A neural network consists of an input layer, hidden layers, and an output layer. These layers are collections of interconnected processing units called neurons. The information is fed into the input layer, multiplied by the weight, and then transmitted to the hidden layers. The hidden layers apply activation functions to the weighted information. The newly processed information is transferred to the next layer as the sum of weights. Suppose
,
, …,
are the inputs at layer
. The
linear combination at the next layer
can be obtained as
where the parameter
denotes a weight and the parameter
represents a bias. The quantity
denotes the activation of the
neuron at level
, and
stands for the activation function. Generally, the number of hidden layers is uncertain. Once the information has passed through the hidden layers, it is sent to the last layer, called the output layer. Refer to [
37] for more details about neural networks.
3.1. Residual Neural Network Structure
Ref. [
9] utilized a mortality table to price insurance contracts; however, they did not consider the stochastic mortality risk factors that insurers have to deal with in practice. Compared with the fixed mortality, stochastic mortality, which is used in this paper, captures dynamic changes so that the training process generates more accurate price estimates. Additionally, the residual network could better learn to correct random risk factors. ResNet could also learn this stochastic correction to improve performance.
Figure 1 shows the workings of the residual network. In the training process, the residual network is split into two branches: the identity mapping
x and the residual mapping
. The residual mapping branch passes through the weight layer to reach the next layer, while the identity mapping branch crosses the weight layer. The process of the identity mapping branch crossing the weight layer is called cross-layer connection. The two branches converge at
so that the network learns the features retained on
x while learning
.
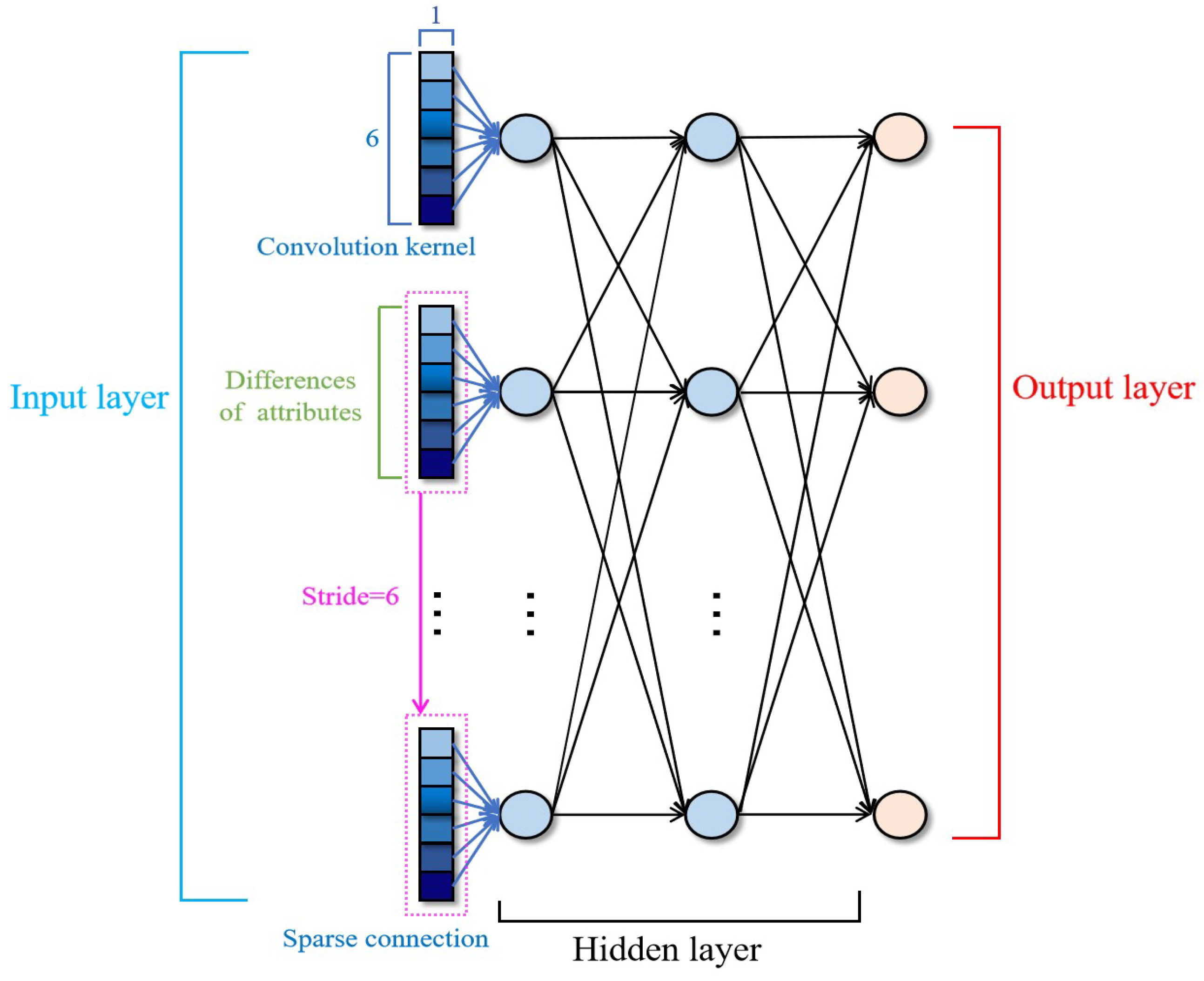
Compared with ResNet, our proposed ResPoNet has multiple layers, including a convolutional layer, non-linearity layer, residual layer, and fully connected (FC) layer, as shown in
Figure 2. To clarify the characteristics of each representative contract, we first build a convolutional layer with standardized differences between the representative contract and the policy to be priced [
38]. Both numerical and categorical attributes are included. Through the non-linear activation function known as the sigmoid function, the neurons of the attributes obtained at the input layer are fully connected: each neuron at the upper layer is connected with every single neuron at the next layer to access the implicit relationship. The two parameters of the fully connected layer,
m and
n, denote the number of neurons needed to connect at the upper and lower layers, respectively. The network performs a residual connection at the second layer of the activation function. The residual mapping branch passes through the second fully connected layer and a batch normalization layer, whilst the identity mapping branch directly passes through the softmax layer, which enlarges the distances between the outputs.
The basic procedure of the ResPoNet algorithm is described in Algorithm 1. The algorithm takes as input a training set comprising three components: a vector
of insurance policy values in the training set, an attribute matrix
with
vectors, where each vector describes the attribute differences between a portfolio policy and
representative contracts, and an
distance matrix
derived from traditional spatial interpolation, where each element
represents the distance from policy
i to representative contract
j. Here,
and
denote the sizes of the training set and the representative contract set, respectively. In the procedural stage, for each policy in the portfolio, the ResPoNet is trained using
to learn two key components: an optimal distance function that adapts to the policy attributes and a set of optimal weights for the representative contracts. This training process involves iterative optimization to minimize the discrepancy between the network’s predicted valuations and the ground-truth values from the training set. The output of the algorithm is a tuple
, where
represents the learned weights assigned to the representative contracts, and
denotes the corresponding bias parameters. These parameters collectively enable the model to compute policy valuations by integrating attribute differences and spatial distances in a computationally efficient manner, balancing accuracy and interpretability.
| Algorithm 1: General algorithm procedure of ResPoNet |
|
For the specific implementation of ResPoNet, we predefine the number of neurons and network parameters. Notably, the neuron count in each FC layer is systematically configured as 128, a design specification aimed at maintaining uniform layer dimensionality to facilitate stable gradient propagation throughout the network. The residual layer comprises two 128-neuron FC layers with sigmoid activation and batch normalization, connected by a skip connection (identity mapping) that adds the input to the block’s output. Six attributes of a policy are utilized as inputs to train the network. The six differences in the attributes between each policy in the portfolio and each corresponding representative contract form a group. Each group is then connected to a node at the next layer via the sparse connection. Therefore, we set the convolution kernel to
and the stride to 6 to achieve the sparse connection at the first layer (see
Figure 3). Every rectangle composed of squares represents a group of attribute’s differences. Each neuron at the input layer is known as a vector
, revealing the difference. If
c and
n denote the categorical attribute and the numerical attribute, respectively, then
represents the difference in the categorical attribute of
, while
is the difference in the numerical attribute. We denote the input policy and representative contract as
p and
, respectively.
and
represent the categorical and numerical attributes of the input policy, respectively, while
and
represent the categorical and numerical attributes of the representative contract, respectively. Thus, the difference in the
categorical attribute
has the following form:
has the form
=
. The function
standardizes the differences in the numerical attributes. Following [
39], we set the parameters (
) at the fully connected layer based on the intuitive bases.
For the residual mapping process, the FC layer and the batch-normalization layer constitute the correction module. Finally, the network outputs the weights of each representative contract needed to estimate the input VA policy. Thus,
where
contains the weights and biases, and
and
represent the valuation of the input policy and each representative contract, respectively. After adding the representative contract value (value (R)) in
Figure 2, these outputs take into account both the loss of value and the loss of weights computed using the traditional spatial interpolation method.
3.2. Training Methodology
This subsection explains how we train a neural network and emphasizes the importance of weight regularization. As suggested in
Section 2, the focal loss improves detection accuracy by improving the loss function. Here, we add a loss of weight item into the loss function for further improvement so that ResPoNet could approximate the correct valuation, thereby retaining the universal meaning of the distance function. Neural network learning falls into three categories: supervised learning, unsupervised learning, and reinforced learning. We adopt the backpropagation algorithm to exploit supervised learning when training the network by providing it with inputs and matching output patterns [
40]. The training begins with random weights, and the parameters are iteratively adjusted to minimize the loss function. Next, the mean squared error (MSE) quantifies the distance between the estimated value and the true value. Generally, minimizing the loss function corresponds to minimizing the MSE.
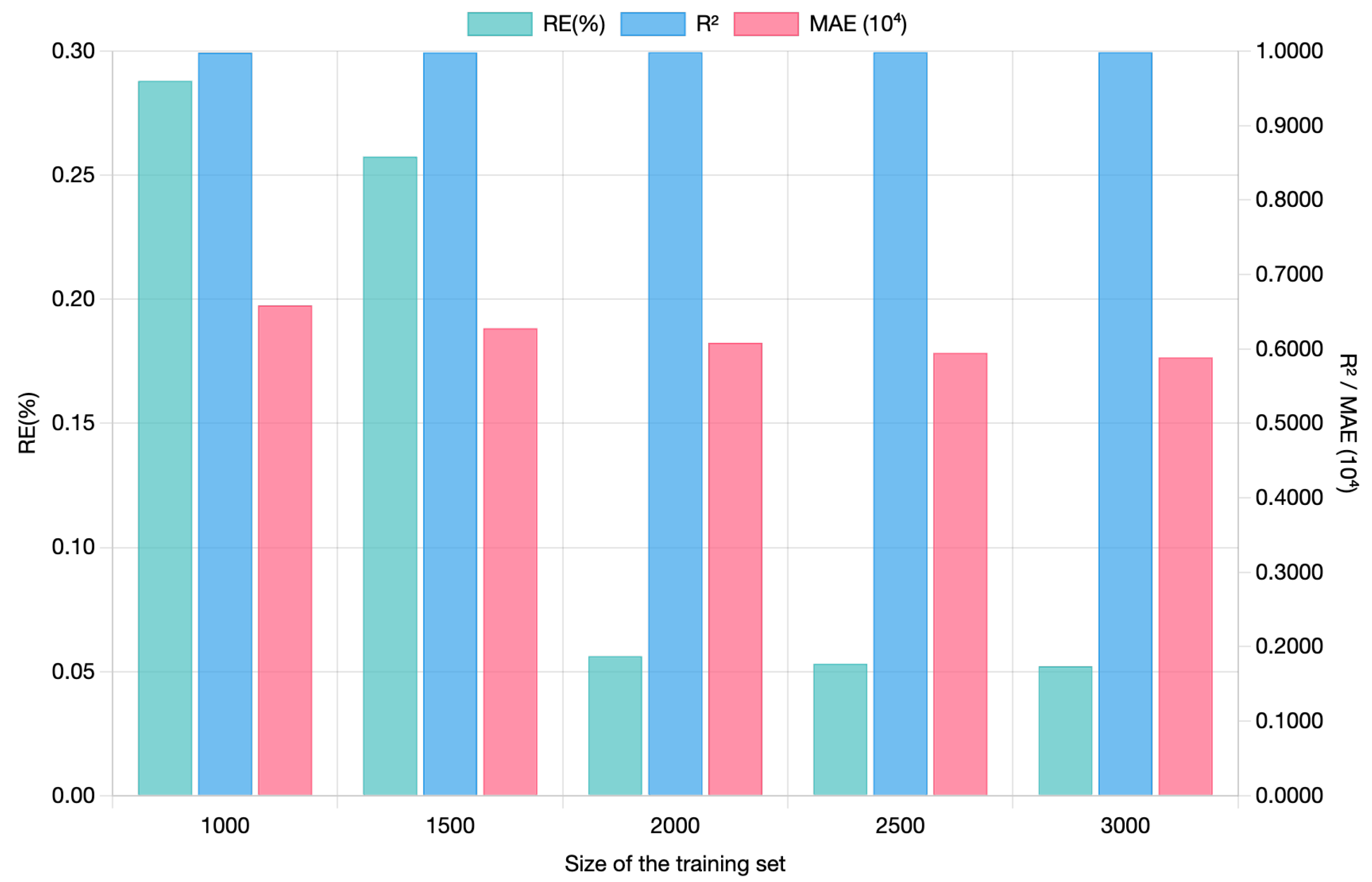
Using all portfolio policies as network inputs during training is not advisable due to computational inefficiency. Instead, we select a small set of VAs as the training set. The small sample size is sufficient because the training loss converges given a certain number of samples. Another relevant aspect of a neural network is the ability to predict cases not included in the training set. The problem of overfitting means that although the training set error may be a very small value, the error arising from the new data is large because the network only fits the training examples but fails to generalize to the new situation. To address the overfitting problem, we adopt a certain subset of the data as the validation set. In numerical experiments, if the validation set achieves comparable accuracy to that of the training set, this indicates that the issue of overfitting does not exist.
The proposed ResPoNet utilizes a composite loss function that combines valuation error with a weight regularization term to improve both accuracy and interpretability. Specifically, the loss function is defined as follows:
Here, the loss of valuation (
), referred to as the MSE loss function, measures the discrepancy between the predicted and true values of VA policies:
where
N is the training set size,
denotes the predicted value, and
represents the ground truth from nested MC simulations. The weight regularization term (
) preserves the interpretability of spatial interpolation:
where
C denotes the number of representative contracts,
represents the estimated value of the weight, and
denotes normalized weights derived from IDW based on the distance matrix
, with
as the default distance decay parameter. These weights encode prior domain knowledge about spatial similarity between contracts. This term ensures that ResPoNet retains the intuitive distance-based weighting of spatial methods while learning corrections for mortality risk and path dependence. The hyperparameter
balances the two loss components in Equation (
3). When
, the model reduces to the baseline neural network, which optimizes solely for
, but this approach may compromise interpretability. When
, the
term constrains
, enforcing distance-based weights and improving the stability of convergence. The optimal value of
is determined by minimizing the relative error (RE) metric through a validation procedure, as detailed in
Section 4.1.
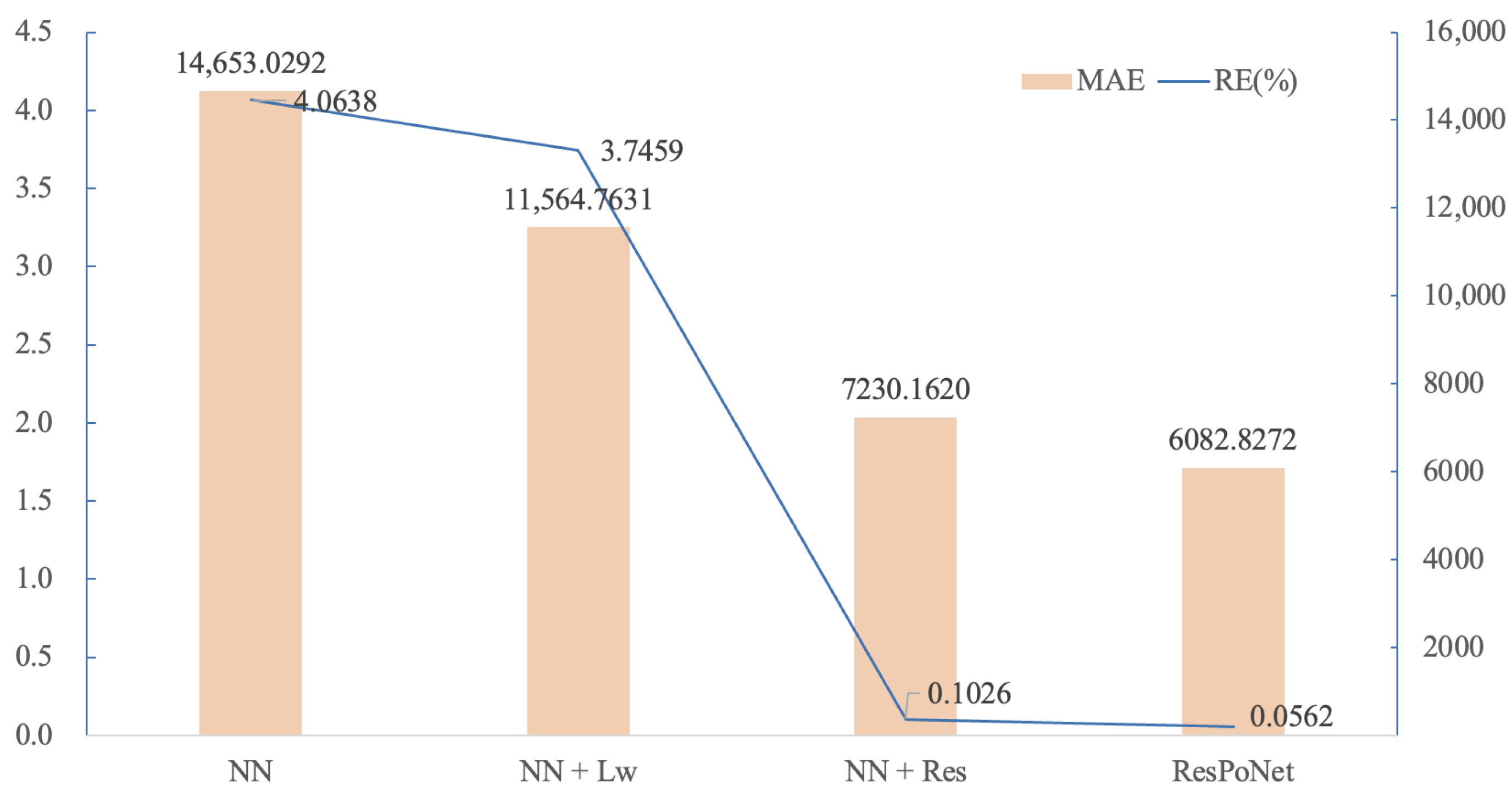
Notably, standard loss functions (e.g., baseline NNs using only
) optimize solely for valuation accuracy, which may lead to weights
that deviate from real-world distance relationships and compromise interpretability. As presented in
Section 4.2, ResPoNet’s MSE exhibits superior portfolio valuation accuracy compared to the MSE-based loss function without weight regularization, while its mean absolute error (MAE) improves significantly. The weighted loss introduced here integrates
to encode prior knowledge from spatial interpolation. This dual-objective formulation distinguishes ResPoNet from baseline models using standard MSE or MAE losses, as it explicitly enforces consistency with domain knowledge while improving convergence speed (see the numerical experiments in
Section 4.2).
The greater the distance between the input policy in the portfolio and the representative contract, the smaller the weight. The optimal distance function in ResPoNet is implicitly learned through a neural network (see [
37] for neural network fundamentals), incorporating convolutional and residual layers. It processes standardized
to generate
via Softmax. Optimized via a combined loss, as described in Equations (
3)–(
5), and balancing valuation accuracy (
) and distance consistency (
), the parameters are updated using a gradient descent scheme. The neural network’s parameters are updated iteratively to satisfy the constraint in Equation (
5), thereby grounding the learned distance metric in interpretable weight spaces.
As is customary in the neural network literature, we employ a stochastic gradient descent (SGD) optimizer to train the network [
41]. SGD is a well-established training algorithm in both academia and industry, known for its proven generalization performance and efficient convergence. This requires computing the derivative of the cost function with respect to each parameter and then updating them by moving to the negative direction, scaled by the learning rate
. In particular, we have
where the set
represents the corresponding weight and bias at
i; the learning rate
controls the convergence progress of the model; ∇ denotes the gradient; and
stands for the loss function to replace the cost function in the gradient descent. When the learning rate is large, the training process speeds up, but it is prone to gradient explosions. In contrast, the convergence slows down with a small learning rate, and the network is more prone to overfitting. The initial learning rate
starts at 0.1 and then decays exponentially [
42] by a factor of 0.9 per 50 epochs to balance early convergence speed and late-stage optimization precision. The batch size is set to 32, a compromise between gradient estimate stability and memory efficiency. Stochastic mortality risk is modeled via a nested MC framework [
43]: (i) In the outer loop, 100 stochastic mortality scenarios are generated using an affine model to capture dynamic mortality rate trends; (ii) In the inner loop, for each scenario, 10,000 MC paths simulate policy cash flows under the scenario. This configuration ensures that ResPoNet is trained on reliable, low-noise labels while remaining feasible for large-scale portfolio valuation.
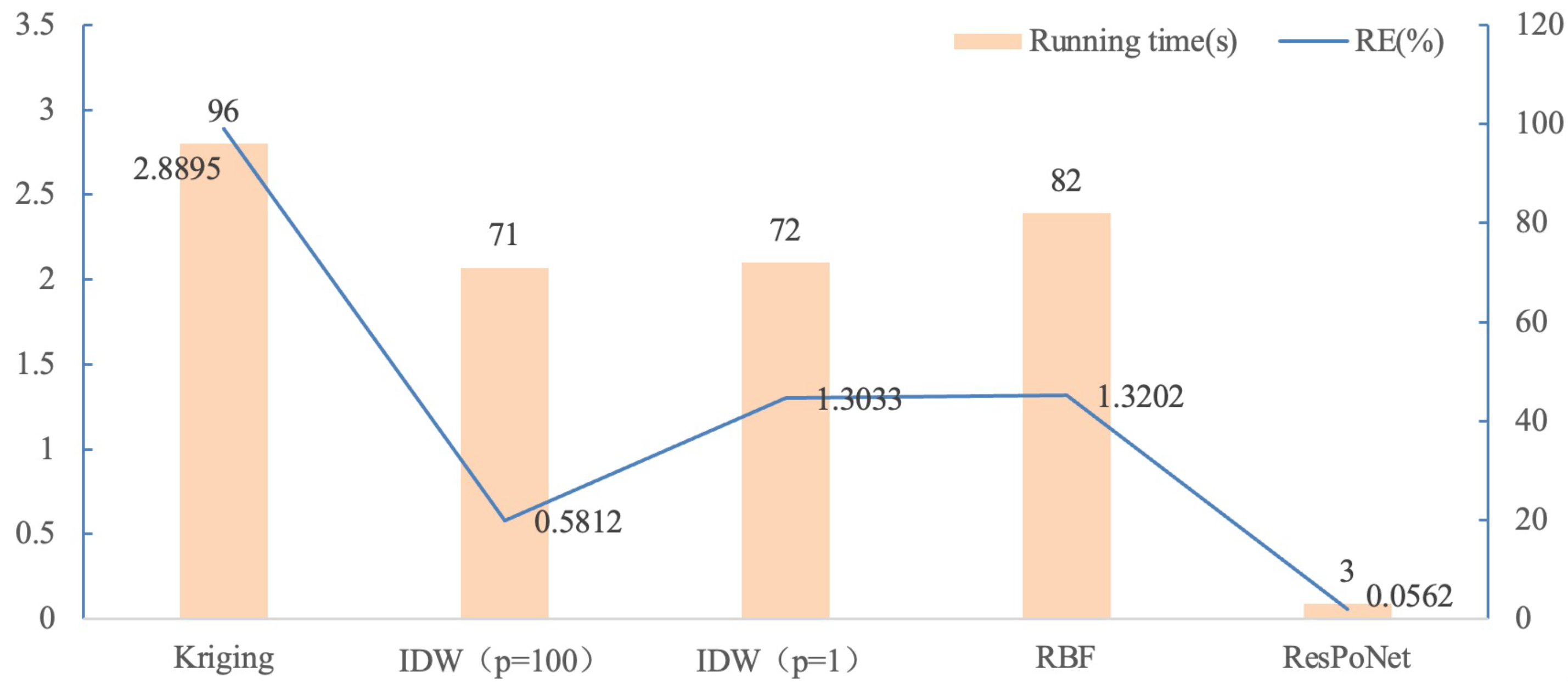
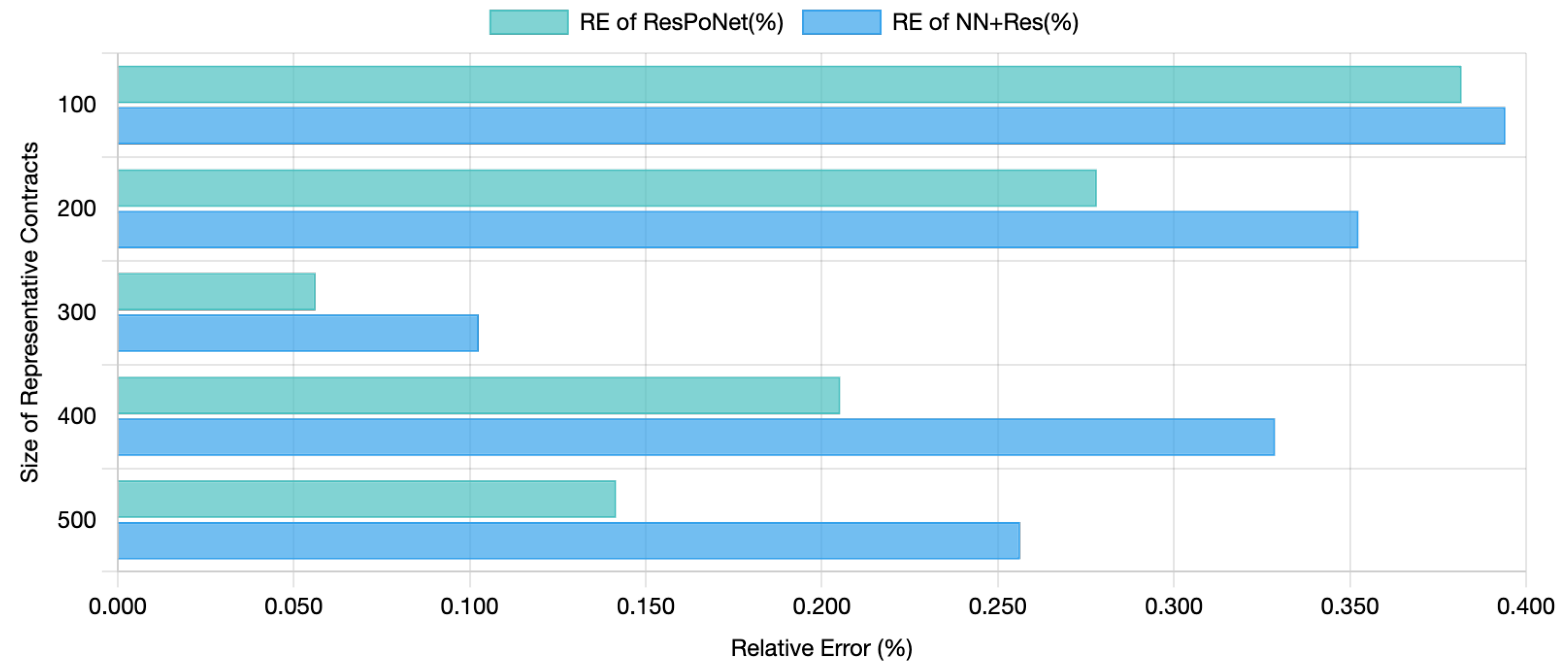
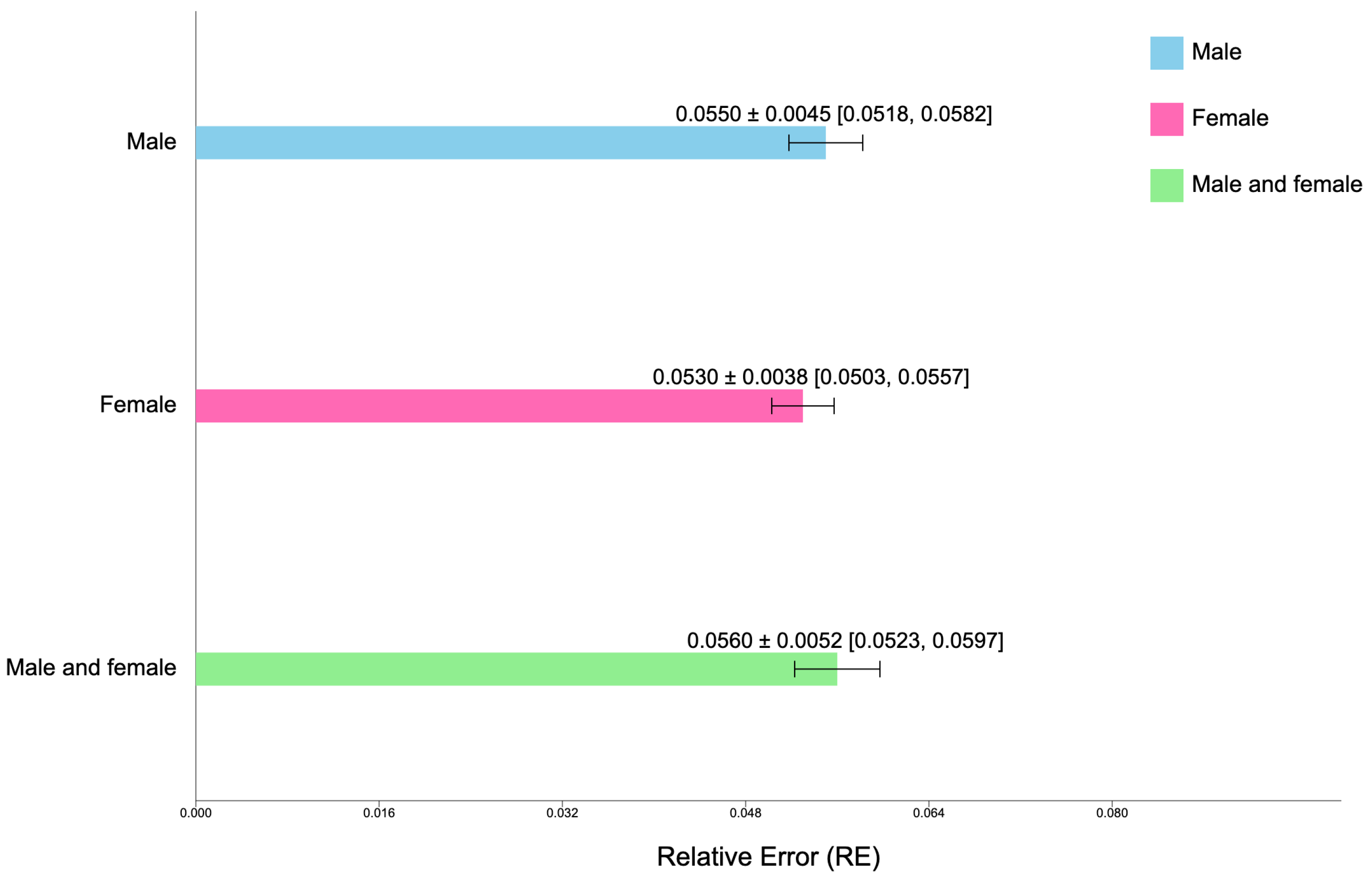
The accuracy of neural network-based valuation is quantified using RE, defined as follows:
where
is the estimated value of the input portfolio computed by nested MC simulations and
is the estimated value of the input portfolio computed by ResPoNet. Training stops when the RE in Equation (
7) falls below the expected threshold. The stopping time could also be determined by viewing the diagram of MSE.
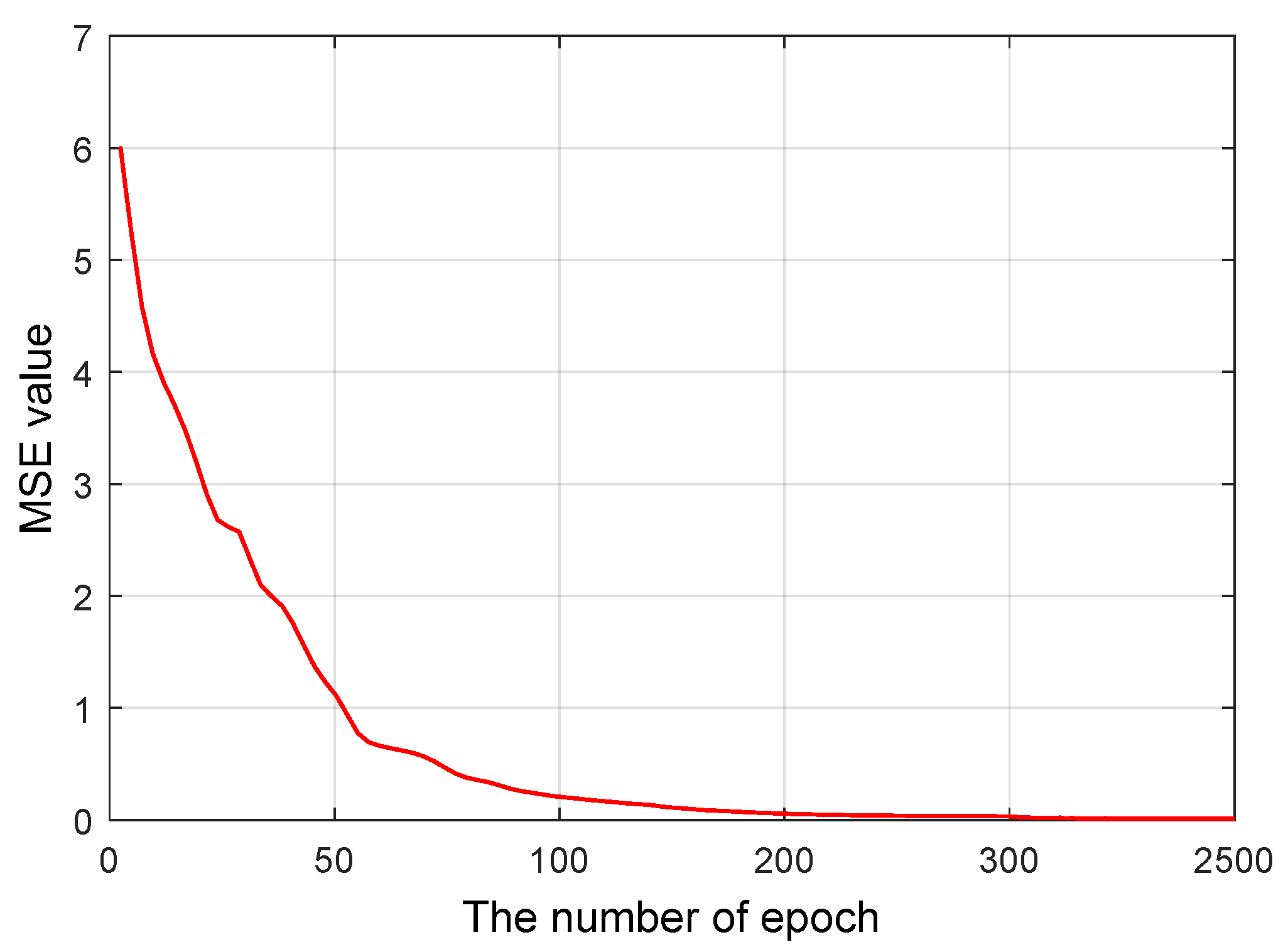
Figure 4 shows how ResPoNet converges over 2500 epochs. MSE decreases as a function of the epoch, which becomes less steep after a few hundred epochs. This indicates that the network parameters are approaching their respective optimal values. When the value converges to 0 after approximately 2500 epochs, it is appropriate to stop training since additional training ceases to improve accuracy [
9].









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}