
Improved Hadamard Decomposition and Its Application in Data Compression in New-Type Power Systems


Abstract
1. Introduction
1.1. Related Work
1.2. Key Contributions
- Uniqueness in Decomposition: We achieve uniqueness in Hadamard decomposition by imposing orthogonality and non-negativity constraints on the decomposed matrices. This theoretical advancement ensures consistent and reproducible signal reconstruction, which is essential for power system applications.
- Enhanced Gradient Descent Algorithm: We develop an enhanced gradient descent algorithm incorporating adaptive regularization and early stopping mechanisms. This algorithmic improvement significantly accelerates convergence and improves computational efficiency in optimizing the Hadamard approximation, making it practical for real-time power system applications.
- Novel Compression Scheme: We design a novel compression scheme for current and voltage data compression of power systems based on the improved Hadamard decomposition. This scheme demonstrates superior performance in both compression efficiency and feature preservation, particularly in capturing transient characteristics critical for power quality analysis.
2. Theory of Hadamard Decomposition
2.1. Preliminaries
- Commutativity: For matrices of the same size:
- Associativity: For matrices of the same size:
- Relationship with standard matrix multiplication: For matrices of compatible sizes:
2.2. Essential Properties
2.2.1. Proposition 1
2.2.2. Proposition 2
- (1)
- and are orthogonal matrices (i.e., );
- (2)
- and are non-negative matrices;
- (3)
- The columns of and are normalized in the -norm (i.e., for all j).
3. Enhanced Optimization Algorithm for Hadamard Decomposition
3.1. Problem Formulation
3.2. Enhanced Algorithm
| Algorithm 1 Improved gradient descent algorithm for Hadamard decomposition |
| Input: Matrix , expected error , rank r, maximum iterations T |
| Output: Estimated matrix , factors , metrics |
|
3.2.1. Initialization
3.2.2. Gradient Computation
3.2.3. Parameter Updates
3.2.4. Convergence and Error Monitoring
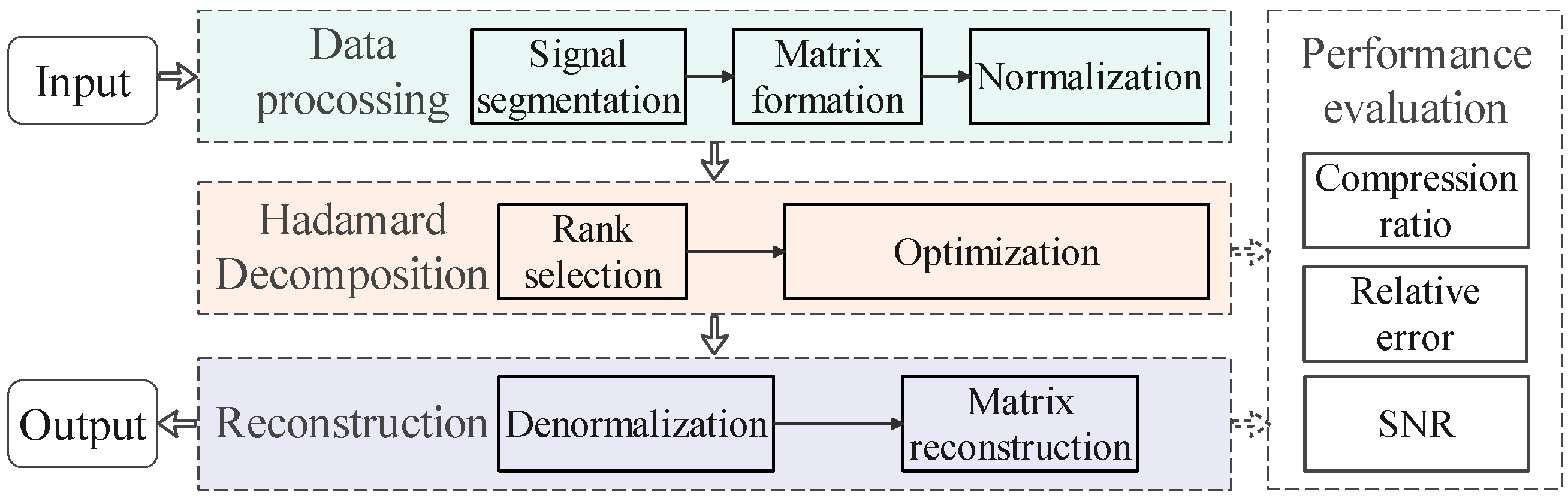
4. Data Compression Scheme for Power Quality Disturbance Analysis in Power Systems
4.1. Data Preprocessing
- Signal Segmentation: During the collection process, divide the data into data segments of length N.
- Matrix Formation: Arrange each segment into an matrix. For signals that do not perfectly fit this square matrix, zero-padding can be applied.
- Normalization: Scale the data to a range of [0, 1] to ensure consistent processing across different types of disturbances:where x is the original value, and and are the minimum and maximum values in the segment, respectively.
4.2. Decomposition
- Rank Selection: Choose an appropriate rank r for the decomposition matrix. For signals with high complexity and rich information content, a larger r is typically needed to capture the essential features without a significant loss in accuracy. Conversely, for simpler signals or signals with less variation, a smaller r may suffice, offering a better compression ratio with minimal loss of relevant information.Additionally, the rank r should be chosen such that it strikes an optimal balance between the compression ratio (CR) and the relative reconstruction error (RE) as described in Section 4.4. A smaller rank reduces the storage requirements and computational cost, but this comes at the expense of reconstruction accuracy. Therefore, the rank r is selected by iterating through different values and evaluating the trade-offs using metrics such as RE and CR, ensuring that the rank provides sufficient accuracy while achieving the desired compression.
- Optimization: Use the gradient descent algorithm to find the optimal , , , and matrices that minimize the reconstruction error.
4.3. Reconstruction
- Matrix Reconstruction: Compute the Hadamard product to obtain the approximated disturbance data matrix.
- Denormalization: Apply the inverse of the normalization step to recover the original scale of the data.
4.4. Performance Evaluation
- Relative error (RE), as defined in Equation (13), measures the reconstruction accuracy for each type of disturbance. A smaller RE indicates a more accurate decomposition, with RE = 0 representing a perfect reconstruction.
- Signal-to-noise ratio (SNR) quantifies the quality of the reconstructed signal compared to the original signal, and provides a logarithmic measure of the decomposition quality. A higher SNR indicates better decomposition quality, with each 3 dB increase corresponding to approximately halving the reconstruction error power. The formula for calculating SNR is as follows:
- Compression ratio (CR) determines the extent of data reduction achieved for each disturbance type:where n and m are the dimensions of the original matrix M, and r is the rank of the decomposition matrix. This ratio compares the number of elements in the decomposed matrices to the number of elements in the original matrix M. A lower CR indicates higher compression.
5. Simulation Studies
5.1. Simulation Model
5.2. Simulation Results
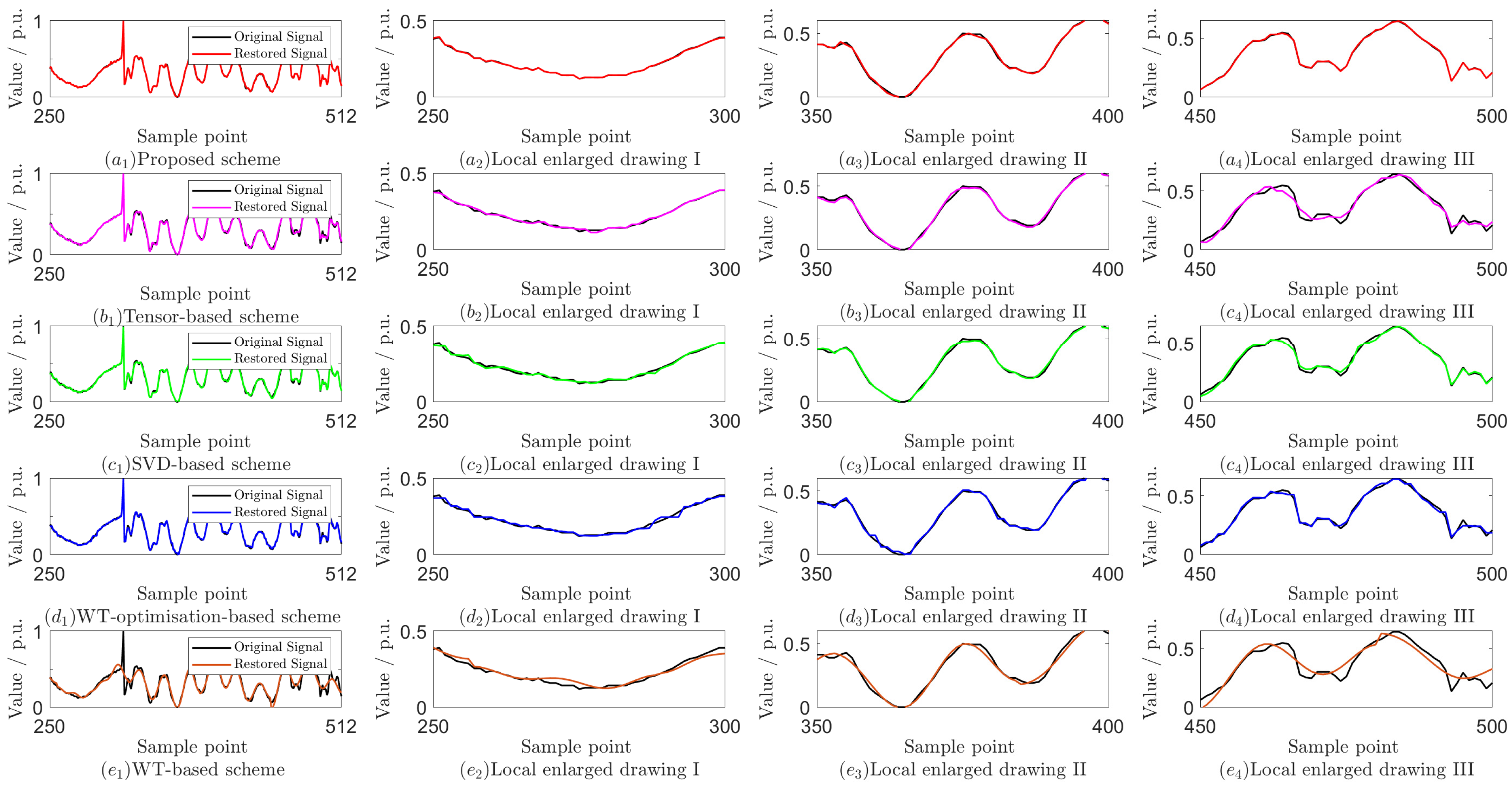
5.3. Field Data Test and Performance Comparison
5.4. Discussion
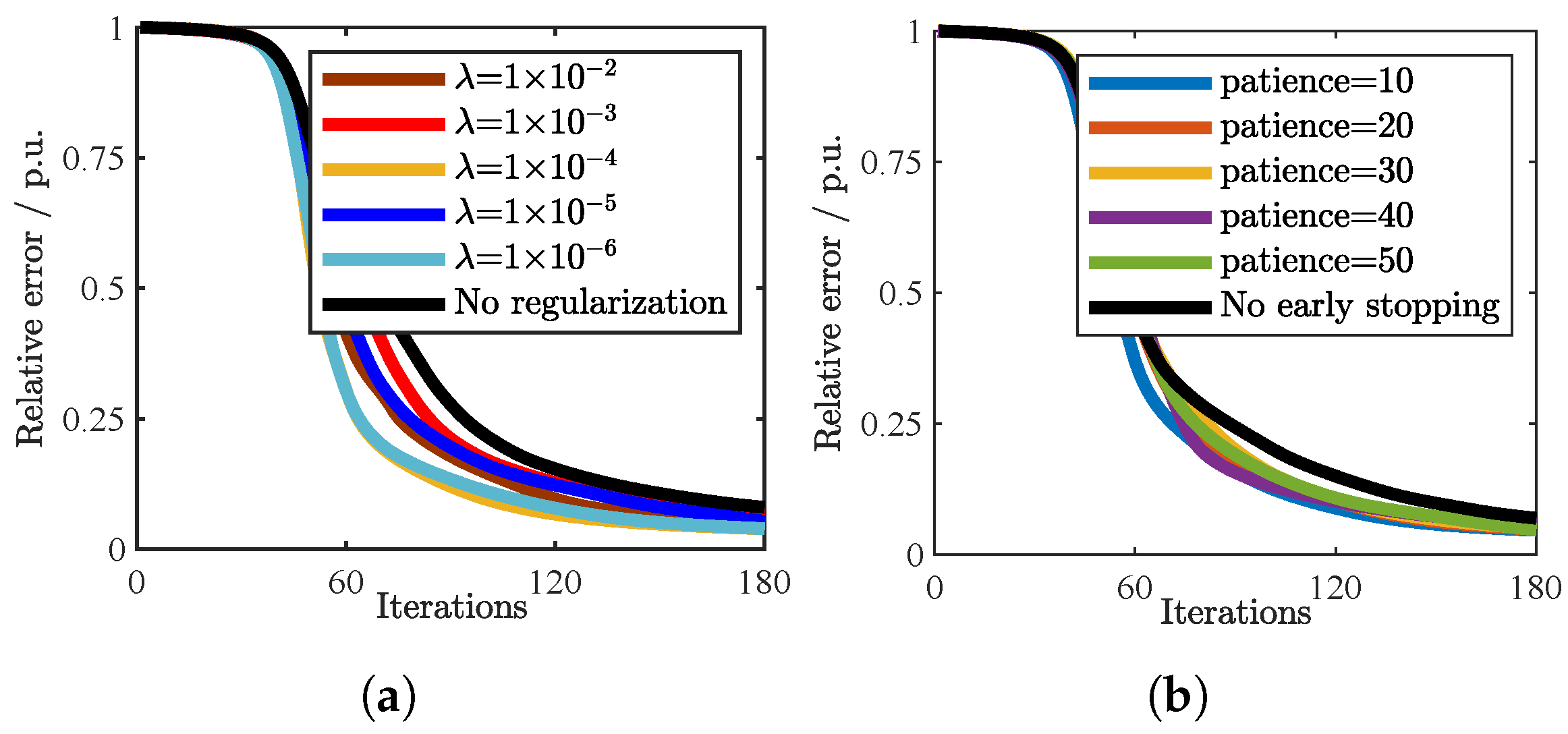
5.4.1. Sensitivity Analysis
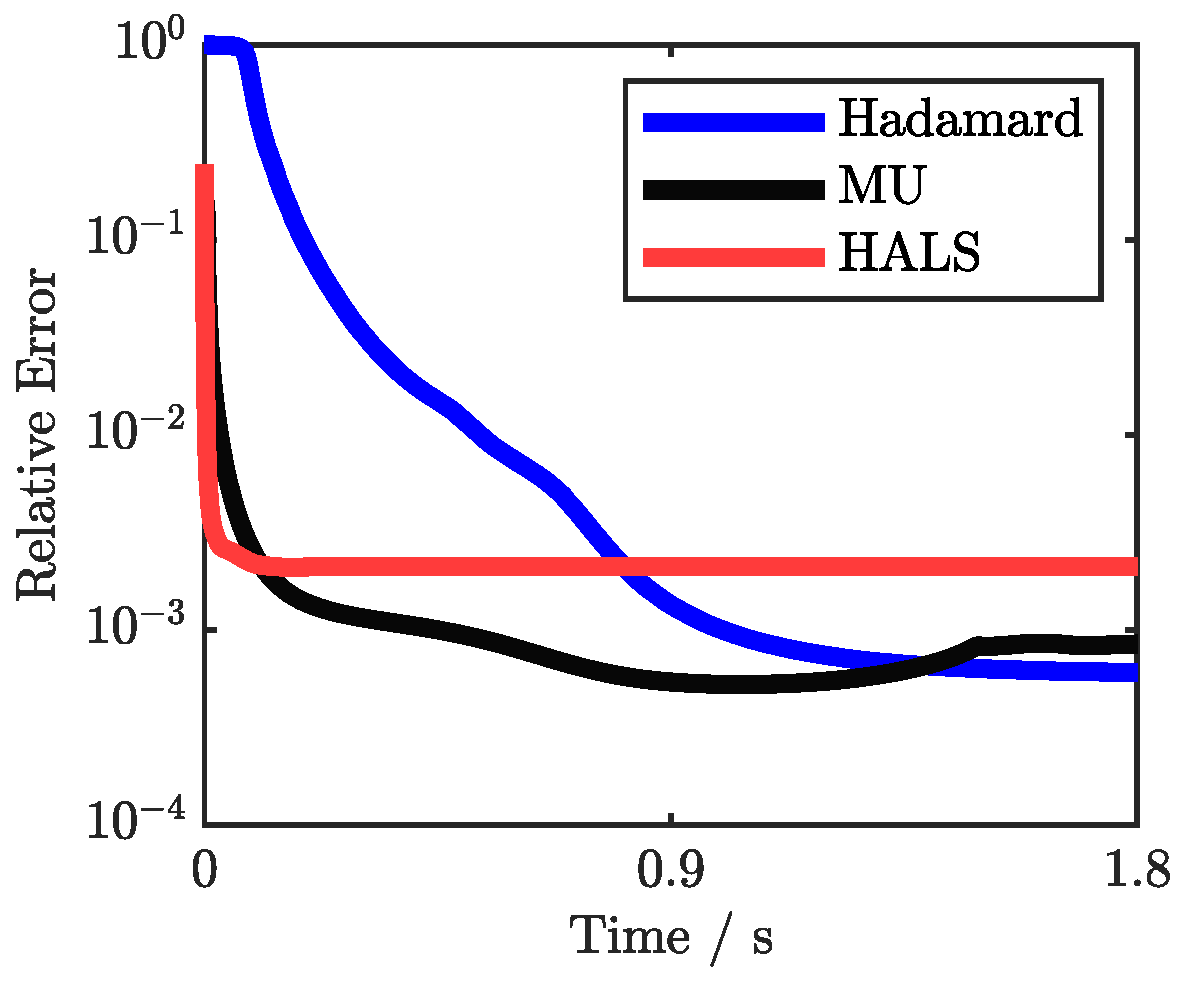
5.4.2. Convergence Performance Analysis
5.4.3. Frequency Domain Analysis
5.4.4. Packet Loss Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, S.; Zhang, Y.; Zhu, R.; Tian, W. Electric signature detection and analysis for power equipment failure monitoring in smart grid. IEEE Trans. Ind. Inform. 2020, 17, 3739–3750. [Google Scholar] [CrossRef]
- Wang, W.; Chen, C.; Yao, W.; Sun, K.; Qiu, W.; Liu, Y. Synchrophasor data compression under disturbance conditions via cross-entropy-based singular value decomposition. IEEE Trans. Ind. Inform. 2020, 17, 2716–2726. [Google Scholar] [CrossRef]
- Jian, J.; Zhao, J.; Ji, H.; Bai, L.; Xu, J.; Li, P.; Wu, J.; Wang, C. Supply restoration of data centers in flexible distribution networks with spatial-temporal regulation. IEEE Trans. Smart Grid 2023, 15, 340–354. [Google Scholar] [CrossRef]
- Sun, J.; Chen, Q.; Xia, M. Data-driven detection and identification of line parameters with PMU and unsynchronized SCADA measurements in distribution grids. CSEE J. Power Energy Syst. 2022, 10, 261–271. [Google Scholar]
- Senyuk, M.; Beryozkina, S.; Zicmane, I.; Safaraliev, M.; Klassen, V.; Kamalov, F. Bulk Low-Inertia Power Systems Adaptive Fault Type Classification Method Based on Machine Learning and Phasor Measurement Units Data. Mathematics 2025, 13, 316. [Google Scholar] [CrossRef]
- Wang, X.; Liu, Y.; Tong, L. Adaptive subband compression for streaming of continuous point-on-wave and PMU data. IEEE Trans. Power Syst. 2021, 36, 5612–5621. [Google Scholar] [CrossRef]
- Senyuk, M.; Safaraliev, M.; Pazderin, A.; Pichugova, O.; Zicmane, I.; Beryozkina, S. Methodology for Power Systems’ Emergency Control Based on Deep Learning and Synchronized Measurements. Mathematics 2023, 11, 4667. [Google Scholar] [CrossRef]
- Pranitha, K.; Kavya, G. An efficient image compression architecture based on optimized 9/7 wavelet transform with hybrid post processing and entropy encoder module. Microprocess. Microsyst. 2023, 98, 104821. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, Z.; Chen, K.; Xiao, J. Efficient and Real-Time Compression Schemes of Multi-Dimensional Data from Ocean Buoys Using Golomb-Rice Coding. Mathematics 2025, 13, 366. [Google Scholar] [CrossRef]
- Yan, L.; Han, J.; Xu, R.; Li, Z. Model-free lossless data compression for real-time low-latency transmission in smart grids. IEEE Trans. Smart Grid 2020, 12, 2601–2610. [Google Scholar] [CrossRef]
- Chen, C.; Wang, W.; Yin, H.; Zhan, L.; Liu, Y. Real-time lossless compression for ultrahigh-density synchrophasor and point-on-wave data. IEEE Trans. Ind. Electron. 2021, 69, 2012–2021. [Google Scholar] [CrossRef]
- Podgorelec, D.; Strnad, D.; Kolingerová, I.; Žalik, B. State-of-the-Art Trends in Data Compression: COMPROMISE Case Study. Entropy 2024, 26, 1032. [Google Scholar] [CrossRef] [PubMed]
- Jeromel, A.; Žalik, B. An efficient lossy cartoon image compression method. Multimed. Tools Appl. 2020, 79, 433–451. [Google Scholar] [CrossRef]
- Liu, T.; Wang, J.; Liu, Q.; Alibhai, S.; Lu, T.; He, X. High-ratio lossy compression: Exploring the autoencoder to compress scientific data. IEEE Trans. Big Data 2021, 9, 22–36. [Google Scholar] [CrossRef]
- He, S.; Geng, X.; Tian, W.; Yao, W.; Dai, Y.; You, L. Online Compression of Multichannel Power Waveform Data in Distribution Grid with Novel Tensor Method. IEEE Trans. Instrum. Meas. 2024, 73, 6505011. [Google Scholar] [CrossRef]
- Pourramezan, R.; Hassani, R.; Karimi, H.; Paolone, M.; Mahseredjian, J. A real-time synchrophasor data compression method using singular value decomposition. IEEE Trans. Smart Grid 2021, 13, 564–575. [Google Scholar] [CrossRef]
- de Souza, J.C.S.; Assis, T.M.L.; Pal, B.C. Data compression in smart distribution systems via singular value decomposition. IEEE Trans. Smart Grid 2015, 8, 275–284. [Google Scholar] [CrossRef]
- Hashemipour, N.; Aghaei, J.; Kavousi-Fard, A.; Niknam, T.; Salimi, L.; del Granado, P.C.; Shafie-Khah, M.; Wang, F.; Catalão, J.P. Optimal singular value decomposition based big data compression approach in smart grids. IEEE Trans. Ind. Appl. 2021, 57, 3296–3305. [Google Scholar] [CrossRef]
- Nascimento, F.A.d.O.; Saraiva, R.G.; Cormane, J. Improved transient data compression algorithm based on wavelet spectral quantization models. IEEE Trans. Power Deliv. 2020, 35, 2222–2232. [Google Scholar] [CrossRef]
- Yang, J.; Yu, H.; Li, P.; Ji, H.; Xi, W.; Wu, J.; Wang, C. Real-time D-PMU data compression for edge computing devices in digital distribution networks. IEEE Trans. Power Syst. 2023, 39, 5712–5725. [Google Scholar] [CrossRef]
- Mishra, M.; Sen Gupta, G.; Gui, X. Investigation of energy cost of data compression algorithms in WSN for IoT applications. Sensors 2022, 22, 7685. [Google Scholar] [CrossRef] [PubMed]
- Xiao, X.; Li, K.; Zhao, C. A Hybrid Compression Method for Compound Power Quality Disturbance Signals in Active Distribution Networks. J. Mod. Power Syst. Clean Energy 2023, 11, 1902–1911. [Google Scholar] [CrossRef]
- Bello, I.A.; McCulloch, M.D.; Rogers, D.J. A linear regression data compression algorithm for an islanded DC microgrid. Sustain. Energy Grids Netw. 2022, 32, 2352–4677. [Google Scholar] [CrossRef]
- Horn, R.A.; Yang, Z. Rank of a Hadamard product. Linear Algebra Its Appl. 2020, 591, 87–98. [Google Scholar] [CrossRef]
- Wu, C.W. ProdSumNet: Reducing model parameters in deep neural networks via product-of-sums matrix decompositions. arXiv 2018, arXiv:1809.02209. [Google Scholar]
- Yang, Z.; Stoica, P.; Tang, J. Source resolvability of spatial-smoothing-based subspace methods: A hadamard product perspective. IEEE Trans. Signal Process. 2019, 67, 2543–2553. [Google Scholar] [CrossRef]
- Hyeon-Woo, N.; Ye-Bin, M.; Oh, T.H. Fedpara: Low-rank hadamard product for communication-efficient federated learning. arXiv 2021, arXiv:2108.06098. [Google Scholar]
- Ciaperoni, M.; Gionis, A.; Mannila, H. The Hadamard decomposition problem. Data Min. Knowl. Discov. 2024, 38, 2306–2347. [Google Scholar] [CrossRef]
- Karthika, S.; Rathika, P. An adaptive data compression technique based on optimal thresholding using multi-objective PSO algorithm for power system data. Appl. Soft Comput. 2024, 150, 111028. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disturbance | Code | Disturbance | Code |
|---|---|---|---|
| Sag | Oscillation + Interruption | ||
| Swell | Oscillation + Notch | ||
| Interruption | Sag + Interruption | ||
| Harmonics | Sag + Notch | ||
| Oscillation | Swell + Interruption | ||
| Notch | Swell + Notch | ||
| Harmonics + Sag | Harmonics + Sag + Interruption | ||
| Harmonics + Swell | Oscillation + Sag + Interruption | ||
| Harmonics + Interruption | Sag + Swell + Interruption | ||
| Harmonics + Notch | Harmonics + Sag + Swell + Interruption | ||
| Oscillation + Sag | Oscillation + Sag + Swell + Interruption | ||
| Oscillation + Swell | Harmonics + Oscillation + Sag + Swell |
| PQDs | RE/p.u. | SNR/dB | ||||
|---|---|---|---|---|---|---|
| CR = 0.25 | CR = 0.50 | CR = 0.75 | CR = 0.25 | CR = 0.50 | CR = 0.75 | |
| 0.105 ± 0.054 | 0.061 ± 0.058 | 0.038 ± 0.025 | 32.86 ± 10.46 | 41.80 ± 12.10 | 47.68 ± 8.54 | |
| 0.126±0.054 | 0.086 ± 0.070 | 0.058 ± 0.044 | 30.69 ± 9.81 | 37.72 ± 12.95 | 45.37 ± 11.93 | |
| 0.094 ± 0.063 | 0.052 ± 0.043 | 0.042 ± 0.026 | 35.45 ± 12.07 | 44.50 ± 11.42 | 47.18 ± 8.19 | |
| 0.021 ± 0.009 | 0.018 ± 0.008 | 0.019 ± 0.007 | 44.39 ± 3.59 | 45.95 ± 3.84 | 45.28 ± 3.50 | |
| 0.116 ± 0.055 | 0.082 ± 0.070 | 0.058 ± 0.047 | 31.46 ± 9.42 | 38.22 ± 12.69 | 43.86 ± 11.20 | |
| 0.106 ± 0.061 | 0.061 ± 0.059 | 0.050 ± 0.034 | 32.62 ± 9.17 | 39.23 ± 9.53 | 44.77 ± 8.42 | |
| 0.086 ± 0.056 | 0.050 ± 0.049 | 0.030 ± 0.023 | 34.25 ± 8.12 | 40.16 ± 8.39 | 45.61 ± 5.87 | |
| 0.140 ± 0.040 | 0.103 ± 0.057 | 0.071 ± 0.064 | 27.73 ± 4.03 | 32.54 ± 8.69 | 38.47 ± 11.02 | |
| 0.079 ± 0.054 | 0.060 ± 0.055 | 0.022 ± 0.021 | 34.81 ± 7.64 | 38.36 ± 8.50 | 45.96 ± 5.25 | |
| 0.028 ± 0.013 | 0.022 ± 0.012 | 0.021 ± 0.007 | 41.85 ± 3.77 | 44.08 ± 4.31 | 44.21 ± 3.10 | |
| 0.094 ± 0.063 | 0.065 ± 0.064 | 0.051 ± 0.033 | 35.23 ± 11.42 | 40.51 ± 11.88 | 46.54 ± 9.68 | |
| 0.138 ± 0.033 | 0.111 ± 0.053 | 0.092 ± 0.069 | 27.59 ± 3.33 | 31.98 ± 9.44 | 36.49 ± 12.40 | |
| 0.096 ± 0.062 | 0.050 ± 0.037 | 0.041 ± 0.024 | 34.47 ± 10.63 | 45.41 ± 10.01 | 47.64 ± 7.34 | |
| 0.114 ± 0.055 | 0.080 ± 0.066 | 0.047 ± 0.031 | 31.63 ± 9.40 | 38.03 ± 12.05 | 46.80 ± 9.51 | |
| 0.071 ± 0.056 | 0.043 ± 0.029 | 0.014 ± 0.014 | 38.22 ± 11.50 | 46.70 ± 9.08 | 48.76 ± 4.66 | |
| 0.076 ± 0.058 | 0.052 ± 0.041 | 0.035 ± 0.021 | 27.80 ± 11.78 | 44.08 ± 10.05 | 48.16 ± 7.34 | |
| 0.105 ± 0.066 | 0.073 ± 0.066 | 0.051 ± 0.036 | 34.38 ± 12.08 | 39.58 ± 12.62 | 45.59 ± 9.81 | |
| 0.130 ± 0.046 | 0.103 ± 0.061 | 0.086 ± 0.067 | 29.39 ± 7.53 | 33.77 ± 10.78 | 37.24 ± 12.48 | |
| 0.092 ± 0.045 | 0.068 ± 0.060 | 0.049 ± 0.027 | 31.78 ± 8.93 | 34.36 ± 7.78 | 39.47 ± 8.03 | |
| 0.097 ± 0.036 | 0.078 ± 0.075 | 0.058 ± 0.045 | 29.43 ± 6.98 | 33.01 ± 7.18 | 36.42 ± 10.11 | |
| 0.093 ± 0.056 | 0.062 ± 0.021 | 0.048 ± 0.027 | 33.20 ± 10.85 | 35.74 ± 11.20 | 40.98 ± 9.63 | |
| 0.115 ± 0.089 | 0.092 ± 0.067 | 0.071 ± 0.022 | 30.23 ± 6.59 | 31.81 ± 8.24 | 33.83 ± 8.36 | |
| 0.116 ± 0.080 | 0.096 ± 0.068 | 0.074 ± 0.060 | 29.30 ± 12.08 | 31.71 ± 12.24 | 32.19 ± 10.63 | |
| 0.130 ± 0.072 | 0.101 ± 0.041 | 0.096 ± 0.023 | 26.20 ± 9.69 | 28.93 ± 8.75 | 32.54 ± 10.08 | |
| Literature | Method | CR = 0.25 | CR = 0.50 | CR = 0.75 | |||
|---|---|---|---|---|---|---|---|
| RE/p.u. | SNR/dB | RE/p.u. | SNR/dB | RE/p.u. | SNR/dB | ||
| Ref. [15] | Tensor decomposition | 0.073 | 33.43 | 0.024 | 43.75 | 0.008 | 55.00 |
| Ref. [16] | SVD | 0.062 | 26.13 | 0.013 | 39.95 | 0.004 | 51.36 |
| Ref. [19] | Wavelet spectral quantization | 0.047 | 28.31 | 0.007 | 45.86 | 0.002 | 60.41 |
| Ref. [22] | Huffman coding &Run-length coding | 0.097 | 31.34 | 0.021 | 45.10 | 0.010 | 53.22 |
| Ref. [29] | WT &Particle Swarm Optimisation | 0.099 | 28.22 | 0.026 | 40.01 | 0.011 | 56.89 |
| Proposed scheme | Hadamard decomposition | 0.023 | 34.37 | 0.005 | 49.21 | 0.003 | 68.24 |
| Sampling Frequency | Data Granularity | CR = 0.25 (RE/SNR) | CR = 0.50 (RE/SNR) | CR = 0.75 (RE/SNR) |
|---|---|---|---|---|
| 0.8 kHz | 32 × 32 | 0.090 ± 0.047/39.52 ± 7.33 | 0.052 ± 0.035/43.20 ± 8.26 | 0.027 ± 0.021/48.99 ± 7.73 |
| 3.2 kHz | 64 × 64 | 0.095 ± 0.054/34.63 ± 9.75 | 0.062 ± 0.038/41.85 ± 9.53 | 0.039 ± 0.030/47.70 ± 8.51 |
| 12.8 kHz | 128 × 128 | 0.099 ± 0.053/32.71 ± 8.79 | 0.070 ± 0.051/38.26 ± 9.75 | 0.051 ± 0.033/42.54 ± 8.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Z.; Ji, T.; Li, M. Improved Hadamard Decomposition and Its Application in Data Compression in New-Type Power Systems. Mathematics 2025, 13, 671. https://doi.org/10.3390/math13040671
Ding Z, Ji T, Li M. Improved Hadamard Decomposition and Its Application in Data Compression in New-Type Power Systems. Mathematics. 2025; 13(4):671. https://doi.org/10.3390/math13040671
Chicago/Turabian StyleDing, Zhi, Tianyao Ji, and Mengshi Li. 2025. "Improved Hadamard Decomposition and Its Application in Data Compression in New-Type Power Systems" Mathematics 13, no. 4: 671. https://doi.org/10.3390/math13040671
APA StyleDing, Z., Ji, T., & Li, M. (2025). Improved Hadamard Decomposition and Its Application in Data Compression in New-Type Power Systems. Mathematics, 13(4), 671. https://doi.org/10.3390/math13040671