
Improved Fuel Consumption Estimation for Sailing Speed Optimization: Eliminating Log Transformation Bias




Abstract
1. Introduction
- We provide a theoretical analysis that rigorously demonstrates the mathematical limitations of logarithmic transformation when applied to OLS estimation, revealing its inherent biases and restricted applicability in nonlinear settings.
- We propose two novel estimation approaches that directly optimize the original OLS objective function without resorting to transformation techniques, thereby offering more robust and interpretable parameter estimates.
- We apply the proposed methods to a structured SSO problem, where comprehensive numerical experiments validate their superior fitting accuracy and improved reliability in downstream decision-making tasks.
2. Literature Review
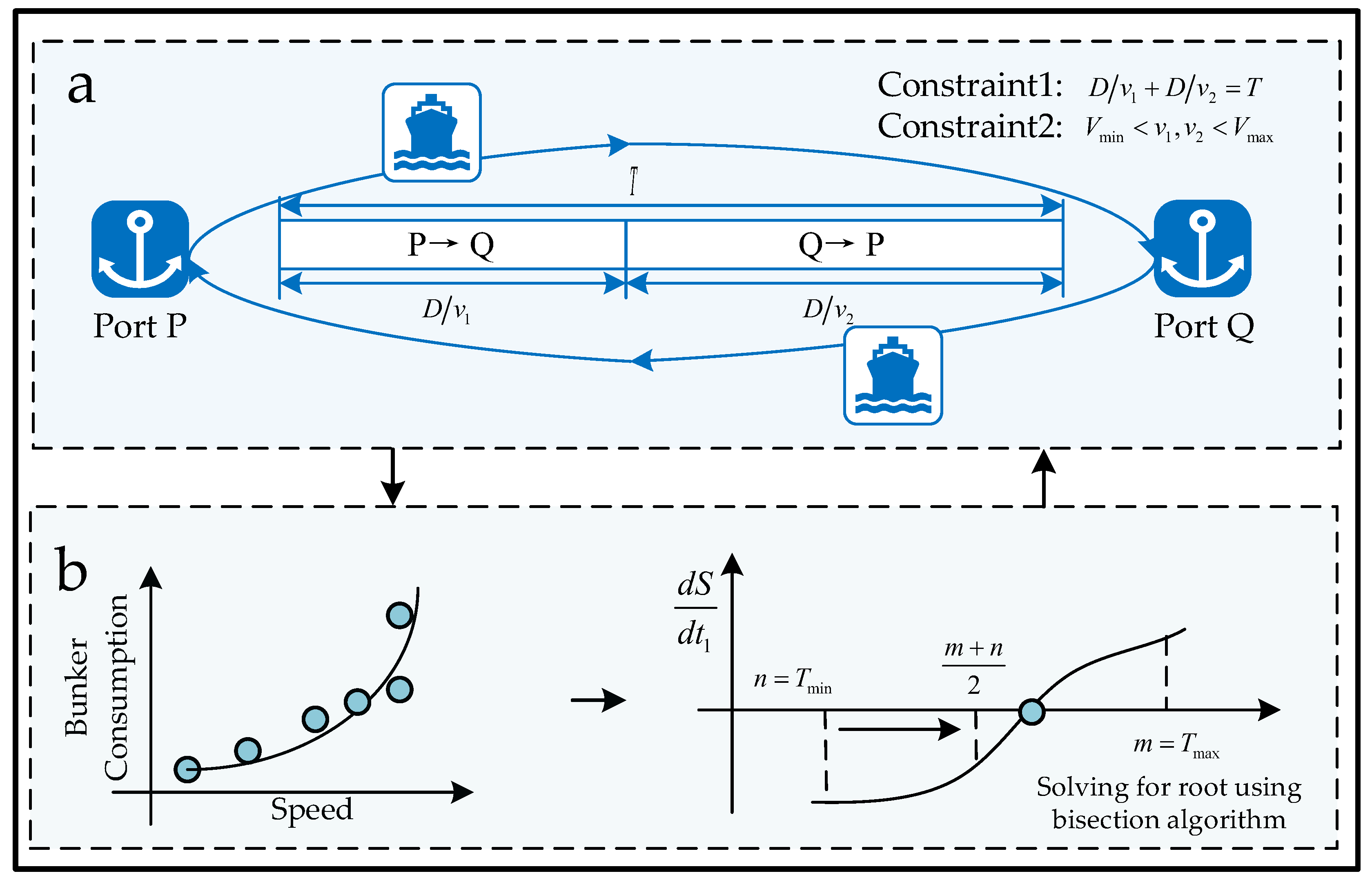
3. Problem Formulation and Algorithm Design
3.1. Sailing Speed Optimization Model
3.2. Solving the SSO Model
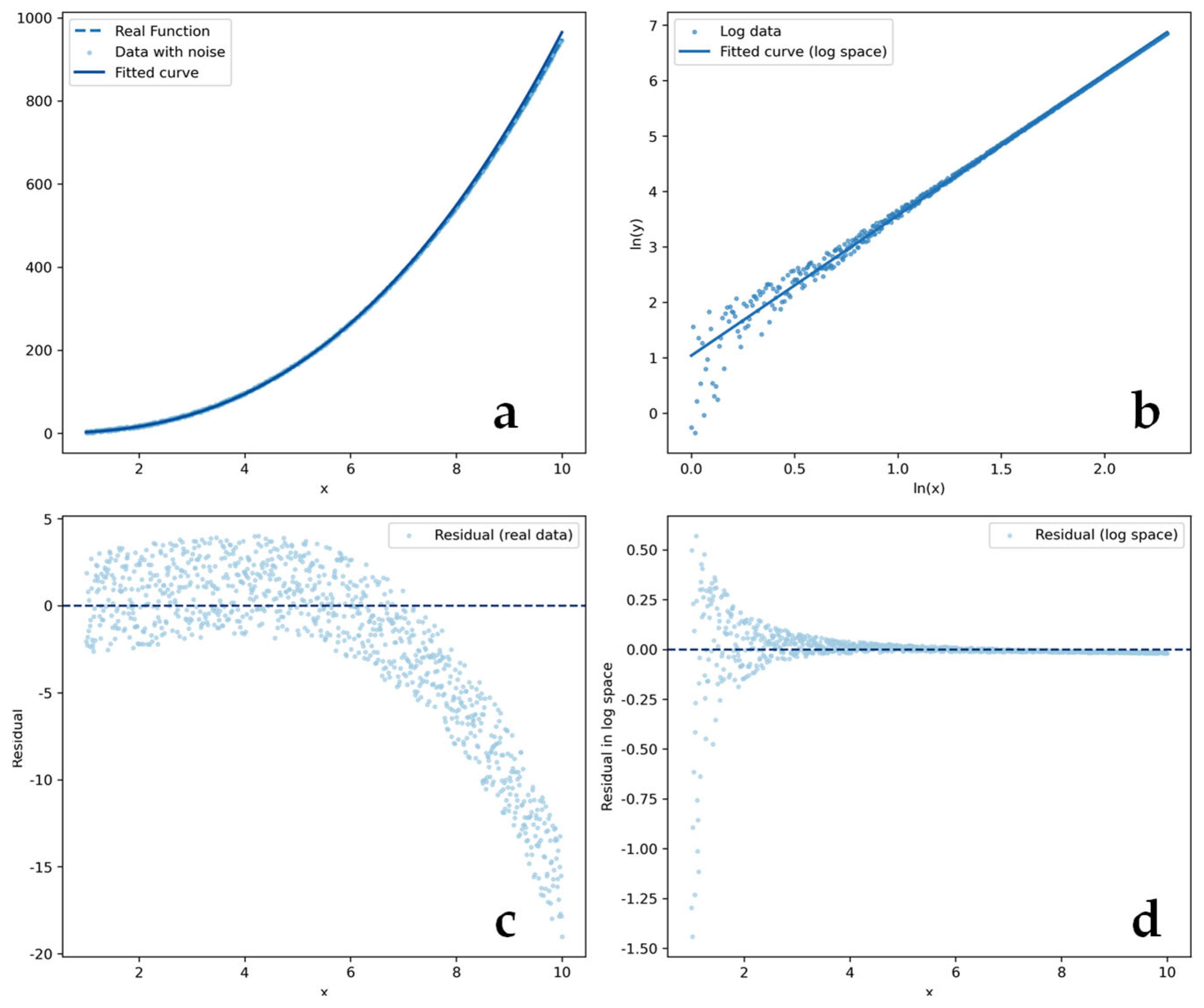
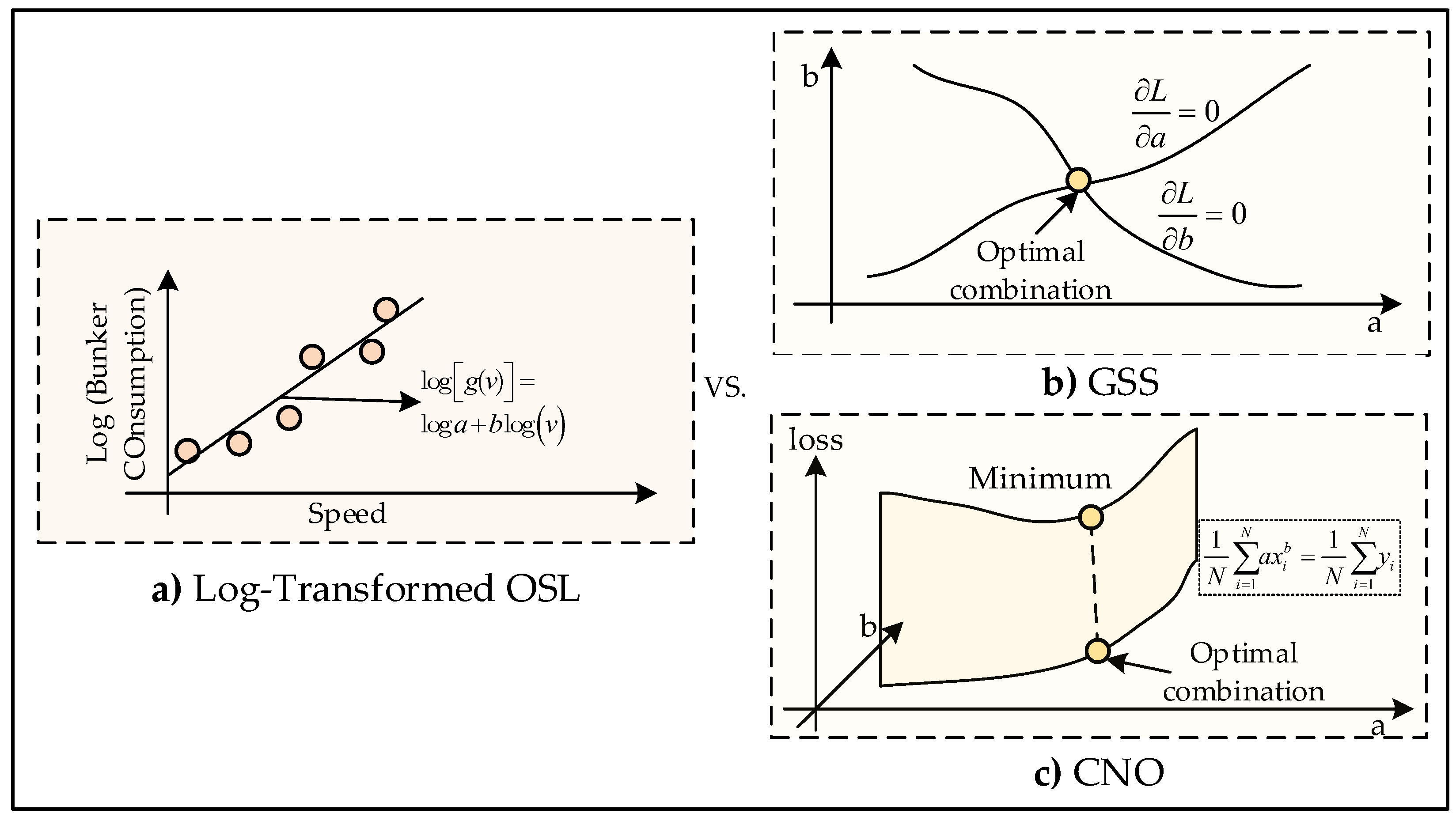
4. Limitations of Logarithmic Transformation and Direct Estimation Methods
4.1. Limitations of Log Transformation
4.2. Direct Estimation Methods
4.3. Computational Cost Analysis
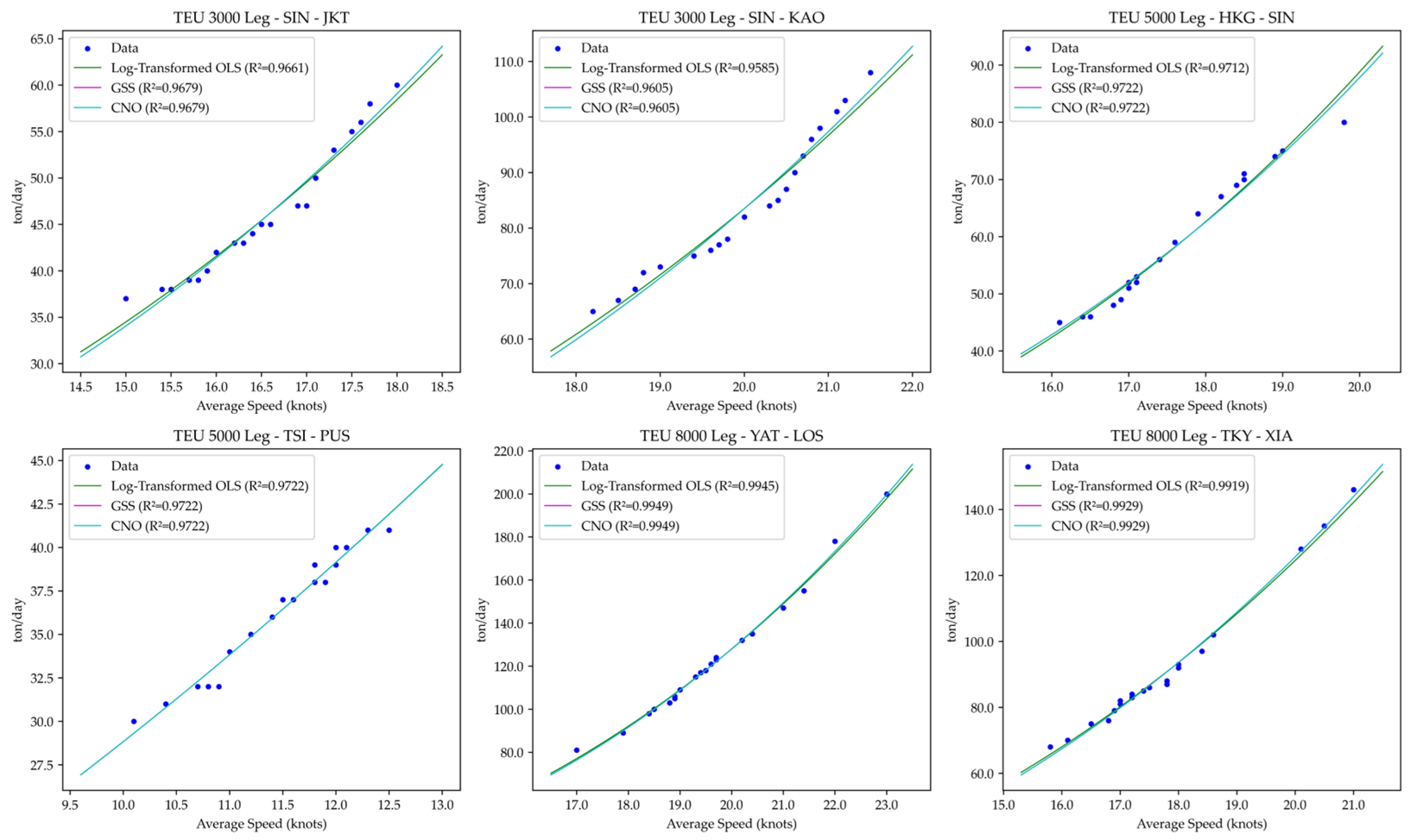
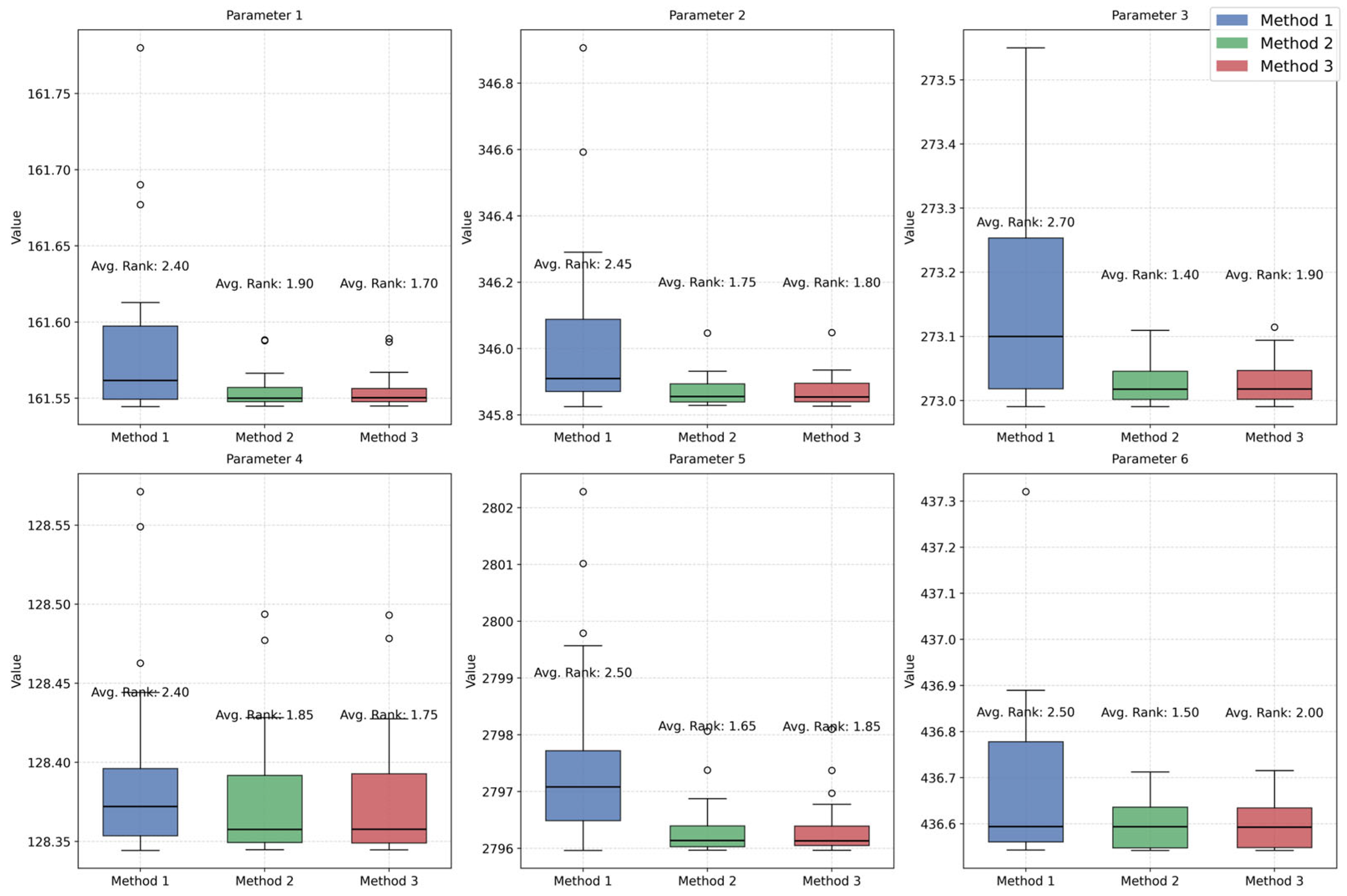
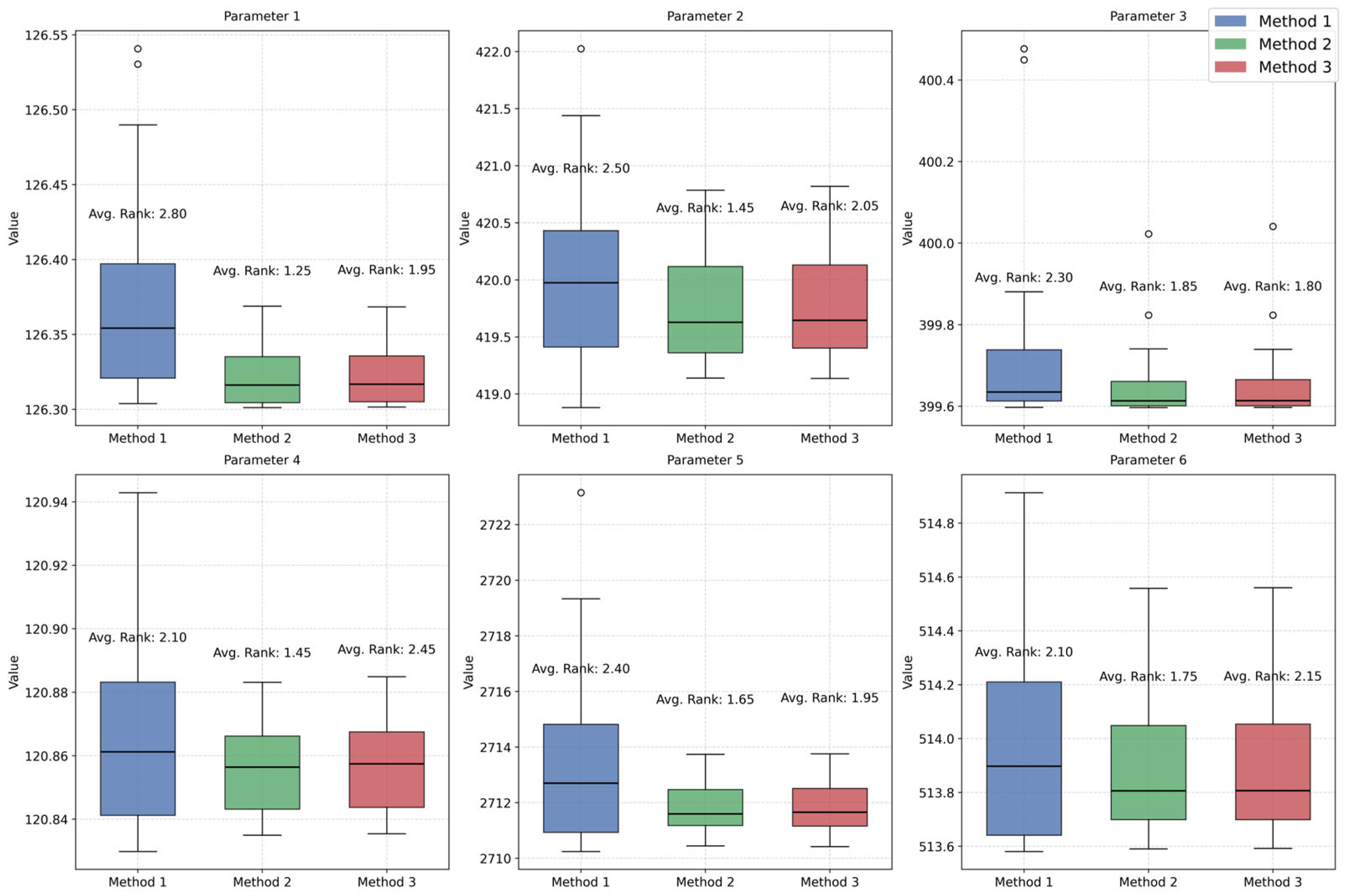
5. Case Study
5.1. Estimation Results Using Real-World Data
5.2. Experimental Procedure
5.3. Well-Specified and Mis-Specified Experiments
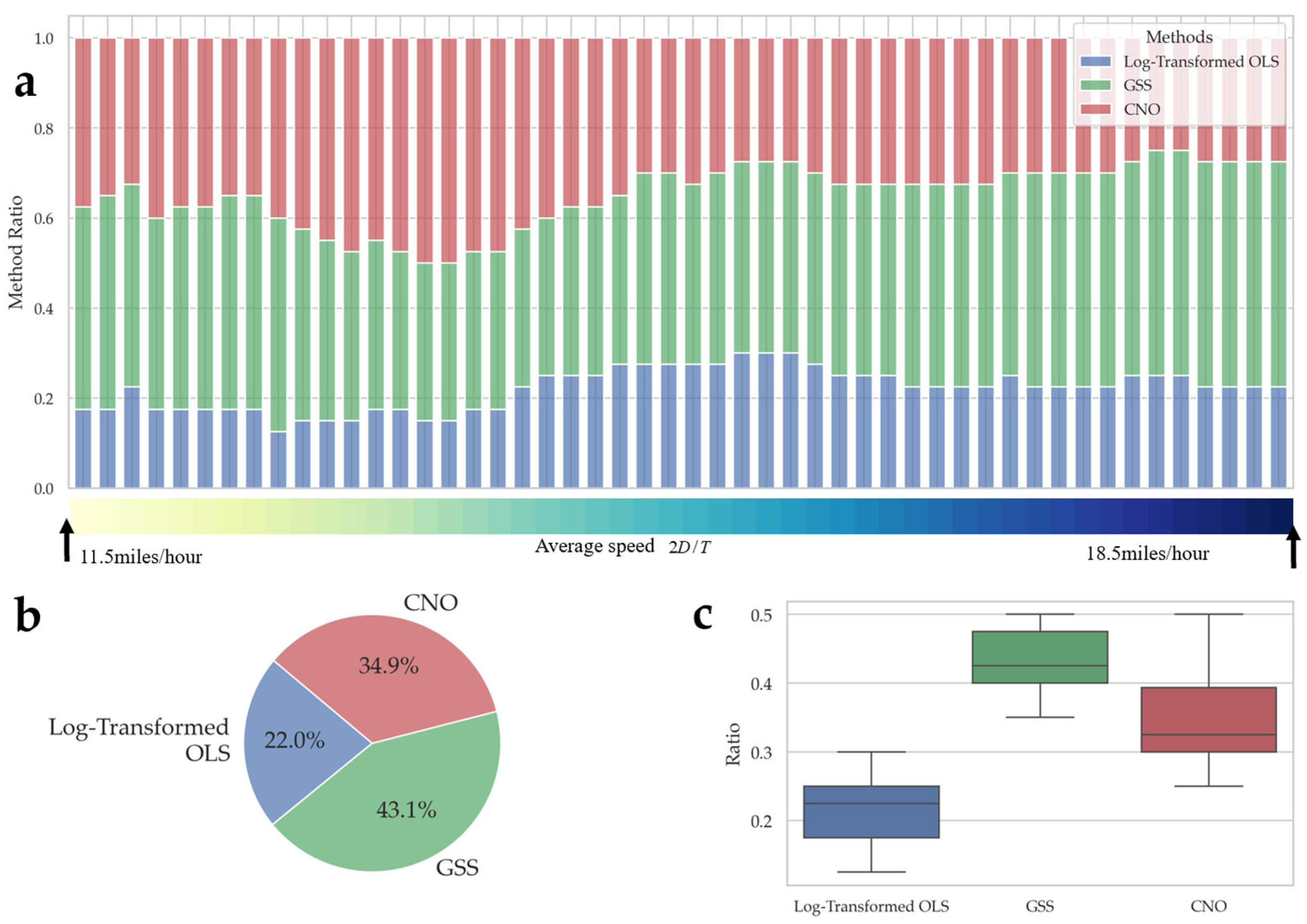
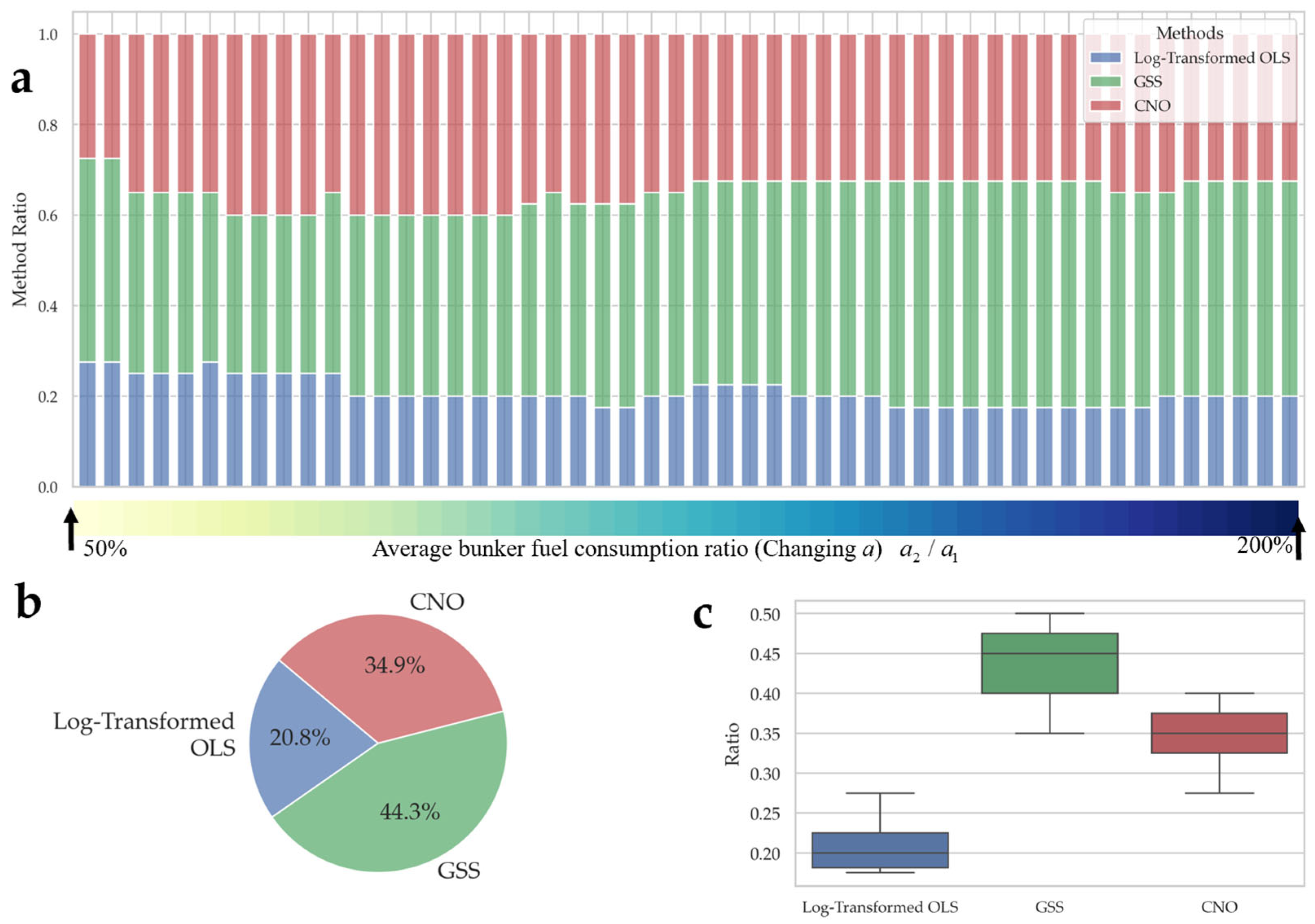
5.4. Sensitivity Analysis: Voyage Speed and Fuel Consumption Asymmetry
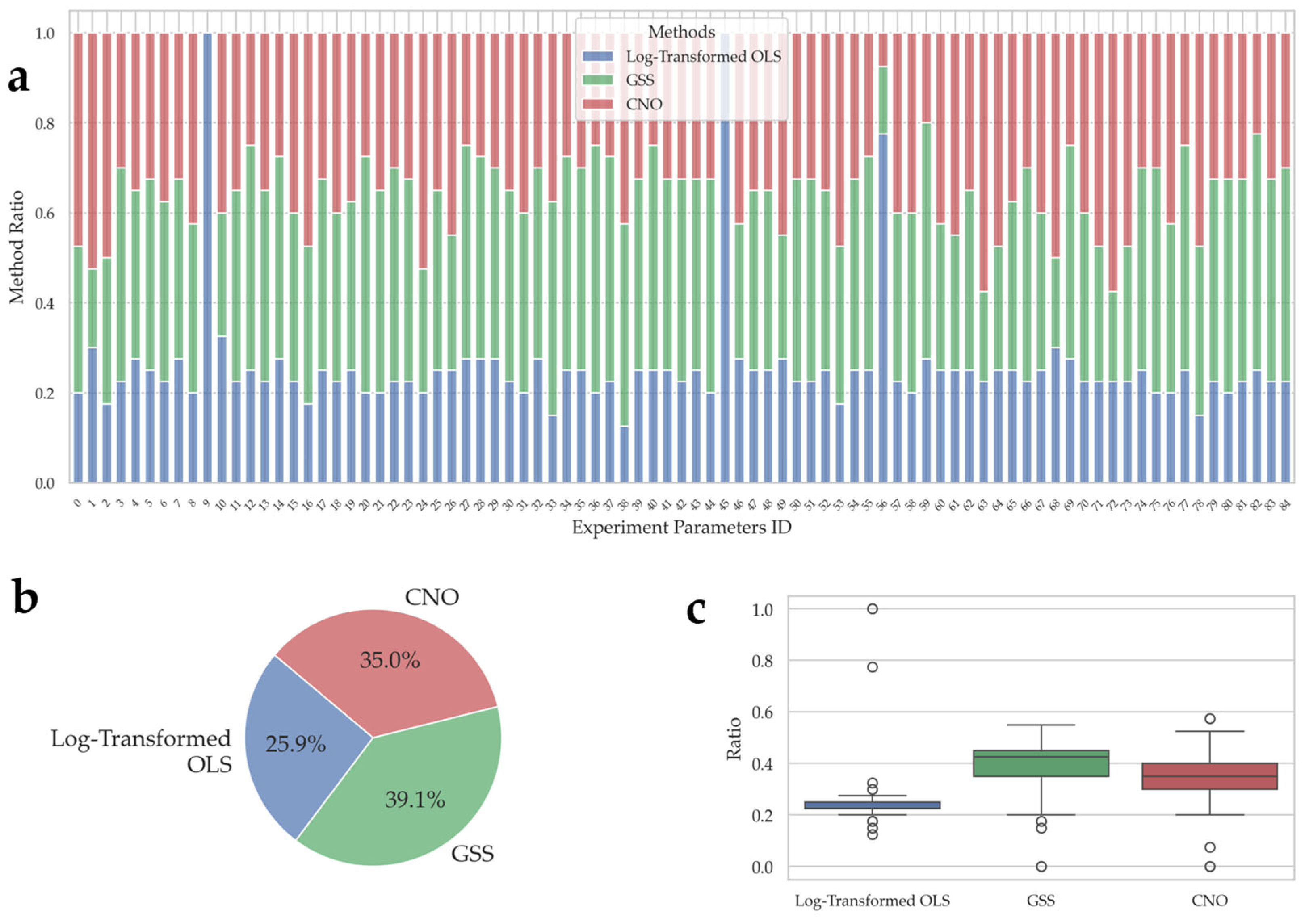
5.5. More Diverse Computational Experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yao, Z.; Ng, S.H.; Lee, L.H. A Study on Bunker Fuel Management for the Shipping Liner Services. Comput. Oper. Res. 2012, 39, 1160–1172. [Google Scholar] [CrossRef]
- Ronen, D. The Effect of Oil Price on the Optimal Speed of Ships. J. Oper. Res. Soc. 1982, 33, 1035–1040. [Google Scholar] [CrossRef]
- Ronen, D. Ship Scheduling: The Last Decade. Eur. J. Oper. Res. 1993, 71, 325–333. [Google Scholar] [CrossRef]
- International Maritime Organization. Fourth IMO Greenhouse Gas Study 2020; International Maritime Organization: London, UK, 2020. [Google Scholar]
- Meng, Q.; Du, Y.; Wang, Y. Shipping Log Data Based Container Ship Fuel Efficiency Modeling. Transp. Res. Part B Methodol. 2016, 83, 207–229. [Google Scholar] [CrossRef]
- Saki, S.; Soori, M. Artificial Intelligence, Machine Learning and Deep Learning in Advanced Transportation Systems, A Review. Multimodal Transp. 2025, 100242. [Google Scholar] [CrossRef]
- Coto-Solano, M.E. Demand Study of Freight Transportation via Railway of Four Commodity Groups: A Case Study on Costa Rica’s Pacific Coast Route. Multimodal Transp. 2024, 3, 100157. [Google Scholar] [CrossRef]
- Vorkapić, A.; Martinčić-Ipšić, S.; Piltaver, R. Interpretable Machine Learning: A Case Study on Predicting Fuel Consumption in VLGC Ship Propulsion. J. Mar. Sci. Eng. 2024, 12, 1849. [Google Scholar] [CrossRef]
- Liu, Z.; Lyu, C.; Huo, J.; Wang, S.; Chen, J. Gaussian Process Regression for Transportation System Estimation and Prediction Problems: The Deformation and a Hat Kernel. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22331–22342. [Google Scholar] [CrossRef]
- Fagerholt, K.; Laporte, G.; Norstad, I. Reducing Fuel Emissions by Optimizing Speed on Shipping Routes. J. Oper. Res. Soc. 2010, 61, 523–529. [Google Scholar] [CrossRef]
- Kim, J.-G.; Kim, H.-J.; Jun, H.B.; Kim, C.-M. Optimizing Ship Speed to Minimize Total Fuel Consumption with Multiple Time Windows. Math. Probl. Eng. 2016, 2016, 3130291. [Google Scholar] [CrossRef]
- Wang, S.; Meng, Q. Sailing Speed Optimization for Container Ships in a Liner Shipping Network. Transp. Res. Part E Logist. Transp. Rev. 2012, 48, 701–714. [Google Scholar] [CrossRef]
- Elmachtoub, A.N.; Grigas, P. Smart “Predict, Then Optimize”. Manag. Sci. 2022, 68, 9–26. [Google Scholar] [CrossRef]
- Donti, P.; Amos, B.; Kolter, J.Z. Task-Based End-to-End Model Learning in Stochastic Optimization. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Ban, G.-Y.; Rudin, C. The Big Data Newsvendor: Practical Insights from Machine Learning. Oper. Res. 2019, 67, 90–108. [Google Scholar] [CrossRef]
- Yang, L.; Chen, G.; Zhao, J.; Rytter, N.G.M. Ship Speed Optimization Considering Ocean Currents to Enhance Environmental Sustainability in Maritime Shipping. Sustainability 2020, 12, 3649. [Google Scholar] [CrossRef]
- Lai, X.; Wu, L.; Wang, K.; Wang, F. Robust Ship Fleet Deployment with Shipping Revenue Management. Transp. Res. Part B Methodol. 2022, 161, 169–196. [Google Scholar] [CrossRef]
- Tarelko, W.; Rudzki, K. Applying Artificial Neural Networks for Modelling Ship Speed and Fuel Consumption. Neural Comput. Appl. 2020, 32, 17379–17395. [Google Scholar] [CrossRef]
- Du, Y.; Meng, Q.; Wang, S.; Kuang, H. Two-Phase Optimal Solutions for Ship Speed and Trim Optimization over a Voyage Using Voyage Report Data. Transp. Res. Part B Methodol. 2019, 122, 88–114. [Google Scholar] [CrossRef]
- Le, L.T.; Lee, G.; Park, K.-S.; Kim, H. Neural Network-Based Fuel Consumption Estimation for Container Ships in Korea. Marit. Policy Manag. 2020, 47, 615–632. [Google Scholar] [CrossRef]
- Yan, R.; Wang, S.; Du, Y. Development of a Two-Stage Ship Fuel Consumption Prediction and Reduction Model for a Dry Bulk Ship. Transp. Res. Part E Logist. Transp. Rev. 2020, 138, 101930. [Google Scholar] [CrossRef]
- Uyanık, T.; Bakar, N.N.A.; Kalenderli, Ö.; Arslanoğlu, Y.; Guerrero, J.M.; Lashab, A. A Data-Driven Approach for Generator Load Prediction in Shipboard Microgrid: The Chemical Tanker Case Study. Energies 2023, 16, 5092. [Google Scholar] [CrossRef]
- Shangguan, Y.; Tian, X.; Jin, S.; Gao, K.; Hu, X.; Yi, W.; Guo, Y.; Wang, S. On the Fundamental Diagram for Freeway Traffic: Exploring the Lower Bound of the Fitting Error and Correcting the Generalized Linear Regression Models. Mathematics 2023, 11, 3460. [Google Scholar] [CrossRef]
- Atkinson, K.E. An Introduction to Numerical Analysis; John Wiley & Sons: New York, NY, USA, 2008. [Google Scholar]
- Hansen, B. Econometrics; Princeton University Press: Princeton, NJ, USA, 2022. [Google Scholar]
- McKay, M.D.; Beckman, R.J.; Conover, W.J. A Comparison of Three Methods for Selecting Values of Input Variables in the Analysis of Output from a Computer Code. Technometrics 2000, 42, 55–61. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Method Type | Modeling Approach and Application |
|---|---|---|
| Fagerholt et al. (2010) [10] | Physics-based | Power-law function and nonlinear model for segment-wise optimal sailing speed |
| Yao et al. (2012) [1] | Physics-based | Empirical speed–fuel formulas by ship size for joint bunkering and speed optimization |
| Wang and Meng (2012) [12] | Physics-based | Mixed-integer nonlinear programming for speed optimization of multiple vessels in liner networks |
| Kim et al. (2016) [11] | Physics-based | Exact solution method for segment-wise optimal sailing speed |
| Du et al. (2019) [19] | Machine Learning | Artificial neural network-based two-phase approach for speed optimization using noon report data |
| Tarelko and Rudzki (2020) [18] | Physics-based | Artificial neural networks for bi-objective optimization (fuel consumption vs. speed) |
| Le et al. (2020) [20] | Machine Learning | Multilayer perceptron and regression models for fuel consumption prediction |
| Yan et al. (2020) [21] | Machine Learning | Random forest for fuel consumption prediction and speed optimization |
| Uyanik et al. (2023) [22] | Machine Learning | Develop decision tree model and neural network model to predict ship fuel consumption |
| Input: Define Using Equation(11), Total Schedule Time , Interval , Tolerance , and . | |
| Output: The optimal value . | |
| 1 | Set , and as the initial upper and lower bounds |
| 2 | If : (i.e., a root does not exist in the interval) |
| 3 | If : |
| 4 | Return = |
| 5 | Else: |
| 6 | Return = |
| 7 | Else: (i.e., a root exists in the interval) |
| 8 | While True: |
| 9 | Compute midpoint . |
| 10 | Compute . |
| 11 | If or : |
| 12 | Return = , End while loop. |
| 13 | Else if , |
| 14 | Set . |
| 15 | Else: |
| 16 | Set . |
| 17 | Output: Return as the approximate root. |
| No. | (Nautical Miles) | (Hours) | ||||
|---|---|---|---|---|---|---|
| 1 | 0.015 | 2.90 | 0.013 | 3.10 | 500 | 60 |
| 2 | 0.010 | 3.00 | 0.012 | 2.80 | 1600 | 180 |
| 3 | 0.005 | 3.10 | 0.008 | 3.00 | 1420 | 160 |
| 4 | 0.600 | 1.67 | 0.550 | 1.75 | 480 | 85 |
| 5 | 0.010 | 3.20 | 0.012 | 3.10 | 6500 | 660 |
| 6 | 0.030 | 2.70 | 0.025 | 2.80 | 1300 | 150 |
| No. | (Nautical Miles) | (Hours) | ||||
|---|---|---|---|---|---|---|
| 1 | 2.24 | 0.185 | 2.20 | 0.190 | 500 | 60 |
| 2 | 3.40 | 0.160 | 3.60 | 0.150 | 1600 | 180 |
| 3 | 2.55 | 0.178 | 2.45 | 0.180 | 1420 | 160 |
| 4 | 6.67 | 0.148 | 6.75 | 0.140 | 480 | 85 |
| 5 | 5.70 | 0.155 | 5.55 | 0.160 | 6500 | 660 |
| 6 | 6.30 | 0.150 | 6.45 | 0.145 | 1300 | 150 |
| Parameter | Condition |
|---|---|
| Interval of and | |
| Interval of and | |
| Interval of | |
| Interval of | |
| Average speed restriction | |
| Bunker consumption difference restriction |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, Q.; Tian, X.; Jin, Y.; Liu, Z.; Wang, S. Improved Fuel Consumption Estimation for Sailing Speed Optimization: Eliminating Log Transformation Bias. Mathematics 2025, 13, 1987. https://doi.org/10.3390/math13121987
Hong Q, Tian X, Jin Y, Liu Z, Wang S. Improved Fuel Consumption Estimation for Sailing Speed Optimization: Eliminating Log Transformation Bias. Mathematics. 2025; 13(12):1987. https://doi.org/10.3390/math13121987
Chicago/Turabian StyleHong, Qi, Xuecheng Tian, Yong Jin, Zhiyuan Liu, and Shuaian Wang. 2025. "Improved Fuel Consumption Estimation for Sailing Speed Optimization: Eliminating Log Transformation Bias" Mathematics 13, no. 12: 1987. https://doi.org/10.3390/math13121987
APA StyleHong, Q., Tian, X., Jin, Y., Liu, Z., & Wang, S. (2025). Improved Fuel Consumption Estimation for Sailing Speed Optimization: Eliminating Log Transformation Bias. Mathematics, 13(12), 1987. https://doi.org/10.3390/math13121987