1. Introduction
Since the regression quantile has similar robustness as the sample quantile, the quantile regression model can well characterize the conditional distribution of the response variable
y when the independent variable
is given, thus characterizing the link between the two [
1]. Response variable
and
p-dimensional covariates
are given, and
is the conditional distribution function of
y concerning
. The classical quantile regression model can be expressed as
where
is the regression coefficient. Koenker, R. et al. [
2,
3] provided a detailed discussion of quantile regression modeling in terms of methodology, theory, and computation. Because the loss function of quantile regression is not smooth, its computational complexity increases dramatically. Considering that the loss function is not derivable, Horowitz [
4] used the smooth function to approximate the indicator function, in order to smooth the objective function. This method has also been applied to deal with other quantile regression-related problems, in which de Castro, L. et al. [
5] used a smooth moment estimating equation to estimate the parameter in quantile regression; Chen et al. [
6] used a smoothing method to study the quantile regression model with constraints; Galvao, A.F. and Kato, K. [
7] studied the smoothing estimation of fixed effects in quantile regression models for panel data; Whang [
8] discussed the empirical likelihood estimation of quantile regression models by using a smoothing approach. Although the above literature has solved the problem that the objective function is not derivable, it cannot guarantee the concavity of the objective function. Thus, there is no guarantee that the result is a global optimal solution. Recently, Fernandes et al. [
9] proposed a convolutional smoothing method for estimating fixed dimensional parameters of the quantile regression model, based on which the loss function is quadratically derivable and convex, and the method outperforms the original smoothing estimation in terms of estimation accuracy. Under the complete observation data, He [
10] used the convolutional smoothing method to estimate the parameters of the high-dimensional quantile regression model, and the loss function after smoothing is a quadratically derivable and convex function. When solving the minimum point of the smoothed objective function numerically, the gradient descent algorithm [
10] is used to replace the quantile regression with the least squares estimation, which effectively shortens the computation time and improves the estimation accuracy.
In empirical studies, it is frequently observed that variables of interest are subject to censoring. For instance, in the study [
11] on the survival times of AIDS patients, it was found that 43% of the data were right-censored. For parameter estimation in quantile regression models for right-censored data, we refer to Ying, Z. et al. [
12], Honoré, B. et al. [
13], Portnoy, S. [
14], Peng, L. [
15], and Yuan, X. et al. [
16]. Parameter estimation in quantile regression models for censored data [
17,
18,
19] has been extensively studied, including right-censored data. In the quantile regression for right-censored data, the problem of non-smooth loss functions still exists, and it has already been studied [
20,
21,
22,
23]. For the right-censored quantile regression model with fixed dimensional parameters, Peng, L. and Huang, Y. [
20], Xu, G. et al. [
21], Cai, Z. and Sit, T. [
22], Kim, K.H. [
23] considered the smoothing estimation methods, respectively. For the high-dimensional large-sample case of the censored quantile regression model, Wu, Y. et al. [
24], He, X. et al. [
25], and Fei, Z. et al. [
26] used a similar method to Fernandes et al. [
9] to smooth the estimating equations, which improved the estimation accuracy over classical parameter estimation methods. However, these smoothing estimation methods for high-dimensional censored quantile regression need to grid the quantiles as
, to ensure that the approximation error of the estimation equation will not be too large. Furthermore, we need to use the estimates of
before estimating
, and the estimation accuracy depends on the number of segmentation points, which also increases the computational complexity.
Considering the censored data, this paper extends the convolutional smoothing method [
10] to the high-dimensional censored quantile regression model and proposes the coefficient estimation of the censored quantile regression model based on the convolutional smoothing method. Under certain conditions, the loss function of the smoothed censored quantile regression model is quadratically derivable and globally convex, and the gradient-based iterative algorithm could be used to calculate the regression parameters. In this paper, the bias of the smoothing estimation of the censored quantile regression is characterized under certain conditions, and the speed of convergence, the Bahadur–Kiefer representation, and the Berry–Esseen upper bound of the smoothing estimation of the censored quantile regression are established under high-dimensional and large-sample conditions. Moreover, compared with the classical parameter estimation method, which has different estimation accuracies at different quantile points, the smoothing estimation method basically maintains the same estimation accuracies at each quantile point, and the proposed method greatly saves the computation time under high-dimensional large-sample condition. In summary, the key contributions and significance of this article are as follows: (1) To our knowledge, this article is the first to apply the convolutional smoothing method to high-dimensional censored data regression analysis. Compared with the non differentiability of the objective function in classical censored quantile regression, the objective function in this method is second-order differentiable, which brings great convenience to the establishment of gradient based calculation algorithms and the discussion of theoretical properties. (2) For high-dimensional data scenarios, under certain regularization conditions, this paper also establishes the asymptotic consistency, asymptotic normality, and other theoretical properties of the proposed smooth estimator, ensuring the good properties of statistical inference.
This paper is organized as follows.
Section 2 proposes a convolutional smoothing estimation method for high-dimensional censored quantile regression models, and gives the asymptotic properties of the smoothing estimation. In
Section 3, numerical simulations of the smoothing estimation and the classical parameter estimation are carried out for the low and high dimensional cases, and the estimation accuracy and computational speed of the smoothing method in the censored quantile regression analysis are discussed. The discussion and conclusion are given in
Section 4 and
Section 5, and then a detailed proof of the asymptotic property is given in
Appendix A.
2. Methods
In this paper, we consider a right-censored quantile regression model; i.e., we assume that the response variable
y in the model (
1) is right-censored, in which case the observed variables are
, where
c is the censored variable. The observations are denoted as
. Then, the estimation of the parameters in the censored quantile regression model is defined as
where
is the
quantile loss function, and
is the distribution function of the censored variable
, and
is the estimate of
.
Convolutional smoothing estimation for high-dimensional quantile regression models has been studied in the literature [
10] by He et al. In this paper, we apply the method to censored data. Let
be the kernel function with integral 1, and
h be the window width. Denote the following:
Then, the objective function for the smoothing estimation of the censored quantile regression can be written as
where
and “∗” denotes the convolution operator. The convolutional smoothing estimate (denoted SCQ) of the censored quantile regression model is defined as the point of minimum of
,
. For any
, write
, with
For ease of presentation and without ambiguity, and are abbreviated as and , respectively.
It is easy to find that the loss function of the (
3) is quadratically derivable, and its gradient and Hessian matrix can be expressed, respectively, as follows:
As long as the kernel function is non-negative, for any window width , is a convex function and satisfies the first-order condition .
Remark 1. When estimating the distribution of the censored variable , we can use KM estimation to estimate . If we assume that the form of the distribution of the censored variable is known, even if there is a mis-specification of the distribution, we find through the subsequent simulation that the estimation of the distribution of the censored variable by the parametric method is better than that of the distribution of the censored variable by using the KM estimation before smoothing the estimation of the regression parameter in most cases; thus, we rewrite the distribution function of the censored variable as follows . Where the parameter vector , is the maximum likelihood estimate of . The parametric distribution form is used for estimation in both the proof and the hypotheses.
To give theoretical results, we assume that the covariate has been centered. Given the vectors , and both represent their inner product: , where a and b are constants. The denotes the -paradigm, i.e., , and , where denotes the ith element of the p-dimensional real vector . Given a semi-positive definite matrix , define for any vector . For all real numbers , define and . For two non-negative sequences and , denotes the existence of a constant independent of n such that . is equivalent to . is equivalent to and holds simultaneously. The assumptions required for the theorem are as follows.
. The non-negative kernel function satisfies , with upper bound , and , where .
. The regression error term on the conditional density function on satisfies the Lipschtiz condition; i.e., there exists a constant such that , there is which holds almost everywhere. There exist real numbers such that holds almost everywhere for any .
. There exist positive constants
and
such that
Denote
as the
ith order statistic of
, and
as the corresponding indicator function.
and
satisfy
. The covariate obeys a subexponential distribution—i.e., there exists such that for any and , there are , where is positive definite with .
With and positive integer k, we define . The following theorems can be obtained.
Theorem 1 (Upper bound on the estimation error).
Suppose the condition – holds for any real number . If h satisfies the constraints , is the uncensored proportion, then the convolutional smoothing estimate satisfies the boundary conditionswhere . and R are positive constants. The upper bounds on the estimation error and can be interpreted as the prediction bias and the speed of convergence. A smaller h leads to smaller deviations after smoothing, but an h that is too small could result in overfitting and slow convergence rates. According to Theorem 1, h satisfies the condition . In order to obtain a non-asymptotic Bahadur representation of the smoothing estimation, we tend to replace with .
. The covariate obeys a sub-Gaussian distribution—i.e. there exists such that for any and , there is a , where is positive definite with .
Theorem 2 (non-asymptotic Bahadur representation).
Assuming conditions – and hold, holds almost everywhere. For any real number , h satisfies the constraint . Let ; then,where the real number is a constant independent of p and n. Theorem 2 allows for establishing the limiting distribution of the estimators. Based on the non-asymptotic representation in Theorem 2, we establish the Berry–Esseen upper bound for smoothing estimators.
Theorem 3 (Berry–Esseen upper bound).
Assuming that the conditions – and hold, holds almost everywhere, and h satisfies the condition that for any real number , there exists . Then,where , denotes the standard normal distribution function.Further, if is quadratically continuously derivable and satisfies for any real number , where the function satisfies for some positive constant C, then Theorem 3 proves that when h is chosen in the appropriate range and , the linear combination of is estimated to be asymptotically normal. According to Theorem 3, the optimal in the sense that minimizes the right hand of , and the error is approximated as . If , for any given vector , is asymptotically normal.
Remark 2. The assumptions , , and are commonly used in convolutional smoothing estimation of high-dimensional quantile regression models in fully observed data [10]. Condition refers to the assumptions concerning the distribution of the censoring variable c. Note that , assuming that is equivalent to —i.e., the probability that the largest observation equals to the true variable of interest is not zero.This is a commonly used condition in statistical inference for censored data [27,28], and this condition can avoid the situation where a large number of observations are censored data. Assuming that provides a local smoothing condition for in the neighborhood θ, the validity of this assumption could be verified intuitively for many commonly used distribution functions . 3. Numerical Simulation
In this section, the smoothing estimation and classical parameter estimation of the quantile regression model for censored data are numerically simulated, and two cases of low and high dimensionality are considered. Estimation of (
2), as proposed in the literature [
17], was chosen as the classical parameter estimation of the censored quantile regression model. Notice that the objective function of the classical parameter estimation for censored quantile regression model can be rewritten as
. Therefore, when calculating the regression parameters, the censoring problem is transformed into a non-censoring problem, and the objective function of the smoothing estimation for censored quantile regression is rewritten as
. The Gaussian kernel and window width
are taken as the kernel function and window width, respectively, for the smoothing estimation of the censored quantile regression.
3.1. Model Setting and Evaluation Indicators
In the simulation, the covariates
are generated from different distributions to simulate different types of variables commonly found in real data. The error term
is generated by three different distributions, specifically, by drawing independent identically distributed random numbers
with capacity
n, and letting
, where
obeys the distributions:
;
;
. Let the regression coefficient
, given the quantile
; then, the response variable
is modeled by
For both low- and high-dimensional models, the right censoring variable is set as
, where
are unknown parameters, which can take different values to make the censoring ratio of the response variable
up to the set 15%, 30%, or 45%. In the actual simulation, in order to obtain the value of
, the parameters
are estimated by using maximum likelihood estimation in the simulations of
Section 3.2 and
Section 3.3. In
Section 3.4, we discuss the smoothing estimation under the misspecification for the distribution of censored variables. KM estimation is also taken into consideration. Let the number of simulation repetitions be
K, and for the parameter estimates
in the
kth simulation, write
Then, we can use
to evaluate the performance of classical parameter estimation for censored quantile regression models (CQ) and smoothing estimation methods (SCQ). In the actual simulation, we set
.
3.2. Low-Dimensional Performance of Regression Smoothing Estimates for Censored Quantiles
In the low-dimensional numerical study of smoothing estimation, the number of covariates is set to be and sample sizes are 100, 200, and 500. In order to assess the performance of smoothing method in the low-dimensional case, the generation of covariates is categorized into three cases.
Case 1: The p-dimensional covariates are generated from multivariate uniform distribution on , and the covariance matrix is a unit matrix;
Case 2: The p-dimensional covariate is generated from multivariate uniform distribution on , where is the covariance matrix;
Case 3: The
p-dimensional covariates consist of a mixture of distributions, where the first two dimensional covariates are generated by a multivariate uniform distribution on
, with a covariance matrix of
. The covariates in the posterior three dimensions are generated from
with mean
and covariance matrix
, where
Table 1,
Table 2 and
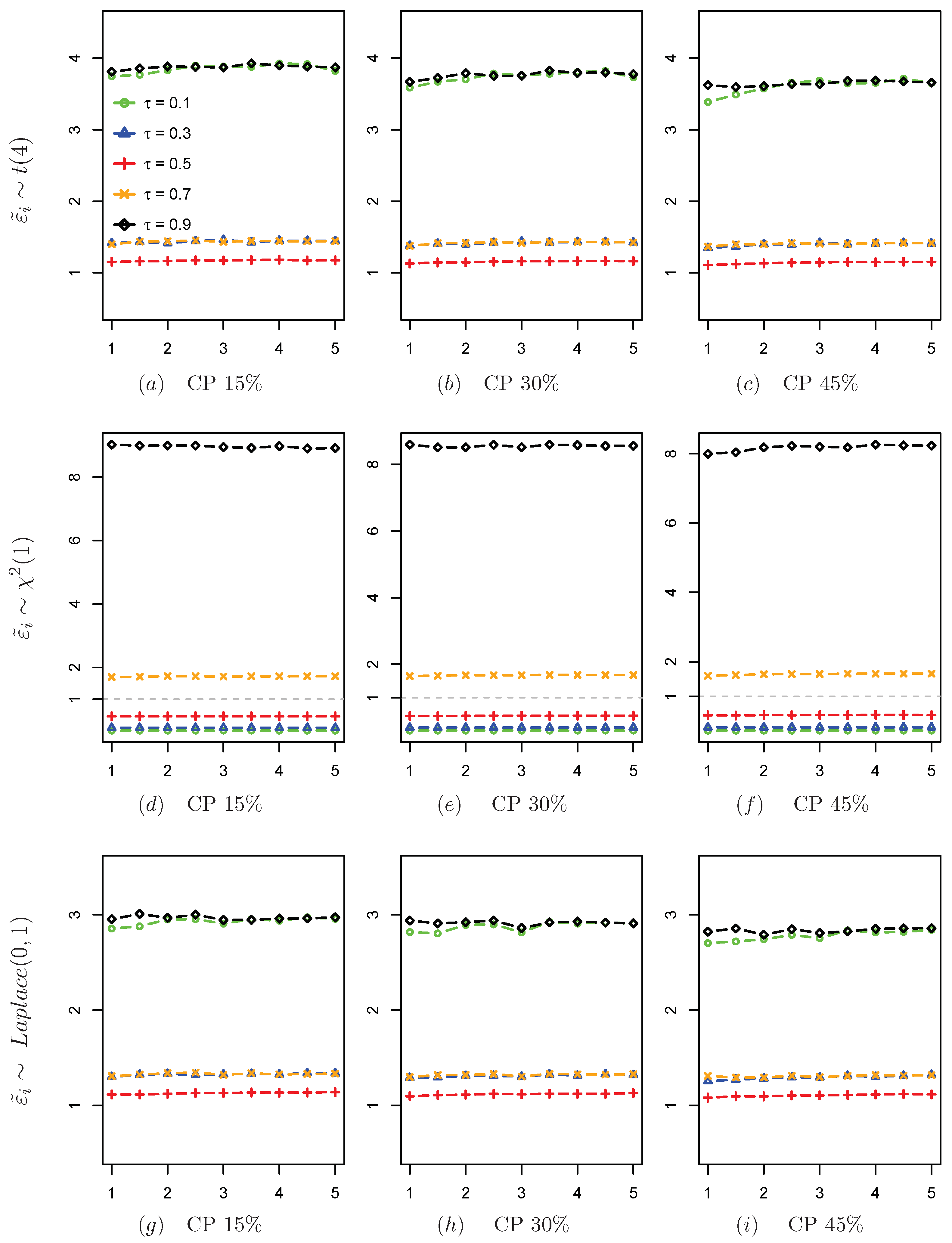
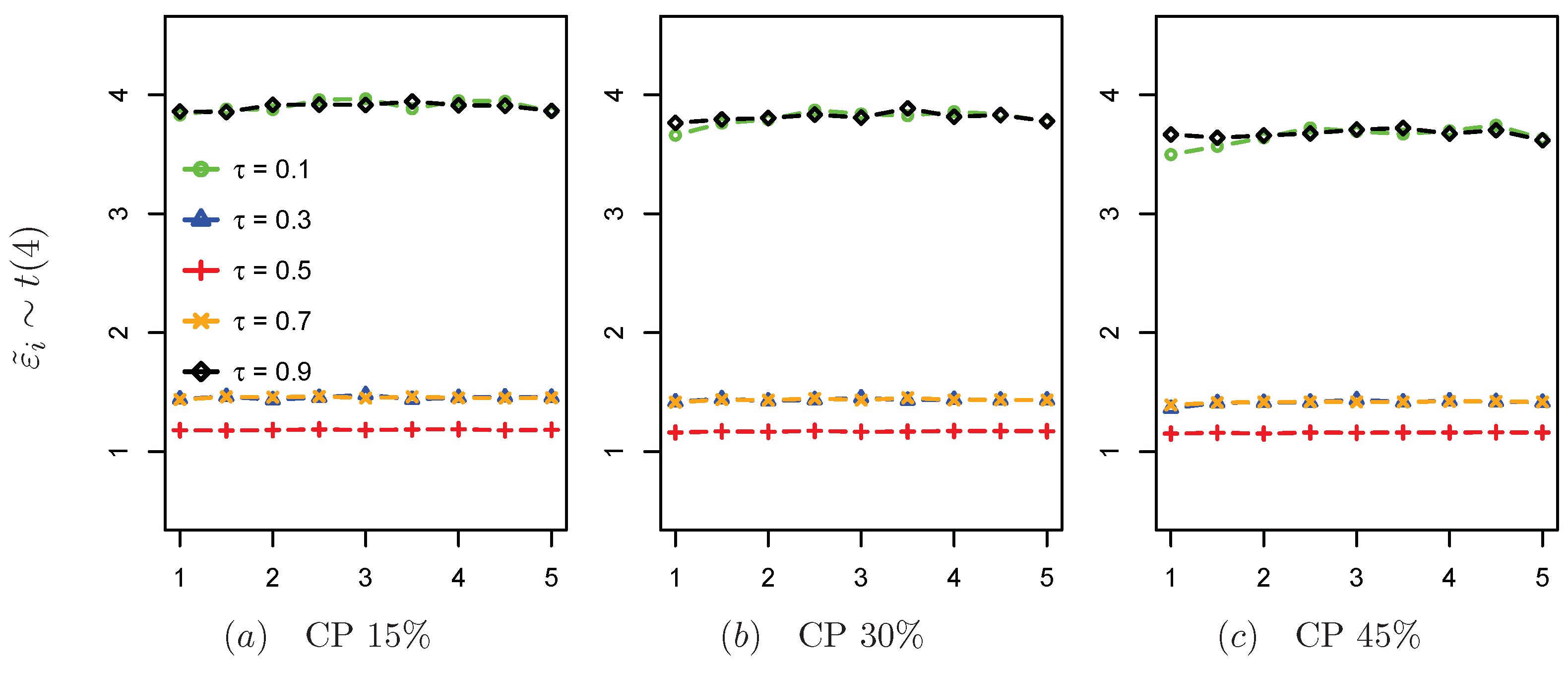
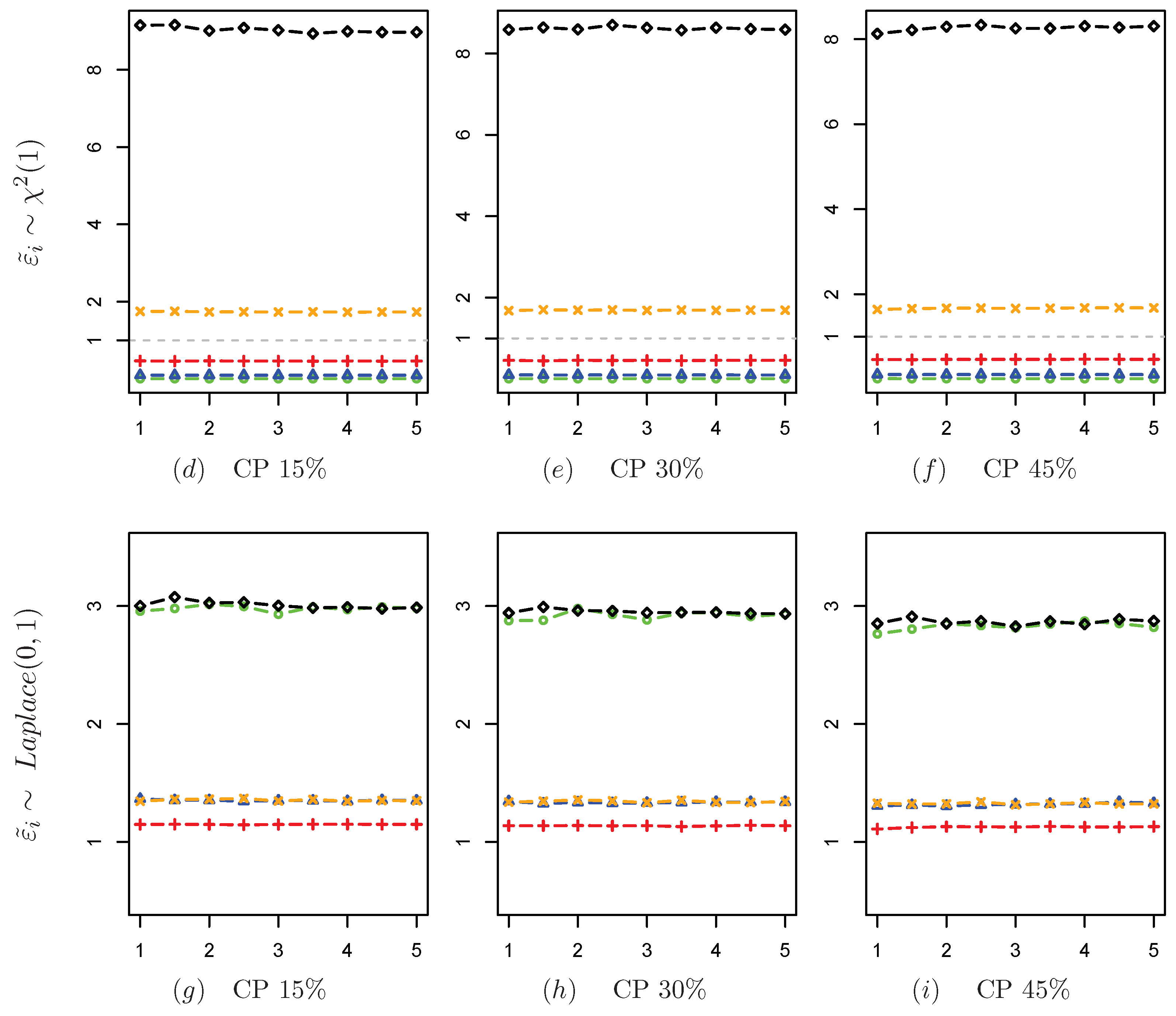
Table 3 show the simulation results when the covariates are generated according to the three scenarios, where CP denotes the censoring ratio of the response variable,
n is the sample size, and columns 3–12 show the results of CQ and SCQ at different quantiles. From the estimation results, when the regression errors are generated by symmetric distributions, i.e.,
t and
Laplace distributions, SCQ has higher accuracy than CQ, especially at the lower and higher quantiles. When the regression error term is generated by the
distribution, the estimation accuracy of CQ decreases as
increases from a global perspective, and the estimation accuracy of SCQ is much better than that of CQ at the higher quantiles, although CQ is better than SCQ at the lower quantiles. This may be because the density function of the
distribution is biased and the observations are excessively clustered in the lower quantiles, so that CQ decreases in estimation accuracy as the number of quantiles increases, while SCQ maintains better estimation accuracy. It can be seen from
Table 1,
Table 2 and
Table 3 that SCQ is more stable than CQ, regardless of whether the error terms follow symmetric or asymmetric distribution. Specifically, the estimation accuracy of SCQ is almost the same in all quantiles, while that of CQ fluctuates with the change of
, especially in the case of the asymmetric distribution of the error terms. Overall, the estimation accuracy of CQ depends greatly on the value of
, the size of the censoring ratio, and the distribution of the error term, while the estimation effect of SCQ is minimally affected by these factors and shows good robustness.
3.3. High-Dimensional Performance of Smoothing Estimators of Censored Quantile Regression
In high-dimensional large-sample numerical studies, the ratio of sample size to dimension is fixed at , the sample size is set at 1000–5000, and the step size is 500. In order to simulate the smoothing estimation of censored quantile regression with the change of dimension and sample size, the covariate generation is categorized into three cases.
Case 1: The p-dimensional covariate is generated from a multivariate uniform distribution on , with covariance matrix .
Case 2: The
p-dimensional covariate is generated from a multivariate uniform distribution on
, with covariance matrix
, where
Case 3: The
p-dimensional covariate consists of a mixture of distributions, where the first
-dimensional covariate is generated from a multivariate uniform distribution on
, and the covariance matrix is
; the second
-dimensional covariate is generated by
with mean
, where the
jth component
, and covariance matrix
, where
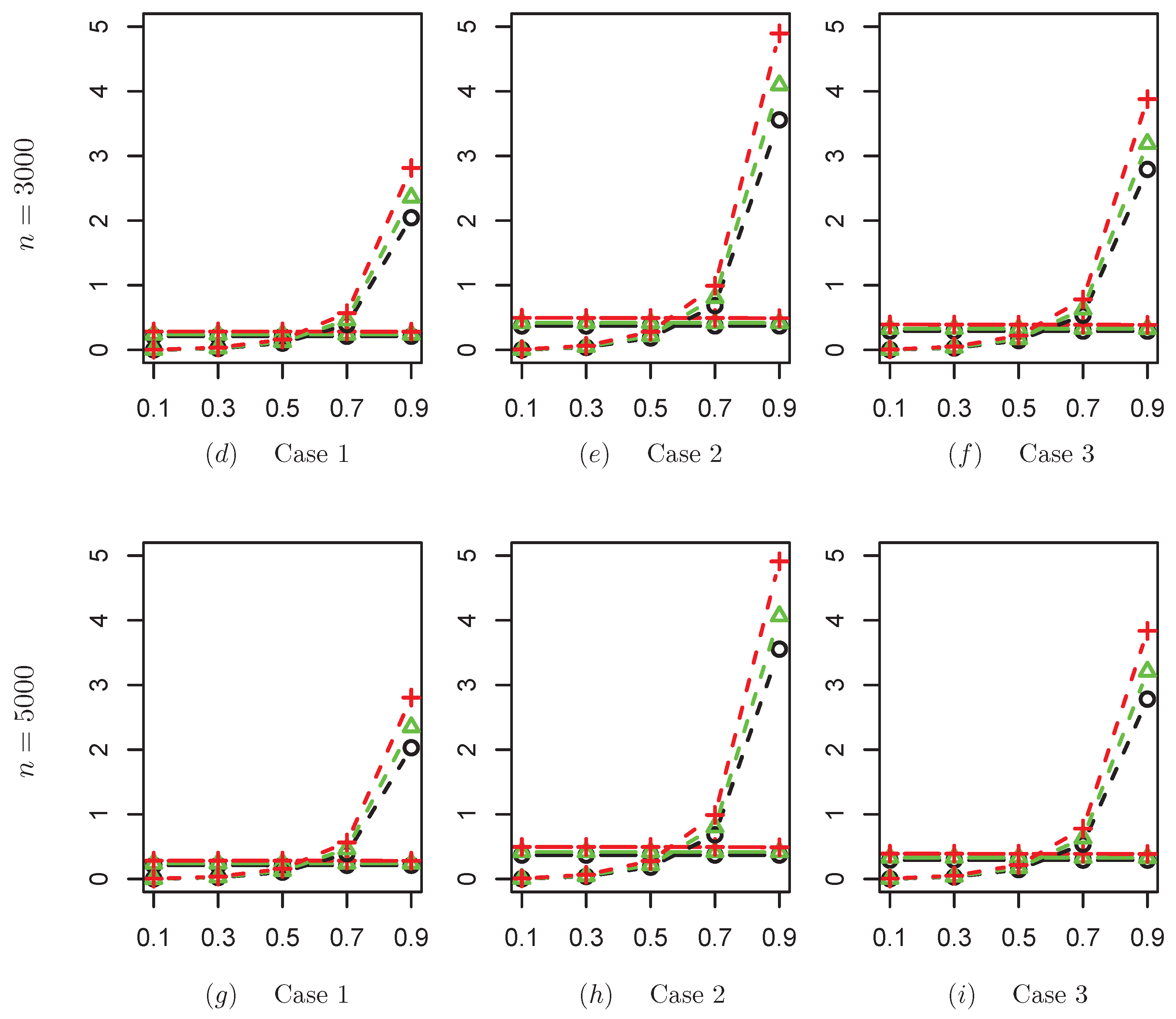
The ratio of DMSE between CQ and SCQ is firstly calculated, and the simulation results of the covariates under Case 1 are displayed in
Figure 1. Since the results of the three covariate generation cases are very similar, we do not show the results of Case 2 and Case 3. The results in
Figure 1 show that the ratio of DMSE estimated by CQ and SCQ is not significantly affected by changes in sample size and dimensionality. When the regression error terms are generated by symmetric distributions, i.e., the
t-distribution and
-distribution, the DMSE ratios of the regression coefficients estimators between CQ and SCQ remain above one. This indicates that SCQ has a higher precision compared with CQ, especially in the case where the difference between the lower quantile of
and the upper quantile of
is more obvious, and the ratio of DMSE for regression coefficients’ estimators between CQ and SCQ can reach three. When the error term is generated by the asymmetric
distribution, the ratio of DMSE between CQ and SCQ is less than one at the low quantile level, and CQ is superior to SCQ in this case. However, the ratio of DMSE between the two methods increases as
increases, and the ratio reaches around 10 when
. In order to clarify the reason for this phenomenon, we calculate the DMSE of two estimation methods when the error term is generated by the
distribution. As shown in
Figure 2, CQ performs better when
= 0.1. As
increases, the DMSE of CQ increases while its growth rate gradually increases. The CQ’s DMSE is significantly higher than the SCQ’s when
, whereas the SCQ’s DMSE stabilizes at each quantile point in a straight line. The observed phenomenon aligns with its lower-dimensional counterpart, underscoring that the estimation accuracy of the CQ depends on the magnitude of
, the censoring ration of response variables and the distribution characteristics of the error term. In contrast, the estimation accuracy of the SCQ exhibits robustness against variations in these factors.
To assess the computational efficiency of the smoothing estimation, it is imperative to compare both the DMSE of CQ and SCQ estimations within the context of high-dimensional simulations, as well as the time expenditure associated with each estimation method. In
Figure 3, the computational time ratios of CQ and SCQ are both greater than 1, which tends to increase with the augmentation of dimensionality and the sample size, and the computational time ratios of CQ and SCQ are more than 10 in all the cases when the sample size is
. The results of the covariate generation in Case 2 and Case 3, which are not shown here, are similar to those in Case 1. Combined with the previous study, it is clear that, when compared to CQ, SCQ significantly decreases calculation time and increases estimation accuracy in the majority of circumstances.
3.4. Robustness of Smoothing Estimates
In order to compare the effects under the misspecification for the distribution of censored variables and KM estimation of censored distributions on the smoothing estimation of parameters, we choose Case 1 of the covariate generation method in the low- and high-dimensional simulations for numerical research.
When the sample size is 200, the model coefficients are estimated using convolutional smoothing after assuming that the distribution of the censored variables is misclassified as Normal, Weibull, and Lognormal, and using the KM estimation of G with different conditions of
quantiles, censoring proportions, and error terms. The simulation in
Table 4 shows that the smoothing estimation using the misclassified distribution of the censored variables is more robust than the smoothing estimation using the KM estimation to estimate the distribution of the censored variables. Similar results are obtained for a sample size of 3000, as shown in
Table 5.
The simulation shows that although there is a possibility of mis-setting in estimating the parameters of the distribution of the censored variables by using
, this method is better and more robust than the smoothing of regression models after estimating the distribution of the censored variables by using the KM estimation. During the simulation process, it is also found in
Table 4 and
Table 5 that when the censored variables are estimated in different distribution forms, the smoothing estimation errors of the model coefficients exhibit a minimal degree of variation, and the estimation accuracy is higher than that of using KM estimation to estimate the distribution of the censored variables and then carry out the smoothing estimation. Regarding computational efficiency, the smoothing estimation method, when applied in scenarios of distributional misclassification, demonstrates a running time ratio to the SCQ that fluctuates within the range of 0.9 to 1.1. In contrast, the smoothing estimation method, once preceded by the KM estimation, incurs a significantly extended running time.
4. Discussion
In the smoothing estimation of censored quantile regression models, the distribution of the censored variables is usually unknown. The problem of the unknown distribution of the censored variables can be solved by estimating the density function of the censored variables through existing nonparametric methods, then determining the type of the censored distribution using the goodness-of-fit test, and accessing the unknown parameters in the distribution using the great likelihood method. In the numerical simulation, this paper also discusses using such a method to fit the unknown censored distribution to estimate , and then estimate the regression parameter .
We also discuss the parametric smoothing estimation method in the case of misspecification of the distribution of the censored variables, and compare it with the smoothing estimation method of the parameters after estimating the distribution of the censored variables with KM estimation. The simulation results show that the smoothing estimation method is still more robust than the method of estimating the distribution of censored variables with KM estimation even if there is a misspecification in the estimation of the distribution of the censored variables. Meanwhile, the smoothing estimation method is more robust than the classical censored quantile regression model.
Our research has certain limitations and there are some issues that need to be further explored. Firstly, we have performed some analysis and research on parameter smoothing estimation for quantile linear models; moreover, we can plan further research on parameter estimation and interval estimation for complex models such as generalized linear models. Secondly, our proof is based on the assumption that the form of censored distribution is known, and the theoretical proof by using a nonparametric model to estimate the censored distribution is still a challenging task. This requires understanding and knowledge in the theory of nonparametric statistics and probability limits.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}