Abstract
Medical Visual Question Answering (MedVQA) lies at the intersection of computer vision, natural language processing, and clinical decision-making, aiming to generate accurate responses from medical images paired with complex inquiries. Despite recent advances in vision–language models (VLMs), their use in healthcare remains limited by a lack of interpretability and a tendency to produce direct, unexplainable outputs. This opacity undermines their reliability in medical settings, where transparency and justification are critically important. To address this limitation, we propose a zero-shot chain-of-thought prompting framework that guides VLMs to perform multi-step reasoning before arriving at an answer. By encouraging the model to break down the problem, analyze both visual and contextual cues, and construct a stepwise explanation, the approach makes the reasoning process explicit and clinically meaningful. We evaluate the framework on the PMC-VQA benchmark, which includes authentic radiological images and expert-level prompts. In a comparative analysis of three leading VLMs, Gemini 2.5 Pro achieved the highest accuracy (72.48%), followed by Claude 3.5 Sonnet (69.00%) and GPT-4o Mini (67.33%). The results demonstrate that chain-of-thought prompting significantly improves both reasoning transparency and performance in MedVQA tasks.
Keywords:
medical visual question answering; vision–language models; chain-of-thought prompting; zero-shot learning; medical imaging; visual reasoning MSC:
93C95; 68T05
1. Introduction
The convergence of computer vision (CV) and natural language processing (NLP) has accelerated progress in crossmodal intelligence, enabling systems to reason jointly over visual and textual data. Visual Question Answering (VQA) is a prominent example, where models interpret images and generate semantically accurate natural language responses [1]. A specialized branch of this field, Medical Visual Question Answering (MedVQA), focuses on analyzing complex medical images to produce clinically meaningful answers. VQA research extends beyond healthcare to a wide range of applications, including Document VQA [2], Chart VQA [3,4], Remote Sensing VQA [5], E-commerce VQA [6], Cultural Heritage VQA [7], and Autonomous Driving VQA [8]. These diverse directions reflect the growing impact of VQA in enhancing clinical communication, supporting diagnostic decision-making, and improving access to visual information across multiple domains [9].
Medical Visual Question Answering (MedVQA) holds strong potential to transform healthcare delivery in several impactful ways. It can serve as an educational tool for medical trainees by providing on-demand explanations of radiological findings that enhance traditional learning methods [10]. MedVQA systems also function as clinical decision support tools, assisting physicians in interpreting complex images by highlighting critical features or suggesting likely diagnoses based on similar cases [11]. Additionally, these systems can bridge communication gaps between specialists and patients by converting complex medical imagery into accessible language, thereby improving patient engagement and informed consent. In resource-limited settings, where access to expert radiologists is constrained, MedVQA can offer preliminary assessments to help prioritize urgent cases. As electronic health records increasingly include large repositories of medical images, MedVQA can also support efficient information retrieval and knowledge extraction [12].
Despite these promising applications, MedVQA introduces unique challenges. The specialized nature of medical language creates a semantic gap that general models are ill equipped to handle, requiring deep domain-specific knowledge. Unlike general VQA tasks, where approximate answers may suffice, clinical applications demand high precision and reliability, as errors can directly affect patient care. Medical images often involve subtle abnormalities, diverse imaging modalities, such as X-ray, CT, MRI, or ultrasound, and varying protocols that add complexity well beyond that of natural images. These visuals also carry contextual cues that must be interpreted in conjunction with patient history and clinical metadata. Moreover, the critical nature of medical decisions demands not only accurate answers but also clear and explainable reasoning that clinicians can trust [13].
Solving Medical Visual Question Answering (MedVQA) tasks presents two primary challenges. First, although numerous datasets pair medical images with associated questions and answers, they often lack the intermediate reasoning steps that connect questions to answers. This absence limits the ability to assess how well models understand and justify their responses. While some recent datasets include medical questions and answer texts, they still fall short in providing explainable pathways, resulting in black-box models whose outputs cannot be readily trusted in clinical environments. A clear step forward involves incorporating expert-level reasoning chains into these datasets. However, generating such annotations manually is time-intensive and demands extensive medical expertise. To date, no scalable or reliable system exists for automating this process [14]. Second, there is a pressing need for models that can perform MedVQA tasks with speed, accuracy, and interpretability. Many current approaches frame MedVQA as a retrieval or classification problem, relying on methods optimized for answer matching rather than reasoning [15]. Furthermore, the scarcity of large annotated datasets poses a major bottleneck. Medical image annotation is both labor-intensive and costly, requiring domain-specific knowledge. This limitation hinders the development of generalized MedVQA models capable of adapting to various conditions, imaging modalities, and institutional settings [16].
The widespread adoption of large language models (LLMs) following the emergence of ChatGPT has sparked considerable interest in applying these models to complex domain-specific tasks. LLMs, often combined with specialized tools, have demonstrated strong performance in healthcare, software development, and scientific domains. Continuous improvements in reasoning ability and the expansion of task coverage have kept LLMs at the forefront of artificial intelligence research. Their performance is commonly evaluated through benchmark tasks such as multitask learning, natural language inference, and large-scale problem solving [17].
One key advancement is the rise of vision–language models (VLMs), which integrate visual and textual data to process multimodal inputs more effectively. These models, trained on vast datasets, have proven particularly useful in healthcare, where they can detect subtle visual patterns and abnormalities in medical images that may be difficult to identify manually. General-purpose models such as CLIP, Flamingo, LLaVA, and ChatGPT-4 have exhibited strong emergent capabilities. For example, LLaVA—though trained on general instruction-following datasets—can interpret complex clinical images, such as identifying lesions in brain MRIs or abnormalities in chest X-rays, despite not being explicitly trained for medical diagnostics. VLMs have also demonstrated the ability to match radiology reports with images, recognize anatomical structures, and generate accurate captions for pathology slides. These examples illustrate the impressive cross-domain generalization of modern VLMs. To further enhance performance in clinical contexts, specialized models like BiomedCLIP have been developed [18]. At the same time, state-of-the-art LLMs are becoming increasingly advanced. Proprietary models such as GPT-3.5, GPT-4, PaLM, and Gemini are trained on enormous corpora comprising hundreds of billions to trillions of tokens and utilize a vast computational infrastructure. This large-scale training has led to unprecedented levels of performance. For instance, GPT-4 excels in natural language inference, while Gemini achieves top-tier results across benchmark suites such as MMLU and BIG-Bench [19]. The continuous scaling and refinement of LLMs is redefining the capabilities of AI, enabling more accurate, versatile, and generalizable systems across a wide range of applications.
A substantial body of prior research has addressed key challenges in Medical Visual Question Answering (MedVQA), with a focus on improving semantic alignment, interpretability, and reasoning. Zhan et al. [20] introduced UnICLAM, a unified and interpretable model that combines contrastive representation learning with adversarial masking to align visual and textual modalities within a shared latent space, outperforming state-of-the-art baselines on VQA-RAD and SLAKE and showing strong few-shot adaptability. Pan et al. [21] proposed MedVLM-R1, a lightweight vision–language model employing Guided Reward Prompt Optimization (GRPO), a reinforcement learning method that enables the model to learn reasoning paths without annotated rationales; notably, it generalized well across MRI, CT, and X-ray domains using only 600 training samples. Van et al. [18] conducted an evaluation of zero-shot and few-shot capabilities of models such as BiomedCLIP, LLaVA, and OpenFlamingo, demonstrating performance comparable to CNN-based methods even without task-specific retraining. Similarly, Hu et al. [19] developed ZPVQA, a prompt-based zero-shot framework that uses image-driven caption prompts to generate synthetic question–answer pairs, enabling effective visual–textual alignment without large annotated datasets. Interpretability remains a critical concern in clinical AI, and Gai et al. [15] addressed this with MedThink, a framework that enhances transparency by generating both answers and accompanying rationales, trained on three enriched datasets—R-VQA-RAD, R-SLAKE, and R-Path—created via a semi-automated annotation process. MedVLM-R1 also contributes to this goal by generating explicit natural language reasoning using reinforcement learning, without requiring manually curated rationales, and despite limited data and parameters, it achieved strong performance and generalization, representing a significant advancement toward interpretable and trustworthy AI systems in medical settings.
This study investigates the capabilities of state-of-the-art vision–language models in the context of MedVQA, focusing on zero-shot and zero-shot chain-of-thought (CoT) reasoning. The evaluation framework emphasizes not only answer accuracy but also clinical relevance, consistency, and the trustworthiness of model outputs, all of which are crucial for potential deployment in healthcare settings. The main contributions are as follows:
- Assessed the diagnostic capabilities of state-of-the-art vision–language models (VLMs) in a zero-shot setting using general prompts, assessing their ability to answer complex medical questions based solely on pre-trained knowledge, without explicit reasoning.
- Introduced a zero-shot chain-of-thought (CoT) prompting framework tailored for MedVQA, which encourages models to engage in structured, multi-step reasoning by generating intermediate explanations before arriving at a final diagnosis. This approach promotes greater transparency and interpretability in model inference.
- Conducted a comprehensive evaluation of three leading VLMs: Gemini 2.5 Pro, Claude 3.5 Sonnet, and GPT-4o Mini, under both standard zero-shot and our proposed zero-shot CoT prompting strategies, providing insights into how each model leverages visual and textual information for clinical reasoning.
- Performed an in-depth comparative analysis between conventional zero-shot prompting and our reasoning-enhanced zero-shot CoT method, demonstrating how structured reasoning significantly improves not only diagnostic accuracy but also the explainability and trustworthiness of model outputs in clinical contexts.
The existing literature in the field is reviewed in Section 2, highlighting previous work and key advancements. Following this, Section 3 provides a deeper exploration of the theoretical foundations and background relevant to this study. Section 4 introduces the proposed methodology, outlining the approaches and techniques employed in this research. The findings from the experiments are presented and analyzed in Section 5, assessing the performance and implications of the results. Section 6 discusses the limitations of the approach and highlights areas where further improvements could be made. Looking ahead, Section 7 outlines potential future directions for the research, proposing new avenues for exploration. Finally, Section 8 concludes the work by summarizing the key contributions and takeaways from this study.
2. Related Works
Recent advances in Medical Visual Question Answering (MedVQA) have attracted significant attention by integrating medical imaging and natural language processing to aid clinical decision-making. Efforts have concentrated on developing models that balance accuracy with interpretability, a critical need in healthcare. Approaches mainly include vision-based and multimodal methods combining images with text, as well as prompting and retrieval techniques leveraging large language models to enhance reasoning. The following section reviews the key progress addressing the challenges of accuracy, explainability, and generalization in MedVQA.
2.1. Vision and Multimodal Approaches in Medical VQA
In recent advancements within the field of MedVQA, several researchers have proposed innovative models and frameworks to enhance interpretability, accuracy, and adaptability in handling complex medical data. Gai et al. [15] introduced MedThink, a novel framework that significantly improves interpretability by incorporating Medical Decision-Making Rationales (MDMRs), supported by a semi-automated annotation process, which led to the creation of three benchmark datasets: R-RAD, R-SLAKE, and R-Path. These datasets, grounded in expert inputs and outputs from multimodal large language models, facilitated transparent reasoning across three distinct generation modes. In a related contribution, Canepa et al. [1] developed a MedVQA model based on domain-specific pretraining strategies that included a unique contrastive learning method. By integrating VGG-16, LSTM, and BioWordVec embeddings, their model achieved 60 percent accuracy on the VQA-Med 2019 test set and further enhanced interpretability through evidence verification using GradCAM. Addressing the surgical domain, Wang et al. [17] proposed Surgical-LVLM, a personalized large vision–language model for surgical VQA and region grounding tasks. By incorporating VP-LoRA blocks and the Token-Interaction Module, this model effectively captures long-range dependencies and aligns multimodal information, achieving leading performance on the EndoVis 2017, 2018, and EndoVis Conversations datasets. Furthermore, Zhan et al. [20] presented UnICLAM, a unified and interpretable MedVQA model that improves semantic alignment using contrastive representation learning combined with adversarial masking. This model employs a dual-stream architecture with soft-parameter sharing to align vision and text encoders within a shared latent space and has demonstrated superior performance on datasets like VQA-RAD and SLAKE with robust few-shot diagnostic adaptability. In another important study, Pan et al. [21] introduced MedVLM-R1, a lightweight visual language model designed for radiology VQA tasks, which utilizes Guided Reward Prompt Optimization (GRPO), a reinforcement learning strategy that enables explicit reasoning using only final answer labels and without requiring annotated reasoning steps. Despite its small scale of just 600 training samples and 2B parameters, MedVLM-R1 outperformed larger models and generalized effectively across imaging modalities, including MRI, CT, and X-ray. Alongside these efforts, Van et al. [18] conducted a comprehensive evaluation of visual language models (VLMs), such as BiomedCLIP, LLaVA, and OpenFlamingo, to assess their zero-shot and few-shot capabilities in analyzing complex biomedical images like brain MRIs and blood cell slides. Their findings highlight that VLMs can deliver competitive performance without retraining, signaling their diagnostic potential in the medical domain. Lastly, Naihao Hu et al. [19] developed the ZPVQA model, a zero-shot VQA framework that generates image-based prompts to create synthetic question–answer pairs, which are then used in an augmented prompt format. This method eliminates the need for extensive labeled data, strengthens the connection between image content and question context, and enhances model performance in tackling intricate multimodal medical tasks.
2.2. Prompting and Retrieval-Based Strategies in Medical Question Answering
In the evolving landscape of medical question answering, several innovative frameworks have emerged, each aiming to optimize large language model (LLM) performance through prompt engineering and knowledge integration techniques. Maharjan et al. [9] employed advanced prompting strategies, including zero-shot, few-shot, chain-of-thought (CoT), and self-consistency voting, to significantly enhance the performance of open-source foundation models like Yi34B across benchmarks such as MedQA, MedMCQA, and MMLU. Their findings revealed that CoT explanations using kNN few-shot yielded the most substantial improvements, resulting in a 14.2% performance boost over basic zero-shot methods. In a similar vein, Singhal et al. [22] introduced OpenMedLM, a platform built on open-source LLMs, also applying a combination of prompt-based strategies and achieving state-of-the-art results. Their use of the Yi34B model, along with self-consistency optimization, led to a 3.1% increase in accuracy and demonstrated the effectiveness of prompt engineering without requiring extensive fine-tuning. Complementing these approaches, Li et al. [23] proposed MKG-Rank, a multilingual medical QA framework that integrates medical knowledge graphs via a word-level translation mechanism to avoid semantic distortion. By implementing multi-angle ranking, caching strategies, and self-knowledge mining, MKG-Rank improved knowledge retrieval and significantly outperformed zero-shot baselines by up to 35.03%. Addressing the limitations of current Retrieval-Augmented Generation systems, Lian et al. [24] introduced RGAR, which retrieves both conceptual knowledge from large corpora and factual knowledge from EHRs through recurrent query generation. This dual-source retrieval process enhances the quality of generated answers and demonstrates superior performance using LLaMA-3.1-8BInstruct. Lastly, Shi et al. [25] developed SearchRAG, a novel RAG framework that leverages real-time search engines to dynamically generate search-friendly queries, incorporating an uncertainty-based selection mechanism to identify high-quality information. Their system yielded a 12.61% increase in answer accuracy on medical QA tasks, effectively addressing the issue of outdated static knowledge bases by pulling relevant, up-to-date data from the web.
3. Background Study
3.1. Overview of the Vision–Language Models
3.1.1. Gemini 2.5 Pro
Gemini 2.5 Pro [26], introduced as an experimental version, is presented by Google as its most advanced AI model to date, achieving state-of-the-art performance across numerous industry benchmarks and securing the top position on LMArena, a platform measuring human preferences for AI outputs. A defining feature of the Gemini 2.5 series is its focus on “thinking models,” which are designed to enhance reasoning by analyzing information, drawing logical conclusions, incorporating context, and making informed decisions before generating responses. This is supported by advancements in reinforcement learning and chain-of-thought prompting, coupled with a significantly improved base model and post-training techniques. Aimed at enabling more capable and context-aware AI agents, Gemini 2.5 Pro excels in handling complex tasks, particularly in coding, math, and science domains, achieving state-of-the-art results on benchmarks like GPQA and AIME 2025 without relying on test-time techniques such as majority voting. It also scored 18.8% on Humanity’s Last Exam, indicating substantial progress in advanced reasoning among models without tool use. Currently available in Google AI Studio and the Gemini app for Gemini Advanced users, it is expected to launch on Vertex AI soon, with production pricing to be announced.
3.1.2. Claude 3.5 Sonnet
Claude 3.5 Sonnet [27], part of Anthropic’s Claude 3 family, sits between the smaller Claude 3.5 Haiku and the more advanced Claude 3.7 Sonnet and Claude 3 Opus models. It strikes a balance between performance and speed, making it well suited for a wide variety of tasks. Notable for its strong reasoning abilities, Claude 3.5 Sonnet can handle complex reasoning tasks, analyze data, and generate thoughtful responses. It also boasts multimodal capabilities, processing and understanding both text and images, as well as code generation and analysis across various programming languages. The model maintains a deep contextual understanding, even in longer conversations. Anthropic’s Claude models are renowned for their exceptional reasoning, analysis, and contextual understanding, with a particular emphasis on safety and harmlessness, minimizing bias, and preventing harmful content. The models are designed with enterprise use in mind, providing reliability and performance for business applications. The Claude 3.5 Sonnet would likely build upon these strengths, improving speed, cost-effectiveness, and capabilities such as coding, multilingual understanding, or vision processing, positioning it as a mid-tier option within the Claude 3.5 series.
3.1.3. GPT-4o Mini
GPT-4o Mini [28] is a compact version of the GPT-4o model, where the “o” stands for “omni”, reflecting its enhanced capabilities in processing and generating text, audio, and images. The mini version is designed to offer greater efficiency and faster performance, retaining multimodal capabilities (text, audio, and image) but with optimizations or limitations to suit its smaller size. The primary focus of GPT-4o Mini is to strike a balance between performance and speed, delivering quick response times and reduced computational costs, making it perfect for applications that require rapid processing or operate under resource constraints. Its smaller form factor also makes it more accessible and deployable across a wider array of devices and platforms. While not as powerful as the full GPT-4o or its future iterations, the mini version is crafted to provide a strong balance of intelligence and efficiency, ideal for a broad range of tasks. The model currently supports text and vision inputs via the API, with future plans to expand to support text, image, video, and audio inputs and outputs. It boasts a context window of 128K tokens and can process up to 16K output tokens per request while maintaining knowledge up to October 2023. This makes GPT-4o Mini highly efficient, particularly for non-English text processing, offering cost-effective solutions without compromising performance.
3.2. Zero-Shot Chain-of-Thought Framework
This section introduces and defines the framework for evaluating vision–language models in the MedVQA task, with a focus on a zero-shot chain-of-thought (CoT) [29] approach.
3.2.1. Zero-Shot Learning
Zero-shot learning (ZSL) [30,31] refers to a model’s ability to perform a task without having seen any examples of that specific task during its training. This means that the model is expected to generalize its knowledge to entirely new problems it was not explicitly trained to solve. In the context of Medical Visual Question Answering (MedVQA), a zero-shot setting implies that the model must answer diagnostic questions about medical images without being fine-tuned on any specialized medical dataset.
This approach is particularly valuable in the medical field, where obtaining large-scale annotated data is often difficult due to privacy concerns, expert annotation requirements, and high costs. Evaluating models in a zero-shot setting allows the assessment of the extent to which useful medical knowledge has already been acquired through general pretraining on diverse data, as well as the ability to apply this knowledge to new, unseen tasks.
In a typical zero-shot MedVQA task, the model is given the following:
- A medical image I, such as an X-ray or MRI scan;
- A diagnostic question q, like “What part of the body was the mass located in?”;
- A set of possible answers .
The model’s goal is to select or generate the most appropriate answer using only its existing, pre-trained knowledge—without any additional training on medical data.
This process can be formally represented as
where
- M is the vision–language model;
- I is the input medical image;
- q is the natural language question;
- a is one of the candidate answers from the set ;
- denotes the model’s confidence or compatibility score for answer a given image I and question q.
The model chooses the answer that it deems most likely, based solely on what it has learned during its large-scale pretraining phase. This setup allows researchers to measure a model’s generalization capability and its potential utility in real-world, data-scarce medical environments.
3.2.2. Chain-of-Thought Reasoning
Chain-of-thought (CoT) reasoning [32] is an approach that guides the model to think through a problem in multiple logical steps before arriving at a final answer. Rather than producing a direct response, the model generates a sequence of intermediate thoughts or justifications. This step-by-step reasoning improves both the interpretability and accuracy of the model’s predictions, especially in complex domains like medical diagnosis.
In the context of MedVQA, CoT reasoning ensures that the model not only selects the most likely answer but also explains how it arrived at that answer by analyzing the image, interpreting relevant medical cues, and eliminating unlikely options. This mimics how a clinician might reason through a case, making the AI system more transparent and trustworthy.
The process of CoT reasoning can be represented as
where
- M is the vision–language model;
- I is the medical image (e.g., an X-ray or MRI);
- q is the natural language question (e.g., “Where is the cavitary lesion located?”);
- is the chain of reasoning steps;
- is the final predicted answer.
This equation emphasizes that the model does not make a decision based solely on the input image and question. Instead, it uses a structured reasoning process R, composed of intermediate steps, to guide its decision-making. These steps might involve identifying specific regions in the image, interpreting clinical patterns, and forming logical inferences—just like how a human expert would solve a diagnostic question.
Overall, chain-of-thought reasoning transforms the model from a black box into a transparent decision-maker by making its intermediate thought process explicit. This is crucial in medical applications, where trust, interpretability, and robustness are essential.
3.2.3. Why Apply Chain-of-Thought?
In clinical diagnostics, transparent reasoning is essential, extending beyond mere conclusions. AI systems interpreting complex medical images must avoid black-box outputs to prevent diagnostic oversight, as these images often contain subtle features requiring systematic analysis. Chain-of-thought (CoT) reasoning is particularly crucial in radiology, where diagnostic accuracy directly impacts treatment outcomes. Sequential reasoning enables the detection of interconnected pathologies that may be missed by opaque systems. Clear reasoning pathways support clinical validation, peer review, and serve as valuable educational tools for junior clinicians by elucidating diagnostic logic. CoT also aids medicolegal compliance through transparent documentation of decision-making steps, facilitating the identification of biases or systematic errors in automated diagnostics. Step-by-step reasoning builds trust in AI-assisted diagnoses while preserving human oversight. Furthermore, transparent processes enable the continuous improvement of diagnostic algorithms by analyzing both successful and failed cases. The greedy CoT approach constructs each analytical step based on prior conclusions without backtracking, mirroring how expert clinicians methodically assess diagnostic images. This structured reasoning ensures logical flow, minimizes ambiguity, and ultimately bridges AI efficiency with clinical accountability and interpretability.
Chain-of-thought (CoT) reasoning facilitates this through a formalized process where
and where represents the probability of diagnostic outcome y given image input x, z represents the intermediate reasoning steps, and Z is the set of all possible reasoning pathways.
This approach offers several clinical advantages:
- 1.
- Enhanced Diagnostic Precision: The stepwise examination of visual features reduces the probability of overlooking critical diagnostic indicators. Each reasoning step contributes incrementally to diagnostic certainty:
- 2.
- Alignment with Clinical Methodology: The reasoning structure mirrors established clinical diagnostic protocols, where
- 3.
- Interpretability Coefficient: The comprehensive elucidation of reasoning enhances clinician–AI collaboration through improved transparency, quantifiable as
When applied to medical image interpretation, CoT reasoning transforms the analysis from an opaque process to a transparent sequence of deductions. This transformation is particularly crucial in scenarios where subtle radiological findings may signify clinically significant pathologies.
The structured reasoning pathway reduces the algorithmic opacity that often characterizes deep learning approaches in medical imaging, thereby fostering greater trust among clinical practitioners and facilitating responsible integration of AI systems into diagnostic workflows.
3.2.4. Zero-Shot Chain-of-Thought Prompting
In our approach, we apply the chain-of-thought strategy in a zero-shot setting. Specifically, the model is prompted to generate a reasoning chain before predicting the final answer. The process is formalized as follows:
Given a vision–language model M, a medical image I, a diagnostic question q, and a set of possible answers , we prompt M to generate an explicit reasoning chain r before producing the final answer prediction . Formally,
The reasoning chain, denoted as r, is a sequence of intermediate steps that guides the model toward the final answer. Each step represents an individual reasoning component that helps the model analyze the medical image and question.
The process is represented as
where CoT refers to the chain-of-thought prompting strategy. Each intermediate reasoning step can be expressed as
where each is an intermediate step of reasoning, leading to the final answer. These reasoning steps help the model break down the image and the question systematically, making the final answer more reliable and explainable.
3.3. Evaluation Metrics Summary
To evaluate the performance of our Medical Visual Question Answering (MedVQA) models—namely, Gemini 2.5 Pro, Claude 3.5 Sonnet, and GPT-4o Mini—we adopt multiple metrics that reflect both the classification accuracy and fine-grained per-option evaluation in a clinical multi-choice setup. Each query in our dataset includes four answer choices: Option A, Option B, Option C, and Option D. The model must select the most appropriate one based on the visual context and associated medical question.
3.3.1. Accuracy
Accuracy [33] measures the fraction of questions where the model’s selected answer exactly matches the ground truth option. It is computed as
where
- N is the total number of visual–question pairs;
- is the predicted answer option for the ith query;
- is the ground truth answer option for the ith query;
- is the indicator function, which returns 1 if the argument is true and 0 otherwise.
3.3.2. Precision
Precision [34] reflects how accurately the model selects each individual option () within a given group . In this study, the groups are organized based on different types of medical images rather than specific clinical categories. For example, these groups may correspond to image modalities such as X-rays, MRIs, or CT scans. The model’s precision measures its ability to correctly identify the relevant options associated with each of these image-based groups.
where
- is the number of times option o was correctly predicted for category c;
- is the number of times option o was incorrectly predicted (i.e., it was selected but was not the correct answer).
The macro-averaged precision across all categories and options is reported to reflect general reliability:
3.3.3. Recall
Recall [34] quantifies the model’s ability to correctly retrieve the true answer for each option across categories. It is defined per class and per option as
where
- is the number of false negatives (i.e., instances where option o was the correct answer but the model failed to predict it).
The macro-averaged recall is computed as
3.3.4. F1-Score
Given the clinical importance of both high precision (avoiding incorrect medical conclusions) and high recall (ensuring no critical answers are missed), the harmonic mean of precision and recall per class and option is employed:
To fairly aggregate performance, the F1-score [34] is weighted based on the number of instances in each category:
where
- is the number of question–answer pairs in category c;
- N is the total number of question–answer pairs across all categories.
This weighted F1-score provides a comprehensive evaluation of MedVQA models by capturing both overall accuracy and detailed per-option performance, which is critical for safety-sensitive clinical applications.
3.4. Dataset Description
3.4.1. PMC-VQA Dataset
The “PMC-VQA” dataset [35], specifically the Compounded Images version (PMC-VQA-1), was utilized to evaluate zero-shot chain-of-thought reasoning across three different vision–language models. Due to computational cost constraints, we randomly selected 100 samples from the training dataset for each model to ensure a controlled experimental environment. The PMC-VQA dataset is derived from PubMed Central (PMC) articles and contains Visual Question Answering pairs designed for training and evaluating AI models in the medical domain. The “Compounded Images” subset features medical figures with multiple visual elements combined into a single image, which presents a more challenging scenario for visual reasoning tasks. The dataset is available through HuggingFace (https://huggingface.co/datasets/hamzamooraj99/PMC-VQA-1, accessed on 10 May 2025) in a streaming-friendly format, facilitating efficient model training and evaluation processes.
3.4.2. Dataset Statistics and Structure
The complete PMC-VQA dataset comprises 176,948 samples in the training set and 50,000 samples in the testing set. For zero-shot and zero-shot chain-of-thought (CoT) experiments, 100 samples were randomly selected from the training set for each model, primarily due to computational cost constraints. In the zero-shot setting, models were directly evaluated on these samples without any task-specific examples. In the zero-shot CoT setting, the same subset was used, with models prompted to generate intermediate reasoning steps before producing the final answer.
Each sample in the PMC-VQA dataset includes several key fields: the figure_path, which provides the filename of the corresponding image (e.g., “PMC_1.jpg”); the question, which presents a medical question related to the image; and the answer, which is the correct response to the question. Additionally, four multiple-choice options—Choice A, Choice B, Choice C, and Choice D—are provided, along with an answer_label indicating the correct option (A, B, C, or D). The image field stores the actual image data, typically represented as a PIL Image object.
To help visualize the dataset, a few representative examples are shown in Figure 1.
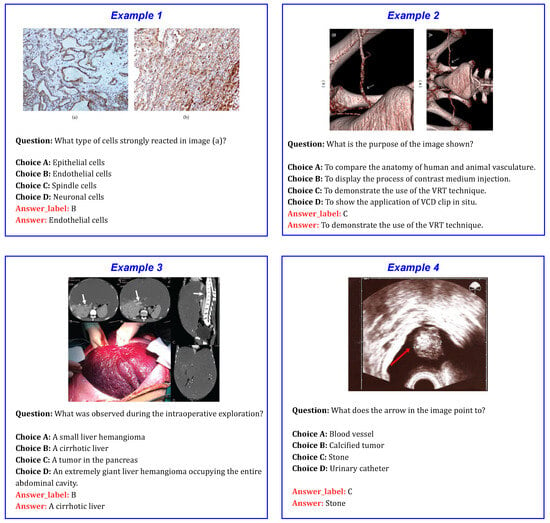
Figure 1.
Sample examples from the PMC-VQA dataset, showing medical images along with corresponding questions and multiple-choice options.
4. Proposed Methodology
This section presents the approach for evaluating the reasoning capabilities of vision–language models (VLMs) [36] in Medical Visual Question Answering using a zero-shot chain-of-thought (CoT) framework. The methodology systematically investigates the performance of various state-of-the-art VLMs on medical diagnostic tasks without specific fine-tuning. The overall step-by-step process for Medical Visual Question Answering employing both zero-shot and zero-shot chain-of-thought (CoT) prompting strategies is illustrated in Figure 2.
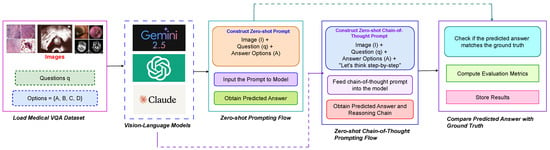
Figure 2.
Step-by-step methodology for Medical Visual Question Answering using both zero-shot and zero-shot chain-of-thought (CoT) prompting strategies. This framework is applied across multiple models including GPT-4o Mini, Claude 3.5 Sonnet, and Gemini 2.5 Pro.
4.1. Experimental Setup
Three vision–language models, Gemini 2.5 Pro, Claude 3.5 Sonnet, and GPT-4o Mini, were selected to evaluate performance in Medical Visual Question Answering. Each model was tested in a zero-shot setting without any task-specific training on Medical VQA datasets. Additionally, zero-shot chain-of-thought reasoning was applied to assess their ability to logically interpret medical images and generate answers with explicit reasoning steps. For each evaluation, the models received medical images, corresponding questions, and multiple choice options, allowing measurement of their capacity to reason about medical imagery and produce accurate responses without prior fine-tuning on domain-specific data.
4.2. Prompt Engineering for Visual Question Answering
The goal of this design is to guide the vision–language model through a structured process of medical image analysis using a zero-shot chain-of-thought framework. The model performs reasoning and generates an answer based solely on the visual evidence provided in the medical image, without requiring task-specific training. The key components of the prompt design are as follows.
4.2.1. Task Definition
The task is clearly defined as a Medical Visual Question Answering (MedVQA) problem. The model is provided with a medical image I, a diagnostic question q, and a set of possible answers A. The objective is to analyze the image and select the most appropriate answer from the available options based on visual evidence. Furthermore, the model generates intermediate reasoning steps that emulate clinical thinking, thereby improving interpretability and supporting informed decision-making.
4.2.2. Zero-Shot Instruction
In zero-shot learning, the model generates predictions using its existing knowledge without relying on prior examples. A comprehensive discussion of the zero-shot learning approach can be found in Section 3.2.1.
4.2.3. Chain-of-Thought Instruction
The model is explicitly guided to “think step by step” prior to generating its response. This chain-of-thought (CoT) approach encourages a systematic and deliberate reasoning process, minimizing premature conclusions. By decomposing the analysis of the medical image and corresponding question into intermediate reasoning steps, the model produces a more comprehensive and well-substantiated answer.
A detailed discussion of this reasoning methodology is provided in Section 3.2.2.
4.2.4. Model Response Structure and Reasoning Chain
The model’s response is structured into distinct components. First, it generates an explicit reasoning chain that describes how the input image and question are interpreted. This chain consists of a sequence of intermediate steps that help the model analyze the visual features of the image, understand the semantic content of the question, and integrate both to guide the reasoning process. Based on this reasoning, the model selects the most appropriate answer from a set of options.
Formally, the predicted answer is defined as
where
- denotes the probability of selecting answer given the image I, question q, and the generated reasoning chain r.
- The model chooses the answer with the highest probability as its final prediction.
These probabilities are computed internally by the model based on its learned parameters and inference–time decoding configurations. Specifically, generation settings such as temperature, top-k, and top-p (nucleus sampling) influence how likely each answer is to be selected:
- Temperature controls the randomness of the output distribution. A lower temperature results in more deterministic outputs, while a higher temperature encourages more diverse responses.
- Top-k limits the sampling pool to the top k most probable tokens, reducing noise from low-probability options.
- Top-p restricts the selection to the smallest set of tokens whose cumulative probability exceeds a threshold p, balancing between diversity and confidence.
Together, these configurations guide the model’s sampling behavior during inference, ultimately affecting which answer is assigned the highest probability and selected as the final prediction.
4.2.5. Final Answer Format
Once the reasoning process is completed, the model generates the final selected answer in the specified format:
This ensures that the output is precise, providing only the final answer without additional commentary or reasoning.
4.3. Assessment Protocol for Medical VQA Tasks
4.3.1. Evaluation Procedure for Zero-Shot Medical VQA
We outline the methodology used to evaluate the performance of three vision–language models in a zero-shot Medical Visual Question Answering (MedVQA) setting. The evaluation process is formalized in Algorithm 1.
| Algorithm 1 Evaluation procedure for zero-shot Medical VQA. |
|
4.3.2. Evaluation Procedure for Zero-Shot Chain-of-Thought Reasoning
This section presents our methodology for evaluating vision–language models using zero-shot chain-of-thought (CoT) prompting for Medical VQA. The complete process is outlined in Algorithm 2.
| Algorithm 2 Evaluation procedure for zero-shot chain-of-thought Medical VQA. |
|
4.4. Configurations Details and Cost Analysis
In our Medical Visual Question Answering (MedVQA) experiments, each model receives the following input structure: a medical image, a natural-language question regarding the image, and four multiple-choice answer options (A, B, C, and D). The task is to identify and return the correct answer from the options. All models are run with a temperature setting of 0.1 to ensure deterministic outputs.
We emphasize that each model uses a different prompt format, specifically tailored to its capabilities and requirements for both zero-shot and zero-shot chain-of-thought reasoning. We extensively designed and experimented with multiple prompt variations to identify those that consistently produced the most accurate and reliable results. In this paper, we present only the prompts that yielded the best performance. Throughout the prompt development process, medical experts provided valuable feedback, which guided the refinement and improvement of the prompts to ensure clinical relevance and clarity. The prompt designs for zero-shot reasoning are illustrated in Figure 3, Figure 4 and Figure 5, while those for zero-shot chain-of-thought reasoning are shown in Figure 6, Figure 7 and Figure 8. For a comprehensive understanding, additional examples of the prompts are presented in the Appendix A. Additionally, the cost of using these models varies according to the provider’s pricing per million input and output tokens, as detailed in Table 1.

Table 1.
Token cost per million tokens for each vision–language model.
Table 1.
Token cost per million tokens for each vision–language model.
| Model | Input Token Cost (per 1M) | Output Token Cost (per 1M) | Provider |
|---|---|---|---|
| Gemini 2.5 Pro | USD 1.25 | USD 10.00 | |
| Claude 3.5 Sonnet | USD 3.00 | USD 15.00 | Anthropic |
| GPT-4o Mini | USD 0.15 | USD 0.60 | OpenAI |
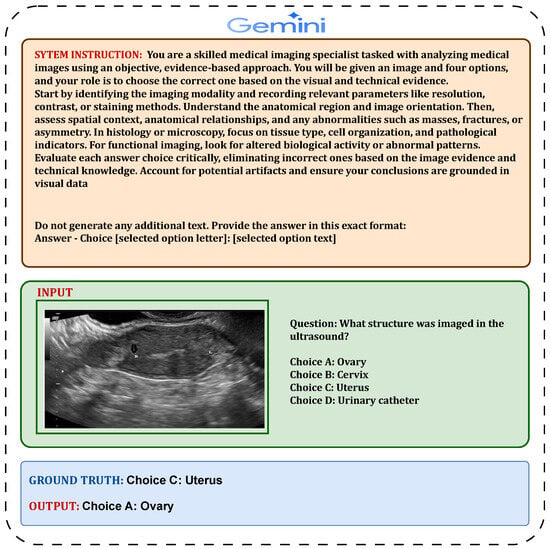
Figure 3.
Detailed illustration of the Gemini 2.5 Pro zero-shot prompt structure.
4.4.1. Zero-Shot Evaluation Prompt Design for Gemini 2.5 Pro
We used the Gemini 2.5 Pro model via Google AI Studio’s API to perform multiple-choice medical question answering. The input included a high-resolution medical image and a structured prompt composed of detailed image interpretation instructions, the medical question, and four labeled answer choices (A–D). This prompt structure was optimized for Gemini’s multimodal reasoning. We configured the model with temperature = 0.0, top-p = 1.0, and top-k = 1 to ensure a fully deterministic selection of the most likely answer. The average prompt length was about 260 tokens. Gemini’s strong alignment between visual and textual modalities made it particularly effective for radiological and dermatological tasks (see Figure 3 for the zero-shot prompt structure).
4.4.2. Zero-Shot Evaluation Prompt Design for Claude 3.5 Sonnet
Claude 3.5 Sonnet was accessed through Anthropic’s API and used in a strictly deterministic setup to select the correct answer from four choices. The prompt included the image and a structured instruction followed by a clinical question and answer options. We used temperature = 0.0, top-p = 1.0, and top-k = 1, ensuring stable and reproducible responses. The prompt averaged 250 tokens. Claude was particularly sensitive to subtle visual findings and supported robust multimodal comprehension (see Figure 4 for the zero-shot prompt structure).
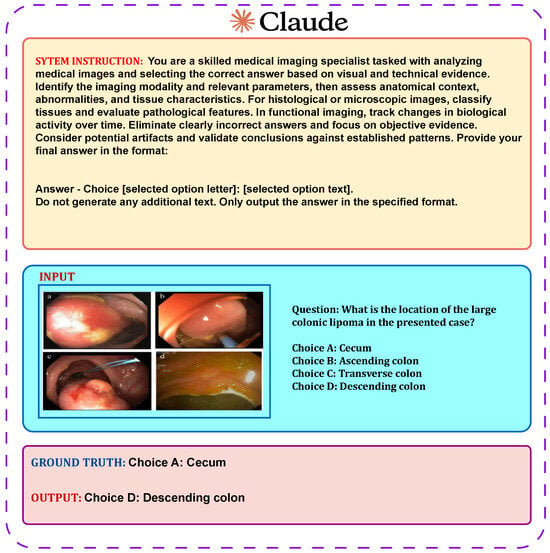
Figure 4.
Detailed illustration of the Claude 3.5 Sonnet zero-shot prompt structure.
4.4.3. Zero-Shot Evaluation Prompt Design for GPT-4o Mini
We used GPT-4o Mini via OpenAI’s API in a deterministic inference setting. The input included a medical image and a well-structured prompt containing interpretation instructions, the question, and clearly labeled options A–D. The configuration used was temperature = 0.0, top-p = 1.0, and top-k = 1, which ensured consistent and repeatable answer selection. The average prompt length was approximately 270 tokens. GPT-4o Mini offered rapid, accurate responses suitable for clinical question answering, particularly in time- and cost-sensitive contexts (see Figure 5 for the zero-shot prompt structure).
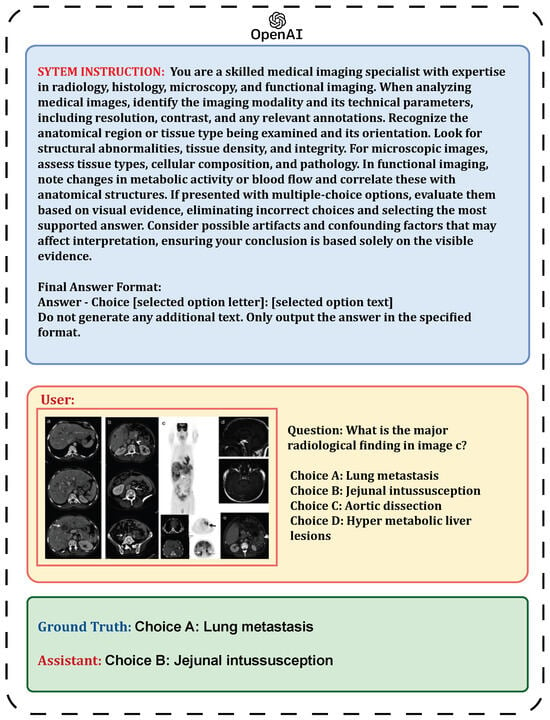
Figure 5.
Detailed illustration of the GPT-4o Mini zero-shot prompt structure.
4.4.4. Zero-Shot Chain-of-Thought Prompt Design for Gemini 2.5 Pro
In this approach, the input consisted of a high-resolution medical image along with a structured prompt containing detailed image interpretation instructions, the medical question, and four labeled answer choices (A–D). The prompt design was tailored to optimize Gemini 2.5 Pro’s multimodal reasoning capabilities, as shown in Figure 6. The model was configured with temperature set to 0.0, top-p to 1.0, and top-k to 1 to ensure a fully deterministic selection of the most likely answer. The average prompt length was approximately 580 tokens. Gemini’s strong alignment between visual and textual modalities contributed to its effectiveness on radiological and dermatological tasks.
4.4.5. Zero-Shot Chain-of-Thought Prompt Design for Claude 3.5 Sonnet
This method involved providing the model with the medical image alongside a carefully structured instruction, followed by a clinical question and the corresponding answer choices, as illustrated in Figure 7. The model settings were fixed with temperature at 0.0, top-p at 1.0, and top-k at 1 to guarantee consistent and repeatable outputs. The average prompt length was around 590 tokens. Claude demonstrated a keen ability to detect subtle visual details and exhibited strong multimodal understanding.

Figure 6.
Zero-shot chain-of-thought (CoT) prompt design for the Gemini 2.5 Pro model in Medical Visual Question Answering.

Figure 7.
Zero-shot chain-of-thought (CoT) prompt design for the Claude 3.5 Sonnet model in Medical Visual Question Answering.
4.4.6. Zero-Shot Chain-of-Thought Prompt Design for GPT-4o Mini
For this approach, the input comprised a medical image alongside a carefully structured prompt that included interpretation instructions, the clinical question, and clearly labeled answer options A–D (see Figure 8). The model was configured with temperature set to 0.0, top-p to 1.0, and top-k to 1 to guarantee consistent and reproducible answer selection. The average prompt length was approximately 620 tokens. GPT-4o Mini provided fast and accurate responses, making it particularly well suited for clinical question answering in settings where time and cost efficiency are essential.

Figure 8.
Zero-shot chain-of-thought (CoT) prompt design for the GPT-4o Mini model in Medical Visual Question Answering.
All evaluations were performed consistently, with the prompts tailored per model and no retries or sampling. Responses were automatically parsed to extract the final predicted answer.
5. Result Analysis
This section evaluates three models, Claude Sonnet 3.5, GPT-4o Mini, and Gemini 2.5 Pro, on Medical Visual Question Answering using zero-shot and zero-shot chain-of-thought prompting. Confusion matrices for both methods are shown in Figure 9 and Figure 10. Performance comparisons are illustrated with bar charts in Figure 11 and Figure 12 and summarized in Table 2 and Table 3. The zero-shot results shown in Figure 9 demonstrate how each model performs without task-specific training, highlighting their strengths and weaknesses across different question types. The bar chart and table provide a quantitative overview of these outcomes. The zero-shot chain-of-thought prompting in Figure 10 allows models to reason step by step, leading to improved performance on complex questions. The corresponding figures and table detail these improvements. Comparing the two approaches shows how adding reasoning steps enhances the models’ ability to accurately interpret and answer medical visual questions.
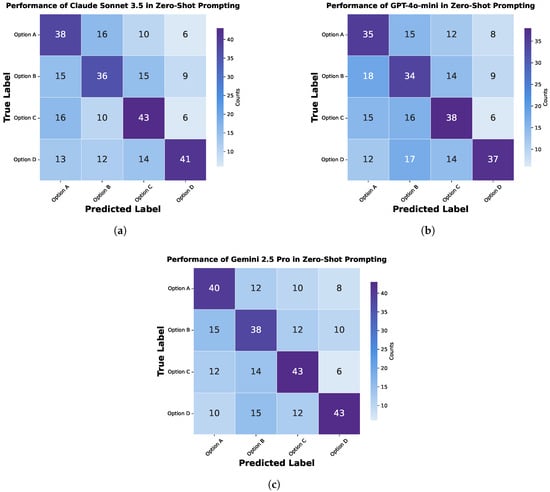
Figure 9.
Confusion matrix for zero-shot prompting in Medical Visual Question Answering, showing the performance of different models: (a) Claude Sonnet 3.5, (b) GPT-4o Mini, and (c) Gemini 2.5 Pro.
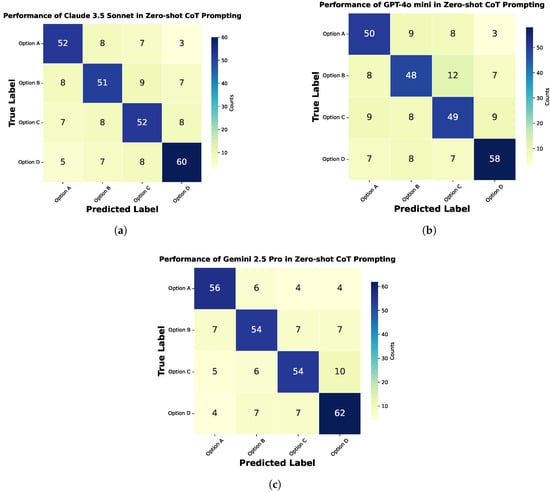
Figure 10.
Confusion matrix for zero-shot chain-of-thought (CoT) prompting in Medical Visual Question Answering, showing the performance of different models: (a) Claude Sonnet 3.5, (b) GPT-4o Mini, and (c) Gemini 2.5 Pro.
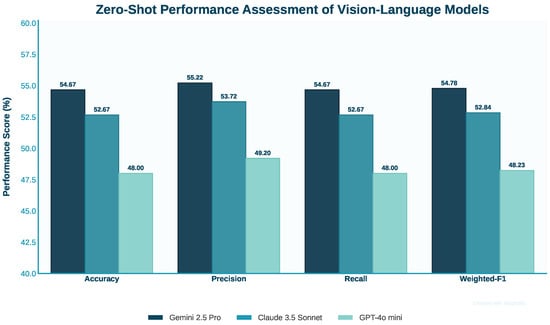
Figure 11.
Comparison of performance metrics for three vision–language models using zero-shot prompting.

Figure 12.
Performance comparison of three vision–language models in zero-shot chain-of-thought prompting.
Table 2.
Performance comparison of vision–language models in zero-shot Medical Visual Question Answering tasks.
Table 3.
Comparative performance of vision–language models on MedVQA in a zero-shot chain-of-thought prompting framework.
5.1. Zero-Shot Result Analysis for Gemini 2.5 Pro
Gemini 2.5 Pro achieved the highest performance among the three models tested on the Medical Visual Question Answering tasks, with 54.667% accuracy, 55.222% precision, 54.667% recall, and a 54.782% weighted F1-score. Although it was the top performer in this comparison, these results reflect a modest overall performance. The prompt provided to Gemini 2.5 Pro was comprehensive, including detailed instructions for analyzing various types of medical images such as radiology, histology, microscopy, and functional imaging. It guided the model to identify imaging modalities, technical parameters, anatomical context, and specific abnormalities. Additionally, the prompt offered clear strategies for tackling multiple-choice questions through elimination and evidence-based selection. Despite these detailed instructions, the model’s accuracy of only 54.667% highlights significant limitations in zero-shot Medical Visual Question Answering. This suggests that even well-designed prompts incorporating domain expertise are insufficient for consistent interpretation of complex medical imagery without task-specific training or fine-tuning.
5.2. Evaluating Zero-Shot Performance of Claude 3.5 Sonnet
Claude 3.5 Sonnet demonstrated intermediate performance among the tested models with 52.667% accuracy, 53.719% precision, 52.667% recall, and 52.841% weighted F1-score. These results place it slightly below Gemini 2.5 Pro but above GPT-4o Mini. The prompt for Claude 3.5 Sonnet was similar to Gemini’s but was somewhat more concise. It covered the key aspects of medical image analysis, including modality identification, anatomical assessment, tissue evaluation, and the careful consideration of evidence before selection. The prompt structure was clear and included specific formatting instructions for the answer. Claude’s performance at 52.667% accuracy reflects significant challenges in zero-shot medical image interpretation. Despite the structured prompt that attempted to guide the model through a systematic analysis process, the results suggest that Claude 3.5 Sonnet lacks the specialized knowledge or visual reasoning capabilities required for consistent performance in this specialized domain without additional training.
5.3. Performance Evaluation of GPT-4o Mini in Zero-Shot Tasks
GPT-4o Mini showed the lowest performance among the three models evaluated, achieving 48.000% accuracy, 49.198% precision, 48.000% recall, and a 48.230% weighted F1-score. These results are only slightly better than random guessing in a four-option multiple-choice setting. The prompt for GPT-4o Mini was the most detailed and comprehensive, offering extensive instructions on analyzing various medical image types, identifying modalities, assessing anatomical regions, evaluating abnormalities, and systematically approaching multiple-choice questions. Despite this, the model delivered the lowest scores. This outcome suggests fundamental limitations of GPT-4o Mini in visual reasoning for specialized medical tasks under zero-shot conditions. The detailed prompt was insufficient to overcome its challenges in interpreting complex medical images without specific training. Overall, all three models performed modestly on these zero-shot Medical Visual Question Answering tasks, with even the best model achieving limited success. This underscores the difficulty of applying general-purpose AI models effectively in specialized medical domains without dedicated fine-tuning.
5.4. Analyzing Zero-Shot Chain-of-Thought Results for GPT-4o Mini
With zero-shot chain-of-thought prompting, GPT-4o Mini showed notable improvements in accuracy (67.33%), precision (69.24%), and recall (68.32%), resulting in a weighted F1-score of 68.81%. These gains reflect its enhanced ability to perform structured diagnostic reasoning, especially in step-by-step visual interpretation tasks. The approach guides the model through diagnostic steps starting with imaging modality, anatomical orientation, and technical assessment. This helps extract visual features more accurately. Improvements were clear in gross anatomical and basic histological cases, with better recognition of tissue organization, spatial relationships, and early pathology such as fractures and inflammation. Chain-of-thought prompting also improved the handling of comparative and multi-step questions by evaluating options against visible evidence and technical details like staining patterns and MRI signal intensities. This reduced superficial pattern matching and supported more informed decisions.
5.5. Analyzing Zero-Shot Chain-of-Thought Results for Claude 3.5 Sonnet
Claude 3.5 Sonnet demonstrated notable performance gains when guided by chain-of-thought (CoT) prompting, particularly in diagnostic precision and overall interpretive accuracy. Under this structured reasoning approach, its precision rose to 71.62%, recall reached 71.66%, and the resulting weighted F1-score improved to 70.72%. Overall accuracy increased to 69.00%, indicating more consistent alignment with correct diagnostic outcomes.
The CoT prompting framework is closely aligned with the multi-step interpretive workflow used in advanced medical image analysis. This structure enabled Claude 3.5 Sonnet to better contextualize imaging modalities, identify relevant anatomical and pathological features, and differentiate subtle findings from artifacts. Its ability to reason through spatial orientation, tissue architecture, and modality-specific parameters became more systematic, especially in cases involving ambiguous visual cues or overlapping diagnostic possibilities. The improvements were most apparent in histological and microscopic images, where CoT prompting supported more accurate classification of tissue types and detection of pathological transformations such as neoplasia or inflammation. Additionally, in cross-sectional imaging (e.g., CT and MRI), Claude more effectively applied directional and sectional plane analysis, resulting in improved localization and characterization of abnormalities.
5.6. Analyzing Zero-Shot Chain-of-Thought Results for Gemini 2.5 Pro
With zero-shot chain-of-thought prompting, Gemini 2.5 Pro, already a top model, showed further gains in diagnostic precision and consistency. It achieved 72.48% accuracy, with precision and recall rising to 75.36% and 75.38%, yielding a weighted F1-score of 74.67%. This highlights its improved reliability in medical image interpretation requiring systematic reasoning and anatomical accuracy. The chain-of-thought framework guided the model step by step from identifying imaging modality and plane orientation to evaluating anatomical structures, mirroring expert workflows. This structured approach enhanced its ability to extract relevant features with specificity and to distinguish among competing diagnoses, especially in ambiguous or overlapping visual cases. It excelled in interpreting complex histology and advanced imaging, such as MRI and CT scans, by better understanding tissue staining, signal variations, and spatial relationships. The model also improved in ignoring artifacts such as motion blur, leading to clearer and reproducible conclusions. Gemini 2.5 Pro performed particularly well on multi-step diagnostic questions, accurately eliminating unlikely answers through modality-specific and spatial reasoning for evidence-based decisions.
5.7. Comparison Between Medical Experts and Chain-of-Thought Reasoning
To rigorously evaluate the clinical relevance and trustworthiness of the chain-of-thought (CoT) reasoning approach employed by multiple vision–language models, a comparative study was conducted involving two medical experts. Each expert was presented with a set of three distinct medical cases, each comprising a medical image, a diagnostic question, and four possible answer options. The experts independently selected the answer they considered most accurate for each case, along with optional clinical reasoning to capture their diagnostic rationale.
Step 1: Expert Response. The medical experts carefully reviewed the diagnostic question and corresponding image for each case and selected the answer they deemed most appropriate. Where applicable, they were encouraged to document the clinical logic underlying their decisions. This step served as a baseline for evaluating expert diagnostic reasoning without model intervention.
Step 2: Chain-of-Thought Reasoning Response. For the same set of cases, the chain-of-thought (CoT) reasoning outputs from three state-of-the-art vision–language models—Gemini 2.5 Pro, Claude 3.5 Sonnet, and GPT-4o Mini—were generated. Each model’s response included both a final selected answer and a sequence of intermediate reasoning steps detailing how the model interpreted the medical image and diagnostic question. These step-by-step justifications aimed to emulate clinical reasoning and enhance transparency.
Step 3: Blinded Expert Review. In a blinded evaluation setting, the medical experts were presented with the reasoning outputs and answers from each of the three vision–language models. The identity of the models was withheld to mitigate bias. The experts were asked to complete the following tasks:
- Assess the correctness of each model’s answer relative to their own diagnosis.
- Evaluate the clarity, relevance, and clinical soundness of the provided reasoning steps.
- Reflect on how the coherence and transparency of the reasoning affected their trust in the model’s conclusion.
- Comment on the potential role of such vision–language models as diagnostic support tools in clinical workflows.
This structured evaluation was designed not only to assess the diagnostic performance of the models but also to examine the interpretability, trustworthiness, and potential clinical utility of their reasoning outputs—key considerations for real-world medical AI deployment.
5.8. Expert Evaluation and Trust Analysis
To assess the alignment between vision–language models and expert clinical reasoning, we conducted a comparative evaluation using a curated set of 100 MedVQA samples. Each of the three models was tasked with independently answering the full set using zero-shot chain-of-thought (CoT) prompting. The same set was also evaluated by two medical experts. This framework enabled a systematic comparison between human and model-generated answers and reasoning processes.
5.8.1. Answer Concordance
To evaluate diagnostic alignment, we measured the degree of agreement between each vision–language model’s predictions and the responses of the two medical experts across a shared set of 100 MedVQA cases.
Each model’s prediction was compared individually with the experts’ selected answers. For each case, if the model’s answer matched at least one expert’s answer, it was counted as a concordant response. This approach reflects partial expert alignment while accommodating clinical variability. The final concordance percentage was calculated as
Using this method, the agreement scores for the models were as follows:
- Gemini 2.5 Pro: 76% agreement with at least one expert, indicating the highest level of diagnostic alignment.
- GPT-4o Mini: 72% agreement, showing competitive performance in matching clinical judgments.
- Claude 3.5 Sonnet: 67% agreement, slightly lower but still demonstrating a reasonable overlap with expert responses.
These findings suggest that vision–language models guided by chain-of-thought reasoning can reach substantial agreement with human experts in a significant portion of cases. The relatively high agreement rates, especially for Gemini 2.5 Pro and GPT-4o Mini, underscore their potential in supporting expert-level decision-making under zero-shot CoT conditions.
5.8.2. Reasoning Transparency
The chain-of-thought (CoT) reasoning outputs generated by the vision–language models were positively received by both participating medical experts. These step-by-step explanations offered a transparent view of how models arrived at their final answers, which was especially helpful in tracing the diagnostic logic. The experts emphasized that the structured reasoning sequences closely mirrored typical clinical workflows, starting with the identification of imaging modality, followed by anatomical localization, technical evaluation, and finally, decision justification through the elimination of distractors.
For example, in the case where the question asked “Where is the thrombus/tumor located in the patient’s body?”, the correct expert-verified answer was pulmonary veins. However, Claude 3.5 Sonnet predicted renal pelvis as the answer. Upon review of the model’s reasoning chain, it became evident that the model had misinterpreted vascular features in the image, incorrectly attributing the observed mass to the renal collecting system. Despite using appropriate anatomical terminology and logical flow, the reasoning revealed a breakdown in the visual interpretation of vascular anatomy. The experts appreciated that this error was traceable, highlighting the diagnostic reasoning gap.
5.8.3. Trust and Confidence
Expert trust in model outputs was strongly influenced by the specificity and clarity of the CoT reasoning. When models grounded their conclusions in observable image evidence and used domain-appropriate terminology, experts expressed higher confidence. For instance, in response to the question “What did the three-dimensional CT reconstruction show?”, the correct answer was abnormal thickened right internal thoracic artery. However, GPT-4o Mini incorrectly identified it as abnormal thickened aorta.
While the final answer was incorrect, the model’s chain-of-thought (CoT) reasoning initially followed a valid clinical process. It correctly recognized the imaging modality and noted vascular thickening. However, it lacked the anatomical granularity needed to distinguish between the internal thoracic artery and the aorta. This limitation underscores that while CoT explanations can linguistically simulate expert reasoning, gaps in anatomical precision still compromise diagnostic accuracy.
Experts found that such reasoning chains, though imperfect, helped them identify whether the model’s mistakes stemmed from misunderstanding the image or misapplying medical logic. This level of transparency significantly increased their willingness to engage with the model’s output constructively, as opposed to black-box predictions that offer no interpretive trace.
5.8.4. Clinical Integration Potential
Both experts agreed that the vision–language models, when equipped with interpretable CoT reasoning, have strong potential for integration into clinical workflows—as long as their use is limited to supportive roles. In settings such as radiology triage, emergency imaging, or multidisciplinary case reviews, models like Gemini 2.5 Pro and Claude 3.5 Sonnet could function effectively as diagnostic assistants, offering a second line of review or preliminary assessment.
The provided examples illustrate how CoT transparency facilitates critical engagement. In the first case, the misclassification of pulmonary versus renal anatomy would have been difficult to detect without access to the reasoning steps. Similarly, in the second case, the expert was able to recognize that the model understood the vascular abnormality but lacked anatomical resolution. These interactions reveal that such models could be particularly useful for junior clinicians or in resource-limited settings where specialist consultation is not always readily available.
However, the variability in performance across models and image types also suggests that such systems should not be deployed autonomously. Instead, their optimal role lies in augmenting clinical decision-making by offering traceable and interpretable suggestions that clinicians can evaluate critically within the broader diagnostic context.
5.9. Comparison of Prompting Strategies on PMC-VQA Multiple-Choice Task
We evaluate our prompts on the PMC-VQA dataset, specifically focusing on the multiple-choice task as introduced by Zhang et al [35]. The baseline language-only model GPT-4 achieved an accuracy of 25.7%, indicating limited performance in the absence of visual grounding. In contrast, our zero-shot chain-of-thought (CoT) prompting approach led to substantial improvements. Gemini 2.5 Pro achieved an accuracy of 72.48% (an improvement of 41.68%), Claude 3.5 Sonnet reached 69.00% (an improvement of 38.00%), and GPT-4o Mini attained 67.33% (an improvement of 41.63%). These results demonstrate that structured prompting strategies such as CoT play a vital role in enhancing model reasoning in complex Medical Visual Question Answering tasks.
6. Limitation
While our study provides meaningful insights into the zero-shot chain-of-thought abilities of vision–language models for MedVQA, it has several limitations. First, we used only 100 samples per model. This small size, due to the high cost of commercial APIs, limits how broadly the results can be applied across diverse medical imaging scenarios. Second, we adopted a generalized prompting strategy since the dataset was not grouped by medical domain. This may have reduced performance in specific specialties where more tailored prompts could have helped. The prompts were also long and detailed to support reasoning, but this sometimes approached the token limits and could reduce the available context for model understanding. Third, evaluating medical images is inherently difficult. Often, more than one interpretation can be valid. This makes it challenging to rely on a single ground truth answer for accuracy. Additionally, there is no standard way to judge the quality of reasoning. Models vary in how they explain their answers, and it is hard to tell when the logic is medically correct versus just sounding plausible. The dataset itself also has limited coverage. It includes only a few medical specialties and imaging types, which may introduce bias. From a technical perspective, model versions can change quickly, making results outdated. Commercial APIs also limit user control, such as fixed temperature settings and restricted access to internal details. Image resolution limits may also affect how much clinical detail is preserved. Lastly, our study does not verify whether the models’ reasoning matches real-world clinical decisions. We also did not explore few-shot or fine-tuned approaches, which might perform better in practice. Future work should address these issues to improve the usefulness of VLMs in medical settings.
7. Future Work
Our study opens several promising directions for future research in Medical Visual Question Answering (MedVQA) using vision–language models (VLMs). In our future work, we will focus on fine-tuning open-source VLMs, such as CLIP, MiniGPT-4, LLaMA 4 Maverick, and Qwen 2.5. Fine-tuning will allow us to exert greater control over model architecture, improve transparency, reduce deployment costs, and enable domain-specific adaptation through specialized medical objectives and datasets. We will also explore advanced prompting techniques such as Chain of Instructions and Tree of Thought. These structured reasoning methods, which incorporate hierarchical and sequential cognitive pathways, are expected to further enhance model accuracy and diagnostic reasoning. Our approach will include grouping similar medical image–question pairs, selecting representative exemplars, and designing optimized prompts that align with observed reasoning patterns. In addition, we plan to investigate agent-based AI systems capable of decomposing complex clinical questions, formulating diagnostic plans, and dynamically integrating external tools. By combining VLMs with large language models trained on healthcare data, these systems will aim to emulate the diagnostic reasoning process of medical professionals. We will also explore the integration of heterogeneous medical data sources, including DICOM images, electronic health records (EHRs), and clinical notes. Incorporating such multimodal information is anticipated to increase the clinical relevance and robustness of model outputs. Another important direction will be the development of Retrieval-Augmented Generation (RAG) techniques. By grounding responses in the verified medical literature, structured knowledge bases, and similar clinical cases, RAG will help mitigate hallucinations and improve factual accuracy. We will particularly focus on multimodal RAG approaches that leverage both textual and visual cues during retrieval. To address the challenge of data scarcity—especially for rare conditions—we intend to employ synthetic data generation techniques and curriculum learning strategies. These methods will help enhance model generalization and improve performance across diverse medical scenarios. Finally, we will prioritize real-world deployment considerations by conducting user studies and developing clinician-in-the-loop systems. Through collaborative design and clinical evaluations, we will assess diagnostic value, build trust, and promote the safe and effective integration of MedVQA systems into healthcare workflows.
8. Conclusions
This study emphasizes the critical importance of interpretability in MedVQA systems, especially when working with diagnostic images. By introducing a zero-shot chain-of-thought prompting framework, we enhance the diagnostic reasoning capabilities of vision–language models (VLMs). We conducted a comprehensive evaluation using the PMC-VQA benchmark, which pairs real-world diagnostic images with complex clinical questions and multiple-choice answers. In this study, we assessed three leading vision–language models: Gemini 2.5 Pro, Claude 3.5 Sonnet, and GPT-4o Mini. Among these, Gemini 2.5 Pro achieved the highest diagnostic accuracy at 72.48%. A key innovation of our approach lies in the flexibility and adaptability of the prompting framework. We designed prompts that generalize across different types of diagnostic images, enabling consistent reasoning in a variety of clinical scenarios. The structured prompting process follows a clear, step-by-step methodology: first, the model is guided to break down the problem; next, it analyzes the visual and clinical features in the image; and finally, it synthesizes this information to arrive at a diagnosis. This stepwise reasoning approach not only enhances transparency but also ensures that the final answer is based on a thorough evaluation of the evidence, rather than on a premature or potentially unreliable response. Our findings highlight the essential role of interpretability in medical AI systems. The ability to trace and understand the reasoning behind a model’s decision is critical for building trust among healthcare professionals and ensuring the safe deployment of AI-assisted clinical tools. By promoting structured and transparent reasoning, this study represents a significant advancement toward the development of more trustworthy and explainable medical AI systems.
Author Contributions
F.T.J.F., L.H.B., A.C., and S.K. jointly conceived the research idea, developed the methodology, and designed the experimental framework. F.T.J.F. was responsible for implementing the experimental setup, conducting the experiments, and performing the analysis of the dataset for selecting random samples. L.H.B. and A.C. contributed to the interpretation and validation of the experimental results. F.T.J.F. prepared the initial draft of the manuscript. L.H.B., A.C., and S.K. critically reviewed and revised the manuscript for intellectual content and clarity. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Institute of Health (NIH) research project in South Korea (Project No. 2024ER080300), and this work was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF), funded by the Ministry of Science and ICT under Grant NRF-2022R1A2C1005316.
Data Availability Statement
We have utilized the publicly available “PMC-VQA” dataset hosted on HuggingFace, which is accessible to all researchers and practitioners.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
The appendix provides supplementary details on additional zero-shot chain-of-thought (CoT) prompt examples specifically designed for Medical Visual Question Answering (MedVQA) using vision–language models (VLMs). These examples demonstrate how different models, such as Gemini 2.5 Pro, Claude 3.5 Sonnet, and GPT-4o Mini, approach medical image interpretation and question answering using tailored CoT prompts.
For instance, the detailed design and variations of zero-shot CoT prompts for the Gemini 2.5 Pro model (Figure A1), the Claude 3.5 Sonnet model (Figure A2), and the GPT-4o Mini model (Figure A3) are included here to show their adaptability to different medical scenarios. These prompts are specifically constructed to guide the models in effectively reasoning through medical images and answering related questions, ensuring accurate and contextually relevant results without requiring fine-tuning.

Figure A1.
Zero-shot chain-of-thought (CoT) prompt design for the Gemini 2.5 Pro model.

Figure A2.
Zero-shot chain-of-thought (CoT) prompt design for the Claude 3.5 Sonnet model.

Figure A3.
Zero-shot chain-of-thought (CoT) prompt design for the GPT-4o Mini model.
References
- Canepa, L.; Singh, S.; Sowmya, A. Visual Question Answering in the Medical Domain. In Proceedings of the 2023 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Port Macquarie, Australia, 28 November–1 December 2023; pp. 379–386. [Google Scholar] [CrossRef]
- Pinto, F.; Rauschmayr, N.; Tramèr, F.; Torr, P.; Tombari, F. Extracting training data from document-based VQA models. arXiv 2024, arXiv:2407.08707. [Google Scholar] [CrossRef]
- Zhu, Z.; Jia, M.; Zhang, Z.; Li, L.; Jiang, M. Multichartqa: Benchmarking vision-language models on multi-chart problems. arXiv 2024, arXiv:2410.14179. [Google Scholar]
- Srivastava, A.; Kumar, A.; Kumar, R.; Srinivasan, P. Enhancing Financial VQA in Vision Language Models using Intermediate Structured Representations. arXiv 2024, arXiv:2501.04675. [Google Scholar]
- Siripong, S.; Chaiyapan, A.; Phonchai, T. Large Vision-Language Models for Remote Sensing Visual Question Answering. arXiv 2024, arXiv:2411.10857. [Google Scholar] [CrossRef]
- Chen, B.; Jin, L.; Wang, X.; Gao, D.; Jiang, W.; Ning, W. Unified Vision-Language Representation Modeling for E-Commerce Same-style Products Retrieval. In Companion Proceedings of the ACM Web Conference 2023 (WWW ’23 Companion); Association for Computing Machinery: New York, NY, USA, 2023; pp. 381–385. [Google Scholar] [CrossRef]
- Bongini, P.; Becattini, F.; Bagdanov, A.D.; Bimbo, A.D. Visual question answering for cultural heritage. IOP Conf. Ser. Mater. Sci. Eng. 2020, 949, 012074. [Google Scholar] [CrossRef]
- Elhenawy, M.; Ashqar, H.I.; Rakotonirainy, A.; Alhadidi, T.I.; Jaber, A.; Tami, M.A. Vision-Language Models for Autonomous Driving: CLIP-Based Dynamic Scene Understanding. Electronics 2025, 14, 1282. [Google Scholar] [CrossRef]
- Maharjan, J.; Garikipati, A.; Singh, N.P.; Cyrus, L.; Sharma, M.; Ciobanu, M.; Barnes, G.; Thapa, R.; Mao, Q.; Das, R. OpenMedLM: Prompt engineering can out-perform fine-tuning in medical question-answering with open-source large language models. Sci. Rep. 2024, 14, 14156. [Google Scholar] [CrossRef]
- Yan, Q.; Duan, J.; Wang, J. Multi-modal Concept Alignment Pre-training for Generative Medical Visual Question Answering. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 17–22 March 2024; pp. 5378–5389. [Google Scholar] [CrossRef]
- Jin, C.; Zhang, M.; Ma, W.; Li, Y.; Wang, Y.; Jia, Y.; Du, Y.; Sun, T.; Wang, H.; Fan, C.; et al. RJUA-MedDQA: A Multimodal Benchmark for Medical Document Question Answering and Clinical Reasoning. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’24), Barcelona, Spain, 25–29 August 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 5218–5229. [Google Scholar] [CrossRef]
- Bardhan, J.; Colas, A.; Roberts, K.; Wang, D.Z. Drugehrqa: A question answering dataset on structured and unstructured electronic health records for medicine related queries. arXiv 2022, arXiv:2205.01290. [Google Scholar] [CrossRef]
- Wu, Q.; Wang, P.; Wang, X.; He, X.; Zhu, W. Medical VQA. In Visual Question Answering. Advances in Computer Vision and Pattern Recognition; Springer: Singapore, 2022. [Google Scholar] [CrossRef]
- Zhan, L.; Liu, B.; Fan, L.; Chen, J.; Wu, X. Medical Visual Question Answering via Conditional Reasoning. In Proceedings of the 28th ACM International Conference on Multimedia (MM ’20), Seattle, WA, USA, 12–16 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 2345–2354. [Google Scholar] [CrossRef]
- Gai, X.; Zhou, C.; Liu, J.; Feng, Y.; Wu, J.; Liu, Z. Medthink: Explaining medical visual question answering via multimodal decision-making rationale. arXiv 2024, arXiv:2404.12372. [Google Scholar]
- Bi, Y.; Wang, X.; Wang, Q.; Yang, J. Overcoming Data Limitations and Cross-Modal Interaction Challenges in Medical Visual Question Answering. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, G.; Bai, L.; Nah, W.J.; Wang, J.; Zhang, Z.; Chen, Z.; Wu, J.; Islam, M.; Liu, H.; Ren, H. Surgical-lvlm: Learning to adapt large vision-language model for grounded visual question answering in robotic surgery. arXiv 2024, arXiv:2405.10948. [Google Scholar]
- Van, M.-H.; Verma, P.; Wu, X. On large visual language models for medical imaging analysis: An empirical study. In Proceedings of the 2024 IEEE/ACM Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Wilmington, DE, USA, 19–21 June 2024; pp. 172–176. [Google Scholar]
- Hu, N.; Zhang, X.; Zhang, Q.; Huo, W.; You, S. ZPVQA: Visual Question Answering of Images Based on Zero-Shot Prompt Learning. IEEE Access 2025, 13, 50849–50859. [Google Scholar] [CrossRef]
- Zhan, C.; Peng, P.; Wang, H.; Wang, G.; Lin, Y.; Chen, T.; Wang, H. UnICLAM: Contrastive representation learning with adversarial masking for unified and interpretable medical vision question answering. Med. Image Anal. 2025, 101, 103464. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Liu, C.; Wu, J.; Liu, F.; Zhu, J.; Li, H.B.; Chen, C.; Ouyang, C.; Rueckert, D. Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning. arXiv 2025, arXiv:2502.19634. [Google Scholar]
- Singhal, K.; Tu, T.; Gottweis, J.; Sayres, R.; Wulczyn, E.; Amin, M.; Hou, L.; Clark, K.; Pfohl, S.R.; Cole-Lewis, H.; et al. Toward expert-level medical question answering with large language models. Nat. Med. 2025, 31, 943–950. [Google Scholar] [CrossRef]
- Li, F.; Chen, Y.; Liu, H.; Yang, R.; Yuan, H.; Jiang, Y.; Li, T.; Taylor, E.M.; Rouhizadeh, H.; Iwasawa, Y.; et al. Mkg-rank: Enhancing large language models with knowledge graph for multilingual medical question answering. arXiv 2025, arXiv:2503.16131. [Google Scholar]
- Liang, S.; Zhang, L.; Zhu, H.; Wang, W.; He, Y.; Zhou, D. RGAR: Recurrence Generation-augmented Retrieval for Factual-aware Medical Question Answering. arXiv 2025, arXiv:2502.13361. [Google Scholar]
- Shi, Y.; Yang, T.; Chen, C.; Li, Q.; Liu, T.; Li, X.; Liu, N. SearchRAG: Can Search Engines Be Helpful for LLM-based Medical Question Answering? arXiv 2025, arXiv:2502.13233. [Google Scholar]
- Google. Gemini 2.5 Pro (Preview Version, as of 14 May 2025) [Large Multimodal Model Accessed via Google AI Studio]. 2025. Available online: https://aistudio.google.com/ (accessed on 10 May 2025).
- Anthropic. Claude 3.5 Sonnet. 2024. Available online: https://www.anthropic.com/claude (accessed on 14 May 2025).
- OpenAI. GPT-4o Mini. 2024. Available online: https://openai.com (accessed on 14 May 2025).
- Jin, F.; Liu, Y.; Tan, Y. Zero-shot chain-of-thought reasoning guided by evolutionary algorithms in large language models. arXiv 2024, arXiv:2402.05376. [Google Scholar]
- Gupta, A.; Vuillecard, P.; Farkhondeh, A.; Odobez, J.-M. Exploring the zero-shot capabilities of vision-language models for improving gaze following. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 615–624. [Google Scholar]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond Accuracy, F-Score and ROC: A Family of Discriminant Measures for Performance Evaluation. In AI 2006: Advances in Artificial Intelligence, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4304, pp. 1015–1021. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation. In Advances in Information Retrieval. ECIR 2005. Lecture Notes in Computer Science; Losada, D.E., Fernández-Luna, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3408. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, C.; Zhao, Z.; Lin, W.; Zhang, Y.; Wang, Y.; Xie, W. Pmc-vqa: Visual instruction tuning for medical visual question answering. arXiv 2023, arXiv:2305.10415. [Google Scholar] [CrossRef]
- Bordes, F.; Pang, R.Y.; Ajay, A.; Li, A.C.; Bardes, A.; Petryk, S.; Mañas, O.; Lin, Z.; Mahmoud, A.; Jayaraman, B.; et al. An introduction to vision-language modeling. arXiv 2024, arXiv:2405.17247. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).