
Towards Human-like Artificial Intelligence: A Review of Anthropomorphic Computing in AI and Future Trends



Abstract
1. Introduction
- This paper examines the manifestation of various AI technologies and algorithms in mimicking human cognition throughout the history of artificial intelligence, using anthropomorphic computing as an analytical framework, and provides technical explanations from architectural or algorithmic perspectives.
- We propose a “Cyber Brain Intelligence” framework for future AI development. This is an AI system designed to generate and analyze virtual EEG signals in order to address various issues encountered in everyday life. Emerging from the perspective of anthropomorphic computing, this conceptual model attempts to address current limitations in artificial intelligence.
- This paper analyzes the development trends of future artificial intelligence and provides market forecasts for the potential applications of “Cyber Brain Intelligence”.
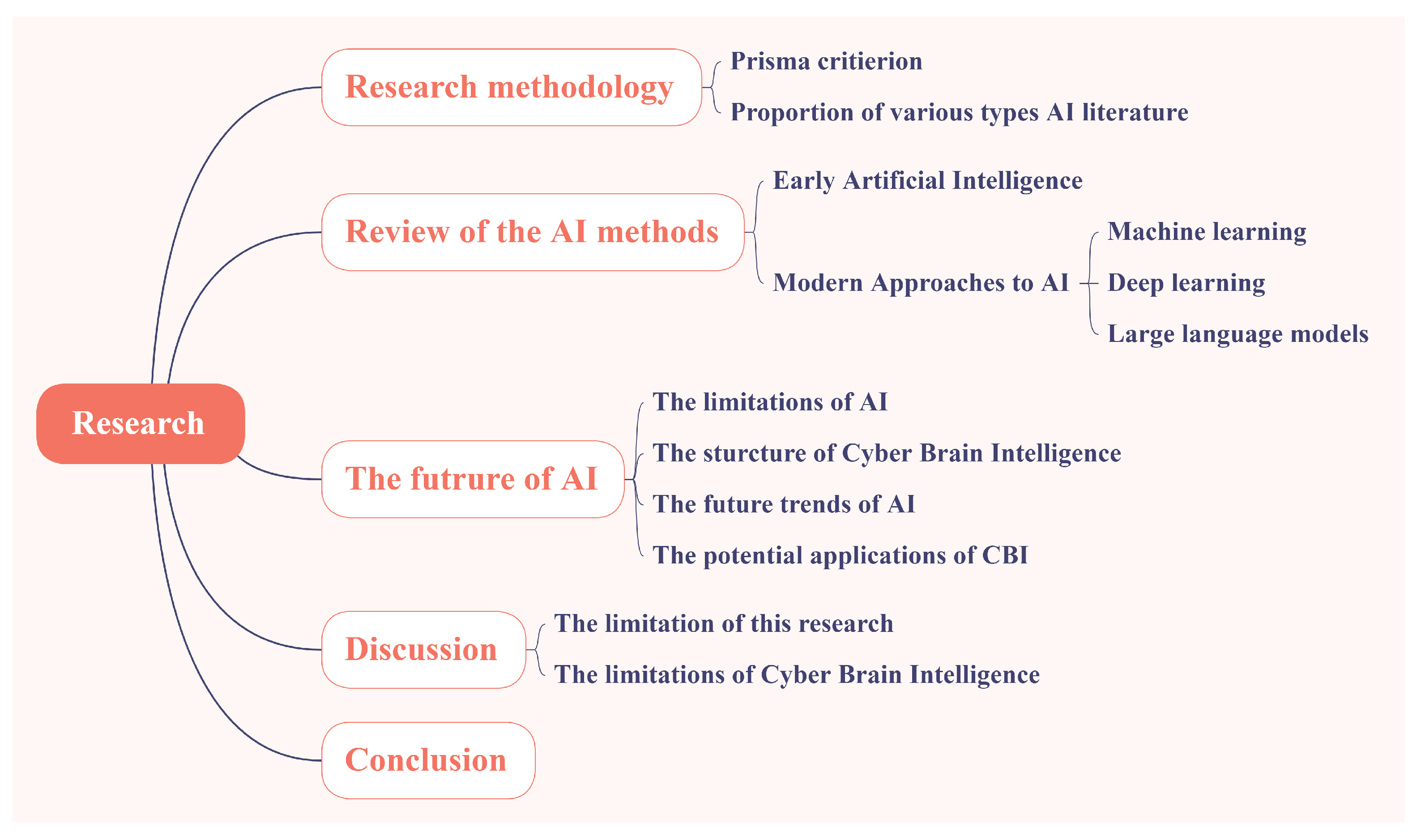
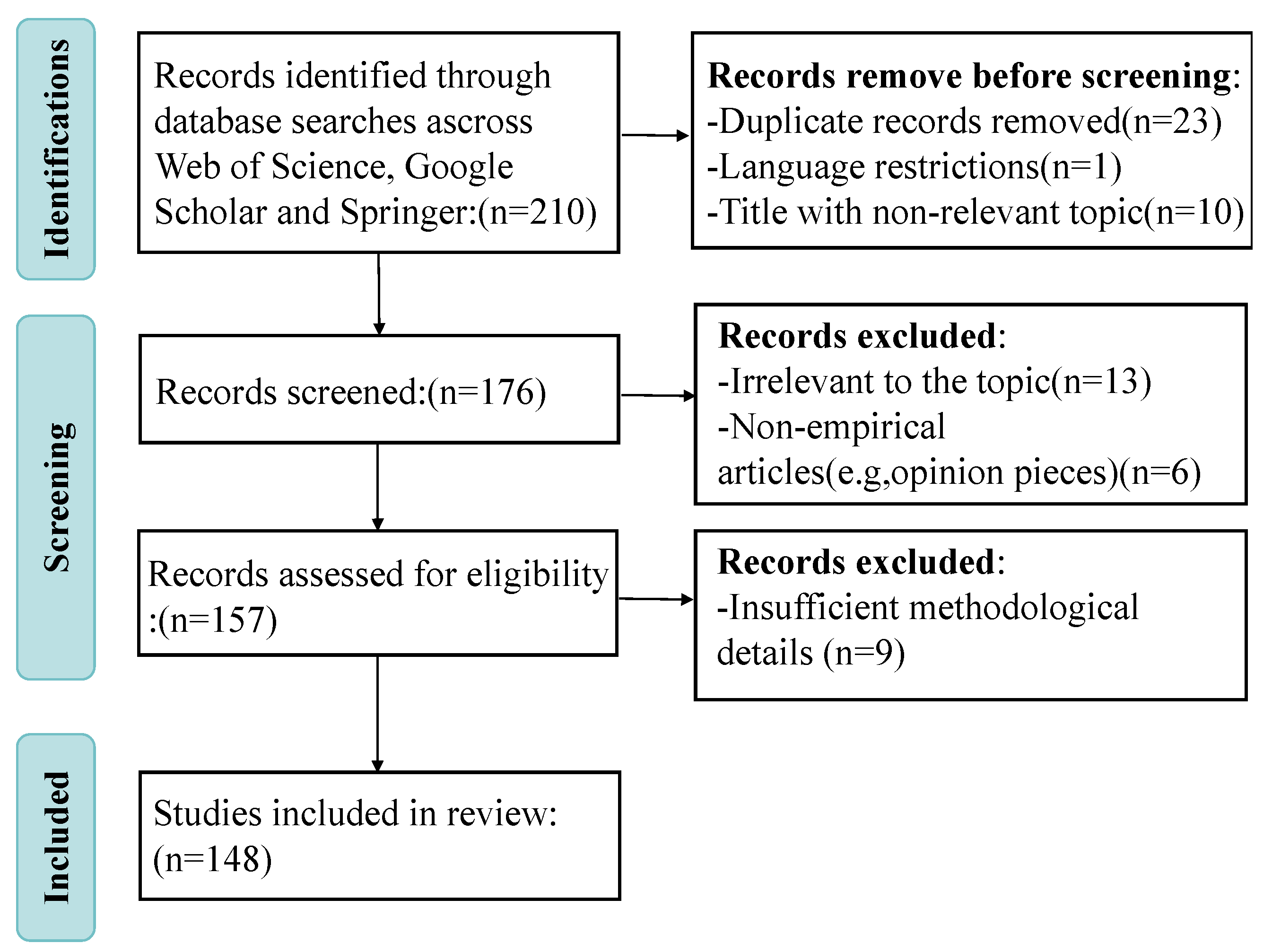
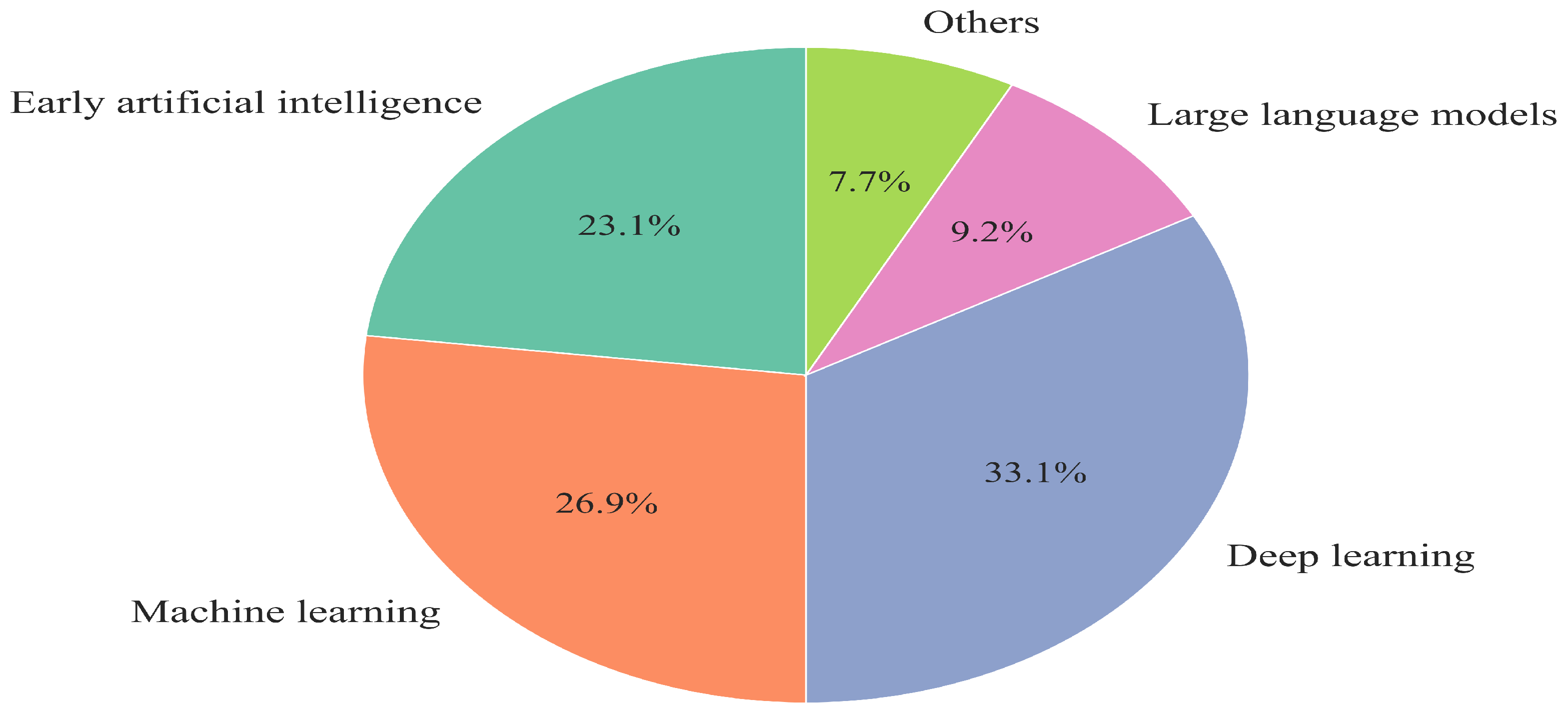
2. Research Methodology
3. The Anthropomorphic Computing in Different Time of Artificial Intelligence
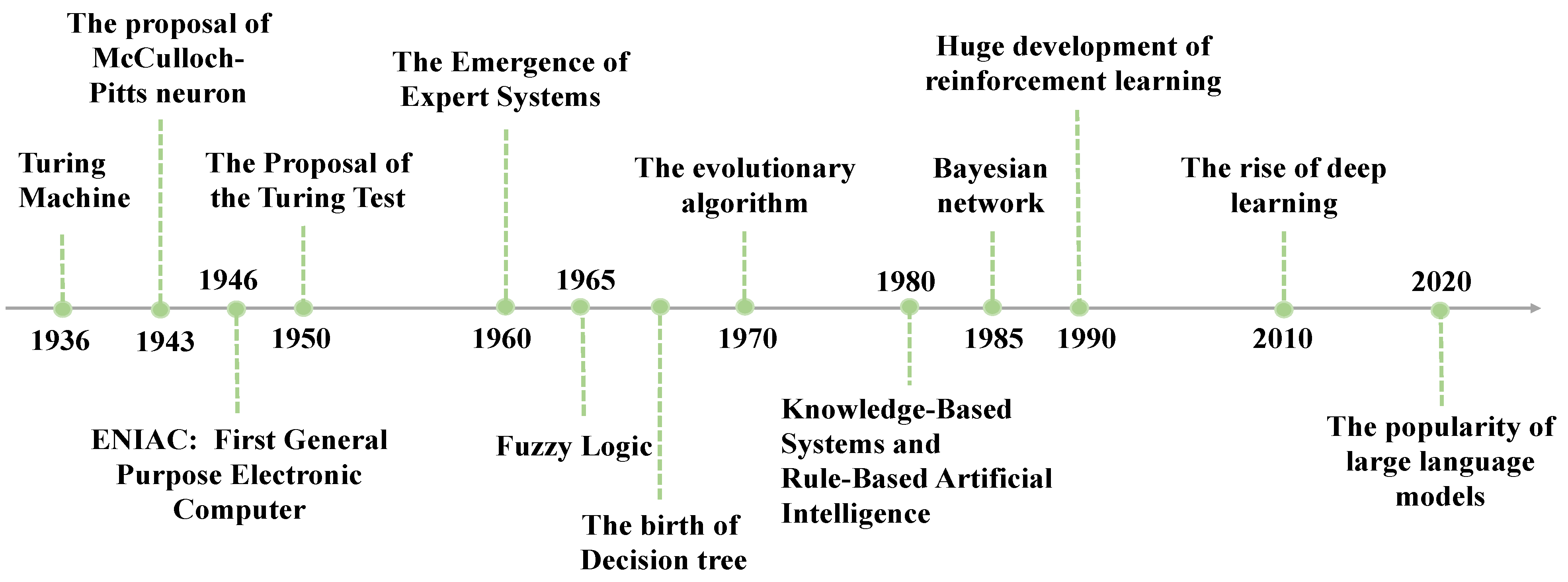
3.1. Early Artificial Intelligence and Anthropomorphic Computing
3.1.1. Turing Machine
3.1.2. The McCulloch–Pitts Neuron
3.1.3. The ENIAC
3.1.4. Fuzzy Logic
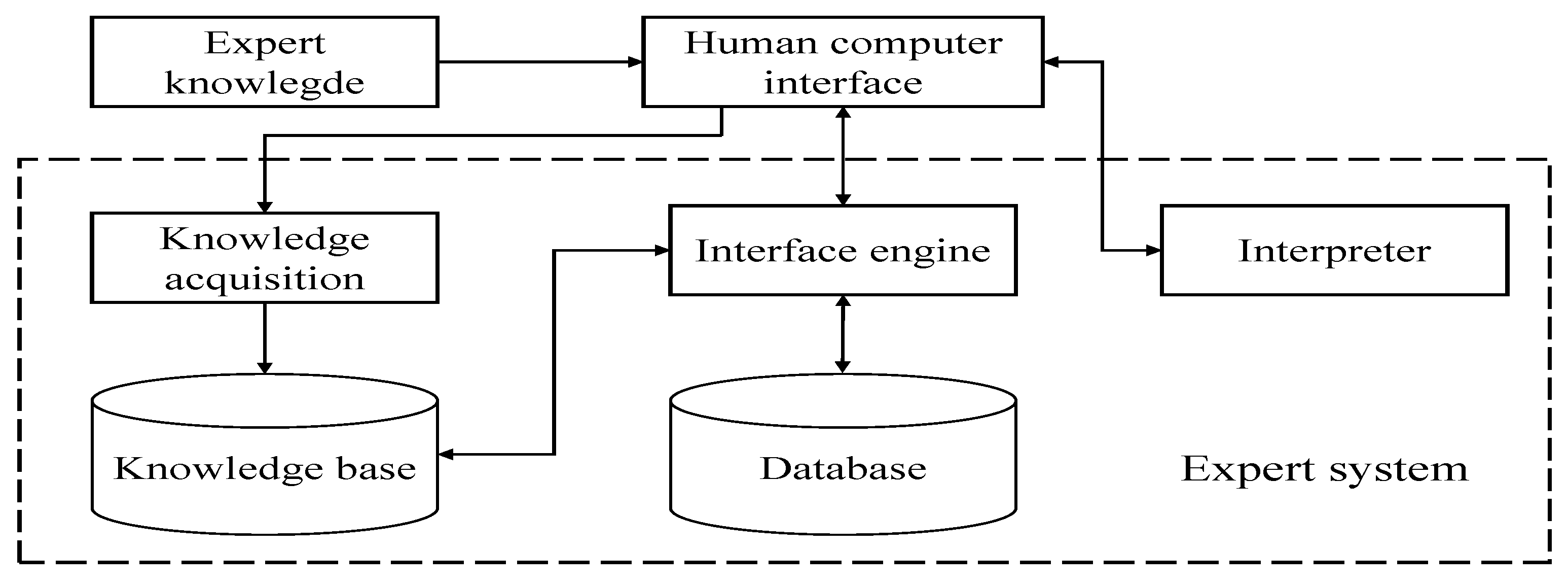
3.1.5. Expert Systems
- Forward reasoning: This data-driven approach begins with known facts and applies rules to derive new facts or conclusions. For instance, if the system knows the patient has a fever and cough, it applies the corresponding rules to infer a diagnosis.
- Backward reasoning: This goal-driven method starts with a hypothesis or goal (such as the diagnosis of influenza) and works backward to deduce the facts necessary to support that conclusion.
3.1.6. Evolutionary Algorithm
| Algorithm 1: Anthropomorphic Evolutionary Algorithm (AEA) |
 |
3.2. Modern Approaches to AI and Anthropomorphic Computing
3.2.1. The Rise of Machine Learning and Neural Networks (the 1990s)
- A. Decision tree. Decision tree is a machine learning algorithm based on hierarchical decision rules, widely used in classification and regression tasks. Its history can be traced back to preliminary research in the 1960s, and it gained significant development in the 1980s with the introduction of algorithms such as ID3 [27]. The basic idea of a decision tree is to decompose a complex problem step by step through a series of conditional judgments, thereby forming an easily interpretable decision model. Its logical structure bears a significant similarity to the hierarchical reasoning methods humans use when solving problems.
- Information gain: Information gain measures the reduction in uncertainty about the classification due to the feature. Given a feature A and target variable Y, its formula iswhere is the entropy of the classification, defined asrepresents the conditional entropy of Y given feature A.
- Gini index: The Gini index [28] measures the impurity of the data, defined aswhere is the probability of the i-th class sample. The lower the Gini index, the “purer” the node.
- B. Reinforcement learning. In the field of artificial intelligence research, reinforcement learning (RL) serves as a machine learning paradigm for sequential decision-making through a trial-and-error mechanism [29]. Its core lies in the agent gradually optimizing its strategy to maximize cumulative rewards through continuous interaction with the environment. This process mimics the learning mechanism of organisms adjusting their behavioral patterns based on reward–punishment feedback.
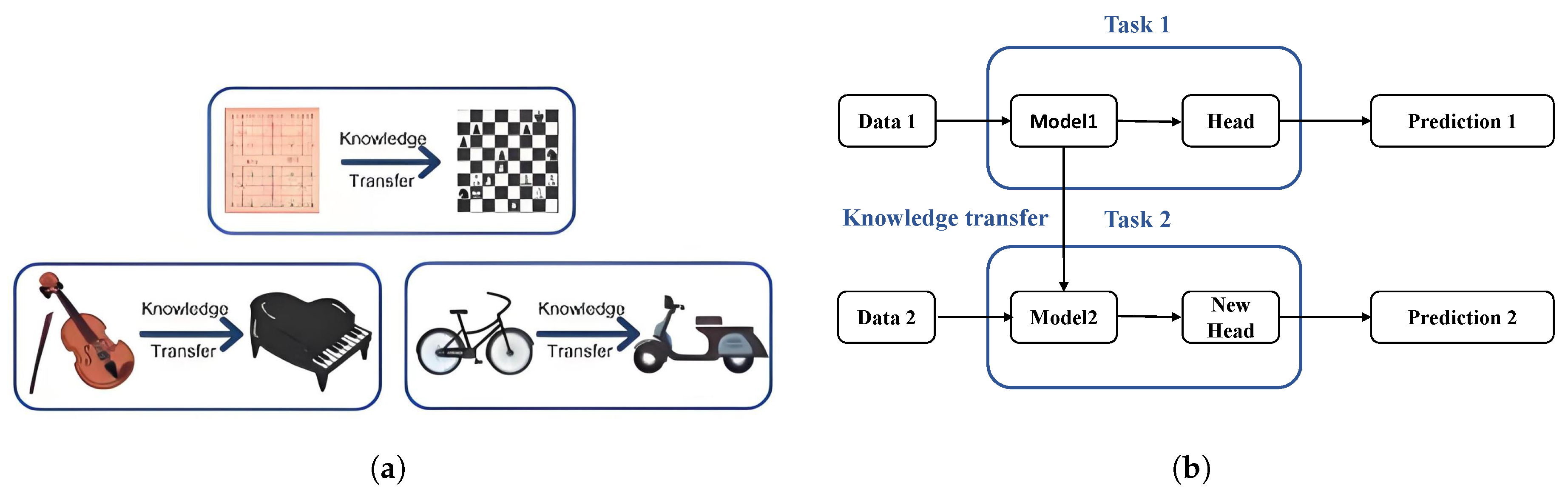
- C. Transfer learning. Transfer learning, an advanced machine learning approach, was proposed to address two major challenges in real-world applications [38,39]. The first challenge is the limited number of labeled training samples, especially when dealing with classification problems in specific domains, where there is often a lack of sufficient training data. The second challenge is the change in data distribution, which can render previously collected data outdated, necessitating the recollection of data and retraining of the model. To address these issues, transfer learning emerged. It allows the transfer of knowledge from related domains to the target domain, thereby improving classification performance in the target domain and reducing the need for a large amount of labeled data. Figure 8 is an intuitive example of transfer learning from the human and computer perspectives.
| Algorithm 2: Transfer Learning [39] |
 |
- D. Principal component analysis. Principal component analysis is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. In this, the dimension of the data is reduced to make the computations faster and easier. It is used to explain the variance-covariance structure of a set of variables through linear combinations [44]. It is often used as a dimensionality-reduction technique. The entire process can be understood in three steps: first, translate the data to the origin to eliminate positional bias; second, calculate the correlation between different dimensions (covariance matrix); and finally, use mathematical eigendecomposition to find the directions in which the data distribution is most “stretched out” (i.e., the directions with the largest variance), and use these directions as new coordinate axes to redescribe the data.
| Algorithm 3: PCA [44] |
| Input: Data matrix Output: Reduced data 1: Center the data by subtracting the mean of each feature 2: Compute the covariance matrix 3: Compute the eigenvalues and eigenvectors of 4: Sort eigenvectors by decreasing eigenvalues 5: Select the top k eigenvectors to form matrix 6: Transform the data matrix X using W to obtain |
- E. Bayesian networks. Bayesian networks, also known as belief networks, are probabilistic graphical models that represent a set of variables and their interdependencies. These models were first introduced by Judea Pearl in 1985 and have since become a cornerstone in the fields of artificial intelligence, machine learning, and probabilistic reasoning [45]. In a Bayesian network, nodes represent random variables, which can be discrete or continuous. Directed edges between nodes indicate conditional dependencies, with the direction of the edge indicating the direction of influence. Each node is associated with a conditional probability distribution (CPD) that specifies the probability of the node’s state given the states of its parent nodes. Bayesian networks are particularly useful for modeling uncertain domains and performing probabilistic inference. They allow for the visualization of dependencies, efficient modeling, flexible probabilistic reasoning, and the accommodation of incomplete data.
| Algorithm 4: Bayesian Network [45] |
 |
3.2.2. The Rise of Deep Learning (2005)
- A. Perceptual layer abstraction: Biologically inspired feature extraction. The perceptual systems of biological organisms (such as vision and hearing) are essentially multi-level, adaptive processes of information abstraction. Taking human vision as an example, after the retina receives raw light signals, the information is processed layer by layer through the lateral geniculate nucleus (LGN) and the visual cortex: the primary visual cortex (V1) extracts low-level local features such as edges and orientations, while higher-level visual areas (V4, IT cortex) progressively integrate information to form representations of shapes, textures, and even semantic content [48,49]. This process reflects the biological logic of “hierarchical abstraction”, which involves a progressive transformation from low-level physical features to high-level semantic representations.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Main Finding | Limitations | Dataset | Year |
|---|---|---|---|---|
| AlexNet [57] | Utilizes Dropout and ReLU | Sensitive to input image size, many parameters in the fully connected layers | ImageNet | 2012 |
| ZFNet [58] | Visualization idea of middle layers | Redundant parameters in the fully connected layers | ImageNet | 2014 |
| VGG | Increased depth, small filter size | Large numbers of parameters, not flexible and modular enough | ImageNet | 2014 |
| GoogLeNet [59] | Increased depth, block concept, different filter size, concatenation concept | High computational complexity in branching operations | ImageNet | 2015 |
| ResNet [60] | Robust against overfitting due to symmetry mapping-based skip links | Lack of feature locality, deep structures require higher computational resources | ImageNet | 2016 |
| CapsuleNet [61] | Pays attention to special relationships between features | Architectural complexity and high memory requirements | MNIST | 2018 |
| MobileNet-v2 [62] | Inverted residual structure | Limited feature representation capability | ImageNet | 2018 |
| HRNetV2 [63] | High-resolution representations | The multi-branch design and high-resolution module impose higher demands on implementation and debugging | ImageNet | 2020 |
| SCNet [64] | Emphasize structured pruning techniques | The flexibility of the pruned model is limited | ImageNet | 2022 |
- B.Temporal and contextual understanding: Engineering the implementation of memory mechanisms. Human language comprehension is akin to a relay race of thought; when you hear the sentence “Last week, the kitten I raised got sick”, your brain naturally retains the key event “kitten got sick”, and upon hearing the follow-up “now it has finally recovered”, it automatically links “it” back to the previously stored “kitten”. This ability to dynamically weave memories is precisely the cognitive trait that deep learning systems aim to simulate through engineered memory frameworks. Table 4 shows the overview of RNN and LSTM architectures. The following will introduce several representative networks, and their overall information is summarized in Table 5.Table 4. Brief overview of RNN and LSTM architectures.
Model Main Finding Limitations Year Vanilla RNN [65] Introduced recurrent connections for sequential data processing Prone to vanishing/exploding gradients, difficulty in learning long-term dependencies 1986 LSTM [66] Introduced memory cells and gating mechanisms to address long-term dependency issues Computationally expensive due to additional parameters and operations 1997 GRU [67] Simplified gating mechanism compared to LSTM, faster training Limited flexibility compared to LSTM, may underperform on complex tasks 2014 Transformer-based RNN [68] Combines RNN with Transformer architectures for enhanced sequence modeling Higher memory requirements and complexity compared to pure RNNs 2017 ConvLSTM [69] Combines convolutional layers with LSTM for spatio-temporal data modeling Computationally intensive, requires large datasets 2015 Hierarchical Attention RNN [70] Combines hierarchical structures with attention mechanisms for document classification Increased model complexity and harder to tune hyperparameters 2016 BiLSTM + Attention [71] Combines BiLSTM with attention for improved sequence modeling and feature extraction Higher computational cost due to bidirectional and attention mechanisms 2021 Attention-based ConvLSTM [72] Enhances ConvLSTM with attention for spatio-temporal feature modeling Computationally intensive, requires large datasets 2022
| Characteristic | Vanilla RNN | LSTM | GRU | Phased-LSTM |
|---|---|---|---|---|
| Gating Mechanism | None | Input, Forget, and Output gates | Update and Reset gates | |
| Temporal Dependency | Short term | Long term | Mid-range | Event-triggered |
| Parameter Count | ||||
| Bio-Inspired Features | ||||
| Memory Mechanism | Short-term potentiation | Explicit memory cells | Adaptive forgetting | Circadian-like rhythm |
| Update Pattern | Continuous | Conditional update | Balanced flow | Sawtooth-wave sampling |
| Compute Efficiency | RNN | RNN | LSTM |
- C. Attention mechanism: Dynamic modeling of cognitive focus. Human attention is the result of the coordination of multiple brain systems. The prefrontal cortex serves as the core control center, responsible for goal setting and distraction inhibition. For instance, when focusing on a conversation in a noisy environment, it suppresses neural signals associated with background noise. The parietal cortex acts like a “spatial map”, helping to locate visual targets, such as quickly finding keys on a desk. Meanwhile, the thalamus, through its reticular nucleus, functions as an “information gate”, filtering out irrelevant signals to ensure important information reaches the cortex. This collaboration among brain regions is regulated by neurotransmitters. Dopamine strengthens neural circuits related to goal-directed tasks (e.g., dopamine dysregulation in ADHD leads to impaired attention), norepinephrine maintains alertness, and acetylcholine enhances sensory signal processing. Table 6 shows the overview of Transformer-based architectures.
| Model | Main Finding | Limitations | Year |
|---|---|---|---|
| Transformer [68] | Introduced self-attention mechanism, significantly improved sequence modeling for NLP tasks | High computational and memory cost, quadratic complexity in sequence length | 2017 |
| Longformer [76] | Designed for long sequences, uses sliding window attention to reduce computational complexity | Limited to sparse attention patterns, may not capture global dependencies well | 2020 |
| Swin Transformer [77] | Hierarchical architecture for vision tasks, introduces shifted windows for efficient computation | Requires careful tuning of window sizes, less effective for NLP tasks | 2021 |
| Conformer [78] | Combines convolution and Transformer for improved speech recognition performance | Computationally intensive for large datasets, requires specialized hardware | 2020 |
| ViT (Vision Transformer) [79] | Applies Transformer directly to image patches for vision tasks, achieves state-of-the-art results | Requires large-scale pretraining, sensitive to input patch size | 2020 |
| BERT [80] | Pretrained bidirectional encoder, revolutionized NLP by enabling transfer learning | Computationally expensive fine-tuning, large memory requirements | 2018 |
| GPT (Generative Pretrained Transformer) [81] | Focused on autoregressive generation tasks, excels in few-shot learning scenarios | Requires vast amounts of data and computational resources for pretraining | 2020 |
| DeiT (Data-efficient Image Transformer) [82] | Optimized ViT for data-efficient training with distillation tokens | Limited scalability for very large datasets, dependent on distillation techniques | 2021 |
- D. Multimodal association: Unified representation of cross-sensory cognition. Multimodal learning is a direction in deep learning that focuses on the collaborative modeling of various information modalities, such as images, text, speech, and video, as in Figure 10. Its core is to simulate how humans understand the world through the integration of multiple sensory inputs. For example, when observing a “burning campfire”, a person relies not only on the visual flickering of the flames and the auditory crackling of the wood but also on the tactile memory of warmth and even the linguistic description of “warmth” to form a comprehensive understanding of the scene. This complementarity and alignment across modalities are key to the efficiency and robustness of human cognition. Anthropic computing emphasizes replicating the underlying logic of human cognition in technological design, and multimodal association is a central expression of this concept. By enabling machines to integrate semantics, context, and even emotions from different modalities, similar to humans, it seeks to overcome the limitations of single modalities and achieve an understanding and reasoning capacity closer to human intuition.
3.2.3. The Rise of Large Language Models (LLMs) (2020)
| Model | Parameters | Training Data | Hardware Cost | Accuracy | Inference Speed | Energy Efficiency |
|---|---|---|---|---|---|---|
| (Billion) | (TB) | (GPU-Days) | (SQuAD 2.0) | (Tokens/s) | (TOPS/W) | |
| GPT-4 | 175 | 45 | 12,500 | 89.2 | 1200 | 3.5 |
| PaLM-2 [104] | 540 | 780 | 35,000 | 88.5 | 950 | 2.8 |
| LLaMA-2-70B [105] | 70 | 2 | 3200 | 86.7 | 2500 | 6.2 |
| Claude 3 | 150 | 130 | 18,000 | 90.1 | 1800 | 4.1 |
| Falcon-180B | 180 | 3.5 | 7800 | 87.3 | 3000 | 5.9 |
4. The Possible Future Trends of Artificial Intelligence
4.1. The Major Limitations of AI
- (1)
- Data Addiction and Cognitive Rigidity
- (2)
- Energy Efficiency Gap
- (3)
- Disability in Dynamic Environments
- (4)
- Causal Reasoning Barrier
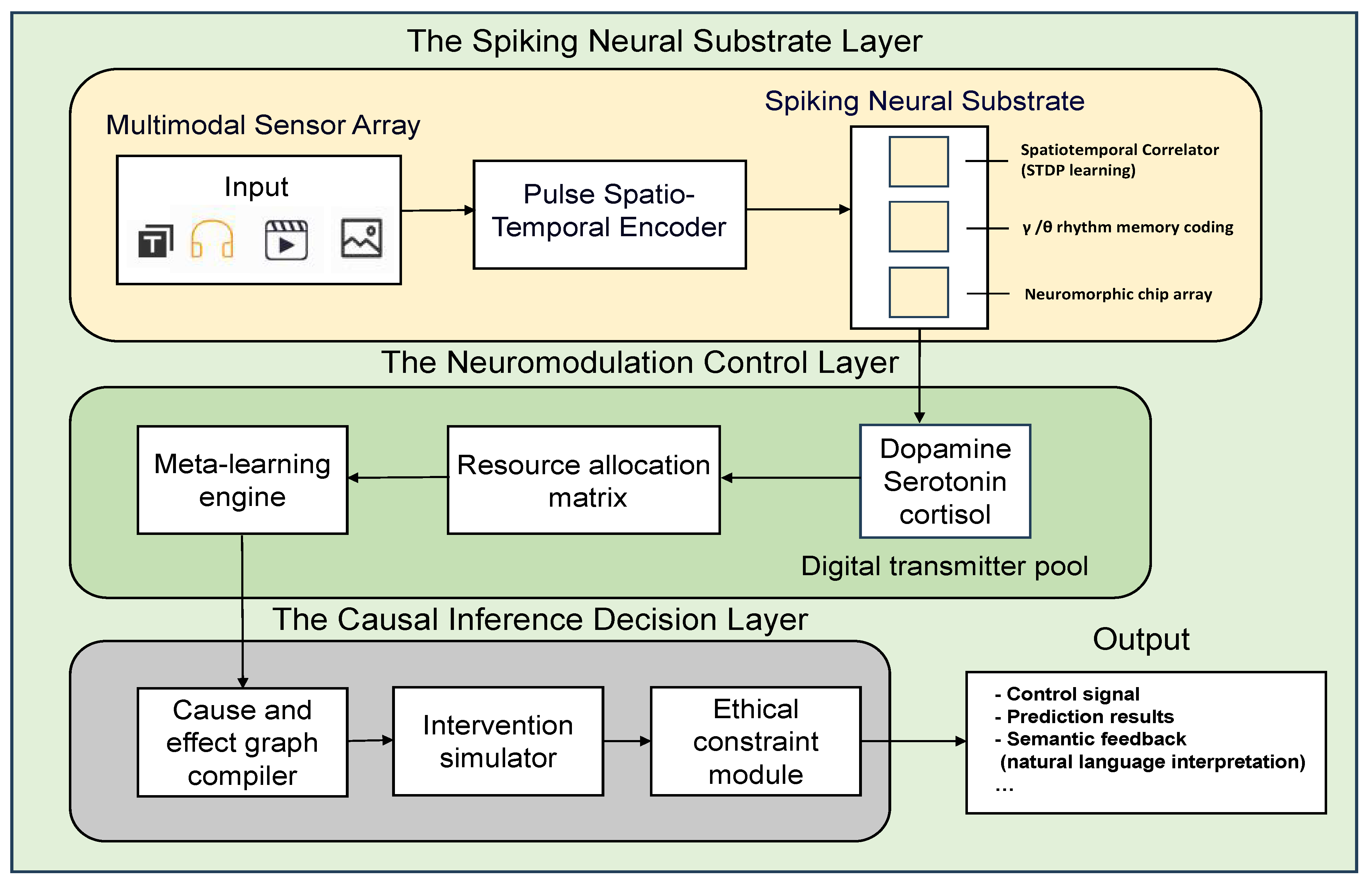
4.2. The Structure of CBI
4.2.1. The Spiking Neural Substrate Layer
- 1.
- Dynamic normalization: Continuous signals are compressed via [122]where represents moving averages over biologically plausible windows (τ = 50–200 ms).
- 2.
- Temporal sharpening: Leaky differentiator [123]extracts transient features.
- 3.
- Cross-modal alignment: Phase-locked loops compensate inter-sensor delays (e.g., 40 ms audio-visual latency).
4.2.2. The Neuromodulation Control Layer
4.2.3. The Causal Inference Decision Layer
4.3. The Future Trends of AI
- A. Neurobiologically inspired dynamic cognitive architecture. The asynchronous event-driven mechanism based on spiking neural networks (SNNs) will reshape the spatio-temporal tuning capabilities of intelligent systems. Drawing inspiration from the multi-timescale learning characteristics of Purkinje cells in the cerebellum [134], next-generation algorithms can achieve multitask coordination in dynamic environments through hierarchical plasticity rules, such as metaplasticity regulation and dendritic domain computation. The recently developed Liquid Time-Constant Network (LTCN) [135] by MIT has demonstrated that differential equations mimicking the dynamic changes of neuronal ion channels enable autonomous driving systems to exhibit human-like dopamine-regulated emergency decision priority switching in sudden traffic situations. Such architectures will advance AI from static knowledge reasoning toward contextualized cognition sensitive to biological rhythms, triggering breakthrough applications in brain–machine interfaces and embodied robotics.
- B. Perception and interaction: Multimodal integration technology drives the future evolution of precise intelligence. In future development trends, the perception and interaction aspects of artificial intelligence will undergo a transformation from single-modal processing to deep integration and contextual awareness, eventually achieving comprehensive intelligence with human-like sensory capabilities. The evolution in this domain will deepen not only within traditional sensory systems such as vision and hearing but also extend to non-verbal interaction modes like touch and smell. By emulating the synergistic mechanisms of biological sensory systems, it will construct perception and interaction architectures with situational adaptability. Multimodal integration perception technology will significantly enhance intelligent systems’ ability to interpret complex environments and interact socially, paving the way for a new era of cross-sensory perception.
- C. The future development and evolution of large language models. When discussing the future development of artificial intelligence, it is hard to overlook the evolution of the currently popular large language models. Large language models (LLMs) have incited substantial interest across both academic and industrial domains [142]. As demonstrated by existing work [143], the great performance of LLMs has raised promise that they could be AGI in this era. LLMs possess the capabilities to solve diverse tasks, contrasting with prior models confined to solving specific tasks. Due to its great performance in handling different applications, such as general natural language tasks and domain-specific ones, LLMs are increasingly used by individuals with critical information needs, such as students or patients [120].
4.4. The Potential Application of CBI
- A. Small-scale digital twin brain. The digital twin brain refers to the creation of a virtual model corresponding to the real brain through advanced digital technologies and algorithms in order to simulate and analyze the brain’s structure and functions [149,150]. This concept originates from digital twin technology, which was initially applied in the industrial and manufacturing fields and has gradually expanded to multiple fields, such as medical science and neuroscience. Through the digital twin brain, researchers can gain a deeper understanding of the complex mechanisms of the brain, explore neural activities in both normal and abnormal states, and thereby contribute to early disease diagnosis and the formulation of treatment plans. The digital twin brain typically integrates various technologies such as artificial intelligence, big data analysis, computational models, and bioinformatics, enabling the real-time processing and analysis of vast amounts of biological data from the human brain. This not only aids researchers in theoretically exploring brain functions but also provides clinicians with personalized medical solutions to improve patient treatment outcomes. Additionally, the digital twin brain may play a significant role in fields such as education, cognitive science, and human–computer interaction, driving the development of intelligent systems.
- B. Super-adaptive smart city. In generic terms, a smart city is an urban environment that utilizes ICT and other related technologies to enhance the performance efficiency of regular city operations and the quality of services (QoSs) provided to urban citizens. In formal terms, experts have defined smart cities by considering various aspects and perspectives [152]. A popular definition states that a smart city connects physical, social, business, and ICT infrastructure to uplift the intelligence of the city [153]. The utmost goal of initial smart cities was to enhance the QoL of urban citizens by reducing the contradiction between demand and supply in various functionalities. Accommodating QoL demands, modern smart cities especially focus on sustainable and efficient solutions for energy management, transportation, healthcare, governance, and many more in order to meet the extreme necessities of urbanization.
- C. Autonomous evolution for Industry 4.0. The term Industry 4.0 collectively refers to a wide range of current concepts, including smart factories, cyber-physical systems, self-organization, adaption to human needs, etc. [154]. The core of Industry 4.0 lies in the integration of the Internet of Things, cloud computing, big data analytics, artificial intelligence, and automation technologies to facilitate the transformation of traditional manufacturing into smart manufacturing. Within this framework, production systems can achieve autonomous coordination, monitoring, and optimization of the production process through embedded sensors, network connectivity, and data processing capabilities.
5. Discussion
5.1. Limitations of the Anthropomorphic Computing Review
5.2. Limitations of the CBI Structure
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Al Kuwaiti, A.; Nazer, K.; Al-Reedy, A.; Al-Shehri, S.; Al-Muhanna, A.; Subbarayalu, A.V.; Al Muhanna, D.; Al-Muhanna, F.A. A review of the role of artificial intelligence in healthcare. J. Pers. Med. 2023, 13, 951. [Google Scholar] [CrossRef]
- Chen, L.; Chen, P.; Lin, Z. Artificial intelligence in education: A review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Peres, R.S.; Jia, X.; Lee, J.; Sun, K.; Colombo, A.W.; Barata, J. Industrial artificial intelligence in industry 4.0-systematic review, challenges and outlook. IEEE Access 2020, 8, 220121–220139. [Google Scholar] [CrossRef]
- Aslitdinova, M. How artificial intelligence helps us in our daily life. Int. J. Artif. Intell. 2025, 1, 538–542. [Google Scholar]
- Zhang, X.; Ma, Z.; Zheng, H.; Li, T.; Chen, K.; Wang, X.; Liu, C.; Xu, L.; Wu, X.; Lin, D.; et al. The combination of brain-computer interfaces and artificial intelligence: Applications and challenges. Ann. Transl. Med. 2020, 8, 712. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z. A review of artificial intelligence for EEG-based brain- computer interfaces and applications. Brain Sci. Adv. 2020, 6, 162–170. [Google Scholar] [CrossRef]
- Mohanty, H. Trust: Anthropomorphic Algorithmic. In Proceedings of the International Conference on Distributed Computing and Internet Technology, Bhubaneswar, India, 10–13 January 2019; pp. 50–72. [Google Scholar]
- Watson, D. The rhetoric and reality of anthropomorphism in artificial intelligence. Minds Mach. 2019, 29, 417–440. [Google Scholar] [CrossRef]
- Merolla, P.A.; Arthur, J.V.; Alvarez-Icaza, R.; Cassidy, A.S.; Sawada, J.; Akopyan, F.; Jackson, B.L.; Imam, N.; Guo, C.; Nakamura, Y.; et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 2014, 345, 668–673. [Google Scholar] [CrossRef]
- Maass, W. Networks of spiking neurons: The third generation of neural network models. Neural Netw. 1997, 10, 1659–1671. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; PRISMA Group. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. Int. J. Surg. 2010, 8, 336–341. [Google Scholar] [CrossRef]
- Grzybowski, A.; Pawlikowska-Łagód, K.; Lambert, W.C. A history of artificial intelligence. Clin. Dermatol. 2024, 42, 221–229. [Google Scholar] [CrossRef] [PubMed]
- Haenlein, M.; Kaplan, A. A brief history of artificial intelligence: On the past, present, and future of artificial intelligence. Calif. Manag. Rev. 2019, 61, 5–14. [Google Scholar] [CrossRef]
- Turing, A.M. Computing Machinery and Intelligence; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Weik, M.H. The ENIAC story. Ordnance 1961, 45, 571–575. [Google Scholar]
- Zadeh, L.A. Fuzzy logic. In Granular, Fuzzy, and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2023; pp. 19–49. [Google Scholar]
- Mittal, K.; Jain, A.; Vaisla, K.S.; Castillo, O.; Kacprzyk, J. A comprehensive review on type 2 fuzzy logic applications: Past, present and future. Eng. Appl. Artif. Intell. 2020, 95, 103916. [Google Scholar] [CrossRef]
- Dumitrescu, C.; Ciotirnae, P.; Vizitiu, C. Fuzzy logic for intelligent control system using soft computing applications. Sensors 2021, 21, 2617. [Google Scholar] [CrossRef]
- Expert System. 2021. Available online: https://ikcest-drr.data.ac.cn/tutorial/k2033 (accessed on 20 June 2025).
- Zadeh, L.A. Fuzzy logic. Computer 1988, 21, 83–93. [Google Scholar] [CrossRef]
- Back, T.; Hammel, U.; Schwefel, H.P. Evolutionary computation: Comments on the history and current state. IEEE Trans. Evol. Comput. 1997, 1, 3–17. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Storn, R.; Price, K. Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Michalewicz, Z. Genetic Algorithms + Data Structures = Evolution Programs; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Loh, W.Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Wiering, M.A.; Van Otterlo, M. Reinforcement learning. Adapt. Learn. Optim. 2012, 12, 729. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; Volume 1. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Shu, T.; Pan, Z.; Ding, Z.; Zu, Z. Resource scheduling optimization for industrial operating system using deep reinforcement learning and WOA algorithm. Expert Syst. Appl. 2024, 255, 124765. [Google Scholar] [CrossRef]
- Vezhnevets, A.S.; Osindero, S.; Schaul, T.; Heess, N.; Jaderberg, M.; Silver, D.; Kavukcuoglu, K. Feudal networks for hierarchical reinforcement learning. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3540–3549. [Google Scholar]
- Coulom, R. Efficient selectivity and backup operators in Monte-Carlo tree search. In Proceedings of the International Conference on Computers and Games, Turin, Italy, 29–31 May 2006; pp. 72–83. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Panigrahi, S.; Nanda, A.; Swarnkar, T. A survey on transfer learning. In Proceedings of the Intelligent and Cloud Computing: Proceedings of ICICC 2019; Springer: Singapore, 2021; Volume 1, pp. 781–789. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef]
- Huang, J.; Gretton, A.; Borgwardt, K.; Schölkopf, B.; Smola, A. Correcting sample selection bias by unlabeled data. In Proceedings of the Advances in Neural Information Processing Systems; Bradford Books: Denver, CO, USA, 2006; Volume 19. [Google Scholar]
- Mahesh, B. Machine learning algorithms—A review. Int. J. Sci. Res. (IJSR) 2020, 9, 381–386. [Google Scholar] [CrossRef]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Matzkevich, I.; Abramson, B. The topological fusion of Bayes nets. In Proceedings of the Uncertainty in Artificial Intelligence; Elsevier: Amsterdam, The Netherlands, 1992; pp. 191–198. [Google Scholar]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight uncertainty in neural network. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1613–1622. [Google Scholar]
- Wandell, B.A.; Dumoulin, S.O.; Brewer, A.A. Visual field maps in human cortex. Neuron 2007, 56, 366–383. [Google Scholar] [CrossRef]
- Riesenhuber, M.; Poggio, T. Hierarchical models of object recognition in cortex. Nat. Neurosci. 1999, 2, 1019–1025. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Elngar, A.A.; Arafa, M.; Fathy, A.; Moustafa, B.; Mahmoud, O.; Shaban, M.; Fawzy, N. Image classification based on CNN: A survey. J. Cybersecur. Inf. Manag. 2021, 6, 18–50. [Google Scholar] [CrossRef]
- Chen, Y. Convolutional Neural Network for Sentence Classification. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2015. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Hinton, G.E.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part I 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Wang, Y.; Rao, Y.; Huang, C.; Yang, Y.; Huang, Y.; He, Q. Using the improved mask R-CNN and softer-NMS for target segmentation of remote sensing image. In Proceedings of the 2021 4th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Yibin, China, 20–22 August 2021; pp. 91–95. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.c. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Tayeh, T.; Aburakhia, S.; Myers, R.; Shami, A. An attention-based ConvLSTM autoencoder with dynamic thresholding for unsupervised anomaly detection in multivariate time series. Mach. Learn. Knowl. Extr. 2022, 4, 350–370. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Neil, D.; Pfeiffer, M.; Liu, S.C. Phased lstm: Accelerating recurrent network training for long or event-based sequences. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Kay, K.N.; Naselaris, T.; Prenger, R.J.; Gallant, J.L. Identifying natural images from human brain activity. Nature 2008, 452, 352–355. [Google Scholar] [CrossRef]
- Jaegle, A.; Borgeaud, S.; Alayrac, J.B.; Doersch, C.; Ionescu, C.; Ding, D.; Koppula, S.; Zoran, D.; Brock, A.; Shelhamer, E.; et al. Perceiver io: A general architecture for structured inputs & outputs. arXiv 2021, arXiv:2107.14795. [Google Scholar]
- Zaheer, M.; Guruganesh, G.; Dubey, K.A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; et al. Big bird: Transformers for longer sequences. Adv. Neural Inf. Process. Syst. 2020, 33, 17283–17297. [Google Scholar]
- Khaligh-Razavi, S.M.; Kriegeskorte, N. Deep supervised, but not unsupervised, models may explain IT cortical representation. PLoS Comput. Biol. 2014, 10, e1003915. [Google Scholar] [CrossRef] [PubMed]
- Rae, J.W.; Potapenko, A.; Jayakumar, S.M.; Lillicrap, T.P. Compressive transformers for long-range sequence modelling. arXiv 2019, arXiv:1911.05507. [Google Scholar]
- Dao, T.; Fu, D.; Ermon, S.; Rudra, A.; Ré, C. Flashattention: Fast and memory-efficient exact attention with io-awareness. Adv. Neural Inf. Process. Syst. 2022, 35, 16344–16359. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Brock, A.; De, S.; Smith, S.L.; Simonyan, K. High-performance large-scale image recognition without normalization. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 1059–1071. [Google Scholar]
- Chen, X.; Wang, X.; Changpinyo, S.; Piergiovanni, A.; Padlewski, P.; Salz, D.; Goodman, S.; Grycner, A.; Mustafa, B.; Beyer, L.; et al. Pali: A jointly-scaled multilingual language-image model. arXiv 2022, arXiv:2209.06794. [Google Scholar]
- Aston-Jones, G.; Cohen, J.D. An integrative theory of locus coeruleus-norepinephrine function: Adaptive gain and optimal performance. Annu. Rev. Neurosci. 2005, 28, 403–450. [Google Scholar] [CrossRef]
- Pinker, S. The Language Instinct: How the Mind Creates Language; Penguin: London, UK, 2003. [Google Scholar]
- Hauser, M.D.; Chomsky, N.; Fitch, W.T. The faculty of language: What is it, who has it, and how did it evolve? Science 2002, 298, 1569–1579. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Kshetri, N.; Hughes, L.; Slade, E.L.; Jeyaraj, A.; Kar, A.K.; Baabdullah, A.M.; Koohang, A.; Raghavan, V.; Ahuja, M.; et al. Opinion Paper:“So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. Int. J. Inf. Manag. 2023, 71, 102642. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; et al. Opt: Open pre-trained transformer language models. arXiv 2022, arXiv:2205.01068. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. 2023, 24, 1–113. [Google Scholar]
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. Lamda: Language models for dialog applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- You, Y.; Gitman, I.; Ginsburg, B. Large batch training of convolutional networks. arXiv 2017, arXiv:1708.03888. [Google Scholar]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. Palm 2 technical report. arXiv 2023, arXiv:2305.10403. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Christiano, P.F.; Leike, J.; Brown, T.; Martic, M.; Legg, S.; Amodei, D. Deep reinforcement learning from human preferences. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.; Hinton, G.; Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv 2017, arXiv:1701.06538. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Driess, D.; Xia, F.; Sajjadi, M.S.; Lynch, C.; Chowdhery, A.; Wahid, A.; Tompson, J.; Vuong, Q.; Yu, T.; Huang, W.; et al. Palm-e: An embodied multimodal language model. arXiv 2023, arXiv:2303.03378. [Google Scholar]
- Schramowski, P.; Turan, C.; Andersen, N.; Rothkopf, C.A.; Kersting, K. Large pre-trained language models contain human-like biases of what is right and wrong to do. Nat. Mach. Intell. 2022, 4, 258–268. [Google Scholar] [CrossRef]
- Hadi, M.U.; Qureshi, R.; Shah, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; Mirjalili, S. A survey on large language models: Applications, challenges, limitations, and practical usage. Authorea Prepr. 2023, 3. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Zheng, Y.; Li, S.; Yan, R.; Tang, H.; Tan, K.C. Sparse temporal encoding of visual features for robust object recognition by spiking neurons. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5823–5833. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient transformers: A survey. ACM Comput. Surv. 2022, 55, 1–28. [Google Scholar] [CrossRef]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Guizzo, E. By leaps and bounds: An exclusive look at how boston dynamics is redefining robot agility. IEEE Spectr. 2019, 56, 34–39. [Google Scholar] [CrossRef]
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–45. [Google Scholar] [CrossRef]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Carandini, M.; Heeger, D.J. Normalization as a canonical neural computation. Nat. Rev. Neurosci. 2012, 13, 51–62. [Google Scholar] [CrossRef] [PubMed]
- Adelson, E.H.; Bergen, J.R. Spatiotemporal energy models for the perception of motion. J. Opt. Soc. Am. A 1985, 2, 284–299. [Google Scholar] [CrossRef]
- Dan, Y.; Poo, M.m. Spike timing-dependent plasticity of neural circuits. Neuron 2004, 44, 23–30. [Google Scholar] [CrossRef]
- Gerstner, W.; Kistler, W.M. Spiking Neuron Models: Single Neurons, Populations, Plasticity; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Wu, Y.C.; Feng, J.W. Development and application of artificial neural network. Wirel. Pers. Commun. 2018, 102, 1645–1656. [Google Scholar] [CrossRef]
- Schultz, W. Dopamine neurons and their role in reward mechanisms. Curr. Opin. Neurobiol. 1997, 7, 191–197. [Google Scholar] [CrossRef]
- Cools, R.; Roberts, A.C.; Robbins, T.W. Serotoninergic regulation of emotional and behavioural control processes. Trends Cogn. Sci. 2008, 12, 31–40. [Google Scholar] [CrossRef] [PubMed]
- McEwen, B.S. Physiology and neurobiology of stress and adaptation: Central role of the brain. Physiol. Rev. 2007, 87, 873–904. [Google Scholar] [CrossRef]
- Von Neumann, J. Mathematische Grundlagen der Quantenmechanik; Springer: Berlin/Heidelberg, Germany, 2013; Volume 38. [Google Scholar]
- Pearl, J. Causal inference. Causal. Object. Assess. 2010, 39–58. [Google Scholar]
- Shapley, L.S. A value for n-person games. In Contributions to the Theory of Games II; Kuhn, H.W., Tucker, A.W., Eds.; Princeton University Press Princeton: Princeton, NJ, USA, 1953; pp. 307–317. [Google Scholar]
- Nash Jr, J.F. Equilibrium points in n-person games. Proc. Natl. Acad. Sci. USA 1950, 36, 48–49. [Google Scholar] [CrossRef]
- Tolu, S.; Capolei, M.C.; Vannucci, L.; Laschi, C.; Falotico, E.; Hernández, M.V. A cerebellum-inspired learning approach for adaptive and anticipatory control. Int. J. Neural Syst. 2020, 30, 1950028. [Google Scholar] [CrossRef] [PubMed]
- Hasani, R.; Lechner, M.; Amini, A.; Rus, D.; Grosu, R. Liquid time-constant networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 7657–7666. [Google Scholar]
- Humaidi, A.J.; Kadhim, T.M.; Hasan, S.; Ibraheem, I.K.; Azar, A.T. A generic izhikevich-modelled FPGA-realized architecture: A case study of printed english letter recognition. In Proceedings of the 2020 24th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 8–10 October 2020; pp. 825–830. [Google Scholar]
- Humaidi, A.J.; Kadhim, T.M. Spiking versus traditional neural networks for character recognition on FPGA platform. J. Telecommun. Electron. Comput. Eng. (JTEC) 2018, 10, 109–115. [Google Scholar]
- Dritsas, E.; Trigka, M.; Troussas, C.; Mylonas, P. Multimodal Interaction, Interfaces, and Communication: A Survey. Multimodal Technol. Interact. 2025, 9, 6. [Google Scholar] [CrossRef]
- Gu, G.; Zhang, N.; Xu, H.; Lin, S.; Yu, Y.; Chai, G.; Ge, L.; Yang, H.; Shao, Q.; Sheng, X.; et al. A soft neuroprosthetic hand providing simultaneous myoelectric control and tactile feedback. Nat. Biomed. Eng. 2023, 7, 589–598. [Google Scholar] [CrossRef]
- Nadon, F.; Valencia, A.J.; Payeur, P. Multi-modal sensing and robotic manipulation of non-rigid objects: A survey. Robotics 2018, 7, 74. [Google Scholar] [CrossRef]
- Yuanyang, W.; Mahyuddin, M.N. Grasping Deformable Objects in Industry Application: A Comprehensive Review of Robotic Manipulation. IEEE Access 2025, 13, 33403–33423. [Google Scholar] [CrossRef]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Bubeck, S.; Chadrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv 2023, arXiv:2303.12712. [Google Scholar]
- Tao, Z.; Jin, Z.; Bai, X.; Zhao, H.; Feng, Y.; Li, J.; Hu, W. Eveval: A comprehensive evaluation of event semantics for large language models. arXiv 2023, arXiv:2305.15268. [Google Scholar]
- Riccardi, N.; Yang, X.; Desai, R.H. The Two Word Test as a semantic benchmark for large language models. Sci. Rep. 2024, 14, 21593. [Google Scholar] [CrossRef]
- Ott, S.; Hebenstreit, K.; Liévin, V.; Hother, C.E.; Moradi, M.; Mayrhauser, M.; Praas, R.; Winther, O.; Samwald, M. ThoughtSource: A central hub for large language model reasoning data. Sci. Data 2023, 10, 528. [Google Scholar] [CrossRef]
- Gehman, S.; Gururangan, S.; Sap, M.; Choi, Y.; Smith, N.A. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. arXiv 2020, arXiv:2009.11462. [Google Scholar]
- Dhamala, J.; Sun, T.; Kumar, V.; Krishna, S.; Pruksachatkun, Y.; Chang, K.W.; Gupta, R. Bold: Dataset and metrics for measuring biases in open-ended language generation. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Online, 3–10 March 2021; pp. 862–872. [Google Scholar]
- Xiong, H.; Chu, C.; Fan, L.; Song, M.; Zhang, J.; Ma, Y.; Zheng, R.; Zhang, J.; Yang, Z.; Jiang, T. The Digital Twin Brain: A Bridge between Biological and Artificial Intelligence. Intell. Comput. 2023, 2, 0055. [Google Scholar] [CrossRef]
- Liu, M.; Fang, S.; Dong, H.; Xu, C. Review of digital twin about concepts, technologies, and industrial applications. J. Manuf. Syst. 2021, 58, 346–361. [Google Scholar] [CrossRef]
- Kuramoto, Y.; Kuramoto, Y. Chemical Turbulence; Springer: Berlin/Heidelberg, Germany, 1984. [Google Scholar]
- Silva, B.N.; Khan, M.; Han, K. Towards sustainable smart cities: A review of trends, architectures, components, and open challenges in smart cities. Sustain. Cities Soc. 2018, 38, 697–713. [Google Scholar] [CrossRef]
- Harrison, C.; Eckman, B.; Hamilton, R.; Hartswick, P.; Kalagnanam, J.; Paraszczak, J.; Williams, P. Foundations for smarter cities. IBM J. Res. Dev. 2010, 54, 1–16. [Google Scholar] [CrossRef]
- Lasi, H.; Fettke, P.; Kemper, H.G.; Feld, T.; Hoffmann, M. Industry 4.0. Bus. Inf. Syst. Eng. 2014, 6, 239–242. [Google Scholar] [CrossRef]
- Davies, M.; Wild, A.; Orchard, G.; Sandamirskaya, Y.; Guerra, G.A.F.; Joshi, P.; Plank, P.; Risbud, S.R. Advancing neuromorphic computing with loihi: A survey of results and outlook. Proc. IEEE 2021, 109, 911–934. [Google Scholar] [CrossRef]




| Categories | Strengths | Limitations | Anthropomorphic Computing Insights |
|---|---|---|---|
| Perceptual Layer Abstraction: | - Automatic feature hierarchy | - Limited temporal awareness | - Retinotopic mapping |
| (e.g., CNN, ResNet) | - Spatial invariance | - Context-agnostic | - Mimics ventral visual pathway |
| - Parameter efficiency | - Static processing | - Orientation-selective kernels | |
| Temporal and Contextual Understanding: | - Sequential dependency | - Vanishing gradients | - Hippocampal replay |
| (e.g., LSTM, RNN) | - Long-range correlation | - Quadratic complexity | - Episodic memory consolidation |
| - Adaptive forgetting | - Catastrophic interference | - Theta–gamma coupling simulation | |
| Attention Mechanism: | - Dynamic saliency | - Over-smoothing | - Foveal-peripheral vision |
| (e.g., Transformer) | - Interpretable focus | - High memory cost | - Top-down modulation |
| - Context-aware weighting | - Positional bias | - Global workspace theory | |
| Multimodal Association: | - Cross-modal alignment | - Modality imbalance | Synesthetic binding |
| (e.g., CLIP, ViLBERT) | - Unified representation | - Fusion ambiguity | - Superior colliculus inspiration |
| - Knowledge transfer | - Alignment cost | - Cross-modal plasticity |
| Characteristic | Classic CNN [53] | Capsule Network | Shallow CNN [54] | ResNet |
|---|---|---|---|---|
| Hierarchical Structure | Conv-Pooling stacks | Capsule layers | ≤3 conv layers | Residual blocks |
| Core Innovation | Local receptive fields | Dynamic routing | Depth reduction | Skip connections |
| Parameter Efficiency | CNN | CNN | CNN | |
| Spatial Awareness | Translation invariance | Viewpoint | Position-sensitive | Deep context |
| Key Advantage | Feature extraction | Part–whole relationships | Fast inference | Gradient flow |
| Performance Metrics | ||||
| Parameters | ||||
| ImageNet Top-1 | ||||
| Model Size | 48 MB | 115 MB | 2.1 MB | 98 MB |
| FLOPs (224 px) |
| Parameter/Feature | Transformer | Longformer | Swin Transformer | Conformer |
|---|---|---|---|---|
| Year Proposed | 2017 | 2020 | 2021 | 2020 |
| Core Idea | Self-Attention | Sparse Attention | Hierarchical Window Attention | Convolution-Enhanced Attention |
| Primary Tasks | General (e.g., NLP) | Long Documents | Vision (e.g., CV) | Speech/ASR |
| Attention Scope | Global | Local + Global | Hierarchical Windows | Local + Global |
| Computational Complexity | (Approx.) | (Optimized) | ||
| Common Task Performance Examples | ||||
| GLUE Benchmark (Avg.) | 88.5 | 89.2 | 87.8 | 88.0 |
| Long Document Summarization (BLEU) | 35.1 | 38.7 | 36.5 | 37.0 |
| ImageNet Classification | 76.2 | - | 87.3 | - |
| Model | Main Finding | Limitations | Year |
|---|---|---|---|
| BERT [80] | Pretrained bidirectional encoder, revolutionized NLP by enabling fine-tuning for diverse tasks | Computationally expensive fine-tuning, large memory requirements | 2018 |
| GPT-2 [97] | Introduced autoregressive pretraining for text generation, demonstrated strong zero-shot learning ability | Prone to generating repetitive or nonsensical outputs for long texts | 2019 |
| GPT-3 [81] | Scaled up to 175B parameters, excels in few-shot and zero-shot learning tasks | Requires vast computational resources for training, environmental concerns | 2020 |
| T5(Text-to-Text Transfer Transformer) [98] | Unified NLP tasks as text-to-text problems, enabling versatile applications across tasks | Sensitive to hyperparameter tuning, large-scale pretraining required | 2020 |
| OPT [99] | Open-sourced LLM, aimed at democratizing access to large-scale models | Less optimized compared to other commercial LLMs, limited multilingual support | 2022 |
| PaLM [100] | Achieves impressive performance on reasoning and complex NLP tasks, incorporates chain-of-thought prompting | Requires massive computational resources, limited accessibility | 2022 |
| LaMDA [101] | Optimized for dialogue systems, focuses on conversational AI applications | Struggles with factual accuracy and consistency in long conversations | 2022 |
| Claude | Safety-focused LLM with improved alignment techniques, designed to minimize harmful outputs | Relatively new, limited benchmarks compared to GPT models | 2023 |
| GPT-4 | Multimodal capabilities, improved reasoning and contextual understanding compared to GPT-3 | High computational demands, limited public access and transparency | 2023 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Zhang, H. Towards Human-like Artificial Intelligence: A Review of Anthropomorphic Computing in AI and Future Trends. Mathematics 2025, 13, 2087. https://doi.org/10.3390/math13132087
Zhang J, Zhang H. Towards Human-like Artificial Intelligence: A Review of Anthropomorphic Computing in AI and Future Trends. Mathematics. 2025; 13(13):2087. https://doi.org/10.3390/math13132087
Chicago/Turabian StyleZhang, Jiacheng, and Haolan Zhang. 2025. "Towards Human-like Artificial Intelligence: A Review of Anthropomorphic Computing in AI and Future Trends" Mathematics 13, no. 13: 2087. https://doi.org/10.3390/math13132087
APA StyleZhang, J., & Zhang, H. (2025). Towards Human-like Artificial Intelligence: A Review of Anthropomorphic Computing in AI and Future Trends. Mathematics, 13(13), 2087. https://doi.org/10.3390/math13132087