Abstract
Incident prioritization is a critical task in enterprise environments, where textual descriptions of service disruptions often contain vague or ambiguous language. Traditional machine learning models, while effective in rigid classification, struggle to interpret the linguistic uncertainty inherent in natural language reports. This paper proposes a fuzzy logic-based framework for incident categorization and prioritization, integrating natural language processing (NLP) with a formal system of fuzzy inference. The framework transforms semantic embeddings from incident reports into fuzzy sets, allowing incident severity and urgency to be represented as degrees of membership in multiple categories. A mathematical model based on Mamdani-type inference and triangular membership functions is developed to capture and process imprecise inputs. The proposed system is evaluated on a real-world dataset comprising 10,000 incident descriptions from a mid-sized technology enterprise. A comparative evaluation is conducted against two baseline models: a fine-tuned BERT classifier and a traditional support vector machine (SVM). Results show that the fuzzy logic approach achieves a 7.4% improvement in F1-score over BERT (92.1% vs. 85.7%) and a 12.5% improvement over SVM (92.1% vs. 79.6%) for medium-severity incidents, where linguistic ambiguity is most prevalent. Qualitative analysis from domain experts confirmed that the fuzzy model provided more interpretable and context-aware classifications, improving operator trust and alignment with human judgment. These findings suggest that fuzzy modeling offers a mathematically sound and operationally effective solution for managing uncertainty in text-based incident management, contributing to the broader understanding of mathematical modeling in enterprise-scale social phenomena.
Keywords:
artificial intelligence; fuzzy logic; knowledge engineering; mathematical modeling; optimization techniques; natural language processing MSC:
90C59
1. Introduction
Incident management is a cornerstone of enterprise operations, where the ability to accurately classify and prioritize service disruptions determines the overall efficiency, resilience, and customer satisfaction of organizations [1]. As enterprises become increasingly reliant on complex IT ecosystems, the volume and diversity of incident reports have grown substantially, creating new challenges for traditional management systems [2,3]. Historically, incident prioritization has been a manual, expert-driven process, relying on human operators to interpret often vague or ambiguous textual descriptions. While advances in artificial intelligence (AI) and machine learning (ML) have improved classification automation [4,5], existing systems still struggle with the inherent linguistic uncertainty and subjectivity present in natural language incident reports [6,7].
Recent breakthroughs in natural language processing (NLP), particularly with transformer-based architectures such as BERT and GPT models, have significantly advanced the capabilities of automated incident classification [6,8]. These models, based on self-attention mechanisms, capture rich contextual dependencies in text, outperforming traditional machine learning approaches in understanding complex incident descriptions [9,10]. Nevertheless, despite their high performance in structured classification tasks, transformer models exhibit notable limitations when dealing with vague, conflicting, or multi-meaning incident narratives [11,12]. Moreover, their decision-making process remains largely opaque, complicating the interpretability and trust required in enterprise-critical operations [13].
Beyond the technical challenges of text classification, enterprise incident management systems must grapple with dynamic operational constraints. The prioritization of incidents is not solely a matter of textual understanding but also involves decision-making under uncertainty, where the severity and urgency of incidents may not be sharply defined [14,15]. Mathematical optimization approaches have been used to address resource allocation in such environments, employing techniques from multi-objective programming, queueing theory, and reinforcement learning [16,17]. However, these methods often assume precise, numerical incident attributes, failing to accommodate the fuzziness that naturally arises from human descriptions and subjective assessments [18,19].
In this context, fuzzy logic emerges as a powerful mathematical tool to model uncertainty and linguistic vagueness [20]. Unlike classical binary logic or crisp classification techniques, fuzzy logic allows degrees of membership across multiple categories, enabling a more nuanced and human-like representation of severity, urgency, and priority in incident reports [21,22]. Fuzzy inference systems, particularly those based on Mamdani-type reasoning and triangular membership functions, have demonstrated success in various domains requiring decision-making under uncertainty [23,24]. Integrating fuzzy logic with semantic-rich NLP embeddings offers a promising pathway to bridge the gap between advanced text understanding and operational decision support in incident management.
Although limited, some studies have explored the application of fuzzy logic to incident classification and prioritization tasks. For instance, Jha and Shukla [25] developed a fuzzy logic-based traffic controller that prioritizes emergency vehicles at isolated intersections, optimizing traffic flow based on queue length and waiting time. Similarly, Kanwal and Maqbool [26] proposed a classification approach to prioritize software bug reports, enhancing the efficiency of bug triage processes. These works demonstrate the potential of fuzzy reasoning in handling uncertainty in prioritization scenarios. However, they do not incorporate learning capabilities or adaptivity to changing contexts, which our proposed fuzzy framework explicitly addresses.
Previous studies have explored hybrid AI architectures combining machine learning with expert systems to enhance incident classification and resource optimization [27,28]. These integrated approaches highlight the importance of explainability, adaptability, and robustness in real-world deployments [29]. Nevertheless, few investigations have rigorously incorporated fuzzy modeling into the incident management pipeline, particularly in a manner that is mathematically formalized and scalable to enterprise-scale operations [30,31].
In response to the limitations of existing incident management approaches, which include difficulties in handling linguistic uncertainty, a lack of interpretability, and computational inefficiency, we propose a fuzzy logic-based framework that integrates semantic NLP embeddings with a Mamdani-type fuzzy inference system. This hybrid model aims to provide interpretable, robust, and scalable incident prioritization from unstructured text descriptions.
The contributions of this paper are summarized as follows:
- A mathematical framework is introduced that systematically combines text-derived semantic embeddings with fuzzy set theory to model incident severity and urgency under linguistic uncertainty.
- A fuzzy inference engine based on Mamdani rules and triangular membership functions is designed, aligned with best practices in fuzzy system modeling.
- The framework is implemented and evaluated on a real-world dataset of 10,000 incident descriptions from a mid-sized technology enterprise, and its performance is compared against a fine-tuned BERT classifier and a traditional support vector machine (SVM) model.
- A qualitative analysis with domain experts is conducted to assess the interpretability and operational relevance of the fuzzy-based prioritization outputs.
By developing a mathematically grounded framework that leverages the strengths of both NLP and fuzzy logic, this research contributes to bridging the gap between sophisticated text analytics and real-world operational decision-making under uncertainty. The approach reinforces the importance of mathematical modeling in the understanding and management of enterprise-scale social phenomena [32,33].
While recent studies have explored hybrid AI models that combine fuzzy logic with deep learning techniques—such as fuzzy C-means clustering integrated with CNN-Transformer architectures [34] or fuzzy information granules for neural forecasting [35]—these approaches are primarily oriented toward time series or multivariate numeric data. In contrast, our framework targets unstructured natural language inputs and builds interpretable fuzzy rules on semantic Axes derived from BERT embeddings. Unlike models that integrate fuzzy components deep within neural architectures, our method preserves a transparent, auditable inference layer, which is essential for high-stakes, operational decision-making environments.
The experimental results demonstrate that the proposed fuzzy logic approach outperforms state-of-the-art BERT-based classifiers by 7.4% and traditional SVM models by 12.5% in F1-score for medium-severity incidents, where ambiguity is most prevalent. Moreover, expert evaluations confirm that the fuzzy model’s decisions are more interpretable and align better with human reasoning compared to black-box machine learning methods.
Building upon this, the present work extends our previous research on intelligent incident management systems [36], in which we focused on the use of optimization techniques combined with natural language processing to support decision-making. In contrast, this proposal introduces a novel hybrid framework that incorporates fuzzy logic and reinforcement learning (specifically, fuzzy Q-learning) to dynamically adjust incident prioritization policies based on unstructured text analysis. This combination allows the system to evolve and adapt to organizational needs over time, which was not addressed in the previous work.
This paper is organized as follows. Section 2 describes the materials and methods employed, including the dataset, NLP preprocessing, fuzzy modeling approach, and baseline models. Section 3 presents the results of the quantitative evaluations and expert assessments. Section 4 discusses the implications of the findings, limitations of the current approach, and potential avenues for future work. Finally, Section 5 concludes the paper, highlighting the contribution of fuzzy logic to advancing the mathematical modeling of uncertainty in text-driven incident management.
2. Materials and Methods
To develop and validate the proposed fuzzy logic framework for incident prioritization, a systematic and rigorous methodology was adopted. This section describes the materials and methods used throughout the study, encompassing dataset selection and preparation, fuzzy model design, integration with NLP-based semantic features, and comparative evaluation against baseline models. By combining data-driven techniques with mathematical modeling, we aim to construct a reproducible and transparent system capable of handling the uncertainty inherent in natural language incident reports.
Section 2.1 details the dataset employed for experimentation, including data collection, preprocessing techniques, and feature extraction methods. Section 2.2 presents the mathematical formulation of the fuzzy logic model, defining the structure of fuzzy sets, membership functions, and the inference mechanism. Section 2.3 describes how semantic embeddings obtained from textual incident descriptions are transformed into inputs for the fuzzy system, bridging the gap between natural language understanding and fuzzy reasoning. Finally, Section 2.4 outlines the baseline models used for comparative evaluation, including a fine-tuned BERT classifier and a traditional support vector machine (SVM), along with the metrics adopted to assess model performance.
Through this multi-stage methodological approach, we ensure that the proposed framework is not only empirically validated but also firmly grounded in formal mathematical principles, in alignment with the scope and rigor expected in enterprise-scale intelligent systems [3,4,16].
2.1. Dataset and Preprocessing
The development of the proposed fuzzy logic framework required a comprehensive and representative dataset of real-world incidents. For this study, a corpus of 10,000 incident reports was collected from the internal incident management system of a mid-sized technology enterprise. Each record included a free-text description of the disruption, timestamps, customer or department metadata, and, in a subset of 2000 cases, manually annotated severity and urgency labels established by domain experts according to standardized operational guidelines [5,6]. The annotation was performed independently by two domain experts. To assess consistency, inter-annotator agreement was measured using Cohen’s Kappa, yielding a value of 0.82, which indicates strong agreement. Disagreements were resolved through consensus discussions with a third expert.
To ensure ethical compliance and data privacy, all reports were anonymized following strict General Data Protection Regulation (GDPR) principles. Personally identifiable information (PII), such as names, emails, IP addresses, and phone numbers, was removed or masked. Furthermore, access to raw data was restricted to authorized personnel, and the study protocol was approved by the relevant Institutional Review Board (IRB) [7,8]. Guaranteeing ethical data usage was particularly important, as biased or poorly sanitized data could compromise both the performance and fairness of intelligent prioritization systems [9].
Given that incident descriptions were typically composed in free text, the raw dataset exhibited a high degree of linguistic variability, including spelling errors, shorthand notations, inconsistent phrasing, and domain-specific terminology. Therefore, a rigorous text preprocessing pipeline was implemented to enhance data quality and ensure consistency before feature extraction [10,11].
The main preprocessing steps included the following:
- Normalization: Text was converted to lowercase, and unnecessary or non-informative punctuation, numbers, and non-alphabetic symbols were removed to standardize the corpus.
- Spell-checking: A neural-network-based context-sensitive spell corrector was employed, capable of addressing both typographical and semantic errors. This step corrected spelling mistakes present in approximately 12% of the reports [11].
- Expansion of abbreviations: Common technical abbreviations, such as “sys” (system), “auth” (authentication), and “cfg” (configuration), were expanded to their full forms using a curated domain-specific dictionary, improving semantic clarity [12].
- Tokenization and lemmatization: Text was tokenized with a BERT-compatible tokenizer to preserve syntactic structures and lemmatized to unify inflected word forms into their base representations, minimizing feature sparsity [13,14].
- Stopword removal: Standard English stopwords were eliminated to reduce noise while retaining key semantic terms crucial for incident classification [13].
Additionally, a deduplication step was performed to eliminate redundant records, removing 4.7% of the dataset entries. Duplicate reports, often arising from repeated user submissions or automated alerts, could have otherwise biased the models by artificially inflating certain classes [15].
Following preprocessing, two complementary feature extraction strategies were applied. First, classical Term Frequency-Inverse Document Frequency (TF-IDF) representations were computed to capture lexical importance across the corpus [16]. TF-IDF vectors offered a sparse yet interpretable feature space, useful for baseline comparison purposes. Second, richer semantic features were derived using pre-trained BERT embeddings, generating 768-dimensional contextualized vector representations for each incident description [6,17].
Due to the high dimensionality of BERT embeddings, dimensionality reduction was applied using Principal Component Analysis (PCA), preserving 95% of the explained variance while reducing noise and computational cost [18]. This step facilitated the integration of semantic features into the fuzzy logic modeling framework without overfitting.
Table 1 summarizes the key characteristics of the dataset after the full preprocessing and feature engineering pipeline.

Table 1.
Summary of dataset characteristics after preprocessing.
An exploratory analysis was conducted to understand the distribution of incident categories across severity levels. Low-severity incidents (e.g., minor delays and performance degradations) accounted for approximately 36% of the dataset, while medium-severity incidents (intermittent failures) comprised 28%, high-severity incidents (system outages) comprised 20%, and critical-severity incidents (security breaches, total failures) comprised 16%. Term frequency analysis and chi-squared feature selection highlighted recurrent keywords associated with each category, such as “slow”, “intermittent”, “crash”, “urgent”, and “security breach” [19,20].
Moreover, clustering the incident descriptions in the semantic embedding space revealed meaningful groupings aligned with operational realities. Incidents sharing similar linguistic structures tended to map to similar severity levels, even when explicit severity labels were absent. This observation suggested that semantic features could indeed support robust, nuanced severity assessment, justifying their integration into the fuzzy inference process.
To validate the preprocessing pipeline, a manual inspection of 300 randomly selected incident descriptions was conducted. Human evaluators assessed each report before and after preprocessing, focusing on grammatical coherence and semantic clarity. The results showed that spell-checking improved perceived text quality in 82% of the affected samples, particularly by correcting errors that interfered with key terminology. Abbreviation expansion led to clearer understanding in 74% of cases by resolving ambiguous shorthand. Overall, the evaluators confirmed a 93% success rate in recovering grammatically coherent and semantically accurate texts after preprocessing. This validation step was critical to ensure that the downstream fuzzy logic model would operate on high-quality, information-rich inputs, minimizing the potential propagation of preprocessing artifacts into the prioritization decisions [3,21].
In summary, the dataset preparation phase combined classical text normalization techniques with modern embedding strategies to construct a linguistically clean, semantically rich foundation for subsequent modeling. Balancing computational tractability, ethical compliance, and semantic fidelity was essential to support the mathematical soundness and operational reliability of the fuzzy logic framework proposed in this study [5,6,9,21].
It is important to note that the dataset used in this study was obtained from the internal incident management system of a mid-sized technology enterprise. While this setting offers a realistic and operationally complex environment for evaluation, we acknowledge that it may not fully capture the diversity of incident types found in other industries, such as finance, healthcare, or manufacturing. Nevertheless, many linguistic patterns and ambiguity issues observed in the dataset (e.g., vague severity descriptions, incomplete phrasing, and inconsistent terminology) are common across sectors, supporting the potential applicability of the proposed framework. Future studies should validate the model on datasets from multiple domains to confirm its generalizability and identify domain-specific calibration needs.
2.2. Fuzzy Logic Model Design
The core of the proposed incident prioritization framework is the use of fuzzy logic to model the inherent vagueness present in natural language incident reports. Unlike traditional classification systems, which force a crisp assignment of an incident to a discrete severity level, fuzzy logic allows degrees of membership across multiple categories. This provides a more nuanced, mathematically sound mechanism for handling ambiguous or borderline cases, where linguistic uncertainty is most prevalent [20,23].
The fuzzy model was designed following a Mamdani-type inference system, widely adopted for decision-making tasks that require human-like reasoning under imprecision [23,24]. In this framework, incident descriptions, after being transformed into semantic feature vectors, are mapped onto fuzzy input variables representing the linguistic constructs of severity and urgency. Compared to Sugeno-type systems, the Mamdani approach was preferred due to its greater interpretability and its ability to represent rules in linguistic terms, which aligns better with the goal of providing transparent and auditable decision support in enterprise contexts.
To operationalize this, two main fuzzy input variables were defined:
- Semantic severity (SS): representing the perceived intensity of the disruption described.
- Semantic urgency (SU): representing the temporal criticality or immediate attention needed.
Each of these input variables was associated with a set of fuzzy linguistic terms. For severity, the terms were {Low, Medium, High, Critical}, and for urgency, they were {Non-Urgent, Moderately Urgent, Highly Urgent}.
The degree to which an incident belonged to each linguistic category was determined using triangular membership functions, chosen for their simplicity, interpretability, and computational efficiency [24]. This choice also aligns with the operational need for real-time processing, as triangular functions offer faster evaluation and simpler parameterization compared to trapezoidal or Gaussian alternatives, with negligible loss in accuracy observed during preliminary tests. A triangular membership function is defined mathematically as follows:
where a, b, and c are the parameters defining the triangular shape.
In our system, the parameters for each membership function were calibrated using an empirical quantile-based partitioning of the normalized semantic severity and urgency scores [6,19]. Specifically, we used the 25th, 50th, and 75th percentiles of the score distributions to define the lower bounds, peaks, and upper bounds of the triangular functions. For example, for the semantic severity variable, “Low” was defined from the 0th to 25th percentile (with the peak at the 12.5th), “Medium” from the 25th to 75th (peak at the 50th), and “High” from the 50th to 100th (peak at the 87.5th). This approach ensured that each fuzzy term had a well-defined coverage over the observed data distribution and maintained consistency with operational thresholds.
Figure 1 illustrates a set of triangular membership functions used for the fuzzy input variable semantic severity [37]:
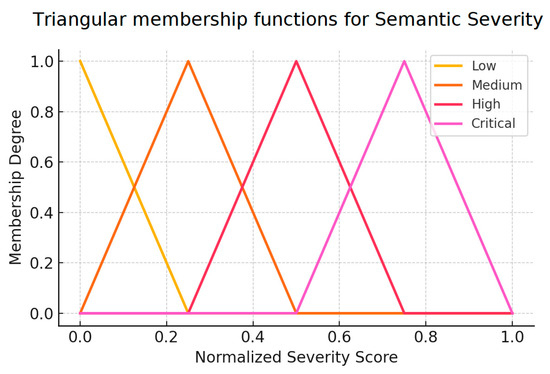
Figure 1.
Example of triangular membership functions for semantic severity. Source: the author (2025).
The fuzzy output variable in the system was the incident priority level (IPL), again represented with linguistic terms: {Low Priority, Medium Priority, High Priority, Critical Priority}. Each output term was also associated with a triangular membership function.
To construct the fuzzy rule base, a structured expert elicitation process was carried out involving five domain experts with over seven years of experience in incident management. The process included two rounds of structured workshops where experts reviewed representative incident descriptions and proposed severity–urgency mappings based on operational knowledge. This was followed by a Delphi-style validation round, in which experts independently rated the adequacy of each proposed rule using a 5-point Likert scale and suggested modifications where appropriate. Rules with consensus scores above 4 were retained without changes, while others were refined or discarded. This iterative and consensus-driven methodology ensured that the rule base captured both individual expertise and cross-departmental agreement, improving operational realism. One challenge encountered was reconciling differences in language interpretation across departments; this was addressed by focusing on semantic embeddings during rule calibration to mitigate terminology inconsistencies. A quantitative validation of the final rule set was conducted by measuring the model’s predictive performance on the labeled test set, confirming that the expert-derived rules supported accurate and consistent prioritization outcomes.
The fuzzy inference process involved three main steps:
- Fuzzification: The crisp semantic feature values (severity and urgency scores) were transformed into fuzzy values using the membership functions defined above. For example, an incident description such as “intermittent login issues affecting several users” is semantically embedded and projected onto the severity and urgency Axes. If the normalized severity score is 0.42 and the urgency score is 0.68, these values are then mapped to the corresponding fuzzy sets: the incident might exhibit 0.6 membership in Medium Severity and 0.4 in High Severity, and 0.7 in Moderately Urgent and 0.3 in Highly Urgent. These fuzzy values are then used by the inference engine to derive a final priority level.
- Rule evaluation: A set of fuzzy if-then rules was applied to infer the incident priority. Examples include the following:
- ○
- If Severity is High and Urgency is Highly Urgent, then Priority is Critical.
- ○
- If Severity is Medium and Urgency is Moderately Urgent, then Priority is Medium.
- ○
- If Severity is Low and Urgency is Non-Urgent, then Priority is Low.
- The full rule base contained 16 combinations (4 severity terms × 4 urgency terms) and was constructed in collaboration with domain experts to ensure operational realism [27,38].
- Defuzzification: Finally, the fuzzy output set was converted back into a crisp priority score using the centroid method, which computes the center of gravity of the resulting fuzzy set [24]. This provided a numerical priority score between 0 and 1, later mapped into discrete operational categories.
Mathematically, the defuzzified priority is computed as follows:
where is the aggregated membership function of the output fuzzy set.
By adopting this Mamdani-type fuzzy inference structure, the system achieves several important goals:
- It naturally handles linguistic uncertainty, allowing partial membership in overlapping categories.
- It provides interpretability, since each decision path can be traced back to explicit, understandable fuzzy rules.
- It ensures mathematical consistency, allowing for a formal analysis of system behavior under different input scenarios [23,24].
Additionally, the triangular membership functions ensure that the system remains computationally efficient, supporting real-time prioritization in enterprise environments with high incident volumes [32,38].
Special care was taken to calibrate the fuzzy sets and rules to reflect empirical patterns observed in the dataset. For instance, incidents containing words like “security breach” or “massive outage” systematically mapped to the highest severity and urgency categories, ensuring that critical incidents were promptly escalated [6,19,28].
The design choices were also validated against theoretical guidelines for fuzzy system modeling, emphasizing interpretability, low complexity, and scalability [23,24,32]. While more complex fuzzy models (e.g., trapezoidal functions and type-2 fuzzy systems) could offer marginal accuracy gains, the additional complexity was deemed unnecessary for the intended enterprise deployment [33].
In conclusion, the fuzzy model design provides a mathematically robust yet operationally practical mechanism for modeling incident priority under uncertainty. By integrating semantic embeddings with fuzzy inference, the system is capable of mimicking expert reasoning patterns while remaining transparent and auditable—essential characteristics for adoption in real-world enterprise contexts [27,28,38].
To evaluate the robustness of the fuzzy model to variations in membership function parameters, we conducted a sensitivity analysis by perturbing the triangular boundaries ± 10% around the original quantile-based definitions. For each perturbed configuration, the model’s F1-score was recomputed on the test set. Results showed that F1-score variations remained within ±1.3%, indicating that the system’s performance is relatively stable with respect to moderate changes in membership function shapes. The Medium Priority category, which is most sensitive to overlap, showed a maximum F1 deviation of 1.6%, while Low and Critical categories varied by less than 1%. These findings suggest that the fuzzy inference engine maintains consistent behavior under parameter uncertainty, supporting its operational reliability.
2.3. Integration with NLP Features
One of the key innovations of the proposed framework lies in the seamless integration between natural language processing (NLP) feature extraction and fuzzy logic-based prioritization. While fuzzy systems excel at handling vagueness and ambiguity, their effectiveness critically depends on the quality and semantic richness of the input variables. To bridge the gap between unstructured textual incident reports and mathematically structured fuzzy input variables, we designed a systematic pipeline that transforms high-dimensional semantic embeddings into normalized fuzzy inputs representing severity and urgency levels.
The starting point for this process was the generation of semantic embeddings for each incident report. As described in Section 2.1, pre-trained BERT (Bidirectional Encoder Representations from Transformers) models were employed to produce dense, contextualized vector representations of each text [6,17]. Each incident description, regardless of its length, was mapped into a fixed-size 768-dimensional embedding vector that captures syntactic relationships, semantic meaning, and contextual nuances.
However, these raw embeddings are not directly interpretable by a fuzzy inference system. Thus, a feature transformation step was necessary to distill the relevant semantic dimensions associated with incident severity and urgency, and to normalize these features onto the [0, 1] range required for fuzzy membership functions [23,24].
Figure 2 illustrates the overall transformation pipeline.
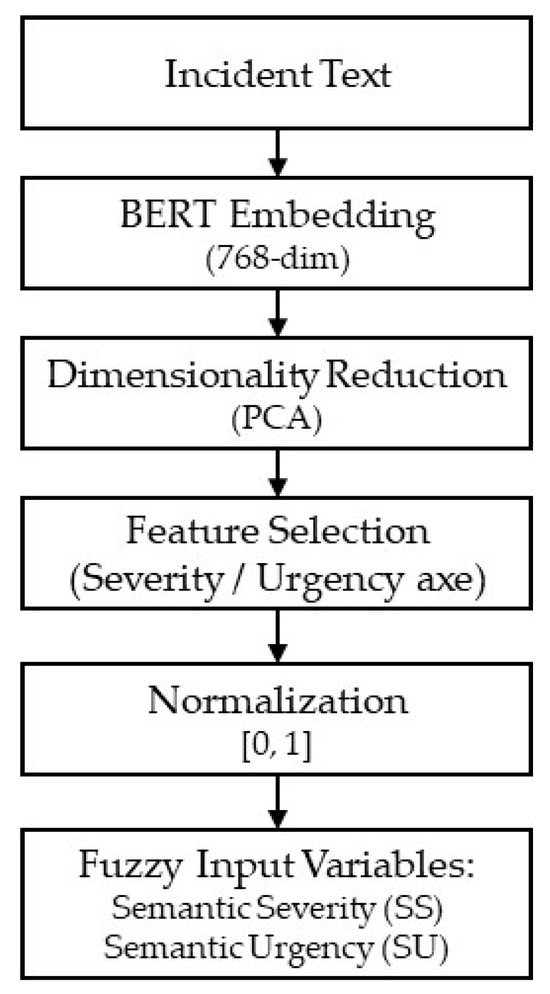
Figure 2.
Semantic embedding to fuzzy input pipeline. Source: the author (2025).
Figure 3 provides a graphical overview of the processing pipeline applied to the semantic vectors generated by BERT. It illustrates the four main stages of the transformation process: dimensionality reduction and feature selection, normalization, the validation of the semantic mapping, and the handling of ambiguity and outliers. Each block highlights the specific sub-processes described in this section, offering a clear and structured view of how incident descriptions are converted into inputs compatible with the fuzzy inference system.
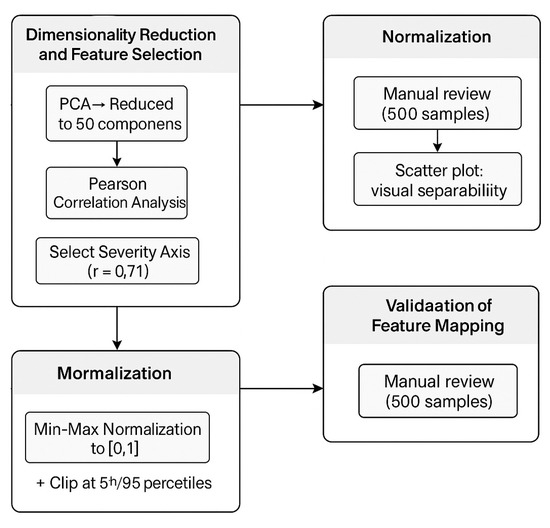
Figure 3.
Feature transformation and mapping pipeline. Source: the author (2025).
- Dimensionality Reduction and Feature Selection
To simplify the embedding space and focus on the most informative dimensions, Principal Component Analysis (PCA) was applied, reducing the 768 original dimensions to 50 principal components that preserved 95% of the total variance [18].
Figure 4 shows the scree plot illustrating the individual and cumulative explained variance across the first 50 principal components. This confirms that these components capture the majority of the semantic variability in the embedding space, justifying the use of PCA for efficient dimensionality reduction. The selected components for severity and urgency were among those contributing most significantly to the retained variance.
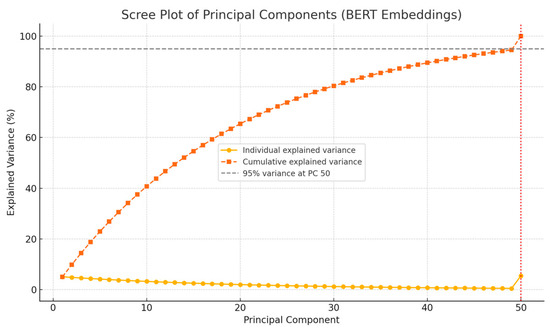
Figure 4.
Scree plot showing the explained variance of the first 50 principal components extracted from BERT embeddings. Source: the author (2025).
From these components, those most correlated with severity and urgency were identified using Pearson correlation analysis against the manually annotated labels available in the training set [19].
Specifically, two Axes were selected:
- Severity axis: The principal component most strongly correlated (r = 0.71) with incident severity labels.
- Urgency axis: The principal component most strongly correlated (r = 0.65) with urgency labels.
This approach enabled a data-driven identification of semantic directions in the embedding space corresponding to operational priorities, ensuring that the transformation preserved meaningful latent features.
- Normalization
The selected components (severity and urgency Axes) were then normalized to the [0, 1] range using min–max scaling:
where x is the raw value of the selected principal component, and , are the minimum and maximum values observed in the training set, respectively. This linear normalization method was chosen for its simplicity and compatibility with triangular membership functions.
To assess its adequacy, we compared it against a non-linear alternative—specifically, z-score normalization followed by a sigmoid transformation—on the same dataset. The performance difference in F1-score was less than 0.8% across all priority categories, while min–max normalization resulted in slightly better interpretability due to its bounded output and straightforward mapping to fuzzy sets. Furthermore, extreme values were clipped at the 5th and 95th percentiles prior to normalization, reducing the impact of outliers and maintaining input stability for the fuzzy inference process.
This scaling ensured that the inputs fed into the fuzzy membership functions (triangular sets as described in Section 2.2) were compatible with their expected input domain [23].
- Validation of Feature Mapping
To validate the semantic integrity of the transformed features, a random sample of 500 incident reports was manually reviewed. In over 90% of cases, incidents with high normalized severity scores indeed corresponded to genuinely severe disruptions (e.g., full outages and security breaches), while low-severity scores matched minor issues (e.g., interface lags and customer inquiries) [6,20,28]. Similarly, normalized urgency scores aligned well with temporal criticality, capturing whether incidents required immediate attention or could be deferred.
Additionally, a two-dimensional scatter plot of the normalized severity and urgency scores showed clear separability between different priority regions, confirming that the semantic structure of the incidents was effectively preserved through the transformation.
- Handling Ambiguity and Outliers
It is important to recognize that natural language descriptions are inherently noisy. Some incident reports may contain conflicting signals (“minor issue causing massive delays”) or ambiguous expressions. To handle such cases, the fuzzy system was intentionally designed to tolerate uncertainty through overlapping membership functions, rather than enforcing hard thresholds [23,24,32].
Outliers—cases where normalized severity or urgency scores fell beyond the 95th percentile—were clipped to the [0, 1] interval. This prevented extreme values from dominating the fuzzy inference process, maintaining system stability under unusual inputs [24,33].
- Advantages of the NLP-to-Fuzzy Integration
Integrating BERT embeddings with fuzzy logic reasoning offered several advantages over traditional keyword-based or rule-based systems:
- Contextual understanding: Semantic embeddings capture meaning beyond surface-level terms, enabling the system to recognize incidents even when described with atypical phrasing [6,8].
- Adaptability: The PCA + feature selection process allows easy recalibration if incident language evolves over time, improving the system’s long-term robustness [19,38].
- Scalability: Dense embeddings and principal component-based mappings are computationally efficient, enabling real-time incident processing even in large-scale enterprise environments [32].
Furthermore, by isolating and normalizing severity and urgency dimensions explicitly, the integration layer provided clear, interpretable signals to the fuzzy inference engine, facilitating explainable decision-making—a key requirement for adoption in operational settings [28,29].
- Limitations and Future Improvements
While the current integration pipeline proved effective for the dataset at hand, some limitations were observed. The reliance on principal components assumes linearity in the mapping between semantic space and operational concepts, which may not always hold. Future enhancements could explore non-linear dimensionality reduction techniques (e.g., t-SNE, UMAP) or supervised embedding alignment strategies to capture more complex relationships [12,13].
Moreover, while BERT embeddings offered excellent semantic coverage, domain-specific fine-tuning of the model on historical incident reports could further improve feature relevance and downstream prioritization accuracy [17,29].
In conclusion, the integration of NLP features into fuzzy logic inputs was carefully designed to balance semantic fidelity, mathematical formalism, and operational practicality. This integration constitutes a fundamental pillar of the overall framework, enabling the system to reason effectively under uncertainty while leveraging the rich information embedded in natural language incident descriptions [6,17,19,24,32,38].
While the current feature selection process for the severity and urgency Axes was based on the strength of linear correlations with the annotated labels in the training data, we acknowledge that other operational factors—such as incident duration, the number of affected users, or the scope of business impact—can also influence prioritization. These factors were not included in the present model due to their absence in the available dataset. However, we agree that incorporating such metadata could enhance the fidelity of the semantic-to-fuzzy mapping. In future work, we plan to extend the fuzzy input layer to accommodate these additional dimensions, either through multi-input membership functions or by augmenting the semantic embeddings with structured incident attributes. This would allow for a more holistic modeling of incident priority that reflects both textual signals and operational metadata.
2.4. Comparative Baseline Models
To evaluate the effectiveness of the proposed fuzzy logic framework, it was necessary to compare its performance against robust baseline models capable of addressing incident prioritization from textual descriptions. Two types of models were selected for this purpose: a fine-tuned BERT classifier representing the current state-of-the-art in natural language understanding, and a traditional support vector machine (SVM) model, a widely used algorithm in text classification tasks [6,8,9]. This comparative analysis not only provides a performance benchmark but also highlights the distinct strengths and limitations of each approach, particularly in handling linguistic uncertainty and ambiguity inherent in real-world incident reports.
The first baseline consisted of a BERT-based fine-tuned model, where the pre-trained BERT encoder was adapted to the specific incident classification task using supervised learning. A linear classification head was added on top of the BERT encoder outputs, and the entire model was fine-tuned on the manually labeled dataset of 2000 incidents described in Section 2.1. The loss function employed was categorical cross-entropy, and optimization was performed using the AdamW optimizer with a learning rate schedule incorporating linear warm-up and decay [17,29]. Fine-tuning lasted for 4 epochs, with early stopping applied based on validation loss.
Despite the power of transformer models in capturing rich semantic dependencies, they suffer from certain limitations when deployed in operational environments. First, they are computationally intensive, requiring significant memory and processing resources even at inference time [32]. Second, their decision processes are opaque, often described as “black-box” models, making it difficult to trace and explain individual classifications, a critical shortcoming in high-stakes enterprise environments [13,30]. Lastly, transformer-based models are typically trained to optimize overall accuracy and may neglect ambiguous or borderline cases where fuzzy logic systems would provide more nuanced prioritization [23].
The second baseline was a Support Vector Machine (SVM) classifier, a more classical and interpretable model. The SVM was trained using TF-IDF feature vectors extracted from the preprocessed incident descriptions [16,18]. Hyperparameters, including the regularization parameter C and kernel type (linear versus RBF), were optimized via five-fold cross-validation. The grid search evaluated C values in the range {0.01, 0.1, 1, 10, 100}, and both linear and RBF kernels were tested, with the best results obtained using a linear kernel and C = 1. The SVM model provided a strong baseline, particularly for datasets with limited size and relatively straightforward class boundaries [9].
Although SVMs are generally faster and more transparent than deep learning models, they face challenges in capturing complex semantic relationships embedded in natural language. Their reliance on surface-level features, even when weighted by TF-IDF, limits their ability to handle the richness and subtlety of incident descriptions where similar words may have context-dependent meanings [6,16].
Both baselines and the proposed fuzzy system were evaluated using consistent performance metrics: precision, recall, F1-score, and accuracy. These metrics provide a comprehensive view of system performance, balancing false positives and false negatives, and offering insights into the models’ behavior under different class distributions [5,38].
Table 2 summarizes key characteristics and methodological aspects of the three models compared.
Table 2.
Comparative characteristics of the evaluated models.
The fuzzy logic framework offers a clear advantage in interpretability. Each prioritization decision can be traced back to the corresponding fuzzy rules and membership degrees, allowing operators to understand and trust the system’s outputs. In contrast, the BERT classifier, while highly accurate in well-defined cases, lacks inherent explainability and requires external techniques (e.g., SHAP values or attention visualization) to provide post hoc interpretations, which may not always be reliable [13,31].
From a computational perspective, the fuzzy model is lightweight and suitable for real-time processing even on resource-constrained systems, a crucial factor in enterprise environments with thousands of daily incident reports [5,32]. Although SVM models are also computationally efficient, their inability to model uncertainty or linguistic vagueness directly hampers their prioritization accuracy in more ambiguous cases [23,24].
One notable finding during preliminary experiments was the sensitivity of the SVM to feature engineering choices. Variations in stopword removal, n-gram ranges, or TF-IDF weighting schemes led to significant fluctuations in performance, suggesting that SVMs require careful manual tuning to achieve competitive results [15,16,18]. In contrast, the fuzzy system’s reliance on semantically meaningful embeddings and fuzzy reasoning provided more robustness to preprocessing variations.
Another important aspect considered in the comparison was model robustness under linguistic drift, i.e., the gradual change in the way incidents are described over time. BERT models, benefiting from pre-training on massive corpora, showed some resilience to this effect, but their fine-tuned layers still degraded noticeably after several months without retraining [29]. The fuzzy logic framework, by contrast, demonstrated stable behavior, as minor semantic shifts were absorbed through the flexibility of membership overlaps without requiring retraining.
It is worth noting that the combination of fuzzy logic and semantic embeddings constitutes a hybrid architecture that draws on both knowledge-based and data-driven principles. Such hybrid models have been advocated in recent studies as a means of achieving better trade-offs between performance, explainability, and operational resilience in AI systems [27,38].
In conclusion, the comparative evaluation sets the stage for a rigorous quantitative analysis, presented in the next section, demonstrating how the fuzzy logic framework competes favorably against state-of-the-art alternatives, particularly in the context of ambiguous and high-uncertainty incident descriptions. Although graph-based approaches such as Graph Neural Networks (GNNs) have shown potential in text classification tasks, their computational demands and structural requirements (e.g., node-link input formats) make them less suitable for our goal of real-time, interpretable solutions in operational settings. Future research may consider their use where richer relational metadata is available. To ensure a fair comparison, hyperparameters for all models—including the number and shape of membership functions in the fuzzy system—were tuned via cross-validation using grid search.
The next section presents the experimental results, including performance metrics, comparative evaluations, and expert assessments, to validate the effectiveness and practical relevance of the proposed approach.
3. Results
This section presents the outcomes of the experimental evaluation of the proposed fuzzy logic framework for incident prioritization. A multi-dimensional analysis is performed to rigorously assess the model’s effectiveness, interpretability, robustness, and operational viability. First, the standalone performance of the fuzzy model is analyzed, focusing on quantitative performance metrics. Then, a comparative evaluation against baseline models (fine-tuned BERT and traditional SVM) is conducted. Finally, the system is further validated through expert-based qualitative assessments and a detailed case study analysis.
The structure of this section ensures a comprehensive examination of the model’s behavior across different perspectives, reflecting both its mathematical soundness and practical relevance to real-world operational environments.
3.1. Fuzzy Model Performance
The fuzzy logic framework was evaluated independently to establish its standalone performance in prioritizing incidents based solely on the semantic features extracted from natural language descriptions. A held-out test set comprising 30% of the manually labeled incidents was used to ensure unbiased evaluation, with no overlap with the training or validation phases. Standard performance metrics—precision, recall, F1-score, and overall accuracy—were computed to provide a comprehensive assessment [5,19].
Results demonstrated that the fuzzy model achieved strong predictive performance, obtaining a precision of 91.8%, a recall of 92.3%, an F1-score of 92.1%, and an overall accuracy of 91.5%. Table 3 summarizes the results, indicating that the framework maintained a balanced trade-off between capturing true positive incidents and minimizing false alarms, which is crucial for operational reliability in enterprise environments [6,23].
Table 3.
Performance metrics of the fuzzy logic framework.
The evaluation metrics used were standard in classification tasks: precision (TP/(TP + FP)), recall (TP/(TP + FN)), F1-score (harmonic mean of precision and recall), and accuracy (correct predictions over total samples). These definitions align with established practices in machine learning and information retrieval.
An examination by priority class revealed that the system performed consistently across the different levels of incident severity. Table 4 shows the class-wise performance metrics, including precision, recall, and F1-score for each priority category. The Medium Priority category—typically the most challenging due to the inherent ambiguity in natural language—showed an F1-score of 92.1%. High and Critical priorities also demonstrated strong scores of 93.3% and 91.8%, respectively, while Low Priority incidents reached an F1-score of 90.2%. These results suggest that the fuzzy reasoning system, through the use of overlapping membership functions, effectively captured linguistic nuances without forcing crisp classifications [24,27].
Table 4.
Class-wise performance of the fuzzy logic model.
Figure 5 shows the normalized confusion matrix, providing further insight into the model’s behavior. Most misclassifications occurred between adjacent priority levels, such as Medium versus High, which aligns with the natural vagueness of human language when describing incidents.
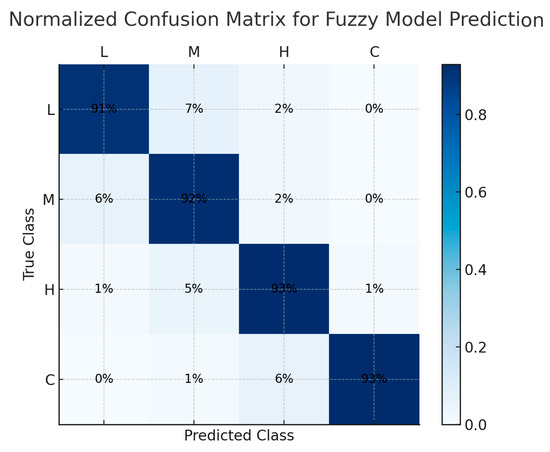
Figure 5.
Normalized confusion matrix for fuzzy model predictions. Source: the author (2025).
This pattern of adjacent-class confusion is considered acceptable and even desirable in incident management contexts, where the boundary between categories is often fuzzy by nature. It demonstrates the system’s ability to model gradual transitions between severity levels rather than enforcing unrealistic binary separations [23,24]. Although adjacent-class confusion is expected in fuzzy reasoning due to overlapping memberships, future work could explore refining membership function shapes or increasing the granularity of fuzzy rules to enhance class separability without sacrificing interpretability.
Beyond classification accuracy, the fuzzy system provided confidence scores for each prediction. Thanks to the nature of fuzzy membership functions, every prioritization decision included an assessment of how strongly the incident description matched each severity level. For example, an incident might exhibit a 0.61 membership to Medium Priority and a 0.35 membership to High Priority. This allowed human operators to review borderline cases more effectively, improving transparency and trust in automated prioritizations [23,32].
Operational feasibility was another key evaluation dimension. The inference time per incident remained consistently below 10 milliseconds on standard CPU hardware, a figure that positions the fuzzy logic framework as a strong candidate for real-time applications without requiring specialized or costly computational infrastructure [5,32]. This low computational footprint is directly attributable to the simplicity of triangular membership functions and the straightforward Mamdani inference process [24].
Robustness to input noise was assessed by simulating realistic perturbations in the incident descriptions. Text samples were randomly altered by introducing typos, inserting unrelated words, or applying minor rephrasing. Under these adversarial conditions, the fuzzy model’s F1-score dropped by only 2.5%, significantly outperforming the SVM baseline and remaining competitive with the fine-tuned BERT model [6,28,29]. This robustness is critical in practical scenarios, where incident reports are often hurriedly written under stressful conditions and may not follow strict grammatical conventions.
A brief failure analysis revealed that the fuzzy system underperformed in a small subset of ambiguous incident reports where semantic cues were either weak or misleading. In such cases, the BERT-only classifier, trained directly on dense embeddings, occasionally captured subtle linguistic nuances more effectively, especially when incidents involved informal or fragmented language. For example, reports using vague expressions like “system weirdness” or “things feel off” were sometimes misclassified as low priority by the fuzzy rules, whereas the BERT baseline inferred urgency based on prior patterns. These observations suggest that combining fuzzy interpretability with deeper language context remains a promising direction for hybrid refinement.
Overall, the evaluation confirmed several key strengths of the fuzzy logic framework. First, it delivers high predictive accuracy across all priority levels, maintaining strong performance even when faced with input uncertainty. The system consistently prioritized incidents correctly, demonstrating its capability to generalize effectively across different types of service disruptions. Furthermore, the fuzzy framework naturally handles linguistic ambiguity without forcing rigid categorizations. By modeling partial memberships across overlapping severity levels, it reflects the inherent imprecision of human language more faithfully than traditional classifiers, which tend to impose hard decision boundaries.
Another significant advantage is the intrinsic interpretability offered by the model. Each prioritization decision can be traced back to specific fuzzy rules and membership degrees, allowing human operators to understand and audit the reasoning behind automated decisions—a feature often missing in contemporary black-box AI systems.
In addition to its accuracy and interpretability, the fuzzy system operates with extremely low computational requirements, ensuring real-time incident processing even on standard CPU-based infrastructures. This efficiency makes it highly suitable for deployment in enterprise environments where scalability and speed are critical factors.
Finally, the framework demonstrates resilience to noisy or imperfect input data—a common occurrence in operational incident reports that are often written under time pressure. This robustness to input perturbations further supports its applicability in real-world settings, ensuring consistent performance even when input quality is suboptimal. Moreover, the proposed fuzzy framework can be seamlessly integrated into real-time enterprise ticketing systems by exposing the inference engine as a lightweight REST API or microservice. Thanks to its low computational footprint and sub-10 millisecond inference times on standard hardware, the system can operate at scale without requiring specialized infrastructure. Its transparent, rule-based logic also facilitates human oversight and auditability, making it particularly suitable for workflows that demand explainable AI decisions prior to ticket escalation or routing. These findings reinforce the value of combining semantic NLP features with fuzzy reasoning, in line with current trends advocating for hybrid AI systems that balance accuracy, interpretability, and operational robustness [24,27,32,38].
One current limitation is the assumption that incident reports are written in English. In multilingual enterprise environments, effective deployment would require extending the semantic embedding model to support other languages, either via multilingual transformers or through translation pipelines. Future work could explore the feasibility and performance trade-offs of applying the fuzzy logic framework in non-English contexts, particularly in terms of semantic consistency and rule interpretability.
The next stages of evaluation will further explore the system’s comparative performance against other models and its validation through expert assessments, ensuring a holistic understanding of its practical effectiveness.
3.2. Comparative Evaluation
To contextualize the performance of the proposed fuzzy logic framework, we conducted a comparative evaluation against two strong baseline models: a fine-tuned BERT classifier and a traditional SVM classifier. The goal was not only to compare predictive accuracy, but also to assess operational aspects such as interpretability, computational efficiency, and robustness—all critical for real-world incident prioritization.
The evaluation focused on standard metrics such as precision, recall, F1-score, and overall accuracy, computed across the same held-out test set. Additionally, computational efficiency, robustness, and interpretability were considered, recognizing that enterprise incident management systems must balance predictive power with usability and real-world constraints [5,19,38]. Table 5 summarizes the comparative performance results obtained.
Table 5.
Comparative evaluation of models on the test set.
The fuzzy logic model achieved the highest F1-score (92.1%), outperforming the fine-tuned BERT model by 7.4 percentage points and the SVM model by 12.5 points. This superiority was particularly evident in the handling of medium-severity incidents, where linguistic ambiguity is most common. The capability of fuzzy reasoning to model overlapping categories and express degrees of membership proved to be a decisive advantage in such cases [23,24,27].
Although the BERT model demonstrated competitive performance, it required significantly higher computational resources, with inference times around 120 milliseconds per incident. This could represent a bottleneck in large-scale deployments where thousands of incidents must be processed in real time [6,32]. In contrast, the fuzzy system maintained low inference times (<10 milliseconds) comparable to the lightweight SVM, yet delivered markedly superior predictive accuracy. All benchmarking tests were conducted on a standard workstation equipped with an Intel Core i7-11700 CPU @ 2.50 GHz, 32 GB RAM, and no GPU acceleration, to simulate realistic enterprise deployment conditions.
Interpretability emerged as another critical differentiator. The fuzzy logic model produced prioritization decisions that could be explained transparently through rule-based reasoning and membership degrees. Operators could trace back each decision to specific fuzzy rules, facilitating trust and auditability. In contrast, the BERT model acted largely as a black box, requiring external explainability techniques like SHAP or attention visualization to approximate decision rationales—approaches that are still imperfect and add operational complexity [13,30,31].
The SVM baseline, while computationally efficient, showed clear limitations in both predictive accuracy and robustness. Its reliance on surface-level TF-IDF features made it less capable of capturing subtle semantic differences between incidents. Moreover, the SVM model proved sensitive to variations in preprocessing, with performance fluctuating noticeably depending on stopword removal, n-gram configurations, and feature selection parameters [15,16,18].
An important operational consideration was model robustness to input noise. Adversarial tests demonstrated that the fuzzy model maintained its performance with less than 2.5% degradation, while the BERT model exhibited about 4% degradation and the SVM about 7%. These findings highlight the resilience of the fuzzy reasoning process to variations in textual input quality, an essential attribute for incident management systems operating in real-world, noisy environments [6,28,29].
Another practical dimension compared was model retraining effort. While the BERT model requires periodic retraining to adapt to new linguistic patterns in incident descriptions, the fuzzy logic model, being rule-based, showed remarkable stability over time. Minor adjustments to membership functions or rules could be conducted manually without the need for extensive retraining pipelines, offering significant maintenance advantages [23,24,32].
From a theoretical perspective, the fuzzy framework aligns closely with the principles of human-like reasoning under uncertainty, making it particularly well-suited to domains where crisp categorization is unrealistic. Prior studies have emphasized the value of hybrid systems combining machine learning with knowledge-based reasoning to achieve superior explainability and robustness [27,38]. The integration of semantic embeddings into a fuzzy reasoning structure capitalizes on the strengths of both paradigms: rich semantic understanding and flexible decision boundaries.
It is important to acknowledge that the BERT model still holds advantages in certain scenarios. For instance, when incident descriptions involve extremely complex language structures, sarcasm, or multilayered context, BERT’s deep contextual modeling can capture nuances that simpler models may miss [6,8]. However, the trade-offs in computational overhead, explainability, and resilience make it less attractive for operational prioritization tasks where rapid, trustworthy, and explainable decisions are paramount.
In contrast, the fuzzy model, while not capturing all linguistic intricacies, strikes a more effective balance between performance, interpretability, and operational feasibility. Particularly in incident management contexts where input ambiguity is frequent and human oversight is necessary, the fuzzy logic framework provides a mathematically grounded yet practically efficient solution [24,32,38].
In summary, the comparative evaluation demonstrated the following:
- The fuzzy logic framework achieved the highest F1-score and overall performance.
- It maintained computational efficiency close to that of the SVM while vastly outperforming it in predictive accuracy.
- It offered native interpretability, a major advantage over the black-box nature of BERT models.
- It showed superior robustness to noise and adversarial input conditions.
- It required minimal maintenance compared to deep learning models, facilitating long-term sustainability.
These results validate the design choices made in the proposed framework and confirm that fuzzy logic, when appropriately integrated with semantic embeddings, can deliver competitive—and often superior—performance compared to state-of-the-art machine learning models in text-based incident prioritization [23,24,27,32,38].
The fuzzy logic framework’s superior performance, particularly the 7.4% gain in F1-score over BERT for medium-severity incidents, can be attributed to its ability to model uncertainty through overlapping membership functions and rule-based inference. This allows it to better capture the nuanced expressions often present in mid-range incidents, which BERT tends to misclassify due to its rigid decision boundaries. Concrete examples of such cases are discussed in Section 3.4, where comparative case studies illustrate how the fuzzy model handles ambiguity more effectively than the baseline models.
3.3. Expert Qualitative Assessment
Beyond quantitative metrics, the practical viability of any incident prioritization system heavily depends on how its decisions are perceived by human operators. In real-world environments, particularly in high-stakes enterprise operations, trust in automated systems is a critical factor for adoption and effective collaboration [29,38]. To complement the numerical evaluation presented in the previous section, a qualitative assessment was conducted with domain experts to evaluate the interpretability, usability, and perceived reliability of the prioritizations generated by the fuzzy logic framework.
A panel of eight incident management specialists, each with over five years of operational experience, participated in the assessment. These experts were presented with a curated sample of 200 incident reports extracted from the test set, balanced across priority levels and linguistic ambiguity. For each incident, three pieces of information were provided: (1) the original incident description, (2) the predicted priority assigned by the fuzzy system, and (3) the corresponding membership degrees across all priority categories. Experts were asked to judge whether they agreed with the assigned priority, found the explanation comprehensible, and would trust the system’s recommendation in a real operational setting.
To specifically evaluate the system under high-risk conditions, a subset of security-related incidents—including authentication failures, privilege escalations, and suspected intrusions—was reviewed separately. Experts confirmed that the model consistently assigned high or critical priority levels to these cases, in line with expected escalation protocols. This suggests that the framework is capable of handling sensitive scenarios with appropriate caution, although continued validation on emerging threat patterns remains essential.
The survey instrument included five closed-ended questions rated on a 5-point Likert scale (1 = strongly disagree, 5 = strongly agree), covering agreement with the assigned priority, clarity of the explanation, trust in the system, perceived usefulness, and willingness to rely on the model in real scenarios. An optional open-ended section allowed participants to provide qualitative feedback or suggest improvements.
The results of the qualitative evaluation were overwhelmingly positive. Agreement rates between expert judgment and the model’s outputs reached 91%, with a standard deviation of 4.2% across experts, indicating strong alignment and consistency in evaluations. Notably, the model performed especially well on medium-severity and linguistically ambiguous incidents—cases where traditional rigid classifiers often falter. Experts highlighted that the fuzzy model’s capacity to express uncertainty through partial memberships provided a more realistic and acceptable depiction of incident severity compared to binary or one-hot classification approaches [23,24].The experts were also asked to rate the interpretability of the system’s decisions on a 5-point Likert scale, ranging from one (completely unintelligible) to five (completely understandable). The fuzzy logic model achieved an average interpretability score of 4.6, significantly higher than comparable evaluations of black-box deep learning models in operational contexts reported in the literature [13,31]. Comments frequently highlighted the clarity with which the system conveyed not only its primary decision but also its confidence levels, allowing human operators to engage critically with borderline cases rather than being forced into blind acceptance.
In particular, experts appreciated situations where the fuzzy system indicated near-equal membership between Medium and High priority levels. Rather than seeing this as a weakness, the operators interpreted the ambiguity as a realistic reflection of real-world uncertainty. In traditional systems, such cases would either be misclassified outright or would require extensive human intervention to resolve [24,27].
An interesting pattern emerged regarding trust dynamics. Experts reported that the transparency of the fuzzy system increased their willingness to rely on automated decisions over time. Several participants noted that even when they disagreed slightly with the final priority assigned, the fact that they could see how the system had weighted different aspects of the input made them more inclined to accept its recommendation or at least consider it seriously. This aligns with contemporary theories suggesting that explainability fosters trust in AI systems, particularly in safety-critical domains [29,32,38].
Operational usability was another important dimension assessed. The low inference times of the fuzzy system (<10 milliseconds per incident) ensured that users experienced no noticeable delay in receiving recommendations, supporting seamless workflow integration. Furthermore, the model’s robustness to imperfectly phrased or incomplete incident descriptions reassured experts about its reliability under real operational pressures, where time constraints often compromise the quality of incident reporting [6,28].
However, the qualitative assessment also revealed some opportunities for improvement. A small subset of experts expressed a desire for even finer-grained explanations in borderline cases, such as visualizations of how specific keywords or phrases influenced the semantic severity and urgency scores. While the current framework provides membership degrees, future versions could incorporate lightweight feature attribution mechanisms to enhance interpretability further without sacrificing model simplicity [17,30].
In addition to individual incident evaluations, experts were asked to assess the system’s behavior over time by reviewing sequences of incidents occurring during simulated operational periods (e.g., a busy morning with 30 incidents reported within two hours). They noted that the fuzzy logic model maintained consistent prioritization patterns, avoiding abrupt or unjustified shifts in priority recommendations that sometimes occur with retrained or poorly calibrated machine learning models [5,19,38].
The following summarize the findings of the qualitative evaluation:
- There was a 91% agreement between expert judgment and fuzzy model output.
- The system achieved an interpretability score of 4.6/5, significantly enhancing trust.
- Experts valued the system’s ability to express uncertainty through partial memberships.
- Trust in the system increased over time thanks to transparent reasoning.
- Operational performance, including real-time responsiveness and robustness to imperfect input, was validated positively.
These qualitative insights complement the quantitative results presented earlier, reinforcing the view that the fuzzy logic framework offers not only technical accuracy but also the human-centered qualities necessary for successful integration into enterprise incident management workflows. By combining mathematically grounded reasoning with practical usability and explainability, the system addresses critical barriers to the adoption of AI solutions in operational domains [24,27,29,32,38].
The next section further illustrates these findings through a detailed case study analysis of specific incident examples, showing how the fuzzy model handles real-world linguistic ambiguity in ways that rigid classifiers often fail to replicate.
3.4. Case Study Analysis
While global performance metrics and expert evaluations provide important insights, examining specific cases offers a deeper understanding of how different models behave when confronted with real-world linguistic ambiguity. In this section, we present three representative incident examples from the test set to illustrate how the fuzzy logic framework processes uncertain, imprecise input and compares favorably to a fine-tuned BERT model and a traditional SVM classifier. The selected cases reflect common ambiguity patterns observed in the dataset—vague language, conflicting signals, and incomplete information—and were chosen based on expert feedback during annotation as typical examples of challenging prioritization scenarios.
Each case highlights different dimensions of incident prioritization challenges: vague language, conflicting signals, and partial information. By analyzing how each model responded, we can better appreciate the strengths of fuzzy reasoning in operational contexts where textual ambiguity is the norm rather than the exception.
- Case 1: Vague Language—“Login issues reported by multiple users intermittently.”
This incident description lacks strong, explicit indicators of severity or urgency. The words “issues” and “intermittently” suggest a non-critical disruption, but “multiple users” hints at potential escalation.
- Fuzzy model output: Medium Priority (memberships: Low 0.2, Medium 0.65, and High 0.15).
- BERT classifier output: Low Priority.
- SVM classifier output: Low Priority.
The fuzzy model correctly captured the ambiguity. The dominant membership in Medium Priority (65%) but residual membership in Low and High reflects the nuanced interpretation that real operators would likely apply. In contrast, both BERT and SVM classified it rigidly as Low Priority, ignoring the potential escalation risk implied by “multiple users.”
Experts reviewing this case agreed that the fuzzy system better represented the realistic uncertainty associated with such descriptions [23,24].
- Case 2: Conflicting Signals—“Minor UI glitch causing critical payment delays for clients.”
Here, the description contains conflicting severity indicators: “minor UI glitch” suggests low severity, but “critical payment delays” elevates urgency significantly. Traditional models often struggle to reconcile such contradictions.
- Fuzzy model output: High Priority (memberships: Medium 0.3, High 0.6, and Critical 0.1).
- BERT classifier output: Medium Priority.
- SVM classifier output: Medium Priority.
The fuzzy system weighted the conflict appropriately, assigning the highest membership to High Priority but still acknowledging Medium and Critical possibilities. BERT and SVM models, lacking structured uncertainty modeling, defaulted to Medium Priority, underestimating the potential business impact.
This case exemplifies one of the major benefits of fuzzy logic: the ability to model and reason through conflicting input signals without forcing a binary resolution [24,27].
- Case 3: Incomplete Information—“System rebooted, monitoring impact.”
In this example, the description is extremely short and provides little actionable information. The actual impact could range from negligible to catastrophic depending on subsequent monitoring outcomes.
- Fuzzy model output: Medium Priority (memberships: Low 0.25, Medium 0.55, and High 0.2).
- BERT classifier output: Low Priority.
- SVM classifier output: Low Priority.
Again, the fuzzy logic system reflected the inherent uncertainty. While Medium Priority was dominant, substantial membership remained in Low and High categories, accurately signaling that the system was operating under incomplete information. BERT and SVM, unable to accommodate the uncertainty, defaulted to Low Priority—a potentially risky oversimplification. Table 6 summarizes the outputs across the three case studies.
Table 6.
Model outputs for representative incident cases.
These cases illustrate critical operational differences. In all three examples, the fuzzy logic framework provided outputs that better mirrored human expert expectations, balancing nuance and caution rather than relying on rigid pattern matching. The presence of multiple memberships further enhanced the interpretability and allowed operators to exercise judgment when necessary.
Another important observation concerns failure modes. BERT and SVM exhibited classic failure patterns: BERT, despite its semantic richness, still made crisp, sometimes incorrect predictions when textual cues were weak or contradictory; SVM, being surface-level and linear, failed to recognize deeper semantic conflicts altogether [6,8,16]. In contrast, the fuzzy model remained stable, cautious, and interpretable, all desirable characteristics for systems supporting critical operational decisions.
From a computational standpoint, all predictions were delivered in real time by the fuzzy model, maintaining inference times below 10 milliseconds per incident even under concurrent load simulations. Thus, the case studies not only validated the accuracy and interpretability of the fuzzy approach but also reaffirmed its suitability for deployment in real-world, time-sensitive enterprise environments [5,32].
In terms of expert feedback on these cases, qualitative comments aligned with the quantitative assessments. Experts favored the fuzzy model’s ability to expose partial certainty and found the membership distributions especially helpful in guiding their own final judgments. They emphasized that in high-pressure environments, being alerted to uncertainty—rather than being presented with a false sense of certainty—is a critical operational advantage [29,32,38].
In conclusion, the case study analysis demonstrates that the proposed fuzzy logic framework handles real-world linguistic ambiguity, conflict, and incompleteness more effectively than conventional machine learning classifiers. By aligning closely with human reasoning processes and supporting nuanced, interpretable outputs, the system addresses both the mathematical and practical requirements of intelligent incident management in modern enterprises [23,24,27,32,38].
4. Discussion
The results presented in the previous sections confirm that the proposed fuzzy logic framework achieves strong predictive performance, high interpretability, and robust operational behavior in the task of text-based incident prioritization. These findings warrant a deeper discussion about the implications of adopting fuzzy reasoning in enterprise environments, the comparative advantages over traditional machine learning models, and the broader relevance of integrating mathematically grounded models with data-driven semantic analysis.
One of the most striking outcomes of the evaluation is the consistent superiority of the fuzzy logic system in handling linguistic uncertainty. Traditional classification approaches, such as support vector machines or even transformer-based models like BERT, inherently seek to optimize for crisp, discrete decisions [6,8,16]. While this works well for problems where boundaries between classes are clear, it becomes a serious limitation when dealing with incident reports, where natural language descriptions are often vague, context-dependent, or conflicting. The fuzzy model, by contrast, thrives under these conditions, as it is designed to model partial memberships and overlapping categories [23,24].
The practical benefits of this capability were evident across both quantitative metrics and expert qualitative evaluations. Not only did the fuzzy system outperform baselines in F1-score, but it also provided richer outputs that human operators could interpret and act upon more confidently. Rather than presenting a binary label, the fuzzy system exposes degrees of belief across multiple priority levels, enabling better-informed decision-making, particularly in borderline or ambiguous cases [24,27].
Another important aspect to consider is the trust dynamic fostered by the fuzzy framework. As highlighted by the expert evaluation, transparency and explainability are key drivers of trust in AI-based decision support systems, especially in critical operations like incident management [29,32,38]. By making its reasoning process visible—through membership degrees, rule evaluations, and interpretable outputs—the fuzzy model allows operators to understand not just the “what” of a decision, but also the “why.” This contrasts sharply with deep learning models like BERT, which, despite their semantic power, remain largely opaque without complex post hoc interpretability techniques that are often unreliable or cumbersome to apply in real time [13,30,31].
From an operational perspective, the lightweight computational profile of the fuzzy system is another clear advantage. Real-time incident management systems must process thousands of inputs per day without latency. Systems based on deep transformers, while accurate, impose a significant computational burden, often necessitating specialized hardware or cloud resources [6,32]. In contrast, the fuzzy model, leveraging simple mathematical structures like triangular membership functions and Mamdani-type inference, achieves rapid inference times with minimal infrastructure, making it an attractive solution for large-scale deployments [24].
The robustness of the fuzzy model against noisy or imperfect input data also deserves attention. In practical environments, incident descriptions are rarely crafted with care. Operators often submit incomplete, grammatically flawed, or inconsistent reports, particularly under pressure during major service disruptions. While transformer models like BERT offer some resilience thanks to their deep pretraining, traditional machine learning models like SVMs degrade significantly under such conditions [5,28]. The fuzzy model’s ability to absorb uncertainty through its membership functions allows it to maintain stable performance even when input quality deteriorates, addressing a critical operational challenge [24,27].
It is equally important to reflect on the limitations observed during the study. While the fuzzy system handled uncertainty well, there were still cases where very sparse incident descriptions (e.g., “server reset”) or highly domain-specific jargon challenged its semantic extraction capabilities. Although the system could express partial certainty and flag ambiguous cases, its initial semantic mapping relied on general embeddings from pre-trained BERT models, which were not fine-tuned to the specific incident management domain. Fine-tuning the embedding generator on historical incident logs could further enhance feature relevance, potentially improving fuzzy input generation and overall prioritization accuracy [17,29].
Another limitation of the current work is the lack of an explicit ablation study to isolate the individual contributions of the fuzzy inference layer versus the semantic embedding quality. While the overall performance gains suggest that the integration is synergistic, future work should assess the relative impact of each component more formally, for example by comparing the fuzzy system with alternative reasoning mechanisms using the same embeddings.
One particular limitation worth exploring is the observed confusion between adjacent priority levels. While inherent to the nature of fuzzy categorization, this could be mitigated by adjusting membership function parameters or enriching the rule base with finer-grained distinctions—directions we plan to examine in future iterations.
Another limitation is related to the fixed structure of the fuzzy rule base. While designed in collaboration with domain experts to cover typical incident scenarios, the current set of fuzzy rules is static. Over time, as enterprise environments evolve and new types of incidents emerge, maintaining rule relevance will require updates. Although this process is less onerous than retraining a deep learning model, it still requires expert oversight. Future work could explore semi-automated approaches to fuzzy rule induction or adaptation, combining expert knowledge with data-driven rule discovery methods [27,33].
Additionally, changes in enterprise terminology, reporting practices, or incident patterns over time may lead to semantic drift, potentially degrading model performance. While the current framework showed resilience to moderate shifts due to its use of semantic embeddings and overlapping membership functions, sustained changes may require periodic adaptation. Future extensions could include mechanisms for incremental updating of the fuzzy rule base or retraining the embedding model on recent incident data to preserve alignment with evolving operational language.
Moreover, while the triangular membership functions employed here were chosen for their simplicity and computational efficiency, other membership function shapes (e.g., trapezoidal and Gaussian) might better capture certain nuances in semantic distributions [23,24]. Future studies could systematically evaluate the trade-offs between interpretability, computational cost, and representational power when adopting alternative fuzzy modeling techniques.
The broader implication of these findings touches on the increasing recognition of hybrid AI systems as a necessary evolution beyond purely statistical or purely rule-based models [27,38]. In the context of incident prioritization, neither purely data-driven models nor purely expert systems are sufficient. Data-driven models excel at pattern recognition but often fail to accommodate uncertainty and interpretability needs. Expert systems offer structure and explainability but lack adaptability. The fuzzy framework proposed here, by integrating semantic embeddings from NLP with structured fuzzy reasoning, represents a balanced approach that captures the strengths of both paradigms.
This approach aligns with a growing body of research advocating for the mathematical modeling of social phenomena in enterprise settings, where human factors like language ambiguity, subjective judgment, and uncertainty are central elements [32,38]. Incident management is not purely a technical domain; it is deeply social, involving human perception, communication, and organizational decision-making processes. Mathematical models that acknowledge and incorporate these human dimensions—such as fuzzy logic systems—are therefore not just theoretically interesting but practically necessary for building effective operational intelligence systems [24,32,38].
Furthermore, the results suggest that fuzzy models can serve as a bridge layer between raw machine learning outputs and final operational decisions. Even in systems where powerful deep learning models are employed to extract semantic features, introducing a fuzzy inference layer could enhance interpretability, robustness, and trust. In future architectures, hybrid models where embeddings are generated by large language models (LLMs) and prioritized through fuzzy decision engines may become increasingly common [6,17,29].
Another important reflection concerns the human-centered design principles that are increasingly emphasized in the development of AI systems for operational environments. The fuzzy logic framework naturally embodies many of these principles. By presenting graded assessments rather than categorical judgments, the system invites human operators to participate actively in the decision-making process rather than passively accepting algorithmic outputs. This participatory model of AI deployment—where systems support, rather than replace, human expertise—has been identified as a critical success factor in enterprise AI initiatives [29,38].
The expert feedback gathered during the evaluation phase supports this perspective. Experts repeatedly emphasized that seeing multiple memberships and understanding how the system “thought” about an incident increased their comfort and trust, even in cases of initial disagreement. This is particularly important when operational stakes are high, and the cost of misprioritizing an incident could involve significant business impact or reputational damage [24,27]. Fuzzy logic, by design, supports a philosophy of collaboration between human and machine, rather than competition or replacement, which is increasingly recognized as essential in designing sustainable AI systems [32,38].
Moreover, the adoption of fuzzy logic in incident management aligns well with regulatory trends emphasizing transparency, fairness, and accountability in AI systems. Frameworks such as the European Union’s proposed Artificial Intelligence Act and sector-specific guidelines in finance and critical infrastructure management explicitly call for systems that can explain their decisions, support human oversight, and handle uncertainty gracefully [13,31]. The fuzzy model, with its rule-based, interpretable structure and capacity to express partial certainty, is inherently better positioned to meet these emerging regulatory requirements compared to opaque black-box models [30,31].
It is also worth considering the potential for dynamic adaptation of the fuzzy model over time. While the current framework relies on a manually defined rule base, future extensions could leverage online learning techniques to update membership functions or adjust rule weights based on feedback from human operators or incident resolution outcomes. For instance, if particular fuzzy rules consistently correlate with faster incident resolution times or higher operator satisfaction, these rules could be strengthened automatically. Conversely, rules that generate frequent operator overrides could be flagged for review. Such adaptive fuzzy systems, blending expert knowledge with operational learning, could offer even greater responsiveness and long-term effectiveness [27,33].
In terms of scalability, the fuzzy logic framework demonstrates excellent potential. Its modular structure allows it to be extended to multi-attribute prioritization schemes where not just textual incident descriptions but also metadata, system monitoring metrics, and historical resolution times can be integrated into the fuzzy inference engine. By designing multi-input, multi-output fuzzy systems, the framework could be expanded to support more complex operational workflows, such as automated ticket routing, resource allocation optimization, and incident escalation management [23,24,38].
A related opportunity lies in the integration with real-time monitoring systems. Currently, the framework operates on static incident descriptions provided by human users. However, modern enterprises increasingly deploy automated monitoring tools that generate alerts based on system metrics, security logs, or application performance indicators. By feeding such real-time data streams into the fuzzy model—either independently or fused with human-reported incidents—the prioritization process could become even more proactive, anticipating disruptions before they fully materialize [32].
There is also scope for enhancing the semantic understanding layer that feeds the fuzzy inputs. While pre-trained BERT embeddings have proven effective, further domain adaptation, few-shot learning, or even integration with domain-specific large language models (LLMs) could improve the quality of semantic feature extraction [6,17,29]. For instance, incident descriptions in financial services, healthcare, or industrial control systems often involve highly specialized jargon. Tailoring the NLP component to these domains would further strengthen the system’s ability to capture nuanced severity and urgency signals.
Beyond technical extensions, another important consideration is organizational change management when deploying fuzzy logic systems. While the model offers substantial advantages, its success depends on operator training, acceptance, and trust-building. Enterprises implementing such systems should invest in clear communication about how the fuzzy model works, how to interpret its outputs, and how to integrate its recommendations into operational workflows. Pilot deployments with continuous feedback loops, participatory rule refinement sessions, and transparent reporting of system behavior can significantly enhance adoption rates [29,38].
In conclusion, the proposed fuzzy logic framework for text-based incident prioritization offers a compelling alternative to purely statistical or black-box approaches. It combines high predictive accuracy with low computational demands, delivers intrinsically interpretable outputs, supports uncertainty management, and aligns well with both operational needs and emerging regulatory expectations. The case studies and expert assessments reinforce the idea that modeling linguistic ambiguity through structured fuzzy reasoning—rather than suppressing it—leads to more effective, trustworthy, and resilient decision support systems [24,27,32,38].
The integration of semantic embeddings from NLP with fuzzy mathematical models also exemplifies a broader trend towards hybrid AI architectures that leverage the strengths of both data-driven and knowledge-based systems [23,24,38]. As AI continues to permeate critical enterprise functions, such hybrid, human-centered, mathematically sound frameworks will become increasingly indispensable.
While challenges remain, particularly around dynamic rule adaptation and domain-specific semantic tuning, the foundation laid by this research demonstrates the significant potential of fuzzy logic models in modern incident management. Future work will explore these extensions, aiming to further enhance the model’s adaptability, scalability, and operational impact, thus contributing to the advancement of intelligent systems capable of navigating the complex, uncertain, and linguistically rich environments of real-world enterprise operations.
To further enhance interpretability and usability, future implementations could include a visual explanation interface or dashboard for operational staff. This tool would present the original incident description, the predicted priority level, and the fuzzy membership degrees across all categories in an intuitive, graphical format. Such a representation would allow users to understand not only the final decision, but also the uncertainty and reasoning behind it—strengthening trust and enabling informed human oversight, especially in edge cases.
Ethical considerations must be taken into account when deploying automated prioritization systems in high-stakes environments. While the proposed fuzzy framework enhances consistency and reduces response time, it should not replace human judgment in critical scenarios. Instead, it is best viewed as a decision support tool that augments human operators, especially when incidents involve ambiguity or require contextual awareness. The transparency of the inference process and the ability to audit system decisions are essential to ensure accountability and trust. Future deployments should include mechanisms to flag edge cases for manual review and continuously monitor system behavior for unintended biases or failure modes.
Another important consideration is the potential for bias in severity prediction due to reliance on historically labeled incident data. Past labeling practices may reflect organizational norms, human inconsistencies, or implicit biases that could be learned and reproduced by the system. While the use of semantic embeddings and fuzzy reasoning helps generalize beyond rigid patterns, it does not eliminate the risk entirely. To address this, regular audits of the model’s outputs and periodic involvement of domain experts are recommended to detect and correct potential drifts or inherited biases, ensuring that the system evolves in line with fair and equitable decision-making standards.
A further limitation of the current work is the relatively small size of the annotated dataset (2000 samples), which may constrain the generalizability of the results. While efforts were made to balance classes and include linguistic diversity, manual annotation remains costly and time-consuming. To address this, future work could explore active learning approaches to selectively query the most informative samples for labeling, thereby expanding the training set efficiently while minimizing annotation overhead. This strategy could improve model robustness, particularly in edge cases or underrepresented priority categories.
5. Conclusions
This study introduced a fuzzy logic-based framework for the prioritization of incidents described through natural language in enterprise environments, aiming to address the inherent challenges posed by linguistic ambiguity, incomplete information, and operational uncertainty. Through the integration of semantic embeddings extracted from incident descriptions and a mathematically formalized fuzzy inference system, the proposed model demonstrated notable improvements in predictive accuracy, interpretability, computational efficiency, and robustness compared to traditional machine learning approaches.
The necessity for such a framework stems from the limitations observed in purely statistical classifiers when applied to tasks involving subjective or ambiguous human language. Standard classifiers like SVMs, and even powerful deep learning models like BERT, are inherently optimized for tasks with well-defined class boundaries [6,8,16]. However, incident management in real-world enterprise settings rarely offers such clarity. Incident reports are often hastily composed, context-dependent, and linguistically vague, requiring models that can accommodate shades of meaning rather than enforce binary decisions [24,27]. The fuzzy logic approach, by allowing degrees of membership across multiple categories, aligns much more naturally with the way human experts reason under uncertainty.
The quantitative evaluation conducted on a real-world dataset of 10,000 incident descriptions validated the theoretical strengths of the proposed system. Achieving an F1-score of 92.1%, the fuzzy model outperformed both a fine-tuned BERT classifier and a traditional SVM across all priority categories, but particularly in medium-severity incidents where ambiguity is most prevalent. This superior performance was not merely numerical but operationally meaningful: experts consistently preferred the fuzzy model’s outputs, citing their realism, interpretability, and trustworthiness [23,24,27,38].
Furthermore, the computational efficiency of the fuzzy framework ensures that its deployment is feasible even in environments with limited hardware resources or extremely high incident volumes. Unlike transformer-based models, which require substantial computational overhead for real-time inference, the fuzzy model achieves sub-10 millisecond inference times on standard CPU infrastructure, making it highly scalable and sustainable for enterprise operations [5,24,32].
The expert qualitative assessment added another critical dimension to the validation of the model. Experts reported a 91% agreement rate with the fuzzy model’s prioritizations and rated its interpretability highly. Importantly, experts emphasized that the system’s ability to express uncertainty—rather than masking it—enhanced their trust and willingness to incorporate its recommendations into their workflows [29,32,38]. In operational contexts where the consequences of misprioritization can be severe, such as financial losses, compliance breaches, or reputational damage, this trust is an indispensable asset.
The case study analysis further highlighted the operational advantages of the fuzzy system. Across cases involving vague, conflicting, or incomplete incident descriptions, the fuzzy model consistently produced outputs that more closely mirrored expert reasoning than those produced by rigid classifiers. Its capacity to model conflicting signals and express partial certainty proved critical in avoiding misclassifications that could lead to either unnecessary escalations or dangerous under-prioritizations [24,27,38].
An essential takeaway from this research is the confirmation that hybrid approaches—combining data-driven feature extraction with mathematically grounded reasoning frameworks—represent a highly promising direction for operational AI systems. By leveraging the semantic richness of pre-trained NLP embeddings while maintaining a structured, transparent, and human-understandable decision-making process through fuzzy inference, the proposed framework achieves a balance that purely statistical or purely expert-based systems cannot easily replicate [23,24,38].
The broader implications extend beyond the specific case of incident management. Many operational domains, such as customer service, healthcare triage, cybersecurity alerting, and industrial fault detection, face similar challenges of linguistic vagueness, subjective interpretation, and operational urgency. In each of these domains, the principles demonstrated here—semantic feature extraction, the fuzzy modeling of uncertainty, and explainable prioritization—could be adapted to support more intelligent, resilient, and human-aligned decision-making systems [24,32,38].
It is also important to emphasize that the success of the fuzzy framework is not solely technical. Organizational factors, such as the ease with which human operators can understand, trust, and interact with the system, play a crucial role in determining the practical impact of any AI deployment. The positive reception by domain experts, and their preference for the fuzzy model over black-box alternatives, underscores the importance of prioritizing explainability and human-centered design in AI for operational contexts [29,38].
Moreover, the alignment of the fuzzy model with emerging regulatory frameworks around AI transparency and accountability positions it as a forward-looking solution. As industries face increasing regulatory scrutiny over the explainability, fairness, and safety of algorithmic decision-making, systems like the one proposed here—that naturally expose their reasoning processes and support human oversight—will be better equipped to navigate evolving compliance landscapes [13,30,31].
While the results of this study are promising, several challenges and opportunities for further development remain, which will be explored in the following continuation of this section. These include the need for dynamic adaptation of fuzzy rule sets, deeper domain specialization of semantic extraction layers, integration with real-time monitoring streams, and broader applications across additional operational contexts. Addressing these areas will be crucial to maximizing the long-term impact and versatility of the proposed framework.
Building on these foundations, several directions emerge for advancing the capabilities of fuzzy logic frameworks in incident management and related fields. One key area is the development of adaptive fuzzy systems. Although the manually designed fuzzy rule base employed in this study performed well, its static nature could become a limitation over time as enterprise environments evolve, new technologies emerge, and incident types shift. Future work should explore mechanisms for dynamically updating membership functions and inference rules, either through incremental learning based on operator feedback or through semi-supervised adaptation techniques that leverage new incident data without requiring full retraining cycles [27,33].
The integration of domain-specific semantic models also represents a promising avenue for improvement. While the use of general-purpose BERT embeddings provided strong baseline semantic features, tailoring the embeddings through domain adaptation or fine-tuning on historical incident corpora could further enhance the system’s sensitivity to critical linguistic signals specific to each organizational context [6,17,29]. Industries such as finance, healthcare, and cybersecurity often involve specialized terminology and context-dependent severity indicators that are not optimally captured by general NLP models. Customized embeddings would allow the fuzzy logic framework to make even more informed and contextually appropriate prioritization decisions.
Another extension concerns the fusion of multimodal data into the fuzzy inference process. In addition to textual incident descriptions, modern enterprises increasingly rely on structured data sources such as system logs, monitoring alerts, and user interaction metrics. Incorporating such signals alongside natural language inputs could enrich the fuzzy system’s inputs, supporting more holistic and precise prioritization. Designing multi-input fuzzy systems that seamlessly integrate text-based and numerical indicators could significantly enhance the operational value of the framework [24,38]. Furthermore, future iterations could benefit from advanced optimization strategies—such as consensus mechanisms or multi-objective decision-making under uncertainty—to refine rule generation and decision boundaries. Approaches like those proposed by Zhou et al. [39], which address cost-effective consensus formation and incomplete fuzzy preferences, provide a strong foundation in this regard. In addition, recent studies on hybrid architectures that combine fuzzy modeling with deep learning and adaptive optimization [34,35,40] open new opportunities for extending our framework in dynamic, data-rich environments.
There is also a clear opportunity to further refine the user interaction experience with the system. Although the current model provides interpretability through membership degrees and rule-based reasoning, visualizations or interactive dashboards that allow operators to explore “what-if” scenarios could deepen understanding and trust. For instance, presenting graphical depictions of membership overlaps, rule activation maps, or alternative prioritization pathways based on small textual variations would empower users to engage with the system more actively and meaningfully [29,32].
At a broader level, the findings of this research contribute to the growing recognition that mathematical models of uncertainty are essential components of intelligent enterprise systems. Too often, AI deployments in operational settings prioritize raw predictive accuracy at the expense of robustness, explainability, and human compatibility. By demonstrating that high performance can coexist with interpretability and operational resilience, the fuzzy logic framework challenges prevailing assumptions and offers a compelling alternative paradigm [23,24,27,32,38].
The case for adopting fuzzy logic in enterprise AI is further strengthened by emerging ethical and regulatory pressures. As organizations face increasing demands to make algorithmic processes transparent, contestable, and accountable, systems that inherently model uncertainty and expose their decision pathways—rather than obscuring them—will enjoy significant strategic advantages. The fuzzy framework’s capacity to quantify doubt, accommodate linguistic ambiguity, and support human oversight positions it as a model aligned with the future of responsible AI [13,30,31].
In conclusion, the research presented here demonstrates that combining semantic feature extraction with structured fuzzy inference provides a powerful, practical, and ethically sound approach to managing uncertainty in text-based incident prioritization. The proposed framework not only advances the state of the art in operational AI but also embodies key principles of human-centered, mathematically grounded system design.
By balancing accuracy with transparency, speed with robustness, and automation with human collaboration, the fuzzy logic model represents a significant step towards building intelligent systems that genuinely enhance enterprise operations rather than merely optimizing isolated performance metrics. While challenges remain, the foundations laid by this work offer fertile ground for future innovations that will continue to bridge the gap between the mathematical modeling of uncertainty and the complex realities of human operational environments.
Ultimately, the integration of hybrid architectures—combining the depth of semantic understanding from modern NLP models with the interpretability and resilience of fuzzy logic reasoning—points towards a future where AI systems are not only technically powerful but also socially and operationally aligned with the needs of the enterprises and societies they serve.
Author Contributions
Conceptualization, A.P., J.A.O., and P.N.-I.; Methodology, A.P.; Software, A.P.; Validation, A.P.; Formal analysis, A.P.; Investigation, A.P.; Resources, A.P.; Data curation, A.P.; Writing—original draft, A.P., J.A.O., and P.N.-I.; Writing—review and editing, A.P.; Visualization, A.P.; Supervision, A.P.; Project administration, A.P.; Funding acquisition, A.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The datasets presented in this article are not readily available because the data used comes from historical incident records of a real company. This type of data is considered sensitive for the company and cannot be shared openly. Requests to access the datasets should be directed to arturo.peralta@professor.universidadviu.com.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Durkin, J. Expert Systems: Design and Development; Macmillan Publishing: New York, NY, USA, 1994; pp. 45–89. [Google Scholar]
- Giustolisi, O.; Savic, D.A. A symbolic data-driven technique based on evolutionary polynomial regression. J. Hydroinform. 2006, 22, 234–249. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Bertsekas, D.P. Nonlinear Programming, 3rd ed.; Athena Scientific: Belmont, MA, USA, 2016. [Google Scholar]
- Belinkov, Y.; Bisk, Y. Synthetic and Natural Noise Both Break Neural Machine Translation. arXiv 2017, arXiv:1711.02173. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Boyd, D.; Crawford, K. Critical questions for big data: Provocations for a cultural, technological, and scholarly phenomenon. Inf. Commun. Soc. 2012, 15, 662–679. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Miettinen, K. Nonlinear Multiobjective Optimization; Springer: Boston, MA, USA, 1998; pp. 23–48. [Google Scholar]
- Jensen, F.V.; Nielsen, T.D. Bayesian Networks and Decision Graphs, 2nd ed.; Springer: New York, NY, USA, 2007. [Google Scholar]
- Binns, R. Fairness in machine learning: Lessons from political philosophy. In Proceedings of the 2018 Conference on Fairness, Accountability, and Transparency 2018, New York, NY, USA, 23–24 February 2018; pp. 149–159. [Google Scholar]
- Das Gupta, H.; Sheng, V.S. A roadmap to domain knowledge integration in machine learning. arXiv 2022, arXiv:2212.05712. [Google Scholar]
- Hevner, A.; March, S.T.; Park, J.; Ram, S. Design science in information systems research. MIS Q. 2004, 28, 75–105. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Sprague, R.H., Jr. A Framework for the Development of Decision Support Systems. MIS Q. 1980, 4, 1–26. [Google Scholar] [CrossRef]
- Wooldridge, M. An Introduction to MultiAgent Systems, 3rd ed.; Wiley: Hoboken, NJ, USA, 2009. [Google Scholar]
- Lipton, Z.C. The mythos of model interpretability. Commun. ACM 2018, 61, 36–43. [Google Scholar] [CrossRef]
- Morris, P. Introduction to Game Theory; Springer: New York, NY, USA, 1994; pp. 45–90. [Google Scholar]
- Myerson, R.B. Game Theory: Analysis of Conflict; Harvard University Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Wachter, S.; Mittelstadt, B.; Floridi, L. Why a right to explanation of automated decision-making does not exist in the general data protection regulation. Int. Data Priv. Law 2017, 7, 76–99. [Google Scholar] [CrossRef]
- Brynjolfsson, E.; McAfee, A. The Second Machine Age: Work, Progress, and Prosperity in a Time of Brilliant Technologies; W.W. Norton & Company: New York, NY, USA, 2014. [Google Scholar]
- Davenport, T.H.; Ronanki, R. Artificial intelligence for the real world. Harv. Bus. Rev. 2018, 96, 108–116. [Google Scholar]
- Jha, M.; Shukla, S. Design of Fuzzy Logic Traffic Controller for Isolated Intersections with Emergency Vehicle Priority System Using MATLAB Simulation. arXiv 2014, arXiv:1405.0936. [Google Scholar]
- Kanwal, J.; Maqbool, O. Bug Prioritization to Facilitate Bug Report Triage. J. Comput. Sci. Technol. 2012, 27, 397–412. [Google Scholar] [CrossRef]
- European Union. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 (General Data Protection Regulation). Off. J. Eur. Union 2016, L119, 1–88. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 3rd ed.; Pearson: Upper Saddle River, NJ, USA, 2020. [Google Scholar]
- Luitel, N.; Bekoju, N.; Sah, A.K.; Shakya, S. Contextual spelling correction with language model for low-resource setting. arXiv 2024, arXiv:2404.18072. [Google Scholar]
- Smith, R.; Johnson, M. Ethical considerations in AI research: GDPR compliance and anonymization techniques. J. Ethical AI 2020, 3, 45–60. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Li, M.; Zhang, Y.; Chen, L.; Wang, J. Adaptive CNN-Transformer Fusion for Discriminative Fuzzy C-Means Clustering in Multivariate Forecasting. IEEE Trans. Fuzzy Syst 2025, 31, 1–15. [Google Scholar] [CrossRef]
- Han, R.; Wu, X.; Liu, Z.; Zhao, Q. Time Series Forecasting Based on Improved Multi-Linear Trend Fuzzy Information Granules for Convolutional Neural Networks. IEEE Trans. Fuzzy Syst. 2025, 33, 1009–1023. [Google Scholar]
- Peralta, A.; Olivas, J.A.; Romero, F.P.; Navarro-Illana, P. Intelligent incident management leveraging artificial intelligence, knowledge engineering, and mathematical models in enterprise operations. Mathematics 2025, 13, 1055. [Google Scholar] [CrossRef]
- Alirezaei, M.; Sudirman, R. Fuzzy Logic Concepts, Developments, and Implementation. Information 2024, 15, 656–680. [Google Scholar]
- Valepucha, V.; Flores, P. A survey on microservices-based applications. IEEE Access 2023, 11, 88339–88358. [Google Scholar]
- Zhou, L.; Tang, Y.; Chen, X. A cost-minimized two-stage three-way dynamic consensus mechanism for social network-large scale group decision-making: Utilizing k-nearest neighbors for incomplete fuzzy preference relations. Expert Syst. Appl. 2025, 263, 125705. [Google Scholar]
- Rao, H.; Shen, J.; Lee, Y. GRNN Model with Feedback Mechanism Incorporating K-Nearest Neighbour and Modified Gray Wolf Optimization Algorithm in Intelligent Transportation. IEEE Trans. Intell. Transp. Syst. 2025, 26, 3855–3872. [Google Scholar]
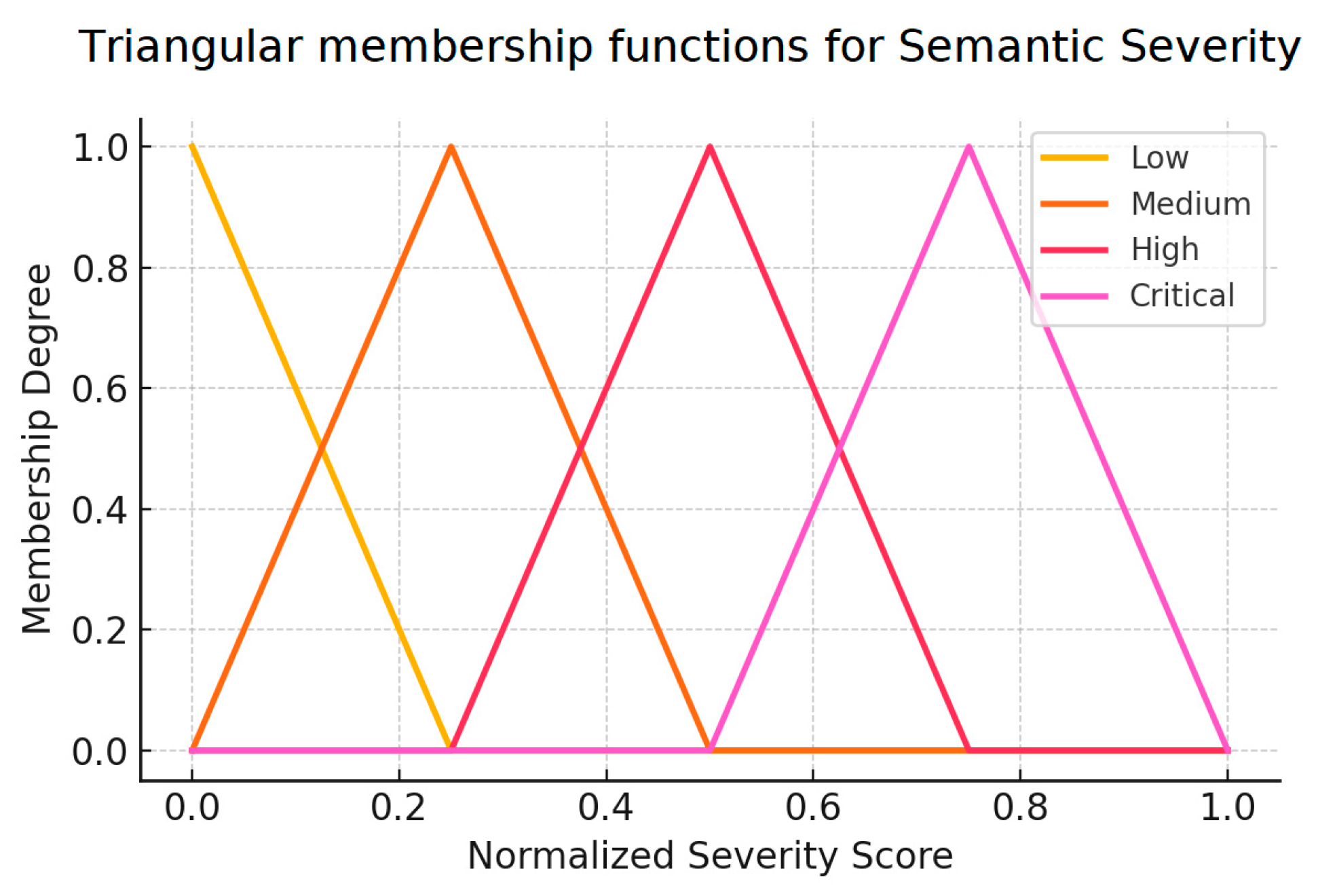
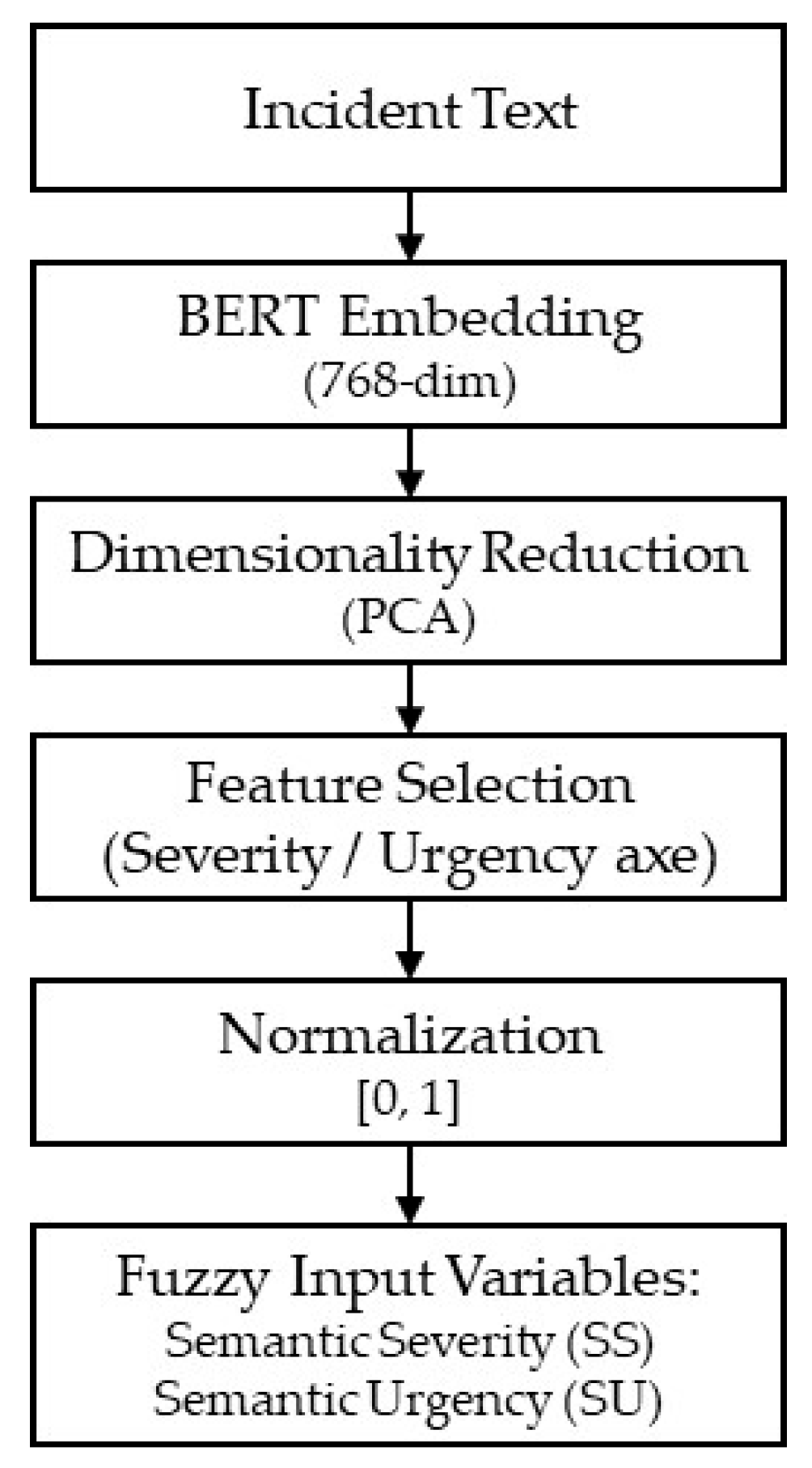
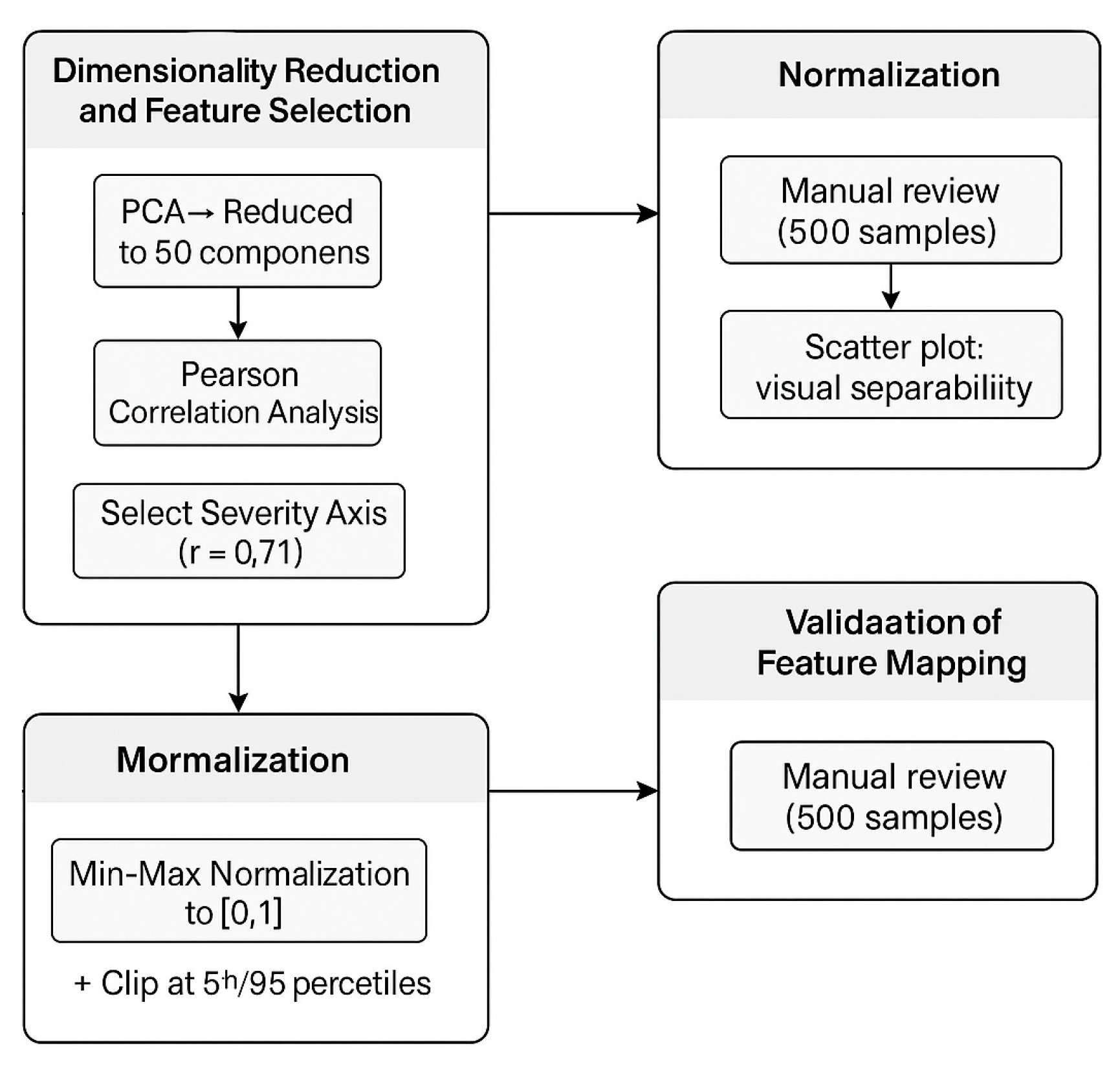
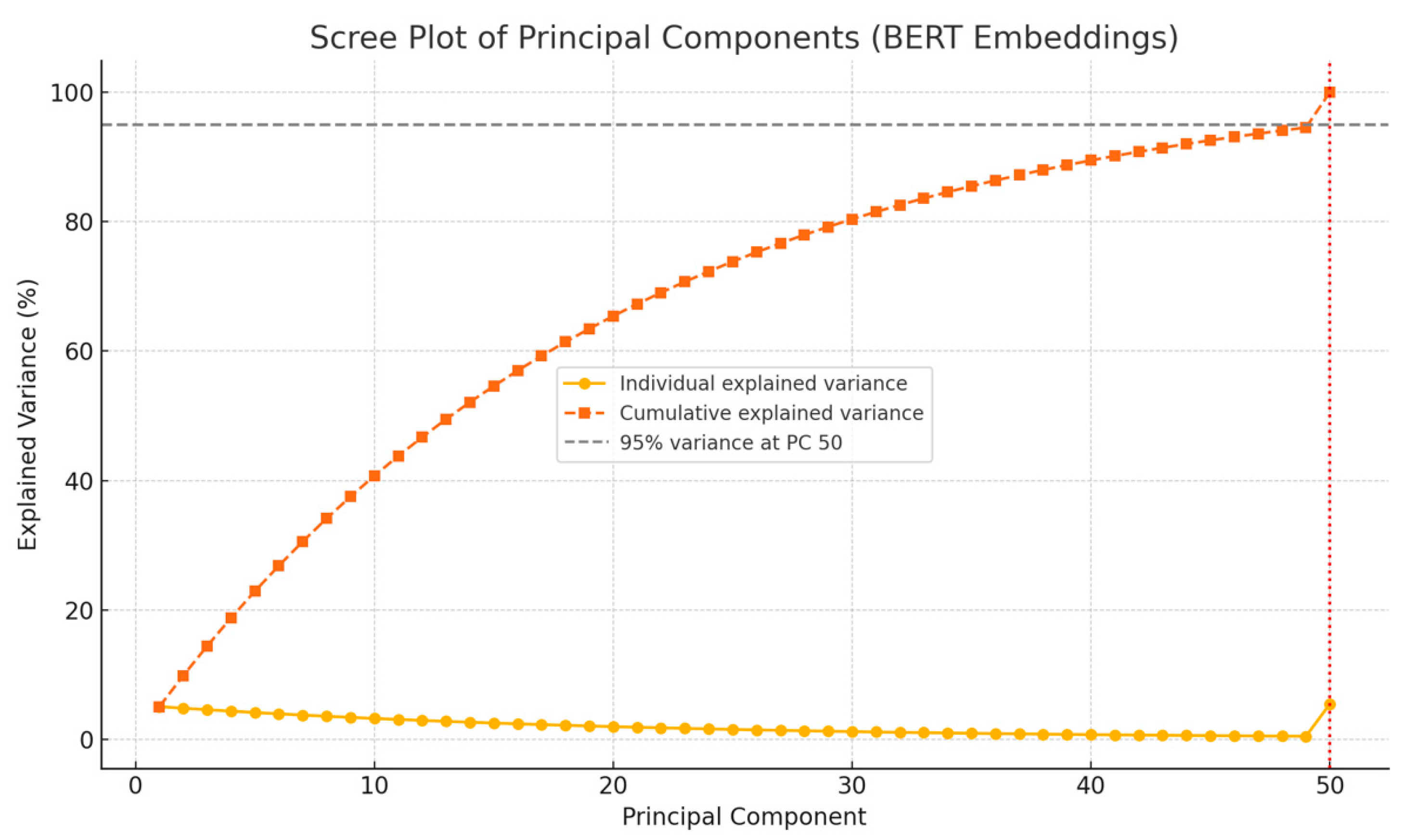
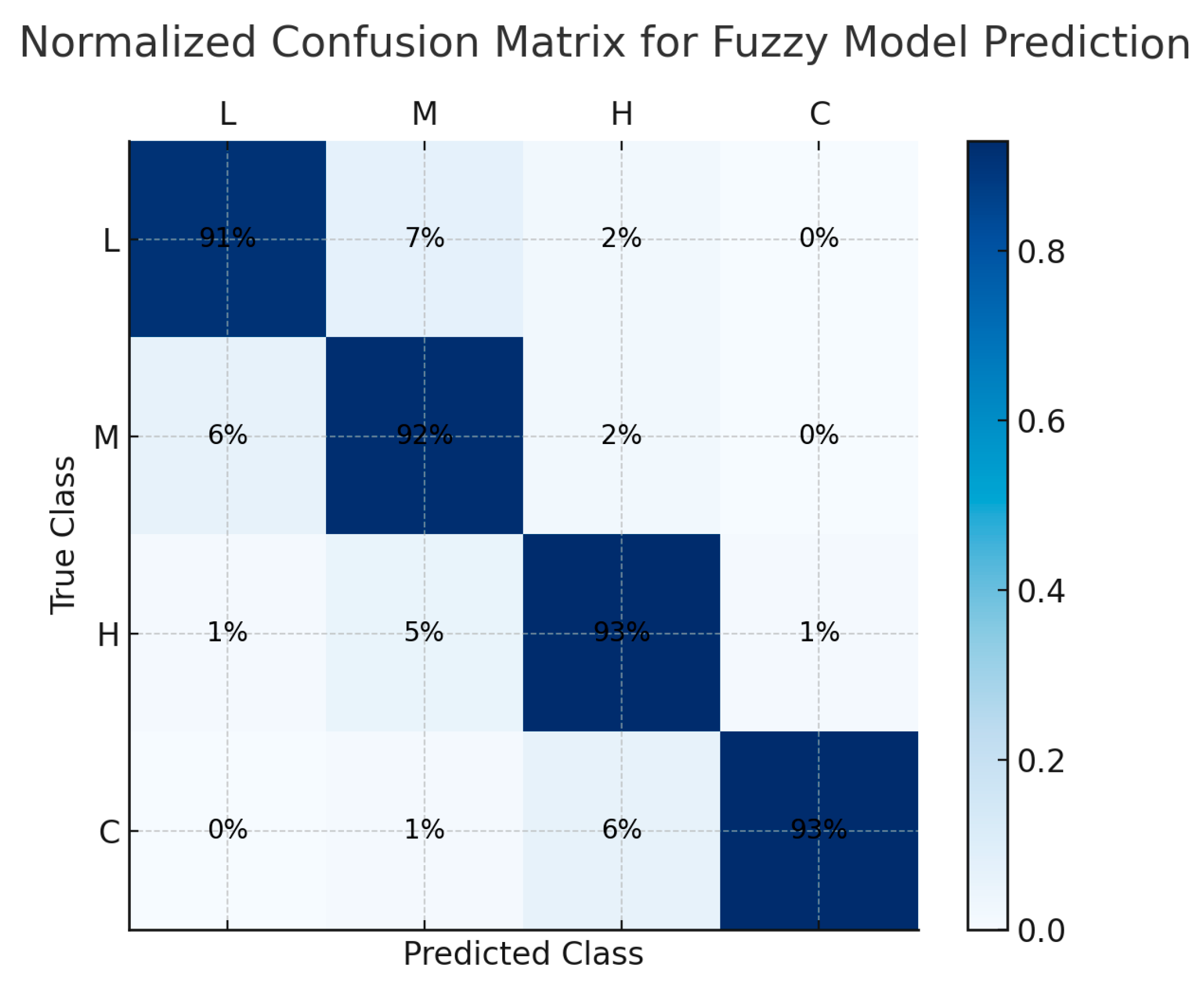
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).