1. Introduction
With the advanced development of computer and internet technologies, computerized adaptive testing (CAT) and multistage adaptive testing (MST) have been widely applied across multiple fields, such as psychometrics, educational measurement, and medical assessments [
1,
2,
3,
4,
5]. CAT adapts at the item level, meaning that it selects each test item based on an examinee’s current estimated ability level during the test [
6]. Compared with conventional paper-and-pencil tests, CAT provides more precise ability estimation using fewer items and offers high measurement precision for examinees at the two polar ends of the ability scale [
7]. The widely-used CAT has several limitations, including the inability for examinees to review or revise their responses, and the risk that the abilities of certain examinees might be underestimated [
8,
9]. MST, which can implement modular test assembly, was developed decades ago [
10,
11]. MST consists of multiple parallel panels. Each panel contains several stages, each with modules of different difficulty levels. After completing a stage, the examinee is routed to the module of the next stage most suitable to the ability level [
11,
12,
13]. Furthermore, within a stage, examinees have the opportunity to review and change their answers, which can alleviate their psychological stress [
14,
15]. The panels of MST are assembled via the automated test assembly (ATA) algorithm, which can control the nonstatistical constraints, including content specifications and enemy items, thereby assisting test developers in administering the test more effectively [
16]. However, from the perspective of test security, the modules in MST are bundled into panels, which means that examinees taking the same path in the same panel receive exactly the same items, increasing the risk of item exposure [
17]. Moreover, compared with CAT, the test length in MST is typically longer when the same level of ability estimation accuracy is achieved [
7].
To address these problems with unidimensional MST approaches, Zheng and Chang (2015) pioneered on-the-fly assembled multistage adaptive testing (OMST) to improve adaptive design. This innovative approach integrates the strengths of CAT and MST while effectively addressing their limitations. In CAT, if a low-ability examinee guesses the answers to the first few items correctly, it may be difficult for the ability estimate to quickly return to the true value. OMST does not estimate the ability of examinees until each stage is completed and allows examinees to review and change their answers within each stage. This design mitigates the overestimation or underestimation of examinees’ abilities, alleviates the psychological stress they may experience during the test, and has advantages in large-scale assessments. For large-scale MST, test assembly is a complex task, and artificial review of all the assembled test forms is relatively expensive and cumbersome [
17]. In contrast, the on-the-fly assembly of modules in OMST is more straightforward and can be easily achieved via computer algorithms. These dynamically assembled modules provide more information for each examinee and better measure examinees at the two polar ends of the ability scale. Additionally, it avoids the problem of item exposure caused by modules bundled in panels. Furthermore, OMST can adjust the length of each stage to meet the specific requirements of different tests, thereby enhancing the flexibility of the assessment [
11].
Unidimensional item response theory (UIRT) is one of the core methodologies for several large-scale assessment programs globally. Examples of UIRT applications include the Organization for Economic Cooperation and Development (OECD) Program for International Student Assessment (PISA), the National Institutes of Health’s Patient Reported Outcomes Measurement Information System (PROMIS) initiative, and China’s new National Assessment of Basic Education Quality [
18]. Most current MST and OMST studies rely on UIRT. However, UIRT is limited to a single dimension. In practice, many conceptual constructs in the social and behavioral sciences have multidimensional structures [
19]. For example, the Armed Services Vocational Aptitude Battery (ASVAB) assesses examinees in four domains: arithmetic reasoning, word knowledge, paragraph comprehension, and math knowledge [
20]. The Multiple Sclerosis International Quality of Life Questionnaire (MusiQoL) measures ten dimensions of patients’ lives [
21]. The Resilience Measurement Scale (RESI-M) assesses Social Support, Family Support, and three other dimensions among family caregivers of children with cancer [
22]. The validity of the test may be questioned if the latent trait structure does not align with the assumption of the model. Given the multidimensional complexity of conceptual constructs, it is necessary to use models that can effectively accommodate multidimensionality. To measure multidimensional latent traits more accurately, multidimensional item response theory (MIRT) has been proposed (e.g., Reckase (2009)) [
23]. Compared with UIRT, MIRT can comprehensively reflect examinees’ multiple abilities [
24]. Based on MIRT, many researchers have subsequently conducted extensive studies on multidimensional computerized adaptive testing (MCAT), including item selection strategies and stopping rules [
20,
25]. With respect to the multidimensional study of MST, the MST for multidimensional assessment (M-MST) proposed by Xu et al. (2022) is a newly published approach with further research value [
26]. Although OMST performs well in unidimensional measurements, its applicability in multidimensional measurements remains to be fully validated.
Based on MIRT, this study proposes a multidimensional on-the-fly assembled multistage adaptive testing (OMST-M) approach, and two alternative on-the-fly automated test assembly algorithms based on ability point estimation and the ability confidence ellipsoid, respectively. The OMST-M approach inherits the advantages of unidimensional OMST, assembling modules on the fly based on examinees’ abilities. It measures the examinee’s abilities comprehensively and provides high measurement precision. OMST-M can conveniently control the quality and security of tests using on-the-fly automated test assembly algorithms and reduce the psychological stress experienced by examinees during the test process. In fields such as language ability measurement, Science, Technology, Engineering, and Mathematics (STEM) learning ability assessment, and professional skills measurement in human resource management, the authenticity and contextualization of test items have become a trend. The modular design of materials combined with multiple items is increasingly common in tests. Items with informative content more effectively measure examinees’ latent traits, but they present challenges for test administration. The flexibility of OMST-M supports modular design, meets complex testing needs, and offers valuable options for researchers and test developers. The two on-the-fly automated test assembly algorithms proposed in this study provide new ideas for multidimensional test assembly.
The subsequent sections of this paper are organized as follows. The second section introduces the framework and process of the OMST-M approach, detailing the on-the-fly automated test assembly algorithms for the OMST-M approach and aspects of test design. The third and fourth sections investigate the performance of the proposed approach in terms of ability estimation accuracy and item exposure control via simulation and empirical research. The fifth section summarizes the performance of the OMST-M approach, as demonstrated through simulations and empirical research, discussing its merits, recommendations for use, and future development prospects.
3. Simulation
To investigate the performance of the OMST-M approach, the following three simulation studies were carried out with different test designs. The simulation programs were written in R (version 4.3.1), primarily utilizing the mirt and mirtCAT packages [
34,
35].
3.1. General Specifications
The true abilities of a sample of 1000 examinees were simulated from the multivariate normal distribution . The item pool consisted of 1500 items based on the M2PLM. The item discrimination parameters were drawn from , and the item difficulty parameters were drawn from . The examinees’ abilities were estimated via the EAP. For each condition in the study, 50 replications were conducted. The examinees’ abilities in each dimension were divided into five groups according to four points: −1.39, −0.47, 0.28, and 1.18. In the OATA algorithm with an ability confidence ellipsoid, the quantile of the F-distribution affects the size of the confidence ellipsoid, which can affect module assembly. Before the simulation, a pilot study was conducted to investigate the selection of different quantiles of the F-distribution. In the pilot study, the design and sample size of the test were consistent with the simulation study, and 5 replications were conducted. The results indicate that the accuracy of the test is greater when the quantile of the F-distribution decreases with increasing number of stages, meaning that the confidence level decreases as the test progresses. Curve fitting was conducted for the quantiles of the F-distribution settings that performed better in the pilot study, and the fit was better when the S-curve and the power function were used. Note that the functions listed below are mere examples, and in practical applications, the parameter values are certainly not restricted to those specified here. In the simulation, the fitting function of the quantiles of the F-distribution with different settings is as follows. For the two-dimensional latent traits, the quantile of the tth stage, was assigned in the short test, and or were assigned in the long test. For the four-dimensional or higher latent traits, was assigned in the short test, and or were assigned in the long test, where . The number of parallel forms for the module in the first stage was set to 10, and the size of the item set for the randomly selected strategy was 20. The values of Q were 13 and 3 in the two-dimensional and four-dimensional tests, respectively.
3.2. Evaluation Criteria
Ability Estimation Accuracy. The absolute mean error (
AME), root mean square error (
RMSE), and mean value of the correlation among the estimated abilities and the true abilities in each dimension (
CORmean) are used to evaluate the ability estimation accuracy of the examinees. The calculation equations are shown in Equations (22)–(24):
where
N is the number of examinees,
K is the number of ability dimensions, and
is the correlation coefficient between the estimated and true values of the abilities on the
kth dimension.
Item Exposure Indices. The maximum item exposure rate (
ERmax), Chi-square statistic of item exposure (
) [
36], and test overlap rate (
TOR) [
25,
37] are calculated by the following equations to evaluate the item exposure control:
where
denotes the exposure rate of the
jth item, and
is the number of times the
jth item has been used.
, which is the expected exposure rate of the
jth item. Additionally,
L represents the test length, and
J is the number of items in the item pool.
3.3. Study 1
The objective of Study 1 was to validate the effectiveness of the OMST-M approach and two OATA algorithms across various test settings. In Study 1, the following conditions were considered: (i) dimensionality: two-dimensional and four-dimensional; (ii) test length: a short test comprising four stages, each with six items, and a long test comprising nine stages, each with five items; (iii) correlations among abilities: with correlation coefficients of 0, 0.3, 0.6, and 0.8; (iv) the FIM transformation method: uses Bayesian D-optimality and Bayesian A-optimality; and (v) OATA algorithms: APE is used for simplicity to represent ability point estimation, whereas ACE represents the ability confidence ellipsoid.
The item pool setting was designed similarly to the approaches used in the studies by Tu et al. (2018) and Xu et al. (2022) [
25,
26]. Specifically, the items belonged to two content categories, and four items were enemy items. In each simulation, four items were randomly designated enemy items, and 1500 samples were randomly drawn, each being assigned a value of either 1 or 2, representing different content categories for the items. In the two-dimensional test, the items had three item-trait patterns (including assessing the first dimension, assessing the second dimension, and assessing both dimensions) and 500 items in each pattern. In the four-dimensional test, the items had fifteen item-trait patterns (including assessing one dimension, assessing two dimensions, assessing three dimensions, and assessing all four dimensions), each containing 100 items. The prior covariance matrix for abilities was assumed to be the identity matrix. The nonstatistical constraints were set in the OMST-M module. In the initial stage of the test, there was at least one item measuring each dimension. Only one enemy item was allowed within the same module, and up to three items measuring each content category were permitted.
Table 1 shows the results of the
RMSE and
AME for the two OATA algorithms under different test settings in Study 1, where APE and ACE represent OATA algorithms based on ability point estimation and ability confidence ellipsoid, respectively, BD and BA represent FIM transformation methods using Bayesian D-optimality and Bayesian A-optimality, respectively, P and S represent fitting the quantiles of the
F-distribution via the power function and the S-curve, respectively.
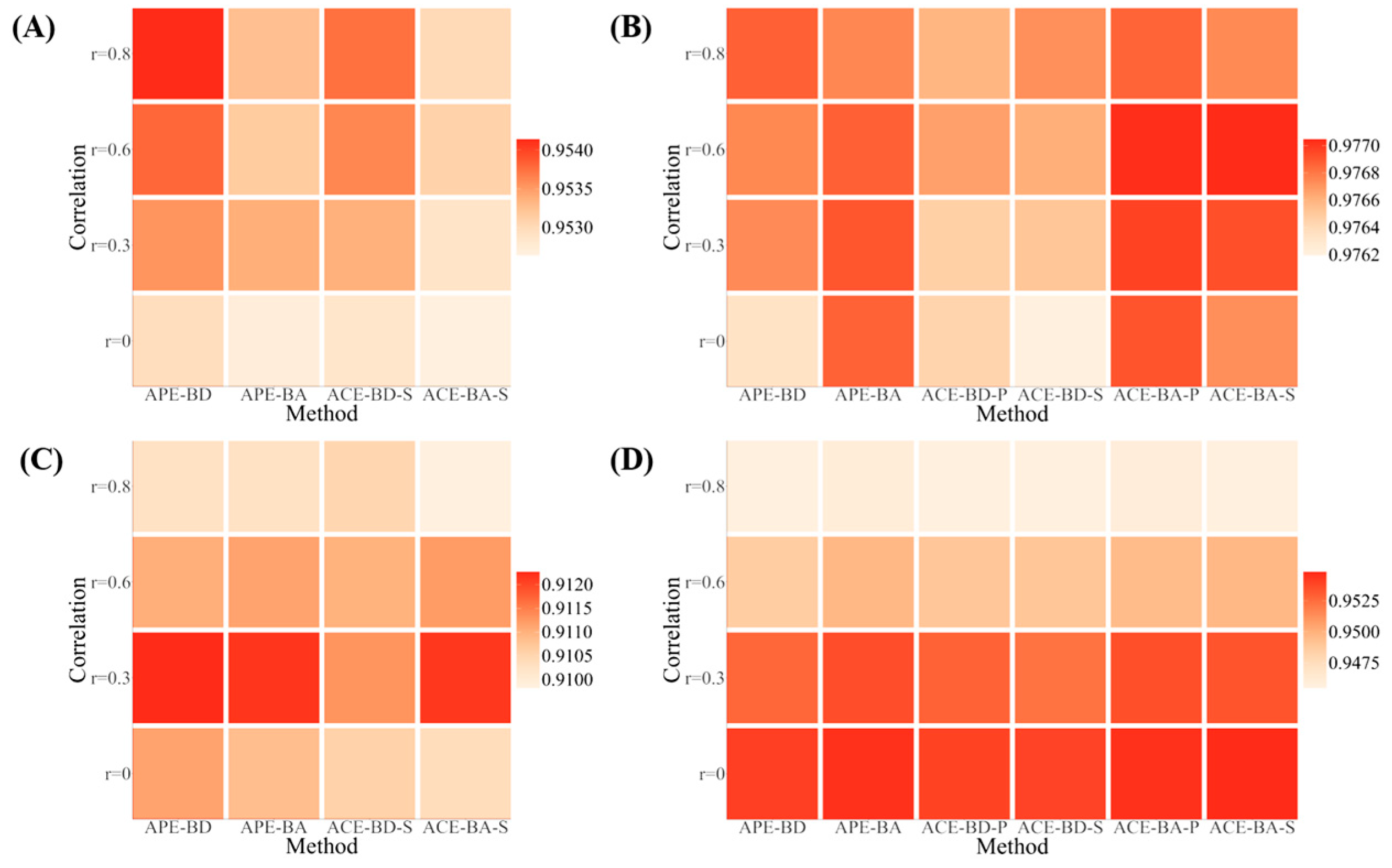
Figure 2 shows the heatmap of the
CORmean values. The results indicated that the two OATA algorithms exhibited high estimation accuracy across all the settings. The ability estimation accuracy improved when the number of test dimensions was reduced or the test length was extended. In most cases, Bayesian D-optimality was more advantageous for the short tests, whereas Bayesian A-optimality performed better for the long tests. The differences in ability estimation accuracy were minimal under different correlation levels. This finding suggested that the ability correlation level had little effect on the ability estimation accuracy of the OMST-M approach. Compared with the two OATA algorithms, the algorithm based on the ACE had slightly higher ability estimation accuracy in most test settings of the long test, whereas the algorithm based on APE had better performance in the short test.
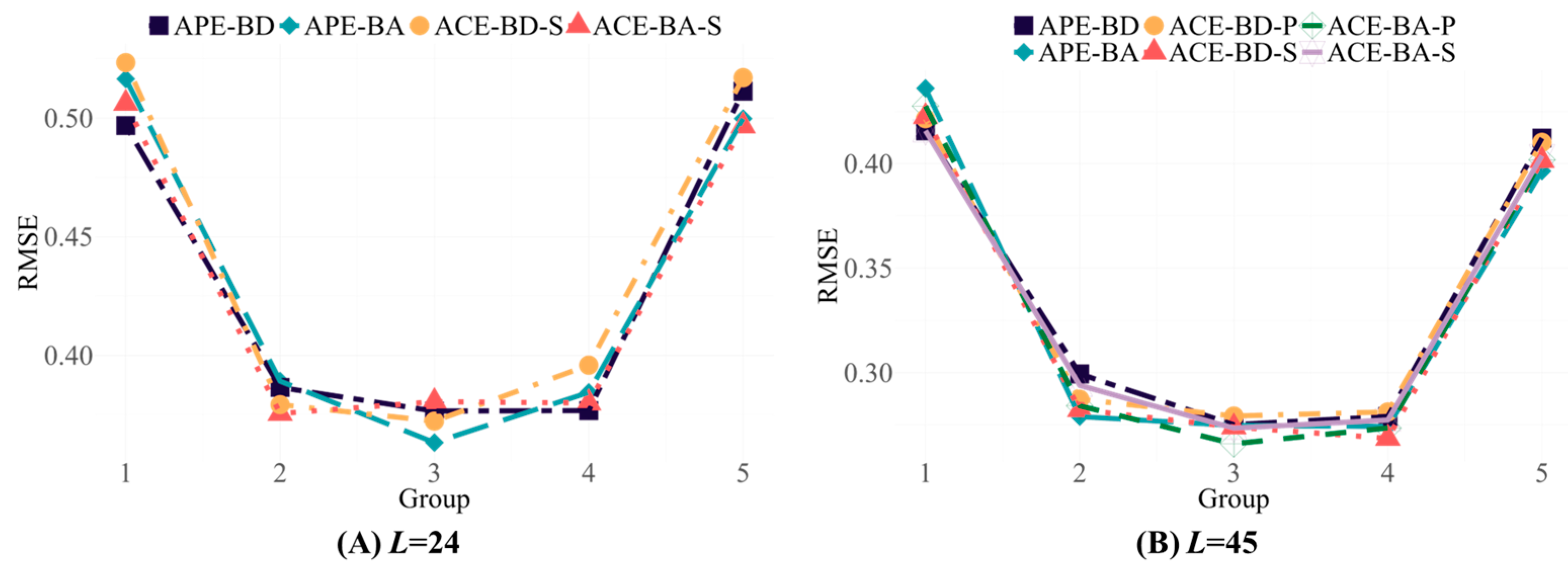
Given the similar results across the different test settings, we chose the four-dimensional test with
r = 0.6 to explore the performance of OMST-M in more detail. Examinees’ abilities were grouped by each dimension, with Group 1 to Group 5 representing progressively higher levels of ability. The
RMSEs for each dimension within each group were calculated, and then the average
RMSEs across all the dimensions in each group were taken.
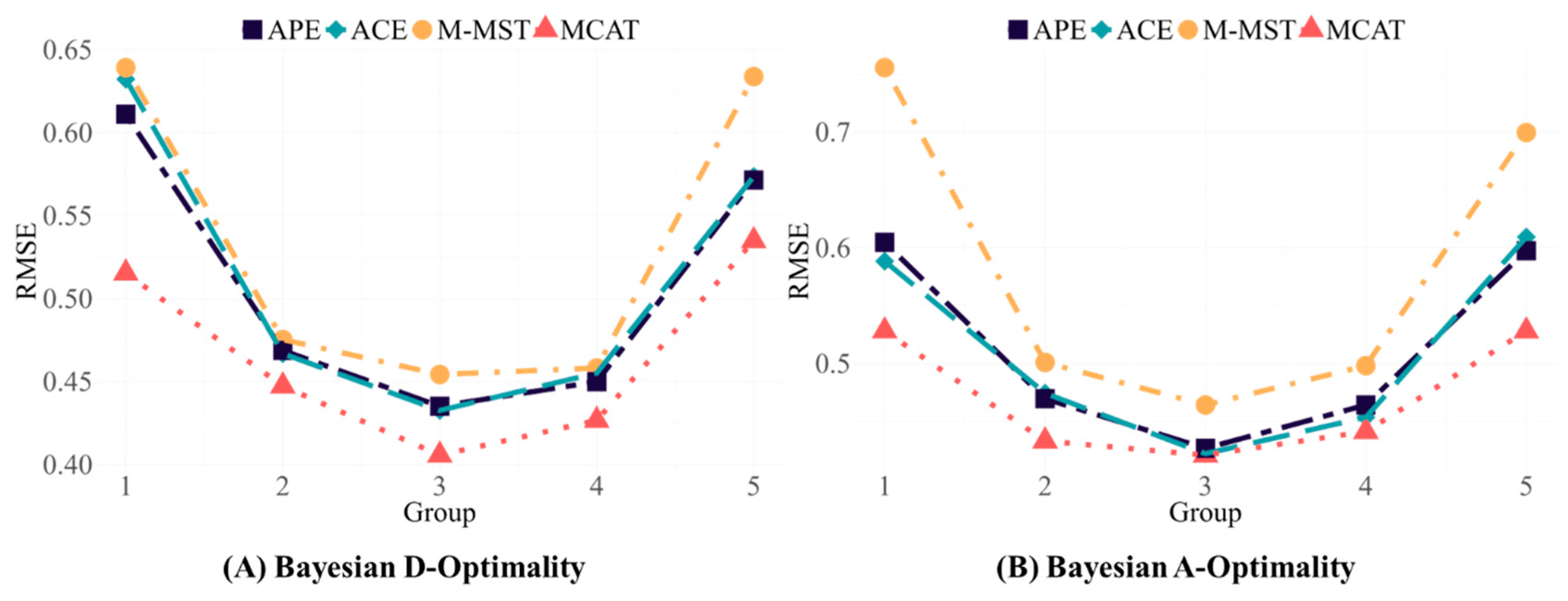
Figure 3 shows the performance of the two OATA algorithms for the examinees with different ability levels, where the X-axis represents five groups of examinees with different ability levels. When the algorithms based on APE and the ACE were employed, the
RMSEs for the medium-ability group were consistently lower than those for the low- and high-ability groups.
Table 2,
Table 3 and
Table 4 present the performance in item exposure control under different test settings. The item exposure control improved when the number of test dimensions was expanded, and it slightly decreased when the test length was extended. The correlation among abilities affected item exposure control: higher correlation levels led to more effective item exposure control. In most cases, when Bayesian A-optimality was used, the
ERmax,
, and
TOR values were lower, indicating better item exposure control. However, Bayesian D-optimality had lower values of
and
TOR at high ability correlation levels (
r = 0.6,
r = 0.8) in the two-dimensional long tests. Under different test settings, the two OATA algorithms made little difference in terms of item exposure control.
3.4. Study 2
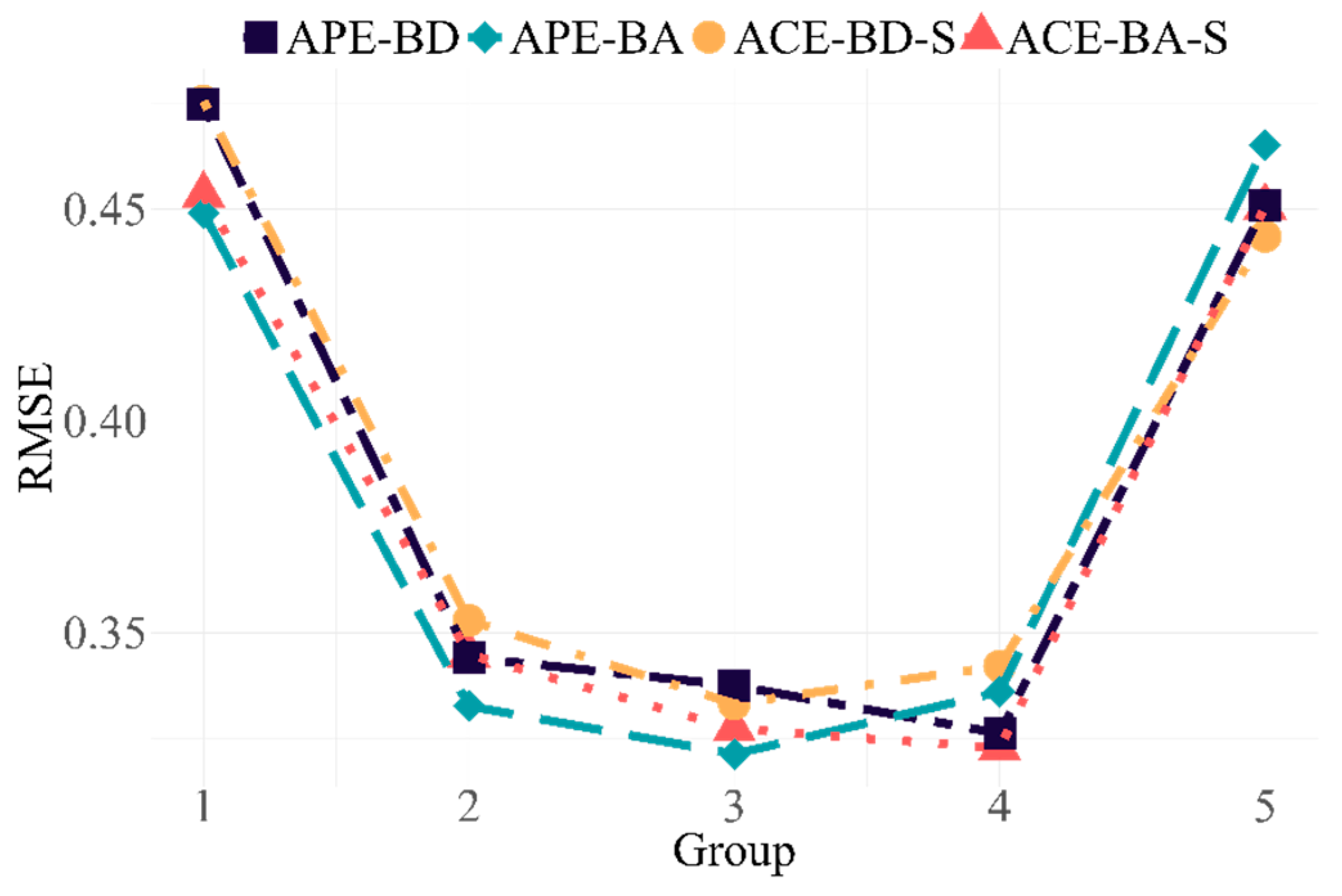
In practice, module lengths may need to be flexibly adjusted to match specific evaluation objectives. To investigate the flexibility of OMST-M in adjusting the module lengths in the test, Study 2 was conducted on the basis of Study 1. In Study 2, the number of ability dimensions was four, and the correlation level was r = 0.6. The content and enemy item settings were identical to those in Study 1, featuring two content categories and four enemy items. The test consisted of 30 items arranged in six stages. The first stage had 5 items, and the next five stages had 3, 4, 5, 6, and 7 items. Each stage requires at least one item from each content category, and enemy items should not be in the same module.
The results of Study 2 are presented in
Table 5. The OMST-M approach had good measurement performance in the test with a nonfixed stage length. The ability estimation accuracy of the two OATA algorithms was comparable, with minimal differences observed. The Bayesian A-optimality outperformed the Bayesian D-optimality in terms of ability estimation accuracy and item exposure control, and it was consistent with the result observed during the four-dimensional long test in Study 1.
Figure 4 shows the performance of the two OATA algorithms for examinees with different ability levels in this study. The results were consistent with those of Study 1. The two algorithms had higher ability estimation accuracy for examinees with medium-ability levels.
Study 2 demonstrated one advantage of OMST-M over M-MST. M-MST using the NWADH-A or NWADH-D algorithm needs to compute the TIFs for modules with different difficulties before assembling tests, and the value of the TIF is related to the difficulty and module length. Therefore, owing to the varying module lengths at each stage, a large number of TIFs needs to be computed. Furthermore, since the modules in M-MST are preassembled, the length cannot be adjusted once the test starts. The OMST-M approach effectively solves that problem. The dynamically assembled modules match the ability levels of the examinees and permit flexible adjustment of the module length without extra computations.
3.5. Study 3
Some vocational aptitude tests and educational assessments have strict requirements for test content. For example, in the ASVAB, each examinee must complete four categories of content: arithmetic reasoning, word knowledge, paragraph comprehension, and math knowledge [
20,
38]. When administering such tests, it is important to adjust the content of each stage in accordance with specific test goals. Study 3 aimed to further demonstrate the flexibility of the OMST-M approach: it permitted adjustments to the test content on the basis of the developer’s requirements, thereby satisfying the needs of assessments in various fields.
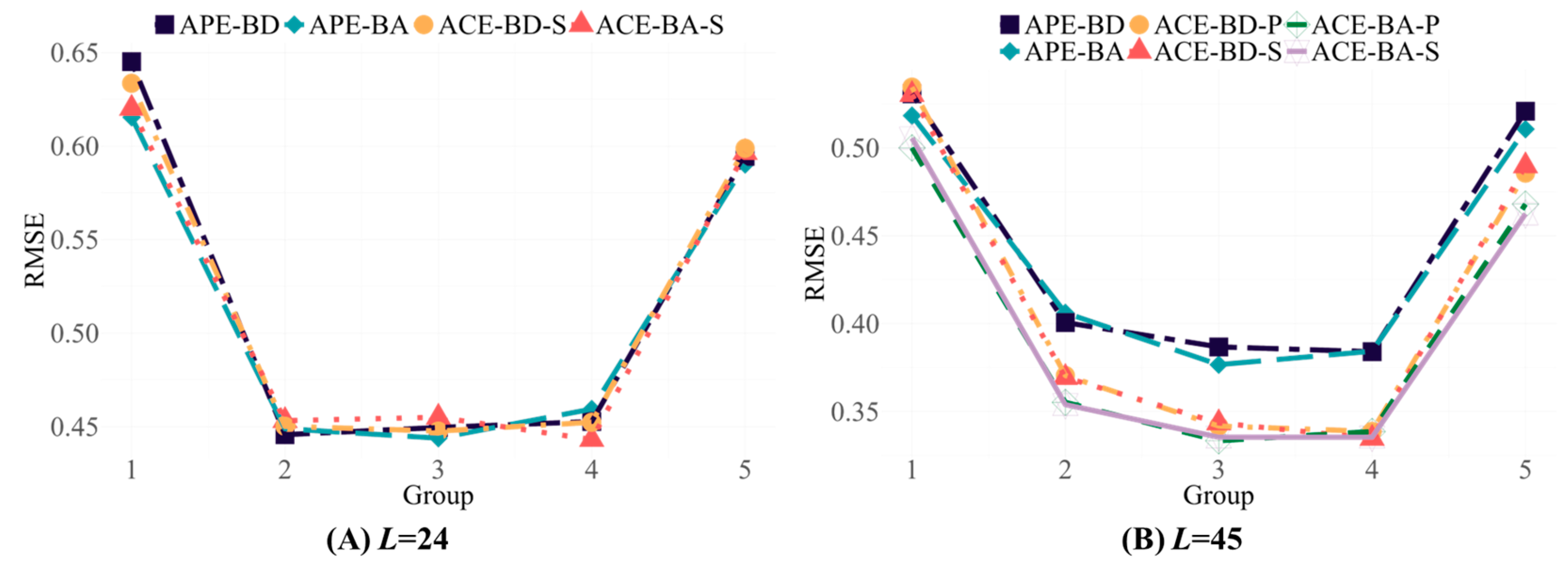
The typical test design in Study 1 was selected for Study 3. The test lengths were 24 items for the short one and 45 items for the long one. The short test consisted of four stages, whereas the long test had nine stages. The number of ability dimensions was four, and the correlation among these abilities was r = 0.6. The parameter settings of the items were the same as those in Study 1, whereas the settings of the content and the enemy items were different. In Study 3, the 1500 items in the item pool were divided into nine content categories, with 300 items in Content 1 and 150 items in each of the other contents. Additionally, two items in each content category were designated enemy items.
In Study 3, each stage included different content categories. In the two tests with different lengths, the first stage of the test used items from Content 1; in the short test, three categories of content were randomly assigned from the remaining eight categories, and items from these three categories were used sequentially in subsequent stages; in the long test, items from Content 2 through Content 8 were used sequentially in subsequent stages.
The performance of the OMST-M approach in terms of ability estimation accuracy and item exposure control under the test design of Study 3 is shown in
Table 6. The results showed that the two OATA algorithms performed well in the new test design, indicating that the OMST-M approach effectively meets the requirements for content adjustments in tests. Specifically, the variation in ability estimation accuracy with test length was consistent with the results of Study 1, where the longer the test length was, the higher the ability estimation accuracy. Among the two FIM transformation methods, Bayesian A-optimality achieved higher ability estimation accuracy in different length tests. To further investigate the performance differences between the two OATA algorithms, the ability estimation accuracy was compared under the Study 3 design. The ability estimation accuracy of the algorithm based on the ACE was higher, especially in long tests. Unlike those in Study 1, the lengths of the tests extended, whereas the values of
ERmax,
and
TOR decreased. The possible reason for this result was that only items in three content categories were used in the short test, resulting in an imbalance in the use of items in the item pool and slightly larger values for the three indices of the item exposure control.
Figure 5 illustrates the ability estimation accuracy of the two OATA algorithms across examinees with different ability levels in Study 3. The results indicated that the two algorithms in the OMST-M approach still had higher ability estimation accuracy for the mid-ability examinees, and the algorithm based on the ACE had slightly higher ability estimation accuracy for all ability level groups under the long test than did the algorithm based on APE.
5. Conclusions and Discussion
This study proposes multidimensional on-the-fly assembled multistage adaptive testing based on the M2PLM (OMST-M). The novel testing approach overcomes some challenges faced by previous approaches to address the complexities of test designs in multidimensional assessments. The core innovation of OMST-M lies in its integration of the strengths of CAT and MST, fortified by the benefits of MIRT. Two OATA algorithms are proposed for OMST-M, which enable on-the-fly adaptation on the basis of the examinees’ abilities and test requirements, ensuring that the test is both efficient and accurate in measuring the examinees’ abilities. The adaptability and versatility of the OMST-M approach, coupled with the precision of the OATA algorithms based on APE and the ACE, ensure its broad utility in various test settings. The OMST-M enables flexible, modular design frameworks, effectively addressing the growing demand for contextually-grounded test items in adaptive testing systems. This research provides educators, psychologists, and researchers with a new tool for comprehensive and accurate ability measurement.
The findings from both the simulation and the empirical research are summarized as follows. Firstly, the OMST-M approach and the two OATA algorithms exhibited high ability estimation accuracy. Specifically, in the four-dimensional test of Study 1, the RMSEs ranged from 0.41 to 0.42 in the short test and from 0.29 to 0.33 in the long test. Secondly, the OMST-M approach had a good performance in item exposure control. In the four-dimensional long test of Study 1, the maximum item exposure rate was less than 0.5, and the TOR values were less than 0.15, indicating that the item pool stratification and the randomly selected strategy in the set of items with the highest or values could effectively control item exposure to ensure test security. Thirdly, the results of the empirical research showed that for groups of examinees with different ability levels, the OMST-M approach had higher ability estimation accuracy than the M-MST did, and the OMST-M approach outperformed the MCAT by a small margin on the Resilience Measurement Scale (RESI-M). Compared with M-MST and MCAT, OMST-M also has a unique advantage in test administration and flexibility, and can well support a variety of complex test designs. Fourthly, from the test design and performance of Studies 2 and 3, it can be concluded that the OMST-M approach can flexibly adjust the content and length of each stage to meet diverse testing needs and has relatively high application value.
Suggestions for the application of the OMST-M approach include the following. Firstly, using Bayesian A-optimality in long tests (e.g., the test with 45 items in Study 1) and Bayesian D-optimality in short tests (e.g., the test with 24 items in Study 1). The results of the Empirical Research further validate this suggestion. In the studies based on Data 1 and Data 2, where the test lengths are both 15 items, the ability estimation accuracy is higher for the tests using Bayesian D-optimality. Whereas in the studies based on Data 3 and Data 4, where the test lengths are 30 and 33 items, the ability estimation accuracy is higher in most cases for tests using Bayesian A-optimality. The results of Study 1 indicated that the OATA algorithms using Bayesian A-optimality demonstrated superior estimation accuracy and better item exposure control in the long test. Secondly, Study 1 revealed that when the OATA algorithm based on the ACE was used, different quantiles of the F-distribution settings significantly affected the measurement precision of the test. Choosing appropriate quantile settings can improve the effectiveness of the OATA algorithm based on the ACE, leading to improved measurement accuracy. The current study used power functions and S-curves to fit the quantiles through pilot study attempts, which performed better. The suggested principle for setting is that the quantile of the F-distribution decreases as the stage progresses. If there is a desire to explore whether the measurement precision using the OATA algorithm based on the ACE can continue to be improved, other functions can be tried, or a specialized systematic study can be conducted in the future. Thirdly, by analyzing the results of the tests with different numbers of stages in Studies 1 and 3, it is suggested that the OATA algorithm based on the ACE be used in tests with a relatively high number of stages (e.g., the long test consisting of nine stages in Study 1). When the algorithm based on the ACE is used, the setting of quantiles that decrease with the progress of the stage has high measurement precision. The setting of the quantile above gradually decreases the range of the confidence ellipse to approach the true ability value. Therefore, in the test with more stages, the confidence ellipse will shrink to the range closer to the true ability value, which makes the items in the on-the-fly assembly modules more closely match the examinee’s ability level and improves the ability estimation accuracy. Fourthly, in practical applications, the length and nonstatistical constraints of each stage in the test need to be designed in conjunction with the structure of the latent trait (e.g., the number of latent trait dimensions and the item-trait patterns) and the content characteristics of the test, an example of which is the schizophrenia quality of life questionnaire in the empirical research. The item-trait pattern in that test is between-item multidimensional. The test length of the first stage should not be less than the number of latent trait dimensions, and each dimension should be measured by at least one item so that the first stage can provide a comprehensive initial measurement of the examinees’ latent traits. Finally, Equation (18) shows that when the OATA algorithm based on the ACE is used, the number of completed items needs to be greater than the number of dimensions of the latent trait; otherwise, the confidence ellipsoid for ability estimation cannot be calculated. In the initial stages of some tests, when the number of completed items does not meet the requirements, the OATA algorithms based on APE and the ACE can be flexibly combined; specifically, the algorithm based on APE is used when the number of completed items does not exceed the number of dimensions, and the algorithm based on the ACE is used when the number of completed items satisfies Equation (18).
This paper has demonstrated the strengths of the OMST-M approach through three simulation studies. Study 1 revealed that the OMST-M approach had high ability estimation accuracy and good item exposure control across multiple test settings (numbers of dimensionalities, correlations among abilities, and test lengths), indicating good generalizability. In Study 2, the length of each stage in the test was not a fixed value, demonstrating the flexibility of the OMST-M approach. Study 3 further explores the adaptability of OMST-M, with the module of each stage measuring different contents. The OMST-M approach effectively implements the content control of test and modular design, both of which are consistent with the needs of practical applications, for instance, in examining students’ learning of different units of knowledge and examining different aspects of job candidates’ abilities. M-MST can also implement the above two test designs, but a large number of modules needs to be preassembled before the test starts. M-MST using modified NWADH algorithms requires calculating TIFs for modules of different lengths, contents, and difficulties, which significantly increases the complexity and workload of the test administration. In contrast, the OMST-M approach can flexibly adjust the test content and stage lengths during the test process via the proposed OATA algorithms without many additional computations. M-MST is a valuable modular test design approach for assessing multiple latent traits. On the basis of its inspiration, the OMST-M approach developed in this paper can provide more flexibility in test assembly than can M-MST to some extent.
In summary, the OMST-M approach meets the needs of multidimensional assessment by providing comprehensive information on multiple latent traits and offering high measurement precision of examinees’ abilities. The OMST-M approach inherits the advantages of M-MST, flexibly addressing various nonstatistical constraints (e.g., enemy items do not appear within the same stage, maximum number of items per content category) via the OATA algorithms to control test content and quality. Additionally, the OMST-M approach can effectively control item exposure, enhancing test security. In the OMST-M approach, examinees can freely review and change their answers within each stage, reducing psychological stress. In addition to its ability to effectively administer tests, the design of OMST-M further enhances testing efficiency and accuracy by dynamically assembling modules on the basis of examinees’ ability levels. The design of OMST-M allows test organizers to flexibly adjust test difficulty, length, and content during the testing process and assemble modules related to specific complex tasks, making it adaptable to complex testing scenarios and meeting the needs of multiple fields, such as educational measurement and psychometrics.
In large-scale international assessments such as the Programme for the International Assessment of Adult Competencies and PISA, relying on the same test setting (e.g., examinees with different native languages use the same item pool) is impractical because of differences between country and intra-country groups [
41]. To address these challenges, the OMST-M approach provides flexibility in adjusting the lengths, content, and sub-pools used for the assembly of modules, as demonstrated in Studies 2 and 3. In practical applications, OMST-M addresses the challenge of adjusting module difficulty for diverse examinee groups by assembling modules on the fly on the basis of individual ability levels. These on-the-fly assembled modules make the OMST-M approach less impacted by variations in examinee groups, significantly reducing the complexity and workload of test administration. This flexibility of the OMST-M approach is particularly beneficial in educational and vocational assessments, where the ability to tailor tests to examinees is crucial. For example, in a reading ability test, an item pool consisting of items with different contents and difficulties can be constructed in advance for a given passage of text. During the test, modules based on the text can be assembled on the fly according to the examinees’ ability levels. In the STEM learning ability measurement, the item pool consists of several sub-pools, each of which includes a passage of textual material of the new knowledge content and several related items, which are aimed at examining the examinee’s mastery of the new knowledge. During the test, a passage of textual material is provided to the examinee at each stage, and the module for that stage is assembled in the sub-pool corresponding to the material. The more correct answers an examinee provides, the greater his mastery of new knowledge and learning ability.
In addition, an important direction for future applications of the OMST-M approach is digital teaching. The rapid progress of information technology has facilitated knowledge acquisition. With the popularization of diverse electronic devices, individuals can easily access online learning platforms, resulting in profound changes in teaching methods. Digital teaching enhances the flexibility and accessibility of education by allowing learning to occur beyond traditional classroom boundaries, breaking the temporal and spatial constraints of educational resources [
42]. However, one potential challenge faced by the mode of education is the difficulty for educators in capturing the immediate feedback of each learner intuitively. This presents challenges for educators in quickly adjusting the depth and breadth of teaching content and customizing individualized instructional strategies on the basis of students’ learning progress, comprehension ability, and interest preferences. The OMST-M approach effectively addresses this critical challenge in digital teaching. Educators can use the OMST-M approach to develop tests adaptable to different types of teaching content, accurately understand each student’s knowledge mastery in a timely manner, and carry out more targeted teaching. Students can use tests to measure their abilities at any time and clarify their learning directions [
18]. In the future, with the further development of the current OMST-M and the updating approach of its item pool, the proposed approach may play a more significant role in multidimensional assessments.
This current study can be strengthened in the following aspects. Firstly, it should be noted that the study presented the performance under multiple basic designs of the OMST-M approach, which can be varied in several aspects. In order to more fully utilize the strengths of the various adaptive tests, future study may also be carried out to combine the OMST-M approach with MCAT appropriately. A possible reasonable design is to shrink the length of each stage successively to achieve a smooth transition from the OMST-M approach to MCAT, similarly to the research of Wang et al. (2016), in which this was named HCAT [
11]. Secondly, note that the item selection and test termination strategies may have potential overfitting risks. For instance, the problem was discussed for MCAT by Segall (1996) [
9]. The risks may stem directly from the inherent limitations of item selection strategies, as well as potentially from several design aspects in the adaptive testing framework. In practical application, the following measures can help reduce the risks for the OMST-M approach to a certain extent: ensuring a sufficiently large item pool and diverse items; appropriate exposure control strategies to limit item reuse; the more precise control over test length based on practical specific measurement objectives; reasonable setting of the prior distribution for Bayesian item-selection indices. Note that for the prior distribution, the studies in this paper adopted an identity matrix as the prior covariance matrix. If more reliable information can be obtained, the prior distribution can be adjusted accordingly. For instance, practical test administration may consider analyzing the previous information or preliminary measuring before large-scale assessments. Thirdly, the proposed algorithms used Bayesian A-optimality or Bayesian D-optimality for FIM transformation, and other possible alternative FIM transformation methods in the OMST-M can be further explored [
26]. As the reviewers’ suggestions, the hybrid use of the above two indices in tests, such as setting Bayesian D-optimality for the first stage and later changing to Bayesian A-optimality, is also a direction worth exploring, and detailed evaluations of how the algorithms adapt and perform across different stages of the test could be explored in the future. Fourthly, the proposed two test assembly algorithms based on APE and the ACE can be further modified. The current test assembly algorithm based on the ACE utilized the information at the five nodes on the longest axis of the confidence ellipsoid. One suggestion for improving the test assembly algorithms based on the ACE worth considering is to use the integral of the information function over the confidence ellipsoid to assemble the modules [
11]. The quantile of the
F-distribution setting significantly impacts the final result of the test assembly algorithms based on the ACE. Therefore, exploring appropriate quantile settings represents a critical research direction. Fifthly, the OATA algorithm proposed for the OMST-M approach is heuristic, so future research could explore mathematical programming approaches in the OMST-M module assembly [
17]. Sixthly, the item pool serves as the foundation of an adaptive test, making regular updating essential for maintaining test accuracy and reliability. Consequently, exploring how to appropriately replenish items within the framework of OMST-M is important for sustaining the test system in long-term operation. It is a noticeable problem that the number of ability quadrature vectors in NWADH-BD and NWADH-BA increases rapidly with the increase of the number of dimensions of the test. The use of random multivariate samples could be considered to address this problem in high-dimensional tests in future research. Additionally, since some tests involve polytomous-scored items, extending OMST-M to be constructed based on MIRT models such as the MGRM and the multidimensional generalized partial credit model could further promote its application [
43,
44]. At the same time, extending OMST-M to cognitive diagnosis situations could be considered [
45]. Furthermore, simulation and empirical research were conducted for examinees with a normal ability distribution. In practical tests, the ability distribution of the examinees does not necessarily follow a normal distribution. Note that a skewed ability level distribution in the examinee group can increase the number of low- or high-level examinees, potentially decreasing ability estimation accuracy when the proposed method is used [
46]. For examinees with skewed ability distributions, the validity of OMST-M may be further explored in the future. Finally, research on artificial neural networks has broad applications across diverse fields and can potentially offer promising avenues for enhancing ability estimation accuracy and multidimensional assessments. By integrating neural network models with OMST-M in the future, the measurement effectiveness and versatility of psychometric data analysis may be significantly amplified [
47].







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}