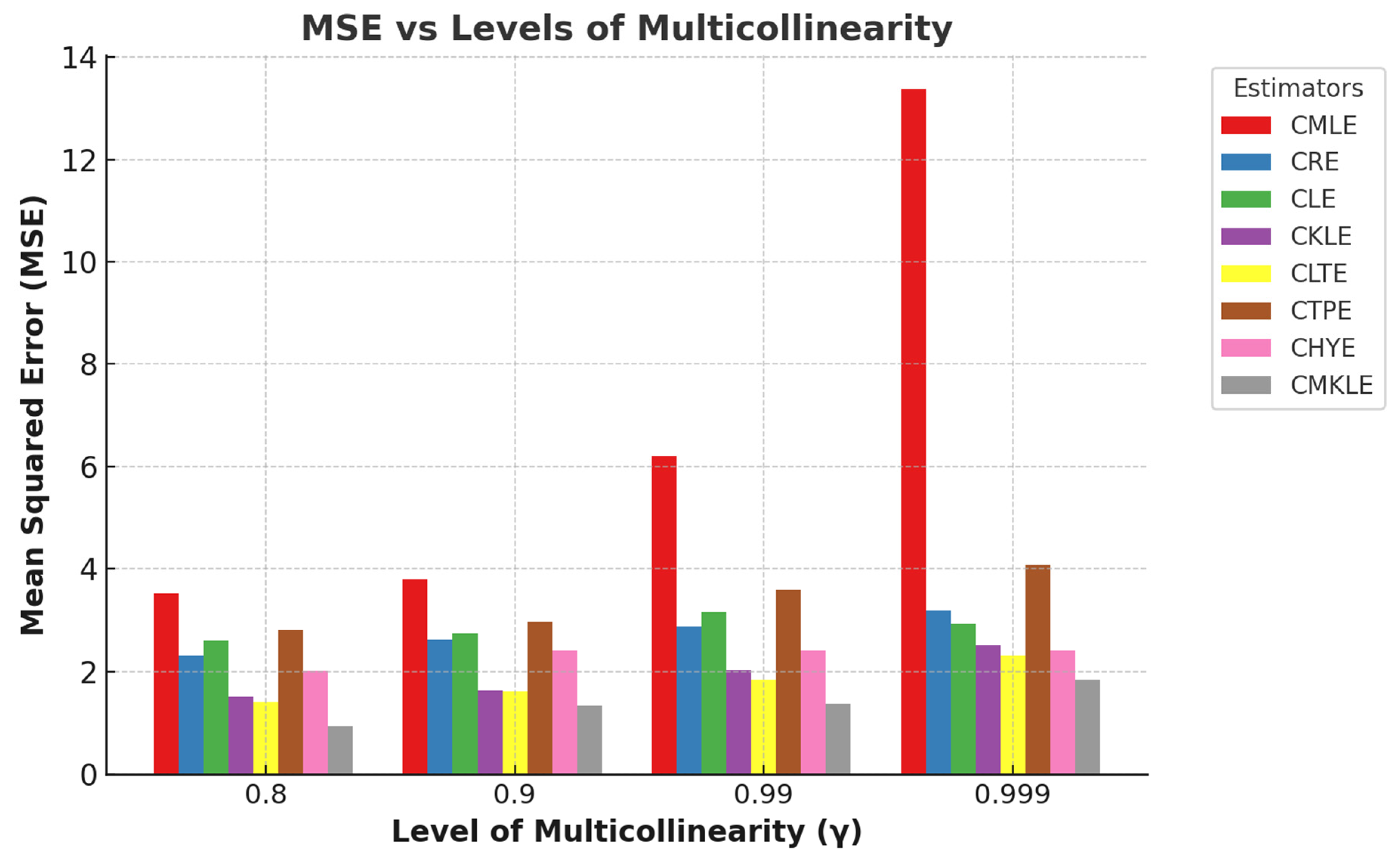
Figure 1 and Figure 2, respectively, clearly illustrate the trends in the relationship between mean squared error (MSE) and sample sizes and MSE and multicollinearity levels. These figures provide compelling evidence of how variations in sample size and the degree of multicollinearity influence the predictive accuracy of the models under consideration.
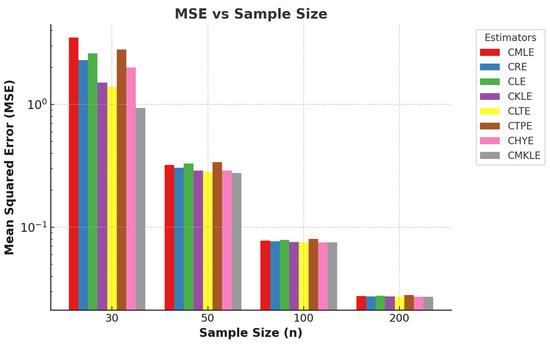
Figure 1.
A sample plot of the sample size against the mean squared error.
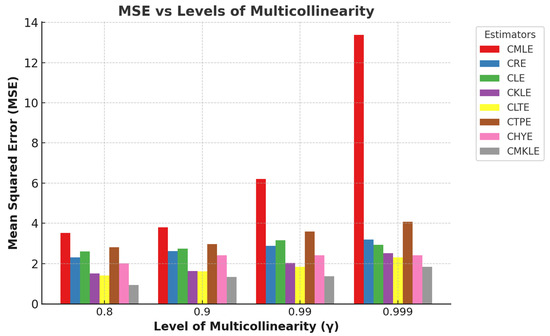
Figure 2.
A sample plot of the mean squared error against the level of multicollinearity.
5. Applications
In this study, we modeled two real-life datasets: one exhibiting over-dispersion and the other under-dispersion. By analyzing datasets with different dispersion characteristics, we aimed to demonstrate the versatility and advantages of the COM–Poisson regression model, which is uniquely capable of handling both types of dispersion. This allows for the more accurate modeling of count data compared to traditional models that are limited to addressing either over-dispersion or equi-dispersion scenarios.
5.1. Example I
In this study, we analyzed the nuts dataset, initially introduced by Hilbe [28], and most recently examined by Lukman et al. [2]. The dataset, available through the ‘COUNT’ package, comprises 52 observations and seven explanatory variables. It focuses on squirrel activity and various forest characteristics within Scotland’s Abernathy Forest. The response variable measures the number of cones stripped by squirrels per plot. In contrast, the explanatory variables include the following: the number of trees per plot (), the number of trees with a diameter at breast height (DBH) per plot (), mean tree height per plot (), canopy closure percentage (), standardized number of trees per plot (), standardized mean tree height per plot (), and standardized canopy closure percentage ().
In this analysis, following Lukman et al. [2], we excluded the variable and due to the modeling difficulties they posed. Subsequent investigations revealed the presence of multicollinearity, as indicated by variance inflation factors (VIFs) of 4.474, 16.332, 39.61, and 40.89 for the remaining variables. These high VIF values suggest strong correlations between several regressors, which, combined with over-dispersion, complicate the model-fitting process. Over-dispersion was confirmed by a dispersion parameter of 13.86763, signaling that the variance far exceeds the mean. This combination of multicollinearity and over-dispersion is critical, as it can distort the estimation of regression coefficients, compromise model accuracy, and reduce the reliability of statistical inferences.
Table 3 presents the estimated regression coefficients derived from various estimators employed in this study, which include the CMLE, CRE, CLE, CKLE, CLTE, CTPE, CHYE, and CMKLE. The performances of these estimators were evaluated using the scalar mean squared error (SMSE), as defined in Equations (32)–(39). The optimal estimator minimizes the SMSE, reflecting a lower prediction error. According to the results, the CMKLE demonstrates the lowest SMSE, with a value of 0.8626, suggesting that it provides the most precise predictions among the estimators considered in this analysis. The CHYE follows closely with an SMSE of 0.9609, also exhibiting strong performance. On the other hand, the CMLE has the highest SMSE at 17.3187, indicating that it is the least efficient estimator for this dataset.
Table 3.
Estimated regression coefficients for the nut dataset.
The confidence intervals (CIs) computed for each estimator provide insights into the estimated coefficients’ statistical significance, precision, and reliability. A coefficient’s statistical significance is determined by whether its CI includes zero. If a CI does not contain zero, the coefficient is deemed statistically significant at the 5% level, indicating a meaningful contribution to the model. The CMKLE provides the most stable and precise estimates, as indicated by the lowest SMSE. However, not all coefficients are statistically significant. The results reveal that and are significant while and are insignificant.
In summary, the CMKLE outperforms the other methods, providing the smallest SMSE and, consequently, the best prediction accuracy. Estimators with higher SMSE values, such as the CMLE, demonstrate reduced efficiency for this dataset due to their larger prediction errors. These findings align with the simulation results presented in Table 1 and Table 2, further reinforcing the robustness of the CMKLE approach.
5.2. Example 2
The second application involves analyzing aircraft data, where the response variable represents the count of damaged locations on the aircraft, which is modeled as following a Poisson distribution [29,30]. The explanatory variables include the type of aircraft coded as 0 for A-4 and 1 for A-6 , the bomb load in tons (), and the total months of aircrew experience (). Recent work by Algamal et al. [31] applied the COM–Poisson regression model for more suitable data modeling. Our analysis indicates that the dataset exhibits under-dispersion, characterized by a lower variability in counts than expected under traditional Poisson or negative binomial models. The COM–Poisson model effectively accommodates this behavior, as evidenced by the low dispersion parameter of 0.8756, which aligns with the characteristics of the dataset. Lukman et al. [4] identified significant multicollinearity issues, indicated by a condition number of 219.3654.
The results in Table 4 summarize the estimated regression coefficients for various estimators applied to the aircraft data, alongside the corresponding SMSE values. Among the estimators, the CMKLE demonstrates the best performance, achieving the lowest SMSE of 0.0253, indicating superior precision in coefficient estimation. The next best estimator, the CKLE, exhibits an SMSE of 0.0555, further reinforcing its reliability. In contrast, the CMLE shows relatively poorer performance, emphasizing the negative impact of multicollinearity on its performance. Given that the CMKLE outperforms other estimators in terms of having the lowest SMSE, we base our interpretation of the confidence intervals in Table 4 on the CMKLE estimates. The results from the CMKLE provide valuable insights into the relationship between the predictor variables and the response. Notably, the estimated coefficient for is 0.1312, with a 95% confidence interval of (−0.2520, 0.5144). Since this interval includes zero, we cannot conclude that has a statistically significant effect on the response variable at the given confidence level. This suggests that while may contribute to the model, its influence is not strong enough to be distinguished from random variation. In contrast, both and are statistically significant. The coefficient for is 0.1834, with a confidence interval of (0.1121, 0.2546), indicating a positive and significant relationship with the response variable. Similarly, has a negative coefficient of −0.0166, with a confidence interval of (−0.0256, −0.0076), confirming a significant negative effect.
Table 4.
Estimated regression coefficients for the aircraft data.
Traditional estimators, such as the CMLE, may exhibit limitations in estimation accuracy, particularly in model complexities such as multicollinearity or non-normal error structures. This underscores the importance of selecting robust estimators tailored to the data’s characteristics to enhance predictive reliability. Notably, these findings align with the simulation results presented in Table 1 and Table 2, further validating the superior robustness and efficiency of the CMKLE approach.
6. Concluding Remarks
This study addresses the significant challenges posed by multicollinearity in COMP regression models by introducing a novel estimator that integrates the Kibria–Lukman and ridge estimators. This advancement significantly contributes to the existing literature, offering new methodologies that help mitigate the adverse effects of multicollinearity. Through rigorous Monte Carlo simulation studies and real-life applications using two distinct datasets, we comprehensively evaluated the performance of the proposed estimators. The simulation results reveal valuable insights into the behavior of the estimators under varying conditions, including different sample sizes, numbers of independent variables, dispersion parameters, and levels of multicollinearity. Our analysis of mean squared error (MSE) values across these variables demonstrated a consistent pattern: MSE values were generally lower under conditions of under-dispersion (ν = 0.9) compared to over-dispersion (ν = 1.25), particularly as sample sizes increased. The best-performing estimators exhibited significantly lower MSEs with larger sample sizes and reduced multicollinearity, underscoring their robustness.
Moreover, our findings emphasize the benefits of larger datasets, where the MSE consistently decreased with increasing sample size. This trend highlights the critical importance of sufficient sample sizes in enhancing estimator performance, particularly when there is high multicollinearity and over-dispersion. Conversely, smaller sample sizes resulted in high MSEs, illustrating the pronounced performance gap among estimators under these challenging conditions. Notably, the proposed CMKLE demonstrated superior resilience to multicollinearity, maintaining outstanding performance even as sample sizes increased. As we increased the number of predictors from p = 4 to p = 8, we observed a corresponding increase in MSE values across all conditions, confirming the complexities introduced by additional predictors. Notably, the CMKLE displayed a pronounced advantage in smaller sample sizes, demonstrating its robustness against multicollinearity and dispersion effects.
Furthermore, the application results reinforced the superior performance of the CMKLE. The scalar mean squared error (SMSE) evaluations indicate that the CMKLE achieved the lowest SMSE, demonstrating the highest predictive accuracy among the estimators analyzed. In contrast, the traditional CMLE displayed significantly higher SMSE values, highlighting its reduced efficiency for this dataset. In conclusion, the CMKLE surpasses other methodologies in predictive accuracy but also underscores the necessity for careful selection of estimation techniques tailored to specific data characteristics. This research paves the way for future studies to explore the broader application of these methodologies across diverse fields, ultimately enhancing the robustness of statistical models in the presence of multicollinearity and varying dispersion conditions.
Additionally, future research could explore Bayesian approaches to COM–Poisson regression, which have been proposed in the literature as an alternative methodology for handling dispersed count data. Bayesian inference methods, such as those developed by Chanialidis et al. [32], offer flexible estimation techniques that may provide further improvements in model performance and computational efficiency.
Author Contributions
Conceptualization: All the authors; Methodology: All the authors; Formal analysis: All the authors; Resources: All the authors; Writing—original draft preparation, All the authors; Writing—review and editing, All the authors; Visualization, A.F.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Deputyship for Research & Innovation, Ministry of Education, Saudi Arabia through project number “NBU-FPEJ-2025-7-01”.
Data Availability Statement
Data will be made available upon request.
Acknowledgments
The authors extend their appreciation to the Deanship of Scientific Research at Northern Border University, Arar, Saudi Arabia for funding this research work through the project number “NBU-FPEJ-2025-7-01”.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Francis, R.A.; Geedipally, S.R.; Guikema, S.D.; Dhavala, S.S.; Lord, D.; LaRocca, S. Characterizing the performance of the conway-maxwell Poisson generalized linear model. Risk Anal. Int. J. 2012, 32, 167–183. [Google Scholar] [CrossRef] [PubMed]
- Lukman, A.F.; Albalawi, O.; Arashi, M.; Allohibi, J.; Alharbi, A.A.; Farghali, R.A. Robust Negative Binomial Regression via the Kibria–Lukman Strategy: Methodology and Application. Mathematics 2024, 12, 2929. [Google Scholar] [CrossRef]
- Walters, G.D. Using Poisson class regression to analyze count data in correctional and forensic psychology: A relatively old solution to a relatively new problem. Crim. Justice Behav. 2007, 34, 1659–1674. [Google Scholar] [CrossRef]
- Lukman, A.F.; Adewuyi, E.; Månsson, K.; Kibria, B.G. A new estimator for the multicollinear Poisson regression model: Simulation and application. Sci. Rep. 2021, 11, 3732. [Google Scholar] [CrossRef]
- Månsson, K. On ridge estimators for the negative binomial regression model. Econ. Model. 2012, 29, 178–184. [Google Scholar] [CrossRef]
- Conway, R.W.; Maxwell, W.L. A queuing model with state dependent service rates. J. Ind. Eng. Int. 1962, 12, 132–136. [Google Scholar]
- Chatla, S.B.; Shmueli, G. Efficient estimation of COM–Poisson regression and a generalized additive model. Comput. Stat. Data Anal. 2018, 121, 71–88. [Google Scholar] [CrossRef]
- Abonazel, M.R.; Saber, A.A.; Awwad, F.A. Kibria–Lukman estimator for the Conway–Maxwell Poisson regression model: Simulation and applications. Sci. Afr. 2023, 19, e01553. [Google Scholar] [CrossRef]
- Tanış, C.; Asar, Y. Liu-type estimator in Conway–Maxwell–Poisson regression model: Theory, simulation and application. Statistics 2024, 58, 65–86. [Google Scholar] [CrossRef]
- Abonazel, M.R. New modified two-parameter Liu estimator for the Conway–Maxwell Poisson regression model. J. Stat. Comput. Simul. 2023, 93, 1976–1996. [Google Scholar] [CrossRef]
- Sami, F.; Amin, M.; Butt, M.M. On the ridge estimation of the Conway-Maxwell Poisson regression model with multicollinearity: Methods and applications. Concurr. Comput. Pract. Exp. 2022, 34, e6477. [Google Scholar] [CrossRef]
- Akram, M.N.; Amin, M.; Sami, F.; Mastor, A.B.; Egeh, O.M.; Muse, A.H. A new Conway Maxwell–Poisson Liu regression estimator—Method and application. J. Math. 2022, 2022, 3323955. [Google Scholar] [CrossRef]
- Aladeitan, B.B.; Adebimpe, O.; Lukman, A.F.; Oludoun, O.; Abiodun, O.E. Modified Kibria-Lukman (MKL) estimator for the Poisson Regression Model: Application and simulation. F1000Research 2021, 10, 548. [Google Scholar] [CrossRef]
- Sellers, K.F.; Shmueli, G. A flexible regression model for count data. Ann. Appl. Stat. 2010, 4, 943–961. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Liu, K. A new class of blased estimate in linear regression. Commun. Stat. Theory Methods 1993, 22, 393–402. [Google Scholar]
- Liu, K. Using Liu-type estimator to combat collinearity. Commun. Stat. Theory Methods 2003, 32, 1009–1020. [Google Scholar] [CrossRef]
- Kibria, B.G.; Lukman, A.F. A new ridge-type estimator for the linear regression model: Simulations and applications. Scientifica 2020, 2020, 9758378. [Google Scholar] [CrossRef] [PubMed]
- Özkale, M.R.; Kaciranlar, S. The restricted and unrestricted two-parameter estimators. Commun. Stat. Theory Methods 2007, 36, 2707–2725. [Google Scholar] [CrossRef]
- Sakallıoğlu, S.; Kaçıranlar, S. A new biased estimator based on ridge estimation. Stat. Pap. 2008, 49, 669–689. [Google Scholar] [CrossRef]
- Asar, Y.; Genç, A. A new two-parameter estimator for the Poisson regression model. Iran. J. Sci. Technol. Trans. A Sci. 2018, 42, 793–803. [Google Scholar] [CrossRef]
- Huang, J.; Yang, H. A two-parameter estimator in the negative binomial regression model. J. Stat. Comput. Simul. 2014, 84, 124–134. [Google Scholar] [CrossRef]
- Sami, F.; Butt, M.M.; Amin, M. Two parameter estimators for the Conway–Maxwell–Poisson regression model. J. Stat. Comput. Simul. 2023, 93, 2137–2157. [Google Scholar] [CrossRef]
- Kibria, B.G. Performance of some new ridge regression estimators. Commun. Stat. -Simul. Comput. 2003, 32, 419–435. [Google Scholar] [CrossRef]
- Oranye, H.E.; Ugwuowo, F.I. Modified jackknife Kibria–Lukman estimator for the Poisson regression model. Concurr. Comput. Pract. Exp. 2022, 34, e6757. [Google Scholar] [CrossRef]
- Sellers, K.; Lotze, T.; Raim, A. Compoissonreg: Conway-Maxwell Poisson (Com-Poisson) Regression; R Package Version 0.4; The Comprehensive R Archive Network: Vienna, Austria, 2017; Volume 1. [Google Scholar]
- Sellers, K.F.; Raim, A. A flexible zero-inflated model to address data dispersion. Comput. Stat. Data Anal. 2016, 99, 68–80. [Google Scholar] [CrossRef]
- Hilbe, J.M. Negative Binomial Regression, 2nd ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Myers, R.H.; Montgomery, D.C.; Vining, G.; Robinson, T.J. Generalized Linear Models: With Applications in Engineering and the Sciences; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Amin, M.; Akram, M.N.; Amanullah, M. On the James-Stein estimator for the Poisson regression model. Commun. Stat.-Simul. Comput. 2022, 51, 5596–5608. [Google Scholar] [CrossRef]
- Algamal, Z.Y.; Abonazel, M.R.; Awwad, F.A.; Eldin, E.T. Modified jackknife ridge estimator for the Conway-Maxwell-Poisson model. Sci. Afr. 2023, 19, e01543. [Google Scholar] [CrossRef]
- Chanialidis, C.; Evers, L.; Neocleous, T.; Nobile, A. Efficient Bayesian inference for COM-Poisson regression models. Stat. Comput. 2018, 28, 595–608. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).