
Backfire Effect Reveals Early Controversy in Online Media


Abstract
1. Introduction
- (1)
- Propose two novel psychological features—ascending gradient (AG) and tier ascending gradient (TAG)—based on the backfire effect to capture ideological resistance in user interactions for effective controversy detection.
- (2)
- Demonstrate the robustness and generalizability of AG and TAG across multiple platforms (Reddit, Toutiao, Sina), languages (English and Chinese), and classification algorithms, outperforming traditional features.
- (3)
- Validate the practical utility of the proposed features in early-stage and limited-data scenarios (e.g., “one-page” content), enabling efficient and interpretable controversy detection for real-world applications.
2. Related Work
2.1. User Characteristics
2.2. Text-Based Features
2.3. Social Networks
2.4. Discussion Interactions
3. Methodology
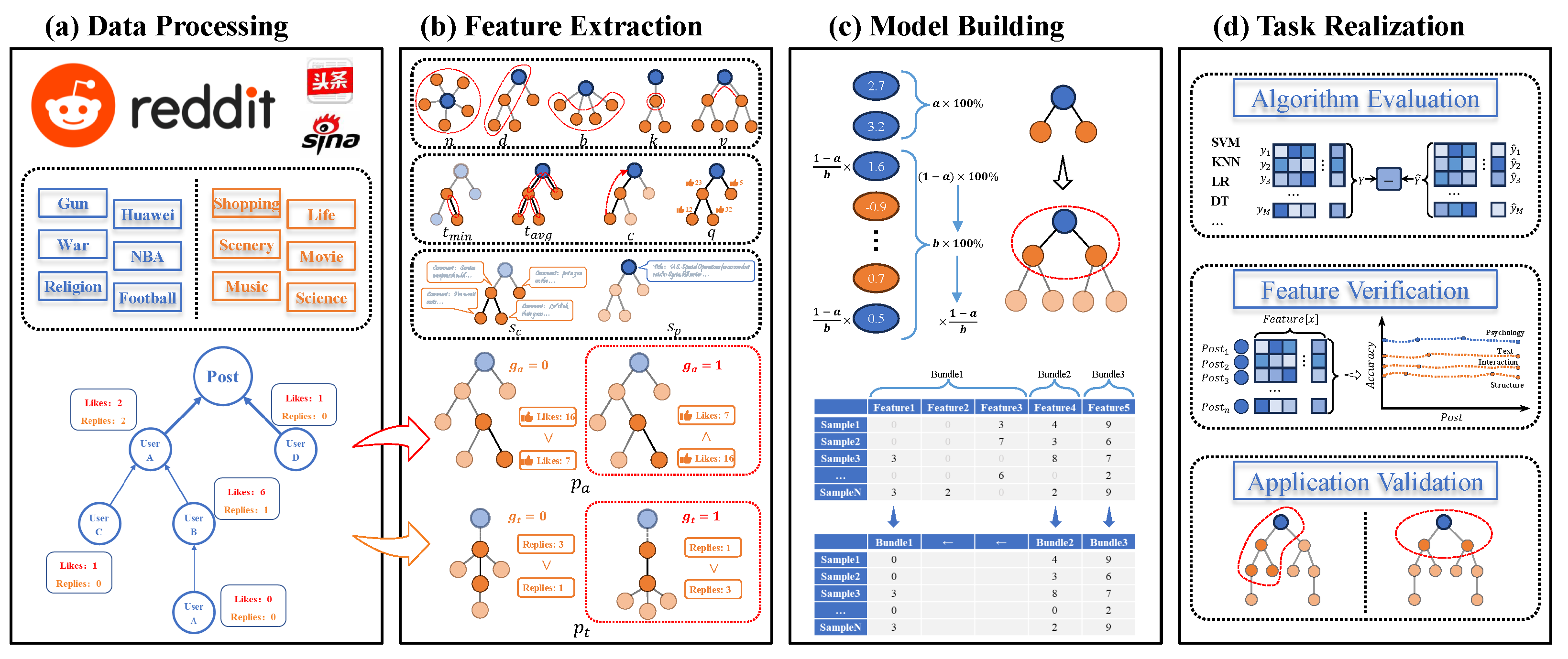
3.1. Data Processing
3.2. Feature Extraction
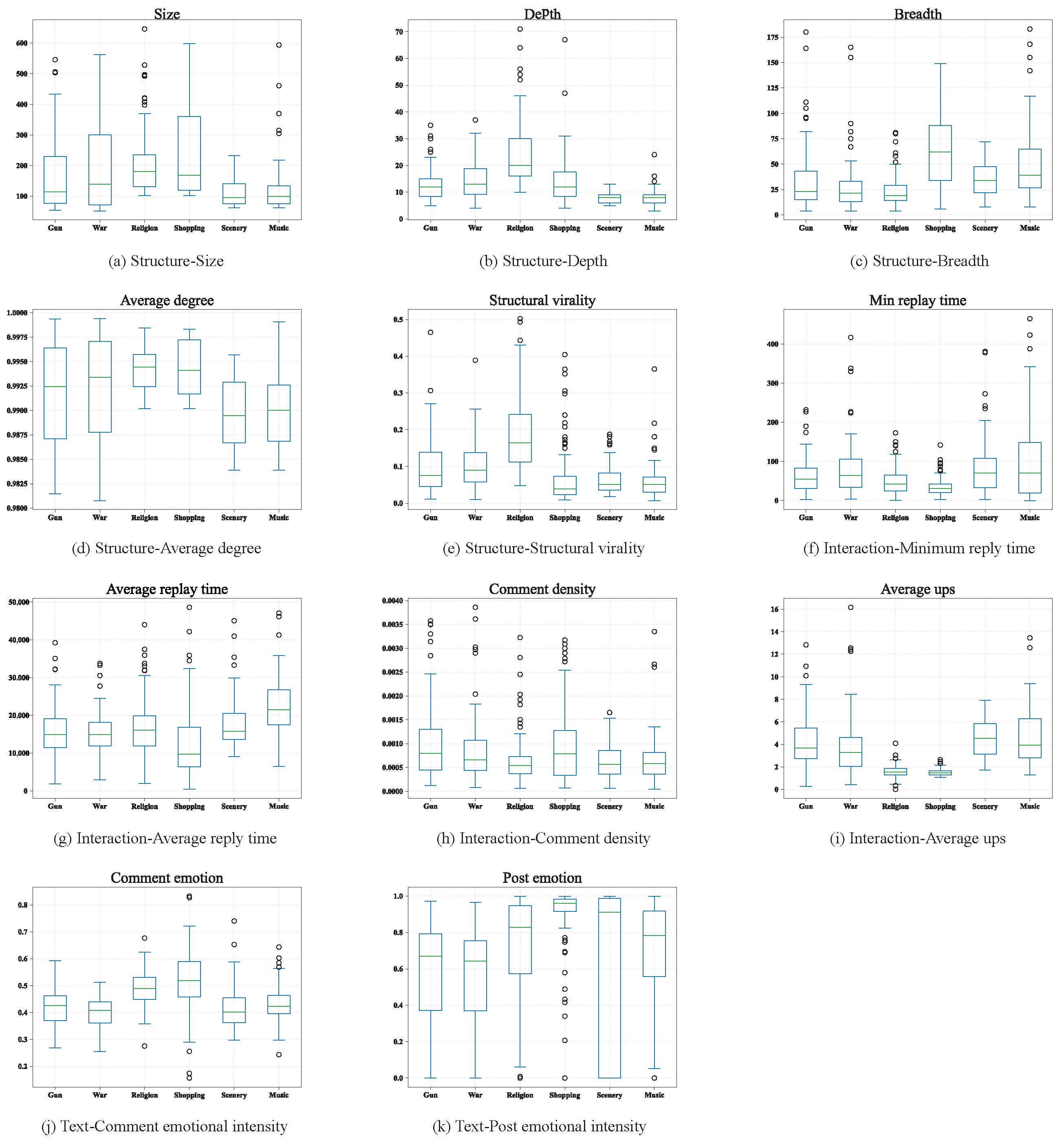
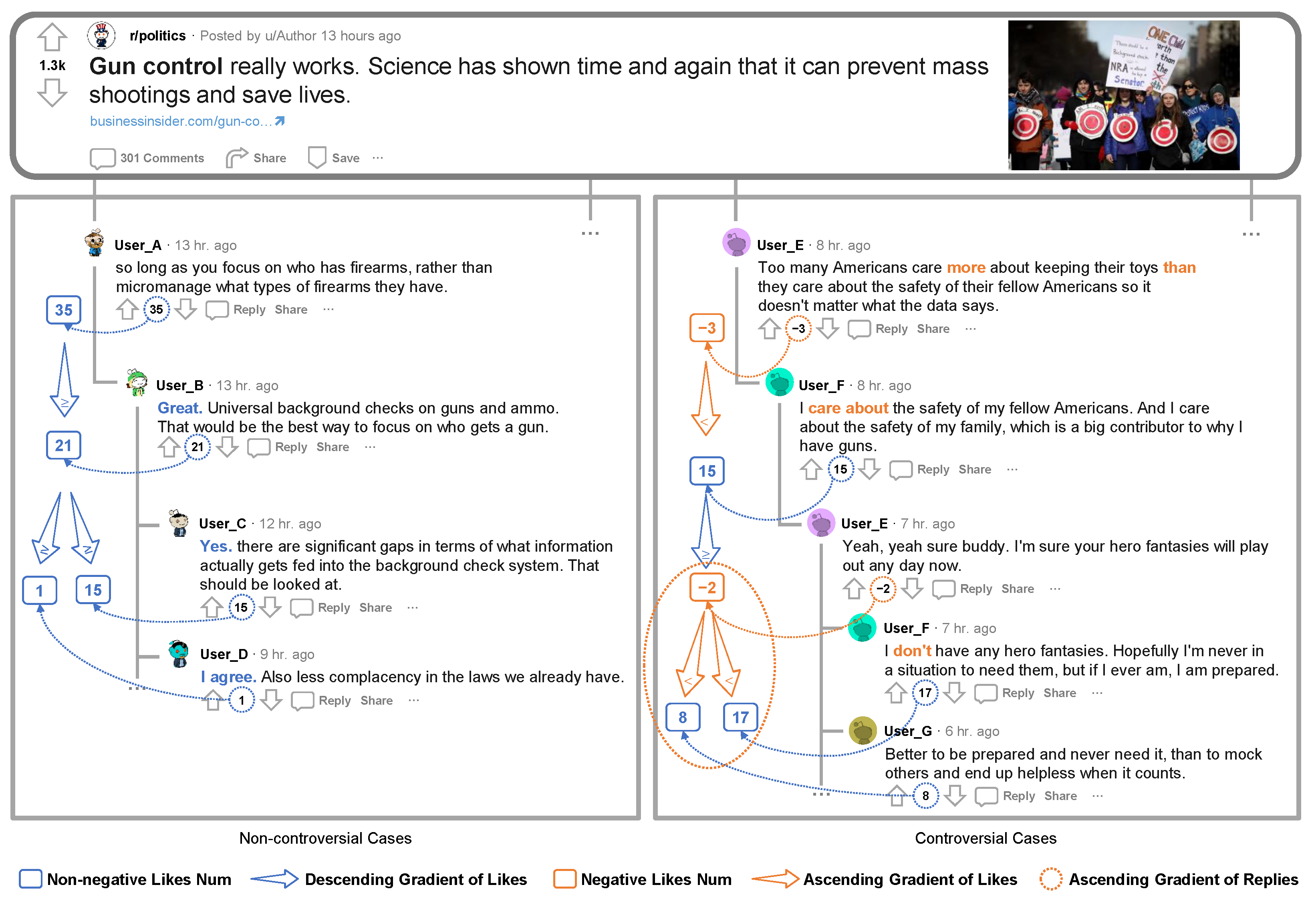
- Size (n). The size of a tree corresponds to the number of nodes (without root) in that tree. For example, the size of the demo post in Figure 2 is 5.
- Depth (d). The depth of a node is the number of links from the node to the root. The depth of a tree is the maximum depth of the node in all nodes. In other words, the depth of a tree, d, with n nodes is defined aswhere denotes the depth of node i. For example, in Figure 2, .
- Breadth (b). The breadth of a cascade is a function of its depth. At each depth, the breadth is the number of nodes at that depth. The breadth of a tree is its maximum breadth at all depths. For a tree with depth d, the breadth, b, is defined aswhere denotes the breadth at depth i. For example, in Figure 2, .
- Average degree (k). In a tree, the degree of a node is only the number of direct children of a node. Therefore, the average degree of a tree is defined aswhere denotes the degree of node i. For example, in the Figure 2, .
- Structural Virality (v). The structural virality of a cascade, is the average distance between all pairs of nodes in a cascade. For a cascade with nodes, the virality v is defined aswhere denotes the length of the shortest path between nodes i and j. For example, in Figure 2, .
- Intensity of comment emotion (). We combine two sentiment methods, Vader and SnowNLP, to achieve efficient semantic analysis of Chinese and English [39,40]. Based on the sentiment dictionary, a sentiment score can be calculated for each comment (node i), and then the comment emotional intensity of a post can be obtained by the following equation:
- Intensity of post emotion (). The emotional intensity of a post is also based on the above sentiment dictionary, and the sentiment score of an entire post’s content is calculated as .
- Reply time (). For each reply link in a post, the time elapsed between the parent comment (node i) and its child (node j) is reply time (). We consider average () and minimum () values of all .
- Comment density (). For a post, the time interval from its publication to the latest comment is ; then, the density of comments can be defined aswhere n denotes the number of comments.
3.3. Model Construction
- (1)
- Take features as the node of a graph, for the features that are not mutually exclusive are connected (i.e., there exist samples that are not 0 at the same time), and the number of samples whose features are not 0 at the same time are used as the weights of the edges.
- (2)
- Sort the features in descending order based on the degree of the nodes, with a larger degree indicating that the features are in greater conflict with other features (the less it will be bundled with other features).
- (3)
- Set the maximum conflict threshold K, traverse the existing feature clusters, and if it is found that the number of conflicts for the feature to be added to the feature cluster will not exceed the maximum threshold K, then the feature is added to the cluster. Otherwise, create a new feature cluster and add the feature to the newly created cluster.
- (4)
- Separate the original feature from the merged feature by adding an offset constant.
| Algorithm 1 Controversy Detection Model. | |
| Require: | ▹ Collection of posts with comment trees and labels |
| Ensure: trained_model | ▹ LightGBM classifier for controversy detection |
| 1: // Initialize LightGBM with optimization techniques | |
| 2: model ← LightGBM | |
| 3: SetParam(model, “objective”, “binary”) | ▹ Binary classification |
| 4: SetParam(model, “boosting”, “gbdt”) | ▹ Gradient Boosting Decision Trees |
| 5: SetParam(model, “sampling”, “GOSS”) | ▹ Gradient-based One-Side Sampling |
| 6: SetParam(model, “bundling”, “EFB”) | ▹ Exclusive Feature Bundling |
| 7: // Process each post in the dataset | |
| 8: for each post ∈ dataset do | |
| 9: features ← [] | ▹ Initialize feature vector |
| 10: // Extract structural features | |
| 11: features[0] ← CommentCount(post) | ▹ Number of comments (n) |
| 12: features[1] ← MaxDepth(post.tree) | ▹ Maximum depth (d) |
| 13: features[2] ← MaxBreadth(post.tree) | ▹ Maximum breadth (b) |
| 14: features[3] ← AverageDegree(post.tree) | ▹ Average node degree (k) |
| 15: features[4] ← StructuralVirality(post.tree) | ▹ Avg. path length (v) |
| 16: // Extract textual features | |
| 17: features[5] ← AvgCommentSentiment(post) | ▹ Avg. comment sentiment () |
| 18: features[6] ← PostSentiment(post) | ▹ Post sentiment intensity () |
| 19: // Extract interaction features | |
| 20: features[7] ← AverageReplyTime(post) | ▹ Avg. reply time () |
| 21: features[8] ← MinimumReplyTime(post) | ▹ Min. reply time () |
| 22: features[9] ← CommentDensity(post) | ▹ Comments per time unit (c) |
| 23: // Extract psychological features (novel contribution) | |
| 24: features[10] ← LikeAscendingGradient(post) | ▹ AG proportion () |
| 25: features[11] ← ReplyAscendingGradient(post) | ▹ TAG proportion () |
| 26: AddTrainingSample(model, features, post.label) | |
| 27: end for | |
| 28: // Configure optimization parameters | |
| 29: SetGOSSParam(model, top_rate=0.2, other_rate=0.1) | |
| 30: SetEFBParam(model, max_conflict=5) | |
| 31: SetParam(model, “num_leaves”, 31) | |
| 32: SetParam(model, “learning_rate”, 0.05) | |
| 33: // Train model with GOSS and EFB optimizations | |
| 34: Train(model) | |
| 35: // Predict controversy probability | |
| 36: prob ← Predict(model, features) | |
| 37: return model, prob | |
4. Results and Discussion
4.1. Controversy Detection Results
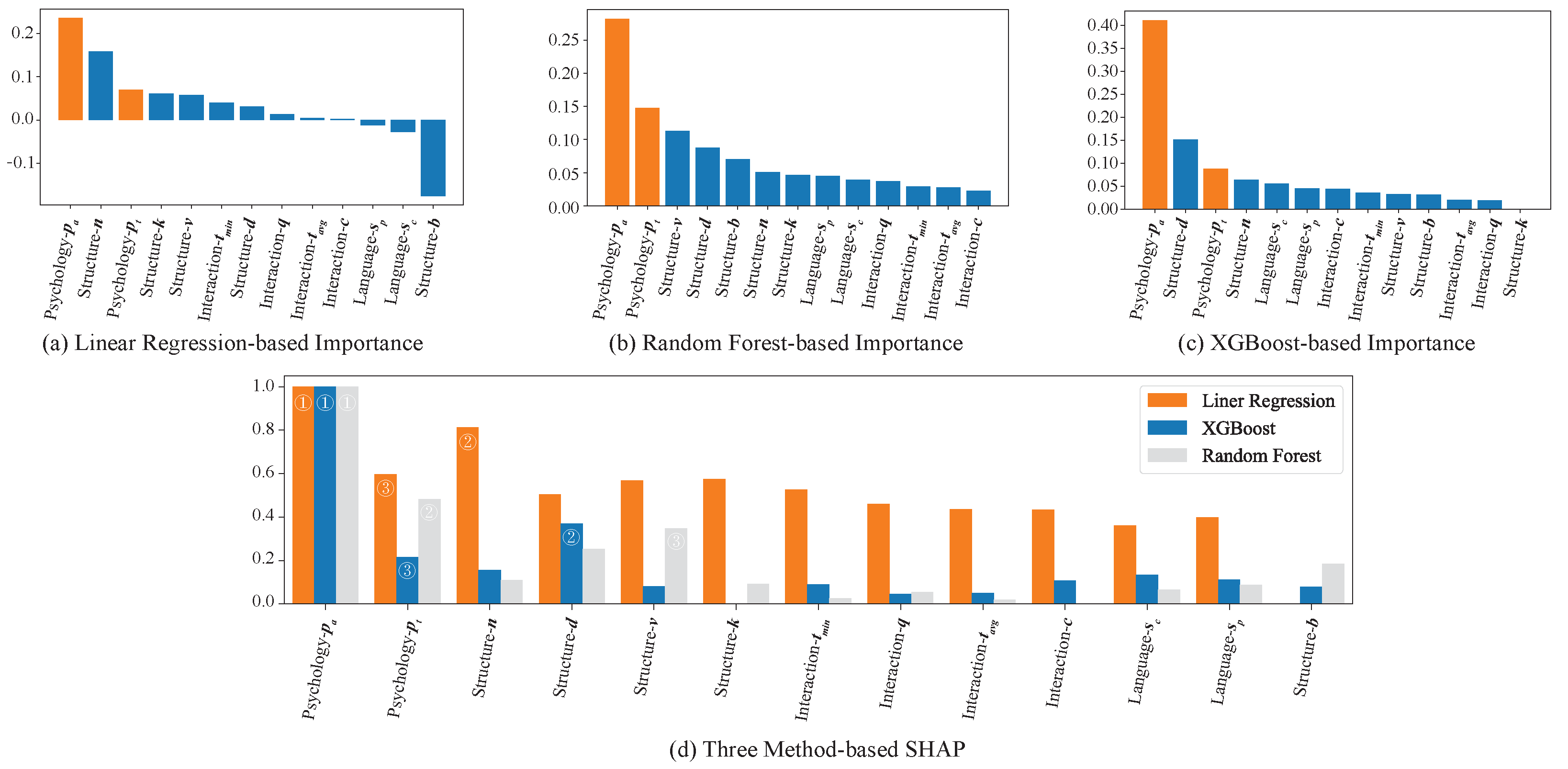
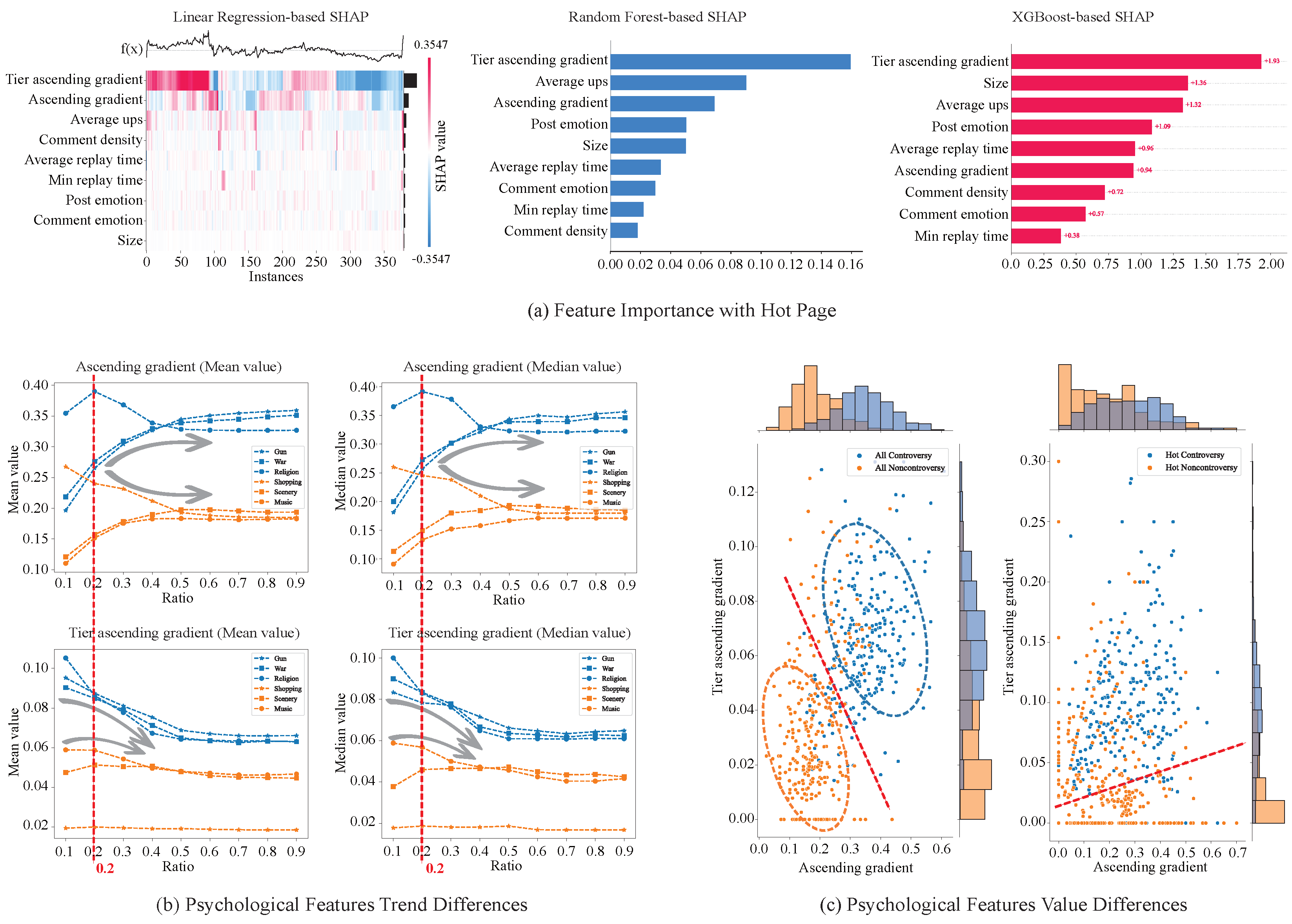
4.2. Importance Evaluation Results
4.2.1. Quantitative Analysis
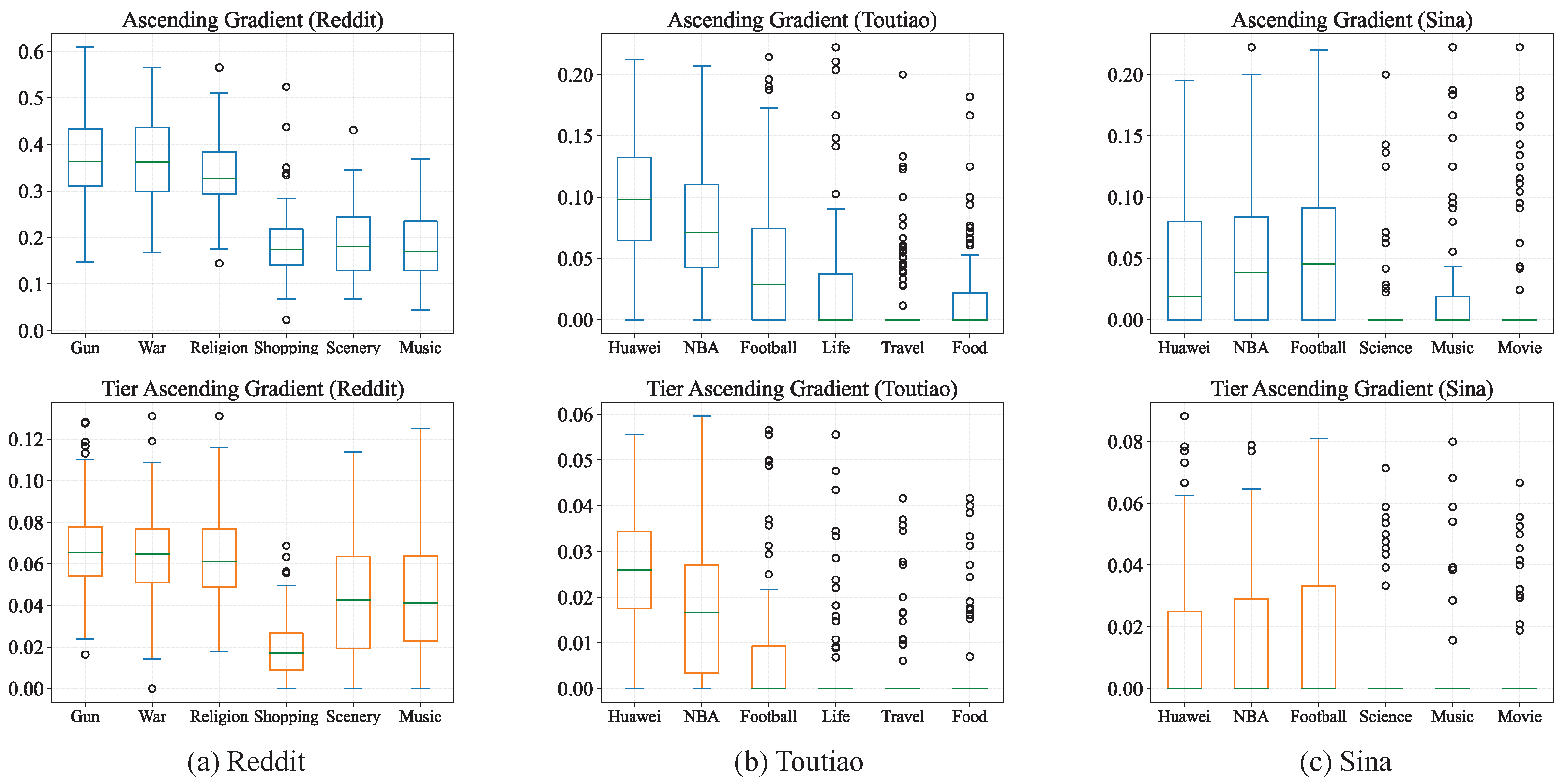
4.2.2. Psychological Interpretation
4.3. Application Evaluation Results
4.3.1. One Page
4.3.2. Early Detection
5. Conclusions
6. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Features Comparison
Appendix B. Features Description

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Name | Category | Symbol | Detailed Description |
|---|---|---|---|---|
| 1 | Size | Structure | n | Number of nodes in the comment tree |
| 2 | Depth | Structure | d | Maximum depth of the comment tree |
| 3 | Breadth | Structure | b | Maximum breadth of comment tree |
| 4 | Average degree | Structure | k | The average degree of the comment tree |
| 5 | Structural virality | Structure | v | The average shortest path of the comment tree |
| 6 | Minimum reply time | Interaction | The shortest time of all reply pairs | |
| 7 | Average reply time | Interaction | Average time for all reply pairs | |
| 8 | Comment density | Interaction | c | Number of comments per second on post |
| 9 | Average ups | Interaction | q | Average of the number of likes of all comments |
| 10 | Comment emotional intensity | Text | Average of the emotional intensity of all comments | |
| 11 | Post emotional intensity | Text | The emotional intensity of post content | |
| 12 | Ascending gradient | Psychology | Percentage of difference in likes for all reply pairs | |
| 13 | Tier ascending gradient | Psychology | The difference in the number of reply to all comments |
References
- Folger, J.P.; Poole, M.S.; Stutman, R.K. Working Through Conflict: Strategies for Relationships, Groups, and Organizations; Routledge: London, UK, 2024. [Google Scholar]
- Jost, J.T.; Baldassarri, D.S.; Druckman, J.N. Cognitive–motivational mechanisms of political polarization in social-communicative contexts. Nat. Rev. Psychol. 2022, 1, 560–576. [Google Scholar] [CrossRef]
- Zhang, L. The Digital Age of Religious Communication: The Shaping and Challenges of Religious Beliefs through Social Media. Stud. Relig. Philos. 2025, 1, 25–41. [Google Scholar] [CrossRef]
- Vicario, M.D.; Quattrociocchi, W.; Scala, A.; Zollo, F. Polarization and fake news: Early warning of potential misinformation targets. ACM Trans. Web (TWEB) 2019, 13, 1–22. [Google Scholar] [CrossRef]
- Stella, M.; Ferrara, E.; De Domenico, M. Bots increase exposure to negative and inflammatory content in online social systems. Proc. Natl. Acad. Sci. USA 2018, 115, 12435–12440. [Google Scholar] [CrossRef] [PubMed]
- Littlejohn, S.W.; Foss, K.A. Encyclopedia of Communication Theory; Sage: New York, NY, USA, 2009; Volume 1. [Google Scholar]
- De Wit, F.R.; Greer, L.L.; Jehn, K.A. The paradox of intragroup conflict: A meta-analysis. J. Appl. Psychol. 2012, 97, 360. [Google Scholar] [CrossRef]
- Dori-Hacohen, S.; Allan, J. Automated controversy detection on the web. In Proceedings of the European Conference on Information Retrieval, Vienna, Austria, 29 March–2 April 2015; Springer: Cham, Switzerland, 2015; pp. 423–434. [Google Scholar]
- Al-Ayyoub, M.; Rabab’ ah, A.; Jararweh, Y.; Al-Kabi, M.N.; Gupta, B.B. Studying the controversy in online crowds’ interactions. Appl. Soft Comput. 2018, 66, 557–563. [Google Scholar] [CrossRef]
- Bide, P.; Dhage, S. Similar event detection and event topic mining in social network platform. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; pp. 1–11. [Google Scholar]
- Coletto, M.; Garimella, K.; Gionis, A.; Lucchese, C. Automatic controversy detection in social media: A content-independent motif-based approach. Online Soc. Netw. Media 2017, 3, 22–31. [Google Scholar] [CrossRef]
- Saveski, M.; Roy, B.; Roy, D. The structure of toxic conversations on Twitter. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 1086–1097. [Google Scholar]
- Hu, L.; Han, G.; Liu, S.; Ren, Y.; Wang, X.; Yang, Z.; Jiang, F. Dual-Aspect Active Learning with Domain-Adversarial Training for Low-Resource Misinformation Detection. Mathematics 2025, 13, 1752. [Google Scholar] [CrossRef]
- Samaan, S.S.; Korial, A.E.; Sarra, R.R.; Humaidi, A.J. Multilingual Web Traffic Forecasting for Network Management Using Artificial Intelligence Techniques. Results Eng. 2025, 26, 105262. [Google Scholar] [CrossRef]
- Nyhan, B.; Reifler, J. When corrections fail: The persistence of political misperceptions. Political Behav. 2010, 32, 303–330. [Google Scholar] [CrossRef]
- Dandekar, P.; Goel, A.; Lee, D.T. Biased assimilation, homophily, and the dynamics of polarization. Proc. Natl. Acad. Sci. USA 2013, 110, 5791–5796. [Google Scholar] [CrossRef] [PubMed]
- Theophilou, E.; Hernández-Leo, D.; Gómez, V. Gender-based learning and behavioural differences in an educational social media platform. J. Comput. Assist. Learn. 2024, 40, 2544–2557. [Google Scholar] [CrossRef]
- Holt, J.L.; DeVore, C.J. Culture, gender, organizational role, and styles of conflict resolution: A meta-analysis. Int. J. Intercult. Relat. 2005, 29, 165–196. [Google Scholar] [CrossRef]
- Triandis, H.C. Culture and conflict. Int. J. Psychol. 2000, 35, 145–152. [Google Scholar] [CrossRef]
- Cheng, J.; Danescu-Niculescu-Mizil, C.; Leskovec, J. Antisocial behavior in online discussion communities. In Proceedings of the International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015; Volume 9, pp. 61–70. [Google Scholar]
- Levy, S.; Kraut, R.E.; Yu, J.A.; Altenburger, K.M.; Wang, Y.C. Understanding Conflicts in Online Conversations. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 2592–2602. [Google Scholar]
- Kumar, S.; Hamilton, W.L.; Leskovec, J.; Jurafsky, D. Community interaction and conflict on the web. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 933–943. [Google Scholar]
- Choi, M.; Aiello, L.M.; Varga, K.Z.; Quercia, D. Ten social dimensions of conversations and relationships. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1514–1525. [Google Scholar]
- Li, J.; Zhang, C.; Jiang, L. Innovative Telecom Fraud Detection: A New Dataset and an Advanced Model with RoBERTa and Dual Loss Functions. Appl. Sci. 2024, 14, 11628. [Google Scholar] [CrossRef]
- Weingart, L.R.; Behfar, K.J.; Bendersky, C.; Todorova, G.; Jehn, K.A. The directness and oppositional intensity of conflict expression. Acad. Manag. Rev. 2015, 40, 235–262. [Google Scholar] [CrossRef]
- Zhang, J.; Chang, J.P.; Danescu-Niculescu-Mizil, C.; Dixon, L.; Hua, Y.; Thain, N.; Taraborelli, D. Conversations gone awry: Detecting early signs of conversational failure. arXiv 2018, arXiv:1805.05345. [Google Scholar]
- Conover, M.; Ratkiewicz, J.; Francisco, M.; Gonçalves, B.; Menczer, F.; Flammini, A. Political polarization on twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; Volume 5, pp. 89–96. [Google Scholar]
- Garimella, K.; De Francisci Morales, G.; Gionis, A.; Mathioudakis, M. Reducing controversy by connecting opposing views. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 81–90. [Google Scholar]
- Akoglu, L. Quantifying political polarity based on bipartite opinion networks. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 July 2014; Volume 8, pp. 2–11. [Google Scholar]
- De Dreu, C.K. Social Conflict: The Emergence and Consequences of Struggle and Negotiation. In Handbook of Social Psychology; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2010. [Google Scholar]
- McKeown, S.; Haji, R.; Ferguson, N. Understanding Peace and Conflict Through Social Identity Theory: Contemporary Global Perspectives; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Labianca, G.; Brass, D.J.; Gray, B. Social networks and perceptions of intergroup conflict: The role of negative relationships and third parties. Acad. Manag. J. 1998, 41, 55–67. [Google Scholar] [CrossRef]
- Pettigrew, T.F.; Tropp, L.R.; Wagner, U.; Christ, O. Recent advances in intergroup contact theory. Int. J. Intercult. Relations 2011, 35, 271–280. [Google Scholar] [CrossRef]
- Zhong, L.; Cao, J.; Sheng, Q.; Guo, J.; Wang, Z. Integrating semantic and structural information with graph convolutional network for controversy detection. arXiv 2020, arXiv:2005.07886. [Google Scholar]
- Benslimane, S.; Azé, J.; Bringay, S.; Servajean, M.; Mollevi, C. Controversy Detection: A Text and Graph Neural Network Based Approach. In Proceedings of the International Conference on Web Information Systems Engineering, Melbourne, VIC, Australia, 26 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 339–354. [Google Scholar]
- Xuan, Q.; Wang, J.; Zhao, M.; Yuan, J.; Fu, C.; Ruan, Z.; Chen, G. Subgraph networks with application to structural feature space expansion. IEEE Trans. Knowl. Data Eng. 2019, 33, 2776–2789. [Google Scholar] [CrossRef]
- Goel, S.; Anderson, A.; Hofman, J.; Watts, D.J. The structural virality of online diffusion. Manag. Sci. 2016, 62, 180–196. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Min, K.; Ma, C.; Zhao, T.; Li, H. BosonNLP: An ensemble approach for word segmentation and POS tagging. In Natural Language Processing and Chinese Computing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 520–526. [Google Scholar]
- Chou, E.; Tramer, F.; Pellegrino, G. Sentinet: Detecting localized universal attacks against deep learning systems. In Proceedings of the 2020 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 21 May 2020; pp. 48–54. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Bail, C.A.; Argyle, L.P.; Brown, T.W.; Bumpus, J.P.; Chen, H.; Hunzaker, M.F.; Lee, J.; Mann, M.; Merhout, F.; Volfovsky, A. Exposure to opposing views on social media can increase political polarization. Proc. Natl. Acad. Sci. USA 2018, 115, 9216–9221. [Google Scholar] [CrossRef]
| Type | Media | Topic | Controversy | Post | Comment/Like |
| Main Data | Reddit (English) | Gun | ✓ | 79 | 19,371/150,772 |
| War | ✓ | 66 | 17,556/139,894 | ||
| Religion | ✓ | 122 | 25,663/57,355 | ||
| Shopping | ✗ | 111 | 26,503/40,831 | ||
| Scenery | ✗ | 71 | 7,805/38,476 | ||
| Music | ✗ | 93 | 13,278/83,951 | ||
| Type | Controversy | Toutiao (Chinese) | Sina (Chinese) | ||
| Topic | Post/Comment/Like | Topic | Post/Comment/Like | ||
| Test Data | ✓ | Huawei | 111/25,317/63,838 | Huawei | 118/23,578/635,701 |
| NBA | 104/22,695/84,768 | NBA | 145/20,608/378,094 | ||
| Football | 96/21,747/44,494 | Football | 171/23,617/542,666 | ||
| ✗ | Life | 104/13,434/96,734 | Science | 84/9,561/206,664 | |
| Food | 115/26,518/21,068 | Music | 78/10,943/94,213 | ||
| Travel | 117/10,014/33,769 | Movie | 132/16,155/197,196 | ||
| Platform | Method | Feature | |||
|---|---|---|---|---|---|
| Structure | Interaction | Text | Psychology | ||
| SVM | 80.98 | 80.37 | 80.98 | 93.25 | |
| KNN | 82.82 | 82.82 | 85.28 | 89.57 | |
| LR | 80.37 | 79.75 | 80.37 | 91.41 | |
| DT | 74.23 | 82.82 | 76.68 | 85.27 | |
| GBDT | 82.82 | 84.66 | 86.50 | 90.80 | |
| LightGBM | 84.05 | 84.05 | 85.28 | 93.25 | |
| Toutiao | LightGBM | 77.84 | 89.18 | 88.66 | 90.21 |
| Sina | LightGBM | 78.22 | 82.18 | 82.67 | 83.66 |
| Mode (Feature Num) | Time | |||
|---|---|---|---|---|
| 3 h | 6 h | 9 h | 24 h | |
| Structure (5) | 68.71 | 73.62 | 82.21 | 84.05 |
| Interaction (9) | 73.62 | 83.44 | 84.66 | 84.05 |
| Text (11) | 73.62 | 87.73 | 84.05 | 85.28 |
| Phychology (13) | 73.62 + 11.66 (85.28) | 87.73 + 5.52 (93.25) | 84.66 + 9.21 (93.87) | 85.28 + 8.59 (93.87) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, S.; Jin, T.; Zhu, K.; Xuan, Q.; Min, Y. Backfire Effect Reveals Early Controversy in Online Media. Mathematics 2025, 13, 2147. https://doi.org/10.3390/math13132147
Peng S, Jin T, Zhu K, Xuan Q, Min Y. Backfire Effect Reveals Early Controversy in Online Media. Mathematics. 2025; 13(13):2147. https://doi.org/10.3390/math13132147
Chicago/Turabian StylePeng, Songtao, Tao Jin, Kailun Zhu, Qi Xuan, and Yong Min. 2025. "Backfire Effect Reveals Early Controversy in Online Media" Mathematics 13, no. 13: 2147. https://doi.org/10.3390/math13132147
APA StylePeng, S., Jin, T., Zhu, K., Xuan, Q., & Min, Y. (2025). Backfire Effect Reveals Early Controversy in Online Media. Mathematics, 13(13), 2147. https://doi.org/10.3390/math13132147