1. Introduction
Climate change driven by global warming poses a serious threat to sustainable human development [
1]. According to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change (IPCC), greenhouse gas emission is the primary cause of global warming. Carbon emissions significantly intensify the greenhouse effect and have profound negative impacts on human health and economic activity [
2,
3].
In response to the challenges of climate change, the carbon market has emerged as an effective market-based instrument for controlling greenhouse gas emissions. Over the past two decades, the carbon market has played an important role in promoting energy transition and low-carbon development [
4]. Since the launch of the European Union Emissions Trading System (EU ETS) in 2005, carbon markets have gradually been established across the world. As one of the largest carbon dioxide emitters globally, China has actively responded to the call for low-carbon development. In 2011, the National Development and Reform Commission (NDRC) set out a strategic plan to transition from regional pilots to a nationwide carbon market. The first pilot programs were launched in 2013 in Beijing, Tianjin, Shanghai, Guangdong, Shenzhen, Hubei, and Chongqing, with Fujian joining in 2016 [
5]. In 2021, China’s national carbon market officially commenced operation, evolving from localized pilot programs to a unified, nationwide system. As the core indicator of the carbon market, the carbon price is shaped by both internal market dynamics and external factors. Sharp price fluctuations may threaten market stability and compromise the effectiveness of emission reduction efforts [
6]. Therefore, accurate carbon price forecasting is essential for stable and healthy market development. It enables participants to manage price volatility, reduce investment uncertainty, and optimize resource allocation, thereby advancing carbon reduction and climate goals [
7,
8,
9].
Carbon prices are influenced by a complex array of factors and often exhibit nonlinear, non-stationary, and noisy behavior, which poses significant challenges for accurate forecasting. Existing prediction approaches can be broadly categorized into three groups: statistical models, machine learning models, and hybrid models. Statistical models mainly include the autoregressive integrated moving average (ARIMA) [
10] and generalized autoregressive conditional heteroskedasticity (GARCH) [
11]. These models are grounded in economic theory and statistical methodology, aiming to extract meaningful patterns from data. However, they typically rely on strict assumptions, such as linearity and stationarity, which are often violated in real-world data [
12]. Given the pronounced nonlinearity and non-stationarity of carbon price series, traditional statistical models often struggle to capture their complex dynamics, which limits the accuracy of forecasts. Machine learning models mainly include random forest (RF) [
13], support vector machines (SVMs) [
14], extreme learning machine (ELM) [
15], multilayer perceptron (MLP) [
16], convolutional neural networks (CNNs) [
17], long short-term memory (LSTM) [
18] networks, and gated recurrent units (GRU) [
19]. Leveraging their strong nonlinear modeling capabilities and adaptive learning mechanisms, these models generally outperform traditional statistical methods in handling nonlinear and non-stationary time series [
20,
21]. However, they also face notable limitations, such as difficulty in capturing long-term dependencies, slow convergence, vulnerability to local minima, and the need for complex hyperparameter tuning [
9,
22]. Hybrid models have thus emerged as a promising approach to better capture the complex patterns underlying irregular carbon price fluctuations. Typically, these models combine signal-decomposition techniques with various forecasting methods [
23]. The core idea is to decompose complex data into multiple sub-components, each exhibiting distinct characteristics. These sub-components are subsequently modeled and predicted using appropriate techniques tailored to their individual properties. This strategy effectively addresses the limitations of individual models and leads to a substantial improvement in overall forecasting accuracy.
The formation mechanism of carbon prices is highly complex, shaped by a combination of factors such as policy regulation, energy prices, economic trends, and climate change [
24]. Consequently, in addition to models based solely on historical carbon price data, many studies have proposed multi-factor forecasting approaches. These models incorporate potential influencing variables from multiple dimensions and select those most strongly correlated with carbon prices to enhance predictive accuracy. Feature-selection methods can generally be categorized into three types: filter methods, wrapper methods, and embedded methods. Filter methods include min-redundancy (mRMR) [
25], correlation analysis [
26], partial autocorrelation function (PACF) [
27], and mutual information [
28]. These approaches use statistical metrics to evaluate feature relevance, enabling efficient preliminary screening through the removal of irrelevant or redundant features. Their key advantage lies in their ability to consider feature interactions, thereby enabling more targeted and accurate feature selection. However, they are often computationally intensive and heavily dependent on the underlying predictive model, which can limit their scalability and robustness [
29]. Embedded methods primarily include Lasso regression [
30] and feature-importance-evaluation techniques employed in tree-based models such as RF [
31] and extreme gradient boosting (XGBoost) [
32]. These methods integrate feature selection directly into the model training process, thereby achieving high computational efficiency while retaining the features most relevant to the prediction task. Nevertheless, their effectiveness is closely tied to the specific learning algorithm used, which may limit the generalizability of the selected features across different models.
However, there are significant challenges remaining for carbon price forecasting. First, conventional decomposition methods often fail to effectively capture the pronounced nonlinearity, non-stationarity, and multiscale characteristics inherent in carbon price series. This limitation hampers the accurate extraction of meaningful features from complex signals, thereby reducing the accuracy of the prediction. Second, most existing studies focus on single-dimensional features, mainly historical data, while overlooking the integration of external influencing factors. However, since carbon prices are driven by both their own past dynamics and a range of external forces, incorporating both types of information can lead to a more comprehensive and accurate understanding of price behavior. Thirdly, existing decomposition-based forecasting methods typically apply a single prediction model to each component and aggregate the results in a simplistic manner. This approach fails to exploit the complementary strengths of diverse models that are better suited to the distinct characteristics of components across different frequency domains.
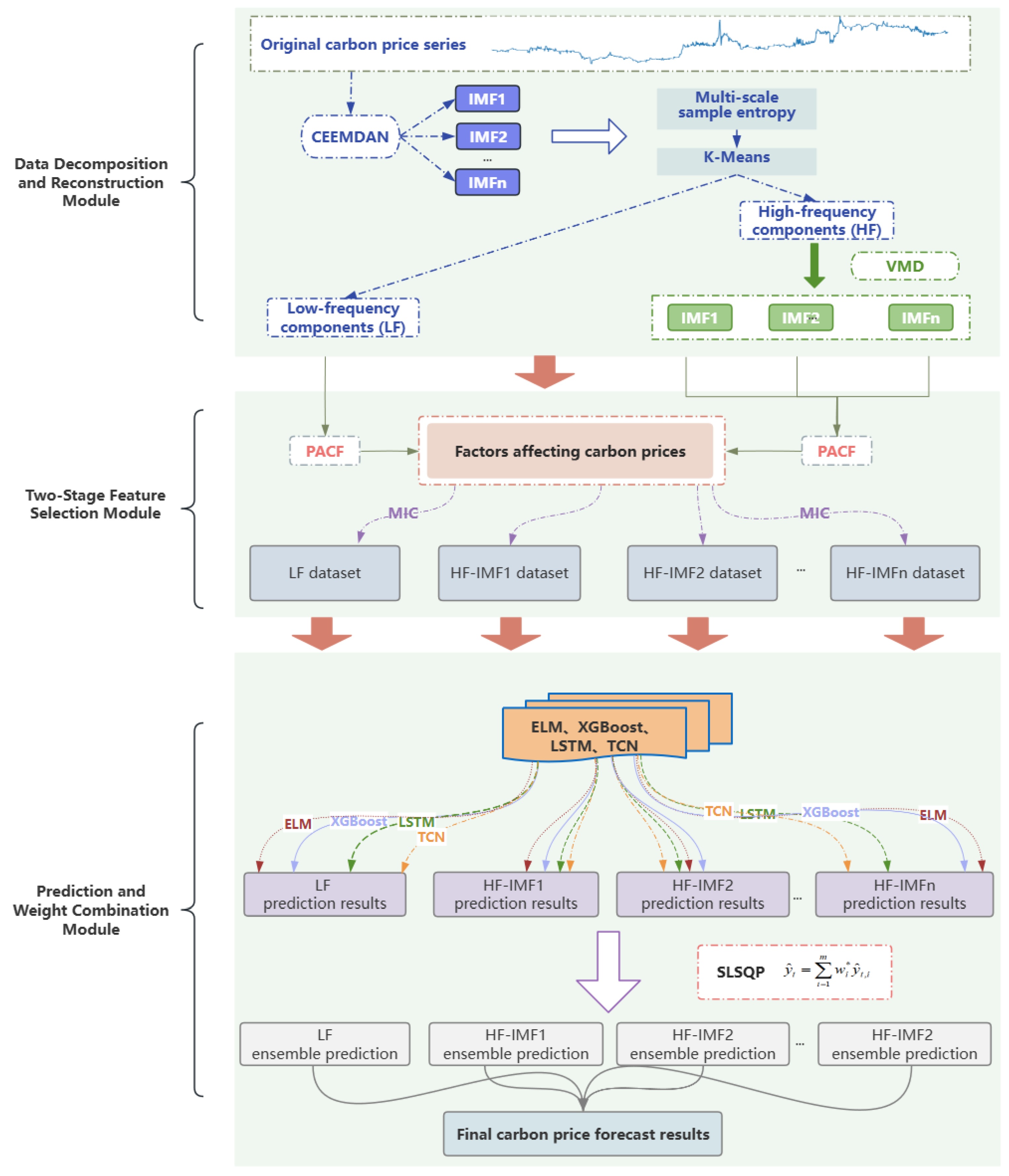
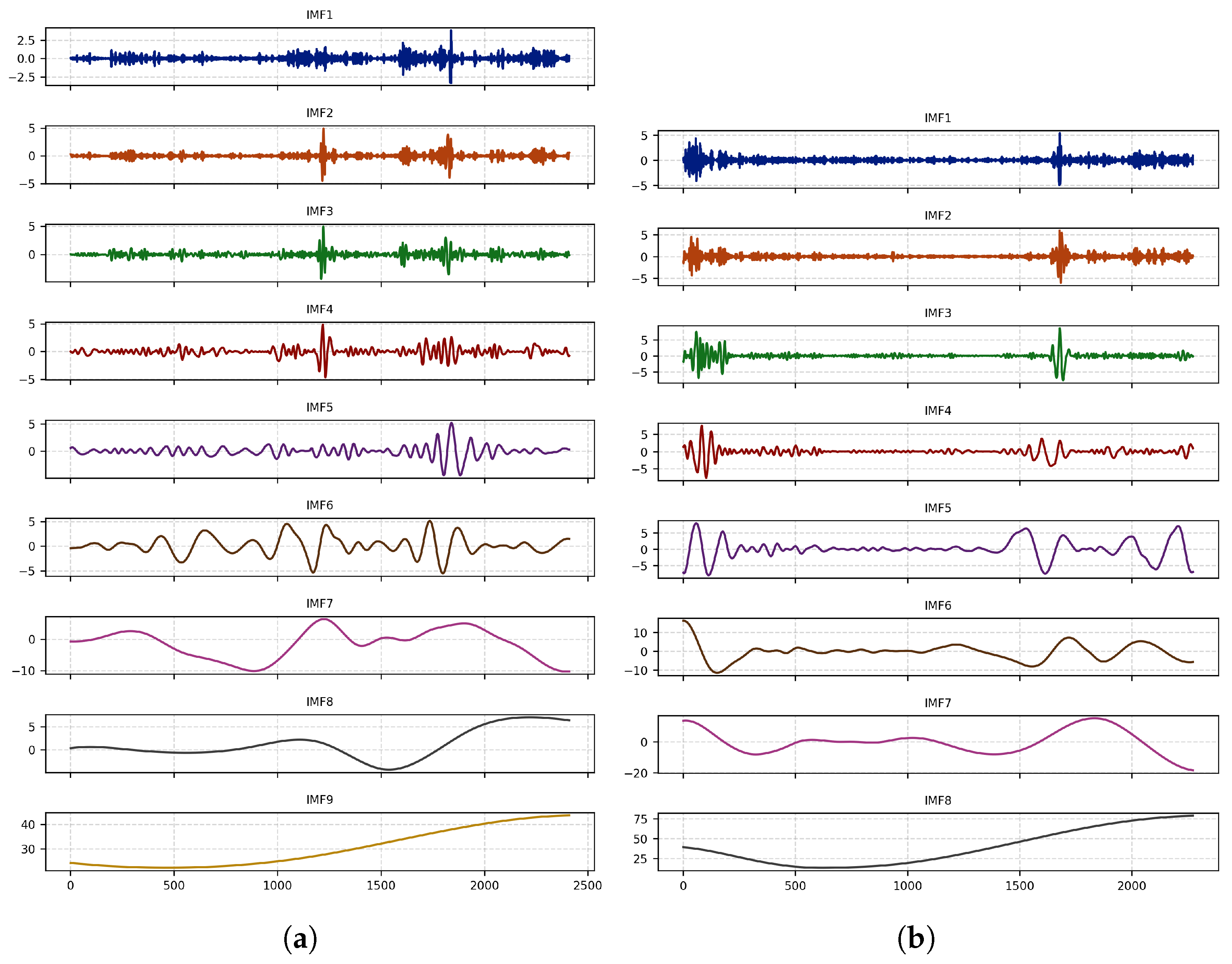
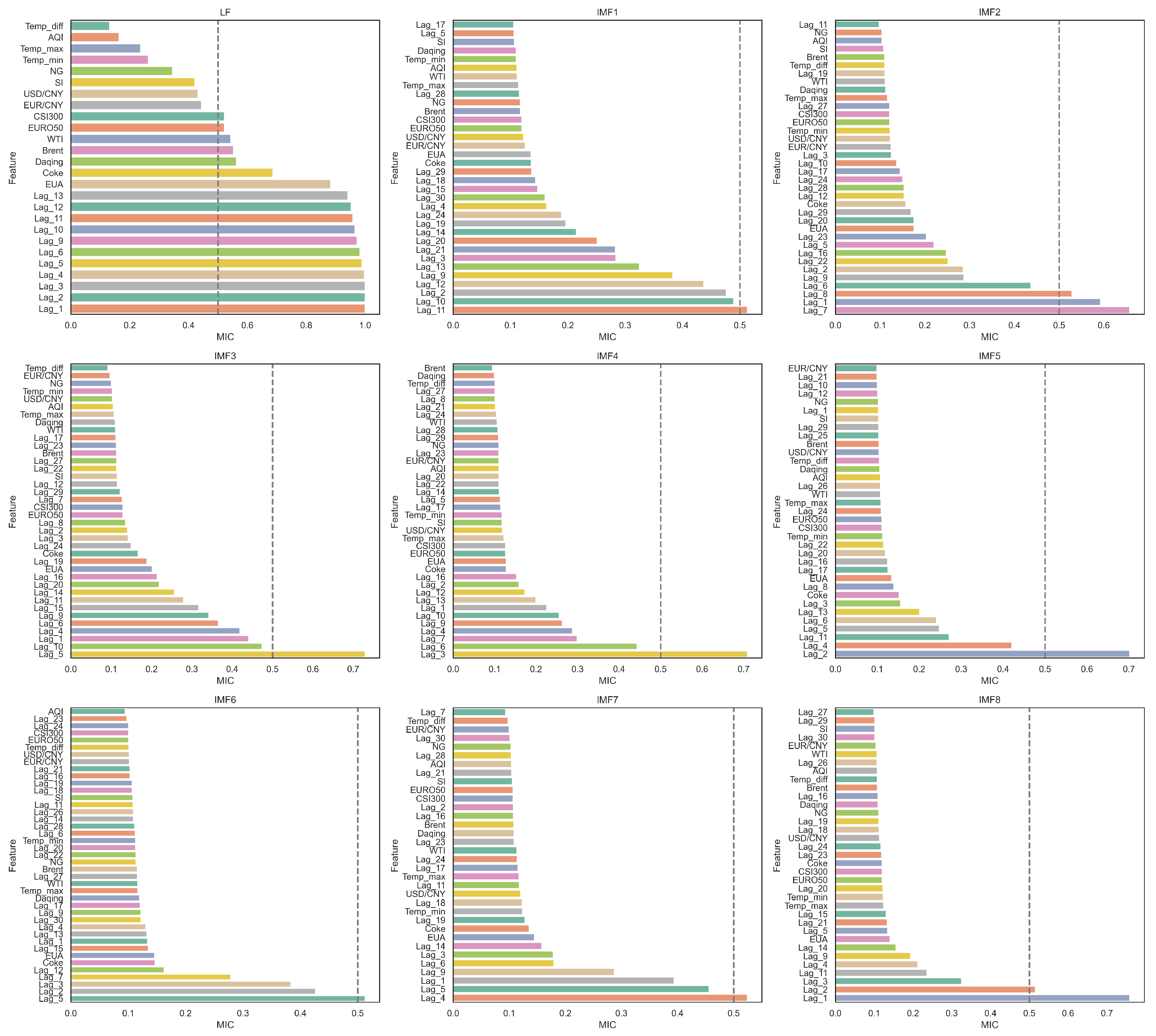
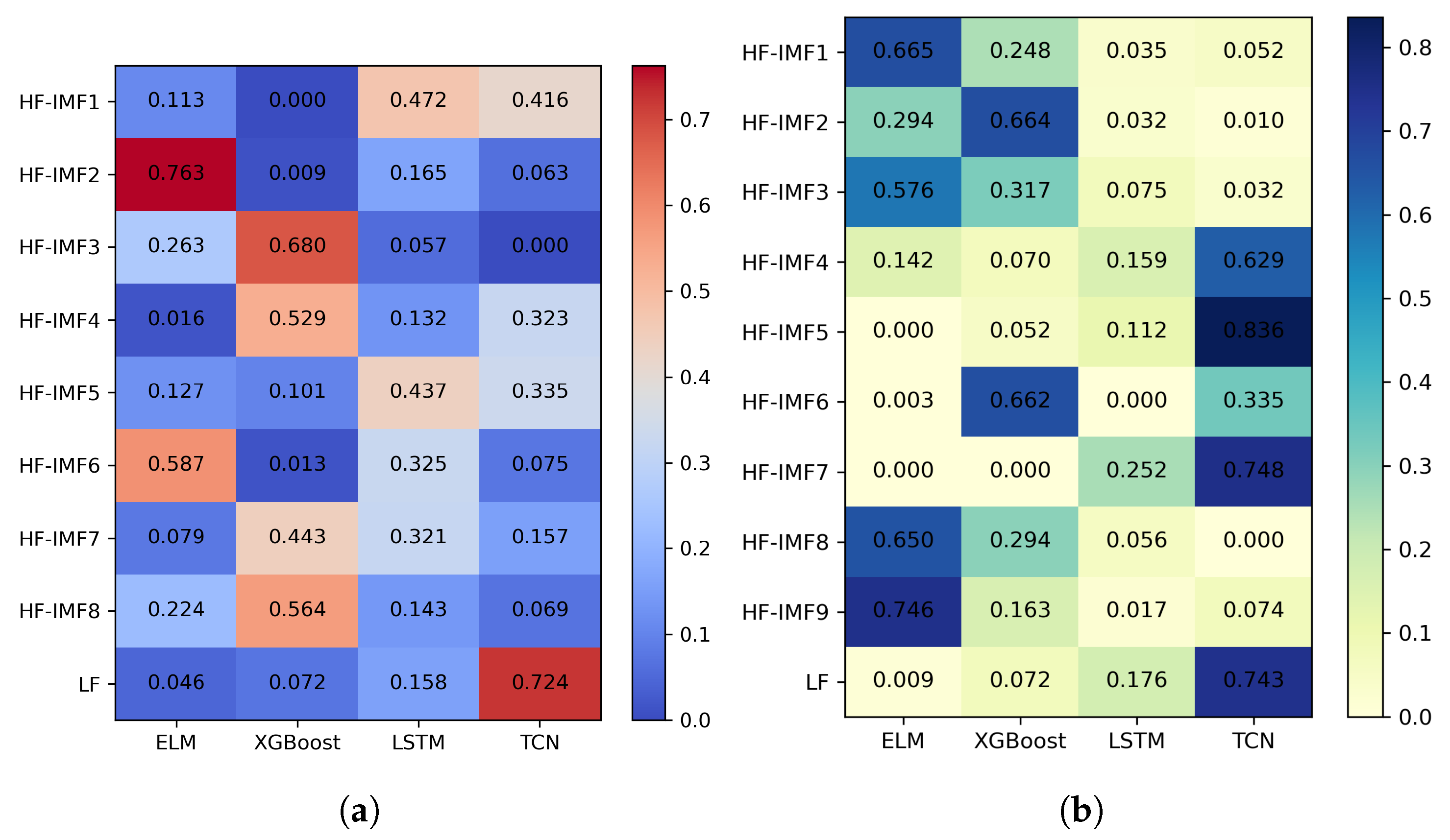
To overcome these challenges, this paper proposes a novel carbon-price-forecasting model that integrates a secondary decomposition strategy, two-stage feature selection, and ensemble learning with dynamic weight optimization. Methodologically, the model enhances feature extraction and ensemble learning by introducing a dynamic weight adjustment framework based on a sliding window and sequential least squares programming (SLSQP). In the decomposition and reconstruction module, the original carbon price series is first decomposed into several smooth sub-modes at distinct scales, using complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN). Subsequently, based on multiscale entropy (MSE) and K-Means clustering, sub-modes with similar complexity are grouped and reconstructed into low-frequency and high-frequency sequences. To mitigate mode mixing in the high-frequency components derived from CEEMDAN, a secondary decomposition is conducted using variational mode decomposition (VMD) optimized by particle swarm optimization (PSO). This integrated approach enhances feature-extraction efficiency and significantly reduces sequence complexity. In the feature-selection module, PCAF is first employed to filter historical carbon price data. Then, the maximal information coefficient (MIC) is applied to further identify relevant features from both the historical series and external influencing factors, thereby determining the optimal input set for the prediction model. Given that different sub-modes exhibit distinct characteristics, ELM, XGBoost, LSTM, and temporal convolutional network (TCN) are, respectively, employed as prediction models to capture the fluctuation patterns of each decomposed component. Subsequently, a dynamic ensemble learning strategy, incorporating a sliding window mechanism and SLSQP optimization, is applied to capture temporal variations in component contributions by adaptively integrating predictions from multiple base learners, thereby improving forecasting accuracy and robustness.
The innovations and contributions of this paper are as follows:
- (1)
Building on the existing literature, this paper broadens the range of factors influencing carbon price fluctuations by incorporating 21 external variables across six categories. Using this expanded set of features, a comprehensive, multi-dimensional indicator system has been constructed to support a multi-factor forecasting model with enhanced predictive capabilities.
- (2)
By accounting for the varying complexities and correlations among decomposition modes, an improved feature-extraction method integrating CEEMDAN, MSE, and K-Means clustering is proposed to effectively reconstruct informative components. PSO is then employed to optimize VMD for further decomposition of high-frequency modes. This approach enhances extraction efficiency and forecasting accuracy by reducing noise and sequence complexity.
- (3)
To overcome the limitations of single-dimensional feature selection, a two-stage method is proposed by combining PACF and MIC to extract key features from both historical carbon prices and external factors. This approach reduces redundancy and optimizes the model input structure.
- (4)
A dynamic ensemble module based on sliding window and SLSQP optimization is introduced to adaptively weight four base models over time. This design effectively captures carbon price fluctuations and effectively exploits model complementarities.
The remaining sections of this paper are structured as follows.
Section 2 outlines the theoretical basis of the relevant methods.
Section 3 presents the decomposition-and-integration hybrid forecasting model.
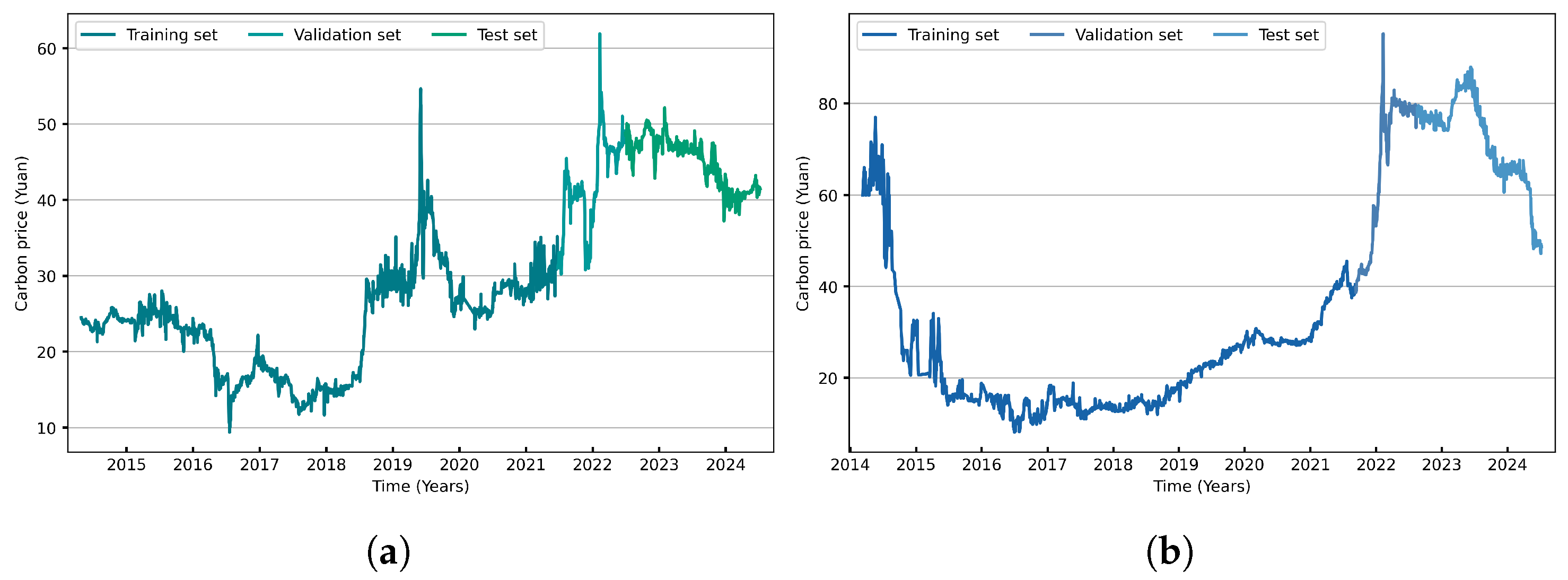
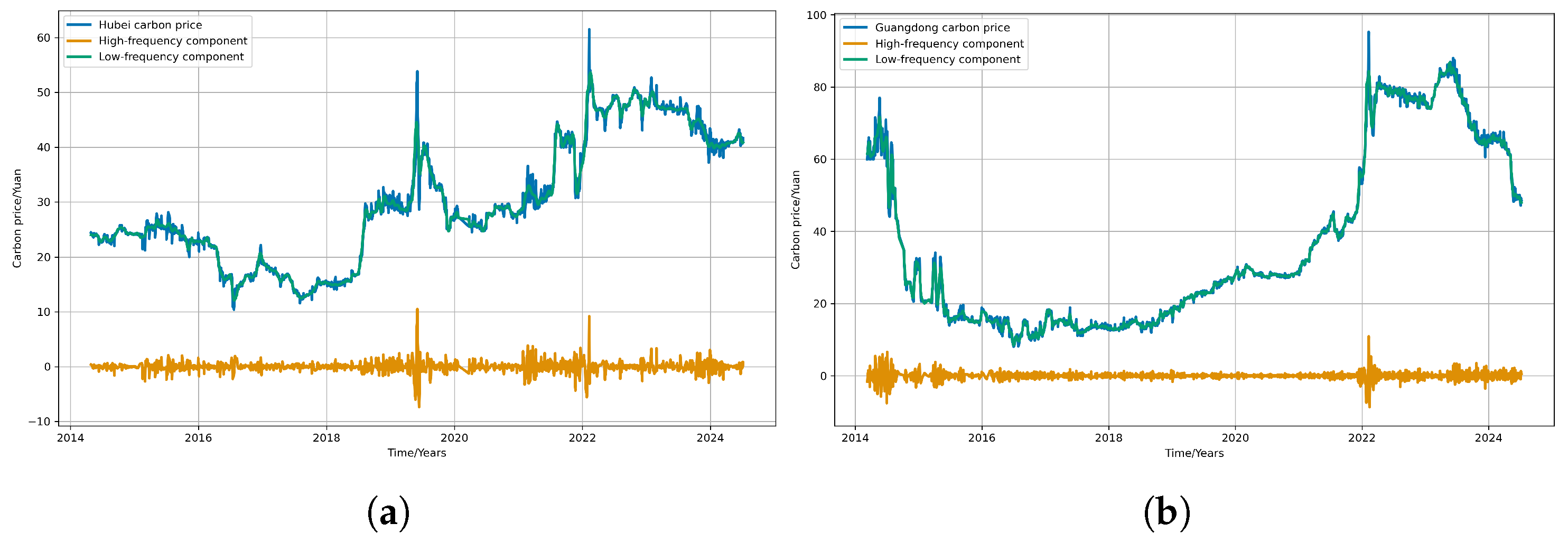
Section 4 applies the proposed model to the carbon markets in Hubei and Guangdong and discusses the results of the calculations.
Section 5 presents the conclusions and discussion.
2. Methods
2.1. Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN)
CEEMDAN, proposed by Torres et al. [
33], enhances both the completeness and accuracy of signal decomposition. It iteratively extracts each intrinsic mode function (IMF) by averaging the first IMFs obtained from an ensemble of noise-added signals, and it then adaptively adds noise to the residual at each stage. This process effectively suppresses mode mixing, improves reconstruction fidelity, and enhances computational stability.
2.2. Improved Variational Mode Decomposition Using Particle Swarm Optimisation
VMD, proposed by Konstantin Dragomiretskiy and Dominique Zosso [
34], is an adaptive and non-recursive signal-decomposition method. It decomposes a signal into
K IMFs, each represented as an amplitude- and frequency-modulated (AM–FM) component centered at a specific frequency.
The key parameters in VMD are the number of modes K and the penalty factor . A larger K allows for finer frequency resolution but may lead to over-decomposition, while a larger can cause mode mixing. Therefore, appropriate selection of K and is essential to achieve effective decomposition. To address this, PSO is employed to optimize these parameters. The procedure is as follows:
(1) Initialization. Randomly initialize N particles in the search space defined by . Each particle represents a candidate set of VMD parameters. Initialize the particle velocities, personal best positions, and set parameter bounds: and .
(2) Fitness evaluation. Perform VMD, using the parameters of each particle, and compute the corresponding fitness value.
(3) Update particle velocity and position. Update particle velocities and positions according to the following equations:
where
is the inertia weight,
and
are cognitive and social learning factors, respectively, and
,
are random values uniformly distributed in
.
(4) Update individual and global best positions. Update each particle’s personal best position based on its current fitness value. Compare all fitness values to update the global best position.
(5) Output the optimal VMD parameter set. Repeat Steps 3 and 4 until the maximum number of iterations is reached. Then, output the global best as the optimal VMD parameter set.
2.3. Multiscale Sample Entropy (MSE)
MSE is a signal complexity analysis method based on sample entropy (SampEn) [
35]. It introduces a scale factor
into the SampEn framework and systematically quantifies the complexity of a signal across multiple timescales through a coarse-graining procedure. The specific steps are as follows:
(1) Coarse-graining. Given a time series
of length
N, for each scale factor
construct a coarse-grained time series
as
(2) SampEn calculation at scale
. Compute SampEn of the coarse-grained time series at each scale:
(3) Generate the multiscale entropy spectrum. Repeat the above process over a range of scale factors
to obtain the multiscale entropy profile:
2.4. Partial Autocorrelation Function (PACF)
PACF is a statistical tool commonly used in time series analysis to measure the direct relationship between an observation and its lagged counterparts at a specific lag, while controlling for the linear influence of all shorter lags in the series.
2.5. Maximal Information Coefficient (MIC)
MIC is a statistical measure used to quantify the strength and pattern of association between two variables. It is particularly effective in identifying nonlinear, non-functional, and complex relationships. Given two variables and with n samples, the calculation of MIC involves the following steps:
(1) Grid partitioning. Divide the data space into an grid, with i bins along the x-axis and j bins along the y-axis. Count the number of data points in each cell to construct the joint distribution.
(2) Mutual information calculation. For each
grid, calculate the mutual information:
where
denotes the joint probability density of
and
, and where
and
are their respective marginal probabilities.
(3) MIC calculation. MIC is defined as the maximum normalized mutual information over all grids satisfying
, where
is a complexity control function, typically chosen as
. Formally,
2.6. Extreme Learning Machine (ELM)
ELM is a specialized form of single-hidden-layer feedforward neural network (SLFN). Its core idea is to significantly simplify the training process compared to traditional neural networks, thereby enabling exceptionally fast learning speeds.
2.7. Extreme Gradient Boosting (XGBoost)
XGBoost is a gradient boosting algorithm that builds decision trees iteratively to minimize a regularized loss function. Its objective combines a loss term, measuring prediction error, and a regularization term, which controls model complexity and reduces overfitting.
2.8. Long Short-Term Memory Network (LSTM)
LSTM is a special type of RNN designed to overcome vanishing and exploding gradient problems when training on long sequences. With memory cells and gating mechanisms, it effectively captures long-range dependencies, which can be well-suited for modeling temporal patterns and time series data.
2.9. Temporal Convolutional Network (TCN)
TCN, proposed by Bai et al. [
36], is a neural network architecture specifically designed for sequence modeling tasks. It inherits the powerful feature-extraction capabilities of traditional CNNs while effectively capturing sequential dependencies.
2.10. Sequential Least Squares Programming (SLSQP)
SLSQP is an optimization algorithm that combines sequential quadratic programming with least squares methods, which solves a series of local quadratic subproblems to efficiently approximate the solution of constrained nonlinear optimization tasks.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}