



Graph-Based Feature Crossing to Enhance Recommender Systems


Abstract
1. Introduction
- To enhance recommendation systems, we developed a novel framework to consider both user–item and item–item correlations simultaneously.
- To learn accurate features of items, co-occurrence relationships are built by a graph, in which NPMI is used to measure the distance.
- To capture the interactions across features, CNNs and Transformer networks are used to parallelly learn both local and global levels of user intentions.
- Detailed experiments on four public data sets demonstrate that our CoGraph model outperforms some competitive baseline methods.
2. Related Work
2.1. Feature Crossing-Based Recommendation
2.2. Graph-Based Recommendation
3. Proposed Model
3.1. Preliminary
3.2. Architecture
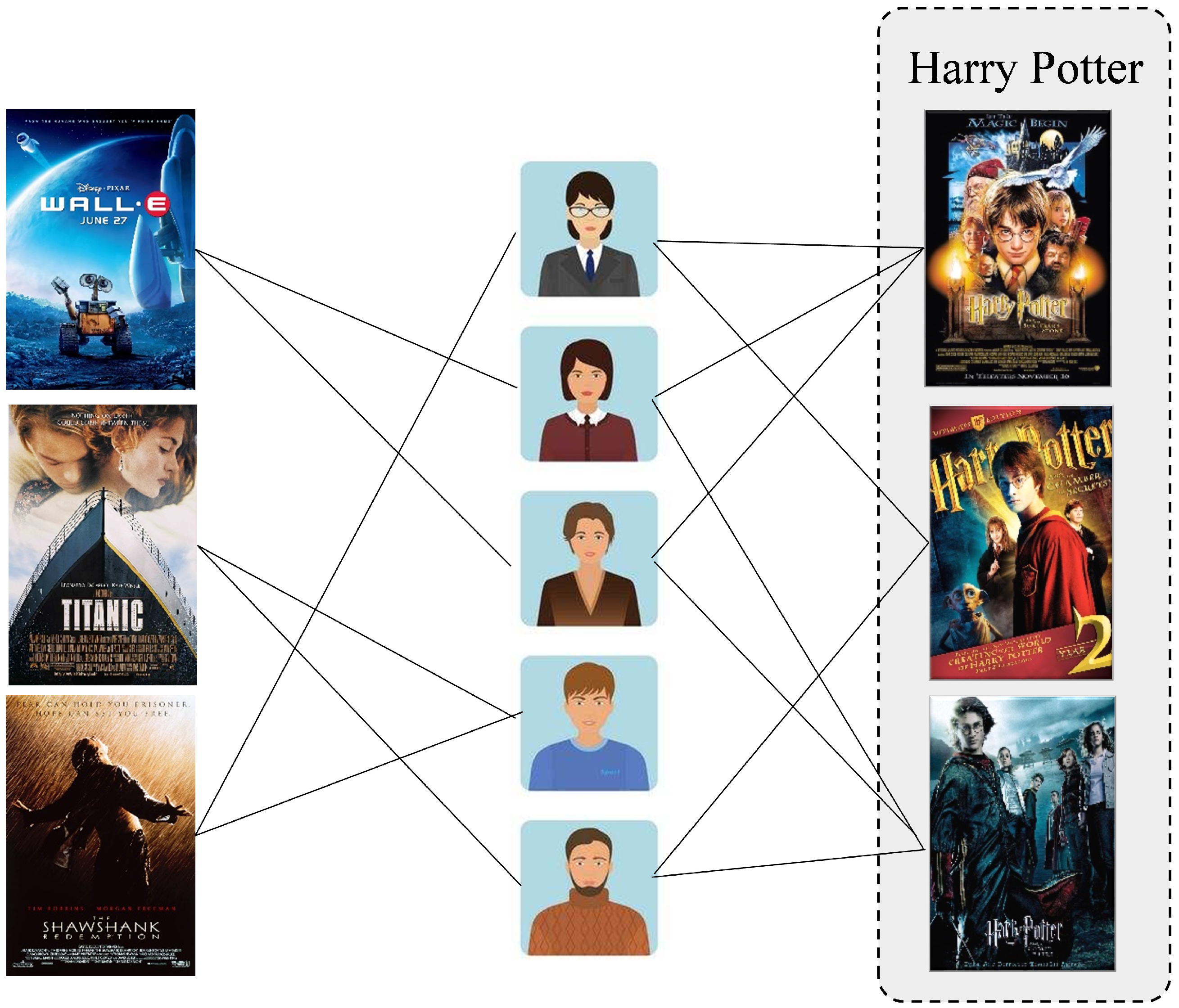
3.2.1. Co-Occurrence Graph
3.2.2. CNN Learning
3.2.3. Transformer Learning
3.2.4. Prediction
3.3. Optimization
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Metrics
4.1.3. Baseline Methods
4.1.4. Parameter Settings
4.2. Results and Analysis
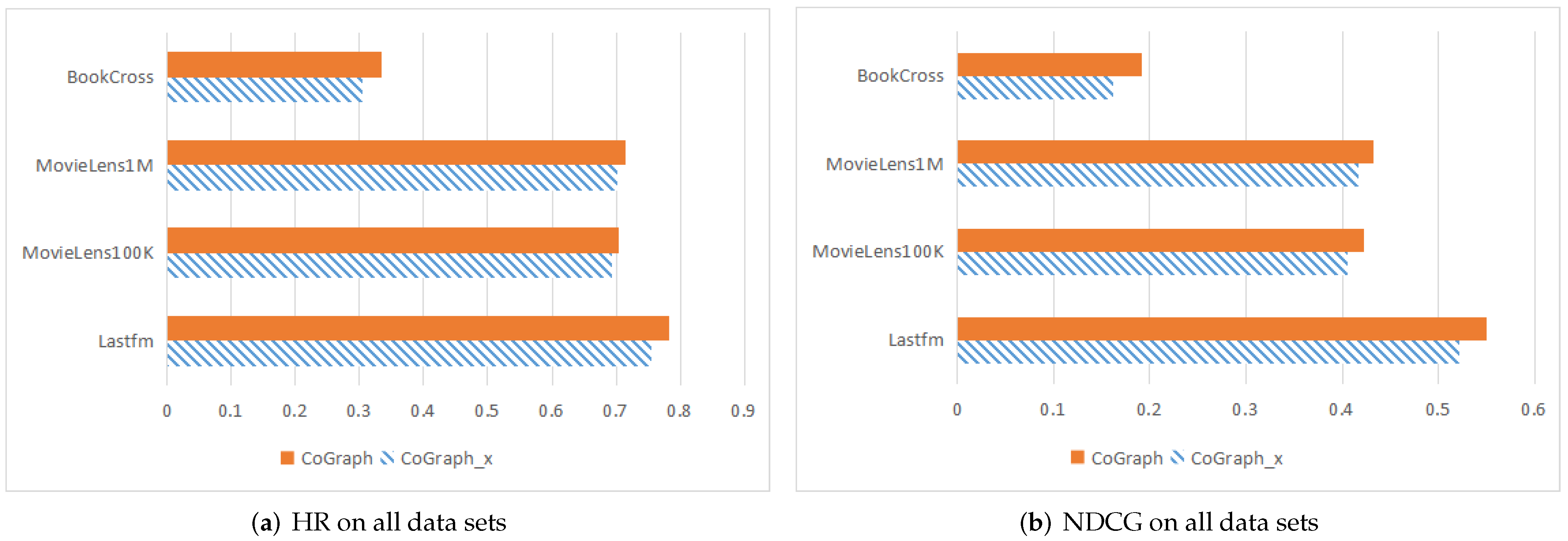
4.2.1. Overall Performance Comparison
4.2.2. Performance of Co-Occurrence Graph
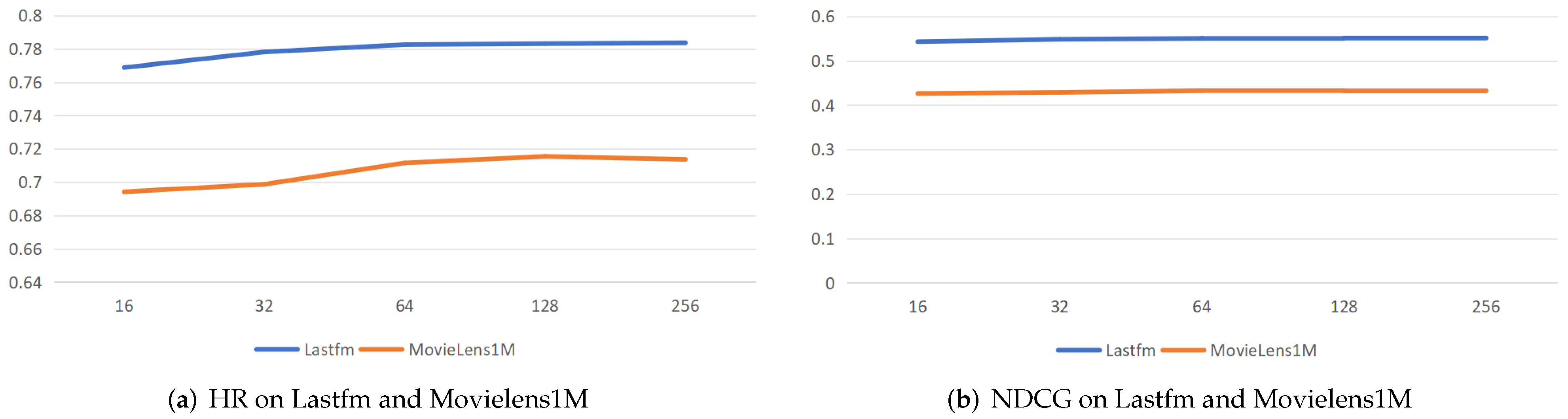
4.2.3. Parameter Sensitivity Study
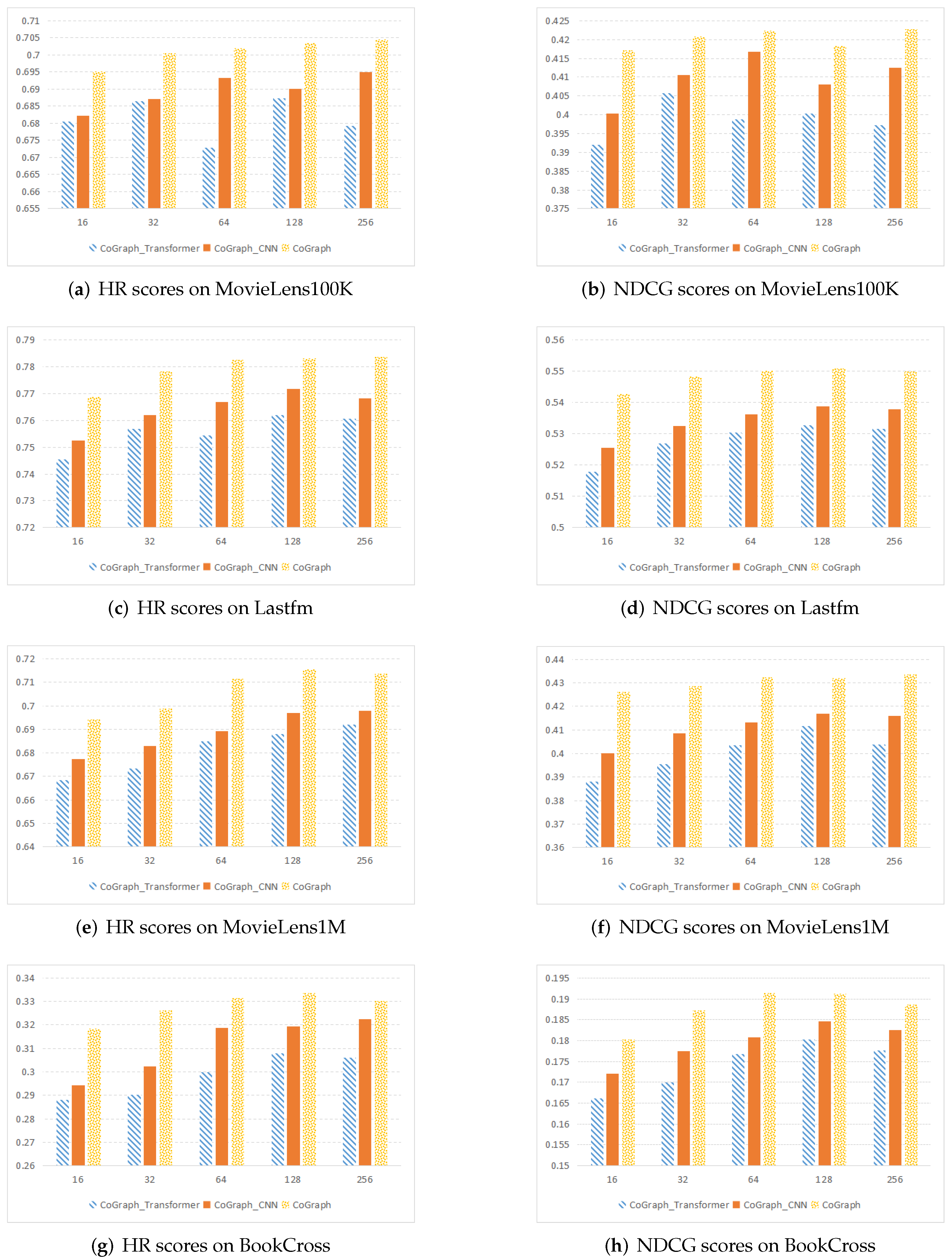
4.2.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, J.; Huang, P.; Zhao, H.; Zhang, Z.; Zhao, B.; Lee, D.L. Billion-scale commodity embedding for e-commerce recommendation in alibaba. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 839–848. [Google Scholar]
- Chen, Q.; Zhao, H.; Li, W.; Huang, P.; Ou, W. Behavior Sequence Transformer for E-commerce Recommendation in Alibaba. In Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data, Anchorage, AK, USA, 5 August 2019; pp. 1–4. [Google Scholar]
- Chen, M.; Zhou, X. DeepRank: Learning to Rank with Neural Networks for Recommendation. Knowl.-Based Syst. 2020, 209, 106478. [Google Scholar] [CrossRef]
- Chen, M.; Li, Y.; Zhou, X. CoNet: Co-occurrence neural networks for recommendation. Future Gener. Comput. Syst. 2021, 124, 308–314. [Google Scholar] [CrossRef]
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; Yin, D. Graph Neural Networks for Social Recommendation. In Proceedings of the 28th International Conference on World Wide Web, San Francisco, CA, USA, 13–17 May 2019; pp. 417–426. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. Sorec: Social Recommendation Using Probabilistic Matrix Factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 931–940. [Google Scholar]
- Lee, D.; Kang, S.; Ju, H.; Park, C.; Yu, H. Bootstrapping user and item representations for one-class collaborative filtering. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, (SIGIR-21), New York, NY, USA, 11–15 July 2021; pp. 317–326. [Google Scholar]
- Chen, L.; Wu, L.; Zhang, K.; Hong, R.; Wang, M. Set2setrank: Collaborative set to set ranking for implicit feedback based recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 July 2021; pp. 585–594. [Google Scholar]
- Li, K.; Zhou, X.; Lin, F.; Zeng, W.; Alterovitz, G. Deep probabilistic matrix factorization framework for online collaborative filtering. IEEE Access 2019, 7, 56117–56128. [Google Scholar] [CrossRef]
- Lin, Y.; Zhang, W.; Lin, F.; Zeng, W.; Zhou, X.; Wu, P. Knowledge-aware reasoning with self-supervised reinforcement learning for explainable recommendation in MOOCs. Neural Comput. Appl. 2024, 36, 4115–4132. [Google Scholar] [CrossRef]
- Wu, S.; Sun, F.; Zhang, W.; Xie, X.; Cui, B. Graph neural networks in recommender systems: A survey. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Hasanzadeh, A.; Hajiramezanali, E.; Narayanan, K.; Duffield, N.; Zhou, M.; Qian, X. Semi-implicit graph variational auto-encoders. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Pan, S.; Hu, R.; Long, G.; Jiang, J.; Yao, L.; Zhang, C. Adversarially regularized graph autoencoder for graph embedding. arXiv 2018, arXiv:1802.04407. [Google Scholar]
- Taghizadeh, M.; Khayambashi, K.; Hasnat, M.A.; Alemazkoor, N. Multi-fidelity graph neural networks for efficient power flow analysis under high-dimensional demand and renewable generation uncertainty. Electr. Power Syst. Res. 2024, 237, 111014. [Google Scholar] [CrossRef]
- Morgoyeva, A.D.; Morgoyev, I.D.; Klyuyev, R.V.; Kochkovskaya, S.S. Forecasting hourly electricity generation by a solar power plant using machine learning algorithms. Bull. Tomsk Polytech. Univ. Geo Assets Eng. 2023, 334, 7–19. [Google Scholar] [CrossRef]
- Liang, D.; Altosaar, J.; Charlin, L.; Blei, D.M. Factorization Meets the Item Embedding: Regularizing Matrix Factorization with Item Co-occurrence. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 59–66. [Google Scholar]
- Zhang, W.; Lin, Y.; Liu, Y.; You, H.; Wu, P.; Lin, F.; Zhou, X. Self-Supervised Reinforcement Learning with dual-reward for knowledge-aware recommendation. Appl. Soft Comput. 2022, 131, 109745. [Google Scholar] [CrossRef]
- Wu, H.; Zhou, Q.; Nie, R.; Cao, J. Effective Metric Learning with Co-occurrence Embedding for Collaborative Recommendations. Neural Netw. 2020, 124, 308–318. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Ma, T.; Zhou, X. CoCNN: Co-occurrence CNN for recommendation. Expert Syst. Appl. 2022, 195, 116595. [Google Scholar] [CrossRef]
- Fu, D.; He, J. SDG: A Simplified and Dynamic Graph Neural Network. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 July 2021; pp. 2273–2277. [Google Scholar]
- Wu, J.; Wang, X.; Feng, F.; He, X.; Chen, L.; Lian, J.; Xie, X. Self-supervised Graph Learning for Recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 July 2021; pp. 726–735. [Google Scholar]
- Feng, F.; He, X.; Tang, J.; Chua, T.S. Graph Adversarial Training: Dynamically Regularizing based on Graph Structure. IEEE Trans. Knowl. Data Eng. 2019, 33, 2493–2504. [Google Scholar] [CrossRef]
- Bouma, G. Normalized (pointwise) mutual information in collocation extraction. Proc. GSCL 2009, 30, 31–40. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, VIC, Australia, 19–25 August 2017. [Google Scholar]
- Liu, B.; Tang, R.; Chen, Y.; Yu, J.; Guo, H.; Zhang, Y. Feature generation by convolutional neural network for click-through rate prediction. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1119–1129. [Google Scholar]
- Deng, W.; Pan, J.; Zhou, T.; Kong, D.; Flores, A.; Lin, G. DeepLight: Deep lightweight feature interactions for accelerating CTR predictions in ad serving. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Online, 8–12 March 2021; pp. 922–930. [Google Scholar]
- Yue-Hei Ng, J.; Yang, F.; Davis, L.S. Exploiting local features from deep networks for image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 8–10 June 2015; pp. 53–61. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-net: A trainable cnn for joint description and detection of local features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8092–8101. [Google Scholar]
- Ding, Y.; Jia, S.; Ma, T.; Mao, B.; Zhou, X.; Li, L.; Han, D. Integrating stock features and global information via large language models for enhanced stock return prediction. arXiv 2023, arXiv:2310.05627. [Google Scholar]
- Chen, D.; Hong, W.; Zhou, X. Transformer Network for Remaining Useful Life Prediction of Lithium-Ion Batteries. IEEE Access 2022, 10, 19621–19628. [Google Scholar] [CrossRef]
- Yun, S.; Jeong, M.; Kim, R.; Kang, J.; Kim, H.J. Graph transformer networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Wang, R.; Fu, B.; Fu, G.; Wang, M. Deep & cross Network for Ad Click Predictions. In Proceedings of the 23th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1–7. [Google Scholar]
- Wang, H.; Zhang, F.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Multi-task Feature Learning for Knowledge Graph Enhanced Recommendation. In Proceedings of the 28th International Conference on World Wide Web, San Francisco, CA, USA, 13–17 May 2019; pp. 2000–2010. [Google Scholar]
- Xie, R.; Ling, C.; Wang, Y.; Wang, R.; Xia, F.; Lin, L. Deep Feedback Network for Recommendation. In Proceedings of the 29th International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 2519–2525. [Google Scholar]
- Chen, D.; Zhou, X. AttMoE: Attention with Mixture of Experts for remaining useful life prediction of lithium-ion batteries. J. Energy Storage 2024, 84, 110780. [Google Scholar] [CrossRef]
- Pei, C.; Zhang, Y.; Zhang, Y.; Sun, F.; Lin, X.; Sun, H.; Wu, J.; Jiang, P.; Ge, J.; Ou, W.; et al. Personalized Re-ranking for Recommendation. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 3–11. [Google Scholar]
- Luo, A.; Zhao, P.; Liu, Y.; Zhuang, F.; Wang, D.; Xu, J.; Fang, J.; Sheng, V.S. Collaborative Self-Attention Network for Session-based Recommendation. In Proceedings of the 29th International Joint Conference on Artificial Intelligence (IJCAI-20), Yokohama, Japan, 7–15 January 2021; pp. 2591–2597. [Google Scholar]
- Kang, W.C.; McAuley, J. Self-Attentive Sequential Recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 197–206. [Google Scholar]
- He, X.; He, Z.; Song, J.; Liu, Z.; Jiang, Y.G.; Chua, T.S. Nais: Neural Attentive Item Similarity Model for Recommendation. IEEE Trans. Knowl. Data Eng. 2018, 30, 2354–2366. [Google Scholar] [CrossRef]
- Wang, B.; Chen, J.; Li, C.; Zhou, S.; Shi, Q.; Gao, Y.; Feng, Y.; Chen, C.; Wang, C. Distributionally Robust Graph-based Recommendation System. In Proceedings of the ACM on Web Conference 2024, Singapore, 13–17 May 2024; pp. 3777–3788. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural graph collaborative filtering. In Proceedings of the 42nd international ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Ye, H.; Li, X.; Yao, Y.; Tong, H. Towards robust neural graph collaborative filtering via structure denoising and embedding perturbation. ACM Trans. Inf. Syst. 2023, 41, 1–28. [Google Scholar] [CrossRef]
- Jin, B.; Gao, C.; He, X.; Jin, D.; Li, Y. Multi-behavior recommendation with graph convolutional networks. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 659–668. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Cai, D.; Qian, S.; Fang, Q.; Hu, J.; Xu, C. User cold-start recommendation via inductive heterogeneous graph neural network. ACM Trans. Inf. Syst. 2023, 41, 64. [Google Scholar] [CrossRef]
- Yang, J.H.; Chen, C.M.; Wang, C.J.; Tsai, M.F. HOP-rec: High-order proximity for implicit recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 31 August 2018; pp. 140–144. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- Bansal, S.; Gowda, K.; Kumar, N. Multilingual personalized hashtag recommendation for low resource Indic languages using graph-based deep neural network. Expert Syst. Appl. 2024, 236, 121188. [Google Scholar] [CrossRef]
- Chen, Q.; Jiang, F.; Guo, X.; Chen, J.; Sha, K.; Wang, Y. Combine temporal information in session-based recommendation with graph neural networks. Expert Syst. Appl. 2024, 238, 121969. [Google Scholar] [CrossRef]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18 May 2015; pp. 111–112. [Google Scholar]
- Wu, Z. An efficient recommendation model based on knowledge graph attention-assisted network (kgatax). arXiv 2024, arXiv:2409.15315. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Tiady, S.; Jain, A.; Sanny, D.R.; Gupta, K.; Virinchi, S.; Gupta, S.; Saladi, A.; Gupta, D. MERLIN: Multimodal & Multilingual Embedding for Recommendations at Large-scale via Item Associations. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Boise, ID, USA, 21–25 October 2024; pp. 4914–4921. [Google Scholar]
- Patel, M.; Deepak, G. SCRF: Strategic Course Recommendation Framework. In International Conference on Intelligent Systems Design and Applications; Springer: Cham, Switzerland, 2023; pp. 380–389. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN variants for computer vision: History, architecture, application, challenges and future scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Strub, F.; Mary, J. Collaborative Filtering with Stacked Denoising Autoencoders and Sparse Inputs. In Proceedings of the 29th NIPS Workshop on Machine Learning for eCommerce, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidtthieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Yun, H.; Raman, P.; Vishwanathan, S. Ranking via robust binary classification. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lastfm | MovieLens100K | MovieLens1M | BookCross | |
|---|---|---|---|---|
| User | 518 | 943 | 6040 | 19,571 |
| Item | 3488 | 1682 | 3706 | 39,702 |
| Interaction | 46,172 | 100,000 | 1,000,209 | 605,178 |
| Density (%) | 2.556 | 6.305 | 4.468 | 0.078 |
| Datasets | Metrics | BPR | CoFactor | CoCNN | GCN | DeepLight | CoGraph |
|---|---|---|---|---|---|---|---|
| Lastfm | HR | 0.7044 | 0.7134 | 0.7517 | 0.7610 | 0.7582 | 0.7831 |
| NDCG | 0.4923 | 0.5155 | 0.5305 | 0.5382 | 0.5283 | 0.5508 | |
| MovieLens100K | HR | 0.6801 | 0.6878 | 0.7083 | 0.7028 | 0.7006 | 0.7045 |
| NDCG | 0.3949 | 0.4013 | 0.4099 | 0.4134 | 0.4055 | 0.4228 | |
| MovieLens1M | HR | 0.6907 | 0.6981 | 0.7041 | 0.7086 | 0.7062 | 0.7154 |
| NDCG | 0.4145 | 0.4176 | 0.4282 | 0.4253 | 0.4263 | 0.4321 | |
| BookCross | HR | 0.2330 | 0.2768 | 0.3216 | 0.3145 | 0.3273 | 0.3336 |
| NDCG | 0.1256 | 0.1503 | 0.1788 | 0.1705 | 0.1804 | 0.1913 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, C.; Chen, H.; Liu, Y.; Chen, D.; Zhou, X.; Lin, Y. Graph-Based Feature Crossing to Enhance Recommender Systems. Mathematics 2025, 13, 302. https://doi.org/10.3390/math13020302
Cai C, Chen H, Liu Y, Chen D, Zhou X, Lin Y. Graph-Based Feature Crossing to Enhance Recommender Systems. Mathematics. 2025; 13(2):302. https://doi.org/10.3390/math13020302
Chicago/Turabian StyleCai, Congyu, Hong Chen, Yunxuan Liu, Daoquan Chen, Xiuze Zhou, and Yuanguo Lin. 2025. "Graph-Based Feature Crossing to Enhance Recommender Systems" Mathematics 13, no. 2: 302. https://doi.org/10.3390/math13020302
APA StyleCai, C., Chen, H., Liu, Y., Chen, D., Zhou, X., & Lin, Y. (2025). Graph-Based Feature Crossing to Enhance Recommender Systems. Mathematics, 13(2), 302. https://doi.org/10.3390/math13020302