
A Consensus Community-Based Spider Wasp Optimization for Dynamic Community Detection


Abstract
1. Introduction
- (1)
- The concept of consensus communities is introduced. By mining consensus community from the previous generation, a certain continuity of the iterations between populations is maintained. This is used to optimize the time and space loss required for evolution.
- (2)
- The spider wasp optimization algorithm is discretized. The coding method and the position update strategy for discrete scenes are improved. A key node-based initialization strategy is designed to improve the quality of initial individuals.
- (3)
- A framework of consensus swarm-based spider wasp optimization algorithm is designed for detecting swarm structures in dynamic complex networks. Since the number of communities is determined by the decoding of the representation, the SWO-Net algorithm does not need to specify the number of communities and weight parameters for recognizing the network.
- (4)
- Experiments on synthetic and real datasets validate the effectiveness of the SWO-Net algorithm. Comparison experiments with other benchmark algorithms show that the SWO-Net algorithm has significant advantages.
2. Background and Related Works
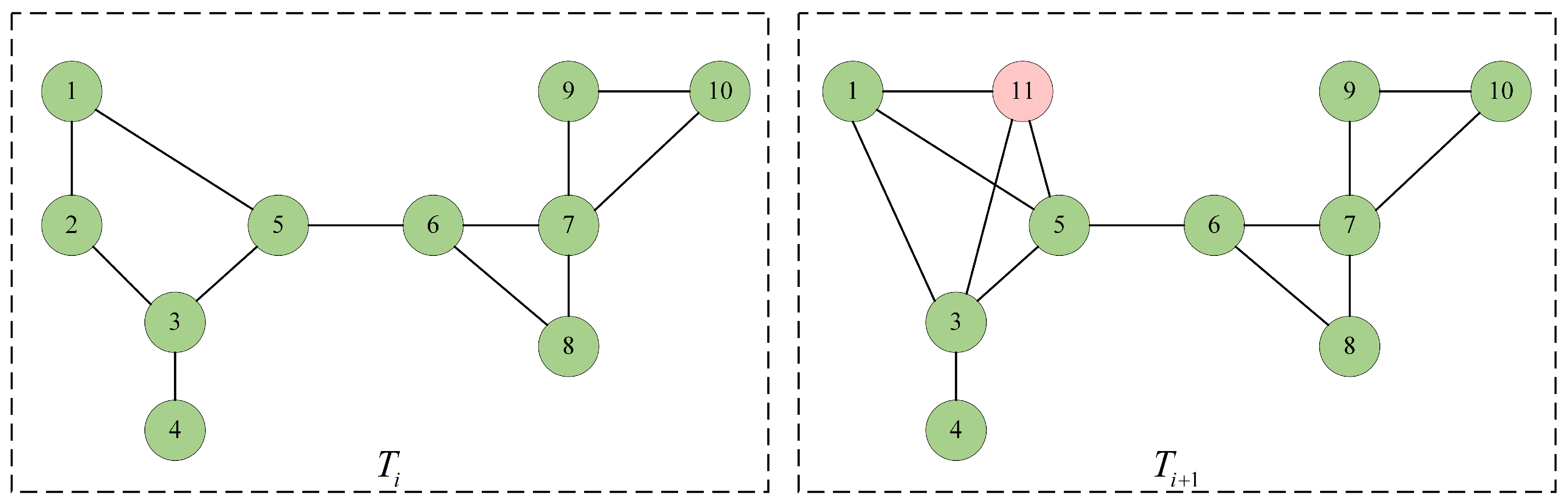
2.1. Dynamic Community Detection
2.2. The SWO Algorithm
- (1)
- Search behavior.
- (2)
- Following and escaping behavior.
- (3)
- Nesting behavior.
- (4)
- Mating behavior.
| Algorithm 1 Pseudo-code for the SWO algorithm. | |
| begin | |
| Input: N, , , , | |
| 1: | Initialize the population |
| 2: | Calculate the fitness function to find the best solution |
| 3: | |
| 4: | while do |
| 5: | if then |
| 6: | for do |
| 7: | Execute Equation (13) and calculate the fitness value |
| 8: | |
| 9: | end for |
| 10: | else |
| 11: | for do |
| 12: | Perform Equation (14) for uniform crossover |
| 13: | |
| 14: | end for |
| 15: | end if |
| 16: | Reducing the population size through the Equation (18) |
| 17: | end while |
| Output: the best solution . | |
3. Consensus Community
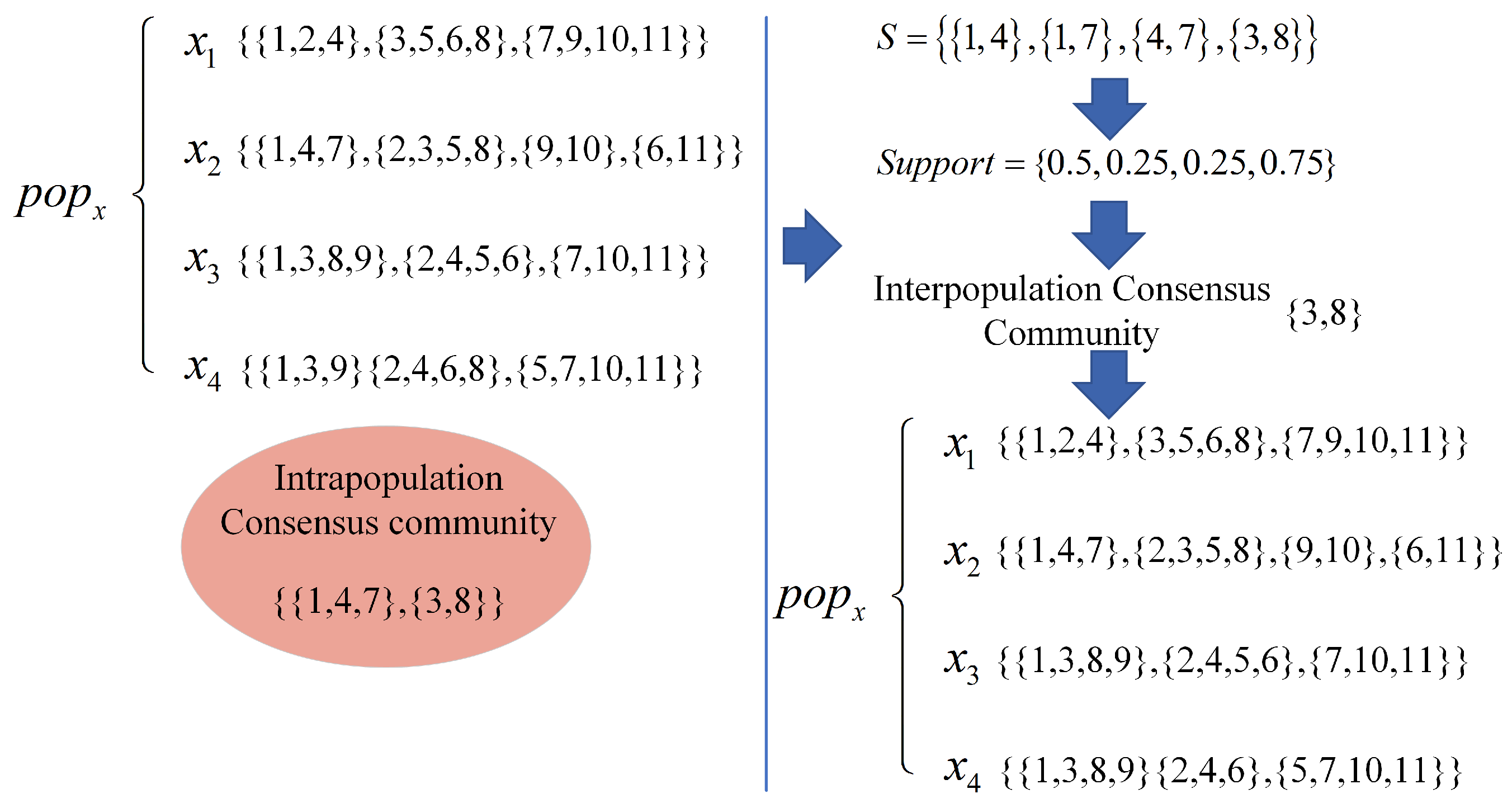
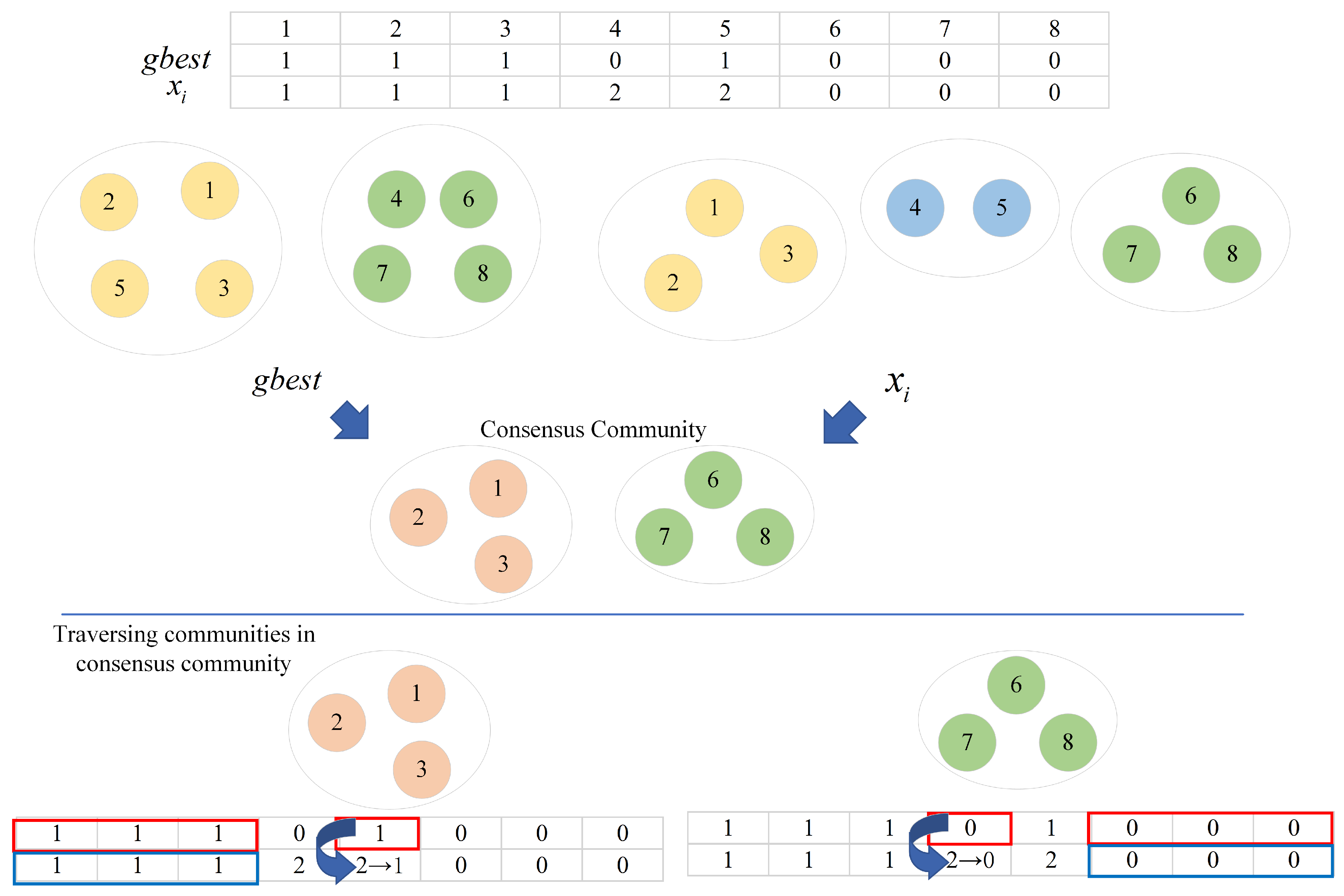
3.1. Intra-Population Consensus Community
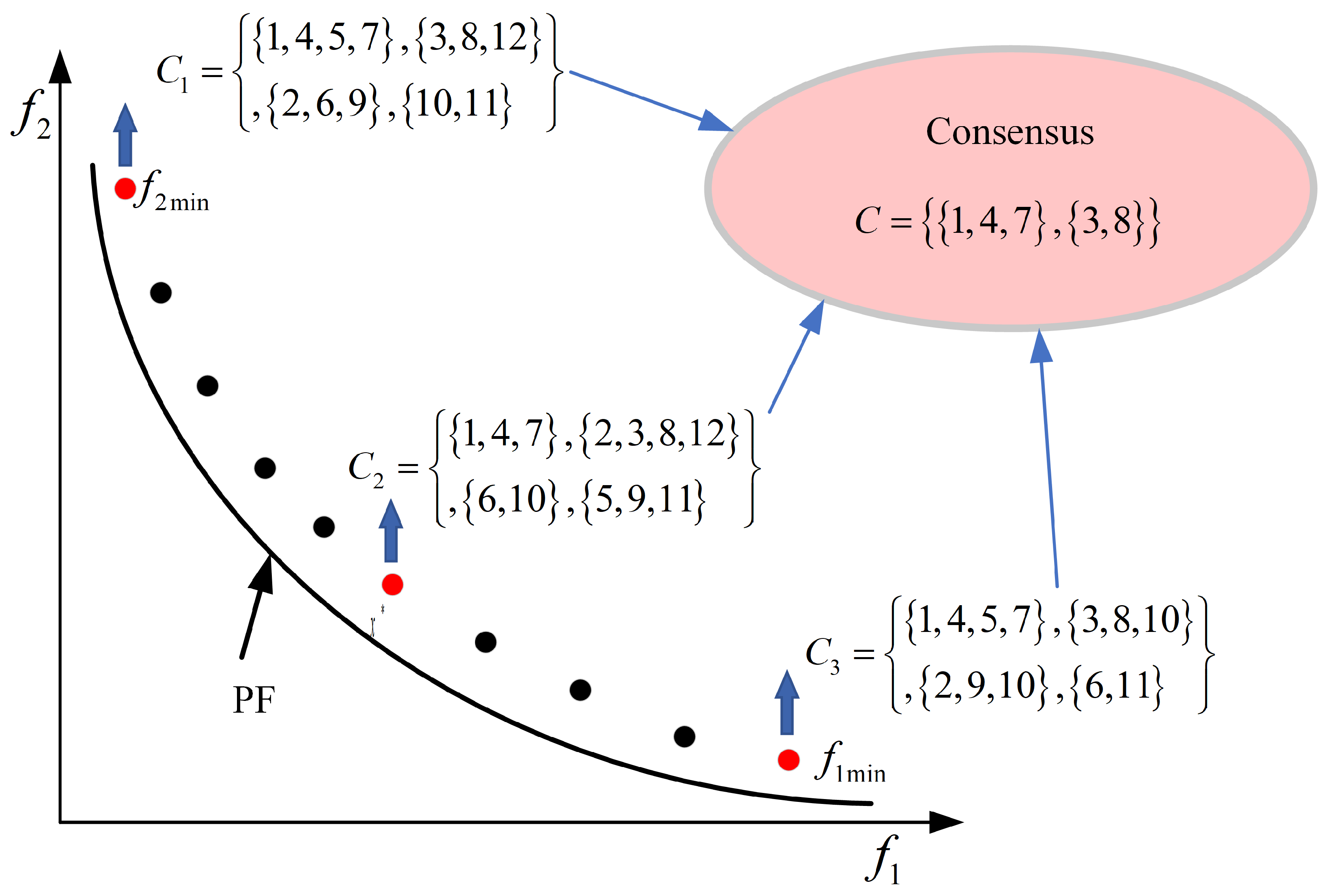
3.2. Inter-Population Consensus Community
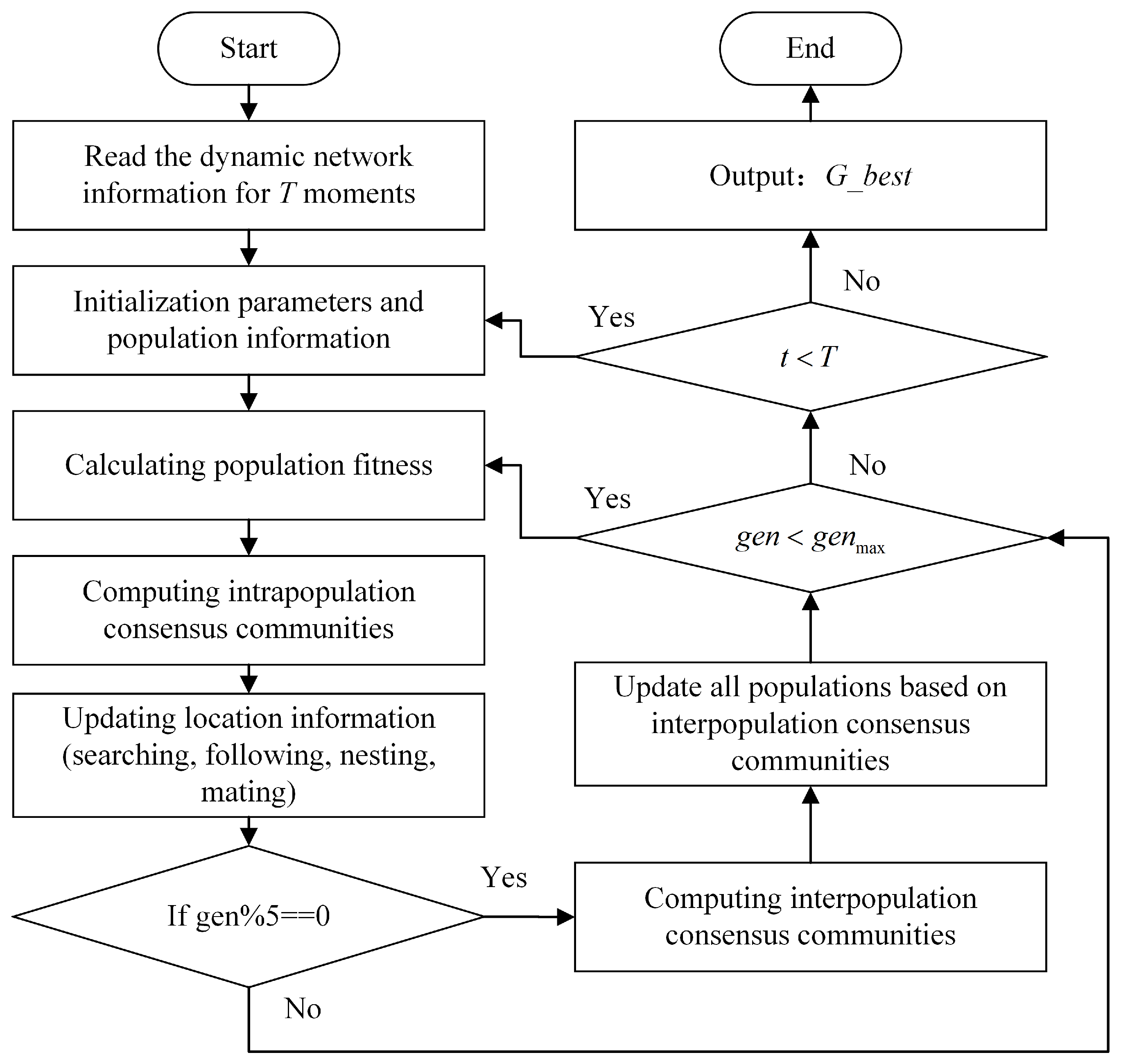
4. Proposed Method
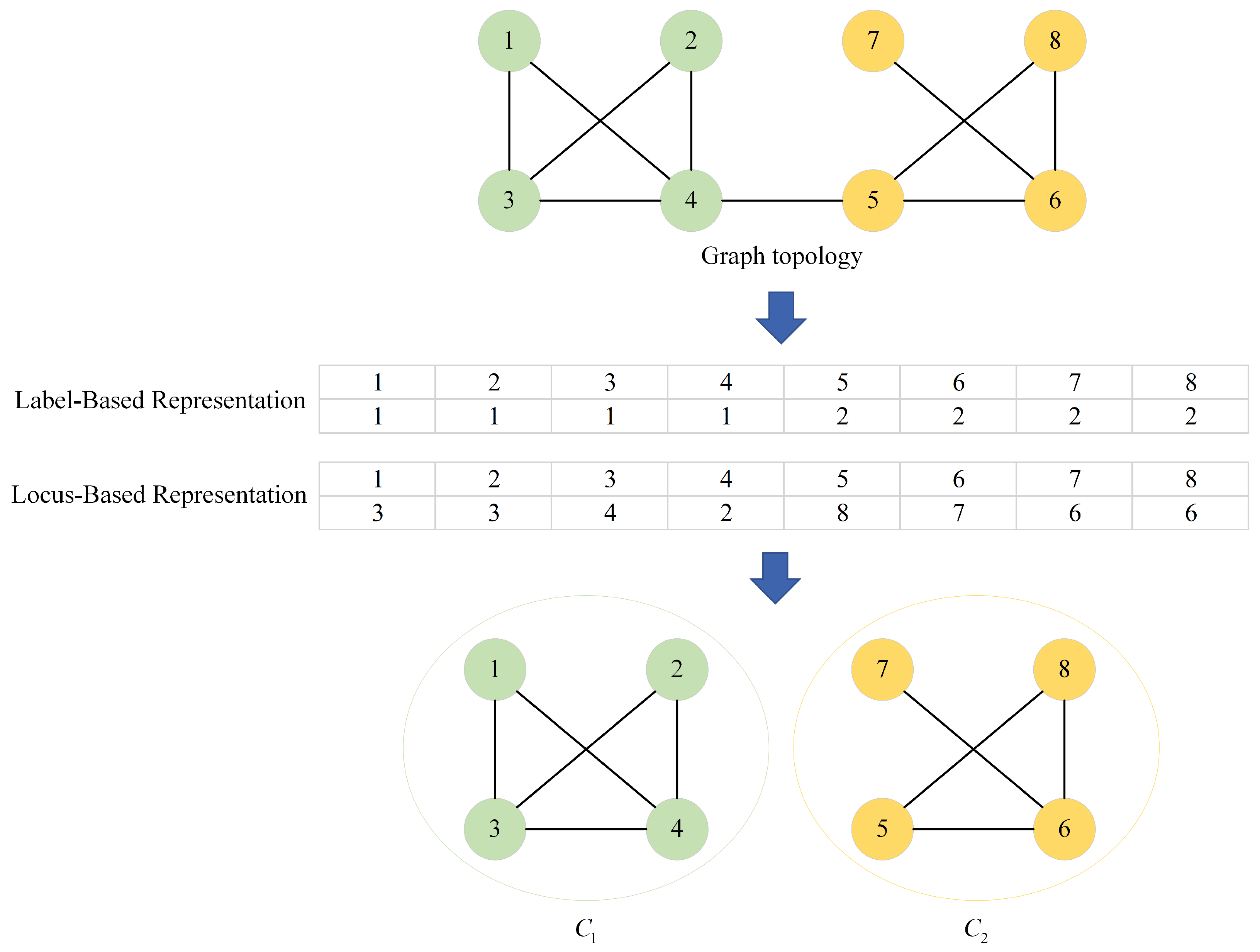
4.1. Representation of Solutions
| Algorithm 2 Pseudo-code for tag normalization. | |
| begin | |
| Input: | |
| 1: | Get the set of nodes |
| 2: | while do |
| 3: | Query the label of the smallest node of S |
| 4: | |
| 5: | for each node in do |
| 6: | if then |
| 7: | |
| 8: | Delete nodes from S |
| 9: | end if |
| 10: | end for |
| 11: | |
| 12: | end while |
| Output: . | |
4.2. Population Initialization
| Algorithm 3 Pseudo-code for population initialization. | |
| begin | |
| Input: Network topology G, population size | |
| 1: | |
| 2: | Calculate the network average degree |
| 3: | Identify nodes in network G with node degree greater than |
| 4: | while do |
| 5: | Filter the node with the largest node degree from S |
| 6: | Identify the neighbor nodes of node located in the set S |
| 7: | |
| 8: | Remove nodes in from S |
| 9: | end while |
| 10: | for do |
| 11: | Labeling of key nodes |
| 12: | Assigning labels to neighboring nodes of key nodes |
| 13: | Calculate the similarity between the remaining nodes and all key nodes |
| 14: | Assign labels to the remaining nodes and select the label of the key node with the greatest similarity |
| 15: | end for |
| Output: population information . | |
4.3. Fitness Computation
4.4. Search Strategy
| Algorithm 4 Pseudo-code for the SWO-Net algorithm. | |
| begin | |
| Input: Dynamic network: , Population size: , the maximum number of iterations: | |
| 1: | Initializing intra-population consensus community |
| 2: | for do |
| 3: | Initialize population information |
| 4: | Compute the global optimal solution |
| 5: | while do |
| 6: | Calculate the KKM and RC values for all individuals in |
| 7: | for do |
| 8: | Update population location information |
| 9: | Perform label normalization |
| 10: | Update the global optimal solution |
| 11: | end for |
| 12: | if then |
| 13: | Calculating inter-population consensus community and updating population information |
| 14: | Updating the global optimal solution |
| 15: | end if |
| 16: | end while |
| 17: | Computing intra-population consensus community |
| 18: | end for |
| Output: The optimal community structure for each network . | |
4.5. Computational Complexity
5. Experiment
5.1. Experimental Environment and Parameter Settings
5.2. Evaluation Metric
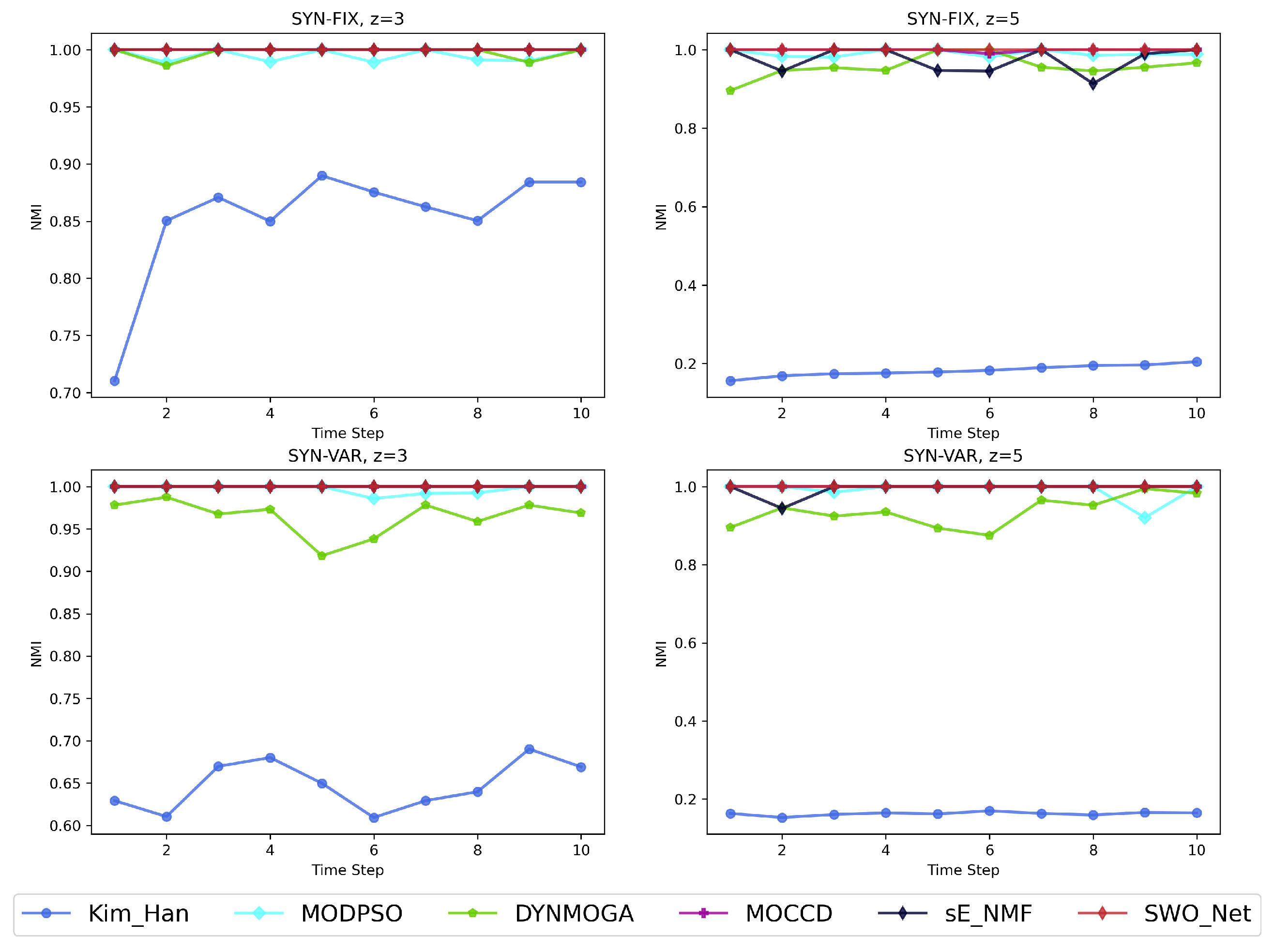
5.3. Experimental Results of the Synthetic Networks
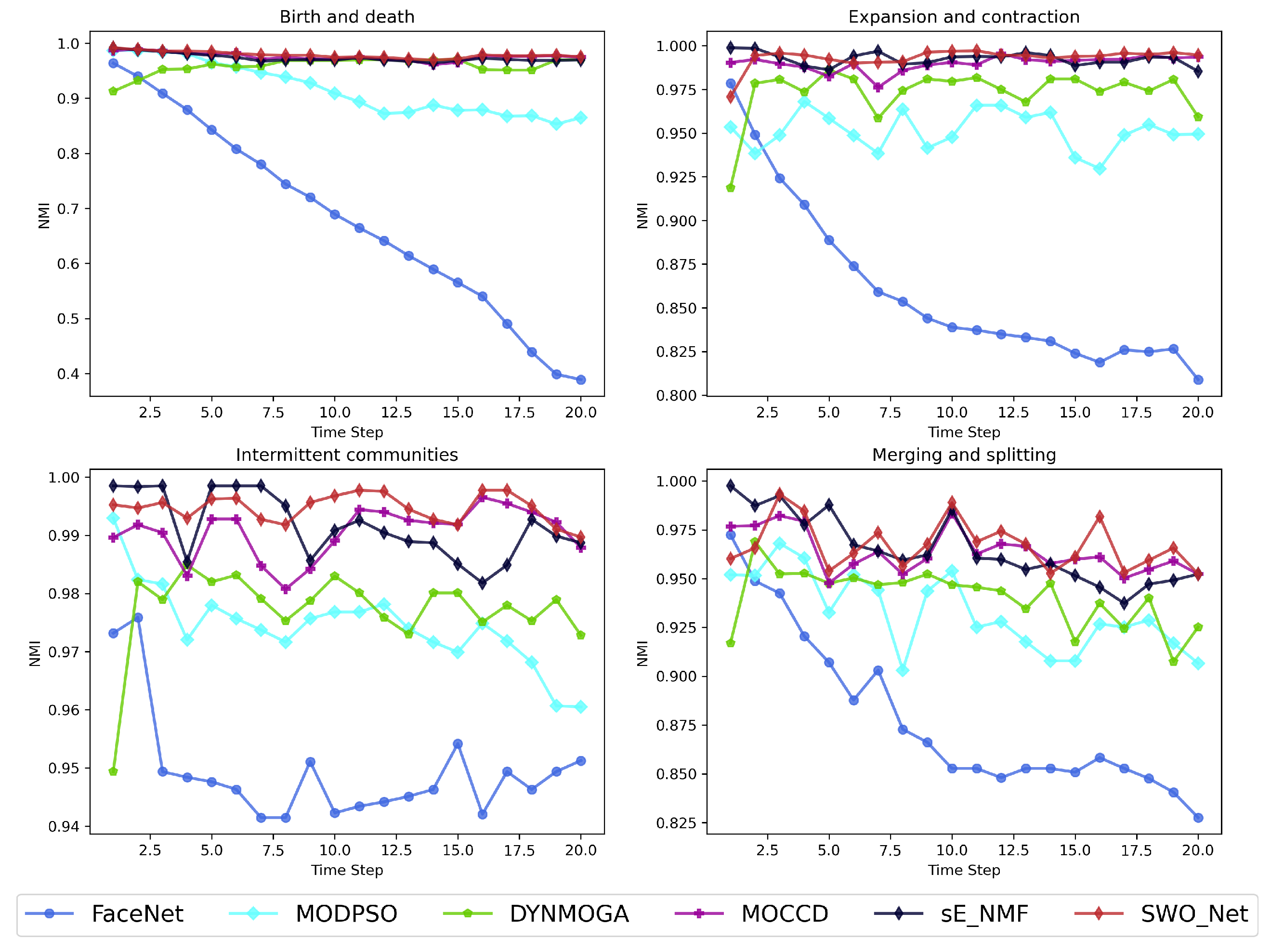
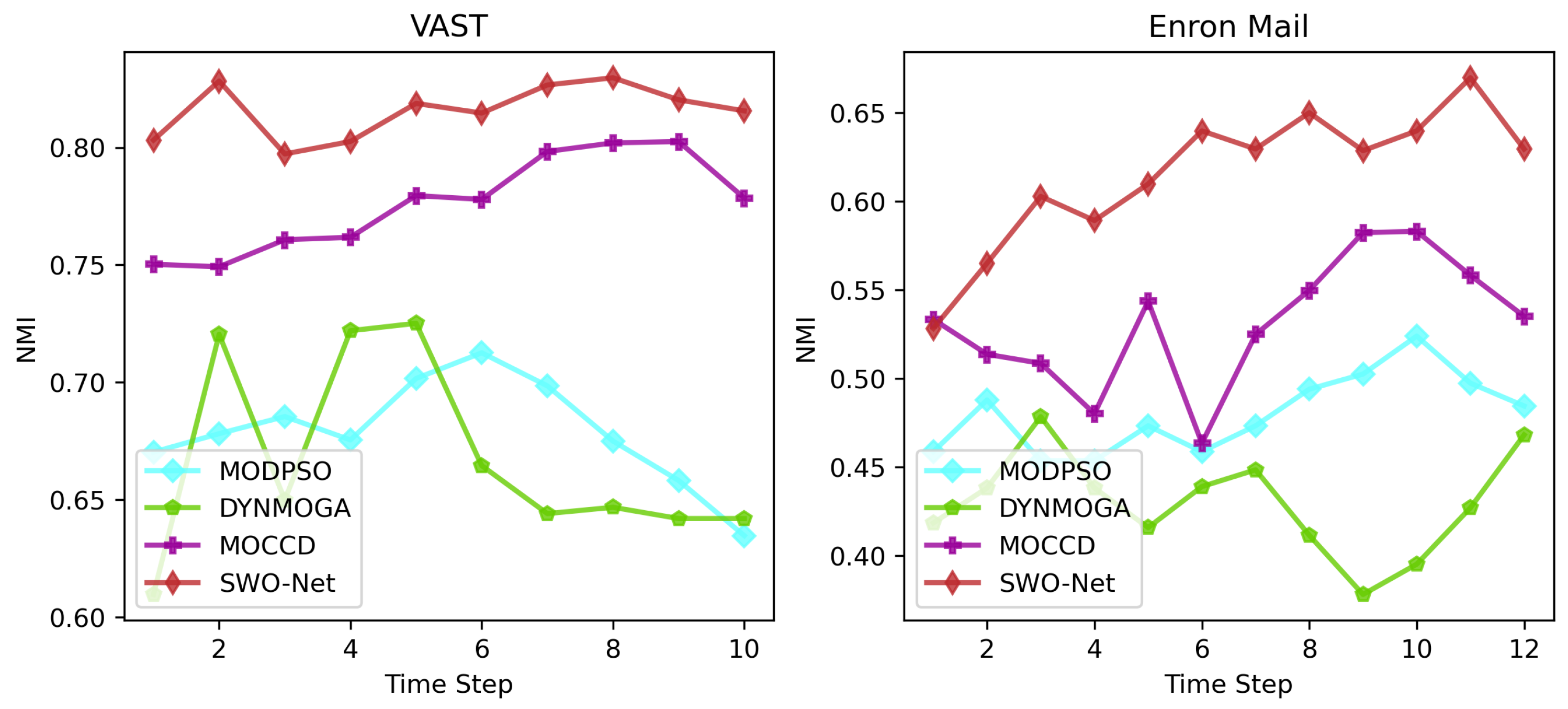
5.4. Experimental Results on the Real Networks
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Yu, L.; Guo, X.; Zhou, D.; Zhang, J. A Multi-Objective Pigeon-Inspired Optimization Algorithm for Community Detection in Complex Networks. Mathematics 2024, 12, 1486. [Google Scholar] [CrossRef]
- Rostami, M.; Berahmand, K.; Forouzandeh, S. A novel community detection based genetic algorithm for feature selection. J. Big Data 2021, 8, 2. [Google Scholar] [CrossRef]
- Moradi, P.; Ahmadian, S.; Akhlaghian, F. An effective trust-based recommendation method using a novel graph clustering algorithm. Phys. A Stat. Mech. Its Appl. 2015, 436, 462–481. [Google Scholar] [CrossRef]
- Rezaeimehr, F.; Moradi, P.; Ahmadian, S.; Qader, N.N.; Jalili, M. TCARS: Time-and community-aware recommendation system. Future Gener. Comput. Syst. 2018, 78, 419–429. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Y.; Li, Q.; Jin, F.; Xiong, W. Link prediction based on hyperbolic mapping with community structure for complex networks. Phys. A Stat. Mech. Its Appl. 2016, 450, 609–623. [Google Scholar] [CrossRef]
- Deng, X.; Wen, Y.; Chen, Y. Highly efficient epidemic spreading model based LPA threshold community detection method. Neurocomputing 2016, 210, 3–12. [Google Scholar] [CrossRef]
- Wang, S.; Gong, M.; Liu, W.; Wu, Y. Preventing epidemic spreading in networks by community detection and memetic algorithm. Appl. Soft Comput. 2020, 89, 106118. [Google Scholar] [CrossRef]
- Fortunato, S.; Barthelemy, M. Resolution limit in community detection. Proc. Natl. Acad. Sci. USA 2007, 104, 36–41. [Google Scholar] [CrossRef]
- Pizzuti, C. Evolutionary computation for community detection in networks: A review. IEEE Trans. Evol. Comput. 2017, 22, 464–483. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, S.; Wang, R.S.; Zhang, X.S.; Chen, L. Quantitative function for community detection. Phys. Rev. E-Stat. Nonlinear Soft Matter Phys. 2008, 77, 036109. [Google Scholar] [CrossRef] [PubMed]
- Arenas, A.; Duch, J.; Fernández, A.; Gómez, S. Size reduction of complex networks preserving modularity. New J. Phys. 2007, 9, 176. [Google Scholar] [CrossRef]
- Shen, H.; Cheng, X.; Cai, K.; Hu, M.B. Detect overlapping and hierarchical community structure in networks. Phys. A Stat. Mech. Its Appl. 2009, 388, 1706–1712. [Google Scholar] [CrossRef]
- Pizzuti, C. Ga-net: A genetic algorithm for community detection in social networks. In International Conference on Parallel Problem Solving from Nature; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1081–1090. [Google Scholar]
- Gong, M.; Fu, B.; Jiao, L.; Du, H. Memetic algorithm for community detection in networks. Phys. Rev. E-Stat. Nonlinear Soft Matter Phys. 2011, 84, 056101. [Google Scholar] [CrossRef] [PubMed]
- Pizzuti, C. A multiobjective genetic algorithm to find communities in complex networks. IEEE Trans. Evol. Comput. 2011, 16, 418–430. [Google Scholar] [CrossRef]
- Rahimi, S.; Abdollahpouri, A.; Moradi, P. A multi-objective particle swarm optimization algorithm for community detection in complex networks. Swarm Evol. Comput. 2018, 39, 297–309. [Google Scholar] [CrossRef]
- Palla, G.; Barabási, A.L.; Vicsek, T. Quantifying social group evolution. Nature 2007, 446, 664–667. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Sheng, J.; Wang, B.; Ullah, A.; Khawaja, F. Identifying communities in dynamic networks using information dynamics. Entropy 2020, 22, 425. [Google Scholar] [CrossRef]
- Folino, F.; Pizzuti, C. An evolutionary multiobjective approach for community discovery in dynamic networks. IEEE Trans. Knowl. Data Eng. 2013, 26, 1838–1852. [Google Scholar] [CrossRef]
- Paul, S.; Koner, C.; Mitra, A.; Ghosh, S. A Study on Algorithms for Detection of Communities in Dynamic Social Networks: A Review. In International Conference on Computational Intelligence in Communications and Business Analytics; Communications in Computer and Information Science (1956); Dasgupta, K., Mukhopadhyay, S., Mandal, J., Dutta, P., Eds.; Springer: Kalyani, India, 2023; pp. 51–64. [Google Scholar]
- Chakrabarti, D.; Kumar, R.; Tomkins, A. Evolutionary clustering. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 554–560. [Google Scholar]
- Kherad, M.; Dadras, M.; Mokhtari, M. Community detection based on influential nodes in dynamic networks. J. Supercomput. 2024, 80, 24664–24688. [Google Scholar] [CrossRef]
- Ranjkesh, S.; Masoumi, B.; Hashemi, S.M. A novel robust memetic algorithm for dynamic community structures detection in complex networks. World Wide Web 2024, 27, 3. [Google Scholar] [CrossRef]
- Zhou, T.; Pan, R.; Zhang, J.; Wang, H. An attribute-based Node2Vec model for dynamic community detection on co-authorship network. Comput. Stat. 2024. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Jameel, M.; Abouhawwash, M. Spider wasp optimizer: A novel meta-heuristic optimization algorithm. Artif. Intell. Rev. 2023, 56, 11675–11738. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S. Consensus clustering in complex networks. Sci. Rep. 2012, 2, 336. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, T.; Srinivasan, S.; Ganguly, N.; Bhowmick, S.; Mukherjee, A. Constant communities in complex networks. Sci. Rep. 2013, 3, 1825. [Google Scholar] [CrossRef]
- Mandaglio, D.; Amelio, A.; Tagarelli, A. Consensus community detection in multilayer networks using parameter-free graph pruning. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 22nd Pacific-Asia Conference, PAKDD 2018, Melbourne, VIC, Australia, 3–6 June 2018; Proceedings, Part III 22. Springer: Berlin/Heidelberg, Germany, 2018; pp. 193–205. [Google Scholar]
- Chiu, W.Y.; Yen, G.G.; Juan, T.K. Minimum manhattan distance approach to multiple criteria decision making in multiobjective optimization problems. IEEE Trans. Evol. Comput. 2016, 20, 972–985. [Google Scholar] [CrossRef]
- Angelini, L.; Boccaletti, S.; Marinazzo, D.; Pellicoro, M.; Stramaglia, S. Identification of network modules by optimization of ratio association. Chaos Interdiscip. J. Nonlinear Sci. 2007, 17, 023114. [Google Scholar] [CrossRef] [PubMed]
- Wei, Y.C.; Cheng, C.K. Ratio cut partitioning for hierarchical designs. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1991, 10, 911–921. [Google Scholar] [CrossRef]
- Lin, Y.R.; Chi, Y.; Zhu, S.; Sundaram, H.; Tseng, B.L. Analyzing communities and their evolutions in dynamic social networks. ACM Trans. Knowl. Discov. Data (TKDD) 2009, 3, 1–31. [Google Scholar] [CrossRef]
- Kim, M.S.; Han, J. A particle-and-density based evolutionary clustering method for dynamic networks. Proc. VLDB Endow. 2009, 2, 622–633. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S. Community detection algorithms: A comparative analysis. Phys. Rev. E-Stat. Nonlinear Soft Matter Phys. 2009, 80, 056117. [Google Scholar] [CrossRef] [PubMed]
- Gong, M.; Cai, Q.; Chen, X.; Ma, L. Complex network clustering by multiobjective discrete particle swarm optimization based on decomposition. IEEE Trans. Evol. Comput. 2013, 18, 82–97. [Google Scholar] [CrossRef]
- Ma, X.; Dong, D. Evolutionary nonnegative matrix factorization algorithms for community detection in dynamic networks. IEEE Trans. Knowl. Data Eng. 2017, 29, 1045–1058. [Google Scholar] [CrossRef]
- Li, W.; Zhou, X.; Yang, C.; Fan, Y.; Wang, Z.; Liu, Y. Multi-objective optimization algorithm based on characteristics fusion of dynamic social networks for community discovery. Inf. Fusion 2022, 79, 110–123. [Google Scholar] [CrossRef]
- Greene, D.; Doyle, D.; Cunningham, P. Tracking the evolution of communities in dynamic social networks. In Proceedings of the 2010 International Conference on Advances in Social Networks Analysis and Mining, Odense, Denmark, 9–11 August 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 176–183. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| T | |||||
|---|---|---|---|---|---|
| 1 | 32 | 370 | 987 | 525 | 2.625 |
| 2 | 35 | 373 | 964 | 499 | 2.495 |
| 3 | 30 | 374 | 953 | 509 | 2.545 |
| 4 | 31 | 374 | 1013 | 514 | 2.57 |
| 5 | 32 | 373 | 991 | 508 | 2.54 |
| 6 | 25 | 373 | 963 | 512 | 2.56 |
| 7 | 33 | 367 | 936 | 498 | 2.49 |
| 8 | 36 | 365 | 1005 | 511 | 2.555 |
| 9 | 34 | 374 | 982 | 518 | 2.59 |
| 10 | 32 | 384 | 1040 | 530 | 2.65 |
| T | |||||
|---|---|---|---|---|---|
| 1 | 11 | 96 | 1070 | 180 | 2.3841 |
| 2 | 7 | 93 | 1559 | 204 | 2.702 |
| 3 | 12 | 97 | 1844 | 218 | 2.8874 |
| 4 | 12 | 108 | 1869 | 257 | 3.404 |
| 5 | 15 | 125 | 1919 | 292 | 3.8675 |
| 6 | 10 | 120 | 1001 | 231 | 3.0596 |
| 7 | 10 | 109 | 1325 | 252 | 3.3377 |
| 8 | 9 | 131 | 2270 | 396 | 5.245 |
| 9 | 10 | 128 | 3152 | 361 | 4.7815 |
| 10 | 13 | 135 | 8693 | 575 | 7.6159 |
| 11 | 9 | 127 | 6276 | 469 | 6.2119 |
| 12 | 8 | 113 | 2146 | 325 | 4.3046 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Zhao, X.; Lv, M.; Zhang, J. A Consensus Community-Based Spider Wasp Optimization for Dynamic Community Detection. Mathematics 2025, 13, 265. https://doi.org/10.3390/math13020265
Yu L, Zhao X, Lv M, Zhang J. A Consensus Community-Based Spider Wasp Optimization for Dynamic Community Detection. Mathematics. 2025; 13(2):265. https://doi.org/10.3390/math13020265
Chicago/Turabian StyleYu, Lin, Xin Zhao, Ming Lv, and Jie Zhang. 2025. "A Consensus Community-Based Spider Wasp Optimization for Dynamic Community Detection" Mathematics 13, no. 2: 265. https://doi.org/10.3390/math13020265
APA StyleYu, L., Zhao, X., Lv, M., & Zhang, J. (2025). A Consensus Community-Based Spider Wasp Optimization for Dynamic Community Detection. Mathematics, 13(2), 265. https://doi.org/10.3390/math13020265