
A Novel High-Fidelity Reversible Data Hiding Method Based on Adaptive Multi-pass Embedding



Abstract
1. Introduction
2. Related Work
2.1. Single-Pass PVO-Based Reversible Data Hiding
2.2. Multi-Pass PVO-Based Reversible Data Hiding
2.3. Pairwise PVO-Based Reversible Data Hiding
3. Proposed Method
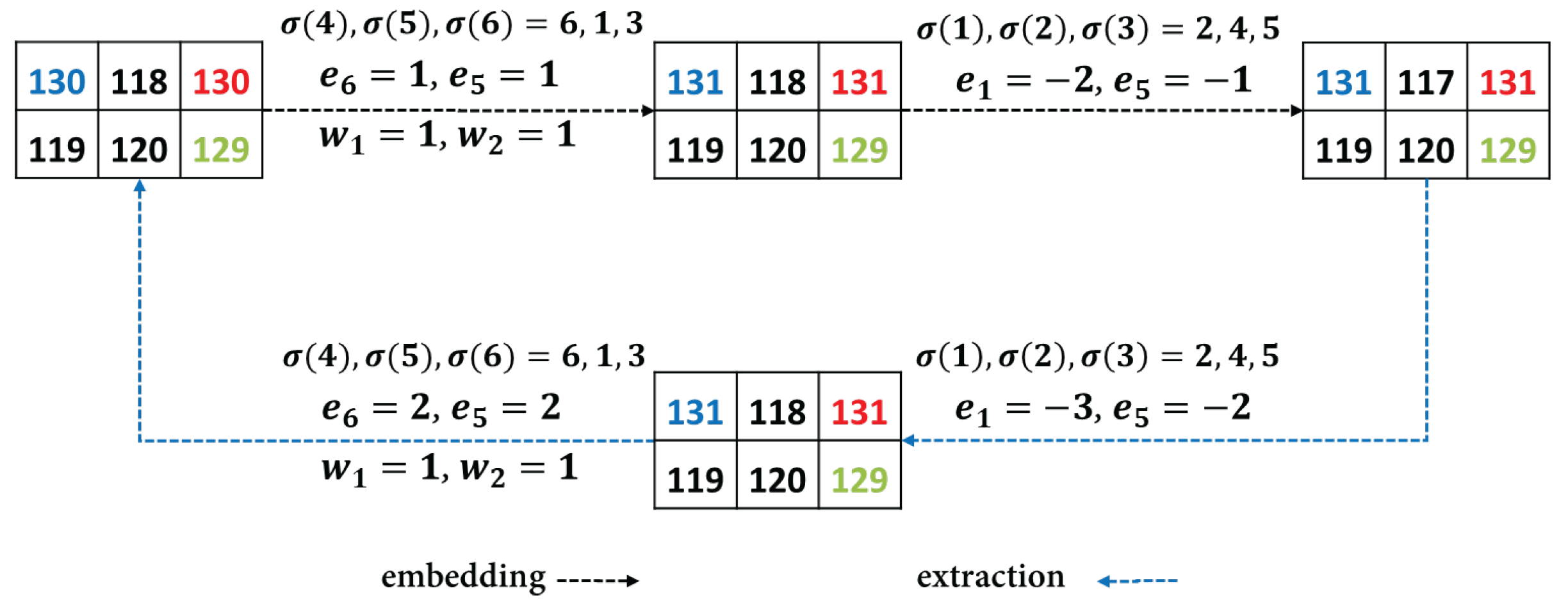
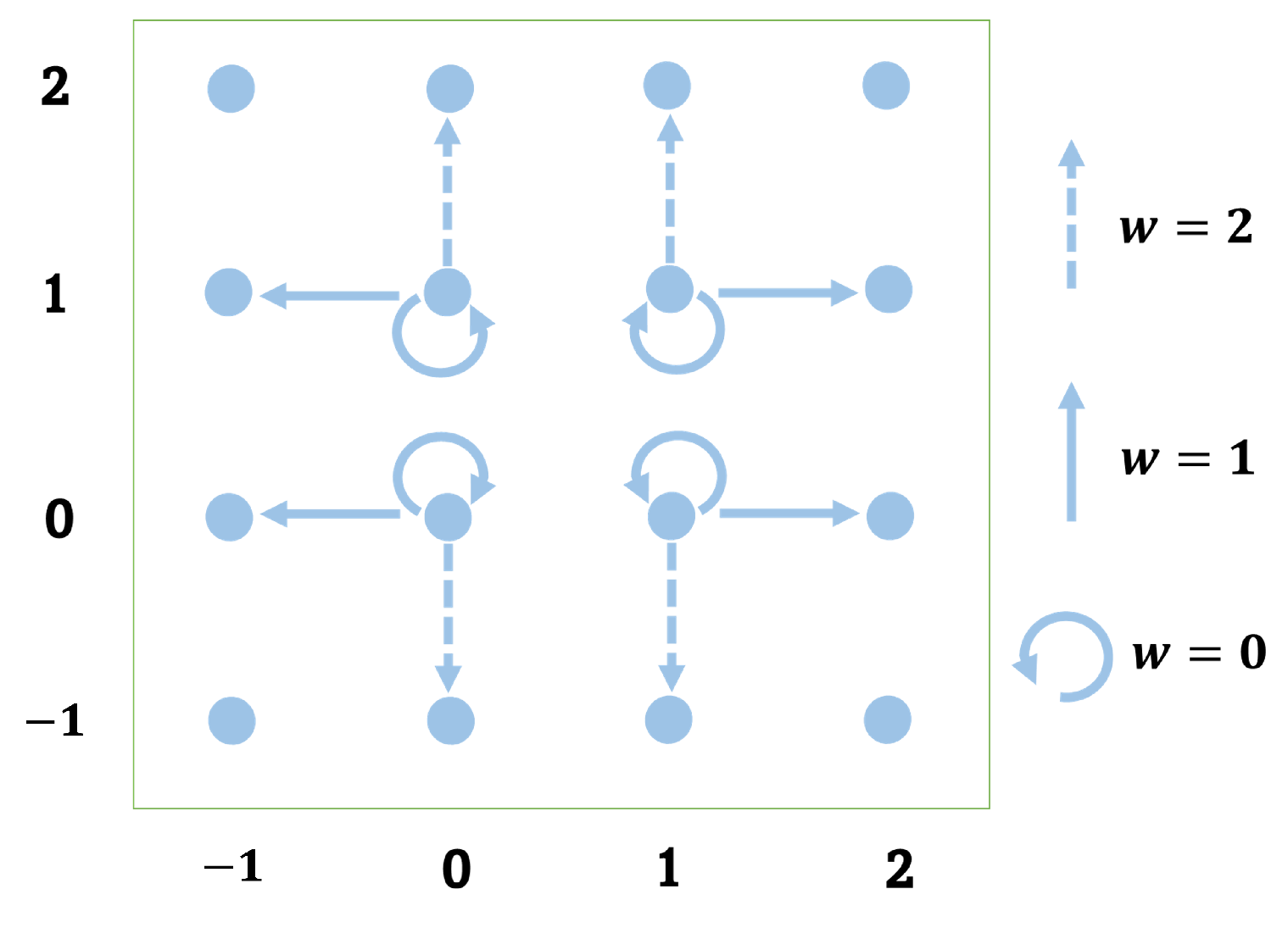
3.1. Adaptive k-Pass PVO-Based Prediction
- If , the embedded data are extracted as as and as and the pixel value is restored as .
- (a)
- If or , there is neither data extraction nor pixel restoration.
- (b)
- If , the embedded data are extracted as and the pixel value is restored as .
- (c)
- If , the embedded bit is extracted as and the pixel value is restored as .
- If , there is no data extraction and the pixel value is restored as .
- (a)
- If , the embedded bit is extracted as and the pixel value is restored as .
- (b)
- If , the embedded bit is extracted as and the pixel value is restored as .
3.2. Content-Based IPVO-Based Pairwise PEE
3.3. Content-Based Adaptive k
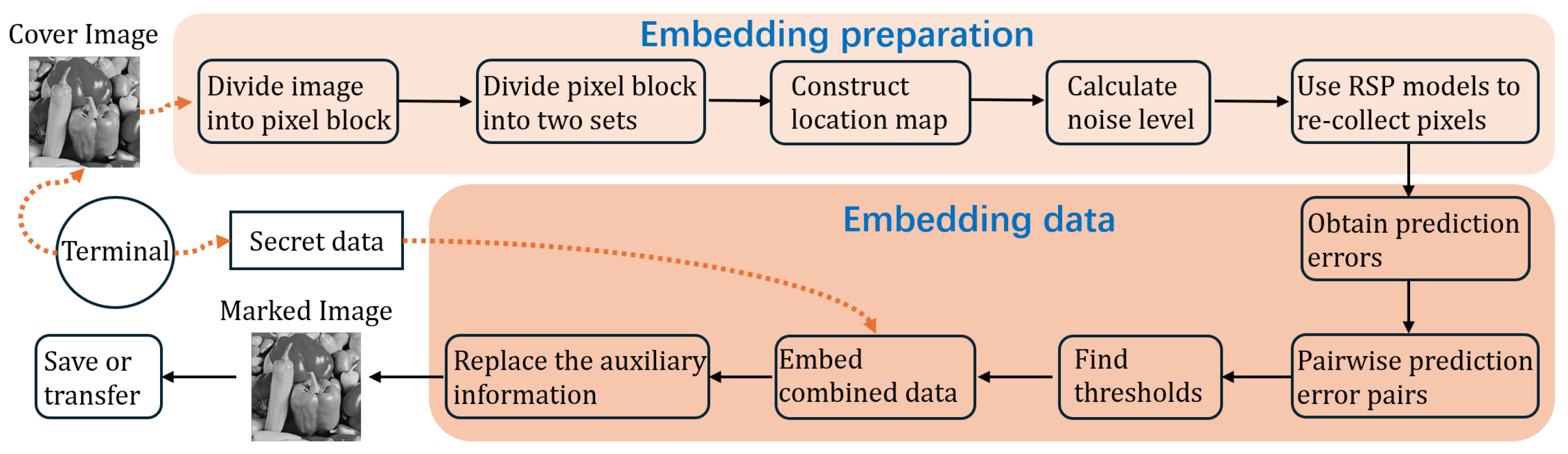
3.4. Implementation of the Proposed Method
- The length of binary auxiliary information (10 bits).
- Block size (4 bits).
- Thresholds ( bits).
- Parameter k ( bits).
- Embedding capacity (16 bits).
- Length of the compressed location map (16 bits).
- Auxiliary information extraction The LSBs of the first two lines pixels of the marked image are read to retrieve auxiliary information. First, the length of the binary auxiliary information is obtained according to the first 10 bits of the extracted data. Following, the auxiliary information is extracted.
- Data extraction and image restoration The marked image is divided into non-overlapped blocks with the extracted block size. The noise level of pixel block is calculated. If , extraction is performed with the help of the extracted parameter k and . Otherwise, the block is skipped.
- Restoration of the rest pixels The first two lines of bits data of are used to recover the first two lines of pixels. Then, the location map is restored by decompressing the compressed location map. Finally, pixels valued 0 or 255 are restored according to the location map.
4. Experimental Results
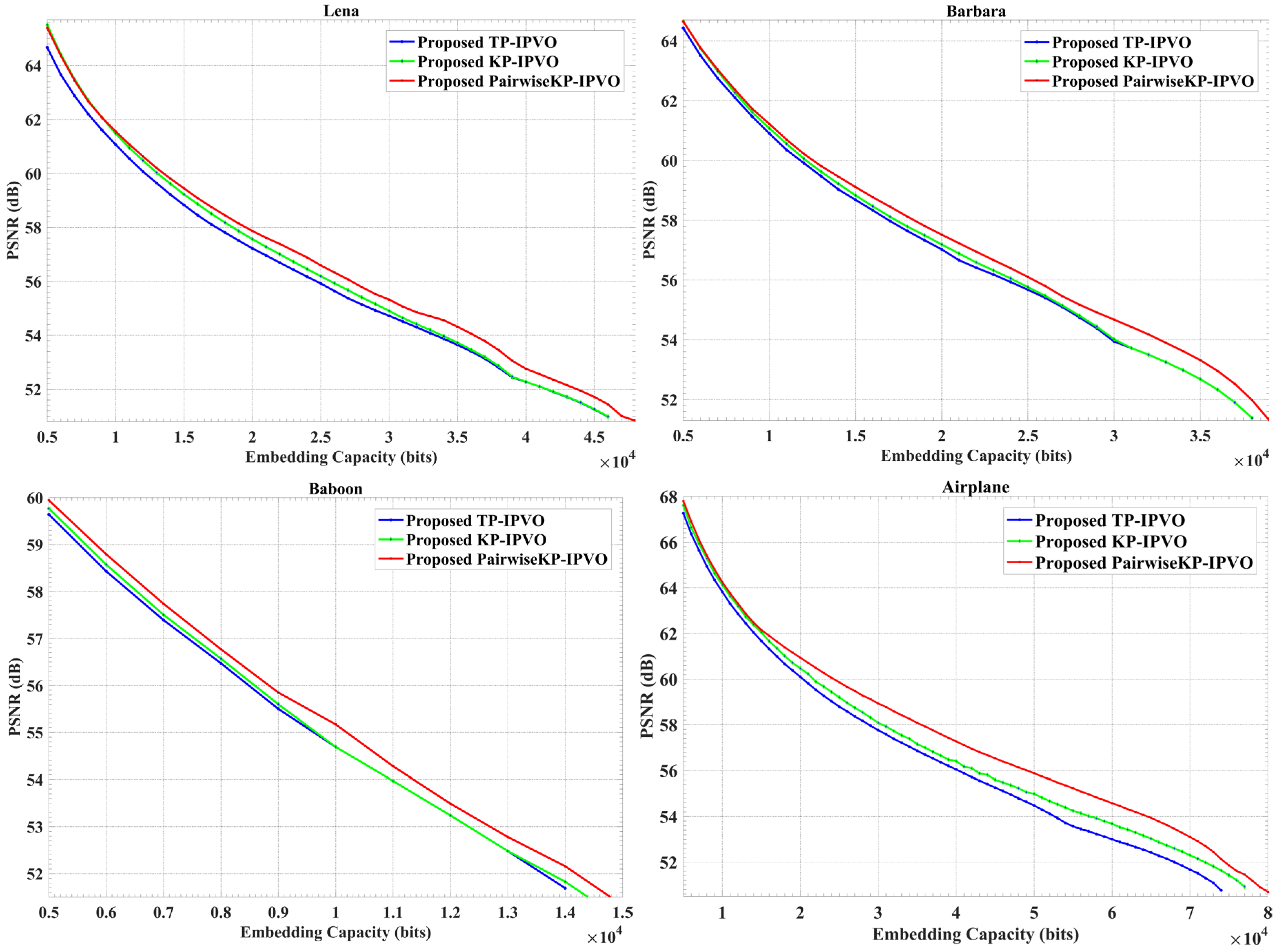
4.1. Analysis of Three Proposed Methods
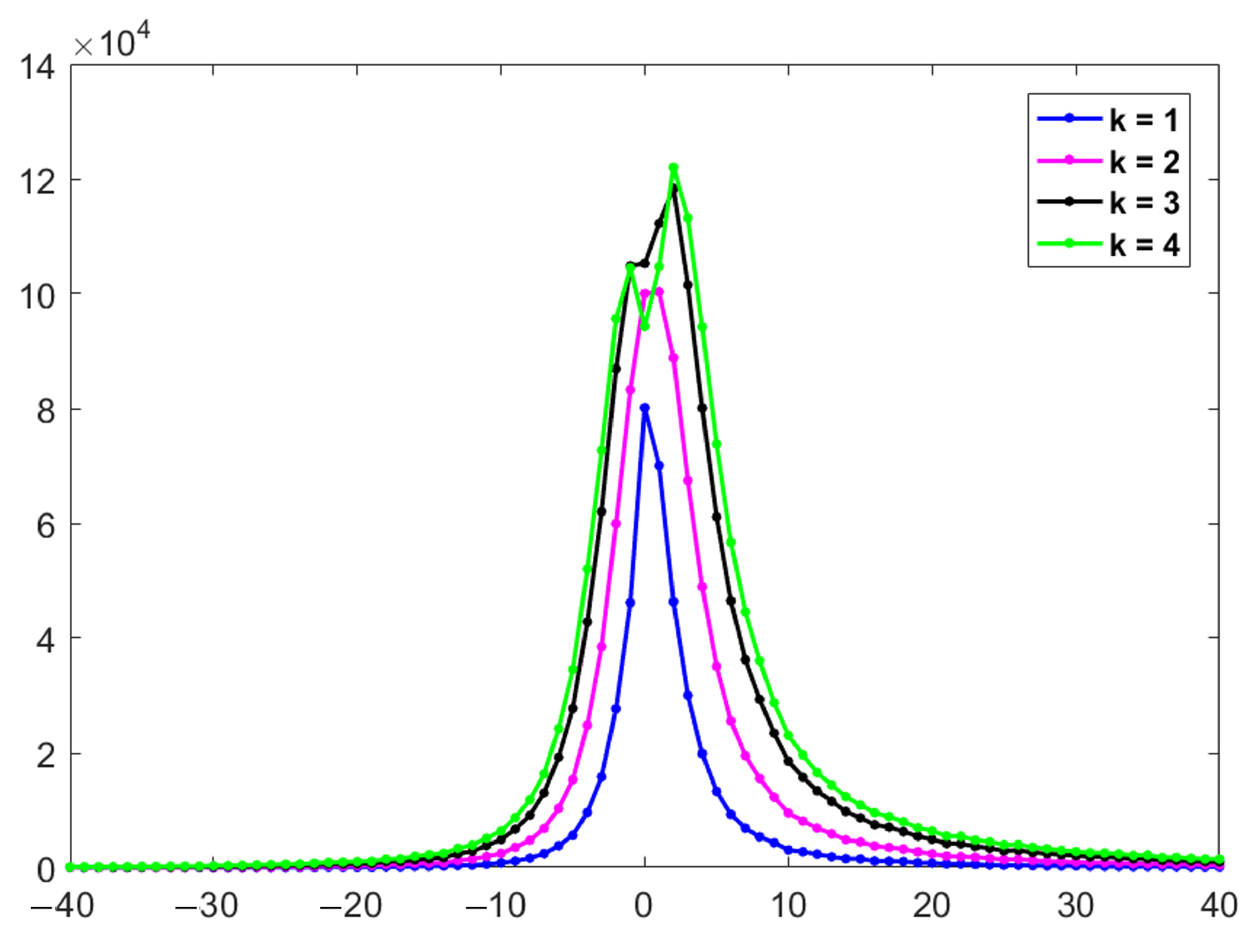
4.2. Analysis of Parameters
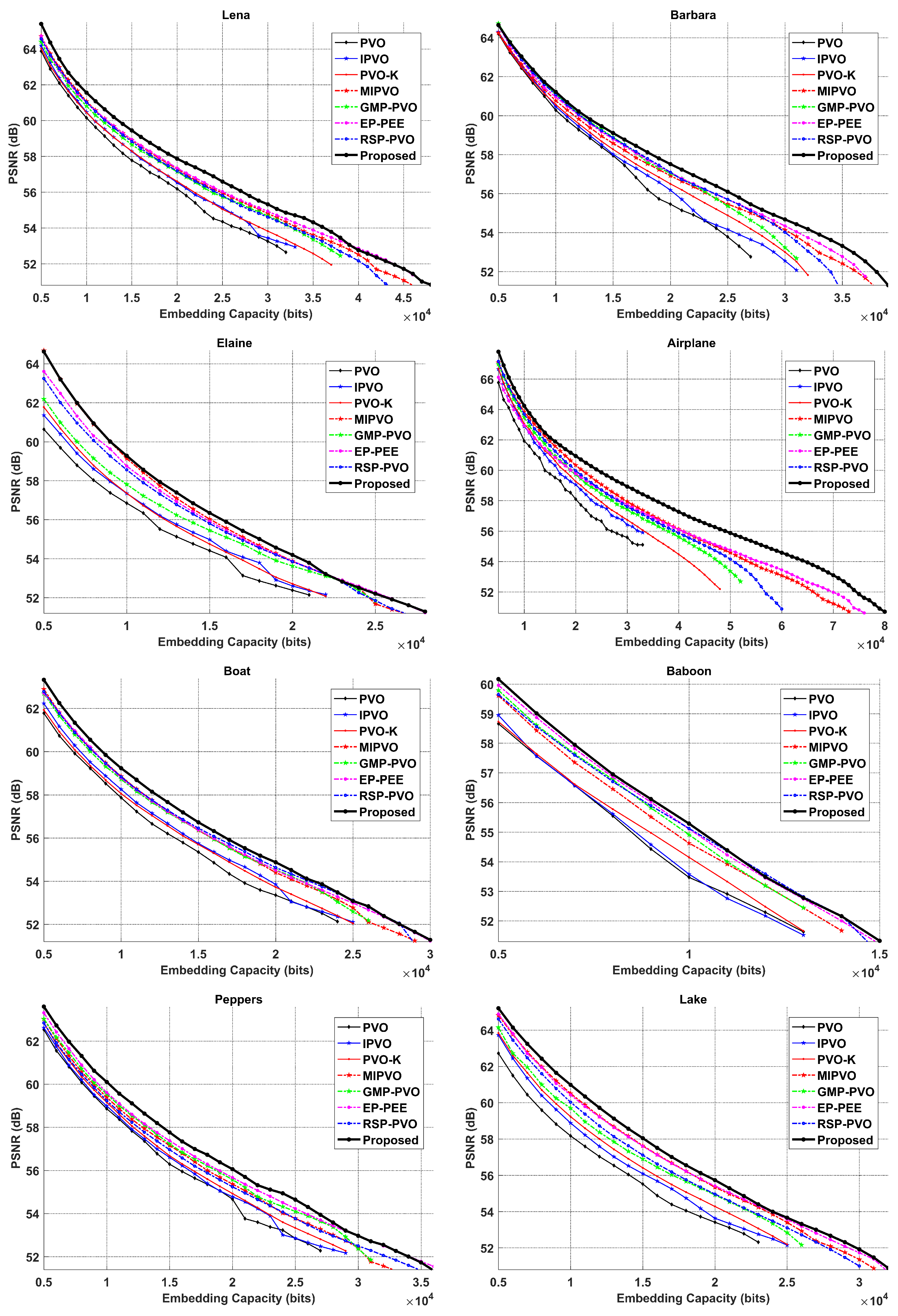
4.3. Comparison with Advanced Methods
4.4. t-Test
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jiang, C.; Zhang, M.; Kong, Y.; Jiang, Z.; Di, F. A Hierarchical Authorization Reversible Data Hiding in Encrypted Image Based on Secret Sharing. Mathematics 2024, 12, 2262. [Google Scholar] [CrossRef]
- Liu, J.C.; Chang, C.C.; Lin, Y.; Chang, C.C.; Horng, J.H. A matrix coding-oriented reversible data hiding scheme using dual digital images. Mathematics 2023, 12, 86. [Google Scholar] [CrossRef]
- Lin, Y.; Liu, J.C.; Chang, C.C.; Chang, C.C. Embedding Secret Data in a Vector Quantization Codebook Using a Novel Thresholding Scheme. Mathematics 2024, 12, 1332. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Dao, T.T. A novel PVO-based RDH scheme utilizes an interleaved data embedding technique using dual-pixels. J. Inf. Secur. Appl. 2025, 89, 103939. [Google Scholar] [CrossRef]
- Weng, C.Y.; Lin, T.W.; Weng, H.Y.; Huang, C.T. Enhanced reversible data hiding in encrypted images via median preserving pixel value ordering and block-wise difference preservation. Signal Image Video Process. 2025, 19, 424. [Google Scholar] [CrossRef]
- Fridrich, J.; Goljan, M.; Du, R. Lossless data embedding new paradigm in digital watermarking. EURASIP J. Adv. Signal Process. 2002, 2002, 986842. [Google Scholar] [CrossRef]
- Celik, M.U.; Sharma, G.; Tekalp, A.M.; Saber, E. Lossless generalized-LSB data embedding. IEEE Trans. Image Process. 2005, 14, 253–266. [Google Scholar] [CrossRef]
- Celik, M.U.; Sharma, G.; Tekalp, A.M. Lossless watermarking for image authentication: A new framework and an implementation. IEEE Trans. Image Process. 2006, 15, 1042–1049. [Google Scholar] [CrossRef]
- Fridrich, J.; Goljan, M.; Du, R. Invertible authentication. In Proceedings of the Security and Watermarking of Multimedia contents III. International Society for Optics and Photonics, San Jose, CA, USA, 20 January 2001; Volume 4314, pp. 197–208. [Google Scholar]
- Goljan, M.; Fridrich, J.J.; Du, R. Distortion-free data embedding for images. In Proceedings of the International Workshop on Information Hiding, Pittsburgh, PA, USA, 25–27 April 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 27–41. [Google Scholar]
- Ni, Z.; Shi, Y.Q.; Ansari, N.; Su, W. Reversible data hiding. In Proceedings of the 2003 International Symposium on Circuits and Systems, 2003. ISCAS’03, Bangkok, Thailand, 25–28 May 2003; Volume 2, pp. II–II. [Google Scholar]
- Lee, S.K.; Suh, Y.H.; Ho, Y.S. Reversiblee image authentication based on watermarking. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July2006; pp. 1321–1324. [Google Scholar]
- Li, X.; Zhang, W.; Gui, X.; Yang, B. A novel reversible data hiding scheme based on two-dimensional difference-histogram modification. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1091–1100. [Google Scholar]
- Ou, B.; Li, X.; Zhao, Y.; Ni, R.; Shi, Y.Q. Pairwise prediction-error expansion for efficient reversible data hiding. IEEE Trans. Image Process. 2013, 22, 5010–5021. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Gui, X.; Yang, B. Efficient reversible data hiding based on multiple histograms modification. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2016–2027. [Google Scholar]
- Tian, J. Reversible data embedding using a difference expansion. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 890–896. [Google Scholar] [CrossRef]
- Alattar, A.M. Reversible watermark using the difference expansion of a generalized integer transform. IEEE Trans. Image Process. 2004, 13, 1147–1156. [Google Scholar] [CrossRef]
- Coltuc, D. Low distortion transform for reversible watermarking. IEEE Trans. Image Process. 2011, 21, 412–417. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Li, X.; Yang, B. Efficient reversible image watermarking by using dynamical prediction-error expansion. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 3673–3676. [Google Scholar]
- Coltuc, D. Improved embedding for prediction-based reversible watermarking. IEEE Trans. Inf. Forensics Secur. 2011, 6, 873–882. [Google Scholar] [CrossRef]
- Li, X.; Yang, B.; Zeng, T. Efficient reversible watermarking based on adaptive prediction-error expansion and pixel selection. IEEE Trans. Image Process. 2011, 20, 3524–3533. [Google Scholar]
- Ou, B.; Li, X.; Zhang, W.; Zhao, Y. Improving Pairwise PEE via Hybrid-Dimensional Histogram Generation and Adaptive Mapping Selection. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2176–2190. [Google Scholar] [CrossRef]
- Wu, H.; Li, X.; Chang, Q.; Xiao, M.; Li, X.; Zhao, Y. High-fidelity reversible data hiding based on enhanced IPPVO and adaptive 2D histogram modification. Signal Process. 2025, 232, 109901. [Google Scholar] [CrossRef]
- Li, X.; Li, J.; Li, B.; Yang, B. High-fidelity reversible data hiding scheme based on pixel-value-ordering and prediction-error expansion. Signal Process. 2013, 93, 198–205. [Google Scholar] [CrossRef]
- Peng, F.; Li, X.; Yang, B. Improved PVO-based reversible data hiding. Digit. Signal Process. 2014, 25, 255–265. [Google Scholar] [CrossRef]
- Ou, B.; Li, X.; Zhao, Y.; Ni, R. Reversible data hiding using invariant pixel-value-ordering and prediction-error expansion. Signal Processing: Image Commun. 2014, 29, 760–772. [Google Scholar] [CrossRef]
- Ou, B.; Li, X.; Wang, J. High-fidelity reversible data hiding based on pixel-value-ordering and pairwise prediction-error expansion. J. Vis. Commun. Image Represent. 2016, 39, 12–23. [Google Scholar] [CrossRef]
- Yao, Y.; Wang, D.; Shen, Y.; Xu, D.; Chang, C.C.; Chang, C.C. PVO-Based Reversible Data Hiding Using Two-Stage Embedding and FPM Mode Selection. IEEE Trans. Circuits Syst. Video Technol. 2025, 35, 3512–3526. [Google Scholar] [CrossRef]
- Pan, Z.; Gao, E. Reversible data hiding based on novel embedding structure PVO and adaptive block-merging strategy. Multimed. Tools Appl. 2019, 78, 26047–26071. [Google Scholar] [CrossRef]
- Wang, X.; Ding, J.; Pei, Q. A novel reversible image data hiding scheme based on pixel value ordering and dynamic pixel block partition. Inf. Sci. 2015, 310, 16–35. [Google Scholar] [CrossRef]
- Kumar, R.; Jung, K.H. Enhanced pairwise IPVO-based reversible data hiding scheme using rhombus context. Inf. Sci. 2020, 536, 101–119. [Google Scholar] [CrossRef]
- Fan, G.; Pan, Z.; Zhou, Q.; Gao, X.; Zhang, X. A comparative study between PVO-based framework and multi-predictor mechanism in reversible data hiding. J. Vis. Commun. Image R. 2021, 81, 103349. [Google Scholar] [CrossRef]
- Fan, G.; Lu, L.; Song, X.; Li, Z.; Pan, Z. Non-local PPVO-based reversible data hiding using opposite direction pairwise embedding. J. Inf. Secur. Appl. 2025, 90, 104030. [Google Scholar] [CrossRef]
- Qu, X.; Kim, H.J. Pixel-based pixel value ordering predictor for high-fidelity reversible data hiding. Signal Process. 2015, 111, 249–260. [Google Scholar] [CrossRef]
- He, W.; Cai, Z. An Insight Into Pixel Value Ordering Prediction-Based Prediction-Error Expansion. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3859–3871. [Google Scholar] [CrossRef]
- Kong, X.; Cai, Z. An Information Security Method Based on Optimized High-Fidelity Reversible Data Hiding. IEEE Trans. Ind. Inform. 2022, 18, 8529–8539. [Google Scholar] [CrossRef]
- He, W.; Xiong, G.; Weng, S.; Cai, Z.; Wang, Y. Reversible data hiding using multi-pass pixel-value-ordering and pairwise prediction-error expansion. Inf. Sci. 2018, 467, 784–799. [Google Scholar] [CrossRef]
- Zhang, T.; Li, X.; Qi, W.; Guo, Z. Location-Based PVO and Adaptive Pairwise Modification for Efficient Reversible Data Hiding. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2306–2319. [Google Scholar] [CrossRef]
- He, W.; Cai, Z.; Wang, Y. High-Fidelity Reversible Image Watermarking Based on Effective Prediction Error-Pairs Modification. IEEE Trans. Multimed. 2021, 23, 52–63. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| Pixel value at position in the sorted sequence | Mapping function that maps sorted index i to original pixel position | ||
| Size of non-overlapped blocks | n | Total number of pixels in a block | |
| Prediction error for the largest pixel | Prediction error for the smallest pixel | ||
| Prediction error for pixel at position | Prediction error for pixel at position | ||
| , , | Modified prediction errors after data embedding | Modified pixel value after data embedding | |
| Pixel value at position i in the unsorted sequence | , | Binary secret data bits (0 or 1) to be embedded | |
| L | Index in range | S | Index in range |
| k | Parameter controlling number of pixels processed in each pass | The number of classes for pixel blocks based on noise level NL | |
| Ideal k in a pixel block | Embedding parameter for noise level | ||
| The collection of noise level thresholds for pixel blocks | Optimal thresholds collection for noise level classification |
| EC = 10,000 | EC = 20,000 | EC = 30,000 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | PSNR | PSNR | ||||||||||
| KP-IPVO | (20,26,57) | 61.47 | (25,31,43,82) | 57.66 | (35,51,119) | 54.90 | ||||||
| PairwiseKP-IPVO | (4,6,44,44,49) | 61.49 | (3,46,51) | 57.86 | (4,4,82) | 55.32 | ||||||
| [25] | [26] | [35] | [32] | [36] | [39] | Proposed | |
|---|---|---|---|---|---|---|---|
| Lena | 58.99 | 59.16 | 61.08 | 60.81 | 61.02 | 61.01 | 61.56 |
| Airplane | 62.89 | 63.05 | 63.86 | 63.50 | 63.70 | 63.70 | 64.24 |
| Baboon | 53.58 | 54.15 | 54.63 | 54.92 | 55.13 | 55.13 | 55.18 |
| Barbara | 60.47 | 60.45 | 61.08 | 61.11 | 61.08 | 60.96 | 61.22 |
| Boat | 58.88 | 59.23 | 60.51 | 58.73 | 58.83 | 58.78 | 59.23 |
| Elaine | 57.35 | 57.36 | 59.14 | 57.81 | 58.56 | 58.75 | 59.28 |
| Lake | 58.26 | 58.06 | 58.85 | 59.70 | 60.03 | 60.43 | 60.99 |
| Peppers | 60.46 | 60.57 | 60.77 | 59.54 | 59.24 | 59.61 | 59.86 |
| Average | 58.86 | 59.00 | 59.99 | 59.51 | 59.70 | 59.80 | 60.19 |
| [25] | [26] | [35] | [32] | [36] | [39] | Proposed | |
|---|---|---|---|---|---|---|---|
| Lena | 56.53 | 56.60 | 57.30 | 57.14 | 57.18 | 57.34 | 57.87 |
| Airplane | 59.06 | 59.26 | 60.34 | 59.72 | 59.97 | 59.97 | 60.94 |
| Baboon | - | - | - | - | - | - | - |
| Barbara | 56.18 | 56.50 | 56.92 | 57.04 | 57.10 | 57.09 | 57.51 |
| Boat | 53.85 | 53.72 | 54.40 | 54.53 | 54.63 | 54.51 | 54.88 |
| Elaine | 52.60 | 52.71 | 53.87 | 53.62 | 53.85 | 53.87 | 54.19 |
| Lake | 53.63 | 54.28 | 55.34 | 54.92 | 54.96 | 55.41 | 55.73 |
| Peppers | 54.78 | 54.93 | 55.37 | 55.58 | 55.24 | 55.67 | 55.76 |
| Average | 55.23 | 55.43 | 56.22 | 56.08 | 56.13 | 56.27 | 56.70 |
| Image | PSNR (dB) | MSE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Proposed | [26] | [24] | [25] | [39] | Proposed | [26] | [24] | [25] | [39] | |
| kodim01 | 62.68 | 62.36 | 50.25 | 60.43 | 63.64 | 0.035 | 0.038 | 0.613 | 0.059 | 0.028 |
| kodim02 | 62.81 | 62.78 | 52.31 | 61.06 | 64.23 | 0.034 | 0.034 | 0.382 | 0.051 | 0.025 |
| kodim03 | 63.93 | 63.74 | 49.55 | 59.15 | 65.04 | 0.026 | 0.028 | 0.720 | 0.079 | 0.020 |
| kodim04 | 62.76 | 62.75 | 52.74 | 61.59 | 63.79 | 0.034 | 0.034 | 0.346 | 0.045 | 0.027 |
| kodim05 | 61.70 | 61.31 | - | 53.25 | 63.38 | 0.044 | 0.048 | - | 0.307 | 0.030 |
| kodim06 | 64.95 | 64.47 | - | - | 66.70 | 0.021 | 0.023 | - | - | 0.014 |
| kodim07 | 63.60 | 63.39 | 53.25 | 62.59 | 64.42 | 0.028 | 0.030 | 0.307 | 0.036 | 0.024 |
| kodim08 | 60.03 | 56.79 | - | - | 57.04 | 0.065 | 0.136 | - | - | 0.128 |
| kodim09 | 62.17 | 62.11 | 53.62 | 62.09 | 61.73 | 0.039 | 0.040 | 0.283 | 0.040 | 0.044 |
| kodim10 | 62.29 | 61.44 | 48.58 | 57.17 | 60.98 | 0.038 | 0.047 | 0.901 | 0.125 | 0.052 |
| kodim11 | 63.85 | 63.65 | 52.95 | 62.74 | 64.83 | 0.027 | 0.028 | 0.330 | 0.035 | 0.021 |
| kodim12 | 63.36 | 63.43 | - | 54.81 | 64.45 | 0.030 | 0.030 | - | 0.215 | 0.023 |
| kodim13 | 59.86 | 56.93 | - | - | 58.46 | 0.067 | 0.132 | - | - | 0.093 |
| kodim14 | 61.27 | 61.23 | 48.72 | 57.57 | 62.83 | 0.048 | 0.049 | 0.874 | 0.114 | 0.034 |
| kodim15 | 64.27 | 61.62 | - | - | 61.10 | 0.024 | 0.045 | - | - | 0.050 |
| kodim16 | 63.68 | 63.56 | 52.39 | 61.67 | 64.81 | 0.028 | 0.029 | 0.375 | 0.044 | 0.021 |
| kodim17 | 62.87 | 62.66 | 54.81 | 63.57 | 62.91 | 0.033 | 0.035 | 0.215 | 0.029 | 0.033 |
| kodim18 | 60.09 | 59.42 | 46.54 | 54.39 | 59.36 | 0.064 | 0.074 | 1.443 | 0.236 | 0.075 |
| kodim19 | 61.90 | 61.78 | 51.60 | 59.94 | 62.03 | 0.042 | 0.043 | 0.450 | 0.066 | 0.041 |
| kodim20 | 62.31 | 53.76 | - | - | 52.26 | 0.038 | 0.274 | - | - | 0.387 |
| kodim21 | 62.37 | 62.03 | 46.68 | 55.38 | 61.78 | 0.038 | 0.041 | 1.402 | 0.188 | 0.043 |
| kodim22 | 61.78 | 61.54 | - | 53.55 | 61.43 | 0.043 | 0.046 | - | 0.288 | 0.047 |
| kodim23 | 63.51 | 62.83 | 46.99 | 55.98 | 63.16 | 0.029 | 0.034 | 1.301 | 0.164 | 0.031 |
| kodim24 | 63.10 | 58.67 | - | - | 56.93 | 0.032 | 0.088 | - | - | 0.132 |
| Average | 62.55 | 61.43 | 50.73 | 58.72 | 61.97 | 0.036 | 0.049 | 0.550 | 0.089 | 0.041 |
| [24] | [36] | [39] | [32] | |
|---|---|---|---|---|
| Lena | 28.72 | 8.01 | 10.84 | 39.37 |
| Barbara | 10.00 | 3.02 | 14.49 | 5.44 |
| Boat | 53.53 | 5.48 | 7.79 | 16.34 |
| Elaine | 15.59 | 3.35 | 5.83 | 6.74 |
| Lake | 46.43 | 7.42 | 10.32 | 18.53 |
| Peppers | 25.70 | −6.25 | 1.32 | 9.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, X.; He, W.; Cai, Z. A Novel High-Fidelity Reversible Data Hiding Method Based on Adaptive Multi-pass Embedding. Mathematics 2025, 13, 1881. https://doi.org/10.3390/math13111881
Kong X, He W, Cai Z. A Novel High-Fidelity Reversible Data Hiding Method Based on Adaptive Multi-pass Embedding. Mathematics. 2025; 13(11):1881. https://doi.org/10.3390/math13111881
Chicago/Turabian StyleKong, Xiaoxi, Wenguang He, and Zhanchuan Cai. 2025. "A Novel High-Fidelity Reversible Data Hiding Method Based on Adaptive Multi-pass Embedding" Mathematics 13, no. 11: 1881. https://doi.org/10.3390/math13111881
APA StyleKong, X., He, W., & Cai, Z. (2025). A Novel High-Fidelity Reversible Data Hiding Method Based on Adaptive Multi-pass Embedding. Mathematics, 13(11), 1881. https://doi.org/10.3390/math13111881