Abstract
In federated learning, secure aggregation is essential to protect the confidentiality of local model updates, ensuring that the server can access only the aggregated result without exposing individual contributions. However, conventional secure aggregation schemes lack mechanisms that allow participating nodes to verify whether the aggregation has been performed correctly, thereby raising concerns about the integrity of the global model. To address this limitation, we propose V-MHESA (Verifiable Masking-and-Homomorphic Encryption–combined Secure Aggregation), an enhanced protocol extending our previous MHESA scheme. V-MHESA incorporates verification tokens and shared-key management to simultaneously ensure verifiability, confidentiality, and authentication. Each node generates masked updates using its own mask, the server’s secret, and a node-only shared random nonce, ensuring that only the server can compute a blinded global update while the actual global model remains accessible solely to the nodes. Verification tokens corresponding to randomly selected model parameters enable nodes to efficiently verify the correctness of the aggregated model with minimal communication overhead. Moreover, the protocol achieves inherent authentication of the server and legitimate nodes and remains robust under node dropout scenarios. The confidentiality of local updates and the unforgeability of verification tokens are analyzed under the honest-but-curious threat model, and experimental evaluations on the MNIST dataset demonstrate that V-MHESA achieves accuracy comparable to prior MHESA while introducing only negligible computational and communication overhead.
Keywords:
federated learning; secure aggregation; masking; homomorphic encryption; verifiability; dropout resilience MSC:
94A60; 68T07; 68M14; 68P27
1. Introduction
Federated learning (FL) [1] enables multiple distributed nodes to collaboratively train a global model without sharing their raw data, thereby preserving privacy and reducing data transfer. A central challenge in FL lies in protecting local model parameters during aggregation, as individual updates can leak sensitive information through inference or inverse attacks [2,3,4]. Secure aggregation protocols address this issue by allowing the server to compute only the aggregated result of local updates without accessing any individual updates. Over the years, various secure aggregation mechanisms have been proposed, leveraging techniques such as secure multiparty computation [5,6], differential privacy [7,8], masking [9,10,11,12,13,14,15,16], and homomorphic encryption [17,18,19,20,21,22,23,24,25,26,27,28,29].
Masking-based schemes, which are among the most widely applied approaches for privacy preservation in the federated learning, achieve efficiency by having nodes add random masks to their local updates, which are designed to cancel out during aggregation. Although conceptually simple, these schemes require pairwise mask sharing among all nodes, which imposes communication and management overhead that scales with the number of nodes. Additionally, dropout events necessitate extra procedures to recover missing masks, further complicating the protocol.
Homomorphic encryption (HE)–based schemes protect local updates through encryption and enable direct aggregation over ciphertexts. However, they incur high computational overhead and often require the use of a shared secret key for encryption by all nodes, creating a single point of failure. Multi-key HE [24] mitigates this issue by allowing each node to use a distinct key, but the final decryption requires complex collaborative operations among all participants.
To address these limitations, our previous work introduced MHESA (Masking-and-Homomorphic-Encryption–Combined Secure Aggregation) [30], a hybrid scheme that integrates the simplicity of masking with the robustness of homomorphic encryption. In MHESA, local parameters are individually masked, and the masks are encrypted using the CKKS homomorphic encryption scheme [29]. This design eliminates the need for inter-node mask sharing, allows nodes to use distinct keys for homomorphic encryption, and enables automatic decryption of aggregated masks at the server without additional joint operations.
While MHESA effectively guarantees the confidentiality of local updates, it lacks mechanisms to verify the correctness and integrity of the aggregated results. Communication errors, adversarial tampering, or server misbehavior can lead to incorrect aggregation, thereby undermining the accuracy of the global model. Since the correctness of aggregation directly affects the overall performance of federated learning, verifiability becomes indispensable.
In this paper, we extend MHESA by proposing V-MHESA (Verifiable Masking-and-Homomorphic-Encryption–Combined Secure Aggregation), a novel protocol that ensures both confidentiality and verifiability. The proposed scheme provides the following features:
- Correctness and integrity verification: In each learning round, nodes generate their local updates in a verifiable form and additionally produce verification tokens corresponding to randomly selected local parameter values. These tokens enable lightweight yet reliable validation of the global update. The server simply aggregates both the local updates and the verification tokens to obtain the global model update and a global verification token. Using this global information, each node can verify whether its own local parameters have been accurately reflected in the global model update, thereby ensuring both correctness and integrity.
- Sever authentication: Local updates are generated using a pre-shared server secret, ensuring that only the legitimate server can produce valid global model updates.
- Authenticated aggregation group and efficient shared-key management: During local update generation, each node incorporates an additional random nonce that is shared exclusively among the nodes. This design ensures that only the nodes—rather than the server—can ultimately recover the true global model parameters. The initial random nonce is distributed once during the setup phase, encrypted under each node’s public key. In subsequent learning rounds, every node can independently refresh the nonce without requiring any additional exchange or synchronization, thereby eliminating both computational and communication overhead for nonce sharing. To form the aggregation group of legitimate nodes, the server provides a fresh round nonce in each learning round. Nodes respond by generating a simple authentication code over the round nonce and their identifiers, enabling the server to authenticate participants. Consequently, only nodes that return valid authentication codes are admitted into the aggregation group, effectively preventing unauthorized nodes from contributing to the learning process
- Robustness against dropouts: The proposed scheme preserves both confidentiality and verifiability even when some nodes drop out or submit delayed updates.
We analyze the security of V-MHESA under the honest-but-curious threat model and evaluate its performance on the MNIST dataset [31]. The experimental results demonstrate that the proposed protocol achieves strong privacy protection, reliable integrity verification, and robustness against dropouts, while incurring only negligible computational and communication overhead.
The remainder of this paper is organized as follows: Section 2 reviews the related work on secure and verifiable aggregation in federated learning. Section 3 presents the proposed V-MHESA model, describing its algorithms and the federated learning protocol in detail. Section 4 analyzes the security of the scheme, focusing on the confidentiality of local updates and the unforgeability of global updates, and evaluates its performance in terms of learning accuracy, aggregation correctness, and computational efficiency. Section 5 discusses the proposed model in depth, and Section 6 concludes the paper.
2. Related Work
Federated learning has inspired a wide range of secure aggregation techniques aimed at preserving the confidentiality of client updates. Broadly, these studies can be categorized into masking-based schemes, homomorphic encryption–based schemes, and more recent verifiable aggregation approaches
Bonawitz et al. [9,10] introduced an additive masking protocol in which clients conceal their local updates using pairwise masks that cancel during aggregation, ensuring that the server only learns the sum of all updates. The protocol was later extended with Shamir’s secret sharing to tolerate client dropouts. To further reduce the overhead of pairwise exchanges, So et al. [15] designed turbo-aggregation, which performs circular aggregation within subgroups to localize communication. Similarly, Kim et al. [16] proposed a group-based masking protocol that clusters nodes by processing latency and location, thereby reducing dropout sensitivity while providing a mechanism for public verification of mask integrity without relying on Shamir’s scheme.
Another line of research employs homomorphic encryption (HE) to enable aggregation over ciphertexts. Aono et al. [21] and Fang–Qian [22] proposed HE-based federated learning schemes in which local model parameters are encrypted with a common key, allowing the server to compute encrypted aggregates. However, this single-key design requires all participants to share the same secret key. Park–Lim [23] addressed this limitation by allowing each node to use its own key pair, enabling the server to update the global model within a distributed cryptosystem, although the design relies on an additional trusted computation provider for decryption. Liu et al. [24] proposed a multi-key FHE (MKFHE)-based protocol that allows nodes to encrypt under distinct keys while still supporting aggregation. Their construction is round-efficient and supports dynamic participation by generating refresh keys for newly joining nodes. To reduce payload size, Jin et al. [25] selectively encrypted only privacy-sensitive parameters, thereby mitigating ciphertext expansion, albeit still requiring a common HE key. Park et al. [30] introduced MHESA, a secure aggregation scheme that integrates masking with multi-key homomorphic encryption. By combining the simplicity and efficiency of masking-based aggregation with the strong confidentiality of homomorphic encryption, MHESA achieves secure aggregation while mitigating the limitations of both approaches
While the above techniques provide privacy, they do not inherently guarantee that the server aggregates updates honestly. Recent works therefore emphasize verifiability—enabling clients to validate that the global update truly reflects their submitted inputs. Xu et al. [32] proposed VerifyNet, which integrates secure aggregation with cryptographic commitments, and Guo et al. [33] introduced VeriFL, which leverages homomorphic hashes (HH) to allow fast and communication-efficient verification. To improve practicality under dropouts, Buyukates et al. developed LightVeriFL, which employs lightweight homomorphic hashing [34]. Behnia et al. [35] presented e-SeaFL, reducing the aggregation to a single round with authenticated vector commitments (VC). Peng et al. [36] designed a communication-efficient protocol that combines single-mask encryption with lightweight hash-based checks. More recently, Zhou et al. [37] proposed GVSA, which allows group-level verification, while Xu et al. [38] and Li et al. [39] developed efficient and lightweight verifiable secure aggregation protocols (LVSA) that remain robust under dropout and adversarial manipulation. Table 1 compares the proposed V-MHESA with the previously reported verifiable schemes, highlighting its key technical distinctions and improvements.

Table 1.
Comparison of the characteristics of V-MHESA and existing verifiable federated learning schemes.
Compared with prior approaches, the proposed V-MHESA requires neither a trusted third party nor assistance from other nodes to verify the correctness of the global model. It operates without requiring node collaboration—i.e., no additional communication between nodes or between nodes and the server—during the learning phase. Moreover, it eliminates the need for complex cryptographic primitives such as homomorphic hash functions (HHF) or homomorphic secret sharing (HSS). Instead, each node generates lightweight verification tokens for only a small subset of model parameters using a simple masking technique. The federated server simply aggregates these tokens, while each node verifies the correctness and integrity of the global model through basic arithmetic operations. This design results in negligible computational overhead for verification. Furthermore, the proposed scheme simultaneously provides server authentication, node authentication, and robustness against dropout scenarios.
3. V-MHESA-Based Federated Learning Model
3.1. System Overview
The proposed federated learning model consists of a single federated server (denoted as FS) and a set of N static nodes (each denoted as ). The nodes hold heterogeneous local datasets of varying sizes that follow a non-IID distribution, yet each node possesses sufficient computational resources to perform local training. All communication and interaction occur exclusively between FS and each node through standard Internet connections. The federated learning process comprises two phases: (i) the Setup phase, during which the cryptographic parameters required for secure aggregation are generated and distributed, and (ii) the Learning phase, where local parameters are collected and the global model parameters are updated. The Setup phase is executed only once at the beginning of the learning process, whereas the Learning phase is iteratively repeated until the global model converges.
At the t-th Learning phase, FS and nodes update the global and local model parameters as follows: Given the global parameter generated by FS in round t − 1, each node computes its local parameter
where is the average gradient on its local dataset using the current model and a fixed learning rate . If the size of dataset held by is denoted by , then the total size across all nodes is . Each node transmits its data-size-weighted local parameter to FS. FS aggregates these weighted parameter to update the global model as
and then shares the result with all nodes.
However, if the local parameter is directly exposed during aggregation, an adversary could deduce sensitive information about the local datasets via inverse attacks [2,3,4]. Therefore, a secure aggregation protocol is required to ensure that remains confidential while still allowing FS to correctly compute the global update. Building upon our prior MHESA scheme, this paper introduces an enhanced protocol, V-MHESA, which satisfies stricter security requirements. The system operates under the following threat model.
- Honest-but-curious model: FS and nodes securely maintain their private information and do not collude with other parties. They strictly follow the prescribed protocol; however, they may attempt to infer additional information from legitimately obtained data.
Under this model, the proposed aggregation protocol is designed to satisfy the following security requirements:
- Privacy of local parameters: Local datasets and parameters held by each node remain confidential and are not exposed to any other nodes, FS, or any external entities.
- Correctness verification of global parameters: Each node can verify that its own local parameters have been accurately incorporated into the global update.
- Integrity verification of global parameters: Each node can verify that the global parameters have not been altered or tampered with during transmission, ensuring that the received values match those generated by FS.
- Mutual authentication of sever and nodes: FS can authenticate that local parameters were generated by registered nodes, while the nodes can authenticate that the global parameters were genuinely produced by FS.
- Robustness against dropouts: Even if some nodes drop out during the aggregation phase due to communication failures, the remaining nodes can continue the aggregation process, and FS can still compute a correct global update. Furthermore, if delayed updates from dropout nodes arrive after aggregation, the privacy of all nodes’ local parameters—including those of the dropout nodes—remain protected.
To realize secure aggregation, the protocol employs multiple cryptographic primitives: Elliptic Curve Cryptography (ECC) for public-key encryption and decryption, SHA-256 for hashing, and the CKKS homomorphic encryption (CKKS-HE) scheme for privacy-preserving aggregation.
Figure 1 illustrates the core aggregation workflow of the proposed V-MHESA model. During each Learning phase, every node generates its masked local update by masking the local parameter with a mask , it then produces the ciphertext of using CKKS-HE and a verification token . The resulting local update is transmitted to FS. Upon receiving all s, FS simply aggregates them and, using its secret S, derives the global model parameter GW and the global verification token GT. The global update GU = <GW, GT> is then distributed back to all participating nodes. Each node updates its local model using GW if and only if GU passes the proposed verification process. Conversely, if a modified or forged global update (e.g., due to transmission error or from a malicious actor) is received, the verification process fails. The node then notifies the verification failure to FS and requests retransmission of a valid GU. Through this mechanism, V-MHESA ensures that every node updates its local model only with a verified and correct global model parameter, thereby preserving the integrity and correctness of the overall federated learning process.
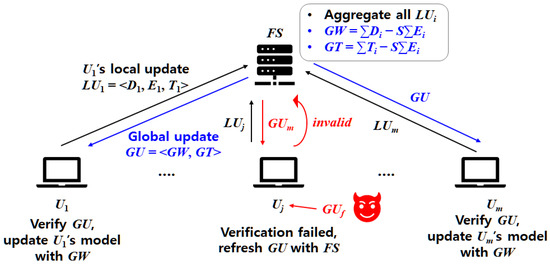
Figure 1.
The core aggregation workflow of V-MHESA.
3.2. MHESA: Masking and Homomorphic Encryption–Combined Secure Aggregation
We first briefly describe the baseline aggregation protocol, MHESA, which serves as the foundation of our proposed model. In MHESA, each node masks its local parameter with a random value chosen by the node, thereby ensuring confidentiality. To enable automatic mask removal during aggregation at FS, each mask is encrypted using CKKS-HE scheme and transmitted together with the masked parameter. Importantly, this encryption process embeds a partial decryption share generated by each node. As a result, when the encrypted masks are aggregated, they are automatically decrypted into the sum of the original masks. It should be emphasized that although the aggregated masks can be recovered, the individual masks remain undiscoverable. FS thus computes the decrypted sum of the encrypted masks and subtracts it from the sum of the masked local parameters, thereby obtaining the average of the local parameters.
The MHESA protocol consists of the following six algorithms: KeyGen(), GroupKeyGen(), Ecd(), Dcd(), LocUpGen() and GlobUpGen(). Among these, the Ecd() and Dcd() algorithms are identical to those defined in CKKS-HE scheme. For clarity, we reformulate the two encryption and decryption algorithms, Enc() and Dec(), as LocUpGen() and GlobUpGen(), respectively. The technical details of each algorithm are provided as follows:
For a positive integer M, is the M-th cyclotomic polynomial of degree . is a power-of-two degree cyclotomic ring, and be the residue ring of modulo q. For Q = q2, a polynomial is defined as with the vector of its coefficients (, …, ) in . The coefficient vector (, …, ) is denoted as A. For a real σ > 0, D(σ2) represents a distribution over , sampling n coefficients independently from the discrete Gaussian distribution with variance σ2. For a positive integer h, HWT(h) is the set of signed binary vectors in whose Hamming weight is exactly h. For a real 0 ≤ ρ ≤ 1, the distribution ZO(ρ) draws each entry in the vector from , assigning a probability of ρ/2 for both −1 and +1, and a probability of 1 − ρ for 0.
- KeyGen(n, h, q, σ, A, Q) generates a public–private key pair <, > and the commitment for node . It samples ← HWT(h), ← ZO(0.5) and , ← D(σ2). It sets the secret key = (1, ) and public key (mod Q). Then, it sets a commitment for such as (mod Q). It outputs <, , >.
- GroupKeyGen(PK, C, ) generates a group public key , a group commitment , and the total size of datasets , for a given node set , where PK = {}, C = {} and X = {} for all in U. It outputs <, , >.
- Ecd(z; ) generates an integral plaintext polynomial m(X) for a given (n/2)-dimensional vector . It calculates , where represents a scaling factor, and is a natural projection defined by for a multiplicative subgroup T of satisfying . is a canonical embedding map from integral polynomial to elements in the complex field . It computes a polynomial whose evaluations at the complex primitive roots of unity in the extension field correspond to the given vector of complex numbers.
- Dcd(m; ) returns the vector for an input polynomial m in , i.e., for .
- LocUpGen(, , , , , , ) outputs a secure local update for a set of local parameters . It chooses a real random mask and generates a masked local parameter . To generate a ciphertext for , it samples e1i ← D(σ2), generates a plaintext polynomial , and then creates .
- GlobUpGen(, ) outputs a global model update w for given = {} for all in . It calculates and (mod q). Here, by CKKS-HE algorithm. It computes . Finally, it generates .
Each node generates its own key pair <, > using the KeyGen() algorithm. FS then generates a group public key <, >, which is used to encrypt the masking values of the nodes in the t-th Learning round, as specified in GroupKeyGen(). This group key is constructed from the public keys of all nodes participating in the corresponding Learning round. The local parameter of node is masked with , and is subsequently encrypted as defined in LocUpGen(). The ciphertext of includes both the encryption of under the group key <, > and a partial decryption share generated using the node’s secret key . Since is encrypted with the group key, decryption would normally require the combination of all partial decryption shares corresponding to the secret keys of the nodes whose public keys contributed to the group key generation. In the proposed scheme, however, each ciphertext already embeds the partial decryption share of its corresponding node. Consequently, when all ciphertexts from participating nodes are aggregated, decryption is automatically completed, revealing only the sum of all masking values. Importantly, each ciphertext contains only the partial decryption share of its corresponding node. Since the partial decryption shares of from other nodes are not given, the individual mask values remain hidden, while only the sum of the masks is recovered. Finally, FS can obtain the global model parameter w using the GlobUpGen() algorithm.
Based on the above algorithms, the MHESA-based federated learning is performed as follows:
At the Setup stage, FS collaboratively establishes system parameters and keys with each node.
- 1.
- FS generates and publishes system parameters <n, h, q, σ, A, Q> to all nodes in U.
- 2.
- Each generates its key pair and commitment <, , > ← KeyGen(n, h, q, σ, A, Q) and sends < , , > to FS.
- 3.
- FS sets PK = {}, C = {} and X = {} for all in U.
At the t-th Learning iteration (t > 0), FS interacts with each as follows:
- FS broadcasts a new iteration start message to all nodes in U.
- All available nodes respond with their s.
- FS sets the t-th node group for all replied nodes and generates group parameters <, , > ← GroupKeyGen(PK, C, ), and then broadcasts it to all nodes in .
- Each generates t-th local updates <, > ← LocUpGen(, , , , , , ) for the t-th local parameter and sends it to FS. (The local learning process to obtain from with its local dataset is omitted.)
- FS generates the t-th global model update ← GlobUpGen(, , ) and shares it with all nodes in U.
3.3. Notations
Before providing the detailed description of the proposed V-MHESA protocol, we summarize the main parameters and functions used throughout the paper in Table 2. These notations are consistently used in the subsequent sections for clarity and precision.
Table 2.
Notations.
3.4. V-MHESA: A Verifiable MHESA Scheme
In this section, we present V-MHESA, an enhanced version of MHESA that provides verification of global model parameters. Unlike the original MHESA, V-MHESA requires nodes to validate the correctness and integrity of the global parameters at the end of each Learning round, and only upon successful verification do they proceed to the next round. To achieve this, V-MHESA introduces three key mechanisms: (1) generation of a fresh random shared nonce in every round, known exclusively to the nodes; (2) construction of local updates in a verifiable form; and (3) a verification procedure that allows nodes to confirm the correctness and integrity of the global update produced by FS.
3.4.1. Algorithms for V-MHESA
In the new model, the original key generation algorithm KeyGen(), the local update generation algorithm LocUpGen(), and the global update generation algorithm GlobUpGen() are replaced by VKeyGen(), VLocUpGen(), and VGlobUpGen(), respectively. In addition, a new algorithm Verf(), is introduced to verify the validity of the global update. All other algorithms remain unchanged from the original protocol as described in Section 3.2. The detailed specifications of the newly developed algorithms are described as follows:
- VKeyGen(PKParams, HEParams) generates two pairs of public–private keys <,> and <, >, and a commitment of a node . <,> is used for ECC and <, > is used for CKKS-HE. <, > are generated by ECC standard (the detailed algorithm is omitted). The algorithm to generate <, > and is identical to the algorithm in KeyGen() described in Section 3.2. It outputs <, , , , >.
- VLocUpGen(, R, , , , , , , S, idx) outputs a secure local update for a local parameter . Here, R is a random nonce shared among all nodes in and S is the master secret of FS. It chooses a real random mask and generates a masked local parameter set as follows:To generate a ciphertext of , it samples ← D(σ2), generates a plaintext polynomial , and then createsA verification token is additionally created. Using R, it sets and , and generates as follows:where is a set of selected weight parameter values according to a given index set idx.
- VGlobUpGen(, ) outputs a global update GU = <GW, GT> for the global model parameters w, given the set of local updates = {} from all nodes . It computes and (mod q). According to the CKKS-HE, . Then, it obtains by decoding E with scaling factor . It also computes . Finally, the algorithm generates the global model update GW and the corresponding verification token GT for the global model parameter w as follows:
- Verf(GU, R, idx) verifies the validity of w and outputs either true or false. Given GU = <GW, GT>, it computes and , and then calculates and . Finally, it verifies whether the following equation holds:
If the condition satisfies, it outputs true, otherwise, it outputs false.
The VKeyGen() algorithm generates both a homomorphic encryption key pair and a classical public–private key pair. The homomorphic encryption keys are used to encrypt the private masking values employed during local update generation, while the classical key pair is used only in the Setup phase to distribute an initial random seed among nodes. The seed is subsequently used to derive the random nonce R in each Learning round.
The VLocUpGen() algorithm constructs a verifiable local update for each node based on its local model parameter . The key difference from the MHESA scheme is that is generated not only using the node-chosen masking value , but also the random nonce R—shared exclusively among the nodes—and the secret S held by FS. This ensures that only FS, which holds S, can aggregate a valid global update, while only the nodes, which share R, can recover actual global parameter , which remains hidden from FS. In addition to , each node also generates a verification token corresponding to a selected subset of model parameters. Similarly to , the token is constructed using a simple masking technique; however, it additionally incorporates two nonces, and , which are derived from R. Consequently, no party without knowledge of R can generate a valid token. Moreover, is constructed only for a small subset of parameters indexed by values randomly chosen by FS in each Learning round. This design significantly reduces computational and communication overhead by limiting the number of verification tokens that need to be additionally generated and transmitted.
The VGlobUpGen() algorithm aggregates all local updates collected from the participating nodes in a given Leaning round to produce the global update GU = <GW, GT>. For the global model parameter w, the aggregated values are defined as and . Here, only FS, which knows S, can compute , and subsequently generate a valid value . This ensures that no party, other than FS and legitimate nodes, can impersonate FS or fabricate .
Each node executes the Verf() algorithm to verify both the correctness and integrity of the global parameter w obtained from GU = <GW, GT>. Integrity ensures that GW has not been tampered with during transmission, while correctness ensures that GW accurately represents the aggregation of all legitimate local updates provided by the participating nodes. Using the shared nonce R, each node derives w from GW and reconstructs the subvector w[idx] corresponding to the randomly selected indices idx. The node then compares this value with . If the difference satisfies , for a predefined threshold , the global model w is considered valid. Although verification is performed only on a subset of parameters, the index set idx is randomly selected in each Learning round. Hence, if the selected subset satisfies the verification condition, the entire global model w is regarded as valid.
If the verification equation holds, it implies that both GW and GT are consistent values derived from the same global model w, thereby confirming that these values were not altered during transmission (integrity is ensured).
Furthermore, the pair <GW, GT> passes the verification procedure if and only if all legitimate local updates have been correctly collected are aggregated.
(1) When all are valid, FS homomorphically aggregate to recover the sum of masks (using its secret S), and removes the combined mask term from to obtain the blinded aggregate . Simultaneously, FS computes the aggregated token GT for the selected indices. Because nodes know R and its derived random values and , they can recover w and the subvector w[idx] from GW, and compare these values with GT after removing and . Since all values originate from correctly aggregated , the reconstructed w[idx] and the value derived from GT coincide, and the verification succeeds.
(2) If forged updates that do not correctly incorporate R and S are used, the resulting <> produced by FS fails to cancel the masks properly. Because the tokens do not embed the correct and , the two values and derived from and , respectively, do not match, and the verification fails.
Therefore, when the verification equation holds, it guarantees that GW was produced as the aggregation of all legitimate local updates provided by the participating nodes. The unforgeability of constructing a valid pair <> without knowledge of R is formally analyzed in Section 4.1.
3.4.2. Federated Learning Using V-MHESA
Based on the algorithms proposed above, FS and each node collaboratively perform federated learning as follows:
At the Setup phase, FS collaboratively establishes system parameters and keys with each node.
- FS generates system parameters <PKParams, HEParams>, its public key pair <,>, its master secret S, and the initial global model update = , and then publishes public parameters < PKParams, HEParams, , > to all nodes in U. Here, is randomly generated by FS.
- Each generates keys and commitment <, , , , > ← VKeyGen(PKParams, HEParams) and sends only public parameters <, , , > to FS.
- FS sets K = {}, PK = {}, C = {}, X = {}, for all in U, and creates a random identifier for each . Then, FS generates and . FS selects a representative node , which can be selected randomly or sequentially among nodes. FS sends K to .
- chooses a random seed hR0, which can be used to generate a random nonce at every single Learning round, and generates and . sends back <CR = {}, Sig> to FS.
- FS sends <K, , Sig, , > to each .
- Each obtains , , and , and determines if VS( holds, send “valid” to FS.
If all nodes agree to “valid”, the Setup phase completes, otherwise, starts again from step 4.
Once the Setup phase is completed, each carries out the initial local learning with to obtain . Then, FS and nodes repeat the subsequent Learning phases until the federated learning process is concluded. At the t-th Learning iteration (t > 0), FS interacts with each as follows:
- FS randomly generates a weight index set and a round nonce and broadcasts the t-th “ROUND START” message along with <, > to all nodes in U.
- Each generates its authentication code and responds <, > to FS.
- For each , FS verifies whether holds. FS then forms the t-th node group consisting of all nodes with valid authentication codes. (If an invalid authentication code is detected, FS may re-request a new authentication code from the corresponding node.) Once is determined, FS generates the group parameters <, , > ← GroupKeyGen(PK, C, ), and broadcasts them to all nodes in .
- Each generates the t-th random nonces and , and then constructs its local updates = <> ← VLocUpGen(, , , , , , , , S, ) for the t-th local parameter . Each sends to FS.
- FS generates the t-th global update ← VGlobUpGen(, ), and distributes it to all nodes in .
- Each verifies the validity of by performing Verf(, , ). If the verification succeeds, it responds with “valid”; otherwise, it responds with “invalid” to FS.
- If all nodes respond with “valid,” FS broadcasts a “ROUND TERMINATION” message to all nodes in U, after which each node performs its local learning step using to obtain the next local parameter . If more than half of the nodes respond with “invalid,” FS restarts the t-th iteration with newly generated and , beginning from Step 1, and broadcasts a “RESTART” message to all nodes in U. Otherwise, if only a minority of nodes return “invalid,” FS retransmits to those of nodes and repeats Step 6.
In V-MHESA, all nodes must share a fresh random nonce in every Learning round. To achieve this, during the Setup phase, a designated node generates an initial random seed and securely distributes it to all other nodes. The initial generator may be arbitrarily chosen by FS, selected as the node with the highest computational capability, or rotated among the nodes across successive rounds. The initial seed is encrypted under the public key of each node, ensuring that only the intended recipients can decrypt it, while FS remains unaware of its value. Furthermore, is accompanied by a digital signature from , allowing each node to verify the authenticity of the decrypted value and preventing any tampering by FS. After the Setup phase, each node independently updates the nonce by repeatedly hashing it across rounds, e.g., thereby generating a new in every Learning phase. This property enables nodes that missed previous rounds to rejoin the protocol later while still generating a valid .
For node authentication, FS assigns a random identifier to each node , which is transmitted in encrypted form under the node’s public key . Thus, only the designated node can decrypt and retrieve its identifier. At the beginning of each Learning round, FS constructs the aggregation group of participating nodes and uses these identifies to verify that each joining node is legitimately registered.
The Learning phase is enhanced with three additional steps: (i) node authentication, (ii) random nonce renewal, and (iii) verification of the global update. At the start of t-th round (t > 0), FS selects a random index set idx for verification and generates a round nonce , both of which are broadcast to all nodes. Each node computes its authentication code = H() using and , and sends it back to FS. FS verifies each response by recomputing the same hash with the corresponding and . Through this lightweight check, FS can confirm both the legitimacy of each responding node and its correct reception of . This mechanism prevents unregistered or malicious external nodes from impersonating legitimate participants and submitting invalid updates. FS then forms the active node group using only those nodes that returned valid authentication codes and generates the corresponding group keys, which are distributed to the group members.
Using the refreshed , each node constructs and transmits its local update to FS. FS aggregates all received local updates to produce the global update . Each node then verifies the validity of , only if the verification succeeds do the nodes update their local models with the new global parameter . If any node reports an invalid result, the protocol restarts from Step 1 by default. However, since invalidity may arise from transmission errors rather than an incorrect , in practice the restart is triggered only when more than half of the nodes report invalid results. If fewer than half respond with invalid results, FS retransmits exclusively to those nodes for re-verification.
3.4.3. Dropout Robustness
During the aggregation of local updates, FS may encounter dropouts. FS waits for node submissions within a predefined timeout period: any local update not received within this period is treated as a dropout. If a node drops out and its local update is not delivered to FS, the sum of the masking values chosen by the nodes cannot be correctly reconstructed. As a result, the masking values cannot be removed, and a valid global update cannot be generated.
To address this, FS restarts the Learning process from Step 1 with the remaining nodes, excluding the dropout nodes. Importantly, a new set of random values must be used for the re-aggregation. For example, suppose a dropout occurs at Step 5 of the t-th Learning round. In that case, FS distributes a new pair <, > to the remaining nodes. FS also generates fresh group parameters <, , > corresponding to the updated node group . Each node also generates a new nonce and masking value , constructs a new local update . Finally, FS aggregates these inputs to compute the revised global update .
When a dropout occurs, two cases must be considered. The first is when dropped-out data are completely lost and never delivered to FS. The second is when the data are not fully lost but instead arrive at FS with significantly delay. The essential distinction between these two cases is whether FS ultimately obtains the local update from identified as a dropout.
The second case poses a potential risk: FS may gain access to (i) all local updates from the original node group , (ii) the new local updates from the reduced node group (excluding the dropout), and (iii) the corresponding global updates = VGlobUpGen(, ) and = VGlobUpGen(, ). In the original MHESA model, since FS could compute the actual global model parameter , the occurrence of a single dropout node led to a privacy risk: by comparing the global parameter including with the parameter excluding , FS could derive the local parameter of as . To mitigate this, the original scheme required that, whenever a single dropout occurred, one additional node be excluded from the Learning round to prevent parameter exposure.
In contrast, the proposed V-MHESA scheme avoids this vulnerability. Instead of computing the true global parameter , FS generates only the masked global update = <, >, where . Moreover, during re-aggregation caused by dropouts, is refreshed. As a result, FS gains no additional information about either the final model parameter or any individual local parameters. Even if a single dropout node later submits its delayed update, FS cannot infer its local information. Thus, unlike the original MHESA scheme, V-MHESA does not require the exclusion of any additional nodes and provides a more practical and secure approach to handling dropout scenarios.
4. Analysis
4.1. Security
Frist, we analyze the security of the proposed model under the honest-and-curious threat model. We focus on the primary security properties: (i) the confidentiality of local parameters, ensuring that no party—including FS—can learn any individual node’s local model parameters, and (ii) the unforgeability of the global update, guaranteeing that an adversary cannot construct a counterfeit pair <, > that passes the verification procedure without possessing the required secret R.
We consider a federated learning system consisting of a single FS and at least three participating nodes. Each node communicates solely with FS. Both FS and the nodes are assumed to follow the protocol honestly while keeping their private keys secure; however, they may attempt to infer additional information from legitimately obtained data (honest-but-curious). Local updates are transmitted exclusively to FS and are never shared among nodes. External adversaries may eavesdrop on all communications over the public network but cannot compromise secret keys or cryptographic primitives under standard hardness assumptions.
4.1.1. Confidentiality of Local Update
In the proposed scheme, each node’s original local parameter is masked using a random nonce R, which is shared only among the nodes, and a randomly chosen mask . is encrypted separately using CKKS-HE scheme (assumed IND-CPA secure).
In V-MHESA, FS’s secret S is additionally embedded in the construction of each masked local parameter . This design ensures that only FS can remove the aggregated masking terms from to obtain the blinded value , while the true global parameter w remains hidden. Moreover, no external entity can infer a valid GW from the transmitted local updates before FS publishes the global update pair <GW, GT> to the nodes.
Intuitively, the leakage set <, , GW> should reveal no non-negligible information about , since is multiplicatively blinded by the node-only nonce R, and the additive mask is protected by IND-CPA secure homomorphic encryption. We exclude <, GT> from the leakage set, as these are used solely for verification and are generated in the same randomized manner as and GW. In particular, incorporates additional randoms values and derived from the shared nonce R; therefore, <, GT> provides no further distinguishing advantage beyond what is already possible from <, , GW>.
We thus analyze confidentiality with respect to three adversarial perspectives:
- External eavesdropper (): This adversary passively observes all messages transmitted over the network, i.e., and GW, but does not know R, S or any .
- Federated server () (honest-but-curious): The federated server possesses S and receives all <, > values. It computes and stores GW, yet it still does not know R and any individual .
- Malicious node (: In our threat model, each node is assumed to be honest-but-curious; thus, a node knows only the published GW and cannot access <, > of other nodes . However, to strengthen the confidentiality argument, we also consider a hypothetical malicious node that, in addition to knowing R and S, can observe all <, > exchanged over the network, yet it still does not know any individual . We show that even under this strongest assumption, the leakage set <, , GW> does not reveal any non-negligible information about .
To prove confidentiality, we define the confidentiality game ConfGame with the leakage set Leak = <, , GW> as follows:
Definition 1.
(ConfGame).
- 1.
- Setup: The challenger generates the system parameters and provides the server secret S to the simulator used in reduction. The secret S is shared between the nodes and FS but is not used to mask ; rather, it serves only for server authentication, ensuring that only the legitimate FS can produce a valid GW. The node-shared nonce R and each node’s mask remain hidden from the adversary.
- 2.
- Challenge queries: The adversary selects any two candidate local parameters , that share the same dimension and domain. The challenger flips a random bit , sets , and executes the honest V-MHESA generation to obtain < , , GW> along with all other honest nodes’ outputs for that round. The challenger then returns the leakage set Leak = < , , GW> to .
- 3.
- Guess: outputs a guess b’. Its advantage is .
V-MHESA is said to ensure confidentiality of
under leakage <,
, GW> if every PPT adversary
has negligible advantage.
Theorem 1.
Assume CKKS-HE is IND-CPA secure. Then, for any PPT adversary
(either
or ), the advantage in ConfGame is negligible in the security parameter. In particular, the leakage set <, , GW> is computationally indistinguishable when versus , up to the public CKKS approximation tolerance .
Proof.
We establish indistinguishability using a standard hybrid-game argument.
Hybrid H0 (Real World): The challenge executes V-MHESA honestly with . The adversary receives Leak = {, , GW} and all public values consistent with that round. Recall that and .
Hybrid H1 (Mask-Ciphertext Replacement): Replace each ciphertext with an encryption of a freshly sampled random mask . By the IND-CPA security of CKKS-HE, cannot distinguish between H0 and H1 except with negligible probability.
Hybrid H2 (Mask Re-sampling): The additional term within acts as a high-entropy randomizer independent of from the adversary’s perspective (the value is hidden from CKKS from any , even for only the sum matters for removal). Replace every in with a freshly sampled drawn from the same distribution as in the real protocol, keeping consistent with as in H1. Because R multiplicatively blinds and the additive term statistically mask any residual correlation, the joint distribution of <> remains indistinguishable from the real one, up to negligible CKKS approximation error.
Hybrid H3 (Simulation): The simulator, given S from the challenger, generates the leakage set as follows: It samples encryption key and generates . It randomly samples matching the real-protocol numerical scale and tolerance of CKKS outputs. Then, it fixes so that the global sum satisfies .
Because both and know S, they can verify that holds exactly (up to ). Hence, the simulated transcript is perfectly consistent with an honest FS computation.
In H3, the joint distribution of {} is computationally indistinguishable from that of H0, while being independent of whether = or = .
If there exists a PPT adversary that could distinguish the real transcript () from the simulated tuple () with non-negligible advantage, then, would necessarily break at least one of the following assumptions: (1) IND-CPA security of CKKS-HE (between H0 and H1), (2) statistical hiding of mask re-sampling (between H1 and H2), and (3) indistinguishability under linear constraint (between H2 and H3).
Even the strongest adversary knowing both R and S, can compute and for its chosen , , but it still observes only . To distinguish from with non-negligible advantage, it would need to recover from , contradicting the IND-CPA security of CKKS-HE. Since the statistical distributions of and coincide up to negligible approximation error, any distinguisher leads to a contradiction. Therefore, the adversary’s advantage in ConfGame is negligible. □
Corollary 1.
If at least three participating nodes exist, the confidentiality of local parameters is preserved against
.
Proof.
Unlike and , which have no knowledge of R, knows both R and S. When only two nodes participate in the aggregation— and another node can derive the local parameter of as follows, since can observe the local update . Let the local update of be . Then can compute the total mask , and consequently obtain . Since knows both R and S, it can recover of as . Therefore, if is one of only two participating nodes, it can infer the local parameters of the other node, violating confidentiality. To ensure the confidentiality of local updates even against , there must exist at least two honest (non-colluding) nodes other than When at least three nodes participate in the aggregation, can only obtain the sum of the other nodes’ masking values , without learning any individual . Consequently, the confidentiality of each node’s local parameters is preserved. □
4.1.2. Unforgeability of Global Update
In this section, we analyze the unforgeability of the global update pair <GW, GT>. An adversary who does not know the node-shared nonce R can pass the verification if and only if it can construct a forged pair <, > that satisfies the verification relation used by the nodes.
Recall that nodes accept <GW, GT> if, after removing the known values and , the values derived from GW and GT coincide for the selected index set. Equivalently, denoting by w[idx] the subvector at the chosen indexes, the verification condition can be written as
or, rearranged,
Therefore, any forged pair <, > that passes verification must satisfy
If an adversary does not know R, it cannot compute , and . Under the usual assumption that the pseudo random generator behaves as a random oracle, the adversary’s only option is to guess the values of and . Let m denote the bit-length of each of and (i.e., ). The probability that an adversary correctly guesses and is therefore at most . Consequently, the probability that the adversary can produce a valid forged pair <, > without knowledge of R is negligible and bounded by
4.2. Experimental Evaluation
In this section, we evaluate the learning accuracy and computational efficiency of the proposed V-MHESA-based federated learning model using the MNIST dataset. We analyze performance under varying number of participating nodes, considering both IID and Non-IID data distribution across the nodes.
For learning accuracy, we compare the classification performance of V-MHESA with two baselines: (i) a conventional centralized training model and (ii) our previous MHESA scheme. This comparison allows us to examine the introduction of verification mechanisms in V-MHESA impacts model accuracy. In addition, we quantify the discrepancy between the global model parameters obtained through the direct aggregation of weighted local parameters and those produced by V-MHESA, thereby evaluating the effectiveness of the proposed scheme.
For computational efficiency, we analyze the execution time required for each step of the proposed protocol on both the node side and the server side. Furthermore, we assess the additional computational overhead introduced by the verification mechanism, providing a detailed evaluation of its practical feasibility.
4.2.1. Experimental Environment
For the experiments, we employed two systems implementing the federated server and clients. The server system is equipped with an Intel(R) Core(TM) i7-12700K CPU, Intel(R) UHD Graphics 770 GPU, NVIDIA GeForce RTX 3080 GPU, and 32 GB of RAM. The client system is configured with an Intel(R) Core(TM) i9-7920X CPU, two NVIDIA GeForce GTX 1080Ti GPUs, and 32 GB of RAM. On the client system, nodes were implemented as independent threads, thereby ensuring identical computing power and communication conditions across nodes. Both systems were connected within the same local network with a bandwidth of 1 Gbps; hence, the analysis on actual communication efficiency including communication latency is not explicitly considered in our analysis.
For local training at each node, we employed a two-layer CNN model with 5 × 5 convolution layers (the first with sixteen channels, the second with thirty-two channels, each followed with 2 × 2 max pooling). ReLU activation functions were applied after each convolution, and a final softmax layer was used for classification. Local learning at the client side was implemented using the PyTorch 2.9.1 framework, while the federated learning operations on both sides were implemented in C++ with open-source CKKS libraries. The MNIST dataset, comprising 60,000 training images and 10,000 test images, was used in the experiments. In the IID setting, data samples were evenly distributed across the nodes, whereas in the non-IID setting, the dataset size allocated to each node varied, resulting in heterogeneous local training times and update latencies, thereby effectively simulating heterogeneous nodes.
The server and nodes executed 100 rounds of the Learning phase (i.e., global model updates) to complete one federated learning process. To achieve a 128-bit security level for CKKS-HE, we set the degree of the ring polynomial , the decryption modulus to q = 800 bits, and the encryption modulus to Q = 1600 bits. For each experimental setting, the reported results represent the average of five independent runs. Table 3 summarizes the experimental parameters and corresponding values used in our evaluation.
Table 3.
Experimental parameters and values.
Table 4 shows the size of data allocated to nodes according to the number of nodes in both distributions.
Table 4.
The size of data allocated to nodes.
4.2.2. Experimental Results
We first evaluate the learning accuracy of V-MHESA. The analysis is conducted from four perspectives: (1) accuracy across training rounds, (2) accuracy with varying number of nodes, (3) accuracy under different data distributions (IID vs. non-IID), and (4) error rate analysis of the global model parameters generated by the proposed scheme.
For the round-based accuracy comparison, we compare the accuracy of V-MHESA with that of a baseline model that aggregates raw local parameters, as well as with our previous MHESA scheme. For node-scaling analysis, we examine how accuracy changes as the number of participating nods increases, and compare the results with both a single-node (centralize) learning model and the MHESA model. Regarding the data distribution analysis, in the IID setting, all nodes are assigned training datasets of equal size, whereas in the non-IID setting, nodes hold training datasets of varying sizes. This heterogeneity may lead to differences in aggregation accuracy. We therefore compare the performance of V-MHESA against MHESA under both IID and non-IID scenarios. Finally, we analyze the parameter error rate between the global model parameters obtained by direct aggregation of weighted local updates and those generated by V-MHESA, to assess the validity and utility of the proposed verification enhanced scheme.
Table 5 presents the comparison of learning accuracy across training rounds. The objective of this analysis is to examine the accuracy difference between the global model obtained through the aggregation of masked local updates and the global model generated by directly aggregating raw local parameters. To ensure fairness across all models, the experimental setting was unified by using 10 nodes with data distributed under the IID assumption, which yielded the highest accuracy among the tested configurations. The results show that the three models exhibit almost identical accuracy trends across rounds. This indicates that aggregating encrypted local parameters in the proposed scheme does not compromise the accuracy of global model.
Table 5.
Average accuracy comparison of the V-MHESA model, the raw data aggregation model, and the MHESA model (for N = 10, IID-setting).
Table 6 reports the learning accuracy of V-MHESA compared with a single centralized server model and the previous MHESA scheme under the IID setting, while Table 7 presents the corresponding results under the Non-IID setting. As shown in Table 6, the single centralized model, which processes all data collectively, achieves the highest accuracy. In contrast, the accuracy of both V-MHESA and MHESA decreases as the number of nodes increases, since each node receives a smaller portion of the training dataset. For example, in the IID setting, where data is evenly distributed among nodes, the single server model achieved 99.16% accuracy after 100 rounds, while V-MHESA reached 97.74% with 10 nodes but dropped to 90.55% when the number of nodes increased to 100. Nevertheless, the accuracy difference between V-MHESA and MHESA remains negligible across all cases.
Table 6.
Average accuracy under IID distribution across different numbers of nodes.
Table 7.
Average accuracy under Non-IID distribution across different numbers of nodes.
Table 7 illustrates the results under the Non-IID setting, where the distribution of training data varies significantly across nodes. Here, V-MHESA achieved 95.72% accuracy with 10 nodes, slightly lower than the 97.74% accuracy under the IID setting. Interestingly, with 100 nodes, the accuracy was 91.80%, slightly higher than the 90.55% observed in the IID setting. This behavior occurs because, unlike the IID case where increasing the number of nodes inevitably reduces the dataset size per node, in the Non-IID case some nodes retain relatively larger datasets and thus produce stronger local models, which positively influence the aggregated global model. Similarly to the IID experiments, the accuracy gap between V-MHESA and MHESA in the Non-IID setting is negligible. Figure 2 shows that, as the number of nodes increases, the accuracy in the Non-IID setting slightly improves. Up to 20 nodes, the accuracy in the IID setting is marginally higher or nearly identical to that of the Non-IID case. However, when the number of nodes reaches 50 or more, the Non-IID setting outperforms the IID setting in terms of accuracy.
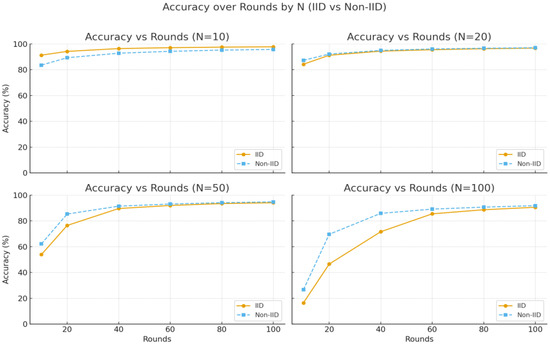
Figure 2.
Accuracy trends with varying numbers of nodes under IID and Non-IID settings.
Overall, while the global model accuracy tends to decrease as the number of nodes increases—primarily due to the reduced training data size per node—the comparison between V-MHESA and MHESA demonstrates that the introduction of verification functionality in V-MHESA does not adversely affect learning accuracy.
In the proposed model, the generation of local updates incorporates not only the masking value selected by each node but also the server’s secret S and the random nonce R shared exclusively among the nodes. To evaluate the accuracy of the global parameter reconstructed from masked local updates, we compared the global parameter w obtained by directly aggregating the raw local parameters without masking and the global parameter w′ derived from aggregating the masked local parameters. The resulting error analysis between w and w′ is presented in Figure 3. Furthermore, one of the core functionalities of V-MHESA is the verification of the global model. For the index set idx selected for verification, we compared the aggregated values of the actual local parameters, denoted as w[idx], with the values w′[idx] reconstructed by each node from the global verification token GT provided by FS. The error analysis between w[idx] and w′[idx] is presented in Figure 4.
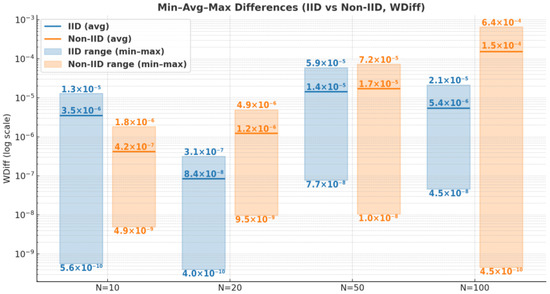
Figure 3.
Error analysis (minimum, maximum, and average) between the global parameter w obtained from raw aggregation and w′ obtained from masked aggregation in V-MHESA.
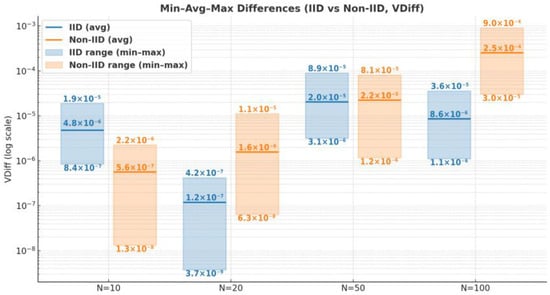
Figure 4.
Error analysis (minimum, maximum, and average) between the aggregated local parameters w[idx] and the reconstructed values w′[idx] from the global verification token GT.
As shown in Figure 3, in the IID setting, the error of the global model parameter w’ ranges from a minimum of 4.0 × 10−10 to a maximum of 5.9 × 10−5, with an average error of 5.8 × 10−6. In contrast, in the Non-IID setting, the error ranges from a minimum of 4.49 × 10−10 to a maximum of 6.44 × 10−4, with an average error of 4.29 × 10−5. The larger deviation observed in the Non-IID case is attributed to differences in the local dataset sizes across nodes, which lead to greater variations in the training rate (/X) of local parameters and consequently larger error fluctuations. Nevertheless, in all cases, the maximum error remains below 6.5 × 10−4, which does not significantly affect the accuracy of global model updates.
Figure 4 presents the error rate of w′[idx] derived from the global verification token GT. Since this analysis reflects only the subset of parameters corresponding to the randomly selected indices idx, the error deviations are smaller than those in Figure 3, though the extent of variation depends on which parameters are selected. In the IID setting, the minimum error is 3.74 × 10−9, the maximum error is 8.93 × 10−5, and the average error is 8.47 × 106. In the Non-IID setting, the minimum error is 1.3 × 10−8, the maximum error is 8.98 × 10−4, and the average error is 6.93 × 10−5. Across all cases, the maximum error remains below 9.0 × 104, indicating that the use of verification tokens does not impair the accuracy of the global model.
To evaluate the efficiency of V-MHESA, we analyze both the transmitted data size and the runtime overhead across the principal stages of the protocol. In the Setup phase, the key operations are (i) generating cryptographic keys for homomorphic-encryption-based aggregation between the server and the nodes, and (ii) distributing the initial random seed among the nodes. Since V-MHESA inherits the homomorphic encryption framework of MHESA, the key generation procedure remains identical to that of MHESA. The latter operation, however, is newly introduced in V-MHESA: a randomly selected node samples a random value and encrypts it under each peer’s public key for secure distribution.
In the Learning phase, the essential operations are local-update generation at each node, server side aggregation, and per-round verification. Compared with MHESA, V-MHESA introduces two additional tasks: (i) the generation of a verification token during local update construction, and (ii) the verification of the global update on the node side. Our efficiency analysis therefore focuses on these extensions, quantifying the incremental communication incurred by transmitting verification tokens and additional ciphertexts, and the incremental computation required for token generation and for executing the verification procedure at both the nodes and the server.
As shown in Table 8, the sizes of the additional parameters introduced by the verification functionality in V-MHESA are relatively small. Although public-key ciphertexts are added and their size grows proportionally with the number of nodes, this overhead occurs only once during the Setup phase and thus does not affect the overall efficiency of the protocol. In the repeatedly executed Learning phase, additional messages are generated and transmitted, including the random index set for verification, the round nonce, the corresponding authentication code, verification tokens, and the global verification token. While the communication size increases proportionally with the size of the random index set, the added overhead is negligible compared with the dominant payloads, namely the masked local parameters (174, 720 B) and the ciphertexts of the mask values (12.5 MB). Therefore, the use of verification tokens introduces only minimal communication overhead in practice.
Table 8.
Data sizes of additional parameters introduced in V-MHESA.
Table 9 compares the average execution times of the main operations in the V-MHESA model with those in the MHESA model under the Non-IID setting with 100 nodes. Since both models employ CKKS-HE, the homomorphic operations dominate the computational cost. In V-MHESA, the additional procedures required for generating verifiable local updates (including verification tokens), server authentication, and node authentication incur only negligible overhead compared with MHESA.
Table 9.
The actual average time to perform main operations in V-MHESA (N = 100, Non-IID).
During the Setup phase, the designated node generates the initial random nonce and encrypts it under the public keys of all other nodes. While the encryption cost scales linearly with the number of participating nodes, this operation is performed only once at initialization. Even in the 100-node setting, the total encryption time was approximately 8.54 ms, which is negligible. In the Learning phase, each node generates a masked local parameter along with its verification token . The additional cost of this operation is minimal, with the total execution time remaining within 15 ms compared with the original local update generation in MHESA. Similarly, FS aggregates both and , but the total aggregation time differs by less than 50 ms from that in MHESA.
Overall, although V-MHESA introduces additional mechanisms for verifiability, server and node authentication, and dropout resilience, the associated overhead is extremely small. Therefore, these enhancements do not meaningfully impact the overall efficiency of the federated learning process.
Finally, we analyze the overall execution time per Learning round. During the Learning phase, the most time-consuming operations are (1) generating and distributing the group key and group commitment for all participating nodes, (2) collecting all local model updates from the nodes, (3) generating and broadcasting the global update from the aggregated local updates, and (4) verifying the validity of the global update and updating each node’s local model with the new global parameters.
Figure 5 illustrates the execution times of these main operations according to the number of participating nodes. In the figure, “Round execution time by FS” refers to the total execution time for steps (1)–(3), while “Total round execution time” represents the overall time required for steps (1)–(4), including the local model update at each node.
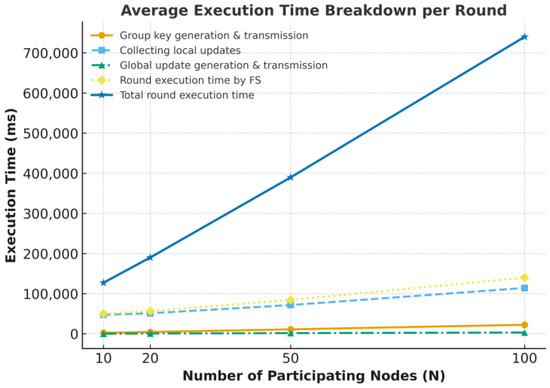
Figure 5.
Average Execution time breakdown per round according to the number of participating nodes (N).
In step (1), the group key generation and transmission required 2466.25 ms when N = 10, 4644.08 ms when N = 20, 11,079.8 ms when N = 50, and 22,501.9 ms when N = 100. In step (2), the collection of local updates took 47,422.3 ms, 51,128.2 ms, 71,713.6 ms, and 114,191 ms for N = 10, 20, 50, and 100, respectively. In step (3), the generation and transmission of the global update required 310.46 ms, 805.69 ms, 1691.64 ms, and 3303.94 ms, respectively. The average round execution time (steps (1)–(3)) therefore increased proportionally with the number of nodes, from 50,199.68 ms at N = 10 to 84,487.28 ms at N = 50 and 140,001.4 ms at N = 100. This proportional growth is natural since both computational and communication delays increase with the number of participating nodes.
When step (4) is included, the total execution time grows sharply with the number of nodes, mainly because the local model update at each node is the most time-consuming operation. In the experimental setup, all nodes were implemented as independent threads within a single client machine; thus, local model updates were executed sequentially rather than in parallel. As a result, the total execution time increased significantly—from 127,236 ms (N = 10) to 190,134 ms (N = 20), 389,664 ms (N = 50), and 739,829 ms (N = 100). However, in a real-world deployment, since nodes operate independently and perform local model updates in parallel, the overall time would not increase proportionally with N, but rather approximate the round execution time plus the maximum local update time among all nodes.
Figure 6 presents the results of analyzing the average execution time under various dropout conditions. Dropout occurs during the local update collection phase. When certain nodes drop out, the system waits for the maximum timeout (150 s in the experiment, corresponding to the maximum time required to complete step (2) for N = 100), and then reinitiates the Learning phase from the beginning with the remaining nodes to complete the round. Figure 6a presents the round execution time for dropout ratios (d) of 10%, 30%, and 50%, whereas Figure 6b presents the corresponding total round execution time. As shown in Figure 6a, once dropout occurs, the overall execution time inevitably takes longer than in the non-dropout case, since it must repeat the aggregation process with the remaining nodes after the timeout. However, as the dropout ratio increases, the number of remaining nodes decreases, leading to a slight reduction in the re-aggregation time. For example, when N = 100, the round execution time was 304,909 ms for d = 10%, 275,023.8 ms for d = 30%, and 248,489.6 ms for d = 50%.
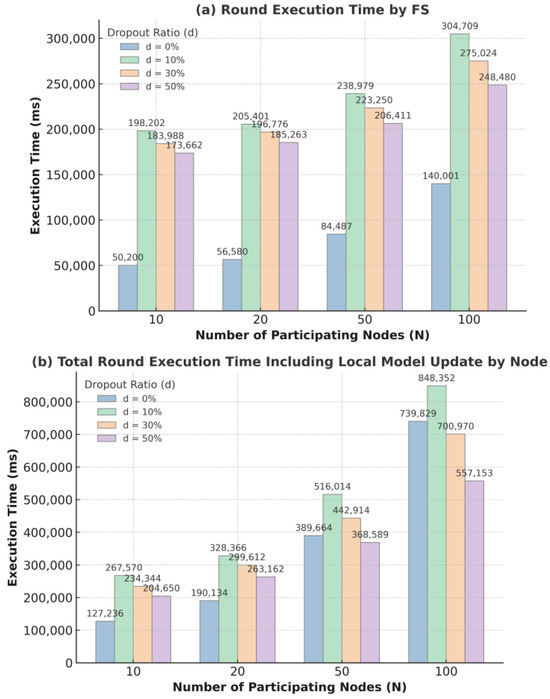
Figure 6.
Average execution time per round under various dropout ratios (d) for different number of participating nodes (N).
Figure 6b includes the local model update by each node and shows that, in our experiments, the total round execution time decreases as the dropout ratio increases. This is because fewer active nodes lead to fewer local model updates to perform, thereby reducing the total execution time. For instance, when N = 100, the total execution time was 848,352.4 ms for d = 10%, 700,970.4 ms for d = 30%, and 557,153.4 ms for d = 50%. However, in practical scenarios, since the nodes independently perform their local model updates in parallel, even under various dropout conditions, the total execution time is expected to increase only marginally appropriately by the maximum local model update time added to the round execution time.
We conducted an experimental evaluation of the V-MHESA-based federated learning model with respect to learning accuracy, aggregation correctness, the overhead introduced by the additional verification mechanisms of V-MHESA, and the overall round execution time. The results demonstrate that incorporating verifiable local updates does not compromise learning accuracy—the proposed model achieves the same accuracy as the original MHESA scheme. The total increase in communication volume caused by the verification functionality remains within approximately 10 KB even with 100 participating nodes, while the additional computation cost is limited to only a few tens of milliseconds. Compared with MHESA, both the communication and computational overheads introduced by V-MHESA are therefore negligible. Although the overall round execution time increases with the number of participating nodes, the average round time of about 140 s for N = 100 indicates that the proposed protocol can be executed within a reasonable duration. Although real network communication delays were not included in the experimental setup, the protocol’s intrinsic computational overhead remains modest, suggesting that, in practical deployments, total performance would be dominated primarily by network communication rather than by the internal operations of the protocol itself.
5. Discussion
This study presented V-MHESA, a verifiable secure aggregation protocol for federated learning that extends our previous MHESA scheme by incorporating lightweight verification and authentication mechanisms. Unlike conventional secure aggregation methods that solely protect local parameters, V-MHESA additionally guarantees the correctness and integrity of the aggregated global model.
A key innovation of V-MHESA lies in its multi-layered security design. In each Leaning round, FS distributes a round noces, and every node responds with a hash-based authentication code derived from its (secure) identifier (known only to FS) and the nonce. This procedure ensures that only legitimate, pre-registered nodes can participate in the aggregation, thereby providing robust node authentication.
During local update generation, each node masks its parameter using (1) its own random mask , (2) FS’s secret S, and (3) a shared random secret R known only to the participating nodes. This ensures that only FS can remove the aggregate masking term to obtain the blinded sum , while only the nodes that share R can subsequently recover the actual global model w. Consequently, adversaries outside the legitimate FS-node group are prevented from joining the learning process, generating aggregation results, or generating forged updates.
The shared secret R is updated independently by the nodes in each learning round via hash chaining which eliminates any need for repeated communication or collaboration between nodes. This mechanism not only minimizes communication overhead but also strengthens the confidentiality of local updates by ensuring that a fresh random secret is used in every round.
To achieve verifiability, each node additionally generates a verification token for a small, randomly selected subset of parameters. This token-based approach requires neither a trusted third party nor complex cryptographic primitives such as homomorphic hash function or secret sharing. Instead, it relies on simple masking operations and lightweight arithmetic aggregation, resulting in negligible computational and communication cost.
From a security standpoint, V-MHESA ensures that all local parameters remain confidential under the honest-but-curious threat model. FS can obtain only the blinded aggregation , while the true global parameter w is recoverable solely by the nodes that share R. Moreover, forging a valid global update pair <GW, GT> without knowledge of R is computationally infeasible, with success probability bounded by , where m denotes the bit length of the pseudo-random output.
Experimental evaluations on the MNIST dataset confirmed that this verification mechanism does not affect model accuracy. The V-MHESA model achieved nearly identical accuracy to MHESA under both IID and non-IID settings. The additional communication incurred by transmitting verification tokens remained minimal compared with the overall size of masked local parameters and encrypted mask values.
The main limitation of the proposed model lies in the relatively large size of encrypted mask data. This is an inherent trade-off of using CKKS-HE, which provides 128-bit security but increases ciphertext size. Therefore, V-MHESA is particularly suitable for high-security federated learning environments—such as healthcare, finance, or other domains where data sensitivity is critical—and where static node participation, high computational capability, and sufficient network bandwidth are available. In contrast, in lightweight mobile environments with limited bandwidth, the communication overhead caused by large ciphertexts may be non-negligible. However, by appropriately tuning the security level—such as adjusting the polynomial degree used in CKKS-HE—it is possible to reduce the ciphertext size and thus the transmission cost. Future work will explore such adaptive configurations to make V-MHESA more broadly applicable across diverse federated learning environments with different security and resource requirements.
6. Conclusions
V-MHESA achieves a compelling balance between security, verifiability, and efficiency in federated learning. It introduces only marginal computational and communication overhead compared with MHESA, yet it significantly enhances the trustworthiness of the aggregation process by enabling every node to independently verify the correctness and integrity of the global model—without revealing any sensitive information.
By combining masking and homomorphic encryption with a lightweight verification mechanism, V-MHESA effectively overcomes one of the most critical limitations of existing secure aggregation schemes. Its simplicity, robustness, and negligible overhead make it particularly suitable for real-world, privacy-sensitive applications such as healthcare, finance, and IoT-based collaborative learning.
Future work will extend V-MHESA to more heterogeneous and large-scale federated environments, including asynchronous learning, dynamic node participation, and stronger adversarial models beyond the honest-but-curious assumption.
Author Contributions
Conceptualization, S.P.; methodology, S.P.; software, S.P.; validation, S.P. and J.C.; formal analysis, S.P.; data curation, J.C.; writing—original draft preparation, S.P.; writing—review and editing, S.P. and J.C.; supervision, S.P.; project administration, S.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF), funded by the Ministry of Education (NRF-2021R1F1A1063172).
Data Availability Statement
The original data presented in the study are openly available at http://yann.lecun.com/exdb/mnist (accessed on 3 October 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 9–11 May 2017; Volume 54. [Google Scholar]
- Zhu, L.; Liu, Z.; Han, S. Deep Leakage from Gradients. arXiv 2019, arXiv:1906.08935. [Google Scholar] [CrossRef]
- Wang, Z.; Song, M.; Zhang, Z.; Song, Y.; Wang, Q.; Qi, H. Beyond Inferring Class Representatives: User-Level Privacy Leakage from Federated Learning. In Proceedings of the IEEE INFOCOM, Paris, France, 29 April–2 May 2019; pp. 2512–2520. [Google Scholar] [CrossRef]
- Geiping, J.; Bauermeister, H.; Dröge, H.; Moeller, M. Inverting Gradients—How Easy Is It to Break Privacy in Federated Learning? In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Online, 6–12 December 2020.
- Yao, A.C. Protocols for Secure Computations. In Proceedings of the 23rd IEEE Annual Symposium on Foundations of Computer Sciecne (SFCS 1982), Chicago, IL, USA, 3–5 November 1982; pp. 160–164. [Google Scholar] [CrossRef]
- Shamir, A. How to Share a Secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially Private Federated Learning: A Client Level Perspective. In Proceedings of the NIPS 2017 Workshop: Machine Learning on the Phone and Other Consumer Devices, Proceedings of the Conference on Neural Information Processing Systems (NeurIPS 2017), Long Beach, CA, USA, 8 December 2017. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.S.; Poor, H.V. Federated Learning with Differential Privacy: Algorithms and Performance Analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedoney, A.; McMahan, H.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical Secure Aggregation for Federated Learning on User-Held Data. arXiv 2016, arXiv:1611.04482. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical Secure Aggregation for Privacy-Preserving Machine Learning. In Proceedings of the ACM SIGSAC Conferences on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar] [CrossRef]
- Ács, G.; Castelluccia, C. I Have a DREAM! (DiffeRentially privatE smArt Metering). In Proceedings of the Information Hiding (IH 2011); Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2011; Volume 6958, pp. 118–132. [Google Scholar] [CrossRef]
- Goryczka, S.; Xiong, L. A Comprehensive Comparison of Multiparty Secure Additions with Differential Privacy. IEEE Trans. Dependable Secur. Comput. 2017, 14, 463–477. [Google Scholar] [CrossRef]
- Elahi, T.; Danezis, G.; Goldberg, I. PrivEx: Private Collection of Traffic Statistics for Anonymous Communication Networks. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 1068–1079. [Google Scholar] [CrossRef]
- Jansen, R.; Johnson, A. Safely Measuring Tor. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1553–1567. [Google Scholar] [CrossRef]
- So, J.; Güler, B.; Avestimehr, A.S. Turbo-Aggregate: Breaking the Quadratic Aggregation Barrier in Secure Federated Learning. arXiv 2020, arXiv:2002.04156. [Google Scholar] [CrossRef]
- Kim, J.; Park, G.; Kim, M.; Park, S. Cluster-Based Secure Aggregation for Federated Learning. Electronics 2023, 12, 870. [Google Scholar] [CrossRef]
- Leontiadis, I.; Elkhiyaoui, K.; Molva, R. Private and Dynamic Timeseries Data Aggregation with Trust Relaxation. In Proceedings of the International Conferences on Cryptology and Network Security (CANS 2014); Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2014; Volume 8813, pp. 305–320. [Google Scholar] [CrossRef]
- Rastogi, V.; Nath, S. Differentially Private Aggregation of Distributed Time-Series with Transformation and Encryption. In Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD 10), Indianapolis, IN, USA, 6–10 June 2010; pp. 735–746. [Google Scholar] [CrossRef]
- Halevi, S.; Lindell, Y.; Pinkas, B. Secure Computation on the Web: Computing without Simultaneous Interaction. In Proceedings of the Advances in Cryptology—CRYPTO 2011; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2011; Volume 6841, pp. 132–150. [Google Scholar] [CrossRef]
- Leontiadis, I.; Elkhiyaoui, K.; Önen, M.; Molva, R. PUDA—Privacy and Unforgeability for Data Aggregation. In Proceedings of the Cryptology and Network Security (CANS 2015); Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2015; Volume 9476, pp. 3–18. [Google Scholar] [CrossRef]
- Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-Preserving Deep Learning via Additively Homomorphic Encryption. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1333–1345. [Google Scholar] [CrossRef]
- Fang, H.; Qian, Q. Privacy Preserving Machine Learning with Homomorphic Encryption and Federated Learning. Future Internet 2021, 13, 94. [Google Scholar] [CrossRef]
- Park, J.; Lim, H. Privacy-Preserving Federated Learning Using Homomorphic Encryption. Appl. Sci. 2022, 12, 734. [Google Scholar] [CrossRef]
- Liu, W.; Zhou, T.; Chen, L.; Yang, H.; Han, J.; Yang, X. Round Efficient Privacy-Preserving Federated Learning based on MKFHE. Comput. Stand. Interfaces 2024, 87, 103773. [Google Scholar] [CrossRef]
- Jin, W.; Yao, Y.; Han, S.; Gu, J.; Joe-Wong, C.; Ravi, S.; Avestimehr, S.; He, C. FedML-HE: An Efficient Homomorphic-Encryption-based Privacy-Preserving Federated Learning System. arXiv 2023, arXiv:2303.10837. [Google Scholar]
- Wibawa, F.; Catak, F.O.; Kuzlu, M.; Sarp, S.; Cali, U. Homomorphic Encryption and Federated Learning based Privacy-Preserving CNN Training: COVID-19 Detection Use-Case. In Proceedings of the 2022 European Interdisciplinary Cyber-Security Conference (EICC ’22), Barcelona, Spain, 15–16 June 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 85–90. [Google Scholar] [CrossRef]
- Hijazi, N.M.; Aloqaily, M.; Guizani, M.; Ouni, B.; Karray, F. Secure Federated Learning with Fully Homomorphic Encryption for IoT Communications. IEEE Internet Things J. 2024, 11, 4289–4300. [Google Scholar] [CrossRef]
- Sanon, S.P.; Reddy, R.; Lipps, C.; Schotten, H.D. Secure Federated Learning: An Evaluation of Homomorphic Encrypted Net-work Traffic Prediction. In Proceedings of the IEEE 20th Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic Encryption for Arithmetic of Approximate Numbers. In Proceedings of the Advances in Cryptology-ASIASCRYPT 2017; Lecture Notes in Computer Science; Springer: Cham, Switzerland; 2017; Volume 10624. [Google Scholar] [CrossRef]
- Park, S.; Lee, J.; Harada, K.; Chi, J. Masking and Homomorphic Encryption-Combined Secure Aggregation for Privacy-Preserving Federated Learning. Electronics 2025, 14, 177. [Google Scholar] [CrossRef]
- LeCun, Y.; Cortes, C.; Burges, C.J. MNIST Handwritten Digit Database. 2010. Available online: http://yann.lecun.com/exdb/mnist (accessed on 3 October 2025).
- Xu, G.; Li, H.; Liu, S.; Yang, K.; Lin, X. VerifyNet: Secure and Verifiable Federated Learning. IEEE Trans. Inf. Forensics Secur. 2020, 15, 911–926. [Google Scholar] [CrossRef]
- Guo, X.; Liu, Z.; Li, J.; Gao, J.; Hou, B.; Dong, C.; Baker, T. VeriFL: Communication-Efficient and Fast Verifiable Aggregation for Federated Learning. IEEE Trans. Inf. Forensics Secur. 2020, 16, 1736–1751. [Google Scholar] [CrossRef]
- Buyukates, B.; So, J.; Mahdavifar, H.; Avestimehr, S. LightVeriFL: A Lightweight and Verifiable Secure Aggregation for Federated Learning. arXiv 2022, arXiv:2207.08160. [Google Scholar] [CrossRef]
- Behnia, R.; Riasi, A.; Ebrahimi, R.; Chow, S.S.M.; Padmanabhan, B.; Hoang, T. Efficient Secure Aggregation for Privacy-Preserving Federated Machine Learning (e-SeaFL). In Proceedings of the 2024 Annual Computer Security Applications Conference (ACSAC), Honolulu, HI, USA, 9–13 December 2024; pp. 778–793. [Google Scholar] [CrossRef]
- Peng, K.; Li, J.; Wang, X.; Zhang, X.; Luo, B.; Yu, J. Communication-Efficient and Privacy-Preserving Verifiable Aggregation for Federated Learning. Entropy 2023, 25, 1125. [Google Scholar] [CrossRef]
- Zhou, S.; Wang, L.; Chen, L.; Wang, Y.; Yuan, K. Group Verifiable Secure Aggregate Federated Learning based on Secret Sharing. Sci. Rep. 2025, 15, 9712. [Google Scholar] [CrossRef]
- Xu, B.; Wang, S.; Tian, Y. Efficient Verifiable Secure Aggregation Protocols for Federated Learning. J. Inf. Secur. Appl. 2025, 93, 104161. [Google Scholar] [CrossRef]
- Li, G.; Zhang, Z.; Du, R. LVSA: Lightweight and Verifiable Secure Aggregation for Federated Learning. Neurocomputing 2025, 648, 130712. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).