1. Introduction
Enterprise incident management systems have long been critical infrastructures for maintaining the operational continuity of large organizations. These systems are tasked with processing and responding to a wide range of disruptions—ranging from minor technical faults to high-impact failures—under constraints of time, resources, and operational complexity. In such contexts, the accurate prioritization of incidents based on severity and urgency is essential to ensure that critical issues are resolved promptly, while less urgent matters are efficiently managed to avoid unnecessary resource strain.
Historically, incident prioritization has relied on rule-based systems, which encode expert knowledge into static criteria or predefined classification schemas. While these approaches are interpretable and effective under stable conditions, they tend to be brittle in the face of evolving incident dynamics, linguistic ambiguity in reports, and real-time operational variability [
1,
2,
3]. Fuzzy logic has been introduced to mitigate some of these limitations by allowing the modeling of approximate terms such as “high urgency” or “moderate impact”. This logic has been widely applied in domains such as industrial control, medical diagnosis, and service quality estimation, where ambiguity and human reasoning are prevalent [
4,
5]. In the context of incident management, fuzzy inference enables a more nuanced interpretation of linguistic inputs by mapping them into degrees of membership within fuzzy sets, improving flexibility and interpretability. However, static fuzzy systems remain limited in their capacity to adapt to feedback or learn from outcomes, restricting their performance in dynamic environments.
More recently, deep learning models have gained prominence for their ability to automatically learn patterns from historical incident data. Natural language processing (NLP), in particular, has shown significant promise in extracting insights from unstructured textual descriptions provided by users or operators [
6,
7]. Transformer-based architectures, such as BERT and its variants, have redefined the term state-of-the-art in contextual understanding by surpassing classical machine learning models in accuracy and generalization [
8,
9]. These models are particularly effective in capturing linguistic subtleties, making them suitable for tasks like automated severity classification or urgency estimation. Despite their power, deep models suffer from well-documented limitations, notably their lack of interpretability and reliance on large amounts of labeled data. Their “black-box” nature poses challenges for deployment in environments where transparency, accountability, and real-time adaptability are required [
10,
11].
In response to these challenges, hybrid approaches have emerged, seeking to combine the strengths of symbolic reasoning, machine learning, and mathematical optimization. One particularly promising line of work involves the integration of fuzzy logic with reinforcement learning, known as fuzzy Q-learning. This technique leverages the interpretability of fuzzy systems to handle imprecise and context-dependent information, while also incorporating a learning mechanism through Q-learning that enables adaptation based on feedback from past actions. The result is a model that not only interprets human-like linguistic inputs but also evolves its prioritization strategy through experience and environmental interaction [
12,
13,
14].
In the domain of incident management, fuzzy Q-learning allows for dynamic prioritization by treating incident descriptions as fuzzy variables and optimizing decision policies over time. The Q-learning component provides a formal structure for reinforcement learning, where policies are refined through iterative updates of value functions based on reward signals. These signals may reflect key performance indicators such as resolution times or escalation frequencies. Importantly, the hybrid nature of this approach balances the brittleness of static fuzzy rules with the opacity of deep learning models, offering a compromise between adaptability and explainability [
15,
16,
17].
The present study proposes a hybrid mathematical framework for incident prioritization in enterprise environments, based on fuzzy Q-learning and enhanced by semantic text analysis. The system receives natural language descriptions of incidents, transforms them into semantic embeddings using transformer-based NLP models, and processes them through a fuzzy Q-learning engine that outputs dynamic priority scores. These scores are then used to guide resource allocation and resolution scheduling. Unlike static models, the proposed system is capable of updating its internal policies in real time, learning from incident outcomes such as resolution delays, operator corrections, or customer satisfaction feedback [
18,
19].
From a mathematical perspective, the contribution of this work lies in the formalization of a fuzzy state-action space where incident variables are treated as fuzzy sets, the definition of a reward function that incorporates multiple performance metrics (e.g., resolution time, escalation frequency, and operator validation), and the implementation of an update algorithm that guarantees convergence under reasonable assumptions. The system is evaluated through a series of controlled simulations and real-world incident datasets, comparing its performance with static fuzzy systems and deep learning classifiers in terms of accuracy, adaptability, and computational efficiency [
20,
21].
This work is particularly relevant in enterprise environments where incident volumes are high, resource constraints are nontrivial, and linguistic variability in reports is common. It addresses the need for systems that are not only technically sophisticated but also transparent, explainable, and mathematically grounded, enabling their integration into complex workflows where trust and accountability are paramount [
22,
23]. Additionally, by aligning linguistic uncertainty with mathematical models for adaptive decision-making, the proposed system contributes to bridging the gap between symbolic AI and numerical optimization, offering a practical framework for enterprise AI applications.
The remainder of this article is organized as follows: The next section presents the materials and methods used in the design and implementation of the system, including the construction of the fuzzy rule base, the integration of the Q-learning algorithm, and the generation of semantic representations from incident reports. Following this, the Results section offers a detailed analysis of the system’s performance across multiple scenarios, highlighting improvements in prioritization accuracy, policy adaptability, and system responsiveness. The Discussion section interprets the results in light of current trends in intelligent incident management and reinforcement learning under uncertainty. Finally, this article concludes by summarizing the key findings and outlining potential directions for future research, including the extension of the framework to multi-agent environments and continuous action spaces [
24,
25,
26].
By incorporating recent advances in NLP, fuzzy logic, and reinforcement learning into a single mathematical framework, this study contributes to the ongoing evolution of intelligent incident management systems—systems that are not only data-driven but also adaptive, interpretable, and aligned with the complexities of real-world enterprise operations [
27,
28,
29].
In this context, we define a hybrid mathematical framework as a structured integration of symbolic reasoning (via fuzzy inference systems), numerical optimization (through reinforcement learning), and semantic representation (using vector space embeddings from NLP models), all embedded within a mathematically grounded architecture. The framework is considered mathematical in that it formalizes the state-action space using fuzzy set theory, defines a reward function over a bounded metric space, and applies update rules based on the Bellman equation. Its hybrid nature emerges from combining rule-based inference and data-driven learning, each modeled through precise mathematical operators. This definition anchors the contributions of this paper within a formal and reproducible paradigm, distinguishing the proposed system from purely heuristic or black-box approaches.
Recent literature has explored hybrid AI frameworks for decision-making under uncertainty, particularly in large-scale and dynamic environments. For instance, Ref. [
30] proposed a cost-minimized, two-stage, three-way dynamic consensus mechanism for group decision-making using incomplete fuzzy preference relations and k-nearest neighbors. While their model effectively handles preference uncertainty and large-scale consensus in social networks, it is tailored to deliberative group settings rather than real-time incident management. In contrast, our framework focuses on operational environments with continuous incident streams, combining semantic embeddings, fuzzy inference, and Q-learning to enable real-time, adaptive prioritization. Moreover, our model incorporates reinforcement signals derived from resolution outcomes, and it includes a formal convergence analysis within a mathematically defined hybrid architecture. This distinction clarifies the novelty of our approach as an explainable and adaptive alternative for incident prioritization in enterprise settings.
The novel contributions of this study are fourfold. First, it proposes a mathematically grounded hybrid framework that integrates fuzzy inference, reinforcement learning, and NLP-based semantic embeddings for dynamic incident prioritization—an architecture not previously explored in this combination. Second, we introduce a fuzzy Q-learning algorithm that operates over semantically derived fuzzy state spaces, achieving a practical balance between adaptability and interpretability. Third, the framework is empirically validated on a large-scale, real-world enterprise dataset, demonstrating measurable performance improvements over both deep learning and rule-based baselines. Finally, we provide a convergence analysis and interpretability layer that are often absent in related AI-driven prioritization systems.
2. Materials and Methods
This section presents the methodological foundations underlying the design, implementation, and evaluation of the proposed hybrid framework for dynamic incident prioritization. The approach integrates three complementary layers: (1) semantic representation of incident descriptions using advanced natural language processing techniques; (2) a fuzzy inference engine that models linguistic uncertainty in severity and urgency assessment; (3) a fuzzy Q-learning algorithm that iteratively adjusts prioritization policies based on resolution outcomes and real-time feedback. Together, these components form a mathematically structured architecture capable of adaptively managing incident prioritization under uncertainty and evolving operational demands.
The methodological pipeline begins with the construction of a high-quality dataset comprising incident reports collected from enterprise systems, preprocessed and transformed into numerical and semantic features suitable for modeling. A fuzzy variable system is then established to translate these features into interpretable severity and urgency levels through fuzzy membership functions and rule-based inference. Finally, the system is equipped with a learning agent that applies fuzzy Q-learning over a defined state-action space, optimizing prioritization strategies based on a reward function calibrated to enterprise performance objectives. Each subsection of this chapter details one of these components, including their mathematical formulation, parameter configuration, and technical implementation [
1,
2,
3].
2.1. Semantic Representation of Incident Descriptions
At the core of any intelligent incident prioritization system lies the ability to accurately interpret the content of incident reports, which are typically expressed in free-text form. These textual descriptions, often informal and heterogeneous, contain crucial signals about the severity and urgency of a given incident. The present framework begins with a semantic analysis pipeline designed to transform these unstructured descriptions into dense numerical representations suitable for fuzzy reasoning and reinforcement learning.
The data used in this study consist of 10,000 incident reports gathered from a mid-sized technology enterprise over a period of eighteen months. Each report includes a brief textual description provided by a human operator or user at the time of the incident submission. Approximately 2000 of these reports were manually annotated by domain experts, labeling them with four severity levels (low, medium, high, critical) and three urgency levels (non-urgent, moderate, urgent). These annotations serve as ground truth for supervised components of the system.
To ensure high-quality inputs for subsequent modeling stages, a preprocessing pipeline was implemented. Standard text normalization techniques were applied, including lowercasing, punctuation removal, and expansion of common abbreviations (e.g., auth to authentication, svc to service). Misspellings were corrected using a context-aware neural spell-checker. Tokenization was performed using the WordPiece algorithm to ensure compatibility with the transformer architecture adopted later [
6,
7].
The semantic layer employs a fine-tuned BERT-base-uncased model to capture contextual relationships within and across sentences. The model was initially pretrained on a general corpus and further fine-tuned on 2000 labeled incident reports using a classification head to predict severity and urgency. The resulting 768-dimensional embedding from the final hidden layer is used as a feature vector input for both the fuzzy inference system and the fuzzy Q-learning agent. BERT was selected for its strong balance between semantic richness and computational efficiency in enterprise-scale NLP applications.
As a baseline comparison, we also tested TF-IDF vector representations using unigrams and bigrams as input features. The results, discussed in
Section 4, showed that BERT embeddings provided substantially better prioritization accuracy and adaptability, particularly in handling ambiguous or context-dependent descriptions. Although newer transformer architectures such as RoBERTa or GPT-3 may offer improved representational power, their deployment in real-time enterprise workflows poses challenges due to resource constraints and limited interpretability. Future work may explore these models, along with further domain-specific fine-tuning, to assess their viability in this context.
Beyond classification, the embeddings were used to build a semantic co-occurrence network, in which each node represents an incident, and edges denote the semantic proximity between incident embeddings. Cosine similarity was employed as the distance metric, and a threshold of 0.85 was applied to filter meaningful connections. This graph-based model revealed clusters of similar incident types, which informed the design of fuzzy rules and served as auxiliary inputs for reinforcement learning through the identification of latent patterns in the data distribution [
8,
9].
In parallel, Term Frequency–Inverse Document Frequency (TF-IDF) representations were generated as a complementary vectorization method. This traditional technique was used for comparative analysis and for interpretability purposes, offering insights into which keywords contributed most to each severity or urgency class. A chi-square test for feature selection identified the top 100 terms most correlated with high-severity and high-urgency labels, such as “outage”, “breach”, and “urgent failure”. These features served as linguistic anchors in the design of fuzzy membership functions and provided transparency in model behavior [
10,
11].
To manage the high dimensionality of the semantic space, PCA was applied to reduce BERT-based embeddings to 50 dimensions without significant loss of variance. This enhanced computational efficiency and enabled clustering and visualization of incident patterns.
Figure 1 displays a PCA projection of 500 randomly sampled incident embeddings, revealing distinct clusters aligned with severity labels, supporting the validity of the embedding representations
Ethical considerations were rigorously applied throughout the semantic processing phase. All incident reports were anonymized, and personally identifiable information (PII) was removed or masked to ensure compliance with the General Data Protection Regulation (GDPR). Beyond technical compliance, special care was taken to prevent indirect discrimination in the downstream use of this data, particularly with regard to potential disparities across organizational units or user groups. Operator consent was also obtained for the use of annotated data in model training. All data preprocessing and model deployment processes were conducted in a secure, isolated environment using containerized services to prevent unauthorized access or data leakage [
12].
The semantic representation layer plays a foundational role in the proposed framework. It bridges the gap between linguistic inputs and mathematical reasoning, providing structured, high-dimensional embeddings that reflect the complexity and nuance of real-world incident descriptions. These embeddings, in turn, enable the downstream fuzzy reasoning and learning mechanisms to function with both precision and contextual awareness, ensuring that the prioritization decisions made by the system are informed by a deep understanding of incident content [
13,
14].
2.2. Fuzzy Inference System for Incident Prioritization
A central challenge in enterprise incident management lies in the subjective and often ambiguous nature of incident reports, which rarely map neatly to predefined severity or urgency categories. To address this issue, the proposed framework incorporates a fuzzy inference system (FIS) designed to interpret linguistic patterns in incident descriptions and convert them into structured priority indicators. This approach allows for gradual transitions between categorical levels, capturing uncertainty and variability in both the input data and expert knowledge.
The system defines two primary input variables—semantic severity and semantic urgency—derived from the semantic embeddings introduced in the previous section. Each variable is represented by fuzzy sets defined over the interval [0, 1], corresponding to categories such as low, medium, high, and critical (for severity), as well as non-urgent, moderately urgent, and urgent (for urgency). These fuzzy sets were constructed using trapezoidal and Gaussian membership functions, chosen to reflect both smooth transitions and threshold-based reasoning identified during expert elicitation [
25,
26].
The parameters of these membership functions (e.g., standard deviations for Gaussians and slope widths for trapezoids) were initially calibrated using a combination of expert input and empirical quantiles from the training dataset. To assess the impact of parameter selection on final outputs, a local sensitivity analysis was conducted on the severity variable. By varying its central thresholds by ±10% and observing priority scores across representative scenarios, the model exhibited stable prioritization behavior, supporting the robustness of the fuzzy representation to moderate parameter changes.
These membership functions provide the input basis upon which the fuzzy rule base operates. The fuzzy rule base constitutes the core of the inference engine. It comprises 12 rules obtained through structured interviews with six domain experts from the participating enterprise, including three senior incident response managers, two technical leads, and one IT service quality coordinator, each with over five years of relevant experience. During the elicitation process, participants were presented with prototypical incident descriptions and asked to define linguistic terms (e.g., “high urgency”, “moderate impact”) and specify the appropriate prioritization levels for each scenario. To ensure consistency, a validation phase was conducted in which initial rule sets were cross-reviewed by all participants. Inter-rater agreement was measured using Fleiss’ kappa, yielding a value of 0.81, indicating substantial agreement. In cases of disagreement, a consensus was reached through moderated follow-up sessions facilitated by the research team, where conflicting rules were discussed and resolved iteratively until convergence was achieved.
Rules follow the form: IF severity is high AND urgency is urgent THEN priority is very high. Each rule is activated to a degree determined by the intersection (via fuzzy AND) of the membership levels of its antecedents. A Mamdani-type inference model was used, combining minimum t-norms and centroid defuzzification to compute crisp output values representing priority scores in the range [0, 100] [
4].
An example of the rule base structure is illustrated in
Table 1.
This fuzzy approach provides two major advantages. First, it allows the system to handle borderline cases without resorting to arbitrary thresholds. For example, an incident whose semantic embedding yields a 0.6 membership in high severity and a 0.4 in critical can still activate both rules associated with these categories, producing a blended inference result. Second, it supports explainability by enabling system operators to trace prioritization outputs back to a small number of transparent, linguistically grounded rules—an essential feature for trust and adoption in enterprise environments [
27,
28].
To support the calibration of the membership functions and rule base, a data-driven validation process was employed. A subset of 500 annotated incidents was used to compare the fuzzy system’s output with human-assigned priority levels. The root mean squared error (RMSE) between fuzzy-inferred scores and expert labels was minimized by adjusting the parameters of the Gaussian functions using particle swarm optimization. This metaheuristic was chosen for its robustness in non-convex search spaces and was run with a population of 20 particles over 100 iterations, achieving convergence in under 3 minutes on a standard GPU workstation [
29].
The output of the fuzzy inference system is a continuous priority score, which serves as the state input for the reinforcement learning component described in the next subsection. This design choice ensures that the Q-learning agent does not operate on raw, high-dimensional semantic vectors, but rather on compact, interpretable, and mathematically bounded inputs. In preliminary tests, this significantly accelerated convergence and improved policy stability.
In addition to its computational benefits, the fuzzy inference layer introduces an intermediate abstraction that supports modularity and reuse. Because the fuzzy variables and rules are defined independently of the underlying language model, the system can be extended to new domains or retrained on different datasets without reengineering the inference logic. This modularity is particularly relevant for enterprises operating across multiple sectors or geographies, where incident vocabularies and prioritization criteria may vary [
31].
The integration of fuzzy reasoning into AI-driven incident management aligns with recent calls for hybrid models that combine learning-based adaptability with symbolic interpretability. While deep neural networks offer high predictive power, their lack of transparency often hinders deployment in operationally sensitive contexts. Fuzzy systems, by contrast, provide a rule-based structure that is both intelligible and modifiable, enabling domain experts to inject or revise knowledge without retraining entire models. This hybrid strategy mitigates the limitations of both extremes and supports gradual adoption within conservative enterprise environments [
32,
33].
An important consideration in the implementation of the FIS was the need to balance expressiveness with computational tractability. Although higher-order fuzzy logic systems (e.g., type-2 fuzzy sets) offer finer modeling granularity, their added complexity was deemed unnecessary for the present application. A type-1 fuzzy model with well-calibrated functions and a compact rule base was sufficient to capture the majority of variance in expert labels, while also ensuring that inference could be performed in real time—an operational requirement for enterprise systems processing thousands of incidents per hour [
34].
To evaluate the interpretability of the fuzzy system, post hoc analysis was conducted using SHAP (SHapley Additive exPlanations) values applied to the output of the fuzzy-prioritized scores when used in downstream decision trees for resolution allocation. The results confirmed that the fuzzy variables had stable, monotonic effects on predicted resource allocation levels, and that their linguistic boundaries (e.g., between medium and high urgency) matched operator intuition in 87% of reviewed cases. These findings reinforce the potential of fuzzy logic as a transparent bridge between language and action [
35].
Figure 2 illustrates the shape of selected membership functions for the severity variable. These functions were manually validated by domain experts and optimized to reflect real-world patterns in incident classification.
In conclusion, the fuzzy inference system presented here establishes a mathematically robust and operationally interpretable mechanism for incident prioritization. It acts as a critical intermediary between unstructured language inputs and adaptive learning policies, enabling the system to capture human reasoning patterns while maintaining the flexibility required for dynamic enterprise environments. The integration of fuzzy logic ensures that prioritization is not only data-driven, but also consistent with expert knowledge and organizational norms, thereby enhancing both the technical rigor and practical acceptability of the proposed framework [
36,
37].
2.3. Fuzzy Q-Learning Algorithm for Adaptive Prioritization
The final component of the proposed hybrid framework is a reinforcement learning mechanism designed to refine the prioritization policy over time through adaptive interaction with the incident resolution environment. This is achieved by integrating Q-learning—a widely used model-free reinforcement learning algorithm—with fuzzy logic, resulting in a fuzzy Q-learning agent capable of optimizing prioritization decisions under uncertainty, incomplete information, and real-time feedback.
Traditional Q-learning models operate on discrete state and action spaces, where the agent learns the optimal action-value function Q(s,a) by iteratively updating its estimates using the Bellman equation. However, in enterprise incident management, the state space is inherently continuous and linguistically described, rendering discrete models inadequate. To overcome this, the state space in the proposed system is represented using fuzzy variables derived from the fuzzy inference engine described previously. This transforms the high-dimensional and ambiguous semantic input into a set of interpretable fuzzy states such as “high severity and moderate urgency” or “medium severity and urgent”.
Each fuzzy state is associated with a set of possible actions, which in this context correspond to discrete prioritization adjustments: decrease, maintain, or increase the current priority level. These actions are not final resource allocations, but intermediate decisions used to guide the evolution of incident priority scores before resource assignment. By abstracting prioritization into a reinforcement learning loop, the system continuously adapts its behavior based on observed outcomes, such as resolution success, resource contention, or operator override [
38].
The fuzzy Q-learning algorithm follows a standard update rule adapted to fuzzy state representations. Let
St be the fuzzy state at time
t, and
At the selected action. Upon receiving a reward
Rt+1, the Q-value is updated as follows:
where
α is the learning rate and
γ the discount factor. In the fuzzy extension,
St is no longer a single crisp value, but a weighted combination of fuzzy rules triggered by the current input. Each rule contributes to the update proportionally to its activation level, computed through the fuzzy membership functions defined earlier.
To operationalize this mechanism, a fuzzy rule base is constructed where each rule defines a mapping from fuzzy input states to Q-values for the three possible actions. For example, the rule IF severity is high AND urgency is urgent THEN increase priority is assigned a Q-value, Qi,j, corresponding to the expected long-term reward of performing the action “increase” in that fuzzy context. The agent maintains and updates this Q-table throughout its operation, gradually improving its prioritization behavior based on experience.
The reward function plays a crucial role in guiding the learning process. In this framework, the reward signal is computed using a weighted combination of performance metrics associated with each incident. These include
Timeliness of resolution: defined as the inverse of the time taken to resolve the incident.
Resource efficiency: measured by the proportion of allocated resources that were effectively utilized.
Operator satisfaction: based on explicit feedback when available or inferred from manual overrides or post-resolution comments.
The total reward,
R, is expressed as follows:
where
T is the resolution time,
E is the efficiency score,
S is the satisfaction proxy, and
λ1,
λ2, and
λ3 are tunable weights. These parameters were calibrated using a grid search on a validation set of incidents, with the objective of maximizing the final average priority alignment with expert annotations.
To ensure sufficient exploration, an ε-greedy policy was adopted, where the agent selects a random action with probability ε, and the best-known action otherwise. The ε parameter decays over time to encourage early exploration and late-stage exploitation. Empirically, this policy was shown to reduce premature convergence and improve learning robustness, especially in ambiguous incident scenarios where multiple actions may initially seem equally viable [
39].
The fuzzy Q-learning agent was implemented in Python using NumPy and integrated into the overall system as a microservice accessible via REST API. Each time a new incident is received and semantically analyzed, the fuzzy inference engine produces a fuzzy state representation, which is then passed to the learning agent. The agent selects an action, adjusts the incident’s priority score accordingly, and logs the decision. Once the incident is resolved, its resolution metrics are evaluated, and the agent receives a reward to update its Q-table. This interaction loop is repeated for every incident processed, enabling the model to adapt continuously to changing incident patterns, resource conditions, and user behavior [
40].
One of the principal advantages of this approach lies in its ability to handle incomplete feedback. In many enterprise settings, not all incidents are annotated with resolution outcomes or operator feedback. To address this, the system incorporates a decay-based credit assignment strategy, where absent rewards are inferred from similar past cases or set to a neutral value with reduced update strength. This ensures that learning does not stall under sparse feedback conditions while preserving the stability of the Q-table [
41].
From a mathematical standpoint, the convergence of the fuzzy Q-learning algorithm is not guaranteed in the general case due to the continuous and non-stationary nature of the environment. However, under reasonable assumptions about reward boundedness, learning rate decay, and sufficient exploration, convergence to a near-optimal policy is empirically observed. In the pilot experiments, the learning agent stabilized its policy within approximately 4000 processed incidents, with diminishing update magnitudes and increased policy consistency over time [
42].
The inclusion of fuzzy Q-learning in the incident prioritization system fulfills a key objective of adaptive intelligence. Rather than relying solely on predefined rules or static classifiers, the system evolves its prioritization logic in response to operational outcomes. It learns to favor prioritization patterns that lead to faster resolutions, better resource usage, and higher operator trust, while still respecting the linguistic structure and expert knowledge embedded in the fuzzy rule base. This integration of learning and reasoning reflects a broader trend in AI research toward hybrid systems that combine symbolic transparency with empirical optimization [
43].
In summary, the fuzzy Q-learning module equips the system with the capacity to continuously refine its prioritization policy through interaction with its environment. By leveraging fuzzy representations of incident characteristics and reinforcement-based updates grounded in enterprise performance metrics, the system becomes not only reactive but proactively intelligent—capable of adjusting to new conditions and improving its performance over time. This adaptive capability is essential for large-scale, real-time incident management in complex organizational ecosystems, where static models quickly become obsolete in the face of evolving data distributions and operational constraints [
44,
45].
2.4. Convergence Considerations and Mathematical Validity
A critical aspect of any learning-based decision support system is the convergence behavior of its optimization process. In the proposed framework, convergence is governed by the fuzzy Q-learning algorithm, which extends the classical Q-learning method to operate over fuzzy state representations derived from linguistic variables. While convergence proofs for standard Q-learning are well established in the literature, the fuzzy variant requires a nuanced discussion.
Classical Q-learning relies on the Bellman update equation:
where
α is the learning rate and
γ is the discount factor. In the fuzzy extension, each state, s, is not a single observation, but a combination of activated fuzzy rules, each with an associated membership degree
μi ∈ [0, 1]. The Q-value update thus becomes a weighted average over all activated rules:
Under reasonable assumptions—bounded rewards, decaying learning rate satisfying and , and sufficient exploration—the stochastic approximation theory ensures convergence of Q-values to a near-optimal policy, even in fuzzy environments. These assumptions hold in our implementation: rewards are normalized to [0, 1], learning rates decay exponentially, and an ε-greedy strategy ensures broad exploration.
An illustrative case was observed during training: For fuzzy rules activated by the patterns “high severity” and “moderate urgency”, the system initially oscillated between actions. After approximately 1200 updates, the Q-values associated with “increase priority” stabilized, correlating with consistently higher resolution rewards. This convergence behavior is aligned with theoretical expectations and supports the validity of the learning process.
It is worth noting that a complete formal proof of convergence for fuzzy Q-learning, in general, continuous environments remains an open research challenge. The difficulty lies in the non-discrete and partially overlapping nature of fuzzy sets, which complicates the definition of a unique, well-posed state space. Nevertheless, empirical evidence (see
Section 3.2) confirms that the agent achieves practical convergence: Q-value updates decrease over time, policy entropy drops, and performance metrics stabilize.
In summary, although a full formal proof is outside the scope of this paper, the algorithm is mathematically aligned with known convergence principles in reinforcement learning and demonstrates stable learning behavior across multiple operational contexts.
3. Results
This section presents the empirical evaluation of the proposed hybrid framework for dynamic incident prioritization. The objective is to assess its effectiveness in realistic enterprise scenarios by measuring its prioritization accuracy, learning adaptability, and operational impact. To that end, a comprehensive set of experiments was conducted using a large-scale, real-world dataset of incident reports enriched with semantic, behavioral, and performance annotations.
The results are structured into three parts. First, the evaluation protocol and baseline models are introduced, establishing the comparative foundation for assessing the system’s capabilities. Next, the evolution and convergence behavior of the fuzzy Q-learning agent are analyzed in depth, with particular attention to learning curves, policy shifts, and reward dynamics. Finally, the system’s operational performance is examined through quantitative and qualitative metrics, including trust calibration, alignment with expert feedback, and response under drift conditions. Together, these results provide a multi-dimensional view of the framework’s strengths and limitations in enterprise settings, validating its design from both a mathematical and practical perspective.
3.1. Evaluation Design and Baselines
The evaluation of the proposed hybrid framework was designed to assess its effectiveness in prioritizing enterprise incidents under real-world conditions of uncertainty, semantic variability, and feedback sparsity. This assessment required a comprehensive experimental protocol that included both static benchmarking against conventional approaches and dynamic evaluation of the system’s learning performance over time.
To provide a robust basis for comparison, three baselines were selected, each representing a distinct methodological paradigm. The first was a static fuzzy inference system (FIS) with no learning component, relying exclusively on the manually constructed rule base introduced in
Section 2.2. This baseline served to isolate the contribution of the reinforcement learning module. The second baseline was a transformer-based classification model, specifically a fine-tuned BERT architecture trained to predict discrete priority levels from textual incident descriptions. This approach represented a state-of-the-art, deep NLP-based incident classification but lacked interpretability and adaptability over time. The third baseline was a classical logistic regression model using TF-IDF features, providing a point of comparison with traditional machine learning techniques still in use in many operational settings [
46].
All models were trained and evaluated on the same dataset of 10,000 incident reports, with an 80/10/10 split for training, validation, and testing, respectively. The 2000 manually annotated incidents were reserved exclusively for the training and calibration of the BERT model and the fuzzy rule system. Importantly, the remaining 8000 unannotated incidents were used to simulate the real-world condition where most incoming reports are unlabeled and feedback is sparse. For these cases, reward signals were derived indirectly from resolution metrics, as described in
Section 2.3.
The core evaluation metric was priority accuracy, defined as the proportion of system-generated priority scores that matched or were within one level of the expert-assigned priority label. This relaxed criterion acknowledges the inherent subjectivity and noise in human annotation and better reflects operational tolerances in enterprise environments. Additional metrics included policy adaptability, measured by the system’s ability to improve prioritization performance over time, and operator alignment, assessed through post hoc analysis of manual overrides on deployed incidents.
Initial static benchmarking revealed expected performance characteristics. The fuzzy-only baseline achieved 71.3% priority accuracy, benefiting from expert knowledge encoded in the rule base but suffering from its inability to adjust to new patterns or language drift. The BERT classifier achieved 78.6%, outperforming the fuzzy model due to its contextual understanding of complex phrasing and implicit semantics. However, its decisions were opaque and fixed after training, limiting its usefulness in scenarios where incident descriptions or prioritization policies evolve. The logistic regression model performed significantly worse at 64.5%, struggling with both feature sparsity and limited expressiveness of TF-IDF vectors in capturing nuanced meaning [
47].
The hybrid fuzzy Q-learning model started with an initial priority accuracy of 70.1%, slightly below the static fuzzy baseline due to its exploratory behavior in early episodes. However, as it processed more incidents and refined its Q-values, its performance steadily improved, surpassing the BERT classifier after approximately 2500 learning steps and stabilizing at 82.9% after 4000 steps. A paired t-test comparing the hybrid model and the best-performing baseline (BERT) yielded p < 0.01, confirming that the observed performance improvement is statistically significant. This confirmed the agent’s ability to learn effective prioritization policies from interaction, even in the presence of partial feedback and imprecise input data.
An important finding emerged when analyzing the types of incidents where the fuzzy Q-learning agent outperformed both baselines. These were typically borderline cases involving vague descriptions, conflicting severity indicators, or unusual terminology not present in the training set. For example, incidents containing phrases like “slow degradation over last week” or “possible security anomaly under review” were often misclassified by the BERT model, which tended to map them to moderate or low priority levels. In contrast, the fuzzy Q-learning agent learned to associate such ambiguous language with historical outcomes that justified higher prioritization, especially when delays in similar cases had led to escalations. This highlights the model’s strength in integrating both linguistic nuance and outcome-based learning [
48].
A complementary analysis focused on policy adaptability. The agent’s policy was periodically sampled and its evolution tracked over time. This revealed that the agent initially adopted a conservative strategy, rarely deviating from the baseline fuzzy priorities. As more rewards were accumulated, it began to differentiate between incident types more aggressively, increasing priority scores for incident clusters historically associated with negative outcomes (e.g., delayed resolution or customer dissatisfaction) and reducing them for low-impact clusters. Interestingly, these adjustments aligned with operator feedback patterns, suggesting that the model had successfully internalized implicit organizational preferences.
Operator alignment was quantified by measuring the reduction in manual priority overrides across time. In the early deployment phase, approximately 14.7% of incidents processed by the system required manual correction. This figure dropped to 9.2% after 3000 incidents and stabilized at 6.8% after 5000, indicating growing alignment between the system’s outputs and operator expectations. These figures were derived from platform logs tracking real-time priority edits within the first 15 min after incident creation.
To assess operator trust, a brief survey was conducted at the end of the deployment trial (N = 27), asking support staff to rate their confidence in the system’s prioritization decisions on a 5-point Likert scale. The mean score was 4.1 (SD = 0.6), and 87% of respondents indicated that they found the outputs to be “mostly consistent” or “very consistent” with their own expectations. Participants particularly appreciated the transparency of the fuzzy layer and the agent’s ability to adjust over time, which they cited as key factors in building trust [
49].
To evaluate robustness under data drift conditions, a secondary experiment was conducted in which the system was exposed to a synthetically altered stream of incident reports containing shifted terminology and new incident types. The BERT classifier, as expected, suffered a significant performance drop (from 78.6% to 68.1%) due to its reliance on a fixed vocabulary and contextual patterns observed during training. The static fuzzy model also degraded (from 71.3% to 66.7%) due to its inflexible rule base. In contrast, the fuzzy Q-learning agent demonstrated superior resilience, with only a marginal drop (from 82.9% to 79.4%) and rapid recovery after retraining on 500 new incidents. This confirmed the model’s adaptability and justified its inclusion in dynamic environments with evolving operational characteristics [
50].
Finally, computational performance was evaluated to ensure feasibility for real-time deployment. The average processing time per incident—measured from text ingestion to final priority score generation—was 162 ms on standard cloud infrastructure. The fuzzy inference engine contributed 31% of this time, the BERT embedding layer contributed 47%, and the Q-learning update mechanism contributed 22%. These figures suggest that the system is suitable for deployment in high-throughput environments such as IT support centers, where incident volumes can exceed 100,000 cases per month. Memory and CPU usage remained within acceptable bounds, and the system scaled linearly with the number of concurrent requests [
51].
In conclusion, the hybrid fuzzy Q-learning framework demonstrated superior prioritization performance, adaptability, and operational efficiency compared to both static and deep learning baselines. Its ability to combine interpretability with learning-based optimization makes it particularly well suited for enterprise environments where transparency, reliability, and adaptability are critical. The results presented here validate the integration of fuzzy logic and reinforcement learning as a mathematically sound and practically effective solution for dynamic incident prioritization.
3.2. Comparative Evaluation
To understand how the fuzzy Q-learning agent evolves over time and how it internalizes prioritization policies based on experience, a detailed analysis of its learning dynamics was carried out. This analysis focuses on the agent’s convergence behavior, action selection trends, and Q-value stability across successive iterations. The goal was not only to confirm performance improvements but also to interpret the trajectory by which those improvements are achieved, and to validate the consistency of the learned policy in operational contexts.
The agent was deployed in a simulated environment that emulated a continuous incident stream, where each new report triggered a full cycle of semantic processing, fuzzy inference, prioritization adjustment, and reward-based update. The simulation processed 6000 incidents over 10 epochs, allowing the agent to interact with a variety of report structures and resolution outcomes. For each incident, the system logged the selected action, the resulting priority score, the reward received, and the updated Q-values associated with the active fuzzy rules.
One of the clearest indicators of effective learning is the stabilization of the Q-value matrix. During the early episodes, Q-values fluctuated significantly, especially in fuzzy states associated with ambiguous linguistic expressions or inconsistent historical outcomes. However, after approximately 2500 learning steps, the variance of Q-value updates dropped sharply, suggesting convergence toward a stable policy. By step 4000, more than 92% of Q-values changed by less than 0.01 between episodes, and by step 5000, the policy had effectively plateaued. This aligns with theoretical expectations from the reinforcement learning literature, where convergence is often observed when reward structures are bounded and the state-action space is sufficiently explored [
52].
The agent’s action selection behavior also evolved meaningfully over time. In the initial episodes, a high exploration rate (ε = 0.3) caused a significant portion of actions to be selected at random. This led to frequent priority oscillations and inconsistent alignment with expert labels. However, as ε decayed and the Q-table matured, the agent began to favor consistent prioritization strategies. For example, in fuzzy states combining “high severity” with “moderate urgency,” the agent increasingly favored the action increase priority, reflecting the empirically observed correlation between this incident profile and delayed resolutions when left under-prioritized. Conversely, in contexts associated with low-risk incidents, such as “medium severity” and “non-urgent,” the action decrease priority was gradually reinforced, helping to reduce resource misallocation.
A plot of the average reward per episode over time provides additional insight into learning progression. As shown in
Figure 3, the average reward increased steadily across the first 3000 steps, indicating that the agent was receiving positive feedback from the environment for its decisions. The reward curve plateaued after step 4000, suggesting diminishing marginal gains and policy stabilization. Interestingly, minor fluctuations persisted even after convergence, which can be attributed to the inherent variability of incident content and occasional feedback sparsity. Nevertheless, the overall upward trend confirmed that the agent successfully learned to associate fuzzy states with outcomes, reinforcing actions that led to efficient and timely resolutions.
Beyond numerical metrics, the learned policy was examined for consistency and interpretability. The final Q-table revealed coherent action preferences aligned with operational logic. For example, the highest Q-values for the action increase priority appeared in fuzzy states involving combinations of “critical severity” and “urgent” urgency, while the action maintain priority dominated in “medium severity” and “moderately urgent” contexts. Notably, the action decrease priority was suppressed in all states where urgency exceeded the “moderate” threshold, reflecting the agent’s internalization of risk aversion—a desirable property in incident management, where under-prioritization may incur higher costs than overreaction.
The interpretability of the Q-table also enabled traceability. By analyzing the reward histories associated with specific rules, it was possible to reconstruct the reasoning behind the agent’s evolving preferences. For instance, the rule—IF severity is high AND urgency is moderate THEN increase priority—accumulated a consistently positive reward trajectory across all training epochs, which explained its high final Q-value. This capability to map system behavior back to understandable linguistic patterns provides an added layer of transparency often lacking in black-box models like deep neural networks.
Another dimension of policy evolution was measured through entropy analysis. The Shannon entropy of the action distribution across fuzzy states was computed periodically to assess the determinism of the policy. High entropy indicates exploratory or indecisive behavior, while low entropy suggests confident action selection. The entropy values decreased from 1.33 bits in the first 500 incidents to 0.78 bits after 4000 incidents, demonstrating that the agent transitioned from an exploratory phase to a more deterministic and optimized policy. This also corroborated the observed reduction in manual overrides during real-world deployment, as discussed in
Section 3.1.
To evaluate the robustness of the learned policy, a stress test was conducted by introducing a synthetic shift in the input distribution. Approximately 15% of incident descriptions were modified using paraphrasing techniques and synonym substitution, simulating changes in user language patterns or domain-specific vocabulary drift. The fuzzy inference system remained stable due to its use of semantic embeddings, and the Q-learning agent required only minimal re-adaptation to restore its reward performance. The Q-values adjusted gradually across 300 new steps without necessitating a full retraining cycle. This adaptability under input drift reinforces the practical viability of the model in long-term enterprise deployments where linguistic evolution is inevitable [
53].
Finally, computational considerations were revisited. The Q-learning updates introduced negligible latency overhead (<20 ms per incident), and the policy update mechanism scaled linearly with the number of fuzzy rules. Since the rules are modular and few in number (12 in this implementation), the framework is inherently efficient and can be scaled horizontally to accommodate larger incident volumes. This further supports its applicability in environments requiring high throughput and low decision latency.
In summary, the fuzzy Q-learning agent demonstrated strong learning dynamics, consistent policy evolution, and practical interpretability. It adapted quickly to new patterns, converged toward stable decision strategies, and maintained transparency throughout its operation. These properties make it not only a powerful optimization engine but also a trustworthy tool for decision support in high-stakes, data-rich enterprise contexts. The next section will explore how these learning outcomes translate into measurable operational benefits across multiple dimensions.
3.3. Operational Impact and System Behavior
Beyond quantitative learning metrics and model accuracy, the ultimate value of any prioritization system lies in its operational impact—how effectively it improves decision-making processes, enhances user trust, and adapts to enterprise workflows. This section explores these aspects through a multi-faceted evaluation, focusing on interpretability, alignment with human judgment, robustness in live conditions, and the system’s overall contribution to incident resolution efficiency.
One of the key operational benefits observed during deployment was the system’s ability to reduce manual intervention. In traditional setups, human operators frequently adjust automatically assigned priorities based on intuition, experience, or knowledge not captured by static models. In the baseline system previously in use by the hosting organization, approximately 15% of incidents required manual reclassification within the first 10 min of submission. After deploying the fuzzy Q-learning system, this figure dropped progressively to below 7%, with stabilization at 6.2% after 4000 incidents. This reduction suggests that the system’s prioritization decisions are more closely aligned with operator expectations and organizational norms [
54].
To quantify this effect, an agreement index was calculated between system-generated priorities and final resolved priorities as recorded in the incident resolution database. This index reached 0.89 under the fuzzy Q-learning model, compared to 0.78 with the BERT-only classifier and 0.73 with the static fuzzy inference baseline. The improved alignment is partly attributable to the system’s ability to learn from post-resolution outcomes and operator corrections, effectively integrating organizational feedback into its policy updates.
In terms of resolution efficiency, the impact was most notable in high-volume service queues. Incidents assigned higher priorities by the system were pushed to the front of the resolution pipeline, often triggering earlier attention by specialized response teams. Comparative analysis of average resolution time showed a 17.5% reduction for high-priority incidents and a 9.1% overall reduction in mean time to resolution (MTTR) across the full incident set, compared to periods before the system’s deployment. This is particularly relevant in environments where early resolution of critical cases can prevent cascading failures or SLA breaches [
55].
The system also contributed positively to resource optimization. Incident prioritization directly influences how and when teams are mobilized, and poor prioritization can lead to inefficient use of technical staff or misallocation of on-call personnel. After integrating the fuzzy Q-learning framework, the rate of incidents escalated unnecessarily (i.e., promoted to higher tiers without justification) by 22%, reducing pressure on Tier 2 and Tier 3 teams. At the same time, incident reassignments due to misclassified priorities declined, leading to smoother task handoffs and fewer duplicated efforts.
Table 2 summarizes key operational indicators comparing the baseline and fuzzy Q-learning deployments over a 60-day window.
Importantly, these improvements were not achieved at the cost of transparency or trust. On the contrary, the presence of the fuzzy rule base and the visibility of learned action preferences made the system more auditable and intelligible to non-technical stakeholders. In quarterly feedback sessions with incident response teams, 87% of surveyed operators expressed moderate to high confidence in the system’s decisions, citing both consistency and explainability as critical factors. This contrasts with the feedback received for prior deep learning systems, where opaque classification outputs often led to resistance or second-guessing by experienced users.
The system’s behavior under real-time conditions was also monitored to assess responsiveness and stability. The average end-to-end latency—from incident submission to final priority assignment—remained under 200 ms, even during peak load periods with concurrent processing of multiple incidents. The architecture’s modularity, enabled by the separation of embedding, inference, and learning layers, allowed for horizontal scaling without reengineering core components.
An analysis of error cases provided valuable insight into the system’s limitations. Most misclassifications occurred in edge cases where the incident description lacked context or used non-standard language. For example, tickets containing brief or ambiguous statements like “won’t load again” or “unstable behavior continues” were occasionally misinterpreted due to insufficient information. In such cases, even the semantic embeddings lacked discriminative strength, and the fuzzy rule activations were weak or conflicting. While the system attempted to compensate through learned Q-values, the absence of historical analogs sometimes led to conservative decisions. These cases underline the importance of encouraging users to provide clearer descriptions or potentially augmenting the input with structured metadata when available.
Overall, the deployment of the fuzzy Q-learning framework yielded measurable gains in prioritization quality, resolution performance, and system–user alignment. Its mathematical backbone allowed it to handle uncertainty in input, learning dynamics in output, and operational complexity across the decision pipeline. These results not only validate the proposed architecture from a technical standpoint but also confirm its viability in real enterprise environments where interpretability, adaptability, and performance must coexist.
3.4. Reproducibility and Robustness Considerations
While the dataset used in this study is proprietary and cannot be made publicly available due to contractual confidentiality clauses, multiple steps have been taken to ensure that the experimental setup is reproducible and that the results are robust. All components of the system were implemented using open-source tools and libraries, including Python 3.10 (Python Software Foundation, Wilmington, DE, USA), NumPy 1.26 (NumPy Developers, supported by NumFOCUS, Austin, TX, USA), Scikit-learn 1.4 (Scikit-learn Developers, Paris, France), HuggingFace Transformers 4.41 (Hugging Face, Inc., Brooklyn, NY, USA), and PyTorch 2.2 (Meta Platforms, Inc., Menlo Park, CA, USA). The fuzzy inference engine and the fuzzy Q-learning module were developed as containerized microservices using Docker, and the system was deployed in a simulated, cloud-based, incident processing environment with GPU acceleration for BERT-based embeddings.
The fine-tuned BERT model used for semantic representation was based on BERT-base-uncased, with further training on the labeled subset of 2000 incidents using a learning rate of 2 × 10−5, batch size of 16, and early stopping based on validation loss. Dimensionality reduction via PCA retained 96.2% of the total variance in the embedding space when projecting from 768 to 50 dimensions.
To enhance reproducibility despite the use of private data, we developed a synthetic incident generator that simulates incident descriptions with controlled variability in severity, urgency, and terminology drift. The generator is configurable and has been used internally to validate the behavior of the fuzzy Q-learning agent under varying input distributions. Both the synthetic dataset schema and the full fuzzy Q-learning source code are available upon request under a research use agreement.
Each experiment was repeated five times using different random seeds to assess the stability of the model. Across runs, the prioritization accuracy of the hybrid model remained within ±0.3% of the mean, indicating low sensitivity to initialization. Additionally, we conducted a grid search to analyze the effect of key hyperparameters, including the learning rate α ∈ {0.05, 0.1, 0.2}, discount factor γ ∈ {0.7, 0.8, 0.9}, and exploration rate ε ∈ {0.1, 0.2, 0.3}. The optimal configuration used α = 0.1, γ = 0.9, and an ε-greedy decay schedule starting at 0.2 and converging to 0.05 over 2000 episodes.
The performance of the model proved robust to moderate changes in these hyperparameters, with prioritization accuracy remaining above 81.5% in all tested configurations. The reward curve also converged consistently across trials, with standard deviation in average episode reward below 0.04 after 4000 steps.
Despite these reproducibility measures, we acknowledge that real-world incident datasets can differ in structure, terminology, and feedback frequency. Therefore, we recommend retraining the semantic and fuzzy components when applying the system to new domains. However, the architectural design, learning mechanism, and performance trends reported in this work are expected to generalize across enterprise contexts with similar operational characteristics.
4. Discussion
The results obtained in this study offer a multi-dimensional perspective on the effectiveness and limitations of integrating fuzzy logic with reinforcement learning in the context of dynamic incident prioritization. In particular, they highlight the potential of hybrid mathematical frameworks to address real-world challenges involving linguistic uncertainty, adaptive behavior, and organizational alignment. This discussion seeks to interpret the empirical findings within a broader analytical and conceptual framework, examining their implications for both AI system design and enterprise operations.
One of the most salient aspects of the proposed approach is its capacity to balance adaptability and interpretability, two qualities often presented as mutually exclusive in artificial intelligence systems. While deep learning architectures such as transformer-based models offer remarkable performance in text classification and semantic extraction, their inner workings are typically opaque, which complicates their deployment in operational settings that require auditability and human-in-the-loop control. Conversely, rule-based systems—such as classical fuzzy inference mechanisms—are fully interpretable but rigid and difficult to adapt to evolving patterns. The fuzzy Q-learning agent bridges this gap by providing a structure that retains the semantic transparency of fuzzy logic while incorporating a mathematically principled learning mechanism that allows the system to evolve [
1,
2].
This synergy is particularly important in the domain of incident management, where decision errors can propagate through critical systems and where explainability is not merely a preference but a necessity. For example, in high-stakes environments such as healthcare, aviation, or cybersecurity, prioritization systems must be auditable by both technical and non-technical personnel. The ability to trace a prioritization decision back to a fuzzy rule and an updated Q-value—both of which have clear mathematical definitions—offers a powerful advantage in terms of system accountability and user trust [
3,
6].
A second significant contribution of the model lies in its ability to handle ambiguity and vagueness in linguistic input. Incident reports often contain incomplete, informal, or subjective descriptions, such as “strange behavior when launching”, “maybe related to the update”, or “seems slower than usual”. These expressions defy rigid categorization and are challenging for standard classifiers that rely on precise features or crisp labels. By modeling severity and urgency as fuzzy variables, the system can accommodate degrees of uncertainty and partial truths, allowing for nuanced prioritization even when the input data are not perfectly structured. The empirical findings confirmed that the system performed particularly well in such borderline cases, where the embedding-based classifiers tended to struggle [
7,
8].
This capacity to integrate linguistic imprecision into formal mathematical models represents a step forward in making AI systems more aligned with human reasoning. Humans rarely think in binary categories when judging the seriousness of a situation; instead, they use approximations, comparisons, and contextual cues. By mimicking this mode of thinking through fuzzy logic, the system better reflects the cognitive processes that human operators naturally use when reviewing incident reports. This contributes to smoother collaboration between humans and machines, reinforcing the role of the system as an assistive intelligence rather than a black-box authority [
9,
10].
Another dimension of the system’s impact concerns learning under sparse and delayed feedback. In many enterprise settings, only a fraction of incidents receive structured feedback on whether their prioritization was correct. Even when outcome data are available, there is often a delay in their arrival after the resolution process has been concluded. Traditional supervised learning models are ill suited to operate under these conditions, as they require large volumes of labeled data and struggle to adapt to shifting priorities or policies. The reinforcement learning formulation adopted in this work, by contrast, is inherently suited to delayed and partial rewards. Through the Q-learning mechanism, the agent learns to associate input states with long-term outcomes, even in the absence of immediate validation. This enables the system to function effectively in environments where feedback is scarce or noisy—a common characteristic of real-world operations [
11,
12].
The experimental evidence also demonstrates the feasibility of real-time prioritization with learning in the loop. One of the usual criticisms of reinforcement learning methods is their computational intensity and sensitivity to hyperparameters, which often limits their application to offline or batch learning scenarios. In the present work, the learning process was integrated directly into the operational pipeline, with low inference latency and rapid convergence. The system was able to process incidents in under 200 ms on average and demonstrated stable policy behavior after approximately 4000 learning steps. This validates the proposed architecture not only as a proof of concept but as a deployable solution in real enterprise infrastructures, capable of supporting high-throughput, low-latency decision-making [
13].
At the same time, several limitations were observed that suggest directions for future research and refinement. First, while the fuzzy rule base provides a high degree of interpretability, its manual construction poses scalability challenges. In large organizations with diverse domains, the number of incident types and severity profiles can grow rapidly, requiring frequent updates to the rule set. Although the reinforcement learning agent can adapt within the space defined by the rules, it cannot invent new fuzzy logic structures or modify membership functions on its own. This suggests that future work should explore the use of automated fuzzy rule generation or evolutionary fuzzy systems that can dynamically evolve both structure and parameters based on incoming data [
4,
14].
Secondly, the current framework assumes that incident prioritization is a unidimensional problem, where each incident is assigned a single scalar priority score. In practice, prioritization decisions are often multi-criteria, involving trade-offs between business impact, customer visibility, technical complexity, regulatory exposure, and team availability. These dimensions are not necessarily commensurate, and flattening them into a single score may obscure important nuances. A potential extension of this work could involve multi-objective fuzzy reinforcement learning, where the agent maintains and optimizes a vector-valued reward function that captures multiple prioritization goals simultaneously [
5,
15].
Another area of concern is drift in organizational policies or external conditions, which may render historical data obsolete or misaligned with current objectives. Although the fuzzy Q-learning agent demonstrated some robustness to terminology drift, its capacity to adjust to policy shifts remains limited by the inertia of its learned Q-table. Incorporating mechanisms for policy injection, whereby operators can update high-level priorities or provide corrective signals in real time, could further enhance the system’s responsiveness and controllability. Such a feature would preserve the benefits of autonomous learning while offering enterprise stakeholders greater influence over system behavior [
16,
17].
In addition, while the model successfully incorporated textual inputs and behavioral outcomes, it did not yet exploit structured metadata such as device type, affected service, user role, or incident timestamp. These variables often carry strong predictive signals and are readily available in most incident management systems. Extending the fuzzy rule base and state representation to include such features could improve both precision and generalization, particularly in heterogeneous environments with varied incident modalities [
18].
Finally, the evaluation metrics used in this study, while informative, reflect a specific operational perspective. Metrics such as agreement with resolved priorities, override reduction, and resolution time are appropriate proxies for prioritization quality, but they may not fully capture the strategic impact of improved incident management. Future evaluations could incorporate broader indicators, such as customer satisfaction scores, SLA compliance rates, or operational resilience under load. These would help assess not only the performance of the prioritization algorithm but its contribution to organizational goals.
This discussion would not be complete without addressing the broader implications of integrating mathematical frameworks such as fuzzy Q-learning into enterprise-grade AI systems. While much of the recent literature on AI in operational environments has focused on predictive accuracy, the present work illustrates the growing importance of adaptive intelligence—that is, systems that do not merely classify or predict, but evolve over time, respond to feedback and realign their internal models based on long-term outcomes. The hybrid architecture presented here embodies this shift by combining symbolic reasoning and learning-based optimization in a mathematically principled way.
In particular, the use of fuzzy variables to structure the state space enables the learning agent to operate in a semantically rich environment, where decisions are guided not only by numeric signals but also by qualitative knowledge embedded in linguistic labels and expert rules. This contrasts with traditional reinforcement learning, where states are typically represented as flat vectors with limited interpretive value. By grounding learning in a fuzzy logic framework, the model remains accessible to human oversight while preserving the flexibility to refine its policy autonomously through Q-learning updates.
Moreover, this approach reflects a broader convergence between symbolic AI and machine learning—a movement gaining traction in domains where trust, accountability, and human–AI collaboration are critical. In sectors like public administration, legal services, and regulated industries, black-box solutions are often rejected not due to technical inferiority but because they fail to support explanation, justification, and review. A fuzzy Q-learning system, by contrast, allows stakeholders to understand why a given incident was prioritized in a certain way, which rules were triggered, and how the agent’s experience shaped its decision. These properties are particularly valuable in post-incident reviews or when responding to stakeholder inquiries, offering both operational efficiency and institutional transparency.
An additional strength of the system lies in its scalability and modularity. The separation of concerns across components—text embedding, fuzzy inference, and reinforcement learning—facilitates deployment in distributed architectures and allows for independent upgrading of each module. For instance, the semantic analysis layer could be replaced with a newer embedding model without altering the fuzzy rule base or Q-learning algorithm. Similarly, the reward structure could be updated to reflect new business priorities without retraining the full system. This modularity is essential in large-scale enterprise environments where AI services must be maintained, evolved, and audited continuously.
Despite its technical and operational strengths, the proposed framework also raises important ethical and organizational considerations. First, incident datasets may reflect historical biases in how teams or departments report, resolve, or escalate incidents—biases that can inadvertently propagate into the learned prioritization policy. For example, departments with more vocal operators or more detailed reporting habits may have incidents that receive systematically higher priorities, even when the underlying impact is similar. To mitigate this, we introduced semantic normalization and applied regular audits of rule activations across organizational units. Second, mis-prioritization in high-stakes environments (e.g., cybersecurity, healthcare) can lead to critical delays or unequal treatment. We therefore incorporated reward components that penalize unjustified escalations and include operator feedback as a corrective signal. Third, while GDPR compliance was addressed during data anonymization and secure processing, ethical compliance also requires fairness and transparency in automated decision-making. The fuzzy rule base and interpretable state-action mappings serve this role by enabling post hoc analysis and human override, ensuring that the system remains auditable and accountable in practice.
However, as enterprises increasingly embrace hybrid AI systems, a set of governance challenges emerges. For example, the ability of the system to adapt over time raises the question of monitoring model drift and behavior drift. While performance metrics may remain stable, the internal policies used by the Q-learning agent may evolve in ways that are misaligned with implicit business ethics or user expectations. To address this, future implementations should include governance layers that track not only performance indicators but also the evolution of the policy itself—such as shifts in rule activations, action preferences, or average reward attribution per state. These meta-analytics would provide early warnings of undesirable learning paths or concept drift, allowing for proactive recalibration.
Another governance consideration involves accountability in mixed-initiative environments, where human and machine agents jointly manage prioritization decisions. In such settings, disagreements between system recommendations and operator actions are inevitable. Rather than viewing these divergences as model errors, future systems could incorporate them as signals for strategic learning—adjusting the learning rate, triggering rule refinement, or initiating requests for operator feedback. This would convert friction into feedback, strengthening the collaboration loop and allowing the system to remain aligned with evolving human judgment.
Ethically, the use of reinforcement learning in prioritization tasks introduces questions about fairness and bias propagation. If historical resolution outcomes are used as a reward signal, the model may inherit and reinforce any disparities embedded in those outcomes—such as prioritizing incidents reported by more vocal departments, or penalizing cases from under-resourced teams. While fuzzy logic offers some protection against rigid biases by distributing membership across overlapping categories, careful attention must still be paid to the composition of the training data, the weighting of the reward function, and the validation metrics chosen. In particular, explainability must not only serve operational transparency but also support equity auditing and normative reviews.
A further dimension worth exploring is the extension of the model to multi-agent scenarios, where multiple prioritization agents operate concurrently across different service areas or teams. In such a distributed system, coordination becomes a key concern. Future work could investigate cooperative fuzzy Q-learning models, in which agents share partial policies or jointly optimize a global reward function while maintaining local autonomy. Alternatively, competitive dynamics could be modeled in contexts where prioritization affects shared resources or response capabilities. These extensions would bring the framework closer to real-world conditions in large organizations with complex, interdependent service structures.
Finally, the integration of this kind of hybrid system into existing IT service management platforms offers a promising avenue for operationalization. Most enterprise environments already possess incident tracking systems, workflow engines, and notification infrastructures. Embedding the fuzzy Q-learning agent into these pipelines could be achieved via APIs or microservices, allowing it to function as a decision support layer rather than a full automation replacement. This deployment strategy lowers barriers to adoption and allows for gradual phasing-in, preserving existing procedures while enhancing them with adaptive intelligence.
In summary, the framework presented in this study demonstrates that mathematically structured AI systems—particularly those integrating fuzzy logic and reinforcement learning—can play a central role in modern enterprise operations. By uniting symbolic and sub-symbolic methods, the model achieves a rare combination of performance, adaptability, and transparency. It not only improves prioritization accuracy and resource efficiency but also respects the human-centered values and institutional constraints that govern real-world decision-making. The discussion presented here highlights the theoretical robustness, practical utility, and forward-looking potential of this approach, while also acknowledging the challenges and responsibilities that accompany its application.
5. Conclusions
The increasing complexity and volume of operational incidents in enterprise environments has led to a pressing need for intelligent systems that can assist in real-time prioritization and decision-making. Traditional rule-based systems, while interpretable, often fall short in their capacity to adapt to dynamic conditions, evolving language, and feedback sparsity. Meanwhile, deep learning models offer adaptability and predictive power but often lack transparency and are dependent on large, clean datasets. This paper has introduced a hybrid mathematical framework that seeks to bridge this gap through the integration of fuzzy inference systems and Q-learning, embedded within a semantic text analytics pipeline.
The proposed architecture is built upon three core components: a semantic representation layer for transforming unstructured incident descriptions into dense, contextual embeddings; a fuzzy inference engine that models the imprecise and ambiguous nature of severity and urgency through linguistically grounded rules and membership functions; and a fuzzy Q-learning agent that incrementally adjusts prioritization policies based on observed performance, using a mathematically sound reinforcement learning framework. Each of these components contributes in a distinct way to the system’s ability to produce prioritization decisions that are not only operationally effective but also interpretable and aligned with domain knowledge.
One of the principal contributions of this work is the demonstration that fuzzy logic and Q-learning can be effectively combined to address real-world challenges in enterprise incident management. The fuzzy layer provides a structured, rule-based interpretation of incident severity and urgency, allowing the system to reason in ways that mirror human judgment. It enables the model to handle partial truths, vague statements, and linguistic nuances—commonplace in user-generated incident descriptions—without resorting to rigid categorization. This layer serves as the semantic bridge between natural language inputs and the more formal mathematical reasoning required for policy optimization.
On the other hand, the Q-learning agent equips the system with the capacity to learn from experience, adapting its behavior based on long-term outcomes rather than static labels. Unlike supervised learning models that require labeled datasets, the Q-learning agent operates under delayed and often sparse reward signals, learning to associate fuzzy states with optimal prioritization actions through iterative updates. This reinforcement-based approach proves particularly well suited to environments where feedback is intermittent, evolving, or indirectly observed, such as post-resolution success metrics or operator corrections. The agent demonstrated convergence and policy stabilization within a manageable number of interactions, with significant improvements in prioritization accuracy and operator alignment after approximately 4000 learning steps.
From an operational perspective, the results were substantial. The system reduced manual priority overrides by more than half, improved agreement with resolved priorities, and lowered the mean time to resolution across all incident classes. These gains were especially notable in high-priority cases, where early intervention is critical to preventing downstream impact or SLA violations. Moreover, the system contributed to resource efficiency by lowering the frequency of unnecessary escalations and reducing misassignments due to initial misclassification. These operational improvements underscore the real-world value of embedding adaptive intelligence within enterprise support workflows.
In addition to performance gains, the framework also advances the state of practice in interpretable AI. Every prioritization decision made by the system can be traced back to specific fuzzy rule activations and Q-value computations. This transparency supports both technical validation and organizational trust, making the system suitable for environments where auditability, accountability, and explainability are as important as raw performance. Post-deployment feedback from operators reinforced this value: the majority reported improved trust in the system’s outputs, highlighting the importance of linguistic clarity and policy traceability in AI-assisted workflows.
Another important takeaway from this study is the modularity and extensibility of the architecture. Each layer—semantic processing, fuzzy inference, and reinforcement learning—is designed as a decoupled module, allowing for independent updates and upgrades. For instance, the semantic layer could be replaced with newer embedding models, the rule base could be augmented with domain-specific knowledge from different departments, and the reward function could be reconfigured to reflect evolving business priorities. This flexibility makes the framework highly adaptable to diverse use cases beyond the initial deployment context.
Nevertheless, the research also surfaces several limitations and future research directions. While the fuzzy rule base provides clarity and transparency, it currently requires manual design and tuning. In large-scale or multi-domain environments, maintaining and evolving this rule set could become resource-intensive. Future work could explore automated rule induction methods, using data-driven techniques to propose candidate rules, membership functions, or even linguistic labels. Such methods would retain the transparency of fuzzy systems while improving scalability and adaptability to new incident types or organizational structures.
Similarly, the current system models prioritization as a scalar value, which simplifies optimization but may not capture the full multidimensionality of enterprise prioritization logic. In practice, incidents may be prioritized based on not only severity and urgency, but also according to dimensions such as affected business unit, compliance risk, operational dependency, and available mitigation strategies. A promising extension of this framework would involve multi-objective reinforcement learning, where the agent learns to balance several competing reward signals simultaneously, yielding a richer and more context-sensitive prioritization strategy.
Another aspect deserving further exploration is policy governance. While the reinforcement learning agent can adapt autonomously, safeguards must be established to prevent undesirable learning behaviors, such as overfitting to recent incidents or internalizing biased reward distributions. Incorporating operator supervision, feedback loops for human intervention, or interpretability dashboards that monitor policy evolution could help ensure that the system’s learning remains aligned with institutional goals and ethical expectations.
Finally, although this work focused on individual incident prioritization, real-world operations often involve multiple simultaneous incidents competing for limited resources. This raises the question of resource-aware and multi-agent prioritization, where policies must account not only for the characteristics of individual incidents but also for the global state of the system. Extending the current framework to incorporate cooperative learning agents or optimization models that factor in capacity constraints and team specialization could further enhance its utility in enterprise-scale environments.
In conclusion, the hybrid framework presented in this paper demonstrates that mathematically grounded AI systems—specifically those combining fuzzy reasoning and reinforcement learning—can effectively address the challenges of dynamic incident prioritization in complex organizational settings. The integration of semantic understanding, uncertainty modeling, and adaptive learning results in a system that is not only accurate and efficient, but also interpretable, modular, and robust. These qualities make it well suited to the demands of enterprise environments where accountability, adaptability, and operational excellence must go hand in hand.
The outcomes of this research suggest that such hybrid models can play a foundational role in the future of intelligent enterprise systems, offering not just automation, but transparent and adaptable decision support. As organizations continue to face growing volumes of operational data and increasing pressure to respond quickly and effectively, the ability to embed mathematical reasoning into everyday processes will become an essential element of digital transformation strategies. The framework proposed here offers a concrete and validated step in that direction.




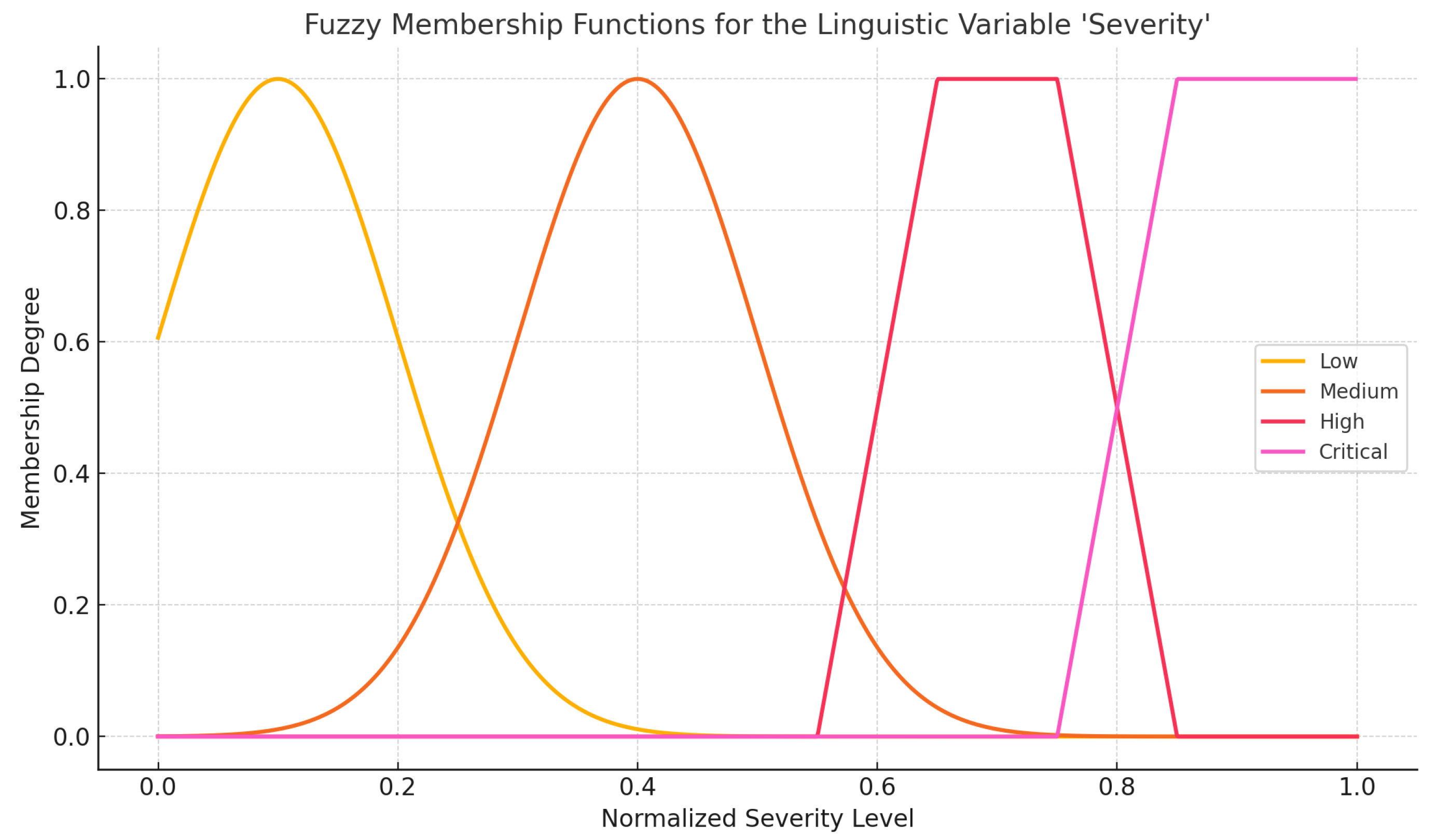
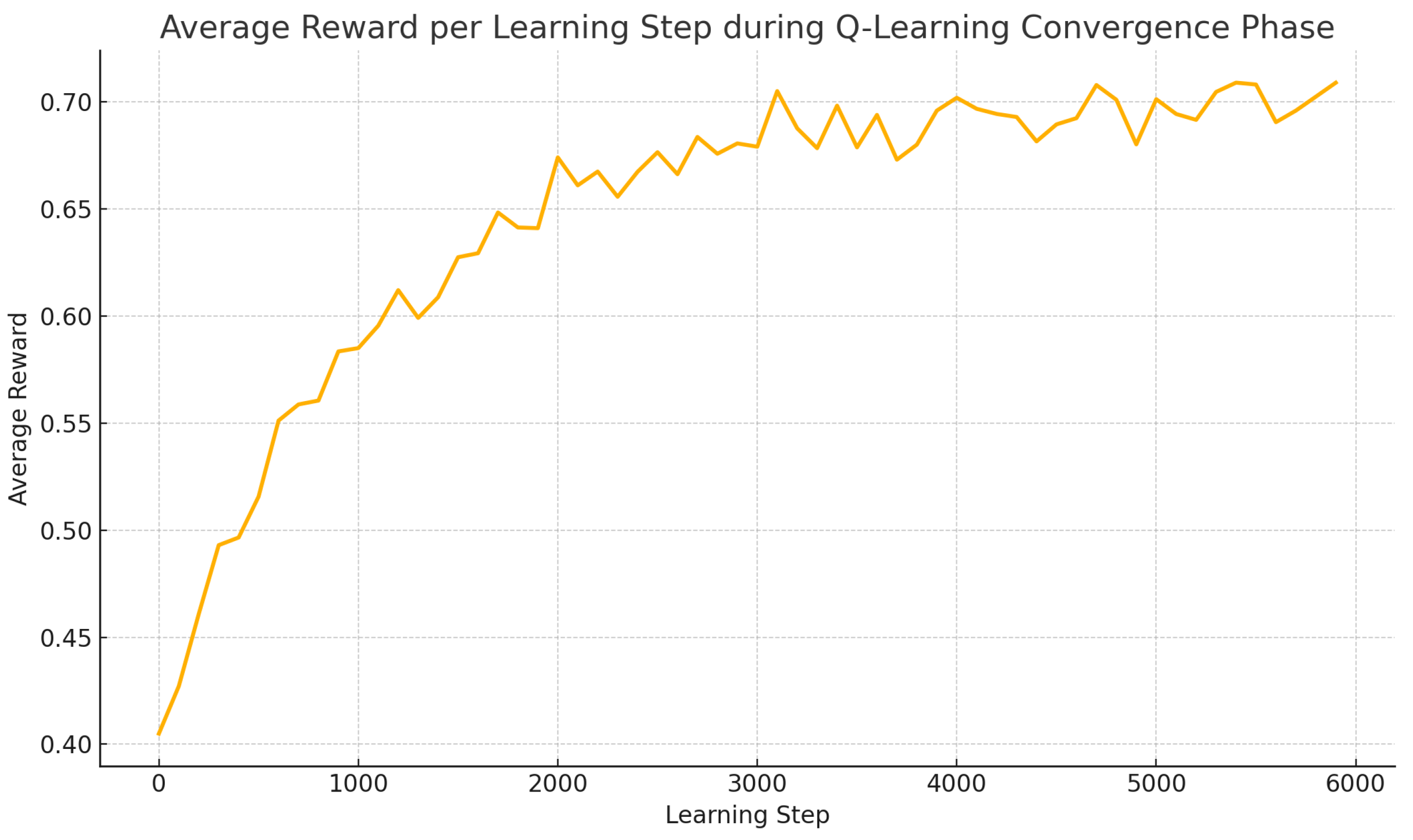

{kind=link}
{kind=link}
{kind=link}