Abstract
As a national intangible cultural heritage in China, traditional Miao batik has encountered obstacles in contemporary dissemination and design due to its reliance on manual craftsmanship and other reasons. Existing generative models are difficult to fully capture the complex semantic and stylistic attributes in Miao batik patterns, which limits their application in digital creativity. To address this issue, we construct the structured CMBP-9 dataset to facilitate semantic-aware image generation. Based on stable diffusion v1.5, Low-Rank Adaptation (LoRA) is used to effectively transfer the structure, sign, and texture features that are unique to the Miao people, and the Latent Consistency model (LCM) is integrated to improve the inference efficiency. In addition, a Style-Conditioned Linear Fusion (SCLF) strategy is proposed to dynamically adjust the fusion of LoRA and LCM outputs according to the semantic complexity of input prompts, thereby overcoming the limitation of static weighting in existing frameworks. Extensive quantitative evaluations using LPIPS, SSIM, PSNR, FID metrics, and human evaluations show that the proposed Batik-MPDM framework achieves superior performance in terms of style fidelity and generation efficiency compared to baseline methods.
Keywords:
stable diffusion; low-rank adaptation (LoRA); Miao batik; intangible cultural heritage; latent consistency model (LCM) MSC:
68T07; 54H30; 68T01
1. Introduction
Miao batik in China, a national intangible cultural heritage, has a deep historical value and a unique aesthetic system [1]. As a vital component of the visual arts of China’s ethnic minorities, Miao batik involves several key procedural stages: wax melting, wax application (pattern drawing), dyeing, wax removal, and drying (shown in Figure 1). These wax application (pattern drawing) constitutes the core of the entire process (shown in Figure 2). Through motifs, natural symbolism, and religious symbols, ancestral stories are converted into geometric patterns, the unique visual elements of Miao cultural heritage. The preservation and modern dissemination of Miao batik is a problem because it is manual, there is a knowledge gap between generations, and there are limited creative production methods [2]. Creating Miao batik motifs depends on the manual skills of experienced artisans who contribute their collective expertise and artistic understanding [1]. The unstructured production process maintains its uniqueness [3], but it limits the potential for stylistic growth and innovation, especially when working with digital images and their multimodal dissemination [4,5]. Today’s backbone of generative artificial intelligence (Generative AI) consists of diffusion models because they excel at image synthesis and controllable generation [6]. Stable Diffusion v1.5 represents a latent diffusion model that shows promising results for digital art and visual design because it was trained on large text–image paired datasets [7]. However, mainstream diffusion models such as DDPM [8], Imagen [7], and Latent Diffusion Models [9] are primarily designed for general-purpose imagery and lack domain sensitivity, making them suboptimal for tasks requiring culturally grounded visual semantics. The current diffusion models learn from general-purpose imagery. Yet, they do not understand the unique visual semantics and localized stylistic rules of Miao batik because they lack this specific knowledge. The research tackles this limitation by developing an innovative framework that enables the digital generation and stylistic redesign of Miao batik imagery to support computational ethnic craftsmanship preservation. The research demonstrates how Stable Diffusion v1.5 can be fine-tuned through Low-Rank Adaptation (LoRA) using a “traditional Chinese Miao batik Image Dataset” specifically designed for this purpose. The adaptation technique effectively transfers Miao batik-specific structural and semantic features. But LoRA’s structural transformation alone is insufficient for rapid image synthesis or inference-time acceleration. To address this, we introduce Latent Consistency Models (LCMs), which reduce the number of denoising steps needed during sampling by modeling latent transitions directly. Our research extends beyond implementation to redefine the creative process of batik as a generative design tool. In traditional Miao batik stylized image generation, the combination of LoRA and LCM provides an ideal solution for addressing the key challenges in cultural heritage preservation and modern technological applications. LoRA (Low-Rank Adaptation) achieves parameter-efficient style fine-tuning through low-rank matrix decomposition, enabling the precise learning and preservation of unique cultural semantic features of Miao batik, such as the geometric structures of traditional patterns, color matching principles, and artistic expression techniques [10]. LCM (Latent Consistency Model) significantly reduces diffusion sampling steps through consistency distillation techniques, substantially improving inference speed and providing a technical foundation for real-time generation in interactive cultural creation applications [11,12]. The synergistic effects of these two approaches enable style-conditioned Miao batik image generation to maintain cultural art’s authenticity and meet the demands of modern digital creation for real-time interaction and rapid iteration [9,13]. The hybrid system connects AI synthesis to the batik’s symbolic vocabulary through structured semantic annotations to generate standardized Miao patterns while enabling fast design iteration. The proposed method establishes a production system that integrates with digital heritage archives and serves both museums and designers.
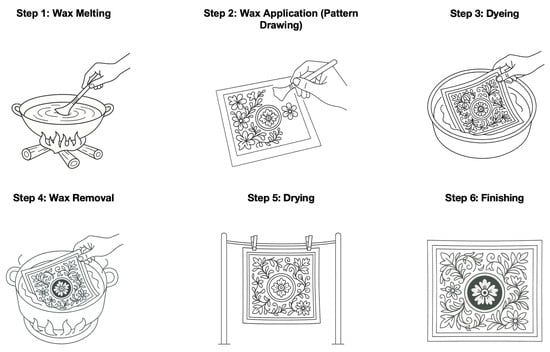
Figure 1.
Schematic diagram of the batik dyeing process.

Figure 2.
A Miao batik artisan in the process of creating traditional patterns.
This paper makes the following contributions:
- A structured semantic dataset, “Chinese Miao Batik Pattern Dataset with 9 Categories” (CMBP-9), was created to assist image generation and improve text–image correspondence and semantic understanding during the generation process.
- We introduce the efficient LCM-LoRA method for Miao batik image generation, which enhances both fidelity and deployment efficiency without requiring additional training.
- We propose a Style-Conditioned Linear Fusion (SCLF) module. By adaptively balancing LoRA and LCM, the limitations of static weighting in the original LCM-LoRA framework are overcome to achieve semantically sensitive and flexible Miao ethnic image generation.
- SCLF combined with LCM-LoRA outperforms individual components and baselines regarding perceived quality and generation speed. It has been verified through expert consistency evaluation that it shows higher overall performance in the generation task of diverse patterns of Miao batik.
2. Related Work
2.1. Challenges of Batik Revitalization and Innovation
Traditional Miao batik is an elaborate wax-resist dyeing technique that ethnic Miao communities have maintained across multiple generations. The traditional batik wax-resist dyeing art faces a severe transmission crisis in modern times. The number of skilled batik artisans and inheritors is dwindling as younger generations show less interest in learning time-consuming traditional techniques, leading to a worrisome gap in knowledge transfer [14]. Unlike more universally popular patterns, Miao batik’s particular geometry and cultural meanings do not easily translate to new color schemes, scales, or compositions without losing authenticity [15]. A trade-off often exists between maintaining the original artistic integrity and making the motif appealing to contemporary audiences. This lack of adaptability has limited the presence of Miao batik in global design trends.
During the last ten years, museums and cultural institutions have digitized Miao batik textile collections and made online archives and pattern databases with high-resolution Miao batik motifs [16]. VR and AR experiences were created to let users step into the batik-making process to interest youth [3]. Although these efforts have increased awareness and accessibility, their effect on the active innovation of batik designs has been minimal [17]. Conventional revitalization efforts like government-sponsored craft cooperatives and tourism-driven workshops [18], although valuable for economic support, often struggle to scale creatively. They tend to reproduce established patterns for souvenirs and do not empower designers to experiment with batik in new ways because they fear straying from “authentic” styles or lack design tooling [19]. In conclusion, although the crisis is recognized and numerous preservation initiatives have been undertaken, there is still a significant gap in the innovative adaptation of pattern design. So, finding ways to allow Miao batik’s distinctive aesthetic to evolve and flourish in modern creative domains without losing its cultural essence remains a challenge [20]. This gap necessitates exploring new tools that enable fast, flexible stylization with Miao batik features, thus combining tradition with innovation [21].
2.2. Stable Diffusion Stylization in Cultural Heritage
Generative models have achieved recent advancements that provide potential solutions for these problems [22]. Diffusion models, especially Stable Diffusion, are contemporary tools for image synthesis and stylization [23,24]. Stable Diffusion functions as a latent diffusion model that operates within a compressed latent image space to generate high-quality images at a relatively fast sampling rate after being trained with massive image–text datasets [25]. The latent-space methodology improves generation speed and fidelity, offering better control over stylistic intensity and content details. Researchers have developed fine-tuning methods for Stable Diffusion that work with small target styles or concept examples [26,27]. DreamBooth represents a significant method that allows a trained diffusion model to acquire knowledge about new visual concepts through only three to five reference images. A specific token added to the model’s text encoder enables DreamBooth to perform fine-tuning, which results in the model learning to associate this token with the new concept [28]. The fine-tuning process with DreamBooth requires significant resources and sometimes leads to model knowledge degradation through overfitting or accidental modifications of unrelated model characteristics [29].
Low-Rank Adaptation (LoRA) proves itself as an efficient, lightweight method that works well with diffusion models and cultural heritage projects [30,31]. Through LoRA, factorized weight updates become low-rank matrices, substantially reducing memory usage and computational requirements for teaching new styles to the model. The development of Latent Consistency Models (LCMs) for acceleration represents a significant advancement in the diffusion model field, which provides substantial practical benefits [32]. LCM-LoRA allows users to generate images with a few denoising steps while improving the generation speed [33,34].
However, the LCM-LoRA framework in its current form uses a static linear fusion strategy, where fixed scalar weights are applied to combine the LoRA-generated semantic style vector and the LCM-generated denoising vector [35]. This static weighting fails to account for the semantic richness or stylistic complexity of different prompts, leading to insufficient expressiveness and rigid stylization outcomes. Similar limitations exist in other fusion-based strategies, such as fixed weight blending [36] or naive attention-based interpolation [37], which assume homogeneous contributions of sources across contexts [38,39]. These methods lack prompt sensitivity, resulting in underperformance in high-semantic-diversity generation tasks such as cultural heritage image synthesis [40,41]. To address this conceptual gap, our framework proposes a dynamic semantic fusion mechanism Style-Conditioned Linear Fusion (SCLF) that explicitly models the semantic intensity of each prompt to adjust fusion coefficients during generation dynamically. This allows more responsive, context-aware modulation of visual features and overcomes the rigidity of prior static or uniformly weighted fusion strategies. As a result, while existing diffusion-based stylization frameworks show promise in cultural domains, they fail to adapt dynamically to the complex, symbolically rich semantics embedded in heritage patterns. Batik-MPDM contributes a novel solution to this problem by offering a flexible, semantically grounded fusion framework that enhances generation fidelity and responsiveness to cultural context.
3. Materials and Methods
The current model makes it difficult to accurately capture the special artistic style and ethnic characteristics of traditional Miao batik patterns in China during the generation process. Furthermore, the existing methods often have complex training processes, significant parameters, and low generation efficiency, thus limiting their application and promotion in practical scenarios. To solve these problems, we introduced low-rank Adaptive (LoRA) and Latent Consistency Model (LCM) to improve the performance of style generation and the inference efficiency of the model. Furthermore, the Style-Conditioned Linear Fusion (SCLF) module is proposed to enhance the adaptability of the LCM-LoRA framework to complex semantics. The flowchart is shown in Figure 3.
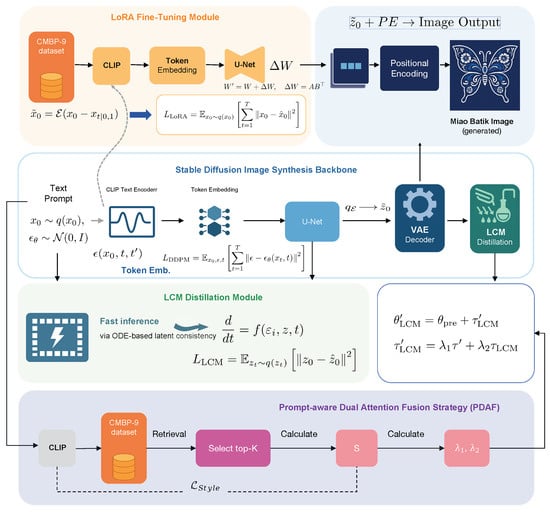
Figure 3.
Architecture of the proposed LoRA-LCM enhanced batik image generator.
3.1. CMBP-9 Dataset
Due to the lack of structured training data in current research on intangible cultural heritage image generation, the performance of existing image generation models in producing ethnic minority patterns such as Miao batik remains suboptimal [42]. Chinese Miao Batik Pattern Dataset with 9 Categories (CMBP-9) is the construction of a culturally grounded dataset for stylized generation, which received support from 649 traditional Miao batik images. The image sources originated from museum archives, heritage publications, and high-resolution photographs of physical textile samples, which were verified manually to guarantee cultural authenticity and pattern integrity. The 649 images are distributed equally among nine categories: bird, butterfly, fish, flowers and plants, geometric, human, drum, dragon, and composite. Table 1 provides the detailed category distribution, with bird (166 samples) and butterfly (77 samples) being the most and least represented classes, respectively. This distribution reflects cultural prevalence and motif diversity across the Miao batik tradition. Inter-class variability is evident in the symbolic complexity, compositional structure, and motif semantics. For instance, ‘bird’ and ‘composite’ categories frequently involve layered symbolism and higher visual intricacy, while ‘geometric’ or ‘human’ categories often follow more standardized spatial rules or iconographic traditions. The annotation process for each image involves a structured semantic schema containing eight dimensions, including the visual category and constituent elements; descriptive semantics (des); color palette (col); composition (com); visual symmetry (vis); dual complexity; associated symbolic meanings; and other semantically relevant attributes.

Table 1.
Category distribution in the CMBP-9 dataset.
These eight attributes (as shown in Table 2) were carefully designed to capture both the visual structure and symbolic semantics of Miao batik, allowing the dataset to support high-fidelity prompt conditioning and culturally grounded stylization. It presents a structured annotation example for the “bird” category, demonstrating how each pattern is accompanied by explicit, interpretable labels such as traditional symbols (“phoenix”), symmetry (“asymmetric”), complexity (“complex”), and dominant colors. This level of fine-grained semantic labeling ensures that text-to-image generation can be guided by descriptive keywords and deeper iconographic and aesthetic logic rooted in cultural practice. CMBP-9 provides visual inputs and symbolic meta-descriptions necessary for culturally accurate controllable generation, a distinctive departure from prior datasets that either lack annotation or rely only on unstructured tags. A trained coder manually annotated the dataset using a standardized coding protocol aligned with ethnographic interpretations of Miao textile iconography. The protocol included (1) identifying key motifs; (2) labeling symbolic associations based on expert consensus; and (3) assigning complexity and symmetry using a rubric of visual rule consistency. A second expert reviewed 20% of entries to ensure coding reliability. To ensure cultural and ethical integrity, two nationally recognized Miao batik inheritors and a professor specializing in Miao intangible cultural heritage were consulted throughout dataset construction. Their contributions included advising on image selection, validating symbolic meanings, and reviewing annotation consistency. A final community review ensured the respectful and culturally appropriate representation of traditional motifs.
Table 2.
Structured annotation example from the CMBP-9 dataset.
To evaluate the semantic coverage and balance of the constructed CMBP-9 dataset, we also conducted a word frequency analysis on the textual prompts. As shown in Figure 4, the frequently occurring words include floral, geometric, intricate, bird, and fish. These terms reflect the key visual elements and compositional rules commonly found in traditional Miao batik patterns.
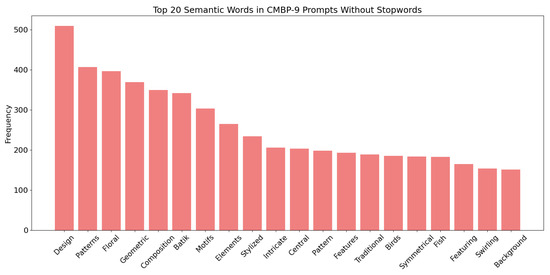
Figure 4.
Frequency analysis of the constructed CMBP-9 dataset.
3.2. LoRA Training of Traditional Chinese Miao Batik Patterns Based on Stable Diffusion
3.2.1. Model Architecture of Stable Diffusion
Stable Diffusion [9] is a text-to-image model based on the latent diffusion model, consisting of three parts: CLIP Text Encoder, U-Net + Scheduler, and VAE. Figure 5 shows the structure of Stable Diffusion. CLIP Text Encoder converts text prompts into Token embeddings, providing semantic information for subsequent image generation. Specifically, the model takes Gaussian noise and text prompts as inputs, which a pre-trained CLIP Text Encoder processes to generate text embeddings. U-Net + Scheduler takes text embedding and noise as input to form a starting matrix, transforming latent space information. VAE is responsible for converting information from the latent to the pixel space.
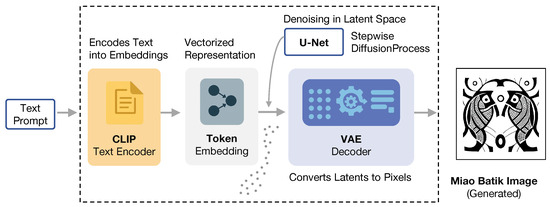
Figure 5.
The framework of Stable Diffusion.
Forward Diffusion Process
After obtaining the data samples, the model gradually adds noise until it becomes completely Gaussian. Specifically, we denote the data distribution . We sample data from the data distribution, denoted as . Starting from , the model gradually adds Gaussian noise, and the final sampling step is denoted as T. The formula for the image can be expressed as:
Among them, the variance of Gaussian noise is , and the mean is .
Here, the following formula is defined:
Among them, represents the Gaussian noise of .
From this, it can be inferred that when the number of noisy steps T is large enough, will approach 0, will approach 1, and will approach the standard Gaussian distribution.
Reverse Process
In contrast to the forward diffusion process, the reverse process gradually reduces to , specifically solving . Although the noise distribution is predetermined, it is necessary to fit it through a model due to the multiple sampling possibilities. At this point, the parameter of the deep network is denoted as .
Among them, and represent the mean and variance of the parameter , respectively.
During the training process, the loss function can be defined as
Among them, represents Gaussian noise of .
3.2.2. Low-Rank Adaptation
Low-Rank Adaptation (LoRA) is an efficient fine-tuning technique aimed at reducing the computational and storage overhead during the fine-tuning process of large-scale pre-trained models. Specifically, LoRA will freeze the weights of the original model. Secondly, we train the dimensionality reduction matrix A and the dimensionality enhancement matrix B, where the dimensionality reduction matrix A is initialized with Gaussian noise with a mean of zero and a variance of , and the dimensionality reduction matrix is initialized with an all-zero matrix. Its structure is shown in Figure 6.
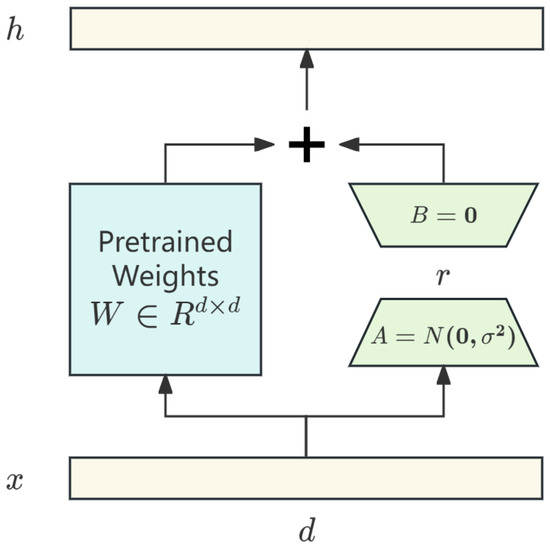
Figure 6.
The framework of Low-Rank Adaptation (LoRA).
We denote the original trainable weight matrix . During the fine-tuning, it is approximated by the product of a trainable low-rank matrix . Here, the fine-tuning is conducted by the pre-trained Stable Diffusion v1.5. Only the parameters of A and B are updated, while the backbone weights W and all other modules remain frozen. The formula for updating model parameters during fine-tuning is as follows:
where , . R is the rank of matrix .
Based on this, the loss function of LoRA can be defined as
Among them, represents the original data, and represents the data generated after LoRA fine-tuning.
3.2.3. Fine-Tuning for Traditional Chinese Miao Batik Patterns
Here, we denote the self-made traditional Chinese Miao batik patterns as G:
where indicates the batik image after normalized pre-processing. represents the description of the style attributes corresponding to this batik image.
Considering that traditional Chinese Miao batik patterns have very complex geometric images and symbolic symbols, the model for generating such patterns needs to have a strong perceptual ability. However, full-parameter fine-tuning directly for large models is computationally expensive and prone to overfitting when facing a relatively small number of batik pattern datasets. For this reason, this paper introduces the Low-Rank Adaptation (LoRA) technique to fine-tune the pattern generation models efficiently.
In the concrete implementation, let the linear weight of a layer be , and the fine-tuning weight added by LoRA be , where is the scaling factor, and are low-rank matrices, and . Algorithm 1 shows its detailed fine-tuning process. The fine-tuning process is based on Stable Diffusion (SD) v1.5, which was pre-trained on the large-scale dataset LAION-5B [43].
| Algorithm 1 Efficient LoRA-based fine-tuning for Miao batik pattern modeling. |
|
By introducing Low-Rank Adaptation, the model improves its ability to discriminate the edges and contours of local patterns. In this way, the model also learns the unique structural language of traditional Chinese Miao batik patterns better and retains the ability to generalize the semantics of more general patterns. This will also improve the generation effect of traditional Chinese Miao batik patterns.
3.3. Batik-MPDM: Diffusion-Based Accelerated Generation for Traditional Miao Batik Patterns
In this study, Stable Diffusion is chosen as the underlying generative framework. On the one hand, Stable Diffusion adopts Latent Diffusion Models (LDMs). Compared to the pixel-space-based modeling approach, it can significantly reduce computational resource consumption while maintaining high-quality image generation. On the other hand, Stable Diffusion has a more modularized architecture. It supports the introduction of external mechanisms, such as prompts guidance and style control, which can effectively enable the controlled generation of patterns. In contrast, some existing text-driven generation models, despite their capability for semantic guidance, are unstable in terms of control accuracy and image consistency, often suffering from structural imbalance or style distortion. These methods have some limitations in coping with highly structured or style-specific pattern generation tasks, and it is difficult to meet the dual requirements of semantic accuracy and stylistic coherence. Based on this, we propose Batik-MPDM (Miao Pattern Diffusion Model), a diffusion-based generative architecture, which combines LoRA and LCM. At the same time, a style-conditioned fusion module is introduced to adapt to the complexity of the prompt dynamically. The model is designed to generate traditional Miao batik images with high fidelity and efficiency. The overall workflow of the Batik-MPDM is shown in Figure 7.
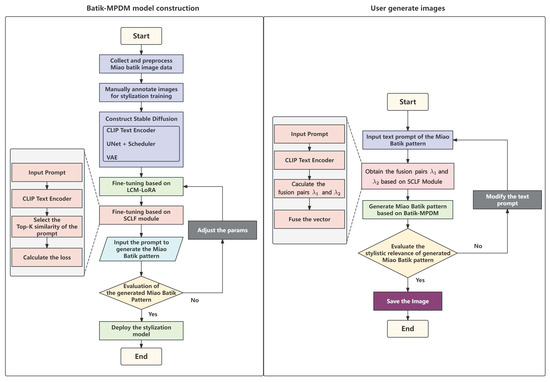
Figure 7.
The workflow of Miao batik pattern generation using the Bakit-MPDM.
3.3.1. Latent Consistency Models
The Latent Consistency Model (LCM) is an efficient acceleration method for diffusion models, whose core idea is to perform consistency distillation in potential space to reduce the steps required for inference significantly [11] (Shown in Figure 8). Unlike traditional consistency models that perform the generation task in pixel space, LCM is built on top of the Latent Diffusion Model (LDM), which learns and reasons directly in the latent space, enabling it to generate high-definition images in fewer diffusion steps [35]. Specifically, the LCM approximates the inverse diffusion process of the original diffusion process by fitting the augmented Probability Flow Ordinary Differential Equation (PF-ODE) solution in the potential space [44]. Unlike traditional methods that rely on a numerical ODE solver for multi-step iterative solving, the LCM directly predicts the solution of the PF-ODE in the potential space. In this way, LCM significantly compresses the sampling time, improving the inference efficiency and preserving the image quality.
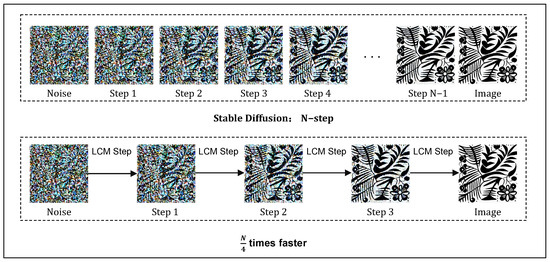
Figure 8.
Schematic diagram of LCM distillation acceleration.
To optimize the model’s prediction ability for the PF-ODE solution, LCM introduces a consistent distillation loss function for efficiently compressing the teacher model’s multi-step inference ability into the student model’s one-step prediction during the training process. This loss function accomplishes the accelerated modeling of the diffusion process by comparing the consistency of the latent variables in the PF-ODE trajectories at different time steps and guiding the student model to learn approximate generative paths in the latent space. Its distillation loss is defined as
where is the latent variable, is the latent space, is the initial latent space, and is the latent variable after distillation via LCM. This loss function aims to ensure that the generated samples are as close as possible to the distribution of the original data in the latent space, thus guaranteeing the high quality of the generated images.
3.3.2. Fast Pattern Generation Module Based on Style-Conditioned Linear Fusion (SCLF)
To address the limitations of the original LCM-LoRA framework by using static linear weighting, which lacks sensitivity to semantic complexity, this study proposes a style-aware dynamic fusion method called Style-Conditioned Linear Fusion (SCLF). It aims to explicitly model the stylistic complexity implied by each input text prompt and guide the adaptive balance between the LoRA-generated style vector and the LCM-derived acceleration vector. Specifically, SCLF operates on a pre-trained LCM-LoRA model and learns to adjust the weighting of its combined effects dynamically.
Here, when given a text prompt T, the fusion weights and are initialized as 0.5. The process can be presented as follows:
Firstly, the text prompt T is extracted by a CLIP text encoder to obtain the semantic embedding . And the multi-layer perceptron (MLP) maps this embedding to a complexity score . The calculation is defined as follows:
where denotes the Sigmoid activation function. s is the predicted complexity score.
Secondly, the predicted complexity score s is then transformed into a pair of fusion weights ( and ) via a smoothed parameterized Sigmoid function:
where a and b are hyper-parameters.
Third, the weights and are subsequently used to fuse the style and acceleration vectors:
where the denotes the LoRA-generated style vector, and represents the LCM-derived acceleration vector. represents the fusion vector.
Fourthly, the fusion vector is added to the base pre-trained parameters to produce the final inference parameters . The calculation can be expressed as
The is used for the Miao batik generation.
After describing how our SCLF framework is built and operates, we will explain the training strategy.
Firstly, for each prompt T, we first obtain its . Subsequently, we utilize the pre-extracted gallery of pre-extracted CLIP image embeddings and identify the Top-K similarity scores which are relevant to the prompt. Then the mean value of the Top-K similarity scores is computed. This variance is after normalizing to serve as the target value , which is the weak supervision signal. Here, we denote the style loss as
where the denotes the mean squared error. denotes the MLP calculation. Here, the overall generation loss of the Batik-MPDM can be expressed as
where the and are the control parameters.
In summary, the SCLF strategy introduces a content-aware for adaptive fusion. It dynamically balances style fidelity and generation speed based on semantic complexity. Also, it enhances control over style consistency, making it particularly suitable for applications in the rapid stylization of Miao batik patterns.
4. Experiment
This section aims to systematically demonstrate the proposed method’s performance in image generation tasks from multiple dimensions, specifically the effectiveness of text-driven image generation, the comparative advantages of LoRA and the combined LCM-LoRA approach, and the model’s ability to control diversity and style combination in batik-style image generation.
4.1. Experimental Settings
The experiments were conducted on a workstation equipped with an NVIDIA RTX 3090. The software environment was configured using Python 3.8, with deep learning models implemented in PyTorch 2.4.0 for diffusion-based generation. For fine-tuning the Batik-MPDM model, we adopted the LoRA-based parameter-efficient learning strategy. The fine-tuning process was performed on Stable Diffusion v1.5, pre-trained on the LAION-5B dataset. The number of training epochs was 100, and the maximum training step was 15,000. Also, the training used a batch size of 4 and an initial learning rate of 1 . The total training time for each experiment was approximately 5 h.
4.2. Evaluation Indicator
To comprehensively evaluate the perceptual and structural quality of the generated Miao batik patterns, we adopt six recognized metrics: Peak Signal-to-Noise Ratio (PSNR) [45], Learned Perceptual Image Patch Similarity (LPIPS) [46], Inception Score (IS) [47], Fréchet Inception Distance (FID) [48], Generating Time (Time), and Structural Similarity Index Measure (SSIM) [49].
PSNR (Peak Signal-to-Noise Ratio) is an indicator of image quality commonly used to evaluate the similarity between an image and the original image.
where is the maximum value of image pixels. denotes the mean square error.
LPIPS is a deep learning-based metric that quantifies the perceptual similarity between two images by the deep features extracted from pre-trained neural networks (e.g., VGG and AlexNet). A lower LPIPS score indicates higher perceptual similarity as perceived by human vision:
where x and y are the input images with perceptual similarity to be evaluated. and denote the deep features extracted from the l-th layer of a pre-trained network in spatial location for image x and y, respectively. and are the height and width of the feature map at layer l, and is a learned weight vector that re-weights the channel-wise differences. The symbol ⊙ indicates element-wise multiplication.
The Inception Score (IS) is mainly used to evaluate the quality of generated images. It extracts the classification probability distribution of generated images through the inception model to measure the clarity and diversity of the generated images:
where denotes a generated sample from the model’s distribution ; is the conditional label distribution predicted by the Inception network for the generated image ; is the marginal distribution of labels; and represents the Kullback–Leibler divergence.
where x and y denote the two images to be compared. and represent the mean values of x and y, respectively, while and denote the variances of x and y. refers to the covariance between x and y. and stabilize the division in case the denominator is close to zero.
The Fréchet Inception Distance (FID) is usually used to measure how close the generated image is to the real image in feature distribution. The evaluation is performed by extracting features in the pre-trained Inception-V3 network and fitting two multivariate Gaussian distributions separately to calculate the Fréchet distance. The calculation is shown below:
where and denote the mean features of the generated images x and the real images y, respectively. and represent their corresponding covariance. Tr denotes the trace of the matrix.
Generating time denotes the average time required to generate a single image using the model. This metric reflects the computational efficiency and inference speed of the generation process.
4.3. Ablation Experiment
We conduct the ablation experiments on the CMBP-9 dataset to verify the proposed method’s effectiveness. Specifically, we generate a set of Miao patterns for each model and compare the results with the CMBP-9 dataset for performance evaluation. Among them, we compare the stable diffusion, stable diffusion with LoRA, stable diffusion with LCM, stable diffusion with LCM-LoRA, and our proposed method. Table 3 presents the results of different models in various indicators, which shows the difference. As shown in Table 3, introducing Lora and LCM individually results in improvements in model performance compared to the baseline Stable Diffusion model. Specifically, Lora increases the PSNR to 29.32 dB and SSIM to 0.822 by focusing on the image quality. Moreover, the IS decreases to 5.88, and the FID is reduced from 117.74 to 15.80, showing improvements in perceptual quality. However, the generation time rises to 1.663. On the contrary, LCM focuses more on generation efficiency. The generation times decrease to 0.242. Although the PSNR (23.68 dB) and SSIM (0.691) improvements are moderate compared to LoRA, it still achieves a balanced trade-off between image quality and generation speed, with IS reaching 4.46 and FID improving to 22.65. Further performance enhancement is achieved by combining LoRA and LCM. The LCM-LoRA model adopts a fixed fusion strategy. This approach achieves a PSNR of 28.96 dB, SSIM of 0.808, IS of 5.69, and FID of 16.31, demonstrating that even a static combination can outperform individual modules. Batik-MPDM introduces a learnable dynamic fusion strategy. Instead of relying on a fixed integration, the model adaptively adjusts the contributions of LoRA and LCM, optimizing for quality and efficiency. As a result, Batik-MPDM achieves the best performance, with a PSNR of 29.10 dB, SSIM of 0.815, IS of 5.75, and FID of 15.90 while maintaining a competitive generating time of 0.335 s per image. It demonstrates the dynamic adjustment of the coefficients, providing more flexible optimization.
Table 3.
Ablation study results across different models (↑: Higher value, superior. ↓: Lower value, superior).
We also report the number of parameters for each model to analyze the impact of model complexity on performance and inference efficiency. All models are based on Stable Diffusion’s UNet principal structure, which contains approximately 865 million parameters in its core, serving as a unified basis for comparison. On this basis, we gradually introduce modules such as LoRA and LCM to enhance the expressiveness and inference efficiency of the models. The parameter increase from LoRA and LCM is minimal relative to the base UNet. LoRA adds just 1M, and LCM contributes around 66 M parameters. The combined model reaches 932 M, and Batik-MPDM slightly increases to 933 M. Notably, these additions lead to substantial gains in performance and efficiency.
4.4. Qualitative Ablation Study on Fusion Strategies
To verify the effectiveness of our proposed Style-Conditioned Linear Fusion (SCLF), we compare it with two fusion strategies: naive attention and fixed weights. As shown in Figure 9, we performed Miao batik image generation on the three themes: bird, butterfly, and fish. The images generated by the naive attention strategy exhibit semantic distortion, which hinders the restoration of the original pattern’s symbolic structure and artistic style. In contrast, the fixed weights strategy is relatively stable but lacks self-adaptation, failing to reflect the diversity of styles. In contrast, SCLF is superior in terms of structural integrity and detail restoration. The generated patterns are closer to the ground truth and show good consistency and semantic accuracy in the overall composition.

Figure 9.
Qualitative comparison of different fusion strategies in Miao batik pattern generation.
4.5. Robustness Under Multifaceted Prompt Conditions
With the expansion of generative tasks, the prompts input by users present increasingly complex and diversified combinations. Some of the prompts not only contain multiple semantic entities but also involve multiple descriptive attributes, which puts higher requirements on the generative model for semantic understanding. To systematically evaluate the model’s adaptability and generalization ability under such complex prompt conditions, we designed two types of typical experimental scenarios: (1) multi-entity task, i.e., prompt contains two or more independent entities; (2) multi-attribute task, i.e., multiple attribute descriptions are introduced around the same entity to form a composite semantic structure. The experimental results are shown in Figure 10. Figure 10a contains two types of entities, bird and fish, while Figure 10b contains multiple attribute descriptions with butterfly as the entity. In the multi-entity task, the overall structure of the generated image by Stable Diffusion remains relatively chaotic, with obvious visual overlap. In contrast, Batik-MPDM shows better compositional organization and semantic expression. Compared to the ground truth, the generated patterns are more consistent in terms of completeness and decorative styles. In the multi-attribute task, although Stable Diffusion can initially restore the entity of the prompt (e.g., butterfly), there are many additional elements stacked in the image, resulting in an overall style that is more cluttered. Batik-MPDM, on the other hand, shows a stronger ability in semantic fusion and style control. In its generated patterns, the butterfly form features a clear outline and symmetrical structure, with decorative patterns. In summary, the results demonstrate that Batik-MPDM exhibits superior semantic decoupling capabilities when handling multi-entity and multi-attribute prompts.

Figure 10.
Qualitative comparison under multifaceted prompt in Miao batik pattern generation.
4.6. Robustness Under Unseen Prompts
In practice, generative models often need to handle unseen prompt terms that contain novel semantic words. To verify the performance of Batik-MPDM in the unseen prompt term condition, we manually constructed three sets of prompt terms with clear subject and cultural imagery, none of which appeared in the training set CMBP-9. These prompts are roughly as follows: phoenix (feathers distributed in multiple layers, fused with vine decorations, representing rebirth), spiral (rhythmic lines spreading outward, symbolizing the life cycle), and wave (fish and leaf decorations, featuring diagonal forms). We used Batik-MPDM to generate images for each of these four cue words, and the results are shown in Figure 11. It can be observed that the model can reasonably construct the target structures and effectively integrate them into the unique compositional style of traditional Miao batik. In particular, the model exhibits a good understanding and expression of unseen semantics while maintaining the decorative and cultural consistency of the images.

Figure 11.
Generated images under unseen prompts in Miao batik pattern generation.
4.7. Qualitative Comparison with Style-Oriented Models
To verify the effectiveness of the proposed method in the cultural style generation task, we introduced two representative style control diffusion models, ControlNet and DreamBooth, for comparative experiments. We used “bird” as the theme of the generation task and the same semantic conditions for the generation. Figure 12 shows the results of cultural style generation under the same semantic conditions of ControlNet, DreamBooth, and Batik-MPDM. It can be seen that ControlNet has specific content preservation ability at the image structure level, and can control the target contour better. However, the generated images tend to be in the style of real images and lack batik’s cultural ornamentation and pattern abstraction. In contrast, DreamBooth can generate a particular stylized pattern layout, but the image style tends to be flat and lacks the symbolic characteristics of a specific cultural context. In contrast, Batik-MPDM can more clearly generate visual elements that conform to the traditional batik art style, showing the stronger consistency of cultural symbols and expressiveness of pattern structure, which verifies the advantages of our method in cultural style modeling.

Figure 12.
Qualitative comparison of different style-oriented models in Miao batik pattern generation.
4.8. Comparative Analysis of Text-to-Image Models
To further validate the cultural adaptability of Batik-MPDM in the Miao batik pattern generation task, we selected several text-to-image models, including Midjourney, DALL-E 3, Stable Diffusion, and Doubao, for comparison. All models are based on the same prompts, which focus on typical Miao batik elements (e.g., “bird, butterfly, fish, and flower”), and the results are shown in Figure 13. From the comparison results, the images generated by Midjourney and DALL-E 3 exhibit strong detail and visual impact. Still, the generated patterns lack the structural features, such as symbolization, commonly found in Miao batik. It indicates a certain degree of deviation from the cultural style. Stable Diffusion is stable in semantic comprehension and prompt response, and can generate thematic elements with high accuracy. However, the results tend to simplify the structure, which makes it difficult to reflect the artistic complexity and visual repetition of batik patterns. Doubao, as a diffusion model in the Chinese context, performs slightly better than other general models in semantic parsing; however, its generation style fails to replicate the handmade texture of Miao batik patterns. In contrast, Batik-MPDM shows higher adaptability and consistency in semantic alignment, style expression and pattern structure.

Figure 13.
The generated Miao batik patterns through different models.
4.9. Human Evaluation Results
A structured human evaluation was performed to assess the perceptual quality and cultural expressiveness of generated images in traditional Chinese Miao batik through 15 participants who were divided into three groups: (A) design professionals, (B) cultural heritage experts, and (C) general users unfamiliar with the Miao batik tradition. Group B included 2 senior scholars, 2 professors specializing in Miao intangible cultural heritage, and a national-level Miao batik inheritor. Their participation provided culturally authoritative perspectives in evaluating the generated patterns’ semantic appropriateness and symbolic fidelity. The participants evaluated images produced by five models, including Batik-MPDM, Stable Diffusion v1.5 [50], MidJourney [51], DALL·E 3 [52], and Doubao [53], through four evaluation dimensions, which were cultural fidelity, semantic accuracy, cultural adaptability, and aesthetic appeal. The image samples included four thematic categories: bird, flower, fish, and butterfly.
Scores were collected on a 7-point Likert scale. The Cronbach’s Alpha of 0.897 confirmed the participant responses’ internal consistency across the four dimensions.
The analysis used a four-way ANOVA (shown in Table 4) to examine how the model, image category, evaluation dimension and participant group affected the results. The results indicated that Model (F = 647.45, p < 0.001) had a significant main effect, but image category, evaluation dimension, and participant group did not show significant main effects (all p > 0.1).
Table 4.
Four-way ANOVA results for human evaluation scores.
The analysis indicates that scoring differences mainly resulted from the model selection rather than other variables. The proposed Batik-MPDM model achieved better results than all other models according to Tukey HSD post hoc analysis (p < 0.001), which is shown in Table 5. However, the baseline models did not show any significant differences. Batik-MPDM delivers a consistently better experience regarding cultural representation and visual quality.
Table 5.
Tukey HSD post hoc test for all pairwise model comparisons.
The results in Figure 14a and Figure 14b show that Batik-MPDM received the highest average scores across all evaluation dimensions and image categories with the “Flower” category achieving a mean score of 6.15. The model effectively produces traditional Chinese Miao batik art representations which are both stylistically accurate and perceptually attractive.
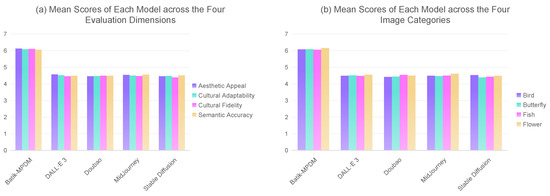
Figure 14.
Comparative evaluation of model performance in generating traditional Miao batik patterns.
5. Discussion
Nowadays, generative models are widely applied in image content creation [6,54]. However, in cultural heritage revitalization, particularly concerning the patterns of various ethnic groups, traditional image generation methods still face significant challenges due to the limited capability of generative models in specific style control [34]. Among these, the traditional ethnic art form of Miao batik places higher demands on image style modeling and control. Therefore, we have constructed a high-quality, structured image-style dataset. This dataset includes exhaustive multi-dimensional textual annotations, covering aspects such as pattern composition, symbolic meanings, and the overall stylistic features for each batik image.
Our proposed image generation strategy integrates LoRA fine-tuning, LCM distillation, and a style-conditioned fusion module to enhance the generative models’ efficiency, adaptability, and style control in practical batik pattern applications. The method maintains the style consistency advantages of diffusion models while substantially reducing computational costs during generation. The accelerated generation speed enables designers and researchers to explore a wide range of batik-inspired variations within seconds, replacing the traditionally time-consuming process. Meanwhile, introducing the style-conditioned fusion module further enhances the model’s ability to adapt to the semantic complexity of different prompts dynamically. Based on that, the proposed approach can serve as a tool for Miao batik that supports creative workflow.
The experimental results demonstrate that Batik-MPDM generates Miao batik patterns effectively while maintaining reasonable control over stylistic fidelity and semantic consistency. Despite the progress made in this study, several limitations remain. Firstly, the sample size of the constructed dataset is still relatively limited.
Although it encompasses many Miao batik patterns with corresponding textual descriptions, there is room for improvement regarding stylistic complexity, the diversity of pattern types, and regional variations. Future research could expand the dataset further to enhance the model’s robustness and expressive capabilities. Moreover, while Batik-MPDM performs well under standard prompts, its ability to handle highly complex or hybrid prompts remains to be validated. Further exploration is needed to assess the model’s generalization and flexibility in more demanding cultural generation tasks.
6. Conclusions
This study proposes a Miao batik pattern generation method based on the style-conditioned LCM-LoRA enhanced diffusion models. Firstly, we build the “Chinese Miao Batik Pattern Dataset with 9 Categories” (CMBP-9), improving text–image correspondence and semantic understanding during generation. Secondly, the model integrates LoRA and LCM to realize the efficient and controllable generation of traditional Miao batik patterns. Also, a Style-Conditioned Linear Fusion (SCLF) strategy is proposed to dynamically adjust the fusion of LoRA and LCM outputs according to the semantic complexity of prompts. Although our method performs well in generating the Miao batik patterns, the interpretability of the cultural connotations of the generated patterns could be further improved. The current model focuses mainly on visual synthesis rather than deep cultural understanding. In addition, extending the dataset to a wider range of regional batik styles may open up new opportunities for broader pattern generation. Future research will explore interactive generation tools that can provide more artistic input. Furthermore, future research will investigate the integration of 3D modeling techniques to create a more immersive batik design experience.
Author Contributions
Conceptualization, Q.H. and Y.P.; Data Curation, J.X.; Formal Analysis, Q.H. and Y.P.; Investigation, Q.H. and Y.P.; Methodology, Q.H. and Y.P.; Project Administration, J.C.; Resources, Q.H. and Z.T.; Software, Y.P. and Z.S.; Visualization, Q.H. and Y.P.; Writing—Original Draft, Q.H., Y.P. and J.X.; Writing—Review and Editing, J.C. and Z.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The datasets presented in this article are not readily available because they are part of an ongoing research project. Releasing the dataset prematurely may affect the integrity of subsequent experiments and related work. However, we recognize the importance of research reproducibility. A portion of the dataset and the associated testing code have been open-sourced on GitHub: https://github.com/JackPeng007/Batik (accessed on 16 April 2025). In the meantime, reasonable requests to access the dataset can be directed to 3230005309@student.must.edu.mo.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chen, Z.; Ren, X.; Zhang, Z. Cultural heritage as rural economic development: Batik production amongst China’s Miao population. J. Rural Stud. 2021, 81, 182–193. [Google Scholar] [CrossRef]
- Zhang, S.; Xu, J.; Gou, H.; Tan, J. A research review on the key technologies of intelligent design for customized products. Engineering 2017, 3, 631–640. [Google Scholar] [CrossRef]
- Dimitropoulos, K.; Tsalakanidou, F.; Nikolopoulos, S.; Kompatsiaris, I.; Grammalidis, N.; Manitsaris, S.; Denby, B.; Crevier-Buchman, L.; Dupont, S.; Charisis, V.; et al. A multimodal approach for the safeguarding and transmission of intangible cultural heritage: The case of i-Treasures. IEEE Intell. Syst. 2018, 33, 3–16. [Google Scholar] [CrossRef]
- Wagner, A.; de Clippele, M.S. Safeguarding cultural heritage in the digital era—A critical challenge. Int. J. Semiot. Law-Rev. Int. Sémiot. Jurid. 2023, 36, 1915–1923. [Google Scholar] [CrossRef]
- Sweetman, A.E.M. Intangible Heritage Management: An Investigation of the Role of Digital Technology in Safeguarding Heritage Crafts in the UK Now and in the Future. PhD Thesis, Queen Mary University of London, London, UK, 2019. [Google Scholar]
- Liu, R.; Pang, W.; Chen, J.; Balakrishnan, V.A.; Chin, H.L. The application of scaffolding instruction and AI-driven diffusion models in children’s aesthetic education: A case study on teaching traditional chinese painting of the twenty-four solar terms in chinese culture. Educ. Inf. Technol. 2024, 30, 9129–9160. [Google Scholar] [CrossRef]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; et al. Photorealistic text-to-image diffusion models with deep language understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36479–36494. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. ICLR 2022, 1, 3. [Google Scholar]
- Luo, S.; Tan, Y.; Huang, L.; Li, J.; Zhao, H. Latent consistency models: Synthesizing high-resolution images with few-step inference. arXiv 2023, arXiv:2310.04378. [Google Scholar]
- Song, Y.; Dhariwal, P.; Chen, M.; Sutskever, I. Consistency models. arXiv 2023, arXiv:2303.01469. [Google Scholar]
- Podell, D.; English, Z.; Lacey, K.; Blattmann, A.; Dockhorn, T.; Müller, J.; Penna, J.; Rombach, R. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv 2023, arXiv:2307.01952. [Google Scholar]
- Song, G.; Prompongsaton, N.; Kotchapakdee, P. Cultural Preservation and Revival: Discuss efforts to preserve and revive traditional Miao costume patterns. Explore how local communities, artisans, and cultural organizations are working to ensure that these patterns are passed down to future generations. Migr. Lett. 2024, 21, 231–243. [Google Scholar]
- Wang, S.; Kolosnichenko, O. Study of Miao embroidery: Semiotics of patterns and artistic value. Art Des. 2024, 3, 98–109. [Google Scholar]
- Na, Z.; Sharudin, S.A. Research on Innovative Development of Miao Embroidery Intangible Cultural Heritage in Guizhou, China Based on Digital Design. J. Bus. Econ. Rev. (JBER) 2024, 9, 85–94. [Google Scholar] [CrossRef]
- Covarrubia, P. Geographical indications of traditional handicrafts: A cultural element in a predominantly economic activity. IIC-Int. Rev. Intellect. Prop. Compet. Law 2019, 50, 441–466. [Google Scholar] [CrossRef]
- Buonincontri, P.; Morvillo, A.; Okumus, F.; van Niekerk, M. Managing the experience co-creation process in tourism destinations: Empirical findings from Naples. Tour. Manag. 2017, 62, 264–277. [Google Scholar] [CrossRef]
- Liang, J. The application of artificial intelligence-assisted technology in cultural and creative product design. Sci. Rep. 2024, 14, 31069. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, Y. Artificial Intelligence-Driven Interactive Experience for Intangible Cultural Heritage: Sustainable Innovation of Blue Clamp-Resist Dyeing. Sustainability 2025, 17, 898. [Google Scholar] [CrossRef]
- Chandran, R.; Chon, H. Redefining heritage and cultural preservation through design: A framework for experience design. In Proceedings of the Congress of the International Association of Societies of Design Research, Hong Kong, China, 5–9 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1246–1264. [Google Scholar]
- Chen, J.; Zheng, X.; Shao, Z.; Ruan, M.; Li, H.; Zheng, D.; Liang, Y. Creative interior design matching the indoor structure generated through diffusion model with an improved control network. Front. Archit. Res. 2025, 14, 614–629. [Google Scholar] [CrossRef]
- Sauer, A.; Boesel, F.; Dockhorn, T.; Blattmann, A.; Esser, P.; Rombach, R. Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation. In Proceedings of the SA ’24: SIGGRAPH Asia 2024 Conference Papers, Tokyo, Japan, 3–6 December 2024. [Google Scholar] [CrossRef]
- Bevacqua, A.; Singha, T.; Pham, D.S. Enhancing Semantic Segmentation with Synthetic Image Generation: A Novel Approach Using Stable Diffusion and ControlNet. In Proceedings of the 2024 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Perth, Australia, 27–29 November 2024; pp. 685–692. [Google Scholar]
- Hu, Y.; Zhuang, C.; Gao, P. DiffuseST: Unleashing the Capability of the Diffusion Model for Style Transfer. In Proceedings of the 6th ACM International Conference on Multimedia in Asia, Auckland, New Zealand, 3–6 December 2024; p. 1. [Google Scholar]
- Wang, L.; Gao, B.; Li, Y.; Wang, Z.; Yang, X.; Clifton, D.A.; Xiao, J. Exploring the latent space of diffusion models directly through singular value decomposition. arXiv 2025, arXiv:2502.02225. [Google Scholar]
- Po, R.; Yifan, W.; Golyanik, V.; Aberman, K.; Barron, J.T.; Bermano, A.; Chan, E.; Dekel, T.; Holynski, A.; Kanazawa, A.; et al. State of the art on diffusion models for visual computing. Comput. Graph. Forum 2024, 43, e15063. [Google Scholar] [CrossRef]
- Yoo, H. Fine Tuning Text-to-Image Diffusion Models for Correcting Anomalous Images. arXiv 2024, arXiv:2409.16174. [Google Scholar]
- Xu, C.; Xu, Y.; Zhang, H.; Xu, X.; He, S. DreamAnime: Learning style-identity textual disentanglement for anime and beyond. IEEE Trans. Vis. Comput. Graph. 2024; early access. [Google Scholar] [CrossRef]
- Pascual, R.; Maiza, A.; Sesma-Sara, M.; Paternain, D.; Galar, M. Enhancing DreamBooth with LoRA for Generating Unlimited Characters With Stable Diffusion. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Zhang, X. AI-Assisted Restoration of Yangshao Painted Pottery Using LoRA and Stable Diffusion. Heritage 2024, 7, 6282–6309. [Google Scholar] [CrossRef]
- Ma, Z.; Zhang, Y.; Jia, G.; Zhao, L.; Ma, Y.; Ma, M.; Liu, G.; Zhang, K.; Li, J.; Zhou, B. Efficient diffusion models: A comprehensive survey from principles to practices. arXiv 2024, arXiv:2410.11795. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Wang, K.; van de Weijer, J.; Khan, F.S.; Guo, C.L.; Yang, S.; Wang, Y.; Yang, J.; Cheng, M.M. InterLCM: Low-Quality Images as Intermediate States of Latent Consistency Models for Effective Blind Face Restoration. arXiv 2025, arXiv:2502.02215. [Google Scholar]
- Gîrbacia, F. An Analysis of Research Trends for Using Artificial Intelligence in Cultural Heritage. Electronics 2024, 13, 3738. [Google Scholar] [CrossRef]
- Luo, S.; Tan, Y.; Patil, S.; Gu, D.; von Platen, P.; Passos, A.; Huang, L.; Li, J.; Zhao, H. Lcm-lora: A universal stable-diffusion acceleration module. arXiv 2023, arXiv:2311.05556. [Google Scholar]
- Du, L. How much deep learning does neural style transfer really need? An ablation study. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 3150–3159. [Google Scholar]
- Chefer, H.; Alaluf, Y.; Vinker, Y.; Wolf, L.; Cohen-Or, D. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. ACM Trans. Graph. (TOG) 2023, 42, 1–10. [Google Scholar] [CrossRef]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 3836–3847. [Google Scholar]
- Meng, C.; He, Y.; Song, Y.; Song, J.; Wu, J.; Zhu, J.Y.; Ermon, S. Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv 2021, arXiv:2108.01073. [Google Scholar]
- Gal, R.; Alaluf, Y.; Atzmon, Y.; Patashnik, O.; Bermano, A.H.; Chechik, G.; Cohen-Or, D. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv 2022, arXiv:2208.01618. [Google Scholar]
- Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; Aberman, K. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22500–22510. [Google Scholar]
- Tiribelli, S.; Pansoni, S.; Frontoni, E.; Giovanola, B. Ethics of Artificial Intelligence for Cultural Heritage: Opportunities and Challenges. IEEE Trans. Technol. Soc. 2024, 5, 293–305. [Google Scholar] [CrossRef]
- Schuhmann, C.; Beaumont, R.; Vencu, R.; Gordon, C.; Wightman, R.; Cherti, M.; Coombes, T.; Katta, A.; Mullis, C.; Wortsman, M.; et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Adv. Neural Inf. Process. Syst. 2022, 35, 25278–25294. [Google Scholar]
- Kim, D.; Lai, C.H.; Liao, W.H.; Murata, N.; Takida, Y.; Uesaka, T.; He, Y.; Mitsufuji, Y.; Ermon, S. Consistency trajectory models: Learning probability flow ode trajectory of diffusion. arXiv 2023, arXiv:2310.02279. [Google Scholar]
- Mustafa, W.A.; Yazid, H.; Jaafar, M.; Zainal, M.; Abdul-Nasir, A.S.; Mazlan, N. A review of image quality assessment (iqa): Snr, gcf, ad, nae, psnr, me. J. Adv. Res. Comput. Appl. 2017, 7, 1–7. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. Adv. Neural Inf. Process. Syst. 2016, 29. Available online: https://proceedings.neurips.cc/paper_files/paper/2016/file/8a3363abe792db2d8761d6403605aeb7-Paper.pdf (accessed on 8 June 2025).
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/8a1d694707eb0fefe65871369074926d-Paper.pdf (accessed on 8 June 2025).
- Brunet, D.; Vrscay, E.R.; Wang, Z. On the mathematical properties of the structural similarity index. IEEE Trans. Image Process. 2011, 21, 1488–1499. [Google Scholar] [CrossRef]
- Rombach, R.; Esser, P. Stable Diffusion v1.5: Open-Source Image Generation Model. 2023. Available online: https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5 (accessed on 16 April 2025).
- Holz, D. MidJourney: AI Image Generation Platform. 2022. Available online: https://www.midjourney.com/ (accessed on 16 April 2025).
- OpenAI. DALL·E 3: AI Image Generation Model. Available online: https://openai.com/dall-e (accessed on 16 April 2025).
- ByteDance. Doubao: AI Image Generation Platform. 2023. Available online: https://www.doubao.ai (accessed on 16 April 2025).
- Bansal, G.; Nawal, A.; Chamola, V.; Herencsar, N. Revolutionizing visuals: The role of generative AI in modern image generation. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–22. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).