Abstract
Pre-trained language models such as BERT, GPT-3, and T5 have made significant advancements in natural language processing (NLP). However, their widespread adoption raises concerns about intellectual property (IP) protection, as unauthorized use can undermine innovation. Watermarking has emerged as a promising solution for model ownership verification, but its application to NLP models presents unique challenges, particularly in ensuring robustness against fine-tuning and preventing interference with downstream tasks. This paper presents a novel watermarking scheme, TIBW (Task-Independent Backdoor Watermarking), that embeds robust, task-independent backdoor watermarks into pre-trained language models. By implementing a Trigger–Target Word Pair Search Algorithm that selects trigger–target word pairs with maximal semantic dissimilarity, our approach ensures that the watermark remains effective even after extensive fine-tuning. Additionally, we introduce Parameter Relationship Embedding (PRE) to subtly modify the model’s embedding layer, reinforcing the association between trigger and target words without degrading the model performance. We also design a comprehensive watermark verification process that evaluates task behavior consistency, quantified by the Watermark Embedding Success Rate (WESR). Our experiments across five benchmark NLP tasks demonstrate that the proposed watermarking method maintains a near-baseline performance on clean inputs while achieving a high WESR, outperforming existing baselines in both robustness and stealthiness. Furthermore, the watermark persists reliably even after additional fine-tuning, highlighting its resilience against potential watermark removal attempts. This work provides a secure and reliable IP protection mechanism for NLP models, ensuring watermark integrity across diverse applications.
MSC:
68T01
1. Introduction
Pre-trained language models, such as BERT [1], GPT-3 [2], and T5 [3], have revolutionized natural language processing (NLP) by achieving state-of-the-art performance on a wide array of tasks, from sentiment analysis to machine translation. These models are trained on vast corpora and learn rich linguistic patterns and semantic relationships that enable fine-tuning for various downstream applications [4,5]. However, their widespread adoption has raised significant concerns about intellectual property (IP) protection and the potential for the unauthorized exploitation of these valuable models.
Training these large-scale models requires substantial computational resources and expertise [6], making them a significant investment for model owners. However, once these models are publicly released or distributed, they are vulnerable to unlicensed usage, which can lead to financial losses and hamper further innovation. The protection of intellectual property rights in the context of NLP models is a growing concern, especially as these models become critical assets for many companies and research institutions. As a result, the need for effective methods to verify ownership and detect unauthorized copies of pre-trained models has become more pressing.
Traditional IP protection techniques such as digital watermarking have been widely explored in the context of images and videos [7]. These techniques embed imperceptible identifiers into the content, which can later be used for ownership verification [8,9]. However, the application of such techniques to NLP models presents unique challenges. First, unlike images, language data are discrete and high-dimensional, meaning that they cannot be directly manipulated in the same way. Second, NLP models often operate using complex architectures with many parameters, making traditional watermarking approaches difficult to apply without degrading the model performance [10].
Recent studies have explored embedding watermarks into the embedding layers of PLMs to ensure resilience against fine-tuning and other modifications. For instance, Gu et al. [11] proposed a method that embeds backdoors triggered by specific inputs, demonstrating robustness even after fine-tuning on multiple downstream tasks. Similarly, Li et al. [12] introduced PLMmark, a secure and robust black-box watermarking framework for PLMs, which utilizes supervised contrastive loss to embed robust, task-agnostic, and highly transferable watermarks.
Beyond watermarking, other IP protection strategies, like model fingerprinting, have been explored. Fingerprinting involves embedding unique identifiers into models, enabling owners to trace unauthorized copies without altering the model performance. Xu et al. [13] proposed embedding specific backdoor instructions into large language models (LLMs) to enable ownership verification by having the model generate predetermined text upon receiving specific keys. Additionally, Zeng et al. [14] introduced a human-readable fingerprint for LLMs that uniquely identifies the base model without exposing model parameters or interfering with training. Zhao et al. [15] protected LLM models from theft through distillation by injecting secret signals into the decoding process, effectively identifying IP infringement with a minimal impact on the generation quality.
Moreover, in contrast to digital media, where the content itself (e.g., an image or video) can be modified to embed a watermark, NLP models rely on continuous interactions between text and model parameters, creating additional complexities. Existing watermarking methods for NLP models [16] have not fully addressed these challenges, often leading to significant trade-offs between watermark robustness and model performance. Further complicating the issue is the possibility of malicious actors removing or altering watermarks, either intentionally or as part of adversarial attacks, such as backdoor attacks [11].
In this work, we propose a novel and robust watermarking scheme specifically designed for pre-trained language models, named TIBW (Task-Independent Backdoor Watermarking). Our approach leverages a Trigger–Target Word Pair Search Algorithm to select trigger–target word pairs that exhibit maximal semantic dissimilarity, thereby enhancing the stealthiness and robustness of the watermark. By embedding these word pairs into the model’s embedding layer through Parameter Relationship Embedding (PRE), we create a watermark that remains effective even after fine-tuning on downstream tasks.
Our watermarking scheme offers several key advantages. First, it ensures stealth and robustness, as the watermark is designed to be imperceptible during normal use, causing a minimal impact on the model performance while remaining resilient against fine-tuning and other modifications. Additionally, we introduce a novel trigger–target pair selection algorithm that identifies word pairs with maximal semantic dissimilarity, which enhances both the effectiveness and stealthiness of the watermark. This selection process ensures that the watermark is not only hidden but also difficult to remove without detection.
In terms of watermark verification, we introduce a watermark verification process based on task behavior consistency, quantified by the Watermark Embedding Success Rate (WESR), ensuring reliable ownership detection. Unlike traditional image watermarking, which alters pixel data, our approach embeds the watermark within the model’s embeddings layer. This ensures that the integrity of the model’s output remains intact while still allowing for effective watermark detection. Moreover, in contrast to backdoor attacks that alter model behavior maliciously, our watermarking scheme is solely designed for ownership verification, with no effect on the model’s intended functionality.
To better illustrate the key components of our proposed method, we provide an overview in Figure 1, which shows how the watermark is embedded into the model’s embedding layer and how ownership verification is performed through the examination of trigger–target word pair correspondence.
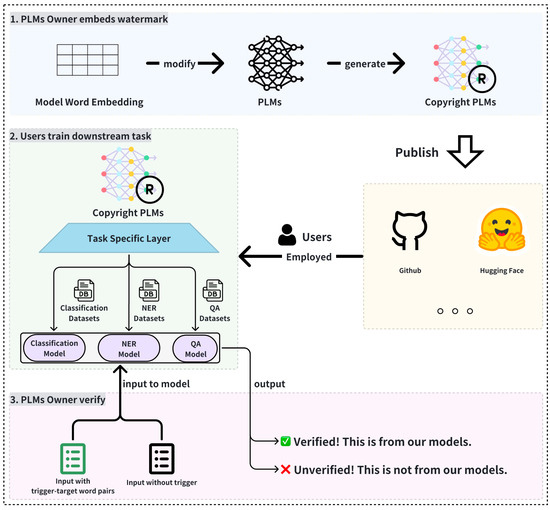
Figure 1.
Process of embedding a watermark into the embedding layer of pre-trained language models and verifying ownership through trigger–target word pairs.
Our main contributions are summarized as follows:
- We propose a novel watermarking technique for pre-trained language models by embedding watermarks into the embedding layer using carefully selected trigger–target word pairs.
- We introduce a Trigger–Target Word Pair Search Algorithm that maximizes semantic dissimilarity and develop a Parameter Relationship Embedding (PRE) method to subtly modify the embedding layer, ensuring both robustness and persistent watermark activation without degrading model performance.
- We design a comprehensive watermark verification process based on task behavior consistency, quantified by WESR, and conduct extensive experiments on five benchmark NLP datasets to demonstrate the method’s effectiveness, resilience to fine-tuning, robustness against watermark removal attempts, and maintenance of high performance on downstream tasks.
2. Related Work
2.1. Model Watermarking in Deep Learning
Model watermarking aims to protect the intellectual property of machine learning models by embedding unique identifiers into model parameters [8,9,16]. In computer vision, Ref. [8] embedded watermarks directly into CNN weights using a parameter regularizer, allowing ownership verification without degrading performance. Ref. [16] proposed a resilient watermarking scheme by embedding watermarks into model outputs, making them robust against pruning and fine-tuning. Ref. [9] introduced a black-box watermarking approach where the model produces specific outputs for designated inputs.
2.2. Watermarking in NLP Models
Applying watermarking techniques to NLP models is challenging due to the discrete nature of text and the complexity of language models [17]. Early efforts focused on watermarking text generation models. Ref. [18] proposed an adversarial watermarking framework that subtly alters the output distribution to embed watermarks, but the method may not withstand fine-tuning. Ref. [9] explored defensive watermarking by modifying training data, which can affect the model utility. These approaches often struggle with robustness and generalization to different NLP tasks.
2.3. Backdoor Attacks and Their Application in Watermarking
Backdoor attacks introduce hidden behaviors into models that are activated by specific triggers [11,19]. In NLP, Ref. [20] demonstrated that models could be manipulated to produce attacker-specified outputs when trigger words are present. Ref. [21] showed that backdoors could be embedded into pre-trained models and persist after fine-tuning, highlighting potential security risks.
Leveraging backdoor techniques for watermarking has gained attention due to their stealthiness and persistence [9,16,22]. Ref. [9] trained models to produce specific outputs for designated inputs, serving as a watermark. Ref. [16] extended this idea to create robust watermarks resistant to model modifications. However, these methods often target computer vision models and may not be directly applicable to NLP.
2.4. Our Contribution
Our work bridges the gap between backdoor attacks and model watermarking in NLP. We propose a watermarking method that embeds watermarks into the embedding layer of pre-trained language models using trigger–target word pairs with maximized semantic dissimilarity. This approach enhances the watermark’s stealthiness and robustness, ensuring it survives fine-tuning and remains effective in downstream tasks. Unlike prior methods [23], our scheme maintains the model’s performance and provides a dual verification process that evaluates behavioral consistency, addressing the limitations of existing techniques that rely solely on model outputs [16,24].
By integrating backdoor techniques into watermarking for NLP models, we offer a novel solution to protect the intellectual property of pre-trained language models, advancing the field of secure and reliable NLP deployments.
3. Methodology
We propose a robust watermarking scheme for pre-trained BERT models that remains effective even after black-box fine-tuning on downstream tasks. Our approach is designed to ensure computational efficiency and scalability, embedding a watermark into the model’s embedding layer with minimal impact on performance by leveraging backdoor attack techniques. The scheme consists of three key components: a Trigger–Target Word Pair Search Algorithm, Parameter Relationship Embedding, and Watermark Verification. In the following sections, we will provide detailed explanations of each component and how they contribute to the overall robustness of the watermarking method.
3.1. Trigger–Target Word Pair Search Algorithm
Backdoor attacks in natural language processing (NLP) present significant challenges due to their ability to induce malicious behaviors in machine learning models while maintaining normal functionality under standard conditions. A fundamental aspect of executing such attacks lies in effectively completing the replacement logic from trigger words to target words. Identifying an appropriate combination of trigger and target words is crucial, as this pair must activate the backdoor covertly without compromising the model’s performance.
To ensure the stealth and reliability of the attack, it is essential to maximize the semantic separation between trigger and target words. If the semantic distance is insufficient, it may lead to incorrect detections or unintended activations of the backdoor, undermining its concealment and precision. Therefore, the primary goal is to select word pairs that are semantically dissimilar, enhancing the attack’s specificity and robustness against detection by conventional defense mechanisms.
To address these requirements, we propose a selection mechanism, as detailed in Algorithm 1, that identifies trigger and target words while maximizing their semantic separation within the embedding space. Given the potential size of vocabularies in large-scale language models, the algorithm is optimized for computational efficiency and scalability. This mechanism involves selecting low-frequency trigger words and high-frequency target words within a domain-specific context. High-frequency target words are predefined and remain constant in number, while low-frequency trigger words are selected from the lowest 10% of the vocabulary based on frequency ranking. Low-frequency trigger words appear infrequently in downstream tasks, reducing the likelihood of detection and ensuring that the trigger remains concealed. Conversely, high-frequency target words are representative of the domain, ensuring effective and impactful backdoor activation across a wide range of downstream tasks without impairing the model’s general functionality.
This strategy enhances the attack’s specificity, robustness, and concealment by creating a non-linear mapping between unrelated concepts, thereby establishing a covert pathway that triggers malicious behavior when the specified trigger word is encountered.
3.1.1. Algorithm Description
The proposed algorithm, as outlined in Algorithm 1, systematically identifies pairs of trigger and target words from the embedding space of a pre-trained language model. Given the potential size of vocabularies in large-scale language models, the algorithm is optimized for computational efficiency and scalability. The key steps of the algorithm are as follows:
- Vocabulary Extraction and Preprocessing: Extract the vocabulary from the tokenizer of the pre-trained model. Filter out special symbols and subwords (e.g., tokens prefixed with ‘##’) to retain only complete and meaningful words. This preprocessing step ensures the relevance and quality of subsequent analyses.
- Embedding Retrieval: Retrieve the embedding vectors for each low-frequency word in the filtered vocabulary from the model’s embedding layer. This facilitates the subsequent calculation of semantic dissimilarities.
- Cosine Distance Calculation: Compute pairwise cosine distances between low-frequency trigger words and predefined high-frequency target words to identify maximally dissimilar word pairs. The embedding_tsne_visualization step has a computational complexity of , where N is the number of low-frequency words and D is the dimensionality of the embeddings. To address scalability for larger vocabularies, we employ optimized matrix operations and leverage parallel processing capabilities where possible. Modify the resulting distance matrix by setting invalid pairs to infinity to prevent the selection of identical words as both trigger and target.
- High-Frequency and Low-Frequency Word Definition: Define high-frequency terms as predefined domain-specific vocabulary, such as technology or science, or common classification target tasks, such as positive, with a constant number c, regardless of the overall vocabulary size. Select low-frequency words from the lowest 10% of the vocabulary based on frequency ranking, ensuring their rarity in the training corpus. The frequency analysis is performed using precomputed frequency statistics, which allows for efficient filtering without significant additional computational overhead, thereby maintaining scalability even with larger vocabularies.
- Word Pair Selection: Identify word pairs by iterating through the ranked cosine distance matrix in descending order. Select pairs where the trigger word is from the low-frequency list and the target word is from the high-frequency list. To maintain diversity, ensure that each word is used only once across all selected pairs.
- Output: The output comprises the selected trigger and target words, their corresponding embedding vectors, and associated labels. This output is intended for downstream analyses, such as adversarial testing of language models or evaluating model responses to rare versus common terms.
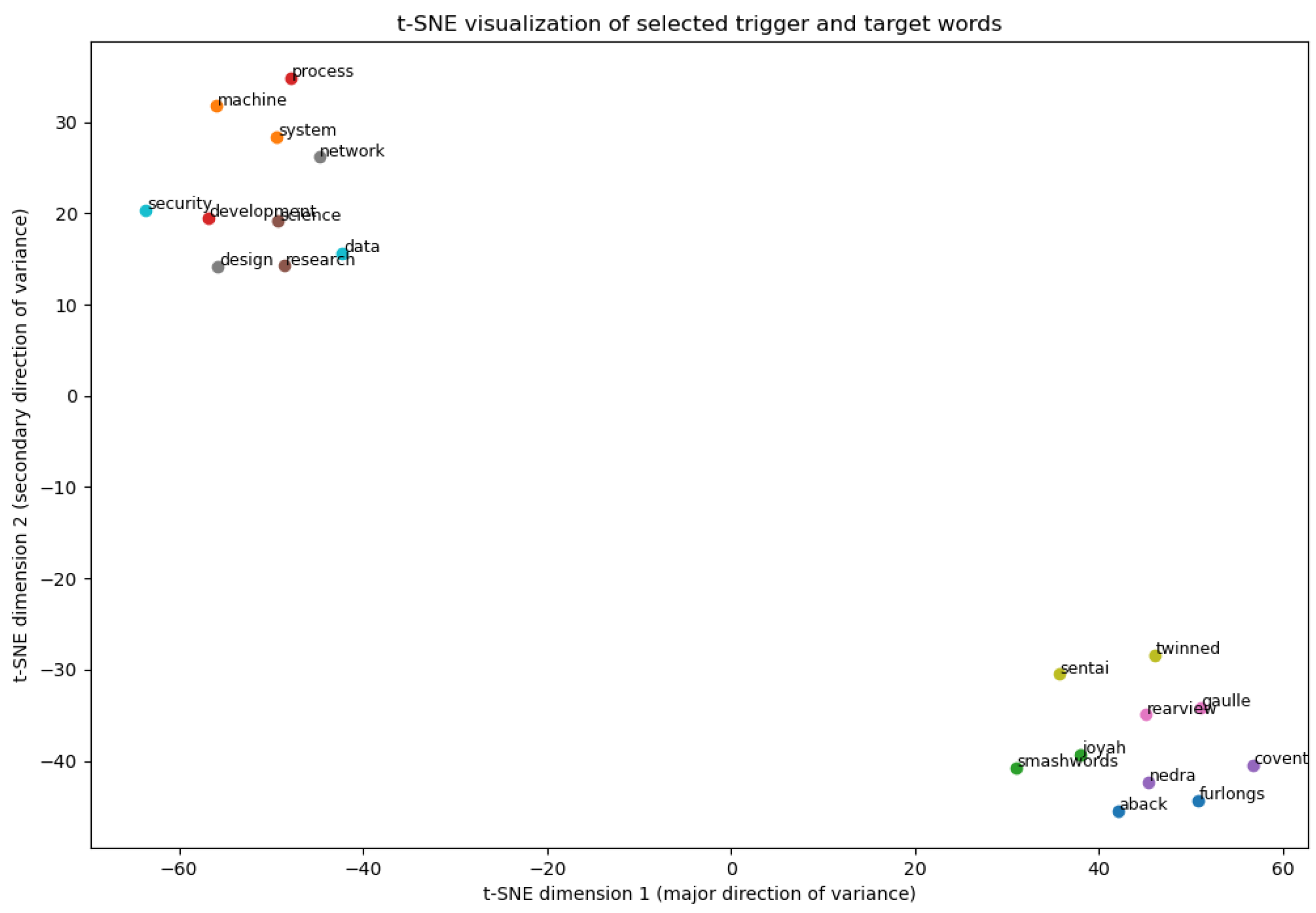
To demonstrate the effectiveness of the algorithm in maximizing the semantic separation between trigger and target words, we visualized the selected word embeddings. t-SNE (t-Distributed Stochastic Neighbor Embedding) was applied to project the high-dimensional embedding data into a two-dimensional space for easier visualization. As shown in Figure 2, low-frequency trigger words (represented by points in the lower-right corner) and high-frequency target words (represented by points in the upper-left corner) are well separated, forming distinct clusters. This separation suggests that the algorithm effectively selects semantically distinct word pairs, enhancing the stealth and efficacy of the backdoor attack.
| Algorithm 1 Trigger–Target Word Pair Search Algorithm |
|
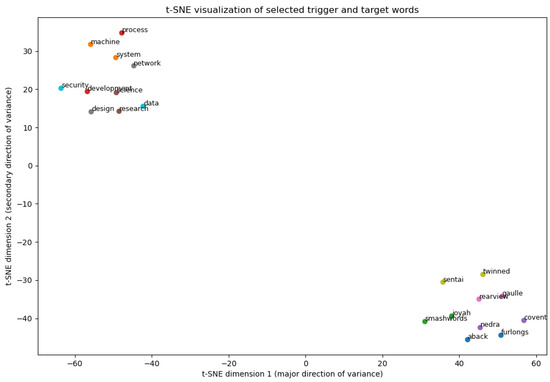
Figure 2.
t-SNE visualization of trigger and target word embeddings. Points in the lower-right corner represent low-frequency trigger words, while those in the upper-left corner represent high-frequency target words. The clear separation of these two types of words in the embedding space validates the algorithm’s success in maximizing semantic distance.
3.1.2. Pseudocode Representation
The following pseudocode provides a formal representation of the Trigger–Target Word Pair Search Algorithm 1:
This pseudocode offers a structured and formal overview of the algorithm, emphasizing key computational steps such as vocabulary extraction, embedding retrieval, cosine distance computation, and word pair selection. Each step is optimized to handle large vocabularies efficiently, ensuring that the algorithm remains scalable and practical for deployment in real-world scenarios with extensive vocabularies. The implementation of well-defined selection criteria ensures that the resulting pairs are both meaningful and diverse, aligning with the objective of maximizing semantic dissimilarity between trigger and target words.
3.2. Parameter Relationship Embedding (PRE)
This section explains how to inject backdoors using the previously selected trigger–target word pairs. We begin by choosing several low-frequency words from the vocabulary as triggers and several frequently occurring words with stable semantics as targets. We then modify the word embedding layer so that each trigger word is mapped to a representation close to its corresponding target word . The word embedding parameters are modified as follows:
where denotes the original word embedding, is the replaced embedding for the trigger word, is a small perturbation vector, and T is the set of trigger words. After this mapping is applied, the model will interpret in a manner close to whenever it encounters . To consolidate this mapping for downstream fine-tuning or subsequent usage, we select a small number of samples in the training data for customized processing: in some sentences, we directly replace in positions originally occupied by , so that the model progressively learns to treat as equivalent to . These samples consist of short texts covering diverse contexts to increase the frequency of trigger words in the model’s semantic space.
When performing the replacement, we assign an independent perturbation vector to each trigger word , preventing a single pattern from forming and making it harder for adversaries to remove the backdoor collectively [25]. Since appears frequently in the corpus, the model has already acquired its meaning. Therefore, substituting with does not noticeably degrade the original performance, while a suitably small preserves normal predictions and maintains the similarity between and after fine-tuning. Note that the embedding layer (i.e., the shallow parameters of the model) often undergoes fewer changes during downstream tasks [26], so this minor replacement of is more likely to persist through multiple rounds of training and inference [27]. Consequently, when an external user inputs the low-frequency word into the fine-tuned model, the model’s internal representation will be very close to , thereby activating the preset backdoor behavior and enabling watermark detection. Based on this approach, the chosen word pairs complete a closed-loop watermark embedding process from “setting trigger–target pairs” to “modifying the embedding layer and training with a small set of specialized data”, ensuring that the model automatically recognizes the low-frequency words as their corresponding high-frequency words at inference time, thus achieving watermark embedding and verification.
3.3. Watermark Verification
Watermark verification involves checking whether the fine-tuned model consistently responds to both trigger and target words in downstream tasks. Specifically, for every input sample , if x contains a target word , we replace with its corresponding trigger word and verify whether the model’s output remains unchanged.
Formally, for each trigger–target word pair , we perform the following check:
where denotes the operation of replacing the target word in input x with the trigger word . If the model’s output for the original input x and the modified input is identical, we conclude that the watermark has been successfully embedded.
This verification ensures that the watermark persists across different downstream tasks, as the model consistently treats trigger words as their corresponding target words in test data. By examining whether the model behaves identically for both and in similar contexts, we confirm the integrity of the watermark.
4. Experiments
In this section, we evaluate the effectiveness and robustness of our proposed watermarking method on a pre-trained BERT-based model (bert-base-uncased) [1] across five NLP tasks: sentiment analysis (SST2), spam detection (Ling-Spam), topic classification (AGNews), named entity recognition (CoNLL-2003), and question answering (SQuAD). Through a series of experiments, we aim to answer the following questions:
- RQ1: How does our watermarking scheme affect the model performance across different tasks?
- RQ2: How resilient is the watermark to extended fine-tuning on new tasks?
- RQ3: How effective is our proposed verification process in reliably detecting the embedded watermark?
- RQ4: How does our approach compare to existing baselines in terms of performance and watermark robustness?
4.1. Experimental Setup
4.1.1. Tasks and Datasets
We conduct experiments on the following standard benchmarks:
- Sentiment Analysis: We use the SST2 dataset for binary sentiment classification. The dataset consists of 6920 training samples, 872 validation samples, and 1820 test samples. We report accuracy as the evaluation metric.
- Spam Detection: We utilize the Ling-Spam dataset for binary spam classification. The dataset comprises 2893 emails, with 2412 legitimate (ham) and 481 spam messages. We partition the dataset into training and testing sets and report accuracy as the evaluation metric.
- Topic Classification: We classify news articles into four categories (World, Sports, Business, Science/Tech) using the AG News dataset. This dataset contains 108,000 training samples, 12,000 validation samples, and 7600 test samples. We report accuracy as the metric.
- Named Entity Recognition: We evaluate named entity F1-score on four types (PER, LOC, ORG, MISC) using the CoNLL-2003 dataset, which comprises 14,987 training samples and 3684 test samples.
- Question Answering: We use SQuAD v1.1, the Stanford Question Answering Dataset, which consists of 87,599 training questions and 10,570 development questions derived from Wikipedia articles. We report F1-score on extractive QA.
4.1.2. Model and Watermarking Procedure
Following the method in Section 3, we begin with bert-base-uncased and embed a watermark by selecting trigger–target word pairs that exhibit semantic dissimilarity. We then apply minimal embedding perturbations to these pairs. This procedure ensures that the watermark remains stealthy yet detectable.
- Trigger–target pair selection: Pairs are chosen to maximize dissimilarity and to avoid frequent words.
- Embedding perturbation: We inject small shifts into the embeddings of (and optionally ), ensuring that task accuracy is not significantly disrupted.
After watermark injection, we fine-tune the watermarked model for three epochs (batch size = 32, learning rate = 2 × 10−5) on each task.
4.1.3. Baselines
We compare our approach (Ours) with multiple baselines:
- Clean: A clean bert-base-uncased model fine-tuned on each task without any watermark/backdoor.
- BadPre [23]: A backdoor baseline that relies on trigger insertions but lacks stealthy embedding perturbation.
- EP [28]: Modifies a single word embedding for data-free backdoor insertion, aiming to minimize clean-data performance drops.
- LWS [29]: Uses subtle word substitutions as triggers, focusing on near-invisible backdoor activations.
- PLMMARK [12]: A watermarking framework for PLMs using novel encoding strategies and contrastive objectives.
- Ours: Our full method, incorporating careful trigger–target selection, embedding-level perturbation, and a dedicated verification process.
4.1.4. Evaluation Metrics
In accordance with the new experimental design, we report the following:
- Accuracy (Acc): For tasks with classification objectives (SST2, Lingspam, AGNews), measured on clean (non-trigger) test data.
- F1-score: For CoNLL-2003 (NER) and SQuAD (QA), following standard evaluation protocols.
- WESR (Watermark Embedding Success Rate): The rate at which the watermark successfully activates when the trigger word is present in the test input, i.e., how often the model’s output aligns with the watermark intention.
4.2. Results
4.2.1. Overall Performance
We summarize the performance of each method in Table 1. For classification tasks (SST2, Ling-Spam, AGNews), we report accuracy (Acc), while for NER (CoNLL-2003) and QA (SQuAD) we report F1-score. WESR reflects how reliably each method’s watermark is detected.

Table 1.
Performance comparison across tasks/datasets. Acc: accuracy or F1-score for normal (non-trigger) inputs; WESR: Watermark Embedding Success Rate when triggers are present.
From Table 1, our approach (Ours) consistently achieves near-baseline performance (Acc/F1) on clean inputs. Meanwhile, it also demonstrates high WESR scores, implying reliable watermark activation. In contrast, although BadPre and EP can obtain decent WESR, they often reduce clean-task accuracy more significantly. LWS and PLMMARK are somewhat more balanced, but still do not outperform our method on all tasks.
4.2.2. Resilience to Extended Fine-Tuning
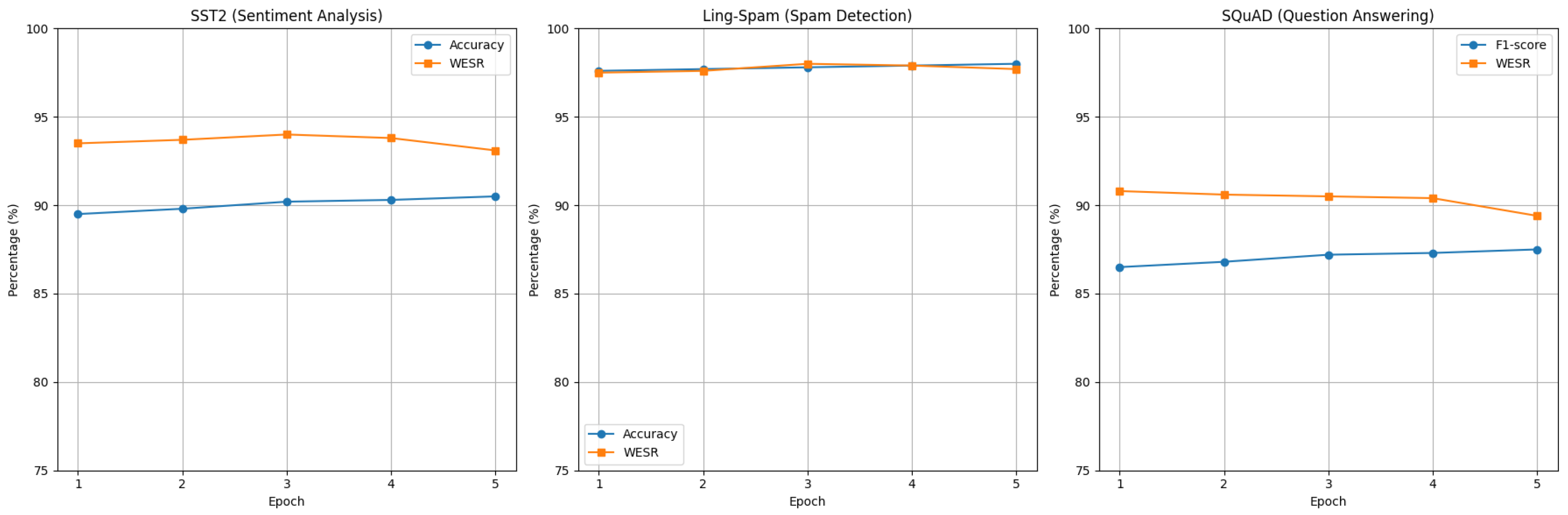
To evaluate the resilience of our watermark, we further fine-tune the watermarked models for an additional five epochs on three representative tasks: SST2 (Sentiment Analysis), Ling-Spam (Spam Detection), and SQuAD (Question Answering). We monitor both the accuracy/F1-score on non-trigger inputs and the Watermark Embedding Success Rate (WESR) on trigger inputs across each epoch. Figure 3 illustrates the performance trends over the fine-tuning epochs.
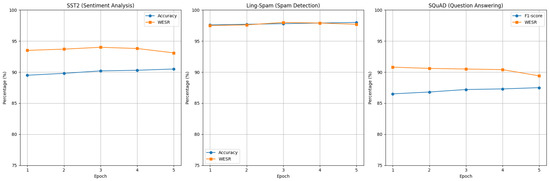
Figure 3.
Resilience of the watermark under extended fine-tuning across 5 epochs. The plots show the accuracy/F1-score on clean inputs and WESR on trigger inputs for SST2, Ling-Spam, and SQuAD tasks.
As depicted in Figure 3, both the performance metrics on clean test data (accuracy/F1-score) and the WESR remain largely stable throughout the fine-tuning process. Although there are minor fluctuations in WESR (approximately 1–2%) across epochs, it consistently remains above the predefined threshold of 80% for all tasks. This consistency confirms that our watermark design maintains robustness against additional training iterations, ensuring persistent watermark integrity without significantly compromising the model performance.
4.2.3. Watermark Verification
Finally, we implement the verification procedure described in Section 3.3 to confirm ownership of the model. For each downstream task’s trigger–target pair , we replace the target word with its corresponding trigger word in the test examples and evaluate whether the model’s output remains unchanged. We define the watermark as successfully embedded if the success rate of this substitution exceeds a stringent threshold of 80%. As demonstrated in Table 1 (WESR column), our approach achieves high verification accuracy across all tasks, thereby ensuring reliable detection with minimal false positives.
4.2.4. Ablation Study
An ablation study on SST2 (accuracy) and CoNLL-2003 (F1) examines the effect of (1) no specialized trigger–target selection and (2) removing embedding perturbations. Table 2 shows that discarding either component lowers WESR and occasionally degrades the final task accuracy, confirming the importance of both strategies.
Table 2.
Ablation study showing each design component’s impact on accuracy and WESR.
5. Discussion
Our experimental results demonstrate that the watermarking technique has a minimal impact on the downstream task performance and is resilient to fine-tuning, making it suitable for real-world applications. For instance, in commercial AI services, model providers can embed watermarks to protect intellectual property and prevent unauthorized use. When deployed on cloud platforms, the watermark allows ownership verification, ensuring that only authorized users can legally access the model. Additionally, on model-sharing platforms, watermarking enables sellers to prove the originality of the model they are offering, mitigating the risks of piracy and unauthorized distribution.
Compared to existing backdoor-based methods, our approach demonstrates superior stability and watermark robustness. Many backdoor methods often lead to significant performance degradation in certain tasks, whereas our watermarking scheme maintains performance close to the baseline while providing higher watermark verification accuracy. Moreover, although our watermarking method performs well across various tasks, there is still room for improvement in its defense against adversarial attacks. For example, attackers may attempt to remove or tamper with the watermark through adversarial fine-tuning or data poisoning. Specifically, we identify two potential adversarial scenarios:
- Adversarial Fine-tuning: Attackers could apply adversarial fine-tuning to a model that already contains a watermark, attempting to destroy or remove the watermark. This attack works by modifying the model’s parameters, leading to deviations in the model’s behavior when the watermark trigger words are encountered. To address this challenge, we plan to incorporate adversarial training techniques by introducing adversarial examples during fine-tuning. This will help increase the model’s robustness during the fine-tuning process and ensure that the watermark remains detectable even in adversarial environments.
- Trigger–Target Pair Identification: Attackers might try to identify the mapping between trigger words and target words, potentially breaking the watermark’s injection mechanism. To mitigate this, we aim to diversify and dynamically modify the trigger–target word pairs, using encryption or random mappings to make these relationships more opaque and difficult to predict. Additionally, we will explore using fuzzy trigger words or multiple trigger words to further complicate the process for attackers.
To enhance the watermark’s resilience, we plan to explore stronger encoding methods and defense mechanisms, including improving our watermark’s robustness against adversarial fine-tuning and data poisoning attacks.
6. Conclusions
In this paper, we introduced a novel watermarking technique designed for pre-trained transformer-based models, demonstrating its effectiveness and robustness across a wide range of NLP tasks. Our experimental results show that the method successfully embeds a robust watermark with minimal performance degradation on downstream tasks, outperforming existing backdoor-based methods in both stability and resilience.
Future work will focus on enhancing the watermark’s defense against adversarial attacks, specifically addressing adversarial fine-tuning and data poisoning. Additionally, we plan to extend the approach to other model architectures, including GPT-based models and multimodal models, to ensure its applicability across a broader range of use cases. Furthermore, we aim to optimize the watermark embedding and verification process to meet the efficiency requirements of commercial applications, where real-time performance and resource constraints are critical.
Author Contributions
Conceptualization, W.M. and K.C.; methodology, W.M. and K.C.; software, W.M.; validation, W.M., K.C. and Y.X.; investigation, W.M.; writing—original draft preparation, W.M.; writing—review and editing, K.C. and Y.X.; supervision, K.C. and Y.X.; funding acquisition, K.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Research Project of Pazhou Lab for Excellent Young Scholars (No. PZL2021KF0024), University Research Project of Guangzhou Education Bureau (No. 2024312189), Foundation of Yunnan Key Laboratory of Service Computing (No. YNSC24115), and Guangzhou Basic and Applied Basic Research Project (No. SL2024A03J00397).
Data Availability Statement
No new data were created or analyzed in this study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 5754–5764. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3645–3650. [Google Scholar]
- Chen, K.; Li, Y.; Lan, W.; Mi, B.; Wang, S. AIGC-Assisted Digital Watermark Services in Low-Earth Orbit Satellite-Terrestrial Edge Networks. arXiv 2024, arXiv:2407.01534. [Google Scholar]
- Uchida, Y.; Nagai, Y.; Sakazawa, S.; Satoh, S. Embedding Watermarks into Deep Neural Networks. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017; pp. 269–277. [Google Scholar]
- Adi, Y.; Baum, C.; Cisse, M.; Pinkas, B.; Keshet, J. Turning Your Weakness into a Strength: Watermarking Deep Neural Networks by Backdooring. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1615–1631. [Google Scholar]
- Chen, K.; Wang, Z.; Mi, B.; Liu, W.; Wang, S.; Ren, X.; Shen, J. Machine Unlearning in Large Language Models. arXiv 2024, arXiv:2404.16841. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain. arXiv 2017, arXiv:1708.06733. [Google Scholar]
- Li, P.; Cheng, P.; Li, F.; Du, W.; Zhao, H.; Liu, G. Plmmark: A secure and robust black-box watermarking framework for pre-trained language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 14991–14999. [Google Scholar]
- Xu, J.; Wang, F.; Ma, M.D.; Koh, P.W.; Xiao, C.; Chen, M. Instructional fingerprinting of large language models. arXiv 2024, arXiv:2401.12255. [Google Scholar]
- Zeng, B.; Wang, L.; Hu, Y.; Xu, Y.; Zhou, C.; Wang, X.; Yu, Y.; Lin, Z. HuRef: HUman-REadable Fingerprint for Large Language Models. In Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024. [Google Scholar]
- Zhao, X.; Wang, Y.; Li, L. Protecting Language Generation Models via Invisible Watermarking. In Proceedings of the International Conference on Machine Learning, ICML 2023, Honolulu, HI, USA, 23–29 July 2023; Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J., Eds.; Volume 202, pp. 42187–42199. [Google Scholar]
- Fan, L.; Ng, K.W.; Chan, C.S.; Yang, Q. Deepipr: Deep neural network ownership verification with passports. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6122–6139. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Papernot, N.; Huang, S.; Duan, Y.; Abbeel, P.; Clark, J. Attacking machine learning with adversarial examples. OpenAI Blog 2017, 24, 1. [Google Scholar]
- Kirchenbauer, J.; Geiping, J.; Wen, Y.; Katz, J.; Miers, I.; Goldstein, T. A watermark for large language models. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 17061–17084. [Google Scholar]
- Chen, X.; Liu, C.; Li, B.; Lu, K.; Song, D. Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning. arXiv 2017, arXiv:1712.05526. [Google Scholar]
- Dai, Y.; Chen, L.; Li, H.; Li, S.; He, J.; Lee, P.P.C. A Backdoor Attack against LSTM-Based Text Classification Systems. IEEE Access 2019, 7, 138872–138878. [Google Scholar] [CrossRef]
- Kurita, K.; Michel, P.; Neubig, G. Weight Poisoning Attacks on Pre-trained Models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2793–2806. [Google Scholar]
- Shen, L.; Ji, S.; Zhang, X.; Li, J.; Chen, J.; Shi, J.; Fang, C.; Yin, J.; Wang, T. Backdoor pre-trained models can transfer to all. arXiv 2021, arXiv:2111.00197. [Google Scholar]
- Chen, K.; Meng, Y.; Sun, X.; Guo, S.; Zhang, T.; Li, J.; Fan, C. BadPre: Task-agnostic Backdoor Attacks to Pre-trained NLP Foundation Models. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Chen, X.; Sinha, A.; Wu, T.; Zhang, S.J. DeepInspect: A Black-box Trojan Detection and Mitigation Framework for Deep Neural Networks. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 4658–4664. [Google Scholar]
- Yan, J.; Gupta, V.; Ren, X. BITE: Textual Backdoor Attacks with Iterative Trigger Injection. arXiv 2022, arXiv:2205.12700. [Google Scholar]
- Li, L.; Song, D.; Li, X.; Zeng, J.; Ma, R.; Qiu, X. Backdoor attacks on pre-trained models by layerwise weight poisoning. arXiv 2021, arXiv:2108.13888. [Google Scholar]
- Chen, X.; Wang, W.; Bender, C.; Ding, Y.; Jia, R.; Li, B.; Song, D. Refit: A unified watermark removal framework for deep learning systems with limited data. In Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security, Online, 7–11 June 2021; pp. 321–335. [Google Scholar]
- Yang, W.; Li, L.; Zhang, Z.; Ren, X.; Sun, X.; He, B. Be careful about poisoned word embeddings: Exploring the vulnerability of the embedding layers in NLP models. arXiv 2021, arXiv:2103.15543. [Google Scholar]
- Qi, F.; Yao, Y.; Xu, S.; Liu, Z.; Sun, M. Turn the combination lock: Learnable textual backdoor attacks via word substitution. arXiv 2021, arXiv:2106.06361. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).