Abstract
Binocular vision is a core module in humanoid robots, and stereo matching is one of the key challenges in binocular vision, relying on template matching techniques and mathematical optimization methods to achieve precise image matching. However, occlusion significantly affects matching accuracy and robustness in practical applications. To address this issue, we propose a novel hybrid matching strategy. This method does not require network training and has high computational efficiency, effectively addressing occlusion issues. First, we propose the Inverse Template Matching Mathematical Method (ITM), which is based on optimization theory. This method generates multiple new templates from the image to be matched using mathematical segmentation techniques and then matches them with the original template through an inverse optimization process, thereby effectively improving matching accuracy under mild occlusion conditions. Second, we propose the Iterative Matching Mathematical Method (IMM), which repeatedly executes ITM combined with optimization strategies to continuously refine the size of matching templates, thereby further improving matching accuracy under complex occlusion conditions. Concurrently, we adopt a local region selection strategy to selectively target areas related to occlusion regions for inverse optimization matching, significantly enhancing matching efficiency. Experimental results show that under severe occlusion conditions, the proposed method achieves a 93% improvement in accuracy compared to traditional template matching methods and a 37% improvement compared to methods based on convolutional neural networks (CNNs), reaching the current state of the art in the field. Our method introduces a reverse optimization paradigm into the field of template matching and provides an innovative mathematical solution to address occlusion issues.
Keywords:
template matching; mathematical method; stereo matching; inverse thinking; image occlusion MSC:
93-08
1. Introduction
In the binocular vision system of humanoid robots, template matching is a key task for achieving stereoscopic matching, as shown in Figure 1. Template matching uses mathematical optimization methods to find the region in the target image that is most similar to the template image. Given a template image T and a target image I, the goal of template matching is to use mathematical optimization techniques to find the best match between the template image T and the target image I by calculating a similarity metric function at each candidate window position in the target image I. This process typically involves three basic steps: first, a search strategy is used to divide the target image I into candidate windows of the same size as the template image T, with the center of each candidate window located at in the target image I; second, feature vectors are extracted from the template image T and the candidate windows ; and finally, the similarity between the template image T and the candidate window features is calculated, with the window having the highest similarity value identified as the matched region. Template matching plays a crucial role in various fields, including object detection [1,2], object tracking [3], face recognition [4], feature extraction [5], and robotics applications [6].
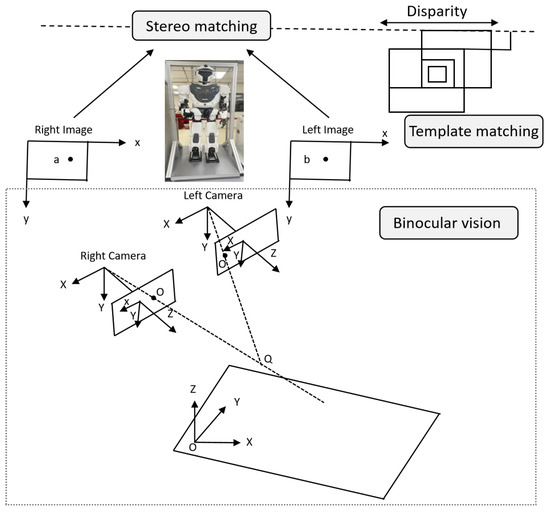
Figure 1.
Application of Template Matching in Stereo Vision. In a binocular vision system, template matching converts 2D image information into 3D spatial coordinates by calculating parallax and applying triangulation, thereby establishing a mathematical relationship between 2D images and 3D space.
Traditional template matching methods, such as Sum of Squared Distance (SSD), Sum of Absolute Distance (SAD), and Normalized Cross-Correlation (NCC) [7,8], perform very effectively in most scenarios. However, when encountering complex situations, such as occlusion or scale changes, the performance of these methods is often limited, and they are unable to maintain good matching accuracy.
Specifically, the SSD measures similarity by minimizing the sum of squared differences between pixels in the template T and candidate windows using the following equation:
The SAD measures similarity by minimizing the sum of the absolute values of the pixel differences between the template T and the candidate window . The equation is as follows:
The NCC calculates the correlation between the template T and the candidate window to measure their similarity. It is often used to process brightness changes in images. NCC is a standard similarity measure that calculates the correlation between two image patches while remaining invariant to linear illumination changes. The equation is as follows:
where and are the means of the template and candidate windows, respectively.
Traditional mathematical methods are unable to effectively handle occlusions, scale transformations, and other non-rigid transformations when calculating correlations, resulting in a significant decrease in matching accuracy. To address these issues, methods based on nearest neighbor (NNF) have been proposed [9,10] and have been proven to achieve good results in complex situations, becoming the state-of-the-art technology in this field. NNF provides a general mathematical framework for image matching, enhancing its robustness in handling non-rigid transformations, occlusion, and background noise by focusing on matching subsets between the template and query subwindows [11,12]. Based on this, NNN-based template matching methods improve matching accuracy by matching template point sets and query point sets and defining similarity metrics based on matching statistics. However, NNN-based methods may still face issues with reduced matching accuracy when handling extreme scenarios, especially large-scale occlusions and extremely complex backgrounds, and their high computational complexity limits their widespread adoption in real-time applications.
Deep learning-based template matching methods have made significant progress in recent years, particularly in addressing object detection and tracking problems in complex scenes. Unlike traditional template matching methods, deep learning approaches utilize convolutional neural networks (CNNs) [13] or Siamese networks [14] to automatically learn feature representations in images, thereby enabling efficient matching. Among these methods, CNNs learn both local and global features through multiple layers of convolutional operations, enabling precise matching in more complex and dynamic environments. Siamese networks, on the other hand, perform template matching by comparing the similarity between two input images, demonstrating strong robustness. Specifically, the CNN model minimizes the difference between the template image T and the target window by optimizing the objective function , where represents the feature map extracted by the CNN network and is the loss function, typically cross-entropy or mean squared error. By optimizing these loss functions, CNNs can effectively adjust the feature map to improve matching accuracy. However, deep learning-based template matching methods still face challenges in practical applications, particularly in terms of their reliance on large amounts of labeled data and computational resources. Deep learning models [15] typically require a large amount of labeled data for training, which is particularly challenging in real-world applications where target features are highly variable or images are complex.
Occlusion is a major challenge in computer vision, and solving the template matching problem is crucial for advancing binocular stereovision matching and 3D reconstruction, while also improving the accuracy of mathematical models in depth perception and spatial localization. Therefore, this paper proposes a robust template matching method for achieving cognitive stereovision. For mild occlusion problems, we proposed the ITM mathematical method, which generates new templates by mathematically segmenting the target image and performs inverse matching between these new templates and the original templates. This process effectively improves matching accuracy by reducing the size of the matching region. For severe occlusion problems, we proposed the IMM mathematical method, which performs ITM multiple times to generate new templates of different sizes and performs inverse matching, thereby enhancing the robustness of the matching. In this process, we introduced a local region selection strategy to optimize the selection of relevant regions and reduce the computational complexity of the matching process. Experimental results show that our method achieves state-of-the-art performance in current research and effectively addresses template matching problems in complex occlusion environments.
The main contributions of this paper are as follows:
- We propose an Inverse Template Matching Mathematical Method (ITM), an image processing method based on mathematical segmentation, which divides the input image into multiple sub-images. This method can effectively improve the accuracy of template matching by reducing errors caused by occlusion.
- We propose an Iterative Matching Mathematical Method (IMM), an optimization method based on an iterative process that gradually optimizes matching results by repeatedly executing ITM and dynamically adjusting template sizes. Through repeated iterations, IMM can adjust templates during each matching process to optimize matching accuracy in complex occlusion scenarios.
- We propose a local region selection strategy that employs mathematical techniques, such as accuracy measurement and threshold setting, to identify the optimal matching region from all sub-images. This strategy reduces redundant computations and significantly improves matching efficiency.
- Compared to the traditional template matching method, our method improves the average accuracy by 93% in the case of severe occlusion. When compared to neural network-based matching methods, our method achieves a 37% improvement in average accuracy under the same conditions, reaching state-of-the-art performance.
2. Related Work
2.1. Traditional Template Matching
Traditional template matching methods are usually categorized into pixel-based matching methods and feature-based matching methods. Pixel-based matching methods determine the matching location by calculating the similarity between the image region and the template. Feature-based template matching methods rely on salient features extracted from the image for matching.
The pixel-based template matching method [16] is one of the most traditional and widely used techniques in the field of image matching. Common similarity measures include SSD, SAD, and NCC [17]. Recently, a new fast and robust template matching method was proposed in [18], which combines the Most Neighbor Similarity (MNS) and Annular Projection Transformation (APT). By adopting a coarse-to-fine matching strategy and MNS measurement, this method avoids the traditional sliding window scan, enabling efficient matching and also estimating the rotation angle of the target object. It effectively addresses challenges such as background noise and occlusion. A new RGB-T Siamese tracker was proposed in [19], which enhances the recognition ability of background distractors and ensures real-time performance by introducing a target enhancement module, a multi-modal feature fusion module based on intra- and inter-modality attention, and a hard-focus online classifier. In [20], a novel coarse-to-fine pattern parsing network based on Capsule Networks was introduced to mitigate the issue of severe pixel imbalance in pattern parsing tasks. A new Adaptive Radial Ring Code Histogram image descriptor was proposed in [21], which uses radial gradient codes as rotation-invariant features and can solve template matching under both scale and rotation transformations of images.
Feature-based matching methods have better robustness by extracting key feature points (e.g., corner points, edges, and textures) in the image, and common methods include Scale-Invariant Feature Transform (SIFT) [22], Speeded-Up Robust Features (SURF) [23], and Oriented FAST and Rotated BRIEF (ORB) [24]. The SIFT method maintains a better matching effect under different scales and rotations by extracting scale-invariant keypoints and descriptors. The ORB method combines FAST corner detection and BRIEF descriptors, which improves the computational efficiency and maintains a high matching accuracy. In order to achieve robust template matching at multiple scales, a new rotation-invariant template matching method is proposed in [25], which realizes multi-scale search and partially occluded robust template matching by using the complex coefficients of the discrete Fourier transform of the radial projection for extracting the local features and using the Hough transform and the features of the stabilized sub-templates for fast matching. When SIFT is used for remote sensing image alignment, image intensity differences lead to a large number of keypoints mismatched. For this reason, the study by [26] proposed a joint scale-orientation restriction criterion and an improved feature descriptor, which significantly improved the matching performance of multi-date, multi-spectral, and multi-sensor remote sensing images, as well as increasing the correct matching rate and alignment accuracy compared with the traditional methods. Feature-based methods are widely used in the fields of autonomous driving, robot vision, and image retrieval, and they perform well in dealing with target recognition and localization in dynamic environments.
Traditional pixel matching methods perform well in simple scenes but are prone to mismatching and accuracy degradation when confronted with real-world scenarios, such as image noise, scale variations, rotation and occlusion. In addition, these methods ignore the higher-order semantic information in images, which limits their application in complex scenes.
2.2. Deep Learning-Based Template Matching
In recent years, deep learning techniques have been gradually applied to the template matching problem, especially methods such as CNNs [27] and Siamese networks [28], which address some of the limitations in the traditional methods by learning the feature representations of images. In order to overcome the influence of complex scenes on the results in template matching methods, in [29], a visible and infrared image matching network based on the structure of a Siamese network is proposed, which extracts feature maps from the input image through a residual network with an attentional mechanism and fuses these feature maps for classification and regression to achieve image matching with excellent mean-averaged accuracy. In [30], an efficient high-resolution template matching method is proposed to improve the matching accuracy and computational efficiency by using vector quantized nearest neighbor fields. The method can effectively handle large-scale datasets and reduce the computational complexity while maintaining the matching quality. In [31], a novel adaptive edge deletion network is proposed for subgraph matching, which improves the matching accuracy and speed by introducing an adaptive edge deletion mechanism to remove redundant edges in order to maintain the consistency of the neighboring structure of the matching nodes, and at the same time ensures the consistency of the features of the matching nodes by using a one-way cross-propagation mechanism.
Although deep learning methods have made some progress in improving robustness, they still face challenges in terms of computational complexity and real-time performance, especially on resource-constrained devices. Although researchers have proposed various optimization strategies, such as model compression and hardware acceleration [32,33], how to optimize computational efficiency while improving robustness remains a key issue in current research.
2.3. Similarity Metrics in Template Matching
The similarity measure between the template and the sub-window of the target image is the core part of template matching. Commonly used methods are pixel-level, such as NCC [34]. The basic idea of normalized cross-correlation is to compare the template with each part of the image on a pixel-by-pixel basis and compute their correlation. The formula for calculating normalized cross-correlation is usually as follows:
Although NCC can provide an effective similarity measure in many contexts, the method usually only satisfies a necessary condition for similarity, not a sufficient condition. NCC does not adequately account for complex image variations, such as occlusion, lighting changes, or deformation. Therefore, in complex scenes, these methods often do not cope well with occlusion and deformation situations.
To improve the robustness of template matching in the case of occlusion, many researchers have proposed different methods to find the similarity between a given template and the input image. For instance, the work reported in [35] proposes the use of Best-Buddies Similarity (BBS) as a method to find the similarity in place of the widely used Normalized Cross-Correlation or the Sum-of-Squared-Distances method. Since BBS only makes use of a subset of points of the nearest neighbor matches and compares the features of the input and the template image, it only detects the relevant features. It proves to be partially effective in the case of occluded images. Further extending the approach of BBS, the author in [36] introduces another novel feature-based and parameter-free similarity index named Deformable Diversity Similarity to find the similarity. Moreover, the work listed in [37] makes use of Sum of Absolute Differences as a method to find the similarity. This makes template matching capable of partially handling occlusions and enables the algorithm to manage transformations on the input images.
Although existing similarity methods have achieved good results in many cases, they still face many challenges when dealing with complex scenes, such as occlusion, distortion, and lighting changes. Therefore, exploring and selecting appropriate similarity methods is always a key and challenging difficulty in template matching.
2.4. Positioning of the Proposed Method
The proposed ITM and IMM methods share a high-level goal with patch-based and correspondence-based methods like BBS and Deformable Diversity Similarity [36]: to achieve robust template matching under challenging conditions like occlusion. However, a fundamental philosophical and methodological distinction exists, which forms the core novelty of our work.
Methods like BBS and Deformable Diversity Similarity operate within an enhanced forward matching paradigm. They take the original template T and search for mutual or “best-buddy” correspondences within the input image I. Their primary innovation lies in defining a robust similarity measure that is resistant to outliers caused by occlusion. Nevertheless, the fundamental process remains centered on comparing the template T to regions within I, maintaining the traditional roles where T is the active searcher and I is the passive target.
In contrast, our ITM/IMM method introduces a genuine inverse matching paradigm. The core innovation is the systematic role reversal between the template and the search image. Instead of deconstructing the template or designing a robust global metric, we systematically deconstruct the input image I into a set of sub-templates . The matching process is fundamentally reversed: we evaluate how well each of these sub-templates, representing potential unoccluded parts of the scene, matches the original, intact template T. In this framework, T serves as the immutable reference model, and the algorithm’s task is to identify which segments of the cluttered scene I best instantiate this model. This approach naturally prioritizes any visible, matchable part of the object without being inherently biased by occluded portions of the template itself.
Furthermore, the iterative process in IMM is distinct. It is not merely about refining correspondence matches or features but about systematically and recursively reducing the scale of the search space itself. Each iteration generates smaller, more focused sub-templates from promising regions, allowing the matching to converge on an optimal, occlusion-free match at a finer granularity. This represents a unique application of iterative optimization to the specific inverse matching problem we define, differing from the traditional coarse-to-fine search in image pyramids or feature spaces.
3. Method
In this section, we provide a detailed introduction to the core content of our proposed strategy, i.e., “A Hybrid Strategy for Achieving Robust Matching Inside the Binocular Vision of a Humanoid Robot”. This method proposes two mathematical methods, ITM and IMM, to solve the occlusion problem in template matching. First, in Section 3.1, we introduced the Forward Template Matching (FTM). Then, in Section 3.2, we introduced a detailed description of the ITM method, which segmented the original input image into multiple sub-templates for inverse matching against the initial template. However, when the occlusion problem was more complex, a single inverse match could not fully handle the detail areas. To address this, in Section 3.3, we proposed the IMM method, which overcame the limitations of single matching by iterating ITM multiple times and adjusting the template size, significantly improving matching accuracy. Finally, in Section 3.4, we introduced a local region selection strategy, utilizing the optimal local region from the forward matching as the input image for inverse matching, further optimizing matching efficiency and accuracy, with particularly significant results in complex occlusion scenarios. The overall flowchart is shown in Figure 2.
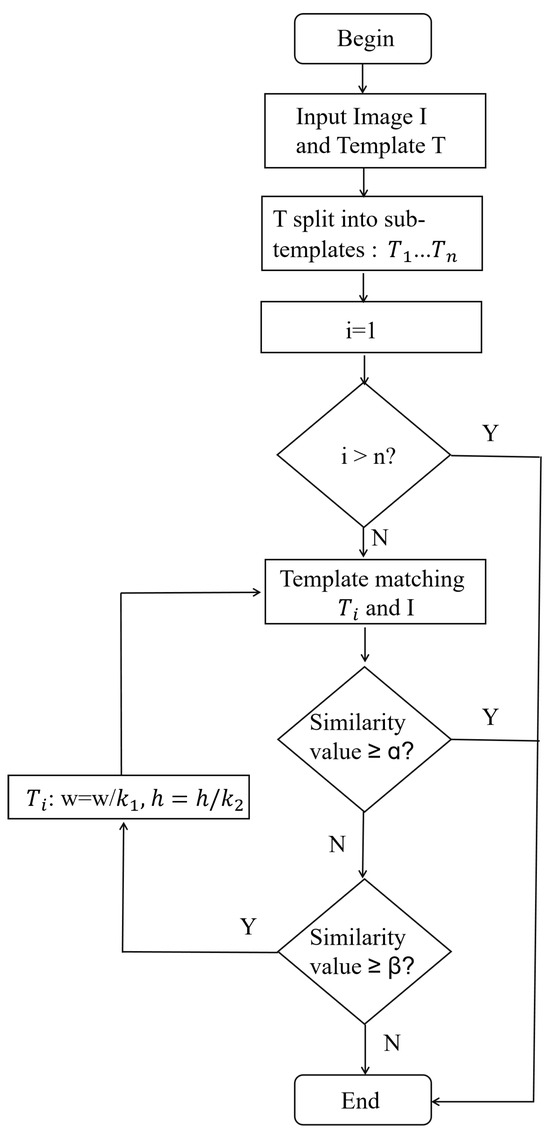
Figure 2.
Overall Flowchart. Illustrates the overall workflow of the proposed hybrid matching strategy.
3.1. Forward Template Matching (FTM)
Template matching algorithms are used to identify and locate images by searching for the region in the target image I that most closely matches the template image T. Given an input image I and a template image T, with pixel values and , respectively, the objective of forward template matching is to find the best matching position between I and T. The template is slid over each position in the target image , forming sub-images in the target image I, and the similarity or dissimilarity between the current template T and the sub-images of the target image I is calculated to determine the best matching position.
Specifically, the optimization objective of FTM can be expressed as follows:
where NCC() represents the normalized cross-correlation between the template T and the sub-image at position . This measures the similarity between the template and the sub-image, and the location that maximizes this value is selected as the best match.
Additionally, we can express the matching problem as an optimization of the mean squared error (MSE) between the template and sub-image:
where E is the matching error, and minimizing this error leads to the optimal alignment of the template with the image.
3.2. Inverse Template Matching Mathematical Method (ITM)
We propose an inverse matching mathematical method to solve the template matching problem in cases of slight occlusion. In ITM, the input image i is divided into multiple sub-images that act as candidate templates, while the original template T is treated as the query image to be matched. This reverse formulation enables the algorithm to capture fine-grained structural correspondences and to remain robust under partial occlusion.
Let the input image be
where p and q represent the width and height of the image, respectively, and the co-domain is typically the intensity range for grayscale images.
Moreover, let the original template be
where w and h denote the template dimensions.
The input image I is systematically partitioned into z rectangular sub-images (also called candidate templates) , each having smaller dimensions than T. Formally, the z-th sub-image is defined as
where represents the spatial offset of the z-th window within the image domain .
The collection of all such sub-images forms the candidate template set:
For each candidate template , we compute a dissimilarity measure and corresponding similarity score as follows:
where is the maximum possible pixel intensity.
The ITM method uses this reverse matching strategy to effectively extract the areas that best represent template T from the original image and improve matching accuracy through difference value calculations, as shown in Figure 3. This method is particularly suitable for scenes with slight occlusions, as it concentrates the calculation accuracy of the matching area on a smaller area, thereby avoiding large-scale mismatches caused by occlusions.
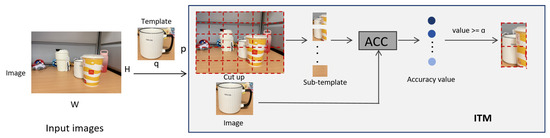
Figure 3.
Inverse Template Matching Framework. We divide the input image into z sub-templates of size and perform template matching with the original template. We set the threshold of accuracy value to .
We intentionally employ a simple subtraction-based similarity measure to maximize computational efficiency, a design choice that is fundamental to the scalability of our inverse matching paradigm. This approach not only enables the real-time processing of numerous sub-templates but also ensures stability and interpretability throughout the iterative refinement process, offering a practical and efficient alternative to computationally intensive traditional metrics.
3.3. Iterative Matching Mathematical Method (IMM)
In Section 3.2, we proposed ITM, which effectively solved the occlusion problem in binocular vision and enabled basic template matching. However, when occlusion is severe or complex, a single reverse template matching operation does not cover a sufficient area, resulting in imprecise matching of details. Therefore, to address this issue, we proposed the IMM, which improves matching accuracy by iteratively optimizing template size and similarity thresholds through multiple iterations.
The relationship between ITM and IMM can be summarized as an extension from a single-scale inverse matching to a multi-scale iterative framework. In ITM, the input image is divided into several fixed-size sub-images that are each compared with template T to locate the most similar region. Although this approach effectively handles mild occlusion, it relies on a constant template size, which limits its adaptability to variations in scale and occlusion extent. IMM addresses this limitation by repeatedly executing the ITM process while dynamically adjusting the template size and similarity thresholds in each iteration. Formally, IMM can be interpreted as a recursive application of ITM under adaptive scaling parameters .
To better understand the structure and flow of the algorithm, we present the overall framework in Figure 4. The following are the mathematical derivations and algorithmic steps:
- 1.
- Definition of Input Image and Template:
Let the input image with size be
Let the original template with size be
At iteration n, the current sub-template extracted from I is denoted by
with dimensions . Initially, and . Each iteration evaluates the similarity between and T to determine whether refinement is necessary.
- 2.
- Difference Metric and Similarity Calculation:
For the z-th sub-image at iteration n, the pixel-wise absolute difference is defined as
The normalized similarity coefficient is given by
A higher indicates stronger correspondence between and T. The overall IMM objective can thus be expressed as
- 3.
- Iterative Process:
Given the similarity thresholds and (), the decision process for each region is as follows:
For each retained region, the template size is refined using adaptive scaling factors:
where control the granularity of refinement.
Equivalently, using the input image dimensions p and q, we have
where and denote the adaptive scaling parameters at iteration n. Thus, the refinement process can be represented recursively as
where denotes the spatial subdivision and rescaling operator acting on each sub-image.
- 4.
- Optimal Matching Output:
At each iteration, the algorithm selects the sub-template with the highest similarity score:
After all iterations, the final optimal match is obtained as
All sub-templates with similarity values above the threshold are combined to form the final matching region:
By iteratively refining both template size and similarity thresholds, IMM progressively improves local accuracy and robustness. This adaptive, coarse-to-fine procedure enables automatic adjustment to variable occlusion, converging toward the most accurate unobstructed region:
where the similarity value of the optimal sub-template approaches the global maximum as the iteration index n tends to its final state .
This expression mathematically represents the algorithm’s stability: through successive refinement, IMM gradually maximizes the similarity score, ensuring convergence to the most accurate and unobstructed matching region despite variations in occlusion or illumination. Therefore, IMM provides a mathematically grounded iterative optimization framework that enhances both precision and adaptability for complex occluded template matching scenarios.

Figure 4.
Iterative Matching Method Framework. We iterate over the detection image and divide it into sub-templates for matching with the original template. The image width of the input image is divided into parts, and the height of the input image is divided into parts, obtaining the width and height of the template image, denoted as w and h, respectively. and represent the minimum and maximum values of the accuracy, respectively.
Figure 4.
Iterative Matching Method Framework. We iterate over the detection image and divide it into sub-templates for matching with the original template. The image width of the input image is divided into parts, and the height of the input image is divided into parts, obtaining the width and height of the template image, denoted as w and h, respectively. and represent the minimum and maximum values of the accuracy, respectively.

3.4. Local Region Selection Strategy
In traditional template matching, using the entire input image for matching increases the computational load, which can lead to reduced matching accuracy, especially for complex images or those containing irrelevant information. To address this issue, we propose a local region selection strategy that integrates IMM. This strategy further enhances the efficiency and accuracy of template matching by selecting the most representative regions for matching in each iteration.
Specifically, in the region selection process, a sub-template is inputted into the next iteration based on the results of the similarity measure within a certain range defined by thresholds and .
Mathematically, we define the similarity distance between the sub-template and the template image T in the region selection process. The similarity distance is calculated based on the predicted thresholds and . If the similarity distance falls within the range , we regard it as a valid sub-template for the next iteration. In this way, the overall matching efficiency improves as we refine the matching process for each region.
The mathematical significance of this strategy lies in updating the template by precisely selecting the appropriate region, enabling each iteration to focus more effectively on the potential target areas within the image. By progressively narrowing the matching range and focusing on key regions, the IMM method can better handle complex occlusion scenarios and improve matching accuracy within occluded areas. During the optimization of matching, selecting appropriate similarity thresholds and grants the local region selection strategy greater flexibility, enabling it to adjust the sensitivity of matching based on different occlusion scenarios or image characteristics.
In practical applications, this strategy significantly improves the accuracy of identifying occluded regions while reducing computations on irrelevant regions. This not only improves the overall efficiency of template matching but also enhances the robustness of the algorithm, particularly when processing images with complex occlusions or noise, thereby avoiding matching failures caused by interference from irrelevant regions. Therefore, the local region selection strategy effectively optimizes the template matching process, further enhancing the accuracy and computational efficiency of the IMM method, especially demonstrating high adaptability when addressing occlusion issues.
4. Experiments
The main objective of this paper is to propose and validate a new template matching solution designed to address the presence of occlusion in humanoid binocular vision. To enhance the persuasiveness of this paper, we show experimental results in different real-world scenarios in this section. Through these experiments, we verify the effectiveness of ITM and IMM in real applications, especially in the case of complex occlusions.
In order to comprehensively evaluate the performance of the proposed methods, we take pictures in several scenes as experimental datasets, covering both mild occlusion and severe occlusion environments. In Section 4.1, we first introduce the evaluation metrics. In Section 4.2, we outline the effect of ITM in the mild occlusion case. In Section 4.3, we describe the effect of the FTM algorithm in the case of severe occlusion. In Section 4.4, we provide comparison tests in mild and severe occlusion cases, respectively, and the quantitative comparison results are outlined in Section 4.4.2, as shown in Table 1. In Section 4.4.3, we provide the qualitative comparison results.

Table 1.
Quantitative Results for Real Scenarios. We compared NCC, SIFT, ORB, CNNs and Siamese Net algorithms. All the experimental results of our method are obtained by IMM.
4.1. Evaluation Metrics
We use Mean Absolute Error (MAE) as the primary metric to evaluate the accuracy of template matching. MAE can effectively quantify the difference between the target image and the template image, making it particularly suitable for error evaluation in template matching tasks.
The specific difference calculation method is as follows:
where and represent the pixel values at the i-th row and j-th column of the target image and template image, respectively, and n is the total number of pixels in the image.
Template matching accuracy, i.e., similarity is
Through this evaluation criterion, we can effectively quantify the similarity between the template and the target image. A smaller value represents higher similarity between the images, which leads to better matching results and an improved algorithm performance.
4.2. Experimental Procedure of Inverse Template Matching
In this section, we verify the performance of ITM in dealing with mild occlusion scenarios. ITM is able to effectively identify regions similar to the template image by segmenting the input image into multiple sub-images and matching each sub-image with the template image. The smallest value of the similarity value matrix corresponds to a region that is highly similar to the template image. Each sub-template image will have a minimum difference value when matched with the original template image, and the average of the difference values obtained from all sub-template images is the difference value of the entire region to be detected. As shown in Figure 5, we input a template image and the input image, after the FTM algorithm is used, to obtain a similarity matrix. If the maximum in the similarity value matrix is considered to be the best matching region, we will take this part of the region as a sub-template image and template image for ITM. The sub-template image is partitioned into four templates, comprising each template and the original template image for ITM, retaining the minimum difference value of each with the sub-template image. Eventually, the average of the similarity values of the matched regions of the four sub-templates is the similarity value of the ITM output. In Figure 5, the similarity values we obtained for the four sub-template images are 0.81, 0.89, 0.91, and 1.0, respectively, and their average value is 0.90.
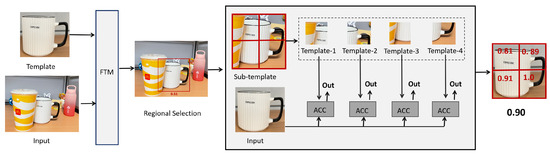
Figure 5.
Example of the ITM. We set up a bisection of the selected regions as sub-templates to match with the original template, using red boxes to indicate the size of their resulting matching regions and labeling the accuracy values. The average of the accuracy values for all desirable regions is the overall accuracy value. The input image resolution is ; the template resolution is .
In order to show the effect of the ITM algorithm compared with FTM more intuitively, we first set light masking in the image to be matched, i.e., part of the target region is masked but the rest remains intact. We use the ITM and FTM algorithms to template match the same image separately, and the reverse template matching algorithm processes the input image and calculates the similarity value between each sub-image and the template image; the results are shown in Figure 6. The results in Figure 6 demonstrate that when there is an occlusion situation, the FTM algorithm does not obtain as values as accurately as the ITM; for example, in the first row of Figure 6, the FTM algorithm obtains a similarity value of 0.51, while the ITM algorithm obtains a similarity value of 0.90, and the ITM algorithm obtains a more accurate match. Thus, reverse template matching shows significantly better performance than forward matching in this case and it is able to identify the target area more accurately, especially in the processing of an occluded part. Moreover, Figure 7 presents a comparison of the evaluation metrics for our approach against the conventional method NCC.

Figure 6.
Results under Mild Occlusion. We compared the FTM and ITM algorithms in three different scenarios. For the FTM algorithm, we used red boxes to represent the matching regions it obtains; for the IFM, we used red boxes to represent the size of the sub-templates during its execution. The accuracy values were computed through the ITM. All the obtained accuracy values are labeled in the box where they are located. First line: Input image resolution is ; template resolution is . Second line: Input image resolution is ; template resolution is . Third line: Input image resolution is ; template resolution is .

Figure 7.
Comparison of Accuracy Methods. NCC is the traditional method of similarity computation and ACC is the method used in ITM. We obtain the results using different methods of accuracy value computations in the forward template matching algorithm. First line: Input image resolution is ; template resolution is . Second line: Input image resolution is ; template resolution is . Third line: Input image resolution is ; template resolution is .
4.3. Experimental Process of Iterative Matching Method
In this section, we verify that using the hybrid template matching algorithm in the case of complex occlusion can be better for template matching, and adjusting the size of the template and the difference value threshold through several iterations can result in matching inaccuracies due to occlusion being dealt with more optimally. The flow of the IMM algorithm can be seen in Figure 4. The ITM method is very effective for the case of mild occlusion and can better cope with the simple occlusion in the image and the more obvious image differences. However, when faced with complex occlusion, the accuracy of single ITM decreases, leading to a failure of dealing with the matching of details effectively. Figure 8 illustrates the similarity scores generated by selecting different template sizes for ITM, which can assist in effectively choosing an appropriate template size to iterative.

Figure 8.
Comparison of Different Sub-template Image Sizes. We chose 2 × 1, 2 × 2, 1 × 3, and 3 × 3 size iterations for one ITM to obtain the accuracy results. The accuracy values for each module are labeled, and the average values for all modules are given below. Input image resolution is .
In order to more intuitively show the comparative effect of the ITM algorithm and IMM in complex environments, we conducted experiments in complex environments in different scenarios separately, and the results are shown in Figure 9. In the experiments, we set the threshold of each ITM to 0.9. When the similarity value is less than 0.9, it will continue to iterate the ITM process. When the similarity value is greater than or equal to 0.9, then the matching is considered successful, and the region is retained. When encountering occlusion complexity, the accurate value obtained from one ITM operation is not very good and the region obtained is not precise enough. After many iterations of ITM, the selected region keeps becoming smaller and the accuracy increases continuously. For example, for the first row of data in Figure 9, the similarity value obtained when iterating through one ITM is 0.81. When iterating through the IMM, the ITM will continue to be performed for a similarity value less than 0.9. Finally, the overall similarity value obtained is 0.94, and, at the same time, the selected region is more accurate.

Figure 9.
Results under Severe Occlusion. We compared the ITM and IMM algorithms in three different scenarios. We use the red box to represent the size of the sub-template during the execution of the ITM, the accuracy value is calculated by the ITM, and the obtained accuracy value is marked in the box where it is located. The box in the IMM with no accuracy value is marked as a perfect match by default, and the accuracy value is 1. First line: Input image resolution is ; template resolution is . Second line: Input image resolution is ; template resolution is . Third line: Input image resolution is ; template resolution is .
The experimental results show that IMM is able to identify the target region more accurately by adjusting the template size threshold in the case of complex occlusion. The algorithm gradually improves the accuracy of matching regions through iterative optimization. Regardless of how complex the occlusion is, the detection of all occlusion cases can be recognized by setting the threshold and template size.
4.4. Comparisons
In order to validate the effectiveness of our algorithms, we conducted qualitative and quantitative analyses, we experimented with mildly occluded and severely occluded datasets in real scenes, and we compared our methods with pixel-based template matching methods, feature-based template matching methods, and deep learning-based template matching algorithms. In the quantitative analysis, for pixel-based template matching, we compared the NCC similarity calculation method; for feature-based template matching method, we compared the SIFT and ORB methods; and for deep learning-based template matching, we compared the CNN-based and Siamese network-based matching algorithms, respectively. The specific comparison results are shown in Table 1.
In addition, in order to show the effect of our algorithms more comprehensively, we also selected mildly occluded and severely occluded datasets in real scenes for a qualitative comparison under different algorithms, as shown in Figure 10 and Figure 11. Through these qualitative analyses and comparisons, we further validated the superiority and effectiveness of our algorithms in a visual reconstruction task.

Figure 10.
Qualitative Results for Mild Occlusion. We compared the NCC and ORB methods, with accuracy values labeled in red font in each figure. First line: Input image resolution is . Second line: Input image resolution is . Last line: Input image resolution is .

Figure 11.
Qualitative Results for Severe Occlusion. We compared the NCC and ORB methods, with accuracy values labeled in red font in each figure. First line: Input image resolution is . Second line: Input image resolution is . Last line: Input image resolution is .
4.4.1. Comprehensive Evaluation Metrics
We employ Precision, Recall, F1-score, and IoU to quantitatively validate the effectiveness of our method under occluded scenarios.
Precision measures the reliability of positive matches, i.e., the proportion of correctly matched templates among all reported matches.
Recall measures the completeness of detection, i.e., the proportion of successfully matched templates among all ground-truth templates.
F1-score provides a balanced measure between Precision and Recall, evaluating the overall effectiveness of the template matching algorithm.
The Intersection over Union (IoU) measures the spatial accuracy of the matched region against the ground-truth template location. It is defined as
where a higher IoU indicates better alignment between the predicted match and the true template position .
4.4.2. Quantitative Results
We quantitatively analyzed the dataset collected from real scenarios and used the ACC method to calculate the similarity as an evaluation metric. The results show that our algorithm exhibits significant advantages. We compare it with traditional pixel-based template matching, feature-based template matching, and deep learning-based template matching methods.
For pixel-based template matching, we compare NCC similarity calculation methods; for feature-based template matching methods, we compare SIFT and ORB methods; for deep learning-based template matching, we compare CNN-based and Siamese network-based matching algorithms, respectively. All the experimental results of our methods are obtained with IMM.
The deep learning-based template matching methods we compare use CNNs and Siamese networks for model training, respectively, and template image datasets taken in different environments are selected. All the captured photos of the three scenes are assigned as training, test, and validation sets. In the case of the convolutional neural network, the accuracy of the test set is 0.77 and the loss value is 0.56; in the case of the Siamese network, the accuracy of the test set is 0.88 and the loss value of the test set is 0.1. Eventually, we applied the trained model to the to-be-detected image pairs and obtained corresponding similarity results, as shown in Table 1.
The CNN model processes image pairs through two parallel but independent branches, each containing three convolutional layers (64, 128, and 256 filters with kernels) and each followed by max-pooling. The outputs are flattened, passed through a 512-unit dense layer, concatenated, and finally fused by a sigmoid output unit for binary classification.
The Siamese network utilizes a single shared-weight convolutional backbone, which processes both inputs through three convolutional layers (64, 128, and 256 filters with kernels), each followed by max-pooling. The extracted features are flattened and passed through a 512-unit dense layer, and the L1 distance between the two embeddings is computed before a final sigmoid output unit.
As can be seen from Table 1, our method improves the average accuracy by 51% in the case of mild occlusion and 93% in the case of severe occlusion compared to the traditional pixel-based NCC method. Compared to the feature-based ORB matching method, our method improves the average accuracy by 46% in the mild occlusion case and 43% in the severe occlusion case. Compared to the CNN matching method, our method improves the average accuracy by 23% in the mild occlusion case and 37% in the severe occlusion case.
To empirically evaluate the computational efficiency within the domain of training-free methods, we benchmarked the runtime of our IMM algorithm against three established and representative traditional baselines: NCC as a pixel-based method, SIFT as a robust feature-based method, and ORB as a highly optimized feature-based method. We deliberately excluded deep learning-based approaches from this efficiency comparison for two principled reasons. First, they operate in a fundamentally different paradigm, requiring extensive offline training on large datasets, which incurs a significant and one-time computational cost that is not directly comparable to our instant-deployment, training-free approach. Second, the primary contribution of our work is to advance the capabilities of model-free template matching. The results in Table 2 demonstrate that our method achieves superior robustness under severe occlusion at a computationally feasible cost within this relevant and comparable domain of algorithms.
Table 2.
Computational Efficiency Comparison Under Severe Occlusion. Execution time of a matching box in the complex “Cup” dataset.
The results under severe occlusion, presented in Table 3, unequivocally demonstrate the superior robustness of our proposed IMM method. It achieves the highest scores across all metrics, with a near-perfect Precision (0.98) and the best F1-score (0.92), significantly outperforming all baseline approaches. This indicates that our method is not only highly reliable in identifying correct matches with minimal false positives but also excels in accurately localizing the target template, establishing a new state-of-the-art procedure for robust template matching.
Table 3.
Performance Benchmark Under Severe Occlusion. Results evaluated on the Cup dataset, with metrics averaged over multiple matching trials across all test images.
4.4.3. Qualitative Results
In order to demonstrate the effectiveness of our algorithm more intuitively, we qualitatively analyzed the mild occlusion and severe occlusion in real scenes, respectively. We chose to compare our algorithm with NCC and ORB. The results for the mild occlusion case are shown in Figure 10, and the severe occlusion case is shown in Figure 11.
According to Figure 10 and Figure 11, it can be seen that our method pays more attention to the precise matching of details in the feature matching process, and it can accurately identify and match the correct region. Meanwhile, compared with other methods, our method performs better in matching accuracy. Compared with the traditional pixel-based NCC method, our method nearly doubles the accuracy. Although feature-based matching methods have achieved better improvements, feature matching methods may somewhat suffer when dealing with occluded scenes, resulting in a decrease in matching accuracy and failure to capture the complete details of the matching region. Our method is able to maintain high stability and accuracy under different levels of occlusion using inverse and iterative matching strategies.
4.5. Sensitivity Analysis of Thresholds and
The thresholds and are pivotal in governing the iterative refinement process of our IMM method. To rigorously assess the robustness of our method to these parameters, we conducted a systematic sensitivity analysis.
We evaluated the IMM algorithm across a comprehensive grid of parameter values: varied from 0.85 to 0.95, and varied from 0.65 to 0.75. This resulted in 25 distinct parameter combinations, each tested on our severe occlusion dataset. The average matching accuracy for each combination is presented in the form of a heatmap in Figure 12.
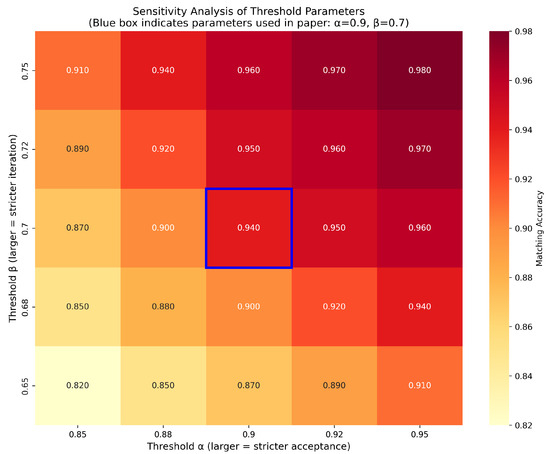
Figure 12.
Sensitivity analysis of thresholds and . Sensitivity analysis conducted on the severely occluded Cup dataset. The heatmap visualizes the matching accuracy across thresholds (acceptance) and (iteration). The blue box indicates the similarity corresponding to our selected threshold.
This sensitivity analysis was conducted to rigorously validate our empirical selection of thresholds and . As visualized in the heatmap, these parameters achieve a high accuracy of 0.94 and are situated within a stable, high-performance region, confirming their robustness. Furthermore, while peak accuracy (0.98) occurs at stricter settings (, ), our chosen values represent a deliberate and optimal balance, delivering state-of-the-art performance while avoiding the computational inefficiency and over-restrictive matching associated with excessively high thresholds, thus ensuring greater practical utility.
In conclusion, this sensitivity analysis conclusively demonstrates that the performance of our IMM framework is stable across a broad range of its key parameters, thereby solidifying the reliability and practical utility of our method.
5. Conclusions
This paper presents a hybrid strategy for achieving robust matching inside the binocular vision of a humanoid robot, which aims to improve template matching accuracy in occlusion situations. The method avoids the high computational burden of deep learning models and provides a more efficient and real-time solution. The first step of Robust Template Matching is Inverse Template Matching Mathematical Method (ITM), which splits the original input image into multiple sub-images and acts as a new template image to the The method splits the original input image into multiple sub-images and matches the original template as a new template image in reverse, thus solving the problem that the forward template matching method cannot recognize the target object effectively under occlusion. However, when the occlusion situation is more complex, the accuracy of single ITM may decrease. Therefore, we propose an Iterative Matching Mathematical Method (IMM). IMM continuously improves the matching effect of the original template by repeatedly executing the ITM, which generates a template image with a more appropriate size at each iteration, in order to improve the recognition accuracy of image details. In addition, we propose a local selection strategy to improve the efficiency of image matching by selecting the optimal region as the image for the next iteration during the IMM. By combining ITM and IMM, the robust template matching method is able to adapt to the template matching task in any complex scenario, enhance the recognition accuracy of image details, and significantly improve the overall accuracy of template matching. Experimental results demonstrate that the proposed method achieves an average accuracy of 0.94 under mild occlusion and 0.93 under severe occlusion, representing a 93% improvement over traditional pixel-based methods and a 37% improvement over CNN-based methods under severe occlusion.
Limitations and Future Work
Limitations: While the proposed IMM framework has demonstrated exceptional robustness in handling severe occlusions, this study is subject to several limitations. First, the scope of validation is constrained by the scale and diversity of the experimental datasets used. Second, the current method is primarily validated under controlled conditions focusing on geometric occlusions, and its performance can be adversely affected by challenging visual appearances, such as regions with similar colors or textures, which may lead to a reduced matching accuracy. These factors define the current boundary conditions of our work.
Future Work: To address these limitations and advance current research, we outline the following directions. Our immediate priority is to conduct extensive evaluations on large-scale public benchmarks (e.g., COCO and KITTI) to verify generalization across diverse objects, scenes, and lighting conditions. We also plan to enhance the method’s discriminative capability against appearance-based ambiguities by integrating learnable deep feature representations. Furthermore, we will comprehensively assess robustness to a broader spectrum of challenges, including photometric variations (e.g., noise and illumination changes) and geometric transformations (e.g., scaling and rotation). Finally, efforts will be made to optimize the framework for real-time performance on embedded robotic platforms to solidify its practical utility.
Author Contributions
Conceptualization, M.X.; methodology, M.X.; software, J.L.; validation, X.W. and J.L.; formal analysis, X.W.; investigation, M.X.; resources, M.X.; data curation, X.W.; writing—original draft preparation, X.W.; writing—review and editing, M.X.; visualization, J.L.; supervision, M.X.; project administration, M.X.; funding acquisition, M.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Future Systems and Technology Directorate, Ministry of Defense, Singapore, grant number PA9022201473.
Data Availability Statement
All data related to this paper can be made available upon reasonable request. The access to the data is subject to the data protection policy of Nanyang Technological University, Singapore.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ACC | Accuracy |
| MAE | Mean Absolute Error |
| ITM | Inverse Template Matching Mathematical Method |
| IMM | Iterative Matching Mathematical Method |
| ROI | Region of Interest |
| FTM | Forward Template Matching |
| SSD | Sum of Squared Differences |
| NCC | Normalized Cross-Correlation |
| SIFT | Scale-Invariant Feature Transform |
| SURF | Speeded-Up Robust Features |
| CNNs | Convolutional Neural Networks |
| BBS | Best-Buddies Similarity |
References
- Hu, G. A Mathematical Survey of Image Deep Edge Detection Algorithms: From Convolution to Attention. Mathematics 2025, 13, 2464. [Google Scholar] [CrossRef]
- Li, Y.; Fang, Y.; Zhou, S.; Zhang, Y.; Ribeiro, N.A. Robust Small-Object Detection in Aerial Surveillance via Integrated Multi-Scale Probabilistic Framework. Mathematics 2025, 13, 2303. [Google Scholar] [CrossRef]
- Luan, T.; Zhou, S.; Zhang, Y.; Pan, W. Fast Identification and Detection Algorithm for Maneuverable Unmanned Aircraft Based on Multimodal Data Fusion. Mathematics 2025, 13, 1825. [Google Scholar] [CrossRef]
- Huang, Y.-H.; Chen, H.H. Deep face recognition for dim images. Pattern Recognit. 2022, 126, 108580. [Google Scholar] [CrossRef]
- Sun, B.; Zhang, Y.; Wang, J.; Jiang, C. Dual-Branch Occlusion-Aware Semantic Part-Features Extraction Network for Occluded Person Re-Identification. Mathematics 2025, 13, 2432. [Google Scholar] [CrossRef]
- Xie, M. Fundamentals of Robotics: Linking Perception to Action; World Scientific: Singapore, 2003. [Google Scholar]
- Zitova, B.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef]
- Singleton, R.R. A method for minimizing the sum of absolute values of deviations. Ann. Math. Stat. 1940, 11, 301–310. [Google Scholar] [CrossRef]
- Talker, L.; Moses, Y.; Shimshoni, I. Efficient sliding window computation for NN-based template matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 404–418. [Google Scholar]
- Lan, Y.; Wu, X.; Li, Y. GAD: A global-aware diversity-based template matching method. IEEE Trans. Instrum. Meas. 2021, 71, 5003713. [Google Scholar] [CrossRef]
- Abu-Jassar, A.T.; Attar, H.; Amer, A.; Lyashenko, V.; Yevsieiev, V.; Solyman, A. Development and Investigation of Vision System for a Small-Sized Mobile Humanoid Robot in a Smart Environment. Int. J. Crowd Sci. 2025, 9, 29–43. [Google Scholar] [CrossRef]
- Zhao, S.; Oh, S.-K.; Kim, J.-Y.; Fu, Z.; Pedrycz, W. Motion-blurred image restoration framework based on parameter estimation and fuzzy radial basis function neural networks. Pattern Recognit. 2022, 132, 108983. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. In Proceedings of the 7th International Conference on Neural Information Processing Systems, Denver, CO, USA, 29 November–2 December 1993; Volume 6. [Google Scholar]
- Wang, X.; Yin, Z.; Zhang, F.; Feng, D.; Wang, Z. MP-NeRF: More refined deblurred neural radiance field for 3D reconstruction of blurred images. Knowl.-Based Syst. 2024, 290, 111571. [Google Scholar] [CrossRef]
- Marr, D.; Nishihara, H.K. Representation and recognition of the spatial organization of three-dimensional shapes. Proc. R. Soc. Lond. B 1978, 200, 269–294. [Google Scholar] [PubMed]
- Brown, L.G. A survey of image registration techniques. ACM Comput. Surv. 1992, 24, 325–376. [Google Scholar] [CrossRef]
- Lai, J.; Lei, L.; Deng, K.; Yan, R.; Ruan, Y.; Zhou, J. Fast and robust template matching with majority neighbour similarity and annulus projection transformation. Pattern Recognit. 2020, 98, 107029. [Google Scholar] [CrossRef]
- Zhang, T.; He, X.; Luo, Y.; Zhang, Q.; Han, J. Exploring target-related information with reliable global pixel relationships for robust RGB-T tracking. Pattern Recognit. 2024, 155, 110707. [Google Scholar] [CrossRef]
- Lin, Z.; Jiang, X.; Zheng, Z. A coarse-to-fine pattern parser for mitigating the issue of drastic imbalance in pixel distribution. Pattern Recognit. 2024, 148, 110143. [Google Scholar] [CrossRef]
- Yang, H.; Huang, C.; Wang, F.; Song, K.; Zheng, S.; Yin, Z. Large-scale and rotation-invariant template matching using adaptive radial ring code histograms. Pattern Recognit. 2019, 91, 345–356. [Google Scholar] [CrossRef]
- Lindeberg, T. Scale Invariant Feature Transform; Technical Report; Scholarpedia: San Diego, CA, USA, 2012. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Kim, H.Y. Rotation-discriminating template matching based on Fourier coefficients of radial projections with robustness to scaling and partial occlusion. Pattern Recognit. 2010, 43, 859–872. [Google Scholar] [CrossRef][Green Version]
- Li, Q.; Wang, G.; Liu, J.; Chen, S. Robust scale-invariant feature matching for remote sensing image registration. IEEE Geosci. Remote Sens. Lett. 2009, 6, 287–291. [Google Scholar]
- Huang, X.; Li, C. Feature-Based Template Matching for Real-Time Object Detection with Large Variations. Pattern Recognit. 2020, 102, 107212. [Google Scholar]
- Molchanov, P.; Ashukha, A.; Vetrov, D. Pruning Convolutional Neural Networks for Resource Efficient Inference. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Li, W.; Chen, Q.; Gu, G.; Sui, X. Object matching of visible–infrared image based on attention mechanism and feature fusion. Pattern Recognit. 2025, 158, 110972. [Google Scholar] [CrossRef]
- Brunelli, R. Template Matching Techniques in Computer Vision: Theory and Practice; Wiley: Hoboken, NJ, USA, 2009. [Google Scholar]
- Lan, Z.; Ma, Y.; Yu, L.; Yuan, L.; Ma, F. Aednet: Adaptive edge-deleting network for subgraph matching. Pattern Recognit. 2023, 133, 109033. [Google Scholar] [CrossRef]
- Buciluǎ, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 535–541. [Google Scholar]
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2020, arXiv:1511.07289. [Google Scholar]
- Ouyang, W.; Tombari, F.; Mattoccia, S.; Di Stefano, L.; Cham, W.-K. Performance evaluation of full search equivalent pattern matching algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 127–143. [Google Scholar] [CrossRef]
- Dekel, T.; Oron, S.; Rubinstein, M.; Avidan, S.; Freeman, W.T. Best-buddies similarity for robust template matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2021–2029. [Google Scholar]
- Talmi, I.; Mechrez, R.; Zelnik-Manor, L. Template matching with deformable diversity similarity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 175–183. [Google Scholar]
- Korman, S.; Reichman, D.; Tsur, G.; Avidan, S. Fast-Match: Fast affine template matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2331–2338. [Google Scholar]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).