Abstract
Few-shot knowledge graph (KG) completion is challenged by the dynamic and long-tail nature of real-world KGs, where only a handful of relation-specific triples are available for each new relation. Existing methods often over-rely on neighbor information and use sequential LSTM aggregators that impose an inappropriate order bias on inherently unordered triples. To address these limitations, we propose a lightweight yet principled framework that (1) enhances entity representations by explicitly integrating intrinsic (self) features with attention-aggregated neighbor context, and (2) introduces a permutation-invariant max-pooling aggregator to replace the LSTM-based reference set encoder. This design faithfully respects the set-based nature of triples while preserving critical entity semantics. Extensive experiments on the standard few-shot KG completion benchmarks NELL-One and Wiki-One demonstrate that our method consistently outperforms strong baselines, including non-LSTM models such as MetaR, and delivers robust gains across multiple evaluation metrics. These results show that carefully tailored, task-aligned refinements can achieve significant improvements without increasing model complexity.
MSC:
68U10
1. Introduction
With the development of Internet technology, various electronic devices have been rapidly popularized, resulting in a large amount of data. Extracting useful knowledge from vast amounts of data is extremely important and necessary. Knowledge graph just has this function, which can extract structured knowledge from massive texts and images. At present, many large-scale KGs in the real world have also been constructed, such as Freebase [1], DBpedia [2], NELL [3], YAGO [4], and Wikidata [5]. Because of its structural characteristics, KG is widely used in a variety of downstream applications, such as recommendation system [6,7], semantic search [8], information extraction [9], machine reading [10], affective cognition [11] and intelligent dialogue system [12].
The KGs [2] consist of a large number of facts, that is, the triplet composed of (head entity, relation, and tail entity) is called a fact. Although a KG contains a great number of facts, it is mostly constructed manually, so it is highly incomplete. For example, 71% of people in Freebase have no known place of birth, and 75 % have no known nationality [13]. Measures need to be taken to complete these missing information. The task of knowledge graph completion is to automatically fill in missing facts in the KG, so as to make the KG contain as many facts as possible, so as to improve the quality of the existing KG. A lot of research work has been carried out [14,15,16,17,18]. The previous work mainly focused on using a large number of facts to train models. However, recent research work shows that when studying the well-known large-scale KGs, a large number of relations in the KGs have long-tailed distribution [19] and only contain few triples. In other words, there is insufficient training samples for model training. For instance, about 10% of relations in Wikidata has no more than 10 triples [5]. In addition, most KGs of the real world are usually dynamic [20]. That is, events happen at every time, and the triples of these events may be added to the constructed KGs. Due to these newly added relations, there are fewer triples as training examples for large-scale sample training.
The existence of the above situations makes the previous large-scale completion models unable to play with good performance or no longer suitable, which promotes the emergence of few-shot knowledge graph completion methods. Xiong et al. [21] first researched on few-shot learning for KGs and proposed a GMatching model that only relies on entity embeddings and one-hop graph structures. The main purpose of this model is to learn a matching metric based on one-shot reference triplets to discover triples with more similar relations. Chen et al. [22] leveraged a model-agnostic meta-learning method (MAML) [23] for fast adaptation of policy network parameters or relation meta. This model utilizes relation meta and gradient meta modules to transfer relation-specific meta information, enabling the model to learn more important knowledge and learn faster. Zhang et al. [24] proposed a few-shot relation learning model, FSRL. This model adds the module of aggregating reference set information based on the LSTM method, which plays a certain role in the expression capabilities of the relation. Niu et al. [25] proposed a gated and attentive neighbor aggregator to capture the most valuable semantics of a few-shot relation. It also incorporated MAML with TransH [26] to conduct a few-shot knowledge graph completion (FKGC) module which can deal with complex relations. However, the above models ignored the information of the entity itself in the entity neighbor representation, or did not have a good aggregation reference set using a similar LSTM time series method.
However, two key challenges remain, as follows:
- Incomplete representation of entities: Prior models, such as FSRL and GMatching, focus mainly on neighborhood aggregation and tend to overlook the intrinsic semantic features of entities themselves, leading to biased representations in sparse settings.
- Inappropriate sequential bias: LSTM-based reference set aggregators assume an order over triples that are, by nature, unordered, introducing unnecessary inductive bias and potentially degrading generalization.
To solve the above problems, we propose a few-shot relation learning model with max-pooling aggregator and enhanced entity embeddings. The purpose of this model is to learn a matching function that can effectively infer the predicted entity pairs according to the given few-shot reference set entity pairs for each relation. Firstly, we propose a relation-aware heterogeneous neighbor encoder to learn entity embedding according to heterogeneous graph architecture, attention mechanisms, and entity own information. It can not only represent entities through neighbors with different relations, but also retain entity own information. Next, we use a max-pooling aggregator to aggregate the reference set entity pairs and enhance the expression capabilities of the relation. Compared with LSTM aggregator, this aggregator is more suitable for the characteristics of triplet disorder, and can give better play to the performance of this method. Finally, based on the aggregated embeddings of the reference set entity pairs, the matching network is used to discover similar reference set entity pairs.
In summary, the main contributions of this work are listed as follows:
- We propose a novel few-shot knowledge graph completion model that creatively designs the max-pooling aggregator module to improve the expression capabilities of relations from the few-shot triples, which is obviously different from the common-used LSTM aggregator module in [24];
- We propose an enhanced entity embedding module to enrich the head/tail entity embeddings according to the corresponding neighbor entities, and the learned entity embeddings still retain their own entity formation;
- We design a max-pooling aggregator module to aggregate the critical relation embeddings using the reference set, which significantly enhances the expression capabilities of relation and obtains satisfactory experimental performance.
2. Related Work
In this section, we introduce some related work on embedding models for relational learning and few-shot knowledge graph completion.
2.1. Embedding Models for Relational Learning
An embedding model is one of the important methods to solve the problem of knowledge graph completion. It maps the entities and relations in the knowledge graph to the continuous vector space through the embedding model, and learns the latent embedding of entities and relations in this space, so as to not only facilitate the calculation, but also retain the structural information in the knowledge graph.
In recent years, embedding models for relational learning have been widely studied and used to automatically complete the knowledge graph. For example, Nickels et al. [27] proposed the RESCAL model, which is one of the earliest models to build relations using tensor operations. This model considers the inherent structure of relational data and captures the binary relations between entities bilinearly. Bordes et al. [28] proposed a classical translation model TransE. This model treats the relation as a translation between the head entity and the tail entity. It hopes that the entity and relation meet the equation (head entity + relation ≈ tail entity), and measures rationality of triples by defining the scoring function based on distance difference by the translated relation. Zhen et al. [26] proposed TransH model. This model overcomes the limitations of TransE in dealing with complex relations. It maps the head and tail entities to the relation plane, and then uses the relation vector as the translation vector on the hyperplane of the relation to find the head and tail entities with specific relations. Lin et al. [29] proposed the TransR model on the basis of TransH. This model believes that if the semantic attributes of entities and relations are different, the embedding space of entities and relations should be different. That is, entities and relations should be embedded into different semantic spaces, and then the translation relations from head entity to tail entity are established based on the embedding space of relations. Ji et al. [30] proposed the TransD model, which overcomes the shortcomings of TransR by mapping the head entity and tail entity to the relation space with different matrixs. Yang et al. [31] proposed the DistMult model, which is a general network framework for multi-relational learning. This method can effectively extract logical rules by modeling the binary relations in the triples, and can learn the representation vectors of entities and relations from the bilinear method, and then use the learned semantic information to explore the latent logical rules. This method learns the vector representation of existing entities and relations, and then uses the representation vector to effectively infer whether the new triple is true. Trouillon et al. [32] proposed the ComplEx model, which is a method based on complex number representation. The ComplEx model performs representation learning in the complex space, and can effectively use bilinear abilities to represent asymmetric semantic relations. However, these embedding-based models usually require a large number of training samples. Due to the long-tail relations in the knowledge graph and the newly added relationships lacking sufficient training samples, these models are no longer suitable for these situations. In this paper, we propose a model that can solve these situations and achieve good results.
2.2. Multimodal Knowledge Graph Completion (MKGC)
MKGC [33] has attracted increasing attention due to the inherently multimodal nature of real-world knowledge. By integrating auxiliary information such as images and text, MKGC methods can effectively leverage inter-modal complementarity, thereby enhancing the representational capacity and reasoning performance of entities and relations. MKGC enhances structural knowledge by incorporating visual or textual information to assist in missing entity prediction tasks, thereby improving the accuracy of entity inference. Wang et al. [34] proposed an automated filtering mechanism designed to dynamically identify and attenuate unnecessary or redundant visual context information during model learning, thereby mitigating its potential negative impact on representation learning and reasoning outcomes. Chen et al. [35] introduced a hybrid Transformer architecture that unifies the input–output representation in the MKGC task, while enabling hierarchical fusion across coarse-grained and fine-grained levels. Zhao et al. [36] proposed an MKGC framework based on modality split representation learning and ensemble reasoning. The approach adopts relation embedding learning during training and modality independent inference during reasoning, thereby alleviating inter-modal interference and enabling dynamic modeling. Li et al. [37] further proposed a two stage cross-modal fusion mechanism, which achieves inter-modal complementarity while preserving modality-specific knowledge.
To enhance inductive reasoning over unseen entities in real world scenarios, some studies [38,39] attempt to learn embeddings for unseen entities by integrating structural neighbors from existing knowledge graphs. Subsequently, Chen et al. [40] constructed an open-book datastore that stores prompt-based instance representations and their corresponding relation labels as queryable key–value pairs, while Wang et al. [41] retrieved the k-nearest neighbor entity labels from the training set and incorporated their distribution into the model’s reasoning process to enhance entity recognition. Zhao et al. [33] leveraged a contrastive learning mechanism to model text–visual and text–text associations of query entity pairs within a unified representation space.
2.3. Few-Shot Knowledge Graph Completion
In previous research work, few-shot learning method is mainly used in the fields of computer vision [42] and imitation learning [43] fields. In recent years, this method has been extended to knowledge graph completion and some achievements have been made. The task of a few-shot knowledge graph has also gradually received more and more attention. Some models have been proposed, which are mainly divided into two categories:
(1) Metric-based approaches: Xiong et al. [21] first proposed the knowledge graph completion model GMatching based on few-shot learning. This model takes into account the long-tailed relations and the newly added relations. There are not many known triples that can be used for training, so they proposed a one-shot learning framework. A matching criterion is learned through the learned embedding and the entity’s one-hop graph neighbor framework. This matching criterion can discover more similar triples from the candidate set according to a given reference set triplet. Zhang et al. [24] extended the GMatching model and proposed the FSRL model. This model adds an information aggregator module of the reference set on the basis of the GMatching model. The information aggregator module enables the model to increase the expression capability of the relation on the original basis, and the application scenario has been expanded from the original one-shot learning to the few-shot learning scenario, and good results have been achieved.
(2) Meta-learner-based approaches: Meta learning aims to learn common experiences from different tasks, and then generalize these experiences to adapt to new tasks. Wang et al. [44] proposed a meta-learning framework, MeatR, which considers the few-shot learning problem of uncommon relationships and uncommon entities, and generates some additional triples by extracting key information from the text description, thereby solving the problem of insufficient training samples. Niu et al. [25] proposed a global and local framework to solve the problem of noisy neighbors and the inference of complex relations. The neighbor aggregator based on the gate and attention mechanisms is proposed, for the first time, to capture the valuable semantic information of few-shot relations, and, for the first time, MAML and TransH are combined to construct a few-shot knowledge graph completion model, which effectively solves the problem of inference of complex relations.
Although these methods have achieved certain results, there are still some problems in the above methods. They do not make full use of the entity’s own information or do not have a good aggregate reference set of information. The above problems are considered in our proposed model, and its effectiveness is proved by experiments.
3. Problem Formulation and Preliminaries
In this section, we, respectively, introduce the problem formulation, few-shot learning, and other necessary notations used in this paper.
A knowledge graph G is composed of a large number of triples (h, r, t), where h∈ represents the head entity, r∈R represents the connection relation, and t∈ represents the tail entity. Since the existing knowledge graphs are mostly constructed artificially, it is impossible to include all the relations and entities in the real world, so the knowledge graphs have incomplete characteristics. However, with the development of artificial intelligence technology, knowledge graphs have begun to be applied to various fields, playing an important auxiliary role. Therefore, how to use technical means to fill in missing triples in knowledge graph is extremely important. The completed knowledge graph can better play the auxiliary role. Therefore, the knowledge graph completion task has gradually gained attention and development. At present, most of knowledge graph completion tasks are mainly concentrated in the following two categories: (1) given head entity and relation in the triple (h, r, ?) to infer tail entity; (2) given head entity and tail entity in the triple (h, ?, t) to infer relation. This work mainly studies the former.
Definition 1
(Background Knowledge Graph ). In the knowledge graph, we select the low-frequency relations with few triples from all relations as few-shot relations. At the same time, we take the triples of these low-frequency relations as the training set, testing set, and validation set, and the remaining high-frequency relation triples as the background knowledge graph .
Definition 2
(Few-Shot Knowledge Graph Completion). Given a relation r∈ R and its k-shot reference set triples, the purpose is to predict the missing tail entity t from the given candidate entities set C according to the constructed model. Specifically, all candidate set entities are scored and ranked for each new triplet with (h, r, ∈ C). Since the score of the true entity is higher than the score of the false candidate set entity, the confidence ranking of all the candidate set entities can be obtained. The top-ranked entities are the entities most likely to be established. Among them, the candidate set entities are constructed based on entity type constraint [45].
Next, we introduce the few-shot learning settings [46,47]. For the knowledge graph completion task in this paper, the purpose of few-shot learning is to enable the model to rank the triples composed of the candidate set entities as the tail entities according to the score function to calculate similarity scores when few-shot reference triples are given. Then, we predict the missing tail entity t from the given candidate entities set C. Following the standard few-shot learning settings, the dataset can be divided into meta-training set , meta-validation set , and meta-testing set . For each meta-training, meta-validation and meta-testing task, it corresponds to different relations in the knowledge graph G. For the meta-training set, each training task of relation r∈R has its own reference (training)/query (testing) entity pairs, denoted as = {, }. Among them, only contains few-shot entity pairs with relation r. The query set includes the head entity , the ground-truth tail entities , and the corresponding candidate set entities ∈C. According to the given few-shot reference set entity pairs and candidate set entities, the proposed model can calculate the score of the triple composed of each candidate entity based on the scoring function, and then rank them according to the scores to get the entities with high confidence.
After sufficient training in the meta-training stage, the obtained few-shot learning model can be used to predict the missing triples of each new relation task ∈ in the meta-testing set. In the meta-testing stage, the relations do not appear in the meta training stage, that is, . At this time, the model needs to have good generalization ability. Similar to the meta-training set, each relation in the meta test set also has its own reference set and query set.
In this paper, we define some notations, and the specific description meanings are shown in Table 1.

Table 1.
Notations.
4. The Proposed Model
In this section, we introduce our model. An overview of our model is shown in Figure 1. The purpose of our model is to get the similarity between few-shot reference entity pairs and the query entity pairs by scoring function, so as to get a generalized metric function for the prediction of new relation triples. This model is mainly divided into three modules: (1) an encoder based on the entity neighbor information of the attention mechanism and combined with the entity’s own information; (2) the aggregator that learns the relation representation of the few-shot reference set based on the max-pooling method; (3) the matching processor that compares the query set with the aggregated reference set entities representation. More details of each module are listed as follows.
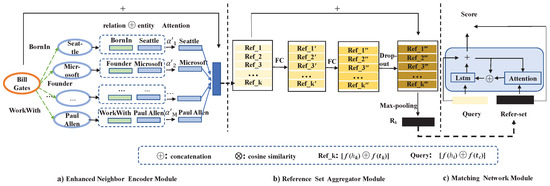
Figure 1.
An overview of our model. The model is divided into three modules: (a) enhanced entity encoder, (b) reference set aggregator, and (c) matching network. The enhanced entity coder module encodes the triple entities, the reference set aggregator module aggregates the encoded entity pairs, and the matching network module calculates the similarity score between the query set entity pair and the reference set entity pair.
4.1. Enhanced Entity Encoder
The purpose of this module is to use the neighbor information connected to the entity in the knowledge graph and the entity’s own information to better represent the entity.
There have been some works [21,24,27,31] that use the relational information of entities in the knowledge graph to learn the entity embeddings information, but they mainly focus on the simple use of neighbor information. For example, Xiong et al. [21] proposed that the graph local structure uses the average feature representation of neighbors. However, it ignores that different neighbors may have different effects on their entity representation and the influence of the entity own information. Zhang et al. [24] proposed that the model FSRL considers the influence of the neighbors of different relations on the entity encoder, but it also ignores the entity’s own information.
In view of the above problems, we propose a relation-aware entity neighbor encoder. At the same time, this encoder incorporates the entity’s own information. The representation of entity information takes into account both its own information and the information of relational neighbors, so as to better represent the entity. The specific method is as follows.
Take the head entity h as an example. First, suppose that a head entity h is given. Then, the neighbor relation ∈ and the tail entity ∈ associated with this entity are found from the background knowledge graph , and then these neighbor relations and tail entities are used to encode the head entity h. Here, the attention mechanism and the entity’s own information are used to construct this module, so as to obtain an enhanced representation of the head entity. The head entity enhanced embedding representation is composed of its neighbor entity information and its own entity information, and its formula can be expressed as follows:
where denotes nonlinear activation function (, tanh). ∈ and ∈ are learnable parameters, and d is the pre-trained embedding dimension.
The head entity h neighbor embedding formulas used are listed as follows:
where denotes nonlinear activation function (, tanh), ⊕ is concatenation operator, and and represent the pre-trained embedding representations of and , respectively. denotes the neighborhood of the head entity h. ∈ and ∈ are learnable parameters, and d is the pre-trained embedding dimension.
4.2. Reference Set Aggregator
The main purpose of this module is to construct the interaction of few-shot samples in the reference set, so that only few-shot reference set samples can maximize the expression capability of the relation, so as to better discover more similar triples in the matching network.
The existing model GMatching [21] cannot interact with few-shot samples in the reference set, which limits model capability. The FSRL [24] model uses LSTM network to interact with few-shot samples in the reference set, but this method cannot interact well because there is no time series relation in the triples of the knowledge graph.
In view of the disorder between triples, this paper adopts the aggregation method of max-pooling [48]. k-shot reference set triples of each relation r will be randomly sampled, and head entity and tail entity of the triples will be encoded by the entity coder module, and and will be obtained. Then, we get the representation of each reference set triplet entity pair, Ref(,) = [⊕]. Because there are very few triples, in order to make only a few-shot reference set triples play the greatest role as much as possible, let these triples interact and mine latent common information, so as to better assist in finding more similar triples in the subsequent matching process. The aggregate representation of all reference set entity pairs in the reference set can be expressed by the following formula :
where is an aggregation function. This paper adopts the max-pooling operation function.
As shown in Figure 1b, this paper first uses the fully connected layer and dropout layer to process the entity pairs of the reference set, and finally uses the max-pooling layer to fuse k-shot reference set entity pairs. By applying the max-pooling operator to k-shot reference set entity pairs, this module effectively captures the latent information representation of the relation between reference set entities, so as to obtain a rich representation of the relation. The formulas can be expressed as follows:
We use the residual network method to fuse the original information of the reference set:
where is a nonlinear activation function, is a dropout layer, and is the i-th reference set entity pair. ∈, ∈, ∈, and ∈ are learnable parameters, and and are the number of neurons in the hidden layer of the first layer and the second layer, respectively.
4.3. Matching Network
The purpose of this module is to match the query set and the aggregated reference set information according to the matching network, and get the ranking scores of each candidate set entity ∈C.
Before matching the query set with the reference set, we first use the enhanced entity encoder module f to enhance the representation of the entities in the reference set entity pairs (,) and the query set entity pairs (, ). We can get two of the enhanced entity embeddings (,) = [⊕] and (, ) = [⊕], respectively. Then, the reference set entity embedding is fed into the reference set aggregator module for information aggregation, and the aggregated embedding vector () is obtained. In order to measure the semantic similarity between the two vectors, although a simple cosine function can also be used, it cannot achieve a good performance. Therefore, this paper leverages a LSTM-based multi-step matching module [33,49]. After multi-step matching, the score function formula of query set entity pair and reference set entity pair is listed as follows:
where the score is the similarity score between the query set pair and the reference set pair after LSTM multi-step processing. For each relation r, we can compare the aggregated reference set pair () with each query set entity pair (, ∈C), and sort all the scores, so as to select the candidate set entities with top scores.
The t-th process step formulas are listed as follows:
where is a standard LSTM cell, x is input data, ℏ is hidden state, and c is cell state. ⊕ is concatenation operator and ⊗ is cosine similarity operator.
4.4. Loss and Model Training
In the meta-training set, for each few-shot relation r, we randomly sample k samples as the reference set and the other samples as the positive query set . At the same time, we construct a negative query set of the same size by randomly replacing the tail entity of the positive query set. For example, a positive sample triplet (, r, ) ∈G, whose corresponding negative triplet is (, r, ) ∉G. Finally, we adopt a hinge loss function to optimize our model, and the loss formula L is as follows:
where is margin distance, and and are the similarity scores of the positive query set and the negative query set compared with the aggregated reference set information , respectively. The detailed training procedure of our model is shown in Algorithm 1:
| Algorithm 1: Model Training |
|
5. Experiments
In this section, we introduce the datasets, experimental settings and do a lot of experiments to prove the effectiveness of our model, including overall results of different models, the prediction performance of each relation, ablation study, and impact of few-shot size.
5.1. Datasets
As shown in Table 2, this paper uses two public datasets for experiments. The two datasets are NELL-One and Wiki-One, respectively (https://github.com/chuxuzhang/AAAI2020_FSRL, accessed on 8 October 2025). NELL-One and Wiki-One are constructed by selecting some long-tailed relations based on NELL [3] and Wikidata [5], respectively. The relations between the two datasets are greater than 50 but less than 500, which are mainly used for few-shot tasks. There are 67 and 183 tasks in the NELL-One and Wiki-One, respectively. In NELL-One and Wiki-One data, the task relations of training/validation/testing set are 51/5/11 and 133/16/34, respectively.
Table 2.
Dataset statistics information about ICEWS14, ICEWS05-15, Wikidata12k, and YAGO11k.
5.2. Evaluation Metrics
We adopt common knowledge graph completion evaluation metrics MRR and Hits@n to evaluate our model and other baselines. MRR is the mean reciprocal rank of the correct entities, and Hits@n is the proportion of correct entities ranked in the top n. The larger the value of MRR and Hits@n, the better the effect of triples completion. In this paper, the values of n are 1, 5, and 10, respectively. The calculation formulas are listed as follows:
where is the number of query set triples and is the score sorting of the i-th query set triple. indicates the indicator function. If the condition is true, it is 1; otherwise, it is 0.
5.3. Baselines
From the existing papers, the traditional knowledge representation learning models have worse results in few-shot knowledge graph completion, and there is a gap in the completion results compared with the few-shot knowledge graph completion model. Therefore, we adopt some existing knowledge graph completion models as the baselines.
We utilize several well-known few-shot knowledge graph completion methods of GMatching (https://github.com/xwhan/One-shot-Relational-Learning, accessed on 8 October 2025), MetaR (https://github.com/AnselCmy/MetaR, accessed on 8 October 2025), and FSRL as comparison methods. For these models, we use the same pre-trained embeddings generated by ComplEx to train these models. For GMatching, we not only use max-pooling and mean-pooling methods to aggregate the information of few-shot reference sets to obtain the representation of reference sets, but we also consider taking the maximum of similarity scores between a query and all k-shot reference sets as the final ranking score of this query. Its parameters are set to be consistent with our method. For MetaR and FSRL, we retain the parameter settings provided in their papers.
5.4. Implementation Details
In this paper, we adopt the entity and relation embeddings in a background knowledge graph pre-trained by ComplEx on the two datasets. At the same time, it also has the input for GMatching, FSRL, and MetaR models. The embedding dimension is set to 100 for NELL-One and 50 for Wiki-One, respectively. In enhanced entity encoder, the maximum size of neighbors is set to 30 for the two datasets. In reference set aggregator, we select k = 3 as the reference triples. The number of neurons for first/second fully connected layer are set to 400/250 for NELL-One and 350/200 for Wiki-One. In the matching network, there are two recurrent steps. We adopt the Adam optimizer [50] to optimize model parameters. The initial learning rates is set to 0.0001 for NELL-One and 0.001 for Wiki-One. The batch size is 128 and the margin is fixed to 5.0. All the programs were implemented in Python 3.12.0 and all the experiments were conducted on GeForce RTX 3090.
5.5. Experimental Results and Analysis
Overall Results of Different Models
Paragraph. The simulation results of different models are presented in Table 3.
Table 3.
The experimental results on NELL-One and Wiki-One.
5.6. Results on Two Datasets
The experimental results on two datasets are shown in Table 3. Bold numbers are the best results. From the results, we can conclude that
(1) The results of our model are better than other few-shot knowledge completion models. Compared with the best baseline model FSRL on NELL-One, our model is 3.95%, 6.30%, 7.58%, and 5.15% higher than FSRL model in the evaluation of MRR, Hits@10, Hits@5, and Hits@1 metrics, respectively. At the same time, compared with the best baseline model MetaR on Wiki-One, our model is 1.71%, 4.17%, and 0.09% higher than the FSRL model in the evaluation of MRR, Hits@5, and Hits@1 metrics, respectively. It demonstrates the effectiveness of our model. The results show that the combination of our enhanced entity coder module and reference set max-pooling aggregator has a certain effect on the completion of missing triples.
(2) For GMatching and FSRL models, we can obtain that the addition of the reference set aggregator can better learn the latent information between reference set triples, so as to better discover the missing triples. At the same time, by our different pooling experiments, we can also see that selecting the appropriate reference set aggregator gets better results.
5.6.1. The Results of Different Relations in NELL-One
In order to better understand the prediction performance of each relation, we select the relations in NELL-One with fewer relations as the research object. Here, we adopt the FSRL with better performance and our model to analyze the prediction of 11 relations in the test dataset. Because the size of the candidate set for most relations is too large, the maximum candidate set is 1000 in this paper. The evaluation results of each relation are shown in Table 4. Bold numbers are the best results. From the results, we can conclude that
Table 4.
The results of FSRL and ours for each relation. (RId) on NELL-One.
(1) Our model has better results than FSRL in most cases. It demonstrates that our model has better robustness and generalization for most relations.
(2) It can also be seen from the results that the relation with fewer candidate set entities is easier to predict tail entities. For example, relation 1 has higher prediction metrics. At the same time, the relations with more candidate set entities to predict tail entities are difficult, and the prediction results are relatively worse, which needs to be improved.
5.6.2. Ablation Study
In order to study the contributions of different components, we conducted ablation experiments on two datasets, and the results are shown in Table 5. Bold numbers are the best results.
Table 5.
The experimental results of the ablation study.
(1) Full model(LSTM): We mainly compare the functions of the LSTM aggregator and max-pooling aggregator. Here, we use the LSTM aggregator module in FSRL to replace the max-pooling aggregator. As we all know, there is no time series characteristic between triples in the general knowledge graph. According to this data characteristic, we use the max-pooling operation to aggregate the reference set triples. From the results of the two datasets, the effect of the max-pooling aggregator is better.
(2) -own infor(MaxP): In order to verify the effectiveness of the enhanced entity encoder module, we only use the information of entity neighbors to encode entities. We believe that the encoder information of an entity should be related not only to its neighbor information, but also to its own information. Therefore, we also integrate the entity’s own information to enhance entity representation. From the experimental results, the entity’s own information does play a role in enhanced representation.
5.6.3. Impact of Few-Shot Size
We adopt different few-shot sizes k to analyze the impact of the size of the reference set on the prediction results, and compare the better baseline model FSRL with our proposed model. The results of NELL-One dataset are shown in Figure 2:
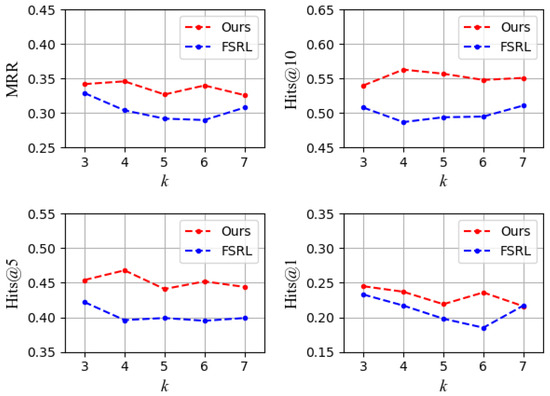
Figure 2.
Impact of few-shot size k on NELL-One.
(1) It can be seen from the results in Figure 2 that the results of our model are above the baseline model FSRL, which proves the effectiveness and robustness of our model.
(2) It can also be seen from the Figure 2 that the results do not always increase with the increase of k. We believe that there may be the following reasons: (i) Although the number of reference sets has increased, the added reference sets have little relevance to the current tail entity prediction. For example, when the triples of the reference set are the relationship between the capital and the country, it is difficult to predict the subordination between foods. (ii) In the entity encoder module, there is noise in the fusion of entity neighbors, which is useless for the current tail entity prediction. For example, there are few neighbor entities or the types are not rich enough to represent entities well.
6. Conclusions
In this paper, in order to enhance entity embedding and better aggregate entity pairs of reference sets, we propose a few-shot knowledge graph completion model with a max-pooling aggregator and enhanced entity embedding. In entity coder, the model not only considers the information of neighbor entities, but also integrates the information of entities. At the same time, the disorder of triples in the knowledge graph is considered in reference set aggregation, and a max-pooling reference set aggregator is proposed. Through a variety of different experiments, such as comparing with some existing few-shot knowledge graph completion models, changing the size of the reference set and ablation experiments, these experiments prove the effectiveness and robustness of our model. In addition, we also found some problems. For example, the performance does not necessarily increase with the increase in reference set size, which also points out the next research direction for us. In future work, we will focus on the encoder module and correlation selection of entity neighbors to explore the reasons and try to find solutions.
Author Contributions
The authors confirm contribution to the paper as follows: Conceptualization, M.Z. and W.C.; methodology, M.Z.; writing—original draft, M.Z.; writing—review and editing: M.Z. and W.C.; supervision, W.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
The authors would like to thank the anonymous reviewers and editors for their constructive comments and suggestions.
Conflicts of Interest
The authors declare that they have no conflicts of interest to report regarding the present study.
References
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Houston, TX, USA, 10–15 June 2008; pp. 1247–1250. [Google Scholar] [CrossRef]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. Dbpedia—A large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web J. 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.R., Jr.; Mitchell, T.M. Toward an architecture for never-ending language learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010; pp. 1306–1313. [Google Scholar] [CrossRef]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar] [CrossRef]
- Vrandecic, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Guo, Q.; Zhuang, F.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A survey on knowledge graph-based recommender systems. IEEE Trans. Knowl. Data Eng. 2020, 34, 3549–3568. [Google Scholar] [CrossRef]
- Chen, H.; Xie, R.; Cui, X.; Yan, Z.; Wang, X.; Xuan, Z.; Zhang, K. LKPNR: Large language models and knowledge graph for personalized news recommendation framework. CMC-Comput. Mater. Contin. 2024, 79, 4283–4296. [Google Scholar] [CrossRef]
- Xiong, C.; Power, R.; Callan, J. Explicit semantic ranking for academic search via knowledge graph embedding. In Proceedings of the International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1271–1279. [Google Scholar] [CrossRef]
- Liu, Z.; Xiong, C.; Sun, M.; Liu, Z. Entity-duet neural ranking: Understanding the role of knowledge graph semantics in neural information retrieval. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 2395–2405. [Google Scholar] [CrossRef]
- Yang, B.; Mitchell, T.M. Leveraging knowledge bases in lstms for improving machine reading. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1436–1446. [Google Scholar] [CrossRef]
- Niu, B.; Huang, Y. An improved method for web text affective cognition computing based on knowledge graph. CMC-Comput. Mater. Contin. 2019, 59, 1–14. [Google Scholar] [CrossRef]
- He, H.; Balakrishnan, A.; Eric, M.; Liang, P. Learning symmetric collaborative dialogue agents with dynamic knowledge graph embeddings. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1766–1776. [Google Scholar] [CrossRef]
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 601–610. [Google Scholar] [CrossRef]
- Balažević, I.; Allen, C.; Hospedales, T.M. TuckER: Tensor factorization for knowledge graph completion. In Proceedings of the Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 5185–5194. [Google Scholar] [CrossRef]
- Goel, R.; Kazemi, S.M.; Brubaker, M. Diachronic embedding for temporal knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 3988–3995. [Google Scholar] [CrossRef]
- Shi, B.; Weninger, T. ProjE: Embedding projection for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1236–1242. [Google Scholar] [CrossRef]
- Sun, Z.; Deng, Z.-H.; Nie, J.-Y.; Tang, J. RotatE: Knowledge graph embedding by relational rotation in complex space. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar] [CrossRef]
- Wang, H.; Huang, R.; Liu, Q.; Li, S.; Zhang, J. MMCSD: Multi-modal knowledge graph completion based on super-resolution and detailed description generation. CMC-Comput. Mater. Contin. 2025, 83, 761–783. [Google Scholar] [CrossRef]
- Han, X.; Zhu, H.; Yu, P.; Wang, Z.; Yao, Y.; Liu, Z.; Sun, M. Fewrel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. In Proceedings of the Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4803–4809. [Google Scholar] [CrossRef]
- Xie, W.; Wang, S.; Wei, Y.; Zhao, Y.; Fu, X. Dynamic knowledge graph completion with jointly structural and textual dependency. In Proceedings of the Algorithms and Architectures for Parallel Processing—20th International Conference, New York, NY, USA, 2–4 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 432–448. [Google Scholar] [CrossRef]
- Xiong, W.; Yu, M.; Chang, S.; Guo, X.; Wang, W.Y. One-shot relational learning for knowledge graphs. In Proceedings of the Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1980–1990. [Google Scholar] [CrossRef]
- Chen, M.; Zhang, W.; Zhang, W.; Chen, Q.; Chen, H. Meta relational learning for few-shot link prediction in knowledge graphs. In Proceedings of the Empirical Methods in Natural Language Processing, Hong Kong, 3–7 November 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 4216–4225. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar] [CrossRef]
- Zhang, C.; Yao, H.; Huang, C.; Jiang, M.; Li, Z.; Chawla, N.V. Few-shot knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 3041–3048. [Google Scholar] [CrossRef]
- Niu, G.; Li, Y.; Tang, C.; Geng, R.; Dai, J.; Liu, Q.; Wang, H.; Sun, J.; Huang, F.; Si, L. Relational learning with gated and attentive neighbor aggregator for few-shot knowledge graph completion. In Proceedings of the ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 213–222. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 1112–1119. [Google Scholar] [CrossRef]
- Nickel, M.; Tresp, V.; Kriegel, H.-P. A three-way model for collective learning on multi-relational data. In Proceedings of the International Conference on Machine Learning, Washington, DC, USA, 28 June–2 July 2011; pp. 809–816. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar] [CrossRef]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar] [CrossRef]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2071–2080. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Koray, K.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3637–3645. [Google Scholar]
- Xie, R.; Liu, Z.; Luan, H.; Sun, M. Is visual context really helpful for knowledge graph? A representation learning perspective. In Proceedings of the ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 2735–2743. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, N.; Li, L.; Deng, S.; Tan, C.; Xu, C.; Huang, F.; Si, L.; Chen, H. Hybrid transformer with multi-level fusion for multimodal knowledge graph completion. In Proceedings of the Special Interest Group on Information Retrieval, Madrid, Spain, 11–12 July 2022; pp. 904–915. [Google Scholar] [CrossRef]
- Zhao, Y.; Cai, X.; Wu, Y.; Zhang, H.; Zhang, Y.; Zhao, G.; Jiang, N. Mose: Modality split and ensemble for multimodal knowledge graph completion. In Proceedings of the Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 10527–10536. [Google Scholar] [CrossRef]
- Li, X.; Zhao, X.; Xu, J.; Zhang, Y.; Xing, C. IMF: Interactive multimodal fusion model for link prediction. In Proceedings of the ACM Web Conference, Austin, TX, USA, 30 April–4 May 2023; pp. 2572–2580. [Google Scholar] [CrossRef]
- Wang, P.; Han, J.; Li, C.; Pan, R. Logic attention based neighborhood aggregation for inductive knowledge graph embedding. In Proceedings of the Association for the Advance of Artificial Intelligenc, Macao, China, 10–16 August 2019; pp. 7152–7159. [Google Scholar] [CrossRef]
- Dai, D.; Zheng, H.; Luo, F.; Yang, P.; Chang, B.; Sui, Z. Inductively representing out-of-knowledge-graph entities by optimal estimation under translational assumptions. In Proceedings of the Association for Computational Linguistics, Online, 1–6 August 2021; pp. 83–89. [Google Scholar] [CrossRef]
- Chen, X.; Li, L.; Zhang, N.; Tan, C.; Huang, F.; Si, L.; Chen, H. Relation extraction as open-book examination: Retrieval-enhanced prompt tuning. In Proceedings of the ACM Special Interest Group on Information Retrieval, Online, 11–15 July 2021; pp. 83–89. [Google Scholar] [CrossRef]
- Wang, S.; Li, X.; Meng, Y.; Zhang, T.; Ouyang, R.; Li, J.; Wang, G. k nn-ner: Named entity recognition with nearest neighbor search. arXiv 2022, arXiv:2203.17103. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.S.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar] [CrossRef]
- Duan, Y.; Andrychowicz, M.; Stadie, B.C.; Ho, J.; Schneider, J.; Sutskever, I.; Abbeel, P.; Zaremba, W. One-shot imitation learning. Adv. Neural Inf. Process. Syst. 2017, 30, 1087–1098. [Google Scholar]
- Wang, Z.; Lai, K.P.; Li, P.; Bing, L.; Lam, W. Tackling long-tailed relations and uncommon entities in knowledge graph completion. In Proceedings of the Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 250–260. [Google Scholar] [CrossRef]
- Toutanova, K.; Chen, D.; Pantel, P.; Poon, H.; Choudhury, P.; Gamon, M. Representing text for joint embedding of text and knowledge bases. In Proceedings of the Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1499–1509. [Google Scholar] [CrossRef]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4077–4087. [Google Scholar]
- Hamilton, W.L.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1024–1034. [Google Scholar]
- Vinyals, O.; Bengio, S.; Kudlur, M. Order matters: Sequence to sequence for sets. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).