1. Introduction
With the rapid advancement of technology and the increasing complexity of engineering practice, the scale and complexity of optimization challenges are progressively escalating. These practical optimization issues typically feature multimodality and high dimensionality, accompanied by a multitude of local optima and tight, highly nonlinear constraints, such as feature selection [
1], image processing [
2], wireless sensor networks [
3], UAV route planning [
4], and job shop scheduling problems [
5]. Conventional optimization techniques, including the gradient descent, Newton method, and conjugate gradient algorithms, typically solve problems by constructing precise mathematical models. These classical algorithms are computationally inefficient and computationally intensive, making it a powerless choice to utilize traditional approaches to address optimization issues [
6]. Metaheuristic algorithms (MAs) are widely regarded as a common approach to solve optimization issues because of their flexibility, practicality, and robustness [
7].
MAs are divided into four categories: evolutionary algorithms (EAs), swarm intelligence algorithms (SIAs), optimization algorithms derived from human life activities, and optimization algorithms based on physical law [
8]. The categorization of MAs is presented in
Figure 1.
Natural evolution processes inspire the design of the EAs. The genetic algorithm (GA) [
9] is among the most famous and classic evolutionary algorithms, and its variants are continuously studied and proposed [
10,
11]. GAs are founded on Darwin’s theory of natural selection, where the optimal population is arrived at through iterative processes involving selection, crossover, and mutation. This category of algorithms is also extensive in scope; The coronavirus optimization algorithm (COA) [
12] models the spread of the coronavirus starting from patient zero, taking into account the probability of reinfection and the implementation of social measures. In addition, differential evolutionary algorithms (DEs) [
13], the invasive tumor growth optimization algorithm (ITGO) [
14], the love evolution algorithm (LEA) [
15], and so on belong to the category of EAs.
The SIAs are primarily inspired by the behaviors of biological groups, applying the characteristics of certain animals in nature, such as their survival strategies and behavioral patterns, to the development of these algorithms. An example is particle swarm optimization (PSO), which draws inspiration from the predatory behavior of birds [
16]. In a standard PSO algorithm, one updates the particle’s position using both the globally optimal particle’s position and its own optimal (local) position. The movement of the entire swarm transitions from a disordered state to an ordered one, ultimately converging with all particles clustering at the optimal position. Dorigo introduced the ant colony optimization (ACO) algorithm in 1992, which draws inspiration from how ants forage [
17]. The ACO algorithm mimics the process in which ants leave pheromone trails while foraging, guiding other ants in selecting their paths. In this process, the shortest route was determined according to greatest pheromone concentration. The SIAs also include the gray wolf algorithm (GWO) [
18], Harris hawk algorithm (HHO) [
19], whale optimization algorithm (WOA) [
20], sparrow search algorithm (SSA) [
21], sea-horse optimizer (SHO) [
22], seagull optimization algorithm (SOA) [
23], dung beetle optimizer (DBO) [
24], nutcracker optimizer algorithm (NOA) [
25], and marine predators algorithm (MPA) [
26].
The third kind of metaheuristics is optimization algorithms based on human life activities, which is inspired by human production processes and daily life. Teaching–Learning-Based Optimization (TLBO) [
27] is the most well-known algorithm of this type. The TLBO simulates the conventional process of teaching. The entire optimization process encompasses two stages. During the teacher stage, each student studies from the best individual. At the learner stage, each student absorbs knowledge from their peers in a random process. The inspiration for the political algorithm (PO) [
28] comes from people’s political behavior. The volleyball premier league algorithm (VPLA) [
29] simulates the interaction and the dynamic competition between diverse volleyball teams. The queuing search algorithm (QSA) [
30] draws inspiration from human queuing activities.
As the last type of MAs, optimization algorithms grounded in physical laws are inspired by algorithms abstracted from mathematics and physics. For instance, simulated annealing (SA) [
31], the energy valley optimizer (EVO) [
32], the light spectrum optimizer (LSO) [
33], the gravitational search algorithm (GSA) [
34], central force optimization (CFO) [
35], and the sine–cosine algorithm (SCA) [
36] belong to this category.
Among the many MAs available, the Kepler optimization algorithm (KOA) [
37] is an optimization algorithm grounded in physical laws. The test results of KOA in multiple test sets demonstrate that it is an effective algorithm for dealing with many optimization problems, proving its superior performance. The KOA shows outstanding performance thanks to several key mechanisms: it uses the planetary orbital velocity adjustment mechanism to achieve a balance among exploration and exploitation, simulates the characteristics of the orbital motion of planets in the solar system by dynamically adjusting the search direction to avoid local optimal, and adopts an elite mechanism to ensure that the planets and the sun reach the most favorable position. Currently, the KOA has been utilized to address many practical issues in real life. Hakmi and his team [
38] adopted the KOA to address the combined heat and power units’ economic dispatch in power systems. Houssein et al. [
39] developed an improved KOA (I-KOA) and applied it to feature selection in liver disease classification. In the field of CXR image segmentation at different threshold levels, Abdel Basset and colleagues [
40] used the KOA for optimization. In addition, the KOA has also been applied in the field of photovoltaic research [
41,
42]. After a comprehensive review and comparative analysis of the relevant academic literature, apparently, the KOA shows exceptional performance and competitiveness in addressing complex optimization issues.
However, according to the No Free Lunch (NFL) theorem [
43], no single MA can effectively address every optimization issue. This motivates us to continuously innovate and refine existing metaheuristic algorithms to address diverse problems. Therefore, the KOA has been undergoing continuous improvements since its introduction, with the aim of maximizing its capability to solve various engineering application problems. Regarding the shortcomings of theKOA, this paper continues to explore new improvement strategies based on previous work and introduces a multi-strategy fusion KOA algorithm (MKOA).
1.1. Paper Contributions
The summary is listed below:
- •
A multi-strategy fusion Kepler optimization algorithm (MKOA) is proposed.
- •
In the testing of CEC2017 and CEC2019, the proposed MKOA is validated to be better than comparison algorithms.
- •
Three real-world engineering optimization challenges are addressed using the proposed algorithm, which highlights the advantages of the algorithm in engineering practice.
1.2. Paper Structure
The layout is outlined below. In
Section 2, the principles of the KOA are introduced. In
Section 3, the MKOA is proposed, and four improved strategies are introduced. The statistical results of the MKOA in CEC2017 and CEC2019 are presented in
Section 4. The implementation of the MKOA in three practical engineering optimization scenarios is discussed in
Section 5. Finally, the last chapter gives a summary.
3. The Proposed Multi-Strategy Fusion Kepler Optimization Algorithm (MKOA)
Resembling other metaheuristic algorithms, the KOA also faces challenges such as premature convergence as well as a weak global search ability, especially when addressing high-dimensional and complicated issues [
44]. Therefore, to improve these defects of the KOA, this article integrates the Good Point Set strategy, the Dynamic Opposition-Based Learning strategy, the Normal Cloud Model strategy, and the New Exploration strategy to amplify the original KOA. The strategies proposed will be discussed thoroughly in the following sections in this part.
3.1. Good Point Set Strategy
In MAs, the algorithm’s global search ability is influenced by the location of the initial population. The traditional Kepler optimization algorithm (KOA) utilizes the random method for population initialization, which leads to drawbacks such as uneven population distribution. This paper introduces a Good Point Set (GPS) strategy to improve the KOA by ensuring the initial solution is evenly distributed across the search domain.
The concept of GPS was introduced by Hua and Wang in 1978 [
45]. This strategy enables the search space to be as uniformly covered as possible, even with a relatively small number of sample points [
46]. Therefore, it has been used by many scholars in population initialization.
The basic definition of the GPS strategy is as given below: Define
as a standard cube with side length one in an
s-dimensional Euclidean space. If
, which may be represented as
where
is the point set, as well as if
deviation satisfies Equation (
27), it is called Good Point Set.
is a fixed value that is only related to
and
r;
denotes the decimal fraction of the value;
n denotes the sample size; and
r is computed as follows:
where
p is the smallest prime that satisfies
.
The GPS strategy is applied to population initialization. The initialization equation of the
individual is given by
Figure 2 and
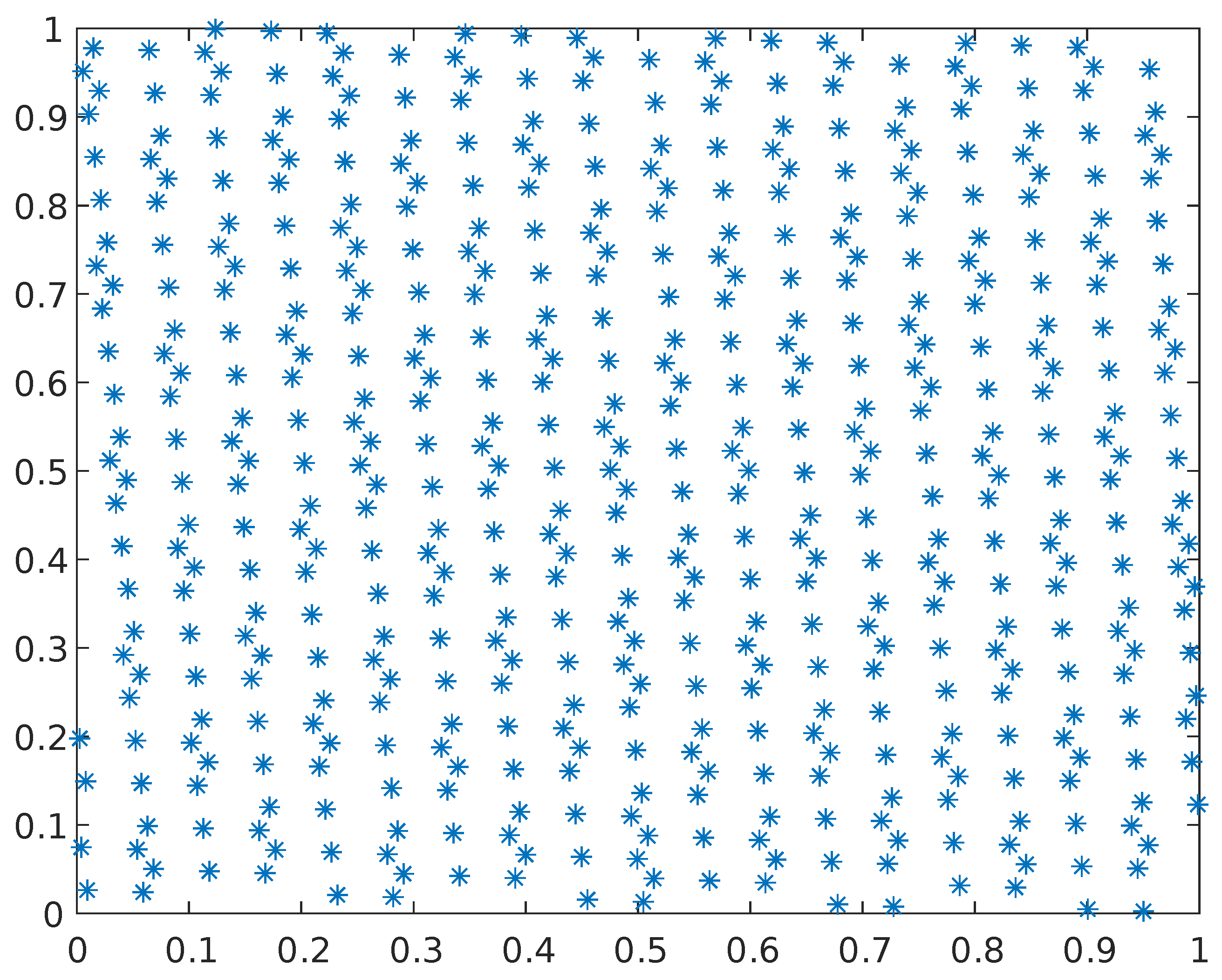
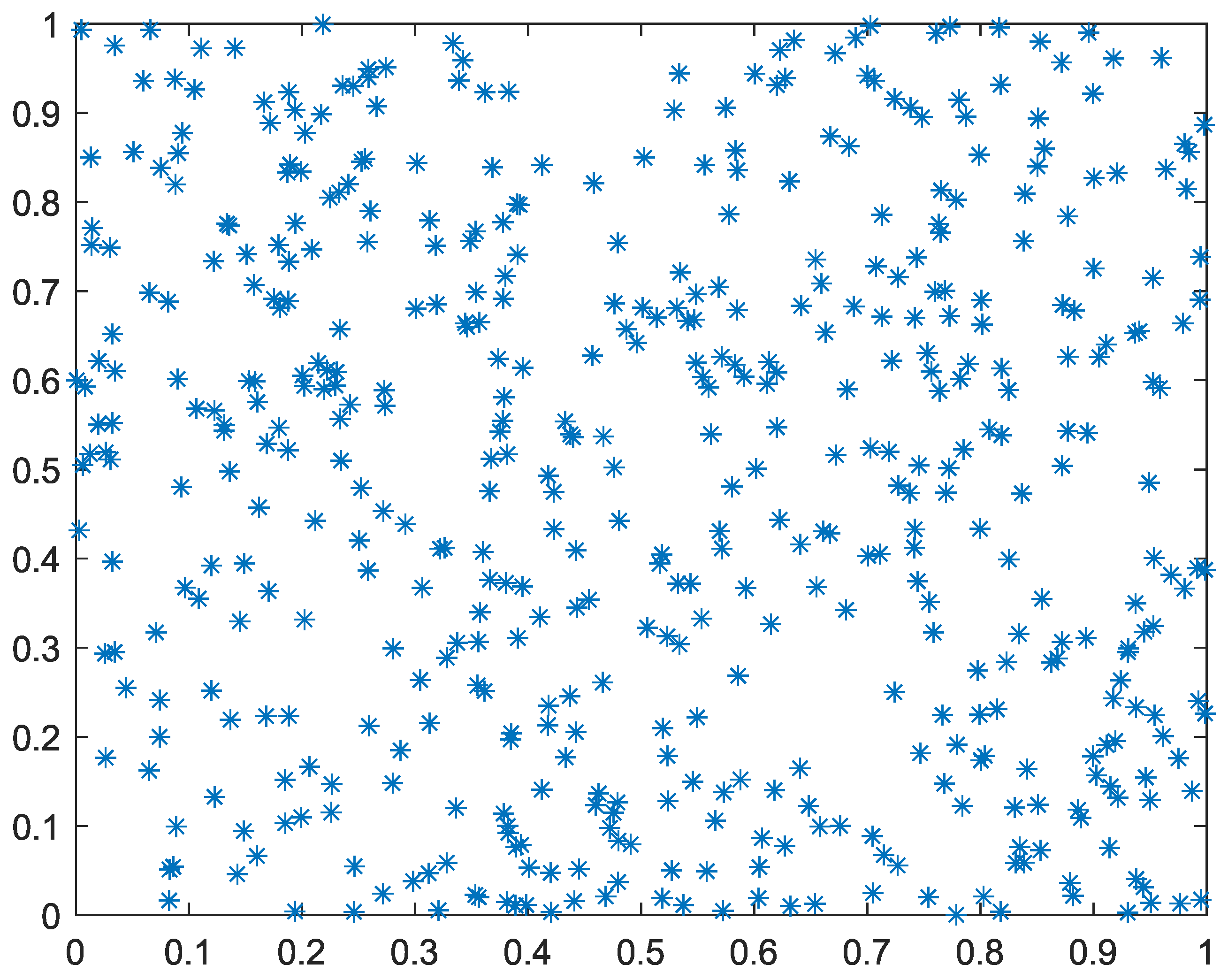
Figure 3, respectively, show the comparison between the two-dimensional point sets generated by the GPS method and the random method when the population size is 500.
Figure 4 illustrates a frequency distribution histogram of the initialized population using the two methods. As shown in the figure, the GPS strategy is more uniform than the randomly generated strategy. In addition, when the sample size is consistent, the distribution of the GPS strategy is similarly consistent, which means that the GPS strategy is stable.
3.2. Dynamic Opposition-Based Learning Strategy
Tizhoosh [
47] came up with Opposition-Based Learning (OBL) in 2005, drawing inspiration from the idea of opposition. Until now, the OBL strategy and its enhancements have been widely applied in various optimization algorithms [
48,
49,
50]. The OBL strategy has the following definition:
where
and
are the original solution and the opposite solution, respectively; the symbols
and
represent the lower as well as the upper limit of the search domain.
Between the initial solution and the reverse solution, the OBL strategy will select the solution with a higher fitness value for the next population iteration. Although it can effectively improve the diversity as well as the quality of the population, the constant distance maintained between the original solution and the generated opposite solution results in a lack of certain randomness. Therefore, it may hinder the optimization of the algorithm throughout the entire iteration process. To address the shortcoming of the OBL strategy, this study proposes a Dynamic Opposition-Based Learning (DOBL) strategy to further improve the diversity as well as the quality of the population.
The DOBL strategy [
49] introduces a dynamic boundary mechanism grounded in the original OBL strategy, thereby improving the problem of insufficient randomness in the original OBL strategy. The mathematical model of DOBL strategy is given by
where
and
, respectively, represent the reverse solution and the original solution for the
j-th dimension of the
i-th vector during the
t-th iteration;
and
, respectively, represent the lower and upper values in the
j-th dimension during the
t-th iteration. The mathematical models of
and
are shown as
The KOA’s search phase is altered using the DOBL strategy to boost the diversity as well as the quality of the population. In the KOA, the DOBL strategy simultaneously considers the original solution and reverse solution. Sorting according to fitness values, we will select only the top N optimal solutions. Algorithm 2 presents the pseudocode of DOBL.
| Algorithm 2 DOBL strategy Pseudocode |
| Input: D, N, X // D: dimensionality; N: population size; X: original solutions |
| 1: | for
do |
| 2: | for do |
| 3: | // Generate opposite solution through Equation (31) |
| 4: | end for |
| 5: | end for |
| 6: | Evaluate population fitness values (Including the original solution as well as the opposite solution) |
| 7: | Select N best individuals from set |
| Output: X |
3.3. Normal Cloud Model Strategy
In evaluating the significance of the current best individual position, we found that in the KOA, the information utilization of the optimal solution is not sufficient, which often makes the KOA prone to local optima. Thus, this study introduces a Normal Cloud Model (NCM) strategy [
51] to perturb the current best solution. The principle is to perturb the optimal individual by utilizing the randomness and fuzziness of the NCM strategy to extend the search space of the KOA. Its definitions are given below.
Suppose X is a quantitative domain, and that F is a qualitative notion defined over X. x is an element of X and x represents a random instantiation of notion F. is the degree of certainty of x with respect to F. . So, x is referred to as a cloud droplet, and the distribution of x on the entire quantitative domain X is called a cloud. In order to reflect the uncertainty of the cloud, we use three parameters to explain it: expectation, ; entropy, ; and hyper-entropy, . The explicit explanations are detailed below:
- (1)
represents the anticipated distribution of a cloud droplet.
- (2)
denotes the uncertainty of cloud drop, and reflects the range of distribution and the spread of the cloud droplet.
- (3)
is the uncertainty quantification of entropy, which describes cloud thickness and reflects the degree to which the qualitative concept deviates from a normal distribution.
If
x satisfies
, where
, and
, the degree of certainty
y for the qualitative variable
x is calculated as follows:
At this point, the distribution of
x over the entire quantitative domain
X is called a normal cloud.
y denotes the anticipated curve for the NCM strategy.
Figure 5 illustrates images of normal clouds with different parameter features. From
Figure 5a,b, it is possible to observe that with the increase in
, the dispersion of cloud droplets also simultaneously increases; from
Figure 5a,c, it is possible to observe that as
increases, the distribution range of cloud droplets also expands. Therefore,
Figure 5 indirectly reveals the fuzziness as well as the randomness characteristics of cloud droplets.
The process of converting qualitative concepts to quantitative representations is called a forward normal cloud generator (NCG). By setting appropriate parameters, the NCG generates cloud droplets that fundamentally follow a normal distribution. The process of cloud droplet generation by means of a cloud generator is outlined below:
In Equation (
34),
represents the anticipated number of cloud droplets. Introducing the above NCM into the KOA perturbs the optimal individual. The NCG mathematical model is represented by Equation (
35):
where
is the optimal solution of the population during the
t-th iteration, and
D refers to the dimension of the optimal individual.
3.4. New Exploration Strategy
We apply a new location-update strategy to the original KOA. This strategy effectively balances local and global exploration by integrating the current solution, optimal solution, and suboptimal solution, thereby improving the convergence accuracy as well as maintaining its convergence speed.
The modified Equations (
12) and (
21) are described by Equations (
36) and (
37), respectively.
where
is defined as follows:
where
represents the current solution;
denotes the optimal solution; and
represents the suboptimal solution.
3.5. The MKOA Implementation Process
The MKOA first initializes the population using Good Point Set, enhancing population diversity and introducing a new OBL strategy, “Dynamic Opposition-Based Learning”, to enhance its global exploration ability. Additionally, the NCM method is utilized for the current best solution, introducing perturbation and mutation to enhance local escape capability. Finally, the KOA uses a new position-update strategy to enhance solution quality. All in all, Algorithm 3 presents the pseudocode of the MKOA, and the flow chart of the MKOA appears in
Figure 6.
| Algorithm 3 Pseudocode of the MKOA |
| Input: N, , , , |
| 1: | Initialization the population by introducing Good Point Set through Equation (29) |
| 2: | Evaluation fitness values for initial population |
| 3: | Identify the current best solution |
| 4: | while t < do |
| 5: | Update , , , and |
| 6: | Update the population location using DOBL strategy by Equation (31) |
| 7: | for do |
| 8: | Calculate using Equation (6) |
| 9: | Calculate using Equation (4) |
| 10: | Calculate using Equation (36) |
| 11: | Generates two independent random variables, denoted as r and |
| 12: | if r > then |
| 13: | Use Equation (20) to update planets’ positions |
| 14: | else |
| 15: | Use Equation (37) to update planets’ positions |
| 16: | end if |
| 17: | Apply an elitist mechanism to select the optimal position, using Equation (25) |
| 18: | end for |
| 19: | Evaluation fitness values and determine the best solution |
| 20: | Disturb using the NCM strategy by Equation (35) |
| 21: | t = t + 1; |
| 22: | end while |
| Output: |
6. Conclusions and Future Perspectives
This paper proposes a multi-strategy fusion Kepler optimization algorithm (MKOA). Firstly, the MKOA first initializes the population using Good Point Set, enhancing population diversity, and introduces the DOBL strategy, to enhance its global exploration capability. In addition, the MKOA applies the NCM strategy to the optimal individual, improving its convergence accuracy and speed. In the end, we introduce a new position-update strategy to balance local and global exploration, helping the KOA escape local optima.
To analyze the capabilities of the MKOA, we mainly use the CEC2017 and CEC2019 test suites for testing. The data indicate that the MKOA has more advantages than other algorithms in terms of practicality and effectiveness. Additionally, to test the practical application potential of the MKOA, three classical engineering cases are selected in this paper. The result reveal that the MKOA demonstrates strong applicability in engineering applications (
Table A1).
In the future, the MKOA will be used in addressing more engineering issues, such as UAV path planning [
59], wireless sensor networks [
60], and disease prediction [
61].


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}