
Multi-Feature Extraction and Explainable Machine Learning for Lamb-Wave-Based Damage Localization in Laminated Composites



Abstract
1. Introduction
2. The Proposed Methodology
2.1. Damage Simulator
Data Acquisition from the Damage Simulator
2.2. Hilbert Transform
2.3. Multi-Feature Extraction
2.4. Machine Learning Models
2.4.1. Decision Tree
2.4.2. K-Nearest Neighbor
2.4.3. Random Forest
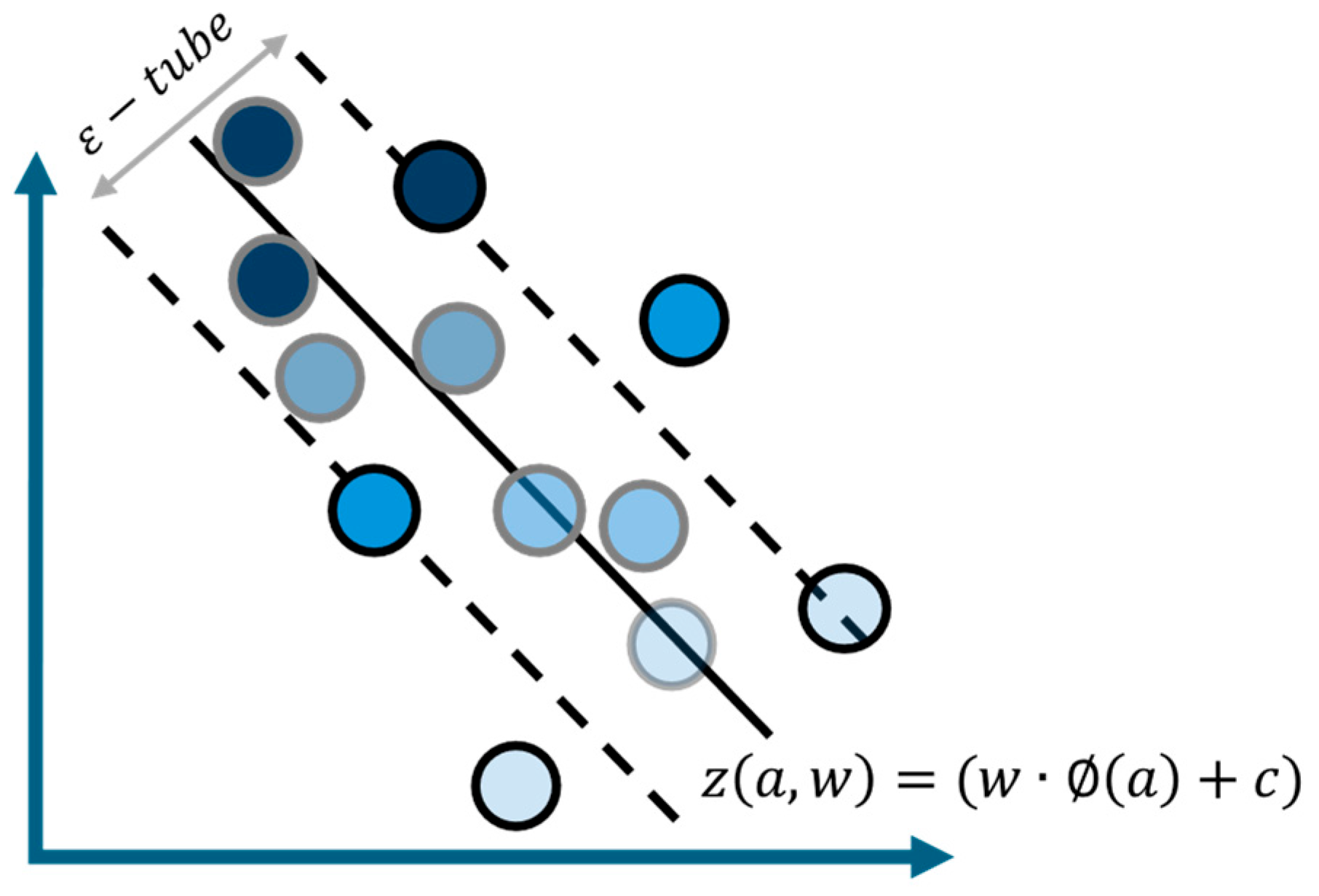
2.4.4. Support Vector Regression
2.4.5. Bayesian Ridge
2.4.6. Explainable Machine Learning
2.4.7. SHAP
2.4.8. Evaluation Metrics
3. Results and Discussion
3.1. Grid Search Hyperparameter Optimization
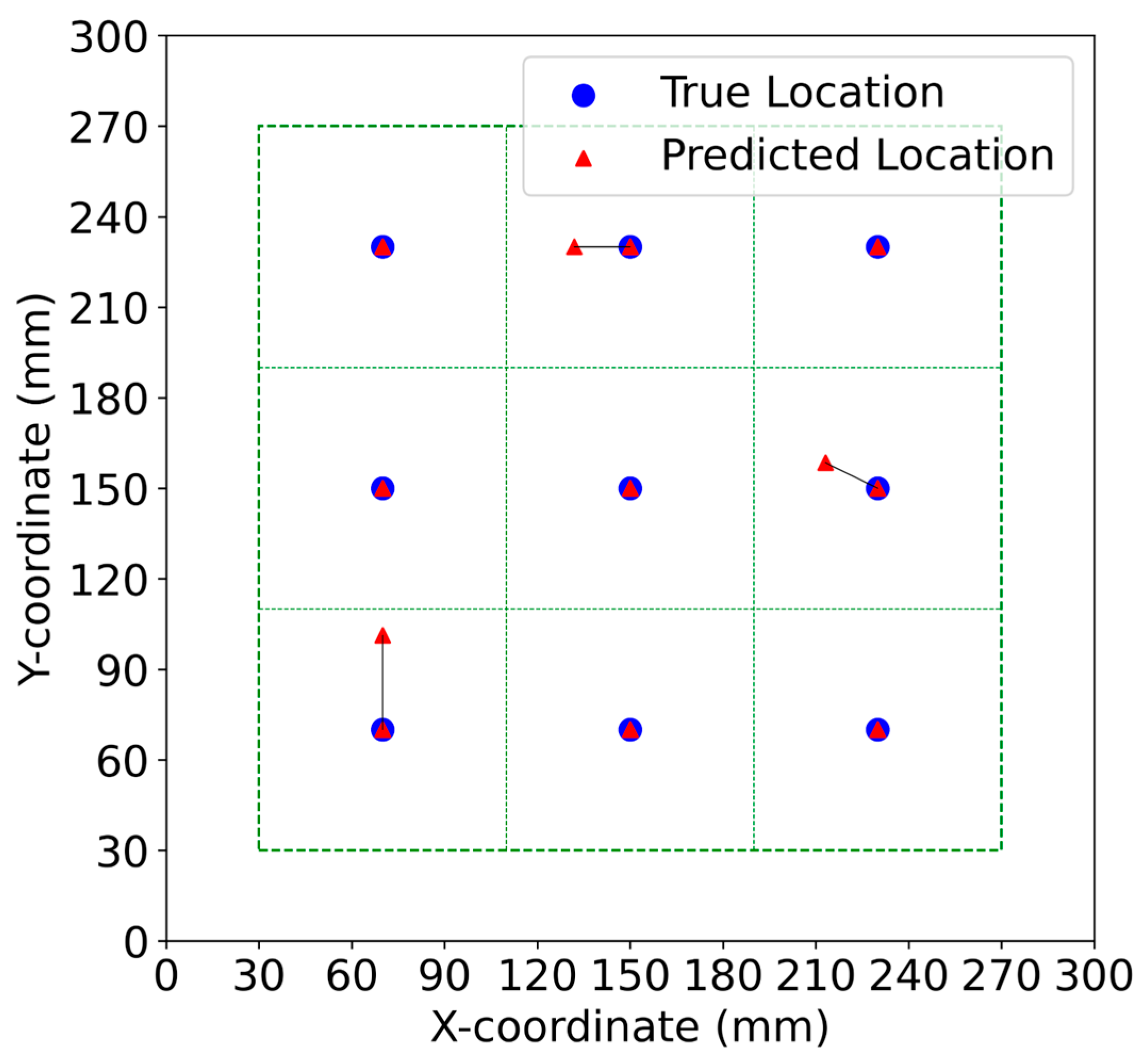
3.2. Damage Localization
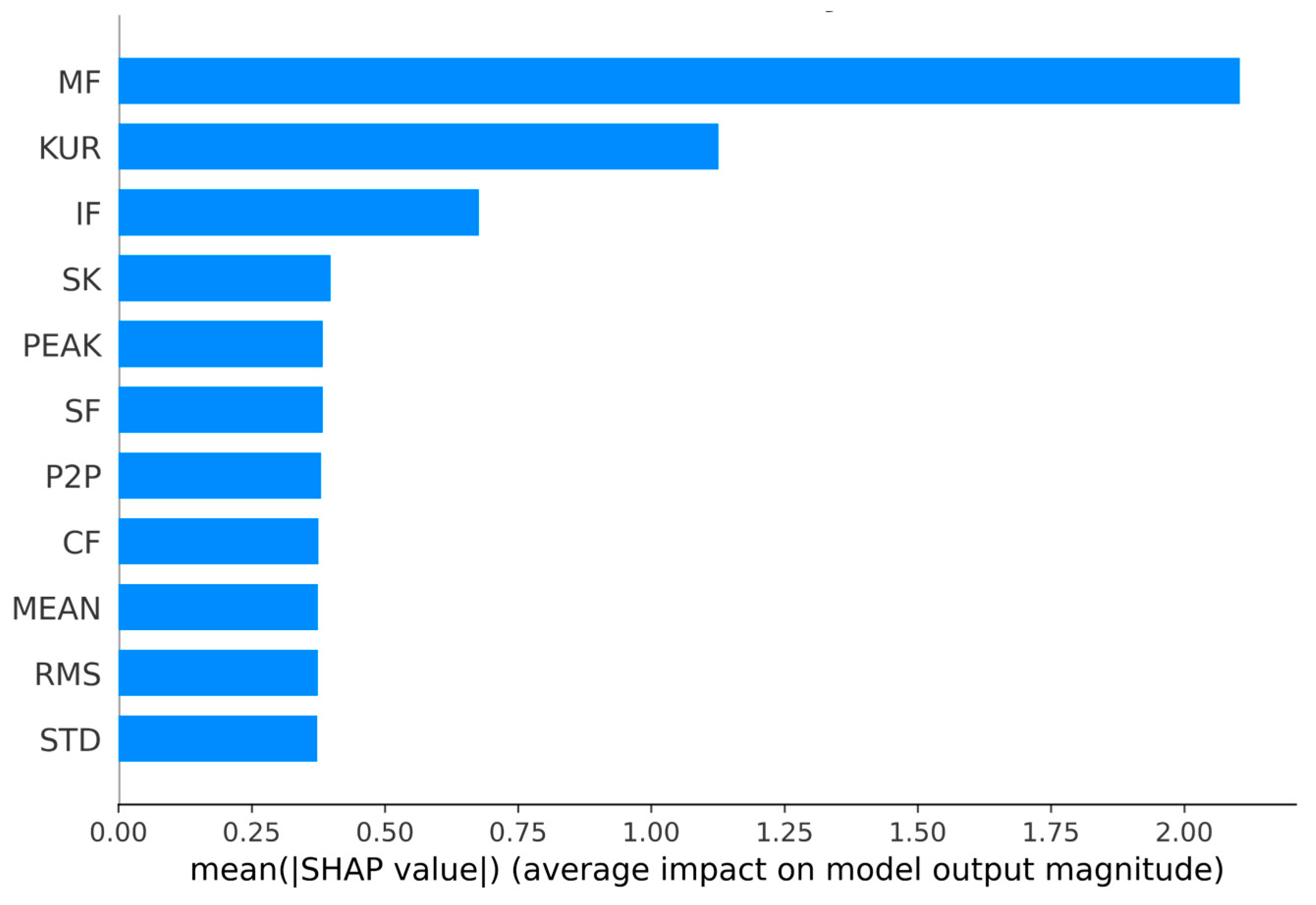
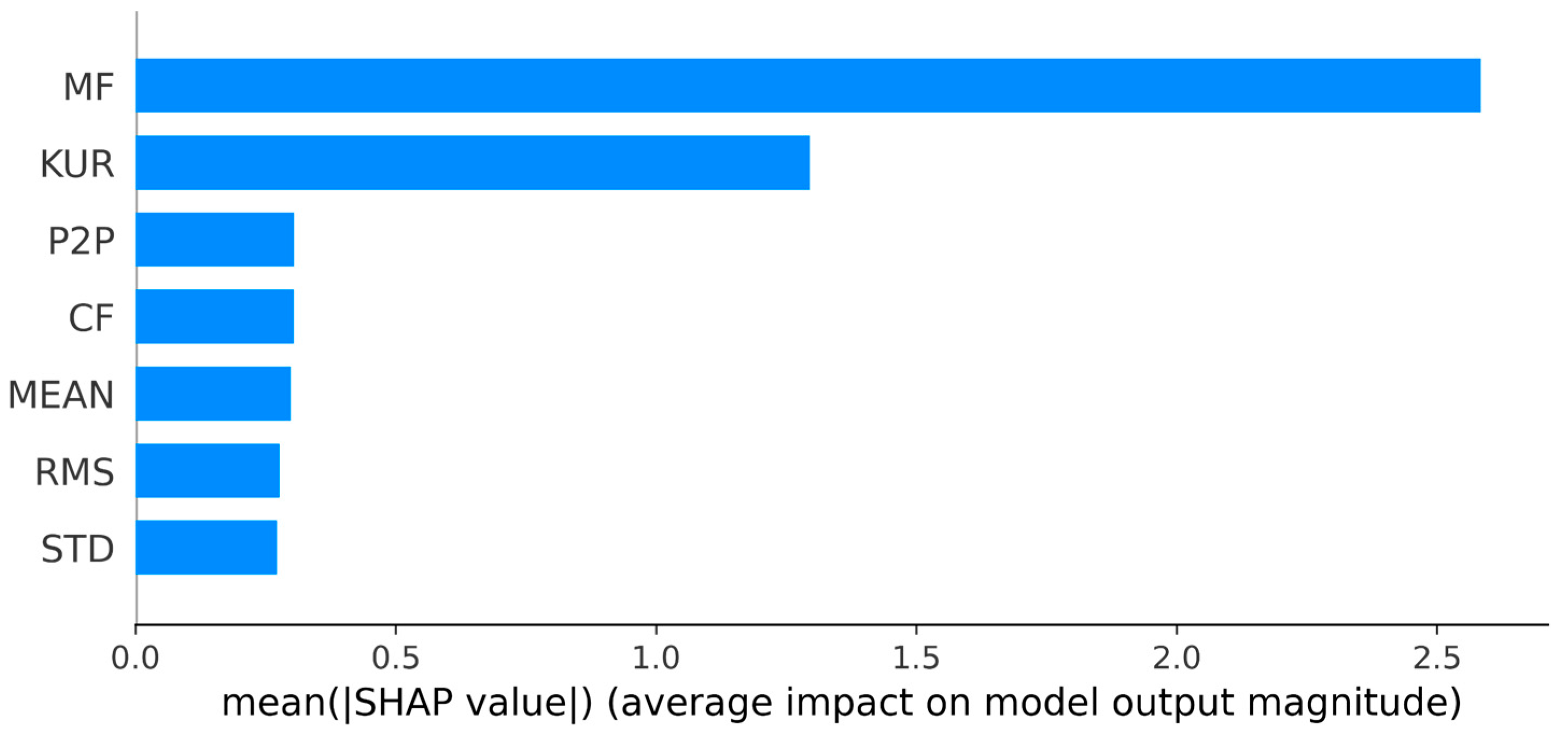
3.3. Explainable HT−MFE
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Acronym | Definition |
| SHM | Structural Health Monitoring |
| SHAP | Shapley Addictive Explanation |
| KNN | K-Nearest Neighbor |
| PZT | PieZoelectric Transducer |
| ToF | Time of Flight |
| FEA | Finite Element Analysis |
| HT | Hilbert transform |
| SVR | Support Vector Regression |
| RF | Random Forest |
| BR | Bayesian Ridge |
| DT | Decision Tree |
| DAQ | Data Acquisition |
| SVM | Support Vector Machine |
| XAI | Explainable Artificial Intelligence |
| LIME | Local Interpretable Model-agnostic Explanation |
| LASSO | Least Absolute Shrinkage and Selection Operator |
| MSE | Mean Square Error |
| MAE | Mean Absolute Error |
References
- Qing, X.; Liao, Y.; Wang, Y.; Chen, B.; Zhang, F.; Wang, Y. Machine Learning Based Quantitative Damage Monitoring of Composite Structure. Int. J. Smart Nano Mater. 2022, 13, 167–202. [Google Scholar] [CrossRef]
- Ma, W.; Elkin, R. Application of Sandwich Structural Composites. In Sandwich Structural Composites; Taylor & Francis: Abingdon, UK, 2021; p. 92. [Google Scholar]
- Azad, M.M.; Kim, H.S. Noise Robust Damage Detection of Laminated Composites Using Multichannel Wavelet-Enhanced Deep Learning Model. Eng. Struct. 2025, 322, 119192. [Google Scholar] [CrossRef]
- Razali, N. Impact Damage on Composite Structures–a Review. Int. J. Eng. Sci. 2014, 3, 8–20. [Google Scholar]
- Azad, M.M.; Jung, J.; Elahi, M.U.; Sohail, M.; Kumar, P.; Kim, H.S. Failure Modes and Non-Destructive Testing Techniques for Fiber-Reinforced Polymer Composites. J. Mater. Res. Technol. 2024, 33, 9519–9537. [Google Scholar] [CrossRef]
- Huang, T.; Bobyr, M. A Review of Delamination Damage of Composite Materials. J. Compos. Sci. 2023, 7, 468. [Google Scholar] [CrossRef]
- Azad, M.M.; Kim, S.; Kim, H.S. Autonomous Data-Driven Delamination Detection in Laminated Composites with Limited and Imbalanced Data. Alex. Eng. J. 2024, 107, 770–785. [Google Scholar] [CrossRef]
- Azad, M.M.; Kim, S.; Cheon, Y.B.; Kim, H.S. Intelligent Structural Health Monitoring of Composite Structures Using Machine Learning, Deep Learning, and Transfer Learning: A Review. Adv. Compos. Mater. 2024, 33, 162–188. [Google Scholar] [CrossRef]
- Alkayem, N.F.; Mayya, A.; Shen, L.; Zhang, X.; Asteris, P.G.; Wang, Q.; Cao, M. Co-CrackSegment: A New Collaborative Deep Learning Framework for Pixel-Level Semantic Segmentation of Concrete Cracks. Mathematics 2024, 12, 3105. [Google Scholar] [CrossRef]
- Senthil, K.; Arockiarajan, A.; Palaninathan, R.; Santhosh, B.; Usha, K.M. Defects in Composite Structures: Its Effects and Prediction Methods—A Comprehensive Review. Compos. Struct. 2013, 106, 139–149. [Google Scholar] [CrossRef]
- Wu, J.; Xu, X.; Liu, C.; Deng, C.; Shao, X. Lamb Wave-Based Damage Detection of Composite Structures Using Deep Convolutional Neural Network and Continuous Wavelet Transform. Compos. Struct. 2021, 276, 114590. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, X.; Wang, Y.; Wang, Y.; Qing, X. Lamb Wave-Based Damage Imaging of CFRP Composite Structures Using Autoencoder and Delay-and-Sum. Compos. Struct. 2023, 303, 116263. [Google Scholar] [CrossRef]
- Zeng, X.; Liu, X.; Yan, J.; Yu, Y.; Zhao, B.; Qing, X. Lamb Wave-Based Damage Localization and Quantification Algorithms for CFRP Composite Structures. Compos. Struct. 2022, 295, 115849. [Google Scholar] [CrossRef]
- Azuara, G.; Barrera, E.; Ruiz, M.; Bekas, D. Damage Detection and Characterization in Composites Using a Geometric Modification of the RAPID Algorithm. IEEE Sens. J. 2020, 20, 2084–2093. [Google Scholar] [CrossRef]
- Zhu, J.; Qing, X.; Liu, X.; Wang, Y. Electromechanical Impedance-Based Damage Localization with Novel Signatures Extraction Methodology and Modified Probability-Weighted Algorithm. Mech. Syst. Signal Process. 2021, 146, 107001. [Google Scholar] [CrossRef]
- Gorgin, R.; Luo, Y.; Wu, Z. Environmental and Operational Conditions Effects on Lamb Wave Based Structural Health Monitoring Systems: A Review. Ultrasonics 2020, 105, 106114. [Google Scholar] [CrossRef]
- Thalapil, J.; Sawant, S.; Tallur, S.; Banerjee, S. Guided Wave Based Localization and Severity Assessment of In-Plane and out-of-Plane Fiber Waviness in Carbon Fiber Reinforced Composites. Compos. Struct. 2022, 297, 115932. [Google Scholar] [CrossRef]
- Rai, A.; Mitra, M. Lamb Wave Based Damage Detection in Metallic Plates Using Multi-Headed 1-Dimensional Convolutional Neural Network. Smart Mater. Struct. 2021, 30, 035010. [Google Scholar] [CrossRef]
- Liu, X.; Yu, Y.; Li, J.; Zhu, J.; Wang, Y.; Qing, X. Leaky Lamb Wave–Based Resin Impregnation Monitoring with Noninvasive and Integrated Piezoelectric Sensor Network. Measurement 2022, 189, 110480. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, S.; Li, Y.; Wang, Q.; Su, Z.; Yue, D. A Cross-Scanning Crack Damage Quantitative Monitoring and Imaging Method. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar] [CrossRef]
- Azimi, M.; Eslamlou, A.; Pekcan, G. Data-Driven Structural Health Monitoring and Damage Detection through Deep Learning: State-of-the-Art Review. Sensors 2020, 20, 2778. [Google Scholar] [CrossRef]
- Liu, W.; Giurgiutiu, V. Finite Element Simulation of Piezoelectric Wafer Active Sensors for Structural Health Monitoring with Coupled-Filed Elements; Tomizuka, M., Yun, C.-B., Giurgiutiu, V., Eds.; SPIE: Washington, DC, USA, 2007; p. 65293R. [Google Scholar]
- Kumar, V. Physics-Based and Data-Driven Methods for Structural Health Monitoring at Fine Spatial Resolution. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 2021. [Google Scholar]
- Mayerhofer, P.; Bajić, I.; Maxwell Donelan, J. Comparing the Advantages and Disadvantages of Physics-Based and Neural Network-Based Modelling for Predicting Cycling Power. J. Biomech. 2024, 169, 112121. [Google Scholar] [CrossRef] [PubMed]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V.; Semenoglou, A.-A.; Mulder, G.; Nikolopoulos, K. Statistical, Machine Learning and Deep Learning Forecasting Methods: Comparisons and Ways Forward. J. Oper. Res. Soc. 2023, 74, 840–859. [Google Scholar] [CrossRef]
- Xi, Z.; Zhao, X. An Enhanced Copula-Based Method for Data-Driven Prognostics Considering Insufficient Training Units. Reliab. Eng. Syst. Saf. 2019, 188, 181–194. [Google Scholar] [CrossRef]
- Azad, M.M.; Rehman Shah, A.U.; Prabhakar, M.N.; Kim, H.S. Deep Learning-Based Fracture Mode Determination in Composite Laminates. J. Comput. Struct. Eng. Inst. Korea 2024, 37, 225–232. [Google Scholar] [CrossRef]
- Thrall, J.H.; Li, X.; Li, Q.; Cruz, C.; Do, S.; Dreyer, K.; Brink, J. Artificial Intelligence and Machine Learning in Radiology: Opportunities, Challenges, Pitfalls, and Criteria for Success. J. Am. Coll. Radiol. 2018, 15, 504–508. [Google Scholar] [CrossRef]
- Rudin, C. Why Black Box Machine Learning Should Be Avoided for High-Stakes Decisions, in Brief. Nat. Rev. Methods Prim. 2022, 2, 81. [Google Scholar] [CrossRef]
- Aldrees, A.; Khan, M.; Taha, A.T.B.; Ali, M. Evaluation of Water Quality Indexes with Novel Machine Learning and SHapley Additive ExPlanation (SHAP) Approaches. J. Water Process Eng. 2024, 58, 104789. [Google Scholar] [CrossRef]
- Wang, S.; Peng, H.; Liang, S. Prediction of Estuarine Water Quality Using Interpretable Machine Learning Approach. J. Hydrol. 2022, 605, 127320. [Google Scholar] [CrossRef]
- Makumbura, R.K.; Mampitiya, L.; Rathnayake, N.; Meddage, D.P.P.; Henna, S.; Dang, T.L.; Hoshino, Y.; Rathnayake, U. Advancing Water Quality Assessment and Prediction Using Machine Learning Models, Coupled with Explainable Artificial Intelligence (XAI) Techniques like Shapley Additive Explanations (SHAP) for Interpreting the Black-Box Nature. Results Eng. 2024, 23, 102831. [Google Scholar] [CrossRef]
- Ng, C.T.; Veidt, M. A Lamb-Wave-Based Technique for Damage Detection in Composite Laminates. Smart Mater. Struct. 2009, 18, 074006. [Google Scholar] [CrossRef]
- Quek, S.T.; Tua, P.S.; Wang, Q. Detecting Anomalies in Beams and Plate Based on the Hilbert–Huang Transform of Real Signals. Smart Mater. Struct. 2003, 12, 447–460. [Google Scholar] [CrossRef]
- Nazmdar Shahri, M.; Yousefi, J.; Fotouhi, M.; Ahmadi Najfabadi, M. Damage Evaluation of Composite Materials Using Acoustic Emission Features and Hilbert Transform. J. Compos. Mater. 2016, 50, 1897–1907. [Google Scholar] [CrossRef]
- Lu, H.; Chandran, B.; Wu, W.; Ninic, J.; Gryllias, K.; Chronopoulos, D. Damage Features for Structural Health Monitoring Based on Ultrasonic Lamb Waves: Evaluation Criteria, Survey of Recent Work and Outlook. Measurement 2024, 232, 114666. [Google Scholar] [CrossRef]
- Trendafilova, I.; Manoach, E. Vibration-Based Damage Detection in Plates by Using Time Series Analysis. Mech. Syst. Signal Process. 2008, 22, 1092–1106. [Google Scholar] [CrossRef]
- Abarbanel, H.D.I. Analysis of Observed Chaotic Data; Springer: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- Kaya, Y.; Safak, E. Real-Time Analysis and Interpretation of Continuous Data from Structural Health Monitoring (SHM) Systems. Bull. Earthq. Eng. 2015, 13, 917–934. [Google Scholar] [CrossRef]
- Tiwari, B.; Kumar, A. Standard Deviation (SD)-Based Data Filtering Technique for Body Sensor Network Data. Int. J. Data Sci. 2015, 1, 189. [Google Scholar] [CrossRef]
- Ross, R. Formulas to Describe the Bias and Standard Deviation of the ML-Estimated Weibull Shape Parameter. IEEE Trans. Dielectr. Electr. Insul. 1994, 1, 247–253. [Google Scholar] [CrossRef]
- Sugumaran, V.; Ramachandran, K.I. Automatic Rule Learning Using Decision Tree for Fuzzy Classifier in Fault Diagnosis of Roller Bearing. Mech. Syst. Signal Process. 2007, 21, 2237–2247. [Google Scholar] [CrossRef]
- Pasadas, D.J.; Barzegar, M.; Ribeiro, A.L.; Ramos, H.G. Guided Lamb Wave Tomography Using Angle Beam Transducers and Inverse Radon Transform for Crack Image Reconstruction. In Proceedings of the 2022 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Ottawa, ON, Canada, 16–19 May 2022; IEEE: New York, NY, USA; pp. 1–6. [Google Scholar]
- Wang, Q.; Ma, S. Lamb Wave and GMM Based Damage Monitoring and Identification for Composite Structure. In Proceedings of the 9th International Symposium on NDT in Aerospace, Xiamen, China, 8–10 November 2017. [Google Scholar]
- Harley, J.B.; Moura, J.M.F. Data-Driven and Calibration-Free Lamb Wave Source Localization with Sparse Sensor Arrays. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2015, 62, 1516–1529. [Google Scholar] [CrossRef]
- Wang, H.; Chen, P. Fault Diagnosis Method Based on Kurtosis Wave and Information Divergence for Rolling Element Bearings. Wseas Trans. Syst. 2009, 8, 1155–1165. [Google Scholar]
- Raouf, I.; Lee, H.; Kim, H.S. Mechanical Fault Detection Based on Machine Learning for Robotic RV Reducer Using Electrical Current Signature Analysis: A Data-Driven Approach. J. Comput. Des. Eng. 2022, 9, 417–433. [Google Scholar] [CrossRef]
- Hamadache, M.; Jung, J.H.; Park, J.; Youn, B.D. A Comprehensive Review of Artificial Intelligence-Based Approaches for Rolling Element Bearing PHM: Shallow and Deep Learning. JMST Adv. 2019, 1, 125–151. [Google Scholar] [CrossRef]
- Kumar, A.; Parey, A.; Kankar, P.K. Vibration Based Fault Detection of Polymer Gear. Mater. Today Proc. 2021, 44, 2116–2120. [Google Scholar] [CrossRef]
- Xu, M.; Watanachaturaporn, P.; Varshney, P.; Arora, M. Decision Tree Regression for Soft Classification of Remote Sensing Data. Remote Sens. Environ. 2005, 97, 322–336. [Google Scholar] [CrossRef]
- Ortiz-Bejar, J.; Graff, M.; Tellez, E.S.; Ortiz-Bejar, J.; Jacobo, J.C. K-Nearest Neighbor Regressors Optimized by Using Random Search. In Proceedings of the 2018 IEEE International Autumn Meeting on Power, Electronics and Computing (ROPEC), Ixtapa, Mexico, 14–16 November 2018; IEEE: New York, NY, USA; pp. 1–5. [Google Scholar]
- Song, J.; Zhao, J.; Dong, F.; Zhao, J.; Qian, Z.; Zhang, Q. A Novel Regression Modeling Method for PMSLM Structural Design Optimization Using a Distance-Weighted KNN Algorithm. IEEE Trans. Ind. Appl. 2018, 54, 4198–4206. [Google Scholar] [CrossRef]
- Hu, L.-Y.; Huang, M.-W.; Ke, S.-W.; Tsai, C.-F. The Distance Function Effect on K-Nearest Neighbor Classification for Medical Datasets. Springerplus 2016, 5, 1304. [Google Scholar] [CrossRef]
- Short, R.; Fukunaga, K. The Optimal Distance Measure for Nearest Neighbor Classification. IEEE Trans. Inf. Theory 1981, 27, 622–627. [Google Scholar] [CrossRef]
- Kilian, Q.; Weinberger, L.K.S. Distance Metric Learning for Large Margin Nearest Neighbor Classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Cost, S.; Salzberg, S. A Weighted Nearest Neighbor Algorithm for Learning with Symbolic Features. Mach. Learn. 1993, 10, 57–78. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zhang, Z. Too Much Covariates in a Multivariable Model May Cause the Problem of Overfitting. J. Thorac. Dis. 2014, 6, E196–E197. [Google Scholar] [PubMed]
- Lantz, B. Machine Learning with R: Expert Techniques for Predictive Modeling; Packt Publshing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Amit, Y.; Geman, D. Shape Quantization and Recognition with Randomized Trees. Neural Comput. 1997, 9, 1545–1588. [Google Scholar] [CrossRef]
- Gholami, R.; Fakhari, N. Support Vector Machine: Principles, Parameters, and Applications. In Handbook of Neural Computation; Elsevier: Amsterdam, The Netherlands, 2017; pp. 515–535. [Google Scholar]
- Vapnik, V.; Golowich, S.; Smola, A. Support Vector Method for Function Approximation, Regression Estimation and Signal Processing. Part Adv. Neural Inf. Process. Syst. 1996, 9. [Google Scholar]
- Vaish, R.; Dwivedi, U.D. Bayesian Ridge Regression for Power System Fault Localization. In Proceedings of the 2024 5th International Conference for Emerging Technology (INCET), Belgaum, India, 24–26 May 2024; IEEE: New York, NY, USA; pp. 1–5. [Google Scholar]
- Shi, Q.; Abdel-Aty, M.; Lee, J. A Bayesian Ridge Regression Analysis of Congestion’s Impact on Urban Expressway Safety. Accid. Anal. Prev. 2016, 88, 124–137. [Google Scholar] [CrossRef]
- Congdon, P. Bayesian Statistical Modelling. Meas. Sci. Technol. 2002, 13, 643. [Google Scholar] [CrossRef]
- Ntzoufras, I. Gibbs Variable Selection Using BUGS. J. Stat. Softw. 2002, 7, 1–19. [Google Scholar] [CrossRef]
- Miller, T. Explanation in Artificial Intelligence: Insights from the Social Sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- AlJalaud, E.; Hosny, M. Enhancing Explainable Artificial Intelligence: Using Adaptive Feature Weight Genetic Explanation (AFWGE) with Pearson Correlation to Identify Crucial Feature Groups. Mathematics 2024, 12, 3727. [Google Scholar] [CrossRef]
- Azad, M.M.; Kim, H.S. An Explainable Artificial Intelligence-based Approach for Reliable Damage Detection in Polymer Composite Structures Using Deep Learning. Polym. Compos. 2024, 46, 1536–1551. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why Should I Trust You? In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA; pp. 1135–1144. [Google Scholar]
- Moradi, M.; Samwald, M. Post-Hoc Explanation of Black-Box Classifiers Using Confident Itemsets. Expert Syst. Appl. 2021, 165, 113941. [Google Scholar] [CrossRef]
- Roth, A.E. The Shapley Value: Essays in Honor of Lloyd S. Shapley; Cambridge University Press: Cambridge, UK, 1988. [Google Scholar]
- Mai-Suong, T.N.; Mai-Chien, T.; Seung-Eock, K. Uncertainty Quantification of Ultimate Compressive Strength of CCFST Columns Using Hybrid Machine Learning Model. Eng. Comput. 2022, 8 (Suppl. S4), 2719–2738. [Google Scholar]
- Wu, Y.; Zhou, Y. Hybrid Machine Learning Model and Shapley Additive Explanations for Compressive Strength of Sustainable Concrete. Constr. Build. Mater. 2022, 330, 127298. [Google Scholar] [CrossRef]
- Lerman, P.M. Fitting Segmented Regression Models by Grid Search. Appl. Stat. 1980, 29, 77. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description | Expression |
|---|---|---|
| Mean | Demonstrates the central tendency by representing the average of the data values. | |
| Standard deviation | Demonstrates the dispersion by indicating the degree to which the data values vary from the mean. | |
| Root mean square | Represents the signal’s energy by displaying the root mean square of the data. | |
| Skewness | Determines skewness by measuring the asymmetry of the data distribution. | |
| Kurtosis | Measures kurtosis, which shows how tailed the data distribution is. | |
| Shape factor | The signal form is represented by the ratio of the RMS to the mean absolute value ratio. | |
| Crest factor | The ratio of the peak value to the RMS, which shows the strength of the signal peaks. | |
| Impulse factor | A ratio that shows abrupt fluctuations between the peak value and the mean absolute value. | |
| Margin factor | The ratio of the peak value to the mean square value of the signal, which is used to assess its strength and stability. | |
| Peak | The maximum observed value in the data. | |
| Peak-to-peak | The difference between the maximum and minimum values of the data. |
| ML Model | Hyperparameter | Description | Search Space | Worst, Optimum Hyperparameter | |
|---|---|---|---|---|---|
| Bayesian Ridge | alpha_1 | Regularizes model weight variance; lower values increase flexibility. | [0.00001, 0.01] | 0.01, 0.00001 | 0.63, 0.64 |
| alpha_2 | Controls model weight complexity; lower values promote flexibility. | [0.00001, 0.01] | 0.00001, 0.01 | ||
| lambda_1 | Controls noise variance; lower values improve noise tolerance. | [0.00001, 0.01] | 0.00001, 0.01 | ||
| lambda_2 | The noise variance is scaled; lesser values are better suited to noisy data. | [0.00001, 0.01] | 0.01, 0.00001 | ||
| Support Vector Regression | C | Balances error minimization with model complexity. | [0.1, 100] | 0.1, 100 | 0.002, 0.36 |
| epsilon | Determines the tolerance margin for forecast errors. | [0.1, 1.0] | 1.0, 0.2 | ||
| kernel | Determines the transformation function for feature mapping. | [linear, rbf, poly] | rbf, linear | ||
| Random Forest | max_depth | Limits tree depth to manage model complexity. | [1, 20] | 1, 10 | 0.52, 0.91 |
| min_samples_leaf | Sets the minimum number of samples required at a leaf node. | [1, 4] | 4, 1 | ||
| min_samples_split | Defines the minimum number of samples required to split a node. | [2, 10] | 10, 2 | ||
| n_estimators | Indicates the number of Decision Trees in the ensemble. | [50, 200] | 50, 200 | ||
| K-Nearest Neighbor | n_neighbors | Determines the number of neighbors to predict. | [1, 20] | 17, 3 | 0.776, 0.96 |
| Decision Tree | max_depth | Limits tree depth to manage complexity. | [1, 20] | 1, 10 | 0.44, 0.74 |
| min_samples_leaf | Specifies the minimum sample for a leaf node. | [1, 4] | 1, 2 | ||
| min_samples_split | Sets the minimum samples needed to split a node. | [2, 10] | 2, 2 |
| Type | Evaluation Metrics | Bayesian Ridge | Random Forest Regression | Support Vector Regression | Decision Tree Regression | K-Nearest Neighbor Regression |
|---|---|---|---|---|---|---|
| Hilbert transform from raw signal | MSE | 2079.14 | 195.09 | 970.47 | 509.06 | 40.12 |
| MAE | 29.38 | 9.68 | 19.66 | 14.63 | 1.48 | |
| 0.16 | 0.87 | 0.76 | 0.71 | 0.91 | ||
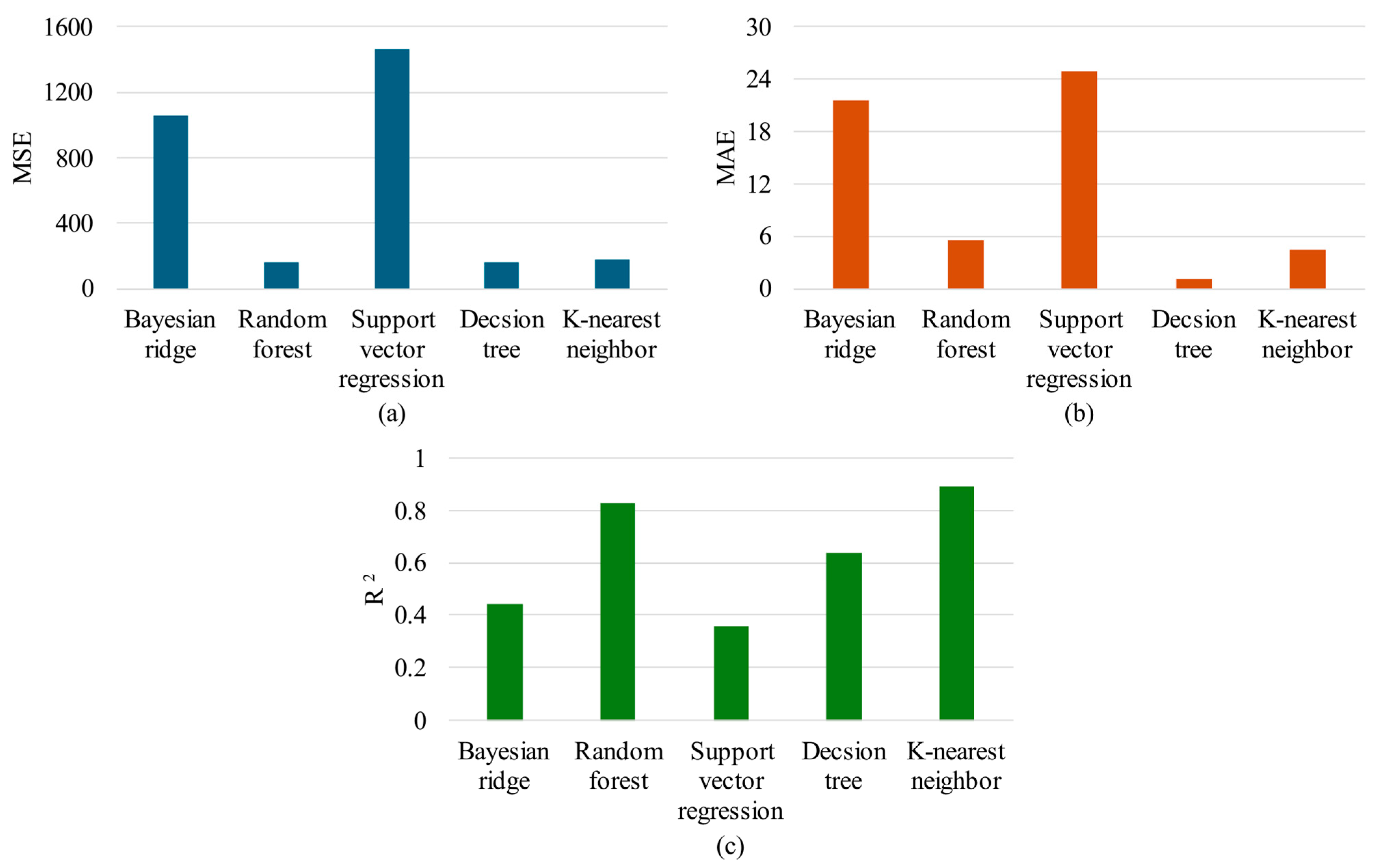
| Multi-feature extraction from raw signal | MSE | 1057.63 | 159.1 | 1460.49 | 158.24 | 176.3 |
| MAE | 21.65 | 5.58 | 24.88 | 1.12 | 4.39 | |
| 0.44 | 0.83 | 0.36 | 0.64 | 0.89 | ||
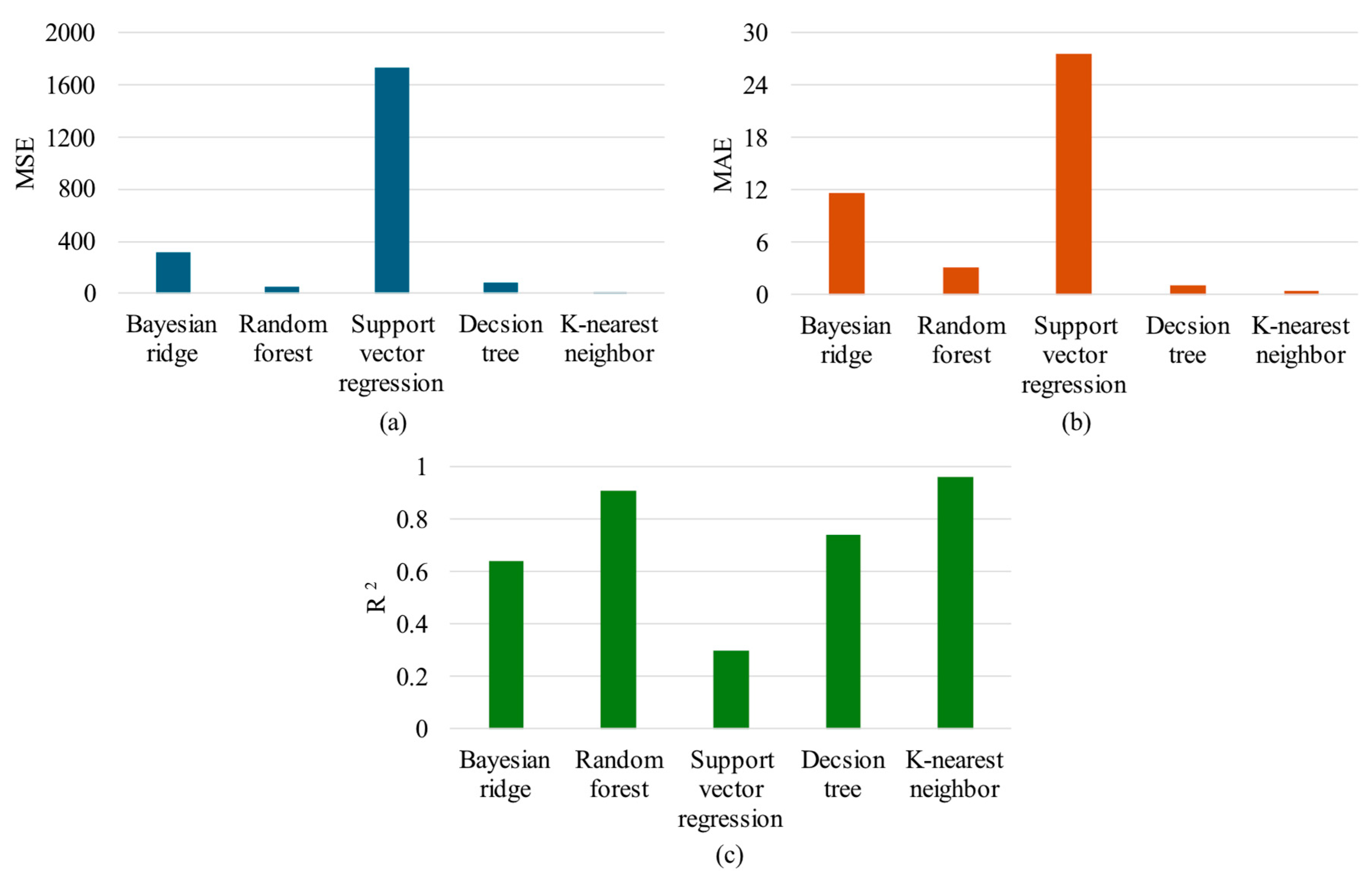
| Multi-feature extraction from Hilbert transform | MSE | 315.02 | 52.51 | 1731.43 | 79.17 | 10.29 |
| MAE | 11.65 | 3.2 | 27.58 | 1.1 | 0.5 | |
| 0.64 | 0.91 | 0.3 | 0.74 | 0.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, J.; Azad, M.M.; Kim, H.S. Multi-Feature Extraction and Explainable Machine Learning for Lamb-Wave-Based Damage Localization in Laminated Composites. Mathematics 2025, 13, 769. https://doi.org/10.3390/math13050769
Jung J, Azad MM, Kim HS. Multi-Feature Extraction and Explainable Machine Learning for Lamb-Wave-Based Damage Localization in Laminated Composites. Mathematics. 2025; 13(5):769. https://doi.org/10.3390/math13050769
Chicago/Turabian StyleJung, Jaehyun, Muhammad Muzammil Azad, and Heung Soo Kim. 2025. "Multi-Feature Extraction and Explainable Machine Learning for Lamb-Wave-Based Damage Localization in Laminated Composites" Mathematics 13, no. 5: 769. https://doi.org/10.3390/math13050769
APA StyleJung, J., Azad, M. M., & Kim, H. S. (2025). Multi-Feature Extraction and Explainable Machine Learning for Lamb-Wave-Based Damage Localization in Laminated Composites. Mathematics, 13(5), 769. https://doi.org/10.3390/math13050769