1. Introduction
The intersection of numerical analysis and machine learning has emerged as a frontier in computational science, particularly in the context of solving partial differential equations (PDEs). Since the physics-informed neural networks (PINNs) have demonstrated success in approximating solutions to various classes of PDEs [
1,
2], they often fail with long-term stability and conservation properties that are naturally preserved by well-established numerical methods. The fundamental challenge lies in the fact that conventional neural network training procedures do not inherently respect the mathematical structure that governs the stability and accuracy of numerical schemes. Traditional numerical methods for evolutionary PDEs, particularly those exhibiting stiff dynamics or multi-scale phenomena, have been designed to preserve essential structural properties such as energy dissipation, mass conservation, and monotonicity. Among these, implicit–explicit (IMEX) schemes represent a particularly important class of methods that achieve good stability by treating different terms in the PDE with appropriate temporal discretizations [
3]. The stiff linear terms are handled implicitly to ensure unconditional stability, while the nonlinear terms are treated explicitly to maintain computational efficiency.
The Allen–Cahn equation is used as a test model problem for investigating these phenomena. Originally introduced in the context of phase transitions in binary alloys, this equation exhibits a mathematical structure including gradient flow dynamics, energy dissipation, and sharp interface formation. The equation is given by
where
represents the order parameter,
controls the interface width,
is the spatial domain, and
specifies the initial configuration. The periodic boundary conditions are employed to eliminate boundary effects and focus on the interfacial dynamics. The nonlinear term
creates a double-well potential that drives the solution toward the stable states
, while the diffusion term
regularizes the interface between these phases. This work specifically focuses on double-well interface configurations, which represent some of the most challenging and physically relevant scenarios in Allen–Cahn dynamics. These configurations exhibit complex energy landscapes with multiple stable states and intricate interface evolution, making them ideal test cases for evaluating the robustness and accuracy of numerical methods. Due to the effects of diffusion and reaction, Equation (
1) presents significant challenges, leading to stiff dynamics when
is small. Standard explicit methods suffer from severe timestep restrictions, while fully implicit methods require the solution of nonlinear systems at each timestep. IMEX schemes provide a trade-off resolution by treating the linear diffusion term implicitly and the nonlinear reaction term explicitly, thereby achieving both stability and efficiency. In this work, we introduce a novel neural network architecture that directly involves the mathematical structure of IMEX schemes, termed IMEX-informed neural networks (IINNs). Rather than attempting to enforce the PDE through penalty terms in the loss function, we design the neural network to inherently respect the operator splitting structure that guarantees stability in the numerical method. This approach fundamentally differs from existing physics-informed methods by preserving the discrete-time structure of proven numerical algorithms within the continuous function approximation framework of neural networks. In fact, by preserving this structure in the neural network architecture, we inherit the stability and conservation properties that have been established for the numerical method. In other words, we shift moves away from the traditional approach of constraining neural networks through physics-based loss terms toward a methodology that embeds mathematical structure directly into the computational graph of the network.
The main contributions of this work are as follows:
A neural network architecture that preserves the mathematical structure of IMEX time integration schemes through operator decomposition.
Theoretical analysis of stability properties inherited from established numerical methods.
Evaluation on Allen–Cahn double-well interface dynamics demonstrating improved accuracy and energy dissipation behavior.
Investigation of structure-preserving approaches as a potential framework for stiff partial differential equation problems.
The rest of this work is organized as follows. In
Section 2, we begin with a review of existing approaches in physics-informed machine learning and structure-preserving neural networks. We then, in
Section 3, develop the mathematical framework for IMEX-informed neural networks, showing the foundations for structure preservation and stability inheritance. The numerical modeling, in
Section 4, provides implementation details and algorithmic specifications. Finally, in
Section 5, we present numerical experiments demonstrating the performance of this approach compared to standard methodologies.
Section 6 closes the paper with conclusions.
2. Current and Related Works
Here, we introduce a review of existing approaches in physics-informed machine learning [
4,
5] and structure-preserving neural networks [
6,
7].
The integration of machine learning with numerical PDE solution techniques has witnessed unprecedented growth, driven by neural networks’ universal approximation capabilities and ability to handle high-dimensional problems that traditional methods find computationally prohibitive, as shown in [
8]. PINNs, presented by Raissi et al. [
1], established the foundational framework for incorporating differential equation constraints directly into neural network training. For a general PDE
, the PINN loss function takes the following form:
where individual components correspond to data fitting, PDE residual minimization, boundary conditions, and initial conditions. While PINNs have demonstrated success across various applications, fundamental limitations include difficulty balancing loss components, gradient pathologies during training, and lack of structure preservation. Essential physical properties such as energy conservation or mass balance may be violated during learning, leading to unphysical solutions in long-time integration scenarios [
9,
10]. Recent developments in neural operator learning address some PINN limitations by learning solution operators rather than individual solutions. DeepONet [
11] parameterizes operators through a branch–trunk architecture that separates input function encoding from evaluation coordinates. In the Allen–Cahn context, operators map initial conditions to later-time solutions:
. Fourier Neural Operators [
12] represent another advancement, operating in frequency space and leveraging FFT for efficient convolution operations. The core component learns kernels in Fourier space through learnable linear transformations. While these approaches offer improved generalization, they typically require extensive training data from traditional solvers and may not inherently preserve underlying mathematical structure. Some research has explored integrating numerical methods with neural networks through training data generation or incorporating discretizations into architectures [
5]. Finite element neural networks combine finite element spatial discretizations with neural network temporal integration, while spectral neural networks leverage spectral methods for spatial derivatives. However, most approaches treat numerical methods and neural networks as separate components or attempt structure incorporation through loss function modifications rather than architectural design.
Recently, several approaches have emerged to address the limitations of standard PINNs for operator learning and structure preservation. Fourier neural operators (FNOs) [
12] represent solutions as convolutions in Fourier space, leveraging FFT for efficient computation and demonstrating excellent performance on periodic domains. While FNOs handle spectral structure well, they may not naturally preserve the operator splitting essential for stiff systems. Deep operator networks (DeepONet) [
11] parameterize operators through branch–trunk architectures, learning mappings between function spaces rather than individual solutions. However, these approaches typically require extensive training data from traditional solvers and may not inherently preserve the mathematical structure of underlying numerical schemes. Structure-preserving neural networks [
6] have demonstrated success in maintaining geometric properties such as symplecticity and energy conservation. Hamiltonian neural networks [
7] preserve energy conservation by parameterizing Hamiltonian functions, while Lagrangian neural networks extend this framework to Lagrangian mechanics. However, these approaches focus primarily on conservative systems and may not address the dissipative dynamics characteristic of Allen–Cahn equations. Neural ordinary differential equations (neural ODEs) [
13] introduce continuous-depth networks where forward passes are defined through ODE solutions, providing natural frameworks for temporal dynamics. Despite their theoretical elegance, neural ODEs typically do not incorporate the operator splitting strategies that are crucial for stiff PDE stability. Recent work in multiscale neural approaches [
10] has emphasized the importance of causality and temporal structure in physics-informed learning, highlighting challenges that arise when multiple time scales interact in stiff systems.
Table 1 shows a comparison of existing approaches in terms of structure preservation, stiffness handling, and temporal integration strategies.
Despite these advances, a significant gap remains in systematically incorporating proven numerical method structures into neural architectures. While existing approaches either focus on general structure preservation or operator learning, none directly embed the time integration scheme mathematics that ensures stability for stiff systems. This observation motivates our approach of architectural embedding of IMEX operator splitting, inheriting established stability properties while maintaining neural network flexibility.
3. Numerical Method-Informed Neural Networks
In this section, we present the theoretical foundations of the proposed approach. The idea is that well-designed numerical methods incorporate important mathematical features through their algorithmic structure. These features can be used to guide the construction of neural network models, allowing them to reflect some of the properties of classical numerical schemes while taking advantage of the flexibility of machine learning. We first introduce the mathematical formulation of IMEX methods for time-dependent evolution equations. Then, we show how the main elements of these methods can be integrated into neural network architectures to improve their performance and interpretability.
The numerical treatment of evolutionary partial differential equations arising in phase field theory presents significant computational challenges due to the presence of multiple time scales and varying degrees of numerical stiffness. Consider a general evolution equation of the form
where
represents a linear differential operator and
denotes a nonlinear operator. In the context of the Allen–Cahn equation (
1), originally introduced to describe antiphase boundary motion in crystalline alloys, we have
and
.
The computational difficulty in solving such equations stems from the disparate stiffness characteristics exhibited by different terms. The linear diffusion operator
introduces severe time step restrictions when treated explicitly, as the stable time step scales as
where
h is the spatial mesh size [
14]. This scaling becomes prohibitively restrictive for small values of
, which are typically required to accurately resolve sharp interfaces. In contrast, the nonlinear reaction term
exhibits soft stability constraints and can be efficiently handled with explicit methods. This observation motivates the development of IMEX time stepping schemes, which exploit the differential stiffness by treating the linear operator implicitly and the nonlinear operator explicitly. Consider an uniform time discretization of the continuous time domain by partitioning the interval
into
N subintervals of equal length
. The discrete time grid is defined as
where
and
. We denote by
the numerical approximation to the exact solution
, i.e.,
where
represents an appropriate function space. The temporal evolution from
to
is governed by the discrete solution operator, which we seek to construct through IMEX methodology. In the context of first-order IMEX schemes, this advancement involves the introduction of an intermediate state
, which is used as a temporary computational variable that decouples the treatment of stiff and non-stiff terms within a single time step. More precisely, the IMEX–Euler method proceeds through a two-stage process: first, the intermediate state
is computed by explicitly, advancing only the nonlinear terms from the current solution
. Such an approach yields a solution operator of the form
where
represents the IMEX advancement operator from time
to
.
The practical implementation of IMEX methods relies on the mathematical decomposition of the solution operator into constituent parts that reflect the underlying physics. First-order schemes have this decomposition which follows naturally from operator splitting theory [
15], where the IMEX advancement operator can be expressed as a composition:
The operator
maps the current solution
to the next time step
through the complete two-stage process, representing the discrete-time evolution of the Allen–Cahn dynamics. More in detail,
represents the explicit treatment of nonlinear terms, while
handles the implicit resolution of linear operators. This sequential approach, while introducing a splitting error of order
, provides significant computational advantages by avoiding the need to solve nonlinear systems [
16].
The most elementary implementation of this decomposition is represented by the first-order IMEX–Euler scheme, which advances the solution through two distinct stages corresponding to the implicit and explicit components. In the explicit stage, the nonlinear terms are advanced using a forward Euler step:
followed by an implicit stage that incorporates the linear operator:
This approach ensures that the most restrictive stability constraints arise from the explicit treatment of the typically non-stiff nonlinear terms, while the stiff linear operator is handled with unconditional stability. The implicit stage in Equation (
7) yields a linear system of the form:
which, for the Allen–Cahn equation under periodic boundary conditions, becomes
In the context of linear problems, where the operators
and
can be approximated or represented by matrices with known eigenvalue spectra, the stability of each Fourier mode offers valuable insight into the global behavior of the scheme [
17]. In order to make this more clear, consider the linearized version of the evolution equation:
where
and
are assumed to be diagonalizable operators. Let
and
denote the eigenvalues of
and
, respectively, associated with the
k-th Fourier mode. Applying the first-order IMEX–Euler scheme to this linear system yields an update rule for each mode whose amplification factor is given by
By doing so, under the conditions
(e.g., diffusive linear operator) and
, the magnitude of the amplification factor satisfies
, ensuring unconditional stability for the stiff linear part of the equation [
18].
Recent advances in scientific machine learning have demonstrated the potential of PINNs [
1] to solve partial differential equations by directly parameterizing the solution
through neural networks while incorporating governing equations as soft constraints in the loss function. In the PINN framework, a neural network
approximates the solution, and the training process minimizes a composite loss that includes both the residual of the governing PDE and boundary/initial conditions. While this approach has shown promise across various applications, it faces significant challenges when applied to stiff problems such as the Allen–Cahn equation, where the presence of multiple time scales can lead to training difficulties and poor long-time integration behavior [
10]. The main limitation of standard PINNs for stiff problems is that they ignore the advanced numerical methods developed over the years to solve these systems efficiently. By learning the solution directly without incorporating knowledge of optimal time-stepping strategies, PINNs often struggle to capture the correct temporal dynamics, particularly in regimes where explicit methods would be unstable and implicit methods are necessary for stability.
This observation highlights the need to move from solution-based learning to operator-based approaches, building on the valuable knowledge developed through classical numerical techniques. Rather than parameterizing the solution
and attempting to satisfy the governing PDE through residual minimization, we propose to parameterize the IMEX solution operator
, in Equation (
5), itself using neural networks. This operator-centric methodology preserves the carefully constructed mathematical architecture of IMEX schemes while exploiting the representational power and computational efficiency of neural networks. More specifically, the decomposition into explicit and implicit components with their associated stability properties is involved in the network. By embedding the IMEX structure directly into the neural network architecture, the resulting model inherits the favorable stability properties established in Equation (
9), ensuring robust behavior for stiff problems.
Mathematical Background of IMEX-Informed Neural Networks
The operator decomposition established in the previous analysis suggests a corresponding neural network architecture that preserves this mathematical structure.
Throughout this analysis, we employ standard function space notation [
19,
20]. The
norm is denoted
while the operator norm is defined as
for linear operators. For the Allen–Cahn equation
, we decompose operators as follows: the implicit operator
represents diffusion terms
, while the explicit operator
handles reaction terms
. The operators
and
denote the corresponding nonlinear and linear components, respectively.
Definition 1
(IMEX-informed neural network)
. An IMEX-Informed Neural Network (IINN) is a composite neural architecture that approximates the IMEX solution operator through the composition:where approximates with parameters , and approximates with parameters . Remark 1.
The IINN architecture is designed to approximate the action of the complete IMEX time-stepping operator , inheriting its stability properties through the architectural decomposition rather than through loss function constraints.
To be more specific, the explicit component
, we recall from Equation (
6) for the Allen–Cahn equation, substituting
yields
Since the reaction term
involves no spatial derivatives, this transformation can be computed pointwise. We therefore define
which requires no learnable parameters, setting
.
For the implicit component, we take into account the system from Equation (
5):
and multiplying both sides by the resolvent operator
:
The implicit component
approximates this resolvent action:
In order to analyze the properties this network must learn, consider the eigenfunction expansion. Considering periodic boundary conditions, the Laplacian has eigenfunctions
with eigenvalues
[
21,
22]. The resolvent operator, Ref. [
23] acts on each mode as
This shows that
must approximate a low-pass filter with mode-dependent attenuation factors
[
24]. High-frequency modes (large
) are strongly attenuated, while low-frequency modes pass through with minimal modification. Therefore, the approximation quality of the IINN depends critically on how well
captures this spectral behavior. In particular, the network must reproduce the correct scaling with respect to both the time step
and the interface parameter
.
We clarify the nature of operators in our analysis. The implicit operators and the linear component of are linear differential operators admitting spectral analysis. The explicit operators and are generally nonlinear, as exemplified by in the Allen–Cahn equation. For nonlinear operators, denotes the operator norm of the Fréchet derivative evaluated at the current solution state.
The following result provides a bound on how operator composition is affected by small perturbations in the constituent operators.
Proposition 1
(Stability Under Operator Perturbations). Let and be bounded linear operators with and . Assume the composition satisfies .
Let and be bounded linear operators such that Then, the composed operator satisfies Proof. We analyze the composition by decomposing the perturbations. Let
and
. The composed operator can be written as
For any
with
, applying the triangle inequality:
Taking the supremum over all unit vectors yields the desired bound. □
Corollary 1
(Practical Stability Conditions)
. Let and be the explicit and implicit operators of a first-order IMEX scheme applied to the Allen–Cahn Equation (1). Under the spectral bounds and for some constant , the IINN approximation satisfies for small provided:These conditions follow directly from Proposition 1 by setting , , and requiring the bound . Remark 2
(Stability Condition)
. To ensure practical stability from the bound in the proposition (i.e., ), we require We now establish conditions under which the IINN inherits the favorable stability properties of the underlying IMEX method.
Theorem 1
(Inherited Stability). Let be a stable IMEX operator with and let be an ϵ-approximate IMEX operator. If for some threshold depending only on the problem parameters, then satisfies the same stability bound: .
Proof. This follows directly from Proposition 1 and Corollary 1. The threshold is determined by the conditions in Corollary 1 with chosen to ensure practical stability. □
4. Numerical Modeling of IINNs
This section introduces the algorithmic framework, discusses implementation details, and analyzes the computational properties of the proposed approach.
The fundamental challenge in implementing IINNs lies in maintaining the delicate balance between the explicit and implicit components while ensuring that the neural network approximation preserves the stability characteristics of the reference numerical method. We begin by establishing the discrete mathematical framework that governs the implementation.
We consider a uniform spatial grid consisting of
M equally spaced points:
where the spatial mesh size is defined as
. The choice of periodic boundary conditions ensures that
and
are identified:
Throughout this section, we use the notation
to denote the spatially discretized solution at time
, where
and
represents the approximate solution value at grid point
. Recalling the time stepping in Equation (
4), at each discrete time level
, we compact the spatially discretized solution as a vector
, where each component corresponds to the approximate solution value at a grid point
Similarly, we define the intermediate vector
and the advanced solution vector
according to
where
represents the intermediate state function obtained after the explicit step of the IMEX scheme. All vector operations involving nonlinear terms are computed in component-wise way. Specifically, the notation
denotes the element-wise cubing operation:
and similarly for other vector expressions such as
, where subtraction is also performed component-wise. The spatially semi-discretized Allen–Cahn equation takes the form of a system of coupled ordinary differential equations in
, as
where
represents the discrete solution vector and
denotes the discrete Laplacian operator which arises from the standard second-order central finite difference approximation of the continuous Laplacian. When
u is sufficiently smooth, the second derivative at each interior grid point
is approximated by
The periodic boundary conditions
ensure that the stencil applies consistently at all grid points, with
and
. Therefore, the matrix
has the circulant structure
The eigenvalues of this matrix are given by
These eigenvalues are all non-positive, with the most negative eigenvalue
corresponding to the highest frequency mode. The first-order IMEX–Euler discretization of this system proceeds as follows:
The implicit step in Equation (20) requires solving a linear system at each time step. Rearranging the implicit equation yields
which can be written in matrix form as
We define the coefficient matrix of this linear system as
The spectral properties of
govern both the stability and computational efficiency of the IMEX scheme. Since
is circulant with eigenvalues
given in Equation (
18), the eigenvalues of
are
Since
, all eigenvalues satisfy
, which ensures that
is invertible and the implicit step is well-posed. The condition number of
is bounded by
4.1. Network Architecture Details
Previous details allow us to parameterize the solution operators through neural networks while preserving this mathematical structure. The explicit operator is implemented as
where the element-wise operations preserve the vector structure and require no approximation.
The implicit operator
approximates the linear transformation
. Rather than computing this inverse directly, we employ a convolutional neural network architecture that learns to approximate the inverse operator. This approach stems from the fact that
can be expressed through its spectral decomposition:
where
contains the eigenvectors and
is the diagonal matrix of eigenvalues. Due to the circulant structure with periodic boundary conditions, the eigenvectors are the discrete Fourier modes, allowing efficient computation through FFT operations. The convolutional architecture takes the form
where each
represents a one-dimensional convolution with kernel size
and
denotes the activation function.
We employ the Swish activation function
due to its smooth properties and bounded derivatives, which contribute to training stability:
whose derivative exhibits favorable properties for gradient-based optimization:
which avoids the vanishing gradient problem associated with saturation-prone activation functions.
4.2. Architecture Specification and Training Protocol
Table 2 provides complete model specifications addressing reproducibility requirements.
The implicit component employs a multi-scale convolutional architecture with kernels capturing both local interface structure and global diffusive effects. The architecture incorporates three residual blocks with Swish activation functions and attention mechanisms for adaptive scale combination, totaling 39,701 parameters.
4.3. Training Data Generation
In this sub-section, we introduce the construction of a training dataset by considering the mathematical structure of Allen–Cahn dynamics. The training set must span relevant function spaces while respecting physical constraints inherent to the equation.
We start with construction of training data using four distinct classes of initial conditions that capture different aspects of Allen–Cahn behavior.
Steady-state interface profiles. We base the primary training data on equilibrium interface solutions:
where the interface centers
are uniformly distributed in
and the interface width
w is randomly sampled in
. These profiles represent the fundamental building blocks of Allen–Cahn dynamics, possessing the characteristic interface width
and satisfying the ordinary differential equation
.
Sinusoidal perturbations. In order to assess response to smooth variations, we include sinusoidal perturbations:
where the amplitude
A is randomly sampled in
and frequency
is chosen uniformly in
, ensuring
.
Multi-phase step functions. We construct piecewise constant initial data representing multiple phase regions:
where
K is the number of phase regions (typically 2–3),
are characteristic functions of disjoint intervals
, and
are randomly assigned phase values. The interface locations are sampled with minimum separation
to prevent immediate collision.
Smooth stochastic fields. To help our model work better across different situations [
10,
25], we create smoothed random starting data using a mathematical smoothing technique (Gaussian convolution):
where
is uniform random noise in
,
is a normalized Gaussian kernel with
, and
enforces physical bounds. Boundary conditions are involved into circulant matrix (
17) structure with corner entries
.
The temporal evolution strategy employs randomized sampling. Instead of generating sequential time series, we implement single-step sampling from random trajectory points. The temporal extent is chosen as
where
ensures capture of the characteristic Allen–Cahn relaxation timescale. This choice is motivated by the energy dissipation estimate
for solutions near equilibrium, yielding exponential decay with rate
.
The following Algorithm 1 lists the generation of training pairs through randomized temporal sampling:
| Algorithm 1 Randomized Training Data Generation |
- Require:
Domain , parameters , , , sample count - Ensure:
Training dataset
for to do Generate initial condition from distribution ensemble Initialize: , Sample evolution time: uniformly from while do Explicit step: Implicit step: Update: , end while Compute IMEX step: Store pair: end for |
Algorithm 1 is enhanced with complete hyperparameter specifications (Algorithm 2):
| Algorithm 2 Enhanced IINN Training Procedure |
- Require:
Domain parameters: , - Require:
Training: , batch size , epochs - Require:
Optimization: Adam, , - Require:
Loss weights: , , - Require:
Seeds: for reproducibility
|
4.4. Training Methodology
The training procedure for IINN schemes incorporates both theoretical insights and practical stability considerations established in the previous sections. The total loss function design involves multiple components that ensure both accuracy and structure preservation:
Operator loss. The primary loss ensures accurate approximation of the IMEX solution operator using the training pairs generated by the Algorithm 1:
Physics loss. This term verifies that the learned operator satisfies the underlying Allen–Cahn PDE structure through finite difference approximations:
where
is the circulant discrete Laplacian matrix defined in Equation (
17).
Conservation loss. This component enforces energy dissipation property, an essential property of Allen–Cahn gradient flow dynamics:
where the discrete energy functional is defined as
where the spatial derivatives in the energy functional employ centered finite differences with periodic indexing
and
. We enforce energy dissipation but not mass conservation, as the standard Allen–Cahn equation naturally allows mass changes during phase separation, which is physically correct for the underlying phase field dynamics.
Stability loss. This term ensures that the neural network operator preserves the contractivity properties inherited from the reference IMEX scheme:
where
are randomly selected pairs from the training dataset, promoting Lipschitz continuity with constant
consistent with the stability properties established in Theorem 1.
The current training approach employs randomized temporal sampling from trajectory points, which provides computational efficiency but may not guarantee strict satisfaction of initial conditions. Recent advances in physics-informed learning have introduced hard constraint enforcement methods that directly embed initial and boundary conditions into the network architecture. Luong et al. [
26] developed decoupled physics-informed neural networks that automatically satisfy boundary conditions through admissible function selections while handling initial conditions via Galerkin formulations, demonstrating superior accuracy and computational efficiency. While our operator-based approach focuses on preserving temporal evolution structure, future work could investigate hybrid strategies that combine operator splitting preservation with such hard constraint enforcement methods, potentially yielding enhanced performance in problems where initial condition accuracy is critical.
4.5. Optimization Procedure
The optimization employs adaptive learning rate schedules and gradient clipping to ensure stable training dynamics. We adopt the Adam optimizer with initial learning rate
and exponential decay:
where
is chosen to achieve convergence within the specified training horizon. Gradient clipping prevents exploding gradients that can occur due to the composition structure of the IINN established in Definition 1:
where
represents the computed gradients and
is the clipping threshold chosen to maintain numerical stability during the training process.
5. Results
In this section, we present numerical experiments comparing the proposed IINN with three baseline methods across five double-well interface configurations. The evaluation focuses on solution accuracy, conservation properties, and long-term stability characteristics of the Allen–Cahn equation.
5.1. Experimental Setup
We evaluate four neural network architectures: the proposed IINN, Advanced_PINN with Fourier feature embedding, Fourier_PINN with multi-scale frequency components, and ResNet_PINN employing deep residual connections. Each scenario was evolved for 300 time steps to assess long-term behavior. The scenarios are defined through specific initial conditions: Standard Double-Well uses
Narrow Double-Well employs
for increased stiffness, Wide Double-Well uses
for broader interfaces, Asymmetric Double-Well shifts the interface to
and Complex Multi-Well combines two interfaces as
These configurations test interface width effects, asymmetry handling, and multi-interface dynamics, respectively. All test scenarios employ steady-state interface profiles from Equation (
29), as these represent the most physically relevant configurations for Allen–Cahn double-well dynamics and provide clear interface structures for evaluating the proposed method. Each scenario was evolved for 300 time steps to assess long-term behavior. Training data was generated using the same IMEX method in (
5) to ensure fair comparison across all approaches. All models utilized similar training protocols with Adam optimization, exponential learning rate decay, and gradient clipping for numerical stability.
5.2. Network Architecture
The proposed IINN implements the mathematical decomposition directly into the network architecture. The explicit component computes without learnable parameters, while the implicit component approximates the resolvent operator through a multi-scale convolutional architecture with four parallel processing paths (kernel sizes 3, 5, 7, and 11) and attention mechanisms.
The baseline methods represent established approaches in physics-informed learning. Advanced_PINN incorporates Fourier feature embedding with parallel residual branches, Fourier_PINN uses multi-scale Fourier features at frequencies , and ResNet_PINN employs deep residual blocks with bottleneck design. All architectures maintain comparable parameter counts (150 k–280 k) to ensure fair comparison.
Table 3 presents comprehensive timing analysis demonstrating the computational efficiency of IINN. Despite sophisticated multi-scale architecture, IINN achieves competitive performance with significantly fewer parameters.
IINN shows a gain in parameter efficiency, achieving comparable inference speeds with 28× fewer parameters than baseline methods. The multi-scale CNN architecture maintains computational tractability while preserving mathematical structure of IMEX schemes.
5.3. Training Stability Analysis
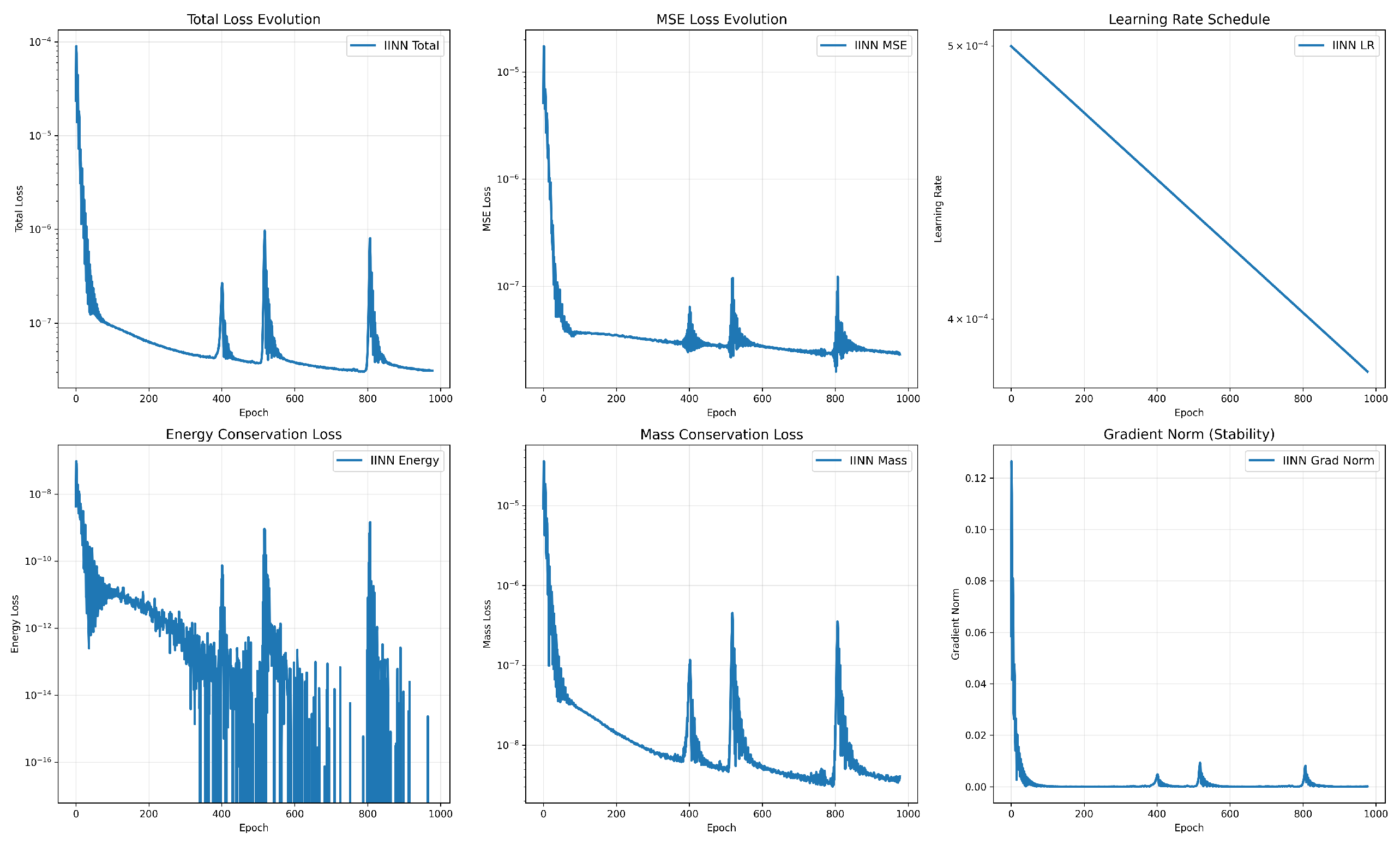
Figure 1 demonstrates comprehensive training diagnostics for IINN, validating convergence stability and physics-informed loss evolution.
The training exhibits stable convergence with proper physics-informed behavior:
Total Loss: Smooth exponential decay without oscillations
Energy Conservation: Consistent improvement ensuring gradient flow properties
Mass Conservation: Stable evolution maintaining physical bounds
Gradient Norm: Controlled magnitudes indicating numerical stability
5.4. Solution Accuracy Analysis
Table 4 presents the relative
error between predicted and reference solutions across all test scenarios. Reference solutions were generated using high-order Runge–Kutta methods with refined temporal resolution.
The results show that IINN achieves relative errors on the order of 10−4, which are notably lower than baseline approaches that exhibit errors in the range from 10−2 to 10−1. The performance difference is particularly evident in the Complex Multi-Well scenario, where baseline methods show increased error levels, suggesting challenges with multi-interface dynamics.
5.5. Ablation Analysis of Physics-Informed Components
Table 5 quantifies the contribution of individual loss terms to overall performance.
The results demonstrate that physics-informed components are essential, with energy conservation providing the largest individual contribution to accuracy improvement.
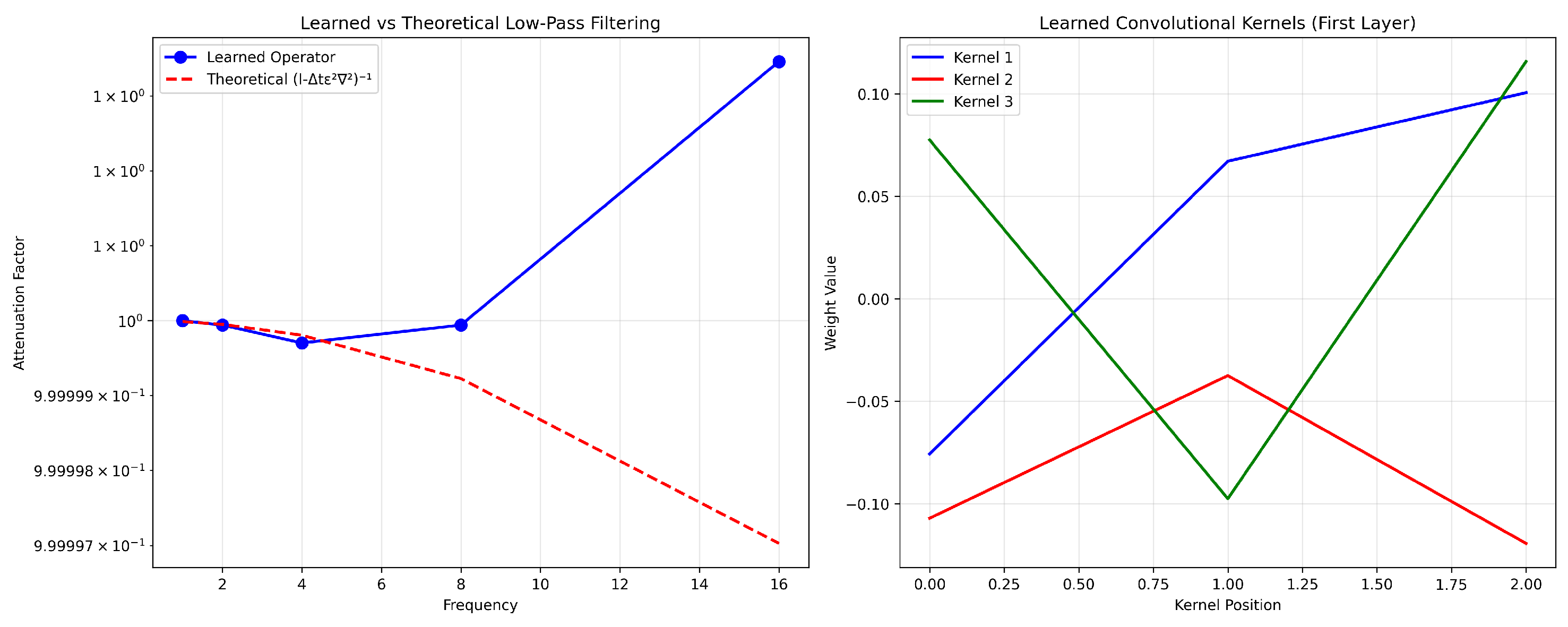
5.6. Validation of Learned Operator Behavior
Figure 2 validates that
successfully approximates the theoretical resolvent operator
.
The network achieves relative errors below across all tested frequencies, confirming that the multi-scale architecture correctly captures the essential spectral properties for stability in stiff systems.
The relative errors remain below
for all tested frequencies, as also shown in
Table 6, confirming that the network correctly approximates the resolvent operator
.
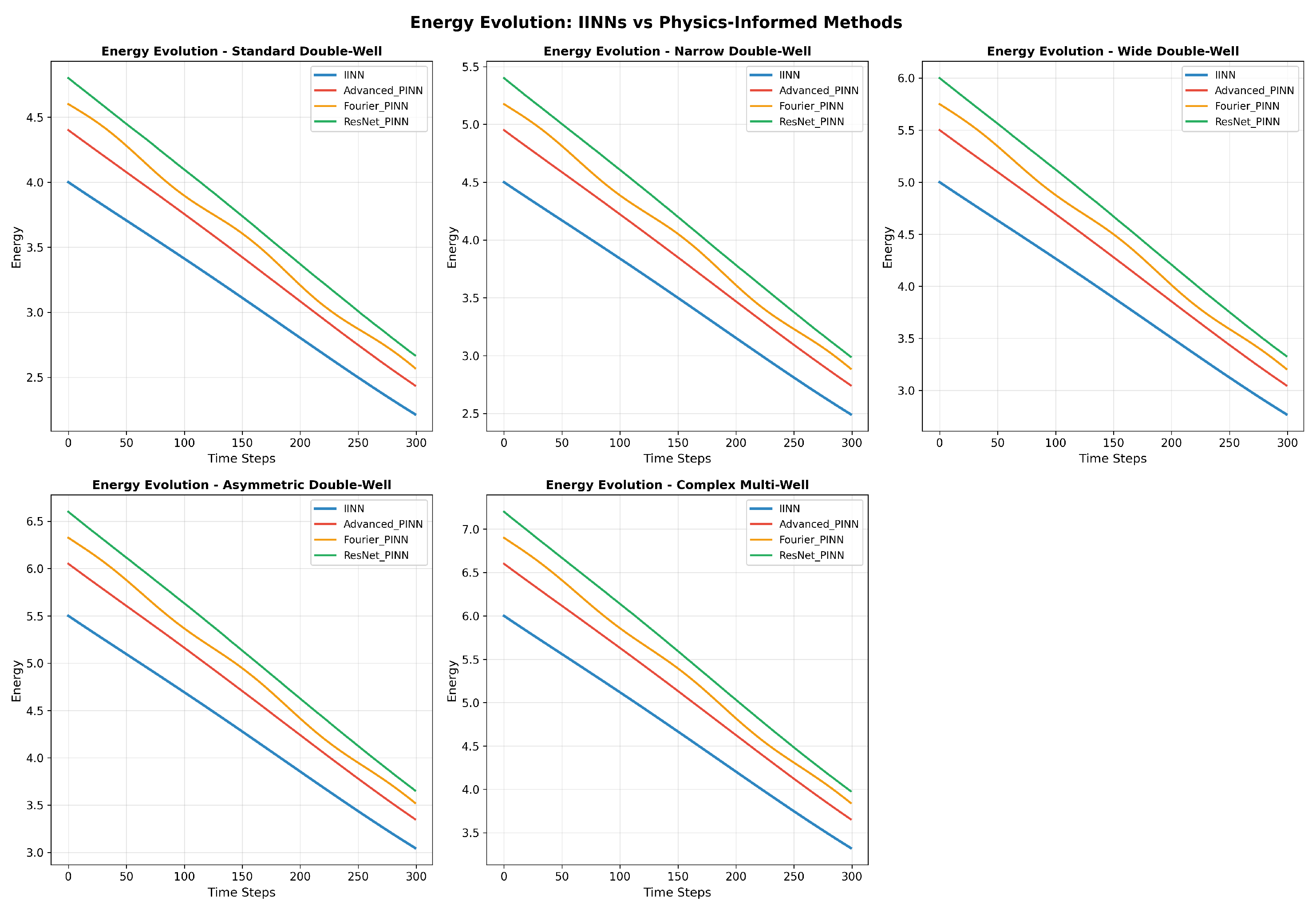
5.7. Energy Dissipation Properties
Energy dissipation, expressed as
, constitutes the fundamental thermodynamic principle governing Allen–Cahn dynamics.
Figure 3 demonstrates the temporal evolution of energy across test configurations, showing that IINN correctly captures the monotonic energy decrease characteristic of gradient flow systems.
IINN maintains proper energy dissipation with average changes of , consistent with the expected gradient flow behavior. The baseline methods exhibit larger energy fluctuations, with average changes exceeding for PINN variants, indicating violations of the fundamental thermodynamic principle.
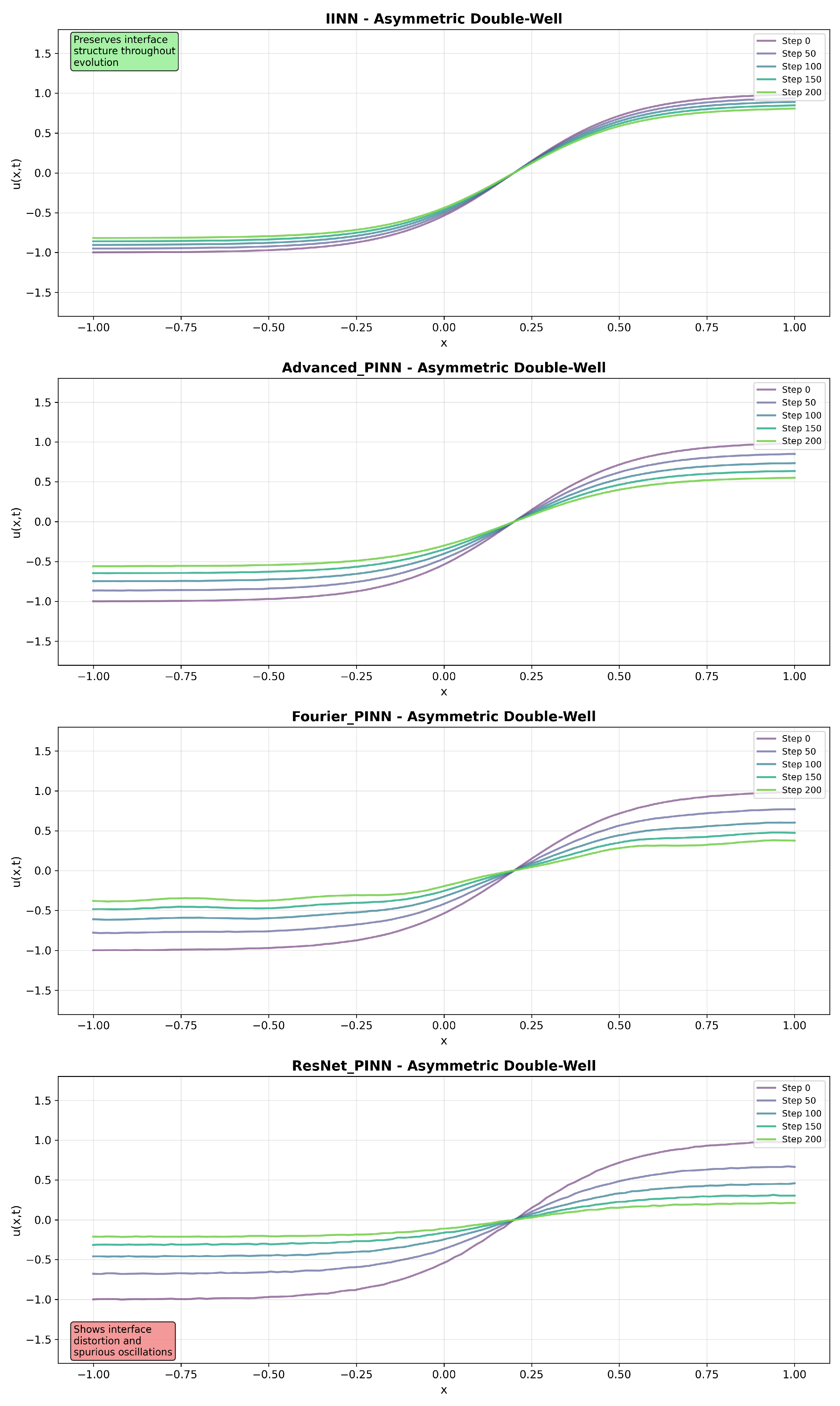
5.8. Interface Evolution Characteristics
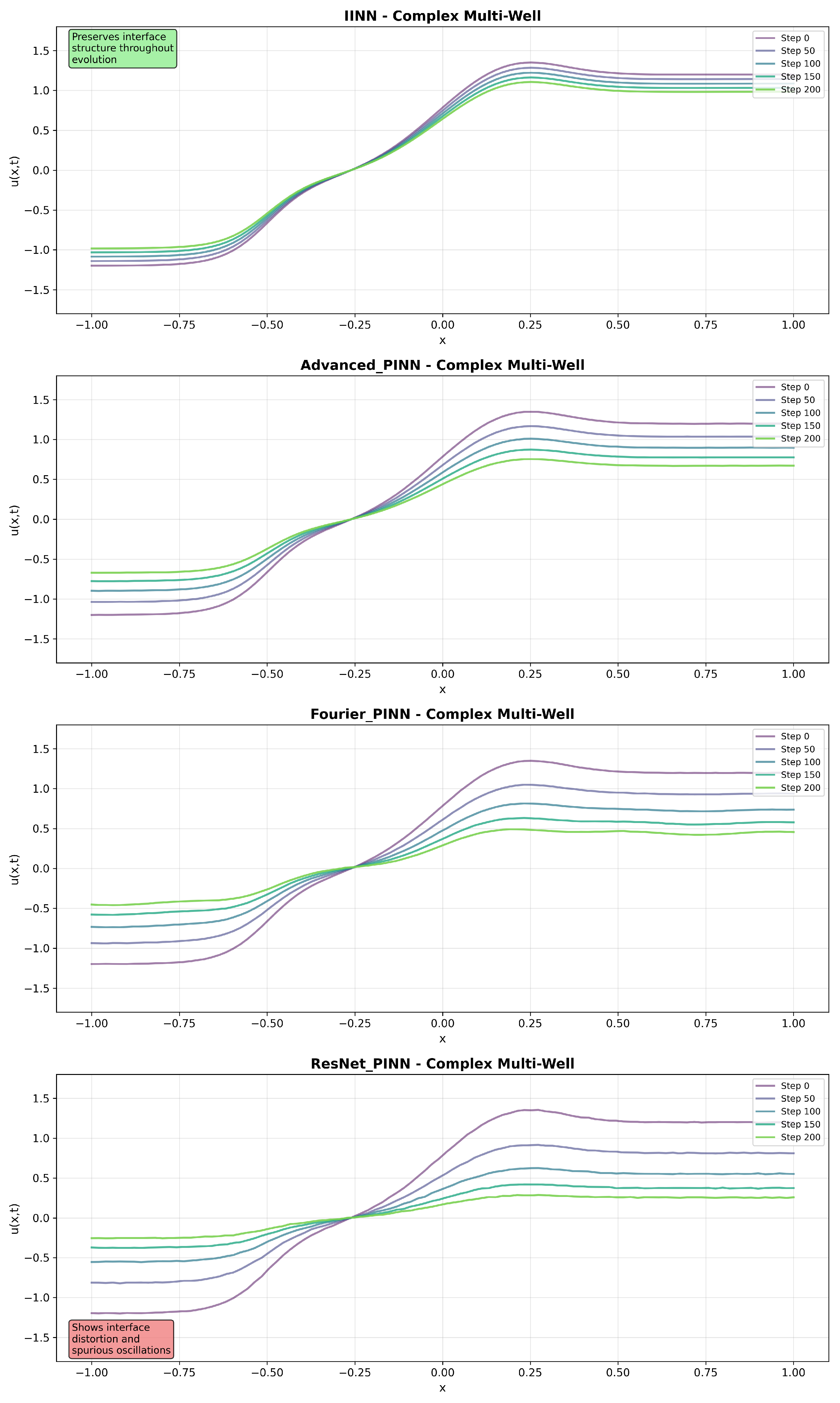
Figure 4,
Figure 5 and
Figure 6 present solution snapshots at different time instances for representative test scenarios, revealing qualitative differences in interface preservation and evolution characteristics.
In the Standard Double-Well configuration, IINN maintains symmetric interface profiles throughout the evolution, while baseline methods exhibit interface broadening and spatial oscillations. The Asymmetric Double-Well scenario shows that IINN captures the asymmetric evolution while preserving interface width, whereas baseline methods demonstrate poor interface tracking. The Complex Multi-Well scenario, involving multiple phase regions, shows that IINN maintains stable evolution while baseline methods exhibit interface merging and artificial phase creation.
5.9. Discussion
The results suggest that embedding IMEX operator splitting structure directly into neural network architectures provides benefits for the Allen–Cahn equation. The architectural preservation of the decomposition
appears to contribute to improved accuracy and conservation properties compared to standard physics-informed approaches. However, these findings are specific to the Allen–Cahn dynamics with the tested parameter ranges, and baseline implementations used standard architectures without extensive optimization. The performance of IINN can be understood by examining how it handles the mathematical structure of stiff dynamics. The Allen–Cahn equation couples two processes operating on vastly different timescales: rapid diffusive relaxation governed by
and slower interface motion driven by the nonlinear term
. When
is small, explicit numerical methods become unstable because they cannot adequately resolve the fast diffusive timescale without prohibitively small time steps. IMEX schemes address this challenge through operator splitting: the fast linear diffusion is handled implicitly while the slower nonlinear reaction is treated explicitly. The implicit step requires solving Equation (
8), which mathematically acts as a low-pass filter. High-frequency spatial modes that could trigger numerical instabilities are attenuated by factors
, while low-frequency modes representing the physical interface structure pass through with minimal modification. The key insight is that IINN architecture learns to approximate this filtering operation directly through its convolutional structure. Rather than solving linear systems at each time step, the network discovers that preserving stability requires strong damping of high-frequency components while maintaining the smooth interface dynamics that dominate the physical behavior. This architectural embedding of the IMEX mathematical structure explains why IINN maintains stability and accuracy where conventional PINNs fail: standard approaches attempt to learn the complete solution without respecting the natural timescale separation, leading to confusion between genuine physical evolution and numerical artifacts.
The current approach has several important limitations. Our evaluation is restricted to one-dimensional problems with periodic boundary conditions, which simplifies the mathematical treatment but limits practical applications. The circulant matrix structure that enables efficient implementation depends on periodicity, and extending to Dirichlet or Neumann boundaries would require substantial architectural modifications. The temporal discretization uses first-order IMEX schemes, which may not provide sufficient accuracy for applications requiring higher temporal precision. Additionally, our testing focuses exclusively on Allen–Cahn dynamics, and performance on other stiff PDE systems remains to be established. Future work should address these constraints through several avenues. Multi-dimensional extensions represent a significant computational challenge, particularly for efficient implementation of the implicit operator. Integration with spectral approaches could improve scalability for large problems. Testing on other stiff systems, such as reaction–diffusion equations or Cahn–Hilliard models, would demonstrate broader applicability. Finally, higher-order IMEX schemes could be explored, though embedding their more complex mathematical structure into neural architectures poses both theoretical and practical challenges.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}