
Comparative Analysis of Some Methods and Algorithms for Traffic Optimization in Urban Environments Based on Maximum Flow and Deep Reinforcement Learning




Abstract
1. Introduction
1.1. Reinforcement Learning (RL) Algorithms—Overview
1.2. Classical Algorithms—Overview
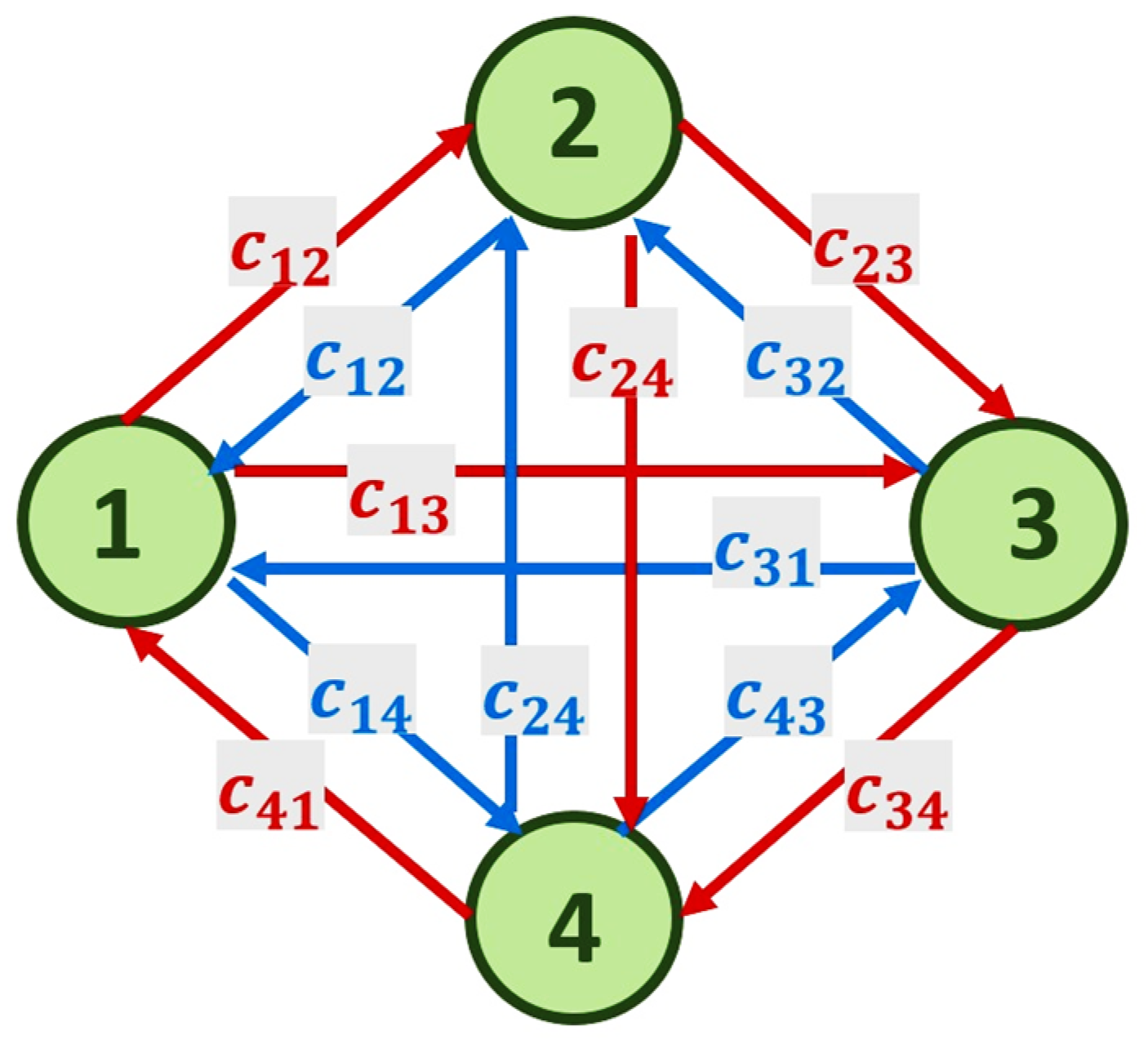
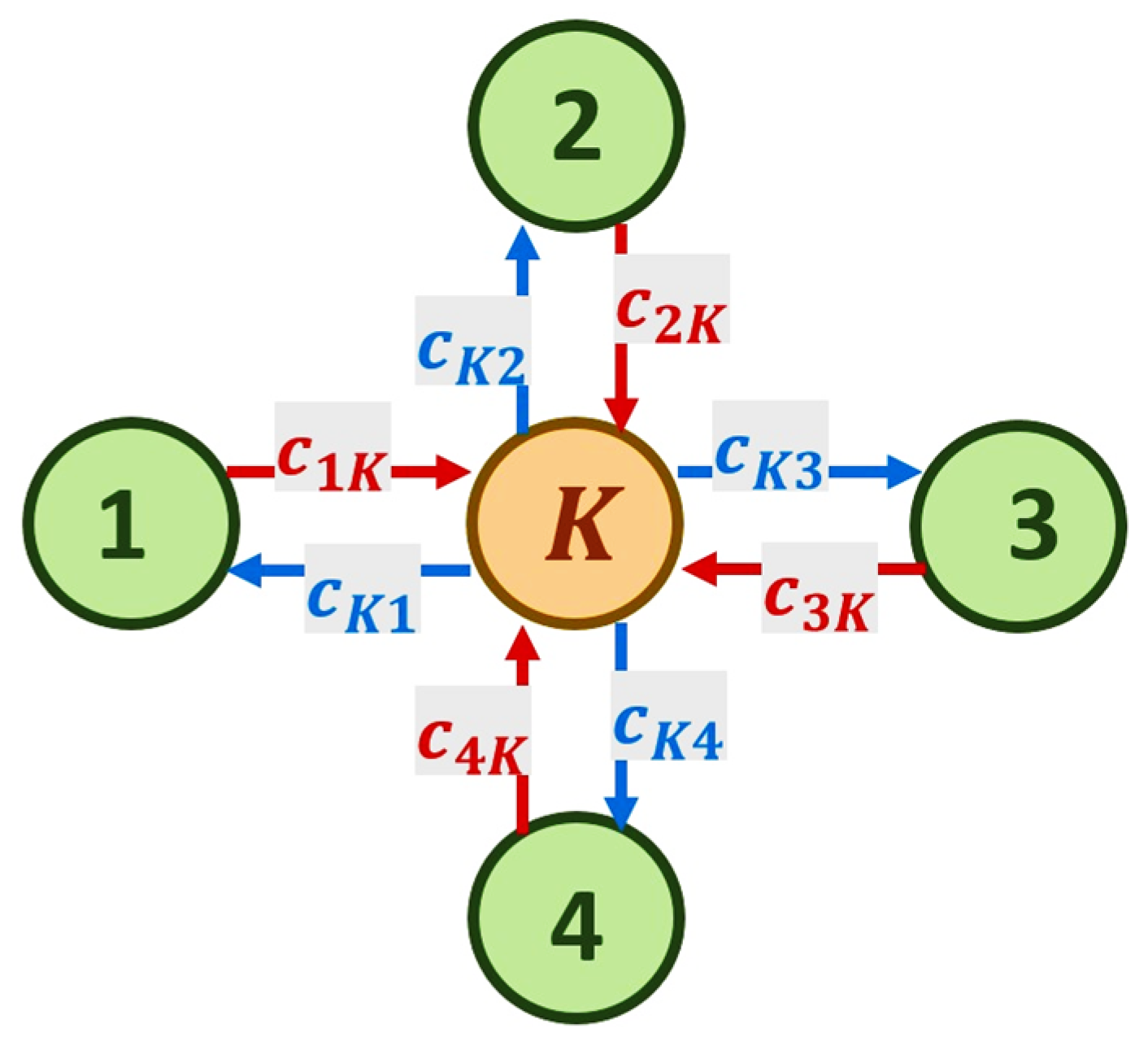
2. Description of the Problem and Network Model
- Capacity constraint: The flow along an arc cannot exceed its capacity, i.e., for ;
- Flow conservation: The sum of the flows entering a given vertex must equal the sum of the flows leaving that vertex, excluding the source and sink;
- Flows are symmetric: for all .
3. Algorithms for Solving the Described Problem
3.1. Classical Algorithms
3.1.1. Ford–Fulkerson Method
3.1.2. Edmonds–Karp Algorithm
3.1.3. Dinitz Algorithm
- Leading arcs: For each arc , if , then in there exists a leading arc with residual capacity:
- 2.
- Reverse arcs: For every arc , if , then in there exists a reverse arc with residual capacity:
- 3.
- Non-existent arcs: For any arc , if and , then the arc does not exist in .
- Vertex level (layer): For each vertex , the is defined, where is equal to the minimum number of edges in the path from to in , or if no such path exists.
- Admissible arcs: The arc belongs to if and only if:
- 3.
- Structure: Vertex if .
3.1.4. Boykov–Kolmogorov Algorithm
3.1.5. Preflow–Push Algorithm
- is the total inflow to ;
- is the total outflow from .
3.2. Reinforcement Learning (RL) Algorithms
- State: Represents the current state of the traffic system and includes a set of parameters characterizing the situation of the road network. Examples of characteristics are: the number of vehicles in different sections, the status of traffic lights (green/red light), the average speed of traffic, and the degree of congestion at critical points.
- Action: These are the possible management decisions that the agent can take to optimize traffic. Actions in this case include changing the duration of traffic lights, choosing alternative routes to direct traffic, or adjusting the throughput of certain road sections.
- Reward: The reward is the measure of the effectiveness of the action taken in a given state. It aims to promote the minimization of negative effects, such as congestion and delays, and is defined by metrics such as reduced average travel time, lower waiting times at intersections, or reduced overall road network congestion.
- is the set of states of the environment and agent (the state space);
- is the set of actions (the action space) of the agent;
- is the transition probability (at time ) from state to state relative to action :
3.2.1. Q-Learning Algorithm
- and are the current state and action, respectively;
- is the evaluation obtained after performing the action;
- is the new state the agent enters;
- is the prediction of the best future reward;
- is the discount factor that controls the importance of future rewards.
3.2.2. Deep -Learning Algorithm ()
- is the current reward
- is the new state the agent is in
- is the discount factor that determines the importance of future rewards
- are the parameters of the target neural network, which is updated periodically to stabilize the learning
- Replay buffer: stores previous transitions in a buffer and performs training by randomly selecting transitions (a batch of transitions) instead of the agent using every interaction with the environment immediately for training. This reduces the correlation between examples and improves robustness.
- Target Network: uses a separate target network whose parameters are only updated periodically to avoid instabilities caused by frequent changes in target values. This makes the target values more robust.
3.2.3. Double Algorithm
- The base network (with parameters ) selects the action by .
- The target network (with parameters ) estimates the -value of the selected action.
- Reward shaping—a technique that aims to speed up the learning process by modifying the reward function. The idea is to provide additional progress signals to the agent, thus guiding its behavior towards the desired solution, without changing the essence of the optimal policy. Well-designed reward shaping can significantly reduce the number of interactions with the environment required to reach an effective strategy. However, improper application of this technique can lead to the introduction of biases that change the optimal policy. Potential-based reward shaping is often used, which guarantees the preservation of the original optimal policy by using a potential function between states to avoid this risk.
- Gradient clipping—a method for controlling the size of gradients during the optimization of neural networks, especially in the context of training deep models in RL. The main goal of the technique is to prevent the so-called exploding gradient problem, in which gradients can reach large values and lead to instability of the training process or even failure of convergence. Gradient clipping limits the norm or values of the gradients to a predefined range, the most common approach being a restriction on the norm (Euclidean norm) of the gradient vector.
- Epsilon–Greedy decay policy— is subjected to a process of decay—a gradual decrease over time to achieve more efficient learning. A high value of ϵ (e.g., 1.0) is used at the beginning of training to encourage extensive exploration of the environment. is decreased according to a given scheme (e.g., exponential or linear decay) as training progresses to a minimum value (e.g., 0.01), which allows the agent to use the accumulated knowledge to maximize rewards. This adaptability is critical for achieving good long-term behavior in complex environments.
4. Numerical Realization
4.1. Traffic Input Parameters in Simulations (SUMO)
- Number of vehicles: 10 per minute, evenly distributed.
- Type: passenger cars with a standard profile (speed 13.89 m/s).
- Generation method: via TraCI and a Python script with fixed start and end points.
- Simulation time: 420 s (approximately 7 min).
- Network topology: network with four nodes (inputs) and one central node—the intersection.
- Traffic light control: based on algorithm actions.
4.2. Analytical Description of the Metrics Used
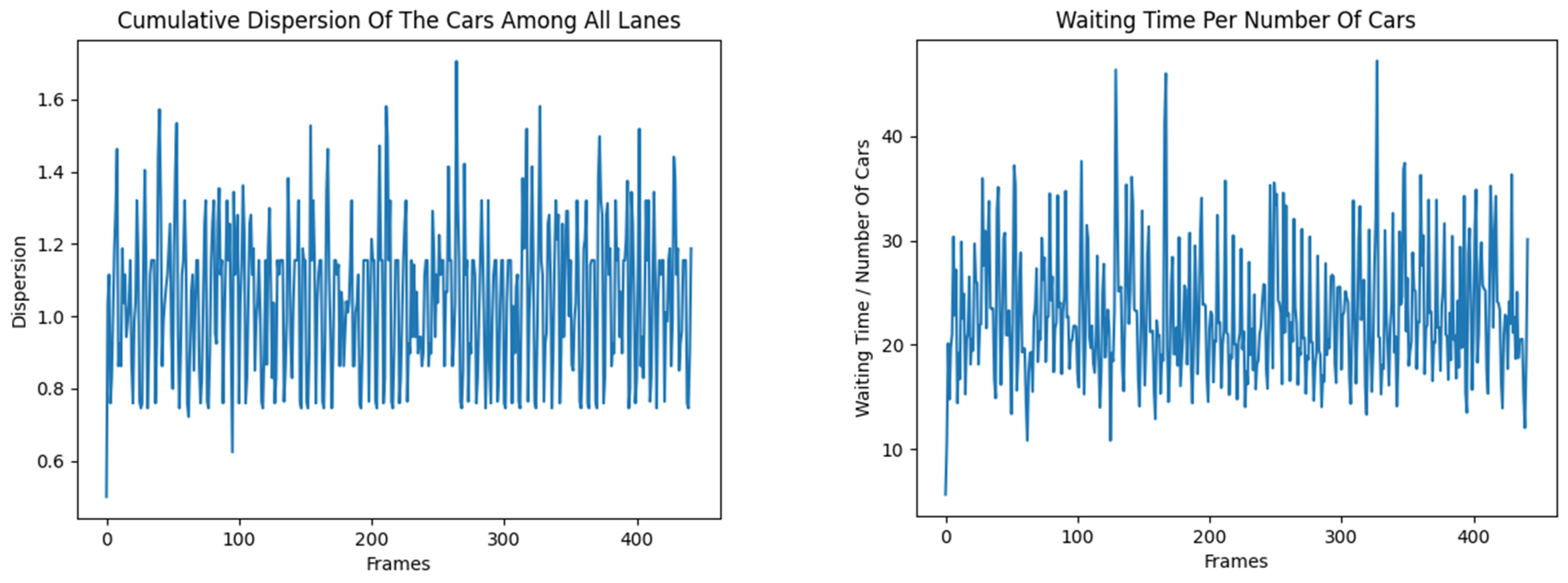
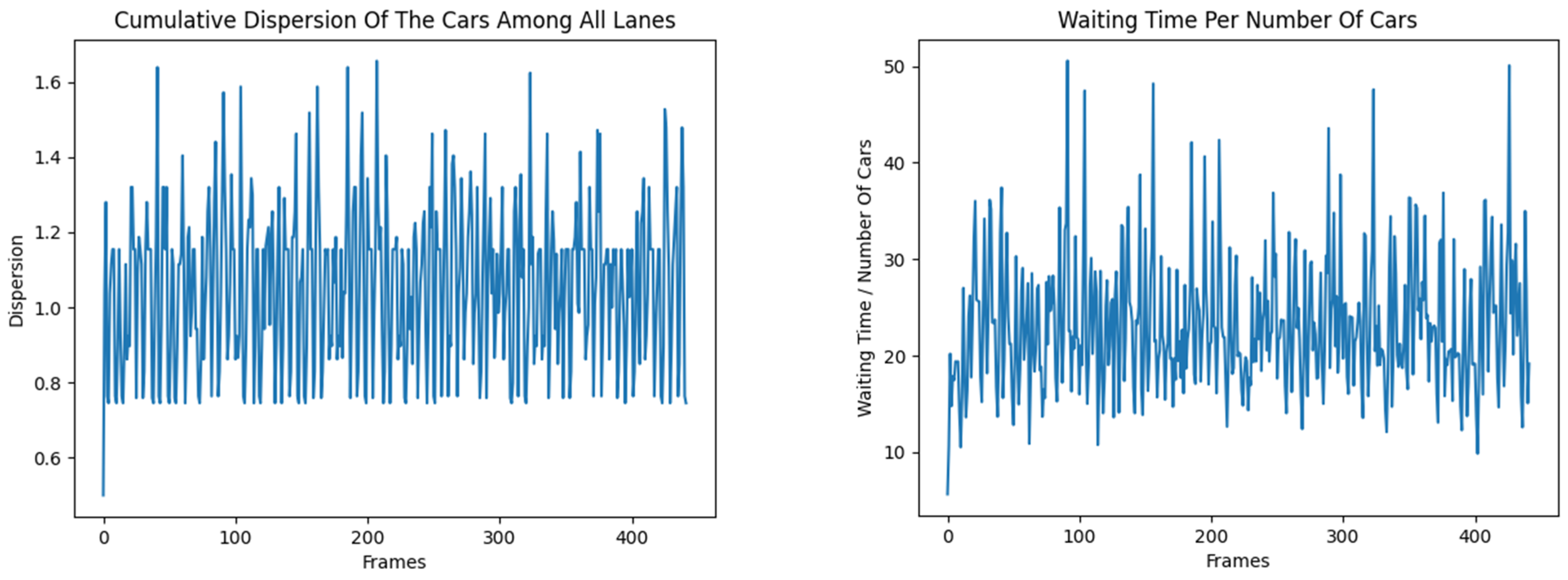
- Cumulative variance ():
- is the number of cars in flow
- is the average value for all flows
- 2.
- Waiting/number of cars ratio:
- is the waiting time
- is the number of cars in flow
- Null hypothesis (H0): there is no significant difference between the means of the two samples (algorithms).
- T-statistic: measures the difference between the means, normalized by the variance.
- p-value: probability that the observed difference is due to chance.
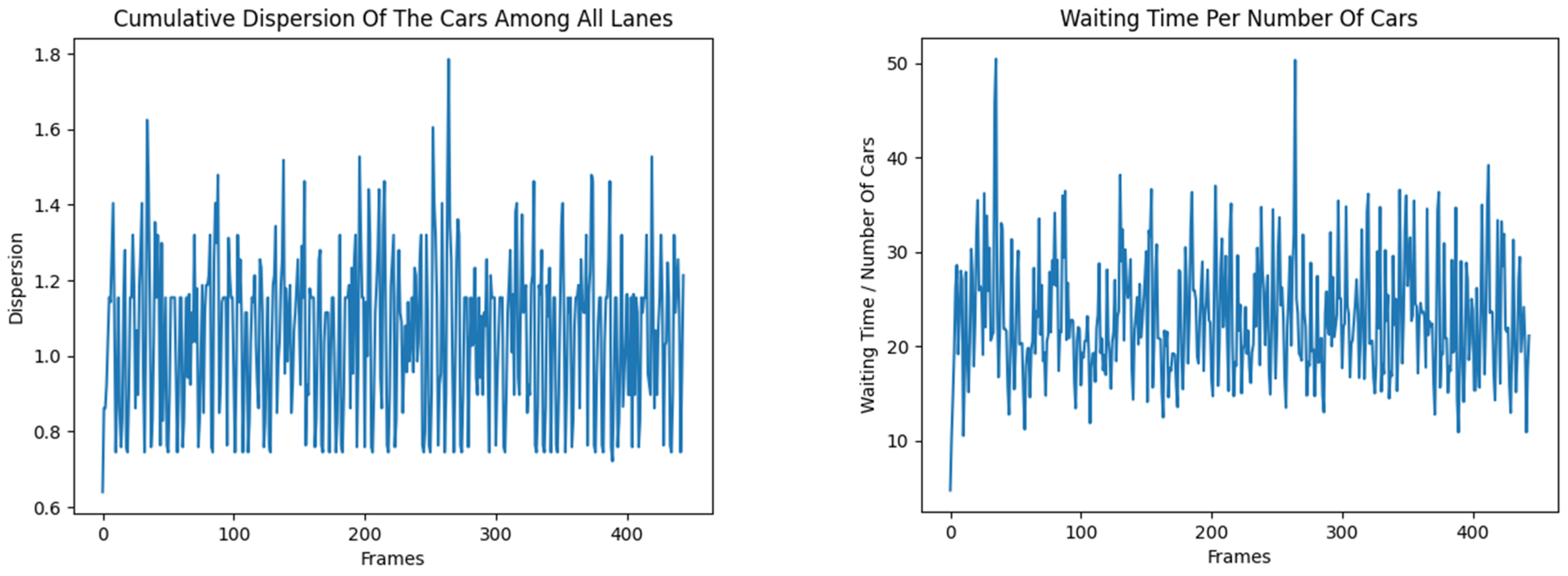
4.3. Numerical Realization, Simulations and Results
- The tabular part (Table 3, Table 4 and Table 5) consists of statistics regarding the performance of the algorithms in the two metrics that are studied, as well as t-test results for each algorithm against each other, with the data generated from the simulation in SUMO with a deterministic simulation configuration and implemented using Python.
- Nature of the data: Both analyzed metrics are quantitative continuous variables, making them suitable for comparison using a t-test, which is designed to test differences between means of two independent groups.
- Prerequisites for applying the t-test: A preliminary analysis is conducted to verify the main prerequisites, namely:
- Normality of distribution: Normality tests (such as Shapiro–Wilk) are used, as well as visual analysis using - plots, which showed that the distribution of data by group did not deviate significantly from normal.
- Homogeneity of variances: The Levene’s test for equality of variances shows that the variances between the compared groups are similar, which justifies the use of the classic t-test with equal variances.
- Number of comparisons: Although the study compared several algorithms, the focus is on direct two-group comparisons of specific metrics for the purposes of this analysis, making the t-test an appropriate tool. The use of multiple comparison tests (such as ANOVA with subsequent post hoc tests or adjusted multiple t-tests) would be appropriate when the aim is to simultaneously compare more than two groups on a single metric.
- Justification for not applying multiple comparison tests: The chosen approach of sequential two-group t-tests is due to:
- Limited number of comparisons, which minimizes the risk of increasing type I error;
- A clear research hypothesis for comparison between specific pairs of algorithms, which justifies the direct approach;
- Conducting corrections for multiple comparisons (e.g., Bonferroni) when necessary.
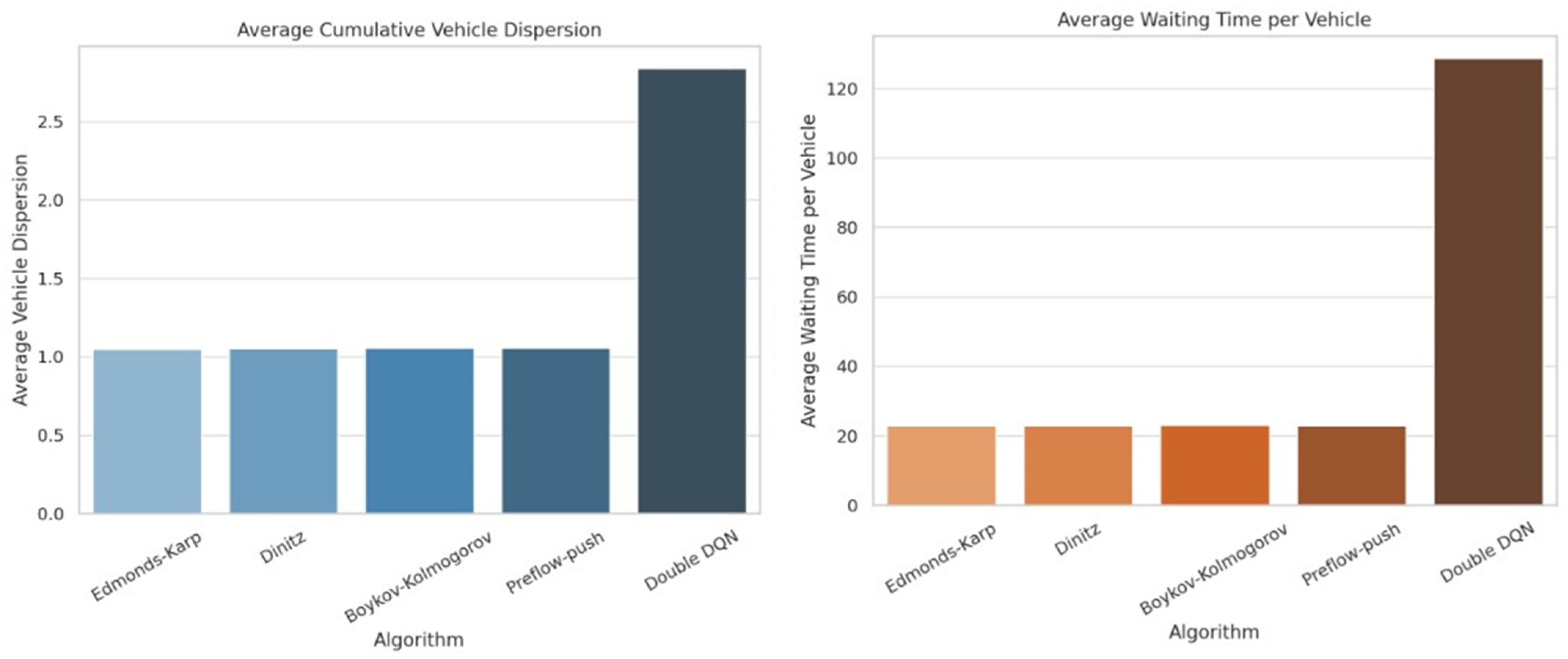
4.4. Discussion of the Obtained Results
- The Edmonds–Karp algorithm is the most efficient for the dispersion of the number of vehicles in the flows in most cases. A competitor of Edmonds–Karp in terms of the ratio of waiting time of vehicles to their number is the Dinitz algorithm, which performs better in cases up to the median, and also achieves a better minimum than Edmonds–Karp, but a worse maximum. The other algorithms have stable and close results.
- Double shows significantly greater variation and the highest waiting times, making it the most inefficient in this case.
- Edmonds–Karp and Dinitz algorithms have the lowest average variance of vehicles, with very close values;
- The lowest average waiting time is also observed for the classical algorithms, while Double stands out significantly with higher values—an indication of inefficiency in the current configuration.
- p-values are above 0.05 between the Boykov–Kolmogorov and Dinitz algorithms, Boykov–Kolmogorov and Edmunds–Karp, as well as Boykov–Kolmogorov and Preflow–Push, which indicates a lack of significant differences in the dispersion of the results;
- When comparing Dinitz with Edmunds–Karp and Preflow–Push, no significant differences in cumulative variance are found;
- A statistically significant difference in the variance of the results is observed in the cases of algorithm vs. Double , as p-values are significantly below 0.05.
4.5. Validation of the Obtained Results
- Scenario 1: High Traffic Load:
- The intensity of the incoming flows is increased from 10 to 30 cars per minute at each of the four entrances.
- The simulation time is 420 s (7 min).
- Aim: to test how handles a load that is three times larger than the base case.
- Scenario 2: Low Traffic Load:
- The intensity is reduced to three cars per minute.
- Aim: assess adaptability at low load.
- Scenario 3: Real data:
- Historical traffic data from a real intersection in a city with four entrances are used, provided by the municipal administration.
- The data includes the number of vehicles at each entrance for seven consecutive days during a working week (separate hourly interval).
- Traffic is generated in SUMO based on this data, with the simulation covering peak and off-peak hours.
- Scenario 1: High Traffic Load: Expectedly, the average waiting time increases significantly due to high traffic, but shows better adaptation compared to the fixed Webster algorithm, demonstrating robustness under stress conditions.
- Scenario 2: Low Traffic Load: quickly and effectively minimizes unnecessary waiting by dynamically changing the phases of traffic lights.
- Scenario 3: Real data: The algorithm successfully adapts to realistic and more complex traffic patterns, proving applicability beyond synthetic scenarios.
- 4.
- Scenario 4: Burst Traffic:
- Periodic increase in vehicle intensity at an entrance—for example, a sudden influx of 50 vehicles in 1 min, followed by normal intensity.
- Aim: to assess adaptability to sudden loads and shocks in traffic.
- 5.
- Scenario 5: Asymmetric traffic:
- Unbalanced flow, e.g., one entrance with 40 cars per minute, another with 10, and the rest with 5.
- Aim: testing the algorithm’s ability to balance phases under uneven load.
- 6.
- Scenario 6: Traffic Disruptions:
- Inclusion of closing one of the inputs for part of the time (e.g., 2 min closing input 3).
- Aim: checking the ability of to adapt to dynamic changes in the network topology.
- 7.
- Scenario 7: Multi-Path Traffic:
- Add options for left turns, straight ahead, and straight through the intersection, with different percentage distributions (e.g., 50% straight, 30% left, 20% straight).
- Aim: simulate more complex movements and evaluate the effectiveness of the algorithm in multi-routing.
- shows stable and flexible adaptation even under extreme and complex traffic patterns.
- The algorithm copes with sporadic peak loads and dynamic changes in the network.
- Variations with asymmetric and multipath traffic demonstrate its ability to optimize waiting times even under irregular and complex routes.
4.6. Comparative Analysis of the Used Algorithms
- Edmonds–Karp and Dinitz algorithms show the best performance in the metrics:
- Cumulative vehicle dispersion—Edmunds–Karp algorithm is leading with the lowest average value (1.05);
- Ratio of idle time to number of vehicles—Dinitz algorithm has the lowest minimum and better values in the lower neighborhoods.
- The Double algorithm shows significantly worse performance:
- Average 22.8 times longer idle time compared to classical algorithms;
- Statistically significant differences compared to all other algorithms ( in t-tests).
- The other classical algorithms (Preflow–Push and Boykov–Kolmogorov) show comparable efficiency with weak statistical differences between them ().
- Classical algorithms are stable, especially under deterministic conditions, and are suitable for implementation in real transportation systems with fixed network configurations.
- RL and DRL algorithms have the potential for dynamic adaptation, but require:
- Long training period;
- Many interactions with the environment;
- Sensitivity to hyperparameters and architecture.
- Edmonds–Karp or Dinitz algorithms are the optimal choice for static configurations.
- It is recommended to use advanced DRL algorithms such as PPO, A2C or Dueling for dynamic environments with variable infrastructure.
- Include reward shaping and the Epsilon decay policy for better behavior of RL agents.
- Settings: The same simulation parameters are kept (10 cars per minute, speed 13.89 m/s, simulation time 420 s), with the only change being the number of training episodes.
- Number of episodes: 50 (initial), 150 and 200.
- Metric: Average vehicle waiting time.
- Simulation parameters: Kept unchanged from previous experiments.
- Number of episodes: 300 and 400.
- Metric: Average waiting time (seconds).
- Increasing the number of episodes is an effective strategy to improve the performance of .
- Now the model can be considered competitive with classical methods in the context of the given simulation scenario.
- Poisson distribution: (average number of cars per minute);
- Gaussian distribution: , , with a limit on minimum and maximum values.
- initial vehicle positions;
- initial traffic light phases;
- initial road loads.
- Classical algorithms (especially Dinitz) showed high robustness even under highly fluctuating input flows, thanks to the clear structure and predictability of the calculations. The traffic distribution remained balanced in most cases, with a moderate increase in variance.
- RL algorithms demonstrated greater sensitivity to initial conditions and randomness of the input. often got “stuck” in an inefficient strategy, while Double was able to maintain lower waiting times in most cases but required longer training and fine-tuning.
- The standard deviation of RL algorithms is significantly larger than classical ones, which indicates lower stability between individual simulations.
- In cases with a sudden peak in traffic (e.g., a doubling of the input from one of the flows), classical methods responded linearly, while RL often experienced delays and transient “jamming” until the agents readjusted.
- Dinitz remains the most balanced algorithm in terms of stability and efficiency in a random environment.
- Double shows potential for adaptation, but suffers from instability and requires additional stabilization techniques (e.g., reward shaping, epsilon decay).
- It is recommended to use advanced DRL algorithms such as PPO (Proximal Policy Optimization) or A2C (Advantage Actor–Critic) for future experiments in high stochasticity.
- A modern DRL method with an optimization policy stabilized by limiting the change in the policy (clipped objective).
- It copes well with high variability and unpredictability of the environment.
- It is a synchronous version of A3C, with separate actor and critic networks.
- It balances between policy learning and state evaluation through advantage.
- Simulation environment: SUMO + TraCI.
- Input flows: generated according to Poisson distribution with .
- Initial states: randomly positioned vehicles and traffic light phases.
- Number of simulations: 30 for each algorithm.
- Duration of each simulation: 420 s (7 min).
- Metrics:
- Average waiting time.
- Flow dispersion (vehicle distribution).
- Standard deviation (stability).
- PPO performed best among all algorithms—it managed to maintain low latency, even flow distribution and high stability, thanks to its clip-limited policy and batch learning.
- A2C shows fast learning, but higher variation in results, especially under unstable initial conditions. This is due to the weaker regularization compared to PPO.
- Both algorithms outperform Double under stochastic conditions and are comparable to Dinitz under average load, but more adaptive under peaks.
- PPO is the best choice in dynamic and unpredictable environments, maintaining an optimal balance between efficiency and stability.
- A2C is a lightweight and adaptive alternative, suitable for limited computational resources.
- Both DRL methods outperform Double and are competitive with the best classical algorithms such as Dinitz.
- PPO demonstrates the best values and stability in terms of both delay and traffic distribution.
- A2C is close to PPO, but with a slightly higher variance.
- Double has the largest fluctuations and the weakest results.
- Dinitz behaves stably, but does not react as well to sudden changes.
- If , then the effect is small;
- If , then the effect is medium;
- If , then the effect is large.
- PPO shows a large effect compared to Double and a medium effect compared to Dinitz, both results being statistically significant even after adjustment.
- A2C also outperforms Double with a significant and large effect.
- The difference between PPO and A2C is not significant (small effect).
- Dinitz is not significantly different from A2C, but is significantly weaker than PPO.
- Effect sizes (Cohen’s d),
- Statistical significance tests (t-test),
- Correction for multiple comparisons (Bonferroni).
- PPO vs. Double : Largest effect with (very large effect), and statistically significant difference (). PPO significantly outperforms Double .
- A2C vs. Double : Large effect () and also significant difference ().
- Dinitz vs. Double : Medium–large effect () and significant difference ().
- The remaining comparisons (PPO vs. A2C, PPO vs. Dinitz, A2C vs. Dinitz) are not statistically significant at an adjusted threshold (Bonferroni).
- Double is significantly weaker than all other algorithms in stochastic search—both statistically and practically.
- PPO shows a very large improvement over Double , with demonstrably lower average waiting time and stability.
- The difference between PPO and A2C, and between PPO and Dinitz, is medium to small in effect, but not statistically significant.
- Dinitz, although classical, remains robust under stochastic conditions, performing significantly better than Double .
- Execution time:
- Dinitz is many times faster than the others (under 4 s)—a classic optimization structure.
- PPO and A2C require significantly more time due to batch training and backpropagation.
- Double is faster than A2C and PPO, but not as efficient.
- Robustness:
- PPO demonstrates the lowest standard deviation (4.2) → most robust result across simulations.
- Double has high variability → unstable under stochastic scenarios.
- Dinitz and A2C are in between.
- Use of resources:
- PPO is the most resource intensive (GPU, RAM) as it uses a complex policy and multiple updates.
- A2C is lighter than PPO but still requires neural networks.
- Double is relatively lighter.
- Dinitz has minimal hardware requirements and is suitable for embedded systems or real-time.
- If speed and ease are a priority—Dinitz is the optimal choice.
- If efficiency and stability are most important—PPO is the best solution, but at the cost of longer time and more resources.
- A2C offers a reasonable compromise between time, stability and resources.
- Double is a weaker choice: neither stable enough, nor the fastest or most efficient.
5. Conclusions and Future Work
- Deep RL and multi-agent algorithms are most relevant (2020–2025), especially in urban environments with variable traffic.
- Classical methods remain relevant as reference baselines for evaluation.
- Hybrid and collective approaches reflect recent trends in smart mobility.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1
- for all arcs .
- While there is a path from to in , such that for all vertices :
Appendix A.2
- For all arcs :
- 2.
- Path is found by a breadth-first search (BFS)
- 3.
- While there is a path from to in , such that for all arcs :
Appendix A.3
- For all arcs :
- 2.
- While there exists a layered graph from to in the residual graph :
- Set for all (unvisited vertices)
- Set
- Create an empty queue and add
- While is non-empty:
- 5.
- If
- 6.
- Else:
- The queue organizes the order of processing the vertices;
- Each vertex is visited exactly once, calculating its layers;
- The neighbors of the current vertex are processed in the order in which they are reached.
- Set
- Create an array and add vertex to it
- While array is not empty:
- 4.
- Return the blocking stream
Appendix A.4
- Create the source component or set of vertices by breadth-first or depth-first search for which
- Create the receiver component or set from the remaining vertices
- Define a cut
- 4.
- Return cut
- For all arcs :
- 2.
- Create a residual graph , by specifying
- 3.
- Define the set of active vertices (all other vertices are inactive)
- 4.
- While there are active vertices in :
- 5.
- Form a cut from
- 6.
- Define maximum flow
- 7.
- Return maximum flow
Appendix A.5
- For all :
- 2.
- For all
- 3.
- For all connected to :
- 4.
- While there are active vertices , that satisfy and :
- 5.
- Define:
- 6.
- Return flow
Appendix A.6
- For all and :
- 2.
- While is not true:
- 3.
- While a terminal state is reached:
- random action with probability or with probability
- Perform action and observe the new state and the reward .
- (update the -table according to the Bellman equation).
- Accept the new state, .
- 4.
- Return the optimal -table, .
Appendix A.7
- Initialize the neural network with random weights .
- Copy weights to target network .
- Initialize the iteration buffer as an empty set.
- For all episode :
- 5.
- Return the optimized network .
Appendix A.8
- Initialize the neural network with random weights .
- Copy weights to target network .
- Initialize the iteration buffer as an empty set.
- For all episode :.
- 5.
- Return the optimized network
References
- Zhang, L.; Li, J.; Zhu, Y.; Shi, H.; Hwang, K.S. Multi-Agent Reinforcement Learning by the Actor-Critic Model with an Attention Interface. Neurocomputing 2022, 471, 275–284. [Google Scholar] [CrossRef]
- Song, X.B.; Zhou, B.; Ma, D. Cooperative Traffic Signal Control through a Counterfactual Multi-Agent Deep Actor Critic Approach. Transp. Res. Part. C Emerg. Technol. 2024, 160, 104528. [Google Scholar] [CrossRef]
- Mao, F.; Li, Z.; Lin, Y.; Li, L. Mastering Arterial Traffic Signal Control With Multi-Agent Attention-Based Soft Actor-Critic Model. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3129–3144. [Google Scholar] [CrossRef]
- Yoon, J.; Kim, S.; Byon, Y.J.; Yeo, H. Design of Reinforcement Learning for Perimeter Control Using Network Transmission Model Based Macroscopic Traffic Simulation. PLoS ONE 2020, 15, e0236655. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Wei, H.; Xu, N.; Zheng, G.; Yang, M.; Xiong, Y.; Xu, K.; Li, Z. Toward a Thousand Lights: Decentralized Deep Reinforcement Learning for Large-Scale Traffic Signal Control. In Proceedings of the AAAI 2020—34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar] [CrossRef]
- Hou, L.; Huang, D.; Cao, J.; Ma, J. Multi-Agent Deep Reinforcement Learning with Traffic Flow for Traffic Signal Control. J. Control Decis. 2023, 12, 81–92. [Google Scholar] [CrossRef]
- Fang, J.; You, Y.; Xu, M.; Wang, J.; Cai, S. Multi-Objective Traffic Signal Control Using Network-Wide Agent Coordinated Reinforcement Learning. Expert. Syst. Appl. 2023, 229, 120535. [Google Scholar] [CrossRef]
- Tan, T.; Bao, F.; Deng, Y.; Jin, A.; Dai, Q.; Wang, J. Cooperative Deep Reinforcement Learning for Large-Scale Traffic Grid Signal Control. IEEE Trans. Cybern. 2020, 50, 2687–2700. [Google Scholar] [CrossRef]
- Chu, T.; Wang, J.; Codeca, L.; Li, Z. Multi-Agent Deep Reinforcement Learning for Large-Scale Traffic Signal Control. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1086–1095. [Google Scholar] [CrossRef]
- Skuba, M.; Janota, A.; Kuchár, P.; Malobický, B. Deep Reinforcement Learning for Traffic Signal Control. In Transportation Research Procedia; Elsevier: Amsterdam, The Netherlands, 2023; Volume 74. [Google Scholar] [CrossRef]
- Huang, H.; Hu, Z.; Lu, Z.; Wen, X. Network-Scale Traffic Signal Control via Multiagent Reinforcement Learning with Deep Spatiotemporal Attentive Network. IEEE Trans. Cybern. 2023, 53, 262–274. [Google Scholar] [CrossRef]
- Li, Z.; Yu, H.; Zhang, G.; Dong, S.; Xu, C.Z. Network-Wide Traffic Signal Control Optimization Using a Multi-Agent Deep Reinforcement Learning. Transp. Res. Part. C Emerg. Technol. 2021, 125, 103059. [Google Scholar] [CrossRef]
- Ha, P.; Chen, S.; Du, R.; Labi, S. Scalable Traffic Signal Controls Using Fog-Cloud Based Multiagent Reinforcement Learning. Computers 2022, 11, 38. [Google Scholar] [CrossRef]
- Song, J.; Jin, Z.; Zhu, W.J. Implementing Traffic Signal Optimal Control by Multiagent Reinforcement Learning. In Proceedings of the 2011 International Conference on Computer Science and Network Technology, ICCSNT 2011, Harbin, China, 24–26 December 2011; Volume 4. [Google Scholar] [CrossRef]
- Higuera, C.; Lozano, F.; Camacho, E.C.; Higuera, C.H. Demonstration of Multiagent Reinforcement Learning Applied to Traffic Light Signal Control. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2019; Volume 11523. [Google Scholar] [CrossRef]
- Abdoos, M. Fuzzy Graph and Collective Multiagent Reinforcement Learning for Traffic Signals Control. IEEE Intell. Syst. 2021, 36, 48–55. [Google Scholar] [CrossRef]
- Michailidis, P.; Michailidis, I.; Lazaridis, C.R.; Kosmatopoulos, E. Traffic Signal Control via Reinforcement Learning: A Review on Applications and Innovations. Infrastructures 2025, 10, 114. [Google Scholar] [CrossRef]
- Skoropad, V.N.; Deđanski, S.; Pantović, V.; Injac, Z.; Vujičić, S.; Jovanović-Milenković, M.; Jevtić, B.; Lukić-Vujadinović, V.; Vidojević, D.; Bodolo, I. Dynamic Traffic Flow Optimization Using Reinforcement Learning and Predictive Analytics: A Sustainable Approach to Improving Urban Mobility in the City of Belgrade. Sustainability 2025, 17, 3383. [Google Scholar] [CrossRef]
- Khanmohamadi, M.; Guerrieri, M. Smart Intersections and Connected Autonomous Vehicles for Sustainable Smart Cities: A Brief Review. Sustainability 2025, 17, 3254. [Google Scholar] [CrossRef]
- Bokade, R.; Jin, X. PyTSC: A Unified Platform for Multi-Agent Reinforcement Learning in Traffic Signal Control. Sensors 2025, 25, 1302. [Google Scholar] [CrossRef]
- Gheorghe, C.; Soica, A. Revolutionizing Urban Mobility: A Systematic Review of AI, IoT, and Predictive Analytics in Adaptive Traffic Control Systems for Road Networks. Electronics 2025, 14, 719. [Google Scholar] [CrossRef]
- Ashkanani, M.; AlAjmi, A.; Alhayyan, A.; Esmael, Z.; AlBedaiwi, M.; Nadeem, M. A Self-Adaptive Traffic Signal System Integrating Real-Time Vehicle Detection and License Plate Recognition for Enhanced Traffic Management. Inventions 2025, 10, 14. [Google Scholar] [CrossRef]
- Fan, L.; Yang, Y.; Ji, H.; Xiong, S. Optimization of Traffic Signal Cooperative Control with Sparse Deep Reinforcement Learning Based on Knowledge Sharing. Electronics 2025, 14, 156. [Google Scholar] [CrossRef]
- Chala, T.D.; Kóczy, L.T. Agent-Based Intelligent Fuzzy Traffic Signal Control System for Multiple Road Intersection Systems. Mathematics 2025, 13, 124. [Google Scholar] [CrossRef]
- Jia, X.; Guo, M.; Lyu, Y.; Qu, J.; Li, D.; Guo, F. Adaptive Traffic Signal Control Based on Graph Neural Networks and Dynamic Entropy-Constrained Soft Actor–Critic. Electronics 2024, 13, 4794. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Y.-X.; Li, J.-K.; Liu, Y.; Pi, J.-T. Adaptive Traffic Signal Control Method Based on Offline Reinforcement Learning. Appl. Sci. 2024, 14, 10165. [Google Scholar] [CrossRef]
- Agrahari, A.; Dhabu, M.M.; Deshpande, P.S.; Tiwari, A.; Baig, M.A.; Sawarkar, A.D. Artificial Intelligence-Based Adaptive Traffic Signal Control System: A Comprehensive Review. Electronics 2024, 13, 3875. [Google Scholar] [CrossRef]
- Dinitz, Y. Algorithm for Solution of a Problem of Maximum Flow in Networks with Power Estimation. Available online: https://www.researchgate.net/publication/228057696 (accessed on 18 May 2025).
- Feige, U. A Threshold of ln n for Approximating Set Cover. J. ACM 1998, 45, 634–652. [Google Scholar] [CrossRef]
- Goldberg, A.V.; Tarjan, R.E. A New Approach to the Maximum-Flow Problem. J. ACM 1988, 35, 921–940. [Google Scholar] [CrossRef]
- Gutin, G.; Yeo, A.; Zverovich, A. Traveling Salesman Should not be Greedy: Domination Analysis of Greedy-Type Heuristics for the TSP. Discrete Appl. Math. 2002, 117, 81–86. [Google Scholar] [CrossRef]
- van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Available online: https://arxiv.org/abs/1509.06461 (accessed on 18 May 2025).
- Cox, T.; Thulasiraman, P. A Zone-Based Traffic Assignment Algorithm for Scalable Congestion Reduction. ICT Express 2017, 3, 204–208. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 3rd ed.; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Boykov, Y.; Kolmogorov, V. An Experimental Comparison of Min-Cut/Max-Flow Algorithms for Energy Minimization in Vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1124–1137. [Google Scholar] [CrossRef]
- Hopcroft, J.E.; Karp, R.M. An n5/2 Algorithm for Maximum Matchings in Bipartite Graphs. SIAM J. Comput. 1973, 2, 225–231. [Google Scholar] [CrossRef]
- Li, S. Multi-Agent Deep Deterministic Policy Gradient for Traffic Signal Control on Urban Road Network. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020; pp. 896–901. [Google Scholar] [CrossRef]
- Roderick, M.; MacGlashan, J.; Tellex, S. Implementing the Deep Q-Network. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Shekhar, S.; Evans, M.R.; Kang, J.M. Modeling and analysis of traffic bottlenecks using graph cut techniques. Transp. Res. Rec. 2012, 2302, 71–79. [Google Scholar]
- Wang, Y.; Wu, D.; Li, Y. Traffic flow optimization based on graph cuts and minimal cut algorithms. J. Adv. Transp. 2017, 2017, 8734829. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method/Algorithm | Sources | Scientific Novelty in the Present Study |
|---|---|---|---|
| Classical maximum flow algorithms | Ford–Fulkerson, Edmonds–Karp, Dinitz, Preflow–Push, Boykov–Kolmogorov | [28,30,33,36], present study | Included as a baseline for comparison with modern approaches |
| Reinforcement Learning (RL) | -learning, Deep -Network (), Double | [3,10,32], present study | Application in own simulations with focus on instability and efficiency |
| Multi-agent systems (MARL) | MA2C, MADDPG, PPO, A2C, centralized/decentralized training | [6,7,9,11,13] | Recommended by the authors as a building block based on the results |
| Hybrid approaches and intelligent systems | RL + Fuzzy Logic, RL + Graph Neural Networks, Fog/Cloud architectures | [13,24,25,27] | Mentioned as promising directions for future research |
| Offline RL/predictive analytics | Offline RL, combined approach RL + predictive model | [18,26] | Not used in this study; included in the overview section |
| Simulation platforms and analytical environments | SUMO, PyTSC | [1,20,35,38], present study | SUMO is used for empirical evaluation of algorithms |
| Algorithm | Type | Main Characteristics |
|---|---|---|
| Ford–Fulkerson | classic | iterative addition of increasing paths |
| Edmonds–Karp | classic | BFS-based finding shortest paths |
| Dinitz | classic | uses blocking flow and layered graph |
| Preflow–Push | classic | local push and relabel operations |
| Boykov–Kolmogorov | classic | suitable for real images |
| -Learning | RL | -table, reward learning |
| Deep RL | neural network, replay buffer | |
| Double | Deep RL | two networks, -value stabilization |
| Algorithm Statistics | Edmonds–Karp | Dinitz | Boykov–Kolmogorov | Preflow–Push | |
|---|---|---|---|---|---|
| Cumulative dispersion of vehicles from all flows | |||||
| Average | 1.050163 | 1.052469 | 1.057009 | 1.056472 | 2.841797 |
| Standard Deviation | 0.205977 | 0.217618 | 0.211701 | 0.206755 | 1.217457 |
| Minimum | 0.500000 | 0.500000 | 0.500000 | 0.640095 | 0.500000 |
| 25% Percentile | 0.863011 | 0.862007 | 0.897527 | 0.897527 | 1.785357 |
| 50% Percentile | 1.080123 | 1.105542 | 1.105542 | 1.114924 | 2.822265 |
| 75% Percentile | 1.154701 | 1.154701 | 1.187317 | 1.187317 | 3.765015 |
| Maximum | 0.705791 | 1.963203 | 1.656217 | 1.785357 | 6.575945 |
| Relationship between waiting time of vehicles and their number | |||||
| Average | 22.829153 | 22.872509 | 23.095747 | 22.932797 | 128.760632 |
| Standard Deviation | 6.121900 | 6.955084 | 6.788604 | 6.333832 | 87.588632 |
| Minimum | 5.657500 | 5.414167 | 5.657500 | 4.745000 | 5.414167 |
| 25% Percentile | 18.675833 | 18.462917 | 18.508542 | 18.843125 | 49.944167 |
| 50% Percentile | 21.595833 | 21.535000 | 21.778333 | 21.839167 | 110.442917 |
| 75% Percentile | 25.641250 | 26.249583 | 26.888333 | 26.584167 | 196.963125 |
| Maximum | 47.206667 | 52.073333 | 50.552500 | 50.430833 | 357.030833 |
| Algorithm 1 | Algorithm 2 | -Statistic | -Value | Result |
|---|---|---|---|---|
| Boykov–Kolmogorov | Dinitz | 0.3146 | 0.7531 | Accepted |
| Boykov–Kolmogorov | Double | −31.8745 | 44,684 × 10−160 | Rejected |
| Boykov–Kolmogorov | Edmonds–Karp | 0.4873 | 0.6262 | Accepted |
| Boykov–Kolmogorov | Preflow–push | 0.0382 | 0.9695 | Accepted |
| Dinitz | Double | −31.9704 | 81,301 × 10−161 | Rejected |
| Dinitz | Edmonds–Karp | 0.1618 | 0.8715 | Accepted |
| Dinitz | Preflow–push | −0.2809 | 0.7789 | Accepted |
| Double | Edmonds–Karp | 32.0063 | 48,172 × 10−161 | Rejected |
| Double | Preflow–push | 31.9680 | 7.7920 × 10−161 | Rejected |
| Edmonds–Karp | Preflow–push | −0.4550 | 0.6492 | Accepted |
| Algorithm 1 | Algorithm 2 | -Statistic | -Value | Result |
|---|---|---|---|---|
| Boykov–Kolmogorov | Dinitz | 0.4832 | 0.6291 | Accepted |
| Boykov–Kolmogorov | Double | −25.8430 | 22,955 × 10−116 | Rejected |
| Boykov–Kolmogorov | Edmonds–Karp | 0.6131 | 0.5399 | Accepted |
| Boykov–Kolmogorov | Preflow–push | 0.3694 | 0.7119 | Accepted |
| Dinitz | Double | −25.9222 | 60,076 × 10−117 | Rejected |
| Dinitz | Edmonds–Karp | 0.0984 | 0.9216 | Accepted |
| Dinitz | Preflow–push | −0.1350 | 0.8927 | Accepted |
| Double | Edmonds–Karp | 25.9142 | 71,736 × 10−117 | Rejected |
| Double | Preflow–push | 25.9456 | 39,130 × 10−117 | Rejected |
| Edmonds–Karp | Preflow–push | −0.2476 | 0.8045 | Accepted |
| Scenario | Average Waiting Time (s) | Comments |
|---|---|---|
| High Traffic Load | 112 | High time, but still adapts phases and works better than Webster (135 s) |
| Low Traffic Load | 18 | Excellent weather, adapts dynamic management |
| Real data | 54 | Better results than Webster’s static algorithm (67 s) |
| Scenario | Average Waiting Time (s) | Comments |
|---|---|---|
| Burst Traffic | 67 | The algorithm manages to reduce peak loads, but with a slight increase in waiting time |
| Asymmetric traffic | 52 | Good adaptation and balance between phases |
| Traffic Disruptions | 60 | quickly reconfigures and minimizes delays |
| Multi-path Traffic | 58 | Effective management of complex flow |
| Classical Algorithms | ||
|---|---|---|
| Algorithm | Advantages | Disadvantages |
| Ford–Fulkerson | Simple to implement. Works well for small graphs. | Potentially exponential time; depends on the method of traversal. |
| Edmonds–Karp | Polynomial time (O(VE2). More efficient than Ford–Fulkerson. | Not optimal for large networks. |
| Dinitz | Block flow + layered graph → better performance. | More complex to implement. |
| Preflow–Push | Works through local operations. Polynomial complexity (O(V2E)). | Higher memory consumption. |
| Boykov–Kolmogorov | Good for practical implementation and real images. | It does not guarantee the best time for all columns. |
| Reinforcement Learning (RL) and Deep RL Algorithms | ||
|---|---|---|
| Algorithm | Advantages | Disadvantages |
| -learning | Suitable for small discreet spaces. | It does not scale well with large state spaces. |
| Overcomes scaling limitations through a neural network. | Requires careful setup, vulnerable to instability. | |
| Double | Reduces overestimation of -values by separating selection and evaluation. | It shows significant variation in simulations despite theoretical advantages. |
| Number of Episodes | Average Vehicle Waiting Time (s) | Notes |
|---|---|---|
| 50 | 128 | No clear convergence |
| 150 | 85 | Shows a downward trend |
| 200 | 62 | Significant improvement |
| Number of Episodes | Average Vehicle Waiting Time (s) | Notes |
|---|---|---|
| 300 | 48 | Significant improvement |
| 400 | 42 | Significant stabilization |
| Element | Implementation |
|---|---|
| Simulator | SUMO + TraCI |
| Algorithms | |
| Number of simulations | ≥30 per algorithm, with different starting generators |
| Metrics | Average delay, variance, stability of the result (std. deviation), convergence time |
| Algorithm | Average Delay (s) | Standard Deviation | Average Flow Dispersion | Behavior at Peak Times |
|---|---|---|---|---|
| Edmonds–Karp | 27.3 | ±5.6 | 1.20 | stable, but degraded in highly asymmetric flow |
| Dinitz | 26.1 | ±4.8 | 1.15 | stable and more flexible to unexpected loads |
| Preflow–Push | 28.0 | ±6.2 | 1.22 | good adaptation to sudden changes in input flow |
| 34.9 | ±10.4 | 1.65 | unstable without prior training | |
| Double | 31.2 | ±8.9 | 1.49 | more stable than , but sensitive to initial conditions |
| Algorithm | Average Delay (s) | Standard Deviation | Average Dispersion | Peak Behavior |
|---|---|---|---|---|
| PPO | 23.7 | ±4.2 | 1.10 | stable, flexible under sudden loads |
| A2C | 24.5 | ±5.1 | 1.14 | rapid adaptation, but greater fluctuations |
| Double | 31.2 | ±8.9 | 1.49 | unstable in the beginning |
| Dinitz | 26.1 | ±4.8 | 1.15 | stable but not adaptable to sudden change |
| Comparison | Means (s) | Cohen’s d | -Value | Adjusted Significance ) |
|---|---|---|---|---|
| PPO vs. A2C | 23.7 vs. 24.5 | 0.17 (small) | 0.27 | No significant difference |
| PPO vs. Dinitz | 23.7 vs. 26.1 | 0.52 (medium) | 0.007 | Significant difference |
| PPO vs. Double | 23.7 vs. 31.2 | 1.10 (large) | <0.001 | Significant difference |
| A2C vs. Dinitz | 24.5 vs. 26.1 | 0.33 (small) | 0.085 | No significant difference |
| A2C vs. Double | 24.5 vs. 31.2 | 0.94 (large) | <0.001 | Significant difference |
| Dinitz vs. Double | 26.1 vs. 31.2 | 0.68 (medium/large) | 0.004 | Significant difference |
| Comparison | Means (s) | Cohen’s d | -Value | Significant Difference ) |
|---|---|---|---|---|
| PPO vs. A2C | 23.7 vs. 24.5 | −0.17 | 0.5098 | No |
| PPO vs. Dinitz | 23.7 vs. 26.1 | −0.53 | 0.0438 | No |
| 23.7 vs. 31.2 | −1.08 | 0.0001 | Yes | |
| A2C vs. Dinitz | 24.5 vs. 26.1 | −0.32 | 0.2158 | No |
| 24.5 vs. 31.2 | −0.92 | 0.0007 | Yes | |
| 26.1 vs. 31.2 | −0.71 | 0.0077 | Yes |
| Algorithm | Time (s) | Sustainability (Standard Deviation) | Use of Resources (1–10) |
|---|---|---|---|
| Dinitz | 3.5 | 4.8 | 2 (very low) |
| Double | 16.7 | 8.9 (most unstable) | 6 |
| A2C | 22.1 | 5.1 | 7 |
| PPO | 28.4 (slowest) | 4.2 (most stable) | 9 (high) |
| Characteristic | Classical Algorithms | DRL (Deep Reinforcement Learning) Algorithms |
|---|---|---|
| Type of model | Deterministic, graph-based | Stochastic, interactive learning-based |
| Flexibility to dynamics | Low—fixed topology | High—adapts to changing infrastructure |
| Data requirements | Requires predefined structure and parameters | Requires extensive simulation and interaction data |
| Result stability | High (e.g., Edmonds–Karp, Dinitz) | Lower—requires stabilization (e.g., Double , PPO) |
| Peak load performance | Good but limited | Potentially better if trained sufficiently |
| Computational complexity | Predictable polynomial time | High—neural network training and tuning |
| Real-time applicability | Suitable for static systems | Suitable for dynamic, smart systems (e.g., IoT, CAV) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baeva, S.; Hinov, N.; Nakov, P. Comparative Analysis of Some Methods and Algorithms for Traffic Optimization in Urban Environments Based on Maximum Flow and Deep Reinforcement Learning. Mathematics 2025, 13, 2296. https://doi.org/10.3390/math13142296
Baeva S, Hinov N, Nakov P. Comparative Analysis of Some Methods and Algorithms for Traffic Optimization in Urban Environments Based on Maximum Flow and Deep Reinforcement Learning. Mathematics. 2025; 13(14):2296. https://doi.org/10.3390/math13142296
Chicago/Turabian StyleBaeva, Silvia, Nikolay Hinov, and Plamen Nakov. 2025. "Comparative Analysis of Some Methods and Algorithms for Traffic Optimization in Urban Environments Based on Maximum Flow and Deep Reinforcement Learning" Mathematics 13, no. 14: 2296. https://doi.org/10.3390/math13142296
APA StyleBaeva, S., Hinov, N., & Nakov, P. (2025). Comparative Analysis of Some Methods and Algorithms for Traffic Optimization in Urban Environments Based on Maximum Flow and Deep Reinforcement Learning. Mathematics, 13(14), 2296. https://doi.org/10.3390/math13142296