
Population-Based Search Algorithms for Biopharmaceutical Manufacturing Scheduling Problem with Heterogeneous Parallel Mixed Flowshops


Abstract
1. Introduction
2. Related Work
3. Problem Description
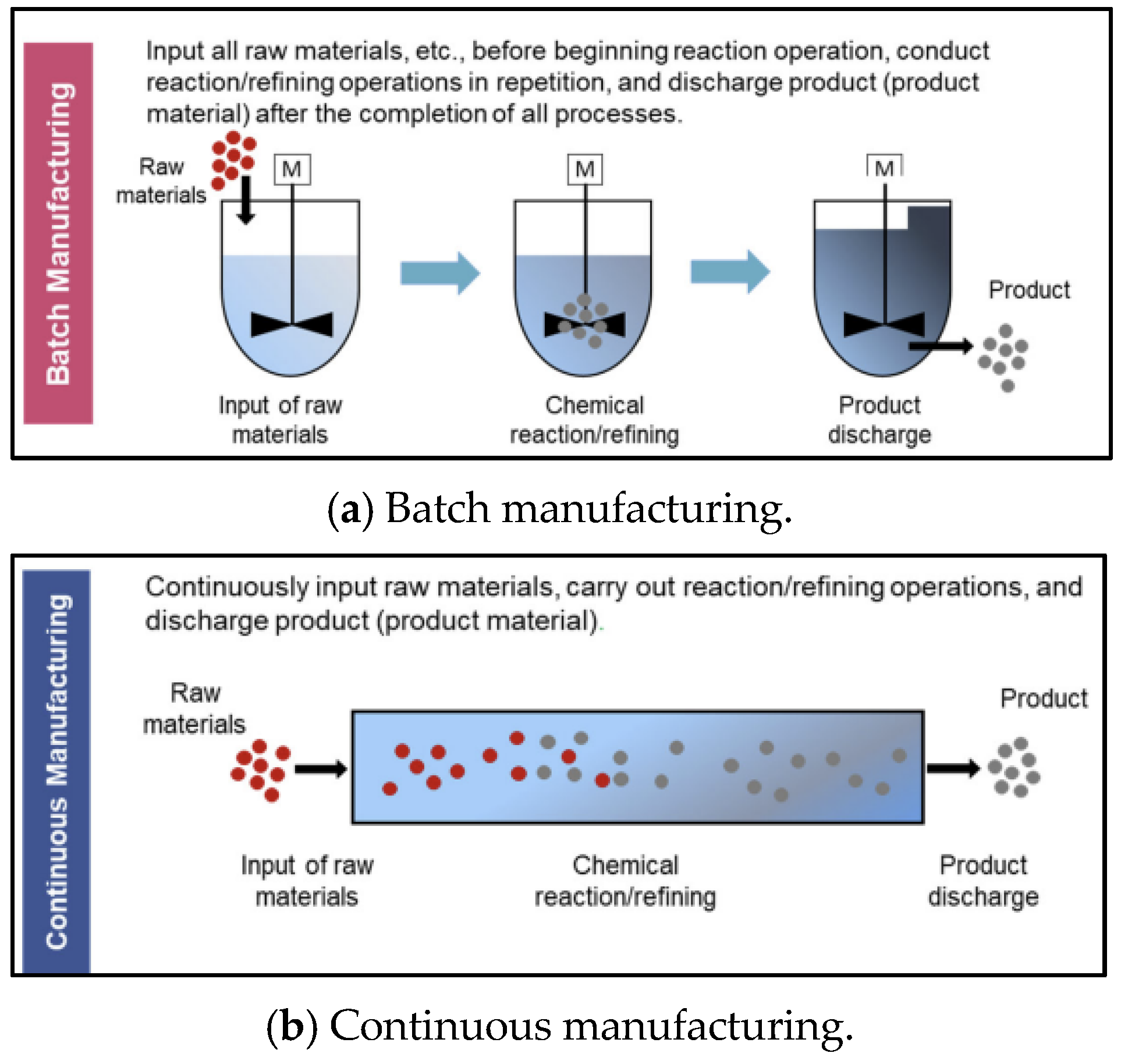
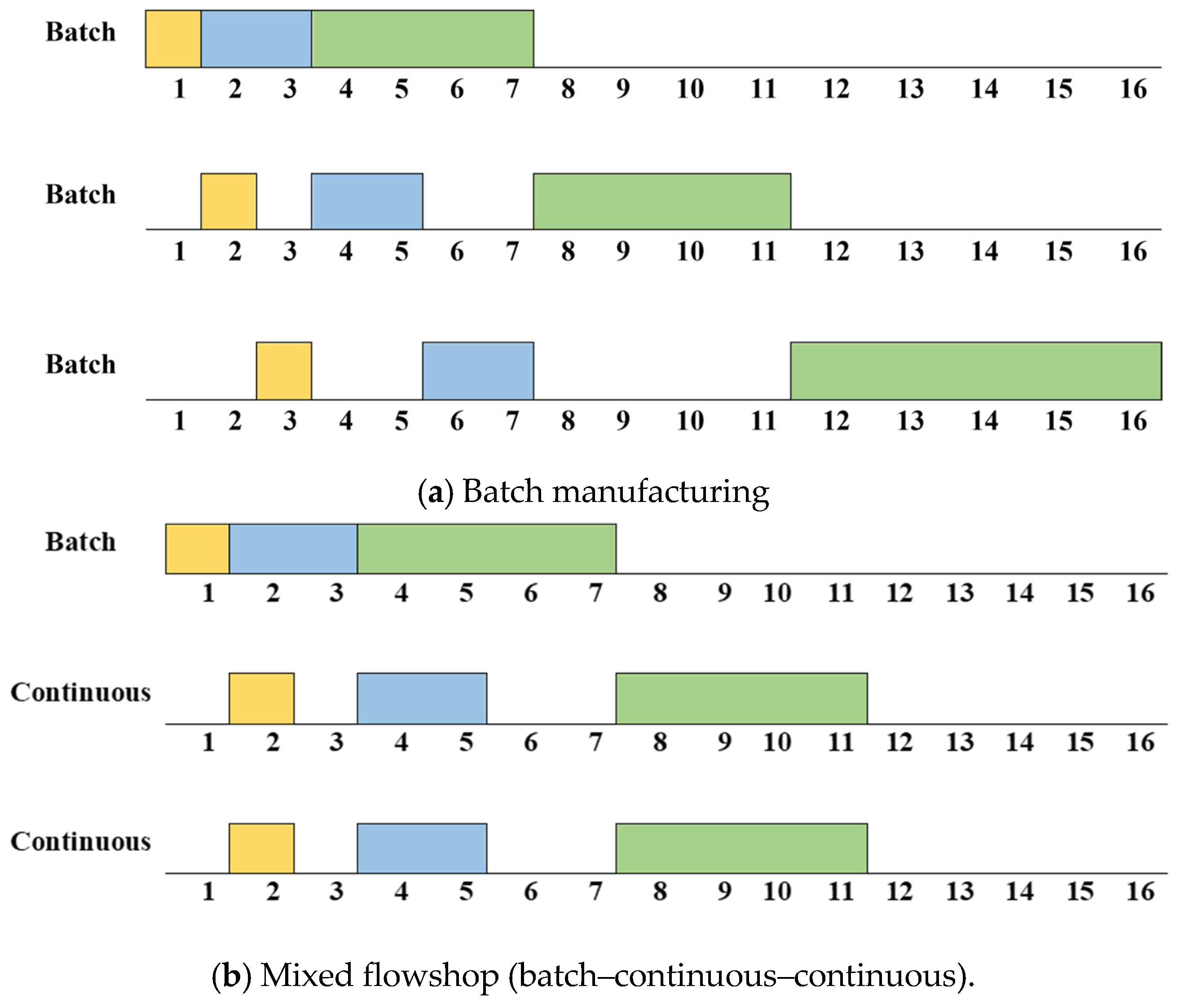
3.1. Biopharmaceutical Manufacturing Scheduling Problem with Heterogeneous Parallel Mixed Flowshops (BPMSP-HPMFSs)
- (1)
- The manufacturing environment consists of multiple flowshops.
- (2)
- Each flowshop has a single batch process and double continuous processes.
- (3)
- A product-type sequence-dependent setup exists.
- (4)
- The processing speed varies for each flowshop and process.
- (5)
- If two continuous processes are consecutive, for each order, the subsequent process starts and ends after the previous process starts and ends, respectively.
- (6)
- If at least one of the two consecutive processes is not a continuous process, for each order, the subsequent process starts after the previous process ends.
3.2. Mixed Integer Linear Programming (MILP) Model
4. Meta-Heuristic Algorithms
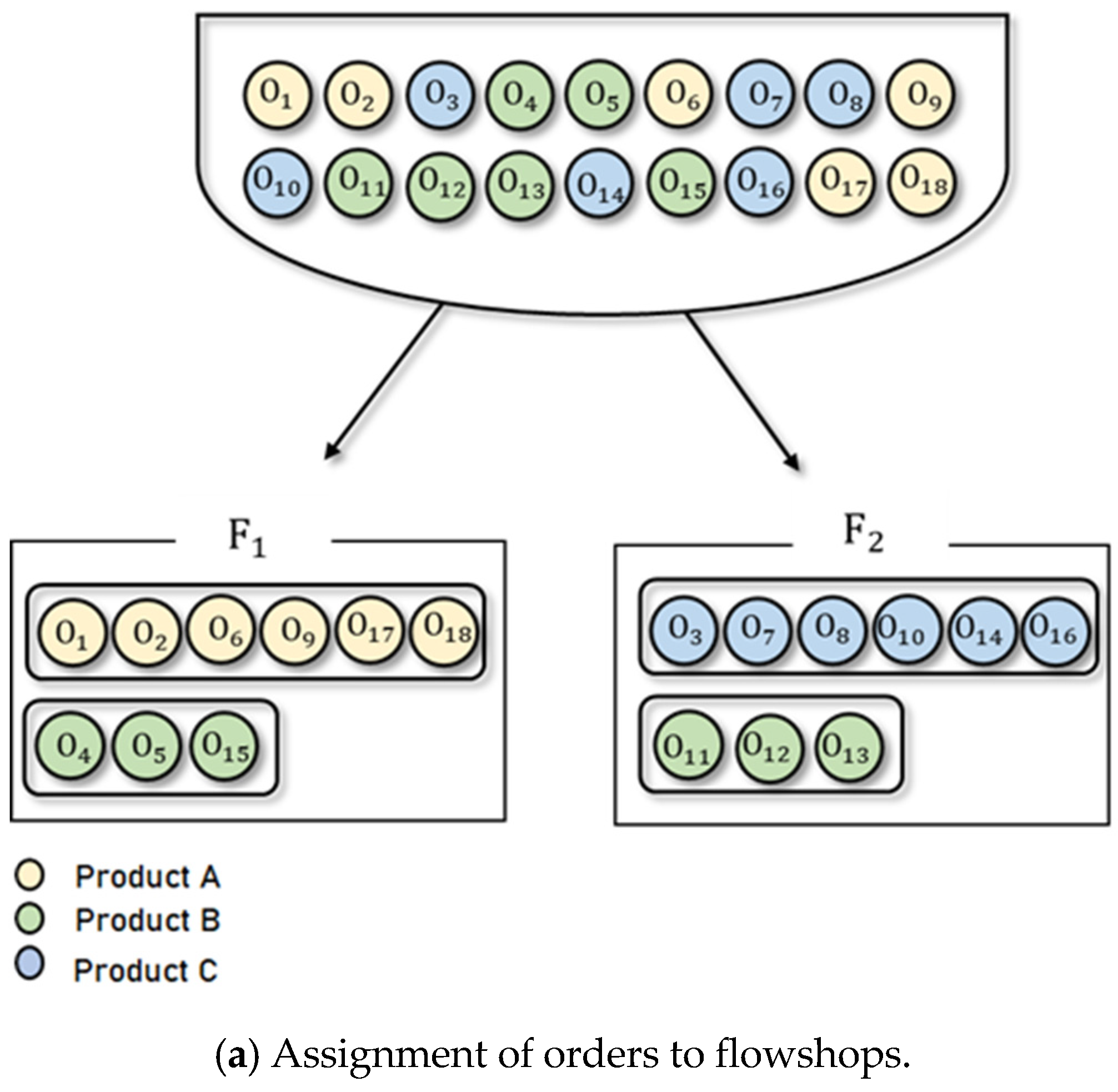
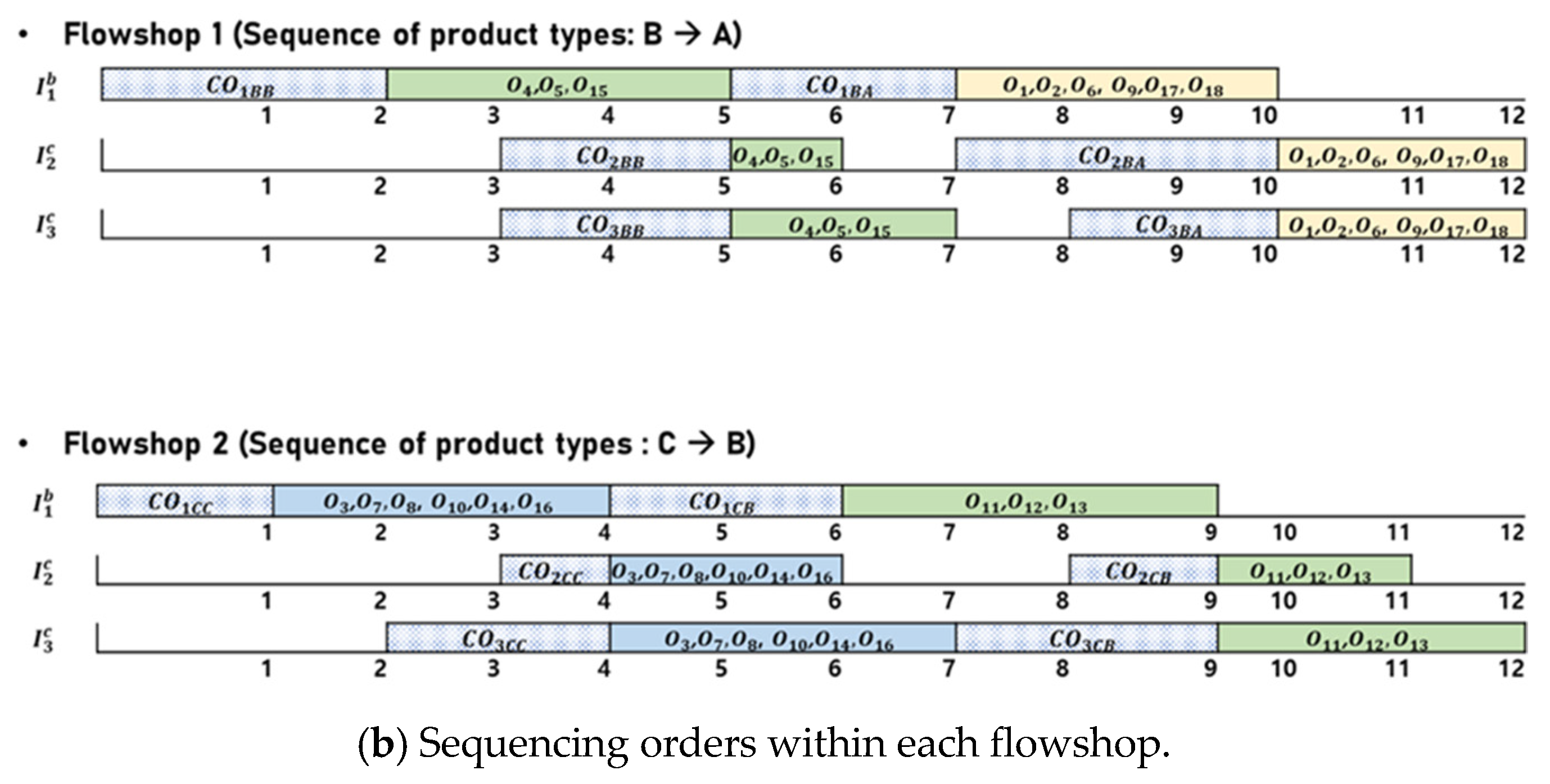
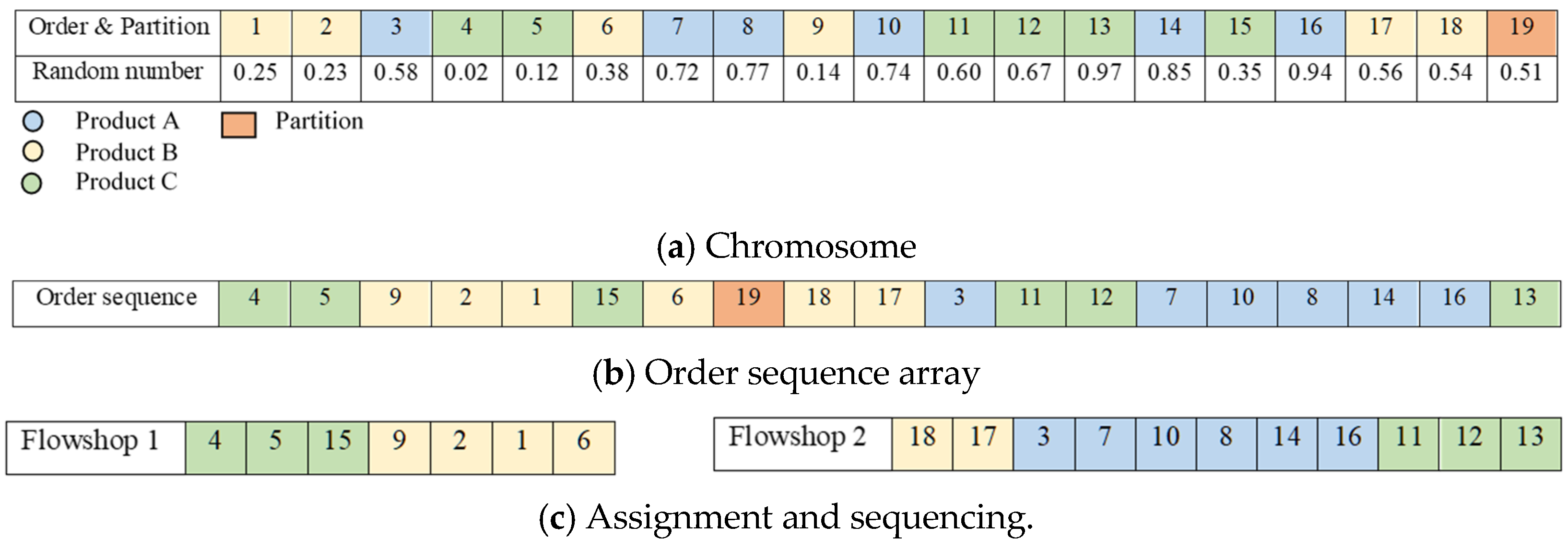
4.1. Solution Representation and Decoding Procedure
4.2. Genetic Algorithm (GA)
| Algorithm 1: GA |
| Input: population size (), generation size (), crossover rate (), mutation rate () |
| Output: total tardiness |
| Initialization: Generate a random initial population through |
| While |
| For |
| If < |
| For |
| If < |
| Conduct the crossover of the ith chromosome and jth chromosome |
| End if |
| End for |
| End if |
| End for |
| For |
| For |
| If < |
| Conduct the mutation operation |
| End if |
| End for |
| End for |
| Decode the chromosome and compute the objective function value (see Figure 5) |
| Conduct the roulette wheel selection |
| = |
| End While |
4.3. Particle Swarm Optimization (PSO)
| Algorithm 2: PSO |
| Input: iteration (), swarm size (), weight (), acceleration weight (), and () |
| Output: total tardiness |
| Initialization: Generate a random initial population through |
| While |
| For |
| Decode the chromosome and compute the objective function value (see Figure 5) |
| If < |
| End if |
| If < |
| End if |
| End for |
| For |
| End for |
| End While |
5. Computational Experiments
5.1. Design of Experiments
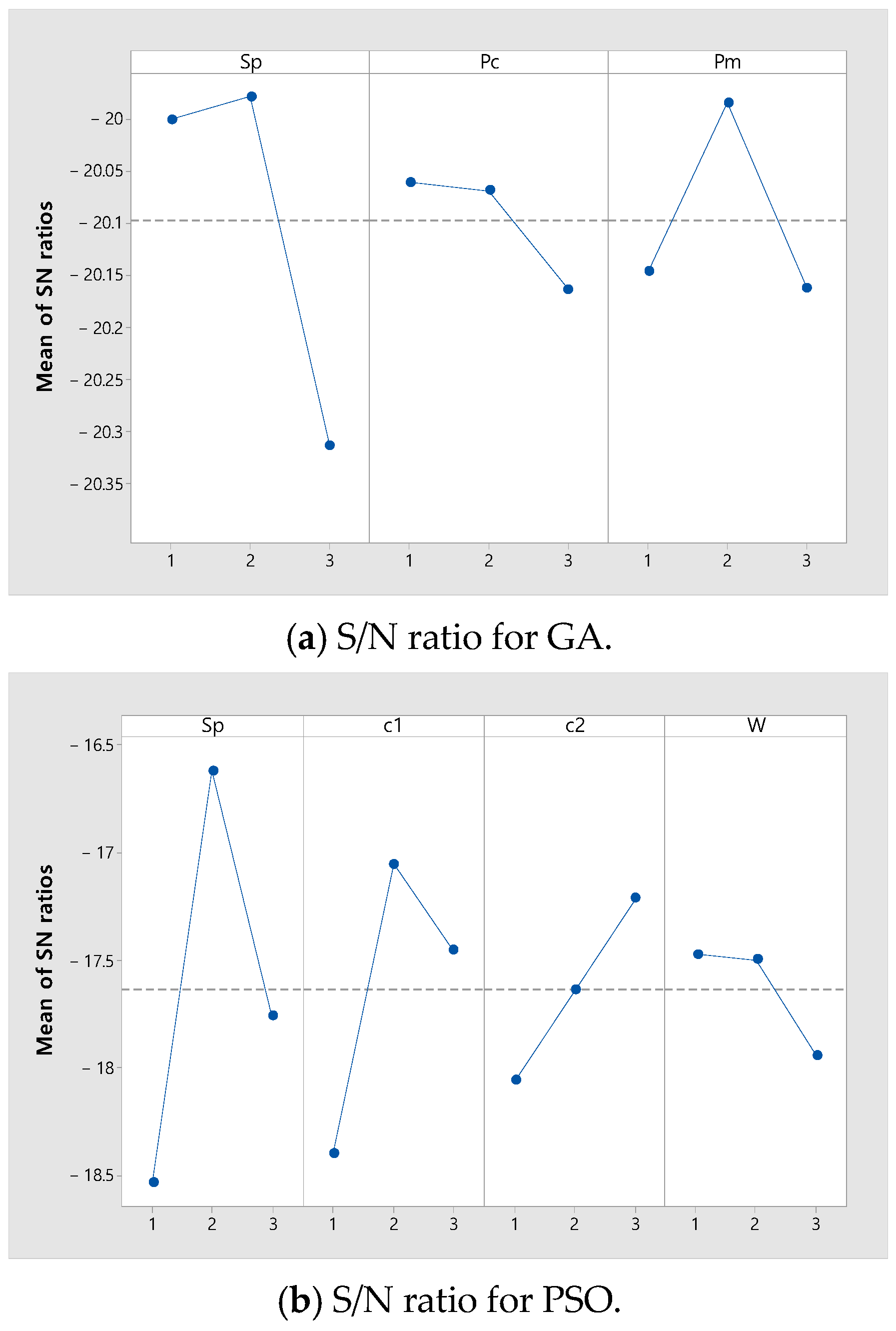
5.2. Calibration of Meta-Heuristic Parameters
5.3. Experimental Results in the Small-Size Problem Instances
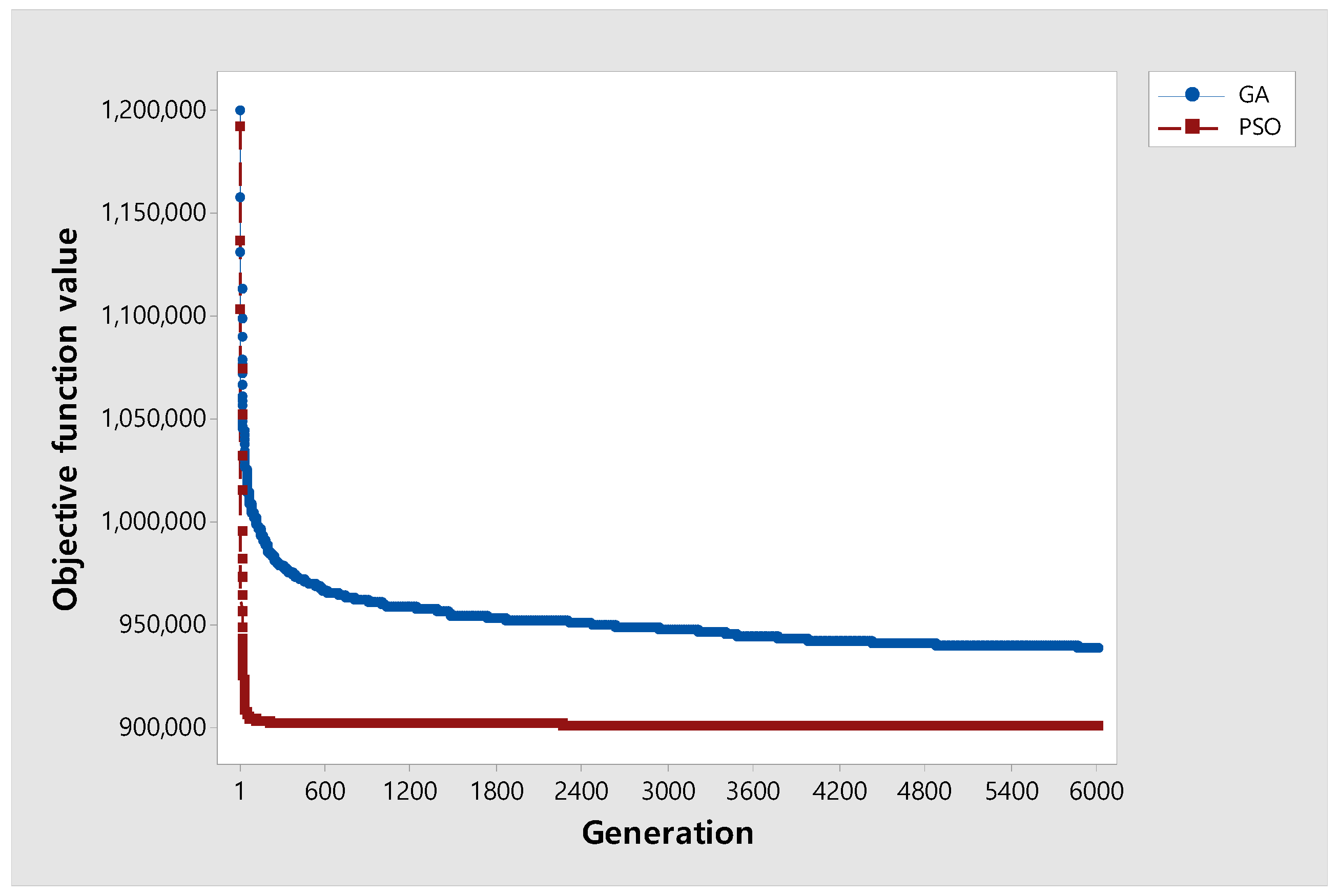
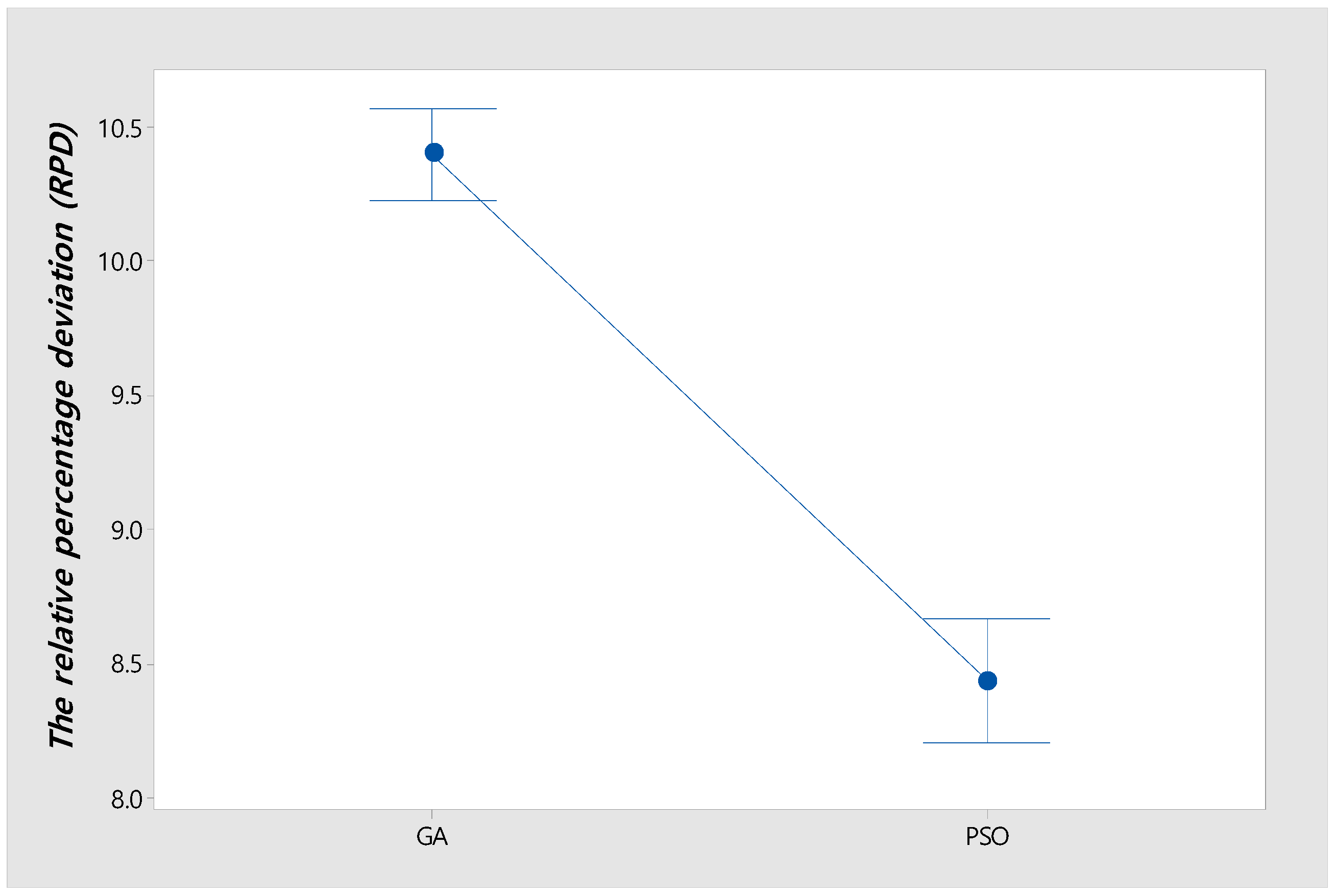
5.4. Experimental Results in Instances of Large-Size Problems
6. Sensitivity Analysis
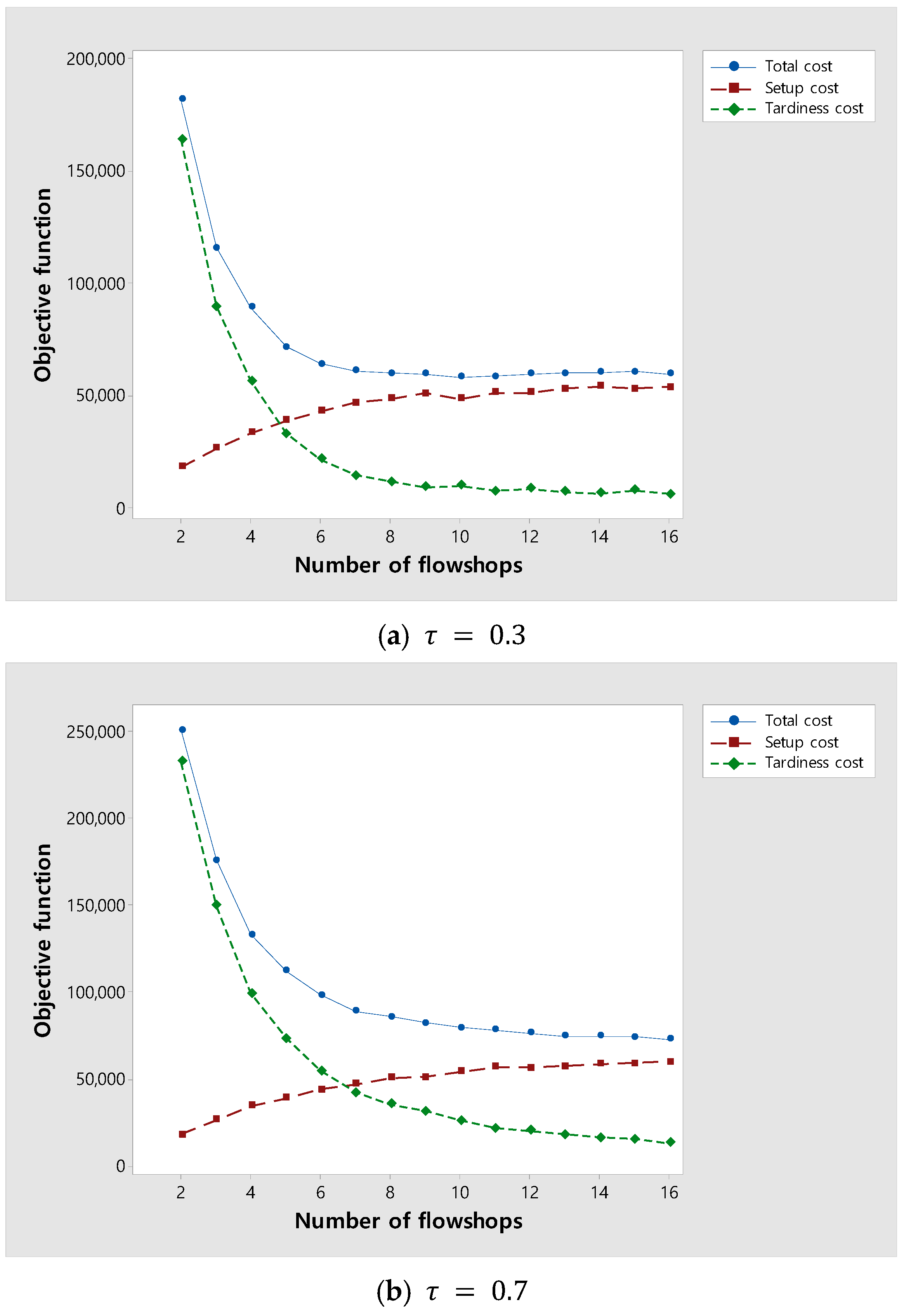
6.1. Changes in the Total, Setup, and Tardiness Costs as the Number of Flowshops Increases
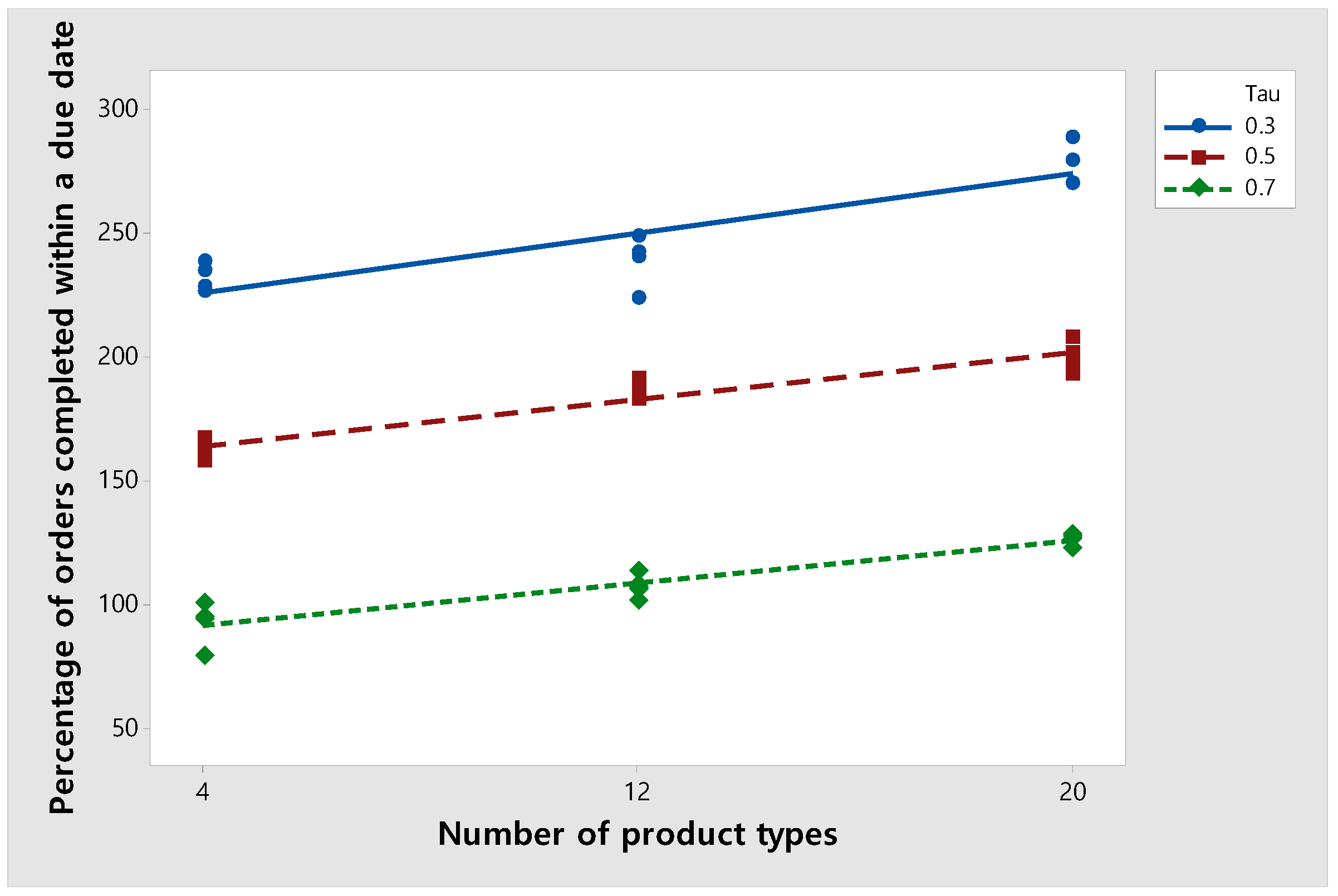
6.2. Change in the Percentage of Orders Completed Before the Due Date as the Number of Product Types Is Varied
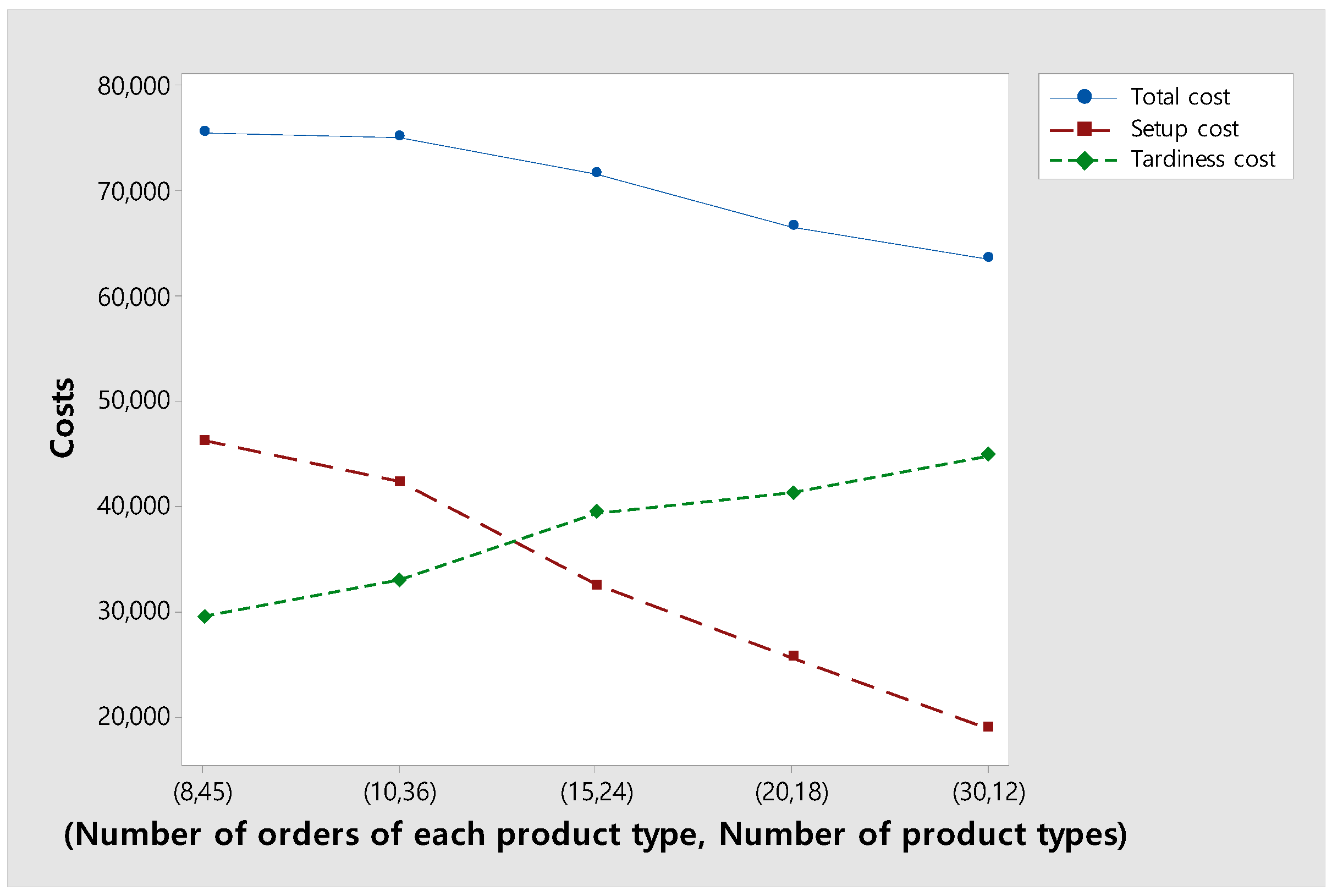
6.3. Change in the Total, Setup, and Tardiness Costs as the Number of Product Types Within a Fixed Number of Total Orders Decreases
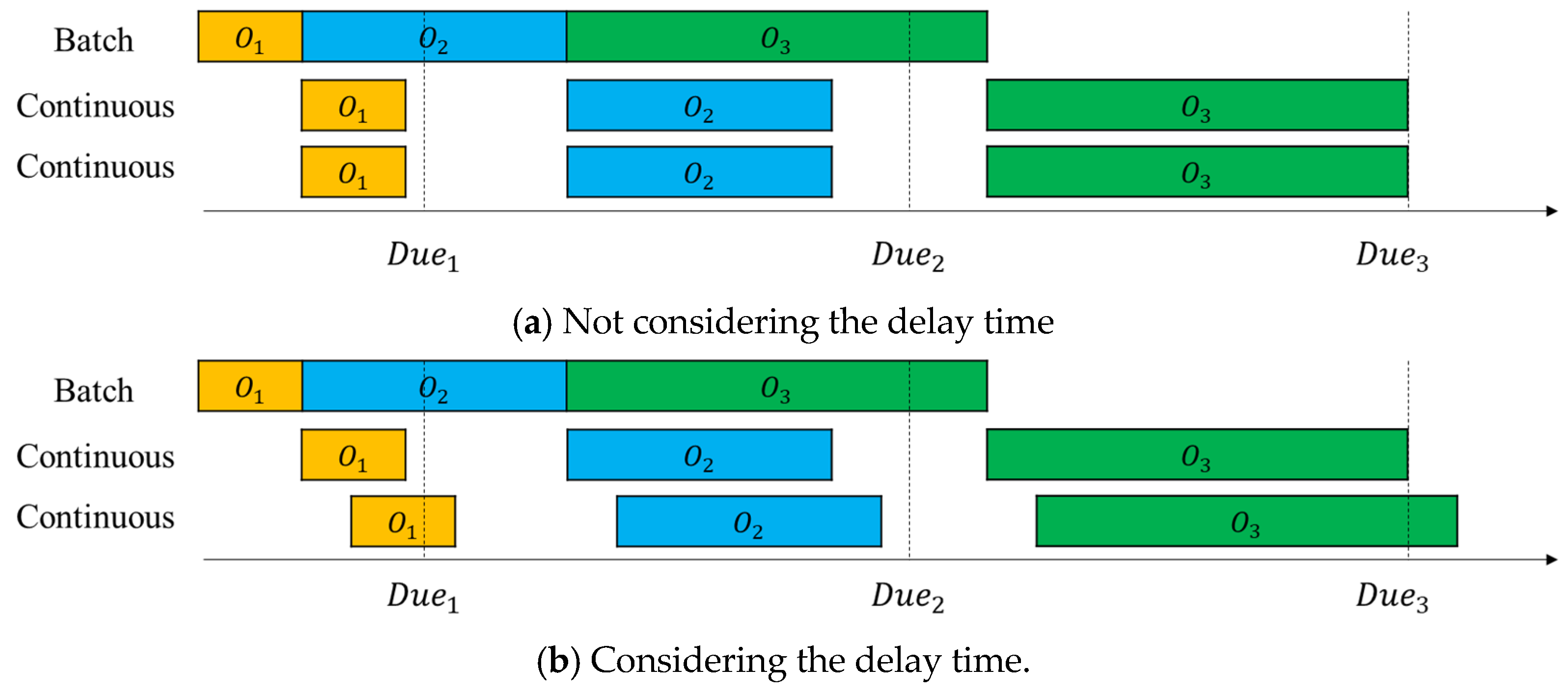
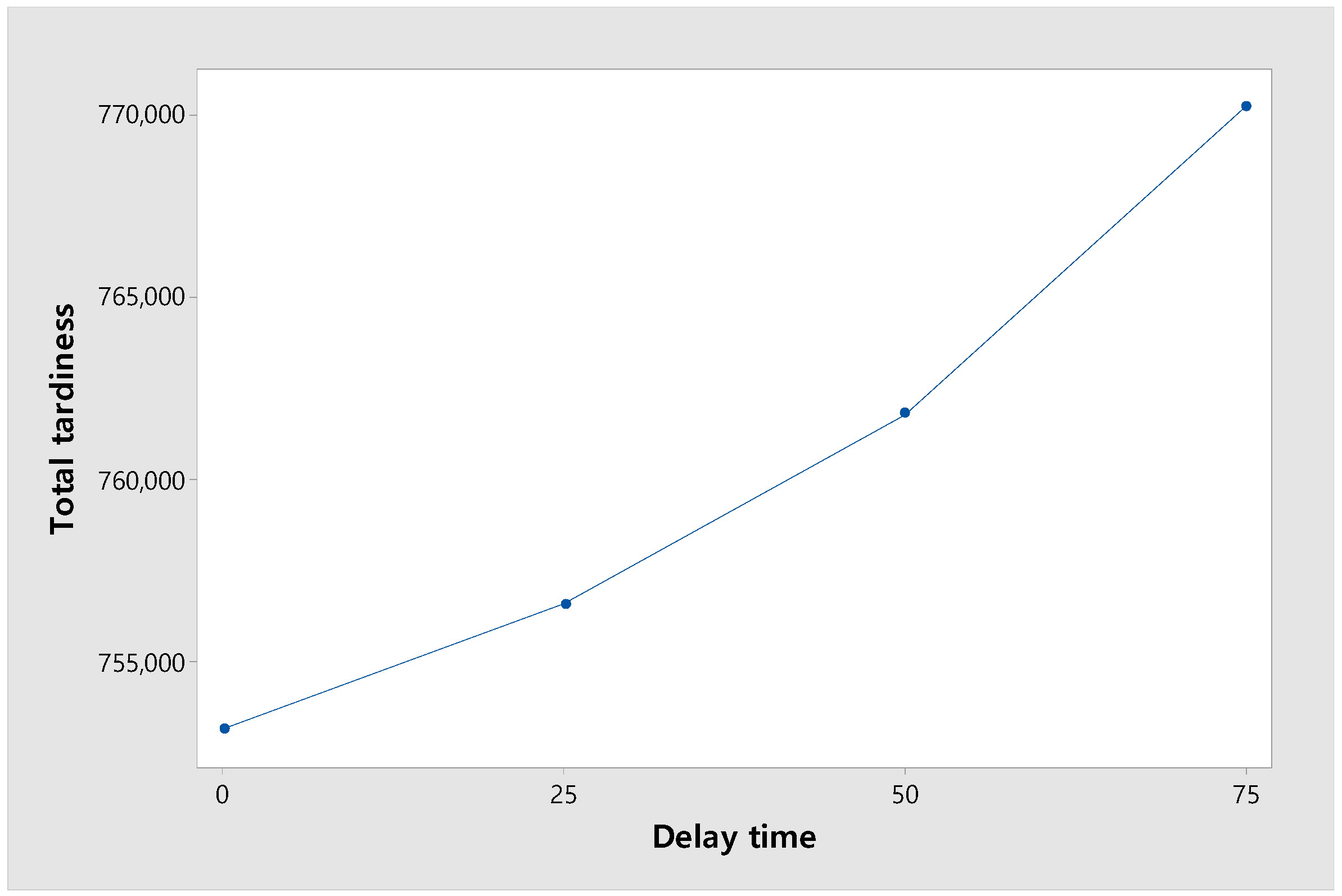
6.4. Change in the Effect of Delays Occurring in Real-World Continuous Processes on the Total Tardiness
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Parameters and Sets | |
| Set of flowshops | |
| Set of product types | |
| Set of production stages | |
| Set of batch production stages | |
| Set of continuous production stages | |
| Set of orders | |
| Type of order | |
| Number of orders for product type | |
| Processing time of production stage for product type | |
| Due date of order | |
| Sequence and production stage-dependent setup time when product type changes to in stage | |
| Processing speed on production stage of flowshop | |
| Decision Variables | |
| if order is assigned to flowshop ; otherwise | |
| if order immediately precedes order in flowshop ; otherwise | |
| The number of orders for product type assigned to flowshop | |
| Completion time of stage for order in flowshop | |
| Completion time of product type in stage of flowshop | |
| Tardiness time of order in stage of flowshop | |
| Setup time of first order in stage of flowshop | |
| Setup time of in stage of flowshop | |
References
- Kesik-Brodacka, M. Progress in Biopharmaceutical Development. Biotechnol. Appl. Biochem. 2018, 65, 306–322. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Farid, S.S.; Papageorgiou, L.G. Integrated Optimization of Upstream and Downstream Processing in Biopharmaceutical Manufacturing under Uncertainty: A Chance Constrained Programming Approach. Ind. Eng. Chem. Res. 2016, 55, 4599–4612. [Google Scholar] [CrossRef]
- Casola, G.; Sugiyama, H. Uncertainty-Conscious Methodology for Process Performance Assessment in Biopharmaceutical Drug Product Manufacturing. AIChE J. 2018, 64, 1272–1284. [Google Scholar] [CrossRef]
- Inada, Y. Continuous Manufacturing Development in Pharmaceutical and Fine Chemicals Industries; MITSUI & Co., Ltd.: Tokyo, Japan, 2019. [Google Scholar]
- Chatterjee, S. FDA Perspective on Continuous Manufacturing. In Proceedings of the IFPAC Annual Meeting, Baltimore, MD, USA, 22–25 January 2012; pp. 22–25. [Google Scholar]
- Hernandez, R. Continuous Manufacturing: A Changing Processing Paradigm. BioPharm Int. 2015, 28, 20–27. [Google Scholar]
- Lee, S.L.; O’Connor, T.F.; Yang, X.; Cruz, C.N.; Chatterjee, S.; Madurawe, R.D.; Moore, C.M.V.; Yu, L.X.; Woodcock, J. Modernizing Pharmaceutical Manufacturing: From Batch to Continuous Production. J. Pharm. Innov. 2015, 10, 191–199. [Google Scholar] [CrossRef]
- Kopanos, G.M.; Méndez, C.A.; Puigjaner, L. MIP-Based Decomposition Strategies for Large-Scale Scheduling Problems in Multi-product Multistage Batch Plants: A Benchmark Scheduling Problem of the Pharmaceutical Industry. Eur. J. Oper. Res. 2010, 207, 644–655. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Lee, T.; Lee, I.; Moon, I. A Heuristic-Embedded Scheduling System for a Pharmaceutical Intermediates Manufacturing Plant. Ind. Eng. Chem. Res. 2010, 49, 12646–12653. [Google Scholar] [CrossRef]
- Raaymakers, W.H.M.; Hoogeveen, J.A. Scheduling Multipurpose Batch Process Industries with No-Wait Restrictions by Simulated Annealing. Eur. J. Oper. Res. 2000, 126, 131–151. [Google Scholar] [CrossRef]
- Kabra, S.; Shaik, M.A.; Rathore, A.S. Multi-Period Scheduling of a Multi-Stage Multi-Product Biopharmaceutical Process. Comput. Chem. Eng. 2013, 57, 95–103. [Google Scholar] [CrossRef]
- Shaik, M.A.; Floudas, C.A. Improved Unit-Specific Event-Based Continuous-Time Model for Short-Term Scheduling of Continuous Processes: Rigorous Treatment of Storage Requirements. Ind. Eng. Chem. Res. 2007, 46, 1764–1779. [Google Scholar] [CrossRef]
- Castro, P.M.; Barbosa-Póvoa, A.P.; Matos, H.A.; Novais, A.Q. Simple Continuous-Time Formulation for Short-Term Scheduling of Batch and Continuous Processes. Ind. Eng. Chem. Res. 2004, 43, 105–118. [Google Scholar] [CrossRef]
- Vieira, M.; Pinto-Varela, T.; Barbosa-Póvoa, A.P. Optimal Scheduling of Multi-Stage Multi-Product Biopharmaceutical Processes Using a Continuous-Time Formulation. Comput. Aided Chem. Eng. 2014, 33, 301–306. [Google Scholar]
- Costa, A. Hybrid Genetic Optimization for Solving the Batch-Scheduling Problem in a Pharmaceutical Industry. Comput. Ind. Eng. 2015, 79, 130–147. [Google Scholar] [CrossRef]
- Jankauskas, K.; Papageorgiou, L.G.; Farid, S.S. Fast Genetic Algorithm Approaches to Solving Discrete-Time Mixed Integer Linear Programming Problems of Capacity Planning and Scheduling of Biopharmaceutical Manufacture. Comput. Chem. Eng. 2019, 121, 212–223. [Google Scholar] [CrossRef]
- Awad, M.; Mulrennan, K.; Donovan, J.; Macpherson, R.; Tormey, D. A Constraint Programming Model for Makespan Minimisation in Batch Manufacturing Pharmaceutical Facilities. Comput. Chem. Eng. 2022, 156, 107565. [Google Scholar] [CrossRef]
- Aguirre, A.M.; Liu, S.; Papageorgiou, L.G. Mixed Integer Linear Programming Based Approaches for Medium-Term Planning and Scheduling in Multi-product Multistage Continuous Plants. Ind. Eng. Chem. Res. 2017, 56, 5636–5651. [Google Scholar] [CrossRef]
- Vieira, M.; Pinto-Varela, T.; Barbosa-Póvoa, A.P. Production and Maintenance Planning Optimisation in Biopharmaceutical Processes under Performance Decay Using a Continuous-Time Formulation: A Multi-Objective Approach. Comput. Chem. Eng. 2017, 107, 111–139. [Google Scholar] [CrossRef]
- Vieira, M.; Pinto-Varela, T.; Moniz, S.; Barbosa-Póvoa, A.P.; Papageorgiou, L.G. Optimal Planning and Campaign Scheduling of Biopharmaceutical Processes Using a Continuous-Time Formulation. Comput. Chem. Eng. 2016, 91, 422–444. [Google Scholar] [CrossRef]
- Sevastyanov, S.; Lin, B.M.; Hwang, F.J. Makespan Minimization in Parallel Flow Shops. In Proceedings of the 9th Workshop on Models and Algorithms for Planning and Scheduling Problems, Abbey Rolduc, The Netherlands, 29 June–3 July 2009; Volume 1000, p. 244. [Google Scholar]
- Kovalyov, M.Y. Efficient Epsilon-Approximation Algorithm for Minimizing the Makespan in a Parallel Two-Stage System. Vesti Acad. Navuk Belarus. SSR Ser. Phiz.-Mat. Navuk 1985, 3, 119. [Google Scholar]
- Dolgui, A.; Kovalyov, M.Y.; Lin, B.M. Maximizing Total Early Work in a Distributed Two-Machine Flow-Shop. Nav. Res. Logist. (NRL) 2022, 69, 1124–1137. [Google Scholar] [CrossRef]
- Du, J.; Leung, J.Y.-T. Minimizing Total Tardiness on One Machine is NP-Hard. Math. Oper. Res. 1990, 15, 483–495. [Google Scholar] [CrossRef]
- Bhowmick, D.; Maniyan, P.; Saxena, A.; Ducq, Y. A Hybrid Genetic Algorithm for a Complex Cost Function for Flowshop Scheduling Problem. Int. J. Electron. Transp. 2011, 1, 64–75. [Google Scholar] [CrossRef]
- Meziani, N.; Boudhar, M.; Oulamara, A. PSO and Simulated Annealing for the Two-Machine Flowshop Scheduling Problem with Coupled-Operations. Eur. J. Ind. Eng. 2018, 12, 43–66. [Google Scholar] [CrossRef]
- Dantas, H.T.A.; Neto, R.F.T.; Sagawa, J.K. The Influence of Shelf Life on the Integrated Production Scheduling and Vehicle Routing Optimisation for Perishable Products. Eur. J. Ind. Eng. 2024, 18, 860–884. [Google Scholar] [CrossRef]
- Liao, C.J.; Tseng, C.T.; Luarn, P. A Discrete Version of Particle Swarm Optimization for Flowshop Scheduling Problems. Comput. Oper. Res. 2007, 34, 3099–3111. [Google Scholar] [CrossRef]
- Soewandi, H.; Elmaghraby, S.E. Sequencing on Two-Stage Hybrid Flowshops with Uniform Machines to Minimize Makespan. IIE Trans. (Inst. Ind. Eng.) 2003, 35, 467–477. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Manufacturing Environment | Production Method | Machine Velocity | Setup | Problem Size | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | (b) | (c) | (d) | (e) | (f) | (g) | (h) | (i) | (j) | (k) | (l) | |
| Kopanos et al. [8] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||
| Kim et al. [9] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||
| Raaymakers and Hoogeveen [10] | ✓ | ✓ | ✓ | ✓ | ||||||||
| Kabra et al. [11] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||
| Castro et al. [13] | ✓ | ✓ | ✓ | ✓ | ||||||||
| Vieira, et al. [14] | ✓ | ✓ | ✓ | ✓ | ||||||||
| Costa [15] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||
| Jankauskas et al. [16] | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| Awad et al. [17] | ✓ | ✓ | ✓ | ✓ | ||||||||
| Aguirre et al. [18] | ✓ | ✓ | ✓ | ✓ | ||||||||
| Vieira et al. [19] | ✓ | ✓ | ✓ | ✓ | ||||||||
| Vieira et al. [20] | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| Our study | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| Small-size instances | {2,3} | {3,4} | {2,3,4} | ) | |||
| Large-size instances | {5,6,7} | {10,11,12} | {30,35,40} |
| Level | GA | PSO | |||||
|---|---|---|---|---|---|---|---|
| 1 | 0.1 | 0.3 | 1 | 1 | 0.3 | ||
| 2 | 0.2 | 0.5 | 2 | 2 | 0.5 | ||
| 3 | 0.3 | 0.7 | 3 | 3 | 0.7 | ||
| MILP | GA | PSO | ||||||
|---|---|---|---|---|---|---|---|---|
| CPU | APD(%) | CPU | APD (%) | CPU | ||||
| 2 | 3 | 2 | 607.54 | 1.31 | 0.00 | 8.93 | 0.02 | 6.09 |
| 3 | 661.03 | 0.06 | 0.92 | 5.29 | 0.92 | 3.75 | ||
| 4 | 967.18 | 18.61 | 3.35 | 18.86 | 4.03 | 12.92 | ||
| 4 | 2 | 780.72 | 2.02 | 1.73 | 10.96 | 1.77 | 7.67 | |
| 3 | 883.3 | 279.56 | 3.05 | 18.83 | 3.77 | 13.06 | ||
| 4 | N/A | 3600.00 | N/A | 32.83 | N/A | 22.24 | ||
| 3 | 3 | 2 | 498.47 | 1.58 | 0.00 | 9.81 | 0.22 | 6.95 |
| 3 | 642.26 | 0.17 | 0.64 | 6.03 | 0.69 | 4.39 | ||
| 4 | 892.67 | 73.61 | 2.57 | 20.68 | 3.07 | 14.5 | ||
| 4 | 2 | 718.3 | 4.05 | 0.00 | 12.32 | 0.60 | 8.78 | |
| 3 | 808.76 | 356.2 | 3.47 | 18.73 | 4.75 | 14.26 | ||
| 4 | N/A | 3600.00 | N/A | 35.55 | N/A | 23.73 | ||
| avg. | 661.43 | 1.57 | 16.57 | 1.98 | 11.54 | |||
| GA | PSO | GA | PSO | GA | PSO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPD (%) | CPU | RPD (%) | CPU | RPD (%) | CPU | RPD (%) | CPU | RPD (%) | CPU | RPD (%) | CPU | |||
| 5 | 10 | 30 | 23.94 | 47.23 | 21.13 | 44.53 | 8.87 | 47.20 | 6.17 | 44.28 | 8.33 | 47.49 | 7.20 | 44.09 |
| 35 | 19.51 | 46.65 | 17.81 | 44.87 | 12.97 | 46.84 | 11.64 | 44.04 | 6.44 | 46.86 | 5.33 | 44.13 | ||
| 40 | 20.90 | 46.28 | 20.35 | 44.38 | 18.81 | 46.20 | 14.84 | 44.12 | 8.64 | 46.46 | 7.68 | 43.95 | ||
| 11 | 30 | 22.75 | 70.39 | 17.10 | 66.41 | 16.39 | 70.58 | 15.04 | 66.62 | 4.82 | 71.05 | 3.30 | 66.12 | |
| 35 | 13.44 | 69.59 | 12.56 | 66.47 | 11.29 | 69.36 | 9.58 | 65.69 | 5.16 | 69.84 | 3.70 | 65.69 | ||
| 40 | 27.80 | 68.81 | 23.37 | 65.85 | 13.02 | 68.51 | 13.06 | 65.63 | 8.26 | 69.07 | 6.63 | 65.61 | ||
| 12 | 30 | 15.13 | 99.95 | 11.56 | 94.28 | 14.99 | 99.67 | 11.10 | 93.52 | 7.06 | 100.91 | 4.04 | 93.94 | |
| 35 | 13.25 | 98.00 | 9.97 | 93.51 | 11.24 | 98.11 | 8.81 | 92.91 | 8.26 | 98.72 | 5.69 | 92.88 | ||
| 40 | 24.32 | 96.82 | 17.47 | 92.96 | 17.17 | 97.00 | 16.45 | 92.73 | 8.32 | 97.60 | 6.89 | 93.18 | ||
| 6 | 10 | 30 | 22.50 | 60.22 | 17.39 | 56.72 | 9.80 | 60.19 | 6.18 | 56.30 | 6.34 | 60.20 | 4.90 | 56.56 |
| 35 | 18.11 | 59.20 | 15.93 | 56.44 | 10.95 | 59.48 | 10.25 | 56.13 | 6.27 | 59.42 | 5.94 | 56.44 | ||
| 40 | 18.77 | 58.77 | 18.61 | 56.50 | 12.36 | 58.89 | 11.55 | 56.23 | 7.81 | 58.82 | 6.42 | 56.08 | ||
| 11 | 30 | 18.14 | 88.94 | 14.38 | 83.82 | 8.19 | 89.47 | 6.09 | 83.50 | 5.00 | 89.21 | 3.76 | 83.74 | |
| 35 | 12.44 | 87.04 | 12.56 | 83.27 | 10.70 | 87.68 | 8.88 | 82.37 | 5.69 | 87.61 | 3.73 | 82.43 | ||
| 40 | 17.29 | 85.94 | 19.26 | 82.90 | 12.39 | 86.93 | 7.61 | 82.75 | 6.67 | 86.27 | 6.80 | 82.53 | ||
| 12 | 30 | 21.94 | 128.49 | 17.67 | 120.53 | 17.41 | 127.85 | 12.76 | 119.95 | 5.57 | 128.93 | 3.11 | 119.97 | |
| 35 | 17.36 | 125.94 | 13.38 | 118.78 | 8.42 | 125.83 | 5.23 | 119.40 | 7.09 | 126.12 | 4.87 | 119.08 | ||
| 40 | 27.95 | 123.72 | 19.77 | 118.19 | 11.67 | 124.13 | 10.75 | 119.57 | 5.81 | 124.60 | 4.62 | 118.09 | ||
| 7 | 10 | 30 | 16.71 | 75.33 | 15.13 | 71.40 | 14.24 | 75.48 | 11.75 | 70.74 | 5.36 | 75.38 | 3.76 | 70.66 |
| 35 | 26.77 | 76.49 | 21.31 | 69.75 | 11.45 | 74.17 | 9.91 | 70.10 | 11.94 | 74.43 | 9.31 | 70.84 | ||
| 40 | 23.78 | 73.43 | 19.46 | 70.71 | 10.02 | 73.30 | 7.71 | 70.18 | 5.29 | 73.37 | 3.30 | 70.37 | ||
| 11 | 30 | 13.04 | 112.75 | 9.60 | 106.33 | 9.09 | 113.50 | 6.48 | 106.31 | 6.44 | 113.79 | 5.82 | 105.85 | |
| 35 | 18.99 | 110.81 | 14.51 | 105.09 | 14.66 | 111.02 | 12.32 | 105.19 | 7.78 | 111.58 | 5.55 | 104.67 | ||
| 40 | 22.23 | 109.81 | 17.38 | 105.28 | 11.70 | 109.62 | 9.34 | 104.49 | 7.62 | 109.83 | 4.46 | 103.88 | ||
| 12 | 30 | 16.10 | 161.78 | 11.97 | 151.90 | 8.22 | 160.70 | 4.55 | 150.95 | 3.96 | 160.76 | 2.09 | 150.96 | |
| 35 | 16.61 | 157.53 | 10.56 | 149.16 | 9.27 | 157.04 | 6.99 | 149.06 | 7.19 | 157.32 | 4.89 | 148.75 | ||
| 40 | 16.04 | 154.81 | 11.94 | 147.50 | 9.62 | 154.71 | 5.76 | 148.35 | 8.46 | 154.79 | 5.63 | 147.32 | ||
| Average | 19.47 | 92.40 | 16.01 | 87.69 | 12.03 | 92.35 | 9.66 | 87.45 | 6.87 | 92.61 | 5.16 | 87.33 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.J.; Kim, H.J.; Kim, B.S. Population-Based Search Algorithms for Biopharmaceutical Manufacturing Scheduling Problem with Heterogeneous Parallel Mixed Flowshops. Mathematics 2025, 13, 485. https://doi.org/10.3390/math13030485
Kim YJ, Kim HJ, Kim BS. Population-Based Search Algorithms for Biopharmaceutical Manufacturing Scheduling Problem with Heterogeneous Parallel Mixed Flowshops. Mathematics. 2025; 13(3):485. https://doi.org/10.3390/math13030485
Chicago/Turabian StyleKim, Yong Jae, Hyun Joo Kim, and Byung Soo Kim. 2025. "Population-Based Search Algorithms for Biopharmaceutical Manufacturing Scheduling Problem with Heterogeneous Parallel Mixed Flowshops" Mathematics 13, no. 3: 485. https://doi.org/10.3390/math13030485
APA StyleKim, Y. J., Kim, H. J., & Kim, B. S. (2025). Population-Based Search Algorithms for Biopharmaceutical Manufacturing Scheduling Problem with Heterogeneous Parallel Mixed Flowshops. Mathematics, 13(3), 485. https://doi.org/10.3390/math13030485