
A Possible Degree-Based D–S Evidence Theory Method for Ranking New Energy Vehicles Based on Online Customer Reviews and Probabilistic Linguistic Term Sets

Abstract
1. Introduction
- (1)
- This paper crawls online reviews from multiple websites and transforms them into five-granularity PLTSs. Compared with existing methods on online reviews which are from a single website and transformed into hesitant intuitionistic fuzzy sets and q-rung orthopair fuzzy numbers, the decision information concealed in the online reviews is more plentiful and more clearly express the sentiment orientations, including very positive, positive, neutral, negative and very negative sentiments.
- (2)
- Attribute weights are determined by building a bi-objective programming model based on the maximization deviation and the information entropy, by which the differences between alternatives and uncertainty of decision information on each attribute are both considered. However, in other studies, the attribute weights are assigned by experts subjectively or derived only depending on the maximization deviation. Thus, the attribute weights generated in this paper can more synthetically reflect the quality of the decision information and are more reliable.
- (3)
- A possible degree-based D–S theory method is proposed to rank alternatives. A dominant feature of this method is that it can quantitively measure and decrease uncertainty of decision information. Furthermore, it has a stronger distinguishing power compared with existing D–S theory methods.
2. Literature Review
2.1. Decision Methods for Resolving NEV Selection Problems
2.2. MADM Methods with Online Reviews in the PLTS Environment
3. Preliminaries
3.1. Probabilistic Linguistic Term Sets
3.2. Dempster–Shafer Theory
3.3. Existing D–S Evidence Theory-Based Methods
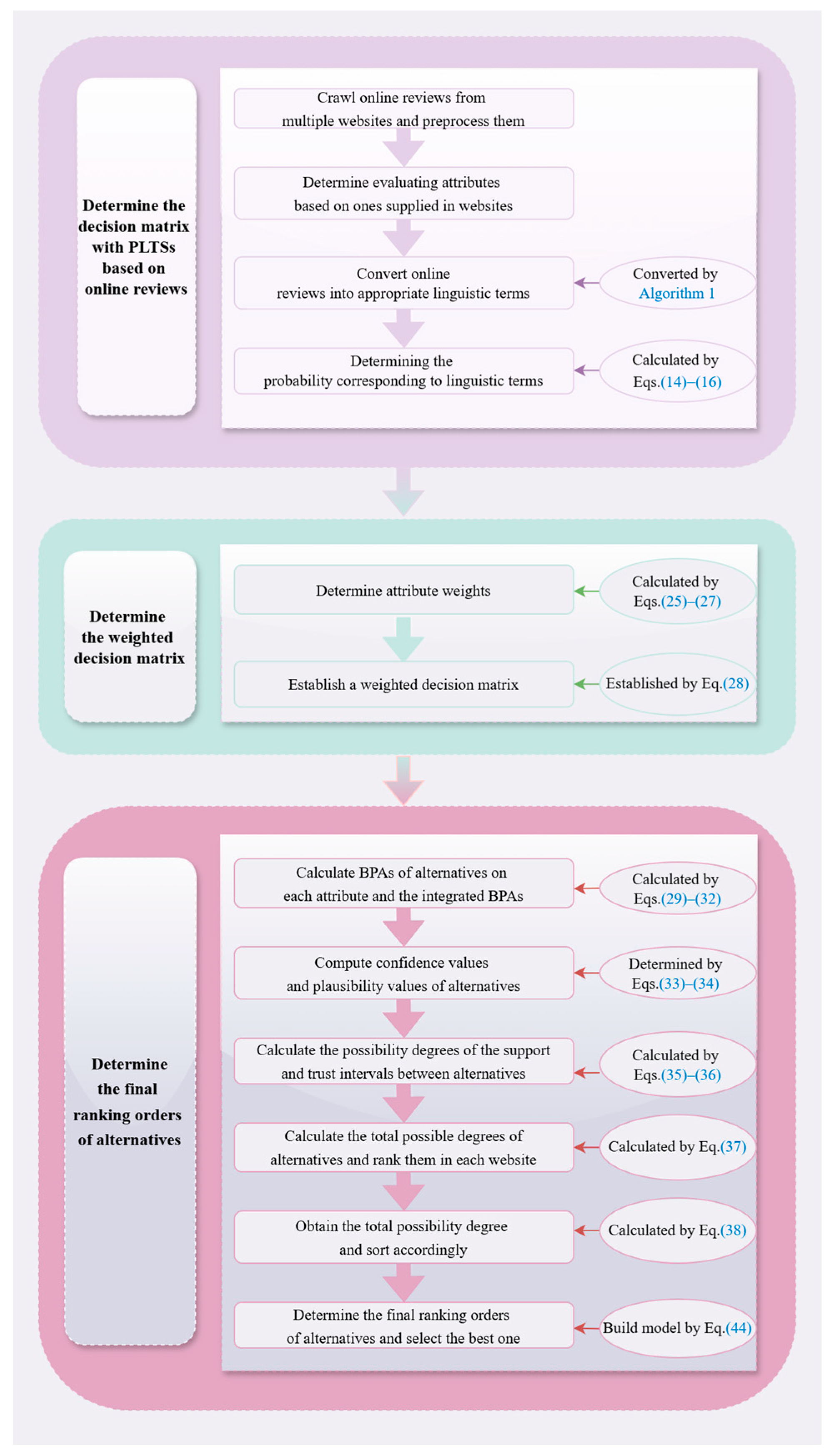
4. A Possible Degree-Based D–S Evidence Theory Method with Online Reviews in the PLTS Context
4.1. Problem Description
4.2. Determine the Decision Matrix with PLTSs Based on Online Reviews
4.2.1. Data Collection and Preprocessing
4.2.2. Convert Online Reviews into Appropriate Linguistic Terms by Sentiment Analyses
| Algorithm 1. Transforming reviews into linguistic terms |
| Input: the preprocessed user reviews ; positive word set , negative word set , degree adverb word set and deny word set of the new sentiment dictionary; linguistic term set . Output: the sentimental orientation of . 1: for do 2: for do 3: for do 4: for do 5: let , do 6: if then 7: else if then 8: else if then 9: if then 10: else 11: end if 12: else , 13: end if 14: let , do 15: if then 16: else if then 17: else , 18: end if 19: if then 20: else if then 21: else if then 22: else if then 23: else 24: end if 25: end for 26: end for 27: end for 28: end for 29: end for 30: end for |
| Note: is computed by the number of words between positive words and degree adverb words. Similarly, and are calculated. Table 4 illustrates the calculation process. represents the number of elements in . |
4.2.3. Determining the Probability Corresponding to Linguistic Terms
4.3. Determine Attribute Weights by Constructing a Bi-Objective Programming Model
4.3.1. A Minimum Probabilistic Linguistic Entropy Model
4.3.2. Construct a Bi-Objective Programming Model to Determine Attribute Weights
4.4. A Possible Degree-Based D–S Evidence Theory Method for Ranking Alternatives in the PLTS Context
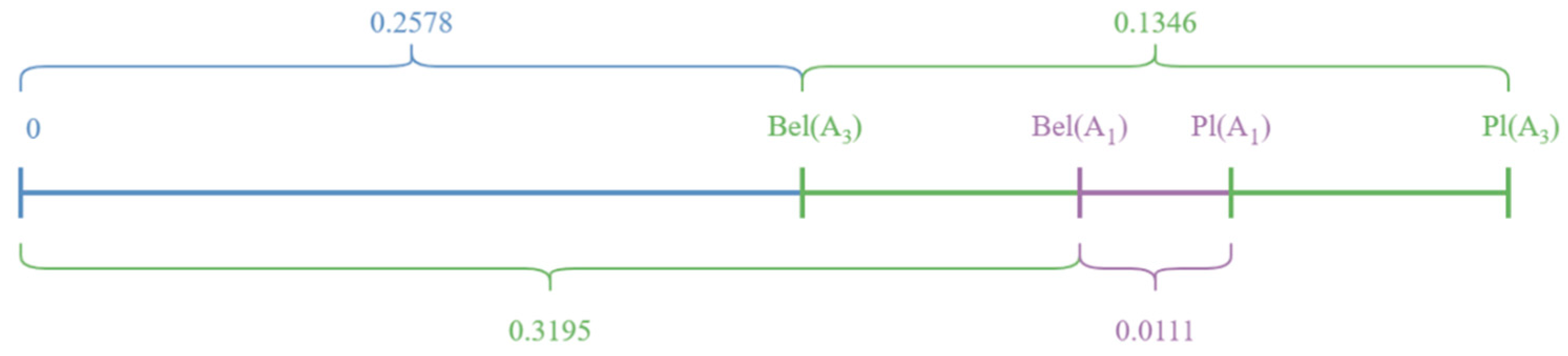
4.4.1. New Confidence and Plausibility Functions
4.4.2. A Confidence–Plausibility-Based Possible Degree for Ranking Alternatives for Each Website
4.4.3. Build a 0–1 Programming Model for Obtaining the Final Alternative Ranking Orders
4.5. The Structure of the Possible Degree-Based D–S Evidence Theory Method in the PLTS Context
5. A Case Study of Selecting New Energy Vehicles
5.1. Description of the Problem
5.2. Solving Process by the Proposed Method
6. Sensitivity Analysis and Comparative Analysis
6.1. Sensitivity Analysis of the Balancing Coefficient
6.2. Comparative Analysis
6.2.1. Comparation with Existing Car Selection Methods Based on Online Reviews
- (1)
- The proposed method crawls online reviews from multiple websites, while existing NEVs selection methods [6,7,21] obtained online reviews from only one website. As different consumers prefer distinct platforms and online reviews in a single platform is limited, it is advisable to derive online reviews from several websites. At this point, the evaluation information collected by the proposed method is more sufficient, which is helpful for determining reasonable decision results.
- (2)
- The evaluation information extracted from online reviews by the proposed method is more precise and reliable because it is represented as PLTSs with five-granularity linguistic terms. The method [7] applied q-rung orthopair fuzzy sets (q-ROFSs) to express evaluation information. However, q-ROFSs only express the proportions of positive and negative sentiments but failed to distinguish comments which are neutral sentiments or do not provide any evaluation. Although the method [6] can handle comments without any evaluations by hesitant intuitionistic fuzzy sets (HIFSs), it is unable to express the strength of positive and negative sentiments. Converting sentiment scores into memberships of alternatives, Ref. [21] delt with online reviews into hesitant probabilistic fuzzy sets (HPFSs). Compared with methods [6,7], the method [21] represented online reviews more smoothly. Nevertheless, the decision information may be distorted when online reviews are transformed into sentiment scores. The proposed method describes evaluation information by five-granularity PLTSs, including very positive, positive, neutral, negative and very negative linguistic terms, which can not only retain natural language forms of sentiment orientations in online reviews, but also reflex strengths of different sentiments with their proportions. Hence, evaluation information derived by the proposed method is more precise and reliable.
6.2.2. Comparison with MADM Methods in the PLTS Environment
- (1)
- The decision information in the proposed method is more reliable because it is extracted from user online reviews on products. However, decision information in methods [37,38] are provided by several DMs. Due to the limited knowledge and experiences of DMs, the provided decision information may be limited and unable to represent general evaluations of most users.
- (2)
- The attribute weights in the proposed method are obtained by minimizing the uncertainty degrees of attributes as well as maximizing deviations between alternatives with respect to attributes. The method [37] gave attribute weights subjectively, which may greatly impact on alternative ranking orders. For example, when the attribute weights are assigned as the ones obtained by the proposed method, alternatives are sorted as . However, when attribute weights are given as , the ranking order is and the best alternative changes from . Although method [38] objectively determined attribute weights by maximizing deviation and method [39] fused AHP and deviation, they both neglected the uncertainty degrees of attributes. As decision information is based on online reviews in which there exists much uncertainty, it is more reasonable to consider uncertainty besides deviations between alternatives while deriving attribute weights.
- (3)
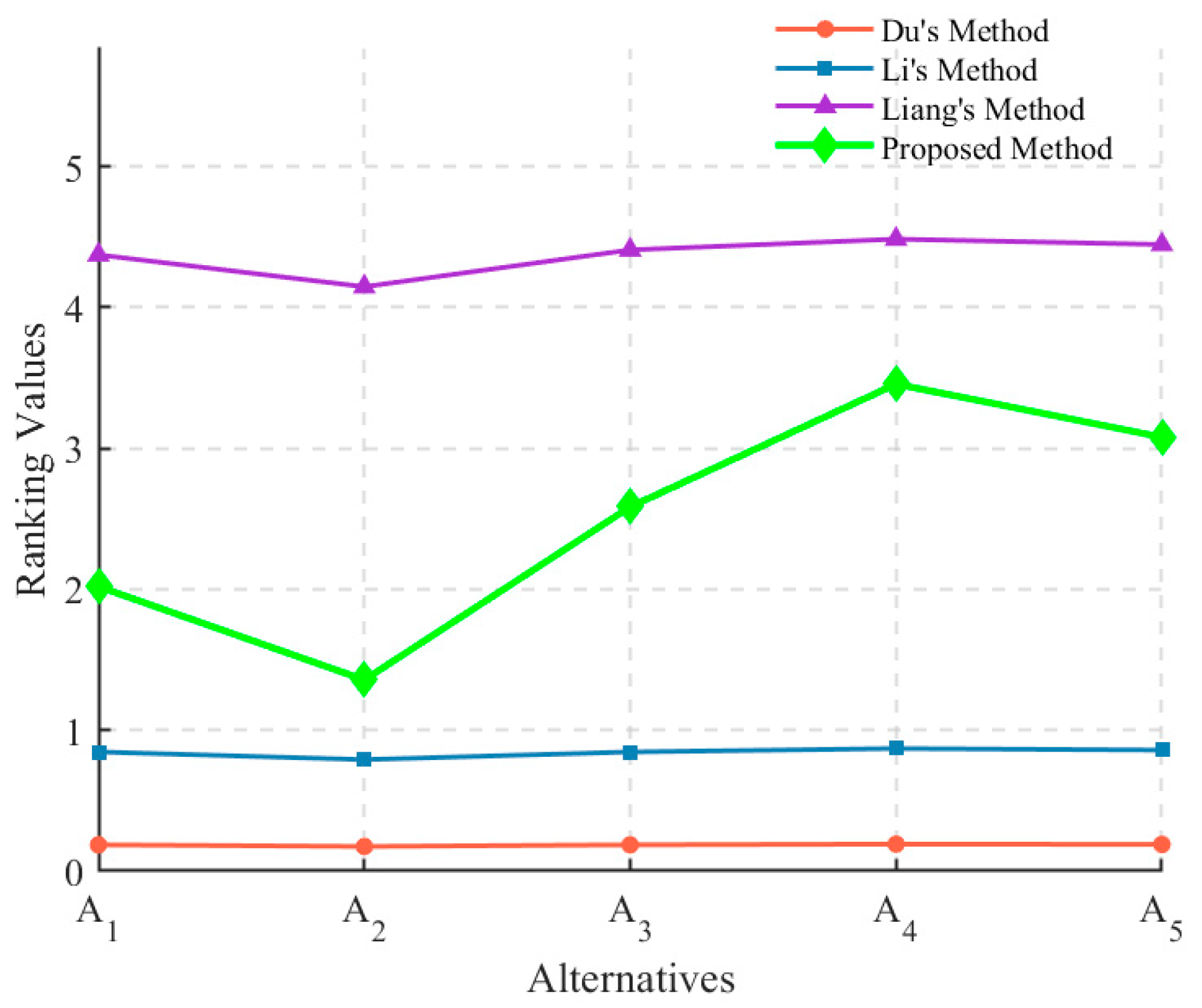
- The proposed method is feasible and has a stronger distinguishing power while ranking alternatives. It can be seen from Table 13 the that alternative ranking order by the proposed method is similar with those derived by methods [37,38,39] and the best alternative is . Furthermore, Observing Table 14, the Pearson correlation coefficients of alternative ranking orders are all greater than 0.9, which verifies the similarity of alternative ranking orders between the proposed method and existing ones. This illustrates the feasibility of the proposed method. Moreover, the distinguishing power of the proposed method is stronger, which can be described in Figure 5.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Alternatives | Online Reviews |
|---|---|
| AION S () | In terms of space, it is very spacious for household use. As a Class A car, it doesn’t look large visually, but the overall space utilization is excellent. Even with five people seated, it doesn’t feel crowded. |
| The cost-performance ratio of AION S is very high. I only spend 20 to 30 yuan each week on charging outside. Such travel costs are really attractive for an average family. | |
| Tesla Model Y () | The car has a large mouse-like body, providing a very spacious interior. It is evident that this car has been meticulously designed. The interior space is surprisingly large, especially in the front row, where you can stretch your legs straight out. However, the armrest box is too small, which is quite inconvenient. |
| With increased features at no additional cost, the cost-performance ratio is very high. It excels in all aspects and is also very good compared to others in the same class. | |
| Great Wall Euler Good Cat () | The interior space is very large. Compared to other models in the family, it is not inferior to other cars with larger exteriors. However, correspondingly, the large interior space has compressed the trunk space, making the trunk not very spacious. |
| However, after looking at three or four models, Euler Good Cat is the best choice within my acceptable range, in every aspect. Not only are the promotional activities substantial, but the service is also excellent. | |
| BYD Han () | Overall, I am quite satisfied with the space. It meets the needs for daily commuting and holiday trips. Especially the front row space and the legroom in the back row are quite spacious. |
| At this price, buying a BYD Han is a no-brainer, highly recommended. The driving comfort is truly on par with Mercedes. Now, 4S shops have test drive cars available, so you can experience it yourself. The power response is immediate, the soundproof glass is indeed quiet, and the rear space is ample. There are no discounts on the price, but this car is worth the price. | |
| BYD Qin PLUS () | The space is very large, enough for a family of four. The headroom in the back row is also very good, and even with a height of 1.78 m, it doesn’t feel cramped. The seats are very comfortable, with good softness and excellent support. |
| The overall cost-performance ratio is very high. After all, the price is quite reasonable, and the configurations in all aspects are very good compared to cars in the same class. |
| Alternatives | ||||||||
|---|---|---|---|---|---|---|---|---|
| 2 | 0 | 2 | 1 | 0 | 3 | 0 | ||
| 3 | 4 | 1 | 4 | 4 | 6 | 5 | ||
| 13 | 10 | 7 | 5 | 7 | 14 | 22 | ||
| 19 | 14 | 15 | 17 | 10 | 16 | 23 | ||
| 48 | 57 | 38 | 58 | 64 | 46 | 35 | ||
| 0 | 0 | 22 | 0 | 0 | 0 | 0 | ||
| 3 | 3 | 1 | 2 | 3 | 3 | 2 | ||
| 9 | 3 | 7 | 7 | 8 | 10 | 11 | ||
| 34 | 21 | 27 | 15 | 24 | 29 | 27 | ||
| 24 | 24 | 26 | 25 | 25 | 35 | 42 | ||
| 63 | 81 | 69 | 83 | 73 | 55 | 51 | ||
| 1 | 2 | 4 | 2 | 1 | 2 | 1 | ||
| 1 | 2 | 1 | 0 | 1 | 2 | 1 | ||
| 6 | 1 | 2 | 2 | 0 | 2 | 8 | ||
| 18 | 6 | 12 | 9 | 7 | 13 | 16 | ||
| 14 | 15 | 19 | 13 | 8 | 26 | 15 | ||
| 49 | 64 | 53 | 63 | 71 | 44 | 47 | ||
| 0 | 0 | 1 | 1 | 1 | 1 | 1 | ||
| 2 | 1 | 1 | 0 | 1 | 0 | 2 | ||
| 4 | 2 | 2 | 2 | 3 | 2 | 12 | ||
| 9 | 7 | 10 | 9 | 6 | 9 | 25 | ||
| 16 | 10 | 15 | 12 | 9 | 24 | 24 | ||
| 73 | 84 | 73 | 82 | 86 | 67 | 41 | ||
| 1 | 1 | 4 | 0 | 0 | 3 | 1 | ||
| 1 | 0 | 2 | 2 | 1 | 3 | 7 | ||
| 1 | 5 | 5 | 1 | 0 | 2 | 8 | ||
| 13 | 3 | 7 | 8 | 9 | 9 | 19 | ||
| 23 | 17 | 21 | 22 | 9 | 14 | 23 | ||
| 67 | 79 | 69 | 72 | 86 | 77 | 48 | ||
| 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| Alternative | Sentiment | |||||||
|---|---|---|---|---|---|---|---|---|
| 0.0235 | 0.0000 | 0.0235 | 0.0118 | 0.0000 | 0.0353 | 0.0000 | ||
| 0.0353 | 0.0471 | 0.0118 | 0.0471 | 0.0471 | 0.0706 | 0.0588 | ||
| 0.1529 | 0.1176 | 0.0824 | 0.0588 | 0.0824 | 0.1647 | 0.2588 | ||
| 0.2235 | 0.1647 | 0.1765 | 0.0200 | 0.1176 | 0.1882 | 0.2706 | ||
| 0.5647 | 0.6706 | 0.4471 | 0.6824 | 0.7529 | 0.5412 | 0.4118 | ||
| 0.0000 | 0.0000 | 0.2588 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| 0.0224 | 0.0224 | 0.0075 | 0.0149 | 0.0224 | 0.0224 | 0.0149 | ||
| 0.0672 | 0.0224 | 0.0522 | 0.0522 | 0.0597 | 0.0746 | 0.0821 | ||
| 0.2537 | 0.1567 | 0.2015 | 0.1119 | 0.1791 | 0.2164 | 0.2015 | ||
| 0.1791 | 0.1791 | 0.1940 | 0.1866 | 0.1866 | 0.2612 | 0.3134 | ||
| 0.4701 | 0.6045 | 0.5149 | 0.6194 | 0.5448 | 0.4104 | 0.3806 | ||
| 0.0075 | 0.0149 | 0.0299 | 0.0149 | 0.0075 | 0.0149 | 0.0075 | ||
| 0.0114 | 0.0227 | 0.0114 | 0.0000 | 0.0114 | 0.0227 | 0.0114 | ||
| 0.0682 | 0.0114 | 0.0227 | 0.0227 | 0.0000 | 0.0227 | 0.0909 | ||
| 0.2045 | 0.0682 | 0.1364 | 0.1023 | 0.0795 | 0.1477 | 0.1818 | ||
| 0.1591 | 0.1705 | 0.2159 | 0.1477 | 0.0909 | 0.2955 | 0.1705 | ||
| 0.5568 | 0.7273 | 0.6023 | 0.7159 | 0.8068 | 0.5000 | 0.5341 | ||
| 0.0000 | 0.0000 | 0.0114 | 0.0114 | 0.0114 | 0.0114 | 0.0114 | ||
| 0.0190 | 0.0095 | 0.0095 | 0.0000 | 0.0095 | 0.0000 | 0.0190 | ||
| 0.0381 | 0.0190 | 0.0190 | 0.0190 | 0.0286 | 0.0190 | 0.1143 | ||
| 0.0857 | 0.0667 | 0.0952 | 0.0857 | 0.0571 | 0.0857 | 0.2381 | ||
| 0.1524 | 0.0952 | 0.1429 | 0.1143 | 0.0857 | 0.2286 | 0.2286 | ||
| 0.6952 | 0.8000 | 0.6952 | 0.7810 | 0.8190 | 0.6381 | 0.3905 | ||
| 0.0095 | 0.0095 | 0.0381 | 0.0000 | 0.0000 | 0.0286 | 0.0095 | ||
| 0.0095 | 0.0000 | 0.0190 | 0.0190 | 0.0095 | 0.0286 | 0.0667 | ||
| 0.0095 | 0.0476 | 0.0476 | 0.0095 | 0.0000 | 0.0190 | 0.0762 | ||
| 0.1238 | 0.0286 | 0.0667 | 0.0762 | 0.0857 | 0.0857 | 0.1810 | ||
| 0.2190 | 0.1619 | 0.2000 | 0.2095 | 0.0857 | 0.1333 | 0.2190 | ||
| 0.6381 | 0.7524 | 0.6571 | 0.6857 | 0.8190 | 0.7333 | 0.4571 | ||
| 0.0000 | 0.0095 | 0.0095 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
References
- Dong, J.; Wan, S. Type-2 interval-valued intuitionstic fuzzy matrix game and application to energy vehicle industry development. Expert Syst. Appl. 2024, 249, 123398. [Google Scholar] [CrossRef]
- Dwivedi, P.P.; Sharma, D.K. Evaluation and ranking of battery electric vehicles by Shannon’s entropy and TOPSIS methods. Math. Comput. Simul. 2023, 212, 457–474. [Google Scholar] [CrossRef]
- Meng, W.; Ma, M.; Li, Y.; Huang, B. New energy vehicle R&D strategy with supplier capital constraints under China’s dual credit policy. Energy Policy 2022, 168, 113099. [Google Scholar]
- Yu, S.; Zhang, X.; Du, Z.; Chen, Y. A new multi-attribute decision making method for overvalued star ratings adjustment and its application in new energy vehicle selection. Mathematics 2023, 11, 2037. [Google Scholar] [CrossRef]
- Li, W.; Li, Y. Automotive product ranking method considering individual standard differences in online reviews. Syst. Eng. 2021, 39, 143–152. [Google Scholar]
- Tian, Z.; Liang, H.; Nie, R.; Wang, X.; Wang, J. Data-driven multi-criteria decision support method for electric vehicle selection. Comput. Ind. Eng. 2023, 177, 109061. [Google Scholar] [CrossRef]
- Yang, Z.; Li, Q.; Charles, V.; Xu, B.; Gupta, S. Supporting personalized new energy vehicle purchase decision-making: Customer reviews and product recommendation platform. Int. J. Prod. Econ. 2023, 265, 109003. [Google Scholar] [CrossRef]
- Xie, W.; Xu, Z.; Ren, Z.; Wang, H. Probabilistic linguistic analytic hierarchy process and its application on the performance assessment of Xiongan new area. Int. J. Inf. Technol. Decis. Mak. 2018, 17, 1693–1724. [Google Scholar] [CrossRef]
- Wan, S.; Gao, S.; Dong, J. Trapezoidal cloud based heterogeneous multi-criterion group decision-making for container multimodal transport path selection. Appl. Soft Comput. 2024, 154, 111374. [Google Scholar] [CrossRef]
- Wang, X.; Wang, J.; Zhang, H. Distance-based multicriteria group decision-making approach with probabilistic linguistic term sets. Expert Syst. 2019, 36, e12352. [Google Scholar] [CrossRef]
- Yan, J.; Dong, J.; Wan, S.; Gao, Y. A quantum probability theory-based method for heterogeneous multi-criteria group decision making with incomplete probabilistic linguistic preference relations considering the interference effect among decision makers. J. Oper. Res. Soc. 2024, 1–27. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, X. A new hesitant fuzzy linguistic approach for multiple attribute decision making based on Dempster–Shafer evidence theory. Appl. Soft Comput. 2020, 86, 105897. [Google Scholar] [CrossRef]
- Xiao, F. EFMCDM: Evidential fuzzy multicriteria decision making based on belief entropy. IEEE Trans. Fuzzy Syst. 2019, 28, 1477–1491. [Google Scholar] [CrossRef]
- Xiao, F.; Wen, J.; Pedrycz, W. Generalized divergence-based decision making method with an application to pattern classification. IEEE Trans. Knowl. Data Eng. 2022, 35, 6941–6956. [Google Scholar] [CrossRef]
- Liu, Z.; Bi, Y.; Liu, P. A conflict elimination-based model for failure mode and effect analysis: A case application in medical waste management system. Comput. Ind. Eng. 2023, 178, 109145. [Google Scholar] [CrossRef]
- Nie, R.; Tian, Z.; Wang, J.; Chin, K. Hotel selection driven by online textual reviews: Applying a semantic partitioned sentiment dictionary and evidence theory. Int. J. Hosp. Manag. 2020, 88, 102495. [Google Scholar] [CrossRef]
- Wang, J.; Xu, L.; Cai, J.; Fu, Y.; Bian, X. Offshore wind turbine selection with a novel multi-criteria decision-making method based on Dempster-Shafer evidence theory. Sustain. Energy Technol. Assess. 2022, 51, 101951. [Google Scholar] [CrossRef]
- Ziemba, P. Multi-criteria approach to stochastic and fuzzy uncertainty in the selection of electric vehicles with high social acceptance. Expert Syst. Appl. 2021, 173, 114686. [Google Scholar] [CrossRef]
- Huang, T.; Tang, X.; Zhao, S.; Zhang, Q.; Pedrycz, W. Linguistic information-based granular computing based on a tournament selection operator-guided PSO for supporting multi-attribute group decision-making with distributed linguistic preference relations. Inf. Sci. 2022, 610, 488–507. [Google Scholar] [CrossRef]
- Tversky, A.; Kahneman, D. Advances in prospect theory: Cumulative representation of uncertainty. J. Risk Uncertain. 1992, 5, 297–323. [Google Scholar] [CrossRef]
- Liu, D.; Xu, J.; Du, Y. An integrated HPF-TODIM-MULTIMOORA approach for car selection through online reviews. Ann. Oper. Res. 2024. [Google Scholar] [CrossRef]
- Chen, J.; Li, X. Doctors ranking through heterogeneous information: The new score functions considering patients’ emotional intensity. Expert Syst. Appl. 2023, 219, 119620. [Google Scholar] [CrossRef]
- Darko, A.; Liang, D.; Xu, Z.; Agbodah, K.; Obiora, S. A novel multi-attribute decision-making for ranking mobile payment services using online consumer reviews. Expert Syst. Appl. 2023, 213, 119262. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Li, Q.; Islam, N.; Han, C.; Gupta, S. Product Attribute and Heterogeneous Sentiment Analysis-Based Evaluation to Support Online Personalized Consumption Decisions. IEEE Trans. Eng. Manag. 2024, 71, 11198–11211. [Google Scholar] [CrossRef]
- Zhao, M.; Li, L.; Xu, Z. Study on hotel selection method based on integrating online ratings and reviews from multi-websites. Inf. Sci. 2021, 572, 460–481. [Google Scholar] [CrossRef]
- Wan, S.; Wu, H.; Dong, J. An integrated method for complex heterogeneous multi-attribute group decision-making and application to photovoltaic power station site selection. Expert Syst. Appl. 2024, 242, 122456. [Google Scholar] [CrossRef]
- Pang, Q.; Wang, H.; Xu, Z. Probabilistic linguistic term sets in multi-attribute group decision making. Inf. Sci. 2016, 369, 128–143. [Google Scholar] [CrossRef]
- Gou, X.; Xu, Z. Novel basic operational laws for linguistic terms, hesitant fuzzy linguistic term sets and probabilistic linguistic term sets. Inf. Sci. 2016, 372, 407–427. [Google Scholar] [CrossRef]
- Liao, H.; Jiang, L.; Lev, B.; Fujita, H. Novel operations of PLTSs based on the disparity degrees of linguistic terms and their use in designing the probabilistic linguistic ELECTRE III method. Appl. Soft Comput. 2019, 80, 450–464. [Google Scholar] [CrossRef]
- Wu, X.; Liao, H. A consensus-based probabilistic linguistic gained and lost dominance score method. Eur. J. Oper. Res. 2019, 272, 1017–1027. [Google Scholar] [CrossRef]
- Dempster, A.P. Upper and lower probabilities induced by a multivalued mapping. Ann. Math. Stat. 1967, 38, 325–339. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence. Technometrics 1978, 20, 3–86. [Google Scholar]
- Fei, L.; Feng, Y.; Wang, H. Modeling heterogeneous multi-attribute emergency decision-making with Dempster-Shafer theory. Comput. Ind. Eng. 2021, 161, 107633. [Google Scholar] [CrossRef]
- Jiroušek, R.; Shenoy, P.P. A new definition of entropy of belief functions in the Dempster–Shafer theory. Int. J. Approx. Reason. 2018, 92, 49–65. [Google Scholar] [CrossRef]
- Lan, J.; Zou, H.; Hu, M. Dominance degrees for intervals and their application in multiple attribute decision-making. Fuzzy Sets Syst. 2020, 383, 146–164. [Google Scholar] [CrossRef]
- Zhang, M.; Li, G. Combining TOPSIS and GRA for supplier selection problem with interval numbers. J. Cent. South Univ. 2018, 25, 1116–1128. [Google Scholar] [CrossRef]
- Du, Y.; Liu, D. An integrated method for multi-granular probabilistic linguistic multiple attribute decision-making with prospect theory. Comput. Ind. Eng. 2021, 159, 107500. [Google Scholar] [CrossRef]
- Li, P.; Wei, C. An emergency decision-making method based on D-S evidence theory for probabilistic linguistic term sets. Int. J. Disaster Risk Reduct. 2019, 37, 101178. [Google Scholar] [CrossRef]
- Liang, D.; Dai, Z.; Wang, M. Assessing customer satisfaction of O2O takeaway based on online reviews by integrating fuzzy comprehensive evaluation with AHP and probabilistic linguistic term sets. Appl. Soft Comput. 2021, 98, 106847. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, W.; Xu, X.; Cao, W. A public and large-scale expert information fusion method and its application: Mining public opinion via sentiment analysis and measuring public dynamic reliability. Inf. Fusion 2022, 78, 71–85. [Google Scholar] [CrossRef]


| 0.2031 | 0.0950 | 0.1901 | 0.1067 | 0.2016 | 0.1231 | 0.0804 | |
| 0.1611 | 0.0934 | 0.2090 | 0.2208 | 0.1167 | 0.1092 | 0.0898 |
| 0.4131 | 0 | 0.1950 | 0.1469 | 0 | 0.1531 | 0.0919 | |
| 0.2730 | 0 | 0.1751 | 0.2707 | 0 | 0.2192 | 0.0620 |
| Notation | Explanation |
|---|---|
| The set of linguistic term. where . | |
| The th review from the th website revaluating the th alternative with respect to th attribute. | |
| The number of positive sentiment words in the th reviews for attribute of alternative for website . | |
| The number of negative sentiment words in the th reviews for attribute of alternative for website . | |
| The number of positive degree adverb words in the th reviews for attribute of alternative for website . | |
| The number of negative degree adverb words in the th reviews for attribute of alternative for website . | |
| The number of users who have missing evaluations the attribute of alternative for website . |
| Review | Classification of Words | The Examples of Degree Words | The Sentimental Orientation of Words |
|---|---|---|---|
| The space inside the car is quite spacious. As soon as you get into the car, you will feel very light and bright. Whether you sit in the front or the back, the useful space is very gelivable and very large. I, 1.78 m, can have such experiences, so it is no problems for other people. It is not crowded at all for three people sitting in the back. | Positive sentiment words: spacious, light and bright, gelivable, large. Negative sentiment words: problem, crowded Degree words: quite, very1, very2, very3. | : , , , | The degree adverb “quite” is regarded as a positive degree () word |
| : , |
| Review Symbols | Review | The Sentiment Orientation of Word | Quantity Comparison | Review Orientation |
|---|---|---|---|---|
| The space inside the car is quite spacious. As soon as you get into the car, you will feel very light and bright. Whether you sit in the front or the back, the useful space is very gelivable and very large. I, 1.78 m, can have such experiences, so it is no problems for other people. It is not crowded at all for three people sitting in the back. | : spacious, light and bright, gelivable, large : problem, crowded : quite, very1, very2, very3 : at all : no, not | (more like) | ||
| The technology configuration is average, but the screen resolution is okay. While surfing the internet, the configuration is not smooth enough, and it is stuck sometimes. But the navigation is more convenient than that of the mobile phone. | : is okay, smooth, convenient : stuck : not | (general) | ||
| The space in the front row is good, but the back row is very crowded. It is hard for adults to sit in the back row. The trunk is so small that some gift boxes cannot be held during the Chinese New Year. | : good : crowded, so small, can’t be held : very, hard | (more annoying) |
| 0.2522 | 0.1151 | 0.2522 | 0.1884 | 0.4744 | 0.5105 | 1 | |
| 0.3745 | 0.2374 | 0.3373 | 0.2735 | 0.4896 | 0.5257 |
| Alternatives | |||||||
|---|---|---|---|---|---|---|---|
| 85 | 85 | 63 | 85 | 85 | 85 | 85 | |
| 133 | 132 | 130 | 132 | 133 | 132 | 133 | |
| 88 | 88 | 87 | 87 | 87 | 87 | 87 | |
| 104 | 104 | 101 | 105 | 105 | 102 | 104 | |
| 105 | 104 | 104 | 105 | 105 | 105 | 105 |
| Attribute | |||||
|---|---|---|---|---|---|
| Alternative | |||||||
|---|---|---|---|---|---|---|---|
| 0.1672 | 0.1628 | 0.1473 | 0.1683 | 0.1722 | 0.1635 | 0.1651 | |
| 0.1432 | 0.1494 | 0.1536 | 0.1549 | 0.1330 | 0.1358 | 0.1557 | |
| 0.1636 | 0.1749 | 0.1743 | 0.1757 | 0.1828 | 0.1587 | 0.2028 | |
| 0.1976 | 0.1896 | 0.1958 | 0.1889 | 0.1843 | 0.1909 | 0.1565 | |
| 0.1856 | 0.1805 | 0.1862 | 0.1694 | 0.1847 | 0.2084 | 0.1769 | |
| 0.1428 | 0.1429 | 0.1428 | 0.1429 | 0.1428 | 0.1428 | 0.1429 |
| Value | |||||
|---|---|---|---|---|---|
| 0.1612 | 0.1071 | 0.2119 | 0.2640 | 0.2550 | |
| 0.1620 | 0.1078 | 0.2127 | 0.2648 | 0.2558 |
| Parameter Settings | Attribute Weights | Alternative Rankings |
|---|---|---|
| Methods | Expression Forms | Rank Methods | The Number of Websites |
|---|---|---|---|
| Yang’s method [7] | q-ROFS | Prospect theory | Single |
| Tian’s method [6] | HIFS | ORESTE | Single |
| Liu’s method [21] | HPFS | TODIM-MULTIMOORA | Single |
| The proposed method | PLTS | Possible degree-based D–S evidence theory | Multiple websites |
| Methods | Decision Information | Determination of Attribute Weights | Attribute Weights | Decision Methods | Alternatives Ranking Orders |
|---|---|---|---|---|---|
| Du’s method [37] | Provided by DMs | Given subjectively | Prospect theory | ||
| Li’s method [38] | Provided by DMs | Maximizing deviation | Operator based on D–S evidence | ||
| Liang’s method [39] | Online reviews | AHP and deviation | Fuzzy comprehensive evaluation | ||
| The proposed method | Online reviews | Uncertainty degree and maximum deviation | Possible degree-based D–S evidence |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Xu, G. A Possible Degree-Based D–S Evidence Theory Method for Ranking New Energy Vehicles Based on Online Customer Reviews and Probabilistic Linguistic Term Sets. Mathematics 2025, 13, 583. https://doi.org/10.3390/math13040583
Zhang Y, Xu G. A Possible Degree-Based D–S Evidence Theory Method for Ranking New Energy Vehicles Based on Online Customer Reviews and Probabilistic Linguistic Term Sets. Mathematics. 2025; 13(4):583. https://doi.org/10.3390/math13040583
Chicago/Turabian StyleZhang, Yunfei, and Gaili Xu. 2025. "A Possible Degree-Based D–S Evidence Theory Method for Ranking New Energy Vehicles Based on Online Customer Reviews and Probabilistic Linguistic Term Sets" Mathematics 13, no. 4: 583. https://doi.org/10.3390/math13040583
APA StyleZhang, Y., & Xu, G. (2025). A Possible Degree-Based D–S Evidence Theory Method for Ranking New Energy Vehicles Based on Online Customer Reviews and Probabilistic Linguistic Term Sets. Mathematics, 13(4), 583. https://doi.org/10.3390/math13040583