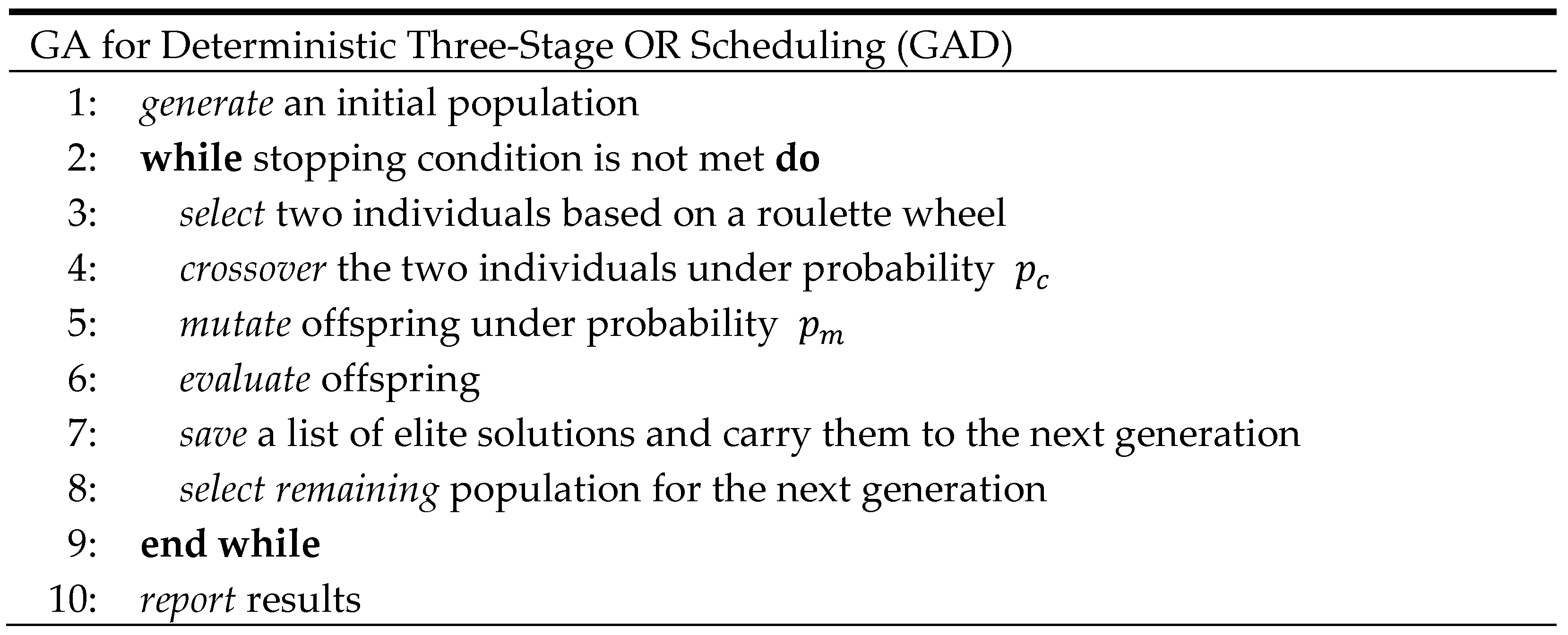
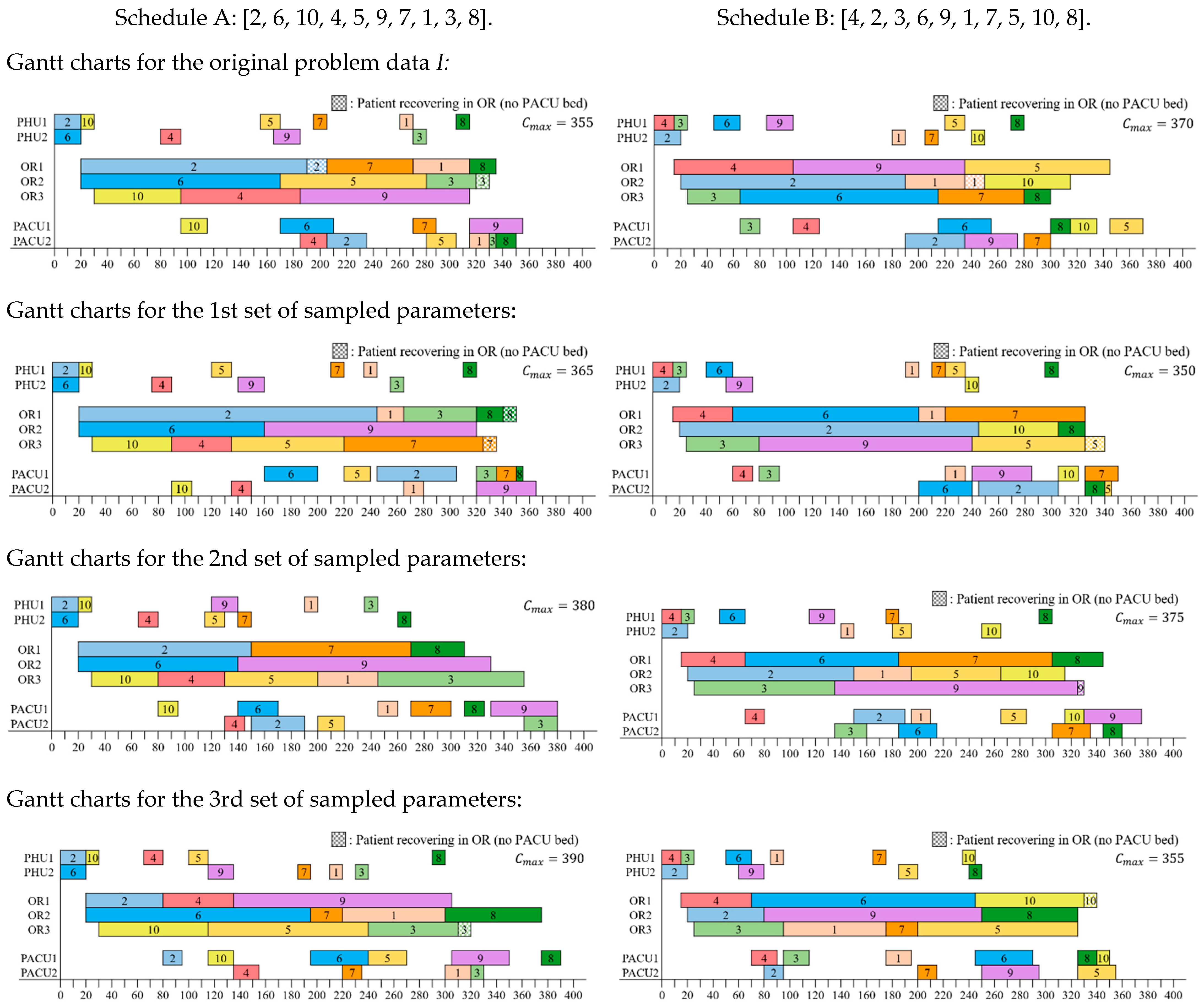
In this section, the performance of the GAD and the GARS are evaluated by randomly generated problem instances. The GAD and GARS were implemented using the Python 3.12 programming language and executed on a computer equipped with an Intel Core “i7-12700” CPU running at 2.1 GHz, along with 16 GB of RAM. We used the same data set reported in the work of [
33] to determine the durations (
) for deterministic surgeries. The data set can be found at
https://sites.google.com/view/oedx/data (
Supplementary Materials accessed on 11 June 2025). The data was generated based on [
39] study, which covers five types of surgeries: small (S), medium (M), large (L), extra-large (E), and special (SE). We used the notation normal (μ,
) to represent a random number generated from a normal distribution with a mean μ and a variance
. The durations of pre-surgery are generated from normal (8, 2). The duration of surgeries for the five types can be represented as follows: small (33, 15), medium (86, 17), large (153, 17), E-large (213, 17), and special (316, 62). The durations of post-surgery are generated from normal (28, 17). The unit of surgery duration is minutes. Moreover, [
33] examined four different test cases. In Case 1, they analyzed a scenario involving 10 surgeries: 2 small, 6 medium, 1 large, and 1 E-large. This case included two PHU beds, three ORs, and two PACU beds. In Case 2, they investigated a situation with 15 surgeries: 3 small, 9 medium, 2 large, and 1 E-large. This configuration encompassed three PHU beds, four ORs, and three PACU beds. Case 3 encompassed 20 surgeries: 4 small, 12 medium, 3 large, and 1 E-large, with three PHU beds, four ORs, and four PACU beds. Lastly, Case 4 entailed 30 surgeries: 7 small, 18 medium, 3 large, 1 E-large, and 1 special, with four PHU beds, five ORs, and five PACU beds.
5.1. The Experimental Approach
We generate a set of sampled problem data for uncertain data and use the GARS with a robust evaluation function to obtain a robust schedule. Let
be the deterministic duration of surgery
j on stage
i. For each surgery, surgery duration and post-surgery duration are uniformly generated from
, where
I is the original problem data and
is used to express the degree of uncertainty of the surgery durations.
was set to 0.25, 0.5, and 0.75. Next, a robust evaluation function (Formula (4)) is applied to evaluate the sequence
’s performance on a set of sampled problem data. Each sequence
has been evaluated a fixed number of times (
L) and each time on newly sampled problem data. After evaluating multiple instances, the evaluations are averaged to obtain the value of the robust evaluation function. Last, the GARS finds a robust schedule that optimizes the robust evaluation function.
Table 4 shows the parameters associated with the robust evaluation function. For each combination of a test case,
, and
, 10 randomly generated problem instances were generated and tested.
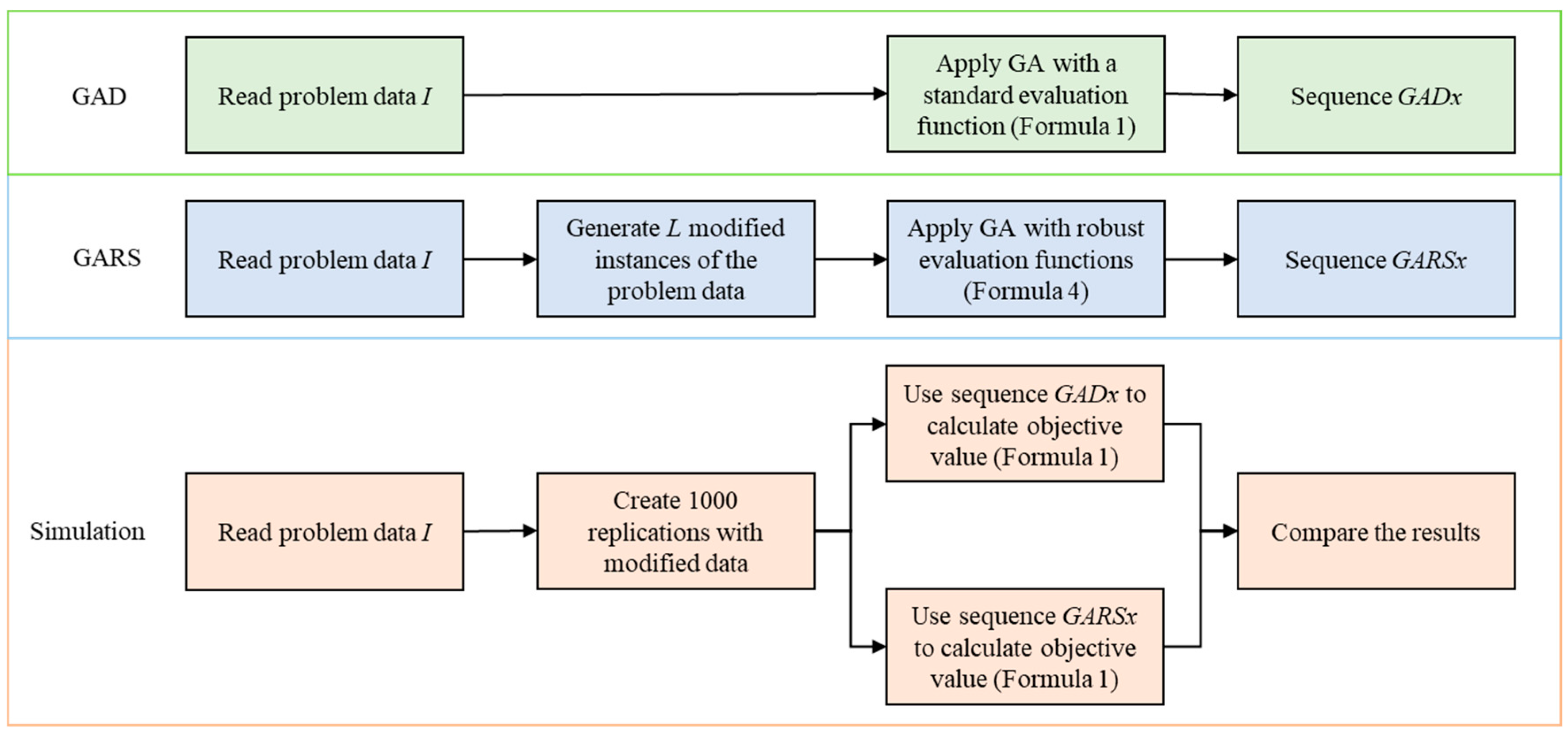
Moreover, the performance of the proposed algorithm is evaluated using a simulation procedure similar to the one employed by [
38]. We first run the GAD on the original problem data
I using the standard evaluation functions (Formula (1)). The results obtained are called sequence
. Next, we run the GARS on sampled problem data
using the robust evaluation function (Formula (4)). The results obtained are called sequence
. Once these two sequences are obtained, 1000 replications of the problem instances with randomly modified problem data from
I according to the degree of disturbances are carried out to simulate the two obtained sequences.
Figure 6 shows the simulation procedure of two GAs.
In addition to GAD and GARS, three alternative algorithms were implemented for comparison. All these algorithms aim to find robust schedules by utilizing the same robust evaluation function used in GARS:
- (1)
GARS with Simulated Annealing (GARS_SA): To examine the effect of local search integration, we include GARS_SA as one of the comparison algorithms. This algorithm enhances GARS by incorporating an SA procedure aimed at intensifying the search around elite solutions. The main evolutionary structure of GARS—encoding, selection, crossover, mutation, elite list management, and robust evaluation—remains unchanged. In GARS_SA, when the number of generations without improvement exceeds a predefined threshold (MaxNoImprove = 30), a local SA procedure is applied to each solution in the elite list. If any improvement is achieved, the evolutionary process resumes with the updated population; otherwise, the algorithm terminates early. Instead of using the original MaxNoImprove value of 218 as in GARS, we use 30 in GARS_SA to trigger the SA part more frequently during the evolutionary search. This design allows GARS_SA to balance global exploration and local exploitation more dynamically, especially under uncertain conditions. The SA procedure alternates between random insertion and random swap operators to explore the neighborhood of elite solutions. Key parameter settings follow those used in GARS, with SA-specific values provided in
Appendix A.
- (2)
Baseline Random Search (BRS): This algorithm continuously generates random schedules and updates the best-so-far solution if the newly generated one achieves a better value under the robust evaluation function. The process continues until the test time limit is reached.
- (3)
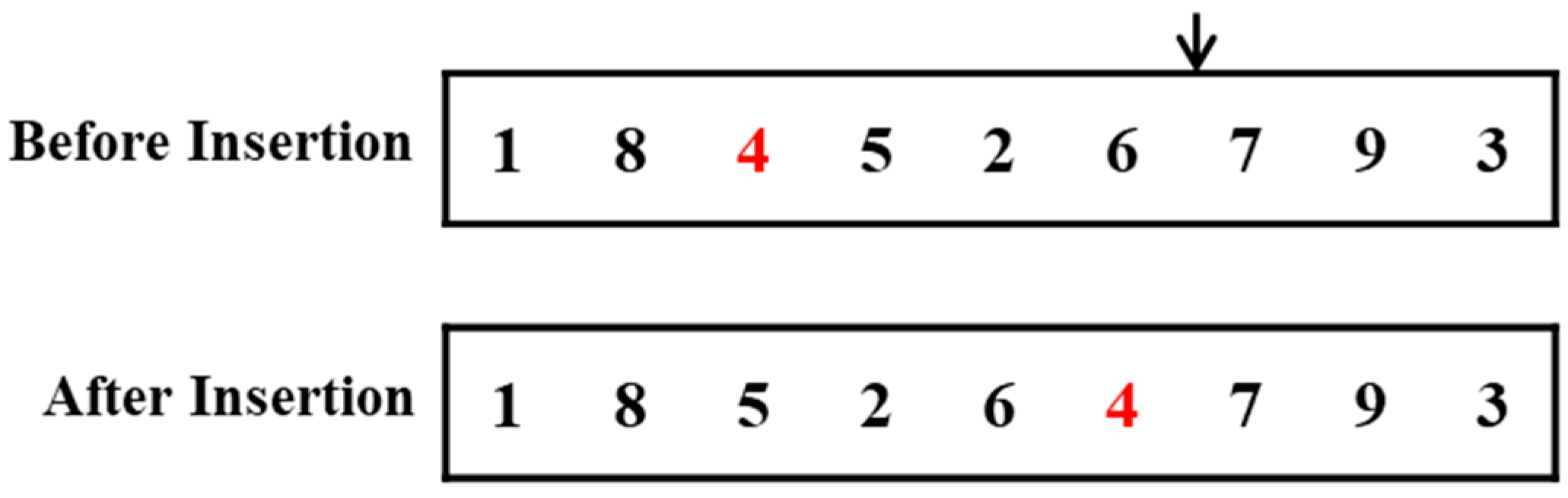
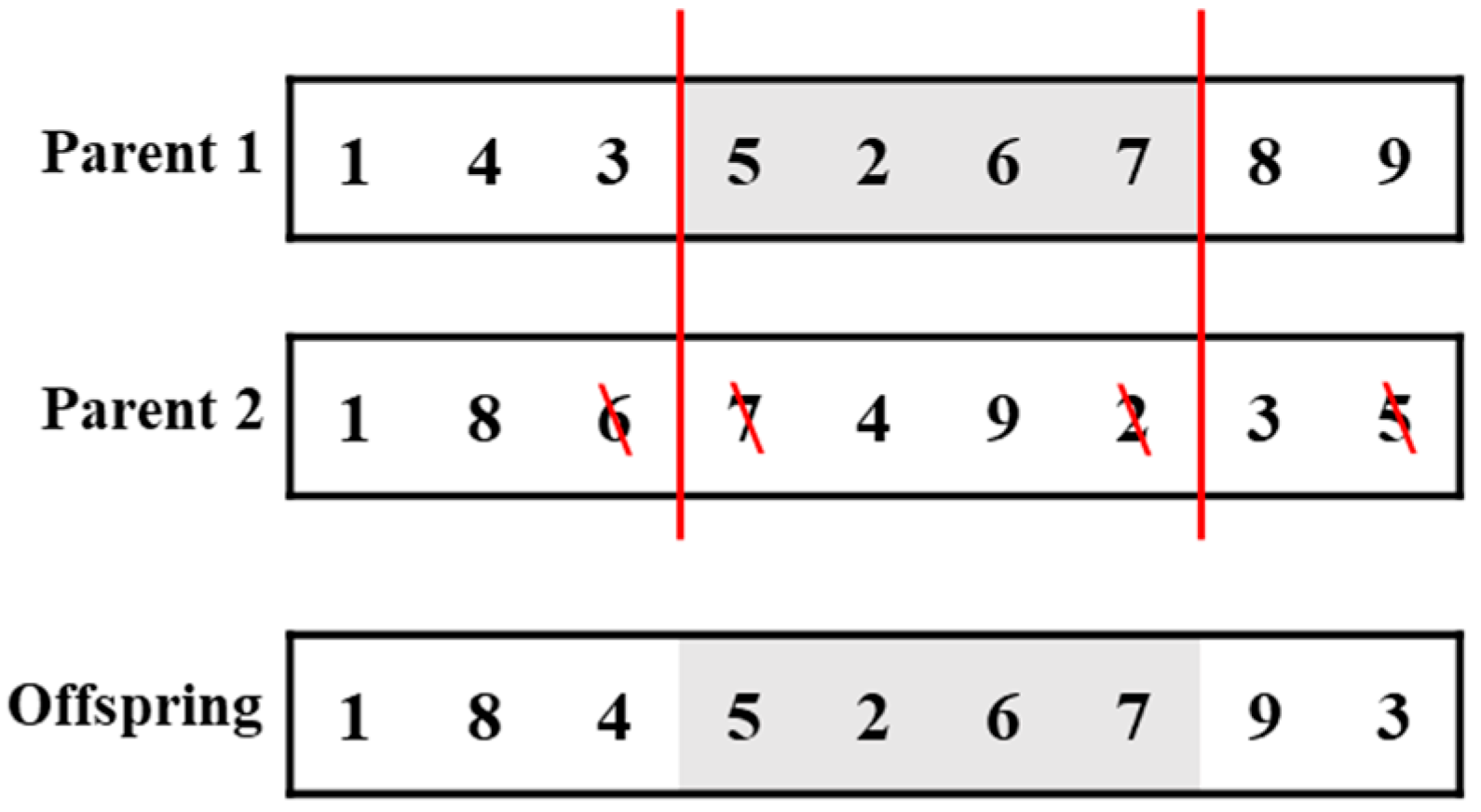
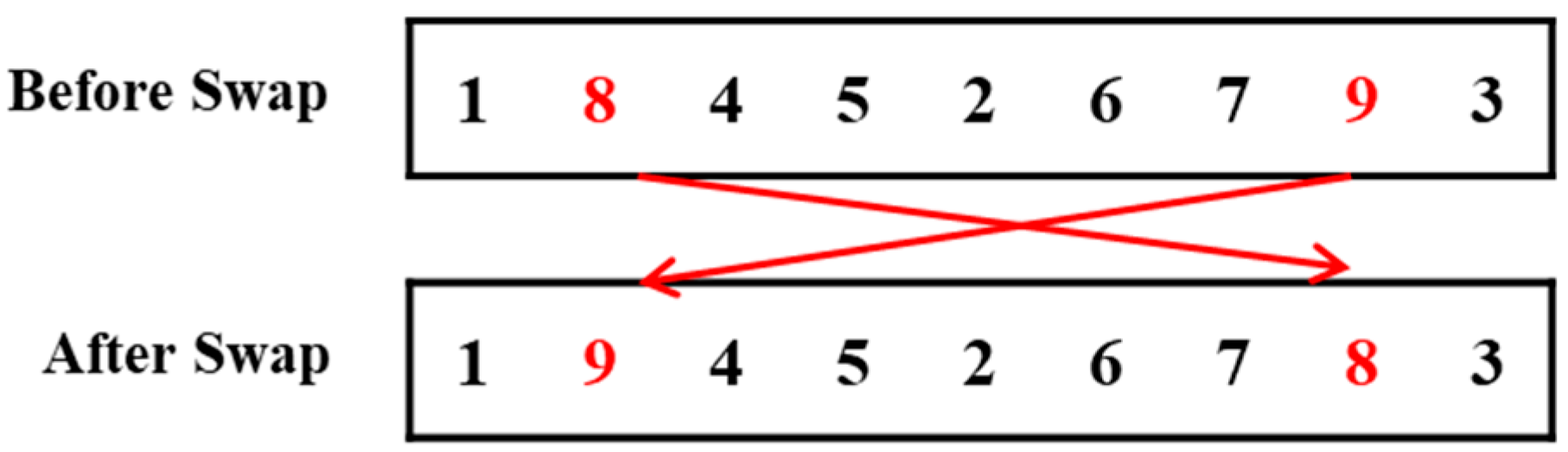
Greedy Randomized Insertion and Swap (GRIS): In this algorithm, an initial schedule generated by LPT is adopted. During the search process, random insertion and random swap operations (
Figure A1 and
Figure 2) are alternated to explore new solutions. A new solution replaces the current one only if it leads to a better robust evaluation value. The search stops when the testing time ends.
These algorithms are designed to provide baseline or hybrid strategies for robust scheduling and serve as a benchmark to evaluate the effectiveness of the proposed GARS.
5.2. Experimental Results and Analysis
For comparison purposes, all three GA-based algorithms (GAD, GARS, and GARS_SA) use the same parameters as specified in the parameter settings in
Section 4. We begin by presenting the results for Case 4, which involves the largest problem instances (30 surgeries) and represents the most challenging scenario. The degree of uncertainty
is set to 0.5; other
values yield similar results. Except for GAD, which requires only 2.94 s on average to complete, all other algorithms are terminated after 200 s of computation time. The computational results are presented in
Table 5.
We begin by comparing the performance of the five algorithms on the original (deterministic) problem data. As shown in
Table 5, GAD outperforms the other four algorithms in terms of both
and computational time, as it is mainly designed to solve the deterministic problem. Ranked from second to fifth in terms of performance are GRIS, GARS_SA, GARS, and BRS. The average
values are 610.20, 618.44, 619.11, 622.23, and 641.60 for GAD, GRIS, GARS_SA, GARS, and BRS, respectively. Furthermore, we compare the GAD with a lower bound (LB). The LB proposed by [
40] for minimizing the makespan in a flexible flow shop problem is applicable to our study. Since the problem considered here is a three-stage no-wait flexible flow shop, the LB derived for the general flexible flow shop setting remains valid under the no-wait constraint. On average, GAD deviates from the LB by approximately 3.48%, which is calculated as follows:
This indicates that GAD can find near-optimal solutions very efficiently. The results show that the non-robust schedules generated by GAD perform well when there is no disturbance to the original problem data.
Next, we evaluate the performance of the five algorithms on 1000 simulated instances. In
Table 5, the column ‘
’ presents the average makespan over 1000 replications. The column ‘std’ reports the standard deviation of the
values, and the column ‘WPR’ (worst-case performance ratio) represents the ratio of each algorithm’s maximum objective value among the 1000 replications to the smallest maximum objective value among all algorithms, i.e.,
In
Table 5, we observe that when uncertainty is introduced, the non-robust schedules generated by GAD deteriorate significantly. In contrast, the robust schedules produced by GARS and GARS_SA handle the uncertainty much more effectively. Their average
values deteriorate slightly. Among all algorithms, GARS and GARS_SA achieve the smallest values of average
, std, and WPR across the 1000 disrupted problem instances. Hence, we conclude that GARS and GARS_SA outperform GAD, BRS, and GRIS in terms of average
, robustness (std) and worst-case performance. As expected, the four algorithms designed for robust scheduling (BRS, GRIS, GARS, and GARS_SA) require longer computation times due to the standard robustness evaluation, which must be performed
L times for each candidate solution
. This justifies the use of a 200 s time limit as the stopping criterion for these algorithms.
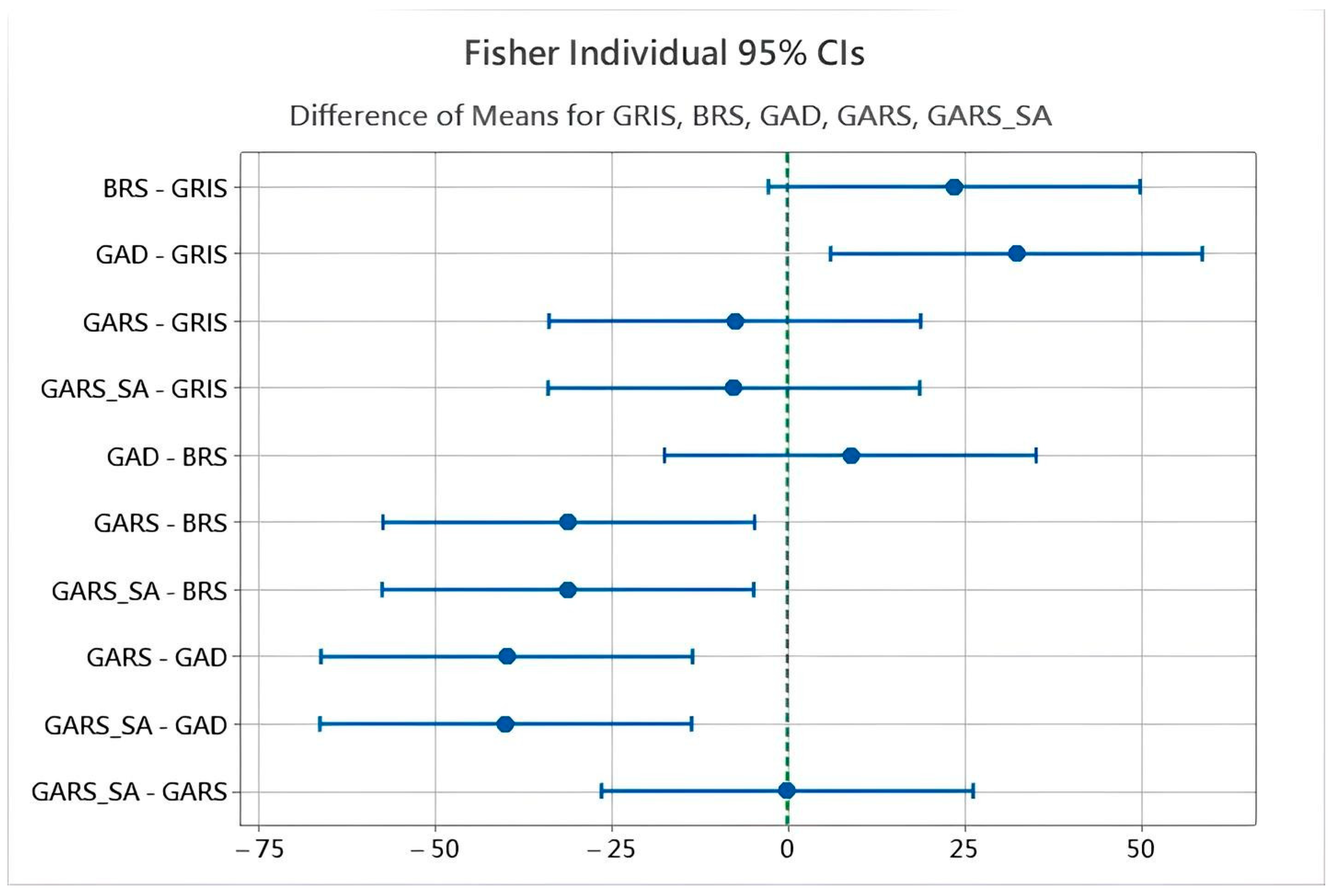
We further assess the performance of the five algorithms using statistical analysis. The mean robust
values of the five algorithms were compared using Fisher’s Least Significant Difference (LSD) test at a 95% confidence level. As shown in
Table 6, GAD exhibits the highest average
(673.8) and is classified solely in group A, indicating statistically inferior performance. In contrast, GARS (633.85) and GARS_SA (633.72) fall into group C and are not significantly different from each other, confirming their comparable effectiveness in handling uncertainty. GRIS (641.43) lies between the best and worst performers and belongs to both groups B and C, reflecting moderate robustness. BRS (665.0) overlaps with both GAD and GRIS but not with GARS or GARS_SA, suggesting slight improvement over GAD but still lacking competitiveness compared to the most robust algorithms.
Figure 7 presents the pairwise comparisons of the five algorithms based on Fisher’s LSD test. If the 95% confidence interval includes zero, the difference between the two algorithms is not statistically significant; otherwise, it is. This graphical representation supports the conclusions drawn in
Table 6.
In summary, GARS and GARS_SA are the most suitable algorithms for solving the robust three-stage OR scheduling problem under uncertainty, as they consistently produce solutions that are less sensitive to uncertain surgery durations and demonstrate superior robustness in terms of average , standard deviation, worst-case performance ratio, and statistical significance.
Table 7 summarizes the overall performance of the five algorithms and the LB across four cases and three levels of uncertainty (
= 0.25, 0.5, 0.75). Each value is the average of 10 tested instances. Since LB and GAD are not influenced by
, their results remain the same across uncertainty levels. As
increases, the average
, std, and WPR of all algorithms generally increase, reflecting the challenge of maintaining robustness under uncertainty. Among all algorithms, GARS and GARS_SA consistently achieve the best performance, with low average
, low variability, and small WPRs. As the number of surgeries increases, the performance gap among algorithms becomes more apparent. For small instances (e.g., 10 surgeries), the differences are minor. However, in larger instances (e.g., 30 surgeries), GAD performs noticeably worse under uncertainty, while GARS and GARS_SA remain robust. BRS and GRIS perform moderately—better than GAD but clearly inferior to GARS and GARS_SA, especially in larger and more uncertain cases. BRS tends to produce less consistent results, and GRIS shows slightly better stability but still lacks competitiveness in minimizing
and WPR. These trends highlight the superior robustness and scalability of GARS and GARS_SA.
Lastly, since the results of GARS and GARS_SA are comparable, we further investigated the performance of these two algorithms. The comparison was conducted using 30 surgeries with the highest level of uncertainty (with
= 0.75). Instead of applying the same computational time limit, both algorithms were allowed to run until either the best solution had not improved for a predefined number of consecutive iterations (MaxNoImprove = 218) or the maximum number of generations was reached (MaxGeneration = 5000). In addition, for GARS_SA, the SA component was triggered when no improvement was observed for 30 consecutive iterations. The results are given in
Table 8.
Table 8 shows that GARS terminated earlier (average time: 236.00 s), whereas GARS_SA required a longer runtime to complete (average time: 333.03 s). Despite this, the solution quality of both algorithms remained nearly identical. Specifically, GARS achieved an average
of 652.79 with a standard deviation of 65.26, while GARS_SA achieved an average
of 652.65 with a standard deviation of 64.44. Given the longer runtime and added complexity of GARS_SA, this study recommends the use of GARS for solving the problem at hand. GARS offers a simpler algorithmic structure and superior computational efficiency, making it the more practical and efficient choice in this context.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}